
ALGORITMO CROMÁTICO APLICADO A UN MODELO DE …
120
ALGORITMO CROMÁTICO APLICADO A UN MODELO DE REGRESIÓN NO LINEAL EN PRONÓSTICOS DE SERIES DE TIEMPO JOSÉ ANTONIO AVILEZ PACHECO RAFAEL EMIRO SABIE LOBO. UNIVERSIDAD DE CÓRDOBA FACULTAD DE INGENIERÍA PROGRAMA DE INGENIERÍA SISTEMAS MONTERÍA - CÓRDOBA 2020
Transcript of ALGORITMO CROMÁTICO APLICADO A UN MODELO DE …

ALGORITMO CROMÁTICO APLICADO A UN MODELO DE REGRESIÓN NO
LINEAL EN PRONÓSTICOS DE SERIES DE TIEMPO
JOSÉ ANTONIO AVILEZ PACHECO
RAFAEL EMIRO SABIE LOBO.
UNIVERSIDAD DE CÓRDOBA
FACULTAD DE INGENIERÍA
PROGRAMA DE INGENIERÍA SISTEMAS
MONTERÍA - CÓRDOBA
2020

ALGORITMO CROMÁTICO APLICADO A UN MODELO DE REGRESIÓN NO
LINEAL EN PRONÓSTICOS DE SERIES DE TIEMPO
JOSÉ ANTONIO AVILEZ PACHECO
RAFAEL EMIRO SABIE LOBO.
Trabajo de grado presentado, en la modalidad de Trabajo de Investigación, como parte de
los requisitos para optar al Título de Ingeniero de Sistemas.
Director (s):
JORGE GÓMEZ, PDH.
UNIVERSIDAD DE CÓRDOBA
FACULTAD DE INGENIERÍA
PROGRAMA DE INGENIERÍA SISTEMAS
MONTERÍA - CÓRDOBA
2020

La responsabilidad ética, legal y científica de las ideas, conceptos y resultados del proyecto,
serán responsabilidad de los autores.
Artículo 61, acuerdo N° 093 del 26 de noviembre de 2002 del consejo superior.

Nota de aceptación
_______________________________
_______________________________
_______________________________
_______________________________
________________________________
Firma del jurado
________________________________
Firma del jurado

En honor al todo poderoso que brinda la sabiduría y
voluntad. A mi madre que ha sido motivo para este gran
logro. A mi compañera de vida Adriana y a mis hijos
Hannah y Maximiliano por ser mi apoyo y sustento
incondicional.
Rafael Emiro Sabie Lobo
Quiero dedicar esta tesis en primer lugar a Dios, sin
duda alguna hizo parte de mi proceso desde un inicio,
A mis padres William Aviles Montes e Iris Pacheco
Noble por ser el motor de mi vida.
A mis hermanos que siempre me dieron una
oportunidad de seguir creciendo.
A mis colegas y compañeros que conocieron mi pasión
por seguir construyendo mis sueños.
Jose Antonio Aviles Pacheco

Agradecimientos especial a:
Profesor Jorge Gómez por su acompañamiento en cada proceso del proyecto
Profesor Mario Macea por su acompañamiento y atención en los escaños del programa.

TABLA DE CONTENIDO
RESUMEN................................................................................................................................... 12
ABSTRACT ................................................................................................................................. 14
1. INTRODUCCIÓN ............................................................................................................. 16
1.1. PLANTEAMIENTO DEL PROBLEMA .......................................................................... 16
2. OBJETIVOS ...................................................................................................................... 20
2.1. Objetivo general ................................................................................................................. 20
2.2. Objetivos específicos ......................................................................................................... 20
3. JUSTIFICACIÓN .............................................................................................................. 21
4. ALCANCE Y LIMITACIONES ....................................................................................... 23
5. MARCO CONCEPTUAL ................................................................................................. 25
5.1. Algoritmia y Optimización de Metaheurísticas. ................................................................ 25
5.2. Pronósticos y Series de Tiempo. ........................................................................................ 33
6. ESTADO DEL ARTE........................................................................................................ 45
7. MATERIALES Y MÉTODOS. ......................................................................................... 56
8. OPTIMIZACIÓN DE PRONÓSTICOS ............................................................................ 59

8.3. Modelo de Regresión ..................................................................................................... 61
8.3.1. Optimización del Modelo ........................................................................................... 63
8.3.2. Función objetivo ......................................................................................................... 64
8.4. Codificación de Parámetros ........................................................................................... 65
8.5. Algoritmo Cromático ......................................................................................................... 66
8.5.1. Vecinos de escala cromática ....................................................................................... 67
8.5.2. Vecinos de Inspiración y de Rotación ........................................................................ 70
8.6. Parámetros y Pseudocódigo del Algoritmo Cromático .................................................. 74
9. RESULTADOS Y DISCUSIONES ................................................................................... 75
9.1.1. Problema de evaluación N°1 (Clase polinomial) ....................................................... 75
9.1.2. Problema de evaluación N°2 Clase (polinomial) ....................................................... 76
9.1.3. Problema de evaluación N°3 (Clase racional) ............................................................ 76
9.1.4. Problema de evaluación N°4 (Clase diversa) .................................................................... 77
10. CONCLUSIONES ............................................................................................................. 99
11. RECOMENDACIONES .................................................................................................. 101
12. BIBLIOGRAFÍA ............................................................................................................. 103
ANEXOS Y DIAGRAMAS APLICATIVO .......................................................................... 106
Pseudocódigo del algoritmo. ............................................................................................... 106

LISTADO DE ILUSTRACIONES
Ilustración 1 Clasificación de los modelos de pronóstico de series temporales. ......................... 34
Ilustración 2 Representación de una solución en el algoritmo Cromático. ................................. 65
Ilustración 3 Vecinos de Rotación descendentes ........................................................................ 72
Ilustración 4 Vecinos de Rotación ascendentes. ......................................................................... 73

LISTADO DE TABLAS
Tabla 1 Comparación de resultados problema N°1. ...................................................................... 1
Tabla 2 Comparación de resultados problema N°2. ...................................................................... 2
Tabla 3 Comparación de resultados problema N°3. ...................................................................... 3
Tabla 4 Comparación de resultados problema N°4. ...................................................................... 4
Tabla 5 Datos y resultados ganado tipo HV. ................................................................................. 1
Tabla 6 Comparación de resultados ganado tipo HV. ................................................................... 5
Tabla 7 Datos y resultados ganado tipo VE ................................................................................... 6
Tabla 8 Comparación de resultados ganado tipo VE. .................................................................. 10
Tabla 9 Datos y resultados ganado tipo TO. ................................................................................ 11
Tabla 10 Comparación de resultados ganado tipo TO. ................................................................ 15

LISTADO DE GRÁFICOS
Gráfico 1 Ajuste para el problema N°1 .......................................................................................... 1
Gráfico 2 Ajuste para el problema N°2. ......................................................................................... 2
Gráfico 3 Ajuste para el problema N°3. ......................................................................................... 3
Gráfico 4 Ajuste para el problema N°4. ......................................................................................... 4
Gráfico 5 Ajuste para el caso tipo HV ........................................................................................... 5
Gráfico 6 Ajuste para el caso tipo VE.......................................................................................... 10
Gráfico 7 Ajuste para el caso tipo TO.......................................................................................... 15

RESUMEN
El presente trabajo utiliza la nueva metaheurística, algoritmo cromático para la optimización de
pronósticos de series de tiempo a través de un modelo de regresión no lineal. En esta nueva
propuesta se maneja el algoritmo cromático debido a sus características de codificación real y a su
memoria de arranque múltiple, que le permiten ser más eficiente a la hora minimizar el error en
los pronósticos del modelo, para lograr esto se utilizan indicadores estadísticos del error que
contribuyen a mejorar las predicciones a cada problema específico.
Además, se idean unas mejoras al modelo de regresión y al algoritmo utilizado de tal manera que
se logra predecir el comportamiento de los problemas, no solo de una variable sino también de
múltiples variables. Hay que resaltar que el algoritmo es capaz de hacer que sus soluciones
cumplan con los supuestos o restricciones que son necesarias para poder hacer uso del modelo
estudiado. El algoritmo junto con el modelo es probado en distintos problemas de una y múltiples
variables proporcionando muy buenas predicciones. Además, se ejecuta en caso de estudio
practico relacionado con la estimación de los precios de ganado según su tipo en la región
estudiada. El desarrollo de este nuevo método genera más posibilidades para alcanzar que los
pronósticos se ajusten y para mejorar cualquier tipo predicción. Esta investigación proporciona

una nueva manera para minimizar los errores en los pronósticos y generar resultados de gran
calidad.
También demuestra que se permite establecer pronósticos tanto en problemas de una variable como
en los de múltiples variables, con tiempos computacionales razonables. Esta sería una excelente
estrategia para las innumerables empresas, entidades u organizaciones que requieren métodos
verdaderamente eficientes que les permitan tomar las mejores decisiones.
Palabras clave: Pronósticos, metaheurísticas, series de tiempo.

ABSTRACT
The present work uses the new metaheuristic, a chromatic algorithm for the optimization of time
series forecasts through a non-linear regression model. In this new proposal, the chromatic
algorithm is handled due to its real coding characteristics and its multiple boot memory, which
allow it to be more efficient when it comes to minimizing the error in the model's forecasts. To
achieve this, statistical error indicators are used. that help improve predictions for each specific
problem.
In addition, improvements are devised to the regression model and the algorithm used in such a
way that it is possible to predict the behavior of the problems, not only of one variable but also of
multiple variables. It should be noted that the algorithm is capable of making its solutions comply
with the assumptions or restrictions that are necessary to be able to make use of the studied model.
The algorithm together with the model is tested in different problems with one and multiple
variables, providing very good predictions. In addition, it is executed in a practical case study
related to the estimation of livestock prices according to their type in the studied region. The

development of this new method generates more possibilities to achieve that the forecasts are
adjusted and to improve any type of prediction. This research provides a new way to minimize
forecast errors and generate high-quality results.
It also shows that it is possible to establish forecasts in both single and multi-variable problems,
with reasonable computational times. This would be an excellent strategy for the countless
companies, entities or organizations that require truly efficient methods that allow them to make
the best decisions.
Key words: Forecasts, metaheuristics, time series.

1. INTRODUCCIÓN
1.1. PLANTEAMIENTO DEL PROBLEMA
• Descripción del problema
En la actualidad es crucial y de gran relevancia el desarrollo de nuevos algoritmos encaminados a
la optimización , todo esto con el objetivo de que se construyan ayuden a solucionar y resolver
problemas que se han considerados de gran complejidad o magnitud, ya sea debido a que estos
problemas posean gran cantidad de variables o por las innumerables restricciones que se
encuentren en los mismos ,de una u otra forma la necesidad de estas herramientas es inminente
para encontrar soluciones optimas en diferentes casos de optimización y a los distintos problemas
que en la actualidad lo requieran .
En el contexto que nos atañe, este tipo de algoritmos llamados metaheurísticas, son
verdaderamente necesarios para la realidad actual, ya que gracias a ellos se pueden encontrar
soluciones a muchos problemas que presentan diariamente y que son considerados imposibles de
resolver en cortos periodos de tiempo. Sin embargo, se están encontrando muchos inconvenientes,
limitaciones o restricciones al momento de hacer uso de estos, ya que sus aplicaciones en casos
reales están siendo muy afectadas debido a que estos algoritmos todavía requieren de un mayor
rendimiento y eficiencia en la búsqueda de sus resultados.

Así mismo, es oportuno indicar que las metaheurísticas existentes han sido de gran importancia
para resolver innumerables problemas de optimización, pero no obstante estás suelen ser muy
complicadas en su programación y manejo, algunas requieren un gran número de parámetros y de
un alto costo de tiempo computacional para alcanzar sus objetivos o para obtener una solución
factible en un modelo de programación. Así que se requiere de mucho conocimiento y estudio para
comprender claramente sus comportamientos, ventajas y desventajas, que implica lo uno o lo otro
o cuál es la mejor manera de elegir los parámetros que se van a utilizar en desarrollo de un
problema de optimización.
Es de aclarar que todos estos aspectos ocasionan gran inconformidad e inconvenientes al momento
de hacer uso de estos algoritmos y son algunos motivos por los cuales estos métodos de búsqueda
se les atribuye comúnmente cierto grado de complejidad y lo que origina que en la actualidad se
restrinja en cierta forma la aplicación de los mismos a muchos problemas actuales de optimización
que lo requieren.
Para el caso en concreto que nos interesa se debe decir que Las diferentes técnicas de modelación
y sus aplicaciones han logrado que se obtengan resultados muy importantes en los pronósticos de
series de tiempo. La determinación de un adecuado modelo y de los parámetros que proporcionen
el mejor ajuste en análisis de series de tiempo se ha convertido en un aspecto muy importante para
la ingeniería y las empresas. Los pronósticos han sido siempre un desafío crucial para las
organizaciones, estos son vitales en la toma de decisiones críticas, lo que ha originado que en las
últimas décadas los especialistas en el tema se hayan dedicado a desarrollar y mejorar los modelos

de pronósticos de series de tiempo. En estos modelos, la mayoría de los investigadores suponen
una relación lineal entre coeficientes de las variables explicativas del pronóstico.
Aunque la hipótesis lineal hace que sea más fácil manipular los modelos matemáticos, esto puede
conducir a la representación inadecuada de patrones que existen en el mundo real, en donde las
relaciones no lineales son más frecuentes. Debido a lo anterior es fundamental la determinación
del modelo que mejor se ajusta al proceso o a la situación, dado que esto permite realizar una mejor
planeación y control. El análisis de series de tiempo es entonces una herramienta muy importante
para el pronóstico del futuro a partir de datos históricos. Estos métodos se utilizan generalmente
cuando no hay mucha información sobre el proceso de generación de la variable subyacente y
cuando otras variables no proporcionan una explicación clara de la variable estudiada (Zhang G. ,
2003). Así que de esta manera y mediante el estudio de muchas variables relacionadas en conjunto,
a menudo se obtiene una mejor comprensión y un pronóstico más sólido y confiable.
Dado que han sido desarrolladas muchas técnicas para el análisis de series de tiempo (De Gooijer
& Hyndman, 2006) publicaron en una revista los métodos más utilizados en series de tiempos
durante los últimos 25 años, y en donde exponen que los métodos más populares son el promedio
móvil, la suavización exponencial y los métodos ARIMA. Todos estos métodos asumen relaciones
lineales entre coeficientes de las variables explicativas del pronóstico, lo que ocasiona que se
obtengan resultados de muy baja calidad, y en muchos casos esto puede conducir a imprecisiones
que causan problemas mayores. Un ejemplo típico es la tendencia de los indicadores económicos
los cuales, si se manejan con este tipo de relación, deben tratarse con mucho cuidado para no caer

en resultados imprecisos. (Tong, 1990) describe algunas de las principales desventajas de la
modelación lineal en el análisis de series de tiempo y la inhabilidad que tienen estos métodos para
explicar cambios repentinos en amplitudes largas o en intervalos de tiempos irregulares.
Todo lo anterior hace necesario que los modelos no lineales se han usados para el análisis datos
en aplicaciones del mundo real, sin embargo, la utilización de métodos alternativos para solucionar
distintos problemas con gran aproximación a tendencias naturales y con pocas restricciones han
sido muchos, pero por lo general los modelos no lineales se han notado en varios autores. Algunos
de estos métodos son por ejemplo la combinación de la estructura ARIMA con redes neuronales
por (Zhang G. , 2003), el uso de redes neuronales para pronósticos de series de tiempo trimestrales
por (Zhang & M., 2007) y seguidamente (Behnamian & Ghomi, 2009) realizaron un nuevo
modelo no lineal para pronósticos de series de tiempo a través de la metaheurística hibrida PSO-
SA. Este trabajo busca implementar la nueva metaheurístico algoritmo cromático en los
pronósticos de series de tiempo, se desarrollan distintos problemas de una variable a través de la
optimización de parámetros en el modelo de regresión no lineal propuesto por (Behnamian &
Ghomi, 2009).
• Pregunta de investigación
Dados cada uno de los anteriores planteamientos, se permite formular el siguiente interrogante:
¿una metaheurística basada en la escala cromática de las notas musicales aplicada a un modelo
regresión no lineal genera resultados con calidad en pronósticos de series de tiempo?

2. OBJETIVOS
2.1. Objetivo general
• Implementar el algoritmo cromático aplicado a un modelo regresión no lineal en pronósticos
de series de tiempo, alcanzando calidad en cada una de sus repuestas y que de igual forma
este no requiera de un alto costo de tiempo computacional.
2.2. Objetivos específicos
• Identificar y reconocer el modelo de regresión no lineal y los parámetros más importantes
del algoritmo de búsqueda, así como los valores o rangos que generan generen mejores
resultados en los problemas solucionados por este método estructural.
• Diseñar la codificación del algoritmo de búsqueda aplicado al modelo regresión no lineal
en pronósticos de series de tiempo para establecer el rendimiento y eficiencia del mismo.
• Aplicar el algoritmo y el modelo de regresión no lineal en ejercicios de alto rendimiento y
caso práctico de estudio de la región.
• Analizar las soluciones del modelo regresión no lineal en pronósticos de series de tiempo
a través del algoritmo de búsqueda y realizar una comparación de resultados.

3. JUSTIFICACIÓN
En contexto con el desarrollo de este trabajo cabe destacar que en la época en la que nos inmiscuye
existe un rápido crecimiento y desarrollo de nuevos algoritmos de búsqueda y de optimización en
todo el mundo, más que todo durante las últimas décadas. No obstante, estos siguen aún rezagados
con respecto a ciertos factores como la calidad de sus respuestas, costo de tiempo computacional,
rendimiento y eficiencia. Debido a esto y al constante afán que existe en la actualidad de solucionar
distintos problemas de optimización, se originan ciertas desventajas a la hora de aplicar estos
algoritmos en la realidad. Todo Esto dificulta aprovechar las posibilidades de mejora que generan
estos métodos de búsqueda.
Sin embargo, cabe resaltar que también existen ciertos algoritmos que se basan por lo general en
búsquedas evolutivas o en búsquedas de vecindad que brindan buenos resultados en sus soluciones.
Pero aun así está latente la necesidad de conseguir nuevos métodos de optimización que mejoren
aún más las soluciones y los resultados de estas metaheurísticas.
Es pertinente indicar que este proyecto de investigación busca a través de una nueva metaheurística
que se basa en la escala cromática de las notas musicales disminuir el efecto negativo de los
distintos factores que están limitando la efectividad y aplicabilidad de los distintos métodos de
búsqueda en los problemas de optimización, específicamente en pronósticos de series de tiempo,
tratando de alcanzar mejores respuestas y resultados con menor tiempo empleado.

Además, se pretende lograr implementar un modelo de regresión no lineal de manera innovadora,
que permita alcanzar óptimos resultados en cada una de sus soluciones, que contenga parámetros
claros y precisos que no dificulten su utilización. De lo que se colige que este estudio se
fundamenta entonces en la aplicabilidad de conceptos primordiales de programación y algoritmia
con el objetivo de hacer un uso eficiente de modelos de regresión no lineales en pronósticos de
series de tiempo.

4. ALCANCE Y LIMITACIONES
• Alcance
Esta investigación se centra en la implementación de un nuevo algoritmo de búsqueda, adoptando
un modelo de regresión no lineal y en la comparación de resultados con métodos convencionales
y/o diversos algoritmos. Además de un análisis de su rendimiento y eficiencia al ser evaluado en
los problemas de serias de tiempo.
• Problemas de Evaluación de Alta Complejidad
− Problema de evaluación N° 1 (Clase polinomial)
Este problema de evaluación tiene 82 datos y es conocido como ‘‘Fillip” y consta de 11
parámetros, el modelo es expuesto en la expresión (1).
𝑦 = 𝛽0 + 𝛽1𝑥 + 𝛽2𝑥2 + … + 𝛽9𝑥9 +𝛽10𝑥10 + 𝐸 (1).
− Problema de evaluación N° 2 Clase (polinomial)
Este problema de evaluación tiene 21 datos, es conocido como ‘‘Wampler4” y consta de 6
parámetros, el modelo es expuesto en la expresión (2).
𝑦 = 𝛽0 + 𝛽1𝑥 + 𝛽2 𝑥2 + 𝛽3 𝑥
3 + 𝛽4 𝑥4 + 𝛽5 𝑥
5 + 𝐸 (2).
− Problema de evaluación N° 3 (Clase racional)

Este problema de evaluación tiene 11 datos, es conocido como ‘‘MGH09”, y consta de 4
parámetros, el modelo es expuesto en la expresión (3).
𝑦 =𝛽1 (𝑥2+ 𝑥𝛽2)
𝑥2+𝑥𝛽3 + 𝛽4 (3).
− Problema de evaluación N° 4 (Clase diversa)
Este problema de evaluación tiene 154 datos, es conocido como ‘‘Bennett5”, y consta de 4
parámetros, el modelo es expuesto en la expresión (4).
𝑦 = 𝛽1 (𝑥 + 𝛽2)−1
𝛽3 + 𝐸 (4).
• Caso de Estudio Practico (Precios del Ganado tipos de Córdoba)
Se efectúa la estimación de precios para tipos de ganado seleccionados según datos históricos que
se asocian con variables de tipo ganado referenciado como lo son; peso, semana-mes y precios de
venta. En esta oportunidad se conviene sobre hechos de venta obtenidos a través de información
recolectada a partir de subasta ganadera Subastar S.A. de la ciudad de Montería- Córdoba.
El objeto aquí es implantar el algoritmo de búsqueda y el modelo no lineal de series de tiempo
para realizar ejercicio de pronóstico en tipos específicos de ganado, conforme a los datos
escogidos.

• Limitaciones
Se analizarán y compararán los resultados con información de literatura y métodos convencionales
en concordancia con los recursos tecnológicos, Lo referente, debido a las diferentes limitaciones
financieras y de tiempo en las que se incurren al revisar y estudiar artículos bibliográficos que
hagan referencia a diferentes algoritmos de búsqueda aplicados en la optimización.
5. MARCO CONCEPTUAL
5.1. Algoritmia y Optimización de Metaheurísticas.
• Algoritmia
Para entender el concepto de este término partimos desde el origen del mismo el cual lo aclara
Valenzuela, (Ruiz, 2003) El origen del término algoritmo se remonta al siglo IX y se le atribuye
su invención al matemático árabe Abu Ja’far Muhammad ibn Musa al-Khwarizmi. El trabajo de
Al- Khwarizmi permitió preservar y difundir el conocimiento de los griegos e indios. De los
primeros, rescató la rigurosidad, mientras que de los últimos rescató la simplicidad. Una de las
principales contribuciones del Al-Khwarizmi fue la de hacer de las matemáticas una ciencia
práctica, capaz de ser entendidas por cualquier persona no experta en la materia.

Por lo general, el concepto de algoritmia es asociado generalmente a problema computacionales o
lenguajes de programación, sin embargo, éste es un concepto que tiene aplicabilidad en las
actividades más simples de la vida cotidiana. (Ruiz, 2003)
De la manera más simple, un algoritmo es una serie finita de pasos para resolver un problema, el
cual incluye sin excepción una secuencia finita de pasos y debe ser capaz de encontrar la solución
del problema o en su defecto avisar explícitamente que dicho problema no tiene solución.
(INACAP, 2003).
Los algoritmos deben tener las siguientes características:
− Entrada: Definir lo que necesita el algoritmo, es decir, los elementos útiles para la ejecución
del algoritmo, como datos, relaciones, instrucciones.
− Salida: Definir lo que produce el algoritmo, expresando claramente que resultados se
obtendrán al final de la ejecución de los pasos.
− No ambiguo: explícito, siempre sabe qué comando ejecutar, en un algoritmo no puede
haber confusión, no pueden llamarse dos cosas diferentes con el mismo nombre.
− Finito: El algoritmo termina en un número finito de pasos.
− Correcto: Hace lo que se supone que debe hacer. La solución es correcta
− Efectividad: Cada instrucción se completa en tiempo finito. Cada instrucción debe ser lo
suficientemente básica como para que en principio pueda ser ejecutada por cualquier
persona usando papel y lápiz.

− General: Debe ser lo suficientemente general como para contemplar todos los casos de
entrada.
Usualmente para resolver los problemas cotidianos no se necesita especificar el algoritmo de
solución, puesto que este se utiliza casi mecánicamente, como, por ejemplo; encender el
computador, realizar una multiplicación, entre otros. Sin embargo, para problemas más amplios y
complicados, como puede ser el hallar la solución a un sistema de variables, se necesita especificar
el algoritmo para asegurar mejores resultados.
Cabe resaltar que un problema puede tener muchos algoritmos a través de los cuales se puede
resolver, y en esta medida, a fin de determinar cuál es mejor, se deben tener en cuenta la cantidad
de recursos como tiempo y espacio que requieran para resolver el problema.
De esta forma, el mejor algoritmo será aquel capaz de manejar conjuntamente la eficacia y la
eficiencia; Donde la Eficiencia es el logro de los objetivos planteados utilizando la menor cantidad
de recursos posibles, es decir, minimizando el uso de memoria, de pasos y de esfuerzo humano.
Por su parte la Eficacia es alcanzar el objetivo primordial, es decir, obtener la solución buscada
por medio del análisis del mismo”. (Silver, 2004)
• Aspectos Generales Sobre Heurísticas y Metaheurísticas
La idea más genérica del terminó heurístico está relacionada con la tarea de resolver
Inteligentemente problemas reales usando el conocimiento disponible. El termino heurística

proviene de una palabra griega con un significa- do relacionado con el concepto de encontrar y se
vincula a la supuesta exclamación eureka de Arquímedes al descubrir su famoso principio.
En Inteligencia Artificial (IA) se emplea el calificativo heurístico, en un sentido muy genérico,
para aplicarlo a todos aquellos aspectos que tienen que ver con el empleo de conocimiento en la
realización dinámica de tareas. Se habla de heurística para referirse a una técnica, método o
procedimiento inteligente de realizar una tarea que no es producto de un riguroso análisis formal,
sino de conocimiento y experto sobre la tarea. En especial, se usa el terminó heurístico para
referirse a un procedimiento que trata de aportar soluciones a un problema con un buen
rendimiento, en lo referente a la calidad de las soluciones y a los recursos empleados. (Melian,
J.A.Moreno, & Moreno, 2003)
En la resolución de problemas específicos han surgido procedimientos heurísticos exitosos, de los
que se ha tratado de extraer lo que es esencial en su éxito para aplicarlo a otros problemas o en
contextos más extensos. Como ha ocurrido claramente en diversos campos de la IA, en especial
con los sistemas expertos, esta línea de investigación ha contribuido al desarrollo científico del
campo de las heurísticas y a extender la aplicación de sus resultados. De esta forma se han
obtenido, tanto técnicas y recursos computacionales específicos, como estrategias de diseño
generales para procedimientos heurísticos de resolución de problemas.

Estas estrategias generales para construir algoritmos, que quedan por encima de las heurísticas, y
van algo más allá, se denominan Metaheurísticas. Las metaheurísticas pueden integrarse como un
sistema experto para facilitar su uso genérico a la vez que mejorar su rendimiento.
El término metaheurística apareció por primera vez en el artículo seminal de Fred Glover acerca
Búsqueda Tabú en 1986. A partir de entonces, se han publicado gran cantidad de artículos e
investigaciones sobre procedimientos que intentan resolver ciertos problemas, que luego son
generalizados, convirtiéndose así en metaheurísticas. La relevancia de las metaheurísticas se
refleja en la publicación de libros sobre este campo en los últimos años, Diversos artículos de
revisión, monográficas y volúmenes especiales sobre metaheurísticas han venido apareciendo en
diversas colecciones editoriales o revistas periódicas de los campos de Investigación Operativa,
Inteligencia Artificial, Ingeniera y Ciencias de la Computación.
Además, en estas publicaciones se observa un incremento considerable del número de trabajos
que incluyen procedimientos heurísticos en los que se realizan planteamientos estándares de las
metaheurısticas. Desde 1985 se viene publican- do la revista Journal of Heuristics que concentra
una parte importante de las publicaciones en este campo. (Melian, J.A.Moreno, & Moreno,
2003)
• Heurísticas
Un concepto de muy claro sobre heurística es el citado por E.A Silver (Silver, 2004) quien dice
que heurística es un método el cual, sobre la base de la experiencia o el juicio, parece probable

obtener una solución razonable a un problema, pero la cual no puede garantizar obtener o alcanzar
la solución matemáticamente óptima. Ello implica, que las heurísticas son mecanismos por medio
de los cuales se da solución a un problema puntual, pero cuyos resultados no pueden llamarse
óptimos, dado que la heurística en sí misma no lo garantiza.
Mientras que, Melián, Moreno y Moreno dicen (Melian, J.A.Moreno, & Moreno, 2003) heurístico
es el calificativo apropiado para los procedimientos que, empleando conocimiento acerca de un
problema y de las técnicas aplicables, tratan de aportar soluciones (o acercarse a ellas) usando una
cantidad de recursos (generalmente tiempo) razonable. En un problema de optimización, aparte
de las condiciones que deben cumplir las soluciones factibles del problema, se busca la que es
óptima según algún criterio de comparación entre ellas.
• Metaheurísticas
El termino Metaheurísticas, se obtiene de anteponer a heurística el sufijo meta que significa “más
allá” o “a un nivel superior” (Melian, J.A.Moreno, & Moreno, 2003). Los conceptos actuales de
lo que es una metaheurística están basados en las diferentes interpretaciones de lo que es una forma
inteligente de resolver un problema. Las metaheurısticas son estrategias inteligentes para diseñar
o mejorar procedimientos heurísticos muy generales con un alto rendimiento.
Otro concepto muy importante es la de, Osman (1995), define: “Dentro de la clase denominada
metaheurística se incluyen todos aquellos procedimientos que, en un proceso iterativo, guían a
una heurística subordinada combinando inteligentemente diferentes conceptos tomados de la

analogía de la naturaleza, y exploran el espacio de soluciones utilizando estrategias de
aprendizaje para estructurar la información, con el objeto de encontrar eficientemente soluciones
cercanas al óptimo”.
También podemos complementar un poco más la definición en lo afirmado a continuación, las
metaheurísticas son estrategias inteligentes para diseñar o mejorar procedimientos heurísticos muy
generales con alto rendimiento (Melian, J.A.Moreno, & Moreno, 2003), de otra forma, se puede
decir que las metaheurísticas son procedimientos generales que exploran el espacio de solución
para problemas de optimización y búsqueda, éstos procedimientos, tienen la virtud de ser
adaptables a cualquier tipo de problemas y a contextos específicos a fin de proporcionar nuevos
algoritmos de solución. (Melian, J.A.Moreno, & Moreno, 2003).
• Tipos De Metaheurísticas
Los tipos de Metaheurísticas se establecen, en función al tipo de procedimientos a los que se
refiere. Así, algunos de los tipos fundamentales de metaheurísticas son: metaheurísticas para
métodos de relajación, procesos constructivos, procesos de búsqueda por entornos y
procedimientos evolutivos. (Melian, J.A.Moreno, & Moreno, 2003)
− Metaheurísticas de relajación: Se refieren a procedimientos de resolución de problemas que
utilizan relajaciones del modelo original, es decir, modificaciones del modelo que hacen al
problema más fácil de resolver, cuya solución facilita la solución del problema original.

− Metaheurísticas Constructivas: Se orientan a los procedimientos que tratan de la obtención
de una solución a partir del análisis y selección paulatina de las componentes que la forman.
− Metaheurísticas de Búsqueda: Guían los procedimientos que utilizan transformaciones o
movimientos para recorrer el espacio de soluciones alternativas y explotar las estructuras de
entornos asociadas.
− Metaheurísticas Evolutivas: Están enfocadas a los procedimientos basados en conjunto de
soluciones que evolucionan sobre el espacio de soluciones.
Cabe anotar, que algunas metaheurísticas han surgido de la combinación de varias metaheurísticas
de diversos tipos, así como hay otras, que no se incluyen claramente en ninguno de los tipos antes
mencionados. (Melian, J.A.Moreno, & Moreno, 2003)
E.A Silver (1980) y Zanakis (1989), proponen otros tipos de metaheurísticas, que no son más que
tipos intermedios entre las antes nombradas (Melian, J.A.Moreno, & Moreno, 2003). Las más
destacadas son:
− Metaheurísticas de descomposición: Establecen pautas para resolver un problema
determinando subproblemas a partir de los que se construye una solución del problema
original. Se trata de metaheurísticas intermedias entre las de relajación y construcción, ya que
se refieren básicamente a las características que se pretenden obtener en los subproblemas y a

cómo integrar las soluciones de éstos en una solución del problema original. El objetivo
fundamental es obtener subproblemas significativamente más fáciles de resolver que los
originales, y cuyas soluciones puedan ser utilizadas efectivamente.
− Metaheurísticas de memoria a largo plazo: Se sitúan entre las metaheurísticas de arranque
múltiple y las derivadas de búsqueda tabú, las cuales, a su vez, forman parte de las
metaheurísticas de búsqueda.
5.2. Pronósticos y Series de Tiempo.
• Pronósticos y Series de Tiempo.
En esta sección se ilustra sobre el marco de soporte de algunos modelos usados en la literatura para
representar tanto el modelo matemático subyacente de las series temporales como los modelos
usados en el pronóstico. Para un mejor entendimiento, se muestran en la ilustración N.º 1, los
métodos más usados en la literatura para pronóstico de series temporales.

Ilustración 1 Clasificación de los modelos de pronóstico de series temporales.
Fuente: (Rodríguez Rivero, 2016)

• Pronósticos
− Pronóstico: Es la predicción de la evolución de un proceso o de un hecho futuro a partir de
criterios lógicos o científicos. El término predicción puede referirse tanto a la acción y al efecto de
predecir como a las palabras que manifiestan aquello que se predice; en este sentido, predecir algo
es anunciar por revelación, ciencia o conjetura algo que ha de suceder. En términos estadísticos,
el pronóstico es el proceso de estimación en situaciones de incertidumbre (Brockwell & Davis,
2010). El término predicción es similar, pero más general, y usualmente se refiere a la estimación
de series temporales o datos instantáneos. La predicción es un problema importante que abarca
muchos campos, incluyendo todas las ciencias, los negocios, la industria, el gobierno, la economía,
la política y las finanzas. Los problemas de predicción a menudo se clasifican en corto, mediano
plazo y largo plazo. Los problemas a corto plazo implican la predicción de eventos sólo en períodos
de tiempo (días, semanas, meses) dependiendo del problema (Box, Jenkins, & Reinsel, 2015.). El
término mediano plazo se extiende de uno a dos años en el futuro, y la predicción a largo plazo
puede extenderse más allá. Por lo general pensamos en un pronóstico como un simple número que
representa nuestra mejor estimación del valor futuro de la variable de interés. (Rodríguez Rivero,
2016)
Algunos métodos causales de pronóstico asumen que es posible identificar los factores
subyacentes que pueden tener influencia sobre la variable a pronosticar (Shumway & Stoffer,

2011). Si estas causas se entienden, se pueden hacer proyecciones de las variables que influyen,
para utilizarlas en la predicción. Algunos de estos métodos son (Hastie, Tibshirani, & Friedman,
Springer):
− Análisis de la regresión, que puede ser lineal o no lineal.
− Modelo autorregresivo de media móvil (ARMA)
− Modelo ARIMA
− Econometría.
• Series de Tiempo
Se llama Series de Tiempo a un conjunto de observaciones sobre valores que toma una variable
(cuantitativa) en diferentes momentos del tiempo. Los datos se pueden comportar de diferentes
formas a través del tiempo, puede que se presente una tendencia, un ciclo; no tener una forma
definida o aleatoria, variaciones estacionales (anual, semestral, etc). Las observaciones de una
serie de tiempo serán denotadas por Y1,Y2,...,YT , donde Yt es el valor tomado por el proceso en el
instante t.
Los modelos de series de tiempo tienen un enfoque netamente predictivo y en ellos los pronósticos
se elaborarán sólo con base al comportamiento pasado de la variable de interés. Podemos distinguir
dos tipos de modelos de series de tiempo [fi] (RÌos, 2008).

− Modelos deterministas: se trata de métodos de extrapolación sencillos en los que no se hace
referencia a las fuentes o naturaleza de la aleatoriedad subyacente en la serie. Su simplicidad
relativa generalmente va acompañada de menor precisión. Ejemplo de modelos deterministas son
los modelos de promedio móvil en los que se calcula el pronóstico de la variable a partir de un
promedio de los ”n” valores inmediatamente anteriores.
− Modelos estocásticos: se basan en la descripción simplificada del proceso aleatorio subyacente
en la serie. En término sencillos, se asume que la serie observada Y1, Y2, YT se extrae de un grupo
de variables aleatorias con una cierta distribución conjunta difícil de determinar, por lo que se
construyen modelos aproximados que sean útiles para la generación de pronósticos. (RÌos, 2008)
− Serie de tiempo: se define como un conjunto de observaciones sobre valores que toma una
variable (cuantitativa) en diferentes momentos del tiempo. Los datos se pueden comportar de
diferentes formas a través del tiempo (Brockwell & Davis, 2010), esto es que presente una
tendencia, un ciclo; no tener una forma definida o aleatoria, variaciones estacionales (anual,
mensual, etc.). Una serie temporal puede estar constituida solo por eventos determinísticos,
estocásticos o una combinación de ambos (Chatfield, 2004). Se sabe que muchas series temporales
presentan comportamientos dinámicos no lineales, cuya complejidad hacen que sea imposible
formular un modelo matemático basado en leyes físicas o económicas que representen su
evolución adecuadamente. El problema de la formulación del modelo se ve agravado por la

presencia de observaciones atípicas y cambios estructurales, para los cuales no existen modelos
matemáticos que permitan su representación en el caso no lineal (Kantz & Schreiber, 2009 ).
Los métodos tradicionales para el análisis de series temporales (Kantz & Schreiber, 2009 ) se hacen
a través de la descomposición de las mismas en varias partes. Se dice que una serie temporal puede
descomponerse en tres componentes que no son directamente observables, de los cuales
únicamente se pueden obtener estimaciones. Estos tres componentes son:
Tendencia: representa el comportamiento predominante de la serie. Esta puede ser definida no
formalmente como el cambio de la media a lo largo de un extenso período de tiempo.
Estacionalidad: es un movimiento periódico que se producen dentro de un periodo corto y
conocido. Este componente está determinado, por ejemplo, por factores climáticos. Aleatorio: son
movimientos erráticos que no siguen un patrón específico y que obedecen a causas diversas. Este
componente es prácticamente impredecible. Estos comportamientos representan todos los tipos de
movimientos de una serie temporal que no son tendencia ni variaciones estacionales ni
fluctuaciones cíclicas. (Rodríguez Rivero, 2016)
− Redes Neuronales Artificiales: Los RNAs estudiadas en esta tesis son los perceptrones
multicapa (MLP), principalmente las redes neuronales con retardo de tiempo (TDNN). Se sabe
bien que las redes neuronales artificiales (RNA) son aproximadores universales de funciones, y
que no requieren un conocimiento a priori sobre el proceso en cuestión. Las RNAs también son

bien conocidas por su capacidad para modelar sistemas no lineales. Estas propiedades son
exactamente por las que son usadas en esta tesis en la modelización de series temporales no
lineales con naturaleza desconocida o muy compleja, es decir, son muy atractivas como
herramientas para predicciones de series temporales. La aplicación de las RNAs a la predicción
con series temporales no es nueva. Desde hace décadas existen numerosos trabajos al respecto,
siendo probablemente los más conocidos los de Werbos (Werbos, 1974), Lapedes, Weigend
(Weigend, Huberman, & Rumelhart, 1990). Desde la estadística, Box y Jenkins [5] desarrollaron
la metodología de los modelos autorregresivos integrados de promedios móviles (ARIMA) para
ajustar una clase de modelos lineales para series temporales. Posteriormente surgieron versiones
robustas de modelos ARIMA y de series temporales no lineales (Zhang G. , 2003) tendientes a
resolver los problemas que introducen la presencia de valores aberrantes o extremos en los datos.
Más recientemente, las RNAs han sido consideradas como una alternativa para modelar series
temporales no lineales. Los modelos de RNAs se ajustan tradicionalmente por mínimos cuadrados
y por lo tanto carecen de robustez en presencia de valores extremos o aberrantes (outliers). Como
algunos de los procedimientos que tratan con RNAs surgen como una generalización natural de
los modelos estadísticos lineales AR y ARMA al caso no lineal NAR y NARMA, los
procedimientos para ajustar las RNAs suelen estar relacionados con los procedimientos
empleados para modelar series temporales robustas. (Rodríguez Rivero, 2016)

− Métodos de Aprendizaje: El aprendizaje es un proceso fundamental de las RNAs y de forma
general, consiste en el ajuste de todos los parámetros de la red, en base a la actividad para la que
se quiera utilizar dicha red. Partiendo de un conjunto de pesos aleatorios, el aprendizaje busca un
conjunto de pesos que permita a la RNA, desarrollar una tarea determinada. El aprendizaje es un
proceso iterativo, en el que la red, va refinando sus parámetros, para alcanzar el objetivo de la
aplicación concreta que se intenta abordar. Las redes perceptrón multicapa (MLP) utilizan una
función de error que mide su rendimiento actual, en función de sus pesos. El aprendizaje se
convierte en un proceso de búsqueda de aquellos pesos que hagan mínima dicha función (Yu,
Efe, & Kaynak), (Alsmadi, Omar, Noah, & A., 2009). El aprendizaje no supervisado es un método
donde un modelo es ajustado a las observaciones. Se distingue del aprendizaje supervisado dado
que no hay un conocimiento a priori. En el aprendizaje no supervisado se hace un tratamiento de
los datos de entrada como un conjunto de variables aleatorias, siendo construido un modelo de
densidad para el conjunto de datos. El aprendizaje no supervisado puede ser usado en conjunto
con la Inferencia bayesiana para producir probabilidades condicionales (es decir, aprendizaje
supervisado) para cualquiera de las variables aleatorias dadas (Alsmadi, Omar, Noah, & A.,
2009). En cambio, el aprendizaje supervisado normalmente funciona mucho mejor cuando los
datos iniciales son primero traducidos en un código factorial. El aprendizaje no supervisado
también es útil para la compresión de datos: fundamentalmente, todos los algoritmos de
compresión dependen tanto explícita como implícitamente de una distribución de probabilidad
sobre un conjunto de entrada. (Rodríguez Rivero, 2016)

−
− Evaluación del desempeño predictivo: Medición del error
Para la evaluación del desempeño predictivo se emplean diferentes indicadores que cuantifican
qué tan cerca está la variable pronosticada de su serie de datos correspondiente. Una de las medidas
más utilizadas es el Promedio del Error Porcentual Absoluto (MAPE). (RÌos, 2008)
El RMSE mide la dispersión de la variable simulada en el curso del tiempo, penalizando
fuertemente los errores grandes al elevarlos al cuadrado. Esta característica hace que el RMSE se
recomiende cuando el costo de cometer un error es aproximadamente proporcional al cuadrado de
dicho error.
No siempre el modelo que genere pronósticos con un menor MAPE generará los pronósticos con
el menor RMSE y viceversa, por lo que en la selección de los mejores modelos de pronóstico se
hace necesario establecer la medida de error a utilizar para la elaboración del ranking de
desempeño. (RÌos, 2008)
Dado que una mala estimación del precio fututo del cobre se traduce en una pérdida de ingresos
proporcional al tamaño del error, el MAPE, y no el RMSE, parece ser la medida de desempeño
más adecuada. A esto se suma la ventaja práctica del MAPE de no requerir ser acompañado por la
media para dimensionar la magnitud del error. Luego, la medida de error que se empleará para
identificar los modelos de mejor desempeño será el MAPE.[fi]. (RÌos, 2008)

− Estimación de la Tendencia: Hay varios métodos para estimar la tendencia T(t), uno de ellos es
utilizar un modelo de regresión lineal. Se pueden utilizar otros tipos de regresiones, como regresión
cuadrática, logística, exponencial, entre otros.
Una forma de visualizar la tendencia es mediante suavizamiento de la serie. La idea central es
definir a partir de la serie observada una nueva serie que filtra o suaviza los efectos ajenos a la
tendencia (estacionalidad, efectos aleatorios), de manera que podamos visualizar la tendencia.
(Rodríguez Rivero, 2016)
− Promedio Móvil: Este método de suavizamiento es uno de los más usados para describir la
tendencia. Consiste en fijar un número k, preferentemente impar, como 3, F, etc., y calcular los
promedios de todos los grupos de k términos consecutivos de la serie. Se obtiene una nueva serie
suavizada por promedios móviles de orden k. De este modo se tienden a anular las variaciones
aleatorias.
El suavizamiento de media móvil es muy fácil de aplicar, permite visualizar la tendencia de la
serie. Pero tiene dos inconvenientes: No es posible obtener estimaciones de la tendencia en
extremos y no entrega un medio para hacer predicciones. Si la serie presenta un efecto estacional
de período k, es conveniente aplicar un suavizamiento de media móvil de orden k. En tal caso se
elimina el efecto estacional, junto con la variación aleatoria, observándose solamente la tendencia.

− Suavizamiento Exponencial: Este modelo se basa en que una observación suavizada, en tiempo
t, es un promedio ponderado entre el valor actual de la serie original y el valor de la serie suavizada,
en el tiempo inmediatamente anterior. Si Y (t) representa la serie de tiempo original, y Z(t) la serie
de tiempo suavizada. (Rodríguez Rivero, 2016)
− Aplicaciones de Series de Tiempo
Hoy en día diversas organizaciones requieren conocer el comportamiento futuro de ciertos
fenómenos con el fin de planificar, prevenir, es decir, se utilizan para predecir lo que ocurrirá con
una variable en el futuro a partir del comportamiento de esa variable en el pasado. En las
organizaciones es de mucha utilidad en predicciones a corto y mediano plazo, por ejemplo, ver
qué ocurriría con la demanda de un cierto producto, las ventas a futuro, decisiones sobre inventario,
insumos, etc.
Algunas de las áreas de aplicación de Series de Tiempo son (RÌos, 2008):
• Economía: Precios de un artículo, tasas de desempleo, tasa de inflación, índice de precios,
precio del dólar, precio del cobre, precios de acciones, ingreso nacional bruto, etc.
• Meteorología: Cantidad de agua caída, temperatura máxima diaria, Velocidad del viento
(energía eólica), energía solar, etc.
• Geofísica: Series sismológicas.
• Química: Viscosidad de un proceso, temperatura de un proceso.

• Demografía: Tasas de natalidad, tasas de mortalidad.
• Medicina: Electrocardiograma, electroencéfalograma.
• Marketing: Series de demanda, gastos, utilidades, ventas, ofertas.
• Telecomunicaciones: Análisis de senales.
• Transporte: Series de tráfico

6. ESTADO DEL ARTE
En el trascurrir del tiempo muchos tipos de metaheurísticas surgido con el fin de ser usadas para
mejorar diferentes tipos de problemas de gran complejidad o magnitud. Estos métodos de van
desde búsquedas de vecindad hasta las evolutivas, así como la combinación de las mismas.
A continuación, se mencionan algunas de los métodos de búsqueda más importantes y
representativos de los últimos años.
En 2004 surge una metaheurística muy popular propuesta por Kang Seok Lee a, Zong Woo Geem
en su artículo, “A new structural optimization method basedon the harmony search algorithm”, en
el cual Se explica claramente que este método se basa en una memoria armónica para alcanzar el
perfecto estado de la armonía. Esta búsqueda se basa en una HS memoria armónica inspirada en
la aleatoriedad para mejorar sus búsquedas por gradientes. No necesita de parámetros iniciales y
se resalta la gran eficacia para resolver problemas en ingeniería de estructuras. (Kang Seok & Zong
woo, 2004)
En el año 2005 Sebastián Urrutia, Irene Loiseau trabajan en “A New Metaheuristic and its
Application to the Steiner Problems in Graphs” un algoritmo llamado (SN) que pertenece al tipo
de metaheurísticas de descomposición debido a que esta se fundamenta en la división de un
problema en subproblemas más sencillos que son solucionados por una heurística doble que realiza
diferentes procedimientos dependiendo de si la condición de solución sea asumida como “si” o
como “no” para cada uno de los casos. Luego se construye una mejor solución por medio de la

asignación de un valor confidencial que se obtiene de la diferencia entre de la calidad de las
soluciones obtenidas por “si” y por “no” en cada iteración (Sebastian Urrutia, 2005)
Otros tipos de método surge en 2005 presentado por E. K. Burke, P. Cowling, J.D. Landa Silvae
en su trabajo “HYBRID POPULATION-BASED METAHEURISTIC APPROACHESFOR THE
SPACE ALLOCATION PROBLEM” este estudio me llama mucho la atención porque se centra en
un híbrido de la competencia metaheurísticas para el problema de la asignación de espacio lo cual
se hace muy llamativo y además tiene gran aplicación.
Este artículo muestra que una metaheurística híbrida basada en la población por el espacio es un
problema de asignación que se presenta en base a experimentos anteriores con una serie de técnicas
incluidas en escalada, recocido simulado, búsqueda tabú y algoritmos genéticos. Buscando con
ellos tener mejores características de cada técnica mencionada, y así parámetros estén acorde a
las características y problemas y además que supere el rendimiento de estas técnicas estándar. Esta
nueva propuesta utiliza métodos de heurísticos de búsqueda local para mejorar sus resultados,
además se realiza una parametrización automática acorde a las características del problema que
genera soluciones con calidad superior a las de los estándares de las distintas técnicas conocidas.
(Burke, Cowling, & Landa silva, 2006)
Otro trabajo importante fue publicado en 2007 por Nader Azizi, Saeed Zolfaghari and Ming Liang,
“A New Meta-heuristic Approach for Combinatorial Optimization and Scheduling Problems”.

Este trabajo muestra un nuevo y eficiente heurístico razonablemente la combinación de diferentes
características de varias heurísticas con recocido simulado.
A diferentes de otros algoritmos híbridos, la componente central de la heurística propuesta es una
simulación recocida que se beneficia de dos memorias a corto plazo.
Información acerca de las soluciones anteriores iteración mejor es conservado en una larga lista
población a largo plazo de la memoria llamada. Sabemos que un operador de cruce genético se
utiliza para producir nuevos la población que usa las soluciones almacenadas en la memoria de
otros en su momento.
Se tiene que el rendimiento del algoritmo es evaluado en comparación con los resultados
obtenidos por otros siete incluidos los métodos de algoritmos exactos, las técnicas generales y
algoritmos híbridos. Se comparan los resultados claramente indica que el algoritmo puede
encontrar mejores soluciones en algunos casos. Este algoritmo propuesto, debido a su generalidad,
se puede aplicarse fácilmente a otros problemas de optimización. Para el caso de la programación
de la tienda de trabajo, la calidad de las soluciones y la eficiencia computacional del algoritmo
puede ser mejorar mediante el uso barrio de problemas específicos estructura y los operadores más
eficientes. (Nader & Zolfaghari, 2007)
En el 2008 aparece una nueva metaheurística de tipo evolutivo viral system planteado por Pablo
Cortés, José M. García, Jesús Muñuzuri y Luis Oneiva, es un método que hace uso de una analogía
biológica inspirada en la ejecución e infección de los virus, más específicamente del Phagocyte.

En este enfoque, se considera que los virus son parte de una infección general, donde cada virus
trata de comportarse a su beneficio, pero a la vez en el beneficio del Viral System. (Cortes, Garcia,
Muñusuri, & Onieva, 2008)
El método parte de que en la naturaleza los virus son organismos que tienen su mayor éxito
cuando atacan células poco saludables, de ahí entonces el estado de salud es representado por F(x),
es decir la función objetivo.
El virus que pretende infectar una célula y replicarse a través de ella puede hacerlo de dos maneras;
la primera se denomina replicación lítica e implica la adherencia del virus al borde de la célula y
la inyección de su ADN, a partir de ese momento se generan varias copias, llamadas Nucleus
Capsids del virus dentro de la célula, los cuales son liberados cuando el número de réplicas llegue
a un nivel máximo y la pared de la célula infectada se rompa. La otra manera de replicarse se
denomina Lisogénica; aquí el virus infecta a la célula alojándose en su genoma y permanece allí
hasta que alguna causa externa provoque la réplica (Cortes, Garcia, Muñusuri, & Onieva, 2008)
En 2009 Alireza Tajbakhsh,, Kourosh Eshghi, Azam Shamsr proponen un hibrido entre el método
de optimización enjambre de partículas y el recocido simulado en este trabajo, “A Hybrid PSO-SA
Algorithm For The Traveling Tournament Problem” se presenta un nuevo modelo matemático
utilizando Programación y además propone un híbrido algoritmo que combina metaheurística PSO
y SA. En este papel se demostró que el híbrido propuesto algoritmo conduce a soluciones que son

comparables u obtiene mejor horario para las instancias de norma y que garantiza resultados de
buena calidad.
MOBAIS, es un novedoso algoritmo desarrollado por Pablo A.D Castro y Fernando J. von Zuben
en el año 2009, que puede ser utilizado como herramienta para solución de problemas multi-
objetivo, y cuya principal aporte es el adecuado manejo de soluciones parciales de alta calidad
(Building Blocks), que pueden estar codificadas en los anticuerpos que representan la solución, las
cuales en los algoritmos tradicionales inmune inspirados pueden llegar a ser destruidas por los
operadores de mutación y clonación.
Según Castro y Von Zuben, los algoritmos inmunes inspirados (AIS) presentan mecanismos para
evolucionar la población, que no tienen en cuenta las relaciones entre las variables del problema,
lo cual causa la destrucción de estas soluciones parciales de alta calidad.
En MOBAIS, los operadores de mutación y clonación son reemplazados por un modelo
probabilístico, más precisamente una red bayesiana, la cual representa la distribución de
probabilidad conjunta de las soluciones más prometedoras, y subsecuentemente, usa dicho modelo
para el muestreo de nuevas soluciones (Castro & V, 2008)
Un Nuevo hibrido simulado recocido surge en 2010 presentado por Stephen C.H.Leung,
DefuZhang, ChangleZhou , TaoWuc en su publibacion, “A hybrid simulated annealing
metaheuristic algorithmforthetwo-dimensional knapsack packing problema”. En este trabajo se
realiza un hibrido entre el recocido simulado y una heurística constructiva. La heurística greddy o

voraz aquí propuesta combinada con el SA proporcionan excelentes resultados en la solución de
problemas planteados en el artículo, además se destaca la rapidez y eficacia del método. (Leung &
DefuZhang, 2010)
Posteriormente surge en 2009, otro método que mejora a la optimización de enjambre de partículas
propuesto por A.J. Nebro, J.J. Durillo, J. Garc´ıa-Nieto, C.A. Coello Coello, F. Luna and E. Alba
en su trabajo “SMPSO: A New PSO-based Metaheuristicfor Multi-objective Optimization”. Este
estudio describe SMPSO, un PSO nuevo multi-objetivo algoritmo que tiene como objetivo
incorporar un mecanismo de constricción velocidad. Con esto se puede obtener Mediante su uso,
la velocidad máxima de las partículas es limitada con el fin de aumentar la capacidad de búsqueda
de la técnica. Esta nueva propuesta ha sido valorada según las dos familias de referencia, ZDT y
DTLZ, y compararon con cinco algoritmos de optimización de esta técnica multi-objetivo: NSGA
– II, SPEA2, OMOPSO, ABYSS Y MOCELL. Estos resultados demostraron que SMPSO supera
las limitaciones de los algoritmos que se ha comparado.
Este articulo muestra nuevos esquemas para la actualización de la velocidad de las partículas, y
aplicar SMPSO se investiga con el fin de demostrar un nuevo multi-objetivo algoritmo de
optimización de enjambre de partículas (PSO), caracterizada por el uso de una estrategia para
limitar la velocidad de las partículas.

Las características de SMPSO incluyen el uso de la mutación polinomio como un factor de
turbulencia y un archivo externo para almacenar las soluciones no dominadas encontradas durante
la búsqueda. (A.J. Nebro, 2009)
Con relación al análisis de series de tiempo para la predicción de los precios del ganado Córdoba
- Colombia se identifica en el año 2007 el trabajo “Estacionalidad, ciclos y volatilidad en los
precios del ganado macho de levante en Montería, Colombia” realizado por Omar Castillo
(Castillo, Estacionalidad, ciclos y volatilidad en los precios del ganado macho de levante en
Montería, Colombia, 2007). En su desarrollo se describe el comportamiento temporal de los
precios del ganado vivo macho de levante de primera calidad en la ciudad de Montería, Colombia
comercializado en las subastas. Materiales y métodos. Se realizaron análisis de los precios
semanales y mensuales durante el período 1997-2006 utilizando técnicas estadísticas y
econométricas como la media móvil multiplicativa, la tasa de crecimiento sobre medias anuales,
12 T12, y modelos auto-regresivos heterocedásticos condicionales, ARCH, o GARCH. Como
resultado se denota evidencias de estacionalidad y ciclos en los precios mensuales; no hubo
evidencia de comportamientos volátiles en precios semanales de los ganados de 1,1¼ y 1½ años
de edad, pero si para los de 1 año.

En este mismo año también se encontró el trabajo “Comportamiento temporal de los precios del
ganado macho de levante de primera en Sincelejo” (Castillo, Comportamiento temporal de los
precios del ganado macho de levante de primera en Sincelejo, 2007). De manera similar el autor
Omar Castillo señala que igualmente el comportamiento temporal de los precios del ganado vivo
macho de levante de primera calidad en la ciudad de Sincelejo, comercializado en las subastas.
Para ello se acude al análisis de los precios mensuales y semanales durante el período 1997 - 2006
utilizando técnicas estadísticas y econométricas como la media móvil multiplicativa, la tasa de
crecimiento sobre medias anuales, 12 T12 , y modelos auto- regresivos heterocedásticos
condicionales, ARCH, o GARCH. Los resultados indican la presencia de estacionalidad y ciclos
en los precios mensuales; en los precios semanales de las edades de 1 y de 1¼ año se observaron
comportamientos volátiles, el precio de los de 1½ año se han movido dentro de rangos estables.
Seguidamente se destaca el trabajo realizado por Botero y Cano en 2008, en su trabajo “Análisis
de series de tiempo para la predicción de los precios de la energía en la bolsa de Colombia”. En
este se realiza un análisis del comportamiento del precio de la energía eléctrica ha incrementado
su volatilidad, reflejando el riesgo existente para los diferentes agentes que intervienen en el
mercado. El objetivo de este artículo es presentar una metodología para la implementación de

modelos de regresión, sobre la serie histórica de precios de bolsa de energía en Colombia (Botero
& Cano, 2008).
En el año 2014 se identifica la investigación “Uso de un modelo univariado de series de tiempo
para la predicción, en el corto plazo, del comportamiento de la producción de carne de bovino en
Baja California, México”. Esta fue desarrollada por Barreras, Sánchez y Figueroa en Baja
California, México. Se utilizó el modelo autorregresivo de promedios móviles ARMA. Los
resultados respaldan el modelo para obtener a corto plazo predicciones de producción de carne en
baja california (Barreras Serrano, Eduardo, & Figueroa Saavedra, 2014).
De manera más reciente de encuentra la investigación titulada “Descripción y pronóstico de la
producción de carne de bovino en el estado de Tabasco”. Esta misma fue efectuada en el año 2017
por Espinosa, Vélez, Quiroz, Granados, Moctezuma y Casanova en México obedeciendo los
siguientes objetivos. Analizar el comportamiento y productividad de la producción de carne de
bovino en Tabasco y encontrar un modelo de series de tiempo capaz de realizar un pronóstico de
la producción, confiable, cercano a los valores de la serie, cuya correlación sea estadísticamente
significativa, se integró una serie de tiempo anual de producción de carne en canal (PCaCa),
animales sacrificados (ASac) y peso en canal (PeCa) de los ASac en los 17 municipios del estado
para el periodo 2006-2015. También se integró una serie mensual de PCaCa de enero de 2003 a

marzo de 2017. Bajo este precedente se encontró que Tabasco produce en promedio por año 65
338 ton de carne con 310 564 ASac con un peso promedio de 211 kg.
También se encontró que tanto la PCaCa, como los ASac presentaron TMAC positivas para el
estado, siendo el DDR de Villahermosa el de mayor dinamismo, con una tasa de crecimiento
promedio de 2 %; y el municipio de Teapa el de a mayor TCMA, con 4,4 %. El modelo de serie
de tiempo que mejor predice la PCaCa fue el autorregresivo integrado de promedio móvil, ARIMA
(p, d, q) (P, D, Q) k, de orden 1, por tanto, la producción de carne en Tabasco tiene un
comportamiento estacional. Se concluye que el modelo seleccionado permite hacer un pronóstico
cercano a la realidad con una confiabilidad estadística significativa. (Espinosa, Vélez, & A., 2017)
Revisando lo más reciente en la literatura del ámbito colombiano encontramos el trabajo
“Determinantes del precio del ganado gordo bovino en pie de Medellín y Bogotá: 2009-2019”.
Este fue elaborado por Sebastián López Nieto en la Universidad EAFIT - Escuela De Economía y
Finanzas. Este trabajo deja en evidencia las dinámicas, entre 2009 y 2019, que rigen los precios
del ganado bovino macho y hembra entre los principales mercados de carne en Colombia; ya que
permite entender de mejor manera el mercado bovino como oferta final de los frigoríficos, lo cual
afecta directamente las decisiones de gran cantidad de agentes que comercian en él. Entender la
dinámica de este mercado, termina impactando positivamente los ganaderos y los frigoríficos.
(Lopez, 2019)

Los ganaderos al tener más y mejor información, pueden mejorar su productividad, beneficiando
su calidad de vida. Por parte de los frigoríficos, con mejor información se puede impulsar de mejor
manera la competitividad del sector, que promete ser clave en los próximos años en materia de
exportaciones. Además, con lo hablado con ambos frigoríficos, es de gran información estos
estudios acerca de los precios y es una manera como estos puedan ayudarles a tomar mejores
decisiones a los agentes.
Des la óptica de lo investigado se señala que es claro que para determinar el precio del ganado
bovino macho hay 3 aspectos claves para tomar, de acuerdo con la literatura y la experiencia. Estos
son el factor del ciclo ganadero, tomando como índice el precio y la dinámica del ganado hembra
y cómo este afecta el macho, que en últimas es el que va principalmente a conformar la carne
suministrada a los consumidores. El segundo factor tiene que ver con lo asociado directamente al
precio del ganado macho entre ciudades, por medio de periodos anteriores cómo estos pueden
afectar el precio en el largo plazo. Por último, la forma en que las precipitaciones como factor
exógeno afectan el precio del ganado en ambas ciudades. (Lopez, 2019)

7. MATERIALES Y MÉTODOS.
• Metodología del Proyecto
Para la realización del proyecto se llevó a cabo la siguiente metodología; revisión bibliográfica,
selección del modelo de regresión no lineal, diseño e implementación de la metaheurística y de
indicador estadístico de error para la optimización de los problemas relacionados. Se ejecutarán
diferentes corridas para los ejercicios de alta complejidad, de conformidad con la Programación y
validación del modelo de regresión no lineal. Finalmente se realizará un estudio caso práctico en
problemas de series de tiempo, así mismo se procederá analizar las soluciones el modelo propuesto
utilizando el algoritmo cromático con sus respectivas soluciones estándares y según resultados.
Es de destacar que para el respectivo análisis de parámetros del algoritmo y con el propósito de
alcanzar en la metaheurística propuesta excelentes resultados se realizaron alguna serie de pruebas
y se tuvieron en cuenta experimentos de la literatura para garantizar la escogencia de los mejores
parámetros posibles. También se acudió al diseño con efectos fijos para evaluar el factor algoritmo
y el rendimiento de este según trabajos consultados previamente. Todo lo referente según
parámetros escogidos en la generación de buenos resultados con la aplicación de un número
razonable de pruebas, con fundamento en lo descrito en el libro de experimentos (Montgomery,
2004).

− Material y Método
En la realización del proyecto se procedió a precisar sobre: Revisión bibliográfica, selección del
mejor modelo, selección de la mejor metaheurística y del mejor indicador estadístico de error para
la optimización de los problemas relacionados. Se elaboró utilizaron los mejores parámetros del
algoritmo y una vez encontrados estos valores se procedió a la Programación y validación del
modelo, para ello fue necesario equipo de cómputo con procesador Intel Inside Core I3- 2.40 GHz,
el uso del software de análisis numérico GNU Octave, versión 4.4.1. en el cual fue codificado el
modelo y se hizo la respectiva validación para comprobar la veracidad de los datos arrojados.
Finalmente se realizó un estudio en tres grupos de problemas de una variable que son considerados
de alto grado de dificultad en la literatura, de los cuales se seleccionaron 4, para comparar el
modelo propuesto con sus respectivas soluciones estándares. No obstante, se prueba esta propuesta
en un problema de múltiples variables.
− Diseño De Experimentos
Este diseño inicia con la concepción o generación con preliminares condiciones en la las cuales
debe tratarse el sistema que se está abarcando, todo esto hace con el fin la garantizar la aleatoriedad
del dentro da la realización de corridas de datos, para disminuir el efecto de variables que no se
pueden controlar. Obteniendo, así como resultado de esta etapa la generación de los valores de los
factores controlables del sistema estudiado.

Seguidamente se examina las respuestas que se encuentran con la modelación diseñada y se realiza
así el análisis correspondiente, teniendo en cuenta la literatura relacionado con el algoritmo de
búsqueda y la región de estudio; implementando los parámetros básicos del algoritmo cromático
y modelo de estudio. (Montgomery, 2004).
Utilizando este tipo de metodología en esta investigación tendríamos que estudiar las
dos fases fundamentales para la ejecución de esta propuesta. En la primera etapa se destinó a la
fijación de los valores de los parámetros y su posterior análisis, se ratificó la veracidad del valor o
los rangos más importantes para cada parámetro.
Posteriormente en la última etapa se deben realizaron pruebas corridas pertinentes para evaluar el
desempeño del algoritmo, así como un profundo un análisis tomando los resultados de nuestro
programa con el de los diferentes métodos a comparar y con los problemas de series de tiempo
seleccionados.

8. OPTIMIZACIÓN DE PRONÓSTICOS
8.1. Ejercicios Problemas de Evaluación de Alta Complejidad
Para el desarrollo de la ruta esbozada, inicialmente se parte de la realización de ejercicios y
análisis de Problemas de Evaluación de Alta Complejidad identificados en la literatura
relacionada con pronósticos; con el objetivo de corroborar el potencial de trabajo del algoritmo
cromático, con ocasión de la búsqueda de respuestas en problemas de optimización en series
de tiempo.
En relación con lo anotado seguidamente se procede a señalar el listado de problemas que se
evaluarán en la parte inicial de este trabajo.
− Problema de evaluación N° 1 (Clase polinomial)
Este problema de evaluación tiene 82 datos y es conocido como ‘‘Fillip” y consta de 11
parámetros, el modelo es expuesto en la expresión (1).
𝑦 = 𝛽0 + 𝛽1𝑥 + 𝛽2𝑥2 + … + 𝛽9𝑥9 +𝛽10𝑥10 + 𝐸 (1).
− Problema de evaluación N° 2 Clase (polinomial)

Este problema de evaluación tiene 21 datos, es conocido como ‘‘Wampler4” y consta de 6
parámetros, el modelo es expuesto en la expresión (2).
𝑦 = 𝛽0 + 𝛽1𝑥 + 𝛽2 𝑥2 + 𝛽3 𝑥
3 + 𝛽4 𝑥4 + 𝛽5 𝑥
5 + 𝐸 (2).
− Problema de evaluación N° 3 (Clase racional)
Este problema de evaluación tiene 11 datos, es conocido como ‘‘MGH09”, y consta de 4
parámetros, el modelo es expuesto en la expresión (3).
𝑦 =𝛽1 (𝑥2+ 𝑥𝛽2)
𝑥2+𝑥𝛽3 + 𝛽4 (3).
− Problema de evaluación N° 4 (Clase diversa)
Este problema de evaluación tiene 154 datos, es conocido como ‘‘Bennett5”, y consta de 4
parámetros, el modelo es expuesto en la expresión (4).
𝑦 = 𝛽1 (𝑥 + 𝛽2)−1
𝛽3 + 𝐸 (4).
8.2. Caso de Estudio Practico (Precios del Ganado tipos de Córdoba)
En la segunda parte de los problemas propuestos para solucionar, se efectúa la estimación de
precios para tipos de ganado seleccionados según datos históricos que se asocian con variables de
tipo ganado referenciado como lo son; cantidad, mes y precios de venta. En esta oportunidad se

conviene sobre hechos de venta obtenidos a través de información recolectada a partir de subasta
ganadera Subastar S.A. de la ciudad de Montería- Córdoba.
El objeto aquí es implantar el algoritmo de búsqueda y el modelo no lineal de series de tiempo
para realizar ejercicio de pronóstico en tipos específicos de ganado, conforme a los datos
escogidos.
8.3. Modelo de Regresión
Los modelos de regresión son usados para encontrar un mejor ajuste a un conjunto de datos. El
propósito en todo tipo de regresión es tener la forma de la expresión (1). Para una serie de datos
en donde Y es la variable dependiente medida para un experimento y X es la variable independiente
que es cambiada durante los experimentos.
y = f(x) + ℰi (1)
F es una función que describe la relación de X y Y, y consta de uno o más parámetros. ℰi es la i-
esima observación del error que proviene de un nivel medio de datos que tiene una distribución
normal con media de cero. El modelo que se utilizó para realizar el ajuste a los datos en los
problemas que se trabajan en este artículo es el propuesto por (Behnamian & Ghomi, 2009) y se
expone a continuación en las expresiones (2) y (3).

𝑓(𝑥) =𝑓1 (𝑥)
𝑐1 + 𝑐2 ( 𝑓1 (𝑥)+ 𝑐3 𝑥 ln( 𝑏0+ ∑ 𝑏𝑖 5𝑖=1 𝑥𝑎𝑖 ))
(2)
En donde 𝑓1 (𝑥) es:
𝑓1 (𝑥) = 𝑏0 + ∑ 𝑏𝑖 5𝑖=1 𝑥𝑎𝑖 + 𝑏6
𝑎6𝑥+ 𝑏7 sin(𝑎7 𝑥) +𝑏8 cos(𝑎8𝑥) (3)
En donde los parámetros del modelo son:
𝑏0, 𝑏1 , 𝑏2 , 𝑏3, 𝑏4 … … 𝑏8, 𝑎1, 𝑎2, 𝑎3, 𝑎4 … … 𝑎8, 𝑐1, 𝑐2 y 𝑐3
El modelo establece la forma general de la ecuación de una regresión logística para prevenir los
distintos casos de comportamientos en los datos. En este trabajo l se realizó una adaptación del
modelo anterior para poder trabajar con problemas de una y varias variables, el procedimiento es
explicado a continuación.
En una serie de datos en donde se tiene que 𝑋0 , 𝑋1 ……… 𝑋𝑚 son variables independientes que
son cambiadas durante el experimento y Y es la variable dependiente medida para un experimento
se propone lo siguiente.
Para una variable 𝑋𝑖 que va desde 𝑋0 hasta 𝑋𝑚 se halla el valor 𝑓(𝑥) correspondiente a las
expresiones (2) y (3) y luego cada uno de los valores obtenidos para cada 𝑋𝑖 se suman para obtener
un �̅�𝑠𝑡 , es decir que se tendría la expresión (4).
𝐹𝑠𝑡 𝑖 = 𝑓(𝑋0) + 𝑓(𝑋1) … . . + 𝑓(𝑋𝑚) (4)

En donde el valor 𝐹𝑠𝑡 𝑖 es hallado hasta el número n de observaciones. Luego entonces se calcula
�̅�𝑠𝑡 y �̅� y con estos valores entonces se obtiene una constante de amplificación 𝐾. Este valor se
obtiene mediante la expresión (5).
𝐾 =�̅�
�̅�𝑠𝑡 (5)
Una vez encontrado 𝐾 se obtiene el valor estimado �̂� 𝑖 para cada variable dependiente 𝑌 𝑖 , el valor
estimado se calcula como se muestra a continuación en la expresión (6).
�̂� 𝑖 = 𝐾 𝐹𝑠𝑡 𝑖 (6)
8.3.1. Optimización del Modelo
Generalmente los modelos no lineales son más complejos debido a que en estos poseen un gran
número de parámetros, los cuales se deben hallar para encontrar el mejor ajuste a una serie de
datos, es por eso que se trata de simplificar en lo posible la optimización de estos valores. Para
obtener estos valores se suele recurrir a dos tipos métodos, el primero de estos es el desarrollo de
métodos exactos para encontrar los valores óptimos de los parámetros del modelo y los segundos
son procedimientos metaheurísticos para encontrar para encontrar los valores de los parámetros
que sean muy cercanos al optimo del modelo (Da Silva, 2008).El segundo método es el más
atractivo por que los procedimientos metaheurísticos no requieren de supuestos acerca de los
parámetros ( como es el caso de los métodos exactos) y ofrecen la posibilidad de obtener un óptimo

global de modelo expuesto en la expresiones (2) y (3), (Behnamian & Ghomi, 2009).Una vez
conocidas la ventajas de los procedimientos metaheurísticos ,se trabaja en base a estos y se utiliza
un nuevo algoritmo de búsqueda llamado cromático desarrollado por (Sabie, 2011) el cual ofrece
alternativas para encontrar muy buenos resultados en la búsqueda de los mejores parámetros para
el modelo de regresión no lineal.
8.3.2. Función objetivo
Existen muchos índices de eficiencia para encontrar el mejor ajuste a una curva o una serie de
datos, entre estos tenemos los indicadores de error como el ME, MAE, MSE y entre otros que son
los más conocidos en medidas de eficiencia en pronósticos. Sin embargo, estos suelen tener
algunas desventajas como la cancelación de errores de valores positivos con los de valores
negativos como es el caso del ME (Tsolacos, 2006), catalogar a errores más grandes con un peso
igual al de errores más pequeños como lo hace el MAE y el MSE (Rasmussen, 2004) y entre otros
aspectos más, lo que nos llevó a un indicador de error más robusto que nos permitiera obtener
resultados más precisos.
El indicador que se utilizo fue el 𝑅2 debido a que consultando en la literatura se encontró que este
índice de error ofrecía los mejores resultados para estos tipos de problemas. Este índice se expone
a continuación en la expresión (7).
𝑅2 = 1 − ∑ (𝑦𝑡−𝐹𝑡 )
2
𝑛𝑖=0
∑ (𝑦𝑡−�̅�𝑡 )2
𝑛𝑖=0
= 𝑆𝑆𝑅
𝑆𝑆𝑡𝑜𝑡𝑎𝑙 (7)

En donde 𝑦𝑡 es el valor observado y 𝐹𝑡 es el valor ajustado, 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 es la varianza de los datos y
𝑅2 es el valor real de la variabilidad que puede tener el modelo. Este índice expresa la proporción
de varianza de la variable independiente explicada por la variable independiente (Eye & Schuster,
1998).
8.4. Codificación de Parámetros
Uno de los aspectos más importantes al trabajar con metaheurísticas, es decidir cómo se deben
representar las soluciones y que tan eficientes serian estas al realizar la búsqueda en el espacio de
soluciones. Lo que se trata de hacer por lo general son codificaciones sencillas y que reduzcan el
costo del algoritmo, debido a esto se decidió utilizar para la representación de todos los parámetros
𝑏0, 𝑏1 , 𝑏2 , 𝑏3, 𝑏4 … … 𝑏8, 𝑎1, 𝑎2, 𝑎3, 𝑎4 … … 𝑎8, 𝑐1, 𝑐2 y 𝑐3
En la codificación de las soluciones del problema para el algoritmo cromático, la propuesta hecha
por (Behnamian & Ghomi, 2009) cómo se muestra a continuación en la (ilustración Nº2).
Ilustración 2 Representación de una solución en el algoritmo Cromático.

8.5. Algoritmo Cromático
Este es un nuevo método de optimización combinatoria que se inspira y hace una relación con las
diferentes maneras con las que un músico u artista realiza y escoge la melodía más apropiada para
una pieza musical, a partir de la combinación de distintas notas musicales de la escala cromática.
La idea principal del método radica en que el músico elige o escoge la mejor melodía, la cual es la
que mejor se adapta y representa apropiadamente una tonada especifica.
Esta metaheurística se caracteriza por qué no necesita de un gran tamaño en el grupo de melodías
que se tienen como opción de búsqueda, es decir, que no necesita de un gran número de soluciones
iniciales para un obtener buenos resultados. El algoritmo trabaja con ML (melodía local) que es
la mejor solución de la iteración y con MM (melodía global) la cual es mejor la solución encontrada
hasta el momento, con estos realiza una búsqueda de vecinos a través de la escala cromática de
las notas musicales y realiza movimientos de búsqueda que se fundamentan en conceptos
musicales , además hace que la exploración del espacio de soluciones sea eficiente gracias a que
utiliza la combinación de poblaciones con diferentes características, logrando así diversificar el
conjunto de soluciones con el que se trabaja , es decir, que este algoritmo realiza arranques
múltiples en su búsqueda para poder salir de óptimos locales, lo cual es una gran ventaja en muchos
problemas de optimización donde existen gran cantidad de variables .
No obstante, se resalta que esta metaheurística ofrece una muy buena alternativa para la
recombinación y búsqueda de vecinos en problemas que son trabajados en codificación real (Sabie,

2011), lo que le da gran relevancia para obtener los mejores parámetros del modelo de las
expresiones (2) y (3) debido a que estos tipos de problemas necesitan de este tipo de codificación.
A continuación, se explican los principales operadores de búsqueda y los aspectos más importantes
del algoritmo cromático.
8.5.1. Vecinos de escala cromática
Para realizar la búsqueda de vecinos en números reales se adoptó la idea de la equivalencia de la
recta numérica con la escala cromática, por lo que se le asignó un intervalo de números reales a
cada nota musical en la recta numérica real, con una distancia de 0.5 entre un intervalo y otro,
tomando como referencia el medio tono de distancia que guarda cada nota en la escala cromática
musical. La equivalencia del número real con la nota musical de la escala se obtiene mediante las
expresiones (8), (9) y (10).
𝑣𝑎𝑙𝑜𝑟 𝑛𝑜𝑡𝑎 𝑚𝑢𝑠𝑖𝑐𝑎𝑙 = 𝛽 − 12𝛼 (8)
En donde β es igual al redondeo del número real δ a su entero siguiente y α es igual a redondeo
del número real Ω a su entero anterior.
Donde tenemos que:
𝛿 =𝑛𝑢𝑚𝑒𝑟𝑜 𝑟𝑒𝑎𝑙
0.5 (9)

𝛺 =𝛽
12 (10)
De igual manera el grado para cada nota es igual al termino α, dado el valor para el grado de cada
nota se calcula el intervalo de búsqueda de vecinos para la nota SI mediante la expresión (11) y
(12).
El límite inferior y superior del intervalo de la nota SI es:
𝐿 𝑖𝑛𝑓 = (𝛼)𝑥 6 − 0.5 (11)
𝐿 𝑠𝑢𝑝 = 𝐿 inf + 0.5 (12)
Entonces el intervalo para la búsqueda de vecinos para la nota SI es igual ((𝛼)𝑥 6 −
0.5, (𝛼)𝑥 6] .
Se aclara que este intervalo es abierto en el límite inferior y cerrado en el límite superior, no
obstante, a partir de este intervalo de la nota SI se hallan los de las demás notas siguientes, sumando
0.5 a ambos límites del para cada nota. Entonces una vez identificado el valor de nota musical para
cualquier número real, se obtiene su nota musical, luego con el grado específico de la nota se
calculan los límites de nota inferiores y superiores para el intervalo de nota correspondiente.

Con los intervalos obtenidos para cada nota se podrían generar buenos resultados, pero debido a
que estos son todavía muy grandes estos se dividen entre dos para realizar una búsqueda más
minuciosa. Esta búsqueda y división es explicada a continuación. Si se desea realizar una búsqueda
de vecinos en escala cromática del valor de la primera posición de la solución, se procede a
encontrar la nota y el intervalo, estos se obtienen con las expresiones correspondientes (8), (9) y
(10) junto con las expresiones (11) y (12).
De aquí se encuentra que el valor numérico que corresponde a la nota y su intervalo de búsqueda
de vecino. Este intervalo de divide en dos y se obtiene dos nuevos intervalos como se expone a
continuación.
El intervalo 1 → ( 𝐿 𝑖𝑛𝑓,𝐿 𝑠𝑢𝑝
2 ] y el intervalo 2 → (
𝐿 𝑠𝑢𝑝
2 , 𝐿 𝑠𝑢𝑝]
− Si el valor j de la posición de la mejor solución, a la que se le generara el vecino se
encuentra en el intervalo 1.
− Entonces se generan dos números aleatorios así:
s→ aleatorio entre 𝐿 𝑖𝑛𝑓 y el valor j (proveniente de una distribución uniforme)
p → aleatorio entre j y el valor 𝐿 𝑠𝑢𝑝
2 (proveniente de una distribución uniforme)
Una vez se obtienen los vecinos s y p se evalúa la solución con cada uno de ellos y se escoge la
de mejor valor.

− Si en el caso contrario valor j de la posición de la mejor solución, a la que se le generara el
vecino se encuentra en el intervalo 2. Entonces se generan dos números aleatorios así:
s→ aleatorio entre 𝐿 𝑠𝑢𝑝
2 y el valor j (proveniente de una distribución uniforme)
p → aleatorio entre j y el valor del 𝐿 𝑠𝑢𝑝 (proveniente de una distribución uniforme)
Una vez se obtienen los vecinos s y p se evalúa la solución con cada uno de ellos y se escoge la
de mejor valor.
8.5.2. Vecinos de Inspiración y de Rotación
− VECINOS DE INSPIRACIÓN: Este tipo de variación resulta de un cambio pensamiento y
sentido en la posición de una nota específica la cual es cambiada de forma imprevista y que
busca mejorar la melodía que se tiene actualmente. Este tipo de vecinos se obtienen generando
un numero aleatorio j entre del número máximo de notas k de la melodía. El número j obtenido
representa la nota y es la posición de la variable que se modificara a través de la inspiración,
luego entonces lo que se hace es cambiar la nota escogida por un numero aleatorio i del espacio
de soluciones del problema y proveniente de una distribución uniforme.
− VECINOS DE ROTACIÓN DESCENDENTES: En los vecinos de rotación descendentes las
variables de cada solución son consideradas notas a las cuales se les modificaran sus
posiciones. Se obtiene la octava de la nota correspondiente. Esta se genera con un número
aleatorio j entre 8 y las k variables del problema.
−

8va→ un número aleatorio j entre 8 y las k notas de la melodía conveniente actual
• Se obtiene la quinta de la nota correspondiente. Esta encuentra al restarle 3 posiciones
a la 8va
5ta → se obtiene de → 8va – 3
• Se obtiene la cuarta de la nota correspondiente. Esta encuentra al restarle 4 posiciones
a la 8va
4ta → se obtiene de → 8va – 4
• Se obtiene la primera de la nota correspondiente. Esta encuentra al restarle 7
posiciones a la 8va
1ra → se obtiene de → 8va – 7
Los movimientos para la generación de vecinos de rotación descendentes son expuestos a
continuación en la (ilustración Nº3). Cada nota gira hacia delante tomando la posición clave más
cercana.

Ilustración 3 Vecinos de Rotación descendentes
− VECINOS DE ROTACIÓN ASCENDENTES: En los vecinos de rotación ascendentes las
variables de cada solución son consideradas notas a las cuales se les modificaran sus
posiciones. Se obtiene la primera de la nota correspondiente. Esta se genera con un número
aleatorio j entre 1 y las (k- 8) variables del problema.
−
1ra → un número aleatorio j entre 1 y las k- 8 posiciones de la melodía conveniente actual
• Se obtiene la cuarta de la nota correspondiente. Esta encuentra al sumarle 3 posiciones
a la 1ra
4ta → se obtiene de → 1ra + 3

• Se obtiene la quinta de la nota correspondiente. Esta encuentra al sumarle 4 posiciones
a la 1ra
5ta → se obtiene de → 1ra + 4
• Se obtiene la octava de la nota correspondiente. Esta encuentra al sumarle 7 posiciones
a la 1ra
8va → se obtiene de → 1ra +7
Los movimientos para la generación de vecinos de rotación ascendentes son expuestos a
continuación en la (ilustración Nº4). Cada nota gira hacia atrás tomando la posición clave más
cercana.
Ilustración 4 Vecinos de Rotación ascendentes.

8.6. Parámetros y Pseudocódigo del Algoritmo Cromático
8.6.1. Parámetros Evaluación De Ejercicios Alta Complejidad
Para esta primera parte se trabajó con un tamaño 10 en el grupo de melodías iniciales por ARRAM,
este parámetro ARRAM fue 100 iteraciones y el criterio máximo de parada fue de 1000 iteraciones.
El valor para AM fue de 0.0971352, MC, VMC y UM fueron de 0.552618 0.233438 y 0.483767
respectivamente (Sabie, 2011). Para todos los parámetros:
𝑏0, 𝑏1 , 𝑏2 , 𝑏3, 𝑏4 … … 𝑏8, 𝑎1, 𝑎2, 𝑎3, 𝑎4 … … 𝑎8, 𝑐1, 𝑐2 y 𝑐3 Se realizaron sus estimaciones en un
rango límite de [-1,1]. Para los parámetros 𝑏0, 𝑐1, 𝑐2 se realizaron estimaciones iniciales de 1, 1
y 0 respectivamente para prevenir indeterminaciones dentro del modelo.
8.6.2. Parámetros Evaluación Caso de Estudio Practico
En esta oportunidad se realizaron corridas con un tamaño 10 en el grupo de melodías iniciales por
ARRAM, este parámetro ARRAM fue 30 iteraciones y el criterio máximo de parada fue de 8
horas. El valor para AM fue de 0.0971352, MC, VMC y UM fueron de 0.552618 0.233438 y
0.483767 respectivamente (Sabie, 2011). Para todos los parámetros:
𝑏0, 𝑏1 , 𝑏2 , 𝑏3, 𝑏4 … … 𝑏8, 𝑎1, 𝑎2, 𝑎3, 𝑎4 … … 𝑎8, 𝑐1, 𝑐2 y 𝑐3 Se realizaron sus estimaciones en un
rango límite de [-1,1]. Igualmente, para los parámetros 𝑏0, 𝑐1, 𝑐2 se realizaron estimaciones
iniciales de 1, 1 y 0 respectivamente para prevenir indeterminaciones dentro del modelo.

9. RESULTADOS Y DISCUSIONES
En esta sección inicialmente se compara el algoritmo propuesto con varios modelos de tipo lineal
y no lineal, en unos cuatro problemas que pertenecen al grupo de modelos ‘‘test problems” los
cuales son considerados por el National Institute Standards and Technology USA website, como
modelos con un alto nivel de dificultad.
Posteriormente son mostrados los resultados del algoritmo en unos problemas multivariables en
caso de estudio práctico. Estos mismos se desprenden de la valoración y análisis de la estimación
de precios para tipos de ganado seleccionados según datos históricos que se asocian con variables
de tipo ganado, referenciado como lo son; cantidad, mes y precios de venta. Cabe resaltar que estos
se obtienen sobre hechos de venta e históricos. Los mismos datos fueron obtenidos a través de
información generada por la empresa Subastar S.A. de la ciudad de Montería- Córdoba.
En específico se implementó el algoritmo de búsqueda y el modelo no lineal de series de tiempo
para realizar los ejercicios de pronóstico en tipos específicos de ganado, conforme a los datos
recolectados.
9.1. Problemas de Evaluación: Ejercicios de Alta Complejidad
9.1.1. Problema de evaluación N°1 (Clase polinomial)
Este problema de evaluación tiene 82 datos y es conocido como ‘‘Fillip” y consta de 11
parámetros, el modelo es expuesto en la expresión (13).

𝑦 = 𝛽0 + 𝛽1𝑥 + 𝛽2𝑥2 + … + 𝛽9𝑥9 +𝛽10𝑥10 + ℰ (13).
Los resultados del modelo propuesto son expuestos en el (Gráfico Nº1) y en la (Tabla Nº1) se
presenta la comparación de resultados de la solución estándar y del modelo propuesto.
9.1.2. Problema de evaluación N°2 Clase (polinomial)
Este problema de evaluación tiene 21 datos, es conocido como ‘‘Wampler4” y consta de 6
parámetros, el modelo es expuesto en la expresión (14).
𝑦 = 𝛽0 + 𝛽1𝑥 + 𝛽2 𝑥2 + 𝛽3 𝑥
3 + 𝛽4 𝑥4 + 𝛽5 𝑥
5 + ℰ (14).
Los resultados del modelo propuesto son expuestos en el (Gráfico Nº2) y en la (Tabla Nº2) se
presenta la comparación de resultados de la solución estándar y del modelo propuesto.
9.1.3. Problema de evaluación N°3 (Clase racional)
Este problema de evaluación tiene 11 datos, es conocido como ‘‘MGH09”, y consta de 4
parámetros, el modelo es expuesto en la expresión (15).
𝑦 =𝛽1 (𝑥2+ 𝑥𝛽2)
𝑥2+𝑥𝛽3 + 𝛽4 (15).
Los resultados del modelo propuesto son expuestos en el (Gráfico Nº3) y en la (Tabla Nº3) se
presenta la comparación de resultados de la solución estándar y del modelo propuesto.

9.1.4. Problema de evaluación N°4 (Clase diversa)
Este problema de evaluación tiene 154 datos, es conocido como ‘‘Bennett5”, y consta de 4
parámetros, el modelo es expuesto en la expresión (16).
𝑦 = 𝛽1 (𝑥 + 𝛽2)−1
𝛽3⁄
+ ℰ (16).
Los resultados del modelo propuesto son expuestos en el (Gráfico Nº4) y en la (Tabla Nº4) se
presenta la comparación de resultados de la solución estándar y del modelo propuesto.
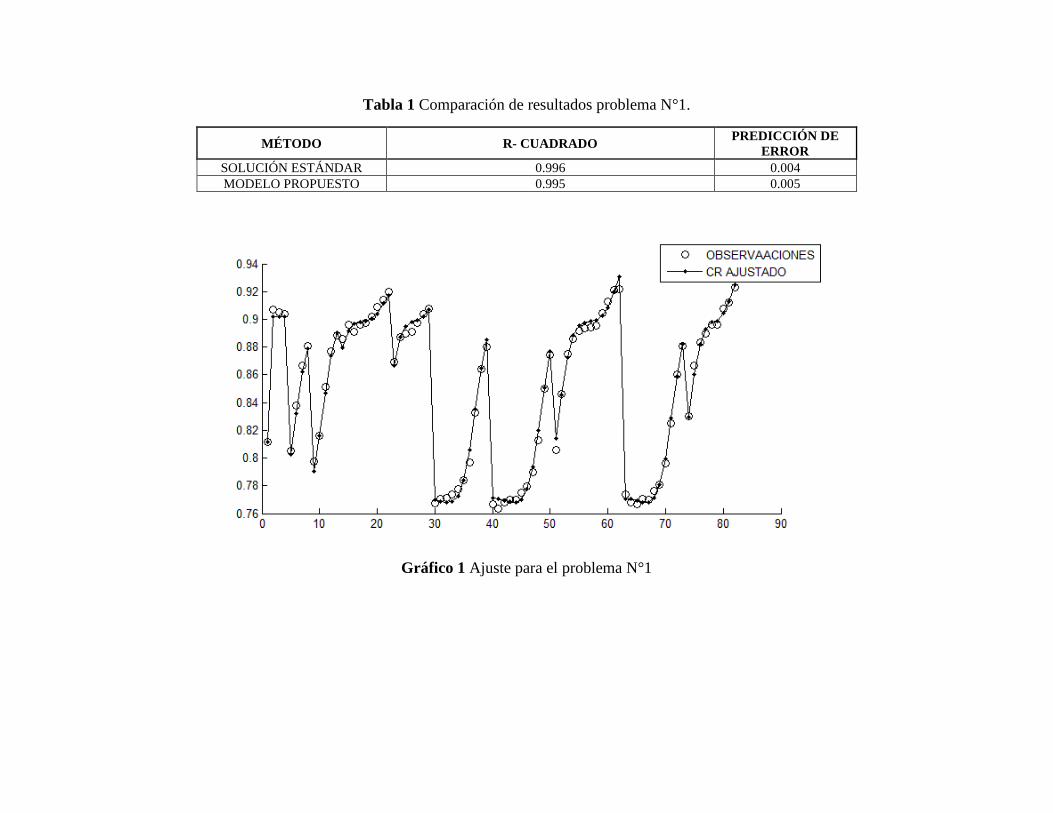
Tabla 1 Comparación de resultados problema N°1.
MÉTODO R- CUADRADO PREDICCIÓN DE
ERROR
SOLUCIÓN ESTÁNDAR 0.996 0.004
MODELO PROPUESTO 0.995 0.005
Gráfico 1 Ajuste para el problema N°1

.
Tabla 2 Comparación de resultados problema N°2.
MÉTODO R- CUADRADO PREDICCIÓN DE ERROR
SOLUCIÓN ESTÁNDAR 0.9574 0.0426
MODELO PROPUESTO 0.9982 0.0018
Gráfico 2 Ajuste para el problema N°2.
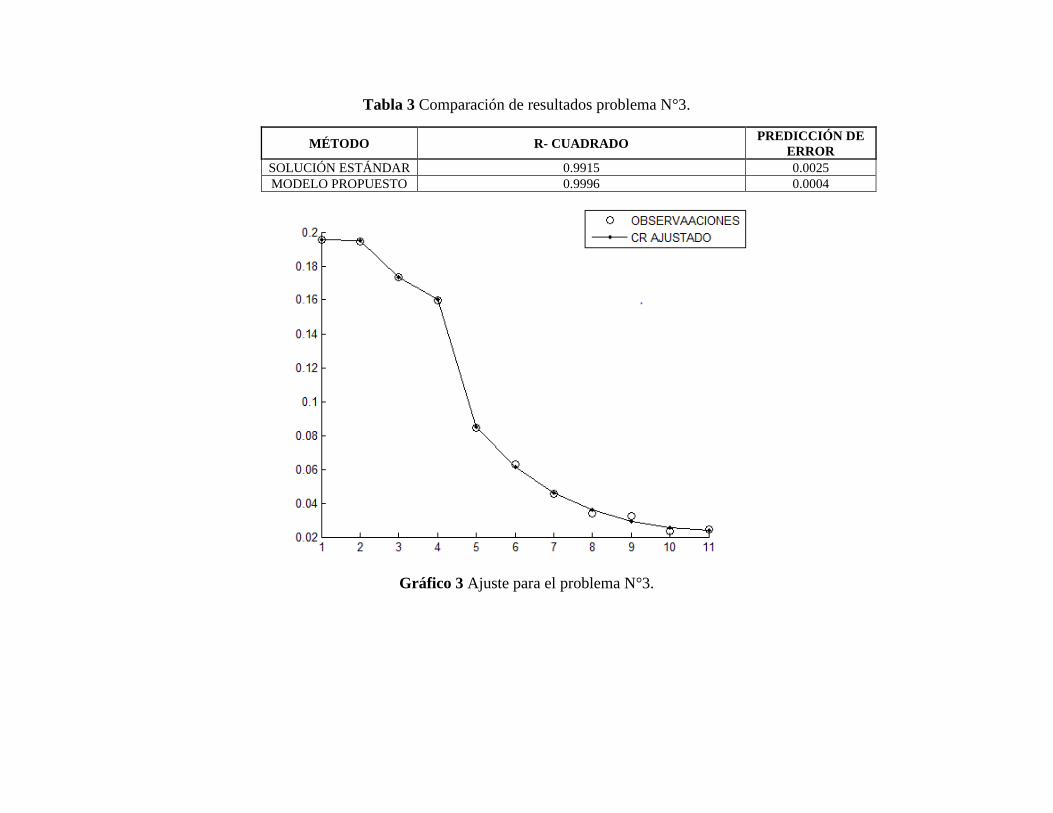
Tabla 3 Comparación de resultados problema N°3.
MÉTODO R- CUADRADO PREDICCIÓN DE
ERROR
SOLUCIÓN ESTÁNDAR 0.9915 0.0025
MODELO PROPUESTO 0.9996 0.0004
Figura Nº6. Ajuste para el problema N°3.
Gráfico 3 Ajuste para el problema N°3.

Tabla 4 Comparación de resultados problema N°4.
MÉTODO R- CUADRADO PREDICCIÓN DE
ERROR
SOLUCIÓN ESTÁNDAR 0.99998 0.00001
MODELO PROPUESTO 0.99998 0.00001
Figura Nº7. Ajuste para el problema
Gráfico 4 Ajuste para el problema N°4.

9.2. Problemas con Múltiples Variables
9.2.1. Caso Precios del Ganado Tipo Hembra de Vientre 2 ¾ (HV) en Córdoba
Este ejercicio de evaluación de se procede a realizar la estimación de precios para ganado tipo
hembra de vientre, edad de 2 ¾ años, HV, a partir de las variables tiempo, cantidad, de la siguiente
manera; mes del año, cantidad promedio mensual, para estimar el valor del precio promedio de
venta del mes por kilogramo.
Importante señalar que la estimación se lleva a cabo con fundamento en los datos históricos
recopilados para los años 2014-2019. La fuente directa de información se concreta gracias al
contenido público disponible en la web oficial la empresa Subastar S.A. de la ciudad de Montería-
Córdoba.
Los datos y resultados del modelo propuesto para la estimación de precios ganado tipo HV son
expuestos en las (Tablas Nº5 y Nº6) y en el (Gráfico Nº5).
9.2.2. Caso Precios del Ganado Tipo Vaca Escotera 3 (VE) en Córdoba
En este punto se estiman los precios para ganado tipo vaca escotera con 3 años de edad, VE, a
partir de las variables tiempo, cantidad, de la siguiente manera; mes del año, cantidad promedio
mensual, para estimar el valor del precio promedio de venta del mes por kilogramo.

La estimación se lleva a cabo con fundamento en los datos históricos recopilados para los años
2014-2019. La fuente directa de información se concreta gracias al contenido público disponible
en la web oficial la empresa Subastar S.A. de la ciudad de Montería- Córdoba.
Los datos y resultados del modelo propuesto para la estimación de precios ganado tipo VE son
en las (Tablas Nº7 y Nº8) y en el (Gráfico Nº6).
9.2.3. Caso Precios del Ganado Tipo Toro 3 (TO) en Córdoba
En el caso de esta aplicación se estiman los precios para ganado tipo toro de 3 años, TO, a partir
de las variables tiempo, cantidad, de la siguiente manera; mes del año, cantidad promedio mensual,
para estimar el valor del precio promedio de venta del mes por kilogramo.
La estimación se lleva a cabo con fundamento en los datos históricos recopilados para los años
2014-2019. La fuente directa de información se concreta gracias al contenido público disponible
en la web oficial la empresa Subastar S.A. de la ciudad de Montería- Córdoba.
Los datos y resultados del modelo propuesto para la estimación de precios ganado tipo TO son
en las (Tablas Nº9 y Nº10) y en el (Gráfico Nº7).
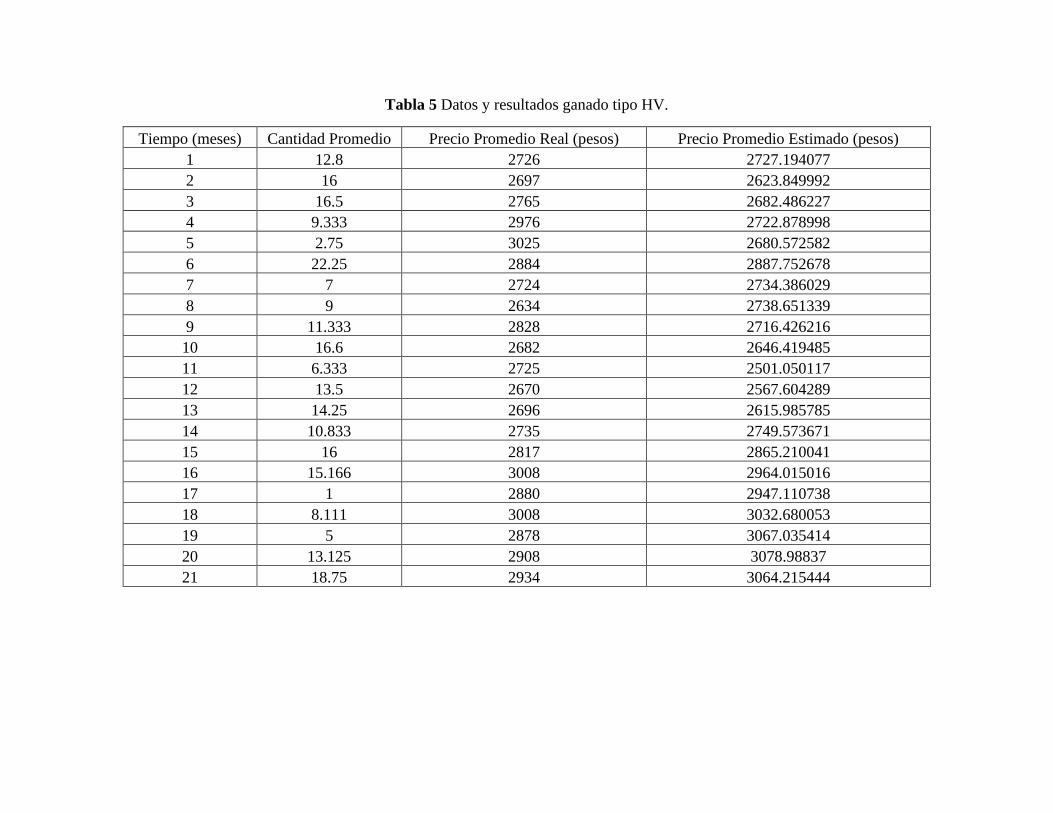
Tabla 5 Datos y resultados ganado tipo HV.
Tiempo (meses) Cantidad Promedio Precio Promedio Real (pesos) Precio Promedio Estimado (pesos)
1 12.8 2726 2727.194077
2 16 2697 2623.849992
3 16.5 2765 2682.486227
4 9.333 2976 2722.878998
5 2.75 3025 2680.572582
6 22.25 2884 2887.752678
7 7 2724 2734.386029
8 9 2634 2738.651339
9 11.333 2828 2716.426216
10 16.6 2682 2646.419485
11 6.333 2725 2501.050117
12 13.5 2670 2567.604289
13 14.25 2696 2615.985785
14 10.833 2735 2749.573671
15 16 2817 2865.210041
16 15.166 3008 2964.015016
17 1 2880 2947.110738
18 8.111 3008 3032.680053
19 5 2878 3067.035414
20 13.125 2908 3078.98837
21 18.75 2934 3064.215444
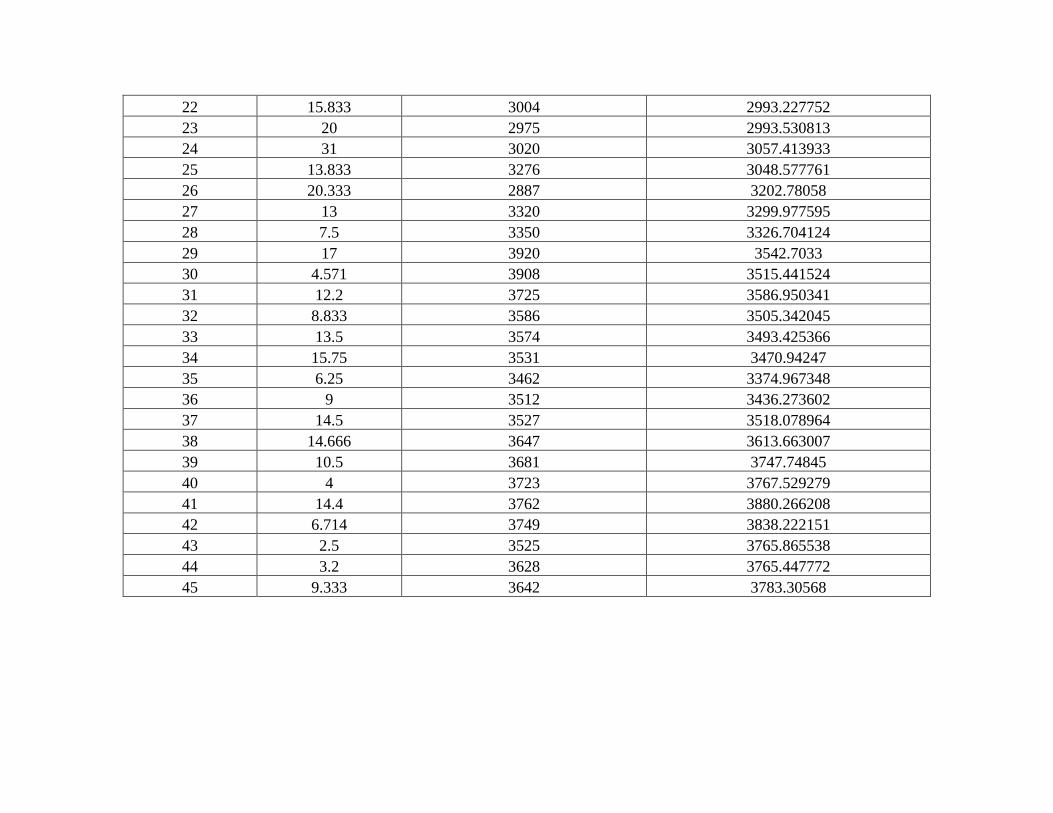
22 15.833 3004 2993.227752
23 20 2975 2993.530813
24 31 3020 3057.413933
25 13.833 3276 3048.577761
26 20.333 2887 3202.78058
27 13 3320 3299.977595
28 7.5 3350 3326.704124
29 17 3920 3542.7033
30 4.571 3908 3515.441524
31 12.2 3725 3586.950341
32 8.833 3586 3505.342045
33 13.5 3574 3493.425366
34 15.75 3531 3470.94247
35 6.25 3462 3374.967348
36 9 3512 3436.273602
37 14.5 3527 3518.078964
38 14.666 3647 3613.663007
39 10.5 3681 3747.74845
40 4 3723 3767.529279
41 14.4 3762 3880.266208
42 6.714 3749 3838.222151
43 2.5 3525 3765.865538
44 3.2 3628 3765.447772
45 9.333 3642 3783.30568
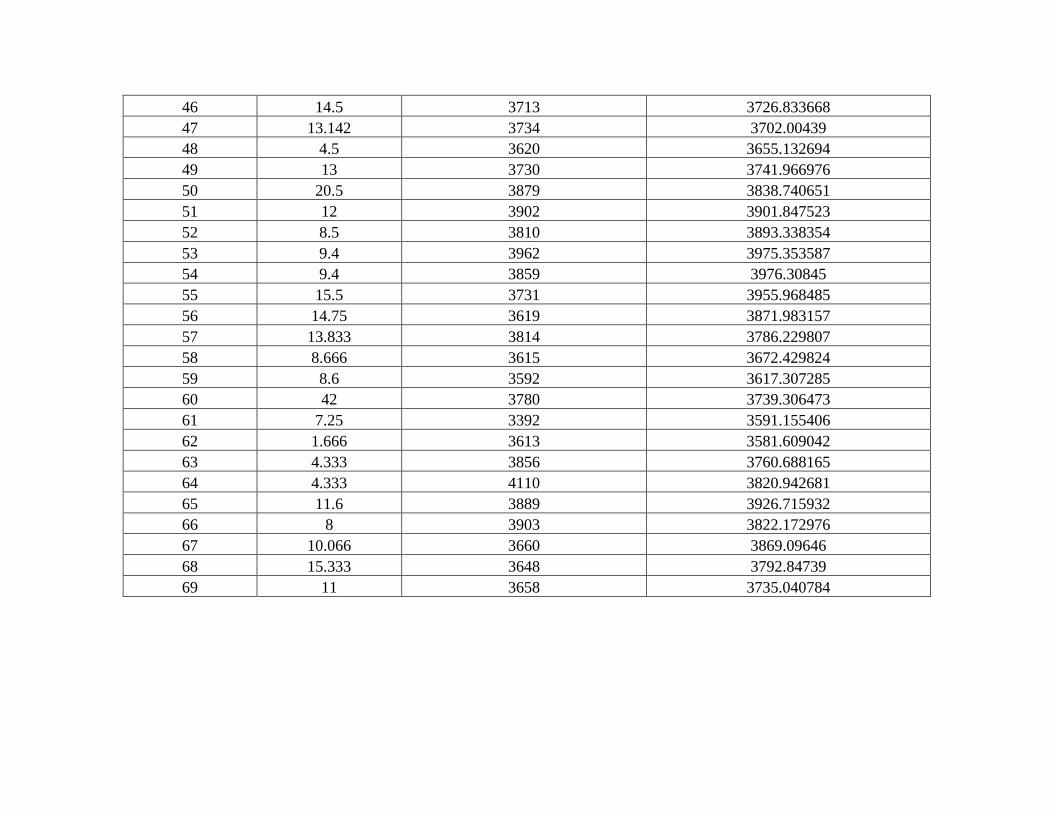
46 14.5 3713 3726.833668
47 13.142 3734 3702.00439
48 4.5 3620 3655.132694
49 13 3730 3741.966976
50 20.5 3879 3838.740651
51 12 3902 3901.847523
52 8.5 3810 3893.338354
53 9.4 3962 3975.353587
54 9.4 3859 3976.30845
55 15.5 3731 3955.968485
56 14.75 3619 3871.983157
57 13.833 3814 3786.229807
58 8.666 3615 3672.429824
59 8.6 3592 3617.307285
60 42 3780 3739.306473
61 7.25 3392 3591.155406
62 1.666 3613 3581.609042
63 4.333 3856 3760.688165
64 4.333 4110 3820.942681
65 11.6 3889 3926.715932
66 8 3903 3822.172976
67 10.066 3660 3869.09646
68 15.333 3648 3792.84739
69 11 3658 3735.040784
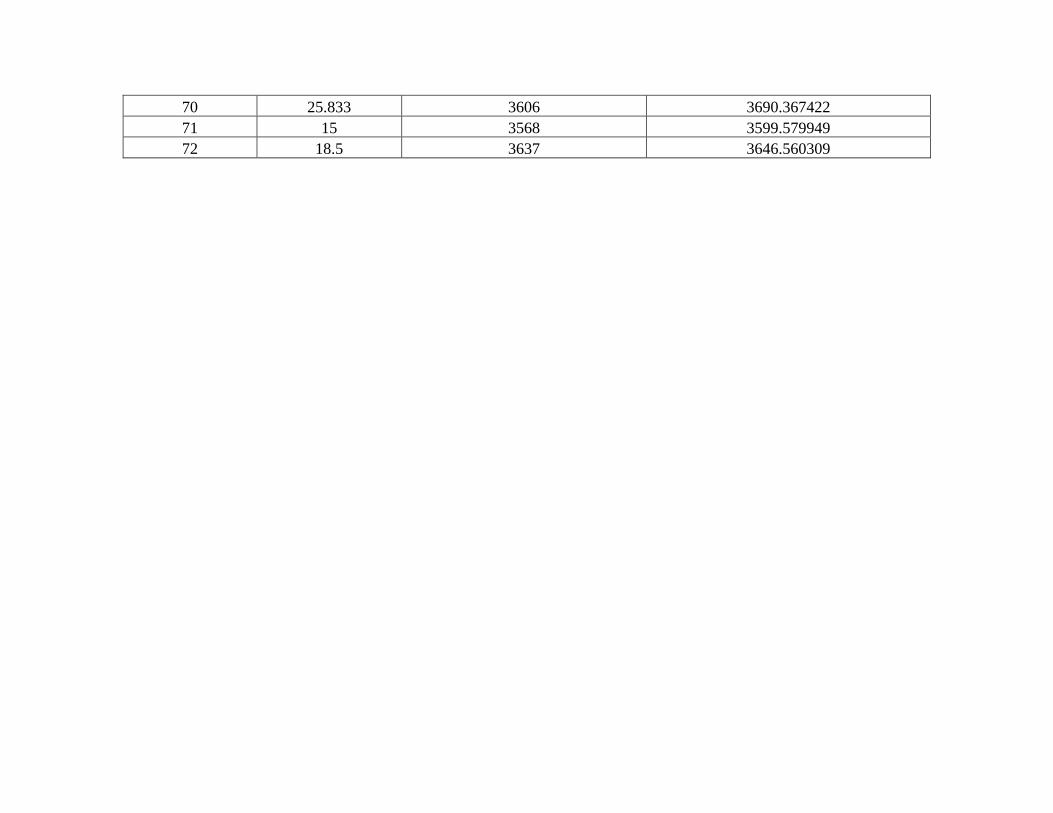
70 25.833 3606 3690.367422
71 15 3568 3599.579949
72 18.5 3637 3646.560309
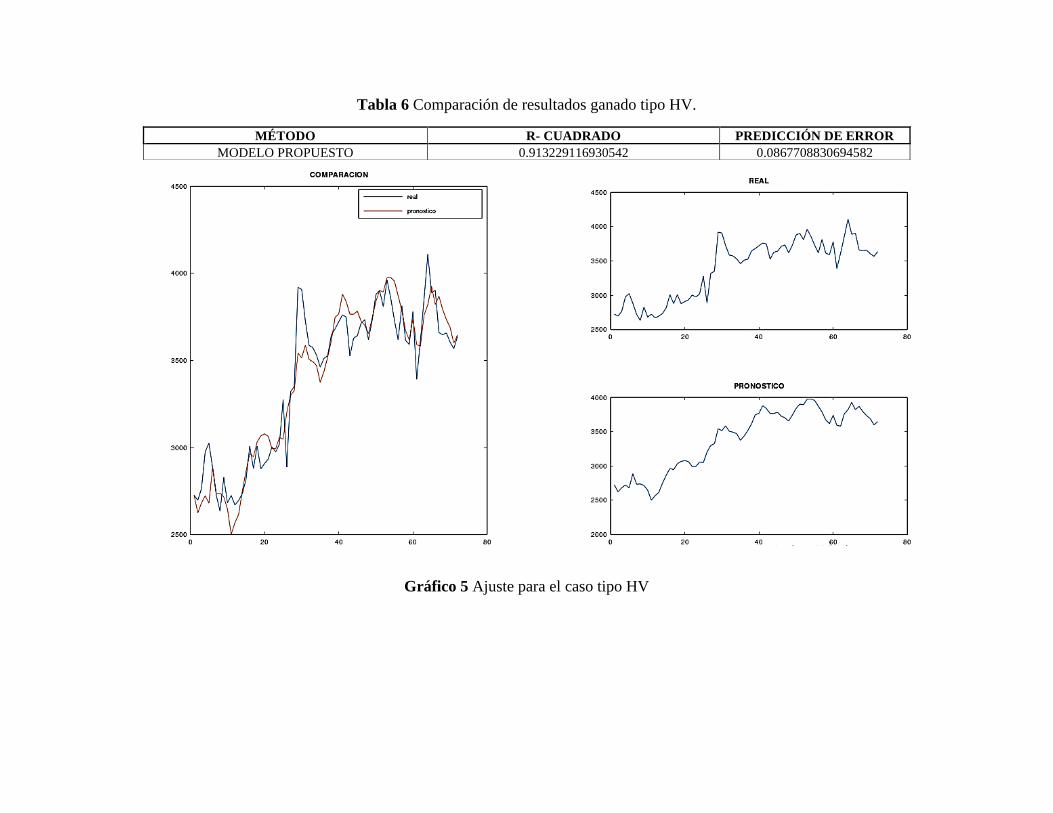
Tabla 6 Comparación de resultados ganado tipo HV.
MÉTODO R- CUADRADO PREDICCIÓN DE ERROR
MODELO PROPUESTO 0.913229116930542 0.0867708830694582
Gráfico 5 Ajuste para el caso tipo HV
Tabla 7 Datos y resultados ganado tipo VE
Tiempo (Meses) Cantidad Promedio Precio Promedio Real (pesos) Precio Promedio Estimado (pesos)
1 48 2665 2635.948822
2 39.85 2609 2626.949422
3 27 2766 2735.810601
4 20.42 2972 2856.773269
5 18.44 2961 2914.947944
6 29.28 2748 2805.197465
7 40 2682 2711.104518
8 34.5 2499 2645.739042
9 57.33 2554 2506.882372
10 58.44 2542 2408.554837
11 62.5 2570 2343.442693
12 68.16 2563 2333.273438
13 71 2554 2383.392814
14 51.125 2606 2484.647471
15 48.222 2730 2605.414679
16 25.444 2812 2806.903656
17 16 2905 2996.92874
18 35.25 2861 2876.528747
19 43 2680 2860.72841
20 35.125 2760 2855.573692
21 30.375 2799 2839.513827

22 34.2 2782 2785.194189
23 55.666 2803 2745.442525
24 41.2 2966 2798.918724
25 40.625 2975 2882.539152
26 46.333 2792 2985.086313
27 28.222 2969 3170.607817
28 22.428 3371 3329.602922
29 17.571 3887 3466.567284
30 26.5 3756 3413.29678
31 27 3408 3417.528277
32 25.75 3343 3408.467434
33 31.625 3327 3335.950001
34 26.875 3301 3340.492852
35 22.75 3357 3372.823099
36 32.285 3380 3324.269852
37 47.166 3380 3338.799216
38 18.75 3399 3575.63406
39 24.222 3500 3591.554816
40 10.285 3649 3815.945202
41 27 3707 3674.475428
42 30.22 3594 3661.924291
43 44 3372 3591.583888
44 40.2 3538 3554.000513
45 31.875 3567 3530.517106

46 21.555 3556 3565.07978
47 23.333 3469 3515.14756
48 26 3378 3489.405673
49 19.42 3599 3588.176893
50 26.85 3605 3558.371729
51 19.57 3624 3685.758795
52 25.14 3789 3665.180415
53 21.22 3750 3724.592906
54 24.62 3767 3677.263234
55 26.11 3586 3625.882643
56 27.62 3515 3556.118702
57 36.28 3545 3443.522414
58 21 3362 3501.401601
59 24 3300 3439.376462
60 31 3418 3391.275918
61 25.66 3350 3465.60834
62 13.42 3441 3653.591383
63 28 3634 3566.750127
64 21.37 3791 3680.020057
65 14.57 3942 3785.177881
66 17.5 3808 3757.956168
67 21.87 3691 3683.998413
68 28.77 3428 3585.2216
69 39.37 3385 3497.219223

70 30.5 3404 3511.118326
71 43.85 3355 3466.364991
72 34.33 3499 3526.940565

Tabla 8 Comparación de resultados ganado tipo VE.
MÉTODO R- CUADRADO PREDICCIÓN DE ERROR
MODELO PROPUESTO 0.92336262 0.07663738
Gráfico 6 Ajuste para el caso tipo VE.

Tabla 9 Datos y resultados ganado tipo TO.
Tiempo (Meses) Cantidad Promedio Precio Promedio Real (pesos) Precio Promedio Estimado (pesos)
1 5.4 2965.2 2840.608083
2 6.428571429 2949 2936.945064
3 2.333333333 3060.333333 3029.201733
4 3.333333333 3170 2983.303759
5 2.2 3256.8 3012.636364
6 3 3016 2876.932097
7 3.888888889 2878.666667 2740.222271
8 3.222222222 2844.555556 2677.720147
9 2.4 2862.2 2688.90682
10 17.33333333 2875.555556 2693.773357
11 6 2890.25 2769.065391
12 4.2 2919.6 2868.96943
13 7.375 2918 3114.848659
14 14 3048.714286 3088.158765
15 5.111111111 3056.25 3219.185255
16 5.857142857 3146.857143 3278.668019
17 4.285714286 3144.571429 3238.342269
18 7.222222222 3338.888889 3288.898306
19 6.625 3103.25 3193.217727
20 6.428571429 3189.714286 3124.356501
21 5.857142857 3234 3073.234311

22 14.55555556 3186.333333 3046.011816
23 7.125 3268.25 3256.265963
24 4.4 3271.2 3294.327097
25 12 3416.571429 3420.138615
26 4.6 3235 3579.883443
27 4 3422.428571 3696.650512
28 3.6 3598.6 3784.770832
29 3.666666667 4129.666667 3824.13027
30 5.25 4166.5 3830.951025
31 9.75 4056.125 3914.77932
32 8.428571429 4036 3925.949287
33 2.833333333 3839.5 3832.812218
34 4.2 3937.4 3791.865827
35 5.833333333 3896 3858.163768
36 2.666666667 4015.166667 3955.521638
37 9.5 4005.666667 4086.738703
38 2.2 3975.2 4146.742319
39 3.333333333 3969 4144.202765
40 2.8 4316.4 4218.608984
41 3.333333333 4173 4210.592109
42 2.5 4056.125 4252.925909
43 8.2 3984 4282.038071
44 6.142857143 4164.428571 4150.308148
45 3.142857143 4074.714286 4093.94908
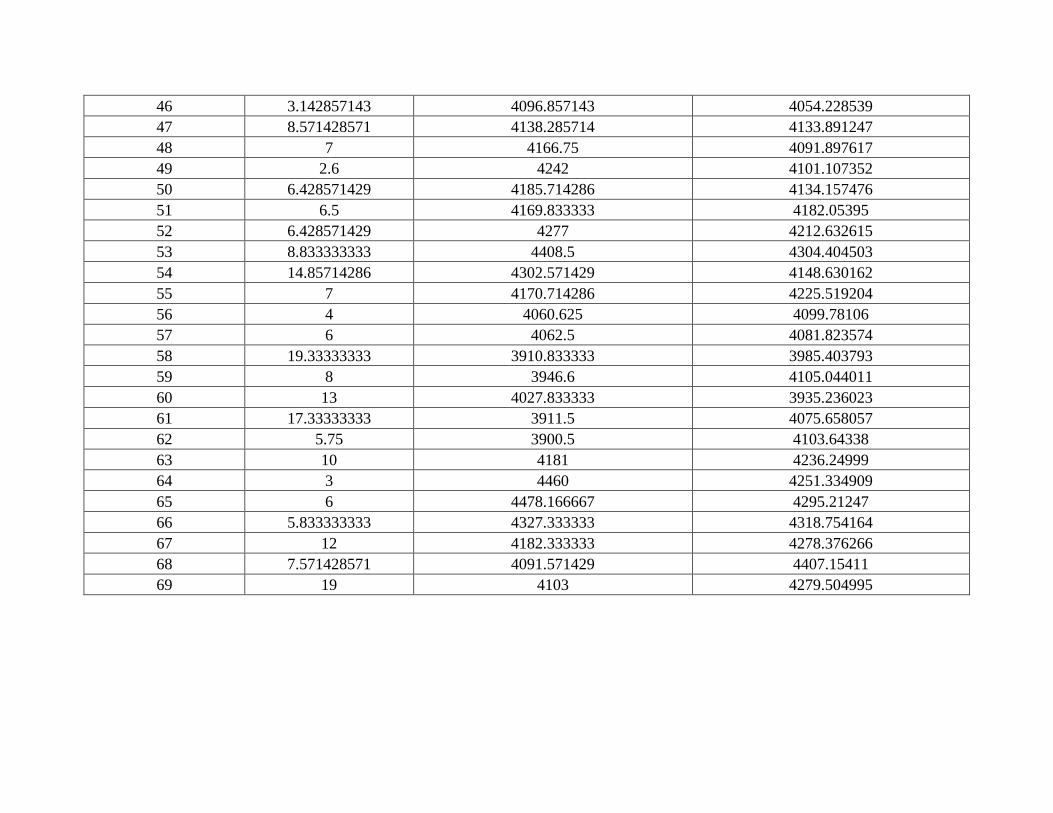
46 3.142857143 4096.857143 4054.228539
47 8.571428571 4138.285714 4133.891247
48 7 4166.75 4091.897617
49 2.6 4242 4101.107352
50 6.428571429 4185.714286 4134.157476
51 6.5 4169.833333 4182.05395
52 6.428571429 4277 4212.632615
53 8.833333333 4408.5 4304.404503
54 14.85714286 4302.571429 4148.630162
55 7 4170.714286 4225.519204
56 4 4060.625 4099.78106
57 6 4062.5 4081.823574
58 19.33333333 3910.833333 3985.403793
59 8 3946.6 4105.044011
60 13 4027.833333 3935.236023
61 17.33333333 3911.5 4075.658057
62 5.75 3900.5 4103.64338
63 10 4181 4236.24999
64 3 4460 4251.334909
65 6 4478.166667 4295.21247
66 5.833333333 4327.333333 4318.754164
67 12 4182.333333 4278.376266
68 7.571428571 4091.571429 4407.15411
69 19 4103 4279.504995

70 15.88888889 4058 4284.599186
71 17 3994 4305.077418
72 29.33333333 4147 4095.807837
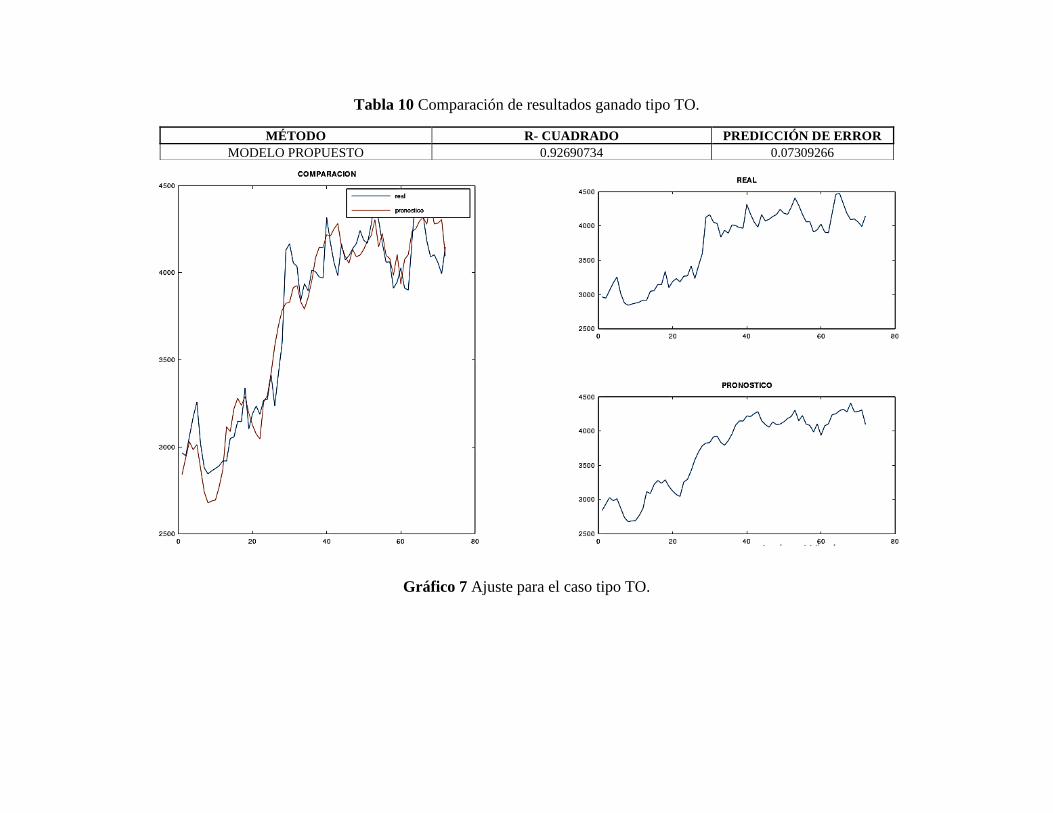
Tabla 10 Comparación de resultados ganado tipo TO.
MÉTODO R- CUADRADO PREDICCIÓN DE ERROR
MODELO PROPUESTO 0.92690734 0.07309266
Gráfico 7 Ajuste para el caso tipo TO.

10. CONCLUSIONES
En este proyecto se trabajó con un modelo de regresión no lineal en pronóstico de series de
tiempo con diferentes problemas de gran dificultad. Se encontró que el algoritmo cromático
ofrece muy buenos resultados en la búsqueda, de conformidad con los parámetros para el
modelo.
De los ejercicios desarrollados, se destaca a este algoritmo debido a que ofrece grandes
ventajas en la exploración y la diversificación de las soluciones, lo que es muy importante a
la hora de encontrar óptimos globales en un espacio de soluciones. Los resultados obtenidos
para los problemas de alta dificultad muestran que se supera en la mayoría de los casos las
soluciones estándares encontradas en la literatura.
Para los ejercicios relacionados con los casos prácticos se identificó que el modelo arroja
buenos resultados para la estimación de valores a partir de múltiples variables, que a su vez
permiten en gran manera efectuar pronósticos para diferentes escenarios en los problemas
de series de tiempo estudiados. Debe indicarse que del análisis de los datos estudiados para
los años 2014-2019, se observa una tendencia estacionaria de precios relacionada con las
características climáticas de la región.

Es notorio que las estimaciones realizadas por el modelo son próximas y ajustadas con la
relación de datos históricos sobre los meses del año y los precios de venta del ganado según
su tipo en la región analizada.
En esta propuesta se evidencia la eficiencia y robustez del modelo propuesto para encontrar
muy buenos ajustes en diferentes series de datos, tanto de una, como de múltiples variables.
El modelo se adecuo satisfactoriamente y tuvo un alto poder predictivo en comportamientos
lineales, no lineales, cíclicos y estacionales.
Además, hay que resaltar que en el algoritmo también logra que este sea capaz de hacer que
sus soluciones cumplan con los supuestos o restricciones que son por lo general necesarias
para hacer uso de los modelos de regresión, lo que ratifica a un mas esta nueva propuesta y
la hace más sólida y confiable.

11. RECOMENDACIONES
En definitiva, después del desarrollo y análisis de los resultados de la investigación, podemos
afirmar que el Algoritmo Cromático ofrece soluciones que se ajustan de manera adecuada
atendiendo las restricciones y la optimización de recursos en la búsqueda.
Se recomienda complementar el desarrollo de esta investigación, aprovechando el
desempeño que evidencia el Algoritmo Cromático y el modelo implementado en más casos
reales, debido a que este promete alcanzar muy buenos resultados con respecto a la calidad
de sus soluciones. Igualmente se sugiere abarcar otras consideraciones para otros tipos de
problemas a fin de conocer más a fondo el desempeño del algoritmo.
Adicionalmente se sugiere que, para realizar ejercicios de búsqueda con el modelo
propuesto, en problemas de pronósticos, se realicen diferentes arranques e iteraciones de
revisión con el fin de estimar mejores resultados y poder comparar los valores obtenidos y
los indicadores de minimización del error.

12. BIBLIOGRAFÍA
A.J. Nebro, J. D.-N. (2009). smpso: a new pso-basedmethaeuristicformulti-objetive optimization. Obtenido
de www.IEEEpress
Alsmadi, M. K., Omar, K. B., Noah, & A., S. (2009). Back Propagation Algorithm: The Best Algorithm
Among the Multi-layer Perceptron Algorithm. International Journal of Computer Science and
Network Security.
Barreras Serrano, A., Eduardo, S. L., & Figueroa Saavedra, F. (2014). Uso de un modelo univariado de
series de tiempo para la predicción, en el corto plazo, del comportamiento de la producción de carne
de bovino en Baja California, México. *Instituto de Investigaciones en Ciencias Veterinarias de la
Universidad Autónoma de Baja California.
Behnamian, J., & Ghomi, F. (2009). Development of a PSO–SA hybrid metaheuristic for a new
comprehensive. Elsevier.
Botero, S., & Cano, J. (2008). Análisis de series de tiempo para la predicción de los precios de la energía
en la bolsa de Colombia. CUADERNOS DE ECONOMÍA 48, 2008 .
Box, G. E., Jenkins, G. M., & Reinsel, G. C. ( 2015.). Time Series Analysis: Forecasting and. Wiley.
Brockwell, P. J., & Davis, R. A. (2010). Introduction to Time Series and Foirecasting. Springer .

Burke, E., Cowling, P., & Landa silva, J. (2006). Hybrid Population-Based Metaheuristica Approachsfor.
the space a llocation problem. Obtenido de www.ieeepress.
Castillo, O. (2007). Comportamiento temporal de los precios del ganado macho de levante de primera en
Sincelejo. Temas Agrarios Universidad de Córdoba, Departamento de Ingeriría Agronómica y
Desarrollo Rural. .
Castillo, O. (2007). Estacionalidad, ciclos y volatilidad en los precios del ganado macho de levante en
Montería, Colombia. Rev MVZ, Cordoba.
Castro, P., & V, F. (2008). Mobais: A Bayesian Artificial Immune System For Muti-Objectives
Optimization. 7 th international conference. phuket thailand.
Chatfield, C. (2004). The Analysis of Time Series: An Introduction. MA: Chapman & Hall .
Cortes, P., Garcia, J. M., Muñusuri, J., & Onieva, L. (2008). Viral System: A New Bio-Inspired
Optimization Aproach. Computers y Operation Reseach 35, 2841.
De Gooijer, J. G., & Hyndman, R. J. (2006). 25 years of time series forecasting. Elsevier.
Espinosa, J., Vélez, & A. (2017). Descripción y pronóstico de la producción de carne de bovino en el estado
de Tabasco. Actas Iberoamericanas en Conservación Animal .
Eye, A. V., & Schuster, C. (1998). Regression analysis for social sciences (1st ed.). . San Diego: Academic
Press.
Hastie, T., Tibshirani, R., & Friedman, J. (Springer). The elements of statistical learning: data mining,
inference and prediction. 2009.

INACAP. (2003). Manual de Analisis y Diseño de Algoritmos. 18. Obtenido de
www.innformatica.INACAP.cl
Kang Seok, L., & Zong woo, G. (2004). A New Structural Optimization Method Basedon The Harminy
Search Algorithm. Obtenido de www.sciencedirect press.
Kantz, H., & Schreiber, T. (2009 ). Nonlinear Time Series Analysis. Springer Series in Statistics.
Leung, S. C., & DefuZhang, C. T. (2010). A Hybrid simulater annealing methaeuristic. Obtenido de
www.algorithmforthetwo-dimencionalknapsackpackingproblemsciencedirectpress
Lopez, S. (2019). Determinantes del precio del ganado gordo bovino en pie de Medellín y Bogotá: 2009-
2019. Medellin, Colombia: Escuela De Economía Y Finanzas - Universidad EAFIT.
Melian, B., J.A.Moreno, & Moreno, J. (2003). Methaeuristicas: A Global View. Universidad De La
Laguna.
Montgomery, D. C. (2004). Desing and analysis of experiments book. 458-459.
Nader, A., & Zolfaghari, S. L. (2007). A New Meta-Heuristic Approach For Cominatorial Optimization
And Scheduling Problems. 7-14. Obtenido de www.ieeepress.
ob . (s.f.). 25, 26.
Rasmussen, R. (2004). On time-series data and optimal parameters. . Omega, 32,111–120.
RÌos, G. (2008). Series de Tiempo. Santiago: Departamento de Ciencias de la Computación - Universidad
de Chile.

Rodríguez Rivero, C. (2016). Modelos no lineales de pronóstico de series temporales basados en
inteligencia computacional para soporte en la toma de decisiones agrícolas. Córdoba, Argentina:
Facultad de Ciencias Exactas, Físicas y Naturales - UNIVERSIDAD NACIONAL DE CÓRDOBA
.
Ruiz, U. V. (2003). Manual de Analisis y Diseño de Algoritmos. INACAP.
Sabie, R. (2011). Un nuevo método de optimización que se fundamenta a través de un algoritmo de
búsqueda basado en la escala cromática de las notas musicales. Montería, Cordoba, Colombia:
Universidad de Córdoba.
Sebastian Urrutia, I. l. (2005). a new metheuristic and its application to the steiner problem in graphs.
universidad de buenos aires.
Shumway, R. H., & Stoffer. (2011). Time Series Analysis and its Applications. Springer.
Silver, E. (2004). An Overview Of Heuristic Solution Methods. The Journal Of The Operational Research
Society, 55(9), 936- 956.
Tong, H. (1990). Non-linear Time Series: A Dynamical System Approach. Oxford: Oxford University
Press.
Tsolacos, S. (2006). An assessment of property performance forecasts, consensus versus econometric. .
Journal of Property Investment & Finance, 24,386–399.
Weigend, A. S., Huberman, B. A., & Rumelhart, D. E. (1990). Predicting the future: a connectionist
approach. International Journal of Neural Systems, 193-209.

Werbos, P. (1974). Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences.
Cambridge: PhD thesis, Harvard University, Cambridge, MA (1974).
Yu, X., Efe, M. O., & Kaynak, O. (s.f.). A General Backpropagation Algorithm for Feedforward Neural
Networks Learning. IEEE, 2002.
Zhang, G. (2003). Time series forecasting using a hybrid ARIMA and neural network model. Elsevier.
Zhang, G. P., & M., K. D. (2007). Quarterly Time-Series Forecasting With Neural Networks. EEE
TRANSACTIONS ON NEURAL NETWORKS.

ANEXOS Y DIAGRAMAS APLICATIVO
Pseudocódigo del algoritmo.
INICIALIZAR LOS PARÁMETROS INCLUYENDO, TAMAÑO(N) DE GRUPO DE MELODÍAS INICIALES(GMI)
POR ARRAM ,MÁXIMO DE ITERACIONES POR ARRAM, AM, UM, MC Y VMC
MIENTRAS QUE NO SE ALCANCE LA CONDICIÓN DE PARADA
MIENTRAS QUE NO SE ALCANCE EL MÁXIMO DE ITERACIONES POR ARRAM
GENERAR GRUPO DE MELODÍAS INÍCIALES (GMI) DE TAMAÑO(N)
PARA i = 1 HASTA EL TAMAÑO (N) DEL GRUPO DE MELODÍAS(GMI)
EVALUAR CADA Xi MELODÍA DEL GRUPO
SI FITNESS DE (Xi) ES MEJOR QUE EL FITNESS (ML)
ML ← Xi ; FITNESS (ML) ← FITNESS (Xi)
FIN SI
SI FITNESS DE (ML) ES MEJOR QUE EL FITNESS (MM)
MM← ML; FITNESS (MM) ← FITNESS (ML)
FIN SI
FIN PARA
PARA i = 1 HASTA EL TAMAÑO (N) DEL GRUPO DE MELODÍAS
SI LA PROBABILIDAD AM ES MAYOR QUE UN NUMERO ALEATORIO
ENTRE CERO Y UNO PARA LA Xi MELODÍA
PARA j = 1 HASTA EL NUMERO K DE VARIABLES DE LA MELODÍA Xi
SI LA PROBABILIDAD UM ES MAYOR QUE UN NUMERO ALEATORIO
ENTRE CERO Y UNO
REMPLAZAR EL VALOR DE LA VARIABLE j DE LA melodía Xi
POR EL VALOR DE LA VARIABLE j DE LA MM
SI NO
REALIZAR UNA BÚSQUEDA DE VECINOS DE ESCALA CROMÁTICA
PARA EL VALOR DE LA VARIABLE j DE LA MELODÍA Xi
FIN SI
FIN PARA
SI NO
SI LA PROBABILIDAD MC ES MAYOR QUE UN NUMERO ALEATORIO
ENTRE CERO Y UNO PARA LA Xi MELODÍA
SE REMPLAZA LA Xi MELODÍA POR LA ML
SI NO
ESCOGER DOS MELODÍAS ALEATORIAS (S, P) DEL GRUPO DE MELODÍAS
ASIGNAR EL VALOR UNO A LA MELODÍA (S) Y DOS A LA MELODÍA (P)
PARA j = 1 HASTA EL NUMERO K DE VARIABLES DE LA MELODÍA Xi
GENERAR UN NÚMERO ALEATORIO ENTRE UNO Y DOS
SI NUMERO ALEATORIO ES IGUAL A UNO
REMPLAZAR EL VALOR DE LA VARIABLE j DE LA MELODÍA Xi
POR EL VALOR DE LA VARIABLE j DE LA MELODÍA S
SI NO
REMPLAZAR EL VALOR DE LA VARIABLE j DE LA MELODÍA Xi
POR EL VALOR DE LA VARIABLE j DE LA MELODÍA P
FIN SI
FIN PARA
FIN SI
SI LA PROBABILIDAD VMC ES MAYOR QUE UN NUMERO ALEATORIO
ENTRE CERO Y UNO PARA LA Xi MELODÍA
SE REALIZA UNA BÚSQUEDA DE VENOS DE INSPIRACIÓN
SI NO
SE REALIZA UNA BÚSQUEDA DE VENOS DE ROTACIÓN DE NOTAS
FIN SI
FIN SI
FIN PARA
FIN PARA
FIN PARA
FIN

Diagrama de bloques algoritmo.
SI
NO
SI
NO
NO
SI
NO
SI
NO
SI
SI SI NO
¿NO SE CUMPLE EL CRITERIO DE PARADA?
INICIO
2
INICIALIZAR PARÁMETROS
EVALUAR LA FUNCIÓN OBJETIVO Y
ACTUALIZAR (MM) Y (ML)
SI NO SE CUMPLE AM
¿SE CUMPLE EL # DE ITERACIONES ARRAM?
SI SE CUMPLE UM
ACTUALIZAR (MM)
SE REALIZA UNA BÚSQUEDA DE
VECINOS CROMÁTICA
EVALUAR F.O
SE UTILIZA UM
GENERAR GRUPO DE MELODÍAS (G M I)
FIN
¿SE CUMPLE LA
MC?
REALIZAR MC
SE COMBINAN 2 MELODÍAS ALEATORIAS
¿SE CUMPLE LA MC?
REALIZAR VECINOS
DE INSPIRACIÓN
REALIZAR VECINOS DE
ROTACIÓN DE NOTAS
2
2

ANEXO: DIAGRAMAS Y CASOS DE APLICACIÓN
− Diseño del Sistema
En este sección se hace hincapié a lo referente a la funcionalidad del sistema, como también a la
descripción de las acciones asociadas al uso de la aplicación, a través de los casos de uso ,
diagramas de actividades y de secuencias.
− Diagramas de casos de usos
o Caso de uso general del sistema
A continuación, se muestra todas las posibles acciones que se presentarán en el sistema.
Caso de uso general del sistema

− Documentación caso de uso Cargar Datos Históricos
Código C2-02
Nombre Cargar Muestra de Datos
Actores Invitado
Descripción Permite subir los datos que serán la muestra
a predecir
Precondición El archivo a cargar debe ser de tipo excel
Flujo de eventos 1. El invitado se dirige a la seccion
cargar muestra de datos
2. Selecciona el archivo a cargar
3. El sistema le muestra los datos
cargados
Poscondición
Excepciones El tipo de archivos a cargar debe ser de tipo
excel , el sistema lanzará un mensaje
notificando si hubo un error
− Documentación caso de uso Cargar Muestra de Datos
Código C2-01
Nombre Cargar Datos Históricos
Actores Invitado
Descripción Permite subir los datos históricos
Precondición El archivo a cargar debe ser de tipo excel
Flujo de eventos 1. El invitado se dirige a la sección de
cargar históricos
2. Selecciona el archivo a cargar
3. El sistema le muestra los datos
cargados
Poscondición
Excepciones El tipo de archivos a cargar debe ser de tipo
excel , el sistema lanzará un mensaje
notificando si hubo un error
Código C2-03
Nombre Establecer el tiempo de ejecución
Actores Invitado
Descripción Permite establecer cuánto tiempo durará la
ejecución del programa
Precondición El tiempo debe ser en minutos
Flujo de eventos 1. El invitado se dirige a la casilla de
tiempo ejecución
2. Digita la cantidad en minutos
Poscondición
Excepciones El tiempo de ejecución debe ser mayor a
cero, el sistema lanzará un mensaje
notificando si hubo un error
− Documentación caso de uso Establecer el tiempo de ejecución
Código C2-04
Nombre Generar Gráficos
Actores Invitado
Descripción Permite generar los gráficos de acuerdo al
pronóstico y valores reales
Precondición Se debe haber completado con éxito el
algoritmo preditictivo sobre el conjunto de
datos entregado
Flujo de eventos 1. El invitado se dirige a la sección
Graficar
2. El programa muestra las gráficas
generadas a través del conjunto de
datos reales y el pronosticado
Poscondición El invitado analiza los gráficos resultantes,
descarga reporte datos
Excepciones La carga de todos los conjuntos de datos y el
establecimiento del tiempo de ejecución
deben ser realizados con éxito, en caso
contrario el sistema lanzará mensajes de
alerta
− Documentación caso de uso Generar Gráficos
Código C2-05
Nombre Generar Reporte
Actores Invitado
Descripción Permite generar el reporte de datos, de
acuerdo al pronóstico y valores reales
Precondición Se debe haber completado con éxito el
algoritmo preditictivo sobre el conjunto de
datos entregado
Flujo de eventos 1. El invitado se dirige a la sección
Reportes
2. El programa muestra el reporte en
formato pdf
Poscondición descarga reporte datos
Excepciones La carga de todos los conjuntos de datos y el
establecimiento del tiempo de ejecución
deben ser realizados con éxito, en caso
contrario el sistema lanzará mensajes de
alerta
Código C2-06
Nombre Iniciar algoritmo de predicción
Actores Invitado
Descripción Permite iniciar la predicción sobre el
conjunto de datos entregados
Precondición Se debe haber cargado el conjunto de datos
históricos, el conjunto de datos de muestra y
el tiempo de ejecución
Flujo de eventos 3. El invitado se dirige a la sección de
Iniciar
4. El programa mostrará el estado de la
ejecución durante todo el proceso
5. El sistema finaliza y muestra los
datos estimados de la predicción
Poscondición El invitado analiza los gráficos resultantes,
descarga reporte datos

Excepciones La carga de todos los conjuntos de datos y el
establecimiento del tiempo de ejecución
deben ser realizados con éxito, en caso
contrario el sistema lanzará mensajes de
alerta
− Documentación caso de uso Iniciar algoritmo de predicción
Diagramas de secuencias
− Diagrama de secuencia: Cargar Datos Históricos

− Diagrama de actividad
ANEXO: MANUAL DE USUARIO APLICACIÓN
La aplicación de escritorio posee varias secciones, las cuales son:
− Carga de datos históricos
− Carga de datos muestrales para la predicción
− Control de tiempo de ejecución
− Resultados de Estimación
− Generación de reportes

− Imagen vista general.
Esta sección permite cargar los datos historicos. El boton inferior permite la descarga de
reportes

− Imagen carga de datos históricos
Esta sección permite cargar los datos muestrales a predecir, también existe una casilla
para mostrar el tiempo de finalización del algoritmo.
− Imagen carga de datos muestrales.
Esta sección permite mostrar el resultado de los datos pronosticados o estimados, también
existe una casilla para establecer el tiempo de finalización del algoritmo en minutos.
− Imagen resultado de datos pronosticados.
En esta sección permite visualizar el R^2, Iniciar o detener el proceso del algoritmo, como el de
reportar los gráficos generados.
− Imagen resultado de R^2

− Ejecución de la Aplicación
o Carga de Datos
- Imagen carga de datos
− Resultados de Ejecución
- Imagen resultado de ejecución

− Gráficos
− Imagen de gráficos generados

- Reportes
− Imagen reporte de resultados


















