
6 Repaso Prueba 1 Estad Stica I 2014
13
Repaso para prueba 1 Estadística IV 2014 Material preparado por el equipo de ayudantes 2014 Unidades I y II Relación entre teoría e investigación. La medición en ciencias sociales. Elementos de una ficha técnica. Organismo responsable Universo Cobertura geográfica Tamaño muestral Tipo de muestra Trabajo de campo Reemplazos Número de variables Población y muestra La población es el conjunto de elementos concreto del que se quiere obtener información y al cual se pretende hacer representativo el estudio, así como el conjunto del que se extraerá la muestra. 1 1 Cabe diferenciar el concepto población del de universo. Si bien suelen utilizarse como sinónimos en la mayoría de las fichas metodológicas de las encuestas, en estricto rigor estadístico, el universo sobrepasa a la población, es decir, podemos identificar múltiples poblaciones dentro de un mismo universo. Por ejemplo: (1) nuestro universo pueden ser todos los chilenos, mientras que nuestra población sólo los mayores de 18 años. (2) El universo puede estar conformado por las personas mayores de 15 años, y la población considerar a los mayores de 15 años que fueron empadronados en el último censo. (3) El Censo también puede ser un universo con distintas poblaciones dentro de él, como la población de personas casadas, o de personas analfabetas o evangélicas. (4) En una encuesta laboral, el universo podría estar compuesto por todas aquellas personas en edad de trabajar, mientras que una población dentro de él podría ser de personas cesantes, o sin contrato, etc. Es a partir de la población que se extrae la muestra.
-
Upload
diego-alvarez -
Category
Documents
-
view
227 -
download
1
description
sdgsdsdgsd
Transcript of 6 Repaso Prueba 1 Estad Stica I 2014

Repaso para prueba 1 Estadística IV 2014
Material preparado por el equipo de ayudantes 2014
Unidades I y II
Relación entre teoría e investigación. La medición en ciencias sociales.
Elementos de una ficha
técnica.
Organismo responsable
Universo
Cobertura geográfica
Tamaño muestral
Tipo de muestra
Trabajo de campo
Reemplazos
Número de variables
Población y muestra La población es el conjunto de elementos concreto del que se quiere obtener información y al cual
se pretende hacer representativo el estudio, así como el conjunto del que se extraerá la muestra.1
1 Cabe diferenciar el concepto población del de universo. Si bien suelen utilizarse como sinónimos en la mayoría de las
fichas metodológicas de las encuestas, en estricto rigor estadístico, el universo sobrepasa a la población, es decir,
podemos identificar múltiples poblaciones dentro de un mismo universo. Por ejemplo: (1) nuestro universo pueden ser
todos los chilenos, mientras que nuestra población sólo los mayores de 18 años. (2) El universo puede estar conformado
por las personas mayores de 15 años, y la población considerar a los mayores de 15 años que fueron empadronados en
el último censo. (3) El Censo también puede ser un universo con distintas poblaciones dentro de él, como la población
de personas casadas, o de personas analfabetas o evangélicas. (4) En una encuesta laboral, el universo podría estar
compuesto por todas aquellas personas en edad de trabajar, mientras que una población dentro de él podría ser de
personas cesantes, o sin contrato, etc. Es a partir de la población que se extrae la muestra.

La muestra es una porción representativa de la población, es como un espejo de ésta. Es sobre la
muestra que se realizan los análisis y conclusiones, pues tiene un tamaño más abarcable, y como
es representativa de la población, es capaz de estimar los valores presente en ella.
Esta información suele venir explicitada en la ficha técnica de cada encuesta, como se observa en
la imagen de arriba (en ‘universo’ y ‘tamaño muestral’, respectivamente).
Unidad de análisis y Unidad de información (u observación) Otra información que puede desprenderse de la ficha metodológica son las unidades de análisis,
muestreo e información u observación.
La unidad de análisis es el objeto del estudio, pueden ser personas, hogares, grupos, instituciones,
problemas, etc., es a quién o a qué se remita la investigación Por su parte, la unidad de
observación o de información es el elemento a partir del cual se extrae la información necesaria
para dar cuenta de la unidad de análisis. Por último, la unidad de muestreo es a través de la cual
se llega a la unidad de información, o sea, quienes integrarán la muestra.
La unidad de análisis no siempre coincide con la unidad de información, por ejemplo, el CENSO
recoge información tanto de persona como de viviendas y hogares, pero esta información es
entregada por las personas. Del mismo modo, la encuesta CASEN tiene por objetivo hacer una
caracterización socioeconómica de hogares (unidad de análisis), pero quien provee la información
son los jefes de hogar (unidad de observación).
Otros ejemplos:
1. Encuesta UDP 2013 (http://www.encuesta.udp.cl/descargas/enc2013-2/manual-sept-2013.pdf)
Objetivo “contribuir a la comprensión de los cambios en las percepciones de los chilenos en diversas áreas donde el país evidencia transformaciones cruciales”
Población “Población de 18 años y más, residentes en 86 comunas con más 20.000 habitantes de todas las regiones, excluyendo Aysén y General Ibáñez del Campo.”
Tamaño muestral
1300 viviendas.
Obtención de la información
“En cada vivienda se listan a las personas de 18 años y más que viven permanentemente en el hogar. Luego, mediante la aplicación de una tabla de sorteo aleatorio única para cada entrevista, se determina la persona a ser entrevistada.
Unidad de análisis: personas chilenas.
Unidad de muestreo: viviendas.
Unidad de información: personas de 18 años y más.
2. Encuesta de Presupuestos Familiares 2008 (INE).
(http://www.ine.cl/canales/chile_estadistico/encuestas_presupuestos_familiares/2008/metodolo
gia_vi_epf.pdf)

Objetivo “La VI Encuesta de Presupuestos Familiares tiene como objetivo determinar la distribución de la estructura del gasto e ingresos entre los hogares”
Población “La población de estudio son los hogares particulares residentes en las comunas descritas anteriormente y las personas que lo componen.”
Tamaño muestral
“La encuesta está basada en una muestra de 10.092 viviendas”
Obtención de la información
“A cada una de las personas de 15 años y más pertenecientes a los hogares seleccionados en la quincena en cuestión se les solicita registren día a día sus gastos durante una quincena.”
Unidad de análisis: hogares.
Unidad de muestreo: viviendas.
Unidad de información: personas de 15 años y más.
Error muestral También llamado ‘error máximo admisible’, es el error propio producto de analizar una muestra y
no la población completa. Los censos, por tanto, no tendrían este tipo de error.
Generalmente se presenta a modo de intervalo y en porcentajes (±3%, por ejemplo), y es
calculado por quien está realizando la investigación, o sea, es conocido. Por ejemplo, si una
encuesta con un ±5% de error muestral arroja como resultado que un 64% de los estudiantes de
cuarto medio consume alcohol, entonces, en la población, el porcentaje real de estudiantes que
consume alcohol estaría entre un 59% y un 69%.
Este intervalo indica la precisión de la estimación realizada con la muestra escogida, y será más
grande mientras mayor sea el error muestral, y viceversa.
Además, el error muestral influye y está influido por el tamaño muestral, el nivel de confianza y la
varianza. Mientras más pequeña sea la muestra, más grande será el error muestral, por lo que si
se quiere que éste se reduzca, se necesitará agrandar la muestra, para que así ésta sea más
representativa de la población y pueda dar cuenta de mejor manera de sus características. Del
mismo modo, si se quiere un mayor nivel de confianza (mayor precisión), se requerirá de un error
muestral máximo admisible menor.
Unidad III
Tipos de variables: niveles de medición. Una variable es la representación de propiedades de las unidades observadas y que recibe
distintos valores (dos o más). En una encuesta, por ejemplo, cada caso de la muestra tiene un
valor para cada variable.
Las variables pueden clasificarse de acuerdo a distintos criterios:
Objetivos de la investigación
Variable dependiente Asociada al fenómeno de estudio y que el investigador manipula (x), pues las escoge
para establecer agrupaciones en el estudio.
Variable independiente Explican el fenómeno a estudiar. Su valor está influido por las variables independientes (y).
Por ejemplo: la ‘decisión de ir a votar o no’ (y), depende de las variables ‘nivel educacional’ (x1),
‘posición política’ (x2) y ‘participación previa en elecciones’ (x3).
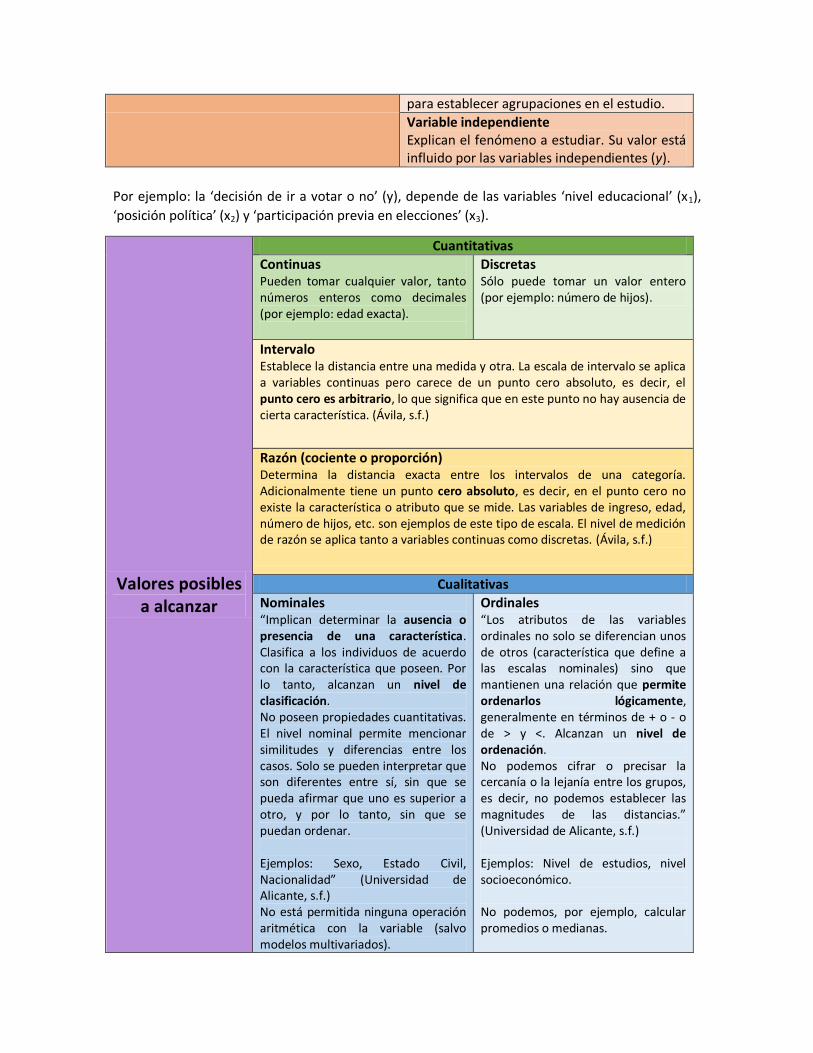
Valores posibles a alcanzar
Cuantitativas
Continuas Pueden tomar cualquier valor, tanto números enteros como decimales (por ejemplo: edad exacta).
Discretas Sólo puede tomar un valor entero (por ejemplo: número de hijos).
Intervalo Establece la distancia entre una medida y otra. La escala de intervalo se aplica a variables continuas pero carece de un punto cero absoluto, es decir, el punto cero es arbitrario, lo que significa que en este punto no hay ausencia de cierta característica. (Ávila, s.f.)
Razón (cociente o proporción) Determina la distancia exacta entre los intervalos de una categoría. Adicionalmente tiene un punto cero absoluto, es decir, en el punto cero no existe la característica o atributo que se mide. Las variables de ingreso, edad, número de hijos, etc. son ejemplos de este tipo de escala. El nivel de medición de razón se aplica tanto a variables continuas como discretas. (Ávila, s.f.)
Cualitativas
Nominales “Implican determinar la ausencia o presencia de una característica. Clasifica a los individuos de acuerdo con la característica que poseen. Por lo tanto, alcanzan un nivel de clasificación. No poseen propiedades cuantitativas. El nivel nominal permite mencionar similitudes y diferencias entre los casos. Solo se pueden interpretar que son diferentes entre sí, sin que se pueda afirmar que uno es superior a otro, y por lo tanto, sin que se puedan ordenar. Ejemplos: Sexo, Estado Civil, Nacionalidad” (Universidad de Alicante, s.f.) No está permitida ninguna operación aritmética con la variable (salvo modelos multivariados).
Ordinales “Los atributos de las variables ordinales no solo se diferencian unos de otros (característica que define a las escalas nominales) sino que mantienen una relación que permite ordenarlos lógicamente, generalmente en términos de + o - o de > y <. Alcanzan un nivel de ordenación. No podemos cifrar o precisar la cercanía o la lejanía entre los grupos, es decir, no podemos establecer las magnitudes de las distancias.” (Universidad de Alicante, s.f.) Ejemplos: Nivel de estudios, nivel socioeconómico. No podemos, por ejemplo, calcular promedios o medianas.

Pueden ser dicotómicas (dos categorías), no dicotómicas (más de dos categorías) o dummy (presencia o ausencia, suelen codificarse con 1 y 0 respectivamente).
Los niveles de medición, por lo tanto, corresponden a: Nominal Ordinal De intervalo o razón.
Representaciones gráficas
La información estadística, tanto la descriptiva como la obtenida al aplicar ciertos procedimientos,
no pude presentarse “en bruto”, es decir, debe estar lógicamente organizada y ser fácil de
entender. En caso de usar figuras, representaciones gráficas, éstas deben ser claras para el lector
incluso antes de revisar los datos detalladamente. Las características que debe tener cualquier
representación gráfica son:
captar la atención del lector;
presentar la información en forma sencilla, clara y precisa;
no inducir a error;
facilitar la comprensión de los datos y destacar las tendencias y diferencias;
ilustrar el mensaje, tema o trama del texto al que acompaña. (INE-España, s.f.)
Gráfico de barras Es una representación gráfica en un eje cartesiano de las frecuencias de una variable
cualitativa a discreta. En uno de los ejes se posicionan las distintas categorías o modalidades de la variable cualitativa o discreta, y en el otro, el valor o frecuencia de cada categoría en una determinada escala.
La orientación del gráfico puede ser vertical, es decir, las distintas categorías están situadas en el eje horizontal y las barras de frecuencias crecen verticalmente. O bien, puede ser horizontal, es decir, las categorías se sitúan en el eje vertical y las barras crecen horizontalmente; suelen usarse cuando hay muchas categorías o sus nombres son demasiado largos.
Los gráficos de barras suelen utilizarse para comparar magnitudes de varias categorías, así
como ver la evolución en el tiempo de una magnitud concreta. Puede ser sencillo (contiene una única serie de datos), agrupado (contiene varias series de
datos y cada una se representa por un tipo de barra de un mismo color), o apilado (contiene varias series de datos, las barras se dividen en segmentos de diferentes colores y cada uno de ellos representa una serie).
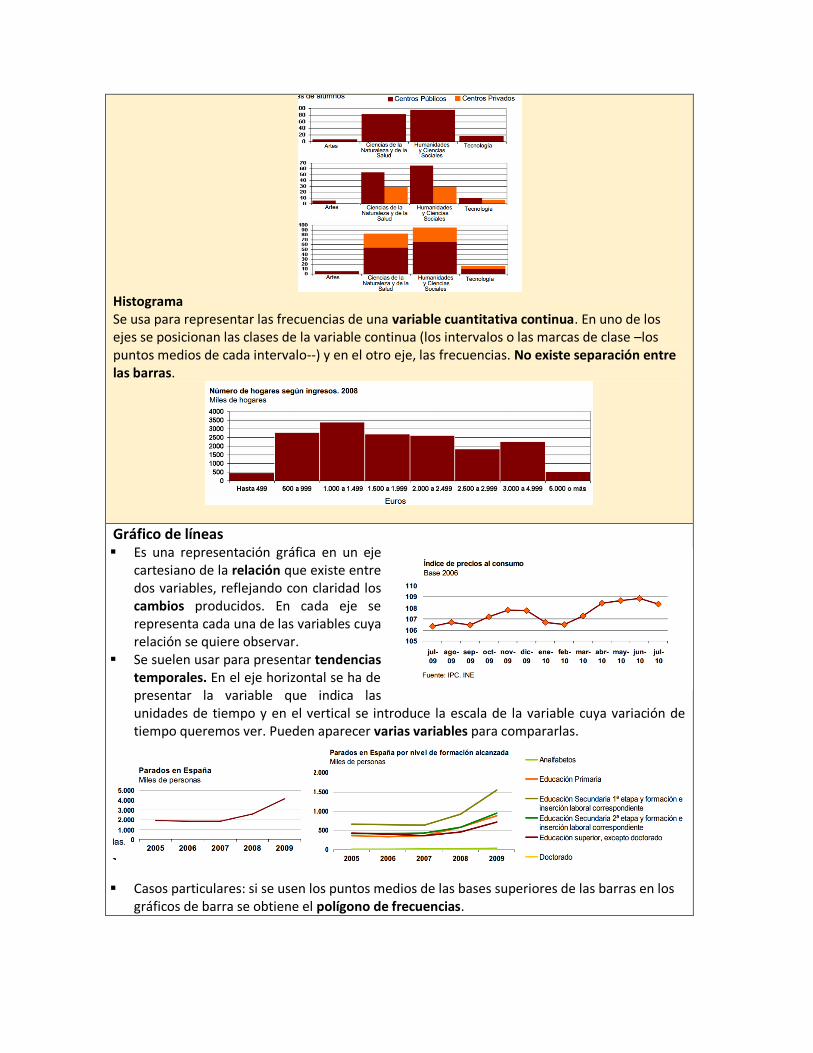
Histograma Se usa para representar las frecuencias de una variable cuantitativa continua. En uno de los ejes se posicionan las clases de la variable continua (los intervalos o las marcas de clase –los puntos medios de cada intervalo--) y en el otro eje, las frecuencias. No existe separación entre las barras.
Gráfico de líneas Es una representación gráfica en un eje
cartesiano de la relación que existe entre dos variables, reflejando con claridad los cambios producidos. En cada eje se representa cada una de las variables cuya relación se quiere observar.
Se suelen usar para presentar tendencias temporales. En el eje horizontal se ha de presentar la variable que indica las unidades de tiempo y en el vertical se introduce la escala de la variable cuya variación de tiempo queremos ver. Pueden aparecer varias variables para compararlas.
Casos particulares: si se usen los puntos medios de las bases superiores de las barras en los
gráficos de barra se obtiene el polígono de frecuencias.

Gráfico de sectores Es una representación circular de las frecuencias relativas de una variable cualitativa o
discreta que permite, de una manera sencilla y rápida, su comparación. El círculo representa la totalidad que se quiere observar y cada porción, llamadas sectores, representa la proporción de cada categoría de la variable respecto del total. Suele expresarse en porcentajes. Los ángulos de cada sector se calculan multiplicando la frecuencia relativa por 360°.
Son útiles cuando las categorías son pocas, si el gráfico tuviera
muchas variables, casi no aportaría información y sería prácticamente incomprensible.
Unidad IV y V
Tablas de frecuencias: frecuencia absoluta, relativa y acumulada
Frecuencia absoluta Es el número de veces que aparece en la muestra determinado valor o categoría de una variable.
Frecuencia relativa La frecuencia absoluta es una medida que está influida por el tamaño de la muestra, al aumentar
el tamaño de la muestra aumentará también el tamaño de la frecuencia absoluta. Esto hace que
no sea una medida útil para poder comparar. Para esto se utiliza la frecuencia relativa, que es el
cociente entre la frecuencia absoluta y el tamaño de la muestra.
Frecuencia acumulada Para poder calcular este tipo de frecuencias hay que tener en cuenta que la variable estadística ha
de ser cuantitativa o cualitativa ordenable, pues de otro modo no tiene mucho sentido el cálculo
de esta frecuencia. La frecuencia acumulada es la suma de las frecuencias absolutas de todos los
valores inferiores o iguales al valor considerado. En el ejemplo, la frecuencia acumulada hasta el
Partido Socialista (PS) es 176 (14%).
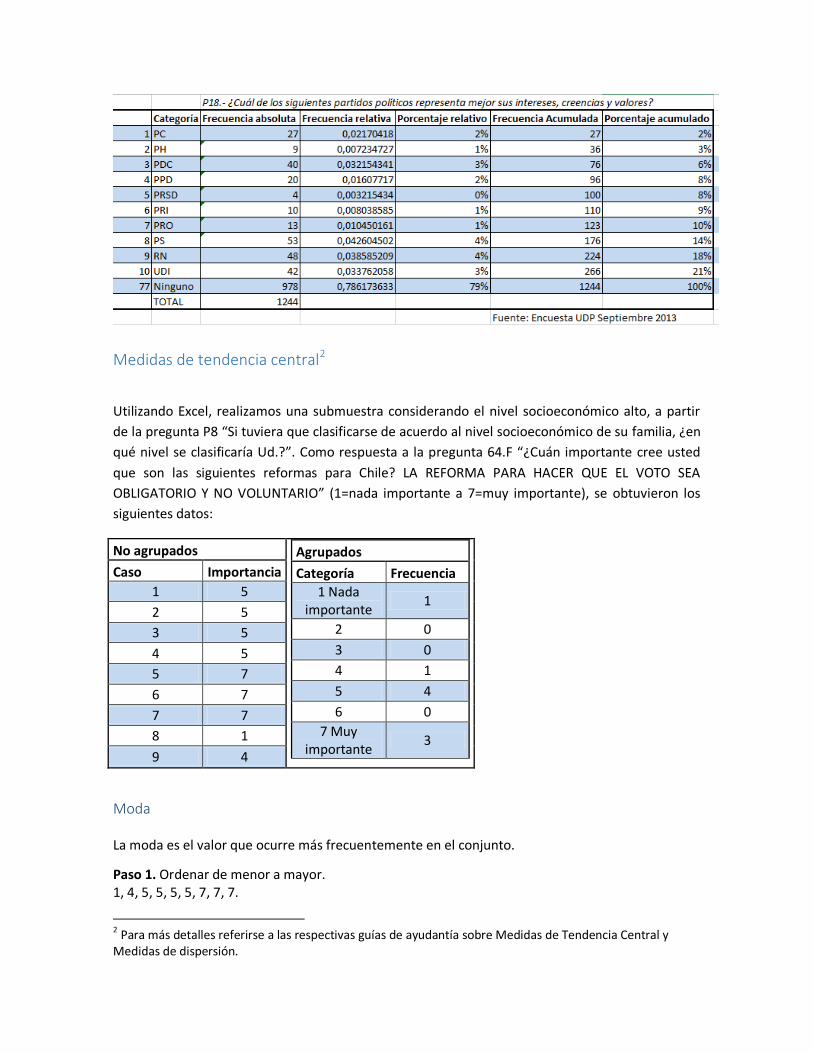
Medidas de tendencia central2
Utilizando Excel, realizamos una submuestra considerando el nivel socioeconómico alto, a partir
de la pregunta P8 “Si tuviera que clasificarse de acuerdo al nivel socioeconómico de su familia, ¿en
qué nivel se clasificaría Ud.?”. Como respuesta a la pregunta 64.F “¿Cuán importante cree usted
que son las siguientes reformas para Chile? LA REFORMA PARA HACER QUE EL VOTO SEA
OBLIGATORIO Y NO VOLUNTARIO” (1=nada importante a 7=muy importante), se obtuvieron los
siguientes datos:
No agrupados Agrupados
Categoría Frecuencia
1 Nada importante
1
2 0
3 0
4 1
5 4
6 0
7 Muy importante
3
Caso Importancia
1 5
2 5
3 5
4 5
5 7
6 7
7 7
8 1
9 4
Moda
La moda es el valor que ocurre más frecuentemente en el conjunto.
Paso 1. Ordenar de menor a mayor. 1, 4, 5, 5, 5, 5, 7, 7, 7.
2 Para más detalles referirse a las respectivas guías de ayudantía sobre Medidas de Tendencia Central y
Medidas de dispersión.

Paso 2. El elemento que más se repite es 5. Al observar los datos agrupados, inmediatamente se determina que 5 es el elemento más frecuente. Interpretar La opinión más frecuente es que la reforma del voto voluntario es importante (5).
Mediana La mediana es el valor del elemento intermedio cuando todos los elementos se ordenan de menor
a mayor.
Paso 1. Ordenar de menor a mayor. 1, 4, 5, 5, 5, 5, 7, 7, 7. Paso 2. Identificar la posición intermedia (N/2) Aproximadamente es 5. La 5° posición es la del medio, es decir, la mediana es 5. En el caso de datos agrupados, la mediana corresponde al valor cuyo porcentaje acumulado corresponde al que inmediatamente contiene al 50% de los datos. Interpretar
El 50% de los casos opina que la reforma para hacer que el voto sea voluntario es importante,
pues le otorgan un valor mayor a 5.
Media La media es la suma de los valores de los elementos dividida por la cantidad de éstos. Es conocida
también como promedio, o media aritmética.
Datos no agrupados
Datos agrupados
Interpretar
En promedio, las personas otorgan una puntuación de 5,1 a la reforma para hacer el voto
voluntario, dándole una alta importancia.
Medidas de dispersión

Rango
Siguiendo los pasos que plantea Ritchey (2008, pág. 138) para calcular el rango de una
distribución, se precisa:
1. Ordenar las puntuaciones de la variable de menor a mayor.
2. Identificar la puntuación máxima (de mayor valor) y mínima (de menor valor).
3. Calcular el rango (puntación máxima-puntuación mínima).
Puede notarse que el cálculo del rango, así como de las demás medidas de dispersión, no tiene
sentido en variables cualitativas (a pesar de que pueden hacerse salvedades con variables de nivel
de medición ordinal). Puesto que los valores asignados a las categorías de una variable cualitativa
son arbitrarios, la diferencia entre el máximo y el mínimo también constituye un valor arbitrario
que no entrega información sobre la dispersión de la muestra.
Caso Importancia Paso 1. Ordenar de menor a mayor. 1, 4, 5, 5, 5, 5, 7, 7, 7. Paso 2 Máximo = 7 Mínimo = 1 Paso 3 Interpretar El rango corresponde a 6, y es la máxima diferencia posible. Por lo
tanto, en el NSE alto existen posiciones en ambos extremos con
respecto a la reforma del voto voluntario.
1 5
2 5
3 5
4 5
5 7
6 7
7 7
8 1
9 4
Como puede verse, el rango es una medida de dispersión que caracterice los datos en
profundidad, puesto que si bien podemos decir que hay personas situadas en los extremos de los
valores posibles, el detalle de los datos muestra que hay una tendencia a considerar la reforma
como algo importante.
Desviación media
“La desviación media o promedio de desviación es otra medida de dispersión que viene dada por
la media aritmética de los valores absolutos de las desviaciones observadas a un determinado
valor medio.” (García Ferrando, 1999, pág. 101)
Utilizando el mismo ejemplo, el cálculo es:
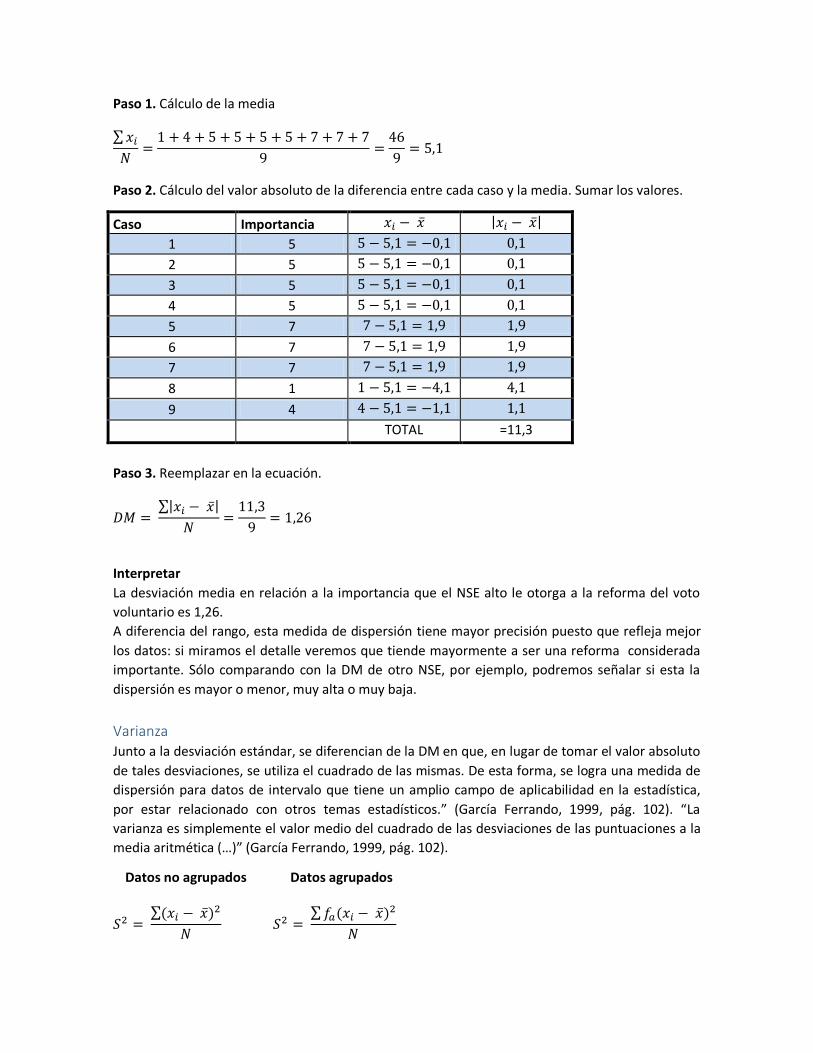
Paso 1. Cálculo de la media
Paso 2. Cálculo del valor absoluto de la diferencia entre cada caso y la media. Sumar los valores.
Caso Importancia
1 5
2 5
3 5
4 5
5 7
6 7
7 7
8 1
9 4
TOTAL =11,3
Paso 3. Reemplazar en la ecuación.
Interpretar
La desviación media en relación a la importancia que el NSE alto le otorga a la reforma del voto
voluntario es 1,26.
A diferencia del rango, esta medida de dispersión tiene mayor precisión puesto que refleja mejor
los datos: si miramos el detalle veremos que tiende mayormente a ser una reforma considerada
importante. Sólo comparando con la DM de otro NSE, por ejemplo, podremos señalar si esta la
dispersión es mayor o menor, muy alta o muy baja.
Varianza Junto a la desviación estándar, se diferencian de la DM en que, en lugar de tomar el valor absoluto
de tales desviaciones, se utiliza el cuadrado de las mismas. De esta forma, se logra una medida de
dispersión para datos de intervalo que tiene un amplio campo de aplicabilidad en la estadística,
por estar relacionado con otros temas estadísticos.” (García Ferrando, 1999, pág. 102). “La
varianza es simplemente el valor medio del cuadrado de las desviaciones de las puntuaciones a la
media aritmética (…)” (García Ferrando, 1999, pág. 102).
Datos no agrupados
Datos agrupados
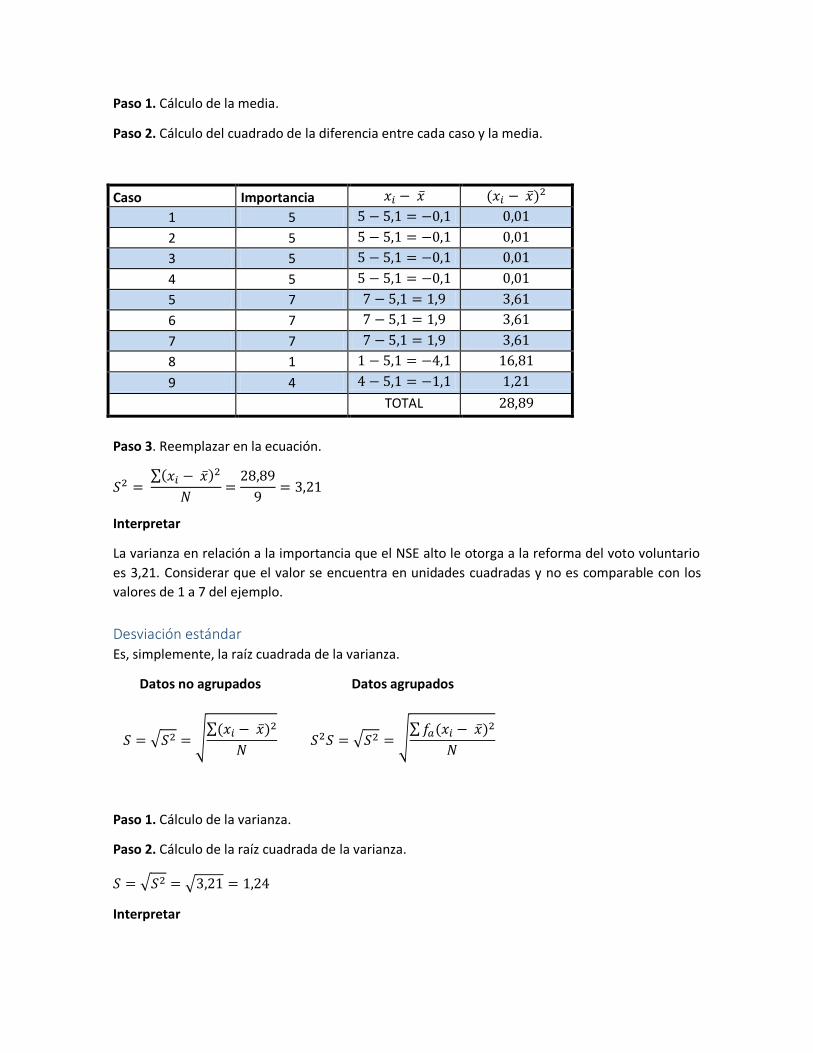
Paso 1. Cálculo de la media.
Paso 2. Cálculo del cuadrado de la diferencia entre cada caso y la media.
Caso Importancia
1 5
2 5
3 5
4 5
5 7
6 7
7 7
8 1
9 4
TOTAL
Paso 3. Reemplazar en la ecuación.
Interpretar
La varianza en relación a la importancia que el NSE alto le otorga a la reforma del voto voluntario
es 3,21. Considerar que el valor se encuentra en unidades cuadradas y no es comparable con los
valores de 1 a 7 del ejemplo.
Desviación estándar Es, simplemente, la raíz cuadrada de la varianza.
Datos no agrupados
Datos agrupados
Paso 1. Cálculo de la varianza.
Paso 2. Cálculo de la raíz cuadrada de la varianza.
Interpretar

La desviación estándar en relación a la importancia que el NSE alto le otorga a la reforma del voto
voluntario es 1,24.
Coeficiente de variación Esta medida sirve para comparar las dispersiones de dos o más distribuciones, con igual o distinta
unidad de medida. Establece la relación entre la desviación estándar y la media. Se expresa
generalmente en porcentaje.
Es el cociente entre desviación estándar (S) y la media aritmética (representada aquí por )
expresado en porcentaje.
Utilizando la misma variable: recordemos que el promedio ( ) es de 5,1, mientras que la
desviación estándar (S) es 1,24:
Interpretar
La variación de la puntuación de la importancia otorgada a la reforma del voto voluntario con
respecto a la media es de un 24,3%.
Como con las demás medidas de dispersión, este valor no dice mucho si no es comparado con el
coeficiente de variación de otra variable.


















