
Aplicación de la Web Semántica en Tráfico · 2018-07-05 · directa de una operación sobre...
70
Aplicación de la Web Semántica en Tráfico J. Javier Samper Zapater Francisco R. Soriano García Ramón V.Cirilo Gimeno Jose Fco García Calderaro Javier Martínez Plumé Silvia Del Campo Romero Enrique Vte. Bonet Esteban N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Transcript of Aplicación de la Web Semántica en Tráfico · 2018-07-05 · directa de una operación sobre...

Aplicación de la Web Semántica en Tráfico
J. Javier Samper Zapater Francisco R. Soriano GarcíaRamón V.Cirilo GimenoJose Fco García CalderaroJavier Martínez PluméSilvia Del Campo RomeroEnrique Vte. Bonet Esteban
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
2
© Plataforma Tecnológica Española de la Carretera (PTC). Av. General Perón, 26 - 2º iz, 28020 Madrid.Reservados todos los derechos. ISBN: 978-84-09-01565-8
J. Javier Samper Zapater
Francisco R. Soriano García
Ramón V.Cirilo Gimeno
Jose Fco García Calderaro
Javier Martínez Plumé
Silvia Del Campo Romero
Enrique Vte. Bonet Esteban

3
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Índice general

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
1. INTRODUCCIÓN .............................................................................................................................7
2. CONCEPTOS BÁSICOS ...................................................................................................................9
3. TECNOLOGÍAS DE LA WEB SEMÁNTICA. ......................................................................................133.1. Metodología de Modelo .....................................................................................................................................163.2. lenguajes de ontologías ...................................................................................................................................17
3.2.1. RDF ............................................................................................................................................................183.2.1.1. Sintaxis de RDF ................................................................................................................................................19
3.2.2. RDFS .........................................................................................................................................................223.2.3. OWL ...........................................................................................................................................................22
3.3. HerraMientas utilizadas ....................................................................................................................................253.3.1. Servicios Web Semánticos ....................................................................................................................263.3.2. Editores .....................................................................................................................................................273.3.3. Razonadores ............................................................................................................................................283.3.4. Sistemas de almacenamiento ..............................................................................................................293.3.5. Lenguajes de reglas ...............................................................................................................................293.3.6. Lenguajes de consulta ...........................................................................................................................30
4. UTILIZACIÓN DE LA WEB SEMÁNTICA..........................................................................................314.1. situación actual ................................................................................................................................................334.2. linked data ........................................................................................................................................................34
4.2.1. Linking Open Data ..................................................................................................................................37
5. APLICACIÓN DE LA WEB SEMÁNTICA A LOS ITS ..........................................................................40
6. EJEMPLOS DE APLICACIÓN DE WEB SEMÁNTICA RELACIONADOS CON TRÁFICO EN CARRETERA ...436.1. reino unido (data.gov.uk) .................................................................................................................................446.2. rss de incidencias de tráfico ...........................................................................................................................456.3. disponibilidad general de servicios seMánticos ................................................................................................456.4. trabajos en universidades y centros de investigación .....................................................................................46
7. SITUACIÓN ACTUAL DE LA DISEMINACIÓN DE TRÁFICO EN ESPAÑA Y POSIBLES ACCIONES. .....54
8. CONCLUSIONES ..........................................................................................................................60
9. BIBLIOGRAFÍA .............................................................................................................................62
4

5
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Índice de ilustraciones

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 1: Principios básicos de la Web Semántica (7) ..........................................................11Ilustración 2: Modelo multicapa de la Web Semántica (11) .........................................................15Ilustración 3: Grafo RDF (23) .........................................................................................................18Ilustración 4: Ejemplo RDF Tripletas ............................................................................................18Ilustración 5: RDF Turtle ...............................................................................................................19Ilustración 6: Ejemplo RDF JSON-LD ..........................................................................................20Ilustración 7: Ejemplo RDF JSON-LD contexto ...........................................................................20Ilustración 8: Ejemplo RDF RDFa .................................................................................................21Ilustración 9: Ejemplo RDF/XML...................................................................................................21Ilustración 10: Estructura de OWL 2 (27)......................................................................................23Ilustración 11: Ejemplo OWL 2.0 con diferentes sintaxis (29) ......................................................25Ilustración 12: Editores de ontologías: Protégé, SWoop, Apollo ................................................27Ilustración 13: Onda semántica de Tim Berners Lee 2003-2008 (40). ........................................33Ilustración 14: Ubicación de la Web Semántica en el ciclo de vida de la adopción de tecnologías. Fuente: Adaptación de figura de Ivan Herman (2011) (41) ...........................................................34Ilustración 15: Opciones de publicación de datos enlazados. (44) ..............................................36Ilustración 16: Linked Open Data cloud diagram (47) ..................................................................38Ilustración 17: Distribución de tripletas y enlaces por dominio del LOD ....................................39Ilustración 18: Estado del arte de la semántica en áreas y sub-áreas ITS (52) ..........................41Ilustración 19: Interfaz de consulta de estaciones en transport.data.gob.uk (58) .....................44Ilustración 20: Algunos conjuntos de datos disponibles sobre tráfico en carretera (76). ..........46Ilustración 21: Subdominios de una ontología para datos de tráfico en carretera ....................47Ilustración 22: Jerarquía para la clase general Situation (3 niveles) ..........................................48Ilustración 23: Datos semánticos (RDF) basados en el estándar DATEX2 .................................49Ilustración 24: Esquema de un entorno basado en ontologías para la asignación de riesgo de accidentes ......................................................................................................................................49Ilustración 25: Esquema Arquitectura para uso de datos abiertos a bordo del vehículo. ..........50Ilustración 26: Posible Consulta sobre accidentes en el proyecto CONECTA. ...........................51Ilustración 27: Resultado de una consulta previa sobre tráfico. .................................................52Ilustración 28: Ontología sobre diferentes tipos de carga. ..........................................................53Ilustración 29: Arquitectura de PAN con datos abiertos. Adaptación de (79) .............................56
6

7
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
1. Introducción

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
En el presente documento se muestra un estudio sobre las tecnologías que constituyen la Web Semántica y su posible aplicación en el tráfico rodado.
En primer lugar, se recoge una introducción a los conceptos básicos y principales tecnologías que conforman la Web Semántica.
A continuación, se trata de ofrecer una visión general del impacto actual de la Web Semántica, enfocando su usabilidad en un entorno generalizado y centrando poco a poco el foco de interés en su aplicabilidad en administraciones europeas y nacionales y particularizando a entornos de tráfico.
Por último, se lleva a cabo una búsqueda de ejemplos de proyectos que desarrollan aspectos semánticos tanto de carácter generalizado, como incluidos en el ámbito de la gestión del tráfico.
8

9
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
2. Conceptos básicos

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
La representación del conocimiento fue desarrollada primeramente como una rama pura de la Inteligencia Artificial. Sin embargo, poco a poco esta rama se ha ido desmarcando de la idea original de esta parte de las ciencias de la computación. En (1) se define la Inteligencia Artificial como la “ciencia de diseño de sistemas computacionales que lleven a cabo tareas que normalmente requerirían de la inteligencia humana”. Tal y como comenta el autor, la realidad demuestra que una gran cantidad de aplicaciones – muchas de ellas relacionadas con representación del conocimiento – necesitan de la inteligencia humana para su funcionamiento. Una definición de representación del conocimiento que tendría en cuenta todos estos matices podría ser la enunciada por el mismo Sowa: “área multidisciplinar que aplica teorías y técnicas de tres campos: Lógica, Ontologías y Computación”.
Para este autor, las ontologías definen la tipología de cosas que existen en el dominio de la aplicación (jugadores), la lógica ofrecería una visión formal y reglas de inferencia (reglas de juego) y la computación lleva a un plano práctico esta representación del conocimiento, distinguiéndolo de la filosofía (partido).
En (2) la representación del conocimiento se describe como el estudio de “cómo las creencias, intenciones y juicio de valores de un agente inteligente pueden ser expresados en una notación transparente y simbólica que permita razonamiento automático”. Este razonamiento automático ofrece ciertas posibilidades a las aplicaciones prácticas que hagan uso de esta rama de la Inteligencia Artificial que no podrían ser alcanzadas de ninguna forma en los desarrollos actuales.
Existen diferentes puntos de vista para abordar el problema de la representación del conocimiento. Desde sistemas basados en lógica matemática (lógica de predicados y sistemas basados en reglas) hasta sistemas de representación basados en estructuras de datos (redes semánticas, marcos o frames, grafos, redes de Petri), todos ellos ofrecen diferentes métodos para la representación del conocimiento.
En (3), se comenta que “una gran parte de las definiciones de ontología insisten en que una ontología específicamente representa estructuras y conceptos comunes y compartidos”, lo cual se ciñe especialmente al objetivo de establecer un modelo semántico común para el intercambio de información de tráfico.
En (4), se ofrece la siguiente definición simple pero que resume totalmente el uso actual de las ontologías: “una ontología es un modelo del mundo el cual puede ser usado para razonar sobre él”.
Aunque en estas definiciones ya han aparecido algunos términos que componen las ontologías (conceptos, relaciones, reglas), en (5), tomando como base a (6) se detallan los
10

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
cinco elementos que componen una ontología:
• Conceptos: sujetos básicos que se intenta formalizar sobre cualquier tipo de clase.
• Relaciones: enlace entre los conceptos, cómo interactúan los conceptos del dominio.
• Funciones: tipo de relación en la que el elemento es el resultado de la aplicación directa de una operación sobre varios conceptos de la ontología.
• Instancias: objetos particulares de un concepto.
• Axiomas: teoremas que se declaran sobre relaciones, y que deberán cumplir los elementos de la ontología. Es la clave de la inferencia de conocimiento.
Por otra parte, en la Web actual existe multitud de información expresada en lenguaje natural y entendible por los humanos, pero ineficiente para la comunicación entre las máquinas y la extracción de conocimiento. Con el objetivo de permitir un nuevo modelo de compartición de información de manera automatizada (o semi-automatizada) que permita el avance hacia la Web 3.0, surgen diversas tecnologías recogidas al amparo de lo que se conoce como Web Semántica. Dichas tecnologías tratan de aportar información extra a los recursos web, proporcionando contenidos con significado que permitan mejorar la interoperabilidad entre los sistemas informáticos e incluso la aparición de agentes capaces de realizar procesos inteligentes de captura y tratamiento de la información.
Un esquema de los principios básicos que conforman la Web Semántica puede observarse en la ilustración 1, conteniendo descripciones y procesamiento automático:
Ilustración 1: Principios básicos de la Web Semántica (7)
La base fundamental de la Web semántica es añadir información semántica a los contenidos de la Web mediante metadatos. Estos se definen como datos que describen otros datos, más concretamente la información de un recurso web que puede ser
11

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
comprendida por las máquinas tal y como dijo Tim Berners-Lee en 1997. Básicamente son datos que permiten identificar, describir, clasificar y localizar un recurso.Mediante ellos, se consigue clarificar la relación entre las entidades que conforman el conocimiento incluyendo el contexto en el que se encuentran y de esta manera facilitar la búsqueda y recuperación de recursos, aportando resultados más precisos y con menor sensibilidad al vocabulario empleado en la búsqueda.
Algunos de los estándares de metadatos más destacados son: Dublin Core (DC), Friend of a Friend (FOAF) y Learning Object Metadata (LOM), que se aplican a entornos de todo tipo de recursos, personas y objetos educativos, respectivamente.
El otro pilar de la Web semántica es la manipulación automática de las descripciones semánticas. Para ello, se emplean mecanismos de representación del conocimiento como la lógica descriptiva o los sistemas terminológicos y, la inferencia como método para extraer conocimiento.
La lógica descriptiva es un lenguaje de representación de conocimiento adaptado para expresar conocimientos sobre conceptos, roles e individuos mediante una semántica formal.
Los servicios de inferencia son procedimientos de decisión sólidos y completos, para problemas claves que a partir de unos hechos, permiten obtener otros hechos que son consecuencia de los primeros.
12

13
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
3. Tecnologías de la Web Semántica

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Desde que en 2001 Tim Berners-Lee publicara un artículo (8) sobre un nuevo enfoque que debía darse a la Web actual, han surgido multitud de experiencias y trabajos que le han dado la razón y que ha hecho considerar seriamente a la Web Semántica como la Web del futuro.
En contraposición a la Web clásica, orientada a que el conocimiento sea intercambiado entre humanos, la Web Semántica se rige por el principio que deberían ser principalmente máquinas y no humanos las que recibieran, procesaran e intercambiaran información en la Web del futuro. Para ello, el lenguaje de la Web en este escenario no debería estar orientado a la presentación de la información de forma inteligible al ser humano, sino a permitir incluir de forma sencilla grandes cantidades de metainformación que identifiquen unívocamente los conceptos que se pretenden transmitir, de tal forma que puedan ser entendidos por todas las aplicaciones que interactúen con dicha información. Además, resulta imposible no pensar que quien reciba el mensaje no será sino un sistema experto (agente) que tendrá la capacidad de razonar sobre dicha información, lo que llevaría al siguiente paso: pensar que este lenguaje de descripción se encontrará mucho más cercano a la lógica matemática que a la mera lista de conceptos no relacionados que se distribuye actualmente en la Web.
Para Berners-Lee, la Web Semántica debería constar de cuatro componentes o características principales:
• Expresión de significado: debe añadir significado y estructura al contenido de la Web actual.
• Representación del conocimiento: no debe suponer un impedimento para que se represente el conocimiento de forma adecuada y se pueda razonar sobre él.
• Ontologías: adaptación del concepto antiguo de Ontología a la Web. Se encarga de plasmar el conocimiento del dominio en un formato común entendible por cualquier elemento del sistema.
• Agentes: actores que deberían intercambiar la información, substituyendo a los humanos, y encargándose de presentar de forma adecuada la información procesada al usuario.
En la ilustración 2 se recogen las principales tecnologías que conforman la arquitectura del modelo multicapa de la Web Semántica planteado por Tim Berners Lee en 2000 (9), (8), (10):
14

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 2: Modelo multicapa de la Web Semántica (11)
El primer elemento necesario para el acceso a los recursos de la web, es la posibilidad de que puedan ser identificados unívocamente en cualquier idioma, con lo que se precisa el uso de Unicode e identificadores URI.
Para la descripción sintáctica de los recursos se utiliza XML y XML-Schema como estándares de base, pero es necesario utilizar lenguajes que permitan imponer restricciones semánticas para descripciones completas.
RDF (Resource Description Framework) es una recomendación del W3C para la descripción de metadatos de los recursos de la Web con base lógica. Es un lenguaje basado en XML que permite expresar tripletas que indican el sujeto, verbo y objeto de una sentencia. Estas sentencias indican qué recursos, tienen qué propiedades y con qué valores, identificando cada objeto con una URI. Este modelo de datos permite expresar las relaciones entre los recursos y establecer jerarquías.
Junto al RDF, se usa RDFS (RDF Schema) para definir las propiedades de los recursos y los tipos de recursos que son descritos. Es un mecanismo necesario para detallar cada elemento, especificar un vocabulario para definir las clases y propiedades, restringir las posibles combinaciones de clases y relaciones, y detectar violaciones de estas restricciones. Mientras un XML Schema puede ser utilizado para validar la sintaxis de un RDF/XML, un RDF Schema permite comprobar las restricciones semánticas.
Sin embargo, esta aportación de información no es suficiente, por ejemplo, en caso de que dos entornos utilicen diferentes identificadores para referirse al mismo objeto.
15

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Se precisa de un mecanismo que permita cruzar esta información. Se necesitan lenguajes como OWL (Web Ontology Language), con mayor expresividad y capacidad de razonamiento para representar los conocimientos y definir las ontologías, que no son más que documentos o ficheros que definen formalmente las relaciones entre clases dentro de un dominio de la realidad: cardinalidad, igualdad, topologías de propiedades, caracterización de propiedades o clases enumeradas.
Las ontologías pueden ser modeladas con diferentes técnicas de modelado de conocimiento y a su vez implementadas con diferentes lenguajes. Algunas de las técnicas de modelado son utilizando: marcos y lógica de primer orden, lógica descriptiva, UML o bien diagramas Entidad-Relación. Entre los lenguajes de implementación, el W3C recomienda RDF y OWL.
Las características que deben cumplir los lenguajes de ontologías son: sintaxis bien definida, semántica específica, suficiente expresividad, fácilmente traducible entre los lenguajes ontológicos y permitir eficiencia para realizar razonamientos.
Disponiendo de las ontologías para describir la información y las relaciones, se necesitan agentes inteligentes para rastrear la Web de forma automática y localizar exclusivamente, los recursos buscados, con el significado y concepto precisos con el que se interpreta el término buscado. Para ello, es necesario en la capa lógica utilizar reglas de inferencia que describan y permitan obtener conclusiones, y de esta manera comprobar mediante el intercambio de pruebas escritas en un lenguaje unificador, que realmente es el recurso buscado o verificar los pasos de los razonamientos. Además, estos agentes deben ser escépticos de la información obtenida, y contrastar minuciosamente las distintas fuentes de información. De forma adicional, podrán utilizar la firma digital para verificar que la fuente es confiable.
3.1. Metodología de modelo
Existe una gran cantidad de recomendaciones para el desarrollo de ontologías, entre las cuales destaca una orientada al objetivo de la aplicación conocida como Methontology (12). En (5) se realiza una completa revisión de las alternativas clásicas más utilizadas.
En los últimos años la investigación en este campo ha avanzado hacia el ámbito de la Ingeniería, con la aparición de nuevas metodologías que buscan facilitar a las aplicaciones el uso de ontologías (13), (14). Entre ellas destaca MENTOR (15), que orienta el desarrollo de la ontología a facilitar que la información sea compartida por un conjunto de organizaciones, así como UPON (16), completa metodología que convierte el desarrollo de una ontología en un proyecto software.
16

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Por último, una visión todavía más práctica se presenta en (17). Este enfoque consiste utilizar UML y metodologías actuales como MDA (Model Driven Architecture) para el desarrollo de ontologías que permitan una fácil integración en las aplicaciones actuales. Posteriormente esta idea fue ampliada en (18), (19) y también en (20). En todos estos trabajos se estudian diferentes aproximaciones para la transformación de un modelo basado en UML a un modelo ontológico, que posteriormente será enmarcado en arquitecturas reales.
Por otra parte, existen una guías sencillas de desarrollo como (21), que son tenidas en cuenta para establecer los puntos base en la creación de las ontologías:
• Determinar el dominio y alcance de la tecnología: ¿qué se estudia?
• Considerar la reutilización de ontologías existentes: ¿es posible aprovechar investigaciones previas?
• Enumeración de los términos más importantes: definición del vocabulario de trabajo.
• Definición de las clases y su jerarquía: modelado de los objetos del dominio.
• Definición de las propiedades de las clases: particularización de los objetos del dominio.
• Detalle de las propiedades a bajo nivel: rango, dominio, cardinalidad.
• Creación de instancias: definición de elementos finales del dominio, “literales” inmutables.
3.2. Lenguajes de ontologías
Existe gran diversidad de lenguajes que permiten la representación de ontologías, cada uno con un nivel de expresividad. Entre ellos los hay de carácter más tradicional, basados en frames, lógica descriptiva, en predicados de primer y segundo orden o bien orientados a objetos. En los siguientes subapartados se permite consultar ejemplos de los principales lenguajes que se han desarrollado orientados a ser utilizados en la Web.
17

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
3.2.1. RDF
RDF (Resource Description Framework, en castellano podría traducirse como Plataforma para la descripción de recursos), es un estándar W3C que proporciona un entorno para expresar la información de un recurso Web de tal forma que pueda ser intercambiada entre aplicaciones sin pérdida de significado. Por este motivo, se considera más un lenguaje para la definición de metadatos que para el modelado de ontologías. Es decir, permite codificar, intercambiar y reutilizar metadatos estructurados. (22), (23).
El modelo de datos de RDF está formado por recursos y pares de atributo y valor. Un recurso representa cualquier entidad que pueda ser referenciada por un URI (Identificador Único de Recurso), los atributos representan las propiedades de los recursos y los valores pueden ser entidades atómicas o bien otros recursos. Se utilizan URIs y namespaces para la identificación de los recursos y las relaciones se pueden plasmar mediante un grafo o mediante sintaxis XML (con declaraciones explícitas).Un ejemplo de uso en modo gráfico se puede observar en la Ilustración 3 y su correspondencia textual en tripletas en la Ilustración 4:
Ilustración 3: Grafo RDF (23)
Ilustración 4: Ejemplo RDF Tripletas
18

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
La versión de RDF v1.1 admite diferentes sintaxis para expresar la información de los grafos: N-Triples (o tripletas), Turtle, Json-LD, RDFa, RDF/XML.
Para soportar la definición de vocabularios, RDF proporciona el lenguaje RDF Schema.
3.2.1.1. Sintaxis de RDF
Los grafos RDF pueden serializarse mediante diferentes formatos. Todos los modelos pueden describir las mismas tripletas de significado y ser equivalentes. Se comentan brevemente a continuación.
RDF Turtle (Terse RDF Triple Language)Es una recomendación del W3C del 25 de Febrero de 2014 que detalla una sintaxis para RDF que permite escribir un grafo RDF en forma de texto natural y compacto. La gramática de Turtle es un subconjunto de SPARQL y permite representar las tripletas (sujeto, predicado, objeto) utilizando IRIs (Identificador de Recursos Internacionalizado). Turtle no se basa en XML a diferencia de RDF y se reconoce generalmente por ser más fácil de leer y más fácil de editar manualmente.
El grafo del ejemplo anterior puede representarse tal y como se muestra en la ilustración 5:
Ilustración 5: RDF Turtle
Para la especificación de múltiples grafos, se necesita recurrir a la extensión de Turtle TriG y para el intercambio de grandes grafos RDF, se usa la extensión N-Quads que permite incluir un nuevo elemento que especifica el grafo IRI a la tripleta, reduciendo la cantidad de texto necesario.
19

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
JSON-LDEsta sintaxis permite una sencilla transformación de datos escritos en JSON en documentos RDF con mínimos cambios. Se proporciona un mecanismo de identificadores para los objetos JSON, de tal forma que se puede referenciar a objetos de otro documento JSON. Se requiere de un JSON auxiliar usado para determinar el contexto (ilustraciones 6 y 7).
Ilustración 6: Ejemplo RDF JSON-LD
Ilustración 7: Ejemplo RDF JSON-LD contexto
RDFaEs una extensión del HTML5 propuesta por el W3C que permite incorporar metadatos a personas, lugares, eventos, recetas y artículos. Utiliza atributos simples como meta y link de los elementos div o span de los propios documentos HTML para intercalar los datos RDF. De esta forma, los usuarios están más dispuestos a incorporar esta información en los recursos Web. Los algoritmos de búsqueda y los servicios Web usan este marcado para generar mejores listas de resultados y dar una mejor visibilidad a las webs personales.
20

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Algunas grandes compañías apuestan por la indexación con RDFa, con lo que es buena idea incorporar los metadatos en la Web mediante este formato. Como se comenta más adelante, esto permite obtener un formato mejorado en los resultados obtenidos en los principales motores de búsqueda.
En la ilustración 8 se puede observar un ejemplo del formato RDFa:
Ilustración 8: Ejemplo RDF RDFa
RDF/XMLLa primera versión de RDF sólo soportaba esta sintaxis basada en XML para expresar los grafos. Un ejemplo para expresar el grafo anterior en formato RDF/XML es mostrado en la ilustración 9:
Ilustración 9: Ejemplo RDF/XML
21

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
3.2.2. RDFS
RDF Schema es un vocabulario que permite definir clases y propiedades, y establecer jerarquías y herencia entre clases y entre propiedades RDF. Básicamente es un lenguaje, recomendación del W3C, para describir ontologías sencillas, comúnmente denominadas vocabularios, que actúa de extensión semántica de RDF. Es capaz de permitir preguntas referentes a su contenido y no a la estructura del documento.
Las tres clases básicas dentro del lenguaje RDFS son:
• rdfs:Class: para indicar la clase del recurso.
• rdfs:Property: para indicar la clase de todas las propiedades RDF.
• rdfs:Resource: todas las entidades descritas por expresiones RDF.
RDF Schema emplea el concepto de clase (“Class”) para especificar categorías que se usan para clasificar recursos. Las relaciones entre una instancia y su clase se realizan a través de la propiedad tipo (“type”). Se pueden crear jerarquías de clases y subclases y de propiedades y subpropiedades. Las restricciones de tipo entre sujetos y objetos de tripletas particulares pueden ser definidas a través de las restricciones de dominio (“domain”) y rango (“range”). El conjunto completo de clases y propiedades definidas en RDFS se puede consultar en (24).
RDFS tiene ciertas limitaciones como que carece de expresividad para: información negativa (los hombres no son mujeres), cuantificadores (para que alguien sea considerado padre debe tener al menos un hijo), cardinalidad (un buen estudiante tiene que tener aprobadas más de 3 asignaturas), no permite atributos de propiedades (transitiva, simétrica, inversa, etc.) (25). Otro problema que plantea es que con RDFS pueden llegar a declararse paradojas. Por todo esto, no se considera lo bastante completo para describir los recursos de la Web con el detalle necesario, pero se utiliza porque se puede emplear en muchos dominios y porque puede actuar de puente entre vocabularios.
3.2.3. OWL
OWL 2 Web Ontology Language es recomendación del W3C desde el 27 de Octubre de 2009 para la edición de ontologías, que es una extensión de la primera versión OWL 1.0 publicada en 2004.
22

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Realmente, OWL es una extensión del lenguaje RDF y emplea tripletas de RDF, aunque es un lenguaje con más poder expresivo. Deriva de DAML+OIL.
Provee de más vocabulario para la descripción de propiedades y clases, por ejemplo: relaciones entre clases, cardinalidad, equivalencia y características de propiedades (26).
En la ilustración 10 se muestra el esquema de las relaciones entre los componentes del lenguaje. La zona central representa el concepto abstracto de una ontología expresada como una estructura abstracta o bien como un grafo RDF. En la parte superior se muestran varias sintaxis que se pueden utilizar para serializar e intercambiar ontologías y, en la parte inferior se sitúan las dos especificaciones semánticas que definen el significado de las ontologías de OWL 2. Cabe notar, que la mayoría de los usuarios sólo necesita una sintaxis y una semántica.
Ilustración 10: Estructura de OWL 2 (27)
La semántica directa asigna significado directamente a la estructura de la ontología, resultando en una semántica compatible con el modelo teórico semántico de lógica descriptiva SROIQ.
La semántica basada en RDF asigna significado directamente a los grafos RDF y así indirectamente a estructuras ontológicas vía el mapeado de grafos RDF.
23

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
OWL 1 Proporciona tres sublenguajes que van creciendo con respecto al nivel de expresión (28):
• OWL Lite, resulta útil para la creación de jerarquías y restricciones simples.
• OWL DL, es el lenguaje habitual de ontologías. Está basado en lógica descriptiva y proporciona la máxima capacidad de expresión que garantiza computabilidad y decidibilidad (todas las conclusiones pueden ser deducidas y todos los cálculos se realizan en un tiempo finito).
• OWL Full, permite expresividad de segundo orden, pero sin decidibilidad (no hay garantía computacional).
En OWL 2 se definen tres nuevos perfiles. Se proporcionan tres sublenguajes que ofrecen ventajas en escenarios particulares, todos más restrictivos que OWL DL y cada uno con diferentes aspectos expresivos a cambio de diferentes beneficios computacionales y/o de implementación:
• OWL 2 EL: Permite algoritmos de tiempo polinomial para todas las tareas de razonamiento estándar. Particularmente útil con grandes ontologías.
• OWL 2 QL: Permite consultas conjuntivas que se contestarán en LogSpace usando tecnología de bases de datos relacionales estándares. Particularmente útil para aplicaciones con ontologías relativamente ligeras y usadas para organizar un gran número de individuos y donde es útil o necesario acceder directamente a través de las consultas relacionales.
• OWL 2 RL: Permite la implementación de tiempo polinomial de algoritmos de razonamiento utilizando las tecnologías de bases de datos de reglas extendidas operando directamente en tripletas RDF. Particularmente útil para aplicaciones donde se usan ontologías relativamente ligeras que se usan para organizar grandes números de individuos y donde es útil o necesario la operación directa de los datos mediante tripletas RDF.
Se mantiene la compatibilidad con OWL 1, salvo algunos cambios en los nombres de bloques. Las ontologías de la versión 1 permanecen válidas en la dos.
La versión 2 añade nuevas funcionalidades que ofrecen nueva expresividad: claves, cadenas de propiedad, tipos de datos ricos, rangos de datos, restricciones de cardinalidad calificados, propiedades asimétricas, reflexivos y propiedades disjuntas y capacidades mejoradas de anotación (27).
24

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
En OWL las clases se construyen a partir de descripciones que especifican las condiciones que deben ser satisfechas para que un individuo sea miembro de la clase.
A continuación, en la ilustración 11 se puede observar un ejemplo de OWL 2.0 con sus diferentes formatos:
Ilustración 11: Ejemplo OWL 2.0 con diferentes sintaxis (29)
Entre las sintaxis utilizadas en OWL 2 se encuentra la Sintaxis Manchester, utilizada en Prótégé y TopBrais Composer, entre otros. Es una sintaxis compacta para ontologías de OWL 2. Está basada en frames, en oposición a las sintaxis basadas en axiomas. Se espera que haya herramientas que extiendan esta sintaxis y se colabore para extender el lenguaje común (30).
3.3. Herramientas utilizadas
En el proceso de aplicación de las tecnologías relacionadas con la Web Semántica, se pueden utilizar una serie de herramientas que facilitan la generación y testeo del material semántico generado como son editores, entornos de desarrollo, razonadores,
25

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
sistemas de almacenamiento, lenguajes de consulta, etc. A continuación se comentarán algunos de los más relevantes (31), (32).
3.3.1. Servicios Web Semánticos
Los servicios Web Semánticos proporcionan una nueva infraestructura para los Servicios Web al añadir la posibilidad de definir la semántica de los mismos. Con ello, se resuelven algunos aspectos que plantean los servicios web tradicionales, dando la opción de resolver de manera automática o semi-automática los problemas en el descubrimiento de los servicios web y las capacidades que presentan, siendo procesables por máquinas (28), (33).
Las ventajas que se obtienen con esta tecnología son:
• Buscadores basados en Web Semántica para Servicios Web.
• Ontologías descentralizadas y compartidas.
• Posibilidad de proporcionar un Servicio Web que realice deducciones lógicas de forma automática, y sea capaz de determinar si cumple el objetivo mediante inferencia lógica.
Para conseguir estos beneficios surge WSMO (Web Service Modeling Ontology, presentado a discusión ante el W3C), que proporciona un framework y un lenguaje formal para describir semánticamente todos los aspectos relevantes de los servicios web para facilitar el descubrimiento automático, combinación e invocación de servicios electrónicos a través de Internet. Proporciona un marco completo para la especificación, construcción y ejecución de servicios web semánticos. El proyecto está formado por tres líneas:
• WSML: definición del lenguaje o representación formal con F-logic.
• WSMO: ontología compuesta para WSML.
• WSMX: Implementación y entorno de ejecución.
Los elementos básicos que define WSMO para definir un Servicio Web Semántico son: ontologías, Servicios Web, Goals (metas de los usuarios respecto a la funcionalidad solicitada) y mediators (aquellos componentes que gestionan la interoperabilidad entre los elementos de WSMO).
26

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Para obtener información más detallada sobre cada una de estas tecnologías, puede consultarse (34).
3.3.2. Editores
Los editores de ontologías permiten automatizar y facilitar el desarrollo de ontologías mediante un entorno gráfico. Permiten al usuario manipular visualmente, inspeccionar, navegar, codificar ontologías, soportar el desarrollo de ontologías y tareas de mantenimiento. Entre los principales editores de ontologías aparecen (ver ilustración 12):
• Protégé, caracterizado por su escalabilidad y extensibilidad y por sus grandes capacidades gráficas que facilitan la edición de ontologías. Es de código abierto y gratuito.
• Swoop, con gran capacidad de resolver consultas SPARQL y con la capacidad de justificar las inferencias realizadas por su razonador (Pellet).
• OntoEdit, que además de representar gráficamente las ontologías, también permite almacenarlas y posteriormente manipularlas en una base de datos relacional.
• SemanticWorks, de ALTOVA es un editor gráfico de RDF/OWL para construir aplicaciones que permite una vista gráfica y una en modo textual. Permite exportar a RDF o a código de N-Triples.
Otros posibles editores de ontologías son: Apollo, OntoStudio, TopBraid Composer Free Edition, Ontolingua Server, WebOnto, WebODE, OilEd.
Ilustración 12: Editores de ontologías: Protégé, SWoop, Apollo
Se puede consultar un análisis comparativo de los editores en “Comparativa de editores de ontologías” en (35).
27

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
3.3.3. Razonadores
Un razonador es un programa software capaz de deducir las consecuencias lógicas de un conjunto de hechos o axiomas afirmados. Permite obtener nuevo conocimiento realizando inferencia a través de los conceptos y las instancias.
Para cada formalismo de representación del conocimiento existen diferentes técnicas de obtener nuevo conocimiento. Se utilizan principalmente tres en relación con el razonamiento de ontologías: razonamiento lógico de primer orden (LPO), razonamiento con lógica descriptiva (DL) y razonamiento con reglas. También hay ejemplos de razonadores probabilísticos.
Un motor de razonamiento con lógica descriptiva, dispone de dos mecanismos de entendimiento del conocimiento: TBox (caja terminológica) describiendo conceptos jerárquicos y ABox (caja de aserciones) describiendo instancias, indicando a dónde pertenecen los individuos en la jerarquía.
Los razonadores basados en lógica descriptiva deben poseer la suficiente expresividad para poder permitir que el conjunto de constructores que forman parte de los lenguajes de ontologías sean soportados y permitir ambos tipos de inferencia: de conceptos y de instancias.
Algunos de los principales razonadores son (36), (37):
• RACER: Permite la inferencia tanto en conceptos como en instancias, soporta ontologías escritas en RDF, RDFS, DAML y OWL y, posee un lenguaje sencillo para la inferencia de instancias. Puede ser usado por OilEd y por Protégé tanto para comprobar la consistencia de la ontología como para hacer consultas sobre el conocimiento.
• BOR: Soporta inferencias sobre instancias y sobre conceptos, chequeo de la consistencia y del modelo de la ontología, construcción de la jerarquía de conceptos y, clasificación de conceptos definidos. Soporta ontologías DAML+OIL y OWL Lite. Se puede incorporar en la aplicación Sesame.
• Pellet: Razonador de OWL basado en Java. Puede ser utilizado conjuntamente con bibliotecas del API de Jena o del OWL. Mediante su uso es posible validar, comprobar la consistencia de ontologías, clasificar la taxonomía y contestar a un subconjunto de consultas RDQL (conocido como consultas a ABox en terminología del DL). Soporta todas las construcciones del OWL DL.
28

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Otros razonadores existentes son: FaCT (Fast Classification of Terminologies), DamlJessKB, Cerebra y JTP (Java Theorem Prover), HermiT, Owlgres, OWLIM, Oracle Database 11g OWL Reasoner.
3.3.4. Sistemas de almacenamiento
Mediante los sistemas de almacenamiento es posible mantener las ontologías en bases de datos. Entre los más destacables aparecen:
• Sesame: Tiene funciones para añadir y eliminar información escrita en RDF en los repositorios, para ser almacenada en cualquier tipo de base de datos (MySQL, Oracle, etc). Soporta los lenguajes de consulta RQL, RDQL y SeRQL para acceder al conocimiento.
• KAON Tool: Permite almacenar las ontologías en cualquier base de datos o en fichero de texto e implementa un API para leer las descripciones de los recursos. Emplea RQL como lenguaje de consulta. Soporta ontologías DAML+OIL y RDF.
• JENA: Es una colección de herramientas entre las que incluye un parseador de RDF, un API de Java para diferentes lenguajes de ontologías (RDF, RDFS, OWL y DAML) y un subsistema de razonamiento. Soporta RDQL y SPARQL como lenguajes de consulta y diferentes bases de datos para almacenamiento como MySQL, Oracle y PostgreSQL.
Otras herramientas disponibles son: ICS-FORTH (Institute of Computer Science – Foundation for Research and Technology - Hellas), RDFSuite y RdfDB.
Por su parte, Oracle proporciona un conjunto de herramientas para almacenar información sobre datos semánticos y ontologías, así como para consultar los datos y editar ontologías de datos relacionales. Se puede consultar más información sobre el entorno en (38).
3.3.5. Lenguajes de reglas
Las reglas son de utilidad a los razonadores como métodos para inferir sobre el conocimiento en la capa lógica, obtener nueva información, y ser empleadas por los SW para especificar tareas. Entre los lenguajes de reglas más destacables se encuentran:
• RuleML: Es una iniciativa que trata de definir un lenguaje de hechos y reglas
29

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
semánticas que pueda ser utilizado en los diferentes sistemas de inferencia comerciales de reglas. En la primera especificación, se trató de abarcar todo tipo de reglas, pero al ser demasiado extenso se decidió por proporcionar una sintaxis que sólo permitiese especificar reglas de implicación y hechos.
• SWRL (Semantic Web Rule Language): En este lenguaje las inferencias se limitan a propiedades estructurales. Extiende ontologías OWL-Lite, OWL-DL y RuleML. La propuesta de SWRL es la de permitir definir reglas de Horn en una base de conocimiento OWL. El principal inconveniente es que es indecible al unirse con OWL.
SWRL se ha convertido en el lenguaje de reglas recomendado por la comunidad de Web Semántica. Actualmente se puede encontrar un editor de este lenguaje como plugin del editor de ontologías Protégé.
3.3.6. Lenguajes de consulta
Los lenguajes de consulta son aquellos que permiten extraer información a partir del conocimiento guardado en los sistemas de almacenamiento. Entre los más destacables aparecen:
• SPARQL (Simple Protocol and RDF Query Language): Es un lenguaje estandarizado por el W3C que permite extraer información de modelos RDF, utilizando una sintaxis derivada del SQL (Structured Query Language) para las bases de datos relacionales. Es muy rápido y permite obtener resultados de las búsquedas como grafos de RDF.
• RDQL (RDF Data Query Language): Creado para que fuese el lenguaje de consulta de Jena, por lo que la inferencia o razonamiento no es posible. Entre sus ventajas están la sencillez y la integración con Java.
• SeRQL (Sesame RDF Query Language): Lenguaje de consulta RDF y RDFS desarrollado para integrarse en Sesame. Este lenguaje presenta dos formas diferentes de lanzar las consultas, la devolución de tablas con los posibles valores que pueden tomar las variables y, devolviendo el resultado en la forma de subgrafo.
Otros lenguajes de consulta son: DQL (Daml Query Language), OWL-QL, RQL (RDF Query Language).
30

31
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
4. Utilización de la Web Semántica

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
El uso de la Web Semántica se debate entre el entusiasmo y el escepticismo. Desde que surgió en 1994, no ha conseguido implantarse de forma notoria, pero se ha comenzado el camino mediante el éxito de los RSS, microformatos, XBRL, etc.
Existen razones de peso para que los gobiernos fomenten la incorporación de la semántica en sus datos públicos como pueden ser: fomentar la investigación, acelerar la tasa de descubrimiento, acercar el conocimiento a la ciudadanía, facilitar las contribuciones externas, la interoperabilidad. Todo ello, promueve la reducción de costes, fomenta la participación, genera confianza y evita la aparición de datos alternativos no oficiales (39).
Sin embargo, el coste de la aplicación de la Web Semántica es alto: inserción de metadatos de los recursos existentes, mapeo de la estructura de bases de datos a ontologías, explotación de metadatos y creación de agentes, extracción automática de metadatos a partir del texto y recursos multimedia o facilitar la interoperabilidad.
Otro problema latente de la expansión de la Web Semántica es la consensuación de ontologías. Converger en una representación común del conocimiento es una tarea compleja ya que deben encontrarse puntos de acuerdo entre los distintos usos y visiones que se tienen en diversos campos sobre un mismo objeto. La solución propuesta es tomar ontologías comunes para el intercambio de información, y el establecimiento de compatibilidades mediante extensión y especialización de ontologías genéricas o bien por mapeo y exportación entre ontologías.
Además del coste de implantación, existe otro problema relacionado con el modelo de negocio establecido actualmente. Las empresas basadas en publicidad no apoyan el desarrollo de la Web Semántica ya que sus ingresos provienen precisamente de las visitas a los enlaces publicitarios que no se producirían en el caso de que el usuario fuese capaz de obtener los datos mediante procesos automáticos. Con lo que se necesita un nuevo marco empresarial que permita suplir ese descenso de la rentabilidad.
Con lo mencionado anteriormente, el principal impacto que ahora se analiza es en materia de transparencia y en el acceso a la información pública.
Ejemplos de los beneficios obtenidos al adoptarla son: informar al ciudadano y promocionar el uso de la información en diversas áreas como la educación o la investigación, encontrar respuestas mejores en las búsquedas y, mejorar el marketing dirigido al usuario utilizando indirectamente las preferencias de compra.
32

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
4.1. Situación actual
En cuanto a la situación del uso de las tecnologías relacionadas con la Web Semántica, se puede consultar el gráfico comparativo realizado por Tim Berners Lee entre la situación de 2003 y 2008 ( ilustración 13), donde ya se pone de manifiesto la promoción de tecnologías como RDF, OWL y la inferencia mediante SPARQL:
Ilustración 13: Onda semántica de Tim Berners Lee 2003-2008 (40).
En la siguiente imagen, se puede observar la representación gráfica de la situación del atributo de visibilidad del modelo de Rogers sobre difusión de innovaciones, que dibuja una curva que combina el factor temporal junto con la cantidad de usuarios que adoptan una tecnología, estableciéndose varias tipologías de usuarios que representan los ciclos de vida de la tecnología. En la ilustración 14 se muestra la percepción del W3C en la que se señala que las tecnologías semánticas aparecen aún en la fase ascendente de un mercado precoz.
33

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 14: Ubicación de la Web Semántica en el ciclo de vida de la adopción de tecnologías. Fuente: Adaptación de figura de Ivan Herman (2011) (41)
A continuación se comentaran algunas de las pruebas o repercusiones del intento de promover la etapa de los datos enlazados como son: el apoyo de particulares y organizaciones como W3C, el uso que empiezan a hacer las grandes compañías o el fomento por parte de las organizaciones gubernamentales.
4.2. Linked Data
Gracias a la evolución natural de la Web y con ayuda de figuras de referencia como Tim Berners-Lee, Miller, Health, Hendler o Bizer, se ha impulsado la Web Semántica para evolucionar el concepto inicial a un enfoque más práctico como son los datos enlazados (Linked Data) que permiten introducir el concepto de “Web de datos”.
El término Linked Data se refiere a un conjunto de buenas prácticas para la exposición, edición, compartición e interconexión de datos estructurados en la Web. El supuesto básico detrás de Linked Data es que el valor y la utilidad de los datos aumentan cuanto más se está interrelacionado con otros datos. En resumen, es simplemente el uso de la Web para crear vínculos con tipo entre los datos de diferentes fuentes (42).
La tendencia de Linked Data es utilizar RDF para la publicación de datos estructurados en la Web, y usar enlaces RDF para interconectar datos de diferentes fuentes.
Los principios básicos de los datos enlazados (introducidos por Tim Berners-Lee en Web Architecture (43)) son:
• Uso de URIs para nombrar a los recursos.
• Uso de HTTP URIs para que se puedan encontrar estos recursos.
• Proporcionar información útil acerca de los recursos cuando su URI está accesible, usando estándares (RDF, SPARQL).
34

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
• Incluir links a otros recursos, de forma que se puedan descubrir más recursos.
La publicación de los datos, debe ser un proceso progresivo, alcanzando las diferentes etapas de la escala definida por Tim-Berners-Lee, a medida que los datos son más accesibles y fáciles de usar. Los pasos serían (43):
• 1 estrella: disponible en la web pero sin licencia abierta.
• 2 estrellas: disponible como datos estructurados legibles por máquinas.
• 3 estrellas: disponible como en (2) pero en un formato no-propietario.
• 4 estrellas: disponible como el anterior, pero además usando estándares abiertos del W3C (RDF y SPARQL).
• 5 estrellas: disponible como el anterior, pero además con enlaces salientes a los datos de otras personas para proporcionar contexto.
El hecho de que la web de datos se base en estándares y en modelos de datos comunes, hace que sea posible implementar aplicaciones genéricas que operen sobre el espacio de datos. Entre ellos, destacan los navegadores que permiten visualizar los datos y seguir los enlaces para ir descubriendo nuevos datos, motores de búsqueda que permiten rastrear la web de datos y proporcionar la capacidad de hacer consultas en toda la web de datos.
Para publicar los recursos, éstos deben cumplir los principios de Linked Data y luego publicarlos normalmente en un servidor web. Para los documentos de texto, se les puede pasar un extractor que obtenga los enlaces RDF a otros recursos (44).
Los diferentes patrones de publicación de datos enlazados se pueden observar en la ilustración 15:
35

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 15: Opciones de publicación de datos enlazados. (44)
Los datos pueden publicarse como ficheros estáticos de RDF/XML, embebido en ficheros HTML, scripts personalizados del lado servidor con RDF y HTML, sirviendo datos enlazados desde bases de datos relacionales, almacenes de tripletas RDF o envolviendo las aplicaciones existentes o con APIs Web.
El consumo de los datos enlazados puede realizarse mediante aplicaciones generales como los buscadores o bien por aplicaciones específicas del dominio.
En el primer caso, se han desarrollado algunos motores de búsqueda para Linked Data que siguen enlaces RDF, y proporcionan capacidades de consulta sobre los datos agregados. Éstos, integran información de cientos de fuentes y así demuestran las ventajas de la arquitectura Linked Data (comparándola con la web 2.0 que sólo trataba con información fija de fuentes expuestas por sus propietarios). Algunos ejemplos son: Sig.ma, Falcons, SWSE o VisiNav que enfoca y responde consultas completas sobre datos Web. Estas aplicaciones tienen capacidades orientadas a los seres humanos, mientras que otras están más orientadas a los índices como Sindice, Swoogle y Watson que proporcionan APIs con las que las aplicaciones Linked Data pueden descubrir documentos RDF en la Web que referencia una determinada URI o que contiene ciertas palabras clave. Otra herramienta para ayudar a los desarrolladores a integrar datos es uberblic, que actúa como capa entre los publicadores y los consumidores.
En el caso de aplicaciones específicas, se deben considerar ciertos aspectos a la hora de crear una nueva aplicación que siga los principios de Linked Data. Las características
36

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
más básicas son:
• Partir de una URI que actúa como semilla inicial e ir descubriendo fuentes de datos siguiendo enlaces RDF.
• Descargar los datos desde la fuente de datos descubierta y almacenar la meta-información obtenida en un sistema de almacenamiento local de RDF.
• Recuperar la información para ser mostrada en la página web mediante un lenguaje de consulta (como puede ser SPARQL).
El estudio de algunos ejemplos de aplicaciones específicas dentro del dominio de tráfico se abordará en posteriores apartados.
4.2.1. Linking Open Data
Linking Open Data es un proyecto comunitario desarrollado por el grupo de la W3C encargado de divulgar y explicar la Web Semántica, con el objetivo de ampliar la Web con una base de datos común mediante la publicación en la Web de datos en RDF y mediante el establecimiento de enlaces RDF entre datos de diferentes fuentes (45).
Las actividades del proyecto Linking Open Data (LOD) del W3C, tienen como objetivo identificar los conjuntos de datos existentes bajo licencias abiertas, convertirlos en RDF de acuerdo a los principios de Linked Data, y publicarlos en la Web. Es un proyecto abierto para cualquiera que publique datos siguiendo la guía de metadatos de Linked Data de CKAN. Posteriormente el grupo de editores revisa las descripciones y se encarga de incorporar el conjunto de datos en el grupo lodcloud (46).
Los conjuntos de datos publicados han ido creciendo cada año y se pueden consultar en el catálogo LOD Cloud Data Catalog, que es mantenido por la comunidad LOD dentro del Comprehensive Knowledge Archive Network (CKAN). Si se añade un nuevo catálogo al listado, posteriormente se incluye en el diagrama (44).
El siguiente diagrama (ilustración 16) muestra los conjuntos de datos en la nube LOD así como sus relaciones en 2017. Cada nodo representa un conjunto de datos diferentes publicado en Linked Data y los arcos representan los enlaces RDF que existen entre los ítems de cada par de conjunto de datos relacionados. Como nota a la ilustración puede comentarse que el conjunto que aparece como nodo central es el perteneciente a DBpedia que es el referente a la abstracción semántica de la Wikipedia.
37

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 16: Linked Open Data cloud diagram (47)
En el portal web (48) se pueden consultar estadísticas sobre los datos publicados en los años 2011 y 2014 como los que se pueden observar en la siguiente ilustración que hacen referencia a la distribución de tripletas y de enlaces por dominio (ilustración 17):
38

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 17: Distribución de tripletas y enlaces por dominio del LOD
Pueden considerarse de interés, los vocabularios definidos en LOD (49) y (50) entre los que se pueden destacar los referentes a comunicación de incidencias (Vocabulary related to incident communication) y los referentes a información geográfica (como por ejemplo: OWL representation of ISO 19107 and 19115 (Geographic Information) ).
El funcionamiento de este esquema radica en que se analiza la fuente de solicitud de la petición de información recibida y en función de ésta, se devuelve una versión del documento adaptada al tipo de usuario: una página HTML en caso de ser un ser humano accediendo mediante un navegador y un documento RDF en caso de tratarse de un agente software (51).
39

40
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
5. Aplicación de la Web Semántica a los ITS

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Durante 2013, dentro del proyecto europeo T-TRANS, se realizó un estudio del estado del arte de las tecnologías relacionadas con los sistemas ITS (Intelligent Transport Systems), así como de las evaluaciones de los diferentes desarrollos hasta la fecha. En dicho proyecto queda de manifiesto la importancia de las tecnologías en el campo del transporte y el uso de ontologías como elemento que permite organizar los diferentes conceptos tecnológicos, propiedades y características. En el informe técnico (52) se comparan diversos estudios sobre semántica y el área y sub-área ITS abarcada en cada uno de ellos (ilustración 18) .
Ilustración 18: Estado del arte de la semántica en áreas y sub-áreas ITS (52)
41

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
En la tesis (5) se desarrolló desde cero una ontología de información de tráfico, y se definió una arquitectura basada en servicios Web semánticos que permitiera la interacción con la información contenida en el sistema. Se profundizó especialmente en el concepto de emparejamiento semántico, familia de algoritmos que consisten en la búsqueda de dos descripciones de servicios que comparten gran parte (o toda) su especificación. Otro concepto que interesante que apareció fue la determinación de profiles de publicación de los servicios Web semánticos. Estos profiles incluyen una descripción detallada de las capacidades de un servicio, facilitando el acceso a los clientes que quieran consumir la información del servicio.
En cuanto a las publicaciones que derivaron de la aparición de esta tesis destaca (53), artículo que explica la ontología de tráfico desarrollada en la tesis y la engloba en una arquitectura multiagente que permite el intercambio de información mediante servicios Web semánticos. Basándose en este artículo, en (54) se propone otra ontología de tráfico que introduce lógica difusa para la descripción de algunas variables lingüísticas habituales en tráfico. Un ejemplo que utilizan es la velocidad de un vehículo, en muchas ocasiones no es posible determinar la velocidad exacta del vehículo, o simplemente no es necesaria esta representación. Valores difusos como “rápido” o “lento” podrían ser suficientes para una gran cantidad de casos de uso. En el artículo se incluye esta información categórica en las tripletas RDF generadas que albergan la información de tráfico, y posteriormente acceden a estas bases de conocimiento mediante Sesame (55), un almacén de tripletas RDF de alto rendimiento.
Otra tesis enfocada en la aplicación de semántica a los ITS fue (56). En este trabajo se construyó otro sistema multiagente, esta vez más orientado a la gestión del tráfico, por lo que estaría ligeramente más alejado de los objetivos planteados. Sin embargo, se considera especialmente interesante la metodología aplicada para el modelado del dominio del tráfico interurbano y su posterior utilización en un entorno multiagente basado en la plataforma JADE (57).
42

43
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
6. Ejemplos de aplicación de Web Semántica relacionados con tráfico en carretera

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
En este apartado se ha tratado de recopilar algunos de los proyectos relacionados con la gestión del tráfico que puedan servir como referencia.
6.1. Reino Unido (data.gov.uk)
El principal ejemplo encontrado con información de tráfico es el proporcionado desde el apartado transporte de la iniciativa de datos gubernamentales del Reino Unido (58), que permite consultar la información sobre estaciones de tren, aeropuertos y paradas de autobús entre otros, mediante consultas SPARQL.
Por ejemplo para las estaciones de tren, se pueden lanzar las consultas mediante una interfaz similar a la de la ilustración, obteniendo el listado de las estaciones resultantes en diferentes formatos disponibles (ilustración 19):
Ilustración 19: Interfaz de consulta de estaciones en transport.data.gob.uk (58)
Desde data.gob.uk, también se puede acceder a información como los datos de tráfico, eventos planeados y no planeados en (59) pero esta vez en formato XML, siguiendo la estructura propuesta por DATEX II v1.0. El ejemplo de futuros eventos planificados puede consultarse en (60).
Otra información disponible son los datos relativos a los conteos de tráfico en una región, pero éstos sólo están disponibles en CSV o bien en PDF, sin integrar tampoco formatos RDF. Se pueden consultar desde (61).
44

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Estos ejemplos, son interesantes debido al tipo de información que publican, pero es necesario destacar que no se utilizan estándares de Web Semántica en la publicación de los datos, con lo que no se alcanzarían las 4 estrellas de la escala comentada en el apartado 4.2 Linked Data.
6.2. RSS de incidencias de tráfico
Algunas organizaciones han seleccionado el formato RSS para publicar las incidencias de tráfico, presentando la posibilidad de suscribirse a la información de tráfico de las diferentes carreteras. Ejemplos de ello pueden observarse en la Traffic Scotland, Highways Agency y Houston Transtar, entre otros para consultar las incidencias de Escocia, Inglaterra o Houston. En este caso, es necesario destacar que se emplea RSS como mecanismo para publicar los datos, pero no implica que la información a publicar tenga un formato especial, es decir no se exige que esté formateado en RDF (62), (63), (64).
6.3. Disponibilidad general de servicios semánticos
Datahub (ilustración 20) es una plataforma de gestión de datos potente y libre del Open Knowledge Foundation, basada en el sistema de gestión de datos CKAN. De forma generalizada, se puede consultar el listado de conjuntos de datos compartidos en Datahub en (65) y consultar el estado de los endpoints SPARQL desde (66).
Desde este enlace se pueden consultar los incidentes de tráfico del País Vasco o bien las publicaciones de la AEMET (Agencia Estatal de Meteorología), aunque estos últimos no están disponibles desde 2011 cuando el FTP de AEMET todavía era público. Del mismo modo que en ejemplos anteriores, estos datos pueden no incluir publicación en RDF y ofrecer sólo el formato XML, pero aun así son destacables por su contenido.
45

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 20: Algunos conjuntos de datos disponibles sobre tráfico en carretera (76).
6.4. Trabajos en universidades y centros de investigación
Pueden resultar de interés los estudios realizados en universidades y centros de investigación como (67):
• Prototipo de un sistema semántico de diagnosis para congestiones de tráfico en carretera desarrollado por IBM (68), donde se presenta un prototipo que analiza de forma semántica y mediante enfoques de inteligencia artificial el histórico de congestiones de tráfico para determinar las causas de situaciones inesperadas en casi tiempo real de la situación del tráfico en la ciudad de Dublín.
• Servicio semántico basado en ontologías para la cooperación de equipos urbanos, desarrollado en la Universidad de Sevilla (69). Se propone un mecanismo semántico que describe todos los aspectos relevantes de los servicios urbanos para facilitar la automatización del descubrimiento, combinando e invocando los servicios urbanos de plataformas distribuidas. Se realizan consultas mediante SPARQL para obtener
46

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
los datos de entrada en RDF/XML.
• Sistema de gestión de tráfico urbano basado en ontologías y sistemas multiagente, desarrollado en el Instituto de Automatización de la Academia de Ciencias de China (70). Se crea un framework donde la tecnología ontológica juega un papel importante en la unificación de los campos relacionados y con un gran potencial de aplicación. Se diseña una ontología de tráfico que incluye subontologías sobre tráfico urbano y sistemas de gestión: red de carreteras, entorno (uso o dedicación de los edificios), información de tráfico, señalización luminosa, vehículos, algoritmos de gestión de tráfico y medición de tiempo. Y se adapta una arquitectura de agentes dividida en tres niveles: organización global, coordinación regional, y ejecución local.
• La propuesta de una ontología para la información del tráfico en carretera basada en Web Semántica y el desarrollo de una herramienta para la descripción de servicios web semánticos partiendo de portales web existentes, estudio realizado por José Javier Samper de la Universidad de Valencia (32). Una vez construidas las diferentes subontologías de tráfico se fusionan en una ontología de conceptos de tráfico llamada (Traffic Ontology). Los diferentes subdominios que abarca se pueden observar en el siguiente diagrama (ilustración 21):
Ilustración 21: Subdominios de una ontología para datos de tráfico en carretera
47

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
• Evolución de DATEX II a un modelo semántico, estudio realizado por David Torres de la Universidad de Valencia (71). En este trabajo se construye una ontología de tráfico basada en DATEX II (ver ilustraciones 22 y 23), estableciendo de esta forma una base para abordar la problemática de la gestión de información de tráfico. Por otra parte, se diseña una plataforma de publicación de información semántica basada en perfiles de usuarios, que tiene como idea fundamental la expresión de preferencias de usuarios para adecuar la extracción de información a las necesidades de cada perfil. De esta forma cada usuario obtiene una vista personalizada de la información del sistema, mejorando el rendimiento que obtiene del mismo.
Ilustración 22: Jerarquía para la clase general Situation (3 niveles)48

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Ilustración 23: Datos semánticos (RDF) basados en el estándar DATEX2
• Propuesta de un entorno basado en ontologías para la asignación de riesgo de accidentes de tráfico en carretera, desarrollado en la Universidad de Calgary, Canadá (72). En la ontología se representa el conocimiento espacial y no espacial acerca de los accidentes, y devuelve el conjunto de datos más adecuado según los objetivos del usuario (ilustración 24).
Ilustración 24: Esquema de un entorno basado en ontologías para la asignación de riesgo de accidentes
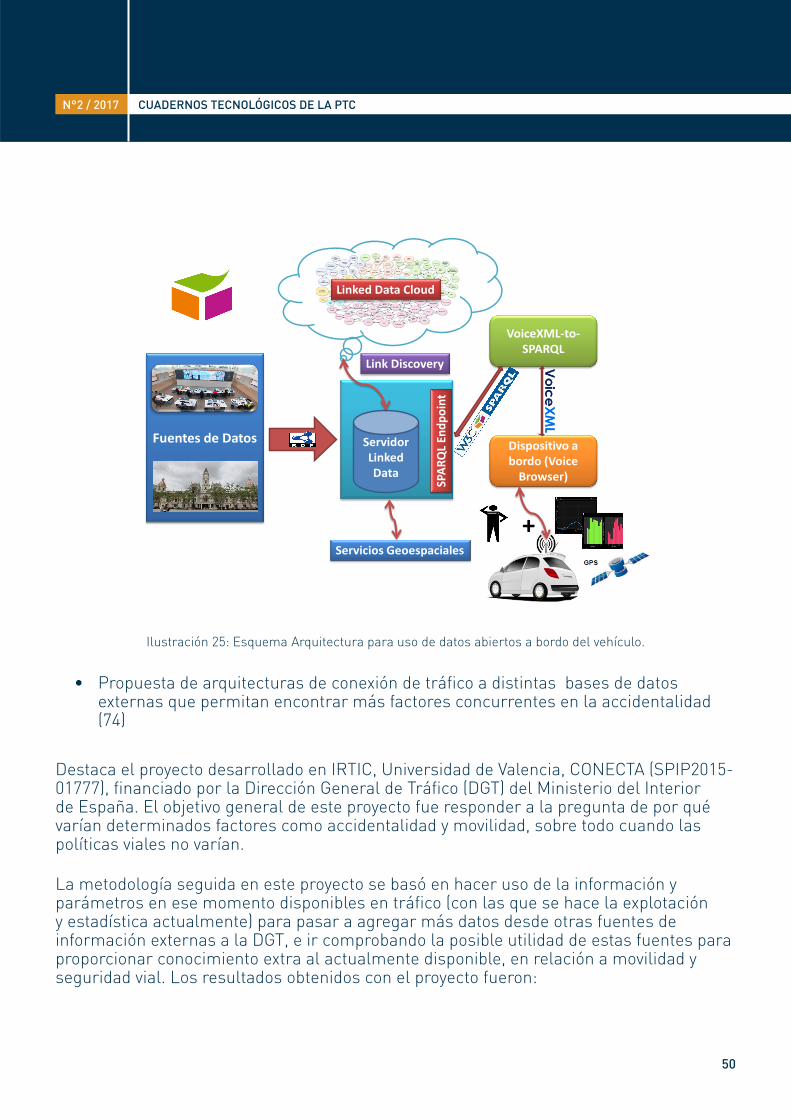
• Propuesta de arquitecturas para uso de LOD en sistemas a bordo de vehículos.
La integración de información del vehículo y la propia del usuario, hacen posible la obtención de información más precisa desde la red de información abierta que hoy en día inunda nuestro entorno. Aspectos como la geolocalización, enriquecimiento de datos, reconocimiento de voz, conversión de texto al habla, datos abiertos y plataformas abiertas para la obtención de datos dinámicos del vehículo son tecnologías algunas de ellas emergentes y otras de amplio uso pero no como una solución integrada. En este sentido, en (73) se propone una arquitectura de integración que puede ser vista en la ilustración 25.
49
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Fuentes de Datos Servidor LinkedData
VoiceXML-to-SPARQL
Dispositivo a bordo (Voice
Browser)
Linked Data Cloud
SPAR
QL E
ndpo
int
Link Discovery
+Servicios Geoespaciales
Ilustración 25: Esquema Arquitectura para uso de datos abiertos a bordo del vehículo.
• Propuesta de arquitecturas de conexión de tráfico a distintas bases de datos externas que permitan encontrar más factores concurrentes en la accidentalidad (74)
Destaca el proyecto desarrollado en IRTIC, Universidad de Valencia, CONECTA (SPIP2015-01777), financiado por la Dirección General de Tráfico (DGT) del Ministerio del Interior de España. El objetivo general de este proyecto fue responder a la pregunta de por qué varían determinados factores como accidentalidad y movilidad, sobre todo cuando las políticas viales no varían.
La metodología seguida en este proyecto se basó en hacer uso de la información y parámetros en ese momento disponibles en tráfico (con las que se hace la explotación y estadística actualmente) para pasar a agregar más datos desde otras fuentes de información externas a la DGT, e ir comprobando la posible utilidad de estas fuentes para proporcionar conocimiento extra al actualmente disponible, en relación a movilidad y seguridad vial. Los resultados obtenidos con el proyecto fueron:
50

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
• Una propuesta de arquitectura de sistemas abiertos y enlazados externos a los que se debería conectar la DGT para mejorar su explotación y entendimiento de lo que ocurre en las carreteras españolas.
• Un plan de despliegue para llevar a cabo dicha conexiones incluyendo no solamente las comunicaciones sino la metodología que permita relacionar las bases de datos internas con las externas nuevas a las que se conectará.
Para la realización del proyecto CONECTA se tuvieron en cuenta bases de datos “internas” de la DGT de las cuales se obtuvo un listado de parámetros usados que a su vez permitieron poder ser enlazados con las otras bases de datos “externas”. Entre las fuentes externas analizadas destacan las siguientes:
• Ministerio de Fomento (incluyendo información de transporte público, infraestructuras de transportes, obras públicas en la carretera, vialidad de túneles o puertos de montaña).
• INE (Instituto Nacional de Estadística) que recopila información variada que incluye factores macroeconómicos y microeconómicos del país como precios de combustibles, densidades de población o mejoras situación económica.
• Ministerio de Industria que dispone de información relativa a Inspecciones Técnicas de Vehículos (ITV).
• Información meteorológica de la agencia pública AEMET.
En las ilustraciones 26 y 27 podemos observar la consulta y resultado respectivamente de información sobre información enlazada.
Ilustración 26: Posible Consulta sobre accidentes en el proyecto CONECTA.
51

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
ACCIDEN T LO CATIO N DATE PRO PERTY V ALUE
Ilustración 27: Resultado de una consulta previa sobre tráfico.
El proyecto CONECTA, permitió demostrar que enlazar bases de datos diferentes y aparentemente sin relación, puede permitir una mejor explicación de comportamientos o situaciones, como por ejemplo, averiguar el motivo del aumento del tráfico y los accidentes cuando se mejora la situación económica o se produce por ejemplo un cambio horario.
• Uso de Ontologías para el control de mercancías.
En (53) se describe un proyecto de investigación (Ref. TRA2004-06276 / MODAL) cuyo objetivo principal fue el desarrollo de ontologías que permitieran el intercambio automático de información entre dispositivos instalados en el interior camiones y cualquier dispositivo externo que pudiera pertenecer a cualquier administración u organismo oficial. Mediante este sistema de intercambio de información semántica, un vehículo podría registrar su carga inicial en el origen así como cualquier cambio
52

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
que la carga pudiera sufrir después, y que este registro fuera conocido a lo largo de su trayectoria por cualquier organismo que lo solicitase de forma totalmente transparente para el conductor del vehículo. Este proyecto permitió realizar varias ontologías en el dominio de transporte. Las más importantes:
• Ontología referente a la legislación que afecta al tipo de transporte por carretera
• Ontología referente a los diferentes tipos de carga que puede transportar un camión (Ilustración 28).
• Ontología referente a los diferentes tipos de camiones
Ilustración 28: Ontología sobre diferentes tipos de carga.
53

54
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
7. Situación actual de la diseminación de tráfico en España y posibles acciones

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Actualmente, la mayoría de datos publicados en las diferentes administraciones de tráfico no son datos en formato semántico, por lo que habría que realizar un proceso de transformación.
Los pasos a seguir en la implantación serían los siguientes:
1. Selección de los datos implicados.
La primera tarea imprescindible es la selección del conjunto de datos que se desea hacer accesible mediante Web Semántica. Entre la información que puede considerarse como sensible de ser publicada bajo los formatos de la Web Semántica se encontrarían: los listados de sucesos activos, la información recopilada de los equipos de tráfico en carretera como pueden ser las imágenes obtenidas de las cámaras de tráfico, la posición de los cinemómetros, los datos tomados desde las estaciones meteorológicas, los detectores, etcétera, así como cualquier otro dato de interés susceptible de ser explotado posteriormente por los usuarios. Actualmente, la mayoría de estos datos son accesibles vía web y en formato XML.
2. Publicación del conjunto de datos seleccionado en formato RDF.
El enfoque práctico que se tiene actualmente de la Web Semántica consiste en la publicación de datos enlazados y el objetivo final es alcanzar el nivel más alto de la escala de accesibilidad de los datos planteada en el apartado 4.2 que consiste en publicar los datos en formatos abiertos y estándares del W3C, con enlaces salientes a otros datos.
En este caso se recomienda alcanzar la etapa de 4 estrellas, que consiste en publicar los datos con formato RDF y accesible mediante SPARQL, dejando para más adelante el enlazado con datos externos.
Las administraciones de tráfico como la DGT son entidades públicas que debe ajustarse a normativas. Esto permite que los datos enlazados puedan ser recogidos por el Catálogo de Información Pública de la Administración General del Estado y por tanto publicados y disponibles en el portal datos.gob.es.
Merece en este punto, especial atención, el hecho de que en el año 2010 la Unión Europea creó una directiva para promover el desarrollo y el despliegue de los sistemas ITS (Intelligent Transport Systems) en Europa (75). Esta directiva (muy general) se complementó con la creación posterior (años 2013 y 2015) de un conjunto de prioridades reguladas a través de reglamentos delegados que establecen las especificaciones necesarias para garantizar la compatibilidad, interoperabilidad y continuidad de la
55

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
implantación y de la utilización operativa de los datos y procedimientos para facilitar, cuando sea posible, de información referente al tráfico. A su vez, también establecia la obligación de crear Puntos de Acceso Nacionales (PAN) con información que permita la reutilización de datos (tanto públicos como privados) disponibles en cada país para el desarrollo de posibles mercados. Cabe mencionar que el uso de una plataforma de datos abiertos como pueda ser CKAN se ajusta enormemente a los requerimientos exigidos. Permitirá publicar y administrar colecciones de datos con muy pocos recursos y, una vez publicados, los usuarios podrán explorarlos e incluso pre-visualizarlos a través de mapas, gráficas y tablas. Como pasos previos a la publicación, habría que establecer las condiciones de uso, adopción de licencias y preparación de los datos (formatos, metadatos). Para ello, habrá que tener en cuenta la “Norma Técnica de Interoperabilidad de Reutilización de Recursos de la Información en España” (NTI) (76) ya que es la normativa nacional de referencia a la hora de garantizar la interoperabilidad y facilidad de uso de los datos que publicamos para su reutilización y permitir la federación de los datos de nuestra plataforma con el catálogo nacional de datos “datos.gob.es” y posteriormente en el portal de la Unión Europea de Datos, “europeandataportal.eu”. La publicación de datos enlazados en categoría 5 (77) haría posible implementar de forma complementaria un servicio SPARQL endpoint (78) que permitiría a los usuarios consultar los datos (ver ilustración 29) (74).
CKAN SistemaGestorde Datos
Servidor Virtuoso Datos enlazados
SPARQL endpoint
Usuario / ClienteAdministrador
Ilustración 29: Arquitectura de PAN con datos abiertos. Adaptación de (79)
3. Selección de vocabularios a utilizar.
Uno de los factores importantes en el acceso y compartición de información es el hecho de consensuar los vocabularios utilizados. En el caso de que sea posible, se deben emplear vocabularios ya existentes y validados que permitan mejorar el intercambio de
56

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
información entre usuarios.
Dada la naturaleza de los datos a tratar, en este caso resulta interesante incorporar un vocabulario regulado para especificar la información referente a la localización, de forma que resulte sencilla la explotación posterior de los datos mediante criterios geográficos.
Del mismo modo, se debe intentar incorporar vocabularios que permitan la amplia difusión de los datos por su carácter referente al tráfico y más concretamente para la gestión de incidencias y para la comunicación de datos provenientes de cámaras y radares.
En particular, se recomienda realizar un análisis detallado de las relaciones entre los datos y sus restricciones y realizar un estudio de aplicabilidad de los vocabularios OWL representation of ISO 19107 and 19115 Geographic Information en relación a la expresión de la información geográfica, Vocabulary related to incident communication en referencia a la comunicación de incidencias, Traffic Ontology como base para expresar la información relacionada con incidencias de tráfico y, la ontología basada en DATEX II para la comunicación de incidencias en formato DATEX II (49), (32), (71).
Para la expresión de la información de cámaras y radares, se recomienda buscar más exhaustivamente la existencia de un vocabulario que pueda ajustarse a las necesidades o bien diseñar uno nuevo que sea capaz de representar el conocimiento asociado, partiendo de los anteriormente comentados.
Se propone centrar la atención en primer lugar en la aplicación de un vocabulario que permita expresar la localización y permita extraer el máximo partido de la información geográfica, y otorgar menor relevancia a la inclusión de vocabularios complejos que permitan poner de manifiesto la información más específica de las incidencias de tráfico, ya que ésta puede resultar más complicada de cruzar con otra información que comparta el mismo vocabulario.
4. Explotación de los datos.
A partir de disponer de la información dotada de contenido semántico pública en la Web, los diferentes usuarios externos pueden comenzar a explotar la información.
Para ello, pueden simplemente utilizar el lenguaje de consultas seleccionado (se recomienda utilizar SPARQL que es el estandarizado por el W3C). Algunos ejemplos de consultas directas sobre el conjunto de datos que podría lanzar un usuario serían:
57

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
• ¿Hay una retención en el punto concreto en el que me encuentro?
• ¿Hay incidencias en la ruta habitual de vuelta a casa?
• ¿Cuál es la imagen asociada a la cámara de la A-3, pk 6.8?
• ¿Cuál es la imagen asociada a la cámara más cercana al punto en el que me encuentro?
Es interesante notar que en un tratamiento tradicional de la información, en el que la información estuviera publicada en formato XML, sería necesario parsear cada uno de los documentos implicados para consultar la información e implementar el consiguiente modelo y sistema de información que realice el cruce de datos solicitado. Mediante las consultas semánticas, es posible abstraerse de estos pasos, ya que el estándar facilita un entorno común y herramientas para que simplemente sea necesario centrarse en especificar la consulta SPARQL.
Por ejemplo, para realizar una consulta sobre incidencias que abarque toda España, sólo es necesario incluir en el FROM de la consulta los distintos orígenes de datos: DGT, País Vasco, Servei Català de Trànsit y Abertis. Incluso si en algún momento se publican incidencias desde los ayuntamientos, sólo sería necesario incorporarlos en el listado del FROM. Sin embargo, en caso de no usar consultas semánticas, sería imprescindible la integración previa de las nuevas fuentes en el sistema por separado para poder realizar la consulta.
Como anotación al uso de vocabularios, se debe destacar la ventaja que se adquiere con su uso ya que se permite aplicar reglas avanzadas y restricciones fuertes para la catalogación automática de los datos. La idea principal es que se pueden establecer condiciones que al cumplirse aplican una categoría al objeto desde la definición de la propia ontología. De esta manera, se pueden lanzar consultas sobre esta categoría aplicada, directamente sin tener que realizar los cálculos para cada objeto de forma explícita. Este es un mecanismo que puede utilizarse para asegurar en cierta medida la calidad o fiabilidad de los datos.
Por ejemplo, se puede incluir una condición que indique si un tramo de carretera es válido sólo si su velocidad máxima no es negativa. Después, se puede lanzar una consulta que pregunte directamente sobre los tramos válidos, sin tener que realizar la comprobación del atributo velocidad para cada objeto. Otro ejemplo en el que puede resultar óptima su utilización es para validar características de las incidencias meteorológicas, como controlar que no puede existir un riesgo de nevada en caso de que se reciba una temperatura superior a 25 0C.
58

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Para obtener más conocimiento adicional, se puede hacer uso de las relaciones entre diferentes sistemas terminológicos, es decir, entre distintos subdominios. De este modo, un intermediario podría cruzar la información con datos publicados por otras fuentes, y posteriormente publicar un servicio disponible en la Web, que permitiría consultar nueva información relacionada. Ejemplos de este tipo pueden obtenerse mediante los datos publicados en datos.gob.es y la posible información publicada por las diferentes administraciones de tráfico y podrían ser:
• Cruzando los datos de incidencias de tráfico, con la información de la evolución meteorológica a lo largo del día actual facilitada por la AEMET (Agencia Estatal de Meteorología), se podría obtener conocimiento sobre:
§Si existen incidencias en las zonas en las que se espera niebla intensa.
• Cruzando información geográfica entre las incidencias de tráfico y las zonas de aparcamiento disponibles, se podría ofrecer un servicio que permitiera:
§Indicar a los camioneros zonas de aparcamiento disponibles en las áreas en las que se localicen retenciones.
• Cruzando la información geográfica entre las incidencias de tráfico y las gasolineras o los puntos de recarga del vehículo eléctrico para permitir consultar:
§Cuál es la gasolinera o punto de recarga más cercana antes de quedar inmovili-zado en la cola de una retención.
• Cruzando la información geográfica entre las incidencias de tráfico y diversos conjuntos de datos que proporcionan la situación de diversos servicios, para permitir consultar:
§Qué aparcamientos, aparcamientos para motos, áreas recreativas, alojamientos, empresas de alquiler de coches, bancos y cajeros están cercanos en caso de cierre de un puerto de montaña que impida el paso a largo plazo.
Otra alternativa de explotación de datos más avanzada, conlleva que los usuarios, como pueden ser empresas de terceros del sector transporte o bien publicadores de información de tráfico, desarrollen su propia aplicación de carácter específico, creando su propio conjunto de consultas SPARQL, por ejemplo cruzando los datos facilitados con otros de su propiedad.
En ambos casos, se puede hacer uso de agentes que permitan ejecutar consultas más complejas o bien embeber las consultas en aplicaciones ya existentes mediante APIs de integración.
59

60
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
8. Conclusiones

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
Después de revisar el estado de desarrollo actual del campo de la Web Semántica, así como el impulso llevado a cabo tanto de las organizaciones gubernamentales como desde empresas del ámbito privado, se deduce que uno de los pasos más relevantes y a su vez más costosos es la obtención de material con capacidad semántica.
El paso fundamental para la obtención de los beneficios que puede aportar la Web Semántica es el de publicar información acompañando a los datos de sus correspondientes metadatos, seleccionando la tecnología adecuada entre las analizadas en apartados anteriores. Por tanto es recomendable publicar información sobre incidencias de tráfico, cámaras, radares etc. en RDF, formato estándar de W3C.
Otro de los pasos importantes a seguir es la selección del vocabulario a utilizar para permitir la el consenso de ontologías entre los diferentes ámbitos de uso y facilitar de esta forma el intercambio de información, evitando uno de los grandes impedimentos de difusión de la Web Semántica. En el caso de los datos seleccionados para la publicación, toma especial interés emplear bien una ontología que permita posteriormente explotar en profundidad la información referente a la localización geográfica de los datos.
Con el esfuerzo de publicar información en formatos semánticos, se abre el camino para la explotación de los datos con carácter semántico (se recomienda mediante consultas SPARQL) tanto por parte del responsable de la publicación como por terceras empresas, que a su vez pueden cruzar esta información con la disponible en otros orígenes de datos.
El objetivo a perseguir debería consistir en lograr que esta infraestructura se realimente, al conseguir que los usuarios externos publiquen a su vez los nuevos resultados con formatos semánticos, potenciando de esta forma seguir fomentando la expansión de la Web Semántica.
61

62
N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
9. Bibliografía

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
1. Sowa, J. F. “Knowledge Representation: Logical, Philosophical, and Computational Foundations”. Brooks/Cole, 2000. Pacific Grove, CA : Brooks Cole Publishing Co., 2000. pág. 594. 0-534-94965-7.
2. Randall Davis, Howard Shrobe, Peter Szolovits “What Is a Knowledge?”. Association for the Advancement of Artificial Intelligence, 1993, AI Magazine , Vol. 14. Nº1 https://doi.org/10.1609/aimag.v14i1.1029 .
3. Brewster and K. O’Hara, “Knowledge representation with ontologies: the present and future,” in IEEE Intelligent Systems, vol. 19, no. 1, pp. 72-81, Jan-Feb 2004. doi: 10.1109/MIS.2004.1265889.
4. Christopher Brewster, Kieron O’Hara. “Knowledge Representation with ontologies: Present challenges— Future possibilities”. 7, 2007, International Journal of Human- Computer Studies, ISSN 1071-5819. Vol. 65, pp. 563-568. https://doi.org/10.1016/j.ijhcs.2007.04.003.
5. Samper Zapater, José Javier. “Ontologías para servicios web semánticos de información de tráfico: descripción y herramientas de explotación”. [En línea] 2005. http://www.tdx.cat/bitstream/handle/10803/10000/SAMPER.pdf?sequence=1.
6. Thomas R. Gruber “A translation approach to portable ontology specifications”. 1993, Knowledge Acquisition Journal, Vol. 5, ISSN 1042-8143. pp. 199-200. https://doi.org/10.1006/ knac.1993.1008.
7. Méndez Rodriguez, Eva Mª. “El ciclo del conocimiento en el entorno académico.” [En línea] https://es.slideshare.net/HernnCapchaCarbajal/web-semantica-y-bibliotecas-digitales-jbdu-eva-mndez.
8. Tim Berners-Lee, James Hendler & Ora Lassila,”The Semantic Web”.Scientific American (May 17, 2001).
9. Lamarca Lapuente, María Jesús. “Hacia la Web Semántica”. [En línea] http://www. hipertexto.info/documentos/web_semantica.htm.
10. Eduardo Peis, Enrique Herrera-Viedna, José M. Morales-del-Castillo. “Aproximación a la Web Semántica desde la perspectiva de la Documentación”. [En línea] http://www. scielo.org.mx/scielo.php?pid=S0187-358X2007000200003&script=sci_arttext.
11. Paredes Moreno, Antonio. “Introducción a las Ontologías en la Web Semántica”. [En línea] http://personal.us.es/aparedes/ws.pdf.
12. Mariano Fernández, A. G. “METHONTOLOGY: From Ontological Towards Ontological Engineering”. Madrid : s.n., 1997. AAAI Technical Report . SS-97-06.
13. Jorge Calmon de Almeida Biolchini, Paula Gomes Mian, Ana Candida Cruz Natali, Tayana Uchôa Conte, Guilherme Horta Travassos, “Scientific research ontology
63

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
to support systematic review in software engineering”, Advanced Engineering Informatics, Volume 21, Issue 2, 2007, Pages 133-151, ISSN 1474-0346, https://doi.org/10.1016/j.aei.2006.11.006.
14. M. B. Sarder and S. Ferreira, “Developing Systems Engineering Ontologies,” 2007 IEEE International Conference on System of Systems Engineering, San Antonio, TX, 2007, pp. 1-6. doi: 10.1109/SYSOSE.2007.4304237
15. J. Sarraipa, J. P. M. A. Silva, R. Jardim-Goncalves and A. A. C. Monteiro, “MENTOR — A methodology for enterprise reference ontology development,” 2008 4th International IEEE Conference Intelligent Systems, Varna, 2008, pp. 6-32-6-40. doi: 10.1109/IS.2008.4670436.
16. Antonio De Nicola, Michele Missikoff, Roberto Navigli. “A software engineering approach to ontology Building”. s.l.: Elsevier, 2009, Information Systems , Vol. 34, pp. 258-275. https://doi.org/10.1016/j.is.2008.07.002.
17. D. Gasevic, D. Djuric, V. Devedzic and V. Damjanovic. “From UML to ready-to-use OWL ontologies”. Proceedings. 2004. 2nd International IEEE Conference, 2004. Vol. 2, pp. 485-490. doi: 10.1109/IS.2004.1344798.
18. Stephen Cranefield, Jin Pan. “Bridging the gap between the model-driven architecture and ontology engineering”. International Journal of Human-Computer Studies, ISSN 1071-5819 Vol. 65, pp. 595-609. https://doi.org/10.1016/j.ijhcs.2007.03.001.
19. P. Wongthongtham, D. Dillon, T. Dillon and E. Chang, “Use of UML 2.1 to Model Multi-Agent Systems based on a Goal-driven Software Engineering Ontology,” 2008 Fourth International Conference on Semantics, Knowledge and Grid, Beijing, 2008, pp. 428-432. doi: 10.1109/SKG.2008.45.
20. Manuel Noguera, María V. Hurtado, María Luisa Rodríguez, Lawrence Chung, José Luis Garrido. “Ontology-driven analysis of UML-based collaborative processes using OWL-DL and CPN”. 2010, Science of Computer Programming, Vol. 75, Issue 8, pp. 726- 760. https://doi.org/10.1016/j.scico.2009.05.002.. 0167-6423.
21. Noy, Natalya F. and McGuinness, Deborah L. Ontology Development 101: “A Guide to Creating Your First Ontology”. (2001).
22. W3C. RDF Current Status. [En línea] http://www.w3.org/standards/techs/rdf#w3c_all.
23. W3C Working Group. RDF 1.1 Primer. [En línea] http://www.w3.org/TR/rdf11-primer/.
24. W3C. RDF Schema 1.1. [En línea] http://www.w3.org/TR/2014/REC-rdf-schema-20140225/.
64

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
25. Labra Gayo, Jose Emilio. “Ontologías y Web Semántica”. [En línea] http://www. slideshare.net/jelabra/25-ontologias-27781099.
26. Barrón Cedeño, Alberto. “Ontologías 2“. [En línea] http://www.matem.unam.mx/ rajsbaum/cursos/web/ontologias2.pdf.
27. W3C. OWL 2 Web Ontology Language. [En línea] http://www.w3.org/TR/owl2-overview/.
28. Márquez Solís, Santiago. “La Web Semántica”. [En línea] https://books.google.es/books?isbn=184753192X
29. Web Ontology Language. [En línea] http://en.wikipedia.org/wiki/Web_Ontology_ Language.
30. W3C. OWL 2 “Web Ontology Language Manchester Syntax”. [En línea] http://www. w3.org/TR/2012/NOTE-owl2-manchester-syntax-20121211/.
31. Ziouziou, Mouna. “Desarrollo de una ontología y de un sistema de recuperación de la información para el sector del mueble y afines”. [En línea] http://robotica. uv.es/~jsamper/Mouna.pdf.
32. Samper Zapater, José Javier. “Ontologías para servicios web semánticos de información de tráfico: descripción y herramientas de explotación”. [En línea] http:// www.tdx.cat/bitstream/handle/10803/10000/SAMPER.pdf?sequence=1.
33. Rebollo Pedruelo, Miguel. “Servicios Web Semánticos”. [En línea] http://www. slideshare.net/mrebollo/serviciosweb.
34. W3C. Web Service Modeling Ontology (WSMO). [En línea] http://www.w3.org/ Submission/WSMO/.
35. Salem Alatrish, Emhimed. Comparison of Ontology Editors. [En línea] http://joc.raf. edu.rs/4/_k_0020.pdf.
36. Centrodeartigos. Lista de los razonadores semánticos. [En línea] http:// centrodeartigos.com/revista-digital-webidea/articulo-revista-2765.html.
37. W3C. OWL/Implementations. [En línea] http://www.w3.org/2001/sw/wiki/OWL/ Implementations.
38. Oracle. Oracle Database Semantic Technologies Overview. [En línea] http://docs. oracle.com/cd/E11882_01/appdev.112/e25609/sdo_rdf_concepts.htm#RDFRM100.
39. Labra Gayo, Jose Emilio. “Caminando hacia la Web Semántica: Datos abiertos enlazados”. [En línea] http://www.slideshare.net/jelabra/datos-abiertos-enlazados.
40. Herman, Ivan, W3C. “Semantic Web Adoption and Applications”. [En línea] http://
65

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
www. w3.org/People/Ivan/CorePresentations/Applications/Applications.pdf.
41. Tomás Saorín, Fernanda Peset, Antonia Ferrer-Sapena. “Factores para la adopción de linked data e implantación de la Web Semántica en bibliotecas, archivos y museus”. [En línea] http://www.informationr.net/ir/18-1/paper570.html#.U2d5avl47uP.
42. Chris Bizer, Richard Cyganiak, Tom Health. “How to Publish Linked Data on the Web”. [En línea] http://wifo5-03.informatik.uni-mannheim.de/bizer/pub/LinkedDataTutorial/.
43. Berners Lee, Tim. Linked Data. [En línea] http://www.w3.org/DesignIssues/ LinkedData.html.
44. Tom Health, Christian Bizer. “Linked Data: Evolving the Web into a Global Data Space”. [En línea] http://linkeddatabook.com/editions/1.0/.
45. W3C. Linking Open Data. [En línea] http://www.w3.org/wiki/SweoIG/TaskForces/ CommunityProjects/LinkingOpenData.
46. Linking Open Data Cloud. [En línea] http://datahub.io/group/about/lodcloud.
47. Linking Open Data community. The Linking Open Data cloud diagram. [En línea] http://lod-cloud.net/.
48. Anja Jentzch, Richard Cyganiak, Chris Bizer. State of the LOD Cloud. [En línea] http:// lod-cloud.net/state/.
49. Vanderbussche, Pierre-Yves. Linked Open Vocabularies. [En línea] http://lov.okfn.org/ dataset/lov/.
50. W3C. Common Vocabularies / Ontologies / Micromodels. [En línea] http://www.w3.org/wiki/TaskForces/CommunityProjects/LinkingOpenData/CommonVocabularies.
51. R. Míguez Pérez, J.M. Santos Gago, V.M. Alonso Rorís, L.M.Álvarez Sabucedo, F.A. Mikic Fonte. “Linked Data como herramienta en el ámbito de la nutrición”. [En línea] http://scielo.isciii.es/scielo.php?script=sci_arttext&pid=S0212-16112012000200001.
52. Enhancing the transfer of ITS innovations to the market. Deliverable 3.1 – ITS state of the art assessment. T-TRANS project Seventh Framework Programme. s.l. : Susanne Kellberger (Fraunhofer CML), 2013. pág. 147, Informe Técnico. The technology map states and assesses the ITS developments in general and defines the technological scope of the T-TRANS project.. Project Reference Nº 314263.
53. J. J. Samper, V. R. Tomas, J. J. Martinez and L. van den Berg. “An ontological infrastructure for traveller information Systems”. Toronto, Ont. : s.n., 2006. 2006
66

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
IEEE Intelligent Transportation Systems Conference. pp. 1197-1202. doi: 10.1109/ ITSC.2006.1707385.
54. Web. J. Zhai, Y. Yu, Y. Liang and J. Jiang. “Traffic Information Retrieval Based on Fuzzy Ontology and RDF on the Semantic”. 2008. IITA ‘08. Second International Symposium on Intelligent Information Technology Application . pp.779-784. doi: 10.1109/IITA.2008.401.
55. W3C Semantic Web. Sesame. [En línea] https:// www.w3.org/2001/sw/wiki/Sesame.
56. Tomás López, V. R. “Tácticas mixtas para la negociación automática de múltiples servicios con información incompleta en entornos multiagente. Aplicación a problemas de gestión de tráfico”. 2006. Tesis Doctoral.
57. JAVA Agent DEvelopment Framework. [En línea] http://jade.tilab.com.
58. transport.data.gov.uk. [En línea] http://transport.data.gov.uk/.
59. Live traffic information from the Highways Agency. [En línea] http://data.gov.uk/ dataset/live-traffic-information-from-the-highways-agency-road-network.
60. Future Planned England. [En línea] http://hatrafficinfo.dft.gov.uk/feeds/datex/ England/ FuturePlanned/content.xml.
61. Traffic count UK. [En línea] http://www.dft.gov.uk/traffic-counts/area.php.
62. Traffic Scotland. [En línea] http://trafficscotland.org/rss/.
63. Highways Agency. [En línea] http://www.highways.gov.uk/news/connect/rss-feeds/ traffic-information-rss-feeds/.
64. Houston Transtar RSS Feeds. [En línea] http://traffic.houstontranstar.org/rss/rss_info. html .
65. Datahub. [En línea] http://datahub.io.
66. Availability. [En línea] http://sparqles.okfn.org/availability.
67. ScienceDirect. [En línea] http://www.sciencedirect.com/.
68. Marco Luca Sbodio, Freddy Lecue, Anika Schumann. A Prototype for Semantic based Diagnosis of Road. [En línea] http://ceur-ws.org/Vol-914/paper_47.pdf.
69. D. Gregor, S.L. Toral, T. Ariza, F. Barrero. “An ontology-based semantic service for cooperative urban equipments”. [En línea] http://www.sciencedirect.com/science/ article/pii/S1084804512001786.
70. Dong Shen, Songhang Chen. “Urban Traffic Management System Based on Ontology and Multiagent System”. [En línea] http://www.sciencedirect.com/science/article/pii/
67

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
B978012397037400017X.
71. Torres Garrigós, David. “Evolución de DATEX II a un modelo semántico”. [En línea] http://robotica.uv.es/~jsamper/trabajoInvestigacion_DavidTorres.pdf
72. Jing Wang, Xin Wang. “An Ontology-Based Traffic Accident Risk Mapping Framework”. [En línea] http://link.springer.com/chapter/10.1007%2F978-3-642-22922-0_3#page-1.
73. M. Pla-Castells, J. J. Martinez-Durá, J. J. Samper-Zapater and R. V. Cirilo- Gimeno. “Use of ICT in Smart Cities. A practical case applied to traffic management in the city of Valencia”. 2015 Smart Cities Symposium Prague (SCSP). pp. 1-4. doi: 10.1109/ SCSP.2015.7181559.
74. F. R. Soriano, J. J. Samper, J. J. Martinez, R. V. Cirilo and E. Carrillo, “Smart cities technologies applied to sustainable transport. Open data management,” 2016 8th Euro American Conference on Telematics and Information Systems (EATIS), Cartagena, 2016, pp. 1-5. doi: 10.1109/EATIS.2016.7520155
75. Directive 2010/40/EU of the European Parliament and of the Council. [En línea] http://eur-lex.europa.eu/LexUriServ/ LexUriServ.do?uri=OJ:L:2010:207:0001:0013:IN:PDF.
76. Norma Técnica de Interoperabilidad (NTI) para la Reutilización de recursos de información. [En línea] http://www.boe.es/boe/ dias/2013/03/04/pdfs/BOE-A-2013-2380.pdf.
77. W3.org – Dessign Issues – Linked Data. [En línea] http://www.w3.org/DesignIssues/LinkedData.html.
78. SPARQL Endpoint. [En línea] http://semanticweb.org/wiki/SPARQL_endpoint.
79. Pantoja, Jorge. Linked Open Data At the UPF. Master Thesis UPF /2013. Master in Information and Communication Technologies Strategic Management. Barcelona School of managemet. Barcelona : Universitat Pompeu Fabra (UPF), 2013.
68

En colaboración con: Con el apoyo de:
PLATAFORMA TECNOLÓGICA ESPAÑOLA DE LA CARRETERA (PTC)Goya, 23 - 3º, 28001 Madrid (España)
Web: www.ptcarretera.es / email:[email protected]

N°2 / 2017 CUADERNOS TECNOLÓGICOS DE LA PTC
70


















