
Análisis factorial confirmatorio.pdf
55
Doctorado Interuniversitario en Marketing Análisis de Datos Avanzado ANÁLISIS FACTORIAL CONFIRMATORIO Apuntes y ejercicios Dr. Joaquin Aldas-Manzano Departamento de Comercialización e Investigación de Mercados Departamen t de Comercialitza ció i Investigació de Mercats
-
Upload
mariopadilla -
Category
Documents
-
view
228 -
download
0
Transcript of Análisis factorial confirmatorio.pdf

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 1/55
Doctorado Interuniversitario en MarketingAnálisis de Datos Avanzado
ANÁLISIS FACTORIAL CONFIRMATORIO
Apuntes y ejercicios
Dr. Joaquin Aldas-Manzano
Departamento de Comercialización e Investigación de Mercados
Departament de Comercialització i Investigació de Mercats

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 2/55
2
Nota importante
Los presentes apuntes forman parte del borrador del libro de Joaquín
Aldás y Ezequiel Uriel Análisis Multivariante Aplicado que será
próximamente publicado por la editorial Thomson-Paraninfo. Por lo
tanto, como tal borrador pueden existir erratas, siendo bienvenidos todoslos comentarios que las detecten y sugerencias sobre la mejora del
capítulo.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 3/55
3
13 ECUACIONES ESTRUCTURALES:
ANÁLISIS FACTORIAL CONFIRMATORIO
13.1 INTRODUCCIÓN
El presente capítulo es el primero de los dos capítulos dedicados a ecuaciones estructurales.
Además de su interés en si mismo, facilita el tránsito al segundo capítulo dedicado a modelosde estructuras de covarianza. ¿Por qué el desarrollo del Análisis Factorial Confirmatorio
(AFC) facilita este tránsito? Básicamente por dos razones. En primer lugar, porque su
desarrollo se sigue con facilidad una vez el lector ha visto el capítulo dedicado al análisis
factorial exploratorio y, en segundo lugar, porque la herramienta estadística que lo resuelve
es, esencialmente, la misma que emplearemos en los modelos de estructuras de covarianza.
Muchos son los textos que el lector puede utilizar para profundizar en el análisis del AFC que,
en su gran mayoría, también incluyen el desarrollo de los modelos de estructuras de
covarianza. La elección de uno u otro suele ir ligada a la decisión acerca del programa
estadístico que se prefiera utilizar. El SPSS incluía, hasta hechas recientes, el programa
LISREL (Jöreskog y Sörbom, 1989) como módulo opcional, convirtiéndolo en el de uso más
extendido. Si se opta por este programa, Sharma (1996) ofrece una buena introducción con
salidas comentadas o, si se prefiere un texto con mayor profundidad, puede recurrirse a Long
(1983). Si, por el contrario, el lector opta por el EQS (Bentler, 1995), con un sistema de
notación mucho más intuitivo en nuestra opinión (Bentler y Weeks, 1980), una buena guía es,
sin duda, el texto de Byrne (1994). Una buena alternativa para aquellos que no se atreven a
decidirse por uno u otro tipo de software, es recurrir al módulo CALIS del SAS, que permite
utilizar alternativamente cualquiera de las dos notaciones. En este caso, Hatcher (1994) es un
buen texto. Finalmente, puede recurrirse a Ullman (1996) para una aproximación a esta
técnica con salidas comparadas de todos los programas mencionados.
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 4/55
4
Dado que, como hemos indicado, la notación de Jöreskog y Sörbon (1989) es la más
conocida, será la que utilizaremos en el desarrollo del tema. Sin embargo, llegado el
momento, presentaremos también la de Bentler y Weeks (1980) y demostraremos la
equivalencia de ambas.
Para introducirnos en el AFC es necesario presentar una serie de convenciones y términos noutilizados hasta el momento. Lo haremos basándonos en un ejemplo que nos servirá para ver
la diferencia entre el AFC y el análisis factorial exploratorio y los modelos de estructuras de
covarianza que analizaremos en el próximo tema.
CASO 13.1 Componentes de la inteligencia
Supongamos que un investigador ha recogido las notas de 275 alumnos de secundaria en seis
asignaturas: Lengua (L), Filosofía (FSF), Historia (H), Matemáticas (M), Física (FSC) y
Química (Q). En el cuadro 13.1 se recogen las correlaciones entre estas seis variables. Nuestro
investigador se plantea una cuestión a la que quiere dar respuesta. Asumiendo que las notas de
un alumno miden su inteligencia (I), desearía saber si estas se agrupan en un único factor (la
inteligencia) o, por el contrario, miden distintos aspectos de la misma, por ejemplo, lainteligencia cuantitativa (IQ) y la inteligencia verbal (IV).
Cuadro 13.1 Matriz de correlaciones entre las notas de los 275 estudiantes
L FSF H M FSC Q
X 1=L 1
X 2=FSF 0,493 1
X 3=H 0,401 0,314 1
X 4=M 0,278 0,347 0,147 1
X 5=FSC 0,317 0,318 0,183 0,587 1
X 6=Q 0,284 0,327 0,179 0,463 0,453 1
Si suponemos que el investigador no tiene una hipótesis a priori acerca de qué estructura es la
adecuada (un único componente de la inteligencia o dos), decidirá efectuar un análisis
factorial exploratorio para ver cuántos factores obtiene. Su planteamiento aparece recogido
gráficamente en la figura 13.1. Las variables observadas o manifiestas o indicadores, es decir,
aquellas que se han medido (las notas en los alumnos en nuestro ejemplo), aparecen insertadas
en un cuadrado y se denotan como X 1,..., X 6. Las variables latentes, esto es las no observables
o subyacentes (por ejemplo, los factores, como la inteligencia en general, o la inteligenciaverbal o cuantitativa en particular), aparecen rodeadas por círculos. Una flecha recta desde
una variable latente a una variable observada, indica una relación de causalidad. Así el factor
“ξ 1” está “causando” las notas de los alumnos en las seis asignaturas, es decir, la mayor o
menor inteligencia “cuantitativa” provoca que los alumnos tengan notas diferentes. El término
λ que aparece en cada una de las relaciones causales o “ paths” es el parámetro que mide la
intensidad de la relación, esto es, el término que denominamos “carga factorial” en una
análisis factorial exploratorio, o el coeficiente estandarizado asociado a una variable
independiente en una regresión múltiple.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 5/55
5
Figura 13.1 Modelo de análisis factorial exploratorio
x1 x2 x3 x4 x5 x6
δ1 δ2 δ3 δ4 δ5 δ6
ξ1 ξ2
λ 11
λ 21 λ 31 λ 41λ 51
λ 61 λ 12
λ 22 λ 32 λ 42 λ 52
λ 62
φ12=φ21
Las variables latentes son de dos tipos. Los mencionados factores comunes (ξ ), que son
comunes en cuanto que sus efectos son compartidos por más de una variable observada, y los
factores específicos o errores (δ ). Como se comprueba en la figura 13.1, cada uno de estos
factores afecta solamente a una variable observada, y son errores aleatorios que se puedenhaber producido en la medida de la variable observada. Finalmente, la flecha curva con dos
puntas que une a los factores comunes, indica que estas variables están correlacionadas con
una intensidad φ 12.
Planteados los convenios de representación y los términos empleados en el AFC que son
comunes a los de los modelos de estructuras de covarianza, que se examinarán en el próximo
tema, nos restaría por señalar las diferencias del análisis factorial confirmatorio con respecto
al análisis factorial exploratorio, examinado en el tema 12, o con respecto al modelo de
estructuras de covarianza.
Volviendo a nuestro ejemplo, el investigador quiere saber si las notas están midiendo un
único componente de la inteligencia o, por el contrario, reflejan el efecto de varios
componentes. Como él no tiene establecida una hipótesis a priori, su análisis factorial ha de
contemplar como plausibles todas las posibilidades. Un caso extremo consistiría en que todas
las variables carguen de forma significativa sobre un solo factor. Un caso intermedio, aunque
puede haber otras muchas combinaciones, consistiría en que un grupo de variables cargue
significativamente sobre un factor y el resto de variables lo haga sobre un segundo factor. La
figura 13.1 recoge todas las posibilidades y, en concreto, estos dos casos. En el primer caso,
λ 11, λ 21, ... , λ 61 serían significativos, mientras que λ 12, λ 22, ... , λ 62 no lo serían. En el segundo
caso, λ 11, λ 21 y λ 31 tendrían un valor significativo y λ 41, λ 51, λ 61 no (las notas en literatura,
filosofía e historia cargan sobre un factor, inteligencia verbal, y no sobre el otro); por otra parte, λ 12, λ 22, λ 32 tendrían un valor no significativo, mientras que λ 42, λ 52, λ 62 sí (las notas en

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 6/55
6
matemáticas, física y química cargan sobre un factor, la inteligencia cuantitativa). El
investigador debe efectuar un análisis factorial exploratorio con objeto de averiguar cuál de
las dos posibilidades (o cualquiera de las otras muchas que sugiere la figura 13.1) es más
verosímil de acuerdo con los datos.
Ahora bien, el investigador basándose en estudios previos o en una revisión de la literaturaexistente, puede considerar la hipótesis, por ejemplo, de que no existe una medida global de la
inteligencia sino dos tipos alternativos de la misma: inteligencia verbal (que explicaría las
calificaciones en lengua, filosofía e historia) e inteligencia cuantitativa (que explicaría las
obtenidas en matemáticas, física y química). Si éste es el caso, el análisis exploratorio ya no
tiene sentido, ya que el investigador lo que pretende es confirmar o no la verosimilitud de su
hipótesis. Su planteamiento aparece recogido ahora en la figura 13.2.
El investigador puede plantearse otra hipótesis alternativa según la cual, sí existe una sola
medida global de la inteligencia que, a su vez, causa la inteligencia verbal y la cualitativa
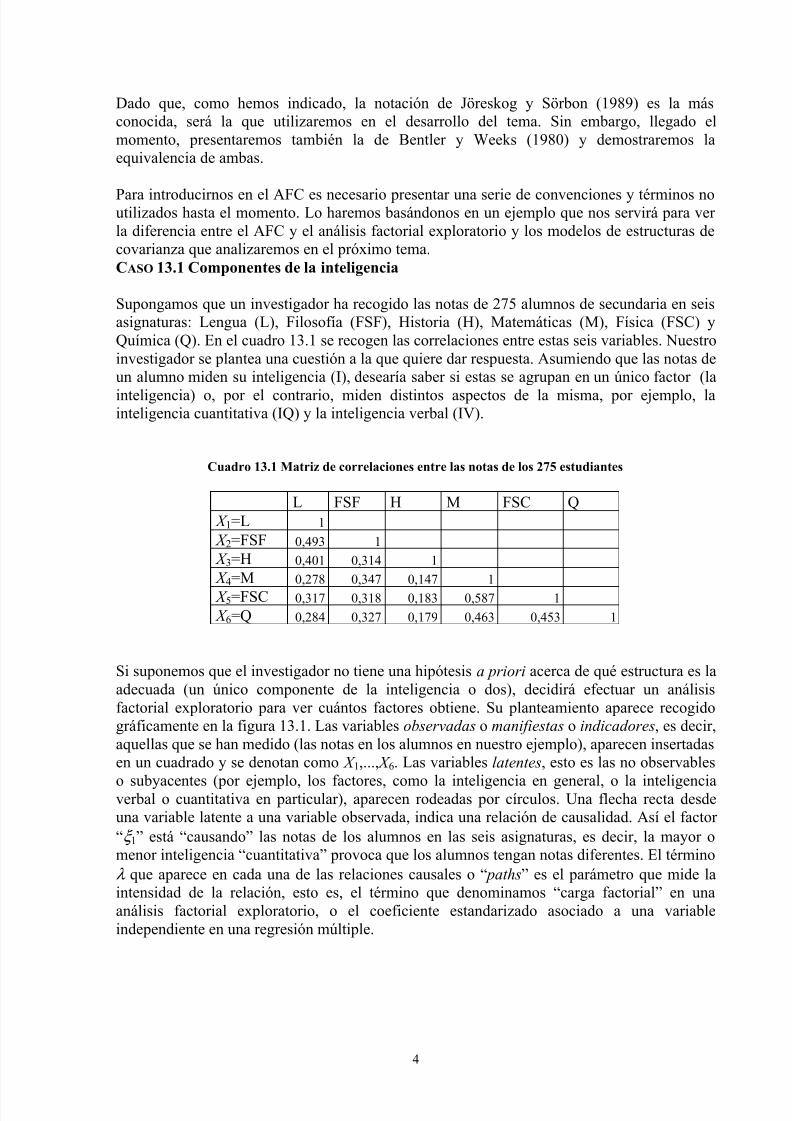
(figura 13.3). Su misión consistiría, ahora, en determinar cuál de los dos modelos es más
verosímil de acuerdo con los datos. En este segundo caso, ha establecido una relación decausalidad, no de correlación, entre una o más variables latentes. El modelo deja de ser un
AFC para convertirse en un modelo de estructuras de covarianza. Nótese en la figura 13.3
que, ahora, los factores ξ 1 y ξ 2 no son variables independientes (además de salir una flecha
causal de ellas, también la reciben), por lo que están sujetos a un error de predicción que se
denomina perturbación (disturbance) y que se suele denotar mediante la letra ζ . Los
coeficientes de estos path se designan con la letra β .
Figura 13.2 Modelo de AFC
x1 x2 x3 x4 x5 x6
δ1 δ2 δ3 δ4 δ5 δ6
ξ1 ξ2
λ 11
λ 21 λ 31λ 42
λ 52 λ 62
φ12=
φ21
θ12=θ21 θ32=θ23 θ45=θ54 θ56=θ65
θ13=θ31 θ46=θ64
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 7/55
7
Figura 13.3 Modelo de estructuras de covarianzas
x1 x2 x3 x4 x5 x6
δ1 δ2 δ3 δ4 δ5 δ6
ξ1 ξ2
λ 11
λ 21 λ 31 λ 42
λ 52 λ 62
ξ3
β13 β23
ζ1 ζ2
13.2 FORMALIZACIÓN MATEMÁTICA DEL AFC
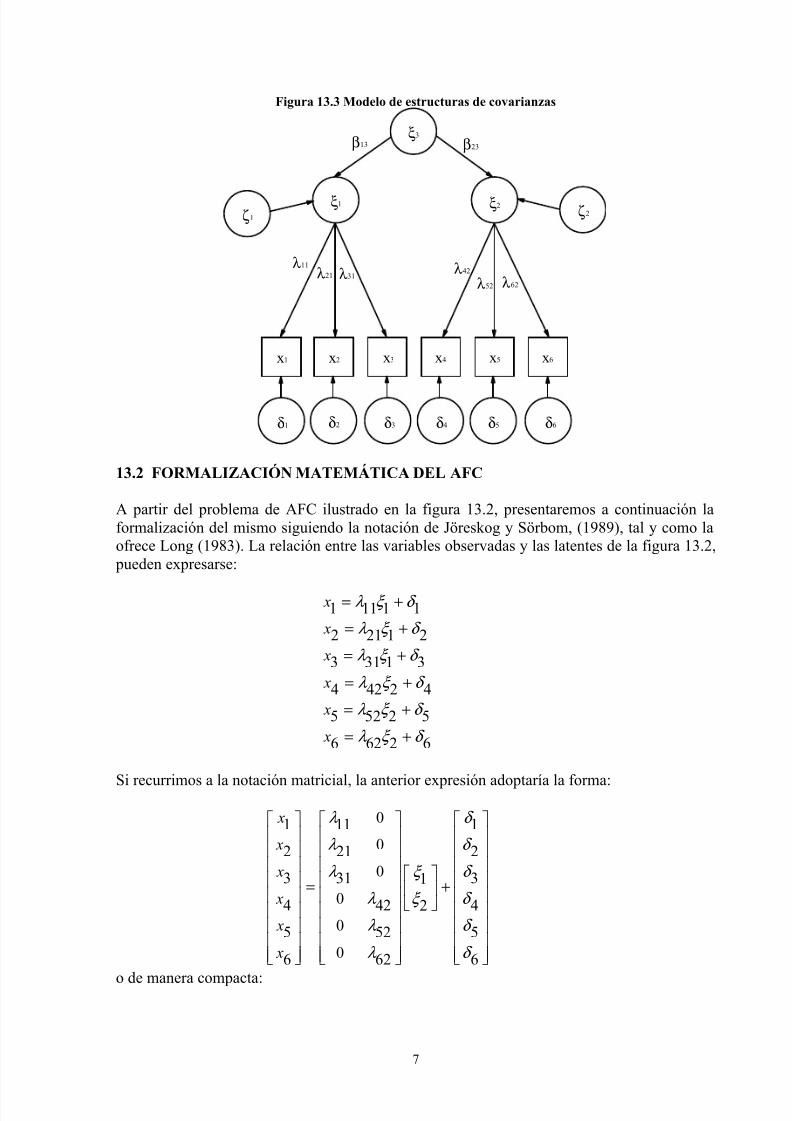
A partir del problema de AFC ilustrado en la figura 13.2, presentaremos a continuación la
formalización del mismo siguiendo la notación de Jöreskog y Sörbom, (1989), tal y como la
ofrece Long (1983). La relación entre las variables observadas y las latentes de la figura 13.2,
pueden expresarse:
1 11 1 1
2 21 1 2
3 31 1 3
4 42 2 4
5 52 2 5
6 62 2 6
x
x
x
x
x
x
λ ξ δ
λ ξ δ
λ ξ δ
λ ξ δ
λ ξ δ
λ ξ δ
= +
= +
= +
= +
= +
= +
Si recurrimos a la notación matricial, la anterior expresión adoptaría la forma:
01 11 1
02 21 2
03 31 31
04 42 42
05 52 5
06 62 6
x
x
x
x
x
x
λ δ
λ δ
λ δ ξ
λ δ ξ
λ δ
λ δ
⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥
⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎢ ⎥= +⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦⎢ ⎥ ⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦ ⎣ ⎦
o de manera compacta:

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 8/55
8
= +x Λ δ (13-1)
donde, en general, x es un vector q×1 que contiene las q variables observadas, es un vector
s ×1 que contiene los s factores comunes, Λ es una matriz q× s que contiene las cargas
factoriales de las variables latentes y δ es un vector q×1 de los factores específicos o errores.
Asumimos que el número de variables observadas será siempre mayor que el de factorescomunes, o lo que es lo mismo que q> s.
Tanto las variables latentes como las observadas de la expresión (13-1) vienen expresadas
como desviaciones sobre la media, con lo que la esperanza de cada vector es otro vector de
ceros:
E (x)=0; E ( )=0 y E (δ)=0.
Este desplazamiento respecto al origen, no afecta a las covarianzas entre las variables.
Si denotamos como Σ a la matriz de varianzas covarianzas entre las variables observadas
(vector x), de acuerdo con 13.1, resulta que:
( ) ( )( ) E E ⎡ ⎤′′= =⎣ ⎦
xx Λ + δ Λ + δ
Teniendo en cuenta que la traspuesta de una suma de matrices es la suma de las traspuestas y
que la traspuesta de un producto es el producto de las traspuestas en orden inverso, tenemos
que:
( )( )[ ] E ′ ′ ′= Λ + δ Λ + δ
y teniendo en cuenta la propiedad distributiva y calculando la esperanza:
[ ]
[ ] [ ] [ ] [ ]
E
E E E E
′ ′ ′ ′ ′ ′= + + +
′ ′ ′ ′ ′ ′= + + +
Σ Λ Λ Λ δ δ Λ δδ
Λ Λ Λ δ δ Λ δδ
Dado que la matriz Λ no contiene variables aleatorias, al ser constantes los parámetros
poblacionales, se tiene que:
[ ] [ ] [ ] [ ] E E E E ′ ′ ′ ′ ′ ′= + + +Λ Λ Λ δ δ Λ δδ (13-2)
Si hacemos
[ ]
[ ]
E
E
′=
′=
Φ
Θ δδ
y asumimos que δ y están incorrelacionados entre sí, la expresión (13-2) puede escribirse
del siguiente modo:

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 9/55
9
′ += ΛΦΛ Θ (13-3)
Es muy importante, para desarrollos posteriores, analizar el contenido de la expresión (13-3).
Así, en el primer miembro aparece una matriz que contiene q(q+1)/2 varianzas y covarianzas
distintas de las variables observadas1 . En el segundo miembro aparecen q× s cargas factoriales
(Λ), s( s+1)/2 varianzas y covarianzas entre los factores comunes (
) y q(q+1)/2 varianzas ycovarianzas entre los factores específicos (δ). Por lo tanto, la expresión (13-3) expresa los
q(q+1)/2 elementos distintos de Σ en función de [qs+ s( s+1)/2+q(q+1)/2] parámetros
desconocidos de las matrices Λ, Φ y Θ. Así pues, los parámetros que se deberán estimar
aparecen vinculados mediante la expresión (13-3) a los valores de las varianzas y covarianzas
poblacionales de las variables observadas.
En el ejemplo ilustrado en la figura 13.2 se introducen restricciones adicionales sobre las
cargas factoriales y se asume que δ 1, δ 2 y δ 3 están incorrelacionadas con δ 4, δ 5 y δ 6. Teniendo
en cuenta estas restricciones y dado que existen q=6 variables observadas y s=2 factores
comunes, las matrices que contienen los parámetros a estimar adoptarán la forma siguiente:
11 12 13
21 22 23
11 12 31 32 33
12 22 44 45 46
54 55 56
64 65 66
011 0 0 00 0 0 021
0 0 0 031; ;
0 0 0 0420 0 00 520 0 00 62
λ θ θ θ
λ θ θ θ
λ φ φ θ θ θ
λ φ φ θ θ θ
θ θ θ λ
θ θ θ λ
⎡ ⎤⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎡ ⎤⎢ ⎥= = = ⎢ ⎥⎢ ⎥⎢ ⎥ ⎣ ⎦ ⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥⎣ ⎦⎢ ⎥⎣ ⎦
Λ Φ Θ
donde los subrayados indican que esos elementos de las matricesΛ
yΘ
son 0 por laespecificación concreta que tiene el modelo que se quiere contrastar. Lógicamente, si el
investigador asumiera otras hipótesis la configuración de estas matrices sería distinta. De
hecho, tal como hemos comentado anteriormente, en general, la matriz Θ tiene 6(6+1)/2 = 21
elementos distintos a estimar (el triángulo inferior), mientras que en nuestro caso, dado el
modelo especificado, sólo hay 12.
¿A qué se reduce, a grandes rasgos, el método AFC? La finalidad de este método es obtener
estimaciones de las matrices Λ, Φ y Θ que hagan que la matriz de varianzas y covarianzas
poblacional estimada Σ obtenida a partir de ellas, sea lo más parecida posible a la matriz de
varianzas y covarianzas muestral que se obtiene a partir de los valores muestrales de las
variables observadas. Pero para poder entrar en el procedimiento de estimación, es necesarioabordar previamente el problema de la identificación que se plantea en el método AFC.
13.3 IDENTIFICACIÓN DEL MODELO EN EL AFC
En el epígrafe anterior, hemos visto que en el método AFC disponemos de una serie de datos
(las varianzas y covarianzas muestrales de las variables observadas) y con ellos hemos de
estimar una serie de parámetros (cargas factoriales, varianzas y covarianzas de los factores
comunes, y varianzas y covarianzas de los factores específicos o errores). Al igual que ocurre
1 Para determinar el número de varianzas y covarianzas distintas, téngase en cuenta que Σ es una matriz q × q simétrica

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 10/55
10
con un sistema de ecuaciones lineales, podemos disponer en principio de más ecuaciones que
incógnitas, del mismo número o de mayor número de incógnitas que ecuaciones. Pues bien, la
identificación del modelo en el AFC hace referencia, precisamente, a la cuestión de si los
parámetros del modelo pueden o no ser determinados de forma única.
En palabras de Long (1983), si se intenta estimar un modelo que no esté identificado, losresultados que se obtendrán serán estimaciones arbitrarias de los parámetros lo que
desembocará en interpretaciones carentes de sentido. En el apéndice A13.1 se demuestra
cómo, si no se imponen restricciones a los parámetros a estimar, necesariamente habrá un
número infinito de soluciones posibles para los mismos.
¿Qué tipo de restricciones pueden imponerse a los parámetros? Por ejemplo, si una carga
factorial λ ij de la matriz Λ se fija a 0, estaremos indicando que el factor ξ j no afecta
causalmente a la variable observada xi. Si fijamos a 0 el elemento φ ij de la matriz Φ,
estaremos señalando que los factores ξ i y ξ j están incorrelacionados. Si todos los elementos de
la matriz Φ fuera de la diagonal se fijan a 0, los factores serán ortogonales (como ocurre en el
análisis factorial exploratorio, por ejemplo). Restricciones similares se pueden imponer a los
elementos de la matriz Θ.
Long (1983) señala que existen una serie de condiciones para que el modelo esté identificado:
necesarias (si no se dan, el modelo no está identificado), suficientes (si se dan el modelo está
identificado, pero si no se dan no tiene porqué no estarlo) y necesarias y suficientes (si se dan
el modelo está identificado y si no se dan está no identificado). No hay acuerdo entre la
literatura acerca de si existen o no las condiciones necesarias y suficientes. Jöreskog y
Sörbom (1989) señalan que el análisis de la llamada matriz de información, construida a partir
de la matriz de varianzas y covarianzas de los estimadores de los parámetros, puede servir
para establecer si el modelo está identificado. Estos autores señalan que “si la matriz deinformación es definida positiva es casi seguro que el modelo está identificado. Por el
contrario, si la matriz de información es singular, el modelo no está identificado”. Las
cursivas son de Long (1983) y las introduce porque indica que, dado que los programas
existentes verifican esta condición, si no hacen advertencias acerca de problemas en esta
matriz, estaríamos ante un buen indicador de que el modelo está identificado pero, en su
opinión, aún siendo la matriz definida positiva es posible, aunque improbable, que el modelo
no esté identificado. Otros autores, como Hatcher (1994) y Ullman (1996) confían también en
las advertencias de los programas como indicadores de no identificación. En general, la
mayoría de textos optan por recomendar que se comprueben una serie de condiciones
necesarias que suelen demostrarse como lo suficientemente exigentes para garantizar la
identificación del modelo. Siguiendo a Hatcher (1994) y Ullman (1996), el investigadordebería centrarse en las siguientes tareas:
1.
Comparar el número de datos con el número de parámetros que han de estimarse. Los
datos son siempre las varianzas-covarianzas muestrales, y hemos visto que existen
q(q+1)/2. Como el número de parámetros a estimar es qs+[ s( s+1)/2]+[q(q+1)/2], el
modelo estará sin identificar si no se imponen, al menos, qs+[ s( s+1)/2] restricciones.
Decimos “al menos” porque sólo si hay más datos que parámetros, el modelo está
sobreidentificado (caso particular de identificación), lo que hace que, al existir grados
de libertad, será posible la aceptación o el rechazo del modelo.
2.
Establecer una escala para los factores comunes. Esto se consigue fijando la varianza
de cada factor común a 1 o el coeficiente de regresión (carga factorial) de una de lasvariables observadas que cargan sobre cada factor a 1. Si esto no se hace se produce el

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 11/55
11
denominado problema de indeterminación entre la varianza y las cargas factoriales, es
decir, es imposible distinguir entre los casos en los que un factor tiene una varianza
grande y las cargas son pequeñas y el caso en que las varianzas son pequeñas y las
cargas altas.
3. Asegurar la identificabilidad de la parte del modelo que contiene la relación entre las
variables observadas y los factores. Para ello debe analizarse el número de factores yel número de variables observadas que cargan sobre cada factor. Si solo hay un factor,
el modelo puede estar identificado si el factor tiene al menos tres variables con cargas
no nulas sobre él. Si hay dos o más factores, examínese el número de variables
observadas de cada factor. Si cada factor tiene tres o más variables que cargan sobre
él, el modelo puede estar identificado si los errores asociados con los indicadores no
están correlacionados entre sí, cada variable carga sólo sobre un factor y los factores
pueden covariar entre ellos. Si sólo hay dos indicadores por factor, el modelo puede
estar indentificado si los errores asociados con cada indicador no están
correlacionados, cada indicador carga sólo sobre un factor y ninguna de las
covarianzas entre los factores es igual a cero.
4.
Fijar arbitrariamente el coeficiente de regresión del término de error al valor 12.
La aplicación de las condiciones expuestas al modelo de la figura 13.2, que nos viene
sirviendo de ejemplo, se ilustran en figura 13.4.
Figura 13.4 Modelo de AFC identificado
x1 x2 x3 x4 x5 x6
δ1*
ξ1*
1=λ 11
λ 21=* λ 31=*
1=λ 42
λ 52=*
φ12=φ21=*
0=θ12=θ21 0=θ32=θ23 0=θ45=θ54 0=θ56=θ65
ξ2*
λ 62=*
1 1 1 1 1 1
δ2* δ3* δ4* δ5* δ6*
0=θ13=θ31 0=θ46=θ64
2
En el modelo (13-1), como puede verse, los coeficientes correspondientes al término de error (δ ) son 1. Sinembargo, en algunos programas de ordenador para tratamiento del AFC se permite fijar los coeficientes δ avalores distintos de 1.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 12/55
12
En primer lugar, recordemos que disponemos para estimar el modelo señalado de
6(6+1)/2=21 datos, que se corresponden con las varianzas covarianzas de las variables
observadas. Tenemos que estimar, en principio, 6×2+(2×3/2)+(6×7/2)=36 parámetros. Estos
parámetros son 12 coeficientes de regresión (cargas factoriales), la varianza de los 2 factores
comunes, la covarianza entre ellos, 6 coeficientes de regresión entre las variables observadas
y los factores específicos, las 6 varianzas de los factores específicos y las 15 covarianzas entreesos factores específicos.
Veamos en qué medida las condiciones de determinación anteriores influyen en esta situación.
En primer lugar, resolvemos el problema del establecimiento de la escala de los factores
comunes. Obsérvese en la figura 13.4 como se ha fijado a 1 el coeficiente de regresión entre la
variable x1 y el primer factor y ente la variable x4 y el segundo factor. Como indicábamos
podríamos haber fijado a 1 la varianza de ambos factores y dejar libres los mencionados
parámetros. Nótese que hemos señalado con un ‘*’ aquellos parámetros que sigue siendo
necesario estimar tras la identificación del modelo.
A continuación aseguramos la identificabilidad de la parte del modelo que contiene la relación
ente las variables observadas y los factores. En nuestro caso tenemos dos factores y tres
variables observadas sobre cada uno de ellos. Entonces, tal como señalamos con anterioridad,
se han adoptado los supuestos de que los errores asociados con los indicadores (δ ) no estan
correlacionados entre sí (es decir, las covarianzas θ ij se han hecho 0, como se observa en la
figura 13.4), y de que cada variable carga sólo sobre un factor. Por otra parte, sí se ha
permitido que las covarianzas entre los factores sean no nulas (las φ ij están marcadas con *
para ser estimadas).
Finalmente, los coeficientes de regresión entre las variables observadas y los términos de
error se han fijado arbitrariamente a 1.
Tras haber efectuado estas restricciones, cabe preguntarse ¿el modelo está identificado, o
sobreidentificado, y, en consecuencia, puede ser sometido a contraste? En otras palabras,
¿hay más datos que parámetros a estimar? O, análogamente, ¿disponemos de grados de
libertad suficientes? Los datos son, según hemos visto, 21, mientras que los parámetros a
estimar son los siguientes:
• 1 covarianza entre los factores comunes
•
2 varianzas de los factores comunes• 4 coeficientes de regresión entre las variables observadas y los factores comunes.
• 6 varianzas de los factores específicos (errores).
Es decir, hay 13 parámetros a estimar, con lo que tenemos 8 grados de libertad, dado que el
número de datos es 21. Por tanto, el modelo puede someterse a contraste. A continuación
aprovecharemos el ejemplo para presentar la sintaxis que nos permite estimarlo mediante uno
de los programas que indicábamos al comienzo del capítulo, concretamente, el EQS.
El EQS se basa en la notación de Bentler y Weeks (1980) que se limita a distinguir entre
variables dependientes e independientes en el AFC. Una variable será independiente cuando
de ella sólo salga una flecha causal y será dependiente si recibe alguna. Este programa denota
como V i a las variables observadas, como F i a los factores comunes y como E i a los factores

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 13/55
13
específicos. Si un parámetro se ha de estimar, aparece señalado con un asterisco en la
ecuación correspondiente y si se ha fijado que toma un valor determinado, se indica
expresamente. Las covarianzas, de no especificarse, se suponen que son nulas.
El cuadro 13.2 muestra la sintaxis del EQS para estimar el modelo de AFC, tal y como se ha
especificado en la figura 13.4.
Cuadro 13.2 Sintaxis de EQS para el problema de AFC
Bajo el apartado de /SPECIFICATIONS se refleja la siguiente información: el número de
casos, (CASE=275, tal y como se indicó en el cuadro 13.1 que recogía los datos originales);
numero de variables observadas (VAR=6); la selección de máxima verosimilitud como
método de estimación3 (ME=ML); indicación de que la matriz de datos suministrada es una
matriz de correlaciones (MA=COR); e indicación de que el análisis se efectúe sobre la matriz
de varianzas covarianzas (ANAL=COV). Estas dos últimas instrucciones tienen dos
implicaciones: en primer lugar, es necesario suministrar al programa la matriz de
3 En el epígrafe siguiente se examinarán los métodos de estimación
/TITLE
CFA INTELIGENCIA VERBAL Y CUANTITATIVA
/SPECIFICATIONS
CASE=275; VAR=6; ME=ML; MA=COR; ANAL=COV;
/MATRIX
1.000
0.493 1.000
0.401 0.314 1.000
0.278 0.347 0.147 1.000
0.317 0.318 0.183 0.587 1.000
0.284 0.327 0.179 0.463 0.453 1.000
/STANDARD DEVIATIONS
1.0900 0.5900 0.9800 1.1000 0.4100 1.1100
/LABELS
V1=L; V2=FSF; V3=H; V4=M; V5=FSC; V6=Q;
F1=IV; F2=IQ;
/EQUATIONS
V1= F1+E1;
V2=*F1+E2;
V3=*F1+E3;
V4= F2+E4;
V5=*F2+E5;V6=*F2+E6;
/VARIANCES
F1 TO F2=*;
E1 TO E6=*;
EFFECT=YES;
FIT=ALL;
/COVARIANCES
F1 TO F2=*;
/LMTEST
/WTEST
/END

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 14/55
14
correlaciones, lo que se hace bajo el apartado /MATRIZ y, en segundo lugar, para que el EQS
realice el análisis en términos de matriz de varianzas covarianzas es necesario ofrecerle las
desviaciones típicas de las variables observadas (/STANDARD DEVIATIONS).
El planteamiento de las ecuaciones se hace en el apartado /EQUATIONS. Puede comprobarse
que las variables observadas son dependientes siendo explicadas por los factores comunes ( F i)y por los específicos ( E i). Así, la primera ecuación:
V1=F1+E1
La anterior ecuación recoge la particularidad de que el parámetro de F1 (ξ 1, en la notación
anterior) es 1, porque se ha fijado a este valor tal y como se ve en la figura 13.4 (λ 11=1) y lo
mismo ocurre con el parámetro del término de error E1. En cambio, en la segunda ecuación:
V2=*F1+E2
el coeficiente del término de error sigue estando fijado a 1, pero es necesario estimar el parámetro de F1 (λ 21=*).
Todas las varianzas, tanto de los factores específicos como de los comunes han de estimarse,
tal como indica la instrucción /VARIANCES y lo mismo ocurre con las covarianzas ente los
factores comunes F1 y F2 (así lo indica la instrucción / COVARIANCES). Así pues, queda
comprobada la sencillez de la sintaxis del programa cuando seguimos la notación de Bentler y
Weeks (1980), dado que todo se reduce a distinguir entre variables dependientes e
independientes, lo que permite deducir de manera natural las ecuaciones. Las dos últimas
instrucciones (/LMTEST y /WTEST) las analizaremos más adelante. En el epígrafe siguiente,
que dedicamos a la estimación del modelo, comentaremos las salidas resultantes de la
ejecución del programa EQS con la sintaxis anterior.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 15/55
15
13.4 ESTIMACIÓN DE MODELOS EN EL AFC
A partir de lo descrito, y siguiendo a Sharma (1996), el proceso de estimación del AFC puede
sintetizarse en los dos pasos siguientes:
•
1) Dada la matriz de varianzas covarianzas muestrales (S), se estiman los parámetrosdel modelo factorial hipotetizado.
• 2) Se determina el ajuste del modelo hipotetizado. Esto es, se determina en qué
medida la matriz de varianzas covarianzas estimada ( ˆ ) está próxima a la matriz de
varianzas covarianzas muestral S.
Presentaremos a continuación algunos de los métodos de estimación disponibles. Profundizar
en todos ellos va más allá del alcance de este libro, y recomendamos recurrir a Bentler (1995)
para ello. Sin embargo, se ofrecerán los fundamentos básicos de cada uno de ellos.
Como hemos señalado, el investigador parte de una matriz de varianzas y covarianzas
muestral S. Como ya se ha indicado, la matriz de varianzas y covarianzas poblacional
Σ, condicionada al modelo (13-1), está relacionada con los parámetros poblacionales por la
conocida expresión (13-3):
′= +ΛΦΛ Θ
Estimar el modelo, supone encontrar valores, a partir de los datos muestrales, para las
matrices anteriores (que denotamos con “^”) que cumplan las restricciones impuestas en el
proceso de identificación y que hagan que la matriz de varianzas y covarianzas estimada
mediante la expresión siguiente, sea lo más parecida posible a S:
ˆ ˆ ˆˆ ˆ ′= +ΛΦΛ Θ (13-4)
Long (1983) ilustra el proceso de estimación como sigue. Inicialmente existirán infinitas
matrices estimadas de Λ, Φ y Θ que satisfagan la expresión anterior, pero habrá que rechazar
todas aquellas soluciones que no cumplan las restricciones que se han impuesto en la
identificación del modelo. Llamemos genéricamente Λ
*, Φ
* y Θ
* a las matrices que sí
cumplen las restricciones. Esas matrices permiten obtener una estimación de la matriz de
varianzas covarianzas poblacional Σ* mediante (13-4). Si esta última matriz está próxima a S,
entonces las estimaciones de los parámetros contenidas en Λ
*, Φ
* y Θ
* serían razonables en el
sentido de ser consistentes con los datos de S.
Necesitamos una función, a la que denominamos una función de ajuste, que nos indique en
qué medida “Σ
* está próxima a S”. Long (1983) denota a estas funciones de ajuste con la
expresión F (S;Σ*) y están definidas para todas las matrices que cumplen las restricciones
marcadas en la identificación del modelo. Si entre dos matrices que cumplen esta condición se
verifica que F (S; 1∗
Σ
) < F (S; 2∗
Σ
), entonces concluiremos que 1∗
Σ está más “próxima” a S que
2∗
Σ . Consecuentemente, aquellos valores de Λ
*, Φ
* y Θ
* que minimizan el valor de F(S;Σ*)
serán las estimaciones de los parámetros poblacionales finales ˆ ˆ ˆy, Θ Φ .
Los procedimientos de estimación que vamos a describir a continuación son los siguientes:
mínimos cuadrados no ponderados, mínimos cuadrados generalizados, máxima verosimilitud,

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 16/55
16
estimación por la teoría de la distribución elíptica y estimación con libre distribución
asintótica.
13.4.1 Estimación por mínimos cuadrados no ponderados
La estimación por mínimos cuadrados no ponderados ULS (Unweighted Least Squares) tomacomo estimadores a los valores que minimizan la siguiente función de ajuste:
( ) ( )2*1
2ULS F tr ⎡ ⎤= −
⎣ ⎦SΣ;Σ Σ (13-5)
donde por tr indicamos la traza de la matriz resultante de la operación subsiguiente, esto es, la
suma de los elementos de su diagonal. Long (1983) y Ullman (1996) indican que este método
tiene dos limitaciones que hacen que no sea muy utilizado. En primer lugar, no existen
contrastes estadísticos asociados a este tipo de estimación y, en segundo lugar, los
estimadores dependen de la escala de medida de las variables observadas, esto es, no se
alcanzaría el mismo mínimo de (13-5) si las unidades del nivel de renta, por ejemplo,estuviera medida en pesetas que si lo estuviera en millones.
Este método tiene, sin embargo, algunas ventajas. Así, no es necesario asumir ningún tipo de
distribución teórica de las variables observadas, frente a la hipótesis de normalidad
multivariante que asumen otros métodos de estimación. Por ello, si la violación de esta
hipótesis fuera muy evidente, algunos autores recomiendan recurrir a la estimación por este
método, pero tomando como datos de partida la matriz de varianzas covarianzas estandarizada
– o matriz de correlaciones - para corregir el problema de la dependencia de las unidades de
medida.
13.4.2 Estimación por mínimos cuadrados generalizados
La estimación por mínimos cuadrados generalizados GLS (Generalized Least Squares) se
basa en ponderar la matriz cuya traza se calcula en (13-5) mediante la inversa de matriz de
varianzas covarianzas muestral, esto es:
( ) ( )2* * 11
;2
GLS F tr −⎡ ⎤= −⎣ ⎦S S SΣ (13-6)
13.4.3 Estimación por máxima verosimilitud
La estimación por máxima verosimilitud ML ( Maximum Likelihood ) implica minimizar la
siguiente función de ajuste:
( ) ( )* * 1 *; log log ML F tr q− ⎡ ⎤= + − −⎣ ⎦S S SΣ Σ (13-7)
donde toda la notación es conocida, salvo q que es el número de variables observadas y elhecho de denotar como | | al determinante de la matriz de referencia. Como señala Long
(1983) cuanto más se aproximen las matrices S yΣ
*
, más se aproximará el producto SΣ
*−1
a lamatriz identidad q×q. Como la traza de esa matriz identidad es la suma de los q unos de la

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 17/55
17
diagonal (o sea, q), el primer término de (13-7) se aproximará a q cuando las matrices estén
próximas, compensándose con el término q de (13-7). Por otra parte, la diferencia de los
logaritmos de los determinantes de S y Σ
*tenderá a 0, dado que, cuando las matrices estén
próximas, también lo estarán sus determinantes. De esta forma, cuando las matrices sean
iguales la función de ajuste será cero.
13.4.4 Estimación por la teoría de la distribución elíptica
La estimación EDT ( Elliptical Distribution Theory) se basa en la distribución de probabilidadde este nombre. La distribución normal multivariante es un caso particular de esta familia con parámetro de curtosis4 igual a cero. En este caso, la función a minimizar adopta la forma:
( ) ( ) ( ) ( )2 21* * 1 * 11
; 12
EDT F tr tr κ δ − − −⎡ ⎤ ⎡ ⎤Σ = + − Σ − − Σ⎣ ⎦ ⎣ ⎦S S W S W (13-8)
siendo κ y δ funciones de curtosis y W cualquier estimador consistente de Σ.
13.4.5 Estimación con libre distribución asintótica
La estimación ADF ( Asymptotically Distribution Free) minimiza una función definida
mediante la siguiente expresión:
( ) ( )[ ] ( )[ ]* 1; ADF F σ σ −′= − −S s W sΘ Θ (13-9)
donde s es el vector de datos, es decir, la matriz de varianzas covarianzas muestrales pero
escrita en forma de un solo vector; σ es el la matriz de varianzas covarianzas estimada, de
nuevo puesta en forma de vector y donde con el término (Θ) se ha querido indicar que sederiva de los parámetros del modelo (coeficientes de regresión, varianzas y covarianzas). W
es una matriz que pondera las diferencias cuadráticas entre las matrices de varianzas y
covarianzas muestrales y estimadas. En este caso, cada elemento de esa matriz se obtiene:
ijkl ijkl ij kl w σ σ σ = −
siendo σ ijkl momentos de 4º orden y σ ij y σ kl las covarianzas.
13.4.6 Comparación de los distintos procedimientos de estimación
Resumimos a continuación los resultados del trabajo de Hu, Bentler y Kano (1992), que
analizaron mediante simulación de Monte Carlo cómo se comportaban los distintos
procedimientos de estimación ante distintos tamaños muestrales, violación de las hipótesis denormalidad y de independencia entre los términos de error y los factores comunes.
Estos autores encontraron que, en caso de que fuera razonable asumir la normalidad, el
método ML funcionaba mejor cuando el tamaño muestral era superior a 500, mientras que
4 El coeficiente de curtosis de una distribución es igual al coeficiente estandarizado de cuarto orden menos 3.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 18/55
18
para tamaños inferiores a esa cifra tenía un mejor comportamiento el método EDT.
Finalmente, el método ADF sólo ofrecía buenos resultados con muestras superiores a 2500
casos.
Cuando el supuesto de normalidad se violaba, los métodos de ML y GLS solo daban buenos
resultados con muestras superiores a 2500 casos, aunque el GLS funcionaba algo mejor que elML en muestras inferiores. Pese a no adoptar el supuesto de normalidad, el método ADFtampoco daba buenos resultados con muestras inferiores a 2500 casos.
Cuando se produce una violación del supuesto de independencia entre los términos de error y
los factores comunes, los métodos de ML y GLS funcionan muy mal, y también el ADF salvoque la muestra fuera superior a 2500 casos. En cambio, el EDT funcionaba significativamente
mejor que los demás.
A la luz de lo expuesto, Ullman (1996) recomienda:
•
Los métodos de ML y GLS son la mejor opción con pequeñas muestras siempre quesea plausible la asunción de normalidad e independencia.
• En el caso en que ambos supuestos no parezcan razonables, se recomienda recurrir a laestimación ML denominada “escalada”. Una descripción de este procedimiento se
encuentra en Bentler (1980) y es una opción de estimación del EQS.
Veamos, a modo de ilustración, el resultado de estimar mediante máxima verosimilitud las
matrices de (13-4). Para facilitar la familiarización con el EQS se ha seleccionado la parte deloutput resultante de aplicar la sintaxis recogida en el cuadro 13.2 que contiene esta
información.
En primer lugar, el programa ofrece la matriz S de varianzas covarianzas muestrales (cuadro
13.3). Como se señaló al comentar la sintaxis, al programa se le ha suministrado una matriz decorrelaciones y las desviaciones típicas de las variables observadas. A partir de esta
información el programa calcula la matriz de varianzas covarianzas muestral.
Cuadro 13.3 Matriz S de varianzas covarianzas muestrales
La matriz Λ, que contiene los coeficientes de regresión entre las variables observadas y losfactores comunes, se obtiene directamente de las ecuaciones que el EQS denomina ecuacionesde medida y que se recogen en el cuadro 13.4. En estas ecuaciones aparecen también losestadísticos para contrastes de significatividad de cada coeficiente, así como los errores
estándar, cuya interpretación se ofrecerá más adelante.
L FSF H M FSC Q
V 1 V 2 V 3 V 4 V 5 V 6
L V 1 1.188
FSF V 2 0.317 0.348
H V 3 0.428 0.182 0.960
M V 4 0.333 0.225 0.158 1.210
FSC V 5 0.142 0.077 0.074 0.265 0.168
Q V 6 0.344 0.214 0.195 0.565 0.206 1.232

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 19/55
19
De este cuadro se deduce directamente que la estimación de Λ es la siguiente5:
1 0
0,509 0
0,604 0ˆ0 1
0 0,373
0 0,817
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥
= ⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
Λ
Cuadro 13.4 Matriz Λ de coeficientes de regresión
La estimación de Φ (matriz de varianzas covarianzas de los factores comunes) aparece
separada en dos elementos de la salida del EQS (ambas recogidas en el cuadro 13.5):
“varianzas entre las variables independientes” y “covarianzas entre las variables
independientes”. De esta salida se obtiene que la estimación de la mencionada matriz es:
0,636 0,388ˆ0,388 0,698
⎡ ⎤= ⎢ ⎥⎣ ⎦
Cuadro 13.5 Matriz Φ estimada de varianzas covarianzas entre factores comunes
5 Los subrayados indican que ese parámetro se fijo al valor señalado durante la identificación del modelo.
MEASUREMENT EQUATIONS WITH STANDARD ERRORS AND TEST STATISTICS
L =V1 = 1.000 F1 + 1.000 E1
FSF =V2 = .509*F1 + 1.000 E2.068
7.467
H =V3 = .604*F1 + 1.000 E3
.096
6.319
M =V4 = 1.000 F2 + 1.000 E4
FSC =V5 = .373*F2 + 1.000 E5
.039
9.467
Q =V6 = .817*F2 + 1.000 E6.096
8.552

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 20/55
20
Finalmente resta por obtener la estimación de la matriz Θ, que contiene las varianzas y
covarianzas entre los factores específicos o términos de error. Si se observa la figura 13.4, se
comprueba que, durante la identificación del modelo, todas las covarianzas se fijaron a 0
(como se indica con un subrayado en la matriz que se muestra a continuación), por lo que sólo
se han estimado las varianzas. El cuadro 13.6 ofrece la información que nos permite obtener
la estimación de la matriz Θ:
0,552 0 0 0 0 0
0 0,183 0 0 0 0
0 0 0,728 0 0 0ˆ
0 0 0 0,512 0 0
0 0 0 0 0,071 0
0 0 0 0 0 0,767
⎡ ⎤
⎢ ⎥⎢ ⎥⎢ ⎥
= ⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
Θ
Basta operar matricialmente de acuerdo con la expresión (13-4) para obtener la estimación de
la matriz de varianzas covarianzas poblacional (el EQS no la ofrece):
1,188
0,324 0,348
0, 384 0,196 0, 960ˆ
0, 388 0,197 0, 234 1, 210
0,145 0, 074 0, 087 0, 260 0,168
0,317 0,161 0,191 0,570 0, 213 1, 232
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥
= ⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
Σ (13-10)
VARIANCES OF INDEPENDENT VARIABLES
----------------------------------
V F
--- ---
I F1 - IV .636*I
I .117 I
I 5.443 II I
I F2 - IQ .698*I
I .112 I
I 6.244 I
I I
COVARIANCES AMONG INDEPENDENT VARIABLES
---------------------------------------
V F
--- ---
I F2 - IQ .388*I
I F1 - IV .068 I
I 5.712 I
I I

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 21/55
21
Cuadro 13.6 Matriz Θ estimada de varianzas covarianzas entre factores específicos
La diferencia entre la matriz de varianzas covarianzas muestral S y la matriz de varianzas y
covarianzas poblacional estimada recogida en (13-10) es la denominada matriz residual de
covarianzas. Esta matriz nos indica en qué medida el modelo ha sido capaz de ajustarse a los
datos. Para que el ajuste sea bueno, los valores de cada uno de sus elementos deben ser pequeños. El EQS ofrece esta matriz tal y como la recogemos en el cuadro 13.7.
Cuadro 13.7 Matriz residual de varianzas covarianzas
13.5 BONDAD DE AJUSTE DEL MODELO ESTIMADO
Antes de pasar a interpretar los resultados del análisis factorial confirmatorio que se ha
efectuado, es necesario determinar hasta qué punto el modelo asumido se ajusta a los datosmuestrales. Si detectáramos problemas de ajuste, sería necesario plantear algún tipo de
VARIANCES OF INDEPENDENT VARIABLES
----------------------------------
E D
--- ---
E1 - L .552*I I
.088 I I6.256 I I
I I
E2 - FSF .183*I I
.025 I I
7.294 I I
I I
E3 - H .728*I I
.071 I I
10.281 I I
I I
E4 - M .512*I I
.075 I I
6.828 I I
I I
E5 - FSC .071*I I
.010 I I6.807 I I
I I
E6 - Q .767*I I
.079 I I
9.655 I I
I I
RESIDUAL COVARIANCE MATRIX (S-SIGMA) :
L FSF H M FSC Q
V 1 V 2 V 3 V 4 V 5 V 6
L V 1 0.000
FSF V 2 -0.007 0.000
H V 3 0.044 -0.014 0.000
M V 4 -0.055 0.028 -0.076 0.000
FSC V 5 -0.003 0.003 -0.014 0.004 0.000
Q V 6 0.027 0.053 0.003 -0.005 -0.006 0.000
AVERAGE ABSOLUTE COVARIANCE RESIDUALS =
0.0163
AVERAGE OFF-DIAGONAL ABSOLUTE COVARIANCE RESIDUALS = 0.0228

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 22/55
22
reespecificación del mismo hasta que se lograra un mejor ajuste. Analizaremos, a
continuación, una serie de criterios que se calculan en la mayor parte de programas que
abordan este tema. Como ya avanzamos, los estadísticos elaborados con esta finalidad son
muchos más de que los que aquí se muestran. La selección efectuada recoge, desde nuestro
punto de vista, los más utilizados.
13.5.1 Matriz residual de covarianzas
Como indicábamos al presentar los distintos métodos de estimación del AFC, el objetivo
básico de los mismos es que la matriz de covarianzas poblacional estimada se parezca lo más
posible a la muestral S. En otros términos, puede expresarse lo anterior diciendo que la
diferencia entre ambas matrices, a la que llamamos matriz residual de covarianzas, esté lo más
cercana posible a una matriz nula 0. Los valores de esta matriz deberían ser pequeños y estar
homogéneamente distribuidos. Como señala Byrne (1994), residuos grandes asociados a
algunos parámetros, podrían indicar que han sido mál especificados, y ello afectaría
negativamente al ajuste global del modelo. El EQS proporciona la matriz residual de
covarianzas recogida en el cuadro 13.7, así como su versión estandarizada que mostramos enel cuadro 13.8. En ambos casos calcula los promedios de estos residuos teniendo en cuenta los
elementos de la diagonal y obviándolos. Este segundo promedio se justifica porque,
normalmente, son los elementos de fuera de la diagonal los que tienen más influencia sobre el
estadístico χ 2 que mostraremos más adelante (Bentler, 1995).
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 23/55
23
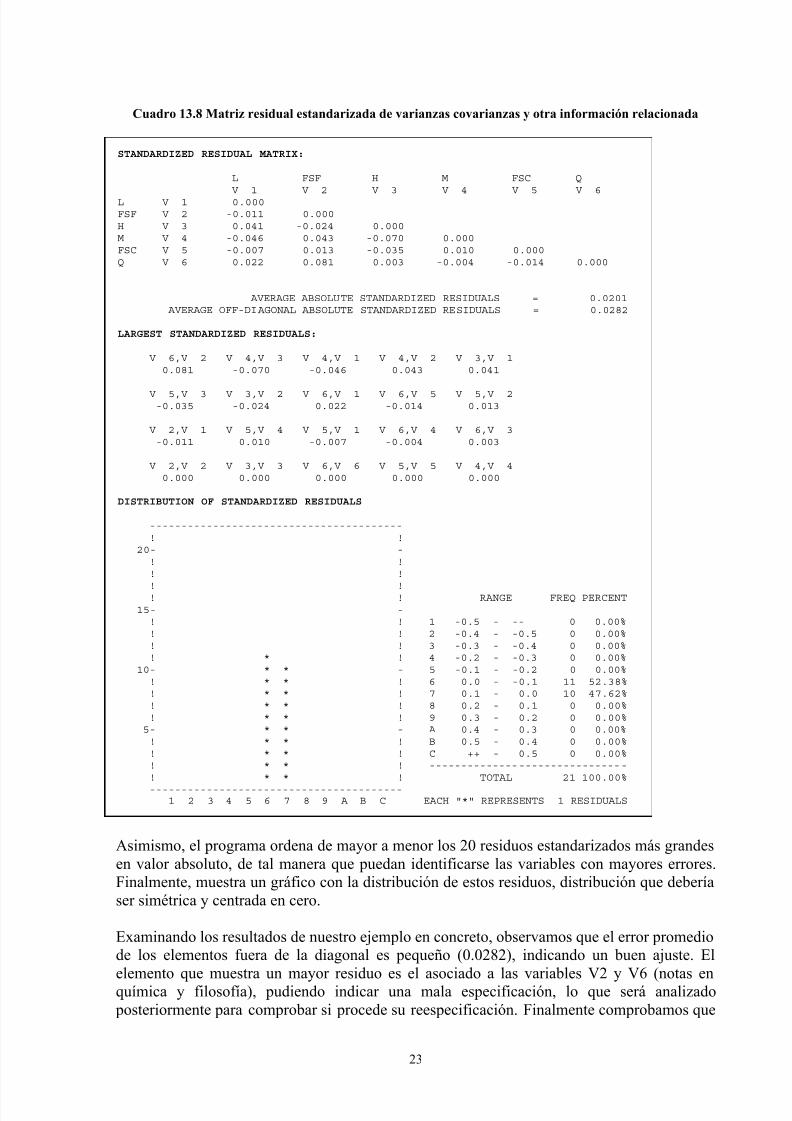
Cuadro 13.8 Matriz residual estandarizada de varianzas covarianzas y otra información relacionada
Asimismo, el programa ordena de mayor a menor los 20 residuos estandarizados más grandes
en valor absoluto, de tal manera que puedan identificarse las variables con mayores errores.
Finalmente, muestra un gráfico con la distribución de estos residuos, distribución que debería
ser simétrica y centrada en cero.
Examinando los resultados de nuestro ejemplo en concreto, observamos que el error promedio
de los elementos fuera de la diagonal es pequeño (0.0282), indicando un buen ajuste. El
elemento que muestra un mayor residuo es el asociado a las variables V2 y V6 (notas en
química y filosofía), pudiendo indicar una mala especificación, lo que será analizado
posteriormente para comprobar si procede su reespecificación. Finalmente comprobamos que
STANDARDIZED RESIDUAL MATRIX:
L FSF H M FSC Q
V 1 V 2 V 3 V 4 V 5 V 6
L V 1 0.000
FSF V 2 -0.011 0.000
H V 3 0.041 -0.024 0.000
M V 4 -0.046 0.043 -0.070 0.000
FSC V 5 -0.007 0.013 -0.035 0.010 0.000
Q V 6 0.022 0.081 0.003 -0.004 -0.014 0.000
AVERAGE ABSOLUTE STANDARDIZED RESIDUALS = 0.0201
AVERAGE OFF-DIAGONAL ABSOLUTE STANDARDIZED RESIDUALS = 0.0282
LARGEST STANDARDIZED RESIDUALS:
V 6,V 2 V 4,V 3 V 4,V 1 V 4,V 2 V 3,V 1
0.081 -0.070 -0.046 0.043 0.041
V 5,V 3 V 3,V 2 V 6,V 1 V 6,V 5 V 5,V 2-0.035 -0.024 0.022 -0.014 0.013
V 2,V 1 V 5,V 4 V 5,V 1 V 6,V 4 V 6,V 3
-0.011 0.010 -0.007 -0.004 0.003
V 2,V 2 V 3,V 3 V 6,V 6 V 5,V 5 V 4,V 4
0.000 0.000 0.000 0.000 0.000
DISTRIBUTION OF STANDARDIZED RESIDUALS
----------------------------------------
! !
20- -
! !
! !
! !! ! RANGE FREQ PERCENT
15- -
! ! 1 -0.5 - -- 0 0.00%
! ! 2 -0.4 - -0.5 0 0.00%
! ! 3 -0.3 - -0.4 0 0.00%
! * ! 4 -0.2 - -0.3 0 0.00%
10- * * - 5 -0.1 - -0.2 0 0.00%
! * * ! 6 0.0 - -0.1 11 52.38%
! * * ! 7 0.1 - 0.0 10 47.62%
! * * ! 8 0.2 - 0.1 0 0.00%
! * * ! 9 0.3 - 0.2 0 0.00%
5- * * - A 0.4 - 0.3 0 0.00%
! * * ! B 0.5 - 0.4 0 0.00%
! * * ! C ++ - 0.5 0 0.00%
! * * ! -------------------------------
! * * ! TOTAL 21 100.00%
----------------------------------------
1 2 3 4 5 6 7 8 9 A B C EACH "*" REPRESENTS 1 RESIDUALS

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 24/55
24
el 100% de los residuos cae dentro del intervalo [–0.1; 0.1] de forma prácticamente simétrica
y, como se ha señalado, centrada en cero. En síntesis, el ajuste del modelo, a partir del análisis
de los residuos es bueno, aunque puede existir un problema debido a la interrelación entre las
variables V2 y V6.
13.5.2 Estadísticos χ
2 para el contraste global del modelo
Como hemos visto anteriormente, se ha denominadoΣ
a la matriz de varianzas covarianzas
del vector x condicionado al modelo (13-1); su estimación se ha denotado por Σ̂ . Por otra
parte, vamos a denominar nc a la matriz de varianzas covarianzas de x no condicionada al
modelo; la estimación de esta matriz es directamente la matriz muestral S. En el caso de que
el modelo sea adecuado para explicar el comportamiento de x, ambas matrices serán iguales.
Por lo tanto, podemos establecer la siguiente hipótesis nula:
0 : nc H =Σ Σ (13-11)
La hipótesis alternativa postula que la matriz nc es igual a cualquier matriz que sea definida
positiva. Para el contraste de estas hipótesis en Bentler y Bonett (1980) se propone el
siguiente estadísico:
0
L N F ×
donde N es el número de datos y 0 L
F es el valor que toma la función de ajuste (13-7) al
realizar la estimación por máxima verosimilitud. Este estadístico se distribuye, bajo la
hipótesis nula, como una χ 2 con ½q(q+1)-k grados de libertad, siendo q el número de
variables independientes y k el número de parámetros a estimar. Si el modelo es el adecuado,
se puede esperar que se rechace la hipótesis nula planteada en este contraste. En el EQS a
este estadístico se le denomina Chi Square.
El EQS ofrece, además, un segundo estadístico denominado independence model chi-square.
Este estadístico se distribuye también como una χ 2 bajo la hipótesis nula de que existe una
completa independencia entre las variables (matriz de correlaciones identidad). En este caso,
si el modelo es el apropiado, cabe esperar que el estadístico tome valores elevados. Por elcontrario, si todas las variables observadas fueran independientes entre sí el modelo de AFC
propuesto no tendría sentido y, consecuentemente, este estadístico tomaría valores bajos.
El cuadro 13.9 recoge junto a los dos estadísticos citados, otros estadísticos que miden la
bondad del ajuste que comentaremos posteriormente. Por otra parte el estadístico χ 2 para este
modelo en que son independientes las variables observadas es efectivamente muy alto
(392,8). Por otra parte, el estadístico χ 2 para contrastar la hipótesis nula (13-11) tiene ½ 6
(6+1)-13 = 8 grados de libertad y toma el valor 8,84 con un p=0,355, lo que nos permite
aceptar la hipótesis nula de igualdad entre las matrices para los niveles usuales de
significación. Este estadístico se utiliza, en definitiva, para contrastar la validez del modelo
teórico propuesto por el investigador.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 25/55
25
Cuadro 13.9 Estadísticos de bondad de ajuste
En la construcción del estadístico χ 2 se ha tenido en cuenta que (i) se asume la hipótesis de
normalidad de las variables observadas, (ii) el análisis se basa en una matriz de varianzas y
covarianzas y no en una matriz de correlaciones y (iii) el tamaño muestral es lo
suficientemente grande para que se justifiquen las propiedades asintóticas del contraste.
Ahora bien, dado que rara vez se cumplen simultáneamente estos requisitos, Bentler y Bonett
(1980), Long (1983) y Ullman (1996), entre otros, señalan que la utilización de este
estadístico debe efectuarse con precaución con muestras grandes, dado que incluso pequeñas
diferencias entre las matrices de covarianzas muestral y estimada serán evaluadas como
significativas por el contraste. Este limitación ha llevado al desarrollo de más de 30
indicadores ad hoc de bondad de ajuste (véase Marsh, Balla y McDonald, 1988; Tanaka,1993; Browne y Cudeck, 1993 o Williams y Holahan, 1994 para una revisión de los mismos),
algunos de los cuales se mostrarán a continuación.
13.5.2 Estadísticos ad hoc
Un primer grupo de estadísticos se correspondería con los denominados por Ullman (1996)
índices comparativos de ajuste. Los distintos modelos que se pueden plantear en un AFC van
desde el que hemos denominado modelo independiente (variables sin ninguna relación) y que
tendría tantos grados de libertad como el número de datos menos el de varianzas que se han
de estimar, hasta el llamado modelo saturado, con ningún grado de libertad. Los índices que
se proponen son comparativos en el sentido de que comparan el valor del modelo teórico quese evalúa, con el del modelo independiente.
Índice NFI
El índice NFI ( Normed Fit Index) ha sido propuesto por Bentler y Bonnett (1980) y compara
el valor del estadístico χ 2 del modelo teórico con el del modelo independiente:
2 2
2
indep teorico
indep
NFI χ χ
χ
−=
GOODNESS OF FIT SUMMARY
INDEPENDENCE MODEL CHI-SQUARE = 392.818 ON 15 DEGREES OF FREEDOM
INDEPENDENCE AIC = 362.81793 INDEPENDENCE CAIC = 293.56637
MODEL AIC = -7.15793 MODEL CAIC = -44.09210
CHI-SQUARE = 8.842 BASED ON 8 DEGREES OF FREEDOM
PROBABILITY VALUE FOR THE CHI-SQUARE STATISTIC IS 0.35579
THE NORMAL THEORY RLS CHI-SQUARE FOR THIS ML SOLUTION IS 9.157.
BENTLER-BONETT NORMED FIT INDEX= 0.977
BENTLER-BONETT NONNORMED FIT INDEX= 0.996
COMPARATIVE FIT INDEX (CFI) = 0.998
BOLLEN (IFI) FIT INDEX= 0.998
McDonald (MFI) FIT INDEX= 0.998
LISREL GFI FIT INDEX= 0.989
LISREL AGFI FIT INDEX= 0.971
ROOT MEAN SQUARED RESIDUAL (RMR) = 0.027
STANDARDIZED RMR = 0.044
ROOT MEAN SQ. ERROR OF APP.(RMSEA)= 0.020
90% CONFIDENCE INTERVAL OF RMSEA ( 0.000, 0.075)

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 26/55
26
Para que sea satisfactorio este estadístico, como la mayor parte de los que examinaremos a
continuación, debe alcanzar valores superiores a 0,90 (Bentler, 1992).
En nuestro ejemplo, como puede comprobarse en el cuadro 13.9, su valor es el siguiente:
392,81 8,84 0,977392,81
NFI −= =
Algunos trabajos han demostrado que este índice tiene una tendencia a subestimar el ajuste
del modelo si las muestras son pequeñas (Bearden, Sharma y Teel, 1982), llevando a sus
autores a plantear dos modificaciones del mismo, el índice NNFI y el CFI.
Índice NNFI
El Nonnormed Fit Index (NNFI) incorpora los grados de libertad de los modelos teórico e
independiente y aunque se evita así la subestimación del ajuste, puede provocar en algunos
casos extremos valores fuera del rango 0-1. Otra limitación es que, en pequeñas muestras,
puede indicar un ajuste excesivamente bajo si se compara con otros modelos, tal y como
apuntan Ullman (1996) y Anderson y Gerbing (1984).
2 2
2
indepindep teorico
teorico
indep indep
gl
gl NNFI
gl
χ χ
χ
−=
−
En el ejemplo que nos ocupa, y tomando la información del cuadro 13.9, este estadístico
ofrece también un buen ajuste:
15392,81 8,84
8 0,996392,81 15
NNFI −
= =−
Índice CFI
Este índice (Comparative Fit Index), propuesto por Bentler (1988), corrige por el número de
grados de libertad del siguiente modo:
( ) ( )( )
2 2
2
indep indep teorico teorico
indep indep
gl gl CFI
gl
χ χ
χ
− − −=
−
En nuestro ejemplo este índice también toma un valor satisfactorio:
( ) ( )
( )
392,81 15 8.84 80,998
392,81 15CFI
− − −= =
−

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 27/55
27
Índice IFI
Propuesto por Bollen (1989), pretende corregir la posibilidad de que el NNFI tome valores
por encima del intervalo razonable 0-1. Para ello se formula así:
2 2
2
indep teorico
indep teorico
IFI gl
χ χ
χ
−=
−
En nuestro ejemplo este índice también alcanza valores de ajuste razonables. A partir de la
información del cuadro 13.9, se obtiene el siguiente valor:
392,81 8,840,998
392,81 8 IFI
−= =
−
Índice MFI
Propuesto por McDonald y Marsh (1990), el índice MFI entraría en los denominados índices
de ajuste absoluto en contraposición a los anteriores que hemos denominado comparativos,
por basarse en poner en relación el modelo teórico con el independiente. El MFI solo toma en
consideración la χ 2 del modelo teórico y responde a la expresión siguiente:
21
2teorico teorico gl
N MFI e χ −
− ⋅=
donde toda la notación es conocida salvo N que indica el tamaño de la muestra. Con los datos
del cuadro 13.9 se comprueba que:
1 8,84 8
2 275 0,998 MFI e−
− ×= =
Índice GFI
Ullman (1996) denomina a este índice y al AGFI que, como se verá, es una sencilla
corrección de aquel, índices de proporción de varianza. El índice GFI (Goodness of Fit Index)
es una ratio entre los elementos ponderados de la matriz de covarianzas poblacional estimaday los elementos ponderados de la matriz de covarianzas muestral. Concretamente, su
expresión es la siguiente:
( )
( )
ˆ ˆ
ˆ ˆ
tr GFI
tr
′=
′
Ws Wsσ σ
donde el vector σ̂ contiene las varianzas de la matriz de covarianzas estimada y el vector s las
de la matriz muestral. La matriz W es una matriz de ponderación que varía en función delmétodo de estimación elegido: la matriz identidad en el ULS, la matriz de covarianzas
muestral en el GLS, la inversa de la matriz de covarianzas estimada en el ML, etcétera. Según puede verse en el cuadro 13.9, este estadístico toma el valor 0,981.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 28/55
28
Índice AGFI
El Adjusted Goodness of Fit Index (AGFI) es una corrección del anterior que se hace en
función del número de parámetros que se han de estimar (a los que denominanmos k ) y el
número de datos disponibles (a los que denominamos d ). Esta corrección adopta la forma:
11
1
GFI AGFI
k d
−= −
−
En nuestro ejemplo, con la información del cuadro 13.9, y recordando que se disponía de 21datos y 13 parámetros a estimar, el valor del estadístico es el siguiente:
1 0,9891 0,971
131 21
AGFI −
= − =
−
Índice AIC
Este índice, denominado Akaike Information Criterion (Akaike, 1987) forma parte de unnuevo grupo que Ullman (1996) denomina índices de grado de parsimonia, por cuanto tienen
en cuenta no solamente la bondad de ajuste estadístico sino también el número de parámetrosa estimar. Su expresión adopta la forma:
2 2teorico teorico AIC gl χ = −
Para nuestro ejemplo, con la información del cuadro 4.9 se obtiene el siguiente valor:
8,84 2 8 7,15 AIC = − × = −
¿Qué valor debe tomar este índice? Ullman (1996) señala que “lo suficientemente bajo” pero,
dado que no está normalizado a un intervalo 0-1, “suficientemente bajo” solo puede
entenderse en términos comparativos con otros modelos teóricos, es decir, servirá comoindicador para señalar si el modelo que hemos contrastado es mejor o peor que otro modelocontrastado previamente, pero no ofrece un nivel de ajuste absoluto. Esta es la razón de que
siempre vaya acompañado por el AIC del modelo independiente, que se supone que es la baseque cualquier modelo teórico debe mejorar y cuanto mayor sea la diferencia del valor del AICdel modelo comparado con el valor correspondiente independiente, tanto mejor. En nuestro
ejemplo lo mejora muy claramente, dado que el AIC en el modelo independiente toma elvalor:
392,81 2 15 362,81 AIC = − × =
Índice CAIC
El Consistent AIC (CAIC) es la corrección propuesta por Bozdogan (1987) al AIC, siendo
válidos todos los comentarios efectuados para este último. Su expresión es la siguiente:

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 29/55
29
( )2 ln 1teorico teoricoCAIC N gl χ = − +
En nuestro ejemplo, como puede verse en el cuadro 13.9, toma el siguiente valor:
( )8,84 ln 275 1 8 44,09CAIC = − + = −
que debe compararse con el CAIC del modelo independiente:
( )392,81 ln 275 1 15 293,56CAIC = − + =
Índice RMR
El último grupo de índices que analizaremos son los que Ullman (1996) denomina basados enlos residuos que no son sino un promedio de las diferencias entre las varianzas y covarianzasmuestrales y las estimadas que se derivan del modelo. Esto es:
( )
( )
2
1 1
ˆ
1 / 2
q i
ij iji j
s
RMRq q
σ = =
−
=+
∑∑
donde toda la notación es conocida, pero recordemos que q era el número de variables
observadas. En nuestro ejemplo este índice toma el valor de 0.027.
Como los residuos sin estandarizar están afectados por la escala en que se mide la variable, se
suelen utilizar los residuos estandarizados construyéndose el llamado SRMR (Standardized
RMR) que está acotado entre 0 y 1, siendo recomendables valores inferiores a 0,05. Como puede verse en el cuadro 13.9, el índice SRMR se sitúa ligeramente por debajo de 0,05
(0,044).
13.5.3 Convergencia en el proceso de estimación
Byrne (1994) plantea que, en cuanto que la estimación del modelo es un proceso iterativo, elhecho de que el algoritmo converja de una manera rápida, es indicador de un buen ajuste delmodelo. La autora considera que, si después de dos o tres iteraciones, el cambio medio en las
estimaciones de los parámetros se estabiliza en valores muy bajos, estaremos probablemente
ante un ajuste adecuado.
El EQS ofrece (cuadro 13.10) la información del número de iteraciones que han sidonecesarias para la convergencia y el cambio medio en los parámetros en cada una de ellas
( parameter abs change). Puede comprobarse como, efectivamente, esta convergencia se ha
producido en apenas 6 iteraciones y cómo, a partir de la tercera, los cambios han sidomínimos.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 30/55
30
Cuadro 13.10 Historial de iteraciones
Al presentar los distintos índices de ajuste, hemos podido comprobar que en el modelo que
hemos tomado como ejemplo se ha obtenido un buen ajuste a los datos. Llegados a este
punto, vamos a analizar e interpretar los resultados que hemos mostrado.
13.6 INTERPRETACIÓN DEL MODELO
Hasta este momento nos hemos centrado en analizar la razonabilidad del modelo en términos
globales (su ajuste). Ahora vamos a examinar si los estimadores de los parámetros sontambién razonables en dos sentidos: (i) ¿toman valores adecuados teóricamente? y (ii) ¿son
significativos?.
La mayor parte de la información necesaria para esta fase, ya se ha mostrado en los cuadros
13.4, 13.5 y 13.6 y a ellos referiremos nuestros comentarios.
En primer lugar, vamos a analizar si los valores que toman los parámetros estimados son o no
compatibles con el modelo estadístico. Para que exista tal compatibilidad las respuestas a lassiguientes preguntas deben ser en todos casos negativas:
• ¿Existen correlaciones superiores a la unidad?
• ¿Existen cargas factoriales estandarizadas fuera del intervalo –1,+1?
• ¿Son los residuos estandarizados anormalmente grandes o pequeños?
• ¿Hay estimaciones negativas de las varianzas?
Si hubiera respuestas no negativas, y aunque el ajuste global del modelo fuera óptimo,
estaríamos ante un indicador claro de que (Long, 1983) esta incompatibilidad puede haberseoriginado por uno o más de los siguientes motivos:
1. El modelo está mal especificado.2. Los datos no respaldan la hipótesis de normalidad multivariante de las variables
observadas3. La muestra es demasiado pequeña
4. El modelo está demasiado cerca de no estar identificado, lo que hace la estimación de
algunos parámetros difícil o inestable.5. Los valores perdidos de algunas variables observadas han provocado que cada
elemento de la matriz de covarianzas muestral esté calculado sobre una muestradiferente.
ITERATIVE SUMMARY
PARAMETER
ITERATION ABS CHANGE ALPHA FUNCTION
1 0.298689 1.00000 0.88599
2 0.124292 1.00000 0.10692
3 0.026794 1.00000 0.03287
4 0.008439 1.00000 0.03231
5 0.001469 1.00000 0.03227
6 0.000443 1.00000 0.03227

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 31/55
31
Si se revisan los cuadros 13.4 a 13.6 se puede comprobar que, en el modelo del ejemplo, no se presenta ninguna de las incompatibilidades señaladas.
La segunda cuestión que debemos examinar es la significatividad estadística de cada
parámetro individual. Centraremos la explicación en los coeficientes de regresión entrevariables observadas y factores comunes, aunque lo expuesto es válido para el resto de parámetros (varianzas y covarianzas).
Si tomamos, por ejemplo, la segunda ecuación del cuadro 13.4, comprobamos que aparecen
las tres líneas que están reproducidas en el cuadro 13.11. La primera de ellas ofrece laecuación correspondiente a la variable observada “calificación en Filosofía” (FSF o V2). Esta
ecuación se expresa como una combinación lineal del factor común “inteligencia verbal” (F1)
multiplicado por el coeficiente de regresión estimado (0,509) y un error de medida (E2).
Cuadro 13.11 Ecuación con errores estándar y estadístico t
En la segunda línea aparece el error estándar (0,068) y el estadístico t (coeficiente/error
estándar = 7.467) que permite contrastar la hipótesis nula de que el parámetro es nulo.
Aunque la significatividad depende de los grados de libertad, para una muestra de un tamaño
mayor de 60, valores superiores a ± 1,96 permiten rechazar dicha hipótesis nula para un nivel
de significación α ≤ 0,05, o superiores a 2,56 para α ≤ 0,01. La carga factorial (o coeficiente
de regresión) es, pues, significativa en este caso, así como en el resto de los coeficientes queaparecen en el cuadro 13.4.
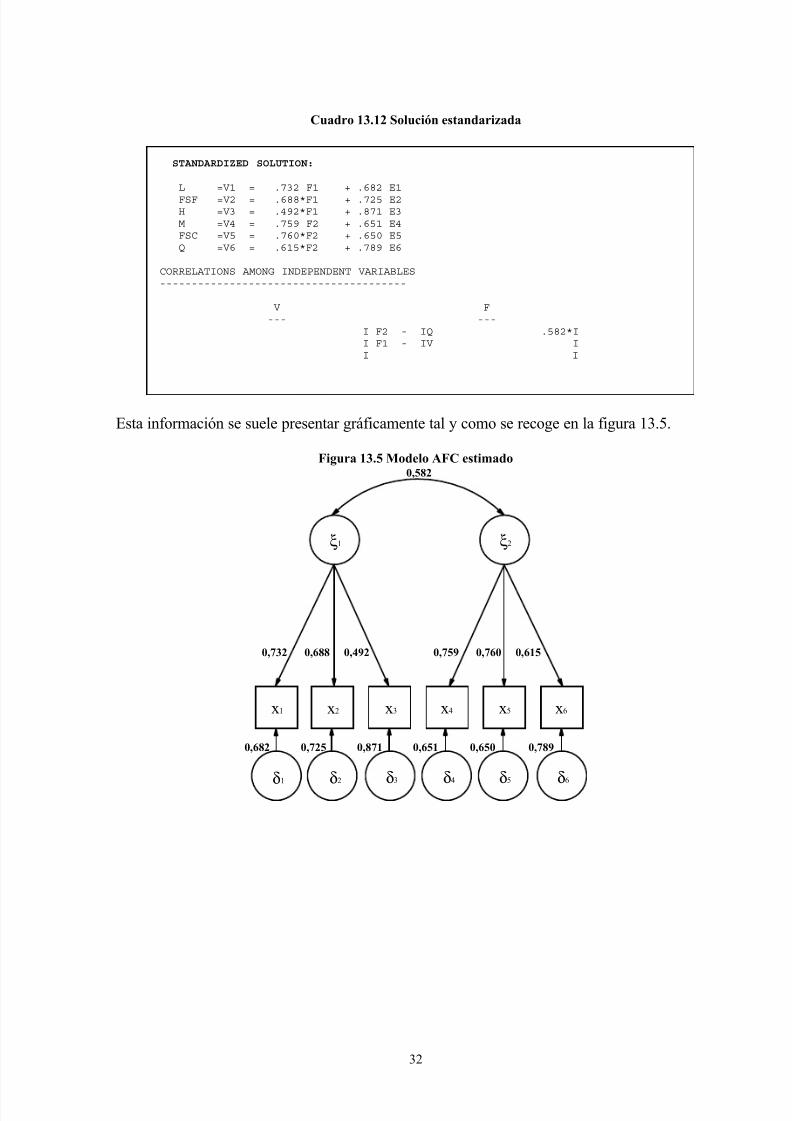
Es habitual ofrecer, sobre todo en la publicación de los resultados, la solución estandarizada
del AFC, esto es, aquella en que se recalculan los estimadores para asegurar que las varianzasde los factores comunes y de las variables observadas son igual a la unidad. Esto se hace,
básicamente, para facilitar la comparación de los resultados con trabajos precedentes. Estainformación, tal como la proporciona el EQS, se recoge en el cuadro 13.12 para las
ecuaciones fundamentales (estimación de las coeficientes de regresión de los factores
comunes y de los factores específicos), y las correlaciones entre los factores comunes.
FSF =V2 = .509*F1 + 1.000 E2
.068
7.467
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 32/55
32
Cuadro 13.12 Solución estandarizada
Esta información se suele presentar gráficamente tal y como se recoge en la figura 13.5.
Figura 13.5 Modelo AFC estimado
x1 x2 x3 x4 x5 x6
δ1
ξ1 ξ2
δ2
δ3
δ4
δ5
δ6
0,582
0,732 0,688 0,492 0,759 0,760 0,615
0,682 0,725 0,871 0,651 0,650 0,789
STANDARDIZED SOLUTION:
L =V1 = .732 F1 + .682 E1
FSF =V2 = .688*F1 + .725 E2
H =V3 = .492*F1 + .871 E3
M =V4 = .759 F2 + .651 E4
FSC =V5 = .760*F2 + .650 E5
Q =V6 = .615*F2 + .789 E6
CORRELATIONS AMONG INDEPENDENT VARIABLES
---------------------------------------
V F
--- ---
I F2 - IQ .582*I
I F1 - IV I
I I

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 33/55
33
13.7 REESPECIFICACIÓN DEL MODELO
Como señala Ullman (1996), existen básicamente dos motivos para reespecificar un modelo
(esto es, eliminar o introducir relaciones entre las variables que los conforman): (i) mejorar su
ajuste o (ii) contrastar alguna hipótesis teórica. Existen, sin embargo, muchos problemas que pueden generarse como consecuencia de una reespecificación poco meditada. Como veremosa continuación, existen dos instrumentos analíticos –el contraste del multiplicador de
Lagrange y el contraste de Wald– que nos indican qué relaciones causales pueden añadirse oeliminarse y qué mejoras en el ajuste obtendríamos con cada una de esta modificaciones. Si el
investigador cae en la tentación de ir incorporando o eliminando relaciones sin más, hastalograr un ajuste razonable y no tiene en cuenta si estas modificaciones están o no soportadas
por el marco teórico que sustenta su investigación, puede provocarse que el modelo al que se
llega no sea en absoluto generalizable (McCallumn, Roznowski y Necowitz, 1992).
En este mismo sentido, Pedhazur (1982) y Sorbom (1989) afirman que es científicamente
incorrecto modificar un modelo simplemente porque mejore su ajuste, ya que el cambio debeser teóricamente interpretable y el investigador debe ser capaz de justificar cuál es el motivo
para añadir una relación causal determinada.
Todo lo expuesto lleva a Hatcher (1994) a plantear las siguientes recomendaciones para lamodificación de un modelo, aunque la mayoría se basan en el trabajo de McCallumn,
Roznowski y Necowitz (1992):
1. Utilizar muestras grandes. Los modelos basados en menos de 100 o 150 casos llevan
a modelos finales poco estables si las modificaciones se basan en los datos y no en lateoría.
2.
Hacer pocas modificaciones. Es posible que las primeras modificaciones puedan estar
derivadas de un modelo que refleje las relaciones poblacionales; las siguientes, probablemente, reflejarán relaciones específicas de la muestra.
3. Realizar solo aquellos cambios que puedan ser interpretados desde una perspectivateórica o tengan soporte en trabajos precedentes. En todo caso, se deben detallar todos
los cambios realizados sobre el modelo inicial en el informe del trabajo final.
4. Seguir un procedimiento paralelo de especificación. Siempre que sea posible, elinvestigador debería trabajar con dos muestras independientes. Si las dos muestras
desembocan en las mismas modificaciones del modelo, se podrá tener una mayorconfianza en la estabilidad del mismo.
5.
Comparar modelos alternativos desde el principio. Más que proponer un modelo e irmodificándolo, puede ser conveniente en algunas ocasiones plantear modelosalternativos y determinar con cuál se obtiene un mejor ajuste.
6. Finalmente, describir detalladamente las limitaciones de su estudio. Como indicaHatcher (1994), la mayoría de los trabajos que se publican están basados en una única
muestra y sobre los que se efectúan sucesivas modificaciones basadas en los datos
hasta lograr un ajuste razonable. Si se sigue este enfoque, sería recomendable que eltrabajo advirtiera al lector de todas estas circunstancias.
Una vez planteadas estas precauciones, veamos a continuación los instrumentos de que sedispone para reespecificar un modelo.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 34/55
34
13.7.1 Significatividad de los parámetros
La primera modificación posible, y la más obvia, para mejorar el ajuste de un modelo es
eliminar aquellos parámetros cuyos estimadores no sean significativos de acuerdo con los
resultados de contraste t . Aunque esta acción puede que no haga disminuir el valor de la χ 2, sí
que puede hacer aumentar la probabilidad de que no sea significativa gracias al aumento delvalor crítico para un nivel de significación determinado al eliminar grados de libertad (Long,1983).
En nuestro ejemplo, tal y como se comprueba en los cuadros 13.4, 13.5 y 13.6, todos loscoeficientes estimados son significativos
13.7.2 Contraste del multiplicador de Lagrange
El contraste ML permite evaluar la mejora que se obtiene al añadir una relación causal o una
nueva covarianza al modelo teórico. Para determinar si esta mejora es estadísticamentesignificativa, el estadístico lleva asociado un nivel de significación.
El EQS ofrece dos versiones de este contraste, la univariante y la multivariante. En la
univariante se muestra el incremento que se produciría en la χ 2 si se introdujera, por separado,cada una de las relaciones consideradas. Esta aproximación univariante tiene el problema de
que, al no considerar las covarianzas entre los distintos parámetros estimados, harán queaparezcan como candidatos a añadirse al modelo y mejorar su ajuste bastantes parámetros. El
enfoque multivariante, sin embargo, identifica el parámetro que conduciría a un mayor
incremento en el estadístico χ 2 del modelo. Después de tener en consideración su
introducción, muestra el parámetro cuya inclusión causaría el siguiente mayor incremento.
Cuadro 13.13 Contraste univariante del multiplicador de Lagrange
LAGRANGE MULTIPLIER TEST (FOR ADDING PARAMETERS)
ORDERED UNIVARIATE TEST STATISTICS:
NO CODE PARAMETER CHI-SQUARE PROBABILITY PARAMETER CHANGE
-- ---- --------- ---------- ----------- ----------------
1 2 6 E3,E1 4.741 0.029 0.156
2 2 12 V2,F2 4.741 0.029 0.174
3 2 6 E5,E4 2.098 0.148 0.063
4 2 12 V6,F1 2.098 0.148 0.182
5 2 6 E4,E1 1.714 0.190 -0.065
6 2 6 E4,E2 1.680 0.195 0.035
7 2 6 E2,E1 1.675 0.196 -0.091
8 2 12 V3,F2 1.675 0.196 -0.142
9 2 6 E4,E3 1.540 0.215 -0.058
10 2 6 E6,E2 1.413 0.235 0.034
11 2 12 V1,F2 1.125 0.289 -0.167
12 2 6 E3,E2 1.125 0.289 -0.039
13 2 12 V4,F1 1.000 0.317 -0.134
14 2 6 E6,E5 1.000 0.317 -0.031
15 2 6 E5,E2 0.387 0.534 -0.006
16 2 6 E5,E1 0.190 0.663 0.008
17 2 12 V5,F1 0.069 0.793 -0.013
18 2 6 E6,E4 0.069 0.793 -0.022
19 2 6 E6,E3 0.055 0.815 0.012
20 2 6 E6,E1 0.034 0.853 0.010
21 2 6 E5,E3 0.017 0.897 -0.00222 2 0 V1,F1 0.000 1.000 0.000
23 2 0 V4,F2 0.000 1.000 0.000

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 35/55
35
Cuadro 13.14 Contraste multivariante del multiplicador de Lagrange
Los cuadros 13.13 y 13.14 recogen la información señalada que se solicitó al programa con la
opción /LMTEST que aparecía en la sintaxis ofrecida en el cuadro 13.2. En el contrasteunivariante, se observa que hay dos parámetros que, individualmente, serían candidatos a
conseguir una mejora significativa del modelo. Estos dos parámetros se corresponden con laintroducción de una covarianza entre los factores específicos E1 y E3, en el primer caso, y
con la inclusión de una relación causal entre la variable observada V2 y el factor común F2,en el segundo caso. En ambos casos el contraste ofrece el valor aproximado que tendría el
parámetro si se añadiera ( parameter change).
Sin embargo, como se ha señalado, estos contrastes tienen el inconveniente que no tiene en
cuenta las covarianzas entre los distintos estimadores de los parámetros, por lo que esconveniente centrar la atención en el contraste multivariante, que descuenta estos efectos
comunes. Si nos fijamos en el cuadro 13.14, comprobamos que ahora sólo propone lainclusión de una relación, o path causal, entre la variable V2 y el factor común F2. Y sóloincluye este parámetro porque el enfoque multivariante hace que compruebe que, tras hacerlo,
ninguna otra adición provocaría mejoras significativas en la χ 2. La necesidad estadística deintroducir este parámetro no es excesiva, dado que el contraste demuestra que la mejora sería
sólo significativa al 5% y no al 1% ( p=0.029) y haría que el estadístico χ 2 disminuyera en4.74 unidades. ¿Debe producirse esta modificación del modelo? La respuesta debe proceder
del análisis teórico del investigador. El modelo tiene un ajuste suficientemente razonable,
¿tiene sentido que exista una relación causal entre la inteligencia cuantitativa y la filosofía?¿existe soporte teórico para esta relación? ¿hay trabajos previos que lo apuntan? Si no es así,
no debería introducirse la relación propuesta por el contraste LM, dado que el ajuste delmodelo sin ella es razonable.
13.7.3 Contraste de Wald
Mientras que el contraste LM se utiliza para plantearse si deberían añadirse nuevos
parámetros al modelo, en el contraste de Wald se aplica para cuestionarse si deberíansuprimirse algunos de los parámetros existentes. En este caso, para confirmar la validez del
modelo lo deseable sería, al contrario de lo que ocurre con el contraste de los multiplicadores
de Lagrange, no poder rechazar la hipótesis nula de que los parámetros son cero.
MULTIVARIATE LAGRANGE MULTIPLIER TEST BY SIMULTANEOUS PROCESS IN STAGE 1
PARAMETER SETS (SUBMATRICES) ACTIVE AT THIS STAGE ARE:
PVV PFV PFF PDD GVV GVF GFV GFF BVF BFF
CUMULATIVE MULTIVARIATE STATISTICS UNIVARIATE INCREMENT
---------------------------------- --------------------
STEP PARAMETER CHI-SQUARE D.F. PROBABILITY CHI-SQUARE PROBABILITY
---- ----------- ---------- ---- ----------- ---------- -----------
1 V2,F2 4.741 1 0.029 4.741 0.029

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 36/55
36
En nuestro ejemplo, como se comprueba en el cuadro 13.15, no hay relaciones que pudieran
suprimirse pero, en el caso de que existieran, deberían hacerse las mismas consideraciones denaturaleza teórica que se han efectuado en el caso de inclusión de nuevos parámetros.
En general, tanto el contraste LM como el de Wald son procedimientos “paso a paso”, por loque el error tipo I suele sobreestimarse. Por esta razón algunos autores (Ullman, 1996)
recomiendan ser conservadores en el nivel de significación considerado. Por ejemplo α =0,01
para Lagrange y α =0.05 para Wald.
También señala esta autora que, de acuerdo con McCallum (1986), el orden en que los
parámetros se eliminen o añadan puede afectar a la significatividad de los restantes, por lo quese recomienda añadir todos los parámetros necesarios antes de eliminar los innecesarios.
Cuadro 13.15 Contraste de Wald
13.8 UN EJEMPLO COMPLETO DE AFC
Desarrollaremos ahora un ejemplo completo de AFC pero recurriendo, en esta ocasión a un programa distinto, el módulo CALIS del SAS, de tal forma que el lector pueda apreciar las
similitudes y diferencias entre dos de los programas más utilizados para este tipo de análisis.
CASO 13.2 Validez convergente de una escala de medida de la orientación de mercado
El problema con que nos enfrentamos es el siguiente. Como señala Martín Armario (1993),
las organizaciones se ven obligadas a estar pendientes tanto de sus clientes como de lacompetencia, aunque su gestión de marketing puede variar la importancia que concede a unou otro factor a lo largo del tiempo. Nuestro investigador quiere desarrollar un instrumento de
medida de estos dos aspectos del enfoque de marketing, la “orientación al cliente” y la
“orientación a la competencia”, para determinar, en cada momento del tiempo, cuál está primando por encima del otro en un sector determinado.
Basándose en el trabajo de Narver y Slater (1990), desarrolla una escala de 11 preguntas
donde las 6 primeras se han diseñado para medir la “orientación al cliente” y las 5 siguientes
para medir la “orientación a la competencia”, tal y como se sintetiza en el cuadro 13.16.
Pero una escala de medida debe demostrar su validez convergente, esto es, si se supone queesas 11 preguntas están midiendo dos factores latentes o constructor distintos, cada grupo de
WALD CONTRASTE (FOR DROPPING PARAMETERS)
MULTIVARIATE WALD TEST BY SIMULTANEOUS PROCESS
CUMULATIVE MULTIVARIATE STATISTICS UNIVARIATE INCREMENT
---------------------------------- --------------------
STEP PARAMETER CHI-SQUARE D.F. PROBABILITY CHI-SQUARE PROBABILITY
---- ----------- ---------- ---- ----------- ---------- -----------
************
NONE OF THE FREE PARAMETERS IS DROPPED IN THIS PROCESS.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 37/55
37
variables observadas deben tener cargas significativas sobre su respectivo factor común, y no
sobre los demás (puede consultarse Küster, Vila y Aldás, 2000 para profundizar en el tema dela validación de escalas). Por este motivo, tras realizar una encuesta a 375 empresas, con el
cuestionario del cuadro 13.16, se realiza una aplicación del método AFC para constatar la
plausibilidad del modelo recogido en la figura 13.6. Si este modelo ofrece un ajuste razonable
y todas las cargas factoriales planteadas son significativas, será una evidencia que apoyará lavalidez convergente de estos indicadores (Anderson y Gerbing, 1988).
Cuadro 13.16 Escala de medida a validar
Fuente: adaptado de Narver y Slater (1990)
Sometido a un primer análisis descriptivo las 11 variables, obtenemos la matriz de varianzas y
covarianzas que se recoge en el cuadro 13.17 y que será el punto de partida de nuestro
análisis.
Valore su acuerdo o desacuerdo con las siguientes afirmaciones en una escala de siete puntosdonde 1=totalmente en desacuerdo; 7=totalmente de acuerdo.
ORIENTACIÓN AL CLIENTEV1. Nos preocupamos por responder a las exigencias de los clientesV2. Ofrecemos servicios post-ventaV3. Comprendemos las necesidades de los clientes
V4. Nos fijamos objetivos de satisfacción del clienteV5. Medimos el grado de satisfacción del clienteV6. Las acciones de mi empresa van dirigidas a que el cliente obtenga más por el mismo precio
ORIENTACIÓN A LA COMPETENCIAV7. Poseemos información sobre la cuota de mercado de la competenciaV8. Damos una respuesta rápida a las acciones de la competencia
V9. La alta dirección efectúa análisis de las estrategias de la competenciaV10. El personal de ventas regularmente comparte información con nuestro negocio en relación a
la estrategia de los competidores.
V11. Vemos como ventajas competitivas las oportunidades de mercado

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 38/55
38
Figura 13.6 Modelo teórico sujeto a contraste
ξ1 ξ2
v1
δ1
v2 v3 v4 v5 v6
δ2 δ3 δ4 δ5 δ6
v7 v8 v9
δ7 δ9 δ9
v10
δ10
v11
δ11
λ 11 λ 21 λ 31 λ 41 λ 51 λ 61
φ12=φ21
λ 72 λ 82 λ 92 λ 102 λ 112
Orientaciónal cliente
Orientación a la
competencia
Cuadro 13.17. Matriz de varianzas covarianzas del ejemploV1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11
V1 8,48
V2 4,03 8,79
V3 3,32 2,68 5,32
V4 4,76 4,81 2,71 10,14
V5 5,34 4,62 2,62 5,02 8,60
V6 2,72 1,89 1,68 2,23 2,33 7,31
V7 1,97 3,54 1,05 3,45 2,46 0,60 8,61V8 1,56 1,47 1,39 2,52 1,03 1,07 1,94 7,07
V9 1,81 2,97 1,70 2,26 2,36 0,53 3,04 2,53 7,34
V10 1,53 2,72 0,28 2,43 1,55 0,27 3,03 1,92 3,08 8,09
V11 0,06 0,52 0,60 -0,37 0,84 1,34 -0,61 0,29 0,83 0,43 1,34
El primer paso consiste en identificar el modelo teórico ilustrado en la figura 13.6. Para ello
es necesario determinar los parámetros que se han de estimar y los que se han de constreñir a
un valor prefijado, de acuerdo con las especificaciones dadas. En este sentido, se llevan acabo las siguientes tareas:
1.
Establecimiento de la escala de los factores comunes. Puede fijarse la carga factorialentre una variable observada y el factor común a 1 o la varianza de ese factor común a1. En este caso, se ha optado por fijar la varianza del factor común a uno, como se
ilustra en la figura 13.7.2. Comprobación de la identificabilidad de la parte del modelo que contiene la relación
entre las variables observadas y los factores. Como tenemos dos factores y más de tres
variables observadas por cada uno de ellos, se han asumido las siguientes supuestos:los términos de error estén incorrelacionados entre sí; cada variable carga solo sobre
un factor; se permite a los factores que covaríen; y se fijan a 1 los parámetros de loscoeficientes de regresión de los términos de error en las ecuaciones de las variables
observadas. Todos estos supuestos se recogen en la figura 13.7.
.
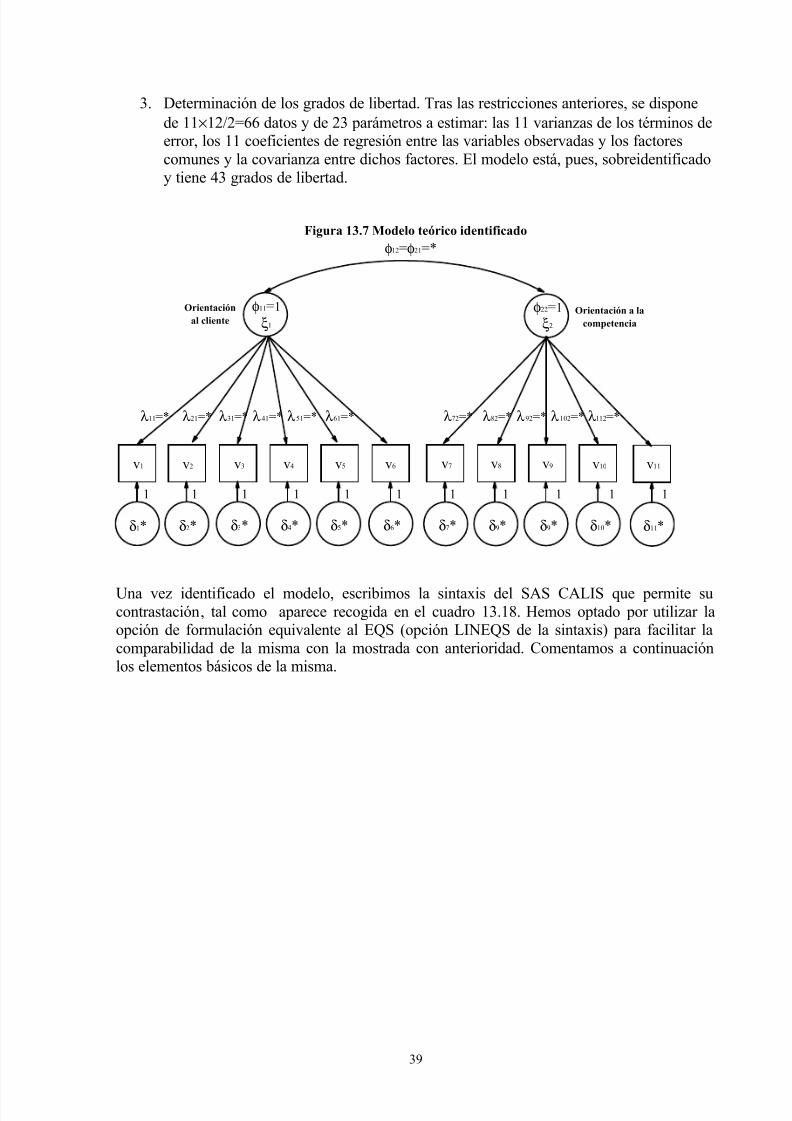
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 39/55
39
3. Determinación de los grados de libertad. Tras las restricciones anteriores, se dispone
de 11×12/2=66 datos y de 23 parámetros a estimar: las 11 varianzas de los términos deerror, los 11 coeficientes de regresión entre las variables observadas y los factores
comunes y la covarianza entre dichos factores. El modelo está, pues, sobreidentificado
y tiene 43 grados de libertad.
Figura 13.7 Modelo teórico identificado
ξ1 ξ2
v1
δ1*
v2 v3 v4 v5 v6
δ2* δ3* δ4* δ5* δ6*
v7 v8 v9
δ7* δ9* δ9*
v10
δ10*
v11
δ11*
λ 11=* λ 21=* λ 31=* λ 41=* λ 51=* λ 61=*
φ12=φ21=*
λ 72=* λ 82=* λ 92=* λ 102=* λ 112=*
Orientaciónal cliente
Orientación a lacompetencia
φ11=1 φ22=1
1 1 1 1 1 1 1 1 1 1 1
Una vez identificado el modelo, escribimos la sintaxis del SAS CALIS que permite sucontrastación, tal como aparece recogida en el cuadro 13.18. Hemos optado por utilizar laopción de formulación equivalente al EQS (opción LINEQS de la sintaxis) para facilitar la
comparabilidad de la misma con la mostrada con anterioridad. Comentamos a continuaciónlos elementos básicos de la misma.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 40/55
40
Cuadro 13.18 Sintaxis del SAS CALIS
Como se puede comprobar al examinar el cuadro 13.18, la sintaxis del SAS CALIS es muysimilar a la del EQS. La primera parte de la misma (DATA) se limita a suministrar al
programa la matriz de varianzas covarianzas con la que ha de trabajar y el número de casos
(375) que la han generado. En la segunda parte (PROC CALIS) se dan las siguientesinstrucciones: el análisis se ha de efectuar sobre la matriz de varianzas covarianzas
(COVARIANCES) y no sobre la matriz de correlación; se debe imprimir la matriz decorrelación (CORR); se debe imprimir la matriz de varianzas covarianzas residual, tanto la
absoluta como la estandarizada (RESIDUAL); se solicita que ofrezca los indicadoresnecesarios para reespecificar el modelo, caso de que el ajuste no sea bueno, es decir, los
contrastes de Wald y multiplicadores de Lagrange (MODIFICATION); y, finalmente, seindica al programa que efectúe una estimación por máxima verosimilitud (METHOD=ML).
Caso de optar por otro procedimiento se utilizarían los siguientes códigos: GLS para mínimoscuadrados generalizados; LSGLS para realizar primero una estimación por mínimos
DATA D1 (TYPE=COV);
INPUT _TYPE_ $ _NAME_ $ V1-V11;
CARDS;
N . 375 375 375 375 375 375 375 375 375 375 375COV V1 8.48 . . . . . . . . . .
COV V2 4.03 8.79 . . . . . . . . .
COV V3 3.32 2.68 5.32 . . . . . . . .
COV V4 4.76 4.81 2.71 10.14 . . . . . . .
COV V5 5.34 4.62 2.62 5.02 8.60 . . . . . .
COV V6 2.72 1.89 1.68 2.23 2.33 7.31 . . . . .
COV V7 1.97 3.54 1.05 3.45 2.46 0.60 8.61 . . . .
COV V8 1.56 1.47 1.39 2.52 1.03 1.07 1.94 7.07 . . .
COV V9 1.81 2.97 1.70 2.26 2.36 0.53 3.04 2.53 7.34 . .
COV V10 1.53 2.72 0.28 2.43 1.55 0.27 3.03 1.92 3.08 8.09 .
COV V11 0.06 0.52 0.60 -0.37 0.84 1.34 -0.61 0.29 0.83 0.43 8.25
;
PROC CALIS COVARIANCE CORR RESIDUAL MODIFICATION METHOD=ML;
LINEQS
V1=LV1F1 F1+E1,
V2=LV2F1 F1+E2,
V3=LV3F1 F1+E3,
V4=LV4F1 F1+E4,
V5=LV5F1 F1+E5,
V6=LV6F1 F1+E6,
V7=LV7F2 F2+E7,
V8=LV8F2 F2+E8,
V9=LV9F2 F2+E9,
V10=LV10F2 F2+E10,
V11=LV11F2 F2+E11;
STDF1=1,
F2=1,
E1-E11=VARE1-VARE11;
COV
F1 F2=CF1F2;
VAR V1-V11;
RUN;

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 41/55
41
cuadrados sin ponderar, seguida de otra por mínimos cuadrados generalizados; LSML para
realizar primero una estimación por mínimos cuadrados sin ponderar seguida por una pormáxima verosimilitud; y, finalmente, ULS para realizar una estimación por mínimos
cuadrados sin ponderar.
El paso siguiente consiste en introducir las ecuaciones que, como se señaló, se efectúa en estecaso siguiendo la notación de Bentler y Weeks (1980), lo que se le indica al programamediante la instrucción LINEQS. A partir de aquí la sintaxis es inmediata y se deriva de
manera directa de la figura 13.7. Las variables se denotan con la letra V, los coeficientes deregresión con la letra L (de loadings) seguida por los dos elementos que une (V1 y F1, por
ejemplo), los factores comunes se denotan con la letra F y los términos de error por la letra E.El término STD introduce las varianzas que se desea estimar o fijar a un valor determinado. Si
se fijan se pone el valor (F1=1) y si se dejan libres para su estimación, se le asigna un nombre
(E1-E11=VARE1-VARE11). De forma análoga, las covarianzas entre los factores comunes seintroduce con COV; así se indica que se quiere estimar la covarianza entre F1 y F2
asignándole el nombre CF1F2 mediante la instrucción: F1 F2 = CF1F2.
Explicada la sintaxis del SAS CALIS, pasamos a examinar los resultados. En primer lugar, el
programa ofrece la matriz de varianzas covarianzas residual como primer indicador de ajuste.Lo hace tanto en su versión original como estandarizada y, al igual que el EQS, muestra los
10 residuos más grandes y una media de los residuos, tanto global, como los que están fuerade la diagonal. En el cuadro 13.19 ofrecemos la matriz de residuos estandarizados. De su
análisis se comprueba que existen algunas variables con residuos elevados, como V7 y V2 o
V10 y V3, lo que constituye un indicio de que la relación entre las mismas no ha sido bienrecogida por el modelo propuesto.
Si se analiza gráficamente la distribución de los residuos (cuadro 13.20) se comprueba que
aunque la distribución es aproximadamente simétrica y centrada en cero, existen demasiados
residuos fuera del intervalo [-1;1], mostrando también problemas en el ajuste del modelo.
Finalmente, el análisis del historial de iteraciones (cuadro 13.21) no muestra problemas deconvergencia, ya que ésta se produce a partir de la tercera iteración, no efectuando el
programa ninguna advertencia sobre la misma (“GCONV convergence criterion satisfied ).

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 42/55
42
Cuadro 13.19 Matriz de residuos estandarizados
Asymptotically Standardized Residual Matrix
V1 V2 V3 V4 V5 V6
V1 0.000000000 -3.357227097 2.967204321 -1.246975692 3.069122401 1.877452055
V2 -3.357227097 0.000000000 0.076573558 1.190600216 0.003342966 -1.095682629
V3 2.967204321 0.076573558 0.000000000 -1.095790386 -2.237389256 1.328560327
V4 -1.246975692 1.190600216 -1.095790386 0.000000000 -0.208504765 -0.509764345
V5 3.069122401 0.003342966 -2.237389256 -0.208504765 0.000000000 -0.260239832
V6 1.877452055 -1.095682629 1.328560327 -0.509764345 -0.260239832 0.000000000
V7 -1.059194816 4.496137954 -1.053078900 3.393318795 0.480245969 -1.372962599
V8 -0.262920898 -0.138686540 1.601857105 2.567732915 -2.183475608 0.864289775
V9 -2.517730704 2.723908897 1.162790049 -0.628459373 -0.427554446 -1.977122902
V10 -1.962033167 2.459194714 -3.515198142 0.916976181 -2.047080370 -2.106146228
V11 -0.570490414 0.702822447 1.403369934 -1.558406356 1.539342408 3.138667879
V7 V8 V9 V10 V11
V1 -1.059194816 -0.262920898 -2.517730704 -1.962033167 -0.570490414
V2 4.496137954 -0.138686540 2.723908897 2.459194714 0.702822447
V3 -1.053078900 1.601857105 1.162790049 -3.515198142 1.403369934
V4 3.393318795 2.567732915 -0.628459373 0.916976181 -1.558406356V5 0.480245969 -2.183475608 -0.427554446 -2.047080370 1.539342408
V6 -1.372962599 0.864289775 -1.977122902 -2.106146228 3.138667879
V7 0.000000000 -1.144338122 -1.465373166 1.084653990 -3.135821742
V8 -1.144338122 0.000000000 1.252373332 -0.449518533 0.093296378
V9 -1.465373166 1.252373332 0.000000000 0.699166646 1.881433740
V10 1.084653990 -0.449518533 0.699166646 0.000000000 0.310648263
V11 -3.135821742 0.093296378 1.881433740 0.310648263 0.000000000
Average Standardized Residual = 1.256
Average Off-diagonal Standardized Residual = 1.507
Rank Order of 10 Largest Asymptotically Standardized Residuals
V7,V2 V10,V3 V7,V4 V2,V1 V11,V6 V11,V7 V5,V1 V3,V1 V9,V2
4.4961 -3.5152 3.3933 -3.3572 3.1387 -3.1358 3.0691 2.9672 2.7239
V8,V4
2.5677

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 43/55
43
Cuadro 13.20 Distribución de los residuos estandarizados
Cuadro 13.21 Historial de iteraciones
Covariance Structure Analysis: Maximum Likelihood Estimation
Distribution of Asymptotically Standardized Residuals
(Each * represents 1 residuals)
-3.75000 - -3.50000 1 1.52% | *
-3.50000 - -3.25000 1 1.52% | *
-3.25000 - -3.00000 1 1.52% | *
-3.00000 - -2.75000 0 0.00% |
-2.75000 - -2.50000 1 1.52% | *
-2.50000 - -2.25000 0 0.00% |
-2.25000 - -2.00000 4 6.06% | ****
-2.00000 - -1.75000 2 3.03% | **
-1.75000 - -1.50000 1 1.52% | *
-1.50000 - -1.25000 2 3.03% | **
-1.25000 - -1.00000 6 9.09% | ******
-1.00000 - -0.75000 0 0.00% |
-0.75000 - -0.50000 3 4.55% | ***
-0.50000 - -0.25000 4 6.06% | ****
-0.25000 - 0 2 3.03% | **
0 - 0.25000 14 21.21% | **************
0.25000 - 0.50000 2 3.03% | **
0.50000 - 0.75000 2 3.03% | **0.75000 - 1.00000 2 3.03% | **
1.00000 - 1.25000 3 4.55% | ***
1.25000 - 1.50000 3 4.55% | ***
1.50000 - 1.75000 2 3.03% | **
1.75000 - 2.00000 2 3.03% | **
2.00000 - 2.25000 0 0.00% |
2.25000 - 2.50000 1 1.52% | *
2.50000 - 2.75000 2 3.03% | **
2.75000 - 3.00000 1 1.52% | *
3.00000 - 3.25000 2 3.03% | **
3.25000 - 3.50000 1 1.52% | *
3.50000 - 3.75000 0 0.00% |
3.75000 - 4.00000 0 0.00% |
4.00000 - 4.25000 0 0.00% |
4.25000 - 4.50000 1 1.52% | *
Covariance Structure Analysis: Maximum Likelihood Estimation
Levenberg-Marquardt Optimization
Scaling Update of More (1978)
Number of Parameter Estimates 23
Number of Functions (Observations) 66
Optimization Start: Active Constraints= 0 Criterion= 0.428 Maximum Gradient Element= 0.036
Radius= 1.000
Iter rest nfun act optcrit difcrit maxgrad lambda rho
1 0 2 0 0.4045 0.0233 0.0439 0 0.882
2 0 3 0 0.4032 0.00128 0.00188 0 0.903
3 0 4 0 0.4031 0.000074 0.00304 0 0.956
4 0 5 0 0.4031 5.396E-6 0.00018 0 1.037
5 0 6 0 0.4031 4.375E-7 0.00022 0 1.120
6 0 7 0 0.4031 3.825E-8 0.00003 0 1.187
7 0 8 0 0.4031 3.513E-9 0.00002 0 1.236
8 0 9 0 0.4031 3.32E-10 4.06E-6 0 1.267
Optimization Results: Iterations= 8 Function Calls= 10 Jacobian Calls= 9 Active Constraints= 0
Criterion= 0.40309939 Maximum Gradient Element= 4.06181E-6 Lambda= 0 Rho= 1.267
Radius= 0.00005455
NOTE: GCONV convergence criterion satisfied.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 44/55
44
Cuadro 13.22 Indices de bondad de ajuste
Los indicadores de bondad de ajuste aparecen en el cuadro 13.22. En dicho cuadro se hansubrayado aquellos que se comentaron en el desarrollo del tema y que están presentes en el
programa SAS CALIS. Todos parecen señalar que existe un problema de ajuste. Así aunque
la chi cuadrado es inferior a la del modelo independiente (150,75<1109,31), es significativa,
con lo que se rechaza la hipótesis nula de que las matrices nc y Σ sean iguales, hecho no
deseable. Por otra parte, los índices NFI (0,8641) y NNFI (0,8693) no son superiores a 0,9; lomismo ocurre con los índices CFI (0,8978) y AGFI (0,8940).
Esta información ya debería llevar al investigador a dudar de la validez convergente de la
escala que ha utilizado. Pero si pese a saber que su escala no es válida en este sentido, desea
saber cuál es la causa que origina los problemas en su instrumento de medición, deberíaseguir con el análisis de los resultados. En primer lugar, debe analizar la significatividad de
los parámetros estimados, dado que quizás los problemas de ajuste se deban solamente a quealguno de los items de la escala no guarde una relación significativa con el factor. El cuadro
13.23 nos muestra la parte de la solución que afecta a la relación entre las variables
observadas y los factores comunes. De su análisis se aprecia que prácticamente todas lascargas factoriales son significativas, ya que los estadísticos t , excepto el correspondiente a
V11, superan ampliamente a 2 en valor absoluto.
Una primera modificación podría ir en la línea de eliminar esta relación. Pero recordemos
nuestra insistencia de que no se trata de lograr un ajuste estadístico, sino que cadareespecificación del modelo debe tener una justificación teórica de acuerdo con los objetivos
de la investigación. En este caso, si la eliminación de la relación desembocara en un buen
ajuste, la única consecuencia sería que la escala que mide la orientación a la competencia
Covariance Structure Analysis: Maximum Likelihood Estimation
Fit criterion . . . . . . . . . . . . . . . . . . 0.4031
Goodness of Fit Index (GFI) . . . . . . . . . . 0.9309GFI Adjusted for Degrees of Freedom (AGFI). . . . 0.8940
Root Mean Square Residual (RMR) . . . . . . . . . 0.4684
Parsimonious GFI (Mulaik, 1989) . . . . . . . . . 0.7278
Chi-square = 150.7592 df = 43 Prob>chi**2 = 0.0001
Null Model Chi-square: df = 55 1109.3122
RMSEA Estimate . . . . . . 0.0819 90%C.I.[0.0679, 0.0963]
Probability of Close Fit . . . . . . . . . . . . 0.0001
ECVI Estimate . . . . . . . 0.5302 90%C.I.[0.4391, 0.6422]
Bentler's Comparative Fit Index . . . . . . . . . 0.8978
Normal Theory Reweighted LS Chi-square . . . . . 152.5770
Akaike's Information Criterion. . . . . . . . . . 64.7592
Bozdogan's (1987) CAIC. . . . . . . . . . . . . . -147.0986
Schwarz's Bayesian Criterion. . . . . . . . . . . -104.0986
McDonald's (1989) Centrality. . . . . . . . . . . 0.8662
Bentler & Bonett's (1980) Non-normed Index. . . . 0.8693
Bentler & Bonett's (1980) NFI . . . . . . . . . . 0.8641
James, Mulaik, & Brett (1982) Parsimonious NFI. . 0.6756
Z-Test of Wilson & Hilferty (1931). . . . . . . . 7.2937
Bollen (1986) Normed Index Rho1 . . . . . . . . . 0.8262
Bollen (1988) Non-normed Index Delta2 . . . . . . 0.8989
Hoelter's (1983) Critical N . . . . . . . . . . . 149

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 45/55
45
tendría un item menos de los inicialmente propuestos, pero sería válida en un sentido
convergente, lo que puede ser hasta deseable en términos de parsimonia.
Para estimar este nuevo modelo, bastaría eliminar la última ecuación del cuadro 13.18 y
cualquier referencia a la variable V11 de la sintaxis, incluyendo la matriz de varianzas y
covarianzas. Si se hace esto, se obtendría el ajuste del modelo que sintetizan los índices delcuadro 13.24 donde, aunque se producen ligeras mejoras, estas no son suficientes paraconsiderar como bueno el ajuste del modelo. Llegados a este punto, el investigador ya sabe
que en ningún caso su escala va a gozar de validez convergente, porque cualquier otro tipo demodificación que ahora presentaremos ya supone cambios demasiados importantes respecto al
modelo teórico como para considerarlo válido. ¿Qué otras modificaciones se puedenintroducir? El cuadro 13.25 nos ofrece los contraste de Lagrange y de Wald que nos sirven
como indicador.
Cuadro 13.23 Parámetros estimados
Covariance Structure Analysis: Maximum Likelihood Estimation
Manifest Variable Equations
V1 = 2.2132*F1 + 1.0000 E1
Std Err 0.1372 LV1F1
t Value 16.1305
V2 = 2.0465*F1 + 1.0000 E2
Std Err 0.1443 LV2F1
t Value 14.1828
V3 = 1.3029*F1 + 1.0000 E3
Std Err 0.1180 LV3F1
t Value 11.0399
V4 = 2.2377*F1 + 1.0000 E4
Std Err 0.1541 LV4F1t Value 14.5202
V5 = 2.2573*F1 + 1.0000 E5
Std Err 0.1375 LV5F1
t Value 16.4143
V6 = 1.0553*F1 + 1.0000 E6
Std Err 0.1454 LV6F1
t Value 7.2583
V7 = 1.7469*F2 + 1.0000 E7
Std Err 0.1663 LV7F2
t Value 10.5077
V8 = 1.2564*F2 + 1.0000 E8
Std Err 0.1539 LV8F2
t Value 8.1613
V9 = 1.8519*F2 + 1.0000 E9
Std Err 0.1523 LV9F2
t Value 12.1590
V10 = 1.6100*F2 + 1.0000 E10
Std Err 0.1619 LV10F2
t Value 9.9469
V11 = 0.2065*F2 + 1.0000 E11
Std Err 0.1745 LV11F2
t Value 1.1834

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 46/55
46
Cuadro 13.24 Indices de bondad de ajuste tras eliminar V11
Si nos fijamos en las propuestas de modificación de la matriz Λ (se denomina GAMMA en el programa SAS), esto es, las que afectan a las relaciones entre las variables observadas y los
factores comunes, vemos que el multiplicador de Lagrange mayor corresponde a una posiblerelación entre V2 y F2 que, en ningún momento estaba planteada teóricamente. Sin embargo,
si el modelo ajustara mejor con su inclusión, podríamos estar ante un indicador que es
compartido por los dos constructos analizados (F1 y F2) que, quizás, pueda servir de base para realizar una posible modificación de la escala. ¿Por qué no prestamos atención a los
multiplicadores de Lagrange asociados al vector de errores (PHI)? Eso es debido a que, alestablecer relaciones entre los términos de error entre sí y con los factores, no tendríamos
justificación teórica para hacer alguna propuesta sobre ellos. Finalmente, el contraste de Wald
nos plantea que eliminemos la relación entre la variable V11 y el factor F2, lo que yasabíamos, puesto que este parámetro (LV11F2) había resultado ser no significativo.
Covariance Structure Analysis: Maximum Likelihood Estimation
Fit criterion . .......................... 0.3157
Goodness of Fit Index (GFI) . . . . . . . . . 0.9395GFI Adjusted for Degrees of Freedom (AGFI). . .0.9022
Root Mean Square Residual (RMR) . . . . . . . 0.4415
Parsimonious GFI (Mulaik, 1989) . . . . . . . .0.7099
Chi-square = 118.0681 df = 34 Prob>chi**2 =0.0001
Null Model Chi-square: df = 45 1075.2518
RMSEA Estimate . . . 0.0813 90%C.I .[0.0656, 0.0976]
Probability of Close Fit . . . . . . . . 0.0008
ECVI Estimate . . . . 0.4314 90%C.I.[0.3521, 0.5316]
Bentler's Comparative Fit Index . . . . 0.9184
Normal Theory Reweighted LS Chi-square . . 120.3436
Akaike's Information Criterion. . . . . . . . 50.0681
Bozdogan's (1987) CAIC. . . . . . . . . .. -117.4474
Schwarz's Bayesian Criterion. . . . . . . -83.4474
McDonald's (1989) Centrality. . . . . . . . . 0.8940
Bentler & Bonett's (1980) Non-normed Index. . .0.8920
Bentler & Bonett's (1980) NFI . . . . . . . . .0.8902
James, Mulaik, & Brett (1982) Parsimonious NFI.0.6726
Z-Test of Wilson & Hilferty (1931). . . . . . .6.4426
Bollen (1986) Normed Index Rho1 . . . . . . . .0.8547
Bollen (1988) Non-normed Index Delta2 . . . . .0.9193
Hoelter's (1983) Critical N . . . . . . . . . . . 155
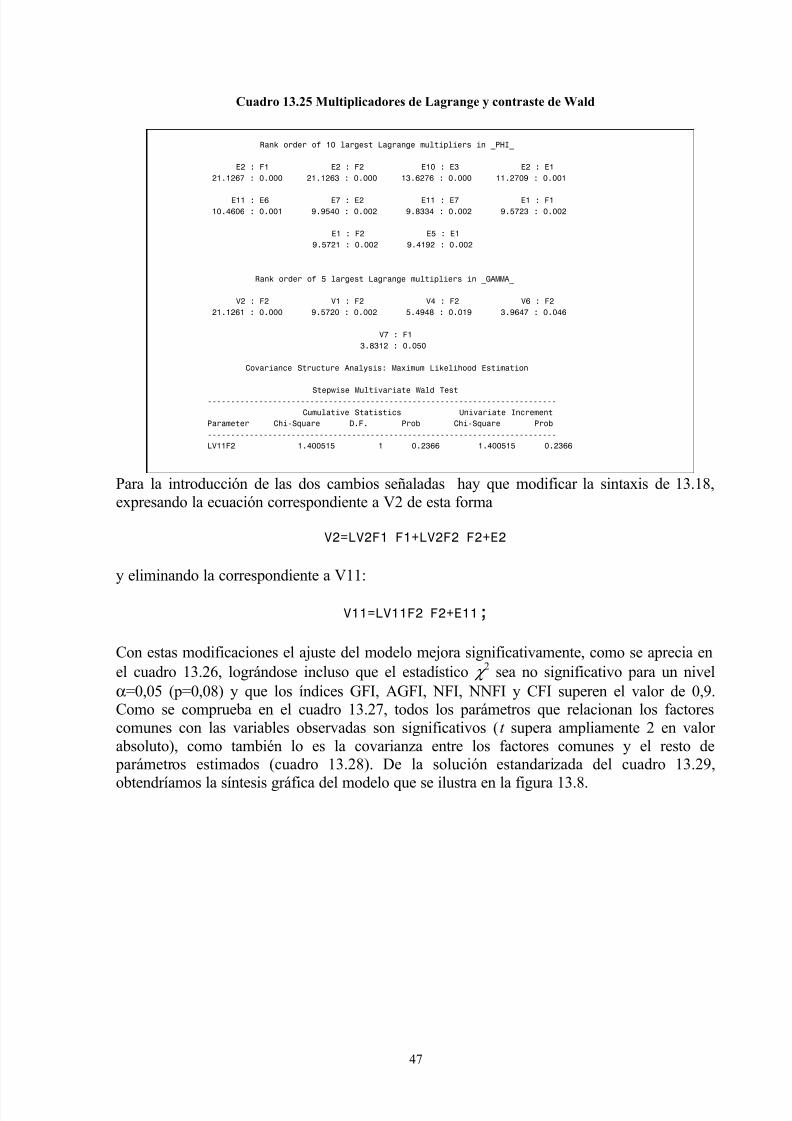
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 47/55
47
Cuadro 13.25 Multiplicadores de Lagrange y contraste de Wald
Para la introducción de las dos cambios señaladas hay que modificar la sintaxis de 13.18,
expresando la ecuación correspondiente a V2 de esta forma
V2=LV2F1 F1+LV2F2 F2+E2
y eliminando la correspondiente a V11:
V11=LV11F2 F2+E11;
Con estas modificaciones el ajuste del modelo mejora significativamente, como se aprecia en
el cuadro 13.26, lográndose incluso que el estadístico χ 2 sea no significativo para un nivel
α=0,05 (p=0,08) y que los índices GFI, AGFI, NFI, NNFI y CFI superen el valor de 0,9.Como se comprueba en el cuadro 13.27, todos los parámetros que relacionan los factores
comunes con las variables observadas son significativos (t supera ampliamente 2 en valor
absoluto), como también lo es la covarianza entre los factores comunes y el resto de parámetros estimados (cuadro 13.28). De la solución estandarizada del cuadro 13.29,
obtendríamos la síntesis gráfica del modelo que se ilustra en la figura 13.8.
Rank order of 10 largest Lagrange multipliers in _PHI_
E2 : F1 E2 : F2 E10 : E3 E2 : E1
21.1267 : 0.000 21.1263 : 0.000 13.6276 : 0.000 11.2709 : 0.001
E11 : E6 E7 : E2 E11 : E7 E1 : F1
10.4606 : 0.001 9.9540 : 0.002 9.8334 : 0.002 9.5723 : 0.002
E1 : F2 E5 : E1
9.5721 : 0.002 9.4192 : 0.002
Rank order of 5 largest Lagrange multipliers in _GAMMA_
V2 : F2 V1 : F2 V4 : F2 V6 : F2
21.1261 : 0.000 9.5720 : 0.002 5.4948 : 0.019 3.9647 : 0.046
V7 : F1
3.8312 : 0.050
Covariance Structure Analysis: Maximum Likelihood Estimation
Stepwise Multivariate Wald Test---------------------------------------------------------------------------
Cumulative Statistics Univariate Increment
Parameter Chi-Square D.F. Prob Chi-Square Prob
---------------------------------------------------------------------------
LV11F2 1.400515 1 0.2366 1.400515 0.2366

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 48/55
48
Cuadro 13.26 Indices de bondad de ajuste tras eliminar V11 e introducir la relación V2F2
Covariance Structure Analysis: Maximum Likelihood Estimation
Fit criterion . . . . . . . . . . . . . . . . . . 0.2580
Goodness of Fit Index (GFI) . . . . . . . . . . . 0.9519GFI Adjusted for Degrees of Freedom (AGFI). . . . 0.9198
Root Mean Square Residual (RMR) . . . . . . . . . 0.3884
Parsimonious GFI (Mulaik, 1989) . . . . . . . . . 0.6980
Chi-square = 44.8992 df = 33 Prob>chi**2 = 0.0810
Null Model Chi-square: df = 45 500.2508
RMSEA Estimate . . . . . . . . . 0.0455 90%C.I.[., 0.0764]
Probability of Close Fit . . . . . . . . . . . . 0.5596
ECVI Estimate . . . . . . . . . . 0.5280 90%C.I.[., 0.6556]
Bentler's Comparative Fit Index . . . . . . . . . 0.9739
Normal Theory Reweighted LS Chi-square . . . . . 43.9820
Akaike's Information Criterion. . . . . . . . . . -21.1008
Bozdogan's (1987) CAIC. . . . . . . . . . . . . . -158.5388
Schwarz's Bayesian Criterion. . . . . . . . . . . -125.5388
McDonald's (1989) Centrality. . . . . . . . . . . 0.9666
Bentler & Bonett's (1980) Non-normed Index. . . . 0.9644
Bentler & Bonett's (1980) NFI . . . . . . . . . . 0.9102
James, Mulaik, & Brett (1982) Parsimonious NFI. . 0.6675
Z-Test of Wilson & Hilferty (1931). . . . . . . . 1.3992
Bollen (1986) Normed Index Rho1 . . . . . . . . . 0.8776
Bollen (1988) Non-normed Index Delta2 . . . . . . 0.9745
Hoelter's (1983) Critical N . . . . . . . . . . . 185

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 49/55
49
Cuadro 13.27 Ecuaciones entre variables observadas y factores comunes
Manifest Variable Equations
V1 = 2.2636*F1 + 1.0000 E1
Std Err 0.2004 LV1F1t Value 11.2943
V2 = 1.4923*F1 + 0.8903*F2 + 1.0000 E2
Std Err 0.2551 LV2F1 0.2674 LV2F2
t Value 5.8511 3.3291
V3 = 1.3095*F1 + 1.0000 E3
Std Err 0.1733 LV3F1
t Value 7.5568
V4 = 2.2110*F1 + 1.0000 E4
Std Err 0.2275 LV4F1
t Value 9.7174
V5 = 2.2799*F1 + 1.0000 E5
Std Err 0.2018 LV5F1
t Value 11.2967
V6 = 1.0767*F1 + 1.0000 E6
Std Err 0.2133 LV6F1
t Value 5.0485
V7 = 1.8117*F2 + 1.0000 E7
Std Err 0.2400 LV7F2
t Value 7.5486
V8 = 1.1893*F2 + 1.0000 E8Std Err 0.2249 LV8F2
t Value 5.2878
V9 = 1.8173*F2 + 1.0000 E9
Std Err 0.2201 LV9F2
t Value 8.2568
V10 = 1.6372*F2 + 1.0000 E10
Std Err 0.2344 LV10F2
t Value 6.9860
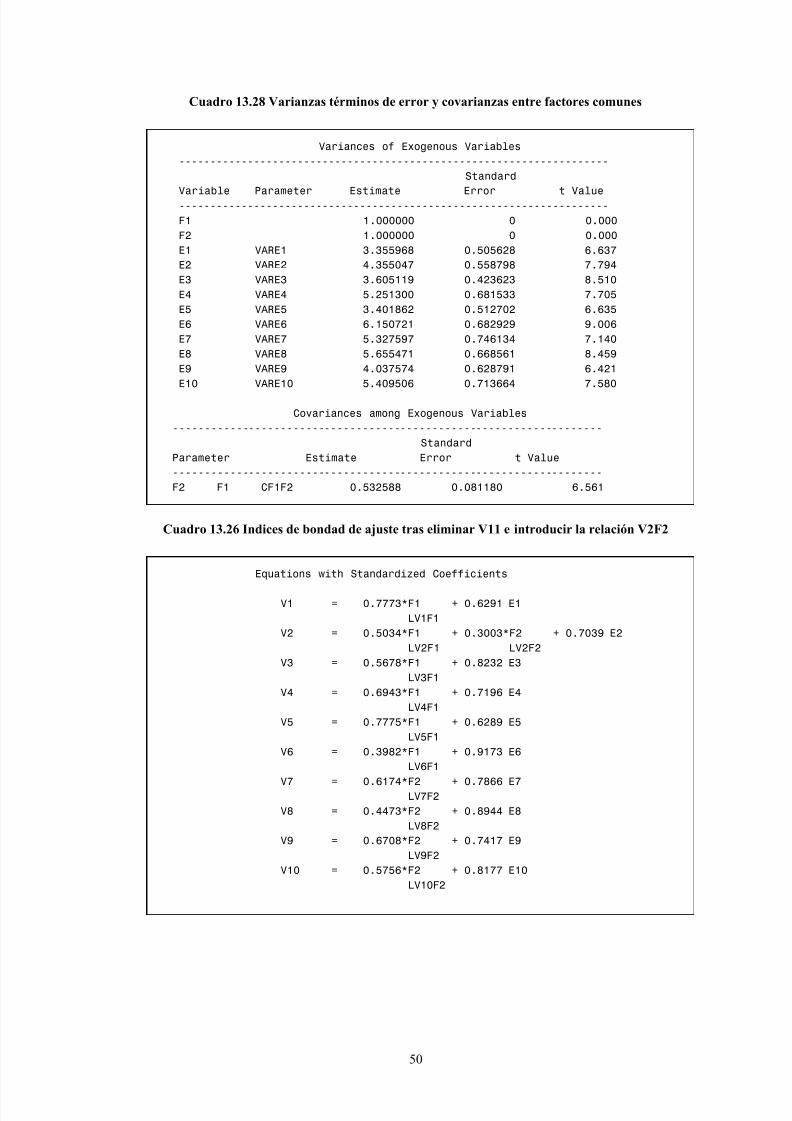
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 50/55
50
Cuadro 13.28 Varianzas términos de error y covarianzas entre factores comunes
Cuadro 13.26 Indices de bondad de ajuste tras eliminar V11 e introducir la relación V2F2
Variances of Exogenous Variables
---------------------------------------------------------------------
Standard
Variable Parameter Estimate Error t Value---------------------------------------------------------------------
F1 1.000000 0 0.000
F2 1.000000 0 0.000
E1 VARE1 3.355968 0.505628 6.637
E2 VARE2 4.355047 0.558798 7.794
E3 VARE3 3.605119 0.423623 8.510
E4 VARE4 5.251300 0.681533 7.705
E5 VARE5 3.401862 0.512702 6.635
E6 VARE6 6.150721 0.682929 9.006
E7 VARE7 5.327597 0.746134 7.140
E8 VARE8 5.655471 0.668561 8.459
E9 VARE9 4.037574 0.628791 6.421
E10 VARE10 5.409506 0.713664 7.580
Covariances among Exogenous Variables
--------------------------------------------------------------------
Standard
Parameter Estimate Error t Value
--------------------------------------------------------------------
F2 F1 CF1F2 0.532588 0.081180 6.561
Equations with Standardized Coefficients
V1 = 0.7773*F1 + 0.6291 E1
LV1F1
V2 = 0.5034*F1 + 0.3003*F2 + 0.7039 E2
LV2F1 LV2F2
V3 = 0.5678*F1 + 0.8232 E3
LV3F1
V4 = 0.6943*F1 + 0.7196 E4
LV4F1
V5 = 0.7775*F1 + 0.6289 E5
LV5F1
V6 = 0.3982*F1 + 0.9173 E6
LV6F1
V7 = 0.6174*F2 + 0.7866 E7LV7F2
V8 = 0.4473*F2 + 0.8944 E8
LV8F2
V9 = 0.6708*F2 + 0.7417 E9
LV9F2
V10 = 0.5756*F2 + 0.8177 E10
LV10F2
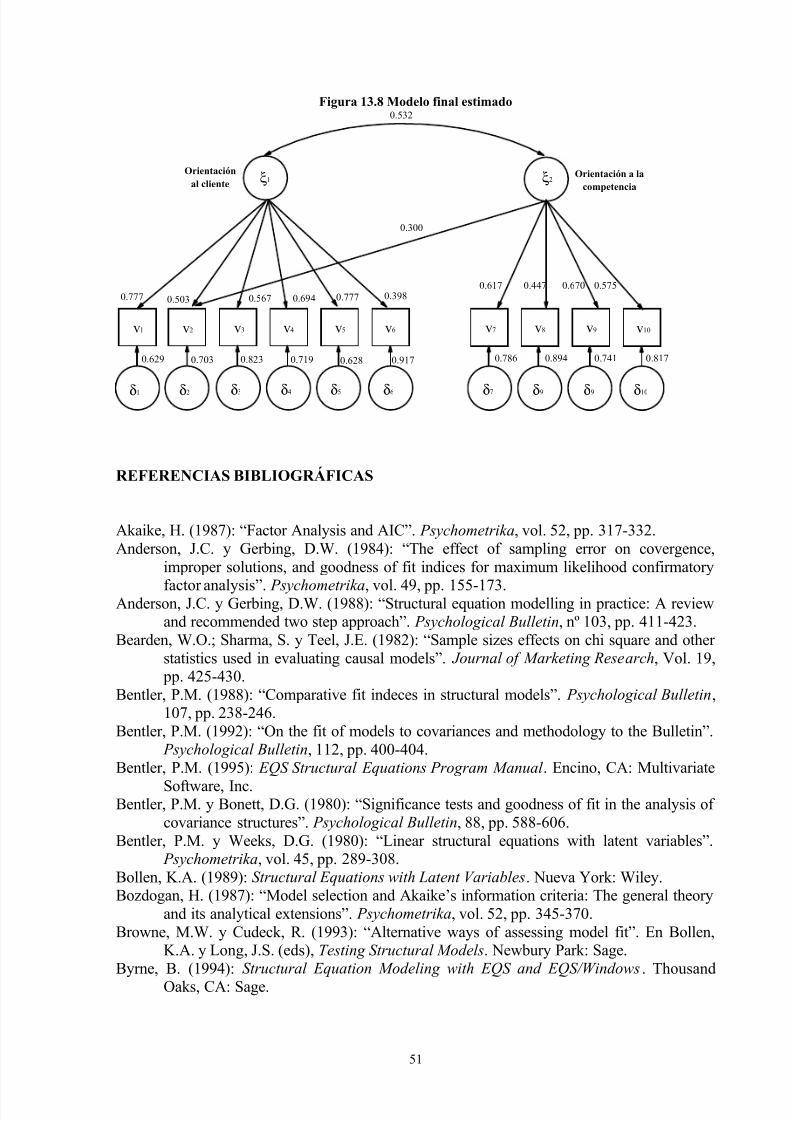
8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 51/55
51
Figura 13.8 Modelo final estimado
ξ1 ξ2
v1
δ1
v2 v3 v4 v5 v6
δ2 δ3 δ4 δ5 δ6
v7 v8 v9
δ7 δ9 δ9
v10
δ10
Orientaciónal cliente
Orientación a lacompetencia
0.532
0.629 0.703 0.823 0.719 0.628 0.917 0.786 0.894 0.741 0.817
0.617 0.447 0.670 0.575
0.567 0.694 0.777 0.398
0.300
0.5030.777
REFERENCIAS BIBLIOGRÁFICAS
Akaike, H. (1987): “Factor Analysis and AIC”. Psychometrika, vol. 52, pp. 317-332.
Anderson, J.C. y Gerbing, D.W. (1984): “The effect of sampling error on covergence,
improper solutions, and goodness of fit indices for maximum likelihood confirmatory
factor analysis”. Psychometrika, vol. 49, pp. 155-173.Anderson, J.C. y Gerbing, D.W. (1988): “Structural equation modelling in practice: A review
and recommended two step approach”. Psychological Bulletin, nº 103, pp. 411-423.
Bearden, W.O.; Sharma, S. y Teel, J.E. (1982): “Sample sizes effects on chi square and other
statistics used in evaluating causal models”. Journal of Marketing Research, Vol. 19, pp. 425-430.
Bentler, P.M. (1988): “Comparative fit indeces in structural models”. Psychological Bulletin,107, pp. 238-246.
Bentler, P.M. (1992): “On the fit of models to covariances and methodology to the Bulletin”. Psychological Bulletin, 112, pp. 400-404.
Bentler, P.M. (1995): EQS Structural Equations Program Manual . Encino, CA: Multivariate
Software, Inc.Bentler, P.M. y Bonett, D.G. (1980): “Significance tests and goodness of fit in the analysis of
covariance structures”. Psychological Bulletin, 88, pp. 588-606.
Bentler, P.M. y Weeks, D.G. (1980): “Linear structural equations with latent variables”. Psychometrika, vol. 45, pp. 289-308.
Bollen, K.A. (1989): Structural Equations with Latent Variables. Nueva York: Wiley.Bozdogan, H. (1987): “Model selection and Akaike’s information criteria: The general theory
and its analytical extensions”. Psychometrika, vol. 52, pp. 345-370.
Browne, M.W. y Cudeck, R. (1993): “Alternative ways of assessing model fit”. En Bollen,K.A. y Long, J.S. (eds), Testing Structural Models. Newbury Park: Sage.
Byrne, B. (1994): Structural Equation Modeling with EQS and EQS/Windows. Thousand
Oaks, CA: Sage.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 52/55
52
Hatcher, L. (1994): A Step-by-Step Apporach to Using the SAS System for Factor Análisis andStructural Equation Modelling . Cary, NC: Sas Institute Inc.
Hu, L.T.; Bentler, P.M. y Kano, Y. (1992): “Can test statistics in covariance structure
analyses be trusted?. Psychological Bulletin, nº 112, pp. 351-362.
Jöreskog, K.G. y Sörbom, D. (1989): Lisrel 7: A guide to the Program Applications. Chicago:
SPSS Inc.Long, J.S. (1983): Confirmatory Factor Analysis. Sage University Paper series on
Quantitative Applications in the Social Sciences, nº 07-033. Newbury Park, CA: Sage.
Marsh, H.W.; Balla, J.R. y McDonald, R. (1988): “Goodness of fit indexes in confirmatoryfactor analysis: the effect of sample size”. Psychological Bulletin, Vol. 105, pp. 430-
445.Martín Armario, E. (1993): Marketing . 1ª edición. Barcelona: Ariel.
McCallum, R.C. (1986): “Specification searches in covariance structure modelling. Psychological Bulletin, 100, pp. 107-120.
McCallum, R.C.; Roznowski, M. y Necowitz, L.B. (1982): “Model modifications in
covariance structure analysis: the problem of capitalization on chance. Psychological
Bulletin, 111, pp. 490-504.McDonald, R.P. y Marsh, H.W. (1990): “Choosing a multivariate model: noncentrality and
goodness of fit”. Psychological Bulletin, 107, pp. 247-255. Narver, J.C. y Slater, S.F. (1990): “The effect of a market orientation on business
profitability”. Journal of Marketing , vol. 54, octubre, pp. 20-35.Pedhazur, E. (1982): Multiple Regression in behavioural research. Nueva York: Holt.
Sharma, S. (1996): Applied Multivariate Techniques. Nueva York: John Wiley & Sons, Inc.
Sorbom, D. (1989): “Model modification”, Psychometrika, vol 54, pp. 371-384.Tabachnick, B.G. y Fidell, L.S. (1996): Using Multivariate Statistics. 3ª edición. Nueva York:
Harper Collins.Tanaka, J.S. (1993): “Multifaceted conceptions of fit”. En Bollen, K.A. y Long, J.S. (eds),
Testing Structural Models. Newbury Park: Sage.
Ullman, J.D. (1996): “Structural Equation Modelling”, en Tabachnick y Fidell (1996), pp.709-812.
Vila, N.; Küster, I. y Aldás, J. (2000): “Desarrollo y Validación de Escalas de Medida enMarketing”. Quaderns de Treball . Nº 104. Facultad de Economía, Universitat de
Valencia.
Williams, L.J. y Holahan, P.J. (1994): “Parsimony-based fit indices for multiple indicatormodels: Do they work? Structural Equation Modeling , Vol. 1, pp. 161-189.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 53/55
53
APÉNDICE
A13.1 El problema de la indentificación
Consideremos un modelo de AFC tal y como fue planteado en la ecuación (13-1):
= +x Λ δ
Por otra parte, la matriz Σ que contiene las varianzas y covarianzas de las variablesobservadas puede descomponerse tal y como se mostraba en la ecuación (13-3)
′= ΛΦΛ + Θ
Si no se impone ningún tipo de restricción a los parámetros de Λ, Θ y Φ y si existe unconjunto de parámetros que cumplen (13-3), entonces habrá un infinito número de ellos.
Veámoslo. Sea M cualquier matriz s× s no singular, por tanto, invertible. Si definimos:
1;− =M M&&&&= Λ
entonces:
( ) ( )
( )
1
1
−
−
= +
=
M M
M M
&&&& + δ Λ δ
Λ + δ
= Λ + δ
de tal forma que si x cumple (13-1), también se cumple que:
=x &&&& + δ
La matriz de varianzas covarianzas de && vendrá dada por
[ ] [ ] E E E ′ ′ ′ ′ ′= = =⎡ ⎤⎣ ⎦ Μ (Μ M M M M&&&&&&Φ = ( ) ) Φ
Si operamos en (13-3) se obtiene que:
( ) ( )( )( ) ( )
1 1
1 1
− −
− −
′ ′ ′ ′= +
′ ′ ′=
′
M M M M
MM M M&& &&&&ΦΛ + Θ Λ Φ Λ Θ
Λ Φ Λ + Θ
= ΛΦΛ + Θ = Σ
Por lo tanto, si Σ cumple (13-3), también se cumple que:
′&& &&&&= ΛΦΛ + Θ
Dado que las matrices marcadas con “¨” sólo serían iguales a las originales en el caso en que
M=I, existen infinitas matrices M invertibles que dan lugar a infinitas soluciones del modelo.En consecuencia, este modelo se definiría como no identificado.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 54/55
54
Ejercicio Análisis Factorial Confirmatorio
Shimp y Sharma (1987) desarrollaron una escala de 17 ítemes para medir las tendencias
etnocéntricas de los consumidores en lo referente a comprar productos hechos fuera de los
Estados Unidos frente a comprar productos norteamericanos. Se adjunta una copia del
mencionado artículo con el fin de que, quien no lo haya trabajado, pueda profundizar en
el concepto de etnocentrismo que ha generado numerosa literatura en marketing.
En ese trabajo, los autores identificaron una batería de sólo 10 ítemes que podían
también utilizarse como indicadores de la tendencia etnocéntrica y que se muestran
(conscientemente sin traducir) en el cuadro 1.
La escala fue administrada a 575 individuos que expresaron su acuerdo o desacuerdo
con cada una de las afirmaciones del cuadro 1 en una escala tipo Likert de 7 puntos en laque 1 significaba completo desacuerdo y 5 completo acuerdo. La matriz de varianzas-
covarianzas que sintetiza los datos se ofrece en el cuadro 2.
Los autores parten de la hipótesis de que el etnocentrismo en un concepto
unidimensional, esto es, que los 10 ítemes deberían conformar un único factor. Dado lo
expuesto se pide:
1. Dibuja el esquema del modelo que permitirá contrastar la hipótesis señalada.
2.
Escribe la sintaxis de EQS que permitiría contrastar la hipótesis mencionada, estoes, que efectúe un análisis factorial confirmatorio donde los 10 ítemes carguen
sobre un sólo factor. Ten en cuenta lo explicado sobre la correcta especificación
del modelo.
3. Rueda la sintaxis y, con los diversos indicadores explicados en la teoría, determina
si el ajuste es o no razonable.
4. Interpreta los resultados. Determina si los parámetros estimados toman valores
adecuados teóricamente.
5.
¿Pueden los autores asumir la unidimensionalidad de la esacala de etnocentrismo?
Presta especial atención a los resultados de los test de Wald y multiplicadores de
Lagrange para contestar a esta pregunta.

8/20/2019 Análisis factorial confirmatorio.pdf
http://slidepdf.com/reader/full/analisis-factorial-confirmatoriopdf 55/55
Cuadro 1. Afirmaciones de la escala para medir las tendencias etnocéntricas
Item Afirmación
I1 Only those products that are unavailable in the US should be imported
I2 American products, first, and foremost.
I3 Purchasing foreign-made products is un-American
I4 It is not right to purchase foreign products, because it puts American out of jobs
I5 A real American should always buy American made products
I6 We should purchase products manufactured in America instead of letting other countries get rich off us
I7 Americans should not buy foreign products, because this hurts American business and causes
unemployment
I8 It may cost me in the long-run but I prefer to support American products
I9 We should buy from foreign countries only those products that we cannot obtain within our own country
I10 American consumers who purchase products made in other countries are responsible for putting their
fellow Americans out of work
Cuadro 2. Matriz de varianzas-covarianzas de la escala.
I1 4.174 I2 2.769 4.340 I3 1.845 1.994 2.742 I4 2.791 2.827 2.257 4.300 I5 2.386 2.610 1.609 2.737 3.689 I6 2.645 2.950 2.101 2.901 2.697 4.080 I7 2.619 2.719 1.795 2.999 2.908 2.802 3.988 I8 2.134 2.535 2.057 2.739 2.334 2.785 2.582 3.590 I9 2.522 2.369 1.856 2.776 2.375 2.610 2.774 2.341 3.987
I10 1.831 2.091 1.132 1.832 1.831 1.920 2.074 1.740 1.736 3.284


















