
1 - UPMlorien.die.upm.es/juancho/pfcs/NPM/PFC_Nuriapm.doc · Web viewserver->StartThread();...
246
UNIVERSIDAD POLITÉCNICA DE MADRID ESCUELA TÉCNICA SUPERIOR DE INGENIEROS DE TELECOMUNICACIÓN DEPARTAMENTO DE INGENIERÍA ELECTRÓNICA PROYECTO FIN DE CARRERA Mejora de la interfaz vocal de control de un robot autónomo móvil. Adaptación acústica y generación supervisada de mapas NURIA PÉREZ MAGARIÑOS Ingeniero de Telecomunicación Madrid, 2008
Transcript of 1 - UPMlorien.die.upm.es/juancho/pfcs/NPM/PFC_Nuriapm.doc · Web viewserver->StartThread();...

UNIVERSIDAD POLITÉCNICA DE MADRIDESCUELA TÉCNICA SUPERIOR DE INGENIEROS
DE TELECOMUNICACIÓNDEPARTAMENTO DE INGENIERÍA ELECTRÓNICA
PROYECTO FIN DE CARRERA
Mejora de la interfaz vocal de control de un robot autónomo móvil.
Adaptación acústica y generación supervisada de mapas
NURIA PÉREZ MAGARIÑOSIngeniero de Telecomunicación
Madrid, 2008


UNIVERSIDAD POLITÉCNICA DE MADRIDDEPARTAMENTO DE INGENIERÍA ELECTRÓNICAESCUELA TÉCNICA SUPERIOR DE INGENIEROS
DE TELECOMUNICACIÓN
PROYECTO FIN DE CARRERAMejora de la interfaz vocal de control
de un robot autónomo móvil. Adaptación acústica y generación
supervisada de mapas
NURIA PÉREZ MAGARIÑOSIngeniero de Telecomunicación
Tutor del ProyectoJUAN MANUEL MONTERO MARTÍNEZ
Doctor Ingeniero de Telecomunicación2008


PROYECTO FIN DE CARRERA
Título: Mejora de la interfaz vocal de control de un robot autónomo móvil. Adaptación acústica y generación supervisada de mapas.
Autora: Nuria Pérez Magariños
Tutor: Dr. Ingeniero Juan Manuel Montero Martínez
Departamento: Ingeniería Electrónica de la Escuela Técnica Superior de Ingenieros de Telecomunicación de Madrid de la Universidad Politécnica de Madrid
Grupo: Tecnología del Habla
MIEMBROS DEL TRIBUNAL
Presidente: D. Javier Ferreiros López Firma:
Vocal: D. Rubén San Segundo Hernández Firma:
Secretario: D. Juan Manuel Montero Martínez Firma:
Suplente: D. Javier Macías Guarasa Firma:
Fecha de Lectura:
Calificación:


ÍNDICE ÍNDICE..........................................................................................................................................7Índice de figuras...........................................................................................................................11Índice de cuadros..........................................................................................................................13Índice de tablas...............................................................................................................................11.- INTRODUCCIÓN....................................................................................................................1
1.1.- Sistemas de reconocimiento de voz...................................................................................21.1.1.- Los reconocedores......................................................................................................21.1.2.- Métodos de reconocimiento.......................................................................................4
1.1.2.1.- Reconocimiento de patrones...............................................................................51.1.3.- Variabilidad de la señal de voz..................................................................................7
1.1.3.1.- Variaciones en el contexto..................................................................................71.1.3.2.- Variaciones en el estilo.......................................................................................71.2.3.3.- Variaciones en el locutor....................................................................................81.1.3.4.- Variaciones en el entorno....................................................................................8
1.1.4.- Prestaciones................................................................................................................91.2.- Proyecto “ROBINT”........................................................................................................10
1.2.1.- Evolución de los robots y la tecnología el habla......................................................101.2.1.1.- Robots Sociales.................................................................................................111.2.1.2.- Interacción Hombre-Robot...............................................................................12
1.2.2.- Proyecto ROBINT....................................................................................................121.2.2.1 Definición del sistema.........................................................................................131.2.2.2.- Implementación.................................................................................................13
1.3.- Objetivos y fases del proyecto.........................................................................................141.3.1.- Objetivos..................................................................................................................14
1.3.1.1.- Adaptación de los modelos acústicos...............................................................141.3.1.2.- Guiado del robot...............................................................................................141.3.1.3.- Aprendizaje automático....................................................................................15
1.3.2.- Fases del proyecto....................................................................................................152.- DESCRIPCIÓN DE LAS TÉCNICAS Y HERRAMIENTAS EMPLEADAS......................17
2.1.- Técnicas empleadas.........................................................................................................172.1.1.- Adaptación...............................................................................................................17
2.1.1.1.- Regresión Lineal de Máxima Verosimilitud (MLLR)......................................182.1.1.2 Máximo a posteriori (MAP)................................................................................21
2.1.2.- Etiquetado automático..............................................................................................222.1.2.1.- Preprocesamiento..............................................................................................222.1.2.2.- Técnicas de desambiguación en el etiquetado morfosintáctico........................22
2.2.- Herramientas empleadas..................................................................................................232.2.1.- HTK..........................................................................................................................23
2.2.1.1.- HLEd.................................................................................................................242.2.1.2.- HCopy...............................................................................................................252.2.1.3.- HCompV...........................................................................................................252.2.1.4.- HERest..............................................................................................................262.2.1.5.- HHEd................................................................................................................262.2.1.6.- HVite.................................................................................................................274.2.6.1.- Algoritmo de paso de testigo............................................................................282.2.1.7.- HResults............................................................................................................29
2.2.2.- Perl...........................................................................................................................292.2.2.1.- Estructura del lenguaje......................................................................................29
2.2.3.- AWK........................................................................................................................322.2.3.1.- Variables...........................................................................................................322.2.3.2.- Sentencias de uso frecuente..............................................................................32
2.3.- Proyectos Fin de Carrera Precedentes.............................................................................332.3.1.- Proyecto Fin de Carrera de Sergio Díaz Municio....................................................33

2.3.2.- Proyecto Fin de Carrera de Javier López García......................................................343.- DESCRIPCIÓN DEL SISTEMA............................................................................................35
3.1.- Ámbito del proyecto........................................................................................................353.2.- Diagrama de contexto y guión de los casos de uso.........................................................353.3.- Arquitectura del sistema..................................................................................................373.4.- Tarea de guiado...............................................................................................................40
3.4.1.- Conclusiones obtenidas en la reunión......................................................................403.4.2.- Pasos a seguir para el desarrollo del módulo...........................................................41
4.- PORTABILIDAD Y CONFIGURACIÓN DEL SISTEMA..................................................434.1.- Portabilidad y estructura de directorios...........................................................................43
4.1.1.- Directorio “bin”........................................................................................................444.1.2.- Directorio “data”......................................................................................................44
4.1.2.1.- Directorio de tarea.............................................................................................444.1.2.2.- Directorio de grabaciones.................................................................................454.1.2.3.- Directorio de modelos.......................................................................................454.1.2.4.- Directorio de adaptación...................................................................................454.1.2.5.- Directorio temporal...........................................................................................46
4.2.- Configuración del sistema...............................................................................................465.- GENERACIÓN AUTOMÁTICA DEL SUBSISTEMA DE COMPRENSIÓN....................57ADAPTADO A UNA TAREA....................................................................................................57
5.1.- Aproximación al sistema.................................................................................................575.2.- Implementación de la comprensión mediante reglas.......................................................57
5.2.1.- Método “cargaPalabrasFuncion”..............................................................................585.2.1.- Método “main_ppal”................................................................................................58
5.2.1.1.- Método “leeFrasesFichero”..............................................................................585.2.1.2.- Método “procesaFrases”...................................................................................605.2.1.3.- Método “evaluaGlobal”....................................................................................615.2.1.4.- Método “estimaCategorías”..............................................................................625.2.1.5.- Fase de aprendizaje...........................................................................................64
5.3.- Modificaciones en el reconocimiento..............................................................................676.- IMPLEMENTACIÓN DE LOS MECANISMOS DE ADAPTACIÓN DE MODELOS ACÚSTICOS................................................................................................................................69
6.1.- Clases y comportamiento dinámico.................................................................................696.2.- Implementación...............................................................................................................73
6.2.1.- Interfaz gráfica de adaptación..................................................................................736.2.1.1.- Ventana de características.................................................................................736.2.1.2.- Ventana de grabación........................................................................................79
6.2.2.- Métodos....................................................................................................................806.3.- Scripts de HTK................................................................................................................82
6.3.1.- Preparación y generación de los ficheros.................................................................826.3.1.1.- Acondicionamiento de los ficheros para HTK..................................................846.3.1.2.- Adaptación de los diccionarios.........................................................................886.3.1.3.- Generación de los ficheros maestros de etiquetas.............................................896.3.1.4.- Parametrización de los ficheros de audio..........................................................926.3.1.5.- Normalización Cepstral....................................................................................92
6.3.2.- “adaptaMap.bat”.......................................................................................................936.3.3.- “adaptaMLLR.bat”...................................................................................................94
7.- EVALUACIÓN Y PRUEBAS DEL SISTEMA.....................................................................977.1.- Pruebas de adaptación con emociones.............................................................................97
7.1.1.- Reconocimiento con los modelos genéricos............................................................977.1.2.- Determinación de la τ óptima...................................................................................987.1.4.- Pruebas cruzadas....................................................................................................1067.1.5.- Reconocimiento con modelos entrenados con varias emociones...........................116
8.- CONCLUSIONES Y LÍNEAS FUTURAS DE INVESTIGACIÓN...................................1178.1.- Conclusiones..................................................................................................................117

8.1.1.- Funcionalidad del sistema......................................................................................1178.1.1.1.- Configuración.................................................................................................1178.1.1.2.- Adaptación......................................................................................................1188.1.1.3.- Primera versión del guiado del robot..............................................................1198.1.1.4.- Comprensión...................................................................................................119
8.1.2.- Análisis de las pruebas realizadas..........................................................................1198.1.2.1.- Reconocimiento con los modelos genéricos...................................................1198.1.2.2.- Determinación de la τ óptima.........................................................................1208.1.2.3.- Pruebas cruzadas.............................................................................................1218.1.2.4.- Reconocimiento con modelos entenados con varias emociones.....................122
8.2.- Líneas futuras de investigación.....................................................................................1229.- BIBLIOGRAFÍA..................................................................................................................12310.- PLIEGO DE CONDICIONES............................................................................................125
10.1.- Condiciones generales.................................................................................................12510.2.- Condiciones generales a todos los programas.............................................................12610.3.- Condiciones generales de prueba................................................................................12610.4.- Recursos materiales.....................................................................................................12610.5.- Recursos lógicos..........................................................................................................126
11.- PRESUPUESTO.................................................................................................................12711.1.- Presupuesto de ejecución material...............................................................................127
11.1.1.- Relación de salarios..............................................................................................12711.1.2 Relación de obligaciones sociales..........................................................................12811.1.3 Relación de salarios efectivos totales.....................................................................12811.1.4 Coste de la mano de obra........................................................................................12811.1.5 Coste total de materiales.........................................................................................12911.1.6 Importe total del presupuesto de ejecución material..............................................129
11.2.- Importe de ejecución por contrata...............................................................................13011.3.- Honorarios Facultativos...............................................................................................13011.4.- Importe Total del Proyecto..........................................................................................131
I.- MANUAL DE USUARIO.....................................................................................................133II.- PROPUESTA DE FRASES PARA GUIADO.....................................................................151III.- FRASES DEL QUIJOTE....................................................................................................153IV.- FRASES DE URBANO PARA LA EVALUACIÓN DEL SISTEMA.............................157V.- FUNCIONES DE GENERACIÓN DE REGLAS...............................................................159


Índice de figurasFigura 1: Diagrama de bloques de un reconocedor obtenido de [Lucas 2006]..............................3Figura 2: Arquitectura básica de un sistema reconocedor obtenido de [Huang 2001]...................4Figura 3: Esquema de un reconocedor de dos etapas, obtenido de [Lucas 2006]..........................5Figura 4: Árbol de regresión con cuatro clases [Díaz 2002]........................................................20Figura 5: Jerarquía de los niveles de reconocimiento..................................................................27Figura 6: Diagrama de contexto del sistema................................................................................36Figura 7: Diagrama de clases del SERVIVOX............................................................................39Figura 8: Diagrama de clases de reconocimiento.........................................................................40Figura 9: Nueva estructura de directorios....................................................................................43Figura 10: Ventana de configuración del sistema........................................................................50Figura 11: Diagrama de la implementación de los casos de uso..................................................52Figura 12: Situación inicial de listaConceptos y listaCategorías................................................63Figura 13: Resultado después de relacionar el concepto con la categoría...................................63Figura 14: Diálogo para la grabación...........................................................................................71Figura 15: Comunicación entre las hebras...................................................................................72Figura 16: Ventana de características de adaptación....................................................................74Figura 17: Lista desplegable para seleccionar el tipo de entorno.................................................74Figura 18: Lista desplegable para seleccionar el tipo de micrófono............................................75Figura 19: Ventana de grabación..................................................................................................79Figura 20: Formato de línea del fichero .DATA..........................................................................81Figura 21: Formato de línea del fichero de diccionario...............................................................84Figura 22: Formato de línea del fichero .DATA..........................................................................84Figura 23: Formato de descomposición de una frase en el MLF.................................................89Figura 24: Tasa de error reconociendo con modelo genérico en función del locutor..................97Figura 25: Evolución de la tasa de error en función de τ para el hombre en el experimento 1. . .99Figura 26: Evolución de la tasa de error del hombre en función de τ en el experimento 2.......100Figura 27: Evolución de la tasa de error en función de τ para la mujer en el experimento 1....101Figura 28: Evolución de la tasa de error para la mujer en función de tau en el experimento 2. 102Figura 29: Mejora del reconocimiento para la mujer con τ =3..................................................104Figura 30: Mejora del reconocimiento para el hombre con τ=2................................................105Figura 31: Reconocimiento cruzado de emociones en el hombre en el experimento 1.............107Figura 32: Reconocimiento cruzado de emociones en el hombre en el experimento 2.............108Figura 33: Reconocimiento cruzado de emociones en la mujer en el experimento 1................109Figura 34: Reconocimiento cruzado de emociones con la mujer en el experimento 2..............110Figura 35: Esquema de agrupación de las emociones de la mujer.............................................113Figura 36: Intervalos de confianza del hombre incluyendo la emoción de entrenamiento........114Figura 37: Intervalo de confianza de la mujer incluyendo la emoción de entrenamiento..........114Figura 38: Intervalo de confianza del hombre sin incluir la emoción de entrenamiento...........115Figura 39: Intervalo de confianza de la mujer sin incluir la emoción de entrenamiento...........115Figura 40: Resultado de reconocer con modelos entrenados de forma diferente.......................116


Índice de cuadrosCuadro 1: Ejemplo de MLF a nivel de palabra............................................................................24Cuadro 2: Instrucciones de un edit-scrip de HHEd......................................................................27Cuadro 3: Tipos de variables de Perl............................................................................................30Cuadro 4: Principales expresiones de control de Perl..................................................................30Cuadro 5: Expresión regular de emparejamiento.........................................................................31Cuadro 6: Expresión regular de sustitución.................................................................................31Cuadro 7: Ejemplo de utilización de los metacaracteres en expresiones regulares.....................31Cuadro 8: Sentencias habituales de AWK [Collado 2006]..........................................................32Cuadro 9: Ejemplo de uso de las sentencias de AWK.................................................................32Cuadro 10: Ejemplo de palabras función del fichero Palfunc.lis.................................................44Cuadro 11: Comprobación del tipo de entorno seleccionado y asignación de valores................49Cuadro 12: Inicialización original del servidor............................................................................51Cuadro 13: Nueva inicialización del servidor..............................................................................51Cuadro 14: Implementación del método "buscaLocutor()".........................................................53Cuadro 15: Proceso para cargar automáticamente los modelos de un locutor conocido.............54Cuadro 16: Creación de la ventana para seleccionar el modelo a cargar.....................................55Cuadro 17: Ejemplo de las reglas generadas................................................................................66Cuadro 18: Instrucción para crear una ventana que bloquee la ventana desde la que se llama.. .70Cuadro 19: Instrucción que indica el fin de la inicialización.......................................................70Cuadro 20: Creación de la ventana de adaptación bloqueando al reconocedor...........................70Cuadro 21: Creamos la ventana de características.......................................................................70Cuadro 22: Instrucciones para bloquear una hebra mediante flags..............................................71Cuadro 23: Comparación para determinar el elemento seleccionado de la lista..........................75Cuadro 24: Instrucción para añadir elementos a las listas............................................................75Cuadro 25: Programa dic2data.per...............................................................................................85Cuadro 26: Formato de líneas en el fichero .alp a nivel de frase.................................................85Cuadro 27: Formato de líneas en el fichero .alp a nivel de palabra.............................................85Cuadro 28: Formato de líneas en el diccionario a nivel de palabra.............................................86Cuadro 29: Programa dic2dicgth.per............................................................................................86Cuadro 30: Programa dic2alf.per.................................................................................................86Cuadro 31: Formato de línea de los ficheros .lif..........................................................................87Cuadro 32: Programa dic2lif.per..................................................................................................87Cuadro 33: Programa generaNopath.per......................................................................................88Cuadro 34: Programa awk_dic2...................................................................................................89Cuadro 35: Instrucción para combinar el fichero de diccionario con los silencios......................89Cuadro 36: Programa awk_words2..............................................................................................90Cuadro 37: Programa awk_comillas2..........................................................................................91Cuadro 38: Programa awk_slash2................................................................................................91Cuadro 39: Programa editaMono.per...........................................................................................91Cuadro 40: Programa awk_scp.....................................................................................................92Cuadro 41: Programa awk_list2...................................................................................................92Cuadro 42: Llamada a HERest.....................................................................................................93Cuadro 43: Fichero de configuración de HERest para la técnica MAP.......................................93Cuadro 44: Instrucción para crear los árboles de clases de regresión..........................................94Cuadro 45: Script regtree128.hed.................................................................................................94Cuadro 46: Comando para realizar la primera transformación con HERest................................94Cuadro 47:Llamada a HERest para la transformación final de los modelos mediante MLLR....95Cuadro 48: Configuración de las variables relativas al ruido en el entorno...............................134


Índice de tablasTabla 1: Principales metacaracteres de Perl.................................................................................31Tabla 2: Variables predefinidas en AWK [Collado 2006]...........................................................32Tabla 3: Slots de referencia..........................................................................................................61Tabla 4: Slots predichos...............................................................................................................61Tabla 5: Parámetros de la llamada a HERest...............................................................................93Tabla 6: Tabla con las nuevas opciones de HERest.....................................................................95Tabla 7: Media y varianza del reconocimiento genérico según locutor para todas las emociones......................................................................................................................................................98Tabla 8: Tasa de error para el hombre en el experimento 1 en función de τ................................99Tabla 9: Tasa de error del hombre en el experimento 2 en función de τ...................................100Tabla 10: Tasa de error de la mujer en función de τ en el experimento 1.................................101Tabla 11: Tasa de error de la mujer en función de τ en el experimento 2..................................102Tabla 12: Mejora en el reconocimiento para τ bajas..................................................................103Tabla 13: Resultados de la mejora del reconocimiento para la mujer con τ=3..........................104Tabla 14: Resultados de la mejora del reconocimiento para el hombre con τ=2.......................105Tabla 15: Tasas de error para voz neutra en función de los datos de adaptación y test.............106Tabla 16: Deterioro de la tasa de error en el hombre al reducir las frases de entrenamiento....106Tabla 17: Deterioro de la tasa de error en la mujer al reducir las frases de entrenamiento.......106Tabla 18: Tasa de error en el reconocimiento cruzado con el hombre en el experimento 1......107Tabla 19: Tasa de error en el reconocimiento cruzado con el hombre en el experimento 2......108Tabla 20: Tasa de error en el reconocimiento cruzado con la mujer en el experimento 1.........109Tabla 21: Tasa de error en el reconocimiento cruzado con la mujer en el experimento 2.........110Tabla 22: Tasa de error en el reconocimiento cruzado con el hombre sin la emocion de entrenamiento.............................................................................................................................111Tabla 23: Resultado de los promedios de agrupar emociones por proximidad..........................111Tabla 24: Agrupación de las emociones según proximidad en base a la tasa de error..............112Tabla 25: Tasa de correctas en el reconocimiento cruzado con la mujer...................................112Tabla 26: Resultado de los promedios de agrupar las emociones por proximidad....................113Tabla 27: Agrupación de las emociones según proximidad en base a la tasa de error..............113Tabla 28: Sueldos de las personas que han intervenido en el proyecto.....................................127Tabla 29: Obligaciones sociales.................................................................................................128Tabla 30: Salarios efectivos totales............................................................................................128Tabla 31: Coste de la mano de obra...........................................................................................128Tabla 32: Coste de materiales....................................................................................................129Tabla 33: Presupuesto de ejecución material.............................................................................129Tabla 34: Importe de ejecución por contrata..............................................................................130Tabla 35: Honorarios facultativos..............................................................................................130Tabla 36: Honorarios totales......................................................................................................130Tabla 37: Importe total del proyecto..........................................................................................131


Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
1.- INTRODUCCIÓNLos robots interactivos son máquinas que deben ser programadas para navegar,
razonar, aprender y sobrevivir en entornos casi humanos. Este tipo de robots son capaces de llevar a cabo tareas sociales útiles como robots instructores (en museos y colegios), robots de entretenimiento (en parques de atracciones), o robots de compañía (en hogares o en hospitales). [Marín 2006]
ROBINT es un proyecto cuyo objetivo es la integración de comportamientos inteligentes en robots guía. El objetivo de este proyecto es el desarrollo de un sistema inteligente de asistencia para el acceso personalizado a lugares públicos, y una interacción fluida con la información y con ciudadanos allí presentes. Busca fomentar la integración en la sociedad de técnicas relacionadas con la automática e inteligencia artificial, mediante el uso de las nuevas tecnologías de la información.
Dentro de las Tecnologías del habla aplicadas al diálogo, entre otros, se plantea un subobjetivo de asistencia en la adaptación un nuevo usuario o a una nueva exposición o entorno.
Cuando se plantea la construcción de un sistema de reconocimiento de habla, la opción más directa es el entrenamiento de un sistema específico para la tarea que se va realizar. Si queremos que el entrenamiento sea robusto, necesitaremos disponer de un elevado número de datos de entrenamiento.
Puesto que el robot se moverá en lugares públicos, pese a que la tarea a desarrollar sea la misma, las condiciones acústicas del entorno o el hablante que se dirigirá al robot varían de un entorno a otro. Por este motivo, no dispondremos de un número de datos suficiente como para realizar un buen entrenamiento pero necesitamos construir un sistema de reconocimiento fiable, haciéndose necesaria la aplicación de técnicas de adaptación del robot al entorno.
El objetivo de las técnicas de adaptación es desarrollar un sistema de reconocimiento con prestaciones similares a las de un robusto sistema entrenado, pero empleando una cantidad muy reducida de datos. Se basan en modificar un sistema de reconocimiento previo entrenado para otra tarea, para ajustarlo a las características de la nueva tarea. El ajuste se realizará mediante la modificación de los parámetros acústicos de los modelos en base al hablante, al ruido y al entorno acústico del lugar en el que el robot tenga que llevar a cabo sus actividades.
1

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
1.1.- Sistemas de reconocimiento de voz
El reconocimiento automático del habla mediante máquinas ha sido un objetivo que la investigación ha perseguido a lo largo de las cuatro últimas décadas. Sin embargo, a pesar de lo atractivo que resultaría diseñar una máquina capaz de reconocer la palabra hablada y comprender su significado, y a pesar de los enormes esfuerzos realizados en investigación tratando de crear dicha máquina, nos encontramos lejos del objetivo de conseguir una máquina capaz de entender el discurso hablado sobre cualquier tema, realizado por todos los locutores en todos los entornos posibles. [Rabiner 1993]
1.1.1.- Los reconocedores
[Lucas 2006] El módulo reconocedor de voz tiene como objetivo convertir una secuencia de palabras emitidas por un usuario en una secuencia textual que sea lo más fiel posible a aquella. Para lograr esto deberá analizar la secuencia acústica en busca de las unidades de información que se desean obtener. El conjunto de unidades de información sobre el cual el reconocedor compara las tramas acústicas se denomina vocabulario del mismo.
Los reconocedores de voz se pueden clasificar según diferentes criterios. Los principales tipos de reconocedor se pueden resumir en los siguientes:
- Según el objetivo último del reconocimiento existen:
o Reconocedores de habla: Lo más importante es conseguir la secuencia de palabras que se ha dicho.
o Reconocedores de locutor: Lo que interesa es averiguar la identidad del hablante.
o Reconocedores de idioma: El objetivo es identificar el idioma en el que se está hablando.
o Reconocedores de emoción: El objetivo es determinar el estado emocional del locutor.
- Según el tamaño del vocabulario, las prestaciones y complejidad del sistema varían:
o Pequeños: Son capaces de reconocer los dígitos del 0 al 9, si, no…o Medianos: Vocabularios cuyo máximo es 1000 palabras.o Grandes: Vocabularios con más de 1000 palabras.
- Según el tipo de reconocimiento:
o Habla aislada: Basados en órdenes simples y sin pausas.o Habla continua: Permiten reconstruir un mensaje emitido por un
locutor en condiciones normales incluyendo pausas, dudas o símbolos que se encuentren fuera del vocabulario.
2

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
El modelo genérico de un sistema de reconocimiento de voz se presenta a continuación, explicando brevemente cada uno de sus componentes:
Figura 1: Diagrama de bloques de un reconocedor obtenido de [Lucas 2006]
- Micrófono : Es el elemento transductor del sistema, encargado de recoger las vibraciones del aire producidas en el proceso de habla y convertirlas en una señal analógica.
- Conversor analógico/digital : Este elemento tiene una doble misión. Por una parte realiza un muestreo de la señal. Por otra parte, debe digitalizar la señal, asociando a cada valor analógico de la señal en el instante de muestreo un valor perteneciente a un dominio finito de símbolos.
- Detector : Extrae de la señal digital un conjunto de características (features) que serán empleados por el subsistema reconocedor.
- Reconocedor : Mediante los vectores de características obtenidos mediante el detector y empleando tanto los modelos acústicos como los modelos de lenguaje para generar la secuencia de palabras que más se asemeje a dichos vectores de características. El reconocedor también puede proporcionar la información necesaria para llevar a cabo una adaptación de los modelos anteriormente mencionados para mejorar los resultados obtenidos. Un esquema más detallado del reconocedor puede verse en la Figura 2.
3

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
Figura 2: Arquitectura básica de un sistema reconocedor obtenido de [Huang 2001]
1.1.2.- Métodos de reconocimiento
Durante años, se utilizó una aproximación fonético-acústica como principal método de reconocimiento del habla. Sin embargo, dicha aproximación no obtuvo en la práctica tan buenos resultados como otras aproximaciones alternativas [Rabiner 1993]. En líneas generales, podemos decir que actualmente existen tres aproximaciones al reconocimiento del habla:
- Aproximación fonético-acústica : Está basada en la teoría de la fonética acústica, según la cual existe un número finito y diferenciable de unidades fonéticas en el lenguaje hablado y que dichas unidades están caracterizadas, en términos generales, por una serie de propiedades que se manifiestan en la señal de voz o en su espectro. Aunque, las propiedades acústicas de estas unidades fonéticas son muy variables debido principalmente a los locutores y a las unidades fonéticas vecinas, se asume que las reglas que gobiernan esa variabilidad son sencillas y que pueden ser rápidamente aprendidas y aplicadas en situaciones prácticas.
- Aproximación de reconocimiento de patrones: Este método tiene dos pasos, el entrenamiento de los patrones y el reconocimiento mediante la comparación de patrones. El “conocimiento” sobre el habla se introduce en el sistema mediante un proceso de entrenamiento. La idea es que si se dispone de un número suficiente de versiones diferentes del patrón que se desea reconocer en el conjunto de datos de entrenamiento que se proporciona al algoritmo de reconocimiento, el proceso de entrenamiento debe ser capaz de caracterizar adecuadamente las propiedades acústicas del patrón, que quedan reflejadas en el modelo acústico que es un modelo oculto de Markov. La utilidad del método está en el paso de comparación de patrones, que realiza una comparación directa entre la voz que debe reconocerse (habla desconocida) con cada uno de los posibles patrones que ha aprendido en la fase de entrenamiento y clasifica el habla desconocida en función de lo bien que encaja con los patrones.
4

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
1.1.2.1.- Reconocimiento de patrones
En líneas generales, se puede decir que un reconocedor basa su funcionamiento en dos eventos bien diferenciados: la segmentación y el reconocimiento.
La mayoría de los reconocedores actuales optan por utilizar un esquema estocástico basado en representar la secuencia acústica mediante modelos ocultos de Markov (HMM, Hiden Markov Models), así como técnicas de reconocimiento de patrones y algoritmos avanzados basados en la teoría de programación dinámica para resolver ambos problemas de manera integrada.
A lo largo de los años, el desarrollo de las tecnologías y algoritmos de reconocimiento ha dado lugar, como consecuencia, a un incremento de la complejidad de las tareas que debe llevar a cabo el reconocedor de habla. Para tratar de dividir esta complejidad, es habitual dividir el trabajo del mismo en dos fases, aplicando diferentes modelos en cada una de ellas para obtener un mejor resultado global.
Figura 3: Esquema de un reconocedor de dos etapas, obtenido de [Lucas 2006]
El reconocedor el Grupo de Tecnología del Habla que se ha empleado en la realización de este Proyecto presenta este tipo de funcionamiento. En un primer proceso, denominado one pass, se aplica como modelo acústico un HMM por cada alófono y como modelo lingüístico uno basado en bigramas. Una vez efectuado el reconocimiento y asignada una puntuación o score a cada una de las palabras reconocidas, se pasa a un segundo bloque conocido como etapa de rescoring, en la cual se utiliza el modelo acústico de la etapa previa y se varía el modelo lingüístico a uno basado en trigramas, aprovechando que este modelo contiene mayor información.
La información entre ambas etapas no se limita a los parámetros acústicos sino que puede reutilizar una mayor información del one pass para simplificar el trabajo del rescoring.
A continuación haremos una breve explicación de los elementos que intervienen en este reconocedor.
- Confianza : Se entiende como medida de confianza la puntuación que le asigna el reconocedor a cada una de las decisiones que toma, constituyendo de esta forma un sistema de medida de lo bien o lo mal que el propio reconocedor
5

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
asume que está realizando su tarea. La confianza suele medirse en dos niveles diferentes: palabra y frase.
o Nivel de palabra : Indica el grado de corrección que el sistema asigna a cada una de las palabras que reconoce. Esta medida sólo se aplica a las palabras que han sido reconocidas, de manera que no se tendrán en cuenta posibles errores debidos, por ejemplo, al borrado de palabras.
o Nivel de frase : Expresa la corrección de la frase en conjunto. Esta medida se realiza confrontando la frase reconocida con la trascripción de la frase original, de manera que ahora sí se tendrán en cuenta los posibles borrados de palabras.
- Modelos acústicos : Los modelos acústicos se construyen a partir de Modelos ocultos de Markov de los alófonos. Los alófonos aislados se tratan como HMM, con el objetivo de tener en cuenta la variabilidad que introducen los alófonos adyacentes en la pronunciación de cada alófono.
- Modelos lingüísticos : El conocimiento léxico, es decir, la definición del vocabulario y la pronunciación de las palabras son parte esencial de la sintaxis y semántica de la lengua y, como tales, definen reglas que determinan qué secuencias de palabras son gramaticalmente correctas y dan lugar a un discurso comprensible. En los reconocedores automáticos suelen emplearse modelos estocásticos del lenguaje, que modelan las características del idioma desde un punto de vista probabilístico. La clave de estos modelos consiste en proporcionar la información probabilística adecuada, de manera que las secuencias de palabras más comunes tengan mayor probabilidad. Esto no sólo mejora el resultado del reconocimiento, sino que contribuye a restringir el espacio de búsqueda del reconocedor, aumentando la rapidez del sistema.
- Grafos : El trabajo de reconocimiento se puede asimilar como un problema de búsqueda y los grafos son una de las herramientas más potentes para resolver este tipo de problemas. Permiten evaluar diferentes alternativas de actuación en base a una determinada función de coste, que asocia un valor a cada uno de los caminos que recorren el grafo.
Todo grafo consta de un conjunto de nodos y una serie de uniones entre ellos. Si el grafo es dirigido, dichas uniones reciben el nombre de flechas y son unidireccionales. En función del problema considerado, los nodos y las flechas constituirán sistemas de almacenamiento de información. [Lucas 2006]
6

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
1.1.3.- Variabilidad de la señal de voz
Aunque en la actualidad pueden construirse reconocedores muy precisos para un determinado locutor, con un lenguaje determinado y un estilo de hablar particular, en un entorno conocido y para una tarea concreta, todavía no somos capaces de crear un reconocedor que entienda a cualquier locutor, independientemente del entorno, el lenguaje o la tarea. [Huang 2001]
Es por esto que la precisión y la robustez son las últimas medidas a tener en cuenta para un resultado exitoso de los algoritmos de reconocimiento. Hay varias razones por las que los algoritmos o sistemas actuales no dan los resultados esperados por los usuarios. A continuación se describen algunos de ellos.
1.1.3.1.- Variaciones en el contexto
La interacción hablada entre las personas requiere un conocimiento del significado de las palabras y el contexto en el que son dichas. Palabras con significados muy diferentes pueden tener la misma pronunciación como, por ejemplo, vaca y baca.
En ocasiones se da el caso de que no sólo hay palabras que se pronuncian igual, sino que la combinación de dos de ellas, además de poder tener la misma pronunciación, tienen un significado semántico diferente como por ejemplo “toma té verde” o “tomate verde” que se pronuncian casi igual pero no tienen un significado parecido. Incluso disponiendo de la mejor información semántica y lingüística, es casi imposible descifrar la secuencia de palabras correcta a menos que el locutor haga pausas entre las palabras o utilice la entonación para distinguir entre estas frases confusas desde el punto de vista semántico.
Además de las posibles variaciones de contexto en los niveles de palabra y frase, también pueden encontrarse variaciones de contexto a nivel de fonema. En función del contexto, la realización de un fonema puede ser diferente. Esta dependencia del contexto se hace más evidente en habla rápida o espontánea en la que muchos fonemas no llegan a pronunciarse con precisión.
1.1.3.2.- Variaciones en el estilo
Para intentar solucionar los problemas de pronunciación, pueden imponerse unas condiciones para el uso de los reconocedores. Podemos tener un sistema de reconocimiento de habla aislada, en el cual el locutor debe realizar una pausa después de cada palabra, de modo que se eliminan los problemas derivados de la combinación de palabras con similar pronunciación. Además, el habla aislada proporciona un correcto contexto de silencios lo que facilita el modelado y decodificación del habla, reduciendo significativamente la complejidad computacional y la tasa de error. El problema es que este reconocedor de habla aislada no es natural para la mayoría de las personas.
7

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
En el reconocimiento de habla continua, la tasa de error la tasa de error para el habla espontánea que puede surgir en cualquier conversación diaria es mucho mayor que para un discurso cuidadosamente articulado y leído en voz alta. La tasa de habla también afecta a la tasa de reconocimiento de palabras. Generalmente, cuanto mayor es la tasa de habla (palabras/minuto) mayor es la tasa de error. Además, si una persona susurra o grita para reflejar sus estados emocionales, la variación se incrementa más significativamente.
1.2.3.3.- Variaciones en el locutor
Cada individuo habla de una forma diferente. La forma que la que una persona habla es el reflejo de una serie de características físicas, edad, sexo, dialecto, salud y educación. De esta manera, los patrones de habla de una persona pueden ser totalmente diferentes de los de otra. Incluso si eliminamos las diferencias debidas a locutores diferentes, un mismo locutor a menudo es incapaz de reproducir exactamente los mismos sonidos.
Para un reconocimiento independiente del locutor, se suelen crear modelos que combinan las características de miles de locutores. Para mejorar el funcionamiento de un reconocedor independiente del locutor, es necesario definir una serie de condiciones. Una podría ser definir un registro del usuario por el cual dicho usuario tenga que hablar durante, por ejemplo, 30 minutos. Con los datos y entrenamiento dependientes del locutor, podremos ser capaces de capturar varias características acústicas dependientes del locutor que puedan mejorar significativamente el funcionamiento del reconocedor. En la práctica, el reconocimiento dependiente del locutor permite no sólo mejorar la precisión sino también la velocidad, puesto que la decodificación puede realizarse de manera más eficiente al emplear un modelo acústico y fonético más apropiado. Un sistema de reconocimiento dependiente del locutor típico puede reducir el error de reconocimiento de palabras de forma significativa comparado con un sistema de reconocimiento independiente del locutor similar.
El problema de los sistemas dependientes del locutor es el tiempo que se necesita para obtener todos los datos del locutor, que resulta poco práctico desde el punto de vista de algunas aplicaciones como puede ser una operadora telefónica automática. Muchas aplicaciones deben funcionar con locutores desconocidos que trabajarán con el sistema durante un período determinado de tiempo, de manera que el reconocimiento independiente del locutor sigue siendo una característica importante. Cuando se dispone de una cantidad limitada de datos dependientes del locutor, es necesario emplear tanto los datos dependientes del locutor como los independientes empleando técnicas de adaptación al locutor, que se detallarán en el capítulo 6 puesto que el empleo de dichas técnicas constituyen uno de los objetivos de este Proyecto.
1.1.3.4.- Variaciones en el entorno
El mundo en el que vivimos está lleno de sonidos de distinta intensidad y procedentes de muy diversas fuentes. Cuando empleamos un ordenador, podemos tener a otras personas hablando en segundo plano, alguien puede cerrar de un portazo una puerta o el aparato de aire acondicionado puede comenzar a funcionar. Si el reconocimiento de habla se encuentra integrado en dispositivos móviles como teléfonos móviles o PDA’s (Personal Digital Assistants), los ruidos debidos al espectro varían más, principalmente porque el usuario se puede estar moviendo.
8

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
Todos estos parámetros externos como son el ruido ambiente o la colocación del micrófono pueden afectar en gran medida al funcionamiento del reconocedor. También hay que tener en cuenta que, además de los ruidos que pueda haber en segundo plano, el locutor también produce ruidos como pueden ser extraléxicos que emite cuando está dudando, por ejemplo. El ruido también puede provenir de los propios dispositivos de entrada como son los micrófonos o los convertidores A/D.
Al igual que sucede en el entrenamiento de un sistema independiente del locutor, podemos construir un sistema a partir de datos recogidos en numerosos y variados ambientes. Podemos emplear técnicas de adaptación para minimizar las diferencias entre los posibles entornos de manera similar a lo que hacíamos en un entrenamiento para adaptar a un locutor. Sin embargo, y a pesar de los progresos que se han llevado a cabo en este campo, las variaciones en el entorno siguen siendo uno de los mayores retos que deben afrontar los actuales sistemas de reconocimiento de habla.
1.1.4.- Prestaciones
En la actualidad, tal como comentábamos en el inicio de esta sección, no existen reconocedores perfectos, todos cometerán un cierto error a la hora de transcribir los mensajes acústicos que reciben. Algunos de los motivos que llevan a este reconocimiento erróneo pueden ser el entorno en que se obtiene la señal de voz (puede ser más o menos ruidoso) o la ausencia de referencias en el vocabulario (out of vocabulary). [Lucas 2006]
La calidad de un reconocedor se puede medir evaluando cada una de las palabras que constituyen la frase. Esto se hace así debido a la forma en la que se desarrolla el alineamiento y la confrontación de la frase reconocida con la transcripción escrita de la secuencia acústica de entrada, recogida en una base de datos de entrenamiento. De esta manera, al confrontar dos frases pueden darse los siguientes casos:
- Acierto: La palabra reconocida coincide con la original.- Sustitución: La palabra reconocida no coincide con la original sino con otra.- Borrado: El reconocedor no ha reconocido una palabra que sí se encontraba en
la frase original.- Inserción: El sistema introduce una palabra que no se encontraba en la frase
original.
A partir de estos valores se definen una serie de porcentajes que proporcionan información sobre la calidad del reconocedor:
- %aciertos =
(1.1)
- %sustituciones = (1.2)
- %borrados = (1.3)
9

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
- % inserciones = (1.4)
Realmente las tres primeras tasas constituyen el 100%, dado que el índice por el cual se normalizan es la longitud en palabras de la hipótesis y en esta no tiene sentido definir las inserciones, puesto que una inserción es un palabra ajena a la hipótesis que ha introducido el reconocedor.
La suma de las tres últimas tasas es el porcentaje de error del reconocedor:
%error = %sustituciones + % borrados + % inserciones (1.5)
El parámetro de mayor utilidad para la medida de las prestaciones de un reconocedor no es la tasa de palabras correctas, sino la tasa de precisión de palabra o word accuracy (WA) , definida como:
WA = 100% - %error = %aciertos - %inserciones (1.6)
1.2.- Proyecto “ROBINT”
En este capítulo explicaremos con un poco más de detalle en qué consiste el proyecto “ROBINT” (dentro del cual se enmarca el proyecto fin de carrera) su evolución y su situación actual.
1.2.1.- Evolución de los robots y la tecnología el habla
El planteamiento de este trabajo ha surgido de considerar la evolución en el desarrollo de robots y de la tecnología del habla, lo cual ha llevado en los últimos años, a abrir un importante campo de investigación en la creación de robots personales, capaces de interaccionar de forma más cercana con el hombre tratando de incorporarlos en sus entornos cotidianos como puede ser el doméstico, el lugar de trabajo, etc. [Marín 2006] Incluso, se ha planteado la posibilidad de que estos robots sean capaces de realizar tareas tradicionalmente abordadas únicamente por humanos.
Este nuevo campo de aplicación de los robots será completamente viable si se logra una comunicación óptima con los humanos. Esto tiene una doble implicación:
1. Estudiar nuevas técnicas de interacción y nuevos métodos de comunicación2. Mejorar la eficiencia de los ya existentes
Para que los robots sean aceptados en los entornos humanos, los niveles de comunicación o de interacción deben llegar a ser similares a los que aparecen en cualquier comunicación humano-humano cuando se mueven en su vida diaria. Una base importante de esa comunicación se basa sin duda en el lenguaje hablado.
10

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
1.2.1.1.- Robots Sociales
Se denominan robots sociales o sociables aquéllos que presentan las características necesarias para que el acercamiento al hombre resulte lo más natural posible. El hombre, como ser social, suele aplicar modelos sociales para explicar, comprender y predecir el comportamiento de lo que le rodea y ello justifica, en cierta medida, la necesidad de tener robots sociales o sociables.
Tradicionalmente, el término robots sociales se aplicaba a sistemas multi-robot en los cuales la motivación procedía del comportamiento colectivo de seres vivos tales como insectos, pájaros, peces, etc. No obstante, ahora, el concepto de “lo sociable” ha migrado hacia la distinción entre estilo antropomórfico y la interacción hombre-robot. Este uso más moderno del término social está más ligado al comportamiento social antropomórfico, pero mantiene el término “sociable” para designar a una subclase dentro de los robots sociales.
Es frecuente que cuando una persona que interactúa con un robot autónomo aplique un determinado modelo social tratando de adaptarse a las circunstancias. Un robot autónomo es capaz de percibir su entorno, tomar decisiones por sí solo y desarrollar acciones destinadas a llevar a cabo la tarea asignada. Como los seres vivos, su comportamiento es fruto de la combinación entre su estado interno y las leyes físicas. Un comportamiento orientado a sí mismo, unido a rasgos característicos de una criatura viva tales como la habilidad de comunicarse, cooperar y aprender de las personas, conducen a un intento de aplicar modelos antropomórficos, es decir, atribuirle características humanas o animales.
Si bien es cierto que el campo de los robots sociales es relativamente nuevo, ya existe una clasificación de los mismos en función de las habilidades que presenten para soportar el modelo social de entornos y escenarios complejos. Dicha clasificación se menciona brevemente a continuación:
- Socialmente evocador: Tiene como finalidad interaccionar con las personas haciendo que éstas les atribuyan características humanas.
- Socialmente comunicativo: Por medio del empleo de signos sociales humanos y modalidades de comunicación hacen que la interacción resulte más natural y familiar.
El robot Urbano pertenece a esta clase de robots. El modelo social que tiene el robot de las personas es poco profundo, puesto que sólo se dispone de una interfaz para valorar el comportamiento social, y actualmente, su comportamiento es “pregrabado”.
- Socialmente activo: Son robots que aprenden de la interacción con las personas a través de la demostración por parte de algún ser humano. La interacción con las personas afecta a la estructura interna del robot (reorganizando el sistema motor para desarrollar nuevos gestos, asociando etiquetas simbólicas a nuevas percepciones, etc.). Esta clase de robots tiende a dar más importancia a la percepción de pistas o signos sociales, permitiendo enriquecer la manera en que las personas entienden su comportamiento. Sin embargo, son socialmente pasivos respondiendo a los esfuerzos de la gente por
11

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
interaccionar con ellos pero no considerando a las personas de modo que éstas puedan satisfacer sus propios fines.
- Sociable: los robots sociables son criaturas socialmente participativas con sus propios fines y motivaciones internos. Interaccionan con las personas activamente de un modo social no sólo para beneficiar a la persona (ayudándola a realizar alguna tarea, facilitando la interacción con el robot, etc.), sino también buscando su propio beneficio (buscar su supervivencia, mejorar sus propias acciones, aprender de los humanos, etc.). La interacción social con la gente no se valora únicamente como una interfaz, sino que se considera en un nivel funcional.
1.2.1.2.- Interacción Hombre-Robot
La incorporación de robots en ambientes humanos exige dotar a éstos de mecanismos que les permitan una interacción bidireccional. Bajo el apelativo de bidireccional entendemos que el robot sea capaz de reconocer los signos implícitos del humano, y que el humano sea capaz de reconocer y distinguir en el robot los signos “normales” que un humano mostraría como reacción a la información intercambiada. Para que los robots sean aceptados dentro de nuestra sociedad, la comunicación hombre-máquina debe resultar inteligible y natural.
Generalmente, para lograr la comunicación hombre-máquina que acabamos de describir, es necesario contar con dos módulos:
- Entrada multimodal: Análisis de imágenes (visión), análisis de habla (voz) y análisis de la escritura manual.
- Salida multimedia: Síntesis de voz, de imágenes, de gráficos por computador y de animación.
1.2.2.- Proyecto ROBINT
El proyecto ROBINT (DPI2004-07908-C02-02) es continuación del proyecto URBANO que contempla, la “Integración de Robots Autónomos en la Sociedad mediante el Uso de Nuevas Tecnologías: DPI2001-3652-C02”).
El Robot Urbano es el resultado de varios años de investigación del departamento de automática, ingeniería electrónica e informática industrial de la Universidad Politécnica de Madrid y del Grupo de Tecnología del Habla del Departamento de electrónica de la Universidad Politécnica de Madrid (UPM).
El objetivo general es introducir el uso de robots como guías en ferias y museos. El robot va a interaccionar dentro de una feria o museo en el que hay una multitud de visitantes. Se trata de conseguir que los asistentes tengan una experiencia única, compartiendo un entorno con robots inteligentes, y que exista la posibilidad de una interacción entre los hombres y las máquinas.
12

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
El proyecto comenzó a desarrollarse el 13 de diciembre de 2004, y su duración fue de tres años. Durante este periodo, el objetivo global fue profundizar en el modelado e implementación de comportamientos inteligentes en robots-guía, lo cual está íntimamente ligado al modelado de emociones y diálogo, síntesis, reconocimiento y comprensión automáticos de habla. Por último, este proyecto abre las puertas a dos líneas de investigación que, en la actualidad, cuentan con amplias perspectivas de futuro y están experimentando un notable impulso en los últimos años: por un lado, el interfaz hombre-robot, y por otro, el comportamiento cognitivo y el aprendizaje.
1.2.2.1 Definición del sistema
A continuación se enumeran las características mediante las cuales podría quedar definido el sistema:
- Movilidad: El sistema se compone de un cuerpo artificial que da al robot cierta capacidad de movimiento.
- Autonomía: Entendemos como tal que el robot posea cierto nivel de inteligencia.
- Interacción con el exterior: Es posible interaccionar con el robot a través de Internet y de manera presencial. Además, el lenguaje hablado será otro método de interacción con el mismo.
- Usuarios: Cualquier persona puede interactuar con el robot.
- Módulos: El sistema se compone de una seria de módulos que permiten implementar las siguientes funciones:
o Navegación: Control reactivo y SLAM basado en láser de proximidad.
o Web: Control del robot para realización de visitas remotas.o Habla: Reconocimiento y síntesis de voz, gestión de diálogos.o Cabeza: Expresión de emocioneso Kernel: Coordinación de los módulos y gestión de las
comunicaciones.o Inteligencia: Toma de decisiones y gestión de comportamientos del
robot.o
1.2.2.2.- Implementación
Agrupados por líneas de investigación, entre los objetivos del proyecto cabe reseñar los siguientes:
- Navegación: Mejora del método de localización y modelado simultáneos (SLAM, Simultaneous Localization and Mapping).
- Consciencia y emociones: Desarrollo de modelos de consciencia, diseño de una metodología de desarrollo y su implementación. Generación de modelos de emociones del robot, como reacción ante eventos de entrada.
13

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
- Conocimiento: Modelado del conocimiento sobre el que el robot “trabaja” (presenta, enseña, explica) y sus interrelaciones; modelado del conocimiento “social” necesario para interactuar con su entorno.
- Diálogo: Mejora de la síntesis de una voz adecuada para un robot que incluya emociones; reconocimiento de habla continua, procesamiento del lenguaje natural para conseguir una comprensión semántica del diálogo mantenido y adaptación de los modelos acústicos al locutor y a la tarea a realizar para que mejore la tasa de reconocimiento.
Este proyecto fin de carrera se encuentra especialmente enfocado hacia el último de los puntos, con la idea de que el sistema de reconocimiento de habla permita facilitar y mejorar la tarea de navegación.
1.3.- Objetivos y fases del proyecto
1.3.1.- Objetivos
En base a lo anteriormente expuesto, los objetivos que se han definido para la realización de este proyecto fin de carrera son los siguientes:
1.3.1.1.- Adaptación de los modelos acústicos
Como hemos indicado anteriormente, el robot se moverá por diversos lugares y no siempre interactuará con los mismos locutores. Es por este motivo que se ha definido este objetivo de manera que el sistema sea capaz de adaptar los modelos acústicos genéricos de que dispone a un locutor y unas características acústicas del entorno concretas.
Para llevar a cabo este proceso, se creará un interfaz gráfico sencillo para que el usuario del sistema pueda especificar las características del entorno y la tarea que va a llevar a cabo sin necesidad de dedicar horas al estudio del mismo. También se pretende reducir el tiempo de grabación que el locutor deberá llevar a cabo para que el sistema pueda modificar y adaptar los modelos genéricos a sus características de una manera fiable.
1.3.1.2.- Guiado del robot
Actualmente, cuando el robot llega a un lugar cuyo mapa desconoce, una de las personas responsables del mismo o maestro, recorre el nuevo lugar junto con el robot manejándolo mediante un mando analógico e introduciendo manualmente etiquetas que definan lugares o zonas especiales como pueden ser los puntos en los que el robot deberá dar una explicación o zonas peligrosas para la integridad física del robot a las que no deberá acercarse.
Este objetivo se centra en realizar un estudio inicial para el proyecto robonauta que seguirá a éste, en el que se realizará un prototipo del sistema de guiado del robot mediante comandos de voz. Definir y preparar una propuesta de gramáticas que
14

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
permitan al maestro guiar al robot mediante la voz sin necesidad de emplear el mando analógico. De esta manera se permite una mayor versatilidad y libertad a la hora de recorrer un nuevo escenario, definir etiquetas y comprobar que el robot ha generado un mapa correcto del lugar con las etiquetas asociadas al mismo.
1.3.1.3.- Aprendizaje automático
El sistema de comprensión que emplea el reconocedor de habla para que el robot sea capaz de traducir las frases que los usuarios le dicen por comandos que comprenda puede realizar dicha traducción mediante el empleo de dos técnicas:
- Reglas contextuales- Método estocástico
En la versión del reconocedor de la que se partió, no se encontraba en funcionamiento el aprendizaje mediante el empleo de reglas contextuales. Este objetivo tiene como fin activarlas y utilizarlas según desee el usuario, así como modificar las medidas de confianza del reconocedor para que estime la confianza de un reconocimiento a partir de las palabras que realmente aportan información.
1.3.2.- Fases del proyecto
Para llevar a cabo los objetivos que acabamos de definir, hemos dividido el trabajo en cuatro fases de investigación y desarrollo estructuradas en base al cumplimiento y requisitos de los mismos.
En la primera fase se llevará a cabo un estudio del sistema y simplificación del mismo mediante la definición de métodos que encapsulen tareas concretas que hasta ahora se realizaban como parte del método principal, permitiendo de este modo que sean empleados por otros métodos o hebras. También se ha llevado a cabo una simplificación y reducción de los ficheros de configuración que necesita el sistema de manera que el usuario pueda encontrar de una manera más sencilla las variables que desea modificar.
La segunda fase se centra en la fase de adaptación. Ésta a su vez puede dividirse en tres etapas, cada una de ellas orientada a la consecución de un subobjetivo para conseguir la adaptación.
- Primera etapa : Crear una interfaz gráfica que le permita al usuario introducir las características de la situación a la cual quiere adaptar el sistema, así como poder grabar de forma sencilla las frases que sean necesarias para llevar a cabo el proceso de adaptación de los modelos.
- Segunda etapa : Crear los scripts que lleven a cabo todo el proceso de adaptación a partir de los scripts ya existentes de Linux. Esto implica dar el formato correcto a los ficheros que se vayan a emplear y realizar las llamadas a los distintos programas que constituyen la herramienta HTK.
- Tercera etapa : Llevar a cabo pruebas en distintos contextos que permitan validar la adaptación realizada.
15

Proyecto Fin de CarreraNuria Pérez Magariños 1.- Introducción
La tercera fase está enfocada a la definición y validación del vocabulario y la gramática que permitirán llevar a cabo la tarea, mediante el estudio de los requisitos de la misma.
La cuarta y última fase engloba las actividades que nos permitirán aplicar el aprendizaje incremental de reglas contextuales para acelerar dicho proceso, así como mejora de las técnicas de medida de confianza de manera que se lleve a cabo un filtrado de las palabras fuera de vocabulario, de aquellas palabras que no aporten información a la frase. También se pretende permitir la posibilidad de que se pueda asociar más de un comando a cada una de las frases definidas en el vocabulario de forma que el diálogo con el robot pueda realizarse de forma parecida al lenguaje natural.
16

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
2.- DESCRIPCIÓN DE LAS TÉCNICAS Y HERRAMIENTAS EMPLEADAS
En este capítulo se realizará un estudio de las técnicas y herramientas que se emplearán en el desarrollo de este Proyecto así como un análisis de los proyectos fin de carrera que lo precedieron.
2.1.- Técnicas empleadas
2.1.1.- Adaptación
Como se comentó en el primer capítulo el objetivo de las técnicas de adaptación es desarrollar un sistema de reconocimiento con prestaciones similares a las de un robusto sistema entrenado, pero empleando una cantidad muy reducida de datos. [Díaz 2002]
En base a lo expuesto anteriormente, llevaremos a cabo dos adaptaciones:
- Adaptación a tarea : En este caso modificaremos los modelos ya existentes mediante diversas técnicas para aproximarlos a las características de la nueva tarea.
- Adaptación a locutor: A partir de una pequeña cantidad de datos, modificaremos unos modelos previos independientes del locutor, de forma que se ajusten a las características vocales del locutor que vaya trabajar e interactuar con el robot.
Existen varias técnicas para adaptar el sistema entre las que destacan dos:
- Regresión Lineal de Máxima Verosimilitud (MLLR): Consiste en aplicar un conjunto de transformaciones lineales a los parámetros de los modelos de partida para ajustarlos a los datos de adaptación. El cálculo de dichas transformaciones lineales se realiza buscando maximizar la verosimilitud con los datos de entrenamiento.
La técnica MLLR no calcula una transformación lineal para cada una de las gaussianas a adaptar, sino que agrupa las gaussianas parecidas entre sí y genera una única transformación para todas ellas. Esto permite adecuar el número de transformaciones lineales a estimar a la cantidad de datos disponibles para la adaptación.
- Máximo a Posteriori (MAP): Esta técnica se basa en el conocimiento previo de la distribución de los parámetros de los modelos. Este conocimiento previo son los modelos de partida para la adaptación, que nos permitirá realizar una estimación fiable de los modelos acústicos del sistema adaptado con una reducida cantidad de datos de adaptación.
La adaptación MAP consiste en estimar los nuevos parámetros acústicos de los modelos de modo que se maximice la verosimilitud de la distribución a posteriori. Cada uno de los parámetros acústicos se adapta por separado, a diferencia de MLLR que agrupa varias gaussianas formando una clase de regresión y las adapta juntas.
17

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Como ha podido verse, ambas técnicas se basan en modificar los modelos acústicos del sistema de partida. MLLR y MAP pueden adaptar las medias, las varianzas y los pesos de las gaussianas, así como las probabilidades de transición entre estados. En general, las características más específicas de un nuevo locutor o tarea conciernen por orden de importancia a las medias, a las varianzas, a los pesos y, por último, a las probabilidades de transición. Es por esto que lo más común es no adaptar la matriz de transiciones, sino modificar únicamente las medias, ya que en ellas reside la mayor parte de la información específica de la nueva tarea o locutor.
El usuario de nuestro sistema podrá elegir cuál de estas dos técnicas desea aplicar para adaptar el sistema a su voz y a la tarea que está realizando, por lo que a continuación las explicaremos con un poco más de detalle.
2.1.1.1.- Regresión Lineal de Máxima Verosimilitud (MLLR)
Esta técnica, conocida por el acrónimo de sus siglas en inglés (Maximum Likelihood Linear Regresion), consiste en calcular un conjunto de transformaciones lineales que, aplicadas sobre los modelos de partida, los ajusten a los datos de adaptación. Más concretamente, MLLR se basa en estimar un conjunto de transformaciones lineales para modificar los parámetros de las medias y varianzas de las gaussianas del sistema de partida, de forma que se maximice la verosimilitud con los datos de adaptación. [Díaz 2002]
No vamos a detallar el conjunto de ecuaciones que permiten modificar los parámetros acústicos del sistema de partida, pero presentaremos de forma superficial las ecuaciones de transformación de las medias, para ilustrar el funcionamiento de la técnica MLLR. Básicamente, los parámetros de las medias de las gaussianas son adaptados con la siguiente expresión:
(2.1)
donde A es la matriz de transformación n×n, y b es un vector de offset de dimensión n (siendo n la dimensión de las observaciones, que en nuestro caso es 39). Como sabemos, las medias iniciales y adaptadas son también vectores de n valores. Para estimar A y b se emplea el algoritmo Expectation-Maximisation (EM).
En nuestro caso los vectores de las observaciones tienen parámetros estáticos, delta y aceleración. En esta situación se obtiene aproximadamente la misma eficiencia en la adaptación empleando matrices A de forma diagonal en bloques (block diagonal), en lugar de matrices completas.
(2.2)
18

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Estas matrices diagonales en bloques tienen como base asumir que, para la adaptación, no hay correlación entre los parámetros estáticos, delta y aceleración. En la práctica esta suposición funciona bastante bien y proporciona resultados similares al caso de considerar una matriz A completa. El formato diagonal en bloques reduce el número de parámetros de transformación a estimar, lo cual hace más rápido el proceso de adaptación y disminuye el número de datos de adaptación necesarios. En cuanto a los requerimientos de almacenamiento, la matriz diagonal en tres bloques precisa una capacidad de almacenamiento mucho menor que la matriz completa. En el extremo, podría pensarse en trabajar con matrices A diagonales, pero en la práctica sus resultados quedan muy alejados de los obtenidos con matrices diagonales en bloques.
En el caso de la matriz de transformación de las varianzas, y dada la menor importancia de éstas en la adaptación, es común trabajar con matrices diagonales que son almacenadas como un simple vector.
El método de adaptación MLLR puede ser aplicado de manera muy flexible dependiendo de la cantidad de datos de adaptación disponibles. Esta propiedad se basa en que una misma transformación puede aplicarse a un número elevado de gaussianas, lo que además acelera el proceso de adaptación. Cuando sólo disponemos de un número reducido de datos podemos aplicar una transformación global. En este caso se calcula una única transformación que se aplicará a todas las gaussianas de los modelos de partida. Del mismo modo, si dispusiésemos de un mayor número de datos de adaptación, incrementaríamos el número de transformaciones, de forma que ahora cada transformación será más específica y se aplicará sólo a ciertos grupos de gaussianas. El hecho de compartir una misma transformación entre varias gaussianas hace posible adaptar estados para los que no tenemos ninguna observación en los datos de adaptación, lo cual es una ventaja clara de la técnica MLLR.
Para determinar el número adecuado de transformaciones, y los grupos de gaussianas a los que se aplicará cada una, MLLR emplea árboles de clases de regresión (regresion class tree). El trabajo con árboles de regresión presenta especiales ventajas para la adaptación dinámica, ya que el proceso de adaptación se podrá ir refinando según hay más datos de adaptación disponibles.
El árbol de clases de regresión se construye de forma que las gaussianas que están próximas en el espacio acústico pertenezcan al mismo nodo. El árbol es construido utilizando los modelos de partida, luego es independiente de la nueva tarea o locutor al que estamos adaptando. Para generar el árbol empleamos un algoritmo divisor de centroides que hace uso de la métrica de la distancia. Comenzamos con todas las gaussianas agrupadas en el nodo raíz, y vamos dividiendo hasta obtener el número deseado de nodos terminales, llamados clases base (base classes).
19

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Figura 4: Árbol de regresión con cuatro clases [Díaz 2002]
En la figura anterior mostramos un ejemplo de un árbol de regresión con cuatro clases de base: los nodos 4, 5, 6 y 7. MLLR emplea un algoritmo de arriba abajo ( top-down) para recorrer el árbol de clases de regresión. Así, comenzamos con el nodo raíz y vamos descendiendo en el árbol, de forma que se generarán transformadas para los nodos que cumplan las siguientes condiciones:
- Dichos nodos han de tener un número suficiente de datos de adaptación.- Deben ser, o bien nodos terminales, o bien tener algún descendiente con un
número insuficiente de datos de adaptación.
La cantidad de datos considerada como suficiente se determina mediante un umbral de ocupación. Dicho umbral representa el número de tramas o vectores de observación considerado suficiente para estimar adecuadamente una transformación, y puede ser ajustado según nuestras necesidades.
Volviendo al ejemplo anterior, los nodos sombreados indican que poseen un número suficiente de datos de adaptación. Sin embargo, sólo se generarán transformadas para los nodos 2, 3 y 4, y las llamaremos W2, W3 y W4. Para el nodo 1 no generamos transformada ya que sus dos hijos tienen un número de datos suficiente. Estas tres transformadas se aplicarán a las gaussianas de las cuatro clases base según el siguiente esquema: W2 se empleará con la clase de base 5, W3 se aplicará a las clases de base 6 y 7 y W4 se utilizará para la clase de base 4.
El control del proceso de adaptación MLLR se ejerce mediante la elección del número adecuado de transformaciones lineales, que puede modificarse variando el umbral de ocupación y manteniendo fijo el número de clases de base del árbol de regresión o viceversa, manteniendo fijo el umbral de ocupación y variando el número de clases de base del árbol de regresión.
20

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
2.1.1.2 Máximo a posteriori (MAP)
La técnica de adaptación MAP, también llamada adaptación Bayesiana, se basa en la utilización de un conocimiento previo acerca de la distribución de los parámetros de los modelos. Dicho conocimiento podemos emplearlo para conocer de forma aproximada cómo van a ser los parámetros de los modelos, antes incluso de tener los datos de adaptación. De este modo podremos generar una estimación aceptable de los modelos adaptados con un número reducido de datos de adaptación. El conocimiento previo del que estamos hablando son los modelos que empleamos como punto de partida para la adaptación. [Díaz 2002]
La mayoría de los sistemas de reconocimiento de habla basados en HMM son entrenados empleando un procedimiento de reestimación de máxima verosimilitud (Maximum Likelihood o ML). Los valores de los parámetros acústicos, λ, son reestimados de forma que la verosimilitud, p(x|λ), de los datos de entrenamiento, x, sea maximizada. De un modo similar, la técnica de adaptación MAP estima los modelos tratando de maximizar la siguiente distribución p(x|λ)*p0(λ), llamada distribución a posteriori. En la expresión anterior, p0(λ) es la distribución de los parámetros de los modelos de partida.
Al igual que hicimos en MLLR, trataremos de ilustrar la explicación anterior mostrando la fórmula empleada para adaptar las medias. Si disponemos de un conjunto de adaptación compuesto por R observaciones Or, la expresión para adaptar la media de la gaussiana m en el estado j es:
(2.3)
Donde μjm es la media del sistema de partida para la adaptación, Lrjm (t) representa la
probabilidad de que la gaussiana m del estado j en el instante t emita la observación or, y or
t es el vector de adaptación r en el instante t. El parámetro τ se emplea para ajustar el equilibrio entre el efecto de los datos de adaptación y el efecto de los valores de los modelos de partida. Por tanto, es este parámetro el que controla el proceso de adaptación MAP. Se le suelen asignar valores en el intervalo entre 2 y 20, y su comportamiento se explica a continuación.
- Valores altos de τ conceden más peso en la expresión (2.3) a los valores de los modelos de partida. Es fácil observa que cuando τ tiende a infinito la expresión queda como sigue:
(2.4)
- Valores bajos de τ implican potenciar el efecto de los datos de adaptación. Es más, cuando τ tiende a cero, la expresión adquiere la misma forma que la ecuación de reestimación de las medias del algoritmo de Baum-Welch, como mostramos a continuación.
21

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
(2.5)
La técnica de adaptación MAP presenta una ventaja fundamental: cuando la cantidad de datos de adaptación es elevada, la estimación que proporciona de los parámetros de los modelos converge con la reestimación de máxima verosimilitud (ML). Es decir, los resultados obtenidos de la adaptación a tarea o locutor convergen con los que proporcionaría un sistema robusto entrenado desde cero. Esto hace que los resultados obtenidos sean claramente superiores a MLLR.
Sin embargo, MAP presenta dos desventajas fundamentales frente a MLLR. En primer lugar, MAP es una técnica que se aplica gaussiana a gaussiana, luego sólo los parámetros que disponen de datos de adaptación serán actualizados. Esto quiere decir que cuando el número de datos de adaptación es muy reducido, la capacidad de aprovechamiento de los mismos que tiene MLLR es muy superior a MAP.
En segundo lugar, en el caso de MLLR, el cálculo de una misma transformación se emplea para varias gaussianas, mientras que MAP ha de adaptar una a una todas las mezclas, lo que implica que el tiempo de ejecución del algoritmo MAP es muy superior al del algoritmo MLLR, y dependiente de la cantidad de datos de adaptación. En nuestro caso este problema se reduce muy significativamente debido al reducido vocabulario que manejamos.
2.1.2.- Etiquetado automático
El primer paso para la realización de un análisis de un texto es el etiquetado morfosintáctico (POS tagging) o categorización de sus palabras o expresiones [Montero 2003]. Podemos dividir este problema en 2 sub-problemas: las palabras fuera de vocabulario (cobertura léxica) y las palabras presentes en el diccionario (desambiguación).
2.1.2.1.- Preprocesamiento
El procesamiento de texto sin restricciones requiere la normalización del texto de entrada, procesando las palabras consideradas como no-estándar: nombres propios, fechas y horas, letras aisladas, palabras con signos de puntuación, acrónimos, expresiones numéricas (árabes o romanas), abreviaturas, nombres propios, palabras mal escritas, expresiones relacionadas con Internet, etc.
2.1.2.2.- Técnicas de desambiguación en el etiquetado morfosintáctico
Existen diversas escuelas dentro del procesamiento de lenguaje natural, no siempre disjuntas: métodos estocásticos, métodos simbólicos, clasificadores, métodos automáticos basados en corpus (data driven), métodos manuales. Nosotros nos centraremos principalmente en dos de ellos:
22

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Métodos estocásticos basados en modelos de Markov : Los modelos pueden ser discretos de orden 1 o 2 y en frecuencias de coocurrencia. Son equivalentes a los llamados n-gramas con programación dinámica. Como suele suceder con las técnicas estocásticas es necesario suavizar los modelos para tener en cuenta la escasez de los datos (data sparsity), produciéndose significativos cambios según el tipo de suavizado. También es habitual el empleo de heurísticos o biases, para mejorar su tasa máxima, produciéndose así una convergencia con métodos basados en conocimiento.
Una de las ventajas de este método estocástico es que permite ordenar hipótesis, pudiendo ser utilizado en procesos de desambiguación no completa. También nos permiten obtener un ordenamiento de las posibles soluciones, así como obtener medidas de confianza sobre el etiquetado obtenido. Aunque por medio de la programación dinámica es capaz de modelar fenómenos globales como la propagación de género y número, no puede modelar otras relaciones de larga distancia como la rección verbal, aunque se trata de técnicas inevitables por su robustez.
Métodos simbólicos basados en reglas de transformación : Inicialmente se le asigna a cada palabra su etiqueta más probable según un diccionario; luego se va transformando esta etiqueta en función del contexto.
Las principales objeciones que realizar a la técnica TBL son el coste computacional de su entrenamiento (crece cuadráticamente con el número de palabras multiplicado por el número de posibles patrones de reglas) y el hecho de que, partiendo de una información morfosintáctica completa en forma de lexicón, se quede con la etiqueta más probable de cada palabra, procediendo a continuación a corregir algunos de los errores cometidos; las reglas de transformación no tienen en cuenta las posibilidades incluidas en el diccionario.
2.2.- Herramientas empleadas
2.2.1.- HTK
Una parte importante del proyecto se centra en la adaptación del sistema de reconocimiento al hablante. Para poder llevar a cabo este proceso de adaptación se ha empleado el conjunto de herramientas HTK. [Díaz 2002]
Dichas herramientas están diseñadas para la construcción de modelos ocultos de Harkov (HMM, Hiden Markov Models). El núcleo de HTK está dividido en dos procesos claramente diferenciados:
Herramientas de entrenamiento : Se utilizan para estimar los parámetros de un conjunto de HMM, empleando locuciones de entrenamiento y sus transcripciones asociadas.
23

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Herramientas de reconocimiento : Su finalidad es obtener las transcripciones de locuciones desconocidas.
A continuación se procederá a una breve explicación de la funcionalidad de las herramientas del HTK que se han empleado para la realización de este proyecto. [HTK]
2.2.1.1.- HLEd
En el proceso de adaptación trabajamos con las transcripciones de los ficheros de audio, que son las etiquetas asociadas al mismo. Cuando el número de ficheros que deben ser procesados es elevado, conviene manejar las transcripciones mediante un fichero maestro de etiquetas (MLF, Master Label File). Un MLF es un fichero indexado que contiene las transcripciones de todos los ficheros con los que estamos trabajando. Dichas transcripciones pueden ser a nivel de palabra, de alófono o de trifonema, según a qué correspondan cada uno de los segmentos en que están divididos los ficheros de voz.
#!MLF!#"*/nuria_0_15.lab"túquiéneres."*/nuria_0_19.lab"cómoestás.
Cuadro 1: Ejemplo de MLF a nivel de palabra
Para editar y modificar los ficheros de etiquetas emplearemos la herramienta HLEd, que puede verse como un intérprete de comandos de edición. Los comandos de edición son órdenes simples que realizan modificaciones muy concretas en las transcripciones. La secuencia de comandos de edición se guarda en un edit-script que ejecutará HLEd.
El uso principal que se ha dado a HLEd en el proceso de adaptación ha sido la conversión de un MLF a nivel de palabra en un MLF a nivel de alófono, y éste en un MLF a nivel de trifonema.
Lo ilustramos con el siguiente ejemplo a partir de la frase: “¡A comer!”. SENT-START representa el silencio inicial y SENT-END el silencio final.
SENT-START a comer SENT-END
La trascripción a nivel de alófono sería:
sil ‘a sp k o m ‘e r sil
y por último tenemos la trascripción de trifonemas internos, es decir, un fonema en el contexto de otros dos:
sil ‘a sp k+o k-o+m o-m+’e m-‘e+r ‘e-r+sil sil
24

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
2.2.1.2.- HCopy
Es una herramienta de propósito general que se emplea para copiar, filtrar y extraer features de los ficheros de audio.
Por defecto HCopy realiza una simple copia del fichero de origen en el fichero destino. Dicho comportamiento puede modificarse con las opciones especificadas en el fichero de configuración. En este fichero pueden detallarse un conjunto de transformaciones y que se aplican sobre el fichero origen y se guardan en el fichero destino. La idea es que exista un tipo de parámetros origen y un tipo de parámetros destino de forma que, especificando dichos tipos en el fichero de configuración, HCopy realice la conversión entre ambos formatos.
Se emplearán como parámetros de origen el formato de los ficheros de audio generados en la fase de reconocimiento, que son del tipo .WAV. Los parámetros de destino son del tipo predicción lineal perceptiva (PLP).
El motivo de la elección de ese tipo de parámetros de salida es que este tipo de parametrización es una combinación de las dos principales familias de parámetros empleadas en el proceso de habla: el análisis espectral y el análisis de predicción lineal. La técnica PLP tiene en cuenta el efecto fisiológico de las señales acústicas sobre el oído humano, tratando de compensar de este modo la variación de la sensibilidad del oído con la frecuencia y la intensidad sonora.
2.2.1.3.- HCompV
Este programa calcula la media y la covarianza de un conjunto de datos de entrenamiento. Lo emplearemos en la fase de normalización Cepstral ya que trabajaremos con dos tipos de normalizaciones: normalización cepstral de la media (CMN, Cepstral Mean Normalisation) y normalización cepstral de la varianza (CVN, Cepstral Variance Normalisation).
CMN, Normalización cepstral de la media
En el dominio de la frecuencia, el efecto de insertar un canal de transmisión es multiplicar el espectro de la voz por la función de transferencia del canal. En el dominio logarítmico de los coeficientes cepstrales esta multiplicación se convierte en una sencilla suma, que puede ser eliminada restando la media cepstral a todos los vectores de parámetros.
En la práctica, la media se estima a partir de una cantidad limitada de datos, de forma que la cancelación del efecto del canal de transmisión no es perfecta. La media se estima calculando el promedio de cada parámetro cepstral a lo largo del fichero o agrupación de ficheros en cuestión. Es importante destacar que CMN se aplica a los coeficientes estáticos, luego se calculan los coeficientes delta y aceleración, y por último se realiza CVN sobre los tres tipos de coeficientes.
25

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Respecto a la aplicación de CMN, el resultado de la estimación de las medias cepstrales de los coeficientes estáticos se guarda en un fichero. De modo que las herramientas de HTK que necesiten trabajar con CMN tendrán que restar a cada fichero de parámetros su correspondiente fichero de medias durante la ejecución.
CVN, Normalización cepstral de la varianza
De un modo paralelo, también podemos normalizar la varianza de los parámetros cepstrales. Con esto logramos que los márgenes de variación de los parámetros en todos los ficheros de la base de datos sean similares, hecho que favorecerá el entrenamiento de los HMM. CVN se realiza normalizando a 1 la varianza del fichero en cuestión dividiendo todos sus vectores de parámetros por su varianza cepstral, y multiplicando posteriormente por la varianza global.
La estimación de la varianza cepstral se obtiene calculando la varianza de cada parámetro cepstral a lo largo de ese fichero o agrupación de ficheros. Y por varianza global nos referimos a la varianza de los parámetros cepstrales calculada a lo largo de toda la base de datos. Al igual que CMN, CVN también se realiza en tiempo de ejecución.
2.2.1.4.- HERest
En nuestro sistema partimos de unos modelos generales, siendo el objetivo de la fase de adaptación entrenarlos y adaptarlos al hablante. Este es un proceso iterativo en el que se irán introduciendo sucesivas mejoras en los modelos y se reestimarán sus parámetros.
Los datos de entrenamiento consisten en grabaciones de voz y no disponemos de las divisiones temporales entre la secuencia de modelos que componen cada locución. Es por esto que seguimos un esquema de entrenamiento no segmentado (embedded training) empleando HERest.
2.2.1.5.- HHEd
HHEd es una herramienta que permite realizar modificaciones en un conjunto de HMM. Al igual que sucede con HLEd, esta herramienta puede verse como un intérprete de comandos de edición.
HHEd toma como entrada un conjunto de HMM y devuelve como salida otro conjunto de HMM modificado. La secuencia de comandos de edición que HHEd debe aplicar se le pasa en un fichero edit-script. Algunos de los comandos que pueden aparecer en este edit-script son:
26

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
TI T_a {("a").transP}AT 1 3 0.2 {"'u".transP}
Cuadro 2: Instrucciones de un edit-scrip de HHEd
La primera instrucción es asociar los elementos de la lista que aparece entre llaves con la macro que le precede, en este caso “T_a”. La segunda instrucción es, en nuestro caso, añadir una transición del estado 1 al 3 con probabilidad 0.2 para las matrices de transición que aparecen entre llaves.
2.2.1.6.- HVite
HVite es una herramienta de reconocimiento de voz que emplea el algoritmo un algoritmo de paso de testigo (token passing) que se describirá a continuación. HVite recibe como entrada una red de palabras (word network) donde se especifican las secuencias de palabras permitidas, y un diccionario en el que cada palabra se asocia con su correspondiente modelo de Markov. La red de palabras se expande con la información del diccionario para obtener una red de modelos, que puede verse en un nivel inferior como una red de estados. La Figura 5 ilustra esta jerarquía de niveles de reconocimiento: palabra, modelo y estado.
Figura 5: Jerarquía de los niveles de reconocimiento
Dada una secuencia desconocida de T observaciones, cualquier camino entre el nodo inicial y el nodo final que pase por T estados emisores es potencialmente una hipótesis de reconocimiento. Cada uno de estos caminos tiene una probabilidad calculada sumando las probabilidades logarítmicas de todas las transiciones entre estados y las probabilidades logarítmicas de que cada estado emisor genere el correspondiente vector de observación. Las transiciones entre estados de un mismo modelo están determinadas por los propios parámetros del modelo en cuestión. Sin embargo, las transiciones entre los modelos de una misma palabra tienen asignada una probabilidad constante, y las transiciones entre palabras están determinadas por la verosimilitud del modelo de lenguaje especificado en la red de palabras.
27

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
El objetivo del reconocedor en encontrar de entre todos los caminos posibles, aquél que posee la máxima probabilidad. Para ello se emplea el algoritmo de paso de testigo.
4.2.6.1.- Algoritmo de paso de testigo
Supongamos que en el instante t todos los estados j poseen un testigo (token) que contiene la verosimilitud parcial Фj (t). [Díaz 2002]
donde aij es la probabilidad discreta de la transición del estado i al estado j y bj (ot) es la probabilidad de que, en el instante t, la observación ot fuera emitida por el estado j.
Un testigo representa un camino parcial a través de la red de reconocimiento que se extiende desde el instante 0 hasta el instante t, es decir, representa la probabilidad parcial de haber observado las primeras t tramas y estar en el estado j en el instante t.
El algoritmo de paso de testigo comienza poniendo un testigo en cada uno de los posibles nodos iniciales de la red de reconocimiento. A continuación, en cada instante de tiempo, los testigos se propagan a través de las transiciones de la red hasta llegar a un estado emisor. Cuando un nodo tiene varias salidas, el testigo es copiado y propagado por cada una de ellas, explorándolas todas en paralelo. Este algoritmo se basa en los siguientes aspectos:
Cuando un testigo pasa de un estado i a un estado j, su verosimilitud logarítmica parcial se ve incrementada por las correspondientes probabilidades de transición y de salida.
(2.6)
Cada nodo de la red sólo puede tener un testigo, de modo que escogemos el testigo con la mayor verosimilitud y eliminamos el resto.
La verosimilitud parcial no es la única información que contiene un testigo. Además deberá tener como mínimo un registro de las palabras por las que ha pasado. Sin embargo, en algunas aplicaciones podría ser interesante incluir información temporal o de la secuencia de modelos o estados.
Típicamente las redes de reconocimiento poseen muchos nodos, implicando tiempos de ejecución del reconocedor elevados. Una forma de acelerar el tiempo de cálculo es propagar los testigos sólo por los caminos que parezcan más probables a priori. Este proceso se conoce como pruning y se implementa manteniendo un registro del mejor testigo en cada instante de tiempo, de modo que desactivamos todos los testigos cuyas probabilidades bajen un cierto margen respecto del mejor testigo.
Como ya hemos comentado, las probabilidades de transición entre palabras vienen dadas por el modelo de lenguaje especificado mediante la red de palabras. Sin embargo, HVite posee además dos parámetros de ajuste del reconocedor. Estos parámetros son:
28

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Penalización por inserción de palabra ( Word insertion penalty ) : Es un valor fijo que se suma a cada testigo que pase de una palabra a otra.
Factor de escala gramatical ( grammar scale factor ) : Es un valor que premultiplica la probabilidad logarítmica del modelo de lenguaje antes de sumarse al testigo cuando pasa de una palabra a otra.
Ajustando estos dos parámetros podemos modificar el comportamiento del reconocedor en cuanto a los errores de inserción y de borrado.
2.2.1.7.- HResults
Una vez que el conjunto de datos de evaluación ha sido procesado por el reconocedor, el siguiente paso es analizar los resultados. Para ello HTK dispone de HResults, cuya finalidad es comparar las transcripciones generadas por el reconocedor con las transcripciones de referencia y calcular las diferentes estadísticas. HResults compara las transcripciones reconocidas y de referencia mediante un algoritmo dinámico de alineación óptima del texto. En su funcionamiento básico esta comparación se realiza sin considerar ningún tipo de información temporal que pudieran tener las transcripciones.
El algoritmo de alineación óptima funciona calculando un score para cada una de las opciones posibles de alinear la trascripción reconocida con la trascripción de referencia. El score total de una alineación se calcula asignando un score 0 a las coincidencias de dos etiquetas, un score 7 a las inserciones y borrados de etiquetas, y un score 100 a las sustituciones de etiquetas. El alineamiento que posea menor score es el elegido como alineamiento óptimo. [Díaz 2002]
2.2.2.- Perl
Perl (Practical Extraction and Report Language) es un lenguaje de propósito general originalmente desarrollado para la manipulación de texto y que ahora es utilizado para un amplio rango de tareas incluyendo administración de sistemas, desarrollo web, programación en red, desarrollo de GUI y más. [Perl 1]
Se previó que fuera práctico (facilidad de uso, eficiente, completo) en lugar de hermoso (pequeño, elegante, mínimo). Sus principales características son que es fácil de usar, soporta tanto la programación estructurada como la programación orientada a objetos y la programación funcional, tiene incorporado un poderoso sistema de procesamiento de texto y una enorme colección de módulos disponibles.
2.2.2.1.- Estructura del lenguaje
Perl se considera un lenguaje interpretado, es decir, no es necesaria una previa compilación para poder ejecutarse, lo único que se necesita es darle al interprete, perl, el código que queremos que ejecute.
29

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
A continuación se realiza una breve explicación de los elementos que componen las instrucciones que se han empleado en la implementación de los programas en perl que se utilizan en este proyecto:
Tipos de datos
Perl tiene tres tipos de datos: escalares, listas y hashes.
Un escalar es un solo valor; puede ser un número, un string (cadena de caracteres) o una referencia
Una lista es una colección ordenada de escalares (una variable que almacena una lista se llama array)
Un hash, o memoria asociativa, es un mapeo de strings a escalares; los strings se llaman claves y los escalares valores.
Todas las variables están precedidas por un símbolo, que identifica el tipo de dato que es accedido (no el tipo de dato de la misma variable). Se puede usar el mismo nombre para variables de diferentes tipos, sin que tengan conflictos.
$var # un escalar@var # un “array”%var # un ''hash''
Cuadro 3: Tipos de variables de Perl
Estructuras de control
Perl tiene estructuras de control orientadas al bloque, similar a las que tienen los lenguajes de programación C y Java. Las condiciones están rodeadas por paréntesis y los bloques subordinados mediante llaves:
while (condicion) {. . .}while (condicion) {. . .} continue {. . .} for(expresión_inicial;expresión_condicional;expresión_incremental) {}if (condicion) {. . .}if (condicion) {. . .} else {. . .}if (condicion) {. . .} elsif (condicion) {. . .} else {. . .}
Cuadro 4: Principales expresiones de control de Perl
Expresiones regulares
El lenguaje Perl incluye una sintaxis especializada para escribir expresiones regulares y el intérprete contiene un motor para emparejar strings con expresiones regulares. [Perl 2]
Los operadores empleados en el desarrollo de este proyecto son:
30

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Operador emparejamiento : El operador m/ / permite comprobar un emparejamiento mediante una expresión regular (el precedente m puede ser omitido para abreviar). Un ejemplo sencillo es el siguiente:
$x =~ m/abc/Cuadro 5: Expresión regular de emparejamiento
Esta expresión evalúa como verdadero si y sólo si el string $x coincide con la expresión regular abc.
Operador sustitución : El operador s/ / / especifica una operación de búsqueda y reemplazo:
$x =~ s/abc/aBc/; #Convierte la b en mayúscula Cuadro 6: Expresión regular de sustitución
Metacaracteres :
En Perl se emplean metacaracteres principalmente en las expresiones regulares para especificar condiciones de las cadenas de caracteres que queremos modificar o tratar. Algunos de estos metacaracteres son:
METACARACTER DESCRIPCIÓN+ Indica que el elemento o patrón que le precede puede aparecer
una o más veces\d Cualquier dígito del 0 al 9\D Cualquier no dígito\s Cualquier espacio en blanco\S Cualquier no espacio\w Todos los caracteres alfa-numéricos incluido el guión\W Todos los caracteres no alfa-numérico
Tabla 1: Principales metacaracteres de Perl
Un ejemplo de expresión regular que utilice estos metacaracteres puede ser la siguiente:
if (m/\*(\s+)(\d+)(\s+)(\d+)(\s+)([a-zA-Záéíóú])/)Cuadro 7: Ejemplo de utilización de los metacaracteres en expresiones regulares
En este caso, la condición se cumplirá si se encuentra un * seguido de uno o más espacios, seguido de uno o más números, a los que siguen uno o más espacios seguidos de uno o más números y que termina con uno o más espacios seguidos de un conjunto de letras.
31

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
2.2.3.- AWK
AWK es un lenguaje de programación diseñado para procesar datos basados en texto, bien sean ficheros o flujos de datos. El nombre AWK deriva de los apellidos de los autores: Alfred Aho, Peter Weinberger y Brian Kernighan. [AWK 1]
AWK es un ejemplo de un lenguaje de programación que usa ampliamente el tipo de datos de listas asociativas (listas indexadas por palabras clave) y expresiones regulares. Su estructura es similar a lenguaje de programación Perl, del que fue el precursor.
2.2.3.1.- Variables
No es necesario declarar las variables ya que éstas se crean al utilizarlas, tomando valores nulos. El lenguaje presenta algunas variables predefinidas:
VARIABLE DEFINICIÓNNF Número de campos. Toma su valor de forma automática con cada línea.NR Número de la línea (global). Toma su valor de forma automática con
cada línea.FNR Número de la línea (local al fichero). Toma su valor de forma
automática con cada línea.FILENAME Nombre del fichero actual. Toma su valor de forma automática con cada
línea.FS Separador de campos de entrada (“ ”)RS Separador de líneas de entrada (“ \n ”)
Tabla 2: Variables predefinidas en AWK [Collado 2006]
2.2.3.2.- Sentencias de uso frecuente
Las siguientes sentencias se emplean muy a menudo en programas implementados mediante AWK:
var = expresiónif (condicion) accion [else accion]while (condicion) accionfor (k=ini; k<=fin;k++) accion{sentencia; sentencia . . .}print [expresion, expresion. . .]printf (formato, expresion, expresion. . .)
Cuadro 8: Sentencias habituales de AWK [Collado 2006]
for (n=4; n<=NF; n++)if (($n!="[sta]")&&($n!="[int]"))
if ($n=="[fil]")printf "!FIL\n";
else if ($n=="[spk]")printf "!SPK\n";
elseprintf "%s\n", $n
Cuadro 9: Ejemplo de uso de las sentencias de AWK
32
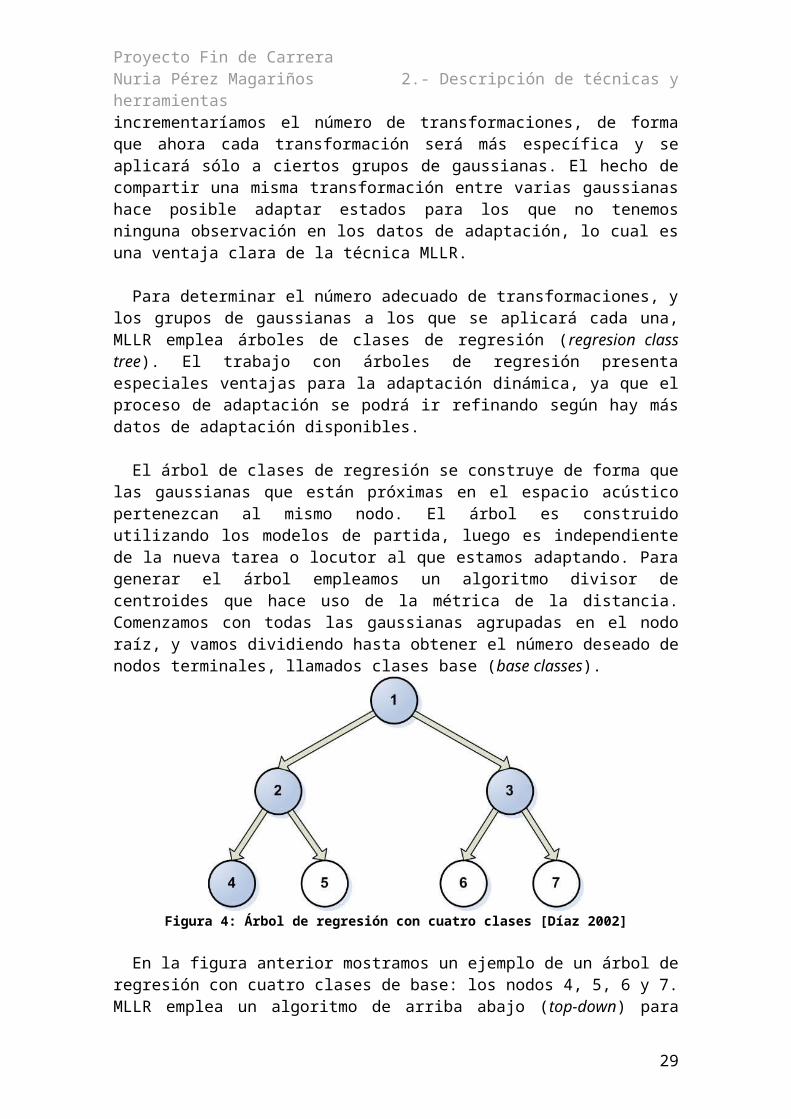
Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
2.3.- Proyectos Fin de Carrera Precedentes
En esta sección se procederá a explicar brevemente los proyectos fin de carrera que preceden a éste y que han servido como base para su desarrollo.
2.3.1.- Proyecto Fin de Carrera de Sergio Díaz Municio
En éste proyecto se lleva a cabo un estudio exhaustivo de las técnicas de adaptación MAP y MLLR mediante el empleo de HTK. También se han realizado mejoras sobre el software de este programa para ajustar los algoritmos y obtener mejores resultados, realizando una comparativa entre la versión original y la mejora. [Díaz2002]
A partir de una extensa base de datos, se han definido y realizado los siguientes experimentos, cada uno de ellos con su alfabeto, base de datos y diccionarios asociados:
Familiarización con el sistema HTK para lograr refinar el procedimiento de trabajo mediante la realización de experimentos sobre un sistema inicial de habla aislada independiente de contexto y sobre otro sistema de habla aislada pero dependiente de contexto.
Aplicar las técnicas de adaptación al locutor, a tarea y a género sobre un sistema de habla aislada para lograr un sistema independiente de locutor, lo más robusto posible, para una aplicación genérica de reconocimiento de habla aislada.
Aplicar las técnicas de adaptación a tarea y a género sobre un sistema de habla continua para lograr un sistema independiente de locutor, lo más robusto posible, para una aplicación genérica de reconocimiento de habla continua.
Entrenar nuevos sistema de habla aislada y continua en inglés.
Algunas de las conclusiones obtenidas que más relevancia tienen para el desarrollo del presente proyecto son:
La comparación entre las normalizaciones cepstrales de la media y la varianza devolvió mejores resultados para CVN. El resultado parece lógico ya que CVN normaliza tanto las medias, aportando la misma mejora que CMN, como las varianzas, lo que supone una mejora añadida frente a CMN.
Los resultados obtenidos son mejores si el modelado del sistema es dependiente del contexto.
Tras la adaptación a tarea, a mejora relativa frente al sistema de partida está comprendida entre 16,5 y 33,0% para MLLR y para MAP se consigue una mejora relativa igual al 36,4%.
En caso de que se produzca una sobre adaptación, la técnica MLLR es muy vulnerable mientras que la técnica MAP posee una protección frente a este problema gracias al parámetro τ.
33

Proyecto Fin de Carrera Nuria Pérez Magariños 2.- Descripción de técnicas y herramientas
Al aumentar el número de datos de entrenamiento en la adaptación al locutor, aumenta la mejora relativa frente al sistema independiente de locutor.
En general, los valores de mejora relativa obtenidos en la adaptación a tarea son inferiores a los obtenidos en la adaptación al locutor.
2.3.2.- Proyecto Fin de Carrera de Javier López García
En este proyecto fin de carrera se modificó la arquitectura del SERVIVOX de manera que éste estuviese diseñado mediante el empleo de técnicas de desarrollo orientado a objetos. [López2001]
Las principales conclusiones que se han obtenido del mismo son:
Para facilitar la integración de cualquier nuevo módulo de TIDAISL en el sistema SERVIVOX éste debe estar formado por una pareja de ficheros “.h” y “.c”. Además, todas las variables de configuración que necesite deben estar declaradas en el propio módulo.
Las clases que realicen la parametrización deben heredar de TParam_base.
Las clases que lleven a cabo el reconocimiento deben heredar de Trecono_base.
34

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
3.- DESCRIPCIÓN DEL SISTEMA
En este capítulo partiremos del sistema telefónico desarrollado principalmente durante el proyecto fin de carrera de Javier López, lo analizaremos y realizaremos algunas mejoras en su arquitectura.
3.1.- Ámbito del proyecto
El objetivo de esta parte de análisis consiste en definir lo más exactamente posible cuáles serán las competencias y responsabilidades de nuestro sistema, y cuáles no. Esto queda reflejado en forma de un breve discurso:
Un sistema que permita ejecutar y configurar aplicaciones de reconocimiento de voz mediante una estructura cliente-servidor con comunicación mediante shockets.
Será competencia de nuestro sistema proporcionar un servicio de reconocimiento de voz mediante el empleo de un reconocedor de habla continua independiente del locutor; empleará un protocolo de comunicación con el cliente según el cual, primero pedirá permiso para empezar a reconocer, no haciéndolo hasta que dicho permiso haya sido concedido; proporcionar varios métodos de comprensión configurables así como diferentes medidas de confianza sobre la bondad de un reconocimiento.
También será competencia de nuestro sistema proporcionar un servicio de adaptación de los modelos acústicos al locutor, la tarea y/o el entorno de trabajo, mediante una interfaz de usuario sencilla que le permita indicar las características de la adaptación que se va a realizar así como realizar la grabación de las frases necesarias para llevar a cabo dicho proceso. No será competencia de nuestro sistema la síntesis del habla.
3.2.- Diagrama de contexto y guión de los casos de uso
El objetivo de esta parte era identificar las entidades o agentes externos, para estudiar las relaciones de nuestro sistema (visto como caja negra) con estos. A continuación, definimos los diferentes casos de uso para tener un esquema claro de las líneas de implementación a seguir para que se cubriesen todos ellos.
35

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
Figura 6: Diagrama de contexto del sistema
Los casos de uso que pueden presentarse a la hora de interactuar con el sistema son los siguientes:
Modo de funcionamiento automático: Toda la configuración del sistema se realiza mediante ficheros de configuración. La única posibilidad de interacción con el sistema es indicarle acciones a realizar mediante los comandos de voz.
Modo de funcionamiento no automático con adaptación: En esta situación, al usuario se le da la posibilidad de configurar las principales variables del sistema. También se le pide que lleve a cabo un pequeño proceso de adaptación de los modelos acústicos a su voz y características del entorno con el fin de mejorar los resultados del reconocimiento.
36

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
Modo de funcionamiento no automático sin adaptación: Al igual que en el caso anterior, el usuario tiene la posibilidad de configurar los valores de las principales variables del sistema con el objetivo de que éstas sean más adecuadas a las condiciones de uso del sistema. En esta ocasión se solicitará al usuario que indique qué modelos acústicos desea cargar para llevar a cabo el reconocimiento con ellos. Podemos definir dos sub-modos en este caso:
o Usuario conocido: Dicho usuario ha llevado a cabo previamente el proceso de adaptación del sistema, de manera que tiene una carpeta particular en la que se guardan sus modelos acústicos ya adaptados, por lo que se le da la posibilidad de cargarlos directamente desde su carpeta personal sin necesidad de navegar por el sistema.
o Usuario desconocido: En este caso, el usuario es la primera vez que utiliza el sistema o no ha realizado adaptación previa, por lo que se le muestra la carpeta que contiene los modelos acústicos genéricos para que los seleccione sin necesidad de buscarlos.
Por encima de todos estos casos de uso podría definirse otro caso que es el del desarrollador, que tiene acceso a todos los ficheros tanto de configuración como de implementación, pudiendo cambiar las configuraciones del sistema para que se adecúen a la situación y al caso de uso que se desea utilizar.
3.3.- Arquitectura del sistema
Una vez modelado el entorno del sistema mediante el Diagrama de Contexto y definidos los casos de uso, pasamos a realizar un breve análisis de la arquitectura del sistema.
El sistema consta de cinco subsistemas: backend, interfaz de desarrollo, hardware multimedia y telefónico, voz, NLP (Natural Language Processing) y kernel.
Backend: Éste subsistema proporciona las interfaces con entidades externas. Las interfaces disponibles a día de hoy son:
o Servidor: Interfaz con el cliente externo. Se comunica con él mediante sockets empleando un protocolo según el cual el servidor pide permiso al cliente para comenzar a reconocer.
o Infrarrojos: Interfaz que permite la comunicación del sistema mediante el empleo de infrarrojos. Actualmente se utilizan en el sistema HIFI.
Interfaz gráfica de usuario: En este subsistema se agrupan las interfaces que se ofrecen al usuario en función del equipo con el que deseen interactuar:
37

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
o ROBINT: Es la interfaz que permite al usuario interactuar con un robot, ordenándole acciones mediante comandos de voz.
o HIFI: Interfaz que permite al usuario utilizar una cadena de música y realizar todas las tareas asociadas a ella mediante comandos de voz.
o SIGNOS: Interfaz que traduce al lenguaje de signos las frases dichas por otros usuarios mediante un agente animado.
Hardware multimedia y telefónico: Ofrece a las aplicaciones las facilidades para manejar el hardware (tarjetas de sonido) que permite ofrecer al usuario interfaces vocales. Integra las siguientes clases:
o Audio: Interfaz con la tarjeta/dispositivo de audio. Proporciona al sistema las utilidades de grabación y reproducción de muestras de voz.
o Multimedia y agentes: Interfaz entre el lenguaje y el sistema que implementa los agentes animados multimedia y las facilidades para reproducir vídeos. Esta funcionalidad no está activa.
o Interfaz telefónico: Interfaz entre el lenguaje y el sistema que permite manejar las diferentes tarjetas para efectuar y detectar llamadas. Actualmente no se encuentra activo.
Voz: Esta clase agrupa las facilidades de reconocimiento y síntesis de voz, es decir, el paso del discurso oral al texto y viceversa. Agrupa las siguientes clases:
o Reconocimiento: Es la clase que proporciona las utilidades de reconocimiento de voz al sistema.
o Sintetizador(sinte): interfaz con el sistema que sintetiza un discurso oral a partir de un texto escrito. Sería posible activarlo.
NLP: Parte de un texto escrito en lenguaje natural que puede provenir de un reconocedor de habla continua e interpreta su significado. Consta de la siguiente clase:
o Primitivas: Interfaz con el módulo de interpretación del texto reconocido empleando la comprensión por reglas.
Kernel: Es la parte central del sistema. Se encarga de ejecutar las aplicaciones. Para ello debe leer el fichero del autómata, desencriptarlo, cargarlo en memoria y ejecutarlo. Para ejecutarlo debe ir estado por estado del autómata y ejecutar las transiciones pertinentes en función del evento ocurrido. Actualmente no se encuentra activo.
A continuación se muestra el diagrama de clases que componen el sistema SERVIVOX y las relaciones entre ellas:
38

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
Figura 7: Diagrama de clases del SERVIVOX
Una vez tenemos el diagrama general de clases del SERVIVOX, describimos con más detalle el diagrama de clases que componen el módulo de reconocimiento:
39

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
Figura 8: Diagrama de clases de reconocimiento
3.4.- Tarea de guiado
Como resultado de una reunión celebrada con los ingenieros de la Escuela Técnica Superior de Ingenieros Industriales responsables de todo el módulo de guiado y generación de mapas de robot, se obtuvo una primera aproximación de la funcionalidad que debía añadir el módulo de reconocimiento a la generación y recorrido de mapas.
3.4.1.- Conclusiones obtenidas en la reunión
A continuación se enumeran todos los aspectos del guiado del robot que se deben tener en cuenta en el momento de desarrollar el módulo del reconocedor que se encargará de gestionar esta tarea.
Dentro de las posibles tareas que pueda llevar a cabo el robot, se definirá una que sea Modo Mapa. El robot dispondrá de varias gramáticas, una para guiado y otras para las diferentes tareas que pueda llegar a realizar. En principio, el robot deberá ser capaz de pasar de una gramática a otra, es decir, cambiar de tarea sin necesidad de parar el sistema y reiniciarlo.
Para generar el mapa el robot irá siguiendo a una persona que hará de master o guía.
40

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
Dado que el software de seguimiento es delicado y todavía no está del todo depurado, existe la posibilidad de que el robot se equivoque de guía. Si se detecta que esto ha sucedido, deberá determinarse un vocabulario que permita preguntarle al robot a qué persona sigue, que la señale y poder corregirle en caso de que la persona señalada sea equivocada.
Durante la visita, el robot tendrá disponible un conjunto de etiquetas de lugares que irá asignando a medida que se realiza el recorrido. Cuando el guía le indique que la zona o lugar en el que se encuentran se corresponde con una etiqueta, debería ser posible indicarle la etiqueta deseada y contemplar la posibilidad de que el robot verifique la etiqueta seleccionada mediante sintetización o presentación de un texto explicativo asociado a la etiqueta.
Ofrecer la posibilidad de marcar puntos de información en los que el robot tendrá que explicar o hacer algo.
En cada punto de información, explicar al robot dónde se encuentra el objeto al que hará referencia (altura y posición 2D), así como indicarle cuál sería el lugar más recomendable para colocar al público.
Definir la etiqueta de sitio prohibido para aquellas zonas o caminos por las que el robot no pueda pasar.
En el momento de dar indicaciones al robot sobre giro y avance, deben contemplarse dos posibilidades: indicar el número de grados o metros que debe moverse de forma exacta mediante un número o de forma indefinida como sería un poco o bastante.
Una vez recorrido todo el lugar, se pasaría a la fase de verificación en la que el robot va sugiriendo posibles trayectorias para recorrer todos los puntos de información. El guía deberá poder denegar o aceptar dichas trayectorias.
El robot no retrocede. Para retroceder lo que tiene que hacer es girar 180º y avanzar.
3.4.2.- Pasos a seguir para el desarrollo del módulo
El desarrollo del módulo para el guiado del robot mediante comandos de voz tendrá una primera etapa en la que se realizarán pruebas con un robot aspiradora. Este robot se comunica con el módulo de reconocimiento para guiado mediante una comuniación cliente servidor.
Con esta aspiradora se podrán implementar y probar de manera práctica los comandos y frases relacionados con el avance y giro del robot, etiquetado de lugares, tanto prohibidos como de información. La tarea típica que se deberá llevar a cabo durante la prueba práctica del sistema será conseguir que la aspiradora recorra una habitación o un lugar determinado mediante el empleo de frases que el guía irá diciendo.
41

Proyecto Fin de Carrera Nuria Pérez Magariños 3.- Descripción del sistema
Una vez se haya conseguido un guiado correcto de la aspiradora mediante comandos de voz, se pasará a implementar toda la parte correspondiente a las indicaciones en tres dimensiones como pueden ser indicar la posición del objeto al que se va a hacer referencia en la explicación, indicar el lugar óptimo de posicionamiento del público y que el robot sea capaz de colocarlos, así como indicar a qué persona está siguiendo durante la generación del mapa, corrigiéndole en caso de que siga a una persona equivocada.
42

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
4.- PORTABILIDAD Y CONFIGURACIÓN DEL SISTEMA
Tal como se encontraba la estructura de directorios y los ficheros de configuración del sistema al inicio de este proyecto resultaba muy complicado disponer de un ejecutable que resultase fácil de trasladar a otras máquinas y sencillo de configurar. Es por esto que una fase del proyecto se centró en solucionar estos problemas, cuyo proceso y resultado se detalla en este capítulo.
4.1.- Portabilidad y estructura de directorios
Originalmente, la estructura de directorios del sistema se encontraba incluida dentro de todo el sistema de carpetas y archivos del SERVIVOX de forma que si se deseaba ejecutar el programa desde un ordenador diferente al que se estuviese empleando para el desarrollo, era necesario copiar al ordenador de destino todo el SERVIVOX que actualmente tiene un tamaño de 1 GB. Esto resulta inviable, principalmente porque un gran número de archivos que se encuentran en el SERVIVOX no se emplean en el funcionamiento del reconocedor de ROBINT.
Por este motivo, se ha modificado la estructura de directorios, lo que ha permitido
reducir de forma muy significativa el número de ficheros que se necesitan para poder ejecutar correctamente el programa.
En el siguiente esquema puede verse la nueva estructura de directorios:
Figura 9: Nueva estructura de directorios
43

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
4.1.1.- Directorio “bin”
Dentro de la carpeta “bin” se encuentran los ejecutables que se deben lanzar para poner en funcionamiento el reconocedor. El ejecutable del reconocedor se llama “mfc_ROBINT_release.exe” pero ese nombre puede modificarse.
Para llevar a cabo una prueba aislada sin necesidad de tener en funcionamiento un kernel o simulador del robot, dentro de esta carpeta también se encuentra un acceso directo a un cliente que simula la comunicación entre el reconocedor y el robot. Dicho cliente automatiza el envío de mensajes necesarios para establecer la comunicación con el servidor y permite comprobar que los comandos se han traducido y enviado correctamente.
4.1.2.- Directorio “data”
En este directorio se encuentran los subdirectorios asociados a cada una de las tareas que puede realizar el robot, un subdirectorio en el que se guardarán las grabaciones, otro subdirectorio para archivos y operaciones temporales, un directorio para los modelos que se hayan generado en caso de haber realizado algún proceso de adaptación, un subdirectorio en el que se realizan los primeros pasos del proceso de adaptación, archivos de configuración del sistema y otros ficheros básicos e invariantes necesarios para el reconocimiento.
4.1.2.1.- Directorio de tarea
Dentro del directorio “Data” se creará una nueva carpeta por cada tarea diferente que pueda llevar a cabo el robot. Cada directorio de tarea debe contener desde el principio tres archivos fundamentales:
“dicc.dic”: Este fichero es necesario para el aprendizaje mediante reglas. Permite agrupar las palabras en categorías de forma que el sistema es capaz de aprender con menos reglas y en menos tiempo. La estructura del fichero es: el número de palabras que contiene el fichero en la primera línea y a continuación, una palabra con su categoría en cada línea. Puede estar vacío pero en ese caso debe tener un cero en la primera línea.
“Palfunc.lis”: Fichero necesario para el aprendizaje mediante reglas. Contiene las palabras que se considera que no aportan significado, de forma que no se generan reglas con ellas. Debe contener alguna palabra, no puede estar vacío. Cada palabra función se pone en una nueva línea.
el laloslasununaunosunas
Cuadro 10: Ejemplo de palabras función del fichero Palfunc.lis
44

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Fichero de comandos: Este fichero contiene las frases que el sistema debe ser capaz de reconocer, cada una de ellas seguida del comando con el que debe asociarse. La estructura del fichero es la siguiente:
o No puede haber líneas en blanco ni al principio ni al final del fichero.o Las líneas no pueden comenzar por mayúscula.o Soporta tildes.o Cada línea contiene una frase y el comando por el que debe ser
traducida. El formato de una línea es:
eres inteligente -> orden=[inteligencia]
A la izquierda de la flecha se escribe la frase y a la derecha debe aparecer el concepto asociado a la frase y, entre corchetes, el valor que se da a ese concepto que es lo que se mandará al robot como comando entendido. El valor puede coincidir con alguna de las palabras de la frase y debe escribirse en minúscula. Es recomendable que haya el menor número de espacios posibles en la parte derecha de la sentencia para evitar errores.
4.1.2.2.- Directorio de grabaciones
En este directorio se guardan las grabaciones que se van realizando de las frases dichas por el usuario. El nombre de las mismas está relacionado con el usuario y la sesión de grabación. Un ejemplo de nombre de grabación sería:
locutor_sesion_numero de grabacion.wav
En el caso de que se esté llevando a cabo un proceso de adaptación de los modelos acústicos al hablante, las grabaciones relacionadas también se guardan en este directorio pero dentro de una subestructura de directorios que se explicará con más detalle en el capítulo 6.
4.1.2.3.- Directorio de modelos
En este directorio se guardarán los modelos que hayan sido modificados en el proceso de adaptación. Tiene una estructura interna similar a la del directorio de grabaciones, por lo que ésta podrá verse en detalle en el capítulo 6.
4.1.2.4.- Directorio de adaptación
En este directorio se encuentran los programas ejecutables necesarios para llevar a cabo las primeras transformaciones de formato en los ficheros de diccionario, necesarias para el proceso de adaptación. En este directorio también se irán guardando los ficheros intermedios que se necesiten para dar formato a los ficheros de diccionario y transcripciones, de manera que sean comprensibles por el programa HTK.
45

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
4.1.2.5.- Directorio temporal
Este directorio se emplea para realizar operaciones intermedias en el momento de la generación de diccionarios y gramáticas, y para guardar los archivos de depuración que se generan durante la ejecución. Puede limpiarse en función de un flag que se lee del fichero de configuración.
4.2.- Configuración del sistema
La configuración del sistema del que partimos se realizaba mediante lecturas de ficheros .INI de configuración. El directorio SERVIVOX tenía alrededor de 120 archivos con esa extensión, muchos de los cuales ya no se utilizaban y podían dar lugar a error a la hora de buscar un parámetro de configuración que se deseaba variar.
La primera tarea que se llevó a cabo en esta línea de simplificar la configuración del sistema para hacer más sencilla su portabilidad y manejo fue determinar qué ficheros de configuración realmente eran utilizados en nuestro sistema y cuáles no. De ésta limpieza nos quedamos con seis ficheros de configuración que realmente se utilizaban en esta versión del programa. Esos ficheros son:
Detector.ini: Contiene las variables asociadas al detector como los niveles en decibelios que debe ir superando la voz de la grabación para que sea considerada como un discurso real o el tiempo que debe estar en cada uno de esos niveles.
Entorno.ini: En este fichero se definen las diferentes prioridades que puede tener una hebra de ejecución, así como variables de activación de alguna de las funcionalidades que presenta el sistema (como utilizar el método de reconocimiento N-Best).
Tade.ini: Tiene variables relacionadas con los directorios de grabación, número de intentos para reconocer lo dicho antes de desecharlo o el timeout del sistema.
Voz.ini: Contiene variables de configuración relativas a la grabación y el reconocimiento de ficheros como el tiempo máximo de grabación, el formato de la grabación, el número máximo de gramáticas y diccionarios que se pueden utilizar o cuál es el fichero de configuración de la parametrización.
Reco_cfg_generico.ini: Es el fichero de configuración para el reconocimiento. Contiene variables relacionadas con las gramáticas, parametrización, ficheros de audio, tramas o penalización por inserción de palabras.
Prb_htk_generico_Speechdat.ini: Contiene las variables asociadas a la parametrización de los ficheros de audio como pueden ser las varianzas, el número de parámetros a considerar o la longitud y el tamaño de las ventanas.
46

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Una vez identificamos los ficheros de configuración relevantes, realizamos una selección de los parámetros que más frecuentemente solían que ser modificados por los usuarios para ponerlos en un nuevo fichero de configuración. El objetivo de este procedimiento es que el usuario del sistema sólo tenga que abrir un fichero de configuración para modificar los parámetros que más habitualmente serán modificados para adaptarlos a las circunstancias concretas de la tarea que vaya a realizarse.
Así es como surge en fichero “urbano.ini”. El contenido de este fichero puede verse detalladamente en el manual de usuario del anexo 1. Pese a que también están reflejadas en el manual de usuario, queremos explicar con un poco más de detalle las principales variables de configuración que intervendrán en el desarrollo de este proyecto. Dichas variables son:
modoAutomatico: Es la variable que indica si el usuario desea que el proceso de configuración del sistema sea o no transparente para él. Los posibles valores que puede tomar son:
o Valor 0: El modo automático está desactivado y, por tanto, el usuario puede modificar manualmente la configuración del sistema.
o Valor 1: El modo automático está activado y, por tanto, la configuración/ funcionamiento del sistema es transparente al usuario, realizándose a través de los ficheros .ini. Este es el modo de funcionamieto normal del robot.
adaptacionNecesaria: Es la variable que indica al sistema si es necesario que el usuario lleve a cabo un proceso de adaptación de los modelos de lenguaje a su voz. Si el modo automático está activo, se ignorará el valor de esta variable. Los valores que puede tomar son:
o Valor 0: No es necesario adaptar los modelos acústicos al locutor.
o Valor 1: Es necesario que el locutor lleve a cabo un proceso de adaptación.
dir_dic: Es el directorio en el que se encuentran los diccionarios. Puesto que cada tarea tiene asociados unos diccionarios, este directorio deberá corresponderse con el de la tarea.
dir_gram: Es el directorio en el que están las gramáticas de la tarea y, por lo tanto, tiene el mismo valor que el directorio de los diccionarios.
regeneraComprensión: Es un flag que indica al sistema la necesidad de generar los dicheros de compresión, es decir, asociar las frases con los comandos por las que deben traducirse una vez sean reconocidas. Si tiene un valor igual a 0, no se regenerará la comprensión y, por lo tanto, el tiempo que tardará el sistema en estar preparado para reconocer será menor. Hay que tener cuidado con este flag porque si se realiza un cambio en el fichero de comandos y el flag está a 0, el sistema no asimilará los nuevos cambios realizados.
47

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Locutor: guarda el nombre del usuario que habla al sistema.
Una vez definidas las principales variables de configuración y agrupadas en un único fichero de configuración, también decidimos seleccionamos nueve variables para que se presentasen al usuario del sistema mediante una ventana y éste pudiese modificar su valor, evitando que modifique los valores del fichero “urbano.ini” algo que no sería deseable si se trata de un usuario eventual o inexperto. Las variables seleccionadas para ser presentadas en la ventana de configuración son las siguientes:
Tipo de entorno : Mediante un checkBox el usuario puede indicar si se encuentra en un entorno ruidoso o en un entorno no ruidoso. A partir del cuadro seleccionado, el sistema ya internamente asigna a las variables del detector los valores correspondientes al tipo de entorno. Si no se selecciona ninguna de las opciones, se carga la configuración por defecto definida en “urbano.ini”. Para más información, véase [San-Segundo1997]
//vemos que tipo de entorno esta seleccionadoif(m_ruidoso.GetCheck()==BST_CHECKED){
nivel_low = 3; //dBsnivel_speech = 6; //dBsnivel_high = 9; //dBs
entornoRuidoso=TRUE;}else if(m_noRuidoso.GetCheck()==BST_CHECKED){
nivel_low = 6; //dBsnivel_speech = 20; //dBsnivel_high = 25; //dBs
entornoRuidoso=FALSE;}else{
//Cargamos la configuracion por defectodouble aux, ValorPorDefecto;char nombreSeccion[MAX_PATH];
sprintf(nombreSeccion,"Linea 0");
// Nivel bajo de energía habla continua.ValorPorDefecto = 5; // dBs.if (SIN_ERROR != DameProfileDouble (nom_fich_configuracion,
nombreSeccion, "Nivel low del detector HC", ValorPorDefecto, &aux, verboseProfile))
warningPrintf_telef("Nivel low del detector: Lectura del *.ini INCORRECTA");
nivel_low = (int16)aux;
// Nivel de voz habla continua.ValorPorDefecto = 10; // dBs.if (SIN_ERROR != DameProfileDouble (nom_fich_configuracion,
nombreSeccion, "Nivel speech del detector HC", ValorPorDefecto, &aux, verboseProfile))
warningPrintf_telef("Nivel speech del detector: Lectura del *.ini INCORRECTA");
nivel_speech = (int16)aux;
// Nivel alto de energía habla continua.ValorPorDefecto = 20; // dBs.
48

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
if (SIN_ERROR != DameProfileDouble (nom_fich_configuracion, nombreSeccion, "Nivel high del detector HC", ValorPorDefecto, &aux, verboseProfile))
warningPrintf_telef("Nivel high del detector: Lectura del *.ini INCORRECTA");
nivel_high = (int16)aux;
entornoRuidoso=TRUE;
}Cuadro 11: Comprobación del tipo de entorno seleccionado y asignación de valores
Activación vocal : Mediante un checkBox el usuario indica al sistema si desea que el reconocedor reconozca en cualquier momento o sólo a partir de que haya dicho una frase de activación. El procedimiento a seguir para determinar qué cuadro se ha seleccionado es similar al que se lleva a cabo con el tipo de entorno y, como ocurre también en ese caso, se carga la configuración por defecto de “urbano.ini” en caso de que no se seleccione ningún cuadro.
Tipo de comprensión : Mediante esta variable el usuario indica si desea utilizar trigramas como método de compresión o reglas de transformación. El proceso a seguir para determinar el elemento seleccionado es similar a los anteriores.
Regeneración de la comprensión : Como hemos indicado antes, esta variable indica al sistema si es necesario repetir el proceso de generación de reglas y trigramas o no. Se implementa también mediante checkBoxes, empleándose el mismo sistema para determinar qué ha seleccionado el usuario y cargando la configuración por defecto en caso de que no haya seleccionado nada.
Flexibilidad del reconocimiento : Mediante esta variables se modifica el valor del factor de suavizado. Un reconocimiento flexible significa que el sistema es bastante tolerante para comprender frases que no se encuentren en el conjunto de frases predefinidas. Cuanto más estricto, más se limita la comprensión a las frases predefinidas.
Todas las variables anteriormente descritas se han implementado mediante checkBoxes que ofrecen al usuario los posibles valores que puede tomar ese campo. A continuación se enumeran las variables implementadas mediante cuadros de edición ya que el usuario debe introducir su valor mediante el teclado porque no tienen un número finito de posibilidades:
Nombre del usuario : En él se introduce el nombre del usuario que va a interactuar con el sistema.
Directorio de tarea : Ruta del directorio que se corresponde con la tarea que va desarrollarse. Ha tenido que ser previamente definido y contener al menos los ficheros que se indicaron en el apartado 4.1.2. La ruta que se introduzca debe terminar con el carácter “ \ ” ya que en caso contrario el sistema no funcionará correctamente.
49

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Puerto de reconocimiento : En este cuadro el usuario introduce el número de puerto que utilizará para comunicarse con el cliente.
SoundBlaster : Este cuadro permite al usuario indicar cuál es el dispositivo que se corresponde con la tarjeta de entrada de audio.
El aspecto de la ventana de configuración es el siguiente:
Figura 10: Ventana de configuración del sistema
50

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Uno de los principales problemas que se nos presentaron fue conseguir que la ventana de configuración tuviese prioridad sobre el resto de hebras para que los valores introducidos en ella tuviesen alguna efectividad ya que la ventana se lanzaba cuando ya se habían inicializado todas las variables a través de los ficheros de configuración. Para ello, lo que hicimos fue modificar el método de inicialización de la ventana principal del reconocedor en el fichero “robintdlg.cpp”. Antes de que en este método se llamase al método encargado de la inicialización principal, lanzábamos la ventana de configuración de manera que las demás hebras quedasen bloqueadas hasta que se cerrase la configuración.
Dicha ventana sólo se muestra en caso de que el sistema esté funcionando en modo no automático. En caso contrario, se carga la configuración por defecto definida en el fichero “urbano.ini” sin que aparezca ninguna ventana.
Otro de los problemas más importantes que nos surgió en el desarrollo de este método de configuración fue la posibilidad de que el usuario introdujese el número del puerto que se empleará para la comunicación entre cliente y servidor. Si el usuario introducía un puerto diferente al especificado en el fichero de configuración, ignoraba el nuevo valor, quedándose con el definido por defecto. Esto se debía a que antes de comenzar con la inicialización de la ventana de diálogo, se creaba el servidor de manera estática:
CServidor Server;
Cuadro 12: Inicialización original del servidor
La modificación que se ha hecho ha sido crear el servidor como un puntero que se inicializa en el método “inicializaciónPpal” de “robintdlg.cpp” justo antes de lanzar el thread de reconocimiento, pero después de haber configurado el sistema:
server=new CServidor;server->StartThread();
Cuadro 13: Nueva inicialización del servidor
Una vez configurado el sistema, teníamos que introducir las modificaciones necesarias en “robintdlg.cpp”, fichero en el que se llevan a cabo todas las operaciones relacionadas con la interfaz gráfica del sistema, para que los casos de uso explicados en el capítulo 4 tuviesen aplicación real. Para ello, se ha seguido el siguiente esquema de implementación:
51

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Figura 11: Diagrama de la implementación de los casos de uso
Como puede verse sólo algunas combinaciones de las variables “modoAutomatico”, “adaptacionNecesaria” y “locutor” tiene sentido y son las que se muestran en la figura 9. Hay otras configuraciones carentes de significado como puede ser la siguiente:
modoAutomatico=1adaptacionNecesaria=1
locutor=carlos
Esta configuración no tendría sentido ya que en el caso de estar activo el modo automático, el sistema ignora el valor de la variable “adaptacionNecesaria” de manera que, aunque esté indicado que es necesario llevar a cabo el proceso de adaptación, el sistema lo ignorará y que está definido el modo automático y éste tiene mayor prioridad que la adaptación.
El proceso de adaptación se explicará con más detalle en el capítulo 6. Para determinar si un usuario es conocido o no se ejecuta el método “buscaLocutor ()” de “robintdlg.cpp” cuya implementación es la siguiente:
52

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
int buscaLocutor(){ char linea[MAXPATH];
FILE* fichero; if((fichero= fopen(listaLocutores,"r"))==NULL)
warningPrintf("No se puedo abrir el fichero de locutores");
for(int contador=0;feof(fichero)==0;contador++) { fgets(linea,100,fichero);
if (strlen(linea)>0) { if (linea[strlen(linea)-1]=='\n' ||linea[strlen(linea)-1]=='\r')
{ linea[strlen (linea) - 1] = '\0';
}
} else
{ linea[0]=0;
}
/* Si alguno de los locutores leidos del fichero coincide con el locutor actual, devuelve uno indicando que el locutor que esta utilizando el sistema es conocido*/
if(strcmp(linea,locutorActual)==0){
return 1;}
}
fclose(fichero);
/*Si no ha encontrado ninguna coincidencia en el fichero con el nombre del locutor actual devuelve cero para indicar que el locutor es desconocido*/ return 0;
}
Cuadro 14: Implementación del método "buscaLocutor()"
Si el modo automático está activo, el sistema debe encontrar de forma automática los modelos acústicos que debe cargar. En el caso de que el locutor nunca haya trabajado con el sistema es sencillo ya que se emplearán los modelos genéricos que se encuentran en el directorio “data”. La complicación parece si el locutor es conocido, ya que el sistema debe navegar por los directorios personales el locutor y encontrar los modelos adecuados. Para lograrlo se realizan las siguientes operaciones:
53

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
if(locutorConocido){
char nom_tarea[MAXPATH];char fich_comandos[MAXPATH];char micro[MAXPATH];char dir_micro[MAXPATH];char entorno[MAXPATH];char fichero_modelos[MAXPATH];
// Leemos el nombre base del fichero .iniif (SIN_ERROR!=DameProfileString (nom_fich_configuracion, "GRAMATICA",
"NomFicheroTextoEntrenamiento","robint.txt", fich_comandos, MAXPATH, TRUE))warningPrintf("en %s falta la sección [GRAMATICA] o la variable
NomFicheroTextoEntrenamiento", nom_fich_configuracion);
strcpy(nom_tarea,fich_comandos);flhPonerExtension(nom_tarea,"");
/*Leemos del fichero de configuracion el tipo de microfono que usamos*/if (SIN_ERROR!=DameProfileString (nom_fich_configuracion, "WAV","microfono",
"cable", micro, MAXPATH, TRUE))warningPrintf("en %s falta la sección [WAV] o la variable microfono",
nom_fich_configuracion);
if(strcmp(micro,"cable")==0){
strcpy(dir_micro,"MCC");}else if(strcmp(micro,"inalambrico")==0){
strcpy(dir_micro,"MCC");}if(entornoRuidoso){
strcpy(entorno,"ruido");}else{
strcpy(entorno,"noRuido");}
/*Con todos los elementos creamos el directorio donde estan los modelos del usuario*/
sprintf(directorio_usuario,"..\\data\\Modelos\\%s\\%s\\%s\\%s",locutorActual ,dir_micro,entorno,nom_tarea);
sprintf(fichero_modelos,"%s\\SpeechDat_Continua_MMF.ascii",directorio_usuario);
/*Antes de asignar definitivamente ese directorio como el directorio en el que se encuentran los modelos que se van a utilizar, comprobamos si existe y, en caso contrario,asignamos al directorio de los modelos que definido por defecto en el fichero de configuracion*/
if((_access(fichero_modelos,0))!= -1){ sprintf(directorio_final_modelos,"%s\\",directorio_usuario);}else{
if (SIN_ERROR!=DameProfileString (nom_fich_configuracion, "MODELOS", "dir_hmm","..\\..\\datos\\modelos\\", directorio_final_modelos, STRINGLENGTH, TRUE))
warningPrintf("en %s falta la sección [MODELOS] o la variable dir_hmm", nom_fich_configuracion);
}
}Cuadro 15: Proceso para cargar automáticamente los modelos de un locutor conocido
54

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Si nos encontramos en el modo no automático pero no es necesario adaptar, parecerá una ventana emergente para que el usuario seleccione el fichero de modelos que desea cargar. Dicha ventana se abrirá en el directorio “data” si el locutor es desconocido y el la carpeta personal del locutor si ya ha trabajado antes con el sistema realizando el proceso de adaptación. Para crear esa ventana y abrirla en el directorio correcto el proceso es el siguiente:
//creamos una ventana de dialogo para cargar el modelo deseadoCFileDialog filedialog(TRUE,NULL,NULL,OFN_HIDEREADONLY, "All Files (*.*)|*.*||",this);//ponemos el titulofiledialog.m_ofn.lpstrTitle = "Seleccione el modelo a cargar";
sprintf(directorio_usuario,"..\\data\\Modelos\\%s\\",locutorActual);
/*Comprobamos si el directorio que queremos existe y en caso contrario, ponemos el directorio de los modelos por defecto como directorio inicial de apertura de la ventana*/
filedialog.m_ofn.lpstrInitialDir=directorio_usuario;
//creamos la ventanaif (filedialog.DoModal() == IDOK){
char driver[MAXPATH];char fich[MAXPATH];char extension[MAXPATH];char dir[MAXPATH];
//si el usuario pulsa el boton "Aceptar" guarda el path del fichero //seleccionado CString filePath = filedialog.GetPathName();
//separamos los elementos del path para quedarmos solo con el //directorio
_splitpath(filePath, driver, dir, fich, extension);
strcpy(directorio_final_modelos,dir);
flagModeloSeleccionado=TRUE;
}else{//si el usuario no selecciona ningun modelo se carga el directorio por //defecto
if (SIN_ERROR!=DameProfileString (nom_fich_configuracion, "MODELOS", "dir_hmm","..\\..\\datos\\modelos\\", directorio_final_modelos, STRINGLENGTH, TRUE))
warningPrintf("en %s falta la sección [MODELOS] o la variable dir_hmm", nom_fich_configuracion);
flagModeloSeleccionado=TRUE;}
Cuadro 16: Creación de la ventana para seleccionar el modelo a cargar
55

Proyecto Fin de Carrera Nuria Pérez Magariños 4.- Portabilidad y configuración del sistema
Una vez se han cargado los modelos, estará terminado todo el proceso de configuración del sistema, abriéndose la ventana principal del reconocedor y permitiendo al usuario ordenar acciones al robot mediante comandos de voz.
56

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
5.- GENERACIÓN AUTOMÁTICA DEL SUBSISTEMA DE COMPRENSIÓN
ADAPTADO A UNA TAREA
Como se explicaba en el capítulo 2, uno de los métodos que empleados en la desambiguación del etiquetado morfosintáctico es aplicar reglas de transformación. En este capítulo se explicará detalladamente el procedimiento por el cual se generan las reglas adaptadas a la tarea que se está realizando.
5.1.- Aproximación al sistema
El sistema tiene definidas 27 funciones para crear reglas de transformación, cada una con un identificador y un número de parámetros concretos, cuya descripción detallada puede verse en el anexo V.
Mediante dichas funciones, se irán generando y probando todas las posibles reglas que se obtengan al combinar los distintos conceptos y palabras que componen el vocabulario de una tarea. El objetivo principal de este proceso es obtener las reglas que mejor asocien una frase dicha por el usuario del sistema con el comando o comandos que lleva asociados y por el que debe ser traducido. De esta manera, las reglas que no den lugar a un elevado porcentaje de acierto serán desechadas.
El empleo de reglas como método de comprensión es lento ya que tiene que comprobar todas las posibles combinaciones de conceptos y palabras hasta obtener las mejores reglas. Además, esto empeora a medida que aumenta el tamaño del vocabulario, pudiendo dar lugar a situaciones en las que el vocabulario tiene un tamaño tan grande que la máquina sobre la que se ejecuta no tiene suficiente capacidad de procesamiento como para obtener todas las reglas.
Pese a este inconveniente, las reglas son una forma fiable de comprensión y traducción de la frase dicha por un usuario.
5.2.- Implementación de la comprensión mediante reglas
En el momento de generar las reglas que permitirán comprender lo que el usuario del sistema está diciendo, traduciéndolo por un comando a partir del fichero de comandos, lo primero que se hace es cargar en la estructura DatosComprension las palabras función, que serán en su mayoría artículos (determinados, indeterminados, posesivos, demostrativos), preposiciones, verbos auxiliares, verbos modales, verbos en modo imperativo, pronombres (personales,interrogativos).Este proceso se realiza mediante el método “cargaPalabrasFuncion”.
57
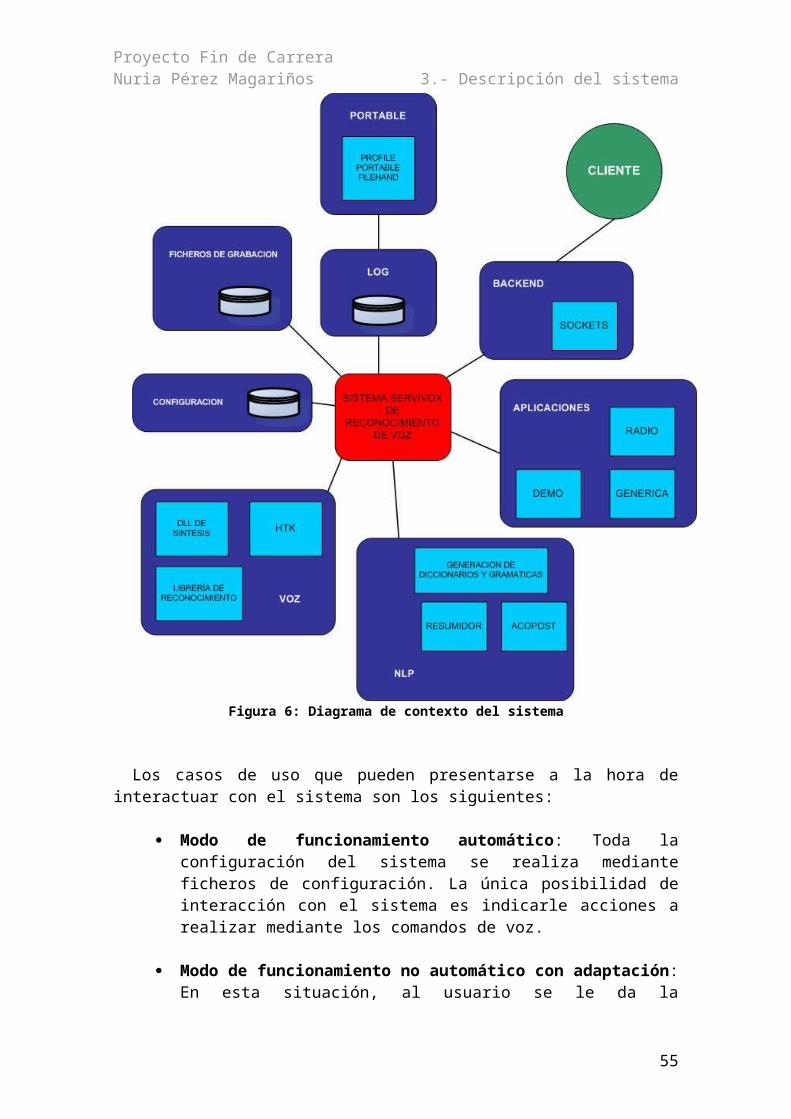
Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión5.2.1.- Método “cargaPalabrasFuncion”
Como parámetros se pasa un puntero a la estructura DatosComprension y el nombre del fichero que contiene las palabras función. Estas palabras función son palabras no fiables o irrelevantes para la comprensión, palabras “basura” a partir de las cuales el sistema no debe aprender ninguna regla, especialmente en el caso de que haya pocos ejemplos de los que obtener reglas. Esto es necesario ya que, en caso de que haya pocos ejemplos, el sistema podría aprender reglas a partir de estas palabras, enmascarando otras posibles reglas que serían mucho más fiables o unívocas, puesto que en el momento que se asocia una frase con un concepto, el sistema no vuelve a evaluar la frase para buscar otra palabra más característica a la hora de aislarla para asignarle un concepto.
Una vez disponemos de todas las palabras función del vocabulario, se ejecuta que método “main_ppal” que es el procesador de comprensión y se emplea para aprender y/o aplicar las reglas.
5.2.1.- Método “main_ppal”
Tiene los siguientes argumentos:
DatosComprension: Puntero a la estructura DatosComprension
p_idioma: Indicador del idioma que se empleará que en este caso será siempre 0 ya que se empleará como único idioma posible el español.
p_fichero_textos: Nombre del fichero de comandos a partir del cual se extraerán las reglas.
p_debug: Entero en función del cual se escribirán unos u otros mensajes de seguimiento del sistema.
p_modo: Entero que determina la forma en la que se leen las frases del fichero de comandos. Si su valor es distinto de cero, lee las frases; si no, no hace nada.
Una vez dentro del método, lo primero es leer las frases del fichero de comandos, mediante el método “leeFrasesFichero”.
5.2.1.1.- Método “leeFrasesFichero”
El objetivo de este método es leer las frases que tiene el fichero de comandos y devolver el número de frases que ha leído. Para ello, necesita los siguientes parámetros:
Puntero a la estructura DatosComprension Nombre del fichero de comandos Entero que determina el idioma que va a emplearse. Como se indica
anteriormente, el idioma que se empleará es el español. Entero que determina el modo de lectura del fichero.
58

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
Además de devolver el número de frases que se han leído, este método es el encargado de crear los siguientes ficheros:
Fichero de textos, que contiene una relación de las frases que pueden ser dichas y comprendidas
Fichero de traducción que contiene cada frase dividida en palabras, cada una de ellas asociada al valor del concepto por el que se debe traducir esa frase.
Fichero de slots que contiene los posibles valores que pueden tomar los conceptos por los que serán traducidas las frases.
Si el modo que se ha pasado como parámetro vale cero, no se realiza ninguna acción. Si, por el contrario, ese valor es diferente de cero, se procede a leer el fichero de comandos.
Las líneas se leen de una en una y a cada una de las mismas se aplica el mismo proceso:
1. Primero se eliminan los caracteres de retorno que pueda tener la línea
2. Después se separa la frase de la orden y se actualiza un puntero para que apunte al concepto que lleva asociada la frase y el valor del mismo.
3. A continuación se calcula el número de palabras que tiene la frase.
4. Se escribe la frase en el fichero de texto.
5. Se guarda la frase en la posición correspondiente del array “línea” de la estructura DatosComprension
6. También se copia la frase al atributo “texto” de las estructuras “SlotsReferencia” y “SlotsPredichos” de la estructura DatosComprension.
7. Se guarda el valor del concepto en el atributo “slots” de la estructura “SlotsReferencia”
8. Se escriben las correspondientes palabras en los ficheros de traducción y de slots.
9. Al atributo “comienzoSlot” de la estructura “SlotsReferencia” se le da el valor cero y el atributo “finalslot” se inicializa con el número de palabras que tiene la frase.
10. Por último se incrementa el número de slots que tiene almacenados la estructura “SlotsReferencia”.
Este proceso se aplica hasta que se han leído todas las líneas del fichero.
59

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
5.2.1.2.- Método “procesaFrases”
Una vez hemos leído todas las frases que componen nuestro vocabulario, necesitamos procesarlas para que sea posible aplicarles las reglas. Con cada una de las frases que componen nuestro vocabulario realizamos el siguiente proceso.
Cada una de las frases que componen las posibles órdenes que se pueden dar al sistema puede considerarse como un array de bloques. El método de aplicación de las reglas es ir recorriendo todos los bloques, comprobando si pueden cuadrar con alguna regla. Es por esto que el siguiente paso en la generación de reglas es crear los bloques iniciales.
Toda la información sobre los bloques se guarda en la estructura “bloques” que forma parte de la estructura “datosComprension”. En este primer paso, crean los bloques iniciales asociados a cada una de las frases. Cada palabra de la frase se guarda como un bloque, guardándola en el atributo “textoBloque”.
Cuando ya se ha recorrido toda la frase, se actualiza el atributo “n_bloques” con el número de bloques que se han identificado y guardado.
“preprocesa_spanish”
Una vez se tiene una división inicial de las frases en bloques, éstos son preprocesados para categorizarlos. Cada bloque tendrá una o más categorías o etiquetas asociadas, aunque inicialmente será una. Si el texto del bloque es una palabra función, dicho bloque será etiquetado como “basura”. Por el contrario, si el texto del bloque se corresponde con una palabra contenido, desde un punto de vista pesimista no sabemos cómo categorizarla inicialmente.
El sistema está preparado para emplear categorías, pero al comienzo no disponemos de dichas etiquetas. En un dominio conocido podría disponerse de unos diccionarios de categorías con palabras etiquetadas, caso que no se da en un entorno general. Por este motivo, cada bloque inicial se etiqueta con su propio texto o palabra. Un bloque puede tener hasta cuatro categorías.
“procesa_spanish”
En este método lo primero que se hace es llamar a “aplicaReglas”, cuyo objetivo es ir aplicando los elementos de la estructura “datosLearning”, es decir, ver qué funciones de creación de reglas están pendientes de ser aplicadas. La primera vez que se llama a este método no se lleva a cabo ninguna acción porque todavía no hay ninguna función guardada en “datosLearning”.
El siguiente paso es comprobar concepto por concepto por medio del método “escribe”. Si hay algún bloque que lo tenga almacenado en su lista de categorías, en cuyo caso añadirá ese concepto a la lista de “slotsPredichos” que se asocian con la frase. Si es la primera vez que se entra en el método no hará nada, porque todavía no hay conceptos.
60

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
“evalua”
Una vez se han aplicado las reglas y rellenado los slots predichos, se pasa a evaluar las predicciones.
Se van recorriendo los slots predichos de la frase comprobando que no han sido ya evaluados, porque no se computan los slots repetidos. En el caso de que no haya sido evaluado, se recorren todos los slots de referencia de la frase, comprobando si se corresponde con alguno de ellos. En caso de que no lo haga, ese slot predicho se contabiliza como fallo. En caso de que coincida con alguno de los slots de referencia, se comprueba si el slot de referencia comienza a la vez o más tarde que el predicho y que termina antes o al mismo tiempo que el predicho. Si esto ocurre, se ha acertado con la predicción y si no, ha sido una predicción fallida. En caso de que no hubiese ningún slot de referencia, se resetea el contador de fallos, porque no tenía nada con lo que comparar. Por último, recorre los slots de referencia en busca de aquellos que todavía no hayan sido predichos, para tenerlos en cuenta como pendientes.
Ilustrándolo con un ejemplo, supongamos que tenemos las siguientes tablas con los slots predichos y de referencia, asociados a una frase, así como sus instantes de inicio y final:
Slot Inicio FinalAtiende 2 296Avanza 296 400
Gira 400 600 Tabla 4: Slots predichos
Según lo que acabamos de explicar, el método irá recorriendo los slots predichos, comprobando que se encuentran en los e referencia. De esta manera, vemos que el slot “Atiende” ha sido correctamente predicho ya que aparece en los slots de referencia y los instantes de inicio y final del slot de referencia están dentro de el inicio y el fin del slot predicho. En el caso del slot “Avanza” vemos claramente que es un fallo porque no aparece en los de referencia. El slot “Gira” también se considera un fallo porque, aunque aparece en los slots de referencia pero situado en un lugar erróneo ya que los instantes inicial y final de slot de referencia no se encuentran dentro del inicio y el final del slot predicho. Por último, el slot de referencia “Para” se guardaría como pendiente ya que no ha sido predicho.
En caso de que sea la primera vez que se llama a este método, no se llevará a cabo ninguna operación, ya que todavía no tenemos ni slots predichos y de referencia.
5.2.1.3.- Método “evaluaGlobal” Una vez hemos aplicado el procesado a cada una de las frases, evaluamos el sistema
global.
Slot Incio FinalAtiende 3 296
Gira 296 400Para 400 600
Tabla 3: Slots de referencia
61

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
Para ello lo primero que hacemos es resetear el número de conceptos de referencia que faltan, ya que cada vez que se evalúa se cuentan los conceptos y en caso de que no, se empiece a contar desde cero, se produciría un error.
Una vez preparadas las variables de cuenta, se realiza el siguiente proceso con cada una de las frases:
1. “comparaSlots”
Este método realiza con los slots de referencia un proceso similar al de evalúa, contabilizando los fallos y los aciertos.
Una vez evaluados los slots predichos, empieza a recorrer los slots de referencia que componen la frase. Si el slot está en la lista de conceptos. En caso afirmativo se incrementa el número de referencias y si no, lo añade a la lista de conceptos.
A continuación, se recorren los slots predichos con el fin de ver si el slot de referencia ha sido predicho, aumentando el número de slots de referencia que faltan por predecir en caso de que no coincida con ninguno.
2. “incoherenciaSlots”
Este método sólo se aplica si hay slots predichos. Su función es coger do slots predichos para ver si son iguales. Si son iguales el resultado es coherente porque se han predicho los mismos conceptos para la frase. Si no son iguales, la frase es incoherente.
3. “ordenaElementoLearning”
El objetivo de este método es ordenar los elementos de la lista de conceptos mediante el método “comparaElementoLearning”, lo que permite acelerar las búsquedas. Tiene varios criterios de ordenación en función del parámetro que se le pase. En esta ocasión ordena los conceptos en función del número de slots que faltan por predecir de los que han sido asociados a cada concepto.
Una vez terminado el proceso, se recorren todos los slots de referencia para ver cuántos han sido encontrados.
5.2.1.4.- Método “estimaCategorías”
El objetivo de éste método es determinar qué conceptos están relacionado con qué categorías y viceversa. A efectos prácticos, lo que se mira es en cuántas frases se relaciona un concepto con una categoría. Los resultados de esta asociación se guardan tanto en la estructura “todasRelacionadas” de los conceptos como en la estructura “todasRelacionadas” de las categorías, lo que acelerará el proceso de búsqueda.
62

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
Ilustrándolo con un ejemplo, supongamos una situación inicial de las estructuras “listaConceptos” y “listaCategorías” en las que cada concepto y cada categoría tienen asociada una estructura “todasRelacionadas” que inicialmente está vacía:
Figura 12: Situación inicial de listaConceptos y listaCategorías
Si en una frase aparece el concepto 1 asociado a la categoría 3, en la estructura de categorías relacionadas asociada al concepto 1, incrementaríamos el contador de la categoría 3 y en la estructura de conceptos relacionados con la categoría 3 incrementaríamos el contador correspondiente al concepto 1, tal como muestra la Figura13:
Figura 13: Resultado después de relacionar el concepto con la categoría
63

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
Este proceso se realiza con todos los conceptos y categorías.
5.2.1.5.- Fase de aprendizaje
Esta fase de aprendizaje se descompone en tres etapas, cada una de ellas con unos requisitos más o menos flexibles desde el punto de vista de aplicación y precisión de las reglas generadas. Los parámetros que se considerarán en cada etapa son los siguientes, variando su valor en cada etapa.
Umbral_buena_regla: indica cómo de buena tiene que ser la regla para ser aceptada, considerando los posibles fallos y aciertos.
Min_OK_interesantes_abs: Número de slots que tiene que acertarse como mínimo con esa regla para considerarla como una regla interesante.
Min_OK_interesante_relativo: Porcentaje de slots que se deben acertar. Max_KO_interesante_abs: Número de slots que puede fallar y aún así ser
aceptada la regla. Max_KO_interesante_relativo: Porcentaje de fallos que puede tener la regla.
Puntualizar que se entiende por acertar el hecho de que el slot predicho se encuentre en los slots de referencia.
Una vez han sido definidos los parámetros que se evaluarán en cada etapa, los valores de los mismos en cada una son:
- Etapa 0 : Es la etapa más estricta y los valores de los parámetros son:
o Umbral_buena_regla = 0,99 que equivale a decir que la regla casi no falla.
o Min_OK_interesante_abs = 10o Min_OK_interesante_relativo = 0,2o Max_KO_interesante_abs = 0 o no están permitidos los falloso Max_KO_interesante_relativo = 0,0
- Etapa 1 : En esta etapa se permiten un menor número de aciertos pero sigue sin permitirse que la regla falle.
o Umbral_buena_regla = 0,95o Min_OK_interesante_abs = 5o Min_OK_interesante_relativo = 0,1o Max_KO_interesante_abs = 0 (o no están permitidos los fallos)o Max_KO_interesante_relativo = 0,0
- Etapa 2 : Es la etapa más flexible en la que con un acierto la regla se considera como interesante y los fallos están permitidos.
o Umbral_buena_regla = 0,95
64

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
o Min_OK_interesante_abs = 1o Min_OK_interesante_relativo = 0,1o Max_KO_interesante_abs = 5o Max_KO_interesante_relativo = 0,1
Cada etapa se compone de iteraciones, aprendiéndose una regla por iteración. Una etapa puede terminar por tres posibles razones:
- Se han aprendido todas las reglas posibles- Se ha superado el número máximo de iteraciones (200)- No se ha aprendido ninguna regla en esa iteración (iteración inútil)
La llamada de una regla tiene la siguiente estructura:
nombre_funcion concepto [categorias]
La llamada siempre tendrá como mínimo el nombre de la función a aplicar, el concepto y una categoría asociada al mismo, pudiendo llegar hasta un máximo de tres categorías. El número de datos que tiene una función de generación de reglas se calcula a partir del concepto más el número de categorías que puede tener. Si, por ejemplo, la función admite 3 datos, necesitará como parámetros el concepto y dos categorías.
Para recorrer todas las posibles combinaciones de conceptos, categorías y funciones, tenemos varios bucles que recorremos de la siguiente manera:
1. El primer bucle se encarga de recorrer los conceptos. Para cada uno de los conceptos se desarrollan los siguientes pasos.
2. El segundo bucle busca la primera de las tres categorías que se pueden utilizar para la llamada a la función y la fija hasta que se terminan de recorrer todos los bucles internos.
3. El tercer bucle realiza una función similar al anterior pero fijando la segunda categoría que se puede utilizar para la llamada a la función.
4. El cuarto bucle fija la última de las categorías.
5. El último bucle recorre las posibles funciones de generación de reglas. En el momento que encuentra una posible función, carga en la estructura “datosLearning” el nombre de la función con todos los parámetros que se le pueden pasar, es decir, primero el concepto y después las categorías asociadas.
6. El siguiente paso es comprobar si la regla ya ha sido probada. Esto lo sabemos de la siguiente manera:
Una vez tenemos fijas todas las categorías, se cargan en “datosLearning” la función activa, a la que se le pasan siempre como parámetros esas categorías y el concepto. Una vez hecho esto y llevadas a cabo todas las funciones de
65

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
evaluación, seguiremos teniendo fijas las dos primeras categorías asociadas, pero cambiaremos la última para volver a cargar todas las funciones con esta nueva combinación de categorías.
Si una de las funciones en lugar de tener 4 datos tiene tres, significa que sólo necesita las dos primeras categorías para ejecutarse, de manera que el cambio en la última categoría no le afecta porque las categorías que se le pasan como parámetros no han variado, de manera que esta función no se ejecuta, porque ya ha sido probada.
Algo similar ocurre cuando se varían tanto la segunda como la tercera categorías y la función sólo tiene dos datos, es decir, el concepto y la primera categoría.
7. También se comprueba que las tres categorías que se pasan como parámetros no sean todas “basura” porque en ese caso darían lugar a una regla poco útil ya que las palabras en las que se basa no aportan ninguna información.
8. Una vez tenemos cargada la función en “datosLearning” llamamos de nuevo al método “procesaFrases”, ya explicado anteriormente, para evaluar los aciertos y los fallos de la nueva regla que se ha creado.
9. A partir de los resultados de la evaluación, se comprueba si éstos superan los criterios anteriormente expuestos y si la nueva regla que se ha obtenido mejora los resultados de las anteriormente encontradas en esa iteración. En caso de que así sea, se actualizan las variables temporales que almacenan los mejores resultados.
10. Una vez se sale de los bucles de las categorías, se guardan en “datosLearning” las funciones y los parámetros que han dado mejores resultados. Realizándose una evaluación global antes de terminar.
//regla 1 OK: 2 KO: 0 OKacum: 2 KOacum: 0 (faltaban: 4 de Dia) //funcion: reescribe2 dato0: Dia dato1: qué dato2: día dato3: qué //numSlot: 35reescribe2("qué","día","Dia");
//regla 2 OK: 2 KO: 0 OKacum: 4 KOacum: 0 (faltaban: 3 de Futuro) //funcion: reescribe1copiando dato0: Futuro dato1: serás dato2: basura //dato3: basura numSlot: 35reescribe1copiando("serás","Futuro","basura");
//regla 3 OK: 2 KO: 0 OKacum: 6 KOacum: 0 (faltaban: 3 de //Inteligencia) funcion: reescribe2 dato0: Inteligencia dato1: basura //dato2: consideras dato3: basura numSlot: 35reescribe2("basura","consideras","Inteligencia");
Cuadro 17: Ejemplo de las reglas generadas
Una vez que tenemos todas las reglas que podemos aplicar para determinar qué ha dicho el usuario, lo que el sistema hará cada vez que se detecte una nueva frase será procesar dicha frase y enviar el comando que se asocia al slot predicho para esa frase.
66

Proyecto Fin de Carrera Nuria Pérez Magariños 5.- Generación del subsistema de comprensión
5.3.- Modificaciones en el reconocimiento
En el método que realiza todo el proceso de grabación y reconocimiento de la frase dicha por el usuario se han realizado algunas modificaciones respecto al sistema de partida desde el punto de vista de evaluar cómo de fiable ha sido el reconocimiento.
Para determinar si un reconocimiento es válido, la confianza con la que el sistema ha reconocido la frase debe superar unos umbrales en función de lo que el usuario haya especificado. Inicialmente sólo se tenía en cuenta la confianza media, con la que se había reconocido la frase. Ahora tenemos tres formas de determinar cuál es la confianza de reconocimiento que queremos utilizar:
1. Confianza media de la frase : Una frase se considerará como válida si la confianza media de la frase supera el umbral definido en el fichero de configuración.
2. Confianza ponderada : La frase se considerará como válida si su confianza ponderada supera el umbral anteriormente descrito. La confianza ponderada se calcula como:
(5.1)
3. Cualquiera de los anteriores : La frase se dará como válida bien si su confianza media supera el umbral como si es la confianza ponderada la que lo supera.
No se ha evaluado la mejora que esta modificación introduce, que quedará como una línea de trabajo futura.
67

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
6.- IMPLEMENTACIÓN DE LOS MECANISMOS DE ADAPTACIÓN DE MODELOS ACÚSTICOS
En este capítulo se detallan los pasos y modificaciones realizados para llevar a cabo la implementación de los mecanismos que permitirán al usuario del sistema adaptar los modelos acústicos predefinidos a las características de su voz y del entorno de grabación.
6.1.- Clases y comportamiento dinámico
Desde un principio, se decidió que el proceso de adaptación tendría asociado una interfaz gráfica que facilitase los pasos al usuario. De esta manera, se definieron dos ventanas que deberían aparecer en este proceso: una ventana de grabación y una ventana en la que el usuario pudiese especificar las características de las circunstancias en las que iba a llevar a cabo la adaptación.
Con esta definición, teníamos tres clases diferentes que hacían referencia a ventanas independientes:
CRobintDlg: Esta clase se encarga de gestionar todas las operaciones relacionadas con la ventana principal del reconocedor.
Caracteristicas_modelo: Lleva a cabo todas las operaciones relacionadas con la especificación de las características del proceso de adaptación.
adaptacion: Controla todas las operaciones asociadas a la ventana de grabación.
En el momento de ejecutar el proceso de adaptación las ventanas deben aparecer en el siguiente orden:
1. La primera ventana que debe aparecer es la ventana de las características porque es lo primero que se debe especificar.
2. A continuación debe aparecer la ventana de grabación para que el usuario genere los archivos de audio que se necesitan para llevar a cabo la modificación de los modelos acústicos.
3. Por último, una vez terminado el proceso de adaptación se verá la ventana principal del reconocedor del sistema.
El primer problema que se planteó fue cómo crear las ventanas de manera que apareciesen en el orden adecuado. La solución fue crear cada ventana en el método que inicializa la ventana siguiente de forma que ésta última quedase bloqueada mientras la otra ventana estuviese activa. Antes de explicar detalladamente el proceso seguido, indicar que la instrucción que crea una ventana y bloquea la ventana “padre” desde la que se crea es:
69

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
int resultado = ventana.DoModal();Cuadro 18: Instrucción para crear una ventana que bloquee la ventana desde la que se llama
El proceso que se sigue es el siguiente:
1. Comienza a ejecutarse el método “onInitDialog()” de la clase CRobintDlg que va inicializando todas las variables y parámetros que permitirán mostrar la ventana. La inicialización estará terminada cuando se ejecute la instrucción
return TRUE;Cuadro 19: Instrucción que indica el fin de la inicialización
2. Por este motivo antes de que termine la inicialización de la ventana principal del reconocedor, creamos la ventana de grabación de manera que la inicialización de la ventana del reconocedor quedará bloqueada hasta que se cierre la ventana de grabación.
BOOL CROBINTDlg::OnInitDialog(){
(instrucciones previas que no afectan al proceso)
adaptacion adp; int resultado = adp.DoModal();
return TRUE;}
Cuadro 20: Creación de la ventana de adaptación bloqueando al reconocedor
3. En el momento que se ejecuta el “DoModal()” que crea la ventana de grabación, pasaremos a ejecutar el “onInitDialog()” correspondiente a la ventana de grabación.
4. Como lo que nos interesa es que antes de que se muestre esa ventana aparezca la ventana para introducir las características, llevamos a cabo un procedimiento similar:
BOOL adaptacion::OnInitDialog() {
CDialog::OnInitDialog();
Caracteristicas_modelo caracteristicas;
//Lanzamos la ventana para seleccionar las caracteristicas del modeloint resultado = caracteristicas.DoModal();
.
.
.}
Cuadro 21: Creamos la ventana de características
70

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
5. De esta manera, la primera ventana que aparecerá será la de las características porque las otras dos han quedado bloqueadas. En el momento que cerremos las características, se desbloqueará la inicialización de la ventana de grabación y se mostrará en pantalla. Cuando terminemos las grabaciones y cerremos la ventana, desbloquearemos la ventana del reconocedor y se mostrará en pantalla.
Una vez solucionado el problema del orden de aparición de las ventanas, comenzamos a implementar el proceso de adaptación. Pero apareció el problema de la comunicación entre hebras, porque se ejecutan concurrentemente la hebra que controla toda la interfaz gráfica y la hebra “threads_Robint” que es la que lleva a cabo todas las operaciones de generación de diccionarios, grabación y adaptación. El principal motivo de este problema era la prioridad de “threads_Robint” sobre la interfaz gráfica y que una hebra necesitaba los datos que proporcionaba la otra.
Por poner un ejemplo, “threads_Robint” no podía generar los diccionarios necesarios para la adaptación antes de que el usuario le indicase qué fichero quería utilizar como base para adaptar, o no podía aparecer la ventana de grabación si todavía no se habían generado los diccionarios y gramáticas. La solución que se ha dado ha sido comunicar las hebras mediante flags, de manera que utilizando instrucciones como la del Cuadro22 bloqueamos una hebra a la espera de que la otra termine.
while (!flagPreparadaAdaptacion){
Sleep(100);}
Cuadro 22: Instrucciones para bloquear una hebra mediante flags
A continuación se muestran los diagramas de comunicación entre la hebra de interfaz gráfica y “threads_Robint” durante todo el proceso de adaptación y un detalle de la comunicación que se realiza durante la grabación ya que ésta se repite tantas veces como frases tengan que ser grabadas.
Figura 14: Diálogo para la grabación
71

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Figura 15: Comunicación entre las hebras
72

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
6.2.- Implementación
Una vez explicadas las clases que intervienen y el comportamiento dinámico del proceso de adaptación, en este apartado explicaremos más detalladamente tanto la interfaz gráfica como los métodos que permiten dotar al sistema de dicha funcionalidad.
6.2.1.- Interfaz gráfica de adaptación
La interfaz gráfica de adaptación del sistema tiene como objetivo fundamental facilitar al usuario la introducción de los datos referentes a una situación de adaptación al sistema, así como simplificar el proceso de grabación de las frases necesarias para llevar a cabo el proceso.
Esta interfaz gráfica se ha dividido en dos ventanas:
- Ventana de características : En esta ventana el usuario introduce las características de la adaptación que va a realizar.
- Ventana de grabación : Mediante esta ventana, el usuario podrá grabar las frases necesarias para llevar a cabo la adaptación de los modelos a su voz.
A continuación se detallan las funcionalidades de cada una de las ventanas
6.2.1.1.- Ventana de características
Esta ventana permite al usuario definir las características de la adaptación que pretende realizar. Concretamente, los campos que puede indicar son:
- Nombre- Tipo de micrófono que se va a emplear- Características ruidosas del entorno- Tipo de adaptación- Técnica de adaptación que desea emplear- Fichero de frases que desea utilizar- Breve descripción en la que indicar alguna particularidad más del proceso
tal y como puede verse en la Figura 16.
73

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Figura 16: Ventana de características de adaptación
Los campos correspondientes al nombre de usuario, al fichero de comandos y a la descripción están implementados como cuadros de edición. Cada cuadro lleva asociada una variable de control del tipo CString cuyo valor se actualiza mediante el método “onEditChange()” que tiene definido cada cuadro. Sin embargo, el valor de esa variable no tendrá efecto práctico a menos que el usuario confirme los datos introducidos pulsando el botón “OK”.
El tipo de entorno está implementado como una lista desplegable o comboBox. Dicha lista posee actualmente tres elementos dos de los cuales se corresponden con posibles tipos de entorno y el otro es un mensaje para el usuario que se muestra en el momento de crear la ventana. El aspecto actual de la lista de tipo de entorno desplegada mostrando todas las opciones actualmente activas es:
Figura 17: Lista desplegable para seleccionar el tipo de entorno
El tipo de micrófono también se ha implementado como una lista desplegable ya que, al igual que ocurre con el tipo de entorno, hemos pensado que era más sencillo ofrecer al usuario unas opciones conocidas y que nos permitiesen tratarlas de forma adecuada al ser un conjunto acotado y conocido. Actualmente, como sucede con los tipos de entorno, la lista consta de tres elementos, dos de los cuales se corresponden con tipos de micrófono y el tercero es un mensaje para el usuario. El aspecto de la lista es:
74

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Figura 18: Lista desplegable para seleccionar el tipo de micrófono
Como hemos comentado, al ofrecer al usuario un conjunto acotado y conocido de posibles entornos y micrófonos, podemos determinar de forma sencilla qué elemento de cada una de las listas ha sido seleccionado, mediante una comparación, como puede verse a continuación para el caso del tipo de entorno:
int entornoIndex = m_comboEntorno.GetCurSel();//obtenemos el indice del elemento seleccionadoif(entornoIndex<0){
return;//si el indice es menor que cero, volvemos}
m_comboEntorno.GetLBText(entornoIndex,entorno);//obtenemos el texto del elemento seleccionado
if((strcmp(entorno,"entorno ruidoso"))==0){
strcpy(tipo_entorno,"ruido");}else if ((strcmp(entorno,"entorno no ruidoso"))==0){
strcpy(tipo_entorno,"noRuido");}
Cuadro 23: Comparación para determinar el elemento seleccionado de la lista
Esta comparación es posible ya que cada una de las listas desplegables lleva asociada una variable de control del tipo CString.
Pese a que se han definido sólo dos opciones tanto para el tipo de entorno como para el tipo de micrófono, añadir nuevas opciones sería sencillo. Habría que escribir la siguiente instrucción en el método “onInitDialog()” tantas veces como elementos queramos añadir:
m_comboMicro.AddString(_T("Texto a introducir"));
Cuadro 24: Instrucción para añadir elementos a las listas
teniendo cuidado de añadir el nuevo elemento al conjunto de comparaciones que se muestran en el Cuadro 23.
Mediante cuadros de selección, el usuario podrá determinar qué técnica de adaptación de entre las dos explicadas anteriormente desea utilizar para adaptar los modelos a su voz y circunstancias de uso.
75

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
También mediante este tipo de cuadros se le permite determinar el tipo de adaptación que desea llevar a cabo. Se le ofrecen dos posibilidades:
- Adaptación genérica : Permite adaptar el sistema a la voz del locutor, pero no adapta los modelos a una tarea concreta. El usuario leerá varias frases del Quijote, que serán grabadas y almacenadas para su posterior procesado. Si el usuario indica un fichero de comandos, se ignorará.
- Adaptación a Tarea : En este caso, el usuario adapta los modelos tanto a su voz como a la tarea que va a realizar. Las frases que el locutor tendrá que leer y grabar se obtendrán del fichero de comandos que el usuario haya indicado en la casilla correspondiente de la ventana.
A partir de los datos introducidos en esta ventana, el sistema genera automáticamente dos directorios:
Directorio de grabaciones : En él se guardarán las grabaciones que haga el usuario para llevar a cabo ese proceso de adaptación.
Directorio de modelos : En él se guardarán los modelos acústicos ya adaptados a las particularidades del locutor y las características de adaptación.
Estos directorios se crean siguiendo la siguiente estructura y permitirán al usuario acceder a su carpeta personal para cargar sus modelos evitando tener que volver a llevar a cabo todo el proceso de adaptación si ya lo ha hecho una vez en las mismas circunstancias.
76

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
MCC = Micrófono con cableMSC = Micrófono sin cableRuido = entorno ruidosoNo Ruido = entorno no ruidoso
Grabaciones
Usuario nº 1 Usuario nº 2 Usuario nº 3
MSC MCC
noRuido
ruido
Genérica
Tarea 1
Tarea 2
77

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
De forma simplificada sería:
Inicialmente, a las carpetas correspondientes al tipo de entorno y al tipo de micrófono se les asignaba el nombre completo de la característica que especificaban para que fuese totalmente intuitiva su posterior selección. Así, si el usuario había seleccionado un entorno no ruidoso, la carpeta correspondiente se creaba con el nombre “entorno no ruidoso” y así con todas las posibles opciones tanto de entorno como de micrófono.
Esto dio problemas en el momento de ejecutar los scripts de HTK que se detallan en el capítulo 2 ya que los nombres completos daban lugar a paths demasiado largos y el programa se cerraba porque no era capaz de manejarlos. Es por esto que se decidió acortar significativamente los nombres, procurando que siguiesen siendo lo más intuitivos posible.
Todos los métodos y funcionalidades de esta ventana pueden verse en el fichero “caracteristicas_modelo.cpp”.
Directorio de grabación o modelos
Usuario
Tipo de micrófono
Tipo de entorno
Tipo de adaptación
78

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
6.2.1.2.- Ventana de grabación
La ventana de grabación es una interfaz gráfica muy simple, tal y como puede verse en la Figura 19.
Figura 19: Ventana de grabación
Está formado por los siguientes elementos:
o Cuadros de texto estáticos : Tiene dos cuadros de texto estático, cada uno de ellos con una variable de control del tipo CString asociada que nos permite mostrar texto en ellos. El cuadro superior muestra al usuario el texto que debe repetir durante la grabación de la frase, y el segundo muestra lo que se he reconocido una vez se le ha indicado al sistema que ha terminado la grabación.
o Iconos : La ventana posee dos iconos que indican al usuario si se está grabando o no. Inicialmente está activo el icono de un círculo rojo que señala al usuario del sistema que no está grabando. En el momento que se pulsa el botón “Comienzo”, se oculta el icono del círculo rojo para mostrar un icono de un círculo verde para indicar que se está grabando.
o Botones : La ventana consta de cuatro botones aunque sólo se muestran tres al mismo tiempo. Dichos botones pueden dividirse en dos grupos, en base a su función:
Botones de grabación: Son los botones “Comienzo” y “Fin” y le permiten indicar al usuario cuándo comienza y termina la grabación de una frase. Inicialmente, se muestra el botón de “Comienzo” mientras que el de “Fin” está desactivado. La visibilidad de los mismos, tal y como pasaba con los iconos, cambia en el momento que el usuario pulsa el botón “Comienzo”, ya que dicho botón se oculta, pasando a mostrarse el botón de “Fin”.
79

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Botones de manejo de frases: Estos botones son “Siguiente” y “Atrás” y nos permiten recorrer todas las frases que el usuario tendrá que grabar para llevar a cabo la adaptación. El que mayor funcionalidad tiene es “Siguiente”, ya que antes de permitir pasar al usuario a la siguiente frase de la lista, comprueba si dicha frase ha sido reconocida con suficiente confianza. En caso de que no haya sido así, muestra una pantalla de aviso, indicándole al usuario la baja confianza en el reconocimiento de la frase y le ofrece la posibilidad de volver a grabar la frase. Actualmente el umbral de confianza que debe superar la frase tiene un valor de 0,71 pero puede ser modificado en caso de que se tengan muchos problemas para reconocer al locutor.
En caso de que el usuario decida no repetir la frase, realiza la misma función que si se hubiese reconocido correctamente la frase, se pasa a la siguiente frase de la lista y, en caso de que ya se hayan grabado todas las frases de la lista, muestra al usuario un mensaje por pantalla indicándole que ya ha terminado el proceso de adaptación.
La mayor complicación en la implementación de esta ventana ha radicado en la comunicación entre las diferentes hebras activas ya que, como se ilustró y explicó en el apartado 6.1, una hebra necesitaba información que proporcionaba la otra además de bloquearse unas a otras. Todos los métodos relacionados con esta ventana se encuentran en el fichero “adaptación.cpp”.
Para mayor detalle sobre la mecánica del proceso de grabación, véase el Anexo I.
6.2.2.- Métodos
Como hemos indicado anteriormente, el objetivo del proceso de adaptación es modificar los modelos acústicos generales de forma que aprenda a las características específicas del locutor y las circunstancias de uso, de manera que mejore el reconocimiento del sistema.
Para ello, al margen de los ficheros relacionados con la implementación de las ventanas, se ha modificado el fichero “threads_ROBINT.cpp” que es la hebra que realiza todas las tareas relacionadas con el reconocimiento propiamente dicho.
Inicialmente, cuando no estaba implementada la posibilidad de realizar la adaptación de los modelos, se cargaba el reconocedor con los modelos generales y el sistema comenzaba a reconocer. Al añadir la adaptación, antes de cargar el reconocedor, se comprueba si es necesario o no adaptar, ya que en función de esto, se cargará el reconocedor con los modelos generales o con los modelos adaptados.
En caso de que esté activa, el programa entrará en el método “adaptación”, en el que se realizan los siguientes pasos.
80
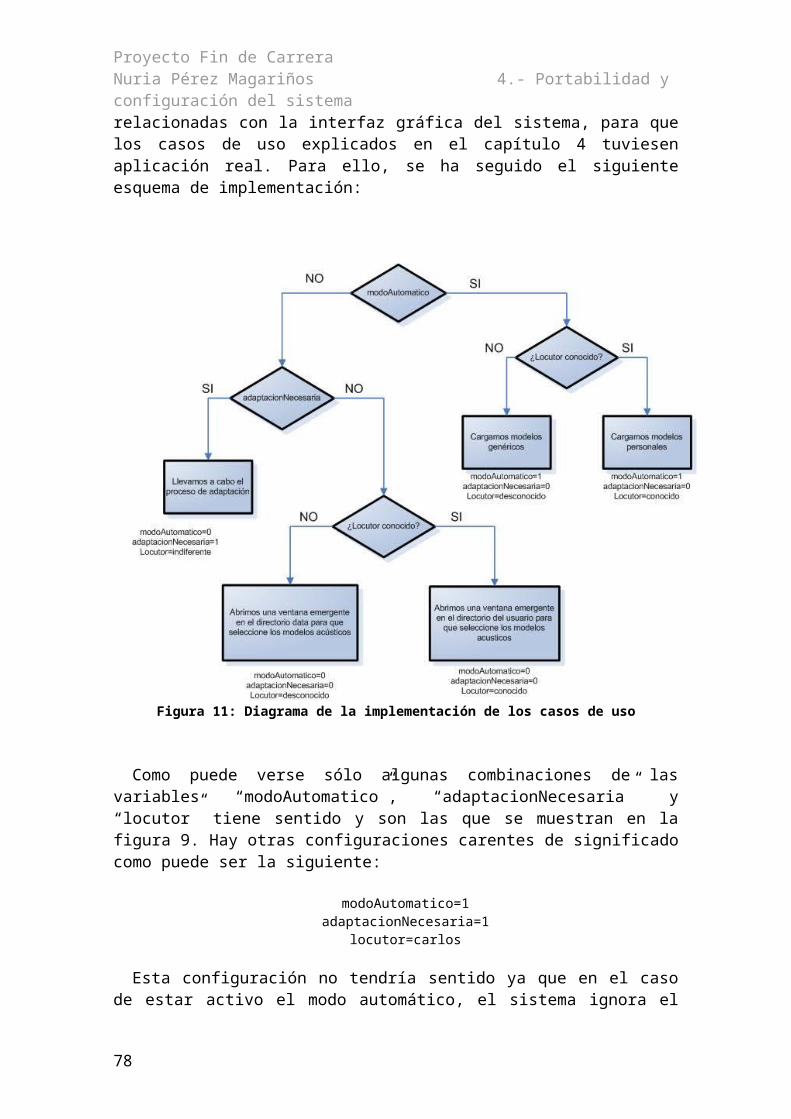
Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Puesto que para llevar a cabo la adaptación es necesario conocer las características de la misma, y tal como se muestra en la Figura 15, la hebra se quedará parada hasta que hayan sido introducidas las características.
Guardamos en una variable el nombre del fichero de comandos que se ha indicado como base en caso de que la adaptación sea para una tarea concreta o el fichero de adaptación genérica en caso contrario, a partir del cual, daremos nombre a los ficheros de gramática y diccionario que se emplearán en el reconocimiento.
El siguiente paso es cargar un reconocedor con los modelos genéricos que deseamos adaptar para poder llevar a cabo el proceso de grabación, y se generan los diccionarios y gramáticas.
Una vez disponemos de los diccionarios y gramáticas, se lee el fichero que contiene las frases que el usuario tendrá que repetir, guardándolas en un array que nos permitirá recorrerlas fácilmente hacia delante y hacia atrás mediante los botones de la ventana de grabación anteriormente descritos.
Una vez hemos hecho todo esto, ya tenemos el sistema preparado para llevar a cabo la grabación de las frases.
Fijamos el estado inicial del reconocimiento
Entramos en el bucle de grabación, que termina cuando el usuario ha grabado todas las frases almacenadas en el array. Internamente, su ejecución depende de que el usuario pulse los botones de “Comienzo” y “Fin”, tal como se muestra en la Figura 14 y se detalla en el Anexo I.
Señalar que en el caso de que la confianza con la que se haya reconocido el texto grabado no supere el umbral definido por el usuario, se activará un flag que permitirá a la interfaz gráfica avisar al usuario de que se ha reconocido el texto con poca confianza y se le da la opción de repetir la grabación.
Una vez finalizada la grabación, se genera el fichero .DATA asociado a las frases dichas. Cada una de las líneas de dicho fichero tiene el siguiente formato:
Figura 20: Formato de línea del fichero .DATA
81

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Para calcular el número total de tramas realizamos la siguiente operación:
(6.1)
(6.2)
siendo longitud el tamaño del fichero en bytes, “cabecera” el número de bytes de la cabecera del fichero de audio y Fs la frecuencia de muestreo.
Una vez tenemos el fichero .DATA, ejecutamos el script de adaptación correspondiente a la técnica de adaptación seleccionada en la ventana de características: “adaptaMap.bat” si la técnica a emplear es MAP o “adaptaMLLR.bat” si se ha seleccionado MLLR. En el apartado 6.3 se realiza una explicación más detallada de estos scripts.
Cuando finaliza el proceso de adaptación, el usuario cierra la ventana de grabación y el sistema carga el reconocedor con los nuevos modelos que se acaban de generar y comienza el reconocimiento.
6.3.- Scripts de HTK
Para llevar a cabo el proceso de adaptación propiamente dicho, ha sido necesario adaptar unos scripts ya escritos para Linux y adaptarlos a Windows, integrándolos dentro de nuestro sistema. Dichos scripts son “adaptaMap.bat” y “adaptaMLLR.bat” y su función es preparar todos los ficheros necesarios en el proceso de adaptación y realizar las llamadas a los diferentes programas de HTK, descritos en el apartado 2.2.1, que llevarán a cabo la adaptación.
Ambos scripts tienen una primera parte consistente en preparar y generar todos los ficheros necesarios para llevar a cabo la adaptación, que es común a los dos. Es por este motivo que inicialmente explicaremos dicha parte, para luego detallar las diferencias de cada uno respecto al proceso de adaptación.
6.3.1.- Preparación y generación de los ficheros
Para obtener todos los ficheros que necesitamos para poder adaptar los modelos, partimos del fichero de diccionario y el fichero .DATA que acabamos de generar en el método de adaptación.
A los scripts se les pasan cinco parámetros de entrada que son:
1. Nombre del fichero de comandos sin extensión : Ese nombre es el que se ha empleado para nombrar los ficheros de diccionario y el .data y será el que empleemos para distinguir unívocamente los ficheros asociados a esa tarea de los ficheros relacionados con otras.
82

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
2. Nombre del usuario del sistema : Mediante este nombre, podremos obtener de forma sencilla el nombre de los archivos de audio que contienen las frases grabadas por ese locutor.
3. Directorio de grabaciones : Ruta del directorio en el que se encuentran las grabaciones de ese locutor y que necesitaremos para la adaptación
4. Directorio de modelos : Ruta del directorio en el que se guardarán los nuevos modelos generados
5. Directorio de tarea : Ruta del directorio de tarea al que debemos volver una vez se haya realizado la adaptación completa de los modelos.
A partir de ellos, definimos tres de los cuatro directorios que vamos a emplear:
Directorio temporal: Directorio en el que se generarán la gran mayoría de los ficheros que necesitaremos en los primeros pasos que realicemos utilizando el HTK. Algunos de los ficheros que se generarán aquí son los .alp que se obtienen como salida del programa “gran2fonVC.exe” que se explica a continuación o los diccionarios cuyo formato vamos variando para que tengan el adecuado para ser comprendidos por HTK.
Directorio de tarea: Directorio al que volveremos una vez terminada la adaptación.
Directorio de grabaciones: Directorio en el que se encuentran las grabaciones realizadas por el locutor y que utilizaremos para adaptar los modelos.
Directorio de modelos: Directorio en el que se guardarán los nuevos modelos.
Antes de comenzar, es necesario asegurarse de que en el directorio temporal (“adapta” en nuestro caso) se encuentran previamente los siguientes ficheros:
graf2fonVC.exe : Programa ejecutable cuya función es obtener la trascripción fonética de las frases contenidas en el fichero cuyo nombre se le pasa como parámetro de entrada.
resumen.exe : Programa ejecutable al que se le pasa un grupo de frases en un fichero .DATA y las divide en tantos ficheros como número se le haya pasado como parámetro. Si, por ejemplo, se pasa como parámetro el 10, el programa generará 10 ficheros, uno con una décima parte de las frases, otro con dos décimas partes de las frases…así hasta el último que contiene la totalidad de las frases pasadas.
Además de estos ficheros, también se ha modificado para generar los archivos complementarios, es decir, para el fichero que contiene la décima parte de las frases, genera el fichero que contiene el resto de frases que no han sido incluidas en el primero.
83

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
alofonos.alo : Es el fichero de símbolos que utilizará el programa “graf2fonVC.exe”. Cada línea contiene un símbolo grafémico del programa precedido por su correspondiente código.
SEV.cfg : Es el fichero de configuración del programa “gran2fonVC.exe”
Antes de comenzar con la explicación detallada, apuntar que vamos a generar dos tipos de ficheros, los que tendrán como objetivo generar los nuevos modelos que se emplearán y los que se utilizarán para evaluar la bondad de la adaptación.
6.3.1.1.- Acondicionamiento de los ficheros para HTK
Antes de comenzar a utilizar el HTK, hay que modificar los ficheros ya existentes para que tengan el formato adecuado y crear los ficheros que necesitaremos pasar como parámetro a alguno de los programas de HTK descritos en el apartado 2.2.1.
Como hemos dicho anteriormente, partimos del fichero .DATA cuyo formato de línea hemos descrito en el apartado 6.2.2, que es a nivel de frase, y un fichero de diccionario, que tiene una primera línea en la que aparece un número que indica el total de palabras que componen el vocabulario y el siguiente formato de línea:
Figura 21: Formato de línea del fichero de diccionario
Lo primero que hacemos es crear otro fichero .DATA pero a nivel de palabra que utilizaremos para generar los diccionarios del HTK y que tiene el siguiente formato de línea:
Figura 22: Formato de línea del fichero .DATA
Para ello tomamos como punto de partida el fichero de diccionario que acabamos de describir, realizando la transformación mediante el programa “dic2data.per”, cuya codificación es:
84

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
while ($_=<stdin>) {
$string = $_;
#si la linea contiene alguna letraif($string =~ /([a-zA-Z]+)/){
#nos quedamos con todo lo que no sea un dígito($palabra) = ($string =~ /(\D+)/);
printf stdout "* 0 0 $palabra";printf stdout " . \n";
}else{
next;}
}Cuadro 25: Programa dic2data.per
En el momento en que disponemos de los dos ficheros .DATA, a nivel de frase y a nivel de palabra, se los pasamos al “gran2fonVC.exe” para obtener las transcripciones fonéticas correspondientes, que pueden verse en los ficheros con extensión .alp. El formato de estos ficheros es el siguiente:
* 0 0 ha sido por lo que a ti te toca . 21 'a s 'i D o p o R* l o k e a t 'i t e t 'o k a 5 33 7 35 3 27 3 44 47 3 29 1 0 28 7 28 1 28 8 29 0
Cuadro 26: Formato de líneas en el fichero .alp a nivel de frase
* 0 0 abrasar . 7 a B R/ a s 'a R* 0 34 45 0 33 5 44
Cuadro 27: Formato de líneas en el fichero .alp a nivel de palabra
En la primera línea aparece el formato que ya hemos comentado anteriormente. En la segunda línea, lo primero que aparece es el número de fonemas que contiene esa frase o palabra, después aparecen los fonemas que las componen y por último la codificación numérica de cada uno de esos fonemas.
Esos ficheros se los pasamos al “resumen.exe” para obtener diferentes porciones del conjunto de frases. Puesto que nos interesa entrenar los modelos con el mayor número posible de datos, pasamos como parámetro que el número de fracciones que queremos es uno, ya que nos interesa mantener toda la información posible. Los ficheros que obtenemos como resultado son diccionarios resumidos.
El diccionario de palabras obtenido no está en el formato adecuado para pasárselo al HTK y es por eso que debemos cambiar su formato. Inicialmente tiene el mismo formato que el .alp de palabra y necesitamos cambiarlo para que su formato sea el siguiente:
85

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
* 0 0 abrasar 7 a B R/ a s 'a R* 0 34 45 0 33 5 44
Cuadro 28: Formato de líneas en el diccionario a nivel de palabra
es decir, le quitamos el punto que hay al final de la primera línea y para ello empleamos el programa “dic2dicgth.per”, que tiene la siguiente codificación:
while ($_=<stdin>){
#si la linea comienza por * 0 0 con un número indeterminado de espacios entre #ellos
if (m/\*(\s+)0(\s+)0(\s+)/){
#buscamos el punto final y lo sustituimos por nada, lo eliminamoss/\.//;printf stdout "%s",$_;
}else{
#si no, dejamos la linea como estabaprintf stdout "%s",$_;
}}
Cuadro 29: Programa dic2dicgth.per
También necesitamos los ficheros .alf, cuyo formato de línea es similar al del fichero .alp a nivel de frase pero que el lugar de un asterisco lleva el nombre del fichero que contiene esa frase, para que el HTK pueda asociar la trascripción fonética con el audio. Para conseguirlo utilizamos el programa “dic2alf.per” al que se le pasa como parámetro el nombre del locutor ya que éste aparecerá en el nombre del fichero, siendo el fichero de entrada sobre el que vamos a realizar los cambios el fichero de diccionario a nivel de frase. Puesto que dicho fichero contiene las tramas inicial y final cuyo valor es desconocido, eso influirá a la hora de implementar la búsqueda de la línea. La codificación de este programa es:
$Cuenta = 1;$locutor = $ARGV[0];
while ($_=<stdin>){#si la linea comienza por *(espacios)(numeros)(espacios) #(numeros)(espacios)(letras)
if (m/\*(\s+)(\d+)(\s+)(\d+)(\s+)([a-zA-Záéíóú])/){
$grabacion = $locutor."_0_".$Cuenta;
#eliminamos el punto al final de la lineas/\.//;
#cambiamos el * por el nombre de la grabacions/\*/$grabacion/;
printf stdout "%s",$_;$Cuenta++;
}else{
printf stdout "%s",$_;}
}Cuadro 30: Programa dic2alf.per
86

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Otros archivos que necesitamos son los ficheros .lif en los que el formato de línea es:
Q_C_00811 0 0 no le he dicho que sí pese a mi linaje .Cuadro 31: Formato de línea de los ficheros .lif
en el que se han eliminado las líneas correspondientes a la trascripción fonética. Para lograrlo partimos el fichero de diccionario a nivel de frase y mediante el programa “dic2lif.per”, al que le pasamos como parámetro el nombre del locutor, conseguimos modificar el formato para obtener el archivo .lif.
$Cuenta = 1;$locutor = $ARGV[0];
while ($_=<stdin>){#si la linea comienza por *(espacios)(numeros)(espacios) #(numeros)(espacios)(letras)
if (m/\*(\s+)(\d+)(\s+)(\d+)(\s+)([a-zA-Záéíóú])/){
$grabacion = $locutor."_0_".$Cuenta;
#eliminamos el punto al final de la lineas/\.//;
#cambiamos el * por el nombre de la grabacions/\*/$grabacion/;
printf stdout "%s",$_;$Cuenta++;
}else{
next;}
}Cuadro 32: Programa dic2lif.per
Por último, necesitamos generar un fichero en el que aparezca una lista con los nombres de todos los ficheros de audio que vamos a emplear para llevar a cabo la adaptación. Dichos ficheros tienen la extensión .scp y los generamos a partir del fichero de diccionario a nivel de frase mediante el programa “generaNopath.per” al que también hay que pasarle como parámetro el nombre del locutor:
87

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
$Cuenta = 1;$locutor = $ARGV[0];
while ($_=<stdin>){#si la linea comienza por *(espacios)(numeros)(espacios) #(numeros)(espacios)(letras)
if (m/\*(\s+)(\d+)(\s+)(\d+)(\s+)([a-zA-Záéíóú])/){
#imprimimos el nombre del fichero de audio$grabacion = $locutor."_0_".$Cuenta;printf stdout "%s\n",$grabacion;$Cuenta++;
}else{
next;}
}Cuadro 33: Programa generaNopath.per
Una vez tenemos todos los ficheros que necesitamos, los copiamos a los directorios en los que serán utilizados incluidos los ficheros de audio.
6.3.1.2.- Adaptación de los diccionarios
El primer paso que debemos llevar a cabo es adaptar los diccionarios que tenemos en formato GTH al formato que deben tener los diccionarios en HTK. El motivo principal es que hay fonemas cuya trascripción no tiene un formato admitido por HTK y es necesario cambiarlo, como por ejemplo:
‘e XeR* R~
Este proceso de cambio se lleva a cabo con el programa “awk_dic2” que es:
#imprime cada palabra, campo 4 de las líneas impares{printf "%s\t\t", $4}
#si la palabra es corta, imprime un tabulador{if (length($4)<8) printf "\t"}
#lee la siguiente línea (par), la que contiene la transcripción{getline}
# lee el número de alófonos de la palabra{MAX = ($1)+0}{n=2}
#busca una ' en la linea leida, y guarda la posicion en la variable i
{i= index ($1, "'")}
#si hay comilla, sustituye el campo $1 por lo que hay detrás de la comilla{if (i!=0) $1= substr($1,i,length($1)+1)}{if (i!=0) n=1}
88

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
{if (i!=0) MAX--}
#recorre los campos, si el primer carácter del campo es ', antepone un barra
{#si no se pone el n=n da error de sintaxisfor (n=n; n<(MAX+1); n++) if (substr($n,1,1)=="\'") printf "\\%s\t", $n;
#si el primer campo es R*, sustituye por R~else if ($n=="R*") printf ("R~ ");
#si no, imprime tal cual, pero con tabuladorelse printf "%s\t", $n}
{if (substr($(MAX+1),1,1)=="'") printf "\\%s \tsp\n", $(MAX+1); else if ($(MAX+1)=="R*") printf ("R~\tsp\n");else printf "%s\tsp\n", $(MAX+1)}
Cuadro 34: Programa awk_dic2
El diccionario que obtenemos puede ser utilizado para entrenamiento. Para pruebas debemos añadir los modelos de silencio al final del fichero:
</s> [ ] sil<s> [ ] sil
proceso que automatizamos creando un nuevo fichero de la combinación del fichero de diccionario y el fichero “silencios.dic” que sólo contiene los modelos de silencio.
copy silencios_HTK_test.dic+%1_HTK.dic %1_HTK_test.dicCuadro 35: Instrucción para combinar el fichero de diccionario con los silencios
6.3.1.3.- Generación de los ficheros maestros de etiquetas
A partir de los ficheros .alf a nivel de frase que teníamos, crearemos los ficheros de etiquetas maestras o MLF (Master Label Files) de nivel de palabra. Cada una de las frases se descompone según el siguiente formato:
Figura 23: Formato de descomposición de una frase en el MLF
89

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Para lograr esta descomposición utilizamos el programa awk_words2:
{#si el numero de linea es 1, escribimos #!MLF!#if (NR==1)
printf ("#!MLF!#\n")}{
#el nombre del fichero de audio debe tener mas de 5 caracteresif (length($1)>5){
{#el nombre del fichero de audio debe tener un maximo de 12 caracteres #tal como indica el tercer parametro de la instruccion substr
printf ("\"*/%s.lab\"\n", substr($1,1,12))}{
#se recorren todos los campos de la linea a partir del cuarto que es la #primera palabra de la frase
for (n=4; n<=NF; n++)if (($n!="[sta]")&&($n!="[int]"))
if ($n=="[fil]")printf "!FIL\n";
else if ($n=="[spk]")printf "!SPK\n";
elseprintf "%s\n", $n
}{printf ".\n"}
}}
Cuadro 36: Programa awk_words2
Es importante resaltar que el nomrbe del fichero debe tener entre 5 y 12 caracteres.
A partir de este MLF a nivel de palabra, generamos el MLF a nivel de fonemas mediante el HLEd. Tendremos dos MLF de nivel de fonema, uno en el que se tiene en cuenta el modelo de pausa corta (tarea_train_mono.mlf) y otro en que se elimina dicho modelo (tarea_train_mono0.mlf).
El último MLF que necesitamos es el de trifonemas internos en el que se considera un fonema en el contexto de los dos que lo rodean salvo en el principio y el final de la palabra, que se emplean modelos independientes de contexto. Lo creamos a partir del MLF de nivel de fonema mediante HLEd.
Debido a problemas de formato es necesario modificar el MLF de trifonemas de manera que las vocales que comiencen por tilde estén entrecomilladas, para lo que utilizamos el programa “awk_comillas2”:
90

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
#si el primer caracter de la palabra es una comita que indica tilde, se #imprime la palabra entrecomillada en caso contrario, se imprime la palabra #tal cualif (substr($1,1,1)=="'")
printf "\"%s\"\n", $1; else
printf "%s\n", $1Cuadro 37: Programa awk_comillas2
En los MLF a nivel de fonema también tenemos que hacer una modificación y poner “ \ ” delante de todas las vocales que tengan tilde. Para ello utilizamos el programa “awk_slash2”:
#si el primer caracter de la palabra es una tilde, le antepone una \#antes de imprimirla, en caso contrario la imprime como estaba {if (substr($1,1,1)=="'")
printf "\\%s\n", $1;else
printf "%s\n", $1}
Cuadro 38: Programa awk_slash2
En los MLF a nivel de fonema, los modelos de silencio y pausa corta deben aparecer al final y según el fichero de que se trate deberán aparecer ambos o únicamente el de silencio, por lo que editamos dichos ficheros mediante “editaMono.per” y “editaMono0.per” que es igual que “editaMono.per” pero eliminando la última línea.
while ($_=<stdin>){
#quitamos los tabuladores y retornos de carrochop;
#comparamos la linea de entrada con el silencio y la pausa corta$Comparacion1 = 'sil' cmp $_;$Comparacion2 = 'sp' cmp $_;
#si coincide con alguno de los dos no la imprimimosif ($Comparacion1==0){
next;}elsif ($Comparacion2==0){
next;}else{
printf stdout "%s\n",$_;}
}
printf stdout "sil\n";printf stdout "sp\n";
Cuadro 39: Programa editaMono.per
91

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
Aunque hemos generado listas con todos los fonemas y trifonemas que aparecen en nuestras frases, es necesario disponer de una lista en la que aparezcan todos los fonemas y trifonemas posibles, así como los modelos de silencio y pausa corta, lo que conseguimos llamando al programa “fulllist_tri”. En estas nuevas listas que acabamos de obtener, hay que realizar otro cambio de formato, cambiando el símbolo “ ’ ” que aparece delante de algunas vocales por “ \’ ”. Para ello nos valemos del programa “awk_slash2” anteriormente mencionado.
6.3.1.4.- Parametrización de los ficheros de audio
Para poder llevar a cabo la parametrización de los ficheros de audio con las grabaciones de las frases, es necesario obtener una lista en la que aparezcan dichos ficheros con su path de manera que el programa que lleve a cabo dicha parametrización pueda encontrarlos. Para ello partimos del fichero .scp que contenía la lista de los ficheros y mediante el programa “awk_scp” les añadiremos el path:
#programa que añade un path y una extension a cada uno de los elementos de una #lista{printf "%s/%s.wav %s/%s.plp\n", DIR_AUDIO, $1, DIR_PAR, $1;}
Cuadro 40: Programa awk_scp
Una vez tenemos la lista de los ficheros de audio y su localización, utilizamos el programa HCopy para parametrizarlos, teniendo en cuenta que son ficheros de audio con las siguientes propiedades:
Formato del archivo: WAV Frecuencia de muestreo: 8 KHz
Por último, a partir de los ficheros .scp originales, generamos un fichero en el que aparezca una lista con todos los ficheros de parámetros (.plp) que acabamos de generar junto con su path. Para ello ejecutamos el programa “awk_list2”:
#programa que añade un path y una extencion a cada uno de los elementos de una #lista generando la lista de archivos .plp con su path{printf "/%s/%s.plp\n", DIR_PAR, $1;}
Cuadro 41: Programa awk_list2
6.3.1.5.- Normalización Cepstral
El siguiente paso es obtener los datos necesarios para llevar a cabo la normalización de la media y de la varianza, como se comentó en el apartado 2.2.1.3. Para ello nos valemos del programa HCompV descrito en dicho apartado junto con sus respectivos ficheros de configuración y las listas de ficheros de parámetros.
92

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
6.3.2.- “adaptaMap.bat”
El proceso de adaptación MAP se lleva a cabo mediante una única llamada al programa HERest:
HERest -H modelos/SpeechDat_Continua_MMF -M hmm_2 -T 1 -B -w 2.0 -m 0 -u mwp -s hmm_2/stats -C ../lib/config/herest2.cvn.map2.cfg -A -V -D –I ../lib/lab/%1_train_tri.mlf -S ../lib/flist/%1.scp ../lib/mlist/lista.cvn_0.5.100.784.tri > hmm_2/LOG
Cuadro 42: Llamada a HERest
Los parámetros que se la pasan a la función son los siguientes:
-H modelos/SpeechDat_Continua_MMF modelos que vamos a reestimar-M hmm_2 directorio en el que se guardarán los nuevos modelos-T 1 trazas que se desean mostrar-B saca el formato binario-w 2.0 mixture weigth con el valor que se le quiere dar-m 0 mínimo número de ejemplos para ensayo necesarios-u mwp flags de configuración :m(media),w(mixture weigth),p(adaptación MAP)-s hmm_2/stats archivo que almacena las estadísticas de ocupación-C ../lib/config/herest2.cvn.map2.cfg fichero de configuración de HERest-A se imprimen los argumentos que se le pasan-V saca listado con versión de la herramienta y los módulos que utiliza-D saca los settings-I ../lib/lab/%1_train_tri.mlf fichero .mlf que cargamos para re-estimar-S../lib/flist/%1.scp fichero script con los nombres de los ficheros de audio../lib/mlist/lista.cvn_0.5.100.784.trilista de trifonemas que se va a procesarhmm_2/LOG fichero en el que se guarda la salida de la ejecución del HERest
Tabla 5: Parámetros de la llamada a HERest
Una vez ejecutada, ya tenemos los nuevos modelos, por los que los copiaremos al directorio de modelos correspondiente y volveremos al directorio de tarea.
El fichero de configuración nos permite variar los parámetros de la adaptación MAP.
HPARM: TARGETKIND = PLP_0_D_A_ZSAVEBINARY = TMAXTRYOPEN = 2
HFWDBKWD: PRUNEINIT = 200.0HFWDBKWD: PRUNEINC = 200.0HFWDBKWD: PRUNELIM = 1200.1HFWDBKWD: MINFORPROB = 20.0HFWDBKWD: TRACE = 1
CMEANDIR = /usuarios/HMMs-CEU/cmnCMEANMASK = *%%%%%%%%%%%%.plp#VARSCALEFN = /usuarios/HMMs-CEU/cvn/globalvarVARSCALEDIR = /usuarios/HMMs-CEU/cvnVARSCALEMASK = *%%%%%%%%%%%%.plp
HMAP:TRACE = 1HMAP:MAPTAU = 3
Cuadro 43: Fichero de configuración de HERest para la técnica MAP
93

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
De todos ellos cabe destacar la variable MAPTAU que nos permitirá modificar el peso de los modelos originales o de las nuevas grabaciones en la re-estimación según la ecuación 2.3.
6.3.3.- “adaptaMLLR.bat”
El proceso de adaptación empleando MLLR supone ejecutar más instrucciones que en el caso de MAP. Los pasos a seguir con sus instrucciones correspondientes son:
1. Generamos el árbol de clases de regresión mediante HHEd.
HHEd –A –V –D –B –H ../modelos/SpeechDat_Continua_MMF –M classes -T 00401 regtree128.hed ../lib/mlist/lista.cvn_0.5.100.784.tri > classes/LOG
Cuadro 44: Instrucción para crear los árboles de clases de regresión
Todos los parámetros se han explicado en la Tabla 5 salvo uno que es “regtree128.hed” que es un script para HHEd con las siguientes instrucciones:
LS "../modelos/stats"RN "rtree"RC 128 "rtree" {(sil,sp).state[2-4].mix}
Cuadro 45: Script regtree128.hed
Donde las instrucciones que se utilizan son:
o LS: Se emplea para leer el fichero de estadísticas que se le pasa como parámetro. Este fichero es necesario para realizar algunas operaciones de clustering ya que contiene la cuenta de la ocupación de cada estado del HMM.
o RN: Renombra el identificador del modelo con el nombre pasado como parámetro.
o RC: Se utiliza para generar árboles de clases de regresión. Se le pasan tres parámetros:
N Número de nodos terminales del árbol Identificador Nombre con el que se guarda el nuevo árbol de
clases Lista de elementos Lista con los sonidos “no hablados” que se
quieren incluir como pueden ser los modelos de silencios.
2. Creamos una transformación global con el fin de modificar todas las gaussianas originales de acuerdo con las características globales del locutor.
HERest –a –A –D –V –T 7 –C ../../lib/config/herest2.cvn.mllr0.cfg -J ../classes –H ../../training/modelos/SpeechDat_Continua_MMF -B –w 2.0 –m 0 –u a –I ../../lib/lab/%1_train_tri.mlf –z regc.tmf –K hmm128 mllr0 –h “*/%%%%%%%%%%%%_*.plp” -S../../lib/flist/%1.scp ../../lib/mlist/lista.cvn_0.5.100.784.tri > hmm128/LOG
Cuadro 46: Comando para realizar la primera transformación con HERest
94

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
En esta llamada a HERest, se utilizan los siguientes parámetros cuya funcionalidad se detalla a continuación:
OPCIÓN SIGNIFICADO
-aUtilizar una transformada de entrada para obtener el alineamiento necesario a la hora de actualizar
los modelos o transformaciones-J dir Añade dir a la lista de posibles directorios en los
que encontrar las transformaciones de entrada-u a Utiliza la transformación lineal al activar el flag a
-z ext Fichero en el que se guardan las transformaciones de salida
-K dir Directorio en el que se guardan las transformaciones de salida
-h mask Indica la máscara que determina que nombre de transformaciones deben utilizarse para las
transformaciones de salida-A Indican que se imprimen los argumentos que se le
pasan-D Saca los settings-V Saca el listado con la versión de la herramienta y
los módulos que utiliza-T num Muestra las trazas que se correspondan con num
-C fich Fichero de configuración de HERest-H hmm Fichero de modelos original que se va a reestimar
-B Se obtiene el formato binario del nuevo fichero-w num Mixture weigth con valor de num-m num Mínimo número de ejemplos para ensayo
necesarios indicados mediante num-I fich Fichero .mlf que cargamos para re-estimar-S fich Fichero script con los nombres de los ficheros de
audioTabla 6: Tabla con las nuevas opciones de HERest
3. Llevamos a cabo la transformación final:
HERest –a –A –D –V –T 7 –C ../../lib/config/herest2.cvn.mllr1.cfg -J ../classes –H ../../training/modelos/SpeechDat_Continua_MMF -B –w 2.0 –m 0 –u a –I ../../lib/lab/%1_train_tri.mlf –z regc.tmf –J hmm128 mllr0 –K hmm128 mllr1 –h “*/%%%%%%%%%%%%_*.plp” -S../../lib/flist/%1.scp ../../lib/mlist/lista.cvn_0.5.100.784.tri > hmm128/LOG
Cuadro 47:Llamada a HERest para la transformación final de los modelos mediante MLLR
Una vez echo esto, ya tenemos los nuevos modelos acústicos adaptados a las características del locutor, así que los copiamos al directorio correspondiente para que puedan cargarse en el reconocedor.
95

Proyecto Fin de CarreraNuria Pérez Magariños 6.-Mecanismos de adaptación
96

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
7.- EVALUACIÓN Y PRUEBAS DEL SISTEMA
Una vez implementadas todas las modificaciones del sistema se realizaron pruebas para comprobar su correcto funcionamiento, así como experimentos de adaptación empleando las grabaciones de habla con emociones de dos locutores, un hombre y una mujer. En este capítulo se detallan todos los experimentos realizados.
7.1.- Pruebas de adaptación con emociones
Una vez comprobamos que el sistema realizaba correctamente el proceso de adaptación, decidimos llevar a cabo pruebas de adaptación empleando las grabaciones de 100 frases del Quijote que se pueden ver en el Anexo III. Dos locutores grabaron esas frases simulando diferentes emociones: alegría, asco, enfado, miedo, neutra, sorpresa y tristeza. Cada locutor tiene características particulares a la hora de representar cada emoción y eso podrá verse reflejado en los resultados obtenidos.
7.1.1.- Reconocimiento con los modelos genéricos
Inicialmente, y para poder comprobar hasta que punto influía la adaptación en la mejora del reconocimiento de las emociones, realizamos un reconocimiento con los modelos originales tanto para el locutor como para la locutora para tener un punto de partida con el que poder comparar. Los resultados se pueden ver en la siguiente gráfica:
Intervalos de confianza en el reconocimiento con modelos genéricos
102030405060708090
100
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTEZA
Emoción reconocida
Tasa
de
erro
r (%
)
Reconocimientohombremodelosgenéricos
Reconocimientomujer modelosgenéricos
Figura 24: Tasa de error reconociendo con modelo genérico en función del locutor
97

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Vemos que tanto como el hombre como la mujer tienen la misma tasa de correctas para la voz neutra que podríamos decir que es la que en teoría se encuentra más cercana a los modelos genéricos. Las siguientes emociones cuya tasa es relativamente parecida en el hombre y en la mujer son el enfado, la sorpresa y la tristeza. Por el contrario, la diferencia entre la alegría, el asco y el miedo dan lugar a pensar que la mujer enfatiza más esas emociones.
También podemos ver que la tasa de correctas en el hombre se encuentra más o menos en los mismos valores, mientras que la mujer varía de unas a otras de forma marcada. Esto puede deberse a que a mujer haga una mayor distinción entre las emociones y las marque más, mientras que el hombre no diferencia tan evidentemente las emociones.
Estas conclusiones se han reforzado calculando la media y la varianza de los valores anteriormente expuestos, obteniéndose los siguientes resultados:
Locutor Media VarianzaMujer 54,2 29,0
Hombre 24,0 9,0Tabla 7: Media y varianza del reconocimiento genérico según locutor para todas las emociones
Donde podemos ver que la diferencia entre el hombre y la mujer es bastante clara ya que esta última, al hacer tan diferentes unas emociones de otras, ha dado lugar a un mayor rango de variación en el habla. Por el contrario, el hombre tiene unas tasas de reconocimiento más uniformes respecto de la neutra con los modelos genéricos a que no destaca tanto un emoción de otra.
7.1.2.- Determinación de la τ óptima
Una vez hemos visto las tasas de reconocimiento de las emociones empleando los modelos genéricos, el siguiente paso es determinar qué valor de τ da lugar a la mejora de reconocimiento más significativa.
Para ello hemos llevado a cabo dos experimentos:
1. Se ha entrenando cada modelo con 90 frases de una emoción y probando con las 10 frases restantes de esa misma emoción, empleándose siempre las mismas frases para entrenamiento y las mismas frases para reconocimiento.
2. Ya que el experimento anterior no daba opción a variar las frases de entrenamiento y reconocimiento, en este experimento hemos dividido las 100 frases de El Quijote en 10 grupos, cada uno de ellos con 90 frases de entrenamiento y 10 frases de evaluación, de manera que se evaluen todas las frases de El Quijote. Para mostrar los resultados, se han promediado los resultados obtenidos con los 10 experimentos.
98

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Los resultados correspondientes al hombre en el experimento 1 son los siguientes:
Tasa de error del hombre en el experimento 1
6
8
10
12
14
16
18
20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Valores de tau
Tasa
de
erro
r (%
) Errores alegriaErrores ascoErrores enfadoErrores miedoErrores neutroErrores sorpresaErrores tristeza
Figura 25: Evolución de la tasa de error en función de τ para el hombre en el experimento 1
Tasa de error de cada emoción reconocida
Val
ores
de
τ
Alegría Asco Enfado Miedo Neutra Sorpresa Tristeza0,25 - - - - - - -
1 12,42 11,11 6,54 14,38 8,5 6,54 10,462 11,11 11,11 6,54 13,07 8,5 6,54 13,073 11,76 11,11 6,54 13,07 9,15 8,5 15,694 11,76 11,11 6,54 15,69 9,15 9,15 17,656 11,76 11,11 7,19 16,65 9,15 9,15 18,958 11,76 11,11 7,19 14,38 9,15 12,42 17,6510 11,76 10,46 7,19 14,38 9,8 12,42 17,6512 11,76 10,46 7,19 16,34 9,8 13,73 17,6514 11,76 10,46 7,19 13,73 9,8 13,07 15,0316 11,76 10,46 7,19 13,73 9,8 13,07 15,03Tabla 8: Tasa de error para el hombre en el experimento 1 en función de τ
99

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Los resultados del hombre en el experimento 2 son:
Tasa de error del hombre en el experimento 2
8
10
12
14
16
18
0,25 1 2 3 4 6 8 10 12 14 16
Valores de tau
Tasa
de
erro
r (%
) AlegríaAscoMiedoNeutroTristezaEnfadoSorpresa
Figura 26: Evolución de la tasa de error del hombre en función de τ en el experimento 2
Tasa de error de cada emoción reconocida
Val
ores
de
τ
Alegría Asco Enfado Miedo Neutra Sorpresa Tristeza0,25 14,2 16,6 10,8 18,5 12,2 - 15,7
1 12,9 16,3 10,3 15,5 12,6 8,6 15,22 13,3 15,7 9,9 16,3 12,3 8,6 14,33 13,5 15,7 10,3 15,9 12,0 8,6 14,44 14,0 15,7 10,5 16,3 12,1 8,5 14,66 13,8 16,1 11,0 16,1 12,0 9,4 15,08 13,8 16,5 11,8 16,7 11,6 10,0 14,910 14,5 16,9 12,1 16,8 11,6 10,2 15,212 14,6 17,1 12,0 17,4 11,3 - 15,014 15,0 17,4 12,2 17,6 11,3 - 14,816 15,2 17,2 12,3 18,3 11,5 - 15,0
Tabla 9: Tasa de error del hombre en el experimento 2 en función de τ
100

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Los resultados de la mujer en el primer experimento son:
Tasa de error de la mujer en el experimento 1
8
13
18
23
28
33
38
43
48
53
58
63
68
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Valores de tau
Tasa
de
erro
r (%
)
Alegría
Asco
Enfado
Miedo
Neutro
Sorpresa
Tristeza
Figura 27: Evolución de la tasa de error en función de τ para la mujer en el experimento 1
Tasa de error de cada emoción reconocida
Val
ores
de
τ
Alegría Asco Enfado Miedo Neutra Sorpresa Tristeza0,25 - - - - - - -
1 43,1 49,7 12,4 50,3 10,5 27,5 24,22 47,0 53,6 13,1 46,4 11,8 22,9 23,53 47,7 52,3 13,1 45,1 11,8 21,6 23,54 49,0 55,6 13,1 45,8 11,1 21,6 24,26 54,3 64,7 13,1 52,9 11,1 22,2 26,88 56,2 62,1 13,7 52,3 11,8 22,2 14,810 56,2 62,8 13,7 51,6 11,8 22,2 21,612 56,2 63,4 15,7 54,3 11,8 22,2 26,114 56,2 64,7 15,0 53,6 11,8 21,6 26,116 58,8 64,1 15,0 58,8 11,8 21,6 26,1
Tabla 10: Tasa de error de la mujer en función de τ en el experimento 1
101

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Los resultados correspondientes al experimento 2 son:
Tasa de error de la mujer en el experimento 2
81318232833384348535863
0,25 1 2 3 4 6 8 10 12 14 16
Valores de tau
Tasa
de
erro
r (%
) AlegríaAscoMiedoNeutraTristezaEnfadoSorpresa
Figura 28: Evolución de la tasa de error para la mujer en función de tau en el experimento 2
Tasa de error de cada emoción reconocida
Val
ores
de
τ
Alegría Asco Enfado Miedo Neutra Sorpresa Tristeza0,25 48,3 56,3 20,3 52,5 10,4 - 26,5
1 43,8 52,0 19,0 50,7 9,0 28,9 24,22 44,5 53,2 17,4 49,2 9,2 27,2 23,93 45,1 52,5 17,3 49,6 9,2 26 23,74 45,9 52,3 17,9 49,5 9,9 25 22,76 46,1 51,3 18,6 49,0 10,5 24,7 22,48 46,3 52,1 18,5 49,4 11,0 25,5 23,410 46,5 52,3 18,3 49,3 11,8 - 23,612 47,5 54,0 17,7 49,0 12,3 - 23,514 47,2 55,9 17,5 50,2 12,6 - 23,816 47,4 57,0 17,7 50,4 12,4 - 23,9
Tabla 11: Tasa de error de la mujer en función de τ en el experimento 2
De las gráficas podemos sacar las siguientes conclusiones generales:
En el caso de adaptación de habla emocionada los mejores resultados se obtienen con valores bajos de τ. Esto es porque al introducir las emociones, aumentan las variaciones respecto a los modelos genéricos de manera que es necesario dar más peso a los nuevos datos de adaptación frente a los originales.
La adaptación no mejora significativamente todas las emociones, habiendo emociones para las que casi se podría decir que es contraproducente. Por el contrario, hay emociones que experimentan una mejora considerable después de realizar la adaptación.
102

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Los resultados obtenidos en el segundo experimento, al haber hecho una media de la evaluación de todas las frases, dan lugar a unas curvas más suavizadas que las obtenidas empleando siempre las mismas 10 frases de evaluación.
En el caso del hombre podemos añadir las siguientes observaciones:
Emociones como el miedo o el asco empeoran en general si se efectúa una adaptación
Emociones como la alegría o la neutra no se ven apenas modificadas por lo que la adaptación podría ser opcional.
Sin embargo, la tristeza y la sorpresa experimentan una mejora significativa al realizar la adaptación.
En el caso de la mujer, las observaciones adicionales son:
Podemos ver dos grupos de emociones claramente diferenciados que definiremos como los más cercanos a la voz neutra y, por tanto, mejor reconocidos por los modelos genéricos, y los más alejados de la neutra en el caso de esta locutora concreta.
o Las emociones más cercanas a la voz neutra son la neutra, el enfado,
la sorpresa y la tristeza y podemos ver que la adaptación no supone una gran mejora para el reconocimiento de estas emociones.
o Por otro lado, las más alejadas son la alegría, el asco y el miedo. En la Figura 24 se puede ver que éstas son las emociones que más marca la locutora y que más se alejan de los modelos genéricos, de manera que la adaptación mejora considerablemente el reconocimiento de estas emociones.
Por último, tenemos que elegir una τ para cada locutor de forma que maximice las tasas de correctas y minimice las tasas de error en general para todas las emociones. Para ello aplicamos la siguiente fórmula a los datos de cada emoción:
(7.1)
Así, obtenemos los siguientes resultados para las τ más bajas:
1 2 3 4 5 6 7Hombre Experimento 1 98,0 98,0 92,1 86,9 83,7 83,0 82,3Hombre Experimento 2 59,1 60,1 60,1 58,8 - 57 -Mujer Experimento 1 161,4 160,8 164,1 158,8 151,7 134,0 135,3
Mujer Experimento 2 129,7 132,7 133,9 134,7 - 134,7 -Tabla 12: Mejora en el reconocimiento para τ bajas
103

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Las pruebas que se realizarán a partir de ahora han tomado como base los resultados del experimento 1 para la elección de la τ óptima. Por esto, elegimos para la mujer τ = 3 y para el hombre τ = 2, que serán las que utilizaremos para generar todos los nuevos modelos que intervengan en las pruebas.
La mejora introducida con estos valores de τ puede verse en las siguientes gráficas, al compararlas con los resultados obtenidos con los modelos genéricos:
Mejora del reconocimiento para la mujer
10
20
30
40
50
60
70
80
90
100
ALEGRIA
ENFADOASCO
TRISTEZA
NEUTRO
SORPRESA
MIEDO
Emoción reconocida
Tasa
de
erro
r (%
)
Modelo adaptado
Modelo genérico
Figura 29: Mejora del reconocimiento para la mujer con τ =3
Alegría Asco Enfado Miedo Neutra Sorpresa TristezaAntes de adaptar 56,2 97,4 32,7 84,3 15,0 37,9 55,6
Después de adaptar
47,7 52,3 13,1 45,1 11,8 21,6 23,5
Mejora (%) 15,1 46,3 60,0 46,5 21,8 43,1 57,6Significativa SI SI SI SI SI SI SI
Tabla 13: Resultados de la mejora del reconocimiento para la mujer con τ=3
104

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Mejora del reconocimiento para el hombre
5
10
15
20
25
30
35
40
ALEGRIA
ENFADOASCO
TRISTEZA
NEUTRO
SORPRESA
MIEDO
Emoción reconocida
Tasa
de
erro
r (%
)
Modelo adaptado
Modelo genérico
Figura 30: Mejora del reconocimiento para el hombre con τ=2
Alegría Asco Enfado Miedo Neutra Sorpresa TristezaAntes de adaptar 26,1 19,0 16,3 36,6 14,4 35,3 20,3
Después de adaptar
11,1 11,1 6,5 13,1 8,5 6,5 13,1
Mejora (%) 57,5 41,4 60,0 64,3 40,9 81,5 35,5Significativa SI SI SI SI SI SI SI
Tabla 14: Resultados de la mejora del reconocimiento para el hombre con τ=2
En las gráficas podemos observar lo siguiente:
Se produce una mejora en el reconocimiento de todas las emociones con los modelos adaptados tanto en el hombre como en la mujer.
Los modelos adaptados mantienen aproximadamente la misma relación en cuanto al reconocimiento relativo entre las emociones de un mismo locutor.
o En el caso del hombre se produce una mejora muy significativa para la sorpresa y el miedo, que son las emociones que más enfatiza y peor reconocía el modelo genérico.
o La mujer en algunas emociones no experimenta mejoras tan evidente, bien porque ya reconocía con bastante acierto la emoción como es el caso de la neutra, bien porque la variedad de entonaciones y ritmos de la emoción es demasiado amplia como para que la adaptación mejore significativamente los resultados, como sucede con la alegría.
105

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
7.1.3.- Variación de la proporción de datos de entrenamiento y de test
En esta ocasión, en lugar de variar la τ, lo que hemos hecho ha sido variar la proporción entre datos de entrenamiento y datos de evaluación. Los resultados obtenidos para la emoción neutra son:
Nº Frases Train Nº Frases Test Tasa error hombre (%) Tasa error Mujer (%)90 10 11,2 9,075 25 11,2 9,966 33 11,5 10,950 50 11,4 11,625 75 13,8 14,0
Tabla 15: Tasas de error para voz neutra en función de los datos de adaptación y test
En la tabla podemos ver que mientras el número de frases de entrenamiento sea mayor o igual al 50% de las frases de que disponemos, los resultados son más o menos similares. En el momento en que reducimos de forma considerable los datos de entrenamiento frente a los de test, vemos que se producen variaciones más evidentes. A continuación comprobaremos hasta qué punto es significativo el empeoramiento de los resultados para las demás emociones de las emociones.
Alegría Asco Enfado Miedo Sorpresa Tristeza90 train – 10 test 12,8 15,7 9,9 15,5 8,5 14,325 train – 75 test 18,2 18,2 14,0 21,0 12,6 16,7
Deterioro (%) 42,2 16,0 41,4 35,5 48,2 16,8Significativo SI SI SI SI SI SI
Tabla 16: Deterioro de la tasa de error en el hombre al reducir las frases de entrenamiento
Alegría Asco Enfado Miedo Sorpresa Tristeza90 train – 10 test 43,8 51,33 17,3 49,0 35,0 22,425 train – 75 test 52,6 69,0 22,6 61,0 24,8 30,1
Deterioro (%) 16,3 34,5 30,6 24,5 -28,6 34,4Significativo SI SI SI SI SI SI
Tabla 17: Deterioro de la tasa de error en la mujer al reducir las frases de entrenamiento
Podemos comprobar que al reducir el número de datos de entrenamiento se produce un deterioro significativo de la tasa de error en el reconocimiento de las emociones.
7.1.4.- Pruebas cruzadas
Una vez definido el valor de τ para cada locutor, las siguientes pruebas que hemos realizado han tenido como objetivo determinar qué emociones son las más difíciles de reconocer, cuáles son más cercanas y ver cómo de bien reconocen las demás emociones los modelos entrenados con una emoción concreta.
Hemos seguido el esquema de experimentos del apartado anterior. Así, para el primer experimento se han obtenido los siguientes resultados en el hombre:
106

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Reconocimiento cruzado en el hombre en el experimento 1
5
10
15
20
25
30
35
40
45
50
55
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRA
SORPRESA
TRISTEZA
Emociones reconocidas
Tasa
de
erro
r (%
)
Modelo de alegría
Modelo de Asco
Modelo de enfado
Modelo de miedo
Modelo de neutra
Modelo de sorpresa
Modelo de tristeza
Figura 31: Reconocimiento cruzado de emociones en el hombre en el experimento 1
Emoción reconocida
Emoc
ión
de
entre
nam
ient
o
Alegría Enfado Asco Tristeza Neutra Sorpresa MiedoAlegría 11,11 16,34 13,73 13,07 8,5 18,95 35,29Enfado 9,15 6,54 13,73 12,42 11,11 14,38 24,84Asco 13,73 11,11 11,11 15,69 10,46 17,65 31,37
Tristeza 10,46 13,73 22,88 13,07 9,8 20,26 33,33Neutra 15,69 14,38 12,42 15,03 8,5 24,84 50,98
Sorpresa 6,54 11,11 11,76 13,73 7,19 5,64 14,38Miedo 14,38 6,54 15,03 15,03 13,07 11,11 13,07
Tabla 18: Tasa de error en el reconocimiento cruzado con el hombre en el experimento 1
107
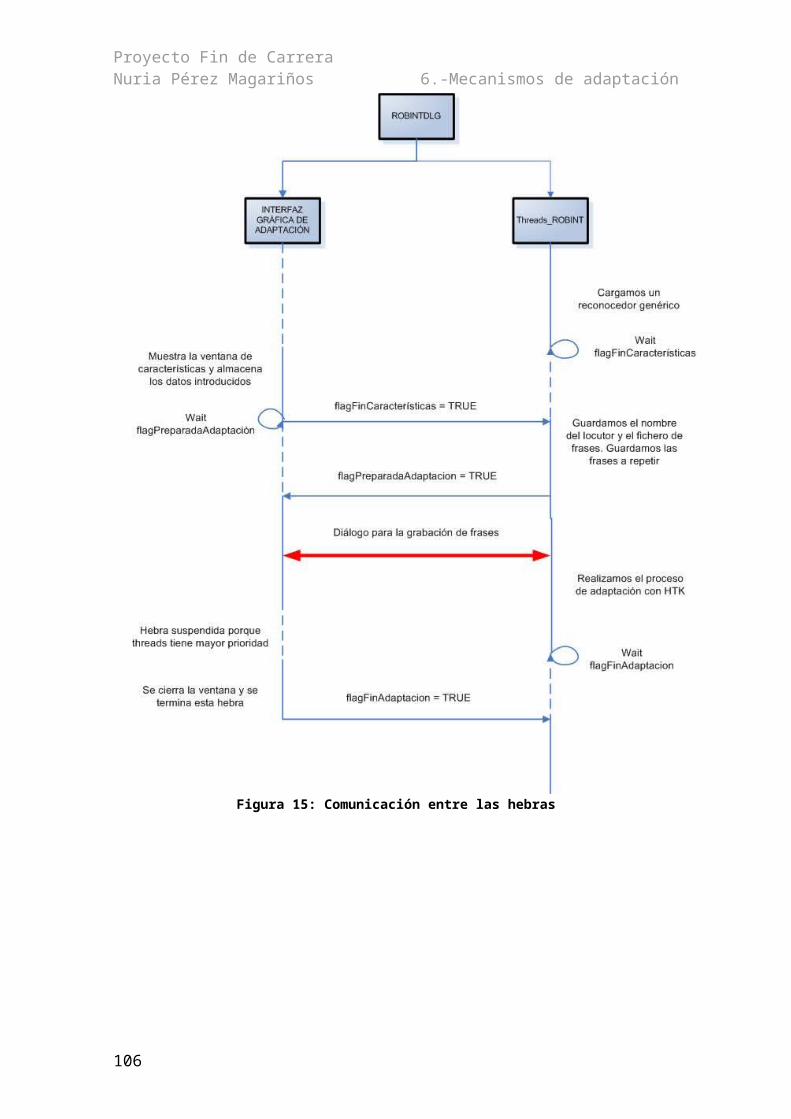
Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Los resultados del hombre para el segundo experimento han sido:
Reconocimiento cruzado en el hombre en el experimento 2
8,0
13,0
18,0
23,0
28,0
33,0
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTE
ZA
Emociones reconocidas
Tasa
de
erro
r (%
) Modelo de alegríaModelo de ascoModelo de enfadoModelo de miedoModelo de neutraModelo de sorpresaModelo de tristeza
Figura 32: Reconocimiento cruzado de emociones en el hombre en el experimento 2
Emoción reconocida
Emoc
ión
de
entre
nam
ient
o
Alegría Enfado Asco Tristeza Neutra Sorpresa MiedoAlegría 12,9 14,4 17,2 14,8 11,2 14,7 31,8Enfado 20,0 10,3 19,0 17,3 11,8 14,4 21,1Asco 19,8 16,4 16,3 19,4 13,0 15,7 27,3
Tristeza 17,4 18,4 26,4 15,2 12,9 20,2 29,1Neutra 18,6 14,9 15,4 13,8 12,6 20,2 34,3
Sorpresa 16,0 12,1 18,0 18,3 14,1 9,9 15,1Miedo 21,3 14.,2 22,1 18,6 15,8 13,3 15,5
Tabla 19: Tasa de error en el reconocimiento cruzado con el hombre en el experimento 2
108

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Los resutados del reconocimiento cruzado de emociones con la mujer en el primer experimento son:
Reconocimiento cruzado en la mujer en el experimento 1
10
20
30
40
50
60
70
80
90
100
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRA
SORPRESA
TRISTEZA
Emociones reconocidas
Tasa
de
erro
r (%
)
Modelo de alegríaModelo de ascoModelo de enfadoModelo de miedoModelo de neutroModelo de sorpresaModelo de tristezaModelo genérico
Figura 33: Reconocimiento cruzado de emociones en la mujer en el experimento 1
Emoción reconocida
Emoc
ión
de
entre
nam
ient
o
Alegría Miedo Asco Sorpresa Neutra Enfado TristezaAlegría 47,71 66,67 69,93 27,45 15,03 30,07 48,37Miedo 54,25 45,1 81,7 25,49 22,22 25,49 47,71Asco 49,67 72,55 52,29 32,68 12,42 31,37 47,71
Sorpresa 49,02 55,56 67,32 21,57 12,42 29,41 49,67Neutra 51,63 67,97 71,9 22,88 11,76 12,42 35,29Enfado 48,67 71,24 65,36 24,84 11,11 13,07 33,99Tristeza 66,67 71,24 81,05 42,48 19,61 28,01 23,53
Tabla 20: Tasa de error en el reconocimiento cruzado con la mujer en el experimento 1
109
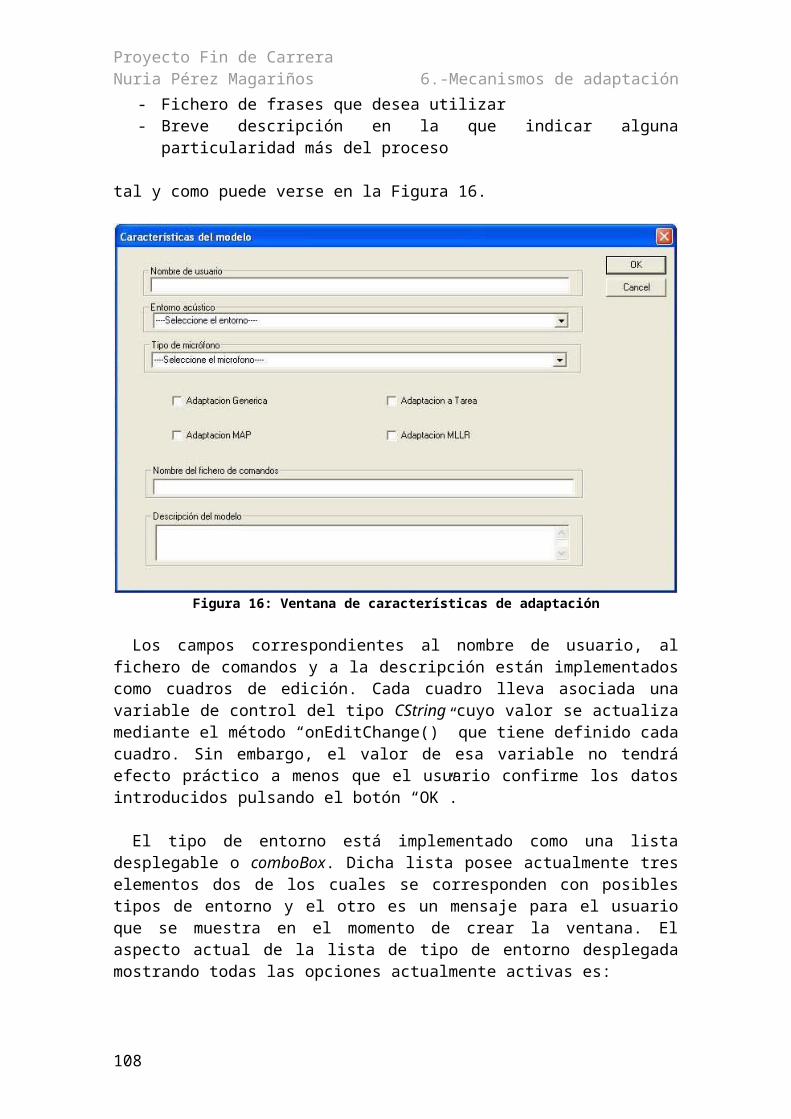
Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Mientras que en el segundo experimento los resultados son:
Reconocimiento cruzado con la mujer en el experimento 2
8,018,028,038,048,058,068,078,0
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTEZA
Emoción reconocida
Tasa
de
erro
r (%
)
Modelo de alegríaModelo de ascoModelo de enfadoModelo de miedoModelo de neutraModelo de sorpresaModelo de tristeza
Figura 34: Reconocimiento cruzado de emociones con la mujer en el experimento 2
Emoción reconocida
Emoc
ión
de
entre
nam
ient
o
Alegría Miedo Asco Sorpresa Neutra Enfado TristezaAlegría 43,8 59,3 70,2 32,1 12,8 26,9 38,8Miedo 48,7 50,7 73,7 34,4 18,7 32,8 49,2Asco 46,3 64,0 52,0 33,2 15,2 25,6 38,6
Sorpresa 41,9 58,2 68,5 28,9 13,3 30,2 44,8Neutra 40,7 66,4 68,4 28,9 9,0 22,3 33,2Enfado 44,4 52,9 63,5 32,0 14,0 19,0 33,5Tristeza 68,4 68,2 82,6 49,9 19,5 26,3 24,2
Tabla 21: Tasa de error en el reconocimiento cruzado con la mujer en el experimento 2
Observamos en las gráficas que:
En ambos locutores la emoción “miedo” es una emoción que resulta difícil de reconocer si se entrena con datos de las demás emociones.
Tanto el enfado como la neutra son emociones relativamente “fáciles” de reconocer con cualquier otra.
En el caso de la mujer también se hace evidente que el asco resulta difícil de reconocer debido principalmente a las peculiaridades que tiene la locutora al simularlo.
110

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
En el hombre la sorpresa aparece como otra emoción difícil ya que, junto con el miedo, es la que más diferencia de las demás.
Al realizar la media del reconocimiento de todas las frases, es decir, en el experimento 2, no se aprecia una mejora relevante de los resultados como para que compense asumir el coste computacional que supone.
También se puede ver, aunque luego lo estudiaremos con un poco más de detalle, que el utilizar la sorpresa como emoción de entrenamiento da lugar a unos modelos que reconocen razonablemente bien al resto de emociones. En el caso del hombre este hecho se hace más evidente que en la mujer, pero no podemos asegurar que sea la mejor opción de adaptación.
Por último, podemos aventurar que entrenar con voz neutra es casi la peor opción porque los resultados obtenidos con este modelo son casi los peores ya que es la más cercana a los modelos originales.
Si analizamos ahora los resultados numéricos obtenidos en el reconocimiento cruzado, podemos agrupar las emociones de cada locutor por su cercanía entre si. En las siguientes tablas se trata de ilustrar este análisis:
Emoción reconocida
Emoc
ión
de
entre
nam
ient
o
Alegría Enfado Asco Tristeza Neutra Sorpresa MiedoAlegría 16,34 13,73 13,07 8,5 18,95 35,29Enfado 9,15 13,73 12,42 11,11 14,38 24,84Asco 13,73 11,11 15,69 10,46 17,65 31,37
Tristeza 10,46 13,73 22,88 9,8 20,26 33,33Neutra 15,69 14,38 12,42 15,03 24,84 50,98
Sorpresa 6,54 11,11 11,76 13,73 7,19 14,38Miedo 14,38 6,54 15,03 15,03 13,07 11,11
Tabla 22: Tasa de error en el reconocimiento cruzado con el hombre sin la emocion de entrenamiento
El promedio total empleando reconocimiento cruzado es un 89,7 %. Tomando este resultado como base, hemos tratado de agrupar las emociones de este locutor por cercanía de manera que la tasa de reconocimiento mejorase respecto al promedio general. Así:
Promedio (%)Total 16,1
Sorpresa-Miedo 12,7Alegría-Asco-Enfado-Tristeza-Neutra 13,2
Tabla 23: Resultado de los promedios de agrupar emociones por proximidad
111

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
La agrupación de las emociones puede verse de forma gráfica en la siguiente tabla.
Tabla 24: Agrupación de las emociones según proximidad en base a la tasa de errorSi realizamos un proceso similar con la mujer, los resultados que obtenemos son los
siguientes:
Emoción reconocida
Emoc
ión
de
entre
nam
ient
o
Alegría Miedo Asco Sorpresa Neutra Enfado TristezaAlegría 66,67 69,93 27,45 15,03 30,07 48,37Miedo 54,25 81,7 25,49 22,22 25,49 47,71Asco 49,67 72,55 32,68 12,42 31,37 47,71
Sorpresa 49,02 55,56 67,32 12,42 29,41 49,67Neutra 51,63 67,97 71,9 22,88 12,42 35,29Enfado 48,67 71,24 65,36 24,84 11,11 33,99Tristeza 66,67 71,24 81,05 42,48 19,61 28,01
Tabla 25: Tasa de correctas en el reconocimiento cruzado con la mujer
En este caso el promedio total de reconocimiento es del 71%. Las emociones más cercanas en el caso de la mujer son:
El enfado y la neutra con un 92,2% de media de reconocimiento entre ellas.
Podríamos decir que tanto la sorpresa como la tristeza están cerca de este grupo.
Si incluimos la tristeza a las anteriores tenemos una tasa de reconocimiento del 84,9%.
Si en lugar de la tristeza incluimos la sorpresa la tasa es del 87,4 %.
La tristeza y la sorpresa no están muy cerca entre ellas porque si agrupamos las cuatro emociones, la tasa de reconocimiento baja al 82,5 %, que sigue siendo significativamente mejor que la tasa global.
Ni la alegría, ni el asco ni el miedo pueden agruparse con otras emociones ya que, como hemos comentado anteriormente, la locutora hace muy evidentes las diferencias entre éstas y el resto de emociones.
112

Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
Esto quedaría resumido en lo siguiente:
Promedio (%)Total 44,1
Enfado-Neutra 11,8Enfado-Neutra-Tristeza 23,4Enfado-Neutra-Sorpresa 18,8
Enfado-Neutra-Tristeza-Sorpresa 26,9Tabla 26: Resultado de los promedios de agrupar las emociones por proximidad
Tabla 27: Agrupación de las emociones según proximidad en base a la tasa de error
Figura 35: Esquema de agrupación de las emociones de la mujer
Lo siguiente que hacemos es estudiar cuál sería la mejor emoción de entrenamiento para reconocer todas las demás emociones. Hemos hecho una aproximación a partir de la Figura 31 y la Figura 33 pero ahora vamos a realizar un estudio un poco más detallado y concreto.
En esta determinación empleamos un intervalo de confianza para una tasa de acierto del 95% cuya fórmula en nuestro caso es la siguiente:
113
Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
De esta manera podremos determinar si los resultados obtenidos son realmente significativos o no, siendo x la tasa de reconocimiento de un modelo entrenado a partir de una emoción determinada.
Intervalo de confianza para hombre incluyendo la emoción de entrenamiento
79
111315171921232527
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTEZA
GENERICO
Emoción de entrenamiento
Tasa
de
erro
r (%
)
Promedio
Margen Inferior
Margen Superior
Figura 36: Intervalos de confianza del hombre incluyendo la emoción de entrenamiento
Intervalo de confianza para la mujer incluyendo la emoción de entrenamiento
33,035,037,039,041,043,045,047,049,051,053,055,057,0
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTEZA
GENERICO
Emoción de entrenamiento
Tasa
de
erro
r (%
)
Promedio
Margen Inferior
Margen Superior
Figura 37: Intervalo de confianza de la mujer incluyendo la emoción de entrenamiento
114
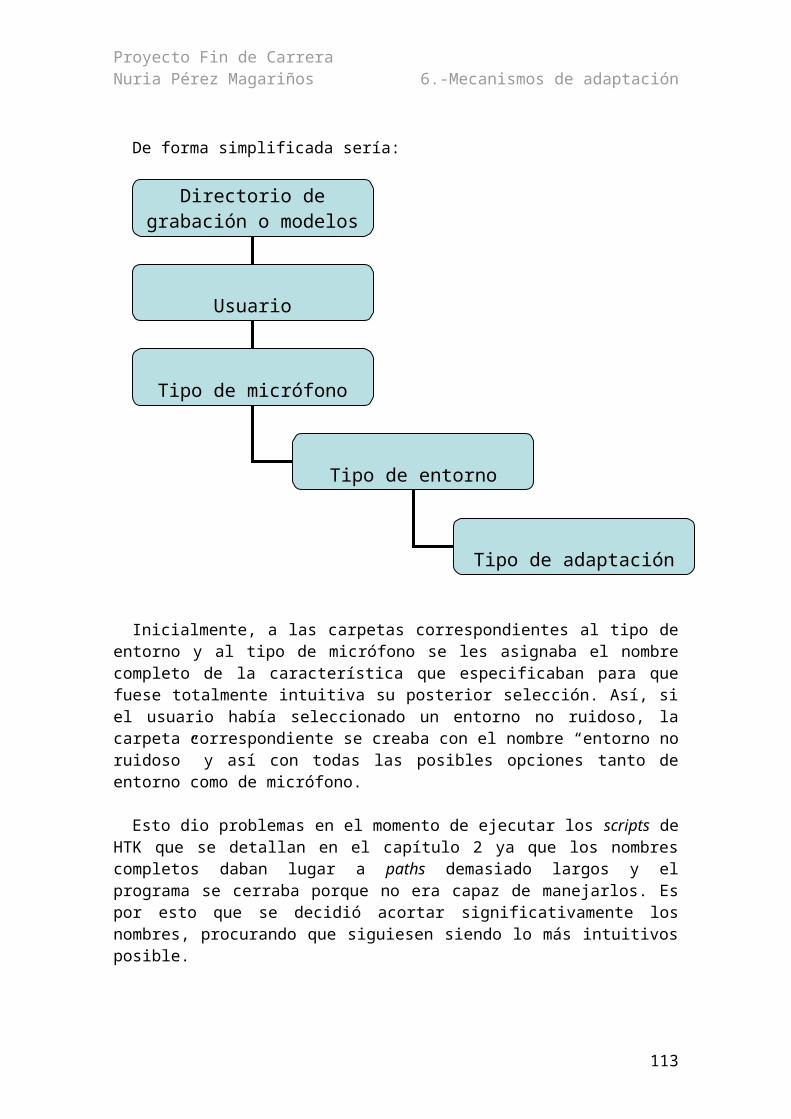
Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
En ambas gráficas se puede observar que los modelos genéricos son los que podríamos determinar como peores en cuando a reconocer a todas las emociones. En el hombre también puede verse que adaptar con los datos de voz neutra no daría buenos resultados, mientras que la sorpresa parece casi la emoción más recomendable para adaptar el habla emocionada de este locutor, seguida del miedo y el enfado. En el caso de la mujer, parece que la emoción que peor reconoce a todas es la tristeza, siendo la neutra y el enfado las que aparentemente dan mejores resultados.
Los datos reflejados en estas gráficas deben completarse con la misma evaluación pero excluyendo la emoción de entrenamiento de las emociones reconocidas ya que la mayor mejora se experimenta reconociendo la emoción que se utilizó para adaptar los modelos, de manera que el promedio se ve mejorado. Las gráficas que se muestran a continuación reflejan esta nueva situación, que nos permitirá evaluar qué emoción adapta mejor a las otras.
Intervalo de confianza del hombre sin incluir la emoción de entrenamiento
79
111315171921232527
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTEZA
GENERICO
Emoción de entrenamiento
Tasa
de
erro
r (%
)
Promedio
Margen Inferior
Margen Superior
Figura 38: Intervalo de confianza del hombre sin incluir la emoción de entrenamiento
Intervalo de confianza de la mujer sin incluir la emoción de entrenamiento
30323436384042444648505254565860
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTEZA
GENERICO
Emoción de entrenamiento
Tasa
de
erro
r (%
)
PromedioMargen Inferior
Margen Superior
Figura 39: Intervalo de confianza de la mujer sin incluir la emoción de entrenamiento
115
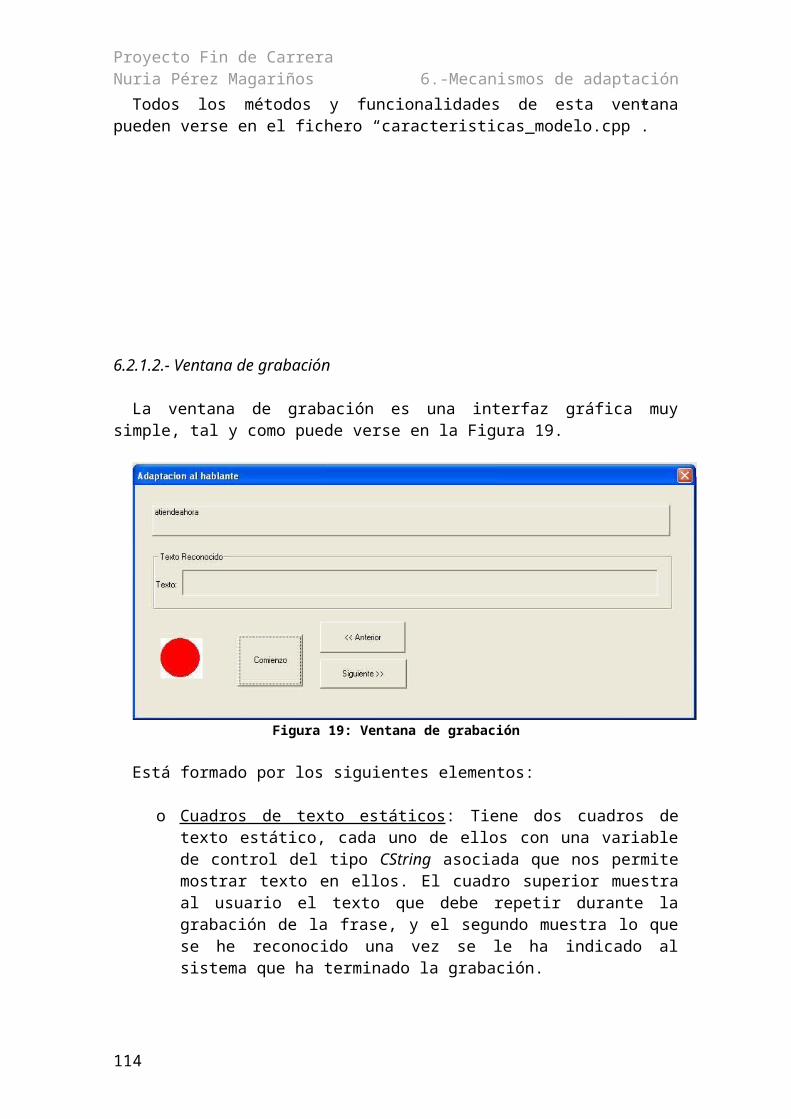
Proyecto Fin de CarreraNuria Pérez Magariños 7.- Evaluación y pruebas del sistema
En base a estas últimas gráficas, vemos que en el caso del hombre se mantienen aproximadamente las mismas proporciones, pero vemos que en el caso de la mujer se igualan las emociones de manera que no se puede determinar una de ellas como la mejor para reconocer las demás. Sí podemos decir que la tristeza es, en general para ambos locutores, la emoción menos recomendable para utilizarla en el entrenamiento. Esto puede deberse a que se trata de un habla más lenta que las demás y con la boca bastante cerrada.
7.1.5.- Reconocimiento con modelos entrenados con varias emociones
Por último, llevamos a cabo pruebas entrenando los modelos con más de una emoción para ver si mejoraban de forma significativa respecto al entrenamiento con una sola emoción. Concretamente, realizamos entrenamientos con dos emociones: primero entrenamos con la neutra y después con cada una de las otras emociones. También entrenamos un modelo empleando todas las emociones para ver qué tasa de reconocimiento tenía. Los resultados se muestran en la siguiente gráfica:
Comparación entre varios tipos de entrenamiento
102030405060708090
100
ALEGRIA
ASCO
ENFADO
MIEDO
NEUTRO
SORPRESA
TRISTEZA
Emoción reconocida
Tasa
de
erro
r (%
)
Modelo genérico
Sólo una emoción deentrenamientoEntrenamiento conneutra+emociónEntrenamiento con todaslas emociones
Figura 40: Resultado de reconocer con modelos entrenados de forma diferente
En la gráfica podemos ver que no se produce una mejora relevante al entrenar los modelos con varias emociones, llegando a ser contraproducente en algunos de los casos. Es por este motivo que podemos considerar que no es rentable introducir el tiempo añadido que supone entrenar con más de una emoción porque los resultados son casi los mismos que se han obtenido realizando el reconocimiento con modelos entrenados con una única emoción.
116

Proyecto Fin de Carrera Nuria Pérez Magariños 8.- Conclusiones y líneas futuras
8.- CONCLUSIONES Y LÍNEAS FUTURAS DE INVESTIGACIÓN
8.1.- Conclusiones
Analizando las actividades desarrolladas a lo largo de la realización del proyecto, hemos llegado a las siguientes conclusiones:
8.1.1.- Funcionalidad del sistema
Gran parte de la realización del proyecto se ha centrado en añadir funcionalidades al sistema que faciliten al usuario su manejo. A continuación se resumen las mejoras realizadas al sistema:
8.1.1.1.- Configuración
Desde el punto de vista de la configuración se han introducido los siguientes cambios y mejoras:
Se ha modificado la estructura de directorios de forma que los datos y los ejecutables se encuentren en directorios independientes entre sí e independientes del código fuente.
Se ha reducido el número de ficheros de configuración necesarios para el funcionamiento del programa y se han agrupado las principales variables de configuración del sistema en un único fichero (urbano.ini) de manera que los cambios más comunes en el entorno que afecten a la configuración puedan ser modificados accediendo a este fichero. De esta manera, el usuario normal del sistema no necesitará conocer los demás ficheros de configuración, dando lugar a un entorno más amigable para el usuario eventual e inexperto del sistema.
Se ha creado una interfaz gráfica de configuración del sistema que abstrae los principales parámetros de configuración todavía más que el fichero general de configuración. De esta manera mediante la selección de flags intuitivos el usuario podrá indicar, por ejemplo, que se encuentra en un entorno ruidoso sin necesidad de indicar de forma exlicita los niveles de intensidad que van asociados a dicho entorno.
Se han añadido varios modos de funcionamiento en función de hasta qué punto el usuario del sistema debe intervenir en la configuración del mismo o no. Esto permite que el usario ejecute el programa y comience a dar instrucciones al robot directamente o que no sólo tenga que indicar los principales parámetros de configuración para que se adapten a su situación concreta, sino que también tiene que llevar a cabo un proceso de adaptación de los modelos acústicos a las características de su voz.
117

Proyecto Fin de Carrera Nuria Pérez Magariños 8.- Conclusiones y líneas futuras
8.1.1.2.- Adaptación
La mayor parte del trabajo realizado se ha dedicado a añadir en el sistema la posibilidad de realizar diferentes tipos de adaptación del sistema al hablante, siendo las mejoras realizadas:
Se ha incluido la posibilidad de que el locutor lleve a cabo una adaptación de los modelos acústicos a las características concretas de su voz. Dicha adaptación puede ser de dos maneras:
o Adaptación genérica : El locutor adaptará los modelos originales a las características de su voz mediante la grabación y evaluación de unas frases de El Quijote que pueden verse en el Anexo III.
o Adaptación a tarea : En este caso, el usuario no sólo adaptará el sistema a las características de su voz sino también al conjunto de frases que se emplearán en una tarea concreta.
Se ha añadido una interfaz gráfica a todo el sistema de adaptación que facilita al usuario la realización del proceso. Consta de la siguientes ventanas:
o Ventana de características : En esta ventana el usuario podrá indicar las características del proceso de adaptación que está a punto de llevar a cabo tales como el tipo de micrófono o entorno, el tipo de adaptación que desea realizar o en el caso de adaptar a una tarea concreta, indicar el fichero que contiene las frases de dicha tarea.
o Ventana de grabación : Permite al usuario llevar a cabo todo el proceso de grabación de frases de una manera sencilla e intuitiva.
Se ha elaborado un script para Windows en base a un procedimiento detallado en Linux de los pasos a seguir para llevar a cabo la adaptación de los modelos acústicos. Este script automatiza toda la interacción entre el programa principal y el HTK, que realiza la adaptación, realizando las llamadas a los programas de HTK en el momento oportuno y modificando el formato de los ficheros necesarios para poder realizar todo el proceso sin que el usuario tenga que intervenir en ningún momento.
Una vez terminada la adaptación, el sistema muestra al usuario el resultado de la evaluación del reconocimiento tras el proceso de adaptación y comienza la ejecución normal del programa sin que el usuario tenga que realizar ninguna acción adicional.
Evaluando el sistema con las grabaciones correspondientes a la emoción neutra el hombre con las frases de El Quijote para determinar un valor de τ óptimo, hemos observado que a medida que la variedad, número y complejidad de las frases de adaptación disminuye, el valor de τ óptimo va aumentando hasta estabilizarse en valores medios alrededor de 10.
118

Proyecto Fin de Carrera Nuria Pérez Magariños 8.- Conclusiones y líneas futuras
8.1.1.3.- Primera versión del guiado del robot
Se ha realizado una primera aproximación a las funcionalidades que serán necesarias en la implementación del módulo de guiado por voz del robot para que cubra todas las necesidades expuestas en la reunión que tuvo lugar en la ETSI Industriales. Dichas funcionalidades ya se están implementando.
También se han propuesto unas frases orientativas de guiado, que pueden agruparse de la siguiente manera en relación con su finalidad:
Relación con el guía : Permitirán facilitar la interacción entre el robot y las acciones relacionadas con el seguimiento de una persona guía.
Movimiento : Juego de frases que definen los movimientos del robot para desplazarse por el lugar en el que se encuentra.
Grafo : Conjunto de frases relacionadas con la generación del grafo o recorrido por todos los lugares de interés que se le han ido marcando al robot, así como la comprobación de que el robot no intenta acceder a lugares que han sido marcados como prohibidos o peligrosos.
Confirmación : Conjunto básico de frases que permitan al guía realizar un proceso de validació o confirmación de la información intercambiada con el robot.
Visita : Frases que definen las etiquetas de los lugares donde se encontrarán puntos de información, situación del objeto que debe explicarse y posible colocación del público entre otras funciones.
8.1.1.4.- Comprensión
Desde el punto de vista de la comprensión:
Se ha incluido el multiconcepto que permite asociar una frase con más de un concepto en el método de reglas.
Se ha compatibilizado el empleo entre trigramas y reglas como método de comprensión, pudiendo elegir entre un método y otro mediante un flag sin que sea necesario volver a compilar todo el sistema.
8.1.2.- Análisis de las pruebas realizadas
8.1.2.1.- Reconocimiento con los modelos genéricos
La tasa de error para la emoción neutra es la misma en el hombre y en la mujer. Esta emoción es la que más se acerca a los modelos genéricos y, por tanto, es la que mejor reconocen.
El hombre presenta una mayor uniformidad en las tasas de error que la mujer debido a que marca menos las diferencias entre unas emociones y otras. Esto está reforzado con los valores de la varianza que se muestran en la Tabla 7.
119

Proyecto Fin de Carrera Nuria Pérez Magariños 8.- Conclusiones y líneas futuras
Las tasas de error más bajas del hombre se corresponden con la sorpresa y el miedo. Éstas son las emociones que enfatiza de una forma más evidente, caracterizándose ambas por variar el ritmo con el que dice las frases.
Las elevadas tasas de error que tiene la locutora se deben pricipalmente a el mayor énfasis que hace de las emociones, pero analizando las grabaciones de las peores emociones hemos sacado las siguientes conclusiones:
o Tristeza : Emplea un ritmo exageradamente lento, combinado con un tono bajo con poca intensidad, lo que lo aleja bastante de la emoción neutra, que es la más parecida a los modelos genéricos.
o Alegría : El ritmo es más rápido y efectúa muchas subidas y bajadas de tono.
o Miedo : Las frases las dice con un ritmo más lento de lo normal, terminándolas con un tono alto.
o Asco : La locutora tiene la boca muy cerrada al hablar.
Los cambios de ritmo principalmente o de tono empeoran mucho los resultados del reconocimiento con los modelos genéricos.
8.1.2.2.- Determinación de la τ óptima
En la adaptación de habla emocionada son mucho más efectivos los valores bajos de τ para dar más peso a los datos de adaptación. Esto es así porque las emociones suponen mucha variación respecto a los modelos originales que están entrenados para reconocer habla no emocionada, tanto en tono como en velocidad.
El emplear los datos resultantes de evaluar distintos bloque de frases (entrenamiento + evaluación) de manera que se evalúen todas las palabras que componen el diccionario permite obtener unos resultados más próximos a la realidad.
Emplear siempre las mismas frases de entrenamiento y evaluación da lugar a que se produzcan resultados falseados, bien porque las frases de evaluación contienen palabras que se reconocen especialmente bien, con lo que se obtendrían mejores resultados que en el caso real o viceversa, que las frases agrupen las palabras que peor se reconocen dando lugar a resultados demasiado pesimistas.
Pese a los dos puntos anteriormente expuestos, vemos en la Tabla 12 que los resultados de las τ más recomendables para llevar a cabo la adaptación no difieren mucho entre emplear el promedio de los resultados de procesar todas las frases posibles o emplear siempre las mismas para la evaluación.
120

Proyecto Fin de Carrera Nuria Pérez Magariños 8.- Conclusiones y líneas futuras
Hay emociones que no mejoran de forma significativa según los valores que toma τ, como es el caso de la emoción alegría o la neutra en el caso del hombre.
Hay emociones que experimentan una mejora muy evidente, como puede ser el caso de la sorpresa o el miedo en el caso del hombre o el asco en el caso de la mujer.
8.1.2.3.- Pruebas cruzadas
Hemos podido comprobar que para ambos locutores resulta difícil reconocer el miedo tanto antes como después de adaptar, mientras que el enfado y la voz neutra pueden definirse como emociones “sencillas” ya que son las que menores tasas de error tienen en ambos locutores.
En contra de lo que pensábamos en un principio, emplear como datos de entrenamiento las grabaciones de neutra no es una buena opción de adaptación para reconocer todas las emociones ya que es la más cercana a los modelos originales. Entrenar con los datos de tristeza tampoco da buenos resultados a la hora de reconocer todas las emociones.
Cualquiera de las otras emociones podría dar mejores resultados como emoción de entrenamiento, pero en el caso del hombre cabe destacar la sorpresa como la emoción que mejor reconoce a todas las demás.
Al intentar agrupar las emociones en base a su cercanía y características comunes, los resultados han sido:
o Debido al poco énfasis que el hombre hace de las emociones, resulta muy difícil agrupar las emociones desde un punto de vista de características concretas, sino más bien se agrupan en base a si el locutor las ha hecho más evidentes o no.
o La mujer, al marcar más las emociones permite ir agrupando las emociones cercanas entre sí. Es por esto que tenemos un conjunto básico consistente en el enfado y la voz neutra al cual se irán añadiendo emociones para llegar a generar un esquema de cercanías entre emociones.
Tener en cuenta el intervalo de confianza a la hora de determinar qué emociones que mejor reconocen a las demás y cuál sería la elección más acertada permite descartar o suavizar emociones que en una primera instancia se perfilaban como la mejor opción de entrenamiento. Esto ha pasado en el caso de la sorpresa, especialmente en el caso de la sopresa en el hombre; aparentemente tiene una tasa de error promedio del reconocimiento de todas las emociones muy bajo, pero su intervalo de confianza se solapa con los del miedo y el enfado, por lo que la sorpresa no necesariamente sería la mejor opción.
121

Proyecto Fin de Carrera Nuria Pérez Magariños 8.- Conclusiones y líneas futuras
Para evaluar la mejora en el reconocimiento cruzado es importante no incluir la propia emoción de entrenamiento ya que los datos obtenidos no se ajustan a la realidad al mejorar mucho más el reconocimiento de la propia emoción, dando lugar a mejores resultados de lo que realmente son. En el caso de la mujer este hecho es mucho más evidente, sobre todo en el caso de entrenar los modelos empleando el enfado.
8.1.2.4.- Reconocimiento con modelos entenados con varias emociones
El hecho de entrenar con más datos correspondientes a varias emociones no significa que se vayan a obtener mejores resultados en el reconocimiento, como se ha podido ver en la Figura 40. De esto podemos concluir que el gasto computacional extra que supone entrenar con más de una emoción no compensa ya que la mejora conseguida no es tanta.
8.2.- Líneas futuras de investigación
Entre los campos o áreas en los que se puede seguir trabajando para la mejora del sistema se tiene:
Prueba de la eficacia de la introducción de la confianza ponderada como método de determinación sobre la validez de una frase.
Implementación de los trigramas para que también permitan enviar más de un comando asociado a la misma frase.
Llevar a cabo la implementación de un prototipo para el sistema de guiado del robot URBANO en base a los requisitos expuestos en el Anexo II.
Realizar un estudio más exhaustivo en el campo de la adaptación de los modelos empleando emociones para obtener más datos que nos permitan llegar a nuevas conclusiones que permitan avanzar en esa línea del reconocimiento de emociones.
Conseguir el fiero “stats” asociado al modelo SpeechDat_Continua_MMF para poder realizar la adaptación empleando la técnica MLLR.
Estudiar la mejora en el reconocimiento de emociones mediante el empleo de la técnica MLLR.
122

Proyecto Fin de Carrera Nuria Pérez Magariños 9.- Bibliografía
9.- BIBLIOGRAFÍA1. [Díaz 2002] Sergio Díaz Municio: “Estudio de técnicas de adaptación a locutor
en sistemas de reconocimiento de habla”. Proyecto fin de carrera. ETSI Telecomunicación. Madrid. UPM. 2002
2. [López 2001] Javier López García: “Nueva arquitectura para un servidor vocal telefónico con reconocimiento automático del habla”. Proyecto fin de carrera- ETSI Telecomunicación. Madrid. UPM. 2001
3. [Marín 2006] Amparo Marín de la Bárcena: “Desarrollo de un asistente de modelos de lenguaje para robots inteligentes con capacidad de comunicación hablada”. Proyecto fin de carrera. ETSI Telecomunicación. Madrid.UPM. 2006
4. [Lucas 2006] Juan Manuel Lucas Cuesta: “Análisis e implementación de mejoras para un reconocedor de habla continua”. Proyecto fin de carrera. ETSI Telecomunicación. Madrid. UPM. 2006
5. [San-Segundo1997] Rubén San-Segundo Hernández: “Optimización de un sistema de reconocimiento de habla aislada por teléfono sobre un ordenador compatible (PC)”. Proyecto fin de carrera. ETSI Telecomunicación. Madrid.UPM. 1997
6. [Montero 2003] Juan Manuel Montero Martínez: “Estrategias para la mejora de la naturalidad e incorporación de variedad emocional a la conversión de texto a voz en castellano”. Tesis doctoral. ETSI Telecomunicación. Madrid. UPM. 2003
7. [Huang 2001] Xuedong Huang, Alex Acero y Hsiao-Wuen Hon: “Spoken language processing. A guide to theory, algorithm and system development”. Prentice-Hall PTR. Upper Saddle River, New Jersey. 2001
8. [Rabiner 1993] Lawrence Rabiner y Biing.Hwang Juang: “Fundamentals of speech recognition”. Prentice-Hall PTR. Englewoods Cliffs, New Jersey. 1993
9. [HTK] Steve Young, Gunnar Evermann, Mark Gales, Thomas Hain, Dan Kershaw, Xunjing Liu, Gareth Moore, Julian Odell, Dave Ollason, Dan Povey, Valrcho Valtchev y Phil Woodland: “The HTK Book”. Cambridge University Engineering Department. 2006
10. [Collado 2006] Manuel Collado: “Herramientas GREP y AWK” Transparencias. Facultad de Informática. Madrid. UPM. 2006
11. [Perl 1] Tutorial de Perl. http://perldoc.perl.org/
12. [Perl 2] Uriel Lizama: “Expresiones Regulares - Las Bases”. http://perlenespanol.baboonsoftware.com/tutoriales/expresiones_regulares/expresiones_regulares_las_bases.html
13. [AWK 1] Alfred Aho, Brian Kernighan y Peter Weinberger: “The AWK programming Language”. Addison - Wesley. 1988
123

Proyecto Fin de Carrera Nuria Pérez Magariños 9.- Bibliografía
14. [AWK 2] Manual de AWK. http://h1.ripway.com/chube/Manual_Awk/Menus.htm
15. [Cole 1997] Ronald Cole, Joseph Mariano, Hans Uszkoreit, Giovanni Battista Varile, Annie Zaenen, Antonio Zampolli y Víctor Zue: “Survey of the state of the art in human language techonology”. Cambridge University Press. 1997
16. [Goronzy 2002] Silke Goronzy: “Robust adaptation to non-native accents in automatic speech recongnition”. Springer. 2002
17. [Córdoba 2004] R. de Córdoba, J. Ferreiros, J.M. Montero, F. Fernández, J. Macías y S. Díaz: “Cross-Task adaptation and speaker adaptation in air traffic control tasks”. Actas III Jornadas en Tecnología del Habla, Valencia, 17-19 November 2004
18. [Córdoba 2006] R. de Córdoba, J. Ferreiros, R. San-Segundo, J. Macías Guarasa, J.M. Montero, F. Fernández, L.F. de D’Haro y J.M. Pardo: “Cross-Task and speaker adaptation in a speech recognition system for air traffic control”. IEEE Aerospace and Electronic Systems Magazine, Vol 21, No 9, ISSN 0885-8985, September 2006
124

Proyecto Fin de Carrera Nuria Pérez Magariños 9.- Pliego de condiciones
10.- PLIEGO DE CONDICIONES
10.1.- Condiciones generales
La obra será realizada bajo la dirección técnica de un Ingeniero de Telecomunicación y el número de programadores necesarios.
La ejecución material de la obra se llevará a cabo por el procedimiento de contratación directa. El contratista tiene derecho a obtener, a su costa, copias del pliego de condiciones y del presupuesto. El ingeniero, si el contratista lo solicita, autorizará estas copias con su firma, después de confrontarlas.
Se abonará al contratista la obra que realmente se ejecute, de acuerdo con el proyecto que sirve de base para la contrata.
Todas las modificaciones ordenadas por el ingeniero-director de las obras, con arreglo a sus facultades, o autorizadas por la superioridad, serán realizadas siempre que se ajusten a los conceptos de los pliegos de condiciones y su importe no exceda la cifra total de los presupuestos aprobados.
El contratista, o el organismo correspondiente, quedan obligados a abonar al ingeniero autor del proyecto y director de obra, así como a sus ayudantes, el importe de sus respectivos honorarios facultativos por dirección técnica y administración, con arreglo a las tarifas y honorarios vigentes.
Tanto en las certificaciones de obra como en la liquidación final, se abonarán las obras realizadas por el contratista a los precios de ejecución material que figuran en el presupuesto, por cada unidad de obra.
En el caso excepcional en el que se ejecute algún trabajo no consignado en la contrata, siendo admisible a juicio del ingeniero-director de las obras, se pondrá en conocimiento del organismo correspondiente, proponiendo a la vez la variación de precios estimada por el ingeniero. Cuando se juzgue necesario ejecutar obras que no figuren en el presupuesto de la contrata, se evaluará su importe a los precios asignados a ésta u otras obras análogas.
Si el contratista introduce en el proyecto, con autorización del ingeniero-director de la obra, alguna mejora en su elaboración, no tendrá derecho sino a lo que le correspondería si hubiese efectuado la obra estrictamente contratada.
El ingeniero redactor del proyecto se reserva el derecho de percibir todo ingreso que en concepto de derechos de autor pudiera derivarse de una posterior comercialización, reservándose además el derecho de introducir cuantas modificaciones crea convenientes.
125

Proyecto Fin de Carrera Nuria Pérez Magariños 9.- Pliego de condiciones
10.2.- Condiciones generales a todos los programas
Estarán realizados en lenguajes estándar.
Se entregarán tres copias de los listados para cada programa o subrutina.
Los programas y subrutinas deberán ir documentados, indicando brevemente su
función, entradas y salidas, y cualquier otra información de interés.
Se entregará, junto con los programas, un manual de uso e instalación.
10.3.- Condiciones generales de prueba
Los programas y subrutinas que se entreguen deberán funcionar sobre un ordenador PC o compatible con microprocesador Pentium Core 2 Duo o superior y con, al menos, 512 MBytes de RAM. Se ejecutarán bajo sistema operativo Windows 2000 XP Professional o superior, en entorno local.
Solamente se aceptarán los programas si funcionan correctamente en todas sus partes, rechazándose en caso contrario. Si, por causas debidas al contratista, los programas no funcionaran bajo las condiciones expuestas anteriormente, la empresa contratante se reservará el derecho de rescindir el contrato.
10.4.- Recursos materiales
Ordenador PC compatible, Pentium Core 2 Duo, 512 MB de memoria RAM y 2
GB de disco duro.
Altavoces.
Micrófono.
Tarjeta de red Ethernet.
10.5.- Recursos lógicos
Sistema operativo Windows XP Professional.
Compilador Microsoft Visual C++ 6.0
HTK 3.4
Office 2003.
126

Proyecto Fin de Carrera Nuria Pérez Magariños 10.- Presupuesto
11.- PRESUPUESTOEl presupuesto consta de cuatro apartados: el cálculo del presupuesto de ejecución
material, el presupuesto de ejecución por contrata que incluirá el cálculo de los gastos generales y del beneficio industrial, el coste de la dirección de obra y, por último, el presupuesto total, suma de todos los conceptos anteriores.
Todas las cantidades que aparecen están contempladas en Euros.
11.1.- Presupuesto de ejecución material
Se incluye en este presupuesto los gastos en herramientas empleadas, tanto hardware como software, así como la mano de obra.
En la ejecución de este proyecto han participado las siguientes personas:
Un Ingeniero Superior de Telecomunicación, encargado del desarrollo y redacción del proyecto, así como de la obtención e interpretación de los resultados.
Un mecanógrafo, encargado de la escritura del proyecto en un procesador de textos, elaboración de gráficos, etc.
11.1.1.- Relación de salarios
Partimos del sueldo base mensual de cada una de las personas que han intervenido en el proyecto para calcular el sueldo base diario respectivo. A éste habrá que añadir las obligaciones sociales.
Sueldo base mensual
Sueldo base diario Gratificación Sueldo total
diarioIngeniero
Superior de Telecomunicación 1.334,59 44,49 6,07 50,56
Mecanógrafo 632,49 21,08 5,67 26,76
Tabla 28: Sueldos de las personas que han intervenido en el proyecto
127

Proyecto Fin de Carrera Nuria Pérez Magariños 10.- Presupuesto
11.1.2 Relación de obligaciones sociales
CONCEPTOVacaciones anuales retribuidas 8,33%
Indemnización por despido 1,60%Seguro de accidentes 7,00%
Subsidio familiar 2,90%Subsidio de vejez 1,80%
Abono días festivos 12,00%Días de enfermedad 0,75%
Plus de cargas sociales 4,25%Otros conceptos 15,00%
TOTAL 53,63%Tabla 29: Obligaciones sociales
11.1.3 Relación de salarios efectivos totales
Sueldo diario Obligaciones sociales Total/día
Ingeniero Superior de
Telecomunicación 50,56 27,11 77,67
Mecanógrafo 26,76 14,35 41,1
Tabla 30: Salarios efectivos totales
11.1.4 Coste de la mano de obra
Para calcular el coste de la mano de obra basta con aplicar el número de días trabajado por cada persona por el salario respectivo.
Días Salario(€)/día Total (€)
Ingeniero Superior de
Telecomunicación 330 77,67 25.630,7
Mecanógrafo 40 41,1 1.644,13
TOTAL COSTE DE MANO DE
OBRA 27.274,83Tabla 31: Coste de la mano de obra
128

Proyecto Fin de Carrera Nuria Pérez Magariños 10.- Presupuesto
11.1.5 Coste total de materiales
Para la ejecución de este proyecto se han empleado un ordenador personal tipo PC basado en el microprocesador Pentium Core 2 Duo y una impresora Láser HP LaserJet 1320N, para la elaboración de toda la documentación necesaria. También se incluyen los gastos de material fungible y de oficina.
Los costes referentes a los materiales utilizados se reflejan en la siguiente tabla:
Precio (€) Uso (meses)
Amortización (años)
Total (€)
1 ordenador personal para diseño
1.502,53 12 5 300,51
Compilador Microsoft Visual C++
420,71 12 5 84.14
Impresora Láser HP LaserJet 1320N
780,71 1 5 13,01
Placa de red Ethernet 120,2 - - 120,2
Material fungible y de oficina 120,2 - - 120,2
TOTAL GASTO DE MATERIAL 638,06
Tabla 32: Coste de materiales
11.1.6 Importe total del presupuesto de ejecución material
El presupuesto de ejecución material se calcula basándose en los costes de mano de obra y los costes materiales.
CONCEPTO IMPORTE (€)
COSTE TOTAL DE MATERIALES 638,06
COSTE TOTAL DE MANO DE OBRA 27.274,83
TOTAL PRESUPUESTO DE EJECUCIÓN MATERIAL 27.912,89
Tabla 33: Presupuesto de ejecución material
129

Proyecto Fin de Carrera Nuria Pérez Magariños 10.- Presupuesto
11.2.- Importe de ejecución por contrata
Al importe de ejecución material hay que añadirle los siguientes conceptos:
CONCEPTO IMPORTE (€)
GASTOS GENERALES Y FINANCIEROS (22%) 6.140,83
BENEFICIO INDUSTRIAL (6%) 1.674,77
TOTAL G.G. Y B.I. 7.815,6
Resultando:
IMPORTE DE EJECUCIÓN POR CONTRATA 35.728,49
Tabla 34: Importe de ejecución por contrata
11.3.- Honorarios Facultativos
Este proyecto se encuadra dentro del grupo XII: Aplicaciones de la Electrónica y Aparatos de Telecomunicación. Si se aplican las tarifas correspondientes sobre el importe del presupuesto de ejecución material se tiene:
Hasta 30.050,61 (Coef. 1,0 sobre 7%) 2.103,54
Hasta 60.101,21 (Coef. 0,9 sobre 7%) 359,16
TOTAL HONORARIOS FACULTATIVOS (€) 2.462,7
Tabla 35: Honorarios facultativos
Los honorarios que hay que aplicar son los correspondientes tanto por redacción del proyecto como por dirección, por lo que el total de honorarios es:
Honorarios de Ingeniero por redacción 2.462,7
Honorarios de Ingeniero por dirección 2.462,7
TOTAL HONORARIOS 4.925,4
Tabla 36: Honorarios totales
130

Proyecto Fin de Carrera Nuria Pérez Magariños 10.- Presupuesto
11.4.- Importe Total del Proyecto
El Importe Total del Proyecto es la suma del Importe de Ejecución por Contrata, los Honorarios de Redacción y los Honorarios de Dirección, al cuál habrá que aplicar el 16% de IVA.
EJECUCIÓN POR CONTRATA 35.728,49
HONORARIOS 4.925,4
IMPORTE 40.653,89
IVA (16%) 6.504,62
IMPORTE TOTAL 47.158,51Tabla 37: Importe total del proyecto
El importe total del presente proyecto asciende a la cantidad de CUARENTA Y SIETE MIL CIENTO CINCUENTA Y OCHO euros CON CINCUENTA Y UN céntimos.
EL INGENIERO AUTOR DEL PROYECTO
Fdo.: Nuria Pérez MagariñosMADRID, FEBRERO DE 2008.
131

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
I.- MANUAL DE USUARIO
1.- Estructura de directorios
La estructura de directorios de trabajo de ROBINT se divide en dos grandes carpetas: “bin” y “data”. En el primer directorio se encuentran los ejecutables del reconocedor y en el segundo están todos los ficheros y subdirectorios relacionados con las diferentes tareas y la configuración del sistema.
1.1.- Directorio “ bin ”
Dentro de la carpeta “bin” se encuentra el ejecutable que se debe lanzar para poner en funcionamiento el reconocedor. Actualmente dicho ejecutable se llama “mfc_ROBINT_release.exe”, pero ese nombre puede modificarse.
Para llevar a cabo una prueba aislada sin necesidad de tener en funcionamiento un kernel o simulador del robot, dentro de esta carpeta también se encuentra un acceso directo a un cliente que simula la comunicación entre el reconocedor y el robot. Dicho cliente automatiza el envío de mensajes necesarios para establecer la comunicación con el servidor y permite comprobar que los comandos se han traducido y enviado correctamente.
1.2.- Directorio “ Data ”
En este directorio se encuentran los subdirectorios asociados a cada una de las tareas que puede realizar el robot, un subdirectorio en el que se guardarán las grabaciones, otro subdirectorio para archivos y operaciones temporales, archivos de configuración del sistema y otros ficheros básicos e invariantes necesarios para el reconocimiento.
1.2.1.- Fichero de configuración “Urbano.ini”
En este fichero de configuración se encuentran todas las variables que será necesario modificar para adaptar el sistema a las condiciones del entorno y tarea que se vaya a desempeñar en cada momento. Está dividido en cuatro grandes secciones: línea 0, Gramática, Modelos y Wav.
1.2.1.1.- Sección línea 0
Al comienzo del fichero se encuentran las variables relacionadas con la configuración del sistema para ejecutar los diferentes casos de uso que se detallan en el siguiente apartado.
- “modoAutomatico” es la variable que indica si el usuario desea que el proceso de configuración del sistema sea o no transparente para él. Los posibles valores que puede tomar son:
133

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
o Valor 0: El modo automático está desactivado y, por tanto, el usuario puede modificar manualmente la configuración del sistema.
o Valor 1: El modo automático está activado y, por tanto, la configuración/ funcionamiento del sistema es transparente al usuario.
- “adaptacionNecesaria” es la variable que indica al sistema si es necesario que el usuario lleve a cabo un proceso de adaptación de los modelos de lenguaje a su voz. Si el modo automático está activo, se ignorará el valor de esta variable. Los valores que puede tomar son:
o Valor 0: No es necesario adaptar los modelos acústicos al locutor.o Valor 1: Es necesario que el locutor lleve a cabo un proceso de
adaptación.
El siguiente grupo de variables que se encuentran son las variables relacionadas con el detector. Está preparado para cambiar de una configuración para un entorno ruidoso o para un entorno con bajo nivel de ruido, según se comenten unas u otras variables. El sistema ignorará todas las líneas y textos que vayan precedidos de punto y coma en los fichero de inicialización, considerándolos comentarios.
;Nivel low del detector HC = 3 ; en dbs Nivel low del detector HC = 6 ; en dbs *;Nivel speech del detector HC = 6 ; en dBsNivel speech del detector HC = 20 ; en dBs *;Nivel high del detector HC = 9 ; en dBsNivel high del detector HC = 25 ; en dBs *
Cuadro 48: Configuración de las variables relativas al ruido en el entorno
Actualmente se encuentra activa la configuración para un entorno de grabación con alto nivel de ruido.
- “Nivel low del detector HC” es el nivel en decibelios relativos al ruido de fondo estimado a partir del cual el detector considera que puede haber habla. Además, una vez se ha terminado de hablar el sistema deberá detectar que los niveles de sonido se encuentran por debajo de este umbral durante un cierto tiempo para considerar que ha terminado de hablarse. Actualmente su valor es 6 dB debido a la configuración de entorno ruidoso. Si el entorno no fuese ruidoso el valor sería 3dB.
- “Nivel speech del detector HC” es el nivel en decibelios que debe superarse durante un cierto tiempo para que el sistema considere que se está hablando. Su valor actual es 20 dB para la configuración de entorno ruidoso. El valor para el entorno no ruidoso es de 6dB.
- “Nivel high del detector HC” es el nivel máximo que debe superarse al menos una vez mientras el usuario habla para que se considere como habla. Su valor actual es 25 dB ya que la configuración activa es la correspondiente a un entorno ruidoso. Si el entorno no es ruidoso el valor de esta variable es 9dB.
134

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
Dentro de este grupo de variables del detector también se encuentran las variables que controlan los tiempos de silencio para determinar el comienzo y el final de la voz. De todas ellas, la más importante es:
- “Tiempo máximo debajo de Speech HC” que determina los milisegundos que deben transcurrir para que el detector considere que el locutor ha terminado de hablar. Su valor actual es 700 ms, pero puede subirse en caso de que haya más ruido o bajarlo si hay menos ruido.
El siguiente bloque de variables determina cuáles son los dispositivos asociados con las tarjetas de sonido del ordenador:
- “SoundBlasterIn”: Dispositivo de entrada de la tarjeta de sonido. Su valor varía entre 0 o 1 dependiendo del ordenador. Actualmente vale 0.
- “SoundBlasterOut”: Dispositivo de salida de la tarjeta de sonido. Su valor varía entre 0 o 1 dependiendo del ordenador. Actualmente vale 0.
Después están las variables para el reconocimiento, la parametrización y la comprensión:
- “Tiempo máximo reconocimiento continua” especifica la duración en segundos de la frase más larga que puede decirse. Una mayor duración de frase implica un mayor consumo de memoria. Su valor actual es 10 segundos.
- “Aprendizaje Reglas” es un flag que indica si el método de aprendizaje que se empleará a la hora de reconocer y traducir lo reconocido al comando que se enviará al robot se realizará mediante el empleo de reglas. Puede tomar dos posibles valores:
o Valor 0: Desactiva el aprendizaje mediante reglas.o Valor 1: Activa el aprendizaje mediante reglas. Es un método más lento
pero permite asociar varios comandos a una frase.
Actualmente el valor de esta variable es 0.
- “Apredizaje Trigramas” es un flag que indica si el método de aprendizaje que se empleará a la hora de reconocer y traducir lo reconocido al comando que se enviará al robot se realizará mediante el empleo de trigramas. Puede tomar dos posibles valores:
o Valor 0: Desactiva el aprendizaje mediante trigramas.o Valor 1: Activa el aprendizaje mediante trigramas. Es un método más
lento pero sólo puede asociarse un comando a cada frase.
Actualmente el valor de esta variable es 1.
Por último, se definen las variables del entorno de trabajo. Las tres primeras variables establecen el método de activación y desactivación del sistema:
135

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
- “ActivacionVocal” tiene dos posibles valores:
o Valor 0: El sistema reconoce y envía comandos al robot sin necesidad de activarlo mediante el empleo de palabras clave.
o Valor 1: Aunque el sistema esté reconociendo, no enviará nada al robot hasta que el usuario no pronuncie la palabra “AtiendeAhora”. Una vez el usuario la diga y el sistema la reconozca, comenzará a enviar los comandos que se digan hasta que el usuario pronuncie la frase “Deja de atenderme”, momento a partir del cual dejarán de enviarse los comandos aunque el reconocedor siga activo.
El valor actual de la variable es 0.
- “PalabraAtiendeahora” es la variable que contiene la palabra con la que el usuario activará el sistema. Actualmente su valor es “Atiendeahora”, pero puede modificarse.
- “PalabraDescansa” es la variable que guarda la palabra con la que el usuario podrá desactivar el sistema. Actualmente su valor es “Dejadeatenderme”, pero puede modificarse.
Hay que tener en cuenta que las palabras o frases que se especifiquen como activación y desactivación del sistema deben formar parte de las frases del fichero de comandos para que el sistema pueda reconocerlas y traducirlas al comando correcto.
Las tres siguientes variables se relacionan con la comunicación entre cliente y servidor:
- “PalabraRuido” contiene la palabra que el cliente enviará como respuesta para permitir al sistema la estimación inicial de los niveles de ruido del entorno. Su valor actual es “ruido” pero puede cambiarse.
- “PalabraEstimarRuido” almacena la palabra que se enviará al cliente para pedir permiso al comienzo de la ejecución para estimar el ruido. Su valor actual es “EstimarRuido”.
- “PuertoReconocimiento” tiene el número de puerto donde se encuentra el servidor de habla. El valor actual es 6003.
Las últimas variables de esta sección se refieren al filtrado de las palabras reconocidas en función de la confianza con que han sido reconocidas y a la posibilidad de eliminar ficheros antiguos que puedan llevar a error en caso de que no se sobre-escriban correctamente.
- “usaconfianzaPonderada” indica al sistema el tipo de filtro que ha de utilizar para determinar cómo de acertado ha sido un reconocimiento. Los valores que puede tomar son:
136

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
o Valor 0: El parámetro que se emplea para determinar si se ha reconocido con suficiente confianza es la confianza media de la frase.
o Valor 1: El parámetro que se emplea para determinar si se ha reconocido con suficiente confianza es la confianza ponderada de la frase según el número de tramas de cada palabra.
o Valor 2: Se tienen en cuenta ambos filtros, dando como bueno el reconocimiento en el momento que pase alguno de ellos.
El valor actual de esta variable es 2.
- “enviaConfianzaCompleta” es una variable que indica si al texto que se ha reconocido hay que añadirle la confianza con que ha sido reconocido o no. Los posibles valores que tiene son:
o Valor 0: No se añade la confianza al texto reconocido y enviado.
o Valor 1: Se añade la confianza al texto reconocido.
Actualmente su valor es 0.
- “limpiaDirectorios” es una variable que indica si el usuario quiere eliminar todos los ficheros y archivos de las carpetas de uso para evitar posibles errores derivados de utilizar archivos antiguos o equivocados. Puede tener los siguientes valores:
o Valor 0: No se eliminan ficheros.o Valor 1: Se eliminan los ficheros conflictivos.
Actualmente su valor es 1.
1.2.1.2.- Sección Gramática
La sección de gramática tiene las siguientes variables:
- “dir_dic” es el directorio en el que se encuentran los diccionarios. Puesto que cada tarea tiene asociados unos diccionarios, este directorio deberá corresponderse con el de la tarea. El formato es: ..\data\nombreDirectorioTarea\. Es muy importante poner la última barra ya que, en caso de no ponerla, el sistema no funcionará.
- “dir_gram” es el directorio en el que están las gramáticas de la tarea y, por lo tanto, tiene el mismo valor que el directorio de los diccionarios.
- “NomFicheroTextoEtrenamiento” contiene el nombre del fichero de frases de cada tarea con la extensión .txt
137

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
- “regeneraComprensión” es un flag que indica al sistema la necesidad de generar la compresión, es decir, asociar las frases con los comandos por las que deben traducirse una vez sean reconocidas. Si tiene un valor igual a 0, no se regenerará la comprensión y, por lo tanto, el tiempo que tardará el sistema en estar preparado para reconocer será menor. Hay que tener cuidado con este flag porque si se realiza un cambio en el fichero de comandos y el flag está a 0, el sistema no asimilará los nuevos cambios realizados. Su valor actual es 1.
- “max_n_palabras_continua” contiene el número de palabras diferentes que es capaz de reconocer el sistema. Su valor actual es 1000 palabras.
- “FactorSuavizado” permite al sistema ser capaz de contemplar casos no aparecidos en el texto de entrenamiento. Esta variable puede tomar valores entre 0 y 1. Si está próxima a cero, permite una mayor flexibilidad a la hora de reconocer frases que no es encuentren en la lista predefinida. Si se aproxima a uno, el sistema estará casi limitado a la lista de frases predefinidas, aunque podría llegar a ser capaz de comprender si el usuario no dice las frases predefinidas exactamente de la manera en que están escritas. Sólo para valores bajos del factor de suavizado se empleará la confianza como medida de aceptación de una frase. Actualmente el valor de esta variable es 0.01.
1.2.1.3.- Sección Modelos
Esta sección sólo contiene una variable:
- “dir_hmm” en la que se indica el directorio en el que están los modelos acústicos que se utilizarán para llevar a cabo el reconocimiento. La extensión de dichos ficheros es .ascii y .tri.
1.2.1.4.- Sección Wav
Las variables de esta sección permitirán diferenciar unas grabaciones de otras, ya que el nombre del locutor y la sesión se emplean en el momento de generar una grabación y nombrarla. La variable micrófono se empleará en el modo automático que se detalla en la siguiente sección de casos de uso. Es importante que no haya espacios después del nombre del locutor y del número de sesión, para evitar posibles problemas para encontrar los ficheros de audio que se han generado.
- “Locutor” guarda el nombre del usuario que habla al sistema. Su valor actual es robint_prueba.
- “Sesion” indica la sesión de grabación en la que se está trabajando. Su valor actual es 0.
- “Micrófono” indica el tipo de micrófono que se está empleando. Puede tomar dos posibles valores que deben estar completamente escritos en minúscula y sin tildes:
138

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
o cable: el micrófono empleado está físicamente conectado al ordenador.
o inalambrico: El micrófono empleado no se encuentra físicamente conectado al ordenador sino lo que está conectado al ordenador es un receptor.
1.3.- Directorio de tarea
Dentro del directorio “Data” se creará una nueva carpeta por cada tarea diferente que pueda llevar a cabo el robot. Cada directorio de tarea debe contener desde el principio tres archivos fundamentales:
- “dicc.dic”: Este fichero es necesario para el aprendizaje mediante reglas. Permite agrupar las palabras en categorías de forma que el sistema es capaz de aprender con menos reglas y en menos tiempo. La estructura del fichero es: el número de palabras que contiene el fichero en la primera línea y a continuación, una palabra con su categoría en cada línea. Puede estar vacío, pero en ese caso debe tener un cero en la primera línea.
- “Palfunc.lis”: Fichero necesario para el aprendizaje mediante reglas. Contiene las palabras que se considera que no aportan significado, de forma que no se generan reglas con ellas. Debe contener alguna palabra, no puede estar vacío. Cada palabra función se pone en una nueva línea.
- Fichero de comandos: Este fichero contiene las frases que el sistema debe ser capaz de reconocer, cada una de ellas seguida del comando con el que debe asociarse. Debe tener el mismo nombre que el FicheroTextoEntrenamiento definido en el archivo de configuración, pero con la extensión .comandos. La estructura del fichero es la siguiente:
o No puede haber líneas en blanco ni al principio ni al final del fichero.
o Las líneas no pueden comenzar por mayúsculao Soporta tildeso Cada línea contiene una frase y el comando por el que debe
ser traducida. El formato de una línea es:
eres inteligente -> orden=[inteligencia]
A la izquierda de la flecha se escribe la frase y a la derecha debe aparecer el concepto asociado a la frase y, entre corchetes, el valor que se da a ese concepto que es lo que se mandará al robot como comando entendido. El valor puede coincidir con alguna de las palabras de la frase y debe escribirse en minúscula. Es recomendable que no haya espacios en blanco en la parte derecha de la sentencia para evitar errores.
139

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
1.4.- Directorio de grabaciones
En este directorio se guardan las grabaciones que se van realizando de las frases dichas por el usuario. El nombre de las mismas está relacionado con el usuario y la sesión de grabación. Un ejemplo de nombre de grabación sería:
locutor_sesion_numero de grabacion.wav
1.5.- Directorio temporal
Este directorio se emplea para realizar operaciones intermedias en el momento de la generación de diccionarios y gramáticas y para guardar los archivos de depuración que se generan durante la ejecución. Puede limpiarse en función de un flag que se lee del fichero de configuración.
2.- Casos de uso
A continuación se detallan las posibles configuraciones de uso del sistema, indicando en cada una de ellas los pasos a seguir para lanzar el programa y las ventanas que aparecerán.
2.1.- Caso 1: Modo automático
Según esta configuración, el sistema cargará automáticamente la configuración del sistema que haya sido definida en el fichero de configuración “urbano.ini” que se ha descrito en la sección anterior. Los pasos a seguir para lograr esta configuración son:
Paso 1 : Abrir el archivo “urbano.ini” que se encuentra en la carpeta “DATA” y realizar los siguientes cambios y/o comprobaciones:
o Comprobar que está activado el modo automático (variable modoAutomático=1), activándola en caso de que no lo estuviese.
o Comprobar que la variable usuario de la sección WAV tiene asociado el nombre del usuario que en ese momento va a utilizar el sistema, cambiándolo en caso de que fuese necesario. Se deben escribir todas las letras minúsculas y teniendo cuidado de no dejar espacios detrás del nombre. Un ejemplo sería:
usuario = carlos
o Verificar que la variable micrófono de la sección WAV tiene el valor que se ajusta a las características del micrófono que va a emplearse. Si el micrófono está físicamente conectado al ordenador mediante un cable:
microfono = cable
Si el micrófono es inalámbrico, la variable debe tener el siguiente valor:
140

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
microfono = inalambrico
En caso de que la variable no tenga el valor deseado, deberá cambiarse al valor correcto, escribiendo todas las letras en minúscula y sin tildes.
Paso 2 : Lanzar la aplicación “mfc_ROBINT_release.exe” que se encuentra en la carpeta “BIN”. Al hacerlo, aparecerá la ventana del reconocedor cuya funcionalidad se detalla en la sección de interfaz gráfica del sistema.
Paso 3 : Lanzar el proceso CLIENTCOM desde el acceso directo que se encuentra en la carpeta “BIN”. Al hacerlo, aparecerá la siguiente ventana:
Paso 4 : Decir las frases que se deseen dentro de las que se hayan definido en el archivo de comandos guardado en el directorio de tarea o frases similares.
2.2.- Caso 2: Modo no automático con adaptación
En esta situación, el usuario tendrá la posibilidad de configurar los parámetros más importantes del sistema y deberá realizar una fase de adaptación del sistema a su voz. Los pasos a seguir para tener esta configuración son:
Paso 1 : Abrir el archivo “urbano.ini” que se encuentra en la carpeta “DATA” y realizar los siguientes cambios y/o comprobaciones:
o Comprobar que está desactivado el modo automático (variable modoAutomático = 0), desactivándolo en caso de que no lo estuviese.
o Comprobar que está activada la adaptación del sistema al hablante (variable adaptacionNecesaria = 1), activándola en caso de que no lo estuviese.
Paso 2 : Lanzar el proceso CLIENTCOM desde el acceso directo que se encuentra en la carpeta “BIN”.
141

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
Paso 3 : Lanzar la aplicación “mfc_ROBINT_release.exe” que se encuentra en la carpeta “BIN”. Al hacerlo aparecerá una ventana de configuración del sistema cuya funcionalidad se detalla en la sección de interfaz gráfica.
Paso 4 : Lo siguiente que aparecerá será una ventana en la que el usuario deberá introducir las características de la situación en la que va a llevar a cabo la adaptación. La ventana es la siguiente:
El usuario debe rellenar todos los campos obligatoriamente salvo el de descripción que es opcional. A continuación se da una breve explicación de cada uno de los campos de la ventana.
Nombre de usuario: El locutor debe introducir su nombre, con minúsculas y sin acentos.
Entorno acústico: Consiste en una lista desplegable en la que se ofrecen los posibles entornos que el usuario puede encontrarse. Actualmente las posibilidades que se ofrecen son: entorno ruidoso o entorno no ruidoso, como puede verse en la figura.
Tipo de micrófono: Al igual que con el tipo de entorno, se ofrece una lista de posibles micrófonos que se pueden emplear. Actualmente esas posibilidades son: micrófono con cable o micrófono inalámbrico, tal como muestra la figura.
142
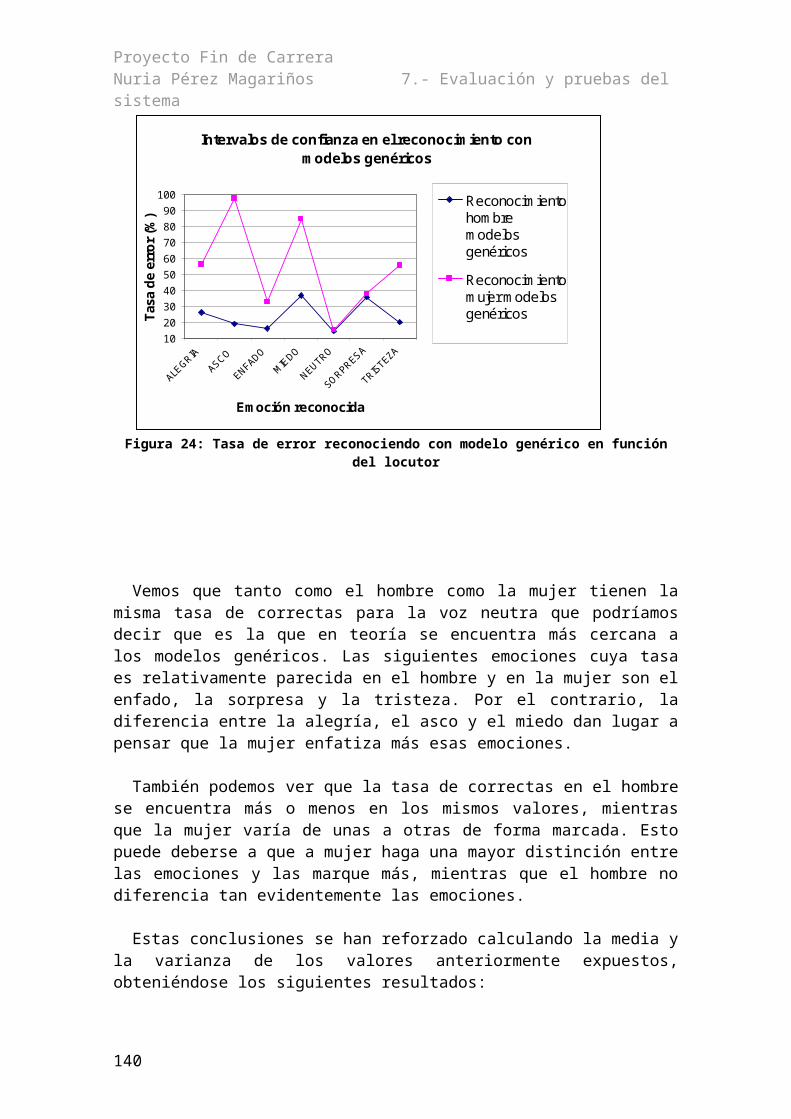
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
Tipo de adaptación: El usuario puede elegir qué tipo de adaptación desea realizar. Puede ser una adaptación genérica del sistema a su voz (seleccionando “Adaptación Genérica”) de forma que pueda realizar cualquier tarea después de esa adaptación o puede ser un adaptación específica para una tarea determinada (seleccionando “Adaptación a Tarea”). Sólo puede seleccionarse un tipo de adaptación.
Técnica de adaptación: También puede determinar qué tipo de técnica desea emplear para adaptar el sistema a su voz. Esas técnicas pueden ser bien MAP (Máximo A Posteriori) o MLLR (Regresión Lineal de Máxima Verosimilitud). Sólo puede seleccionarse una de las técnicas.
Nombre del fichero de comandos: En caso de que el usuario haya seleccionado “Adaptación a Tarea” como tipo de adaptación que desea realizar, debe indicar el fichero de comandos asociado a la tarea que desea utilizar. Debe introducir tanto el nombre del fichero como la extensión, por ejemplo:
Descripción del modelo: El usuario puede rellenar opcionalmente este campo en caso de que quiera añadir alguna particularidad de la situación en la que realiza la adaptación, que no hubiese sido reflejada en ninguno de los campos anteriormente descritos.
Paso 5 : Una vez introducidas y aceptadas las características de la adaptación, aparece la ventana de grabación, mediante la cual el usuario puede grabar las frases necesarias para adaptar el sistema a su voz de manera sencilla. La vista inicial de esta pantalla es:
143

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
Los pasos a seguir para llevar a cabo una grabación son:
Lo primero que hay que hacer es pulsar el botón “siguiente” para que aparezca la primera frase que el usuario debe leer.
Una vez hecho eso y cuando el usuario esté preparado para leer la frase en voz alta y grabarla, debe pulsar el botón “Comienzo”, cambiando la apariencia de la ventana a la siguiente:
144
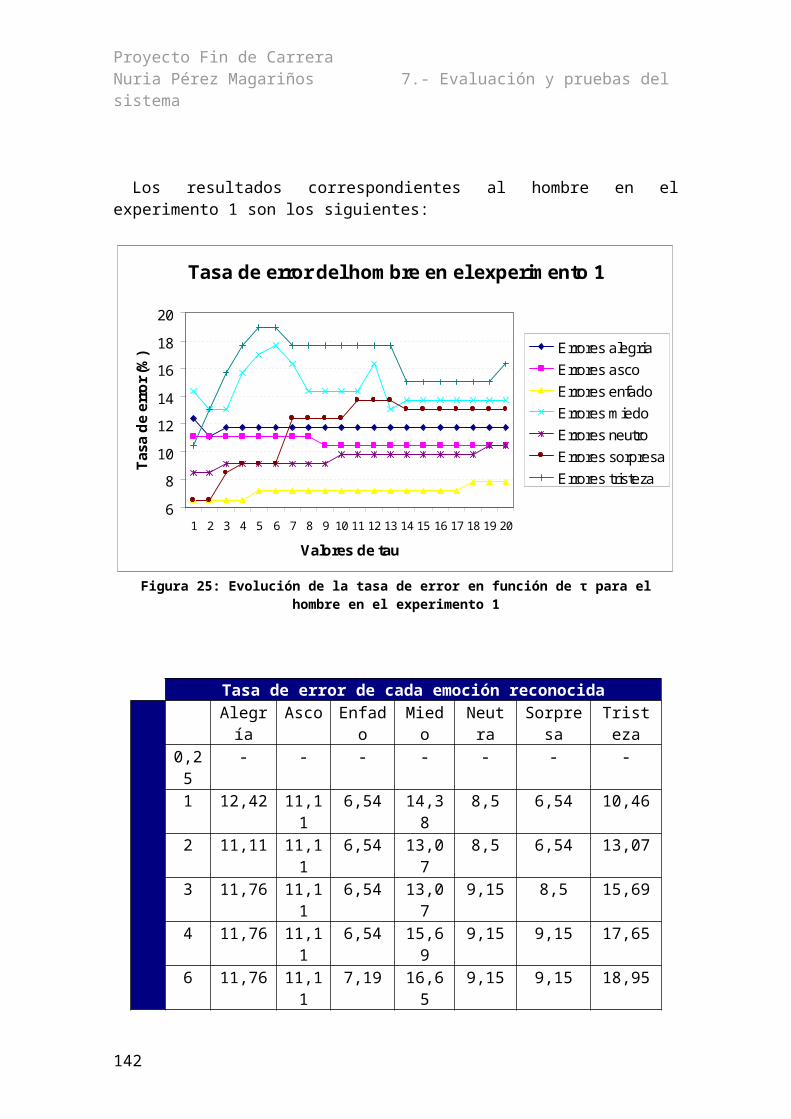
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
Cuando el usuario haya terminado de decir la frase en voz alta, deberá pulsar el botón “Fin” para detener la grabación. Cuando se pulse “Fin”, en el recuadro de “Texto Reconocido” aparecerá el texto que el reconocedor ha entendido. Si el usuario está conforme con lo que se ha reconocido, puede continuar con las grabaciones pulsando el botón “Siguiente” para que aparezca la siguiente frase o, en caso de que no esté conforme con el resultado del reconocimiento, puede pulsar el botón “Atrás” para repetir la grabación.
Si el usuario termina de grabar la última frase y pulsa el botón “Siguiente”, aparecerá en pantalla un mensaje indicándole que ha terminado satisfactoriamente la adaptación al sistema. En el momento que este mensaje aparece, el usuario deberá cerrar la ventana para poder continuar.
Paso 6 : Una vez cerrada la ventana de adaptación, aparecerá la ventana del reconocedor cuya funcionalidad se detalla en la sección de interfaz gráfica del sistema.
Paso 7 : Decir las frases que se deseen dentro de las que se hayan definido en el archivo de comandos guardado en el directorio de tarea o frases similares.
2.3.- Caso 3: Modo no automático sin adaptación
Esta opción permite al usuario configurar los parámetros principales del sistema y seleccionar los modelos acústicos que desea utilizar en el reconocedor del sistema. Los pasos para utilizar esta opción se detallan a continuación:
Paso 1 : Abrir el archivo “urbano.ini” que se encuentra en la carpeta “DATA” y realizar los siguientes cambios y/o comprobaciones:
o Comprobar que está desactivado el modo automático (variable modoAutomático = 0), desactivándolo en caso de que no lo estuviese.
145

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
o Comprobar que está desactivada la adaptación del sistema al hablante (variable adaptacionNecesaria = 0), desactivándola en caso de que no lo estuviese.
o Comprobar que la variable usuario de la sección WAV tiene asociado el nombre del usuario que en ese momento va a utilizar el sistema, cambiándolo en caso de que fuese necesario. Se deben escribir todas las letras en minúsculas y teniendo cuidado de no dejar espacios detrás del nombre. Un ejemplo sería:
usuario = carlos
Paso 2 : Lanzar el proceso CLIENTCOM desde el acceso directo que se encuentra en la carpeta “BIN”. Al hacerlo, aparecerá la siguiente ventana:
Paso 3 : Lanzar la aplicación “mfc_ROBINT_release.exe” que se encuentra en la carpeta “BIN”. Al hacerlo aparecerá una ventana de configuración del sistema cuya funcionalidad se detalla en la sección de interfaz gráfica. El usuario debe introducir su nombre en el campo reservado a tal efecto para asegurarse de que el sistema lo almacena adecuadamente.
Paso 4 : Una vez configurado el sistema, aparece una ventana en la que se pide al usuario que seleccione los modelos acústicos que desea cargar. Para esta selección pueden darse dos situaciones:
o Usuario desconocido por el sistema: Esta situación se da cuando el usuario nunca ha realizado el proceso de adaptación al sistema, motivo por el cual éste no reconoce su nombre como el de un usuario registrado o conocido. En este caso la ventana de selección de modelos se abrirá en el directorio “DATA”, dentro del cual el usuario deberá buscar y seleccionar el fichero “Speechdat_Continua_MMF.ascii”.
o Usuario conocido: Si el usuario ha realizado alguna vez el proceso de adaptación, el sistema reconocerá su nombre como el de un usuario conocido. En este caso, la ventana de selección de modelos se abrirá en su carpeta de modelos personal. Una vez en ella, y si el usuario ha realizado la adaptación para las condiciones en las que se encuentra, deberá ir navegando por las carpetas para localizar el modelo acústico ya adaptado a su voz y a las circunstancias. A continuación se muestra el árbol de directorios que un usuario puede llegar a tener en caso de que haya realizado adaptaciones en todas las circunstancias que actualmente permite el sistema:
146

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
MCC = Micrófono con cableMSC = Micrófono sin cableRuido = entorno ruidosono Ruido = entorno no ruidosoUna vez el usuario llegue a la carpeta que desea, debe seleccionar el fichero “Speechdat_Continua_MMF.ascii” que se encuentra allí.
Paso 5 : Una vez seleccionados los modelos acústicos, aparecerá la ventana del reconocedor cuya funcionalidad se detalla en la sección de interfaz gráfica del sistema.
Paso 6 : Decir las frases que se deseen dentro de las que se hayan definido en el archivo de comandos guardado en el directorio de tarea.
3.- Interfaz gráfica del sistema
3.1- Ventana de configuración
La ventana de configuración permite al usuario modificar la configuración de los parámetros que más a menudo pueden cambiar debido a las condiciones cambiantes del entorno y las tareas.
Grabaciones
Usuario nº 1 Usuario nº 2 Usuario nº 3
MSC MCC
noRuido
Ruido
Genérica
Tarea 1
Tarea 2
147

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
3.2.- Ventana del reconocedor
El entorno de trabajo del reconocedor consiste en una ventana de diálogo. Antes de establecer cualquier tipo de comunicación con el robot o con un cliente de prueba, se cargan e inicializan los diccionarios y gramáticas que se emplearán en el reconocimiento. Mientras se lleva a cabo el proceso, la ventana de diálogo muestra este aspecto:
148
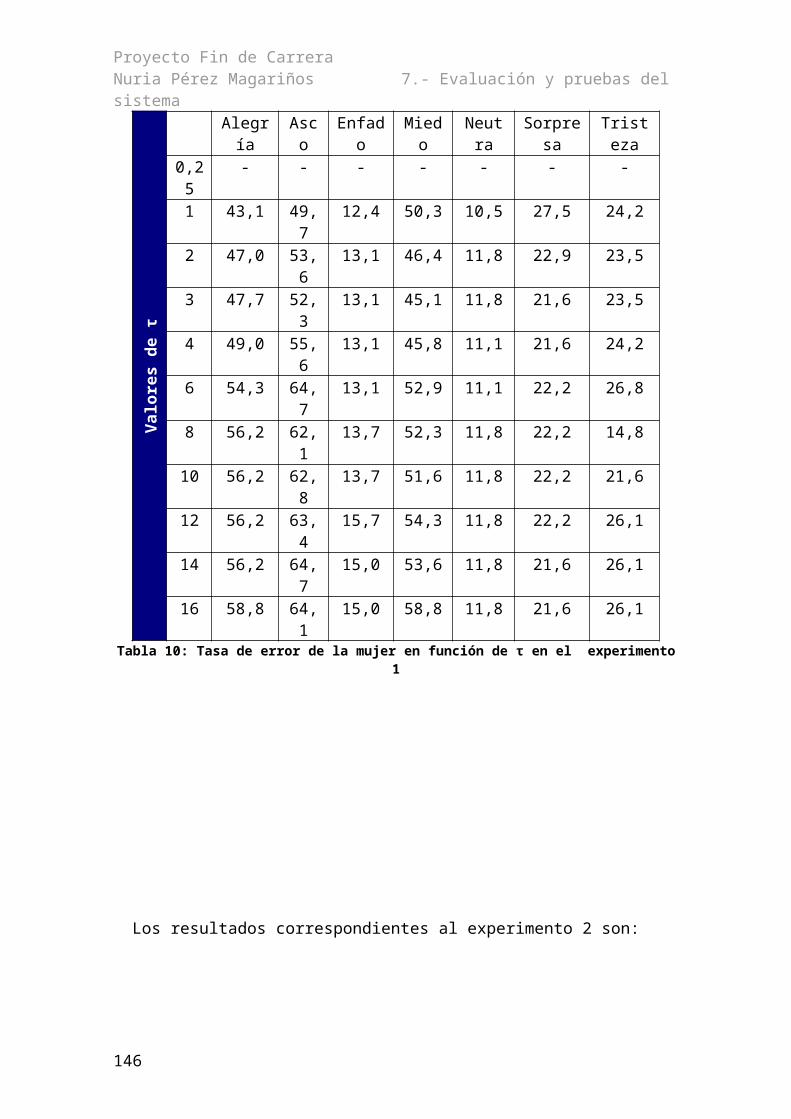
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
Una vez se han cargado los diccionarios y gramáticas, aparece un mensaje que indica al usuario que puede comenzar a hablar.
A continuación se explican con detalle los elementos de la ventana del reconocedor:
- Número 1: Ventana en la que se muestra la forma de onda de la señal que está recibiendo por el micrófono.
- Número 2: Cuadro en el que se muestran los mensajes para el usuario. Estos pueden ser:
o “Cargando los diccionarios e inicializando el reconocedor”: Si el usuario habla, el sistema ignorará lo que se haya dicho.
o “Hable cuando quiera”: El sistema reaccionará a lo que es usuario diga siempre que se haya establecido la comunicación con el cliente o robot.
o “Reconociendo”: El sistema se encuentra procesando lo que ha dicho el usuario y no es recomendable hablar mientras dure este proceso.
149
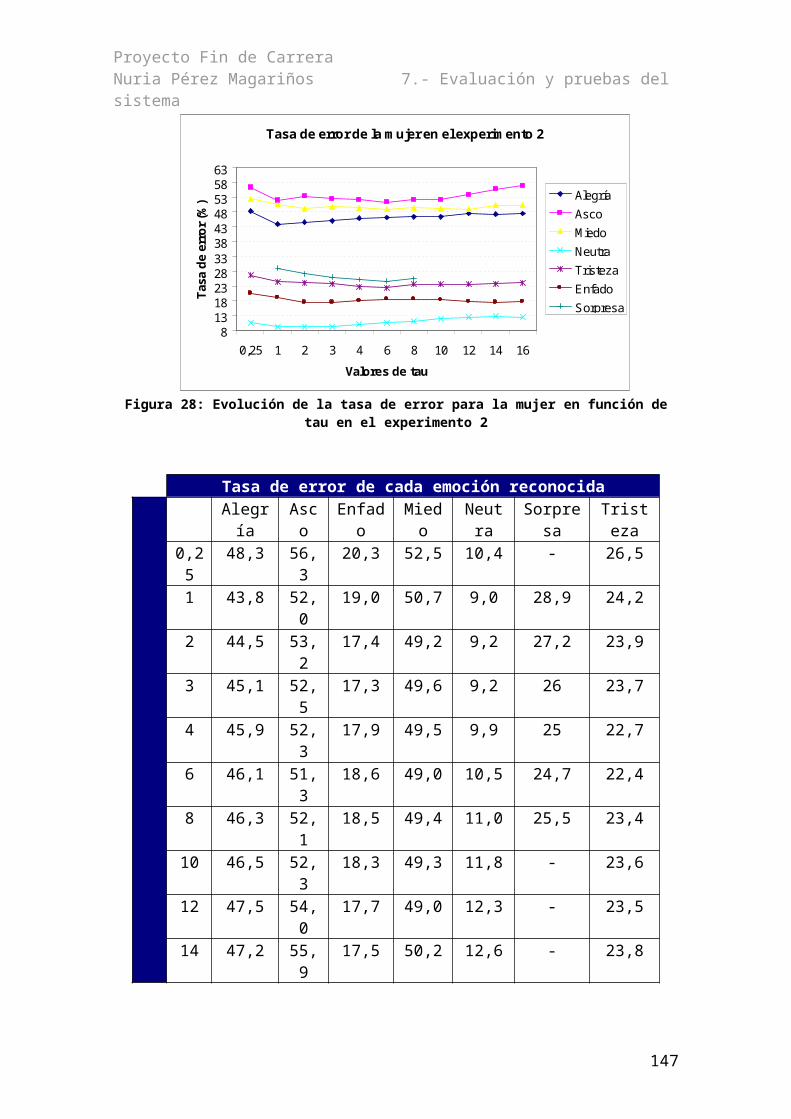
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
- Número 3: Cuadro en el que se muestra el texto que ha sido reconocido. En el
caso de que el aprendizaje se realice empleando trigramas también aparecerá el comando que se envía al cliente.
- Número 4: Botón que permite terminar con la aplicación del reconocedor. En ocasiones la aplicación no se cierra completamente por lo que es recomendable revisar los procesos activos dentro del administrador de tareas para comprobar que la aplicación ha sido cerrada por completo
- Número 5: Cuadro en el que se muestra la confianza con la que el sistema ha reconocido la frase que se muestra por pantalla como texto reconocido. Si dicha confianza no supera el umbral, no se enviará ningún comando al robot. Un cero significa que no tiene ninguna confianza en el texto que ha reconocido, mientras que un 1 supone confianza total en lo reconocido.
- Número 6: Cuadro que muestra el valor del umbral de confianza que deben superar las frases para que el comando que tienen asociado sea enviado al robot. Por configuración dicho valor se inicializa con 0,71 pero puede ser modificado.
- Número 7: Barra de desplazamiento que permite modificar el umbral de confianza, prevaleciendo el valor que se especifique mediante este elemento frente a valores que hayan podido establecerse como valores de inicialización.
150

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo I
151

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo II
II.- PROPUESTA DE FRASES PARA GUIADOA la luz de las conclusiones obtenidas, se proponen las siguientes frases como base
para implementar la tarea de guiado del robot:
Sígueme Párate Para Detente Quieto Quédate quieto Quédate parado Avanza Comienza a andar Avanza Muévete Gira x grados Gira un poco a la izquierda Gira un poco a la derecha Avanza un poco Avanza bastante Avanza x metros Avanza y párate Gira y párate Tienes que seguirme Te voy a enseñar el lugar ¿A quién estás siguiendo? ¿A qué persona sigues? Señala a la persona a la que sigues Indica a quién sigues Dime a quién sigues Sigues a la persona incorrecta Sigue a la persona que está a la derecha Sigue a la persona que está a la izquierda Sala de linux Sala de micrófonos Sala de grabación Sala de doctorandos Punto de información uno Punto de información dos Punto de información tres Punto de información cuatro El objeto está a un metro del suelo La altura del objeto es un metro El objeto está en la posición (x,y) El público debe colocarse en (x,y) Sitio prohibido Lugar prohibido Camino prohibido
153
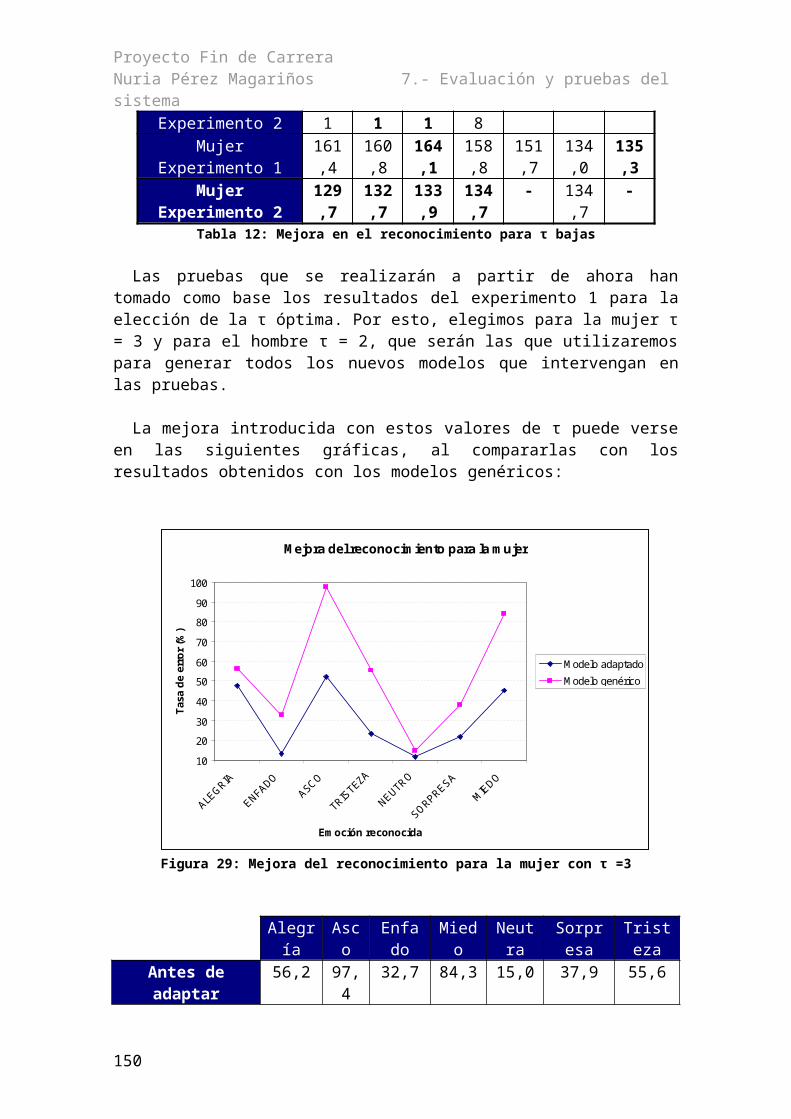
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo II
Zona peligrosa Lugar peligroso Camino peligroso Ruta incorrecta Ruta errónea Ruta correcta Trayectoria incorrecta Trayectoria errónea Trayectoria correcta De acuerdo Bien Mal No Si Correcto Incorrecto Error Lugar equivocado (en caso de que al asignar una etiqueta de lugar confirme si el
lugar que tiene asociado a la etiqueta es el que queremos y lea un pequeño texto explicativo)
Etiqueta de lugar errónea Lugar correcto Etiqueta correcta Avanza al siguiente punto Ve al siguiente punto de información Llévame al siguiente punto ¿Cuál es el siguiente punto de información? Hemos terminado ¿Qué recorrido harías? Hazme un recorrido Recorre el mapa Genera el grafo Haz una visita
154
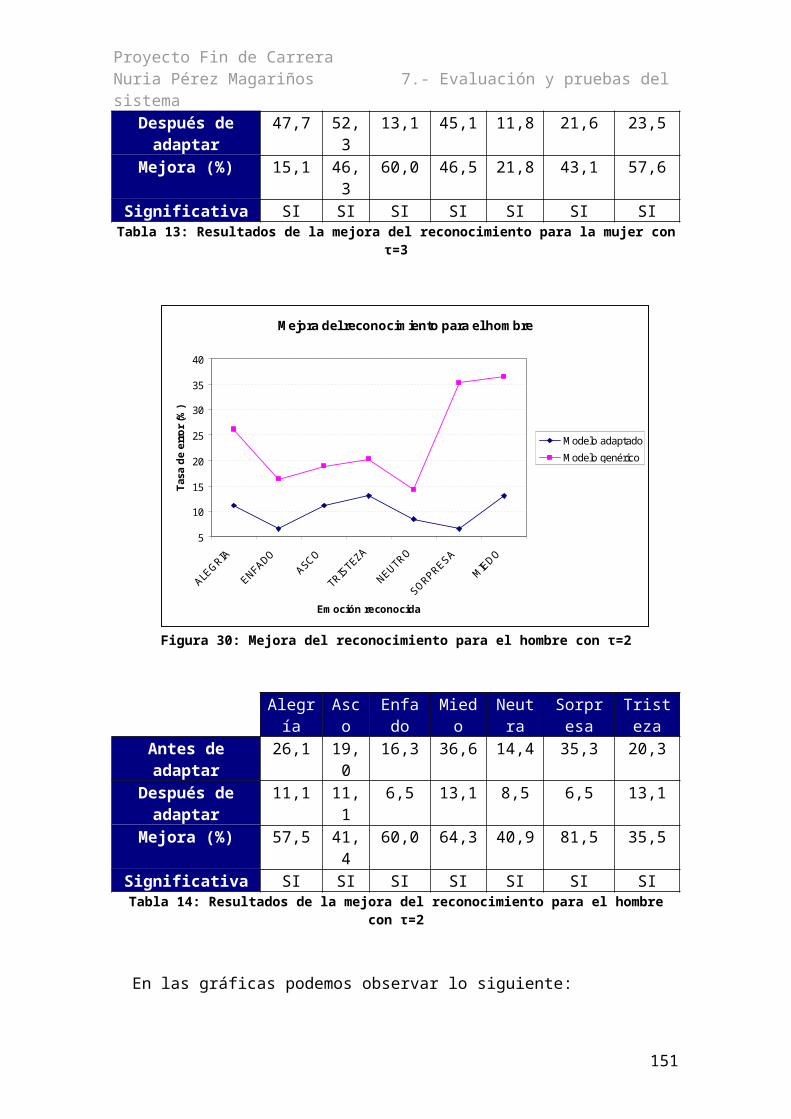
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo III
III.- FRASES DEL QUIJOTE
Para la realización de la adaptación genérica al locutor, se han seleccionado las siguientes frases:
1. Tirad, llegad, venid y ofendedme en cuanto pudiéres, que vosotros veréis el pago que lleváis de vuestra sandez y demasía
2. Y tal es la suavidad de la voz con que los canta, que encanta3. Pero, ¿qué libro es ese que está junto a él?4. En la cual caminaron tanto, que al amanecer se tuvieron por
seguros de que no los hallarían aunque los buscasen5. Antes, pues que la causa por la que naciste con mi desdicha
augmenta su ventura aun, en la sepultura no estés triste6. Pero no me llame cruel ni homicida aquel a quien yo no
prometo, engaño, llamo ni admito7. Que si en su ayuda y defensa acudieren caballeros, yo te sabré
defender y ofenderlos con todo mi poder8. No le he dicho que sí, pese a mi linaje9. A esa cuenta, dos deben de ser dijo sancho, porque de esta
parte contraria se levanta así mismo otra semejante polvareda10. Desesperábase con esto don quijote, y, por más que ponía
las piernas al caballo, menos le podía mover11. Y no digo más, que os batanee el alma12. Los de a caballo, con escopetas de rueda, y los de a pie,
con dardos y espadas13. Y avínole bien, que éste era el de la escopeta14. Porque, si no fuese con mucha voluntad y gusto suyo, no era
luscinda mujer para tomarse ni darse a hurto15. Así que, para conmigo, no es menester gastar más palabras
en declararme su hermosura, valor y entendimiento16. Aunque tengo para mí que ya no tengo ninguno, merced a la
malicia de malos y envidiosos encantadores17. Y, puesto que dos veces le dijo don quijote que prosiguiese
su historia, ni alzaba la cabeza ni respondía palabra18. Sacó el libro de memoria don quijote, y, apartándose a una
parte, con mucho sosiego comenzó a escribir la carta19. Del cual se dirá lo que del otro se dijo20. Quedaron admirados los dos de lo que sancho panza les
contaba21. Y todo fue invención del falso don fernando, pues no le
faltaban a su hermano dineros para despacharme luego22. ¿Qué se me da a mí que mis vasallos sean negros?23. Las barbas le ha derribado y arrancado del rostro , como si
las quitaran aposta24. Y, cuando llegaron allá bajo, se halló en unos palacios y
en unos jardines tan lindos que era maravilla25. Cuanto más que, con lo que ahora pienso decirte, acabarás
de venir en conocimiento del grande error que quieres cometer26. Ha sido por lo que a ti te toca27. Esta es carne de mi carne y hueso de mis huesos28. Mas, cuando entendió que estaba resuelta en matar a
lotario, quiso salir y descubrirse, porque tal cosa no se hiciese
29. Todos reían sino el ventero, que se daba a satanás30. No sabía qué pensar, qué decir, ni qué hacer, y poco a poco
se le iba volviendo el juicio
155

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo III
31. ¿Qué voz es esta que ha llegado a mis oídos?32. Con esto entendimos, o imaginamos, que alguna mujer que en
aquella casa vivía nos debía de haber hecho aquel beneficio33. Y es hermosa la dama a quien se la diste34. ¿Y qué bien es el que te has hecho?, hija35. Siguiendo voy a una estrella que desde lejos descubro, más
bella y resplandeciente que cuantas vio palinuro36. Que todo aquello que canta lo saca de su cabeza37. No hay para qué se dé cuenta aquí de mis cosas38. No parezcas delante de mí, so pena de mi ira39. Que voto a tal que es tanta verdad como es ahora de día40. No querría que por haber yo hablado con esta alimaña tan en
seso, me tuviesen vuestras mercedes por hombre simple41. Que esta manchega dama, y este invito andante caballero, en
tiernos años, ella dejó, muriendo, de ser bella42. Nunca sus glorias el olvido mancha, pues hasta rocinante,
en ser gallardo, excede a brilladoro y a bayardo43. No sirvieron de nada para con el capellán las prevenciones
y advertimientos del retor para que dejase de llevarle44. Todos estos caballeros, y otros muchos que pudiera decir,
señor cura, fueron caballeros andantes, luz y gloria de la caballería
45. Y si lo dices, no lo digas, ni lo pienses46. Y el roto, más de las armas que del tiempo47. Así será respondió sancho, porque por la mayor parte he
oído decir que los moros son amigos de berenjenas48. Entra ahí la aventura de los yangueses, cuando a nuestro
buen rocinante se le antojó pedir cotufas en el golfo49. Llegó sancho a su casa tan regocijado y alegre, que su
mujer conoció su alegría a tiro de ballesta50. Y aun todo esto fuera flores de cantueso si no tuviéramos
que entender con yangueses y con moros encantados51. Y vístele de modo que disimule lo que es y parezca lo que
ha de ser52. Unos, que tuvieron principios humildes, y se fueron
estendiendo y dilatando hasta llegar a una suma grandeza53. ¿Qué le ha acontecido?, que parece que se le quiere
arrancar el alma54. Y advertid, hijo, que vale más buena esperanza que ruin
posesión, y buena queja que mala paga55. El que una vez, señor don quijote, pudo venceros
transformado, bien podrá tener esperanza de rendiros en vuestro propio ser
56. Llegó sancho, y, como vio el rostro del bachiller carrasco, comenzó a hacerse mil cruces y a santiguarse otras tantas
57. Y la historia vuelve a hablar de él a su tiempo, por no dejar de regocijarse ahora con don quijote
58. No entiendo, respondió don quijote, lo que vuestra merced dice ni quiere decir en eso del deslizarme
59. De aquí a mañana muchas horas hay, y en una, y aun en un momento, se cae la casa
60. Las ninfas que al amor seguían traían a las espaldas, en pargamino blanco y letras grandes, escritos sus nombres
61. Guadiana, vuestro escudero, plañendo asimesmo vuestra desgracia, fue convertido en un río llamado de su mesmo nombre
62. Y si la habló ¿qué dijo? Y ¿qué le respondió?63. Señor replicó el mancebo, yo llevo en este envoltorio unos
greguescos de terciopelo, compañeros desta ropilla64. Viendo y oyendo, pues, tanta morisma y tanto estruendo don
quijote, parecióle ser bien dar ayuda a los que huían
156
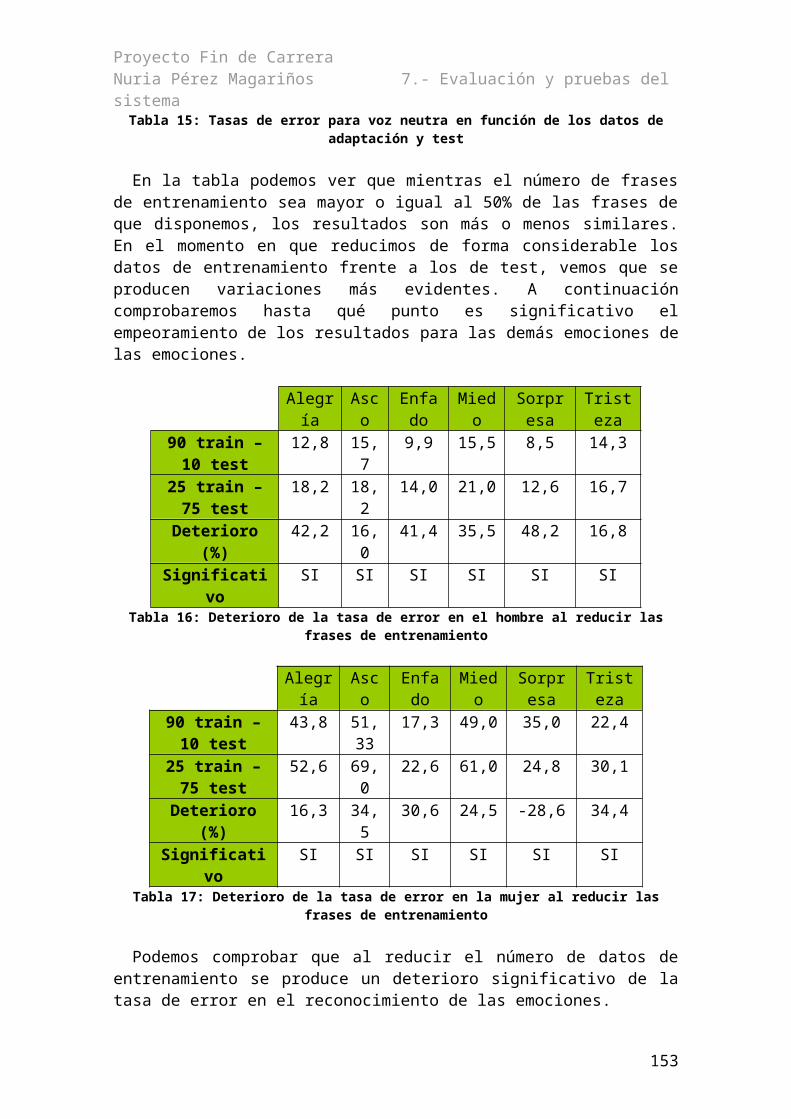
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo III
65. El rey marsilio, mal herido, y el emperador carlomagno, partida la corona y la cabeza en dos partes
66. Cuánto parece que os debo dar más de lo que os daba tomé carrasco
67. Déjeme vuestra grandeza respondió sancho, que no estoy agora para mirar en sotilezas ni en letras más a menos
68. Eso replicó la duquesa más es darse de palmadas que de azotes
69. Venía cubierto el rostro con un trasparente velo negro, por quien se entreparecía una longísima barba, blanca como la nieve
70. A esto dijo la trifaldi que ningún jaez ni ningún género de adorno sufría sobre sí clavileño
71. Y a quien dios quiere bien, la casa le sabe72. No mires de tu tarpeya este incendio que me abrasa, nerón
manchego del mundo, ni le avives con tu saña73. Si la sentencia pasada de la bolsa del ganadero movió a
admiración a los circunstantes, ésta les provocó a risa74. Hízolo así el recién nacido secretario, y, habiendo leído
lo que decía, dijo que era negocio para tratarle a solas75. Aquí está un labrador negociante que quiere hablar a
vuestra señoría en un negocio, según él dice, de mucha importancia
76. Mirad si queréis otra cosa dijo sancho, y no la dejéis de decir por empacho ni por verguenza
77. Pero mire que me ha de dar la mitad de esa sarta78. Y, en tanto que estas razones iba diciendo, iba asimesmo
enalbardando el asno, sin que nadie nada le dijese79. Yo no nací para ser gobernador, ni para defender ínsulas ni
ciudades de los enemigos que quisieren acometerlas80. Más quiero hartarme de gazpachos que estar sujeto a la
miseria de un médico impertinente que me mate de hambre81. No hemos conocido el bien hasta que le hemos perdido82. Quedó admirado el maese de campo de las razones de tosilos83. Lleva usted dos mil suspiros, que, a ser de fuego, pudieran
abrasar a dos mil troyas, si dos mil troyas hubiera84. Déosle dios tan bueno dijo la duquesa, señor don quijote,
que siempre oigamos buenas nuevas de vuestras fechurías85. Pues de las cosas obscenas y torpes, los pensamientos se
han de apartar, cuanto más los ojos86. Que por aquí los suele ahorcar la justicia cuando los coge,
de veinte en veinte y de treinta en treinta87. Y, si no son todas sanas, a lo menos son todas limpias88. Acabóse la plática, vistióse don quijote, comió con los
duques, y partióse aquella tarde89. Prosigue, sancho amigo, y no desmayes le dijo don quijote,
que yo doblo la parada del precio90. No la has de ver en todos los días de tu vida
157

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo III
158
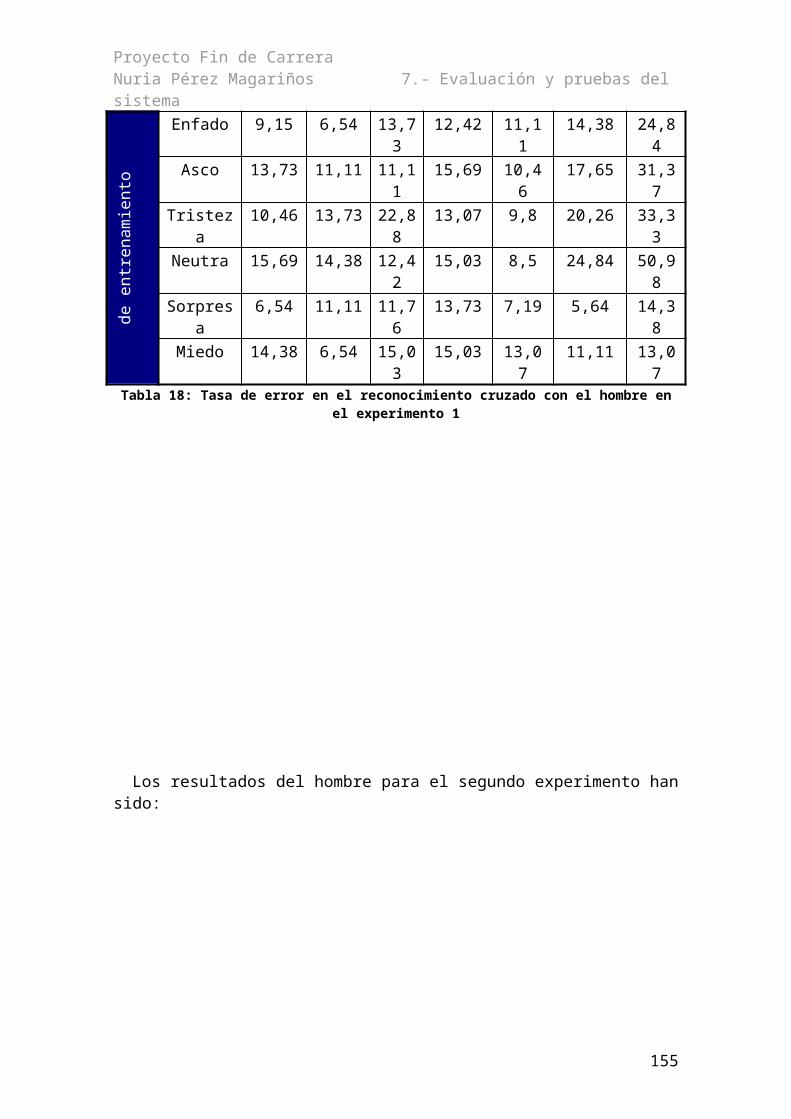
Proyecto Fin de Carrera Nuria Pérez Magariños Anexo IV
IV.- FRASES DE URBANO PARA LA EVALUACIÓN DEL SISTEMA
1. atiendeahora2. dejadeatenderme3. puedes presentarte4. qué tal urbano cómo estás5. te consideras un ser inteligente6. eres inteligente7. cómo serás en el futuro8. qué hora es9. qué día es10. qué fecha es11. qué día es hoy12. qué fecha es hoy13. quién eres tú14. qué eres tú15. tú quién eres16. qué sabes hacer17. qué puedes hacer18. qué haces19. cómo estás20. adios urbano gracias por recibirnos21. me parece que es un eco22. creo que es un elefante23. es un tiburón24. parece un murciélago25. buenos días26. buenas tardes27. buenas noches28. sabes los detalles29. dime los detalles30. explica los detalles31. cuenta los detalles32. enséñanos los detalles33. dinos los detalles34. muéstranos los detalles35. empezamos una visita36. desconecta37. cómo te fue en el colegio38. qué tareas puedes realizar39. qué países son los más adelantados en robótica40. te voy a enseñar el lugar41. sigues a la persona incorrecta42. lugar prohibido43. camino peligroso44. gira un poco a la derecha45. gira a la izquierda46. punto de información cuatro47. punto de información uno48. quieto49. avanza50. tienes que seguirme51. avanza al siguiente punto de información52. recorre el mapa53. ruta equivocada54. ruta correcta55. genera el grafo56. trayectoria incorrecta
159

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo IV
57. etiqueta de lugar errónea58. la altura del obejto es un metro59. de acuerdo60. hemos terminado
V.- FUNCIONES DE GENERACIÓN DE REGLAS
- Reescribe3copiando2conseparador_2o Id: 1o Número de parámetros: 4
- Reescribe3copiando2conseparador_1o Id: 2o Número de parámetros: 4
160

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo IV
- Reescribe3copiando1_3o Id: 3o Número de parámetros: 4
- Reescribe3copiando1_1o Id: 4o Número de parámetros: 4
- Reescribe3copiando1_2o Id: 5o Número de parámetros: 4
- Reescribe2copiando_1o Id: 6o Número de parámetros: 3
- Reescribe2copiando_2o Id: 7o Número de parámetros: 3
- Si_terminao Id: 8o Número de parámetros: 2
- Si_termina_con_2o Id: 9o Número de parámetros: 4
- Reescribe2copiando_bloqueo Id: 10o Número de parámetros: 4
- Reescribe2o Id: 11o Número de parámetros: 3
- Reescribe1copiandoo Id: 12o Número de parámetros: 3
- Si_comienzao Id: 13o Número de parámetros: 2
- Si_comienza_por_n_2o Id: 14o Número de parámetros: 2
- Si_comienza_por_n_3o Id: 15o Número de parámetros: 2
- Si_comienza_por_n_4o Id: 16o Número de parámetros: 2
- Si_comienza_por_n_5
161

Proyecto Fin de Carrera Nuria Pérez Magariños Anexo IV
o Id: 17o Número de parámetros: 2
- Reescribe1_si_n_caracteres_1o Id: 18o Número de parámetros: 2
- Reescribe1_si_n_caracteres_2o Id: 19o Número de parámetros: 2
- Reescribe1_si_n_caracteres_3o Id: 20o Número de parámetros: 2
- Reescribe1_si_n_caracteres_4o Id: 21o Número de parámetros: 2
- Reescribe1o Id: 22o Número de parámetros: 2
- Reescribe3o Id: 23o Número de parámetros: 4
- Reescribe1borrandoo Id: 24o Número de parámetros: 2
- “”o Id: 25o Número de parámetros: 2
- Reescribe3borrandoo Id: 26o Número de parámetros: 4
- Reescribe2borrandoo Id: 27o Número de parámetros: 3
162


















