
Análisis de Servidores Aplicando Planificación de...
155
FACULTAD DE INGENIERÍA ESCUELA DE INGENIERÍA DE SISTEMAS ANÁLISIS DE SERVIDORES APLICANDO PLANIFICACIÓN DE CAPACIDAD (ASAP-C) Peña Allen, Carlos Eduardo Urizar Zapata, Jon Iñaki Tutor: Ing. Gerardo Rodríguez Caracas, marzo de 2002
-
Upload
dangkhuong -
Category
Documents
-
view
216 -
download
0
Transcript of Análisis de Servidores Aplicando Planificación de...

FACULTAD DE INGENIERÍA
ESCUELA DE INGENIERÍA DE SISTEMAS
ANÁLISIS DE SERVIDORES APLICANDO
PLANIFICACIÓN DE CAPACIDAD
(ASAP-C)
Peña Allen, Carlos Eduardo
Urizar Zapata, Jon Iñaki
Tutor: Ing. Gerardo Rodríguez
Caracas, marzo de 2002

UNIVERSIDAD METROPOLITANA
FACULTAD DE INGENIERÍA
ESCUELA DE INGENIERÍA DE SISTEMAS
ANÁLISIS DE SERVIDORES APLICANDO
PLANIFICACIÓN DE CAPACIDAD
(ASAP-C)
Peña Allen, Carlos Eduardo
Urizar Zapata, Jon Iñaki
Tutor: Ing. Gerardo Rodríguez
Caracas, marzo de 2002

DDEERREECCHHOO DDEE AAUUTTOORR
Cedemos a la Universidad Metropolitana el derecho de reproducir y
difundir el presente trabajo, con las únicas limitaciones que establece la
legislación vigente en materia de derecho de autor.
En la ciudad de Caracas, a los días del mes de de 2002
Peña Allen, Carlos Eduardo Urizar Zapata, Jon Iñaki

AAPPRROO BBAACCIIÓÓ NN
Consideramos que el Trabajo de Grado titulado
ANÁLISIS DE SERVIDORES APLICANDO PLANIFICACIÓN DE
CAPACIDAD (ASAP-C)
elaborado por los ciudadanos
PEÑA ALLEN, CARLOS EDUARDO
URIZAR ZAPATA, JON IÑAKI
para optar al título de
INGENIERO DE SISTEMAS
reúne los requisitos exigidos por la Escuela de Ingeniería de Sistemas de la
Universidad Metropolitana, y tiene méritos suficientes para ser sometido a la
presentación y evaluación exhaustiva por parte del jurado examinador que se
designe.
En la ciudad de Caracas, a los días del mes de 2002
Ing. Gerardo Rodríguez

AACCTTAA DDEE VVEERREEDDIICCTTOO
Nosotros, los abajo firmantes, constituidos como jurado examinador y
reunidos en Caracas, el día , con el
propósito de evaluar el Trabajo de Grado titulado
ANÁLISIS DE SERVIDORES APLICANDO PLANIFICACIÓN DE
CAPACIDAD (ASAP-C)
presentado por los ciudadanos
PEÑA ALLEN, CARLOS EDUARDO
URIZAR ZAPATA , JON IÑAKI
para optar por el título de
INGENIERO DE SISTEMAS
emitimos el siguiente veredicto:
Reprobado Aprobado Notable
Sobresaliente Sobresaliente con mención honorífica
Observaciones:
___________________________________________________________________________
___________________________________________________________________________
___________________________________________________________________________
_______________________ ________________________ ________________________
Ing. Jaime Jaimes Ing. Gerardo Rodríguez Ing. Bonell Martínez

A mi madre por siempre estar a mi lado
y ser mi guía durante los tiempos difíciles, brindarme su apoyo, su amor y transmitirme su espíritu de superación sin el que no
podría haber seguido adelante A mi padre porque aunque no está conmigo
siempre me ha apoyado en todo momento aportándome toda sus experiencias y conocimientos en lo que ha podido
A mis Hermanos, están lejos pero siempre presentes
Carlos Eduardo Peña Allen
A mis padres, Marielena y Jon, por enseñarme que con fuerza, constancia y paciencia se
alcanzan los mayores logros en la vida, ustedes son mi ejemplo a seguir, gracias por estar s iempre a mi lado
A mis hermanos por ser una alegría en mi vida, sigan el ejemplo Yo sé que ustedes llegarán mucho más lejos que yo, los quiero demasiado
A Liliana, ella es mi impulso, mi motivo gracias por permanecer a mi lado, por entenderme y apoyarme
has dado alegría mi corazón en esos momentos en lo que más lo necesitaba Maite Zaitut
A la Sra. Ada, por ser una segunda madre para mí, gracias por su apoyo A mi familia por creer en mi
Jon Iñaki Urizar Zapata

AAGGRRAADDEECCIIMMIIEENNTTOOSS
A Dios, a la Virgen del Valle y a la Virgen de la Milagrosa por habernos
iluminado, darnos fuerzas y otorgarnos las habilidades para el desarrollo del
proyecto.
A nuestros Padres que siempre estuvieron ahí en los momentos
difíciles. Sin ellos no seríamos las personas que somos ahora.
A la Tía Esther que con sus conocimientos nos sirvió de guía a lo largo
de este proyecto.
A Liliana por demostrarnos su apoyo incondicional en los momentos
difíciles de la tesis y aportar su ayuda en lo que estaba a su alcance.
A Luis por su ayuda y disposición para orientarnos en lo posible para
desarrollar la Tesis.
Al Ing. Gerardo Rodríguez que más que un tutor se convirtió en un
amigo y gracias a su paciencia, orientación y apoyo salimos adelante en este
trabajo.
A la Sra. Guadalupe Medina por su apoyo, afecto y constante
preocupación, muchas gracias.
A nuestros amigos Mary, Milagro, José Daniel, Tito, Jorge, Alejandro,
Leo, Juan Boada, Carolina Ramírez, Carlos Duque porque de alguna u otra
manera han aportado su ayuda y colaboración con nosotros en el desarrollo
del proyecto.
Y a todas las personas que ayudaron y nos apoyaron que no hemos
colocado aquí pero que están presentes en nuestras mentes.
Muchas Gracias...

TTAABBLLAA DDEE CCOONNTTEENNIIDDOO
LISTA DE TABLAS Y FIGURAS........................................................................ iv
RESUMEN................................................................................................................vii
INTRODUCCIÓN ....................................................................................................... 1
CAPÍTULO I ........................................................................................................ 4
I.1 Planteamiento del Problema................................................................................ 5
I.2 Objetivos de la Investigación ............................................................................... 6
I.2.1 Objetivo General ...........................................................................................6
I.2.2 Objetivos Específicos....................................................................................6
CAPÍTULO II ....................................................................................................... 8
II.1 Planificación de Capacidad................................................................................. 9
II.1.1 ¿Por qué se debe planificar capacidad? ...................................................10
II.1.2 Proyección de CPU....................................................................................12
II.1.2.1 Grupo de Aplicaciones........................................................................13
II.1.2.2 Factor de Captura ...............................................................................14
II.1.2.3 Punto de Saturación ...........................................................................17
II.1.3 Ley de beneficios decrecientes .................................................................26
II.1.3.1 Tráfico .................................................................................................30
II.1.4 Metodología SIO (Start I/O).......................................................................33
II.1.4.1 Mezcla de discos.................................................................................40
II.1.4.2 Ejemplo práctico..................................................................................43
II.2 Metodología para el desarrollo del proyecto ....................................................56
II.2.1 Comunicación con el cliente......................................................................57
II.2.2 Planificación...............................................................................................57
II.2.3 Análisis de riesgo.......................................................................................58

ii
II.2.4 Ingeniería ...................................................................................................58
II.2.5 Evaluación del cliente................................................................................58
CAPÍTULO III ................................................................................................... 59
III.1 Investigación Preliminar...................................................................................60
III.1.1 Investigación sobre Planificación de Capacidad ......................................60
III.1.2 Investigación de la Evaluación del Rendimiento......................................65
III.1.2.1 Definición de rendimiento ..................................................................66
III.1.3 Investigación específica para cada giro ...................................................68
III.1.4 Investigación de infraestructura tecnológica ............................................69
III.2 Desarrollo del Sistema ASAP-C......................................................................70
III.2.1 Desarrollo del primer giro .........................................................................71
III.2.2 Desarrollo del segundo Giro .....................................................................91
III.2.3 Desarrollo del tercer Giro........................................................................ 101
III.2.3.1 Escenario ......................................................................................... 101
CAPÍTULO IV ................................................................................................. 111
IV.1 Situación Actual ............................................................................................. 112
IV.2 Proyección de escenarios ............................................................................. 118
IV.2.1 Archivo de Escenarios ............................................................................ 118
Conclusiones ........................................................................................................... 124
Recomendaciones .................................................................................................... 127
Bibliografía ............................................................................................................. 128
Fuentes Bibliográficas:.......................................................................................... 128
Fuentes Electrónicas:............................................................................................ 130
Glosario de Términos ............................................................................................ 131
Apéndice A........................................................................................................... 135

iii
Apéndice A1 .......................................................................................................... 135
Apéndice A2 .......................................................................................................... 136
Apéndice B ........................................................................................................... 137
Esquema de presentación de las gráficas............................................................ 137
Esquema de reporte para uso de CPU para las cargas de trabajo ................. 138
Esquema de reporte para SIO de las cargas de trabajo.................................. 138
Esquema de reporte para Cantidad de Discos ................................................ 138
Esquema de reporte para Cantidad de Rutas .................................................. 138
Esquema de reporte para Cantidad de Rutas .................................................. 138
Apéndice C ........................................................................................................... 139
Diagrama General de Casos de Uso.................................................................... 139
Diagrama de Secuencia del proceso de carga .................................................... 140
Diagrama de Entidad Relación del Sistema......................................................... 141

iv
LLIISSTTAA DDEE TTAABBLLAASS YY FFIIGGUURRAASS
TTAABBLLAASS
Tabla 1. Porcentajes ajustados de consumo de CPU................................................19
Tabla 2. Total de CPU para los grupos de aplicaciones por Día ...............................20
Tabla 3. RPPD para los diferentes días .....................................................................20
Tabla 4. Estimación de uso de CPU...........................................................................23
Tabla 5. Relación entre Skew y No de actuadores .....................................................28
Tabla 6. Conjunto de actuadores................................................................................29
Tabla 7. Proyección de CPU para los grupos de aplicaciones ..................................35
Tabla 8. Valor de S para los grupos de aplicaciones en 5 años................................36
Tabla 9. Tráfico para la proyección ............................................................................37
Tabla 10. Actuadores para el tráfico previsto .............................................................38
Tabla 11. Rutas para el tráfico previsto......................................................................38
Tabla 12. Datos del ejemplo de Mezcla de Discos ....................................................40
Tabla 13. Caso =U......................................................................................................40
Tabla 14. Caso =S ......................................................................................................41
Tabla 15. Valores de los elementos del ejemplo........................................................45
Tabla 16. Tabla de LBD para rutas con Paralelismo 4 ..............................................64
Tabla 17. LBD para rutas con Paralelismo 4..............................................................64
Tabla 18. Capacidad, velocidad y alcance de los aviones ........................................67
Tabla A1 Ley de Beneficio Decreciente para Actuadores........................................ 135
Tabla A1.2 Ley de Beneficio Decreciente para rutas ............................................... 136

v
FFIIGGUURRAASS
Figura 1. Efecto del Factor de Captura ......................................................................15
Figura 2. Proyección CPU Actual ...............................................................................23
Figura 3. Proyección de CPU Futuro vs. Actual .........................................................25
Figura 4. Modelo en Espiral........................................................................................57
Figura 5. Fases de la Planificación de Capacidad .....................................................62
Figura 6. Datos necesarios para registrar un servidor...............................................79
Figura 7. Datos requeridos para el procesador..........................................................80
Figura 8. Datos necesarios para el registro de la Carga de Trabajo .........................82
Figura 9. Datos para registrar un proceso..................................................................82
Figura 10. Datos para definir la situación actual ........................................................85
Figura 11. Selección de servidores bajo el sistema operativo especificado .............86
Figura 12. Selección de cargas de trabajo para la situación actual ..........................86
Figura 13. Relación de Carga de Trabajo y Servidor .................................................87
Figura 14. Datos de los discos de la empresa...........................................................95
Figura 15. Datos de las rutas del sistema..................................................................97
Figura 16. Interfaz de Ingreso de Mediciones de Cargas de Trabajo........................98
Figura 17. Interfaz mejorada para definir la Situación Actual del segundo giro ........99
Figura 19. Interfaz de Escenario............................................................................... 106
Figura 20. Interfaz para asignar el crecimiento futuro de las cargas de trabajo ..... 109
Figura 21. Situación actual del sistema.................................................................... 114
Figura 22 Gráfica representativa de la situación actual de las cargas de trabajo
definidas .................................................................................................................... 115
Figura 23. Gráfica representativa del porcentaje de CPU en línea ......................... 116

vi
Figura 24. Reporte de la Situación actual en base a la distribución de las cargas de
trabajo del sistema.................................................................................................... 117
Figura 25. Definición del escenario para el ejemplo ................................................ 119
Figura 26. Gráfica de Proyección de CPU para el caso de estudio ........................ 120
Figura 27. Gráfica de proyección de número de discos para el caso de estudio.... 121
Figura 28. Reportes de proyección para escenarios futuros ................................... 122

vii
RREESSUUMMEENN
ANÁLISIS DE SERVIDORES APLICANDO PLANIFICACIÓN DE
CAPACIDAD (ASAP-C)
Autores: Carlos Eduardo Peña Allen Jon Iñaki Urizar Zapata Tutor: Ing. Gerardo Rodríguez Caracas, marzo 2002
En la actualidad, muchas empresas atraviesan por problemas de rendimiento o insuficiencia de capacidad que impiden el crecimiento del negocio, incrementan los costos, causan insatisfacción y disminuyen la productividad.
Existen sistemas que se encargan de estas tareas pero, son de un
costo muy elevado; por es to se hace necesario desarrollar una herramienta automatizada para la evaluación del rendimiento actual de la carga de trabajo en los servidores y su proyección a escenarios futuros, de bajo costo y alto rendimiento.
Para desarrollar el objetivo de este proyecto fue necesario investigar
aspectos generales de Planificación de Capacidad y la evaluación de rendimiento, así como también la metodología aplicada (Metodología en Espiral).
Producto del diseño realizado, se obtuvo una aplicación (ASAP-C) que
permite definir y proyectar escenarios, mediante fórmulas matemáticas y metodologías relacionadas con el proceso de Planificación de Capacidad, proporcionando además gráficos y reportes que apoyen las posibles decisiones que tome el planificador.
El análisis de los servidores mediante el uso de Planificación de
Capacidad, permite estudiar el comportamiento de los recursos de CPU y discos de acuerdo al crecimiento esperado de las cargas del sistema, a través de la proyección de escenarios futuros.
Esta aplicación permite evaluar la situación actual de los recursos de
un sistema y analizar el crecimiento de las cargas que lo componen mejorando la toma de decisiones, al permitir utilizar la experiencia del planificador y facilitando en mucho su labor.

Introducción
1
IINNTTRROODDUUCCCCIIÓÓNN
Las empresas dependen cada vez más de la tecnología para realizar
sus procesos críticos de negocio. El crecimiento que ésta presenta a lo largo
del tiempo les obliga a actualizar con frecuencia los equipos de computación
con los cuales prestan sus servicios, es aquí donde los ejecutivos de las
compañías deben realizar un análisis de cómo invertir su capital para
expandir su plataforma tecnológica, en este momento se hace de vital
importancia la presencia de un ente capaz de desarrollar un estudio sobre
planificación de capacidad, con el fin de brindar la información sobre ¿Cuál
es la mejor opción para mejorar la condición actual que presenta la
empresa?.
En Venezuela las empresas no cuentan, en la mayoría de los casos,
con personal capacitado para realizar esta tarea, por lo cual se ven en la
necesidad de contratar consultores dedicados a esta área cuyo objetivo es
mostrar con un alto grado de certeza la condición actual de los sistemas de
la empresa y su crecimiento a futuro, esto concerniente a la tecnología que
usan o a la que van a adquirir. Los frutos de esta información ayudarán al
negocio a tratar los problemas con un conocimiento preciso para poder tomar
la decisión correcta que evitará que los inversionistas utilicen su capital de
una manera errónea, comprando soluciones que no mejoren o que
solucionen parcialmente el problema.

Introducción
2
Debido al creciente uso de procesos de planificación de capacidad en
las empresas, se hace necesario contar con herramientas de apoyo al
planificador, que le permita manejar escenarios de forma fácil y versátil,
manipulando grandes cantidades de información proveniente del monitoreo
de los sistemas de la empresa.
A pesar de la existencia de grandes paquetes de planificación de
capacidad, cuyos altos costos exceden los presupuestos de inversión de
pequeñas y medianas empresas, es de alta importancia desarrollar un
sistema flexible y de bajo costo, permitiendo el manejo de múltiples
escenarios que apoyen la labor del planificador.
El objetivo de este proyecto es crear un sistema que apoye la labor del
planificador, ofreciéndole procesos automatizados que ayuden a la
evaluación del rendimiento de los servidores con el propósito de conocer su
situación actual frente a la carga de trabajo con la cual funcionan y su
proyección a futuro.
En principio se presenta el marco teórico que fundamenta el proyecto,
en el cual se describe el proceso de Planificación de Capacidad, la
Metodología del Start I/O y la metodología de diseño y desarrollo del sistema.
El desarrollo del proyecto describe las actividades necesarias para
llevar a cabo el objetivo propuesto y permite conocer la estructura y
funciones del sistema planteado.

Introducción
3
Para analizar los resultados se incluyen gráficas, reportes e
información que permite conocer las salidas del proceso de planificación de
capacidad al utilizar el sistema ASAP-C.

4
CCAAPPÍÍTTUULLOO II
ANÁLISIS DE SERVIDORES APLICANDO
PLANIFICACIÓN DE CAPACIDAD (ASAP-C)
En este capítulo se describe el problema que se plantea en este
Trabajo de Grado, lo que representa el eje de esta investigación y sirve de
base para el desarrollo de los siguientes capítulos.
En el Planteamiento del problema se describe la necesidad
fundamental de la realización de este trabajo de grado, enfocando
globalmente el problema y destacando la importancia de la Planificación de
Capacidad dentro de las empresas.
Se plantea como a través del desarrollo de esta herramienta se puede
ayudar a solucionar los problemas de muchas empresas, que actualmente
necesitan evaluar la capacidad de sus sistemas, para mejorar la
productividad e impulsar el crecimiento.

Análisis de Servidores aplicando Planificación de Capacidad
5
I.1 Planteamiento del Problema
Los usuarios están aumentando su dependencia por los sistemas de
Tecnología de Información para el control de las funciones críticas del
negocio. Los problemas que atraviesan, en la actualidad, muchas empresas
se basan en el rendimiento o insuficiencia de capacidad que impiden el
crecimiento, aumentan los costos, reducen la productividad y causan
insatisfacción. En fin, estos puntos anteriores pueden hacer que una
compañía sea menos competitiva y perder clientes importantes. Muchas
empresas no tienen personal con el tiempo o la experiencia suficiente para
evaluar la situación actual del rendimiento del servidor y el análisis de
escenarios futuros.
Mediante el uso de Planificación de Capacidad, se puede prever si un
sistema se satura y cuando esto pueda ocurrir, así como la evolución de las
cargas de trabajo existentes y las nuevas aplicaciones con respecto al
rendimiento deseado.
ASAP Consultores, con la intención de dar solución a estos problemas
ha decidido prestar servicios de Planificación de Capacidad, haciéndose
necesario el uso interno de un sistema que apoye estos servicios. Es
importante destacar que las herramientas existentes en el mercado poseen
altísimos costos de licencia, lo cual restringe su uso a grandes empresas.
Además es necesario disponer del personal experimentado para realizar este

Análisis de Servidores aplicando Planificación de Capacidad
6
tipo de trabajo, el cual, generalmente es escaso. El sistema ASAP-C
permitirá a los clientes de ASAP Consultores controlar el rendimiento de sus
servidores sin incurrir en los costos que implican la adquisición de una
herramienta especializada de planificación de capacidad y la dedicación de
personal propio a estas tareas.
Para la realización de este proyecto se utilizará la metodología Start
I/O, la cual se ha usado exitosamente por más de dos décadas en el
ambiente de computadores de gran escala (“Mainframes”) y su solución
automatizada sólo ha sido implementada para este ambiente. Su
implementación en las otras plataformas permitirá a ASAP Consultores, dar
un servicio a una cartera mucho mayor de clientes.
I.2 Objetivos de la Investigación
I.2.1 Objetivo General
Desarrollar una herramienta automatizada para la evaluación del
rendimiento actual de la carga de trabajo en los servidores y su proyección
para escenarios futuros.
I.2.2 Objetivos Específicos
?? Seleccionar los monitores más adecuados a utilizar en las
plataformas Windows NT 4 Server, Windows 2000, Unix-AIX,
OS/400, VSE/ESA y OS/390.

Análisis de Servidores aplicando Planificación de Capacidad
7
?? Reducir el esfuerzo de la entrada de datos para los monitores
seleccionados.
?? Evaluar los recursos actuales de procesador, memoria y discos.
?? Proporcionar gráficas y reportes a escenarios futuros que el
usuario desee, para que pueda evaluar los recursos de
procesador, memoria y discos de acuerdo a sus necesidades.
?? Permitir al usuario la exportación de la información a Microsoft
Word, Microsoft Excel y archivos de texto.
?? Brindar al usuario un sistema amigable que le permita una gran
flexibilidad para tomar decisiones a la hora de planificar capacidad.
?? Permitir el estudio de casos especiales (What if).
?? Crear una interfaz que le permita al usuario realizar ajustes de
parámetros, para maximizar la toma de decisiones en casos
especiales.
?? Reducir el proceso de toma de decisiones para casos normales.
?? Dar flexibilidad en la definición de escenarios.
?? Contemplar cantidad y tipo de carga de trabajo, hardware,
crecimientos esperados (múltiples escenarios).

8
CCAAPPÍÍTTUULLOO IIII
MARCO TEÓRICO
Este capítulo presenta los basamentos teóricos sobre los cuales se
desarrolla este Trabajo de Grado Análisis de Servidores aplicando
Planificación de Capacidad. En primer lugar, se explica el Proceso de
Planificación de Capacidad y su importancia, destacando los conceptos más
importantes de la Proyección de CPU y la Ley de Beneficios Decrecientes.
Se explica en que consiste la Metodología Start I/O para poder
comprender la relación existente entre el uso del CPU, su velocidad, el
numero de operaciones de entrada y salida (E/S) que se realizan en un
segundo y la densidad de E/S que contiene la carga.
Finalmente se describe la Metodología utilizada para el desarrollo del
proyecto y las fases que las componen, para poder entender así como se
desarrolló la herramienta ASAP-C.

Marco Teórico
9
II.1 Planificación de Capacidad
Proceso sistemático para estimar la capacidad necesaria a fin de
atender la carga de trabajo esperada en el futuro.
Cuando se está realizando un análisis de capacidad siempre se
estudia la relación que existe en el consumo de recursos a lo largo del
tiempo. Una de las preguntas más frecuentes que puede surgir para
establecer la utilidad de la planificación de capacidad es ¿qué pasa si no se
hace?, La respuesta a esta pregunta se puede ver en lo que a algunas
empresas les ocurre en su proceso de crecimiento. Lo que realmente
sucede es que existe una represión en el desarrollo normal de la carga de
informática de la empresa, esto debido a que ya los recursos comienzan a
ser sobre-utilizados haciendo que el proceso de crecimiento se vea reprimido
por no contar con la capacidad suficiente para atender a la demanda que se
está enfrentando.
La demanda desatendida se le conoce como demanda latente, ésta
obliga a adquirir nuevos recursos para lograr solventar la situación, lo que
ocasiona que se aumente vertiginosamente el consumo de éstos, ya que la
utilización de los mismos se incrementa considerablemente debido a que
ahora se atiende a un número mayor de clientes.
De haberse planificado con tiempo el crecimiento esperado por la
empresa se hubiese atacado de una manera certera este asunto y el

Marco Teórico
10
aumento hubiese evolucionado gradualmente, brindando a los clientes un
servicio sin inconvenientes.
II.1.1 ¿Por qué se debe planificar capacidad?
Es importante realizar el proceso de
planificación de capacidad porque las empresas
están en continuo crecimiento, no son estáticas, sino
más bien dinámicas. Es por eso que siempre están
tomando decisiones sobre como invertir su capital, como distribuir mejor sus
recursos, como brindar servicios de calidad y quizá lo más importante brindar
satisfacción al cliente. Como consecuencia de esto tratan de implementar
planes más agresivos, que impulsen el negocio a altos niveles competitivos
en el mercado donde se desenvuelve. Entre los planes que puede tener la
empresa se encuentran:
?? Abarcar mayor cantidad de usuarios.
?? Incorporar sistemas más importantes para la empresa.
?? Buscar mayores beneficios.
Entre los beneficios que se encuentran en la aplicación de la
planificación de capacidad, resaltan los siguientes:
?? Asegura el máximo rendimiento y estabilidad de su entorno en
sistemas actuales y futuros.
?? Incrementa la precisión del análisis de requerimientos de los
recursos computacionales.

Marco Teórico
11
?? Provee una justificación de costos para la adquisición de
tecnologías de sistemas.
Entre las condiciones que señalan una situación bajo la cual ciertos
indicadores conducen a realizar un proceso de planificación de capacidad
están:
?? No se puede mantener un CPU al 90 por ciento en promedio.
o Picos del sistema en línea.
?? Se necesitan sistemas balanceados.
?? Se requiere adelantarse a los problemas.
?? Se necesita manejar un ambiente de cambios constantes.
Finalmente hay que entender que para realizar un análisis de
capacidad es importante tener en claro como está el ambiente actual de la
empresa y sus sistemas.
A continuación se muestran los términos principales relacionados con
la planificación de capacidad. Debido a que el trabajo está orientado hacia la
planificación de capacidad del procesador, los discos y sus rutas, el estudio
presta particular atención a la proyección de la unidad central de
procesamiento y a los métodos utilizados para el cálculo del número de
discos y sus rutas.
La metodología con la que se adquieren estos resultados recibe el
nombre de metodología Start I/O, creada por Joseph B. Major.

Marco Teórico
12
II.1.2 Proyección de CPU
La proyección de CPU juega un papel importante en
el proceso de planificación de capacidad. Los resultados de
realizar estos estudios sobre el procesador dan a conocer
una estimación sobre el tiempo en el cual este recurso
trabaja de una forma adecuada; es dec ir, sin afectar
considerablemente el rendimiento del sistema.
El funcionamiento del CPU va a estar afectado por el crecimiento que
tenga el sistema, en cuanto a usuarios y nuevas aplicaciones adquiridas. Es
importante realizar la proyección del procesador para conocer en que
momento éste se encuentre en los límites de su punto de saturación1. De
lograr identificar a tiempo esta situación, se podrá crear un plan oportuno
que solucione el problema en el que se encuentra el sistema y así evitar
pérdidas del rendimiento por motivo de la saturación del CPU.
Antes de realizar cualquier cálculo para la proyección del CPU es
importante destacar que se deben realizar ciertas consideraciones, para que
el estudio sobre el procesador sea lo más certero posible.
Entre las consideraciones que se deben tomar en cuenta están:
1. Especificar los grupos de aplicaciones.
2. Calcular el factor de captura de las cargas de trabajo.
3. Establecer el punto de saturación del procesador.
1 Límite en el cual el procesador trabaja afectando el rendimiento del sistema.

Marco Teórico
13
4. Medir la velocidad del procesador.
II.1.2.1 Grupo de Aplicaciones
El grupo de aplicaciones se define como el conjunto de
aplicaciones resultantes de la división lógica de la carga total
de un sistema.
Para realizar la agrupación de estos conjuntos es necesario estudiar
ciertas características que acompañan a las cargas de trabajo que
conforman la carga total del sistema.
Las características a las cuales debe prestársele atención para la
agrupación de los conjuntos son las siguientes:
?? Significado de la carga para el negocio.
?? Similitud entre las aplicaciones que la constituyen.
?? Posibilidad de estimar un crecimiento global de las
aplicaciones involucradas.
?? Facilidad de medición.
Es recomendable separar las aplicaciones con un alto consumo de
recursos o con fuertes crecimientos esperados. Además es posible agrupar
aquellas aplicaciones con poco consumo de recursos, pero que presenten un
registro de crecimiento similar.

Marco Teórico
14
Es importante señalar que no se debe especificar un gran número de
grupos, ya que esto puede dificultar tanto la recaudación de los datos como
el proceso de proyección en sí.
La razón fundamental por la que se hace este tipo de división en las
aplicaciones del sistema, es porque el estimar un crecimiento general de
todas las aplicaciones resulta muy difícil.
II.1.2.2 Factor de Captura
El factor de captura no es más que el ajuste que se debe realizar a los
datos recaudados por el monitor sobre la
utilización de los grupos de aplicaciones con el
fin de aproximarlos a valores reales. Expresa
además, la cantidad de consumo de CPU por
parte del grupo de aplicaciones.
Para ilustrar un poco lo antes expuesto véase el siguiente ejemplo:
Suponga que se tienen n grupos de aplicaciones. Se denominará U1,
U2,..., Un el uso de CPU de cada uno de ellos y U el uso total de CPU. Lo
importante a destacar aquí, es que lamentablemente en la mayoría de los
casos la ? Ui < U.
Asignando de la siguiente manera los valores de cada Ui se tiene lo
siguiente:
U1 -> TSO

Marco Teórico
15
U2 -> Lote
U3 -> Préstamos
U4 -> SAFE
El resto queda sin ser capturado.
La suma total de los correspondientes Ui no es exactamente el valor
de U real, es por eso que se necesita calcular un factor o varios factores de
captura FCi para aproximar el valor a U.
Figura 1. Efecto del Factor de Captura
El factor de captura se obtiene de dividir el porcentaje de utilización
medido entre el porcentaje de utilización real. En la medida en que el
Overhead 2 no contabilizado sea mayor, el factor de captura será menor. Por
esta razón las aplicaciones de tipo científico tienen factores de captura altos
(por ejemplo: 0.92). Para calcular el factor de captura general se debe
realizar la sumatoria de los Ui y luego el resultado dividirlo entre U.
2 El uso de los recursos de computación por ejecutar una aplicación específica. Típicamente, el término se usa para describir una función que es opcional, o una mejora a una aplicación existente.

Marco Teórico
16
Una característica adicional que poseen los factores de captura, es
que ellos son independientes de la metodología que se esté utilizando.
Con el ejemplo dado anteriormente se tiene lo siguiente:
U1=30, U2=10, U3=20 y U = 80
Al realizar la suma de los Ui se tiene: 30 + 10 + 20 = 60 < 80
Si se coloca ahora como factor de captura cero punto ocho (0.8) para
U1, cero punto cinco (0.5) para U2 y cero punto noventa y uno (0.91) para U3,
el cálculo queda expresado de la siguiente forma:
(30 / 0.8) + (10 / 0.5) + (20 / 0.91) = 37.5 + 20.0 + 22.0 = 79.5
Se puede observar en este caso que la suma de los valores ajustados
por el factor de captura se aproxima al total de utilización de CPU que se
tiene en el ejemplo como resultado de la ejecución de los grupos de
aplicaciones sobre el procesador.
Los valores obtenidos como factor de captura se pueden determinar
de tres maneras posibles:
?? Experiencia en el manejo de las aplicaciones y del
procesador.
?? Muestras de varios días que permitan estimar el
comportamiento de la aplicación.
?? Manipulaciones matemáticas que consigan aproximar el valor
real del uso de CPU por parte de la aplicación.

Marco Teórico
17
Se ve claramente reflejado el efecto que tiene el factor de captura al
momento de realizar los ajustes del porcentaje de consumo de CPU para los
grupos de aplicaciones seleccionados, de esta manera se puede asegurar
que los datos recolectados se aproximan con más fidelidad a la situación
real.
II.1.2.3 Punto de Saturación
El punto de saturación del CPU se conoce como el límite en el cual el
procesador puede trabajar de una manera eficaz sin degradarse ni afectar
considerablemente el rendimiento del sistema.
Las preguntas frecuentes que se hacen en este
tema son ¿a qué utilización se debe considerar un
CPU saturado, 100%, 90%, 60%? ¿Qué valor utilizar
para promedios, y cuál para picos? ¿Qué valor se
debe utilizar para sistemas en línea, y cuál para
sistemas en lotes?
Regularmente son aceptados como punto de saturación los siguientes
valores: 90% en pico para sistemas en línea y 90% en promedio para
sistemas en lote3. Con la finalidad de saber en que condiciones está
operando el procesador en los períodos picos, se deberían realizar
mediciones en dichos períodos, pero estas mediciones pueden presentar
3 Se entiende como lote a toda la carga que es degradable.

Marco Teórico
18
problemas para la recolección fidedigna de los datos. Entre estos
inconvenientes se encuentran:
?? Pueden ser inestables.
?? Puede ser necesario medir todo el período operacional.
?? Es posible que no coincidan con los picos de entrada y salida.
Debido a esto surge la siguiente interrogante: ¿Es posible calcular el
punto de saturación del procesador para sistemas en línea que considere los
picos?.
En respuesta a esto existe un valor conocido como RPP4 que al
multiplicarlo por el promedio se obtiene el pico. La relación pico promedio se
calcula por días y por muestras.
La fórmula para calcular el RPP se denota de la siguiente forma:
oCPUpromediCPUpico
RPP%
%?
El cálculo de este valor permite tomar mediciones en períodos largos
sin ignorar los picos, por esto las mediciones son más estables trayendo
como consecuencia mejores estimaciones de los valores recolectados. Una
ayuda adicional que brinda el RPP es que: cambios bruscos en su valor
puede ayudar a detectar problemas en el sistema.
Para el cálculo del RPP se hace necesario el conocer el valor de
RRPD i5 que no es más que el resultado de dividir la hora de mayor utilización
4 Relación Pico Promedio

Marco Teórico
19
en el día i y el promedio de utilización de dicho día. Quedando la fórmula de
la siguiente manera:
idíadelpromedioCPU
idíadelpicoCPURPPDi
%%
?
Para mostrar la aplicación de lo antes expuesto considérese el
siguiente ejemplo:
Supóngase que se tienen dos grupos de aplicaciones distintas,
Préstamos y SAFE. Observe los porcentajes ajustados de uso de CPU para
el promedio y el pico (véase la tabla 1).
Tabla 1. Porcentajes ajustados de consumo de CPU
Día %CPU
promedio (Préstamo)
%CPU pico (préstamo)
%CPU promedio
(SAFE)
%CPU pico (SAFE)
1 12.45 15 18 23.63
2 11.39 14.5 20.01 24
3 12.56 16 21.5 24.63
Es importante destacar que cuando se está mencionando los
porcentajes ajustados de consumo de CPU se está hablando de la
participación del factor de captura en los datos recopilados. De no estar
ajustados los valores es necesario realizar esta operación antes de tomar en
cuenta los datos para la proyección.
5 Relación Pico Promedio del Día i

Marco Teórico
20
Sumando los porcentajes en pico y en promedio, se obtiene el total de
consumo del CPU para estos dos grupos de aplicaciones (véase la tabla 2).
Tabla 2. Total de CPU para los grupos de aplicaciones por Día
Día %CPU promedio %CPU pico
1 30.45 38.63
2 31.4 38.5
3 34.06 40.63
Luego que se tiene toda esta información se pasa a calcular el RPPD
para los días que se tienen, esto se expresaría de la siguiente manera:
27.1%45.30%63.38
1 ??RPPD
El resultado de 1.27 es el RPPD para el día 1, de esta manera se
procede a calcular el RPPD para los días restantes.
En la Tabla 3 se pueden ver los resultados obtenidos de esta
operación para los RPPDi restantes.
Tabla 3. RPPD para los diferentes días
Día RPPD por día
1 1.27
2 1.23
3 1.19

Marco Teórico
21
Con el resultado de los RPPD por días se puede calcular ahora el
RPPD general del sistema para el período establecido, en este caso tres
días. Para realizar este cálculo simplemente se toma el resultado de los
RPPD i obtenidos, se suman y su resultado se divide entre el número total de
RRPD i calculados, es decir, se calcula el promedio de los RRPDi
n
RPPDRPPD
n
ii?
?? 1
n: en este caso significa el número total de días en la medición.
Para el ejemplo que se está tratando el RPPD es igual a 1.23
Algo de suma importancia en los valores de los RPPDi es su cercanía
entre sí, esto significa que cada uno es similar al otro, en el momento que
uno de estos valores se disperse notablemente del resto, el día que
representa no entrará en el promedio porque se considera a este atípico en
la medición.
Una vez calculado el RPPD general, se pasa a calcular el RPPM o lo
que es lo mismo la relación pico promedio de la muestra. La fórmula para
obtener este valor se expresa de la siguiente forma:
muestraladepromedioCPUmuestraladepicoCPU
RPPM%
%?
El porcentaje de CPU promedio de la muestra viene dado por la
sumatoria de los valores del promedio de la muestra divididos entre el

Marco Teórico
22
número de días de la medición. El valor del porcentaje pico de la muestra es
igual al máximo valor de consumo de CPU encontrado en la medición.
Para el ejemplo que se está utilizando el resultado queda de la
siguiente manera:
Para el promedio de uso de CPU
97.313
06.344.3145.30?
??
Luego el valor del RPPM queda de la siguiente forma:
07.1%97.31
34.06%??RPPM
Una vez calculados los valores del RPPD y el RPPM se puede
calcular el punto de saturación del procesador. Tomando 90% de uso de
CPU, para considerarlo saturado, la fórmula para obtener este valor se
escribe de la siguiente manera:
RPPMxRPPDPS
90?
Entonces, para este ejemplo, el punto de saturación:
38.6807.123.1
90??
xPS
Si se conoce el porcentaje de crecimiento esperado para cada uno de
los grupos de aplicaciones involucrados en este ejemplo, es posible estimar
la utilización futura que tendrá este procesador en los siguientes años de
operación. Suponiendo que el grupo PRÉSTAMO crece un 25% y el grupo
SAFE lo hace en un 30%, hay que calcular la utilización de CPU para el

Marco Teórico
23
período deseado con el crecimiento esperado, de este modo se puede saber
en que momento el procesador comenzará a bajar su rendimiento en el
sistema.
Si se toma un período de medición de cinco años, el comportamiento
del uso de CPU vendría dado de la siguiente manera (véase tabla 4).
Tabla 4. Estimación de uso de CPU
Situación
Actual Año 1 Año 2 Año 3 Año 4 Año 5
Préstamo 12,13 15,17 18,96 23,70 29,62 37,03 SAFE 19,84 25,79 33,52 43,58 56,66 73,65 Total 31,97 40,95 52,48 67,28 86,28 110,68
Estudiando el crecimiento de los grupos de aplicaciones especificados
en la tabla, se puede ver claramente que el CPU ve afectado su rendimiento
después del tercer año de proyección. (Véase figura 2)
0
20
40
60
80
100
120
1 2 3 4 5 6
Años
Po
rcen
taje
de
uso
de
CP
U
Préstamo
SAFE
Total uso CPU
Punto de Saturación CPUactual
Figura 2. Proyección CPU Actual

Marco Teórico
24
Gracias a la realización de este cálculo es posible obtener también el
punto de saturación para un procesador que puede ser el sucesor del actual.
Para realizar este proceso es necesario conocer el ITR6 del nuevo CPU en
relación con el actual, para ello suponga que el valor M de la unidad actual
es de 700 y el valor M del sustituto es de 1000, de esta manera el ITR del
procesador nuevo respecto al actual se expresaría así:
43.1700
1000??actualCPUalrespectofuturoCPUITR
Una vez obtenido este valor se procede a multiplicarse por el punto de
saturación del procesador actual. El res ultado indica el punto de saturación
del CPU sustituto.
78.9738.6843.1 ?? xPS NuevoCPU
El comportamiento del CPU nuevo es mejor que el actual pero igual se
saturaría al exceder el 97.78% de utilización. (Ver figura 3).
Se puede concluir de la figura que el procesador futuro colapsará en el
último año de la proyección, debido al crecimiento especificado para los
grupos de aplicaciones del ejemplo, pero con este CPU se puede tener un
rendimiento óptimo del sistema dos años más que con el procesador actual.
Realizar la proyección de CPU es una fase muy importante en el
proceso de planificación de capacidad, ya que la metodología SIO, la cual se
explicará más adelante, relaciona al procesador con las operaciones de
entrada y salida.
6 Internal Throughput Ratio

Marco Teórico
25
0
20
40
60
80
100
120
1 2 3 4 5 6
Años
Po
rcen
taje
de
uso
de
CP
U
Préstamo
SAFE
Total de CPU
Pto. SaturaciónCPU ActualPto. SaturaciónCPU Futuro
Figura 3. Proyección de CPU Futuro vs. Actual
Los pasos a seguir para realizar la proyección de CPU se resumen de
la siguiente forma:
?? Dividir la carga de trabajo del sistema en Grupos de
Aplicaciones. Debe calcularse el uso de CPU para los
diferentes grupos.
?? Calcular los factores de captura, que permiten ajustar los datos
recolectados.
?? Calcular el uso de CPU ajustado por el factor de captura para
los grupos de aplicaciones.
?? Obtener el uso futuro de procesador para cada grupo de
aplicaciones.

Marco Teórico
26
?? Conocer el punto de saturación para la unidad de
procesamiento actual.
?? Calcular el punto de saturación para los posibles procesadores
futuros.
II.1.3 Ley de beneficios decrecientes
La ley de beneficios decrecientes dice que para duplicar la cantidad de
trabajo que se desea procesar, es necesario aumentar la cantidad de los
recursos a más del doble, es decir, el doble de los recursos no permite
aumentar la carga de trabajo al doble.
Hace falta realizar las siguientes consideraciones para poder tener
claro lo que se describió anteriormente.
Consideración No 1
Sea:
B : porcentaje de uso de un recurso.
TS : tiempo de servicio típico de cualquier recurso.
TR : tiempo de respuesta por uso de un recurso.
t : instante de tiempo
dt : espacio de tiempo transcurrido.
Véase el siguiente ejemplo:
Se conoce por experiencia que un actuador muestra tiempos de
respuesta razonables para niveles de uso de treinta por ciento (30%) a

Marco Teórico
27
treinta y cinco por ciento (35%) en el pico. Suponga que se tiene en un
instante determinado de tiempo t un porcentaje de uso de treinta por ciento
(30%) con un cociente de TR/TS de uno punto tres (1.3), luego en un
instante t + dt se tiene un porcentaje de uso de treinta y cinco por ciento
(35%) con un cociente de TR/TS de uno punto cuatro (1.4), entonces:
Si B = 30% ? TR/TS = 1.3
Si B = 35% ? TR/TS = 1.4
En general, no es posible utilizar un recurso en el mismo porcentaje
todo el tiempo, esto trae como consecuencia que el tiempo de respuesta del
recurso en estudio contenga variaciones.
En conclusión no se puede esperar que todos los discos tengan un
porcentaje de utilización de treinta y cinco por ciento (35%) y lo mantengan
durante todo el día, esto se debe a que es imposible distribuir la carga
perfectamente entre todos los servidores y en todos los períodos de tiempo
en el día, la dificultad aumenta con el número de servidores.
Consideración No 2
Sea:
Bmax : porcentaje de uso más alto observado sobre un conjunto de
recursos.
Bprom : porcentaje promedio de uso de todos los recursos
Skew: relación entre Bmax y Bprom

Marco Teórico
28
PROM
MAX
BB
Skew?
El Skew sirve para ilustrar la manera en que se distribuye el uso de
los recursos a medida que aumentan.
Según mediciones y análisis que ha llevado a cabo el autor de la
metodología, se tiene lo siguiente:
NxSkew 002.02.4 ??
donde N es igual al número de actuadores.
En la tabla 5 se muestra un ejemplo de los valores típicos en la
relación existente entre el Skew y el número de recursos utilizados (para el
caso de estudio los recursos son actuadores).
Tabla 5. Relación entre Skew y No de actuadores
Número de Actuadores Skew
20 4.6
40 5.0
60 5.4
100 6.2
150 7.2
200 8.2
260 11.4
300 12.2
Fuente: Rodríguez, et al., 1988, p. D.19

Marco Teórico
29
Se puede afirmar de la tabla que el valor del Skew experimenta un
aumento de acuerdo con la cantidad de discos, esto ocurre por la dificultad
existente a la hora de distribuir la carga. De esto se puede decir que es
imposible distribuir la carga de una manera perfecta entre los diferentes
actuadores.
Supóngase que ahora se tiene un conjunto de cien actuadores con un
TS igual a veinte milisegundos (20 ms.) (véase la tabla 6).
Tabla 6. Conjunto de actuadores
Cantidad B TR/TS N x B N x B x TR/TS
50 2% 1.02 100 102.0
20 6% 1.05 120 126.0
10 10% 1.08 100 108.0
8 15% 1.14 120 136.8
6 25% 1.25 150 187.5
4 35% 1.40 140 196.0
2 60% 2.13 120 255.6
Total = 100 850 1111.9
Prom 8.5% 1.31
Fuente: Rodríguez et al., 1988, p. D.21
El comportamiento de un conjunto de cien actuadores al 8.5% en
promedio, puede equivaler, en TR, a un actuador al 30%.

Marco Teórico
30
Finalmente de todo lo expuesto en este punto se puede decir lo
siguiente:
?? A mayor cantidad de discos, menor es la utilización promedio.
?? El Skew aumenta con la cantidad de discos, esto como se
explicó anteriormente es debido a la dificultad existente para
distribuir de una manera perfecta la carga.
?? Como ya se mostró no necesariamente el doble de trabajo se
realiza con el doble de los recursos.
Para obtener más información sobre la ley de beneficios decrecientes
para actuadores y rutas véase la Tabla A1 del apéndice A para actuadores y
la Tabla A2 para rutas. Es importante señalar que las tablas de este
apéndice muestran los actuadores y las rutas para un tráfico en particular. La
definición de tráfico se explica a continuación.
II.1.3.1 Tráfico
Tráfico es una medida, independiente del tipo de
disco. Se aplica cuando se tiene una cantidad de
operaciones de E/S por segundo, y se desea saber cual es
el número de actuadores necesarios para compensar este
requerimiento de entrada y salida. La fórmula que lo
describe es expresada de la siguiente manera:
TSAxSTráfico ?

Marco Teórico
31
donde:
TSA7: Tiempo de servicio del actuador.
S: cantidad de operaciones E/S por segundo.
Cuando se conoce el valor del tráfico, es posible calcular el número de
actuadores que soportan esa cantidad en particular, esta información se
toma de la tabla de la ley de beneficio decreciente (LBD) para actuadores
(véase la tabla A1 del apéndice A).
Siguiendo los mismos lineamientos teóricos se puede calcular el
número de rutas para compensar un tráfico en particular. La fórmula para las
rutas es muy similar a la de los actuadores sólo que en vez de utilizar el TSA
se utiliza el TSR, así:
TSRxSTráfico ?
donde:
TSR: tiempo de servicio de la ruta correspondiente al tipo de disco al
cual se le quiere conocer la cantidad de rutas.
S: cantidad de operaciones E/S por segundo.
Cuando se conoce el tráfico, es posible conocer el número de rutas
para este tráfico mediante la tabla de LBD para rutas (véase la tabla A2 del
apéndice A).
Las rutas poseen un número y una forma en la que se disponen en el
sistema, a esto se le conoce como paralelismo. Al paralelismo también se le
puede denotar por el símbolo “||”. 7 Este tiempo de servicio es para un tipo de disco específico.

Marco Teórico
32
Existen tres tipos de paralelismo con el que se disponen las rutas,
estos son los siguientes:
Paralelismo 1
La transmisión debe empezar y terminar por la misma ruta. Cuando se
efectúan varias operaciones de entrada y salida, una de ellas puede quedar
en espera por la retransmisión, aunque se encuentren otras rutas
disponibles. Esto se traduce en que la unidad de control está compuesta por
una sola ruta, esto es llamado tecnología pre-DLS8, limitado o de acceso no
paralelo.
Paralelismo 2
A diferencia del paralelismo 1 los canales no están aislados, tienen un
control central o unidad de control. La ruta por donde empieza la operación
de E/S no tiene que ser la misma de regreso, este tipo de paralelismo utiliza
la que esté libre. Paralelismo 2 significa que la unidad de control se
encuentra compuesta por dos rutas, esto recibe el nombre de DLS.
Paralelismo 4
Parecido al paralelismo 2 los canales no se encuentran aislados. La
unidad de control se encuentra compuesta por cuatro rutas, las operaciones
de entrada y salida son asignadas a la ruta que se encuentre libre para ese
instante. A esta tecnología se le conoce como DLSE9
8 Device Level Selection 9 Device Level Selection Extended

Marco Teórico
33
II.1.4 Metodología SIO (Start I/O)
La metodología Start I/O está basada en experiencias reales con
comprobación matemática, relaciona el CPU con la carga de operaciones de
E/S por segundo. Esta metodología se automatizó en un sistema llamado
CP80 que es de uso interno en IBM y que fue desarrollado en APL
exclusivamente para Mainframes. Esta metodología, en contraposición a la
mayoría de las metodologías de planificación de capacidad, es fácil de usar y
con una base metodológica generalizada que permite su aplicación a la
mayoría de las plataformas existentes en el mercado.
La metodología del SIO, fue desarrollada por Joseph B. Mayor, en los
años ochenta pero mantiene perfectamente su vigencia. Ha sido utilizada
exitosamente en numerosas ocasiones alrededor del mundo. Esto ha sido
posible gracias a su basamento teórico generalizado, que no requiere el
modelaje de las características específicas del ambiente estudiado. Para la
estimación del procesador se utiliza una proyección lineal basada en su
utilización y una serie de ajustes que dependen del ambiente específico. La
estimación de recursos de discos y rutas utiliza un enfoque no lineal que se
basa en la ley de beneficios decrecientes.
La metodología SIO, como se mencionó anteriormente, está basada
en la relación existente entre el uso del procesador, su velocidad, y el
número de operaciones de entrada y salida (E/S) que se realizan en un

Marco Teórico
34
segundo y la densidad de E/S que contiene la carga de trabajo. Esta relación
puede ser expresada de la siguiente manera:
BxRxMS ?
Donde:
S: cantidad de SIO’s por segundo
M: constante dependiente de la velocidad del CPU. Esta depende
además del tipo de procesador. El valor M es un valor asignado a cada
procesador, su cálculo está basado en el resultado de dividir la cantidad de
E/S por segundo entre el porcentaje de utilización del CPU para diferentes
procesadores pero sin cambiar el tipo de software.
R: significa RIOC (Relative I/O Content), expresa la cantidad de
operaciones de E/S procesadas por unidad de tiempo de procesador. Provee
una descripción de la carga de trabajo en términos de la cantidad de E/S con
relación a la utilización del CPU: Un número alto de R refleja una carga de
trabajo con una cantidad numerosa de operaciones de E/S.
B: expresa la utilización del CPU
La metodología SIO relaciona el procesador con las operaciones de
entrada y salida con el fin de evitar inconsistencias que se pueden presentar
al momento de realizar la proyección. La metodología intenta con su
aplicación dar a conocer el número de rutas y actuadores requeridos.
Para ilustrar como se aplica la metodología SIO para la proyección de
discos, rutas y su relación con el procesador y la ley de beneficio

Marco Teórico
35
decreciente, se usará el ejemplo que se ha venido manejando para ilustrar la
proyección de CPU. Los datos están basados en los dos grupos de
aplicaciones definidos anteriormente y su proyección de crecimiento para los
próximos cinco años (véase la tabla 7).
Tabla 7. Proyección de CPU para los grupos de aplicaciones
Situación
Actual Año 1 Año 2 Año 3 Año 4 Año 5
PRÉSTAMO 12,13 15,17 18,96 23,70 29,62 37,03 SAFE 19,84 25,79 33,52 43,58 56,66 73,65 Total 31,97 40,95 52,48 67,28 86,28 110,68
Como la metodología SIO utiliza la variable R (RIOC), se debe asumir
su valor para los dos grupos de aplicaciones con los cuales se está
trabajando. Este se supondrá en cero punto tres (0.3) para PRÉSTAMO y
cero punto cuatro (0.4) para SAFE.
Se conoce el punto de saturación del procesador, resultado obtenido
en el ejemplo relacionado a la proyección de CPU (68.38%). Además, se
debe asumir su valor M, que para el ejemplo de la proyección se le adjudicó
el valor de 700.
Es necesario también para aplicar la metodología, conocer los valores
que se tienen del TSR (Tiempo de Servicio de la Ruta) y el TSA (Tiempo de
Servicio del Actuador); para este ejemplo se asumirá diez milisegundos (10
ms.) para el TSA y doce milisegundos (8 ms.) para el TSR, con paralelismo
2.

Marco Teórico
36
Una vez conocidos todos los datos necesarios para aplicar la
metodología, se procede a calcular el valor de S para cada uno de los grupos
de aplicaciones:
2.253.012.0700 ??? xxRxBxMS PRÉSTAMOPRÉSTAMOPRÉSTAMO
564.020.0700 ??? xxRxBxMS SAFESAFESAFE
Se aplica esta fórmula para una proyección en un período de cinco
años, para conocer el comportamiento de las operaciones de E/S para los
grupos de aplicaciones (Véase la tabla 8).
Tabla 8. Valor de S para los grupos de aplicaciones en 5 años
Situación
Actual Año 1 Año 2 Año 3 Año 4 Año 5 PRÉSTAMO 25,20 31,50 39,38 49,22 61,52 76,90
SAFE 56,00 70,00 87,50 109,38 136,72 170,90 Total (S) 81,20 101,50 126,88 158,59 198,24 247,80
Una vez que se conoce el valor de S para las aplicaciones, hay que
calcular el tráfico para los años de la proyección, tanto para las rutas como
para los actuadores.
La fórmula que resuelve este problema se expresa de la siguiente
forma. Para la situación actual queda así:
0.8121020.81 ??? xTSAxSTráficoActuador
de manera similar para la ruta quedaría de esta manera:
4.9741220.81 ??? xTSRxSTráficoRuta

Marco Teórico
37
En la siguiente tabla (tabla 9) se muestra el tráfico para la proyección
de los cinco años con los que se está trabajando en este ejemplo.
Tabla 9. Tráfico para la proyección
Situación
Actual Año 1 Año 2 Año 3 Año 4 Año 5
Tráfico Actuadores 812.0 1015.0 1268.8 1585.9 1982.4 2478.0
Tráfico Rutas 974.4 1218 1522.56 1903.08 2378.88 2973.6
Con el tráfico ya calculado para los años de la proyección se procede
a calcular el número de actuadores y rutas necesarias que cumplirán de
manera adecuada con este requerimiento de tráfico específico. Para realizar
este proceso es necesario recurrir a la tabla LBD para los actuadores y las
rutas.
En caso de que no exista en la tabla LBD la cantidad de actuadores
para el tráfico señalado, se debe hacer una interpolación lineal que cubra el
rango en donde se encuentra el tráfico en cuestión. La fórmula se escribe
así:
? ? eriorerioractualeriorerior
eriorerior ActuadoresTráficoTráficoxTráficoTráfico
ActuadoresActuadoresActNúmero infinf
infsup
infsup ???
??
En el caso de las rutas se procede de igual forma con la diferencia de
que en la tabla LBD se debe ubicar el paralelismo con el que están
trabajando las rutas del sistema. Si el tráfico no se encuentra tabulado se
procede a interpolar linealmente y se obtiene el número de rutas que
soportan el tráfico de la proyección.
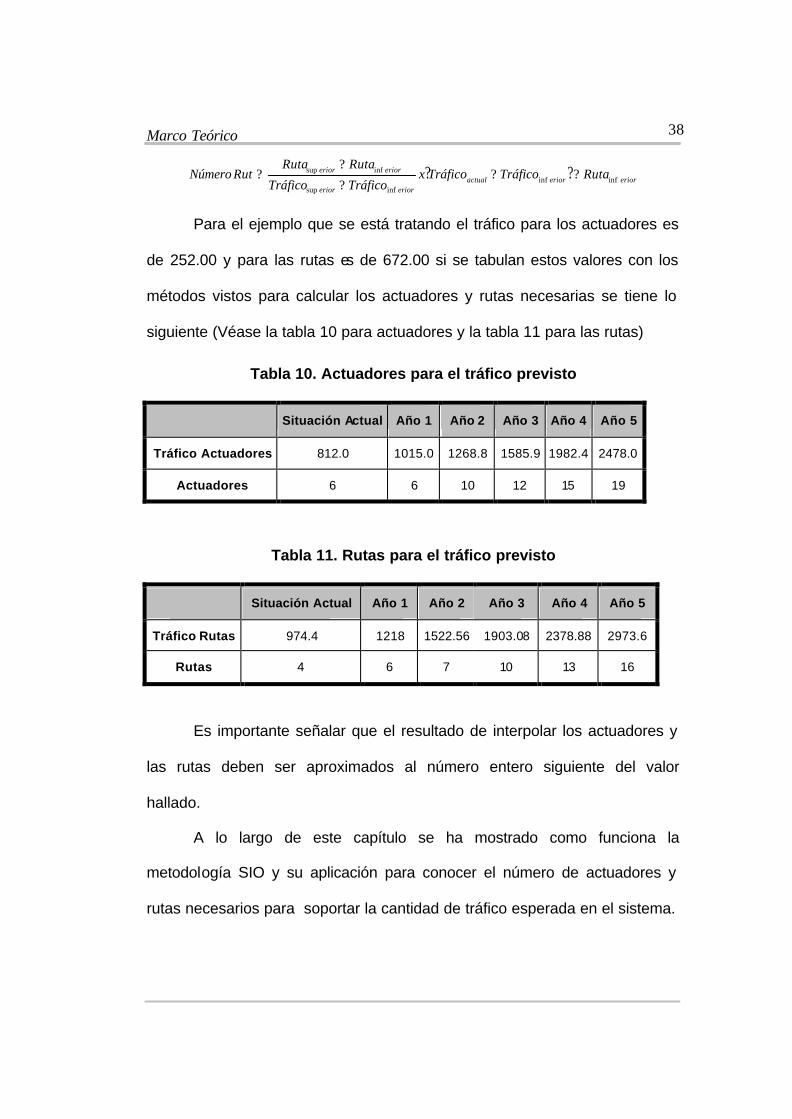
Marco Teórico
38
? ? eriorerioractualeriorerior
eriorerior RutaTráficoTráficoxTráficoTráfico
RutaRutaRutNúmero infinf
infsup
infsup ???
??
Para el ejemplo que se está tratando el tráfico para los actuadores es
de 252.00 y para las rutas es de 672.00 si se tabulan estos valores con los
métodos vistos para calcular los actuadores y rutas necesarias se tiene lo
siguiente (Véase la tabla 10 para actuadores y la tabla 11 para las rutas)
Tabla 10. Actuadores para el tráfico previsto
Situación Actual Año 1 Año 2 Año 3 Año 4 Año 5
Tráfico Actuadores 812.0 1015.0 1268.8 1585.9 1982.4 2478.0
Actuadores 6 6 10 12 15 19
Tabla 11. Rutas para el tráfico previsto
Situación Actual Año 1 Año 2 Año 3 Año 4 Año 5
Tráfico Rutas 974.4 1218 1522.56 1903.08 2378.88 2973.6
Rutas 4 6 7 10 13 16
Es importante señalar que el resultado de interpolar los actuadores y
las rutas deben ser aproximados al número entero siguiente del valor
hallado.
A lo largo de este capítulo se ha mostrado como funciona la
metodología SIO y su aplicación para conocer el número de actuadores y
rutas necesarios para soportar la cantidad de tráfico esperada en el sistema.

Marco Teórico
39
En el momento en que la metodología fue presentada (1981), los
actuadores poseían tiempos de servicio promedio limitados y no era común
que las configuraciones de los sistemas tuvieran discos diferentes, que a su
vez trabajaban con tiempos de servicios diferentes, era común en ese
entonces asumir actuadores del mismo tipo.
Con el paso del tiempo los fabricantes de tecnología comenzaron a
producir unidades de control multirutas (DLS y DLSE) y unidades de disco
con caché, esto trajo como resultado que los tiempos de servicio para
actuadores fuesen distintos, originando que el tiempo de servicio promedio
para una operación de entrada y salida variase en gran cantidad.
Se puede decir entonces que el verdadero problema para la
metodología Start I/O surge cuando se pretende hacer una planificación de
capacidad para estimar el número de actuadores y rutas futuras en un
sistema que presenta mezcla de discos.
El problema de la mezcla de discos se encuentra presente cuando se
tiene un número de rutas y actuadores preservados; Es decir, existen en la
configuración actual del sistema y se desean. Normalmente las rutas y
actuadores nuevos tendrán tiempos de servicio diferentes.
El objetivo es estimar el número de actuadores y rutas nuevas de cada
uno de los tipos seleccionados.

Marco Teórico
40
II.1.4.1 Mezcla de discos
Cuando existen combinaciones de tipos diferentes de discos se puede
distribuir la cantidad de operaciones de E/S de dos maneras:
1. Por igual utilización promedio para cada grupo de discos, lo que
se conoce como caso =U
2. Por igual cantidad promedio de operaciones de entrada / salida
para cada grupo de discos, esta manera se define como caso
=S
Para ilustrar de que se trata lo expuesto anteriormente véase el
siguiente ejemplo:
Tabla 12. Datos del ejemplo de Mezcla de Discos
Actuadores Tipo de disco 1 Tipo de disco 2
TS 10 ms. 20 ms.
Cantidad S 50 75
Supóngase que se tienen los datos anteriores (tabla 12) para dos tipos
diferentes de actuadores preservados.
Tabla 13. Caso =U
Tipo de Disco 1 Tipo de Disco 2 Global
Total S 400 300 700
S/Actuadores 8 4 5.6
B/Actuadores 8% 8% 8%
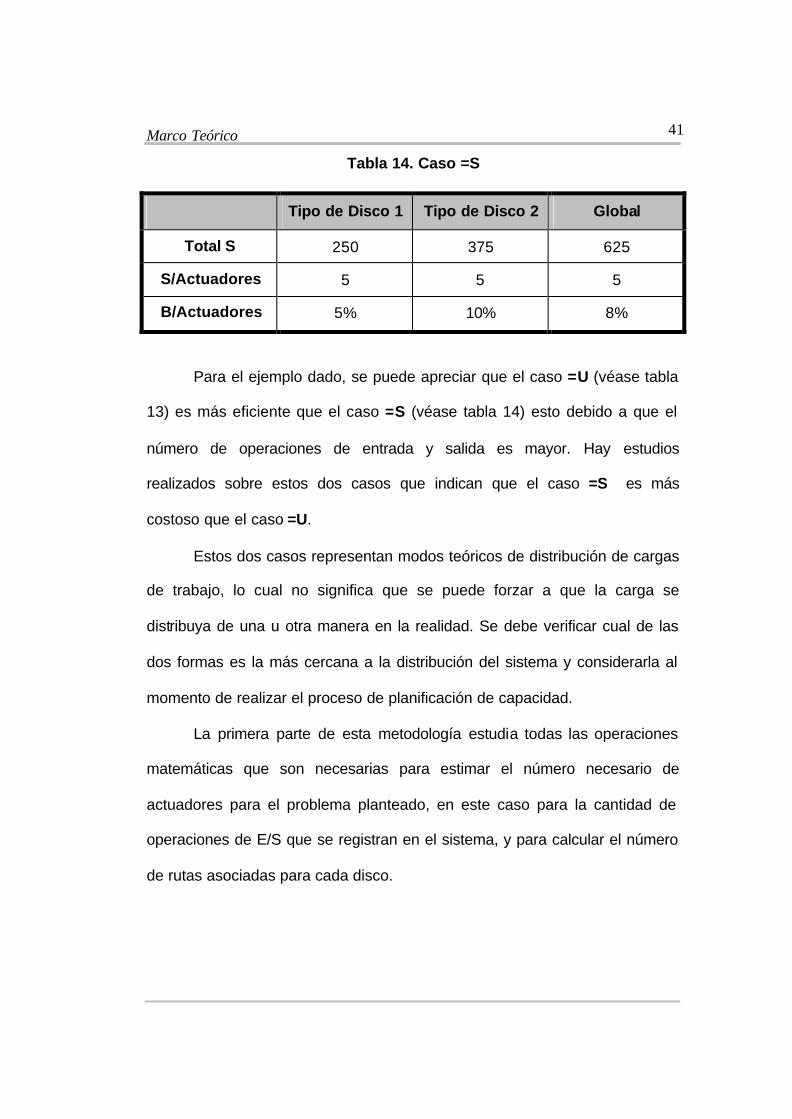
Marco Teórico
41
Tabla 14. Caso =S
Tipo de Disco 1 Tipo de Disco 2 Global
Total S 250 375 625
S/Actuadores 5 5 5
B/Actuadores 5% 10% 8%
Para el ejemplo dado, se puede apreciar que el caso =U (véase tabla
13) es más eficiente que el caso =S (véase tabla 14) esto debido a que el
número de operaciones de entrada y salida es mayor. Hay estudios
realizados sobre estos dos casos que indican que el caso =S es más
costoso que el caso =U.
Estos dos casos representan modos teóricos de distribución de cargas
de trabajo, lo cual no significa que se puede forzar a que la carga se
distribuya de una u otra manera en la realidad. Se debe verificar cual de las
dos formas es la más cercana a la distribución del sistema y considerarla al
momento de realizar el proceso de planificación de capacidad.
La primera parte de esta metodología estudia todas las operaciones
matemáticas que son necesarias para estimar el número necesario de
actuadores para el problema planteado, en este caso para la cantidad de
operaciones de E/S que se registran en el sistema, y para calcular el número
de rutas asociadas para cada disco.

Marco Teórico
42
Debido a la mayor eficiencia y menor costo que genera la aplicación
del procedimiento =U se selecciona este modo para la distribución de carga,
para efectuar los cálculos antes mencionados.
Con el propósito de facilitar la comprensión de los cálculos se
introduce la siguiente notación:
k: índice del tipo de actuador.
S: proyección de entradas y salidas de disco por segundo.
T: promedio del tiempo de servicio, expresado en milisegundos (ms.)
Fk: fracción del tiempo de actuador en la mezcla.
* : símbolo que identifica a los datos que se relacionan con los
actuadores preservados.
** : símbolo que identifica a los datos que se relacionan con los
actuadores que van a ser añadidos al sistema.
p: subíndice que hace referencia a las rutas de disco.
N: número de actuadores.
W: Trabajo (intensidad de tráfico), W = S * T
j: índice del tipo de ruta.
Tp: promedio del tiempo de servicio de la ruta, expresado en
milisegundos (ms.)
Tpjk: promedio del tiempo de servicio del tipo de ruta j para los
actuadores de tipo k (ms.)
Np: número de rutas.
Wp: Trabajo (intensidad de tráfico), Wp = S * Tp

Marco Teórico
43
Wpjk: trabajo sobre la ruta de tipo j para el actuador de tipo k.
Wa: promedio de trabajo por ruta (ms/s)
La notación que se acaba de proporcionar es para k tipo de
actuadores, esta engloba tanto los preservados como los próximos a añadir.
Este tipo de enfoque permite que un tipo específico de actuador pueda
pertenecer a ambas categorías (preservados o nuevos), se puede ver a este
actuador como un conjunto de dos tipos con idénticos tiempos de servicio
promedio, pero con un tipo en el grupo de los que serán preservados y otro
en el grupo de los nuevos.
k es un subíndice que representa al tipo de disco, mientras que K
representa la cantidad total del tipo de discos que se tienen.
Para aclarar un poco más lo antes dicho se explicará un ejemplo
clásico de la situación descrita para estimar las rutas y los actuadores
necesarios para soportar las operaciones de entrada y salida a disco que
genera el sistema.
II.1.4.2 Ejemplo práctico
Se requiere preservar N* actuadores para que formen parte de una
configuración futura que pueda soportar la cantidad de operaciones de
entrada y salida a disco que presenta el sistema (S). Para efectos de explicar
el método para resolver la mezcla de discos en el sistema se supondrá que
existen diferentes actuadores cuyas características no son las mismas, por

Marco Teórico
44
ejemplo: N*1, N*2, ... , N*l, se tienen entonces l grupos de actuadores
preservados de diferentes tipos. De aquí se puede deducir que N*1 + N*2 + ...
+ N*l = N*. Las fracciones por tipo de actuador preservado son: F*1 , F*2 , ... ,
F*l, entendiéndose que F*1 + F*2 + ... + F*l = 1 donde F*k = N*k/N* con k = {
1,..l }.
El promedio del tiempo de servicio para cada actuador preservado
está dado por : T*1, T*2, ... , T*l. El tiempo de servicio de las rutas para los
discos preservados está dada por: Tp*1, Tp*2, ... , Tp*l.
Junto con los actuadores preservados se quiere agregar N**
actuadores nuevos para complementar los requerimientos de S que se tienen
en el sistema. De forma similar los actuadores nuevos pueden ser de tipos
diferentes: N**(l + 1) + ... + N**k , donde N**(l + 1) + ... + N**k = N**. Las
fracciones para los nuevos actuadores son: F**(l + 1), ... , F**k, entendiéndose
que F**(l + 1) + ... + F**k = 1. Igualmente F**k = N**k/N** con k = {(l + 1) ... K}.
Los tiempos promedio de servicios para los discos nuevos, se expresan de la
siguiente manera: T**(l + 1) , ... , T**k, con un tiempo de servicio promedio para
las rutas de cada actuador: Tp**(l + 1) , ... , Tp**k.
Para desarrollar un ejemplo característico de la mezcla de disco, se
supondrán los siguientes valores para los diferentes elementos que van a
intervenir en el desarrollo de este ejemplo (Véase la tabla 15).
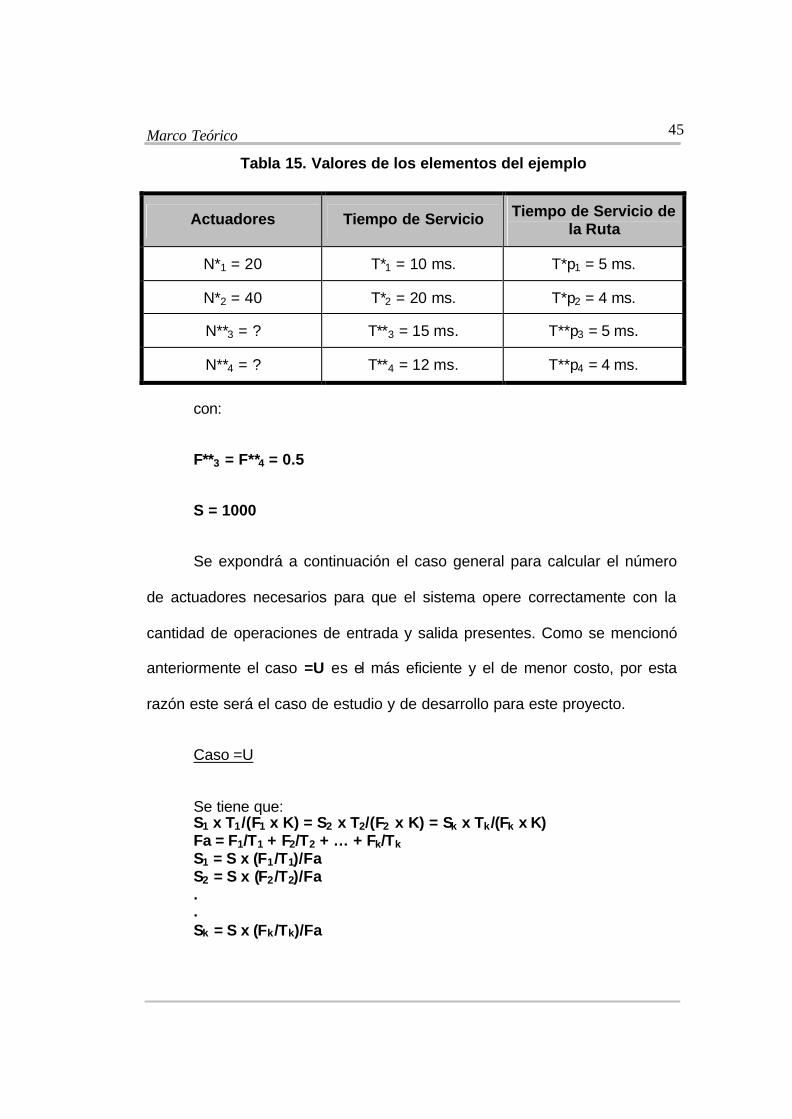
Marco Teórico
45
Tabla 15. Valores de los elementos del ejemplo
Actuadores Tiempo de Servicio Tiempo de Servicio de la Ruta
N*1 = 20 T*1 = 10 ms. T*p1 = 5 ms.
N*2 = 40 T*2 = 20 ms. T*p2 = 4 ms.
N**3 = ? T**3 = 15 ms. T**p3 = 5 ms.
N**4 = ? T**4 = 12 ms. T**p4 = 4 ms.
con:
F**3 = F**4 = 0.5
S = 1000
Se expondrá a continuación el caso general para calcular el número
de actuadores necesarios para que el sistema opere correctamente con la
cantidad de operaciones de entrada y salida presentes. Como se mencionó
anteriormente el caso =U es el más eficiente y el de menor costo, por esta
razón este será el caso de estudio y de desarrollo para este proyecto.
Caso =U
Se tiene que: S1 x T1/(F1 x K) = S2 x T2/(F2 x K) = Sk x Tk/(Fk x K) Fa = F1/T1 + F2/T2 + … + Fk/Tk S1 = S x (F1/T1)/Fa S2 = S x (F2/T2)/Fa . . Sk = S x (Fk/Tk)/Fa

Marco Teórico
46
T = 1/Fa W = S x T
Cuando se conocen todos estos valores se procede a calcular el
número de actuadores necesarios de cada tipo mediante la tabla LBD, si el
dato no se encuentra tabulado directamente es necesario realizar una
interpolación lineal para conocer el valor.
El cálculo de este valor se expresa de la siguiente manera:
Nk = Fk x N
En caso de que no de un valor entero es necesario realizar el
redondeo al número entero siguiente al valor encontrado.
Para solucionar ahora el ejemplo propuesto para el problema de la
mezcla de disco es necesario realizar los siguientes pasos de una forma
ordenada.
Primero debe conocerse el tráfico para los actuadores preservados
partiendo de la idea de que son los únicos que existen en la configuración
del sistema. Para ello se debe utilizar la tabla LBD para actuadores.
Luego debe calcularse T*, una vez conocido se procede a calcular los
Sk. La condición de parada de este algoritmo iterativo es cuando S < S* esto
significa que los actuadores presentes en el sistema soportan la cantidad de
operaciones de E/S pautadas en el sistema. De no ser así debe entonces

Marco Teórico
47
calcularse el número de actuadores nuevos necesarios para cumplir con este
requerimiento.
El desarrollo se explica a continuación
Se tiene N* , N*1 , N*2, ... , N*l, T*1 , T*2 , ... , T*l
Para F*1 = N*1/N* , F*2 = N*2/N* , ... F*l = N*l/N*
El tráfico (W) se calcula con la tabla de ley de beneficio decreciente
para los actuadores preservados.
Se calculan ahora los elementos restantes, siguiendo el caso =U y se
obtiene lo siguiente:
F*a = F*1/T*1 + … + F*l/T*l T* = 1/F*a S* = W*/T* S*1 = S* x (F*1/T*1)/F*a S*l = S* x (F*l/T*l)/F*a
Con los datos de entrada conocidos para este problema los cálculos
quedarían de la siguiente manera:
N* = 60 N*1 = 20, T*1 = 10 ms. N*2 = 40, T*2 = 20 ms. F*1 = 1/3 F*2 = 2/3
Con un total de sesenta actuadores se debe conocer entonces el
tráfico que corresponde a esa cantidad, para ello se utiliza la tabla LBD. Para
este ejemplo el resultado de W es seis mil doscientos (6200).

Marco Teórico
48
Con todos los datos conocidos solo falta calcular las operaciones de
entrada y salida para cada grupo de actuadores.
F*a = (1/3)/10 + (2/3)/20 = 0.067 T* = 1/F*a = 15 S* = W*/T* = 413.33 S*1 = S* x (F*1/T*1)/F*a = 206.66 S*2 = S* x (F*2/T*2)/F*a = 206.66
El siguiente paso en la solución del problema de la mezcla de discos
es calcular el tráfico para los actuadores nuevos. Para este paso el cálculo
del tráfico viene dado de la siguiente manera:
W = (S – S*) x T** + W*
El número de actuadores se puede calcular así:
N** = N – N*
El número de cada tipo de actuador se puede calcular con esta
fórmula:
N**k = F**k x N**
Los tiempos de servicio y la fracción para los actuadores futuros
vienen expresados así:
T**(l + 1), ... , T**k , F**(l + 1) , … , F**k
El cálculo para estos elementos se plantea de esta manera:
F**a = F**(l + 1)/T**(l + 1) + … + F**k/T**k T** = 1/F**a S**(l + 1) = (S – S*) x (F**(l + 1)/T**(l + 1))/F**a S**k = (S – S*) x (F**k/T**k)/F**a W = (S – S*) x T** + W*

Marco Teórico
49
Conociendo el tráfico se puede entonces calcular el valor de N
N** = N – N* N**(l + 1) = F**(l + 1) x N** N**k = F**k x N** Con los datos especificados para el ejemplo los valores de los
elementos del problema quedarían de la siguiente forma:
F**a = 0.5/15 + 0.5/12 = 0.075 T** = 1/F**a = 13.33 S**3/(S – S*) = (0.5/15)/0.075 = 0.4444 S**4/(S – S*) = (0.5/12)/0.075 = 0.5555 W = (S – S*) x T** + W* = (1000 – 413.33) x 13.33 + 6200 = 14022.22 N = 14022 – 2600)/60 = 190.37 N** = N – N* = 190.37 - 60 = 130.37 N**3 = F**3 x N** = 0.5 x 190.37 = 65.185 N**4 = F**4 x N** = 0.5 x 190.37 = 65.185 Hasta este momento se conoce la cantidad de actuadores nuevos de
cada tipo necesarios para cubrir los requerimientos del tráfico calculado. Es
necesario destacar que los cálculos para los actuadores se han hecho sin
combinar preservados con nuevos, es por esta razón que el siguiente paso
consiste en realizar proyecciones para todos los actuadores juntos. De
obtener resultados que difieran en la cantidad de actuadores preservados,
con el propósito de confirmar que la diferencia en resultado no afectará la
proyección total de los discos, se realiza una prueba de convergencia la cual
validará el resultado obtenido en el desarrollo del algoritmo.
Se volverán a calcular los elementos necesarios para el desarrollo de
la proyección pero esta vez no se marcará la diferencia entre actuadores, es
decir, no se tratarán como preservados o futuros sino de su tipo

Marco Teórico
50
correspondiente. Para los valores de los preservados se tomarán los
introducidos por el problema y para los nuevos serán los calculados por el
paso anterior.
Se tiene entonces que:
F1 = N1/N Fk = Nk/N Fa = F1/T1 + F2/T2 + … + Fk/Tk T = 1/Fa S1 = S x (F1/T1)/Fa Sk = S x (Fk/Tk)/Fa W = S x T El valor de N se calcula utilizando la tabla LBD para el tráfico obtenido.
N1 = F1 x N Nk = Fk x N Utilizando los valores conocidos por el ejemplo se obtienen los
siguientes resultados:
F1 = 20/190.37 = 0.1051 F2 = 40/190.37 = 0.2101 F3 = 65.185/190.37 = 0.3424 F4 = 65.185/190.37 = 0.3424 Fa = F1 x T1 + F2 x T2 + F3 x T3 + F4 x T4 = 0.07237 T = 1/Fa = 13.8172 S1 = 1000 x (0.01051/0.07237) = 145.23 S2 = 1000 x (0.01051/0.07237) = 145.23 S1 = 1000 x (0.02285/0.07237) = 315.41 S1 = 1000 x (0.02853/0.07237) = 394.27 W = S x T = 1000 x 13.8172= 13817.2 N = (13817 – 2600)/60 = 186.9534 N1 = 186.9534 x 0.1051 = 19.64 N2 = 186.9534 x 0.2101 = 39.28 N3 = 186.9534 x 0.3424 = 64.02 N4 = 186.9534 x 0.3424 = 64.02 Al observarse el resultado obtenido en este paso se puede apreciar
claramente que existe una diferencia entre los valores encontrados para los

Marco Teórico
51
actuadores preservados. Para saber si los valores obtenidos pueden cumplir
con los requerimientos exigidos de S se realiza una prueba de convergencia
en la cual esta interrogante es contestada.
Como condición de parada para este algoritmo se especifica lo
siguiente: la diferencia entre el número de actuadores preservados
originalmente, es decir, N*k y el número de actuadores preservados
calculados en el paso anterior sea pequeña. La definición de una diferencia
pequeña viene dada por no más de un cero punto cinco (0.5).
Como entrada para este paso se colocan los valores originales de los
actuadores preservados más el número de actuadores nuevos calculados en
el paso anterior.
En el ejemplo que se está trabajando quedaría el valor de N de la
siguiente manera:
N = 20 + 40 + 64.02 + 64.02 = 188.04
Se realiza una nueva iteración y se obtiene lo siguiente:
F1 = 20/188.04 = 0.1064 F2 = 40/188.04 = 0.2127 F3 = 64.02/188.04 = 0.3405 F4 = 64.02/188.04 = 0.3405 Fa = F1/T1 + F2/T2 + F3/T3 + F4/T4 = 0.07234 T = 1/Fa = 13.82345 S1 = 1000 x (0.01064/0.07234) = 147.08 S2 = 1000 x (0.01064/0.07234) = 147.08 S3 = 1000 x (0.0227/0.07234) = 313.79 S4 = 1000 x (0.028375/0.07234) = 392.18 W = 1000 x 13.82345 = 13823.45 N = (13823.45 – 2600)/60 = 187.057 N1 = 187.057 x 0.1064 = 19.90 N2 = 187.057 x 0.2127 = 39.80 N3 = 187.057 x 0.3405 = 63.7

Marco Teórico
52
N4 = 187.057 x 0.3405 = 63.7 Al ver este resultado, se puede apreciar que sigue existiendo una
diferencia entre los actuadores preservados de este cálculo y los actuadores
preservados originales; pero al ver esta diferencia es “fácil” darse cuenta que
no es mayor al límite establecido en esta prueba, el cual fue de 0.5, por lo
que se pueden aceptar estos valores como la cantidad de actuadores
necesarios para compensar el número de operaciones de E/S que está
presente en el sistema.
El resultado del problema queda así:
N*1 = 20, N*2 = 40, N**3 = N**4 = 64
El paso siguiente en el desarrollo de este algoritmo consiste en
obtener el número de rutas necesarias para cada tipo de actuador incluido en
la proyección. Este cálculo se basa también en la tabla LBD para las rutas,
es claro que para este proceso es necesario tener en cuenta el número de
actuadores que se obtuvieron antes de llegar a este paso y sus tipos de
rutas; se sabe por conocimientos previos el tipo de ruta con el que trabaja
cada actuador. Si se calcularan las rutas independientemente del número de
actuadores, podrían obtenerse resultados inconsistentes a la hora de la
asignación de las mismas a cada actuador.
El método a utilizar debe tomar en consideración todas las
especificaciones establecidas anteriormente. Este procedimiento debe
combinar los tipos de rutas para los actuadores ya presentes en la
configuración y calcular la cantidad de rutas según su tipo. Para conocer la

Marco Teórico
53
cantidad de rutas que son capaces de soportar el tráfico Wp estimado, es
necesario recurrir a la tabla LBD para rutas.
En conclusión lo que se busca es identificar para cada tipo de
actuador, el número de rutas que tiene asignado, es decir, el número de
rutas del tipo j para el actuador de tipo k (Npjk).
Existe otra variable de importancia para el cálculo del número de rutas
y tiene que ver con el tiempo de servicio de la ruta, su respectivo paralelismo
y el tipo de disco a la que pertenece, esta variable se denota de esta forma:
Tpjk donde j representa el tipo de ruta para el actuador tipo k.
Ya teniendo en cuenta estos detalles se da curso al siguiente paso en
el algoritmo, el cual estima los números de rutas necesarios para cada tipo
de actuador.
Para calcular el tráfico de la ruta Wpjk para un tipo de actuador, es
necesario utilizar el resultado de Sk por cada tipo de actuador y su respectivo
Tpjk. Por otro lado la suma sobre k para un j dado, es el tráfico total Wpj para
un tipo de ruta j. La suma de esos sobre j es el tráfico de ruta total Wp.
La siguiente variable a calcular es Wa j la cual se obtiene de dividir el
tráfico total entre el número de rutas (cuyo paralelismo es igual a j)
necesarias para soportar este tráfico. El número de rutas es obtenido
mediante la tabla LBD para el tráfico Wp quedando así:
Waj = Wp/Npj
Despejando se sabe que Npj = Wp j/Waj
De igual forma se tiene que:

Marco Teórico
54
Npjk = Wpjk/Wa j
A continuación se pueden ver los cálculos.
T*p41, T*p22, … , T*p1l, … , T**p4(l + 1), … , T**p3k, S*1, S*2, … , S*l,
S*(l + 1), … , S**k.
W*p41 = S*1 x Tp41 W*p22 = S*2 x Tp22 · W*pl = S*l x T*p1l W**p4(l + 1) = S(l + 1) x Tp4(l + 1) · W**p4k = Sk x Tp4k Se calcula Wpj, Wp y Wa j N*p41 = W*p41/Wa4 N*p22 = W*p22/Wa2 · N*p1l = W*p1l/Wa1 N**4(l + 1) = W**p4(l + 1)/Wa4 · N**p4k = W**p4k/Wa4
Luego de ver la forma de realizar los cálculos, se especifican los
valores de los tiempos de servicios para cada una de las rutas involucradas.
Se tienen los siguientes tiempos de servicio:
T*p1 = Tp11 = 5 ms. T*p2 = Tp22 = 4 ms. T**p3 = Tp23 = 5 ms. T**p4 = Tp44 = 4 ms. Los valores de S se conocen de la aplicación de este algoritmo para
determinar la configuración de actuadores y son los siguientes:
S*1 = 147.08 S*2 = 147.08 S**3 = 313.79

Marco Teórico
55
S**4 = 392.18 W*p11 = 147.08 x 5 = 735.4 W*p22 = 147.08 x 4 = 588.32 W**p23 = 313.79 x 5 = 1568.95 W**p44 = 392.18 x 4 = 1568.72
Luego:
Wp1 = 735.4 Wp2 = 2157.27 Wp4 = 1568.72 Wp = 4461.39 Una vez conocidos estos valores, se procede a calcular el Npj
mediante la tabla LBD para rutas. Si no se obtiene directamente el número
de rutas para el tráfico obtenido, es necesario interpolar linealmente los
valores; es importante destacar que debe utilizarse la columna de la tabla
para el tipo de ruta que se está interpolando.
Np1 = [(1/100) x (4461.39 – 2700)] + 20 = 37.61 ? 38
Np2 = [(1/100) x (4461.39-3400)] + 20 = 30.61 ? 32
Np4 = (2/475) x (4461.39-900) = 14.99 ? 16
Wa1 = Wp/Np1 = 4461.39/37.61 = 118.62
Wa2 = Wp/Np2 = 4461.39/30.61 = 145.74
Wa4 = Wp/Np4 = 4461.39/14.99 = 297.62
N*p11 = W*p11/Wa1 = 735.4/118.62 = 6.2 ? 7
N*p22 = W*p22/Wa2 = 588.32/145.74 = 4.04 ? 6
N*p23 = W*p23/Wa2 = 1568.95/145.74 = 10.77 ? 12
N*p44 = W*p44/Wa4 = 1568.72/297.62 = 5.27 ? 8
Es aconsejable, al asignar rutas, que el valor de Npjk sea un múltiplo
cercano a cuatro, esto porque las unidades de control que se encuentran
disponibles en el mercado presentan un número de rutas múltiplo de cuatro.

Marco Teórico
56
II.2 Metodología para el desarrollo del proyecto
Para el desarrollo de este proyecto la metodología debe ser
implementada crecientemente, lo que permite una evaluación más completa
del sistema y una depuración más confiable. Por lo tanto, el desarrollo se
hace utilizando la metodología del espiral, la cual cuenta con ciclos a lo largo
de la evolución del trabajo. El diseño de la aplicación se realiza utilizando
modelado orientado a objetos.
El modelo en espiral combina las principales ventajas del modelo de
ciclo de vida en cascada y del modelo de construcción de prototipos.
Proporciona un modelo evolutivo para el desarrollo de sistemas, mucho más
realista que el ciclo de vida clásico.
Otra característica de este modelo es que incorpora en el ciclo de vida
el análisis de riesgos. Los prototipos se utilizan como mecanismo de
reducción del riesgo, permitiendo tener una versión funcional en menos
tiempo. A medida que se generan otras versiones, las anteriores siguen
siendo depuradas y en forma evolutiva se van agregando las mejoras que
resulten de la evaluación del usuario.

Marco Teórico
57
Figura 4. Modelo en Espiral
El modelo en espiral define cinco tipos de actividades y representa
cada uno de ellos en un cuadrante:
II.2.1 Comunicación con el cliente
Equivale a la etapa de análisis de requerimientos de la aplicación en
el ciclo de vida clásico y permite definir los objetivos, alcances y limitaciones
del sistema a construir.
II.2.2 Planificación
Consiste en planificar los recursos, el tiempo y las actividades a
realizar en cada iteración.

Marco Teórico
58
II.2.3 Análisis de riesgo
El desarrollo de cualquier proyecto complejo lleva implícito una serie
de riesgos que deben ser analizados. Unos riesgos son relativos al propio
proyecto (los riesgos que pueden hacer que el proyecto fracase) y otros
relativos a las decisiones que deben tomarse durante su desarrollo (los
riesgos asociados a que una de estas decisiones sea errónea).
II.2.4 Ingeniería
Equivale a la etapa de diseño en el ciclo de vida clásico y permite
construir una o más representaciones de la aplicación
II.2.5 Evaluación del cliente
Consiste en la valoración, por parte del cliente, de los resultados de la
ingeniería. Esto permite incluir mejoras en el siguiente ciclo y depurar las
versiones tempranas del sistema por un tiempo mayor. Con cada iteración,
se construyen sucesivas versiones del software, cada vez más completas, al
final se obtiene el sistema completo.

59
CCAAPPÍÍTTUULLOO IIIIII
DESARROLLO
Este capítulo describe el proceso llevado a cabo para poder
desarrollar el Sistema de Análisis de Servidores aplicando Planificación de
Capacidad (ASAP-C). Éste se logró a través de la aplicac ión de la
Metodología en Espiral, la cual se explicó en el Capítulo II.
Esta metodología divide el desarrollo de la herramienta en tres (3)
giros, los cuales son descritos a continuación en detalle. Inicialmente se
presentan las actividades de Investigación realizadas y los logros obtenidos,
así como los procesos de Ingeniería Global y especifica para los giros de la
metodología.

Desarrollo de la Investigación
60
III.1 Investigación Preliminar
Para comprender los fundamentos teóricos de este proyecto, se hizo
necesario contar con una etapa de investigación preliminar que abarcara
todo lo relacionado a Planificación de Capacidad, evaluación de rendimiento,
investigación sobre el manejador de Base de Datos adoptado, además del
lenguaje de programación con el que se iba a trabajar.
Para desarrollar el sistema ASAP-C se utilizó la metodología en
espiral, mencionada anteriormente en el capítulo II, dicha metodología consta
de varias etapas (giros) con las cuales se pretende hacer más fácil y
completo el desarrollo de la aplicación.
Una vez realizada esta investigación se dio inicio a los diferentes
pasos planteados por la metodología. Bajo este esquema se desarrolló la
herramienta.
Los pasos de esta investigación se presentan a continuación:
III.1.1 Investigación sobre Planificación de Capacidad
Realizar una búsqueda de material relacionado a este tema, resulta
difícil, pues no existe una variedad significativa de materiales impresos, por
esto fue necesario consultar sitios electrónicos que trataran este tópico o que
prestaran este tipo de servicios.
Uno de los sitios importantes identificados en esta búsqueda fue el de
IBM, el cual ofrece una base de conocimiento que recopila diversos

Desarrollo de la Investigación
61
documentos dedicados al servicio de Planificación de Capacidad que esta
empresa ofrece.
Durante esta etapa se estudiaron los conceptos básicos de
Planificación de Capacidad, así como también las metodologías más
importantes para llevar a cabo este proceso. Esto para conocer lo importante
de su aplicación a las empresas y de como se obtienen beneficios en su
rendimiento al ser ejecutado a tiempo.
En muchas compañías se presenta un fenómeno denominado
demanda latente el cual no es más que un número de peticiones realizadas
al sistema, que no son atendidas y saturan los recursos actuales.
Al no realizar la planificación de capacidad, la adquisición de nuevos
recursos incrementa de una manera vertiginosa su uso, con lo cual, al no
saber la cantidad necesaria de recursos para satisfacer esta demanda, el uso
de los nuevos recursos podría colapsar el sistema nuevamente.
Es importante tener en cuenta, que un proceso de planificación de
capacidad muestra la cantidad de recursos necesarios, para satisfacer las
peticiones existentes sin disminuir significativamente el rendimiento del
sistema.
Uno de los aspectos importantes estudiados, fue la diferencia
existente entre las cargas de trabajo de los sistemas en línea y los sistemas
en lote. Esto permite jerarquizar los tipos de carga y establecer prioridades al
momento de efectuar las proyecciones sobre los recursos de CPU, discos y
sus rutas.

Desarrollo de la Investigación
62
Se identificaron las fases de la planificación de capacidad las cuales
son:
Figura 5. Fases de la Planificación de Capacidad
Se estudió la proyección de CPU, paso importante en la fase de
proyección de Planificación de Capacidad, el factor de captura y la Relación
Pico Promedio (RPP).
Una vez estudiado todo lo referente a la proyección de CPU, se
investigó la metodología Start I/O, la cual sirve para realizar proyecciones
Preparación
Documentación
Recolección de Datos Estimación de Crecimientos
Proyección
Caracterización de las Cargas de Trabajo

Desarrollo de la Investigación
63
sobre la cantidad de actuadores necesarios y sus rutas para soportar la
cantidad de tráfico presente en el sistema.
En este paso se realizaron ejercicios para entender las fórmulas
involucradas en este proceso, dichas fórmulas se ven claramente expuestas
en el capítulo II.1.4.
La ley de beneficio decreciente fue investigada para calcular el
número de actuadores y rutas necesarias para soportar la carga de
operaciones de entrada y salida presentes en el sistema.
Para justificar los resultados presentados en el Marco Teórico, con
respecto a los actuadores y la ley de beneficio decreciente, se estudió una
fórmula, que involucra el tiempo en cola Tc, el tiempo de servicio Ts y el
Tiempo de Respuesta Tr.
75.01
xBTsxB
Tc?
? TcTsTr ??
La relación de Tr y Ts es la siguiente:
BBx
TsTr
???
175.0
1
Esto se hizo para justificar la afirmación mencionada en el análisis
hecho a la Tabla 6 (Conjunto de Actuadores) incluida en el Marco Teórico.
Fue necesario construir la fórmula correspondiente a la Ley de
Beneficio Decreciente para rutas de paralelismo 4, ya que en el material
investigado sólo se encontraron las referentes a paralelismo 1, 2 y 3. Estas
fórmulas conciernen a la tabla LBD para rutas (Tabla A2) y son necesarias

Desarrollo de la Investigación
64
para estimar el número de rutas correspondientes a la cantidad de tráfico
calculado.
Tabla 16. Tabla de LBD para rutas con Paralelismo 4
Número de Rutas Tráfico
4 1600
8 2790
12 3750
16 4700
20 5650
Cada ruta extra 200
Fuente: Cirkovic, 1995, p. 90.
A través de la interpolación de los valores de la tabla 16 se logró
deducir las siguientes fórmulas para realizar el cálculo del número de rutas.
Tabla 17. LBD para rutas con Paralelismo 4
Tráfico Fórmulas
< 1600 400
pP
WN ?
1600 < W p < 2790 ? ?4105.297
1?? pp WxN
2790 < W p < 3750 ? ?870240
1?? pp WxN
3750 < Wp < 5650 ? ?9005.237
1?? pp WxN
> 5650 ? ?16502001
?? pp WxN

Desarrollo de la Investigación
65
III.1.2 Investigación de la Evaluación del Rendimiento
Se analizaron los fundamentos de la evaluación de rendimiento, esto
con el fin de comprender el comportamiento de los sistemas y los distintos
casos comunes en los que se pueden detectar fallas (p.e. cuellos de botella).
Se buscaron diferentes tipos de materiales impresos y electrónicos
que hablaran de la evaluación de rendimiento y su aplicación a los sistemas
de las empresas.
Examinar el rendimiento del hardware, con frecuencia, es clave para la
efectividad de un sistema en su totalidad (software y hardware), determinar el
rendimiento de un sistema puede ser bastante difícil. La estructura y
complejidad de los sistemas modernos, junto con las técnicas (que mejoran
el rendimiento) empleadas por los diseñadores de hardware, han hecho
mucho más difícil la determinación del rendimiento. En efecto, para diferentes
tipos de aplicaciones pueden ser apropiadas ciertas métricas de rendimiento,
y diferentes aspectos de un computador pueden ser más significativos para
la determinación del rendimiento global.
Al momento de adquirir un equipo nuevo hay que comprender la mejor
manera de medir el rendimiento y las limitaciones de sus métricas.
Es necesario que el análisis del rendimiento de la máquina no sea sólo
de las características superficiales que ofrecen los fabricantes, hay que
adentrarse un poco más en detalle en las características del hardware para
comprender las variaciones de comportamiento de una aplicación entre los

Desarrollo de la Investigación
66
diferentes equipos, por qué un conjunto de instrucciones en ciertas
computadoras se ejecutan mejor que en otras. Estos factores varían desde el
manejo de las instrucciones del hardware de base, el funcionamiento de los
mecanismos de E/S, hasta el comportamiento en el acceso a memoria.
Comprender el impacto de estos factores es de suma importancia para lograr
asimilar las diferencias en el diseño de los equipos.
III.1.2.1 Definición de rendimiento
Cuando se dice que un computador tiene mejor rendimiento que otro,
¿qué se quiere indicar?. Aunque esta pregunta pueda parecer simple, una
analogía con los aviones de pasajeros muestra lo sutil que puede ser la
pregunta sobre rendimiento. La tabla 18 muestra algunos aviones típicos de
pasajeros, junto con su velocidad de crucero, alcance y capacidad. Si se
quisiera saber cuál de los aviones de esta tabla tiene mejor rendimiento,
primero vemos que el avión con mayor velocidad de crucero es el Concorde,
el avión con mayor alcance es el DC-8 y el avión con la mayor capacidad es
el 747. Suponga que se define el rendimiento en función de la velocidad.
Esto lleva a dos posibles definiciones.
Se puede definir el avión más rápido como aquel que tiene mayor
velocidad de crucero, llevando a un solo pasajero de un punto a otro en el
tiempo mínimo. Sin embargo, si el interés fuese en transportar 450 pasajeros
de un punto a otro, el 747 claramente sería el más rápido, como muestra la

Desarrollo de la Investigación
67
última columna de la figura. Análogamente, podemos definir el rendimiento
de un computador de varias formas diferentes.
Tabla 18. Capacidad, velocidad y alcance de los aviones
Aeroplano Capacidad
de pasajeros
Alcance de crucero (millas)
Velocidad de crucero (m.p.h)
Productividad de pasajeros (psajeros x
m.p.h.)
Boeing 737 –100 101 630 598 60398
Boeing 747 470 4150 610 286700
BAC/Sud Concorde 132 4000 1350 178200
Douglas DC-8-50 146 8720 544 79424
Si se estuviera ejecutando un programa en dos estaciones de trabajo
diferentes, se diría que la más rápida es la estación de trabajo que finaliza
primero el trabajo. Sin embargo, si se estuviese ejecutando en un centro de
cálculo que dispusiera de dos grandes computadores a tiempo compartido
para ejecutar tareas suministradas por muchos usuarios, se diría que el
computador más rápido es el que completa el máximo número de tareas
durante el día. Como usuario de un computador individual, se está interesado
en reducir el tiempo de respuesta que también se conoce como el tiempo de
ejecución.

Desarrollo de la Investigación
68
III.1.3 Investigación específica para cada giro
Como se mencionó en el capítulo I, la metodología utilizada para el
desarrollo del proyecto fue la metodología en espiral. La esencia de esta
metodología es el trabajo por giros.
Para la primera etapa del trabajo fue necesario investigar y estructurar
en tres giros el desarrollo del trabajo.
En esta etapa se decidieron los puntos a tratar en cada giro, acorde
con la investigación realizada sobre Planificación de Capacidad, por ello la
asignación se hizo de la siguiente manera:
1. En el primer giro se hizo todo lo relacionado a proyección de
CPU.
2. El segundo se orientó al desarrollo de los métodos de proyección
para los discos y sus rutas.
3. Finalmente en el tercer giro se realizó el ensamblaje de los dos
giros anteriores para lograr integrar el proceso de planificación de
capacidad, incorporando el concepto de escenarios múltiples.
Como parte de esta investigación se realizó un curso de planificación
de capacidad, este curso permitió profundizar y aclarar muchos aspectos de
la investigación. La falta de conocimientos sobre este tema, generalmente se
relaciona con la carencia de referencias bibliográficas que hablaran de este
tema.

Desarrollo de la Investigación
69
III.1.4 Investigación de infraestructura tecnológica
Una vez establecida la estructura de los giros, se procedió a investigar
el lenguaje de programación para la producción de la herramienta, así como
el manejador de base de datos (Microsoft SQL Server 7.0) y el método para
realizar el modelado del sistema.
Esta investigación permitió seleccionar a Microsoft Visual Basic 6.0, el
cual proporcionó una plataforma de fácil manejo y diseño gráfico de interfaz
de usuario. Es además un lenguaje de programación que trabaja con objetos
y sus eventos, y ofrece la posibilidad de crear objetos propios del
programador junto con sus métodos.
Se realizó la investigación sobre el tipo de diagramación a utilizar para
modelar el sistema. Debido a que se acordó trabajar con modelos orientados
a objetos se decidió trabajar con UML10, este tipo de diagramación es más
sencillo y representa los objetos con más claridad, también es utilizado para
diagramar los procesos principales del sistema (casos de usos).
El manejador de base de datos seleccionado, Microsoft? SQL Server
versión 7, es un sistema de gestión de bases de datos relacionales con
interfaz cliente / servidor de alto rendimiento. Fue diseñado para admitir un
elevado volumen de procesamiento de transacciones, además de
aplicaciones de almacén y de ayuda a la toma de decisiones.
10 Unified Modeling Language

Desarrollo de la Investigación
70
SQL Server versión 7 proporciona muchas herramientas cliente e
interfaces para trabajo en red para otros sistemas operativos de Microsoft?
como Windows 3.1 y MS-DOS; y gracias a la arquitectura abierta de SQL
Server, otros sistemas, por ejemplo sistemas basados en UNÍX, pueden
interactuar con él.
Una vez establecidos todos estos parámetros, se dio inicio al
desarrollo del primer giro de la metodología. Este giro contempla todo lo
relacionado a la proyección de CPU.
III.2 Desarrollo del Sistema ASAP-C
Una de las fases más importantes de la metodología en Espiral para el
Desarrollo de Sistemas es el desarrollo de los giros, en donde se deben
diseñar prototipos que cumplan con los requerimientos del usuario y se
adapten al objetivo del sistema, para luego traducir el diseño a una forma
legible por la máquina. Es a través de estos giros en donde se verifica si el
diseño del sistema fue realizado correctamente, por esta razón es muy
importante que éste sea de gran calidad para que la realización del código se
facilite substancialmente.

Desarrollo de la Investigación
71
III.2.1 Desarrollo del primer giro
El primer Giro consta de las siguiente actividades:
?? Comunicación con el cliente.
?? Planificación y análisis de riesgo.
?? Ingeniería Global.
?? Ingeniería específica del primer Giro.
?? Evaluación del cliente.
Comunicación con el cliente
Durante este proceso se efectuaron diversas reuniones con la persona
encargada de realizar los procesos de Planificación de Capacidad con el
objetivo de realizar un análisis de requerimientos para el desarrollo del
sistema, de vital importancia para realizar la Ingeniería Global del Sistema.
Una vez determinados los requerimientos y establecido el alcance del
sistema, fue posible elaborar un concepto del producto final, de esta manera
se establecieron los parámetros principales para el desarrollo.
Para poder desarrollar un sistema con éxito es importante comprender
totalmente cada una de sus partes, su comportamiento, sus procesos y sus
funciones, con la finalidad de conocer cómo trabaja y dónde es necesario
efectuar cambios.
De las entrevistas realizadas se establecieron los siguientes
requerimientos:

Desarrollo de la Investigación
72
Requerimientos del Sistema
?? Deben existir 2 tipos de entradas para los datos involucrados en
la proyección.
o Entrada generalizada: este tipo de entrada admite datos
generales sobre el CPU, Discos, Cargas de trabajo,
entre otros.
o Entrada proveniente de un archivo: lectura de un
archivo con datos relacionados con los elementos de la
proyección.
?? Validación de las entradas con el propósito de evitar
inconsistencias.
?? Posibilidad de generar reportes y gráficas que ayuden al
entendimiento de los resultados obtenidos por la proyección.
?? Posibilidad de combinar cargas de trabajo con múltiples
servidores, mediante una interfaz que contenga estos
elementos.
?? Capacidad de exportación a aplicaciones como Word y Excel,
para facilitar el manejo de datos, sobre todo de tablas y
gráficas.
?? La información generada por el sistema se debe acceder desde
diferentes computadores a través del uso de la aplicación.

Desarrollo de la Investigación
73
Una vez definidos y analizados los requerimientos se dio inicio a la
etapa de planificación y análisis de riesgo.
Planificación y Análisis de Riesgo
Se definió una estrategia de desarrollo para cada uno de los giros.
Esta actividad es de suma importancia porque con ella se distribuyen los
recursos a emplear para la producción del sistema, es decir, se realiza un
plan con el cual se intenta aprovechar al máximo el tiempo, los recursos
disponibles y el orden de las actividades a completar para poder lograr un
desarrollo eficiente de los giros.
Se realizó el plan del primer giro de la metodología que consiste en la
proyección de CPU. Se estableció el límite de tiempo prudente para poder
completar todas las etapas del giro correspondiente y se distribuyeron las
tareas a cumplir estructurándose de acuerdo al período establecido.
El análisis de riesgo significó una parte importante en el desarrollo del
proyecto ya que se evaluaron las situaciones que posiblemente se podrían
presentar a la hora de realizar el sistema.
Con este análisis se trata de planificar actividades de contingencia
para solucionar cualquier eventualidad que se pueda presentar durante el
desarrollo del proyecto.
Para que un análisis de la capacidad de los recursos de un sistema se
realice exitosamente se tiene que disponer de una Base de Datos con la

Desarrollo de la Investigación
74
mínima cantidad de errores y una desviación relativam ente pequeña del
desempeño de los sistemas reales.
Existe una posibilidad que se considera importante y debe ser
controlada para evitar fallos en las salidas del sistema (ASAP-C), esta
consiste en ingresar datos corruptos, los cuales pueden generar resultados
erróneos que conduzcan a la falla en las proyecciones realizadas, para esto,
se incorporaron mecanismos de validación de los datos introducidos, a fin de
reducir las diferencias en el manejo de los datos medidos. De forma alterna
ASAP-C está diseñado para recibir datos a través de 2 interfaces diferentes,
con lo cual se busca dar flexibilidad a la carga de grandes mediciones y
permitir la corrección de errores existentes en los datos de entrada del
sistema.
Los riesgos pueden definirse y analizarse a medida que se completan
las etapas en la metodología de desarrollo, es decir, cada vez que se
completa un giro es necesario realizar un análisis de riesgo con el cual se
minimiza la posibilidad de surgimiento de problemas que interrumpan el
normal desenvolvimiento del trabajo.
Ingeniería Global del Sistema
Se realizó el diseño completo generalizado del sistema a desarrollar.
Como herramientas de apoyo para hacer esta actividad se utilizaron los
diagramas de casos de uso (UML) y Diagramas de Entidad Relación (DER),

Desarrollo de la Investigación
75
con ellos se buscaba tener una visión esquematizada del comportamiento del
sistema.
En esta etapa se realizó el diseño de los casos de uso (UML) para
poder identificar los procesos principales que componen al sistema (véase
Apéndice C1 y C2), para lograr esto se identificaron las acciones 11 y los
actores12 que se ven involucrados en el desarrollo de la aplicación.
“Un caso de uso especifica una secuencia de acciones, incluyendo
variantes, que el sistema pueda llevar a cabo, y que producen un resultado
observable para un actor concreto.” (Jacobson et. al, p. 39,2000)
Con la realización de este diagrama se definieron las acciones que
debía desempeñar el sistema, una vez concretada esta parte, se pasó al
diseño de la base de datos.
Para desarrollar este diseño se utilizó el diagrama Entidad-Relación.
Este diagrama (véase Apéndice C3) contempla todas las entidades del
sistema y sus distintas relaciones entre sí.
Por medio del desarrollo de la interfaz se planteó el esquema gráfico
del primer prototipo, el cual describía el funcionamiento de las pantallas del
sistema y la forma en que el usuario interactúa con la aplicación.
11 Conjunto de procesos que realiza el sistema para responder a las peticiones de un usuario. 12 Personas o sistemas externos que interactúan con el sistema.

Desarrollo de la Investigación
76
Selección de monitores
Para registrar las mediciones de datos al sistema se utilizan monitores
para las diferentes plataformas con las que trabaja el sistema ASAP-C. Estos
son los monitores seleccionados:
Windows NT 4 / Windows 2000
?? Performance Monitor: éste monitor mide
o Los recursos de CPU en forma total
o Los procesos que se corren en el servidor
o I/O en forma total
OS 390 / VMS
?? RMF: este monitor es reconocido y de amplia trayectoria,
entre los monitores existentes, este posee las funciones
más completas de los sistemas operativos
UNIX / IBM AIX
?? PS command: realiza el monitoreo de los procesos que
corren en el servidor y mide la cantidad de CPU
?? IOSTAT: mide la cantidad de I/O de sistema
VSE/ESA
?? Explorer: este monitor es una herramienta que no está
integrada al sistema operativo. Esta desarrollado para
registrar las mediciones de I/O y de CPU en el sistema
VSE. Es ampliamente aceptado por pequeños grupos.

Desarrollo de la Investigación
77
Ingeniería específica del 10 Giro
El primer giro de la metodología trata de la proyección de CPU, por
esto se hizo necesario realizar un enfoque más específico hacia este punto.
Para ello se realizó un diagrama de Entidad-Relación, que tomara en cuenta
los elementos necesarios de la proyección de CPU.
Luego de tener precisados los aspectos relacionados para la
proyección se inició la construcción del primer giro, esto se hizo mediante la
aplicación de las fórmulas a los procesos del sistema.
Construcción del 10 Giro
La construcción de este giro se realizó según lo especificado en los
diagramas de diseño del sistema,
Se construyeron los principales procesos de proyección de CPU, estos
pasos se describen a continuación:
1. Registrar los servidores existentes que van a formar parte del
proceso de Planificación de Capacidad.
2. Registrar los distintos procesadores que componen a estos
servidores.
3. Registrar las cargas de trabajo presentes en el sistema.
4. Especificar los procesos que componen las diferentes cargas
de trabajo.

Desarrollo de la Investigación
78
5. Introducir las mediciones obtenidas para las carga de trabajo,
de forma manual o a través de la carga de un archivo de
mediciones.
6. Definir la situación actual que contiene el esquema de
servidores y cargas de trabajo para el sistema.
7. Realizar la proyección de CPU.
Registrar los servidores existentes
Este paso consiste en ingresar al sistema los datos de los servidores
que formarán parte de la Proyección de CPU, con esto se pretende llevar un
registro de los equipos actuales, para poder diferenciarlos de los equipos
candidatos a adquirir por la empresa, al momento de realizar las
proyecciones.
Los datos necesarios para realizar este paso son los siguientes:
?? Familia del Servidor (Nombre)
?? Capacidad de Memoria.
?? Selección de sistema(s) operativo(s) que corre(n) en el
Servidor.
En la siguiente Figura (Figura 6) se puede apreciar gráficamente la
interfaz para registrar estos requerimientos.

Desarrollo de la Investigación
79
Figura 6. Datos necesarios para registrar un servidor
La base de datos de la aplicación pasa a almacenar todo lo
correspondiente al servidor especificado, para tener así la información
necesaria a la hora de consultar o realizar procesos con este servidor
registrado.
Registro de procesadores que componen a los servidores
Una vez registrado el servidor en el sistema es necesario realizar el
ingreso de los diferentes procesadores que lo componen, esto se hace para
complementar la información del equipo, con esto se sabe la capacidad total
que posee el servidor en cuanto al soporte de cargas de trabajo.
En este paso es necesario especificar los siguientes datos:
?? Nombre del procesador.
?? Velocidad de procesamiento (Mhz.)

Desarrollo de la Investigación
80
?? Capacidad del procesador.
?? Selección del servidor en el cual se encuentra instalado.
Viendo la Figura 7 se aprecia la manera de introducir los datos
Figura 7. Datos requeridos para el procesador
Se puede repetir este procedimiento tantas veces como sea necesario
para definir correctamente los equipos presentes en la empresa, de esta
manera se tienen los datos completos y se pueden realizar las proyecciones
sobre estos recursos.
Registrar Cargas de Trabajo presentes en el sistema
En este procedimiento se registran las cargas de trabajo con las
cuales trabaja el sistema, es necesario este paso porque durante la
proyección de CPU es importante especificar las aplicaciones que van a ser
proyectadas, también se conoce cuales son las cargas de trabajo actuales

Desarrollo de la Investigación
81
para diferenciarlas al momento de proyectar las cargas que se esperan
“ejecutar” en el futuro.
Los datos necesarios para registrar las cargas de trabajo en el sistema
son los siguientes:
?? Nombre de la Carga de Trabajo.
?? Porcentaje de utilización de CPU.
?? Procesos relacionados a la carga de trabajo.
En la Figura 8 se puede apreciar de forma visual el esquema
necesario para ingresar los datos de la carga de trabajo.
Para asignar los procesos a las cargas de trabajo, se seleccionan de
la tabla correspondiente y se asocian a la carga que se está registrando, uno
a la vez. Además debe asignarse el porcentaje de utilización de CPU
correspondiente al proceso, el cual puede variar entre 0% y 100%, siempre y
cuando no exceda el total acumulado entre los demás procesos relacionados
a esa carga.

Desarrollo de la Investigación
82
Figura 8. Datos necesarios para el registro de la Carga de Trabajo
Se incluyó una pantalla, para los procesos que no están registrados en
el sistema, que contienen lo necesario para añadir el proceso (Véase la
Figura 9)
Figura 9. Datos para registrar un proceso

Desarrollo de la Investigación
83
Al completar estos datos, se registran las cargas de trabajo en el
sistema junto con los procesos que las componen. Estas cargas de trabajo
son almacenadas junto con sus procesos en la base de datos de la
aplicación.
Introducir las mediciones obtenidas para las carga de trabajo, de
forma manual o a través de la carga de un archivo de mediciones
Una vez registradas las cargas de trabajo en el sistema se permite
introducir las mediciones, que hacen posible la proyección.
Existen dos formas de introducir los datos de las mediciones para las
cargas de trabajo del sistema.
?? Manual, a través de una interfaz con el usuario.
?? Carga de un archivo con los datos requeridos.
La primera es hecha por el usuario en una interfaz diseñada para ello,
en esta pantalla se puede especificar el periodo de la medición para cada
carga previamente registrada (véase la Figura 16).
La segunda forma es a través de una archivo proveniente de un
sistema de monitoreo (ASAP-S) el cual proporciona la información necesaria
para realizar la proyección del procesador.
La estructura de este archivo se describe a continuación:
[UD] Fecha|UD 13 Fecha|UD Fecha|UD
13 Utilización de CPU promedio del día (UD)

Desarrollo de la Investigación
84
[RPPD] Fecha|Valor Fecha|Valor Fecha|Valor [RPPDPromedio] Valor [UM] Valor [RPPM] Valor [PS] Valor Esta estructura, es interpretada por el sistema, a través de la lectura
de los delimitadores del archivo y los encabezados de sección.
Definición de la Situación Actual que contiene el esquema de
servidores y cargas de trabajo para el sistema
La definición de la situación actual es el proceso para relacionar todas
las cargas de trabajo que se encuentran registradas en el sistema y que
forman parte del conjunto de datos a proyectar, sin incluir las cargas de
trabajo futuras. Estas últimas cargas se incluyen en el escenario, el cual será
explicado en el tercer giro.
La Figura 10, muestra la definición de la situación actual.
Para definir una situación actual es necesario realizar las actividades
que se presentan a continuación:
?? Debe seleccionarse el sistema operativo para el cual se desea
plantear la situación actual.

Desarrollo de la Investigación
85
?? Se debe seleccionar de la lista el(los) servidor(es) que se
desea(n) incluir en la situación actual, estos servidores poseen
el sistema operativo seleccionado en el paso anterior(Véase la
Figura 11).
Figura 10. Datos para definir la situación actual

Desarrollo de la Investigación
86
Figura 11. Selección de servidores bajo el sistema operativo especificado
?? Una vez seleccionado el(los) servidor(es) previamente, se
escoge de la lista la(s) carga(s) de trabajo de la situación actual
(Véase la Figura 12).
Figura 12. Selección de cargas de trabajo para la situación actual
?? Cuando se seleccionan las cargas de trabajo debe
especificarse el servidor entre los seleccionados en el primer
paso en el cual se “ejecutó” la carga, especificando además el

Desarrollo de la Investigación
87
porcentaje de consumo de CPU que representa para la
situación actual. (Véase la Figura 13).
Todos estos pasos se pueden repetir las veces que sean necesarias,
una vez culminado se pueden realizar escenarios de proyección sobre ella.
Los escenarios y su proyección serán explicados más adelante.
Figura 13. Relación de Carga de Trabajo y Servidor
Una vez definida la situación actual se comenzó a desarrollar el
proceso de proyección de CPU, tomando en cuenta los fundamentos
explicados en el capítulo II.
Proyección de CPU del primer giro
Para llevar a cabo este paso, fue necesario contar con las mediciones
de las diferentes cargas de trabajo seleccionadas en la situación actual, esto
debido a que la metodología para la proyección de CPU necesita de estos
datos para calcular los elementos claves en el desarrollo de este paso.

Desarrollo de la Investigación
88
Las mediciones de las cargas de trabajo se introdujeron antes de
definir la situación actual, y fueron especificadas para un período de tiempo
en particular.
Mediante el registro de mediciones de las cargas de trabajo se pueden
introducir los datos necesarios para conocer la lectura en el intervalo de
tiempo especificado. Esta pantalla incluye el factor de captura, el cual sirve
para ajustar los datos en caso de ser necesario.
El factor de Captura es estimado de tres (3) formas diferentes:
1. Factor de Captura General del sistema: Se obtiene
realizando los cálculos antes explicados en el Capítulo II,
apartado II.1.2.2
2. Factor de Captura del usuario: Este es conocido por el
usuario del sistema. El sistema permite que el usuario
modifique los valores del sistema, para establecer valores
propios de acuerdo a sus estimaciones.
3. Factor de Captura estimado por el sistema: Este es
calculado realizando iteraciones consecutivas. Para esto se
ajustan los factores de captura para cada iteración, de forma
intuitiva, con el fin de hallar los valores que generen el menor
error posible en la medición.
Una vez que se conocen los datos y se estima el factor de captura, se
debe almacenar en la Base de Datos para disponer de ellos cuando se
realice la proyección. En esta parte las mediciones no son permanentes así

Desarrollo de la Investigación
89
que se da la libertad al usuario de hacer los cambios necesarios antes de
proyectar, ofreciendo flexibilidad a los usuarios.
La proyección de CPU se llevó a cabo calculando la relación pico
promedio RPP y todos los elementos necesarios para obtenerlo, el proceso
se especificó en el capítulo II, con esta información se hizo posible calcular el
punto de saturación del procesador para poder realizar la proyección del
CPU, cuando las cargas de trabajo especificadas se encuentran
ejecutándose sobre este recurso.
Este paso cuenta con gráficas y reportes como salidas para mostrar el
estado del procesador con las cargas de trabajo que se seleccionaron para la
proyección.
Para calcular el RPP antes mencionado, se desarrolló un módulo, que
permite dar flexibilidad al usuario, ya que puede escoger:
1. RPP calculado por el Sistema: Una vez obtenidas las
mediciones, el sistema automáticamente calcula los RPP
diarios.
2. RPP seleccionado por el usuario: Permite al usuario
seleccionar cualquiera de los RPP calculados para cada una
medición en particular.
3. RPP establecido por el usuario: En caso de que el usuario
decida utilizar un RPP diferente a los calculados por el sistema,
este puede establecer el de su preferencia

Desarrollo de la Investigación
90
Evaluación del cliente
En esta actividad se le presentó el primer prototipo al cliente el cual
sólo trabajaba para realizar las proyecciones de CPU, además de registrar
las mediciones de las cargas de trabajo, que estaban definidas para la
realización de este paso.
El cliente en este momento sometió al prototipo bajo una serie de
pruebas para corroborar su funcionamiento y evaluar si los procesos
involucrados en la proyección se adaptaban a sus necesidades.
Para hacer las diferentes evaluaciones se utilizaron distintos casos en
los que se conocían los resultados a obtener, con esto se verificó que las
operaciones matemáticas con las que se está realizando este paso
funcionaban correctamente.
Una vez que se evaluó el proceso de la proyección de CPU, el cliente
examinó la interfaz de entrada para los datos. A partir de la apreciación del
usuario se hicieron correcciones para ir adaptando la interfaz a las
exigencias del cliente, entre las correcciones que se hicieron se encuentra la
redistribución de los elementos en la pantalla, de manera que fuesen fáciles
de ubicar y la reestructuración del área donde se introducen los datos de las
mediciones.
Antes de continuar con el giro siguiente se realizaron las
modificaciones indicadas por el usuario de manera que para la culminación
del segundo giro estas reformas estuviesen presentes en el siguiente
prototipo.

Desarrollo de la Investigación
91
III.2.2 Desarrollo del segundo Giro
El segundo giro, implementa los procesos relacionados a los discos y
sus rutas, la cantidad estimada de rutas es una aproximación a la cantidad
requerida de estos recursos, que son necesarios para soportar la carga de
tráfico presente en el sistema.
Bajo este giro se realizaron las mismas actividades que en el primero,
pero orientadas a los discos y las rutas necesarias para cada tipo de disco.
Comunicación con el cliente
Para establecer los parámetros a seguir en esta etapa, se pautó una
reunión con el cliente el cual fue señalando los lineamientos necesarios para
determinar la forma en la que se van a hacer los cálculos.
En esta etapa se va aplicar la metodología Start I/O, esta metodología
se explicó en detalle en el capítulo II. Con su aplicación se espera obtener
los números de actuadores y rutas necesarios para soportar la carga de
operaciones de entrada y salida que se presentan en el sistema.
Los requerimientos para este giro son los siguientes:
?? Deben registrarse en el sistema los datos relacionados a los
discos preservados 14 en la proyección.
14 Como se explicó en el capítulo II la definición de preservados significa que están presentes en el sistema.

Desarrollo de la Investigación
92
?? Se debe especificar los tipos de discos futuros que se esperan
tener en el sistema.
?? Es necesario contar con la fracción15 de los discos futuros que
se esperan tener, para cumplir con los requerimientos de
entrada y salida.
?? El sistema debe arrojar como resultado la cantidad de discos y
rutas necesarias para tolerar las operaciones de entrada y
salida presentes en el sistema.
Planificación y análisis de riesgo
Una vez conocidos los requerimientos de esta parte del sistema se
pasó a la etapa de planificación y análisis de riesgo, en la cual se estableció
la estrategia para el desarrollo de este giro y se tomaron las consideraciones
que podrían afectar el normal desempeño de este paso.
Como parte de los objetivos de este Trabajo de Grado, se hizo
necesario contar con una interfaz de usuario más “am igable” de acuerdo con
la primera evaluación del cliente, con ello se busca minimizar el riesgo de
realizar futuras modificaciones en la interfaz, antes de continuar con la etapa
final del trabajo.
15 Esta fracción significa la cantidad de disco de este tipo que se espera tener en relación con el total estimado.

Desarrollo de la Investigación
93
Se estudió la posibilidad de extender el periodo de construcción del
segundo prototipo, debido a los inconvenientes con la comprensión de la la
mezcla de disco.
Después de haber realizado el plan para la realización de este giro y
haber considerado todos los riesgos de esta etapa se comenzó a realizar la
ingeniería específica de este giro.
Ingeniería específica del 2o giro
Las actividades relacionadas con el diseño del sistema fueron
realizadas para contemplar todo lo relacionado a la proyección de los discos
y sus rutas.
A través de un Diagrama Entidad Relación (DER16) se realizó el
análisis, realizando los diagramas específicos, correspondientes a la
proyección de los discos y sus rutas, con esto se obtuvo una visión más clara
de este proceso.
Construcción del 2o Giro
La construcción de este giro se orientó a la proyección de los discos y
sus rutas.
El desarrollo de este giro se hizo acorde con lo establecido en los
diagramas resultantes del proceso de ingeniería específica del segundo giro,
similar a como se hizo para la proyección de CPU (primer giro), también se
16 Diagrama Entidad-Relación

Desarrollo de la Investigación
94
construyeron los principales procesos para poder obtener los resultados de la
proyección.
Los procesos necesarios para la construcción del prototipo del
segundo giro son los siguientes:
1. Registrar los discos existentes en el sistema, que forman parte
de la situación actual.
2. Establecer la información de las rutas del disco.
3. Combinar las rutas con el disco indicado.
4. Ingresar la cantidad de operaciones de entrada y salida totales
por cada cargas presentes en la proyección.
5. Estimar los valores de RIOCS
6. Definir la situación actual tomando en cuenta los discos.
7. Realizar la proyección de los discos y sus rutas.
Una vez establecidas las actividades necesarias para llevar a cabo la
proyección de los discos y sus rutas se inició la etapa de construcción de
cada una de ellas.
Registro de los discos existentes en el sistema, que forman parte de la
situación actual.
En esta actividad se desarrolló un módulo en el cual el usuario
especificara los datos necesarios sobre los discos, estos son almacenados
en la base de datos del sistema para guardar la información de los discos de
la sesión de Planificación de Capacidad y poder diferenciarlos de los discos
futuros que sean agregados a futuro.

Desarrollo de la Investigación
95
Para hacer este registro se necesitan los siguientes datos:
?? Marca del disco.
?? Modelo del disco.
?? Tamaño del disco.
?? Tiempo de servicio (expresado en ms.)
?? Paralelismo de la ruta asociada
Es importante destacar que el sistema ofrece soporte en el cálculo del
Tiempo Servicio para el Disco. Basándose en la Utilización del Disco y la
cantidad de operaciones de E/S.
En la Figura 14, se puede observar la interfaz que permite el ingreso
de estos datos.
Figura 14. Datos de los discos de la empresa
Durante el registro del disco nótese que existe un botón de Establecer
Rutas, mediante él se real izan las siguientes actividades en el proceso de la
proyección de CPU.

Desarrollo de la Investigación
96
Suministro de la información de las rutas del disco
Por medio del botón Establecer Rutas se permite al usuario introducir
los datos de las rutas al sistema.
Para esto se necesitan los siguientes datos:
?? Tiempo de servicio de la ruta.
?? Paralelismo.
?? Número de rutas del tipo de paralelismo.
Del mismo modo que para los discos, el sistema permite al usuario
calcular directamente el tiempo de servicio de ruta, a través del uso del
porcentaje de utilización de la ruta y las operaciones de entrada y salida.
Para establecer el número de rutas del tipo de paralelismo, el usuario
es apoyado por el sistema.
La cantidad de operaciones de E/S se deriva del disco, al cual se le
asigna este tipo de ruta. Por esto no puede ser suministrado por el usuario.
En esta interfaz aparece la tabla de los discos registrados en el
sistema, esta tabla se utilizó en el paso siguiente para establecer las rutas a
cada disco de acuerdo a la situación de los discos existentes.
La interfaz para las rutas se puede ver en la Figura 15

Desarrollo de la Investigación
97
Figura 15. Datos de las rutas del sistema
Combinar las Rutas con el disco correcto
En la figura anterior (véase figura 15), se muestra la tabla de discos
registrados en el sistema, a partir de lista se selecciona el disco al cual se le
asigna la ruta registrada, es posible repetir este proceso tantas veces como
sea necesario para asociar, si así lo amerita, el mismo tipo de ruta a más de
un disco. Además de ser necesario se pueden registrar discos al sistema
desde esta interfaz.
Ingresar las mediciones de operaciones de entrada y salida para las
cargas presentes en la proyección
Es necesario para llevar a cabo esta proyección, tener un registro de
la cantidad de operaciones de entrada y salida que presenta cada carga de
trabajo presente en el sistema, con esta información se hace posible calcular
la cantidad de operaciones de E/S por segundo (S), factor fundamental en la
realización de la proyección de los discos y sus rutas.

Desarrollo de la Investigación
98
Figura 16. Interfaz de Ingreso de Mediciones de Cargas de Trabajo
En la figura 16 se muestra la interfaz utilizada para ingresar de forma
manual las mediciones de las cargas. Ofrece al usuario soporte en el cálculo
del Factor de Captura y el valor RIOC.
Estimar los valores RIOC
Debido a su importancia, se diseñó una interfaz flexible para el ingreso
de este valor. Permitiéndole al usuario definirlo a través de una de estas
opciones:
1. Estableciendo directamente el valor del RIOC para la medición
de la carga escogida.
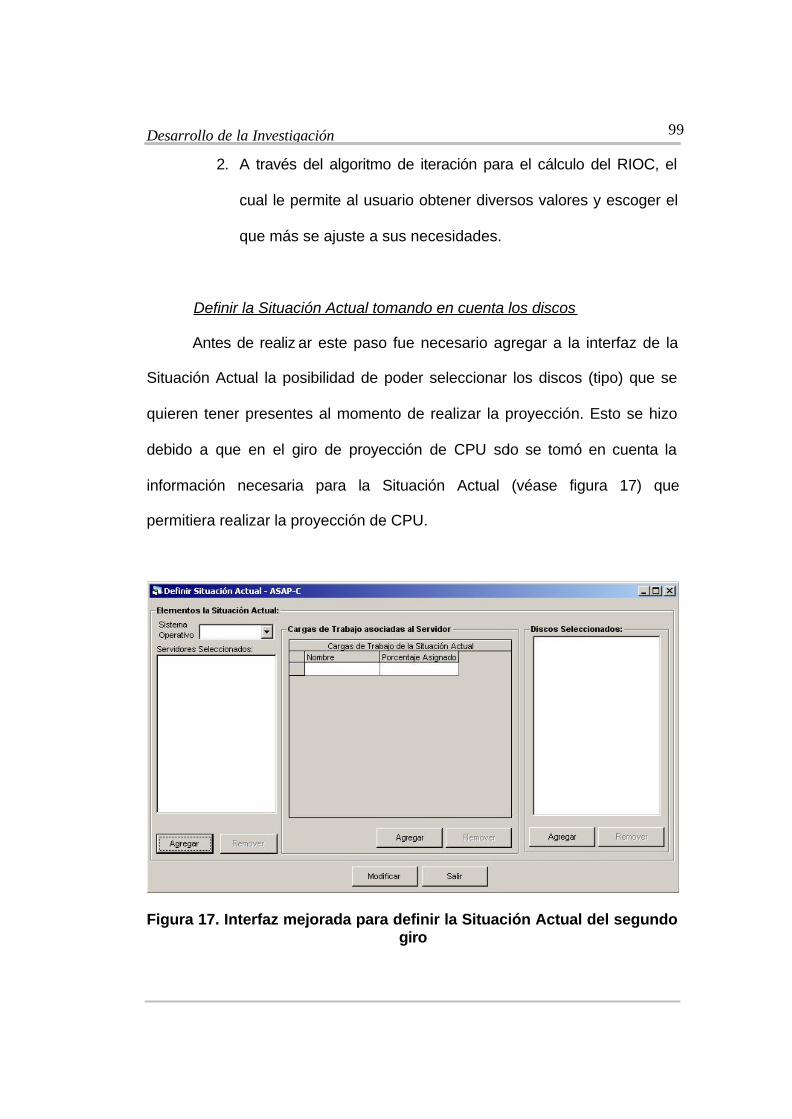
Desarrollo de la Investigación
99
2. A través del algoritmo de iteración para el cálculo del RIOC, el
cual le permite al usuario obtener diversos valores y escoger el
que más se ajuste a sus necesidades.
Definir la Situación Actual tomando en cuenta los discos
Antes de realiz ar este paso fue necesario agregar a la interfaz de la
Situación Actual la posibilidad de poder seleccionar los discos (tipo) que se
quieren tener presentes al momento de realizar la proyección. Esto se hizo
debido a que en el giro de proyección de CPU solo se tomó en cuenta la
información necesaria para la Situación Actual (véase figura 17) que
permitiera realizar la proyección de CPU.
Figura 17. Interfaz mejorada para definir la Situación Actual del segundo giro

Desarrollo de la Investigación
100
Realizar la proyección de los discos y sus rutas
Para realizar la proyección de los discos y sus rutas se hizo necesario
la aplicación de la metodología Start I/O, creada para este propósito y que se
describió en detalle en el capítulo II. La manera en la que se hace esta
proyección es mediante la figura del escenario, de la cual se hablará en el
próximo giro.
Este paso permite conocer la cantidad de rutas y discos necesarios
para poder soportar la cantidad de operaciones de entrada y salida presentes
al momento de la proyección.
Con esto se logró completar los procesos necesarios para realizar la
planificación de capacidad sobre los recursos de procesador rutas y discos.
Una vez culminados todos los pasos necesarios para la realización
esta proyección se hizo la evaluación del cliente.
Evaluación del cliente
Al comenzar esta actividad se revisaron las modificaciones anteriores
del primer prototipo para corroborar que se hicieron acorde con las
especificaciones brindadas por el cliente.
Una vez terminada esta etapa se procedió a evaluar el funcionamiento
del segundo prototipo, verificando así el desempeño de los procesos para
realizar la proyección de disco y sus rutas. De igual manera el usuario realizó
un estudio de la interfaz gráfica para ver si se adaptaba eficientemente a sus
requerimientos.

Desarrollo de la Investigación
101
Como resultado de esta etapa se pudo obtener el prototipo funcional
para realizar proyecciones de CPU, discos y sus rutas, con el que se puede
dar información para la situación actual.
III.2.3 Desarrollo del tercer Giro
Este giro permitió realizar las ac tividades relacionadas con la
definición de los escenarios de proyección, estos forman el área de trabajo
principal para el desarrollo de las proyecciones de discos, rutas y procesador.
III.2.3.1 Escenario
Un escenario se define como el conjunto de elementos de un sistema,
considerados en torno a un proceso de Planificación de Capacidad,
permitiendo representar la situación futura de los sistemas que se
encuentran dentro de los límites de un estudio de Planificación de
Capacidad, agrupando las cargas de trabajo, los discos y los servidores.
Los escenarios permiten realizar las proyecciones de los recursos y
estimar los cambios requeridos para el crecimiento propuesto. Además,
indican el punto en el cuál se vería afectado el rendimiento del sistema,
proporcionan un medio para hacer el cálculo del punto de saturación del
sistema y del número de actuadores y rutas necesarios para soportar el
tráfico registrado.

Desarrollo de la Investigación
102
Dentro de ASAP-C se permite la creación de múltiples escenarios,
esto con la finalidad de proporcionar mayor flexibilidad al planificador a la
hora de variar los elementos del sistema para obtener mejores resultados al
realizar el proceso de planificación de capacidad.
El escenario contiene las cargas de trabajo, servidores, discos. En él
se establece el periodo de proyección, el crecimiento esperado de las cargas
actuales y futuras, la fracción de los actuadores futuros y preservados a
proyectar, así como el nombre y la descripción.
Comunicación con el cliente
Permitió determinar los requerimientos para definir los escenarios. Un
aspecto muy importante de estos requerimientos es la posibilidad de poder
definir escenarios dentro de escenarios previamente creados.
Requerimientos para el desarrollo del tercer giro:
?? Posibilidad de crear escenarios dentro de otros escenarios y
manejarlos al mismo tiempo.
?? Agregar cargas de trabajo futuras, para su proyección.
?? Añadir discos futuros y establecer fracciones para realizar la
proyección de este recurso con sus rutas correspondientes.
?? Incorporar nuevos servidores al escenario.

Desarrollo de la Investigación
103
?? Combinar cargas de trabajo entre los servidores existentes en
la empresa y servidores futuros añadidos para la proyección del
escenario.
?? Crear nuevos escenarios, e identificarlos con Nombre y
Descripción.
?? Establecer el período de proyección y su formato17.
?? Permitir almacenar y cargar escenarios.
?? Presentar reportes y gráficas con la información relevante de la
proyección realizada en el escenario.
Planificación y análisis de riesgo
Se planteó un plan que permitiera distribuir el tiempo restante del
proyecto, para integrar los prototipos del primer y segundo giro (Proyección
de CPU y Proyección de discos con sus rutas) en un solo giro (Proyección de
Escenarios)
La integración de los dos prototipos, fue evaluada, para detectar
inconsistencias en los procesos y validar que la integración de los prototipos
no produjeran fallas de sistema. También se estudió la posibilidad de verificar
el mal ingreso de los datos que eran necesarios para las cargas, discos,
servidores y rutas que no se encontraban registradas en el sistema, de
17 El formato de la proyección viene dado en Años, Semestres y Trimestres

Desarrollo de la Investigación
104
manera que se pudiera realizar la proyección de todos lo elementos del
escenario.
Ingeniería específica del 3o giro
Se consideraron todos los diagramas realizados para entender la
relación existente entre los dos giros anteriores, basándose en la Ingeniería
Global realizada en el primer giro. Para ello fue necesario analizar los DER
para analizar las posibles fallas en la integración de la Base de Datos con el
manejo de Escenarios
Construcción del 3o giro
Basándose en los requerimientos del cliente, se definen los pasos
necesarios para crear escenarios y realizar proyecciones::
1. Definir situación actual.
2. Completar los datos relacionados con el nombre del escenario y
la descripción.
3. Agregar servidores futuros para realizar la proyección (opcional)
4. Agregar cargas de trabajo futuras para realizar la proyección
(opcional).
5. Establecer la cantidad de discos preservados que se quieren
tener en la proyección.
6. Agregar discos futuros junto con la fracción deseada de ellos,
para realizar la proyección (opcional).

Desarrollo de la Investigación
105
7. Establecer el formato y el tiempo de la proyección.
8. De ser necesario crear sub-escenarios a partir del escenario
definido anteriormente.
9. Establecer el crecimiento de las cargas de trabajo.
10. Realizar la proyección de los elementos encontrados en el
escenario.
11. Consultar gráficas y reportes para conocer la situación del
Escenario.
Definir Situación Actual
Tomando en cuenta a los servidores, discos y cargas de trabajo
presentes en el sistema. Es posible completar la definición de la situación
actual, lo que anteriormente no era posible, por la falta de integración de los
prototipos (véase la figura 18).
Completar los datos relacionados con el nombre del escenario y la
descripción.
El escenario es identificado para permitirle al usuario del sistema,
poder crear diferentes combinaciones, para proyectar y comparar resultados.
Por esto es necesario establecer a través de un módulo de registro, la
información correspondiente para cada escenario. Esto es necesario porque
es posible tener múltiples escenarios abiertos en el sistema y es importante
mantener la identificación al momento de seleccionar el escenario que se
desea proyectar (véase la figura 19).

Desarrollo de la Investigación
106
Figura 19. Interfaz de Escenario
Agregar servidores futuros para realizar la proyección (opcional)
El usuario puede incluir servidores que no se encuentran presentes en
la sesión de Planificación con el propósito de estudiar el efecto que estos
tienen en el comportamiento de la proyección.
Agregar cargas de trabajo futuras para realizar la proyección
(opcional).
Se permite especificar cargas futuras, para conocer el impacto de
estas cargas en la proyección del escenario. De ser incluidas nuevas cargas
de trabajo al escenario deben especificarse los datos necesarios para que la
aplicación pueda realizar la proyección del escenario apropiadamente.

Desarrollo de la Investigación
107
Establecer la cantidad de discos preservados que se quieren tener en
la proyección.
Los discos preservados indicados en la situación actual, se reflejan en
el escenario de proyección. Para esto el usuario debe especificar el número
de discos preservados para los diferentes tipos de discos registrados, esto es
necesario para la proyección de los discos y sus rutas.
Agregar discos futuros junto con su fracción para realizar la proyección
(opcional).
El usuario puede agregar diferentes discos, para evaluar el efecto de
ellos sobre la proyección del escenario. Para ello el usuario debe introducir
los datos de los discos nuevos, ya que esta información no se encuentra
registrada en el sistema.
Establecer el formato y el tiempo de la proyección.
Luego que el usuario a definido correctamente todos los elementos
para hacer la proyección este debe especificar el formato y tiempo de la
misma, con esto se desarrollan los cálculos y las gráficas respectivas a este
escenario.

Desarrollo de la Investigación
108
De ser necesario crear sub-escenarios a partir del escenario definido
anteriormente.
Como se contempló en los requerimientos del usuario se dio la
posibilidad de crear múltiples escenarios. Esto se puede realizar de dos
maneras diferentes:
?? Se crea un escenario a partir de un escenario abierto en el
sistema.
?? Se crea un escenario nuevo cuya información base proviene de
la situación actual.
La primera forma permite tener un escenario definido y listo para ser
proyectado, partiendo del contenido del escenario abierto. Se utiliza
generalmente para realizar comparaciones entre los elementos que están
presentes en este escenario en específico, por ello es posible crear un sub-
escenario, cuya información base son los elementos existentes en el
escenario principal.
La segunda forma permite crear un escenario nuevo con los datos de
la situación actual para que el usuario pueda definir combinaciones que no
necesariamente se relacionan con las del escenario anterior.

Desarrollo de la Investigación
109
Establecer el crecimiento de las cargas de trabajo
Para este paso se desarrolló una interfaz (véase figura 20), que
permitiera al Planificar de Capacidad establecer libremente los porcentajes
de crecimiento para las cargas de trabajo seleccionadas.
Figura 20. Interfaz para asignar el crecimiento futuro de las cargas de
trabajo
Con esto se logró definir los últimos parámetros necesarios para
realizar la proyección de los elementos del escenario.
Realizar la proyección de los elementos encontrados en el escenario.
Con todos los elementos bien definidos se realizó la proyección
utilizando los diferentes pasos descritos en el capítulo II y se generaron las
gráficas y reportes necesarios para brindar la información requerida por el
usuario en base a los resultados obtenidos.
Consultar gráficas y reportes para conocer la situación del Escenario.
Una vez realizado el análisis de las proyecciones, se analizaron las
gráficas y reportes para sacar conclusiones sobre los resultados obtenidos.

Desarrollo de la Investigación
110
Examinando estos resultados se logró analizar el comportamiento del
sistema con los parámetros especificados en la situación actual y su
comportamiento en diversos escenarios.
Evaluación del cliente
Una vez concretados todos los aspectos necesarios para el desarrollo
del tercer y último prototipo, se le presentó al usuario para que examinara la
interfaz, para conocer su opinión sobre los ajustes hechos como resultado de
su evaluación del giro anterior.
Luego se sometió el prototipo a pruebas con casos previamente
calculados para saber si las proyecciones de los escenarios se realizaron
correctamente, con la aprobación del usuario se culminó el desarrollo del
sistema.

111
CCAAPPÍÍTTUULLOO IIVV
ANÁLISIS DE RESULTADOS
En este capítulo se presentan los resultados que se obtuvieron al
finalizar este trabajo. Se explicará detalladamente las salidas del sistema, a
través de la presentación de las interfaces de gráficas y reportes.
De igual forma, se refleja el análisis de la información que proporciona
el sistema y el beneficio que aporta el Sistema de Análisis de Servidores
aplicando Planificación a las pequeñas empresas y a los planificadores de
capacidad.

Análisis de los resultados
112
A continuación se muestran los resultados de los procesos principales
del sistema, esto se realizará aplicando un caso de estudio con datos
basados en mediciones reales, protegiendo la confidencialidad de la
empresa.
Para realizar este análisis se dará una explicación de las salidas de
los procesos y los pasos a seguir para las proyecciones del procesador,
disco y rutas. Para esto se muestran las pantallas requeridas para los
procesos principales del sistema.
Brevemente se muestra el proceso de entrada de datos al sistema y la
definición de la Situación Actual y los escenarios de proyección.
IV.1 Situación Actual
Los pasos a seguir para definir la situación actual se muestran a
continuación:
1. Registrar Servidores, cargas de trabajo, discos, rutas,
mediciones de las cargas de trabajo.
2. Definir y analizar la Situación Actual.
Registrar Servidores
Mediante esta interfaz, se registraron todos los servidores de la
empresa, que fueron incluidos en el proceso de Planificación de Capacidad.

Análisis de los resultados
113
Los Procesadores de dichos Servidores fueron registrados luego de
haber ingresado la información de los servidores.
El registro de los servidores se hizo tantas veces como fue necesario
para almacenar todos los equipos presentes en la empresa.
Registrar Cargas de Trabajo presentes en el sistema
Se registraron las cargas presentes en el sistema, esto se hizo
utilizando la interfaz construida para este propósito (véase figura 8). Al igual
que con los servidores este proceso se repitió hasta registrar todas las
cargas requeridas.
Nótese que las cargas tienen procesos que las componen los cuales
son ingresados al sistema a través de su propia interfaz.
Registrar Discos y sus rutas
Se registraron los Discos del sistema junto con sus rutas asociadas,
una vez más, este proceso se realizó varias veces, hasta ingresar toda la
información del caso de estudio.
Los tiempos de servicio los calculó el sistema a través de un algoritmo
de ayuda para este cálculo.
Las rutas se asociaron también en este paso, ingresando a la interfaz
mediante el uso del botón Establecer Ruta. De igual manera se calculó el
tiempo de servicio de la ruta, utilizando el algoritmo de ayuda que
proporciona el sistema al usuario.

Análisis de los resultados
114
Ingresar mediciones de la Cargas de Trabajo
Este proceso se realizó de forma manual, debido a que no se disponía
de un archivo con los datos de las mediciones.
Definir la Situación Actual
Conocidos todos los componentes del sistema se procedió a definir la
situación actual del sistema, esta refleja la base para la proyección de los
recursos del sistema (véase la Figura 21).
Figura 21. Situación actual del sistema
Con esto se definió la situación actual de la empresa.
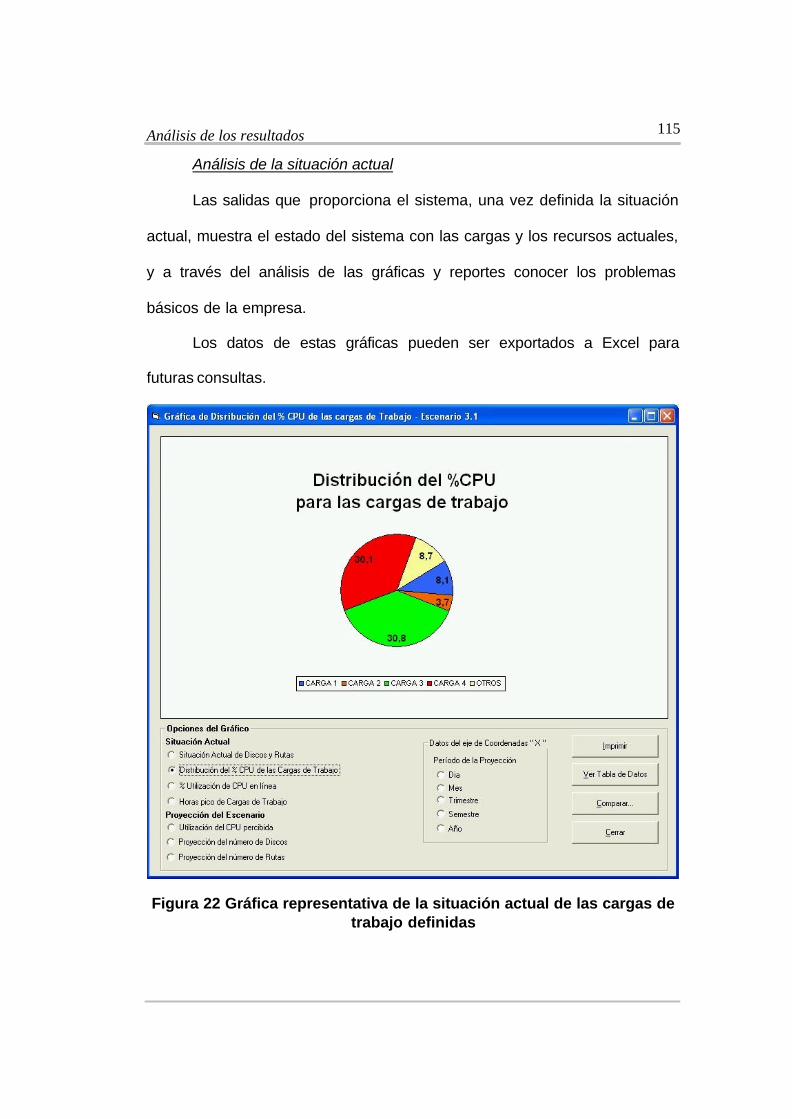
Análisis de los resultados
115
Análisis de la situación actual
Las salidas que proporciona el sistema, una vez definida la situación
actual, muestra el estado del sistema con las cargas y los recursos actuales,
y a través del análisis de las gráficas y reportes conocer los problemas
básicos de la empresa.
Los datos de estas gráficas pueden ser exportados a Excel para
futuras consultas.
Figura 22 Gráfica representativa de la situación actual de las cargas de trabajo definidas

Análisis de los resultados
116
En esta gráfica (véase figura 22) se puede observar la caracterización
de la carga y como se distribuye porcentualmente. Esta gráfica permite
identificar las cargas principales, para el caso de estudio, cargas tres (3) y
cuatro (4).
En este caso la carga cuatro (4), agrupa la carga de B/D asociada a
aplicaciones principalmente administrativas, y la carga tres (3) corresponde a
la aplicación que atiende a los servicios principales de la empresa.
Figura 23. Gráfica representativa del porcentaje de CPU en línea

Análisis de los resultados
117
Esta gráfica incluye a todas las cargas críticas del sistema, permite
conocer si el CPU presenta problemas a la hora de procesar la carga crítica.
Se toman los datos de las mediciones para elaborar esta gráfica y se calcula
el punto de saturación. Con este valor, se puede determinar en que punto el
procesador comienza a degradar la carga crítica, afectando
considerablemente la carga de sistema.
En el caso de estudio, la utilización del CPU en línea varia
dependiendo de las horas del día. Esta gráfica permite visualizar la utilización
pico y compararla con el punto de saturación.
Distribución del porcentaje de CPU de las Cargas de Trabajo
Carga 1 Carga 2 Carga 3 Carga 4 Otros
Porcentaje de uso de
CPU 8,09 3,7 30,8 30,1 8,7
Figura 24. Reporte de la Situación actual en base a la distribución de las cargas de trabajo del sistema
En la figura 24 se muestra uno de los reportes que permite crear el
sistema. Estos reportes se almacenan en archivos de Microsoft Word, lo cual
permite su fácil manejo y distribución.

Análisis de los resultados
118
IV.2 Proyección de escenarios
Posterior al análisis de la situación actual, se elaboran los diferentes
escenarios de proyección.
IV.2.1 Archivo de Escenarios
Con la finalidad de permitirle a los usuarios del sistema poder
transferir los escenarios definidos de un ambiente de trabajo a otro, el
sistema almacena todo el contenido de la B/D relacionado con los escenarios
en archivos, con lo cual se permite la carga de estos datos.
Definir Escenarios
Los escenarios se definen a través de la interfaz orientada a ello
(véase la Figura 25), esta es el área de trabajo principal del planificador,
donde es capaz de realizar combinaciones de cargas de trabajo con
servidores, definir servidores y cargas futuras, así como también establecer
cantidad de discos preservados y la fracción de los discos nuevos que desee
incluir. Una de las actividades más importantes que realiza el planificador es
la proyección de CPU, discos y rutas.

Análisis de los resultados
119
Figura 25. Definición del escenario para el ejemplo
Proyección del Escenario
Una vez definido el Escenario se realiza la proyección bajo los
aspectos requeridos por el usuario y se obtiene el resultado para los recursos
de procesador disco y rutas.

Análisis de los resultados
120
Figura 26. Gráfica de Proyección de CPU para el caso de estudio
Basándose en el punto de saturación, los valores actuales de las
cargas y los crecimientos esperados esta gráfica permite analizar la
capacidad del procesador.
En este caso el procesador XYZ-1 soportaría la carga por un poco
más de tres años. Después de este período comienza a verse afectado el
sistema.

Análisis de los resultados
121
Figura 27. Gráfica de proyección de número de discos para el caso de estudio.
En la figura 27, se muestra una de las posibles gráficas, que permiten
analizar la proyección de discos y rutas para los diferentes escenarios.
En este caso, los discos actuales, soportan el tráfico generado por las
cargas de trabajo. Se observa que se hace necesario la adquisición de
nuevos discos del tipo uno (1) y dos (2) a partir del tercer año de la
proyección.

Análisis de los resultados
122
Estos resultados permiten detectar fallas en el sistema y visualizar el
comportamiento de los recursos actuales a través del tiempo. Los
escenarios, le permiten al planificador, “jugar” con las posibles variaciones
existentes en los crecimientos esperados, de una forma rápida y eficiente. El
uso de subescenarios, permite además realizar ligeras modificaciones en el
contenido de los escenarios, con la finalidad de comparar los resultados
obtenidos y facilitar la tarea planificador.
Proyección de CPU XYZ-1
Año 0 Año 1 Año 2 Año 3
Carga 1 26,9 45,3 63,0 70,4 Carga 2 4,1 4,7 5,4 6,2 Carga 3 9,4 11,9 15,1 19,1 Carga 4 55,6 61,1 67,2 73,9 Carga 5 8,3 9,2 10,1 11,1
Proyección del número de Discos Futuros
Tipo 1 Tipo 2 Tipo 3
Año 0 0 0 0 Año 1 0 0 0 Año 2 0 0 0 Año 3 3 8 0 Año 4 1 6 3
Figura 28. Reportes de proyección para escenarios futuros
Los reportes representados en la figura 28 son algunos de los
generados por el sistema para reflejar las proyecciones de disco y rutas.
Algunos de ellos permiten generar gráficas para analizar los resultados del
proceso de planificación. Estos reportes al igual que los generados en la

Análisis de los resultados
123
Situación actual son almacenados en documentos de Word, para facilitar su
manipulación.

Conclusiones
124
CCOONNCCLLUUSSIIOONNEESS
Las empresas presentan problemas importantes en el área de
rendimiento de sus sistemas, esto les afecta en su desempeño y en el
servicio que prestan a sus clientes. Por lo estudiado en el desarrollo de este
proyecto estos problemas pueden causar pérdidas sustanciales en las
estructuras del negocio, por ello es necesario implementar un proceso de
planificación de capacidad que informe al personal de la empresa la situación
de sus sistemas y su comportamiento en el futuro.
Lo más importante al realizar los procesos de Planificación de
Capacidad, es poder anticipar la disminución del rendimiento del sistema
antes de que esto ocurra en realidad, proporcionando una ventaja
competitiva sobre las empresas del mercado, ya que siempre se podrá estar
un paso adelante ante el posible colapso de los sistemas que se traduce en
desatender las peticiones de los clientes.
Las diferentes etapas para planificar capacidad, proyectan procesador,
discos y sus rutas, estos procesos no cuentan con desarrollos matemáticos
muy complejos, es importante señalar que aunque no resultan difíciles de
aplicar, su basamento teórico radica en procesos estadísticos que estudian el
comportamiento de los servidores y sus recursos.
La proyección de discos y sus rutas es hecha a través de una de las
metodologías más completas que se han desarrollado para esta área
(Metodología Start I/O) combinando la aplicación de esta metodología y la

Conclusiones
125
tabla de Ley de Beneficios Decrecientes se obtienen el número de discos y
rutas necesarias para soportar la cantidad de operaciones de entrada y
salida que se tienen en el sistema.
Es importante destacar que aunque la tabla de Ley de Beneficios
Decrecientes aplica para muchos sistemas operativos del mercado, existen
excepciones, como el AS/400 en donde las proyecciones de la cantidad de
discos no se rigen por esta tabla. Esto obliga a investigar un poco más allá
para lograr obtener los resultados deseados bajo esta arquitectura.
Con la implementación de este sistema la persona encargada de
realizar los procesos de Planificación de Capacidad cuenta con un gran
aliado a la hora de realizar su tarea, facilitando su labor y mostrando la
información que neces ita para detectar problemas en el rendimiento de los
recursos del sistema.
Los monitores seleccionados permiten obtener las lecturas de las
diferentes plataformas, y en base a la investigación realizada miden los
datos necesarios para aplicar el proceso de Planificación de Capacidad.
El desarrollo de una interfaz clara y ordenada permite reducir la
existencia de errores al momento de realizar las proyecciones de los
escenarios.
ASAP-C, a través del manejo de múltiples escenarios, permite al
planificador de capacidad estudiar diversas alternativas que simplifican el
análisis de casos hipotéticos basados en la situación actual.

Conclusiones
126
Mediante la presentación de gráficas y reportes de los distintos
escenarios definidos por el usuario, se muestran las condiciones en la que se
encuentran los recursos de procesador, disco y rutas para diferentes
períodos de tiempo, pudiendo comparar los resultados obtenidos.
El trabajo de investigación ha proporcionado una visión más clara de
los elementos que afectan el desarrollo del sistema y de como deben
atacarse, para evitar que los servicios que presta la empresa a sus clientes
no se detengan y se logre atender la demanda existente.
Existe poco material disponible que haga referencia a los procesos de
planificación de capacidad y sus beneficios al ser aplicados a la empresa, en
la mayoría de los casos la información proviene de empresas extranjeras que
prestan este servicio. En Venezuela no existe una rica variedad de material
que trate este aspecto importante en el desarrollo y crecimiento de las
empresas que dependen de la tecnología de información.
La planificación de capacidad ofrece un campo importante para
ingenieros de sistemas o profesionales de carreras afines para desarrollar
una línea de trabajo del cual las empresas venezolanas están necesitadas
con el propósito de aumentar su productividad, en este un mercado de alta
competencia.

Recomendaciones
127
RREECCOOMMEENNDDAACCIIOONNEESS
A continuación se muestran una serie de recomendaciones resultantes
del análisis de todo el trabajo de grado:
1. El usuario del sistema debe poseer conocimientos avanzados
de planificación de capacidad de manera que pueda entender
las variables y procesos involucrados.
2. Debe realizarse una búsqueda exhaustiva de los valores M de
los procesadores ya que durante el desarrollo de este trabajo
resultó muy difícil recopilar información amplia de dichos
valores, solo se encontraron algunos para determinadas
plataformas.
3. Se deben realizar inspecciones a la base de datos con
regularidad, porque la existencia de inconsistencias puede
incidir en los resultados de la proyección del sistema.
4. La incorporación de módulos nuevos, tales como proyección
de múltiples procesadores en Sistemas Operativos diferentes,
Ajuste de paginación para la recolección de los datos y realizar
las proyecciones mediante el método de regresión lineal,
cubren de esta manera los aspectos que han quedado fuera del
alcance del presente trabajo.

Bibliografía
128
BBIIBBLLIIOOGGRRAAFFÍÍAA
Fuentes Bibliográficas:
?? Pressman, R. (1998). Ingeniería del software un enfoque práctico.
Osborne McGraw-Hill.
?? Carapaica, F., Oliveira, J., Pederzoli, R., Pontes, G., Rodríguez G. y
Santos, R. (1988). Planificación de capacidad. Venezuela: IBM
Corporation.
?? Major, J. (1981). Processor, I/O path and DASD configuration capacity.
IBM Systems Journal, 20, 63–85.
?? Major, J. (1985). Capacity planning with SIO Methodology . Proceeding
of SHARE 65.
?? Major, J. (1987). Empirical Models of DASD response time.
Proceeding, CMG´87.
?? Major, J. (1988). The law of diminishing returns: mixed DASD types .
Document number UKCP0170. IB M-UK.
?? Major, J. (1988). The law of diminishing returns: DASD path.
Document number UKCP0180. IBM-UK.

Bibliografía
129
?? Major, J. (1988). The law of diminishing returns: mixed path types .
IBM- Canadá.
?? Patterson, D. Y Hennessy, J. (1995). Organización y diseño de
computadores. La interfaz hardware/ software. Madrid: McGraw Hill.
?? Groff, J. Y Weinberg, P. (1998). Guía Lan Times de SQL. Madrid:
Osborne McGraw Hill.
?? Soukup, R. Y Delaney, K. (1999). A fondo Microsoft SQL server 7.0.
Madrid: McGraw Hill.
?? Jacobson, I., Booch, G. Y Rumbaugh, J. (1999). El proceso unificado
de desarrollo de software. Madrid: Addison Wesley.
?? Larousse (1992). Diccionario manual ilustrado. (6ta. Ed.). México:
Ediciones Larousse.
?? Microsoft SQL server 7.0 system administration (2000). Madrid:
McGraw Hill.
?? Deitel, H. (1993). Introducción a los sistemas operativos (2da. ed.).
Estados Unidos: Addison-Wesley Iberoamericana.
?? Elmasri, R. y Navathe, S. (1997). Sistemas de bases de datos
conceptos fundamentales (2da. ed.). Estados Unidos: Addison-Wesley
Iberoamericana.
?? Pressman, R. (1997). Ingeniería del Software (4ta. ed.). España:
McGraw-Hill.

Bibliografía
130
Fuentes Electrónicas:
?? OS/390MVS parallel sysplax capacity planning (1998, enero), [en
línea]. Nueva York: IBM international technical support organization.
Disponible en: http://w3.itso.ibm.com/redbooks [2001, 25 de julio].

Glosario
131
GGLLOOSSAARRIIOO DDEE TTÉÉRRMMIINNOOSS
Actuador
Es el conjunto de superficie magnéticas a las cuales se tiene acceso
mediante un brazo (volumen lógico).
Capacidad
Cantidad de información que un canal o una vía pueden transmitir o un
computador puede tratar por unidad de tiempo.
Canal de Entrada / Salida
Sistema de procesamiento de datos, una unidad funcional, controlado
por la unidad de procesamiento que maneja la transferencia de datos entre el
almacenamiento principal y los dispositivos periféricos.
Entrada / Salida (E/S)
(1) Pertinente a un dispositivo cuyas partes realizan un proceso de
entrada y de salida al mismo tiempo. (2) Pertinente a una unidad funcional o
canal involucrando una proceso de entrada, un proceso de salida, o ambos,
concurrentemente o no, y a los datos involucrados en tal proceso.

Glosario
132
Disco
Conjunto compuesto por varios HDA (Ej. El tipo de disco 3380 consta
de dos (2) HDA). Es la unidad mínima adquirible.
Hardware
Bajo este término proveniente del idioma inglés se agrupa a todos los
componentes de un sistema computarizado que sean dispositivos físicos.
Ejemplo de tales componentes son: CPU, terminales, impresoras, discos,
unidades de cintas, etc.
Head of String (HOS)
Conjunto de circuito ubicados en el string responsables de la
transferencia de datos.
Hora Pico
Tiempo en el cual el procesador tiene la más alta utilización en el día.
Internal Throughput Rate (ITR)
Una medida del número de transacciones procesadas por segundo de
procesador ocupado. El ITR es calculado dividiendo el número de
transacciones por segundo por el producto del promedio del CPU ocupado y
el número de procesadores. Véase ITRR.

Glosario
133
Internal Troughput Rate Ratio (ITRR)
Es la relación del ITR con dos procesadores.
Relación Pico Promedio
Una medida de la variación de la utilización del CPU obtenida
dividiendo el pico de la muestra de un conjunto de intervalos medidos
(usualmente una hora) por el promedio de todas las muestras.
Relative I/O Content (RIOC)
La relación del número total de operaciones de I/O a disco (S) por
segundo a la capacidad total usada por el mismo período de tiempo (M*B).
Esto da una forma de describir una carga de trabajo en términos de
contención de I/O, donde un número alto indica una carga de trabajo de alta
contención de I/O.
Ruta
Es la conexión que se establece en momentos de trasferencias de
datos entre. Actuador, Head of String, Storage Path y Canal.
Software
Cualquier conjunto de instrucciones con las que se programe a un
computador. Incluye tanto a los programas realizados por el usuario, como
productos suministrados por la compañías especializadas.

Glosario
134
String
Conjunto de hasta cuatro (4) discos (Ej. Existen ocho (8) para el tipo
de disco 3380-J o K con DLSE ).
Storage Path
Componente del CU responsable de transmitir datos. Una unidad de
control puede tener uno o más Strorage Paths.
Valor M
Una medida de capacidad de procesador relativa basada en radios
ITR. Varia por SCP, modelo del procesador, configuración LPAR y carga de
trabajo.

Apéndice A
135
AAPPÉÉNNDDIICCEE AA
Apéndice A1
Tabla A1 Ley de Beneficio Decreciente para Actuadores
Nº de Actuadores Tráfico
8 1100
10 1350
12 1640
14 1900
16 2130
18 2380
20 2600
24 3070
28 3500
32 3920
40 4700
48 5360
56 5940
60 6200
>60 2600+60*Nactuadores
>260 7800+40* Nactuadores
>500 12800+30* Nactuadores
>1000 22800+20* Nactuadores
>2000 42800+10* Nactuadores

Apéndice A
136
Apéndice A2
Tabla A1.2 Ley de Beneficio Decreciente para rutas
Paralelismo Tráfico (Wp) Nº de Rutas (Np)
1 <420 =Wp/210
420<Wp<800 =(Wp-40)/190
800<Wp<1800 =(Wp-227)/143
>1800 =(Wp-700)/100
2 <550 =Wp/275
550<Wp<1000 =(Wp-100)/225
1000<Wp<1400 =(Wp-200)/200
1400<Wp<3000 =(Wp-440)/160
>3000 =(Wp-1400)/100
4 <1600 =Wp/400
1600<Wp<2790 =2/595*(Wp-410)
2790<Wp<3750 =1/240*(Wp-870)
3750<Wp<5650 =2/475*(Wp-900)
>5650 =1/200*(Wp-1650)

Apéndice B
137
AAPPÉÉNNDDIICCEE BB
Esquema de presentación de las gráficas

Apéndice B
138
Esquema de reporte para uso de CPU para las cargas de trabajo
Año 1 Año 2 Año 3 Año 4 Año 5
Carga 1 ## .## % ## .## % ## .## % ## .## % ## .## % Carga 2 ## .## % ## .## % ## .## % ## .## % ## .## % Carga 3 ## .## % ## .## % ## .## % ## .## % ## .## %
Promedio ## .## % ## .## % ## .## % ## .## % ## .## %
Esquema de reporte para SIO de las cargas de trabajo
Año 1 Año 2 Año 3 Año 4 Año 5 Carga 1 ## .## % ## .## % ## .## % ## .## % ## .## % Carga 2 ## .## % ## .## % ## .## % ## .## % ## .## % Carga 3 ## .## % ## .## % ## .## % ## .## % ## .## %
Promedio ## .## % ## .## % ## .## % ## .## % ## .## %
Esquema de reporte para Cantidad de Discos
Año 1 Año 2 Año 3 Año 4 Año 5 Preservados ## .## % ## .## % ## .## % ## .## % ## .## %
Futuros ## .## % ## .## % ## .## % ## .## % ## .## % Totales ## .## % ## .## % ## .## % ## .## % ## .## %
Esquema de reporte para Cantidad de Rutas
Año 1 Año 2 Año 3 Año 4 Año 5
Preservadas ## .## % ## .## % ## .## % ## .## % ## .## % Futuras ## .## % ## .## % ## .## % ## .## % ## .## % Totales ## .## % ## .## % ## .## % ## .## % ## .## %
Esquema de reporte para Cantidad de Rutas
Año 1 Año 2 Año 3 Año 4 Año 5
Preservadas ## .## % ## .## % ## .## % ## .## % ## .## % Futuras ## .## % ## .## % ## .## % ## .## % ## .## % Totales ## .## % ## .## % ## .## % ## .## % ## .## %
Nota: El período de las Tablas puede venir, además de en años en
semestres o trimestres.

Apéndice C
139
AAPPÉÉNNDDIICCEE CC
Diagrama General de Casos de Uso
Sistema de monitorización que arroja datos sobre mediciones hechas a los didtintos elementos de Hardware. p.e. Discos, CPU, etc.
Sistema ASAP-S
Definir Escenarios
Ingresar AplicaciónModificar propiedades del Hardware
Modificar propiedades de la Aplicación
Almacenar Escenarios
Comparar Hardware
Combinar Hardware y Carga de Trabajo
Ingresar Hardware
Cargar Escenarios
Generación de Reportes
Generación de Gráficas
Cargar Archivo de Mediciones
Establecer límites futuros
Establecer límites actuales
Establecer Ruta
Planificador

Apéndice C
140
Diagrama de Secuencia del proceso de carga
: PlanificadorInterfaz Base de DatosConexión
Ubicación del Archivo
Carga de Archivo
Datos de conexión
Autorización de conexión
Archivo
Carga de información del archivo
Ingreso de información del archivo
Operación realizada
Operación realizada
Carga realizada

Apéndice C
141
Diagrama de Entidad Relación del Sistema
CPU
RUTA
DISCO
CARGA DETRABAJO
ESCENARIO
SERVIDOR
PERTENECE
TIENE
1
N
N
N
CORRETIENE
1
N
PERTENECE
NN
N
N
PROCESO
CONTIENE
N
N
TIENETIENE MEDICIÓN CPUN1
Código de la carga
Tipo
Descripción
% CPU total
TIpo
CodProceso
Nombre
FechaHoraCódigoMed
% CPUParcial
Cant I/O
O/SCodServidor
FamiliaCapac.Memoria
% de lacarga
TIENE
Tipo dedisco
TSR
Cod. Ruta
Cant I/O
ParalelismoN
Crecimiento
CARGA DETRABAJOFUTURA
PERTENECE
Crecimiento
Código de la cargaFutura
% CPU totalDescripción
% delProceso
Tipo
Descripción
Nombre
CodEscenario
Cod CPU
Nombre
MHz
Cod Disco
Tamaño
Modelo
Marca
MIDE
1
N
MIDE MEDICIÓN DISCO1 N
MIDE
SCod
Medición
Fcha
Hora
TIENETIENE
FchaHora
MEDICIÓN RUTAN 1
TSA
S
CodMedición
TSR
Fcha
Hora
N
1
N1


















