
emiliosedanogijon.files.wordpress.com · Web view2016-09-27 · Por ejemplo, si estas en el...
18
INTRODUCCIÓN AL LINUX (UNIX) Introducción a la Gestión de Procesos de Linux En Linux cada proceso o demonio ejecutándose tiene un determinado numero llamado PID (Identificador de proceso). Este identificador es único. Podemos terminar programas no usados deteniendo sus procesos. Para realizar la gestión de procesos necesitamos identificar cierta información del proceso como su propietario, en que terminal esta corriendo y que comando esta ejecutando ese proceso .
Transcript of emiliosedanogijon.files.wordpress.com · Web view2016-09-27 · Por ejemplo, si estas en el...

INTRODUCCIÓN AL LINUX (UNIX)
Introducción a la Gestión de Procesos de Linux
En Linux cada proceso o demonio ejecutándose tiene un determinado numero llamado PID (Identificador de proceso). Este identificador es único. Podemos terminar programas no usados deteniendo sus procesos. Para realizar la gestión de procesos necesitamos identificar cierta información del proceso como su propietario, en que terminal esta corriendo y que
comando esta ejecutando ese proceso .

Comandos Fundamentales Linux
Ps , psaux , pstree , top , kill , killall .
Killall

Kill

Top

Pstree
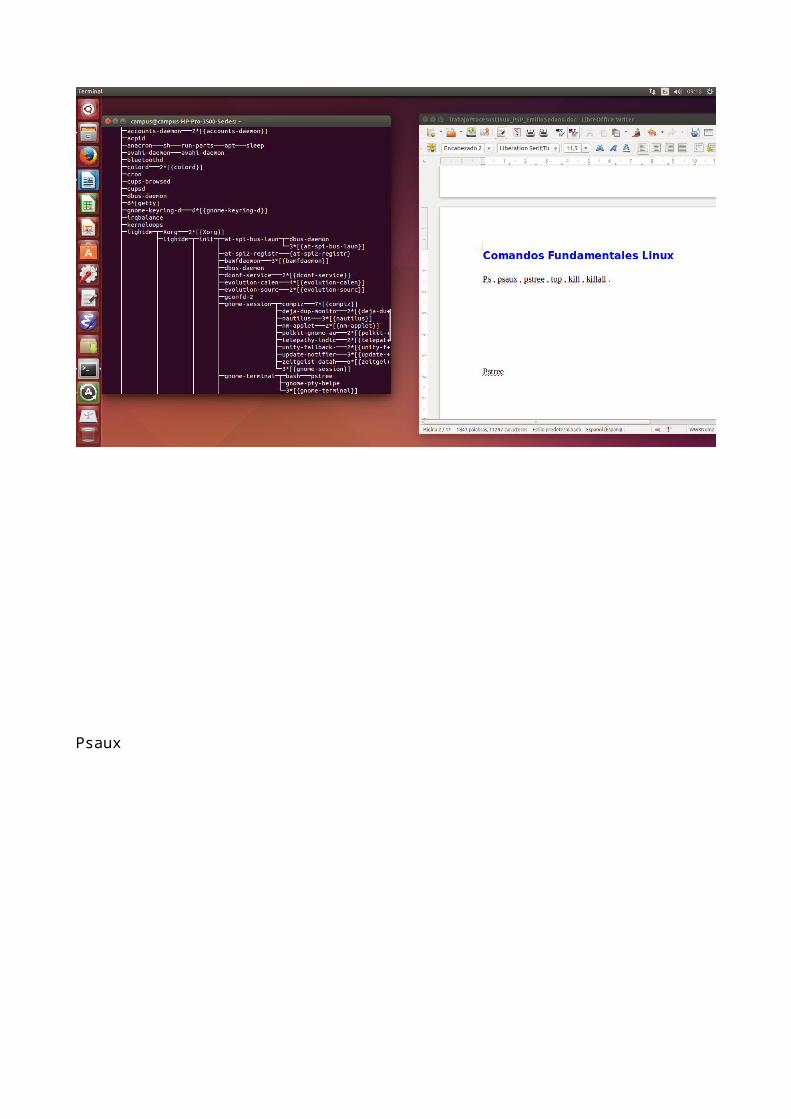
Psaux
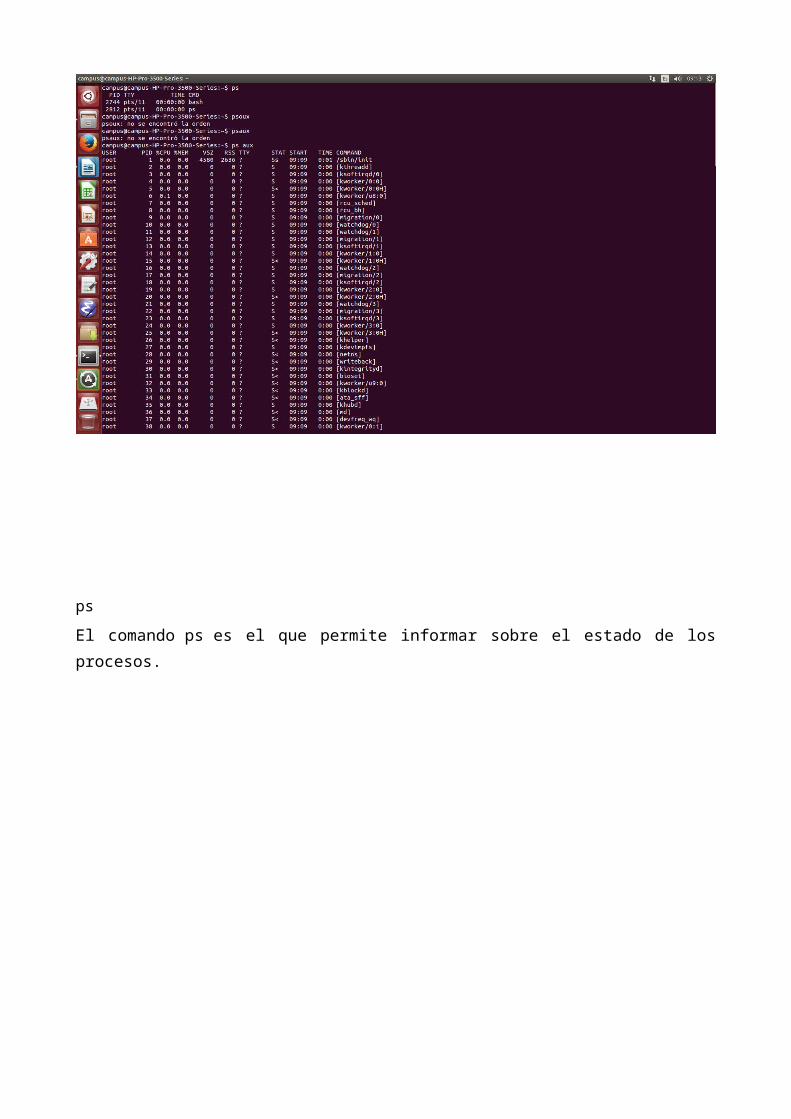
ps
El comando ps es el que permite informar sobre el estado de los procesos.
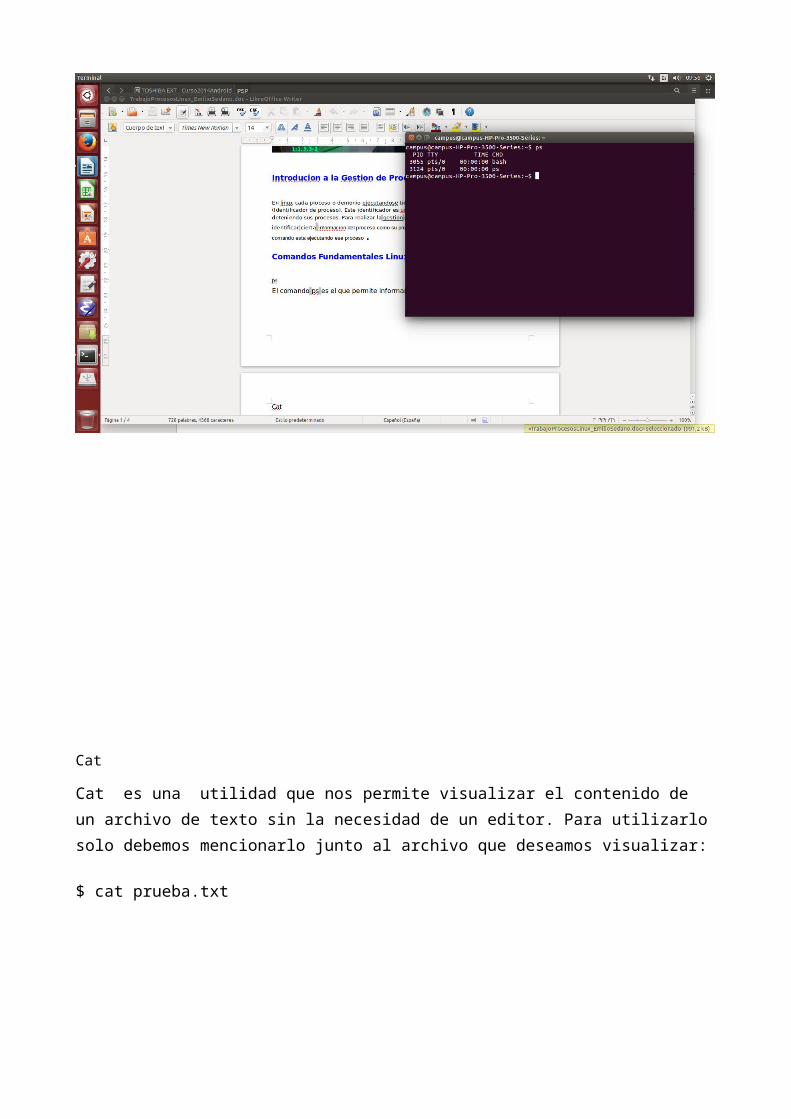
Cat
Cat es una utilidad que nos permite visualizar el contenido de un archivo de texto sin la necesidad de un editor. Para utilizarlo solo debemos mencionarlo junto al archivo que deseamos visualizar:
$ cat prueba.txt
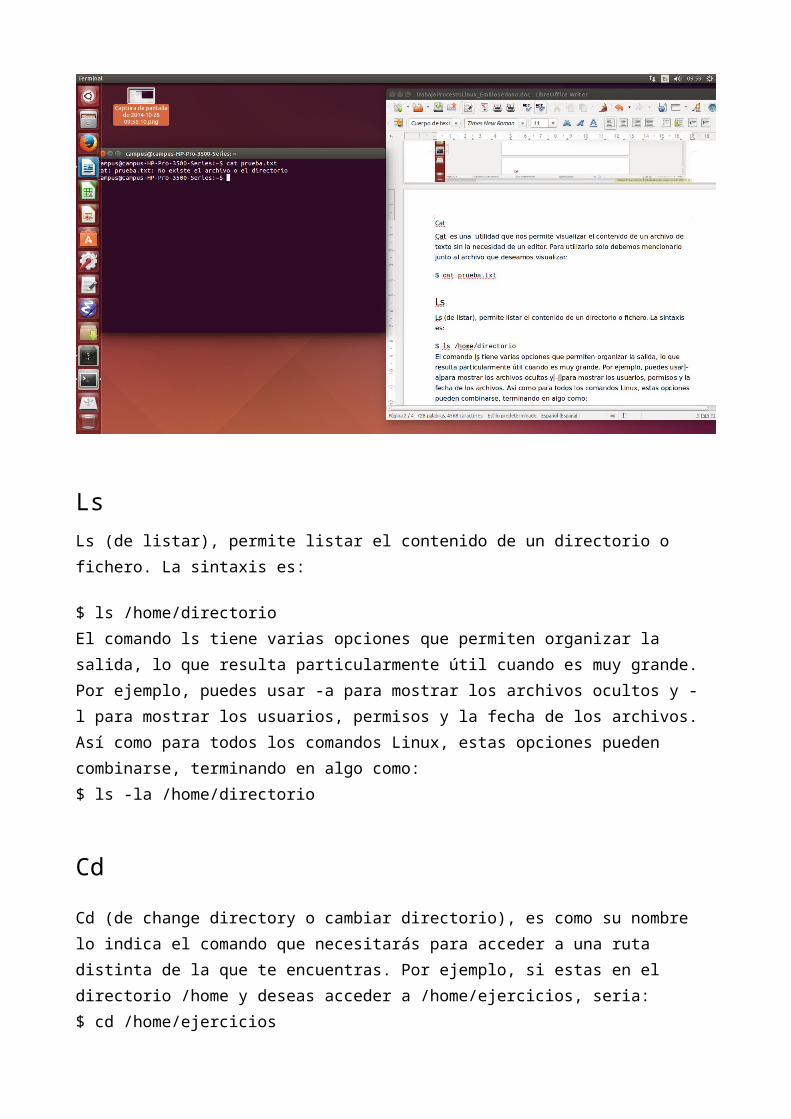
LsLs (de listar), permite listar el contenido de un directorio o fichero. La sintaxis es:
$ ls /home/directorio
El comando ls tiene varias opciones que permiten organizar la salida, lo que resulta particularmente útil cuando es muy grande. Por ejemplo, puedes usar -a para mostrar los archivos ocultos y -l para mostrar los usuarios, permisos y la fecha de los archivos. Así como para todos los comandos Linux, estas opciones pueden combinarse, terminando en algo como:$ ls -la /home/directorio
CdCd (de change directory o cambiar directorio), es como su nombre lo indica el comando que necesitarás para acceder a una ruta distinta de la que te encuentras. Por ejemplo, si estas en el directorio /home y deseas acceder a /home/ejercicios, seria:$ cd /home/ejercicios
Si estás en /home/ejercicios y deseas subir un nivel (es decir ir al directorio
/home), ejecutas:
$ cd ..
TouchTouch crea un archivo vacío, si el archivo existe actualiza la hora de modificación. Para crear el archivo prueba1.txt en /home, seria:
$ touch /home/prueba1.txt
MkdirMkdir (de make directory o crear directorio), crea un directorio nuevo tomando en cuenta la ubicación actual. Por ejemplo, si estas en /home y deseas crear el directorio ejercicios, sería:$ mkdir /home/ejercicios
Mkdir tiene una opción bastante útil que permite crear un árbol de directorios completo que no existe. Para eso usamos la opción -p:
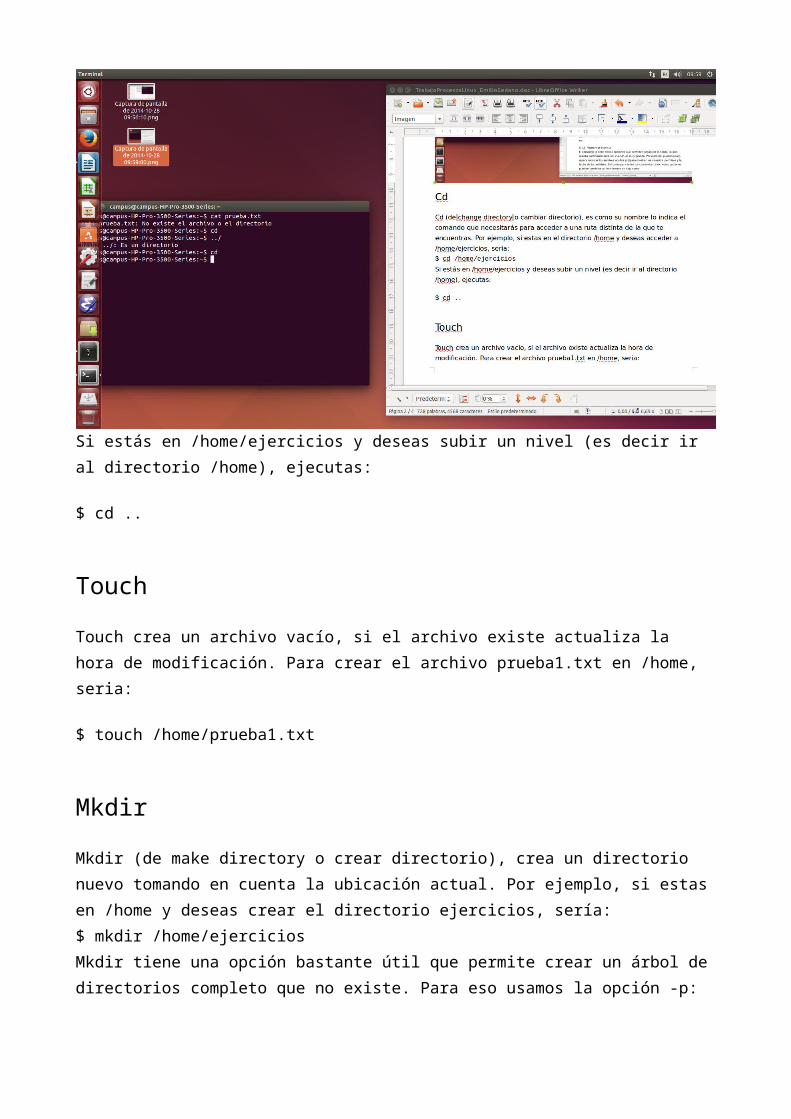
$ mkdir -p /home/ejercicios/prueba/uno/dos/tres
CpCp (de copy o copiar), copia un archivo o directorio origen a un archivo o directorio destino. Por ejemplo, para copiar el archivo prueba.txt ubicado en /home a un directorio de respaldo, podemos usar:$ cp /home/prueba.txt /home/respaldo/prueba.txt
En la sintaxis siempre se especifica primero el origen y luego el destino. Si indicamos un nombre de destino diferente, cp copiará el archivo o directorio con el nuevo nombre.
El comando también cuenta con la opción -r que copia no sólo el directorio especificado sino todos sus directorios internos de forma recursiva. Suponiendo que deseamos hacer una copia del directorio /home/ejercicios que a su vez tiene las carpetas ejercicio1 y ejercicio2 en su interior, en lugar de ejecutar un comando para cada carpeta, ejecutamos:$ cp -r /home/ejercicios /home/respaldos/
MvMv (de move o mover), mueve un archivo a una ruta específica, y a diferencia de cp, lo elimina del origen finalizada la operación. Por ejemplo:
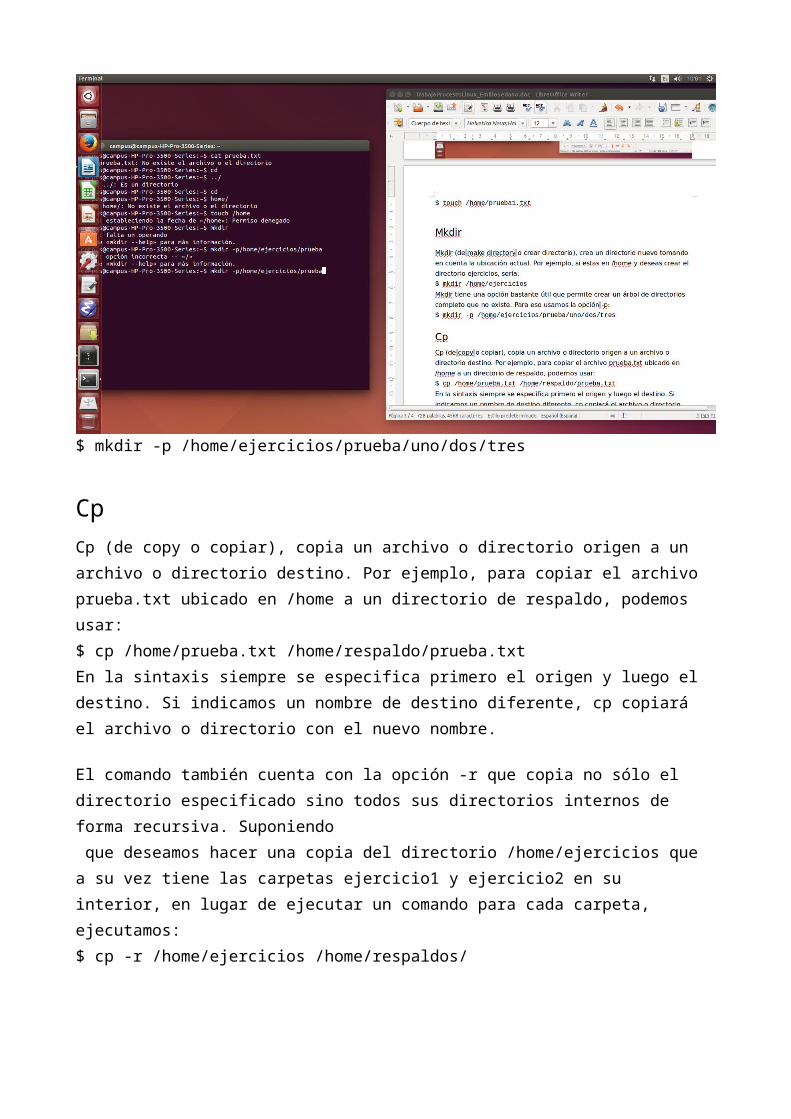
$ mv /home/prueba.txt /home/respaldos/prueba2.txt
Al igual que cp, en la sintaxis se especifica primero el origen y luego el destino. Si indicamos un nombre de destino diferente, mv moverá el archivo o directorio con el nuevo nombre.
RmRm (de remove o remover), es el comando necesario para borrar un archivo o directorio. Para borrar el archivo prueba.txt ubicado en /home, ejecutamos:$ rm /home/prueba.txt
Este comando también presenta varias opciones. La opción -r borra todos los archivos y directorios de forma recursiva. Por otra parte, -f borra todo sin pedir confirmación. Estas opciones pueden combinarse causando un borrado recursivo y sin confirmación del directorio que se especifique. Para realizar esto en el directorio respaldos ubicado en el /home, usamos:$ rm -fr /home/respaldos
Este comando es muy peligroso, por lo tanto es importante que nos documentemos bien acerca de los efectos de estas opciones en nuestro sistema para así evitar consecuencias nefastas.
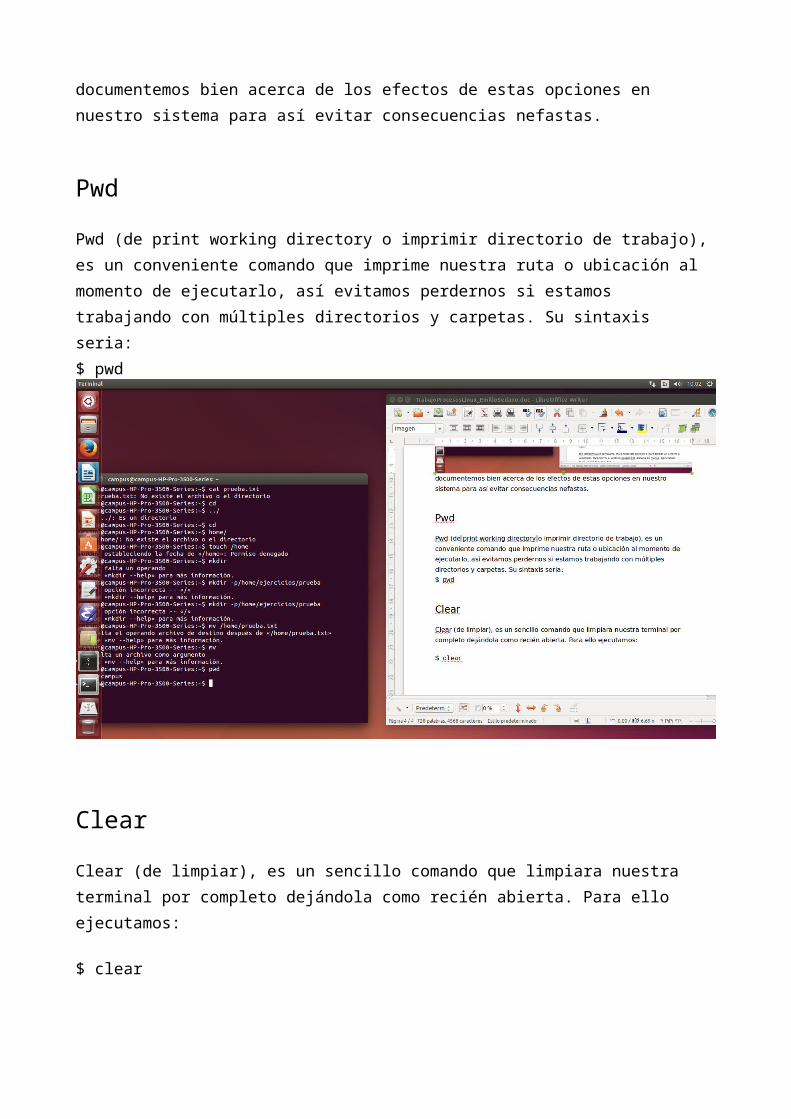
PwdPwd (de print working directory o imprimir directorio de trabajo), es un
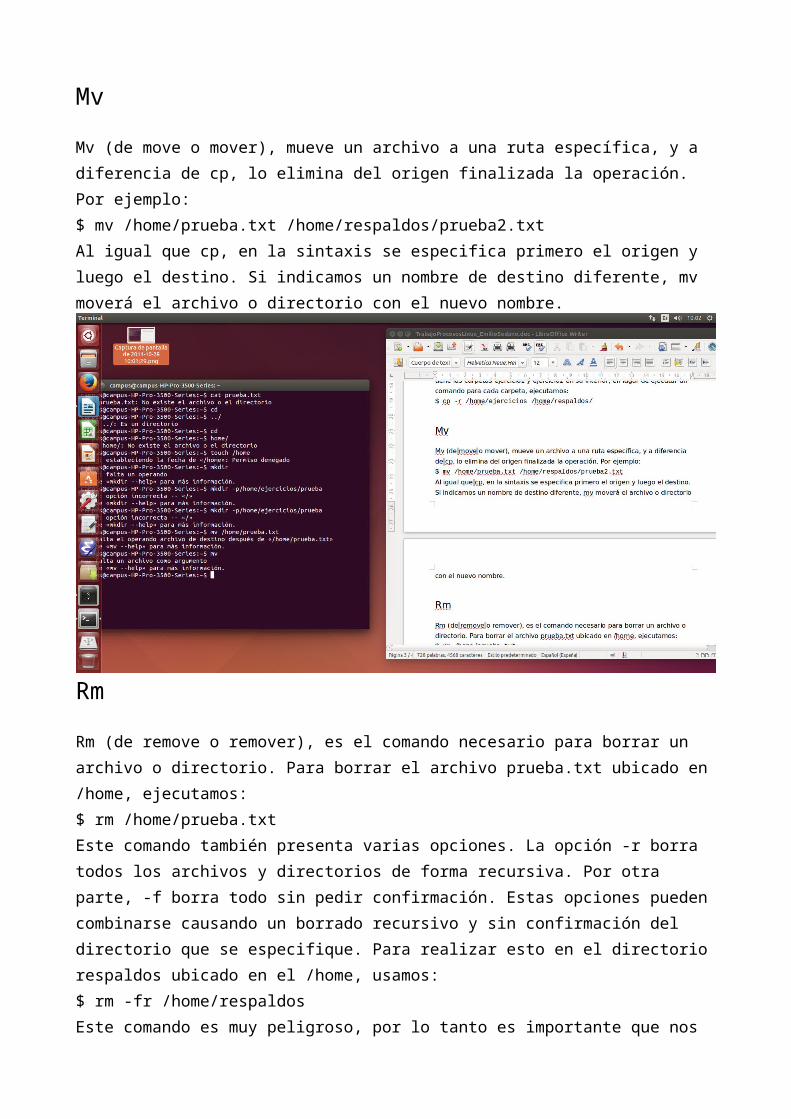
conveniente comando que imprime nuestra ruta o ubicación al momento de ejecutarlo, así evitamos perdernos si estamos trabajando con múltiples directorios y carpetas. Su sintaxis seria:$ pwd
ClearClear (de limpiar), es un sencillo comando que limpiara nuestra terminal por completo dejándola como recién abierta. Para ello ejecutamos:
$ clear
Llamada Fork
int fork ()
fork crea un nuevo proceso; pero no lo inicia desde un nuevo programa. Los segmentos de datos de usuario y del sistema y el segmento de instrucciones del nuevo proceso (hijo) son copias casi exactas del proceso que realizó la llamada (padre). El valor de retorno de fork es: Proceso hijo 0Proceso padre PID del proceso hijofork fracasa y no puede crear un nuevo proceso. -1
El proceso hijo hereda la mayoría de los atributos del proceso padre, ya que se copian de su segmento de datos del sistema. Sólo algunos atributos difieren entre ambos:
PID
archivos: El hijo obtiene una copia de la tabla de descriptores de archivo del proceso padre, con lo que comparten el puntero del archivo. Si uno de los procesos cambia ese puntero (realiza una operación de E/S) la siguiente operación de E/S realizada por el otro proceso se hará a partir de la posición indicada por el puntero modificado por el primer proceso. Sin embargo, al existir dos tablas de descriptores de archivos si un proceso cierra su descriptor, el otro no se ve afectado.
Apis.ual.es> cat ej_fork.c #include <unistd.h> #include <stdio.h> main (arc, argv) int argc; char *argv[]; {
int pidHijo; printf ("Ejemplo de fork. Este proceso va a crear otro proceso\n"); if (pidHijo=fork()) /* Código ejecutado por el padre */
printf ("Proceso PADRE: He creado un nuevo proceso cuyo PID es %i\n", pidHijo);
else /* Código ejecutado por el hijo */
printf ("Proceso HIJO: El contenido de mi variable PID es %i\n", pidHijo);
/* Esta línea es ejecutada por los dos procesos */ printf ("Fin del proceso cuya variable pidHijo vale %i\n", pidHijo); }
Apis.ual.es > cc ej_fork.c -o ej.fork Apis.ual.es > ej_fork Ejemplo de fork. Este proceso va a crear otro proceso Proceso HIJO: El contenido de mi variable PID es 0 Proceso PADRE: He creado un nuevo proceso cuyo PID es 23654 Fin del proceso cuya variable pidHijo vale 23654 Fin del proceso cuya variable pidHijo vale 0 Apis.ual.es>
Llamada exec
La llamada al sistema exec permite remplazar los segmentos de instrucciones y de datos de usuario por otros nuevos a partir de un archivo ejecutable en disco, con lo que se consigue que un proceso deje de ejecutar instrucciones de un programa y comience a ejecutar instrucciones de un nuevo programa. exec no crea ningún proceso nuevo.
Como el proceso continua activo su segmento de datos del sistema apenas es perturbado, la mayoría

de sus atributos permanecen inalterados. En particular, los descriptores de archivos abiertos permanecen abiertos después de un exec. Esto es importante puesto que algunas funciones de la librería C (como printf) utilizan buffers internos para aumentar el rendimiento de la E/S; si un proceso realiza un exec y no se han volcado (sincronizado) antes los buffers internos, los datos de estos buffers se perderán. Por ello es habitual cerrar los descriptores abiertos antes de realizar una llamada al sistema exec.
Hay 6 formas de realizar una llamada al sistema exec:
#include <unistd.h> int execl (char *path, char *arg0, char *arg1, . . . ,char *argN, char *null) int execle (char *path, char *arg0, . . . ,char *argN, char *null, char *envp[]) int execlp (char *file, char *arg0, char *arg1, . . . ,char *argN, char *null) int execv (char *path, char *argv[]) int execve (char *path, char *argv[], char *envp[]) int execvp (char *file, char *argv[])
Llamadas wait y exit
exit finaliza al proceso que la llamó, con un código de estado igual al byte menos significativo del parámetro entero status. Todos los descriptores de archivo abiertos son cerrados y sus buffers sincronizados. Si hay procesos hijo cuando el padre ejecuta un exit, el PPID de los hijos se cambia a 1 (proceso init). Es la única llamada al sistema que nunca retorna.
El valor del parámetro status se utiliza para comunicar al proceso padre la forma en que el proceso hijo termina. Por convenio, este valor suele ser 0 si el proceso termina correctamente y cualquier otro valor en caso de terminación anormal. El proceso padre puede obtener este valor a traves de la llamada al sistema wait.
#include <unistd.h>
int wait (int *statusp)
Si hay varios procesos hijos, wait espera hasta que uno de ellos termina. No es posible especificar por qué hijo se espera. wait retorna el PID del hijo que termina (o -1 si no se crearon hijos o si ya no hay hijos por los que esperar) y almacena el código del estado de finalización del proceso hijo (parámetro status en su llamada al sistema exit) en la dirección apuntada por el parámetro statusp.
Un proceso puede terminar en un momento en el que su padre no le esté esperando. Como el kernel debe asegurar que el padre pueda esperar por cada proceso, los procesos hijos por los que el padre no espera se convierten en procesos zombie (se descartan su segmentos pero siguen ocupando una entrada en la tabla de procesos del kernel). Cuando el padre realiza una llamada wait, el proceso hijo es eliminado de la tabla de procesos.
Terminación de procesos

La forma más complicada pero al mismo tiempo más precisa de matar un proceso es a través de su PID (siglas en inglés de “Identificador de Proceso”). Cualquiera de estas 3 variantes puede servir:
kill -TERM pidkill -SIGTERM pidkill -15 pid
Se puede usar el nombre de la señal (TERM o SIGTERM) que se desea mandar al proceso o su número de identificación (15). Para ver un listado completo de las posibles señales, sugiero verificar el manual de kill. Para ello, ejecutá:
man kill
Veamos un ejemplo de cómo matar Firefox:
Primero, hay que averiguar el PID del programa:
ps -ef | grep firefox
Ese comando devolverá algo parecido a esto:
1986 ? Sl 7:22 /usr/lib/firefox-3.5.3/firefox
Usamos el PID devuelto por el comando anterior para aniquilar el proceso:
kill -9 1986
killall: matar un proceso usando su nombre
Este comando es bien fácil
killall nombre_proceso
Un dato a tener en cuenta al usar este método es que en caso de que haya más de una instancia de ese programa ejecutándose, se cerrarán todas.
pkill: matar un proceso usando parte de su nombre
Es posible aniquilar un proceso especificando el nombre completo o parte del nombre. Eso significa que no hay necesidad de que recuerdes el PID del proceso para enviar la señal.
pkill parte_nombre_proceso
Como contrapartida, este método aniquilará todos los procesos que contengan la palabra ingresada. Eso significa que si tenemos abiertos 2 procesos que comparten una palabra en el nombre, se cerrarán ambos.
Bibliografía
http://www.ual.es/~jjfdez/SOA/pract6.htmlhttp://blog.desdelinux.net/como-matar-procesos-facilmente/



















