Calcul et Controle Stochastiqueˆ · 2018. 1. 18. · F. Comets, Th. Meyre : ”Calcul Stochastique...
147
1 Sorbonne Universit ´ e, Facult ´ e de Sciences Master de Math ´ ematiques M1 2017-2018 Calcul et Contr ˆ ole Stochastique et Applications ` a la finance Camille Tardif 10-01-2018 Polycopi ´ e de Philippe Bougerol
Transcript of Calcul et Controle Stochastiqueˆ · 2018. 1. 18. · F. Comets, Th. Meyre : ”Calcul Stochastique...

1
Sorbonne Universit
´
e, Facult
´
e de Sciences
Master de Math
´
ematiques M1 2017-2018
Calcul et Contr
ˆ
ole Stochastique
et Applications
`
a la finance
Camille Tardif
10-01-2018
Polycopi
´
e de Philippe Bougerol

2

Table des matieres
1 Introduction 9
1.1 Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 Un peu de bibliographie . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2.1 En Francais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2.2 Deux gros livres specifiquement sur les aspects financiers. . . . 11
1.2.3 Un livre en anglais, parmi d’autres . . . . . . . . . . . . . . . . 11
1.2.4 Les articles de Wikipedia . . . . . . . . . . . . . . . . . . . . . 11
I Modeles a temps discret 13
2 Introduction a l’evaluation en finance, Vocabulaire et produits 15
2.1 Finance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.1.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.1.2 Les metiers de la finance . . . . . . . . . . . . . . . . . . . . . . 15
2.2 La valeur du temps: Taux d’interet . . . . . . . . . . . . . . . . . . . . 16
2.2.1 Economiquement . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.2 Mathematiquement . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.3 Actualisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.4 Quelques taux utilises . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Actifs financiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.1 Actifs de Base . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.2 Marche a terme . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3.3 Marches derives: Produits optionnels . . . . . . . . . . . . . . . 19
2.4 Utilite versus AOA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.5 Le modele d’evaluation de base le plus simple . . . . . . . . . . . . . . 21
2.5.1 Le modele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.6 Portefeuille de couverture . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.6.1 Interpretation probabiliste . . . . . . . . . . . . . . . . . . . . . 22
2.6.2 Univers risque neutre . . . . . . . . . . . . . . . . . . . . . . . 23

4 TABLE DES MATIERES
3 Rappels et complements d’analyse et de probabilite 253.1 Probabilites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.1 Mesurabilite et variables aleatoires . . . . . . . . . . . . . . . . 253.1.2 Classe monotone . . . . . . . . . . . . . . . . . . . . . . . . . . 263.1.3 Independance et esperance conditionnelle . . . . . . . . . . . . 26
3.2 Projection dans un Hilbert . . . . . . . . . . . . . . . . . . . . . . . . 273.3 Theoreme de Radon Nikodym . . . . . . . . . . . . . . . . . . . . . . . 283.4 Esperance conditionnelle . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.4.1 Un theoreme de Bayes . . . . . . . . . . . . . . . . . . . . . . . 30
4 Calcul stochastique a temps discret 334.1 Filtration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.2 Martingales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.3 L’integrale stochastique discrete . . . . . . . . . . . . . . . . . . . . . . 344.4 Un theoreme de Doob . . . . . . . . . . . . . . . . . . . . . . . . . . . 364.5 Martingale continue a droite . . . . . . . . . . . . . . . . . . . . . . . . 374.6 Martingale locale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5 Controle stochastique a horizon fini 435.1 Systemes dynamiques a temps discret . . . . . . . . . . . . . . . . . . 43
5.1.1 Systeme dynamique controle deterministe . . . . . . . . . . . . 435.1.2 Systeme dynamique aleatoire . . . . . . . . . . . . . . . . . . . 445.1.3 Systeme dynamique controle aleatoire . . . . . . . . . . . . . . 455.1.4 Strategies markoviennes . . . . . . . . . . . . . . . . . . . . . . 48
5.2 Programmation dynamique . . . . . . . . . . . . . . . . . . . . . . . . 495.3 Premiers Exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.3.1 Cas deterministe . . . . . . . . . . . . . . . . . . . . . . . . . . 505.3.2 Remarque fondamentale sur la complexite . . . . . . . . . . . . 515.3.3 Remplacement de machines . . . . . . . . . . . . . . . . . . . . 515.3.4 Gestion de stock . . . . . . . . . . . . . . . . . . . . . . . . . . 525.3.5 Une solution explicite . . . . . . . . . . . . . . . . . . . . . . . 53
5.4 Arret optimal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.4.2 Enveloppe de Snell d’une suite adaptee . . . . . . . . . . . . . 555.4.3 Cadre markovien . . . . . . . . . . . . . . . . . . . . . . . . . . 565.4.4 Approche du cas Markovien par l’enveloppe de Snell . . . . . . 575.4.5 Approche du cas markovien par la programmation dynamique . 575.4.6 Exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6 Marches a temps discret, AOA, completude 636.1 Modele Stock-Bond . . . . . . . . . . . . . . . . . . . . . . . . . . . . 636.2 Portefeuille du marche (S,B) et autofinancement . . . . . . . . . . . . 64
6.2.1 Portefeuille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 646.2.2 Autofinancement . . . . . . . . . . . . . . . . . . . . . . . . . . 64

TABLE DES MATIERES 5
6.2.3 Changement de numeraire . . . . . . . . . . . . . . . . . . . . . 65
6.3 AOA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.3.1 Lemme sur la transformee de Laplace . . . . . . . . . . . . . . 67
6.3.2 Preuve du theoreme. . . . . . . . . . . . . . . . . . . . . . . . . 68
6.4 Evaluation d’un actif replicable dans un marche viable . . . . . . . . . 70
6.5 Marche complet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
6.5.1 Complet => Unicite de P . . . . . . . . . . . . . . . . . . . . . 72
6.5.2 Unicite de P => Propriete de Bernoulli . . . . . . . . . . . . . 72
6.5.3 Propriete de Bernoulli => Representation previsible . . . . . . 72
6.5.4 Representation previsible => Complet . . . . . . . . . . . . . . 73
6.6 Modele binomial de Cox, Ross et Rubinstein . . . . . . . . . . . . . . 74
6.6.1 Le modele d’arbre recombinant de CRR . . . . . . . . . . . . . 74
6.6.2 Representation previsible . . . . . . . . . . . . . . . . . . . . . 76
6.6.3 Prix d’options, Portefeuille de couverture . . . . . . . . . . . . 77
6.7 Appendice: Preuve de la proposition 6.5.5 . . . . . . . . . . . . . . . . 78
7 Theorie du Portefeuille de Markowitz 81
7.1 La notion d’Utilite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
7.2 Multiplicateurs de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . 83
7.3 Theorie du portefeuille de Markowitz . . . . . . . . . . . . . . . . . . . 84
7.3.1 Cas sans taux fixe . . . . . . . . . . . . . . . . . . . . . . . . . 85
7.3.2 Frontiere de Markowitz . . . . . . . . . . . . . . . . . . . . . . 86
7.3.3 Avec un actif sans risque, a taux fixe, Theorie de Tobin . . . . 87
8 Controle et filtrage lineaire optimal 91
8.1 Le cadre du controle lineaire . . . . . . . . . . . . . . . . . . . . . . . . 91
8.2 Matrices symetriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
8.3 Programmation dynamique . . . . . . . . . . . . . . . . . . . . . . . . 93
8.4 Variantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
8.4.1 Coe�cients dependant du temps . . . . . . . . . . . . . . . . . 95
8.4.2 Correction de trajectoire . . . . . . . . . . . . . . . . . . . . . . 95
8.5 Le probleme du filtrage . . . . . . . . . . . . . . . . . . . . . . . . . . 96
8.5.1 Gaussiennes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
8.6 Le Filtre de Kalman Bucy . . . . . . . . . . . . . . . . . . . . . . . . 98
8.6.1 Le Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
8.6.2 Decomposition a l’aide de l’innovation . . . . . . . . . . . . . . 98
8.6.3 Calcul de la matrice de gain . . . . . . . . . . . . . . . . . . . . 100
8.6.4 L’algorithme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
8.6.5 Equation de Riccati . . . . . . . . . . . . . . . . . . . . . . . . 101
8.7 Controle avec information imparfaite . . . . . . . . . . . . . . . . . . . 101

6 TABLE DES MATIERES
9 Filtrage Markovien non lineaire: Cas fini 1059.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1059.2 Le modele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1059.3 Les equations du filtrage . . . . . . . . . . . . . . . . . . . . . . . . . . 106
9.3.1 L’etape de prediction . . . . . . . . . . . . . . . . . . . . . . . . 1069.3.2 L’etape de mise a jour ou correction . . . . . . . . . . . . . . . 107
II Modeles a temps continu 109
10 Calcul stochastique a temps continu, par rapport au brownien 11110.1 Mouvement Brownien . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
10.1.1 Famille gaussienne . . . . . . . . . . . . . . . . . . . . . . . . . 11110.1.2 Definition du mouvement brownien . . . . . . . . . . . . . . . . 11110.1.3 Quelques proprietes . . . . . . . . . . . . . . . . . . . . . . . . 113
10.2 Propriete de Markov forte du Brownien . . . . . . . . . . . . . . . . . 11410.2.1 Martingales et mouvement brownien . . . . . . . . . . . . . . . 116
10.3 Integrale stochastique . . . . . . . . . . . . . . . . . . . . . . . . . . . 11710.4 Processus arrete, martingale locale . . . . . . . . . . . . . . . . . . . . 11910.5 Formule d’Ito pour le Brownien . . . . . . . . . . . . . . . . . . . . . . 121
10.5.1 Generalisation unidimensionnelle . . . . . . . . . . . . . . . . . 12210.5.2 Cas multidimensionnel . . . . . . . . . . . . . . . . . . . . . . . 123
10.6 Exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12410.7 Theoreme de Girsanov . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
10.7.1 Une application . . . . . . . . . . . . . . . . . . . . . . . . . . . 12610.8 Equations di↵erentielles stochastiques . . . . . . . . . . . . . . . . . . 127
10.8.1 Estimees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12810.8.2 Propriete de Markov . . . . . . . . . . . . . . . . . . . . . . . . 130
10.9 Processus de Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13110.9.1 Feynman-Kac . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
11 Black et Scholes 13511.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13511.2 Le modele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
11.2.1 Le spot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13611.3 Portefeuille autofinance . . . . . . . . . . . . . . . . . . . . . . . . . . 13711.4 AOA et l’univers risque neutre . . . . . . . . . . . . . . . . . . . . . . 13711.5 Marche complet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13811.6 Formules de Black et Scholes . . . . . . . . . . . . . . . . . . . . . . . 14011.7 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
11.7.1 Volatilite implicite . . . . . . . . . . . . . . . . . . . . . . . . . 14111.7.2 Gestion Delta neutre . . . . . . . . . . . . . . . . . . . . . . . . 141
11.8 Generalisations du modele de Black et Scholes . . . . . . . . . . . . . 14111.8.1 Cas particulier . . . . . . . . . . . . . . . . . . . . . . . . . . . 142

TABLE DES MATIERES 7
12 Controle et gestion de portefeuille en temps continu 14312.1 Le cadre du controle de di↵usions . . . . . . . . . . . . . . . . . . . . . 14312.2 L’equation HJB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14312.3 Le modele de consommation investissement de Merton . . . . . . . . . 145

8 TABLE DES MATIERES

Chapitre 1
Introduction
1.1. Plan
De nombreux phenomenes dependent en partie du hasard, il su�t de penser a la meteode demain. On s’interesse dans ce cours a ceux qui varient au cours du temps. NotonsXt l’etat de ce phenomene a l’instant t. Suivant que t prend des valeurs entieres dansN ou reelles dans R+, on aura une modelisation a temps discret ou continu et on diraque Xt est un processus a temps discret ou continu.
Souvent on se place a l’instant t0
representant le present, et l’on cherche a travailleravec le processus Xt, t � t
0
, dans le futur, donc largement inconnu.
Plusieurs questions sont interessantes. En theorie du controle, on peut agir surl’etat Xt a l’instant t et le transformer pour atteindre un but. Ce peut etre amenerune fusee sur la lune, ou gagner de l’argent. En theorie du filtrage, on ne connaitpas bien l’etat lui meme et on cherche donc a l’approcher (quitte a utiliser cetteapproximation ensuite pour faire du controle).
Le but de ce cours est d’introduire les methodes utilisees e↵ectivement pour traiterces problemes. Un des champs d’application est celui de la finance mathematique.C’est aujourd’hui celui qui propose le plus de debouches. Nous l’etudierons en detail.
Dans une premiere partie, on se concentre sur le temps discret. C’est la queles concepts sont les plus clairs et souvent directement applicables sur machines.Ensuite, nous etudions le cas du temps continu. Meme si mathematiquement il estplus sophistique, il est en fait, dans de nombreux cas pratiques, beaucoup plus facileet rapide a utiliser. Pour cette raison il est incontournable.
Le plan, un peu arbitraire, suivi est le suivant:
Premi
`
ere partie; Temps discret
1. On commence par introduire le vocabulaire de la finance et la problematiquede l’evaluation d’actifs derives. Ce sera souvent une source d’exemples.

10 Introduction
2. Ensuite quelques rappels d’analyse et de probabilites. Puis le calcul stochastiquesur les martingales discretes.
3. On traite alors la theorie du controle a temps discret, la programmation dy-namique et l’algorithme de Bellman, le probleme de l’arret optimal.
4. Les theoremes fondamentaux de l’evaluation d’actifs.5. La gestion de portefeuille.6. Controle et filtrage quadratique.
Deuxi
`
eme partie; Temps continu
1. Mouvement Brownien2. Calcul stochatique d’Ito. Theoreme de Girsanov.3. Formules de Black et Scholes.4. Gestion de portefeuille a temps continu.
1.2. Un peu de bibliographie
1.2.1. En Francais
M. Benaım, N. El Karoui : ”Chaınes de Markov et simulations ; martingales etstrategies.” Les Editions de l’Ecole Polytechnique, Eyrolles (2004)
L. Carassus, G. Pages : ”Finance de marche - Modeles mathematiques a tempsdiscret”, Vuibert, (2015).
F. Comets, Th. Meyre : ”Calcul Stochastique et Modeles de Di↵usion” (2015),Collection Master, Dunod
R.A. Dana, M. Jeanblanc-Picque : ”Marches financiers en temps continu: valori-sation et equilibre”. Economica (1998)
J.-F. Delmas, B. Jourdain : ”Modeles aleatoires”, volume 57 de Mathematiqueset Applications. Springer, Berlin, (2006).
G. Demange, J.C. Rochet : ”Methodes mathematiques de la finance”. Economica(1997)
N. El Karoui, E. Gobet: ”Les outils stochastiques des marches financiers”. Leseditions de l’Ecole Polytechnique, (2011).
D. Lamberton, B. Lapeyre : ”Introduction au calcul stochastique applique a lafinance”. Ellipses (1997)
E. Pardoux : ”Processus de Markov et applications: Algorithmes, reseaux, genomeet finance”, Dunod, (2007).

1.2 Un peu de bibliographie 11
1.2.2. Deux gros livres specifiquement sur les aspects financiers.
P. Poncet et R. Portait, Finance de marche de Patrice Poncet et Roland Portait,Dalloz
J. Hull, Options futures et autres actifs derives, 6 eme Edition, Pearson Education.
1.2.3. Un livre en anglais, parmi d’autres
A. Etheridge : ”A Course in Financial Calculus”, Cambridge University Press(2002)
1.2.4. Les articles de Wikipedia
Qui sont souvent tres bien faits...

12 Introduction

Partie I
Modeles a temps discret


Chapitre 2
Introduction a l’evaluation enfinance, Vocabulaire et produits
2.1. Finance
2.1.1. Definition
D’apres Robert Merton (Prix Nobel d’economie en 1997 avec Myron Scholes, FisherBlack etant mort en 1995):
La finance est l’etude des manieres d’allouer des ressources monetaires rares aufil du temps:
• Les decisions financieres engendrent des recettes et depenses reparties dans letemps.
• Les recettes et depenses ne sont generalement pas connues par avance aveccertitude.
Allouer des ressources rares : optimiser risque, rentabilite (ou cout) avec deuxcontraintes : Tenir compte de la valeur du temps et mesurer l’incertitude.
2.1.2. Les metiers de la finance
I. La finance d’entreprise (Direction Financiere) (planification strategique, controlefinancier, etc...)
II. La finance en dehors de l’entreprise.
• marches financiers (beaucoup de produits di↵erents)
• institutions financieres (credit, placement,operations complexes)
• institutions gouvernementales (garanties,financement)

16 Introduction a l’evaluation en finance, Vocabulaire et produits
Le systeme financier est l’ensemble des marches et intermediaires qui sont utilisespar les menages, les entreprises et les Etats pour mener a bien leurs decisions fi-nancieres. Ce systeme inclut les marches d’actions, d’obligations, et autres titres fi-nanciers, ainsi que les banques et les compagnies d’assurance. Les transferts de fondspassent souvent par un intermediaire.
Les actifs financiers principaux qui sont echanges sur les marches sont les dettes(obligations), les actions, les devises et les produits derives :
Les obligations sont des dettes. La vente d’une obligation equivaut donc a un em-prunt et son achat a un pret. Elle est emise par les entreprises (emprunts obligataireset billets de tresorerie), les Etats (OAT, bons du Tresor).
Les actions sont les titres juridiques des proprietaires d’une entreprise. On parled’actions pour les societes anonymes, et de parts pour les Sarl.
Les devises correspondent aux monnaies (etrangeres);
Les produits derives sont des titres financiers comme les options ou les contratsa terme (futures) dont la valeur derive (vient) de la valeur d’un ou plusieurs autresactifs.
2.2. La valeur du temps: Taux d’interet
2.2.1. Economiquement
”Un tiens vaut, ce dit-on, mieux que deux tu l’auras :
L’un est sur, l’autre ne l’est pas.”
La Fontaine, Le petit poisson et le pecheur.
La meme chose, quantifiee: Je prefere 100 Euros aujourd’hui que 102 Euros dansun an. Autrement dit, le temps change la valeur de l’argent. Pour mesurer ceci, onintroduit la notion de taux d’interet.
Le taux d’interet est le loyer de l’argent. Pour un consommateur, l’interet est leprix a payer pour la jouissance immediate d’un bien de consommation (ex : automo-bile, appartement). Pour un epargnant, l’interet est la recompense pour la remise aplus tard de cette jouissance. Pour une entreprise le prix a payer pour utiliser et fairefructifier l’argent prete.
(Pour Wikipedia) Le taux d’interet d’un pret ou d’un emprunt est le pourcent-age, calcule selon des conventions predefinies, qui mesure de facon synthetique, surune periode donnee, la rentabilite pour le preteur ou le cout pour l’emprunteur del’echeancier de flux financiers du pret ou de l’emprunt.

2.2 La valeur du temps: Taux d’interet 17
2.2.2. Mathematiquement
Definition 2.2.1 Le taux d’interet sur la periode de temps [t0
, t0
+ T ] est le reel rtel que K e place a la date t
0
donne K(1 + r) e a la date t0
+ T .
Dans un premier temps faisons comme si ceci ne dependait pas de t0
.
Definition 2.2.2 Le taux d’interet annuel ra le reel ra tel que K e place a la datet0
donne K(1 + ra) e a la date t0
+ 1, mesuree en annees.
La quantite V aujourd’hui place au taux annuel ra donne
Vn = V (1 + ra)n.
au bout de n annees. Plus generalement au bout du temps t compte en annees
Vt = V (1 + ra)t
(on voit apparaitre la notion d’interets composes).
On utilise aussi, surtout en finance theorique et en mathematiques, le taux d’interetcontinu, rc.
Definition 2.2.3 Le Taux d’interet continu rc le reel rc tel que K e place a la datet0
donne Kerct e a la date t0
+ t, mesuree en annees.
Si rc est tres petit, les deux notions se rejoignent car
etrc ⇠ (1 + rc)t.
En pratique ce taux depend de la longueur de t, il y a donc plusieurs taux.
2.2.3. Actualisation
Au taux annuel r, la valeur aujourd’hui actualisee d’une somme W recue a la date t(en annee) est
W
(1 + r)t.
On dit que c’est la valeur actualisee de W .Plus generalement, la valeur actualisee d’une suite de flux Wi, i = 1, 2, · · · , n,
recus aux dates ti (en annee) est
nX
i=1
Wi
(1 + r)ti.

18 Introduction a l’evaluation en finance, Vocabulaire et produits
2.2.4. Quelques taux utilises
En fait les taux varient tout le temps. Il faut donc connaitre toute la ”courbe destaux”, c’est a dire aujourd’hui les taux a toutes tes echeances, donc a 1 jour, 2 jours,4 semaine, 4 mois, 12 ans, etc.. Voici, en europe, les taux de references a court termesprincipaux:
• EONIA (Euro Overnight Index Average) : taux au jour le jour.
• EURIBOR (Euro InterBank O↵ered Rate) : taux a 1, 2, 3 semaines et de 1 a12 mois.
• LIBOR Pareil pour la livre anglaise.
et beaucoup de taux proprement francais (TAM,...)
2.3. Actifs financiers
Le mot actif financier est synonyme de produit financier. Parlons des produits ”stan-dardises” qui se traitent par l’intermediaire d’une bourse (comme l’EURONEXT aParis) ou d’un etablissement similaire. On distingue trois types de produits.
2.3.1. Actifs de Base
Les Actifs de Base (Underlying Asset), ou supports, principaux sont:
• Actions (Stock, Shares): Une action est un titre de propriete representant unefraction du capital de l’entreprise, donnant droit de vote, d’information, dedividende. Notions de Prix, Dividendes.
• Obligations (Bond): Une obligation est un titre de creance (emprunt/ pret) a untaux fixe pour une duree fixee. Notions de Taux nominal, Prix, Taux actuariel.
• Devises (Currency); cours
• Matieres premieres; cours
• Indices (Index) (exemples Cac 40, Nasdaq).
• Energie (Gaz, Electricite)
Ces actifs peuvent etre tous achetes et vendus et sont traites au comptant,

2.3 Actifs financiers 19
2.3.2. Marche a terme
Les actifs precedents peuvent aussi etre traites a terme. Un vendeur et un acheteurse fixent aujourd’hui une date T dans le futur et un prix P . Le jour T il vend (resp.achete) au prix P le produit. Il existe de nombreuses variantes ”organisees”. (forward,future, Fra, swaps), de facon abondante (on dit: avec une grande liquidite). Cesproduits ne seront pas importants pour nous, donc je n’insiste pas.
Quelques exemples sophistiques de marches a termes traites par Nyse-Euronext:MATIF (contrat notionnel 100.000 sur 10 ans, a 3.5, ), EURIBOR 3 mois, CONTRATCAC 40 (voir www.euronext.com si interesse...)
2.3.3. Marches derives: Produits optionnels
Les deux types de produits precedents peuvent etre traites de facon optionnelle, surdes marches organises (type bourse) ou de gre a gre. Decrivons en le principe endetail car c’est sur ce type de produit que les mathematiques jouent un role essentiel,depuis 1973 et l’apport fondamental de Black, Scholes et Merton.
Limitons nous aux options sur les produits au comptant.
Definition 2.3.1 Une option Call est un contrat donnant a son detenteur le droit,mais pas l’obligation, d’acheter un actif donne, appele le sous jacent ou le support,a une date donnee si c’est un Call europeen, et jusqu’a une date donnee si c’est uncall Americain (cette date est appelee echeance ou maturite) et a un prix convenu al’avance, appele prix d’exercice (Strike en anglais).
Si l’achat a lieu, on dit que l’acheteur exerce son option. Puisqu’il n’est pas obligede le faire ce contrat amene un gain qui est toujours positif. Il n’est donc pas gratuit:le contrat a un cout, appele la prime de l’option. Le but de ce cours est de comprendrecomment on peut la calculer. On parle d’evaluation ou de pricing de l’option.
Attention, ce contrat peut etre lui meme acheter ou vendu.
Definition 2.3.2 L’option Put est l’analogue en remplacant acheter par vendre.
On voit donc que l’on peut acheter ou vendre un call ou un put.
Le marche des options sur actions existe de facon organisee depuis 1973 (Creationa Chicago) aux Etas Unis et depuis 1987 a Paris (Creation du MONEP ou Marchedes Options Negociables de Paris). Le Monep a ete remplace par le Euronext-Li↵e.
Le caractere americain ou europeen de l’option n’a aucun rapport avec le pays. Parexemple toutes les options du Euronext-Li↵e sont americaines. Les options americainessont plus di�ciles a evaluer et nous nous limiterons le plus souvent aux options eu-ropeennes.
Appelons St le prix du sous jacent (Spot en anglais) a la date t. Soit T la dated’echeance et K le prix d’exercice. Le detenteur du Call europeen, a la date T a le

20 Introduction a l’evaluation en finance, Vocabulaire et produits
choix d’acheter ou non le sous jacent, au prix K. Si ST > K, il achete donc K unproduit qui vaut ST , il recoit donc (eventuellement en revendant immediatement lesous jacent) le jour T ,
ST �K.
Par contre si ST K il ne fait rien et recoit donc dans ce cas
0.
On voit que de toute facon, il recoit
(ST �K)+
appele le Pay-o↵ du Call ou x+ = max(x, 0). Remarquons, que la valeur actualiseeaujourd’hui (a la date 0) au taux d’interet continu r, de cette somme est
e�rT (ST �K)+
De la meme facon, pour un Put europeen, le detenteur du Put recoit le jour T ,
(K � ST )+,
et la valeur actualisee este�rT (K � ST )
+.
Evidemment ces quantites sont inconnues a la date 0.Pour une option americaine exercee au temps ⌧ la valeur actualisee du Call est
e�r⌧ (S⌧ �K)+
et celle du pute�r⌧ (K � S⌧ )
+
le temps ⌧ ne peut etre choisi qu’en fonction de l’information jusqu’au temps ⌧ , doncen un sens a preciser, un temps d’arret inferieur a T .
Il existe de tres nombreuses variantes, appelees souvent options exotiques. Ellessont par exemple tres developpees dans les marches sur devises (FOREX). On pourraitaussi citer les options binaires ou digitales. Ce sont elles qui justifient la grande activitedes mathematiques financieres en ce moment. Pour les aborder, il faut d’abord biencomprendre les cas classiques.
2.4. Utilite versus AOA
Dans les approches classiques de la finance, on cherchait a optimiser un gain (uneesperance) en minimisant le risque (une variance). C’est l’approche par ”l’utilite”.Elle est basee sur la loi des grands nombres, qui ne s’applique pas pour les produitsderives car il n’a y’a pas beaucoup de produits independants.
La grande nouveaute du pricing des produits derives est de remplacer cette theoriepar la theorie de l’absence d’opportunite d’arbitrage (AOA) qui est fondamentalementdi↵erente. C’est celle ci que nous allons voir.

2.5 Le modele d’evaluation de base le plus simple 21
2.5. Le modele d’evaluation de base le plus simple
Le principe fondamental de l’absence d’opportunite d’arbitrage (AOA) apparait tressimplement dans le cas caricatural d’un actif ne prenant que deux valeurs. C’est ceque nous allons expliquer dans cette courte section.
Le point essentiel a retenir tout de suite est qu’il n’y a pas de probabilite dansle modele et que l’on va en un sens se couvrir contre tous les risques possibles.
2.5.1. Le modele
On suppose que le marche financier ne comporte que deux actifs:
• Un placement sans risque de prix Bt a la date t (comme un livret d’epargne),
• Une action de prix St (le ”spot”),
et qu’il n’y a que 2 dates: la date 0, aujourd’hui et la date 1 (par exemple demain oudans 1 an).
Autrement dit t = 0 ou t = 1. Si r est le taux sans risque on peut supposer que,pour % = 1 + r,
B1
= %B0
Donc B1
est connu au temps 0.On suppose aussi que S0
, le prix de l’action aujourd’huiest connu mais que celui S
1
de l’action a la date 1, inconnu, ne peut prendre que 2valeurs (deux etats du monde, en langage financier) de rendement b ou de rendementh, autrement dit
S1
= bS0
, ou S1
= hS0
(le rendement etant par definition (S1
� S0
)/S0
). On considere une option d’achat(Call), de prix d’exercice K = kS
0
, avec l’hypothese naturelle (pourquoi ?) que
b k h.
2.6. Portefeuille de couverture
On cherche a dupliquer le gain de cette option a l’aide d’un portefeuille constitue departs des 2 actifs: Si on achete ↵ parts d’actions et � parts du placement sans risque,on investit a l’instant 0 la somme
V0
= ↵S0
+ �B0
.
Cette quantite se sera transformee en
V1
= ↵S1
+ �B1

22 Introduction a l’evaluation en finance, Vocabulaire et produits
a l’instant 1. Si on investit la meme somme V0
dans l’achat d’une option Call, onobtiendra a l’instant 1 la somme
V1
= (S1
�K)+.
Le portefeuille duplique l’option (on dit qu’il couvre l’option) si il y a egalite, doncsi V
1
= V1
, soit↵S
1
+ �B1
= (S1
�K)+.
En fait il y a deux cas suivant que S1
= hS0
ou S1
= bS0
et donc on obtient 2equations
↵hS0
+ �B1
= (hS0
� kS0
)+ = hS0
� kS0
↵bS0
+ �B1
= (bS0
� kS0
)+ = 0.
On resoud: par di↵erence,
↵ =h� k
h� b
� = �↵bS0
B1
d’ou
V0
= ↵S0
+ �B0
= ↵S0
(1� bB0
B1
) =h� k
h� b(%� b
%)S
0
(noter que � < 0, il correspond donc a un emprunt). On a donc trouve le prixde l’option, et en meme temps le portefeuille le repliquant: Meme, si cela paraitextremement elementaire, il est essentiel de remarquer qu’il n’y a pas de probabilitedu tout; on est donc tres content car on est couvert contre tous les risques.
2.6.1. Interpretation probabiliste
Ces formules un peu compliquees peuvent s’interpreter intuitivement en imaginantqu’il existe un espace de probabilite (⌦,F ,P) et que S
1
est une v.a. telle que
P(S1
= hS0
) = p,P(S1
= bS0
) = q = 1� p
pour
p =%� b
h� b, q =
h� %
h� b.
Dans ce cas
E(S1
) = phS0
+ qbS0
=(%� b)h+ (h� %)b
(h� b)S0
= %S0
et
E((S1
�K)+) = p(hS0
�K) =%� b
h� b(h� k)S
0
= %V0

2.6 Portefeuille de couverture 23
On voit donc que
S0
= E(S1
/%), V0
= E((S1
�K)+/%)
qui sont des formules tres intuitives puisque elles indiquent que S0
et V0
sont lesesperances des prix des produits a l’instant suivant, reactualises. Notons cependantque ces esperances se font suivant une probabilite qui n’est peut etre pas celle quiregit l’evolution du sous jacent.
2.6.2. Univers risque neutre
Le caractere specifique du Call n’a pas joue de role dans ce qui precede. On aura parexemple pour un Put
Prime du Put = E((K � S1
)+/%)
On voit donc qu’il existe un espace de probabilite (⌦,F ,P) pour lequel les prix ala fois du spot et de beaucoup d’autres produits se calculent par la formule
Prix Aujourd’hui = E(Prix Demain) actualisee.
On appellera cet espace un univers risque neutre. C’est une sorte de monde virtueldans lequel les prix se calculent facilement. Dans les cas plus generaux nous chercheronsa fabriquer un analogue.

24 Introduction a l’evaluation en finance, Vocabulaire et produits

Chapitre 3
Rappels et complementsd’analyse et de probabilite
3.1. Probabilites
Rappelons quelques resultats indispensables du calcul des probabilites.
3.1.1. Mesurabilite et variables aleatoires
Soit (⌦,F ,P) un espace de probabilite et (E, E) un ensemble muni d’une tribu. Unevariable aleatoire
X : ⌦! E
est, par definition, une application mesurable, c’est a dire que {X 2 A} 2 F pourtout A 2 E .
Lorsque E = R ou Rd on sous entend qu’on le munit de la tribu borelienne.
Definition 3.1.1 On appelle variable aleatoire positive etagee, toute v.a. X s’ecrivantX =
Pnk=1
ak1Ak ou ak � 0 et Ak 2 F .
Lemme 3.1.2 Toute v.a. X � 0 est limite croissante d’une suite de v.a. etagees.
Preuve: On a par exemple X = limn!+1Xn ou
Xn =n2nX
k=0
k
2n1{k2
nX<k+1}
Definition 3.1.3 Si {Xi, i 2 I} est une famille d’applications a valeurs dans Rd
definies sur ⌦, on note �(Xi, i 2 I) la tribu engendreee par cette famille. C’est a direla plus petite tribu de ⌦ contenant tous les ensembles {Xi 2 A}, ou i 2 I et A est unborelien de Rd.

26 Rappels et complements d’analyse et de probabilite
En particulier, pour une application X : ⌦! Rd, �(X) est exactement la classe desensembles {X 2 A}, ou A est un borelien de Rd. De meme, la tribu engendree parun ensemble de parties est la plus petite tribu les contenant. Nous aurons l’occasiond’utiliser:
Lemme 3.1.4 Considerons une application X : ⌦ ! Rd. Alors une application Z :⌦ ! R est �(X)-mesurable si et seulement si il existe une application boreliennef : Rd ! R telle que Z = f(X).
Preuve: On ecrit
Z = limn!+1
+1X
k=�1
k
2n1[k2�n,(k+1)2
�n[
(Z).
Puisque Z est �(X)-mesurable, il existe un borelien An,k de Rd tel que
{Z 2 [k2�n, (k + 1)2�n[} = {X 2 An,k}
c’est a dire tel que1[k2�n,(k+1)2
�n[
(Z) = 1An,k(X)
On a alors Z = f(X) si
h(x) = lim infn!+1
+1X
k=�1
k
2n1An,k(x).
3.1.2. Classe monotone
L’outil sophistique pour traiter les tribus engendrees est le suivant:
Theoreme 3.1.5 (de la classe monotone) Soient C et M des ensembles de par-ties de ⌦ tels que C ⇢ M. On suppose que
(i) C est stable par intersection finie (i.e. A,B 2 C implique A \B 2 C).(ii) M est stable par di↵erence propre (i.e. A,B 2 M et A ⇢ B implique B \A 2
M).(iii) M est stable par limite croissante (i.e. An 2 M et An ⇢ An+1
implique[An 2 M).
(iv) ⌦ est dans M.Alors �(C) est contenu dans M.
3.1.3. Independance et esperance conditionnelle
Rappelons que des tribus F1
, · · · ,Fn sont independantes si
P(A1
\A2
· · · \An) = P(A1
)P(A2
) · · ·P (An)
pour tous A1
2 F1
, · · ·An 2 Fn. Des v.a. X1
, · · · , Xn sont independantes si les tribus�(X
1
), · · · ,�(Xn) le sont.

3.2 Projection dans un Hilbert 27
Lemme 3.1.6 (Lemme de regroupement) Si �(X1
), · · · ,�(Xn) sont independanteset n
1
< n2
< nk, alors les v.a.
Zr = (Xnr , Xnr+1
, · · · , Xnr+1�1
)
sont independantes.
Preuve: La preuve utilise le theoreme de la classe monotone. ⇤Il resulte par exemple de ce lemme que si X
1
, X2
, X3
sont independantes, alorsX
1
+X2
est independant de cos(X3
). Deux v.a. X,Y sont independantes si
E(f(X)g(Y )) = E(f(X))E(g(Y ))
pour tout f, g mesurables positives.La proposition suivante est tres importante:
Proposition 3.1.7 Si X,Y sont deux variables aleatoires independantes, X a valeursdans (E
1
, E1
), et Y a valeurs dans (E2
, E2
), pour tout F : E1
⇥ E2
! R mesurablepositive,
E(F (X,Y )) =
Z
⌦
Z
⌦
F (X(!), Y (!0)) dP(!) dP(!0)
Preuve: Notons en general µZ la loi d’une v.a. Z : ⌦! (E, E), qui est la probabilitesur E definie par
µZ(A) = P(Z 2 A)
pour tout A de E . Dire que X et Y sont independantes est equivalent a dire que
µ(X,Y )
(A⇥B) = P(X 2 A, Y 2 B) = P(X 2 A)P(Y 2 B) = µX(A)µY (B),
c’est a dire exactement que µ(X,Y )
est egal a la mesure produit µX ⌦ µY . L’enoncedu lemme est donc une consequence du theoreme de Fubini. ⇤
3.2. Projection dans un Hilbert
Definition 3.2.1 Un espace de Hilbert est un espace vectoriel muni d’un produitscalaire qui est un espace de Banach (i.e. un espace norme complet) pour la normeassociee.
La propriete fondamentale d’un espace de Hilbert est qu’on peut y definir la projec-tion orthogonale sur un convexe ferme: rappelons d’abord quun convexe est un sousensemble C tel que, si x, y 2 C, �x+ (1� �)y 2 C, pour tout � tel qie 0 � 1.
Theoreme 3.2.2 Soit C un convexe ferme d’un espace de Hilbert H. Pour toutx 2 H, il existe un unique v 2 C, appele projection orthogonale de x sur C tel que
kx� vk = inf{kx� zk, z 2 C}.
Lorsque C est un sous espace vectoriel ferme, il est caracterise par les deux proprietes,(i) v 2 V ; (ii) pour tout w 2 C, hx� v, wi = 0.

28 Rappels et complements d’analyse et de probabilite
Preuve: Posons D = inf{kx� vk, v 2 C}. Pour tout n 2 N, il existe vn 2 C tel que
kx� vnk2 D2 +1
n
Montrons que (vn) est une suite de Cauchy. Nous allons utiliser l’egalite suivante (ditedu parallelogramme), immediate a verifier en developpant (mais propre aux Hilberts)
ka� bk2 + ka+ bk2 = 2(kak2 + kbk2).
On a en prenant a = vn � x, b = vm � x
kvn � vmk2 + kvn + vm � 2xk2 = 2(kvn � xk2 + kvm � xk2)
que l’on ecrit
kvn � vmk2 = 2kvn � xk2 + 2kvm � xk2 � 4kvn + vm2
� xk2
On a kvn+vm2
� xk � D2 car (vn + vm)/2 2 C on en deduit que, si m � n,
kvn � vmk2 2(D2 +1
n) + 2(D2 +
1
m)� 4D2 2/n.
La suite vn est donc de Cauchy et on verifie que sa limite v est le point cherche.
Corollaire 3.2.3 Sur un espace de Hilbert H, pour toute forme lineaire continue fil existe z 2 H tel que f(x) = hx, zi pour tout x 2 H.
Preuve: Si f est identiquement nulle, prendre z = 0. Sinon, on appliquer le theoremeau sous espace V = f�1(0) et a un x 2 H tel que f(x) 6= 0: il existe z 2 V tel quef(y) = 0 entraine que hx � z, yi = 0. Posons w = x � z. Alors, pour tout y 2 H,
y � f(y)f(w)
w 2 V donc hy, wi = f(y)f(w)
hw,wi et f(y) = hy, vi pour v = f(w)
hw,wiw.
3.3. Theoreme de Radon Nikodym
Definition 3.3.1 Etant donne deux mesures µ et ⌫ sur (⌦,F) on dit que µ estabsolument continue par rapport a ⌫ si pour tout A 2 F , ⌫(A) = 0 entraine queµ(A) = 0, et que µ est equivalente a ⌫ si pour tout A 2 F , ⌫(A) = 0 si et seulementsi µ(A) = 0.
Definition 3.3.2 Soient µ et ⌫ deux mesures sur un espace (⌦,F) et f : ⌦ ! R+
mesurable. On dit que µ a la densite ' par rapport a µ si, pour tout A 2 F ,
µ(A) =
Z
A' d⌫.
On note souvent ' = dµd⌫ et on ecrit que dµ = ' d⌫.

3.3 Theoreme de Radon Nikodym 29
Theoreme 3.3.3 (Radon Nikodym) On considere deux probabilites µ et ⌫ sur(⌦,F). Alors µ est absolument continue par rapport a ⌫ si et seulement si µ a unedensite par rapport a ⌫.
Preuve: Soit � = µ+ ⌫, pour tout f de L2(�), par Cauchy Schwartz,
|Z
fdµ| Z
|f |dµ Z
|f |d� (
Z|f |2d�)1/2(
Z1d�)1/2
On definit ainsi une forme lineaire sur le Hilbert H = L2(⌦,F ,�). C’est donne parun produit scalaire: il existe 2 H tel que pour tout f de L2(�)
Zfdµ = hf, iH =
Zf d�
donc Zf(1� )dµ =
Zf d⌫.
Prenons f = 1{ �1}, alors
0 �Z
1{ �1}(1� )dµ =
Z1{ �1} d⌫ � ⌫{ � 1}
Donc < 1, ⌫-p.s. et donc aussi µ-p.s. par absolue continuite. En prenant f = 1{ <0}on a
0 Z
1{ <0}(1� )dµ =
Z1{ <0} d⌫ 0
donc � 0, ⌫ et µ p.s. Pour tout n 2 N,Z
f(1� n+1)dµ =
Zf(1 + + · · ·+ n)(1� )dµ =
Zf(1 + + · · ·+ n) d⌫
Quand n ! +1, avec les 2 thm de LebesgueZ
fdµ =
Zf
1� d⌫
il su�t donc de poser dµd⌫ =
1� . ⇤
Rappelons qu’une mesure m sur (⌦,F) est dite �-finie si il existe une suite An
d’elements de F telle que [n2NAn = ⌦ et m(An) < 1.
Lemme 3.3.4 Une mesure �-finie est equivalente a une probabilite.
Preuve: Supposons que m est une mesure �-finie. On pose ↵n = 1
2
n(1+m(An))
et
f =X
n�0
↵n1An
Cette fonction est strictement positive et a :=Rf dm
Pn�0
2�n < 1. La mesure
m est equivalente a la probabilite 1
af dm.
On en deduit que:
Proposition 3.3.5 Le theoreme de Radon Nikodym est vrai pour les mesures �-finies

30 Rappels et complements d’analyse et de probabilite
3.4. Esperance conditionnelle
Dans un espace (⌦,A,P) si F est une sous tribu de A, l’espace L2(⌦,F ,P) est un sousespace vectoriel ferme de L2(⌦,A,P). L’esperance conditionnelle de X 2 L2(⌦,A,P)sachant F est par definition la projection de X sur L2(⌦,F ,P). On montre que cettenotion s’etend aux v.a. positives et que :
Proposition 3.4.1 Soit X une v.a. positive, et G une sous tribu de F . L’esperanceconditionnelle E(X|G) est caracterisee comme l’unique (classe de) v.a. Z qui a lesdeux proprietes suivantes
(i) Z est G-mesurable.(ii) Pour tout ensemble G-mesurable A, E(1AZ) = E(1AX).
Soit X une v.a. telle que E(|X||G) < +1, p.s.. Alors Z = E(X+|G) � E(X�|G)est notee aussi Z = E(X|G).
Proposition 3.4.2 [Un resultat fondamental] Si X est G mesurable et Y est independantde G et � � 0, alors
E(�(X,Y )|G)(!) =Z�(X(!), Y (!0)) dP(!0)
ce que l’on peut ecrire aussi E(�(x, Y )) pour x = X(!).
Preuve: Par Fubini, on sait que l’application x 7! E(�(x, Y )) est mesurable. DoncZ(!) = E(�(X(!), Y )) est G-mesurable, puisque c’est une fonction mesurable de X,lui meme G-mesurable. Si A 2 G, les deux v.a. (1A, X) et Y sont independantes.Donc, en appliquant la proposition 3.1.7,
E(�(X,Y )1A)) =
Z
⌦
Z
⌦
�(X(!), Y (!0)1A(!) dP(!) dP(!0)
=
Z
⌦
[
Z
⌦
�(X(!), Y (!0)1A(!) dP(!0)] dP(!) = E(Z1A)
par Fubini. On a donc bien que Z = E(�(X,Y )|G) par la propriete caracteristiquerappelee au dessus. ⇤
3.4.1. Un theoreme de Bayes
On se donne un espace (⌦,F) muni de deux probabilites P et Q et G une sous tribude F .
Proposition 3.4.3 On suppose que dQ = Z dP. Alors, en notant E l’esperance parrapport a P et EQ l’esperance par rapport a Q. Pour toute v.a. Y � 0,
EQ(Y |G) = E(Y Z|G)E(Z|G) .

3.4 Esperance conditionnelle 31
Preuve: La fonction X = E(Y Z|G)E(Z|G) est G-mesurable et, pour toute v.a. G-mesurable
bornee UEQ(XU) = E(XUZ) = E(XUE(Z|G))
= E(E(Y Z|G)U) = E(Y ZU) = EQ(Y U)

32 Rappels et complements d’analyse et de probabilite

Chapitre 4
Calcul stochastique a tempsdiscret
4.1. Filtration
Une filtration {Fn, n � 0} sur un espace ⌦ est une suite de tribus sur ⌦ telles queFn ⇢ Fn+1
, pour tout n � 0. Pour nous, n representera le temps, et Fn l’informationque l’on possede au temps n. Eventuellement on notera F1 = �(Fn, n � 0).
Une suite Xn, n � 0, est dite adaptee a la filtration {Fn, n � 0} si Xn est Fn-mesurable. Elle est dite previsible si Xn est Fn�1
-mesurable pour n > 0.
Un temps d’arret de la filtration {Fn, n � 0} est une application ⌧ : ⌦! N[{+1}telle que ⌧ n 2 Fn, pour tout n � 0.
La tribu F⌧ = {A;A \ {⌧ n} 2 Fn} est appelee la tribu des evenementsanterieurs a ⌧ .
Lemme 4.1.1 Si ⌧ est un temps d’arret, pour toute v.a. X � 0,
E(X|F⌧ )1{⌧=n} = E(X|Fn)1{⌧=n}.
Preuve: Il nous faut montrer, puisque {⌧ = n} 2 F⌧ que
E(1{⌧=n}X|F⌧ ) = 1{⌧=n}E(X|Fn).
On utilise la propriete caracteristique de l’esperance conditionnelle ??: la v.a. Z =1{⌧=n}E(X|Fn) est F⌧ -mesurable et pour toute v.a. U positive, F⌧ -mesurable, puisqueU1{⌧=n} est Fn-mesurable,
E(UZ) = E(U1{⌧=n}E(X|Fn)) = E(U1{⌧=n}X)
donc Z = E(1{⌧=n}X|F⌧ ).

34 Calcul stochastique a temps discret
4.2. Martingales
On considere (⌦, (Fn),P) un espace de probabilite filtre.
Definition 4.2.1 Une famille Mnn 2 N, est une martingale si Mn 2 L1, (Mn) estadapte et
E(Mn|Fn�1
) = Mn�1
, pour tout n � 1.
Si on seulement E(Mn|Fn�1
) � Mn�1
, on dit que M est une sous martingale.
Si M est une (ss)-martingale sur (⌦, (Fn),P), ca l’est aussi pour la filtrationnaturelle F0
n = �(Mk, k n). Si on dit que M est une martingale sans faire referencea une tribu on sous entend que c’est une martingale pour (F0
n).
Exemple fondamental: Soit X 2 L1. On pose Xn = E(X|Fn). On a, pour s < t,
E(Xn|Fn�1
) = E(E(X|Fn)|Fn�1
) = E(X|Fn�1
) = Xn�1
et Xn est une martingale.
Proposition 4.2.2 Soit X1
, X2
, · · · des variables aleatoires independantes dans L1
telles que E(Xn) = 0, pour tout n � 0. Alors Mn = X1
+ · · ·+Xn est une martingale.Si les Xn sont dans L2, M2
n �Pn
k=1
E(X2
k) est une martingale.
Preuve: Facile
Proposition 4.2.3 Si Mn une martingale, |Mn|, est une sous martingale.
Preuve: On a E(|Mn||Fn�1
) � |E(Mn|Fn�1
)| = |Mn�1
|.
4.3. L’integrale stochastique discrete
Donnons nous un espace probabilise muni d’une filtration (⌦, (Fn)n,P). Si Xn et Mn
sont deux suites relles, on pose, (X ?M)0
= 0 et pour n � 1,
�Mn = Mn �Mn�1
et
(X ?M)n =nX
k=1
Xk�Mk.
Definition 4.3.1 X ?M est l’integrale de X par rapport a M .
Lemme 4.3.2 Pour toutes suites (Xn), (Yn), (Mn) on a �(X ?M) = X�M et
X ? (Y ?M) = XY ?M.

4.3 L’integrale stochastique discrete 35
Une interpretation utile de l’integrale est la suivante: si �Mn est le resultat d’uneexperience aleatoire representant le gain d’un joueur au temps n qui aurait mise 1eautemps n, alors: (X ?M)n est le gain total obtenu apres n parties, lorsque le joueurmise Xn au temps n (par exemple pour Xn = 2n ceci revient a doubler sa mise achaque fois). Dans ce contexte, le theoreme suivant est eclairant:
Theoreme 4.3.3 Si M est une martingale et X un processus previsible tel queX�M 2 L1, alors X ? M est une martingale. Si M est une sous martingale etX positif alors X ?M est une sous martingale
Preuve: Si M est une martingale, Il su�t de remarquer que
E(�(X ?M)n|Fn�1
) = E(Xn�Mn|Fn�1
) = XnE(�Mn|Fn�1
) = 0.
le cas sous martingale est similaire. ⇤Etant donne un processus (Mn) et ⌧ : ⌦! N[{+1} on appelle processus arrete
en ⌧ le processus M ⌧ defini par
M ⌧n = M⌧^n,
ou ⌧ ^ n = min(⌧, n).
Theoreme 4.3.4 (Theoreme d’arret) Si M est une sous martingale (resp. mar-tingale) et M un temps d’arret, alors M ⌧ est une sous martingale (resp. martingale).
Preuve: PrenonsXn = 1{n⌧} ou ⌧ : ⌦! N[{+1} (qui correspond a la strategie=miser1 jusqu’au temps ⌧). Alors X est previsible si et seulement si ⌧ est un temps d’arret.De plus dans ce cas
X ?M = M ⌧
Il su�t donc d’appliquer le theoreme precedent.
Corollaire 4.3.5 Soient {Mn, n 2 N} une (sous) martingale, � et ⌧ deux tempsd’arret. On suppose que � est borne. Alors
E(M�| F⌧ ) � M�^⌧
avec egalite dans le cas d’une martingale
Preuve: Si � est borne par la constante r > 0, puisque M� est une sous martingale,on peut ecrire que, sur {⌧ = n},
E(M�| F⌧ ) = E(M�r | Fn) � M�
r^n = M�^⌧

36 Calcul stochastique a temps discret
4.4. Un theoreme de Doob
Theoreme 4.4.1 Soit Mn, n 2 N, une sous-martingale positive. Pour tout a > 0,
aP( max0kn
Mk � a) E(Mn1{max0kn Mk�a}).
De plus
P( max0kn
Mk � a) E(Mn)
a
etE( max
0knM2
k ) 4E(M2
n).
Preuve: Soit ⌧ = inf{k � 0;Mk � a}. On a {max0knMk � a} = {⌧ n} et
E(Mn1{⌧n}) = E(E(Mn|F⌧ )1{⌧n}) � E(Mn^⌧1{⌧n})
= E(M⌧1{⌧n}) � aP(⌧ n)
ce qui donne la premiere inegalite. La suivante en decoule immediatement. Ensuite,ecrivons que
Z 1
0
aP( max0kn
Mk � a) da Z 1
0
E(Mn; max0kn
Mk � a) da
Avec Fubini ceci s’ecrit, si on pose S = max0knMk
E(Z
max0kn Mk
0
a da) E(Mn
Zmax0kn Mk
0
da)
donc1
2E(( max
0knMk)
2) E(Mn max0kn
Mk)
En appliquant Cauchy Schwarz on obtient
1
2E(( max
0knMk)
2) E(M2
n)1/2E(( max
0knMk)
2)1/2
ce qui donne le resultat, puisque M etant positive, max0knM2
k = (max0knMk)2.
⇤
Corollaire 4.4.2 Si (Mn) est une martingale,
P( max0kn
|Mk| � a) 1
aE(|Mn|)

4.5 Martingale continue a droite 37
Preuve: On applique ce qui precede a la sous martingale positive |Mn|.
Remarquons l’analogie avec l’inegalite de Markov:
Proposition 4.4.3 (Inegalite de Markov) Pour toute v.a. positive X et a > 0,
P(X � a) E(X)
a.
qui s’obtient immediatement en remarquant que 1{X�a} X/a.
Corollaire 4.4.4 (Inegalite de Doob) Si Mn, n 2 N, est une martingale
E( max0kn
M2
k ) 4E(M2
n).
Preuve: On applique le theoreme precedent a la sous martingale |Mn|.
4.5. Martingale continue a droite
Si Mt, t 2 R+, est un processus a trajectoires continues a droite, on a
sup0tT
Mt = limn!+1
sup0k2
nM kT
2n.
En appliquant le Theoreme 4.4.4 a la sous martingale Xk = M kT2n
et l’egalite
{ sup0tT
Mt > a} = [n2N{ sup0k2
nM kT
2n> a}
on obtient immediatement:
Theoreme 4.5.1 (Inegalites de Doob) Soit Mt, t 2 R+, une sous-martingale con-tinue a droite positive. Pour tout a > 0,
aP( sup0tT
Mt � a) E(MT1{sup0tT Mt�a}) E(MT )
De plusE( sup
0tTM2
t ) 4E(M2
T ).
Puisque la valeur absolue d’une martingale est une sous martingale, on en deduit lecorollaire absolument fondamental pour la suite:
Corollaire 4.5.2 Si M est une martingale continue a droite
E( sup0tT
M2
t ) 4E(M2
T ).

38 Calcul stochastique a temps discret
Deduisons un convergence de theoreme de martingales (il en existe d’autres, parexemple pour les martingales positives).
Theoreme 4.5.3 Une martingale continue a droite (Mt) telle que
supt�0
E(M2
t ) < +1
converge p.s. et dans L2 lorsque t ! +1.
Preuve: Puisque M2
t est une sous martingale, E(M2
t ) est une fonction croissante.Par hypothese, elle est bornee. Donc elle converge lorsque t ! +1. On en deduitque, pour tout " > 0, il existe N tel que, si s, t � N
E((Mt �Ms)2) = E(M2
t )� E(M2
s ) < "
lorsque s, t ! +1. La suite Mn est donc de Cauchy dans L2, elle converge vers unev.a. M1. En faisant tendre t ! +1 suivant les entiers on voit, par Fatou, que
E((M1 �Ms)2) < "
donc Ms ! M1 dans L2. Si on applique l’inegalite de Doob a la martingale Nt =Ms+t �Ms on obtient
E(suptT
(Mt+s �Ms)2) 4E((MT+s �Ms)
2) 4"
pour tout T � 0, doncE(sup
t�0
(Mt+s �Ms)2) 4".
Il en resulte en ecrivant que
(Mt+s �M1)2 2(Mt+s �Ms)2 + 2(Ms �M1)2
queE(sup
t�0
(Mt+s �M1)2) 16".
Il existe donc une sous suite ni telle que, p.s., supt�0
(Mt+ni � M1) ! 0, ce quientraine que Mt ! M1, p.s. ⇤
On aurait aussi l’analogue du theoreme d’arret, que nous ne demontrons pas:
Corollaire 4.5.4 Soient {Mt, n 2 N} une (sous) martingale continue a droite � et⌧ deux temps d’arret. On suppose que � est borne. Alors
E(M�| F⌧ ) � M�^⌧

4.6 Martingale locale 39
4.6. Martingale locale
Revenons au cas du temps discret. Attention qu’en temps continu la situation seraplus compliquee. On fixe un espace de probabilite filtre (⌦,Fn, n 2 N,P).
Definition 4.6.1 1. Une martingale generalisee est une suite adaptee Mn telle queE(|Mn||Fn�1
) < +1 et E(Mn|Fn�1
) = Mn�1
.
2. Un processus adapte M est une martingale locale si il existe une suite ⌧n crois-sante de temps d’arret tels que M ⌧n � M
0
soit pour chaque n une martingale et⌧n ! +1, p.s.
Theoreme 4.6.2 On considere un processus adapte a temps discret {Mn, n � 0}.Les conditions suivantes sont equivalentes:
a) M est une martingale locale,
b) M est une martingale generalisee,
c) M�M0
est une integrale stochastique par rapport a une martingale, i.e. M = X?Vpour une martingale V et un processus previsible X, fini p.s.
d) M � M0
est une integrale stochastique par rapport a une martingale locale, i.e.M = X ? V pour une martingale locale V et un processus previsible X fini p.s.
Preuve: Remarquons que Mn est un martingale generalisee ssi Mn �M0
l’est. Sansperte de generalite, on peut supposer que M
0
= 0 pour montrer le theoreme.a =) b: Sur {⌧k > n} 2 Fn, M ⌧k etant une martingale,
E(|Mn+1
||Fn) = E(|M ⌧kn+1
||Fn) < +1
etE(Mn+1
|Fn) = E(M ⌧kn+1
|Fn) = Mn,
puisque, p.s., ⌦ = [k2N{⌧k > n} on en deduit que M est une martingale generalisee.b =) c: Si M est une martingale generalisee, posons
Akn = {E(|�Mn||Fn�1
) k}
AlorsUn =
X
k�0
2�k1Akn
est strictement positif p.s. et previsible. On verifie que V = U ?M est une martingale:en ecrivant que �Vn = Un�Mn on a
E(|�Vn|) = E(E(Un|�Mn||Fn�1
) = E(UnE(|�Mn||Fn�1
))

40 Calcul stochastique a temps discret
X
k�0
2�kE(1AknE(|�Mn||Fn�1
)) X
k�0
2�kk < +1
et,E(�Vn|Fn�1
) == E(UnE(�Mn|Fn�1
)) = 0
car E(�Mn|Fn�1
) = 0. Puisque
M =1
U? (U ?M)
on a bien la representation avec X = 1/U .c =) a: Si M = X ? V ou V est une martingale, posons
⌧k = inf{n � 0; |Xn+1
| > k};
c’est une suite de temps d’arret croissante vers +1 car X est previsible. On a
M ⌧kn =
nX
r=1
1{r⌧k}Xr�Vr
qui est une martingale.c =) d est evident,d =) a: Si M = X ? V pour une martingale locale V , par c) applique a V ,
il existe une martingale W et un processus previsible Z tels que V = Z ?W . AlorsM = X ? (Z ?W ) = (XZ)?W , donc M est une martingale locale (puisque c =) a).
Lemme 4.6.3 Soit Mn, 0 n N , une martingale locale. Si MN est integrable,alors Mn, 0 n N , est une martingale.
Preuve: On a MN�1
= E(MN |FN�1
) puisque Mn est une martingale generalisee.Donc
E(|MN�1
|) E(E(|MN ||FN�1
)) = E(|MN |) < +1
par recurrence chaque Mn est integrable, ce qui montre que c’est une martingale.
Proposition 4.6.4 Soit Mn, 0 n N , une martingale locale positive. Alors, pourtout n � p 2 N,
E(Mn|Fp) = Mp < +1.
C’est une martingale si et seulement si M0
est integrable.
Preuve: Mn est une martingale generalisee. Si Mn � 0,
E(Mn|Fn�2
) = E(E(Mn|Fn�1
)|Fn�2
) = E(Mn�1
|Fn�2
) = Mn�2
etc...

4.6 Martingale locale 41
Il faut faire attention au fait suivant: pour une martingale generalisee il se peutque E(|Mn||Fn�k) = +1 pour k > 1 et donc E(Mn|Fn�k) peut ne pas etre egal aMn�k. A cause de cette remarque la notion de martingale locale sera beaucoup plusdelicate en temps continu.
Exemple: Prenons F0
= {;,⌦},F1
= �(X),F2
= �(X,Y ), ou X et Y sontindependantes avec Y 2 L1,E(Y ) = 0 et X � 0 fini, tel que E(X) = +1. Alorsla suite M
0
= 0,M1
= 0,M2
= XY est une martingale locale car
E(|XY ||F1
) = |X|E(|Y ||F1
) = |X|E(|Y |) < +1
etE(XY |F
1
) = XE(Y |F1
) = XE(Y ) = 0
alors que E(|XY ||F0
) = E(|XY |) = E(|X|)E(|Y |) = +1.

42 Calcul stochastique a temps discret

Chapitre 5
Controle stochastique a horizonfini
Le but de ce chapitre est de presenter l’algorithme clef du controle stochastique a hori-zon fini en temps discret: l’algorithme de la programmation dynamique. Nous com-mencerons par presenter le cadre du controle des systemes deterministes et stochas-tiques. Ensuite nous decrirons cet algorithme. Enfin nous presenterons un certainnombre d’exemples.
5.1. Systemes dynamiques a temps discret
5.1.1. Systeme dynamique controle deterministe
On considere un “systeme” evoluant avec le temps, le temps etant discret, representepar un entier n = 0, 1, · · · . Son etat a l’instant n est represente par un element xn d’unespace E. On dit que ce systeme est regi par un systeme dynamique (deterministe)si il existe pour tout entier n 2 N une fonction fn : E ! E telle que
xn+1
= fn(xn).
La connaissance de l’etat a un instant su�t pour decrire son evolution future. Parexemple, on peut modeliser ainsi un systeme mecanique simple et son etat peut etrele vecteur position-vitesse.
Imaginons maintenant que l’on peut a chaque instant agir sur ce systeme. L’evo-lution se decrit alors par
xn+1
= fn(xn, un)
ou un, a valeurs dans un ensemble C, est un parametre de controle que l’on peutchoisir, a l’instant n, pour modifier l’evolution du systeme. On dit que l’on a unsysteme dynamique deterministe controle. Par exemple, si xn represente l’etat d’unefusee, un peut etre la quantite de carburant que l’on injecte dans le moteur a l’instantn. On parle aussi de commande a la place de controle.

44 Controle stochastique a horizon fini
5.1.2. Systeme dynamique aleatoire
Considerons maintenant un systeme soumis a des perturbations aleatoires {"n, n 2 N}definies sur un espace de probabilite (⌦,F ,P) a valeurs dans un ensemble W , munid’une tribu W. Commencons par considerer un systeme dynamique non controle. Acause des perturbations aleatoires, l’etat est une variable aleatoire que l’on noteraXn, a valeurs dans E muni d’une tribu E . L’equation d’evolution est de la forme
Xn+1
= 'n(Xn, "n), 8n 2 N (5.1)
ou 'n : E⇥W ! E est mesurable. Supposons que les variables aleatoires {"n, n 2 N}sont independantes et de meme loi µ et independantes de l’etat initial X
0
, on dit alorsque l’on a un systeme dynamique aleatoire. Posons, pour x 2 E et A 2 E ,
Pn(x,A) = P('n(x, "n) 2 A) = µ{w 2 W ;'n(x,w) 2 A}.
Definition 5.1.1 On appelle probabilite de transition ou noyau de transition sur(E, E) une famille
P (x,A), x 2 E,A 2 E ,
telle que• Pour tout x 2 E, A 7! P (x,A) est une probabilite sur (E, E).• Pour tout A 2 E, x 7! P (x,A) est mesurable.
On voit donc que chaque Pn defini plus haut est une probabilite de transition.
Definition 5.1.2 Etant donne une suite (Pn) de probabilites de transition sur (E, E),une suite de variables aleatoires Xn, n � 0, a valeurs dans E est appelee chaıne deMarkov inhomogene si pour tout A 2 E et n 2 N,
E(1A(Xn+1
)|�(X0
, · · ·Xn)) = Pn(Xn, A).
Si Pn ne depend pas de n on dit que Xn est une chaıne de Markov.
Lorsque Xn est une chaine de noyau Pn on notera
E(1A(Xn+1
)|Xn = x) = Pn(x,A),
meme si P(Xn = x) = 0. C’est donc seulement une notation.
Proposition 5.1.3 La suite {Xn, n 2 N} definie par (5.1) est une chaıne de Markovinhomogene de probabilites de transition (Pn).
Preuve: Remarquons par recurrence que Xn est une fonction de X0
, "0
, · · · , "n�1
.C’est clair pour n = 0 et si Xn = fn(X0
, "0
, · · · , "n�1
) alors
Xn+1
= �n(Xn, "n) = �n(fn(X0
, "0
, · · · , "n�1
), "n).

5.1 Systemes dynamiques a temps discret 45
On en deduit que "n est independant de �(X0
, · · · , Xn). Comme Xn est trivialementmesurable par rapport a cette tribu, on peut appliquer le resultat fondamental surl’esperance conditionnelle (Proposition 3.4.2), pour ecrire que
E(1A(Xn+1
)|�(X0
, · · ·Xn))(!) = E(1A(�n(Xn, "n))|�(X0
, · · ·Xn))(!) =
= E(1A(�n(Xn(!), "n)) = Pn(Xn(!), A). ⇤En fait, on peut montrer que la reciproque de cette proposition est aussi vraie...
Mais nous ne l’utiliserons pas. L’avantage de la formulation avec les chaines deMarkov est que l’on n’a pas besoin de definir les "n, ce qui peut simplifier la phasede modelisation.
Introduisons l’importante notation suivante: si P est une probabilite de transitionsur E et f : E ! R+ est mesurable on pose, pour x 2 E,
Pf(x) =
Z
Ef(y)P (x, dy).
Proposition 5.1.4 Si Xn est une chaıne de Markov inhomogene de noyaux(Pn), pour f : E ! R+ mesurable,si pour tout A 2 E et n 2 N,
E(f(Xn+1
)|�(X0
, · · ·Xn)) = Pnf(Xn).
Preuve: Lorsque f = 1A c’est la definition. Par linearite, ceci reste vrai pour unefonction etagee f =
Pnk=1
ak1Ak , puis en utilisant le theoreme de Lebesgue monotone,pour toute fonction mesurable positive (car elle est limite croissante d’une suite defonctions etagees)
La encore, on notera
E(f(Xn+1
)|Xn = x) = Pnf(x),
meme si P(Xn = x) = 0.
5.1.3. Systeme dynamique controle aleatoire
Considerons maintenant le cas d’un systeme dynamique controle perturbe par la suite("n). On a alors, pour tout n 2 N
Xn+1
= 'n(Xn, Un, "n), 8n 2 N
ou'n : E ⇥ C ⇥W ! E
et ou Un est un controle eventuellement aleatoire, a valeurs dans un ensemble C munid’une tribu C et �n est mesurable. Interpretant l’indice n comme un indice de temps,nous demandons que Un soit une fonction mesurable de (X
0
, · · · , Xn), autrement ditle choix de Un se fait au plus tard a l’instant n et sans connaitre le futur.

46 Controle stochastique a horizon fini
Definition 5.1.5 On dit que {Un, n 2 N} est une suite de controles si, pour toutn � 0, Un est �(X
0
, · · · , Xn)-mesurable, ou, ce qui est equivalent, si il existe unesuite d’applications mesurables ⌫n : En+1 ! C telles que
Un = ⌫n(X0
, · · · , Xn).
La suite d’applications ⌫ = {⌫n, n � 0}, s’appelle une strategie ou une politique(mot ”franglais” de l’anglais policy).
Resumons: On a acces a l’instant n a l’etat Xn. En fonction de cet etat, et desprecedents, on peut prendre le controle Un, ce qui va nous aider a realiser un but.Par contre "n, lui, n’est pas Xn -mesurable: on ne le connait pas a l’instant n, etc’est une perturbation qui va plutot nous gener. Comme dans le cas d’un systemealeatoire, on va avoir interet a se donner un cadre abstrait pour decrire cette situation.Commencons par un calcul.
Proposition 5.1.6 Posons P (u)n (x,A) = P(�n(x, u, "n) 2 A), pour x 2 E, u 2
C,A 2 E et n � 0. Alors
E(1A(Xn+1
)|�(X0
, · · ·Xn)) = P (Un)n (Xn, A).
Preuve: La preuve est similaire a celle de la Proposition 5.1.3: par recurrence (Xn, Un)est �(X
0
, "0
, · · · , "n�1
)–mesurable. Donc (Xn, Un) est �(X0
, · · · , Xn)-mesurable alorsque "n est independant de cette tribu. On peut appliquer la Proposition 3.4.2 pourecrire que
E(1A(Xn+1
)|�(X0
, · · ·Xn))(!) = E(1A(�n(Xn, Un, "n))|�(X0
, · · ·Xn))(!) =
= E(1A(�n(Xn(!), Un(!), "n)) = PUn(!)n (Xn(!), A). ⇤
Ceci nous amene a un cadre general:
Definition 5.1.7 On appelle modele markovien controle une famille
P (u)n (x,A), n 2 N, u 2 C, x 2 E,A 2 E
de probabilites de transition sur E telle que pour A 2 E, (x, u) 7! P (u)n (x,A) est
mesurable.
Lorsque P (u)n (x,A) ne depend pas de n et on le notera simplement P (u)(x,A).
Etant donne un modele markovien controle, on associe a toute strategie ⌫ = (⌫0
, ⌫1
, · · · )un processus Xn de la facon suivante: X
0
est arbitraire. Conditionnellement a
(X0
, · · · , Xn),
la v.a.Xn+1
suit la loi P (Un)(Xn, .), ou Un = ⌫n(X0
, · · · , Xn), ce qui signifie precisementque
E (1A(Xn+1
)/�(X0
, · · · , Xn)) = P (Un)n (Xn, A). (5.2)

5.1 Systemes dynamiques a temps discret 47
pour tout A de E . Ceci est bien defini car Un ne depend que de X0
, · · · , Xn. Onnotera P⌫x la loi de ce processus lorsque X
0
= x avec probabilite 1, pour mettre enevidence la dependance par rapport a la strategie (⌫). On utilisera la notation E⌫xpour l’esperance. Exactement comme dans la proposition 5.1.4, on a
Lemme 5.1.8 Pour toute fonction f : E ! R mesurable et positive ou bornee,
E⌫x (f(Xn+1
)|�(X0
, · · · , Xn)) = P (Un)n f(Xn).
Ces proprietes definissent completement la loi du processus Xn, comme le montrela proposition suivante.
Proposition 5.1.9 Si � : En ! R+ est mesurable
E⌫x0(�(X
1
, X2
, · · · , Xn)) =
Z
E
Z
E· · ·Z
E�(x
1
, · · · , xn)P ⌫0(x0)
0
(x0
, dx1
)P ⌫1(x0,x1)
1
(x1
, dx2
) · · ·P ⌫n�1(x0,··· ,xn�1)
n�1
(xn�1
, dxn).
Preuve: Par recurrence sur n. Par le theoreme de la classe monotone il su�t demontrer ce resultat lorsque � est une fonction produit c’est a dire du type
�(X1
, X2
, · · · , Xn) = f1
(X1
) · · · fn(Xn).
On sait (cf Lemme 5.1.8) que
E⌫x(fn(Xn)|�(X0
, · · · , Xn�1
)) = P (Un�1)
n�1
fn(Xn�1
).
On a donc
E⌫x(�(X1
, X2
, · · · , Xn)) = E⌫x [E⌫x(f1(X1
) · · · fn(Xn)|�(X0
, · · · , Xn�1
))]
= E⌫x [f1(X1
) · · · fn�1
(Xn�1
)E⌫x(fn(Xn)|�(X0
, · · · , Xn�1
))]
= E⌫xhf1
(X1
) · · · fn�1
(Xn�1
)P (Un�1)
n�1
fn(Xn�1
)i
Supposons donc que la proposition soit vraie au rang n � 1 et appliquons la a lafonction
g(x1
, · · · , xn�1
) = f1
(x1
) · · · fn�1
(xn�1
)P ⌫n�1(x0,x1,··· ,xn�1)
n�1
fn(xn�1
).
On obtientE⌫x(�(X1
, · · · , Xn�1
, Xn)) =Z· · ·Z
f1
(x1
) · · · fn�1
(xn�1
)P un�1(x0,x1,··· ,xn�1)
n�1
fn(xn�1
)P u0(x0)
0
(x0
, dx1
)P u1(x0,x1)
1
(x1
, dx2
) · · ·
· · ·P un�1(x0,··· ,xn�2)
n�1
(xn�2
, dxn�1
)

48 Controle stochastique a horizon fini
donc ce que l’on cherche puisque
P un�1(x0,x1,··· ,xn�1)
n�1
fn(xn�1
) =
Zfn(xn)P
un�1(x0,x1,··· ,xn�1)
n�1
(xn�1
, dxn). ⇤
Si E est denombrable, pour tout noyau de transition P , on pose pour x, y 2 E,
P (x, y) = P (x, {y}).
La proposition precedente se simplifie dans ce cas:
Lemme 5.1.10 Si E est denombrable,
P(⌫)x (X
0
= x,X1
= x1
, · · · , Xn = xn) = P (u0)
0
(x, x1
)P (u1)
1
(x1
, x2
) · · ·P (un�1)
n�1
(xn�1
, xn),
ou u0
, u1
, · · · sont les valeurs de U0
, U1
, · · · lorsque X0
= x,X1
= x1
, · · · .
5.1.4. Strategies markoviennes
Par definition une suite de controle (Un) est telle que chaque Un est une fonctionde X
0
, · · · , Xn. Nous allons voir qu’on peut le plus souvent se restreindre au cas ou,pour tout n, Un ne depend en fait que de Xn seulement, c’est a dire s’ecrit sous laforme
Un = ⌫n(Xn)
ou ⌫n : E ! C. On parle parfois de controle en feedback (ou closed loop) pour insistersur le fait qu’il depend de l’etat.
Definition 5.1.11 On appelle strategie markovienne une telle suite d’applications⌫n : E ! C. Si ⌫n ne depend pas de n on l’appelle strategie stationnaire.
Proposition 5.1.12 Si le controle (Un) est defini par la strategie markovienne (⌫n)(c’est a dire Un = ⌫n(Xn)) alors Xn est une chaıne de Markov inhomogene de prob-abilites de transition
Pn(x,A) = P (⌫n(x))n (x,A)
Si ni ⌫n, ni P(u)n (x,A) ne dependent de n alors Xn est une chaıne de Markov.
Notation: Si ⌫ : E ! C est une application on posera
P ⌫n (x,A) = P (⌫(x))
n (x,A).

5.2 Programmation dynamique 49
5.2. Programmation dynamique
Considerons un modele markovien controle. Un entier N etant fixe, appele parfoishorizon, on cherche a choisir une suite de controles U
0
, · · · , UN�1
de facon a minimiserun cout. Ce cout est choisi de la forme
E(N�1X
k=0
ck(Xk, Uk) + �(XN ))
ou ck : E⇥C ! R[{+1}, � : E ! R[{+1} (voir les exemples ensuite). Nous allonsvoir que cette question admet une reponse sous la forme d’un algorithme tres facile aimplanter sur ordinateur (par contre il est en general di�cile et de toute facon souventinutile d’obtenir une solution “explicite”). Ceci a ete montre par Bellman dans lesannees 50. Cet algorithme a divers noms: programmation dynamique, algorithme derecurrence retrograde (ou backward), principe d’optimalite... On pose
J(x) = min⌫
E⌫x(N�1X
k=0
ck(Xk, Uk) + �(XN )),
le minimum etant pris sur toutes les strategies ⌫ = (⌫0
, · · · , ⌫N�1
).
Theoreme 5.2.1 (Programmation dynamique) Posons JN (x) = �(x), puis suc-cessivement pour n = N � 1, N � 2, · · · , 1, 0,
Jn(x) = minu2C
{cn(x, u) + P (u)n Jn+1
(x)}.
On suppose que tout est integrable et que le minimum sur u est atteint en u = ⌫n(x).Alors J
0
(x) = J(x) et Un = ⌫n(Xn), n = 0, · · · , N � 1, est la strategie optimalecorrespondante.
Preuve: Considerons une strategie arbitraire ⌫. Nous allons utiliser l’egalite, pourtout n < N ,
E⌫x(Jn(Xn)� Jn+1
(Xn+1
)/�(X0
, · · · , Xn)) = Jn(Xn)� P (Un)n Jn+1
(Xn).
Ecrivons (somme telescopique)
J0
(X0
) =N�1X
n=0
(Jn(Xn)� Jn+1
(Xn+1
)) + JN (XN )

50 Controle stochastique a horizon fini
En utilisant que l’esperance est l’esperance de l’esperance conditionnelle, et le faitque J
0
(x) = E⌫x(J0(X0
)), on en deduit que:
J0
(x) = E⌫x[N�1X
n=0
(Jn(Xn)� Jn+1
(Xn+1
)) + JN (XN )]
=N�1X
n=0
E⌫x[E⌫x[(Jn(Xn)� Jn+1
(Xn+1
))/�(X0
, · · · , Xn)]] + E⌫x[JN (XN )]
=N�1X
n=0
E⌫x[Jn(Xn)� P (Un)n Jn+1
(Xn)] + E⌫x[�(XN )]
E⌫x[N�1X
n=0
cn(Xn, Un)) + �(XN )].
car Jn(x)�P (u)n Jn+1
(x) cn(x, u). On a egalite si Un = ⌫n(Xn), pour n = 0, · · · , N�1. Ceci prouve le theoreme.
On interprete cet algorithme en disant qu’a l’instant n, je minimise la somme demon cout a cet instant et de ce que je peux savoir a cet instant de mon cout futur.On montrerait de la meme facon que, pour tout z 2 E,
Jn(x) = min⌫
E⌫z(N�1X
k=n
ck(Xk, Uk) + �(XN )|Xn = x)
Remarquons que le controle optimal est une strategie markovienne (Un ne dependque de l’etat Xn). En appliquant la formule max{xi, i 2 I} = �min{�xi, i 2 I} ouen changeant partout min par max dans ce qui precede on a immediatement:
Theoreme 5.2.2 (Programmation dynamique pour le max) Posons JN (x) =�(x), puis successivement pour n = N � 1, N � 2, · · · , 1, 0,
Jn(x) = maxu2C
{cn(x, u) + P (u)n Jn+1
(x)}.
On suppose que tout est integrable et que le maximum sur u est atteint en ⌫n(x).Alors
J0
(x) = max⌫
E⌫x(N�1X
k=0
ck(Xk, Uk) + �(XN )),
et Un = ⌫n(Xn), n = 0, · · · , N � 1, est la strategie optimale correspondante.
5.3. Premiers Exemples
5.3.1. Cas deterministe
L’algorithme de la programmation dynamique est deja interessant lorsque qu’il n’ya pas d’aleatoire, donc pour les modeles du type xn+1
= fn(xn, un). On l’emploie

5.3 Premiers Exemples 51
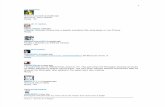
surtout pour les modeles discrets, en l’absence de structure di↵erentiable, car sinonbien d’autres methodes d’optimisation sont possibles (calcul des variations, methodedu gradient,...). Un exemple classique est celui consistant a trouver le plus courtchemin entre deux points. Donnons l’exemple de la “course au tresor”. Chacune desvilles A, B, C, D, E possede un tresor (respectivement 6, 5, 7, 4, 3). Partant de la villeO, et connaissant les couts de transports indiques sur la figure, il faut determiner laroute optimale. La solution est decrite ci dessous (avec une erreur a trouver !).
Figure 5.1: Tresor (avec erreur)
5.3.2. Remarque fondamentale sur la complexite
Il y a evidemment une autre methode pour la course au tresor: on calcule le coutsur tous les chemins et on prend le minimum sur tous ces couts! Imaginons quecette course ne dure pas comme au dessus 5 unites de temps mais N = 5000 lenombre de chemins est de l’ordre de 2N c’est a dire a peu pres 101500 (car 210 ⇠ 103)donc infaisable meme sur un gros ordinateur. Par contre avec Bellman le nombred’operations est de l’ordre de N+(N�1)+ · · ·+1 ⇠ N2/2 en gros. sans comparaison! On retrouvera souvent ce genre de simplification (cf Markov cachees, par exemple).
5.3.3. Remplacement de machines
Notons {0, 1, · · · ,K} les etats dans lesquels peut etre une machine. L’etat 0 corre-spond a une machine neuve, et les autres a des etats de veillissement ou d’usuredi↵erents. L’etat Xn a l’instant n est une v.a. aleatoire. Nous supposons que, enl’absence d’intervention exterieure, l’evolution est markovienne, et nous posons
P (i, j) = P(Xn+1
= j/Xn = i), 0 i, j K.

52 Controle stochastique a horizon fini
Maintenir en marche une machine usagee demande de l’entretien, donc un cout: onnote ↵(i) ce cout en l’etat i. On a aussi la possibilite de changer a chaque instant cettemachine a un cout R et d’obtenir ainsi une machine neuve. On veut decrire la strategieoptimale de maintenance dans l’intervalle de temps [0, N ], en calculant les momentsles meilleurs ou il faut renouveller cette machine. Commencons par modeliser ceprobleme sous forme de controle optimal markovien. Prenons un controle a deuxvaleurs: u = 0 si l’on ne fait rien, u = 1 si on renouvelle. On pose P (0) = P alors queP (1)(i, 0) = 1 et P (1)(i, j) = 0, si j > 0, puisque apres renouvellement la machine setrouve en l’etat 0. Le cout est donne par
c(i, 0) = ↵(i), c(i, 1) = R, �(i) = ↵(i).
On aurait pu choisir une autre condition finale, ceci depend de la situation concretemodelisee. Decrivons l’algorithme de la programmation dynamique. D’abord JN (i) =↵(i), ensuite
Jn(i) = minu2{1,0}
{c(x, u) + P (u)Jn+1
(i)}
= min{R+ Jn+1
(0),↵(i) +KX
j=0
P (i, j)Jn+1
(j)}.
Cette formule est facile a implementer sur machine. Supposons maintenant que ↵(i)et P (i, [j,K]) soient des fonctions croissantes de i, ce qui traduit exactement l’ideeque plus i est grand, plus la machine est usee. La deuxieme condition assure que sif(i) est une fonction croissante de i, alors Pf(i) =
PKj=0
P (i, j)f(j) l’est aussi, ene↵et
Pf(i) =K�1X
j=0
(P (i, [j,K])� P (i, [j + 1,K]))f(j) + P (i, [K,K])f(K)
= P (i, [0,K])f(0) +KX
j=1
(P (i, [j,K])(f(j)� f(j � 1)).
Par recurrence, il resulte de cette remarque que Jn(i) est une fonction croissante de i,pour tout 0 n N (ce qui est assez intuitif). Posons �n(i) = ↵(i) + PJn(i). Cettefonction est croissante. Soit alors
an = inf{i;R+ Jn+1
(0) �n+1
(i)}.
La strategie consiste a renouveller la machine au temps n des que son etat est � an.On determine les an par un calcul sur machine.
5.3.4. Gestion de stock
Le gestionnaire d’un magasin doit tous les soirs adapter son stock en commandanteventuellement une quantite d’un article pour satisfaire la demande des clients.

5.3 Premiers Exemples 53
Le cout pour produire x unites est ax. Chaque client achete une unite. La demande(nombre de clients par jour) est une suite de v.a. independantes, de meme loi µ.Garder en stock une unite coute h par unite gardee jusqu’a la fin de la journee, et ladeception du client qui ne peux plus acheter car il n’y a plus d’articles coute p parunite non donnee.
Si au depart (le soir ) la taille du stock est s, si l’on commande u unites, u � 0,et si il y a w clients (le lendemain) le cout le lendemain soir, sera
C(s, w, u) = au+ p(w � s� u)+ + h(s+ u� w)+
Pour faire un modele controle, on doit se debarrasser de W dans la fonction cout. onpeut proceder ainsi: on note Sk la taille du stock signe (il peut etre negatif) le soirdu jour k, Wk le nombre de clients le jour k + 1 et le cout total est
CN = E(N�1X
k=0
C(Sk,Wk, Uk))
Si on reecrit le cout de la facon suivante:
CN =N�1X
k=0
E(C(Sk,Wk, Uk))
=N�1X
k=0
E(Z
C(Sk, w, Uk) dµ(w))
= E(N�1X
k=0
ZC(Sk, w, Uk) dµ(w))
On voit donc que si l’on pose Xk = Sk et c(x, u) =RC(x,w, u) dµ(w)) on a un modele
markovien controle. Il etait peut etre plus naturel de poser Xk = (Sk,Wk) mais alorson ne serait pas exactement dans notre modele de controle, car le point initial seraitaleatoire (il ne serait pas tres di�cile de generaliser a ce cas). Pour simplifier l’analysenous allons supposer qu’il y a ”backlog”, c’est a dire que les clients non servis restenten attente, jusqu’a satisfaction. Autrement dit on pose
X1
= X0
+ u�W0
ou W0
est une v.a. aleatoire independante de loi µ. (si on avait voulu modeliserla situation ou les clients non satisfaits repartent immediatement. On aurait poseX
1
= (X0
+ u�W0
)+).
5.3.5. Une solution explicite
Utilisons l’algorithme de Bellman, avec ici
JN (x) = 0

54 Controle stochastique a horizon fini
puis
Jn(x) = minu�0
[c(x, u) + E(Jn+1
(x+ u�W ))]
ou W est une v.a. de loi µ et
c(x, u) = E[au+ p(W � x� u)+ + h(x+ u�W )+].
Proposition 5.3.1 On suppose que p, h � 0 et p > a > 0. On peut determiner unesuite �n telle que la decision optimale est un(x) = (�n � x)+.
Preuve: On pose
gn(x) = L(x) + E(Jn+1
(x�W ))
ou
L(x) = ax+ pE(W � x)+ + hE(x�W )+
Alors
Jn(x) = minu�0
gn(u+ x)� ax.
Remarquons que Jn+1
� 0 (car c’est un minimum de quantites positives) et que,puisque p > a,
limx!±1
L(x) = +1
on a donc
limx!±1
gn(x) = +1
Montrons par recurrence retrograde sur n N que Jn est convexe. C’est trivial pourJN qui est la fonction identiquement nulle. Supposons Jn+1
convexe. Les fonctionsx+ et (�x)+ etant convexes, on voit que L est convexe; donc gn est convexe. Notons�n le (plus petit) point ou la fonction gn atteint son minimum. Alors
Jn(x) = gn(�n)� ax, et un(x) = �n � x, si x �n
et
Jn(x) = gn(x)� ax et un(x) = 0, si x � �n
en notant un(x) le controle pour lequel le minimum est atteint. Cette fonction Jn estbien convexe (faire le dessin) et on a
un(x) = (�n � x)+.

5.4 Arret optimal 55
5.4. Arret optimal
5.4.1. Introduction
Considerons les systemes que l’on ne peut controler que de la facon suivante: achaque instant on decide de continuer ou d’arreter. Il s’agit de trouver le momentoptimal pour s’arreter: on parle d’arret optimal. Ce moment ne doit dependre quede l’observation passee ou presente (on ne peut anticiper l’avenir), c’est pourquois’introduisent naturellement les temps d’arret. Donnons quelques exemples: un joueurdoit decider du moment ou il quitte le jeu. Un particulier vend sa maison, desacheteurs successifs proposent un prix. A chaque fois, le vendeur peut vendre a ceprix, mais un prix refuse ne se represente pas. Il faut choisir le meilleur moment pourvendre. Vous vous dirigez en voiture vers un but, en cherchant a vous garer le pluspres de ce but. Vous ne pouvez pas faire demi tour: si vous ne profitez pas d’une placevide quand vous passez devant, vous ne la retrouverez pas. Si vous avez une bonnemodelisation de l’evolution d’un cours de bourse, a quel moment acheter (ou vendre)une action ? (Ce probleme a une version plus realiste: a quel moment exercer uneoption americaine ?).
Le probleme general est le suivant: Etant donne une suite de v.a.r. adaptee (Zn)a une filtration (Fn) integrables, et N > 0 fixe, trouver
supE(Z�)
le sup etant pris sur l’ensemble des temps d’arrets � N . On dit qu’un temps d’arret� est optimal si il realise le sup.
On peut resoudre ce probleme de deux facons, soit parfois en utilisant l’enveloppede Snell, soit en utilisant le cadre Markovien.
5.4.2. Enveloppe de Snell d’une suite adaptee
Fixons un horizonN > 0. Soit Zn, 0 n N, une suite de v.a.r. integrables adaptee aune filtration (Fn). Definisssons par recurrence descendante une suite Un, 0 n N ,par les egalites
UN = ZN , Un = max(Zn,E(Un+1
|Fn)), n = N � 1, N � 2, · · · , 1
La suite (Un) est une surmartingale majorant (Zn) (et c’est la plus petite) appeleeenveloppe de Snell de (Zn).
Proposition 5.4.1 Posons
⌧ = inf{n � 0;Un = Zn};
⌧ est un temps d’arret et U ⌧n est une martingale.

56 Controle stochastique a horizon fini
Preuve: On a �U ⌧n = 1{n⌧}�Un. Sur l’evenement {n ⌧}, Un�1
est strictementsuperieur a Zn�1
par definition de ⌧ , de sorte que Un�1
= E(Un|Fn�1
). On a donc�U ⌧
n = 1{n⌧}(Un � E(Un|Fn�1
)). On en deduit que
E(�U ⌧n |Fn�1
) = 1{n⌧}E(Un � E(Un|Fn�1
)|Fn�1
) = 0
Rappelons qu’un temps d’arret � est optimal si il realise supE(Z�) sur les tempsd’arret � N .
Proposition 5.4.2 Soit (Un) l’enveloppe de Snell de (Zn). Le temps d’arret
⌧ = min{n � 0;Un = Zn}
est optimal et c’est le plus petit p.s.
Preuve: Pour tout temps d’arret � N on a (en utilisant dans l’ordre le fait queU ⌧ est un martingale, le fait que U est une surmartingale et l’inegalite U� � Z�),
E(Z⌧ ) = E(U⌧ ) = E(U0
) � E(U�) � E(Z�)
Donc ⌧ est optimal. Si � est optimal, E(Z�) = E(U�) donc p.s. Z� = U� d’ou ⌧ �.
5.4.3. Cadre markovien
Soit {Xn, n 2 N} une (”vraie”) chaıne de Markov inhomogene de noyaux de transitionPn(., .) sur un espace F muni d’une tribu F . Rappelons que si f : F ! R+ estmesurable,
E[f(Xn+1
)|�(X0
, · · · , Xn)] = Pnf(Xn).
Pour tout entier n � 0, donnons nous une fonction �n : F ! R representant le gainde l’arret au temps n. On fixe un horizon N > 0 et on cherche
max{E(�⌧ (X⌧ )), ⌧ temps d’arret, ⌧ N}.
et le temps d’arret ⌧ realisant ce maximum, pour la filtration Fn = �(X0
, · · · , Xn).Le resultat est le suivant:
Theoreme 5.4.3 Posons pour tout x 2 E, JN (x) = �N (x), et
Jk(x) = max{�k(x), PkJk+1
(x)},
si 0 k < N . Alors
J0
(x) = max{E(�⌧ (X⌧ )/X0
= x), ⌧ t. d’a., ⌧ N}.
Un temps d’arret optimal est ⌧ = min{k � 0;�k(Xk) � PkJk+1
(Xk)} ^N .
Dans ce cadre Markovien, on peut pour montrer ce theoreme, soit adapter l’enveloppede Snell, soit appliquer directement la programmation dynamique.

5.4 Arret optimal 57
5.4.4. Approche du cas Markovien par l’enveloppe de Snell
L’enveloppe de Snell de la suite Zn = �n(Xn) est donnee par
UN = ZN = �N (XN )
puis, par recurrence retrograde,
Uk = max{Zk,E(Uk+1
|Fk)}.
On voit que la solution est Uk = Jk(Xk), ce qui montre le theoreme.
5.4.5. Approche du cas markovien par la programmation dynamique
C’est ici plus long et nous conseillons de ne pas la regarder ! le seul interet est devoir fonctionner cette programmation dynamique dans un cadre un peu complique.Associons donc a ce probleme un modele markovien controle. On ajoute a F un point�, parfois appele “cimetiere”. Soit E = F [ {�}. L’ensemble des controles C estun ensemble a deux points : C = {s, c}, s pour “stop” et c pour “continuer”. On
introduit les noyaux controles P (u)n (., .) par les formules suivantes: si x 2 F et A est
un sous ensemble mesurable de F ,
P (c)n (x,A) = Pn(x,A), P
(c)n (x,�) = 0, P (c)
n (�, A) = 0, P (c)n (�,�) = 1
qui signifient que si l’on decide de continuer, a moins d’etre deja “mort”, on suit lachaıne Xn, et
P (s)n (x,A) = 0, P (s)
n (x,�) = 1, P (s)n (�, A) = 0, P (s)
n (�,�) = 1.
Enfin on introduit les fonctions de perte cn de la facon suivante:
cn(x, u) = �n(x), si u = s et x 2 F, cn(x, u) = 0 sinon,
et la perte finale �(x) = �N (x), si x 2 E et �(�) = 0 . Associons a ce modele lachaıne controlee Xn a valeurs dans E (pour ne pas confondre avec Xn) qui verifie,elle,
E(⌫)(f(Xn+1
)|�(X0
, · · · Xn)) = P (Un)n f(Xn).
Lemme 5.4.4 La solution du probleme de controle markovien associe a ces donneesest celle de l’arret optimal. Autrement dit
max{E(�⌧ (X⌧ )), ⌧ t. d’a. , ⌧ N} = maxU0,··· ,UN�1
E(N�1X
k=0
ck(Xk, Uk) + �(XN )).

58 Controle stochastique a horizon fini
Preuve: Pour toute strategie (U) = U0
, U1
, · · ·UN�1
, posons UN = s et ⌧ = min{n N ;Un = s}. On peut supposer que, sous P(U), Xn = Xn si n ⌧ . Alors
N�1X
k=0
ck(Xk, Uk) + �(XN ) = �⌧ (X⌧ ) = �⌧ (X⌧ )
et ⌧ est un temps d’arret. Donc
max{E(�⌧ (X⌧ )), ⌧ t. d’a., ⌧ N} maxU0,··· ,UN�1
E(N�1X
k=0
ck(Xk, Uk) + �(XN )).
L’inegalite dans l’autre sens s’obtient en associant a un temps d’arret S les controlesdefinis par Un = s si et seulement si S = n.
En traduisant l’algorithme de la programmation dynamique on obtient bien letheoreme 5.4.3, en e↵et En e↵et, l’algorithme general s’ecrit
Jk(x) = maxu=s,c
{ck(x, u) + P (u)k Jk+1
(x)}.
Posons JN (�) = 0. Alors, par recurrence Jk(�) = 0,
ck(x, s) + P (s)k Jk+1
(x) = �k(x)
et
ck(x, c) + P (c)k Jk+1
(x) = PkJk+1
(x)
ce qui donne le theoreme.
5.4.6. Exemples
Proprietaire
Considerons par exemple le cas d’un proprietaire a qui on propose successivement lessommes X
0
, X1
, · · · , XN . Ces variables aleatoires sont supposees independantes et dememe loi. Quel acheteur choisir ? On cherche ici a maximiser. On voit que dans cecas JN (x) = x, puis
Jk(x) = max(x,E(Jk+1
(X0
)))
Il existe donc des seuils ↵0
, · · · ,↵N�1
, determines par ↵N�1
= E(X0
), puis la formulede recurrence ↵k = E(max(X
0
,↵k+1
)), tels que le proprietaire vend au premier instantn tel que le prix propose est superieur ou egal a ↵n. Il est interessant de regarder cequi se passe lorsque N ! +1.

5.4 Arret optimal 59
Secretaires
On considere N candidats a un poste de secretaire. Il s’agit de choisir le meilleur.On les auditionne les uns apres les autres. A la fin de chaque audition, on decidesi on embauche ce secretaire, ou si on essaye d’en trouver un autre meilleur. Lessecretaires sont classes par ordre de qualite. Ils ont donc un rang, qui va de 1 pour lemeilleur a N pour le moins bon. On ne connait pas ce rang, la seule chose que l’onpeut voir, c’est comment ce candidat se place parmi les precedents. Donc son rangrelatif par raport aux precedents. On note Xn le rang relatif du candidat n. DoncX
1
= 1, X2
2 {1, 2}, · · · , Xn 2 {1, · · · , n} ou Xn = k signifie que le n-ieme candidata le rang k parmi les n premiers.
La regle de base est qu’un candidat rejete est fache et s’en va. On ne pourra plusaller le rechercher. En d’autre termes la decision d’embauche est immediate.
On suppose que les candidats arrivent ”au hasard”, donc plus precisement queleur ordre est une permutation aleatoire sur un ensemble a n elements de loi uniforme.
Proposition 5.4.5 Les v.a. Xn sont independantes, Xn ayant la loi uniforme sur{1, · · · , n}
Preuve: Au temps n, conditionnellement a X1
, · · · , Xn, on connait l’ordre relatif desn premiers candidats, le nouveau peut se placer n’importe ou parmi eux. Il peut doncprendre n’importe quel rang, avec la meme probabilite, qui est donc 1/(n+ 1). (Onpeut aussi remarquer que la loi est invariante par les permutations des n premierselements, pour obtenir ce resultat).
On voit qu’en d’autre termes, la suite Xn, n 2 N est une chaine de Markov inho-mogene sur E = {1, · · · , N} de probabilites de transition donnee par
Pn(x, y) = 1/(n+ 1) si y = 1, · · · , n+ 1, Pn(x, y) = 0 si y > n+ 1.
On est donc bien dans le cadre Markovien. Cherchons a maximiser la probabilitede prendre le meilleur candidat. A l’instant n cette probabilite est nulle si le candidatn’a pas le rang relatif 1, et est egale sinon a la probablite que le meilleur de tous soitentre 1 et n donc a n/N puisque le meilleur est reparti uniformeement sur tous lescandidats. On pose donc
'n(x) =n
N1{x=1}.
et on cherchemax⌧N
E(�⌧ (X⌧ )).
L’algorithme donneJN (x) = 'N (x) = 1{x=1}
et pour k = N � 1, · · · , 1,
Jk(x) = max{'k(x), PkJk+1
(x)}.

60 Controle stochastique a horizon fini
Posons, pour k = 1, · · · , N � 1,
vk = PkJk+1
(x) = E(Jk+1
(Xk+1
)) =1
k + 1
k+1X
n=1
Jk+1
(n)
(il est independant de x). La recurrence s’ecrit JN (x) = 1{x=1} puis
Jk(x) = max{ k
N1{x=1}, vk}.
Notons, pour k = 1, · · · , N � 1,
wk =1
k+
1
k + 1+ · · ·+ 1
N � 2+
1
N � 1,
cette suite est decroissante et w1
> 1. Soit
k0
= max{n N � 1;wn > 1}.
Lemme 5.4.6 Pour tout k, vk = min(k,k0)N wmin(k,k0) et J1(x) =
k0N wk0.
Preuve: Montrons ceci par recurrence retrograde sur k. Cette relation est vraie pourk = N � 1 car wN�1
= 1
N�1
et
vN�1
=1
N
NX
x=1
JN (x) =1
N.
Si elle est vraie au rang k > k0
, alors par hypothese de recurrence vk = kNwk. On a
Jk(x) = max{ k
N1{x=1}, vk} = max{ k
N1{x=1},
k
Nwk}
donc, puisque wk 1, Jk(1) =kN et pour x > 1, Jk(x) =
kNwk. On a donc
vk�1
=1
k
kX
n=1
Jk(n) =1
k(k
N+ (k � 1)
k
Nwk) =
1
N+
k � 1
Nwk
=k � 1
N(wk +
1
k � 1) =
k � 1
Nwk�1
.
Traitons maintenant le cas ou k k0
par recurrence. On a deja vk0 = k0N wk0 par ce
qui precede. Si c’est vrai au rang k k0
,
Jk(x) = max{ k
N1{x=1}, vk} = max{ k
N1{x=1},
k0
Nwk0} =
k0
Nwk0
donc vk�1
= k0N wk0 .

5.4 Arret optimal 61
Proposition 5.4.7 Soit k0
= max{k;wk > 1}. Alors J0
(x) = k0N wk0 et la strategie
optimale consiste a voir les k0
premiers candidats, et a choisir ensuite le premier quiest meilleur que les precedents.
Preuve: En e↵et
Jk(x) = max{ k
N1{x=1},
max(k, k0
)
Nwmax k,k0}
Pour N assez grand
1
k+
1
k + 1+ · · ·+ 1
N � 2+
1
N � 1⇠
Z N�1
k
1
xdx ⇠ ln
N
k
donc le premier k tel que ceci soit 1 verifie a peu pres,
N
k= e
On voit donc a peu pres 1/e ⇠ 0.37 des candidats puis on prend le premier qui estmeilleur que ses precedents (faire le calcul pour N = 12 par exemple).. La probabilitede succes de cette strategie est a peu pres k
N ⇠ 1
e , donc assez grande.
Options americaines
Une option Call (resp. Put) americaine sur une action de prix Sn au jour n donne ledroit mais pas l’obligation d’acheter (resp. vendre) cette action au prix d’exercice Kjusqu’a la date T . Ce droit a un cout, le prix de l’action, C pour un Call, P pour unput, paye a la date 0. La theorie de Black et Scholes montre qu’il existe un R � 1 etun espace de probabilite (⌦,A,P) tel que, sous certaines conditions, R�nSn est unemartingale et
C = maxE(R�⌧ (S⌧ �K)+)
P = maxE(R�⌧ (K � S⌧ )+)
ou a chaque fois le maximum est pris sur tous les temps d’arrets ⌧ de la filtration Sn
inferieur ou egaux a T . Dans ces modelisations Sn est une chaıne de Markov. On estdans le cadre de l’arret optimal, qui s’applique directement, en posant, pour un Call
�n(x) = R�n(x�K)+
et pour un Put�n(x) = R�n(K � x)+.
Notons le resultat general suivant:
Lemme 5.4.8 Si (Zk) est une sous martingale, pour tout entier n � 0,
sup⌧n,⌧ t.d0a.
E(Z⌧ ) = E(Zn)

62 Controle stochastique a horizon fini
Preuve: Resulte du fait que, par le theoreme d’arret, E(Zn|F⌧ ) � Zn^⌧ .
Proposition 5.4.9 Pour un Call un temps d’exercice optimal est T .
Preuve: Il su�t de remarquer que R�n(Sn �K)+ est une sous martingale: En e↵et,puisque R�nSn est une martingale et puisque x+ � x on a, si m � n,
E(R�m(Sm �K)+|Fn) � E(R�m(Sm �K)|Fn)
� E(R�mSm|Fn)�R�mK � R�nSn �R�nK
puisque R � 1. Comme par ailleurs l’esperance conditionnelle cherchee est positive,on a bien qu’elle est superieure a R�n(Sn �K)+.

Chapitre 6
Marches a temps discret, AOA,completude
6.1. Modele Stock-Bond
Marche financier: (⌦,Fn, n N) et m mesure de reference �-finie ”naturelle” sur ⌦,par exemple mesure de comptage si ⌦ est fini ou denombrable, mesure de Lebesguesi ⌦ = Rd.
Definition 6.1.1 (Marche (S,B)) Actifs (sous jacents)
Sn, Bn, 0 n N,
avec B previsible strictement positif, B0
= 1 et S adapte (intuitivement valeur a lacloture a 17 h le jour n).
On peut considerer le cas ou Sn = (S1
n, · · · , Sdn) est un vecteur, mais nous nous lim-
iterons dans la suite (sauf cas contraire) au cas undimensionnel d = 1. La generalisationconsiste seulement le plus souvent a remplacer les expressions du type ↵S ou ↵ estun reel par le produit scalaire < ↵, S >.
S pour ”Stock”, exemple typique : action.B pour ”Bond”, exemple typique : placement sans risque (taux d’interet a court
terme comme le JJ).
Role de Bn, exemple Bn = (1 + r)n ou Bn = ern, prix actualises, changt denumeraire. Bn represente l’actualisation aujourd’hui, pour la date n.
Notation:
• actualises des actifsSn = Sn/Bn

64 Marches a temps discret, AOA, completude
• rendement
�Un =�Sn
Sn�1
=Sn � Sn�1
Sn�1
.
6.2. Portefeuille du marche (S,B) et autofinancement
6.2.1. Portefeuille
Le soir n je m’occupe de mon portefeuille, et la bourse est fermee. En fonctions desactifs du jour n je fabrique ce qui sera mon portefeuille pour toute la journee n+ 1.Je connais sa valeur le lendemain jour n+1 a l’ouverture, mais pas le soir n+1. Dansla journee je n’y touche plus mais la bourse evolue.
Strategie de gestion / portefeuille (portfolio)
Definition 6.2.1 On appelle portefeuille du marche (S,B) une suite previsible
(↵n,�n), 1 n N,
a valeur dans R2. La valeur du portefeuille (moralement a 17h 30 le jour n) est, pardefinition, au temps n,
Vn = ↵nSn + �nBn.
↵n et �n representent le nbre de parts des deux actifs que je possede pendant lajournee n. Je l’ai choisi la veille au soir, c’est donc previsible.
La valeur Vn du portefeuille represente la valeur a la fin de la journee n, sachantque le soir (disons apres 17 h 30, heure de cloture de la bourse) je peux decider dere–repartir mon portefeuille pour le lendemain entre les actifs. On commence le soirdu jour 0.
Notons que ↵n,�n peuvent etre negatifs, ce qui correspond a des emprunts ou desachats a decouverts (short selling en anglais).
6.2.2. Autofinancement
Placons nous le soir du jour n� 1. A la fermeture, 17 h.30, on a
Vn�1
= ↵n�1
Sn�1
+ �n�1
Bn�1
.
Le soir meme, (par exemple a 18 h) on repartit di↵eremment Vn�1
entre les deuxactifs (et on pourra le matin avant l’ouverture realiser ce changement).
Vn�1
= ↵nSn�1
+ �nBn�1
.
Pendant la journee n la valeur des actifs peut varier. Le soir du jour n on aura, apresles fluctuations du cours dans la journee,
Vn = ↵nSn + �nBn,

6.2 Portefeuille du marche (S,B) et autofinancement 65
on a donc�Vn = Vn � Vn�1
= ↵n(Sn � Sn�1
) + �n(Bn �Bn�1
)
ce qui s’ecrit�Vn = ↵n�Sn + �n�Bn
ou encoreVn = V
0
+ (↵ ? S)n + (� ?B)n.
Definition 6.2.2 Le portefeuille (↵n,�n), 1 n N , de valeur Vn = ↵nSn + �nBn
est autofinance si, pour tout n N ,
Vn = V0
+ (↵ ? S)n + (� ?B)n,
ou, ce qui est equivalent, pour tout n, 1 n N,
�Vn = ↵n�Sn + �n�Bn.
Remarquons que ces relations entrainent que V0
= ↵1
S0
+ �1
B0
.
6.2.3. Changement de numeraire
On rappelle que l’on pose
Sn =Sn
Bn
que l’on peut interpreter comme la valeur de l’actif dans un nouveau numeraire, oucomme la valeur actualisee de Sn. De la meme facon posons,
Vn =Vn
Bn
on pourrait aussi introduire Bn = BnBn
mais c’est evidemment 1.
Proposition 6.2.3 Un portefeuille (↵n,�n), n N , de valeur Vn = ↵nSn + �nBn
autofinance dans le marche (S,B) est aussi autofinance dans le marche (S, 1) devaleur Vn et la condition d’autofinancement s’ecrit
Vn = V0
+ (↵ ? S)n.
Preuve: La relation Vn = ↵nSn + �nBn s’ecrit aussi
Vn = ↵nSn + �n.
La relation d’autofinancement
Vn�1
= ↵n�1
Sn�1
+ �n�1
Bn�1
= ↵nSn�1
+ �nBn�1
donne
↵n�1
Sn�1
Bn�1
+ �n�1
= ↵nSn�1
Bn�1
+ �n
donc↵n�1
Sn�1
+ �n�1
= ↵nSn�1
+ �n.

66 Marches a temps discret, AOA, completude
Corollaire 6.2.4 Un portefeuille autofinance est determine par V0
et {↵k, 1 k N}.
Preuve: En e↵et si Vn est autofinance on a Vn = V0
+ (↵ ? S)n donc
Vn = Bn(V0
B0
+ (↵ ? S)n).
Remarquons que
�n = Vn � ↵nSn.
Cette quantite est bien previsible (malgre les apparences) car, comme on l’a vu plushaut
�n = (↵n�1
� ↵n)Sn�1
+ �n�1
6.3. AOA
Definition 6.3.1 On appelle ”Opportunite d’arbitrage” un portefeuille autofinancede valeur Vn, 0 n N tel que
V0
= 0,
VN � 0,m� p.s.
m(VN > 0) > 0.
Il y a absence d’opportunite d’arbitrage (AOA) si il n’y a pas de tel portefeuille. Ondit qu’un marche est viable si AOA.
Une autre notion qui va s’averer essentielle est la suivante.
Definition 6.3.2 On appelle mesure martingale une probabilite P sur (⌦, (Fn, 0 n N)) pour laquelle l’actualise du spot Sn = Sn/Bn est une martingale locale.
Un des theoremes fondamentaux est: ”The first fundamental theorem of assetpricing”, du a Harrison et Pliska essentiellement:
Theoreme 6.3.3 (Premier theoreme fondamental de l’evaluation) Il y a ab-sence d’opportunite d’arbitrage (AOA) ssi il existe une mesure martingale equivalentea m. Dans ce cas on dit que le marche est viable.
La preuve est un peu longue et le reste de cette section lui est consacre.

6.3 AOA 67
6.3.1. Lemme sur la transformee de Laplace
Commencons par un lemme sur la transformee de Laplace d’une v.a. reelle.
Lemme 6.3.4 Soit X une v.a. reelle telle que pour tout a 2 R,
�(a) = E(eaX) < +1.
La fonction � est deux fois derivable, de derivees
�0(a) = E(XeaX),�00(a) = E(X2eaX)
donc convexe. De pluslim
a!±1�(a) = +1
si P(X > 0) 6= 0 et P(X < 0) 6= 0.
Preuve: On utilise le theoreme de Lebesgue de derivation sous le signe somme, quiest lui meme une consequence du theoreme de convergence dominee et le fait quepour tout M > 0 si |a| M , x2eax Cte(e(M+1)x + e�(M+1)x) pour tout x 2 R.
Introduisons la methode de relativisation appelee aussi transformation d’Esscheren assurance.
Proposition 6.3.5 Soit X une v.a. reelle telle que
m(X > 0) 6= 0,m(X < 0) 6= 0.
Alors, il existe une proba P equivalente a m telle que
E(eaX) < +1
pour tout a 2 R, E(|X|) < +1 et E(X) = 0.
Preuve: Soit m une probabilite equivalente a m (cf Lemme 3.3.4). Notons P laprobabilite equivalente a m definie par
dP = ce�X2dm.
ou c = 1/Re�X2
dm. Pour tout a 2 R, on pose �(a) = E(eaX) et
dPa =eaX
�(a)· dP
La fonction � est derivable convexe, et lima!±1 �(a) = +1 par l’hypothese. Elleatteint donc son minimum en un point a⇤ tel que �0(a⇤) = 0 alors Pa⇤ est solution. ⇤

68 Marches a temps discret, AOA, completude
6.3.2. Preuve du theoreme.
Apres changement de numeraire on peut supposer que Bk = 1 pour tout k, sans pertede generalite. Nous le supposerons donc. On choisit provisoirement une probabilite Pequivalente a m.
Lemme 6.3.6 Pour n = 1, · · · , N , soit Xn = �Sn,
A = {! 2 ⌦;E(1{Xn>0}|Fn�1
)(!) > 0 et E(1{Xn<0}|Fn�1
)(!) > 0}
etB = {! 2 ⌦;E(1{Xn=0}|Fn�1
)(!) = 1}
Si AOA, P(A [B) = 1.
Preuve: PosonsC = {E(1{Xn<0}|Fn�1
) = 0}.
etD = {E(1{Xn>0}|Fn�1
) = 0}
On a Ac contenu dans C[D. Il su�t donc de montrer que C et D sont contenus dansB. Commencons par C. On construit un portefeuille Vk = ↵kSk + �k, 0 k N, dela facon suivante: V
0
= 0 puis
↵k = �k = 0, si k n� 1,
↵n = 1C ,�n = �1CSn�1
,
↵k = 0,�k = Vn, si k � n+ 1.
On aVk = 0, si k n� 1,
Vn = 1C(Sn � Sn�1
) = 1CXn,
Vk = Vn, si k � n+ 1,
Donc �Vk = ↵k�Sk pour tout k. Ce portefeuille est donc autofinance et VN = Vn =1CXn. On a
E(1C1Xn<0
) = E(1CE(1Xn<0
|Fn�1
)) = 0
donc, p.s., VN � 0. Puisque V0
= 0 on a donc, par AOA, VN = 0, p.s. Donc, p.s.,
1C1Xn>0
= 0
ce qui entraine que son esperance conditionnelle par rapport a Fn�1
est nulle
1CE(1Xn>0
|Fn�1
) = 0,
donc C est p.s. contenu dans B. De meme, par symetrie, D est contenu dans B, p.s.. ⇤

6.3 AOA 69
Preuve du theoreme: (sens direct) On prend Bk = 1 pour tout k sans perte degeneralite. On pose
P(d!) = c exp(�NX
i=0
X2
i (!))m(d!)
ou c est choisi pour que m soit une probabilite equivalente a m (cf Lemme 3.3.4) et,pour chaque n,
�n(a) = E(eaXn |Fn�1
)
Pour chaque ! 2 A, A defini au lemme precedent, la fonction a 7! �n(a)(!) eststrictement convexe et
lima!1
�n(a)(!) = +1, p.s.
en e↵et, par Lebesgue monotone il su�t de voir que
lima!+1
�n(a) � lima!+1
E(eaXn1{Xn>0
|Fn�1
) = (+1)E(1{Xn>0}|Fn�1
)
et l’analogue quand a ! �1. En adaptant la preuve du lemme 6.3.4 au cas condi-tionnel on voit qu’il existe un unique an tel que �n(an) = mina2R �n(a) et donc telque
�0n(an) = 0
c’est a direE(Xne
anXn |Fn�1
) = 0. (6.1)
Par unicite ! 7! an(!) est mesurable car l’ensemble {(a,!);�0n(a)(!) = 0} estmesurable. Sur Ac on pose an = 0, Xn = 0 et (6.1) est encore vrai.
On pose Z0
= 1 puis, par recurrence,
Zn = Zn�1
eanXn
E(eanXn |Fn�1
)
etdP = ZN dP.
Remarquons queE(Zn|Fn�1
) = Zn�1
(martingale). En particulier E(ZN ) = 1. Donc P est une probabilite. Montrons quesous P, Sn est une martingale locale. Par Bayes (Lemme 3.4.3)
E(Xn|Fn�1
) =E(XnZN |Fn�1
)
E(ZN |Fn�1
)
OrE(XnZN |Fn�1
) = E(E(XnZN |Fn)|Fn�1
) = E(XnE(ZN |Fn)|Fn�1
)
= E(XnZn|Fn�1
) = E(XnZn�1
eanXn
E(eanXn |Fn�1
)|Fn�1
)

70 Marches a temps discret, AOA, completude
=Zn�1
E(eanXn |Fn�1
)E(Xne
anXn |Fn�1
) = 0
Ceci montre que E(Sn|Fn�1
) = Sn�1
, (le fait que E(|Sn||Fn�1
) est fini se voit de lameme facon) on a donc bien une martingale locale. La probabilite P est donc unemesure martingale equivalente a m.
Reciproquement, si P est une mesure martingale equivalente a m, Sn est sous Pune martingale locale, si Vn = (↵?S)n est tel que VN � 0 p.s., (Vn) est une martingale(c.f. Proposition 4.6.4) et si E(VN ) = E(V
0
) = 0, VN = 0, p.s.
6.4. Evaluation d’un actif replicable dans un marche vi-able
On se donne un ”marche” (S,B) sur ”l’univers” (⌦,A, (Fn, 0 n N),m). Rap-pelons qu’on a appele marche viable un marche (Sn, Bn), 0 n N , dans lequel il ya AOA. Alors il existe une mesure martingale P.
Definition 6.4.1 (i) Un actif (derive) est par definition une v.a. FN -mesurable.
(ii) Un actif Z est replicable si il existe un portefeuille autofinance de valeurVN = Z (m p.s.).
Theoreme 6.4.2 Dans un marche viable, si Z est un actif replicable, il existe unseul portefeuille autofinance (Vn) de valeur VN = Z, m p.s.. En particulier il nedepend pas de la mesure martingale P. On appelle V
0
le prix a l’instant 0 de l’actifderive Z.
Preuve: Supposons qu’il existe deux portefeuilles autofinances V (1)
n et V (2)
n tels que
V (1)
N = V (2)
N = Z, m p.s.. Soit P une mesure martingale equivalente a m. Sous P,V (1)
n = V (1)
n /Bn et V (2)
n = V (2)
n /Bn sont des martingales locales. Montrons par
recurrence retrograde sur n que V (1)
n = V (2)
n , m-p.s. C’est vrai pour n = N , et si
c’est vrai au rang n+ 1, alors V (1)
n+1
= V (2)
n+1
et donc
V (1)
n = E(V (1)
n+1
|Fn) = E(V (2)
n+1
|Fn) = V (2)
n
Donc V (1)
n = V (2)
n , m-p.s. Ceci montre l’unicite. Dire qu’il depend de P voudrait direqu’il existe au moins deux mesures martingales et deux portefeuilles autofinancesdi↵erents associees. Ceci contredit l’unicite du portefeuille.⇤
On peut donc bien poser:
Definition 6.4.3 Dans un marche viable, le prix a l’instant 0 d’un actif replicableZ est la valeur V
0
d’un portefeuille autofinance verifiant VN = Z.Ce portefeuille est appele Portefeuille de couverture de l’actif.

6.5 Marche complet 71
Remarquons qu’on trouve concretement ce portefeuille en choisissant une mesuremartingale P equivalente a m, puis en ecrivant par recurrence retrograde
VN = Z
puis, pour n < N ,Vn = E(Vn+1
|Fn)
sous la formeVn = ↵nSn + �n
avec ↵n et �n previsibles (ce n’est possible que si Z est replicable).Dans les exemples d’options, Z est positive, on a (en utilisant la Proposition
4.6.4),
Proposition 6.4.4 Si Z est un actif replicable tel que Z � 0, m-p.s. ou si Z/BN 2L1, pour toute mesure martingale equivalente a m,
V0
= E( Z
BN|F
0
).
6.5. Marche complet
Par le premier theoreme fondamental on sait que la viabilite est equivalente a l’absenced’opportunite d’arbitrage. On va supposer dans cette section que Bn et Sn sont lesdeux seuls actifs intervenants. Autrement dit que
Fn = �(B0
, S0
, B1
, S1
, · · · , Bn�1
, Sn�1
, Sn)
A l’instant 0 on connait l’etat du marche donc S0
et B0
et B1
(rappelons que l’oncommence au soir du jour 0). On peut donc les supposer constants. On a donc F
0
={;,⌦}. On en deduit par recurrence que
Fn = �(S1
, · · · , Sn).
Definition 6.5.1 On dit que le marche est complet si tout actif Z tel que Z/BN estborne est replicable.
Theoreme 6.5.2 (Deuxieme Theoreme fondamental) Un marche viable est com-plet si et seulement si il existe une seule mesure martingale P equivalente a m.
Le plan de la preuve, un peu longue est le suivant: on va montrer queComplet =>Unicite de P=> Propriete de Bernoulli => Representation previsible
=>Complet

72 Marches a temps discret, AOA, completude
6.5.1. Complet => Unicite de PCeci resulte du theoreme 6.4.2.
6.5.2. Unicite de P => Propriete de Bernoulli
On dit que le marche a la propriete de Bernoulli si m p.s. la loi conditionnelle de Sn
sachant S0
, · · · , Sn�1
est portee par deux points. Autrement dit il existe pour toutn, deux v.a. previsibles Un et Dn (up et down) telles que, p.s.,
Sn 2 {Dn, Un}.
Puisque D1
et U1
sont F0
mesurables, ils sont constants. Donc S1
ne prend que deuxvaleurs. Mais alors, D
2
et U2
ne prennent chacun que deux valeurs (puiqu’ils sontfonctions de S
1
). Donc S2
est (non-conditionnellement) a valeurs dans un ensemblea 4 elements, etc... Finalement, l’ensemble ⌦ = {! 2 ⌦;m(!) > 0} est fini et il portem et tous les Sn. On peut donc, quitte a remplacer ⌦ par ⌦, supposer que ⌦ est finiet que m est la mesure de comptage.
Proposition 6.5.3 Si il y a unicite de la mesure martingale, on a la propriete deBernoulli.
La preuve est un peu technique. On pourra l’admettre. Je la donne en appendice.
6.5.3. Propriete de Bernoulli => Representation previsible
Donnons nous un espace de probabilite (⌦, (Fn), 0 n N,P) et une martingalelocale S.
Definition 6.5.4 On dit qu’une martingale Mn a la propriete de representationprevisible si il existe un processus previsible (↵k) tel que, pour 0 n N ,
Mn = M0
+ (↵ ? S)n
Proposition 6.5.5 Avec la propriete de Bernoulli, si le modele est viable, sous lamesure martingale, on a representation previsible de toute martingale.
Preuve: On peut supposer que Bn = 1, que ⌦ est fini et m uniforme. Soit Mn unemartingale, nulle en 0, que l’on veut ecrire sous la forme M = ↵?S avec ↵ previsible.Cherchons par recurrence sur n, un processus ↵n previsible tel que �Mn = ↵n�Sn,avec
↵n = fn(S0
, · · · , Sn�1
).
Sur l’ensemble S0
= a0
, · · · , Sn�1
= an�1
, la valeur de Mn�1
est fixee, disons mn�1
,�Sn ne prend que deux valeurs, notees d1n d2n et �Mn (etant Fn mesurable), ne

6.5 Marche complet 73
prend aussi que deux valeurs, disons �1n quand �Sn = d1n et �2n quand �Sn = d2n, avec�1n = �2n quand d1n = d2n. La relation �Mn = ↵n�Sn donne donc deux equations:
�1n = ↵nd1
n, �2
n = ↵nd2
n.
ou l’inconnue est ↵n. Par ailleurs on sait que Sn et Mn sont des martingales, donc
0 = E(�Sn|S0
= a0
, · · · , Sn�1
= an�1
)
et0 = E(�Mn|S0
= a0
, · · · , Sn�1
= an�1
),
ce qui s’ecrit, si pn = P(�Sn = d1n|S0
= a0
, · · · , Sn�1
= an�1
) et qn = 1 � pn =P(�Sn = d2n|S0
= a0
, · · · , Sn�1
= an�1
)
pnd1
n + qnd2
n = 0,
pn�1
n + qn�2
n = 0.
Si d1n = d2n alors �1n = �2n donc d1n = d2n = �1n = �2n = 0 et on peut prendre ↵n = 0. Sid1n 6= d2n, et si par exemple d1n 6= 0, on peut poser
↵n =�1nd1n
on aura bien
�2n = �pn�1nqn
=d2n�
1
n
d1n= ↵nd
2
n
ce qui prouve le theoreme.
6.5.4. Representation previsible => Complet
Proposition 6.5.6 Si le marche est viable, le marche est complet si et seulement sitoute martingale bornee a la propriete de representation previsible par rapport a S.
Preuve: Quitte a tout actualiser on peut supposer que Bn = 1, pour tout 0 n N .1. Supposons d’abord la propriete de representation previsible. Soit Z une v.a.
FN mesurable bornee. Alors Mn = E(Z|Fn) est une martingale bornee et MN = Z.Par representation previsible, on peut l’ecrire Mn = M
0
+ (↵ ? S)n. On pose �n =Mn � ↵nSn, alors � est previsible, car
�n = M0
+ (↵ ? S)n � ↵nSn = M0
+ (n�1X
k=1
↵k�Sk)� ↵nSn�1
.
On en deduit queMn = ↵nSn + �n
est un portefeuille autofinance. Donc l’actif Z est bien duplicable.

74 Marches a temps discret, AOA, completude
2. Reciproquement, supposons le marche complet. Soit (Mn) est une martingalebornee. L’actif MN est duplicable, donc il existe un portefeuille autofinance V tel queVN = MN . Puisque Bn = 1, Vn = V
0
+ (↵ ? S)n est sous la mesure risque neutre unemartingale (locale). On a
Vn = E(VN |Fn) = E(MN |Fn) = Mn
donc Mn representable par ↵.
6.6. Modele binomial de Cox, Ross et Rubinstein
On va appliquer ce qui precede dans le modele le plus simple: le modele binomial oumodele de Cox, Ross et Rubinstein, invente pour des raisons pedagogiques, mais quis’est avere tres utile (methodes d’arbres).
6.6.1. Le modele d’arbre recombinant de CRR
On suppose qu’il existe r > 0 et une suite %n telles que
�Bn = rBn�1
, B0
= 1,
�Sn = "nSn�1
(on modelise donc les rendements), ou "n est une suite de variables aleatoires neprenant que deux valeurs b, h. Si l’horizon est fixe a N on voit que l’alea est donnepar
⌦ = {b, h}N
Il est naturel de prendre comme mesure de reference la mesure de comptage sur cetensemble par exemple (ou la probabilite uniforme, si on prefere, ce qui ne changerien). On prend F
0
= {;,⌦} et Fn = {S1
, · · · , Sn}. Remarquons que Bn = (1 + r)n.
Lemme 6.6.1 Le marche est viable si et seulement si
b < r < h.
Preuve: Si P est une mesure martingale,
Sn =Sn
Bn= (1 + r)�nSn
est une martingale sous P. On a
(1 + r)�nSn = E((1 + r)�(n+1)Sn+1
/Fn)
donc puisque Sn+1
= (1 + "n+1
)Sn,
r = E("n+1
|Fn).

6.6 Modele binomial de Cox, Ross et Rubinstein 75
D’ou
bE(1{"n+1=b}|Fn) + hE(1{"n+1=h}|Fn) = r
et
E(1{"n+1=b}|Fn) + E(1{"n+1=h}|Fn) = 1
donc
E(1{"n+1=b}|Fn) =h� r
h� b
et
E(1{"n+1=h}|Fn) =r � b
h� b.
On doit donc avoir b < r < h
Remarquons que ce calcul montre l’unicite de P, on retrouve donc le fait que cemarche est complet (aussi consequence de la propriete de Bernoulli)
Theoreme 6.6.2 Sous la mesure martingale, les v.a. "i sont independantes de memeloi donnee par
P("1
= b) =h� r
h� b= q, P("
1
= h) =r � b
h� b= p.
Cela resulte d’un lemme general interessant:
Lemme 6.6.3 Sur une espace de probabilite (⌦,A,P), soit F est une sous tribu deA. Si X est une v.a. a valeurs dans un espace mesure (E,E) telle que pour toutefonction mesurable positive f : E ! R+
E(f(X)|F) est presque surement constante,
alors X est independante de F (et reciproquement).
Preuve: Soit A 2 F et B 2 E . Prenons f = 1A, puisque E(1A(X)|F) est presquesurement constante d’esterance egale a P(A), on a
E(1A(X)|F) = P(A)
On en deduit donc, que si B est F-mesurable,
P(B \ {X 2 A}) = E(1B1A(X))
= E(1BE(1A(X)|F)) = E(1BP(X 2 A)) = P(X 2 A)P(B).

76 Marches a temps discret, AOA, completude
6.6.2. Representation previsible
On sait que ce modele a la propriete de representation previsible, puisqu’il a la pro-priete de Bernoulli. Faisons le explicitement pour avoir des formules explicites. Soitdonc (Mn) une martingale sur (⌦, (Fn),P). Posons
Tn = ("1
, · · · , "n)
On peut ecrire queMn = fn(Tn).
Puisque c’est une martingale,
E(Mn+1
|Fn) = Mn
donc, ecrivant que fn+1
(Tn+1
) = fn+1
(Tn, "n+1
),
pfn+1
(Tn, h) + qfn+1
(Tn, b) = fn(Tn) (6.2)
ce qui donnefn+1
(Tn, h)� fn(Tn)
q=
fn(Tn)� fn+1
(Tn, b)
p
Ceci s’ecrit aussi
�n+1
:=fn+1
(Tn, h)� fn(Tn)
h� r=
fn(Tn)� fn+1
(Tn, b)
r � b
On a donc�Mn+1
= fn+1
(Tn, "n+1
)� fn(Tn) = �n+1
("n+1
� r)
c’est a dire�Mn = �n("n � r).
Remarquons que (�n) est previsible. Par ailleurs
�(Sn) =Sn
Bn� Sn�1
Bn�1
= (1 + "n1 + r
� 1)Sn�1
Bn�1
="n � r
1 + rSn�1
donc
"n � r =1 + r
Sn�1
�(Sn)
et finalement
�Mn =�n(1 + r)
Sn�1
�(Sn)
Theoreme 6.6.4
�Mn =�n(1 + r)
Sn�1
�(Sn)

6.6 Modele binomial de Cox, Ross et Rubinstein 77
Pour la section suivante il est interessant de regarder ce qui se passe si a un instantN , la variable aleatoire MN ne depend que de SN . Montrons qu’alors ceci reste vraipour tout n N . On ecrit donc MN = �N (SN ). Montrons par recurrence arriere quel’on peut ecrire, pour une fonction �n,
Mn = �n(Sn)
si n N . C’est vrai pour N , et si Mn+1
= �n+1
(Sn+1
) alors
Mn = E(�n+1
(Sn+1
)|Fn) == p�n+1
(Sn(1 + h)) + q�n+1
(Sn(1 + b))
Il su�t donc de poser
�n(s) = p�n+1
(s(1 + h)) + q�n+1
(s(1 + b))
pour bien avoir que Mn = �n(Sn). On peut dans la preuve precedente remplacer Tn
par Sn et on en deduit que �n est fonction de Sn�1
.
6.6.3. Prix d’options, Portefeuille de couverture
Considerons un actif derive ZN . On a vu que sa valeur a l’instant 0 est
Theoreme 6.6.5
Z0
=1
(1 + r)NE(ZN )
Un cas tres important est celui ou ZN est une fonction de SN . dans ce cas
Theoreme 6.6.6 Si ZN = �(SN )
Zn =1
(1 + r)N�nE(ZN |Fn) =
1
(1 + r)N�nFN�n(Sn)
ou
Fn(x) =nX
k=0
✓n
k
◆�(x(1 + h)k(1 + b)n�k)pk(1� p)n�k
Cette formule s’applique par exemple pour un Call europeen, ou ZN = (SN � K)+
ou bien un put.En terme de portefeuille autofinance, on cherche ↵n et �n de telle sorte que, si
Vn = ↵nSn + �nBn,
Vn = (1 + r)�nVn soit une martingale et
VN = ZN/BN .

78 Marches a temps discret, AOA, completude
On applique les resultats de la section precedente. Par le theoreme 6.6.4
�(V/B)n =�n(1 + r)
Sn�1
�(Sn)
donc
(V/B)n =�n(1 + r)
Sn�1
(Sn) + �n
avec �n = (V/B)n � �n(1+r)˜Sn�1
(Sn) previsible, comme on l’a vu, donc
Vn =�n(1 + r)
Sn�1
Sn + �nBn
La quantite de parts de l’actif: �n(1+r)˜Sn�1
s’appelle le delta de l’option.
Comme on l’a vu dans la section precedente si ZN est fonction de SN alors �n nedepend que de Sn�1
.
6.7. Appendice: Preuve de la proposition 6.5.5
Commencons par un lemme. Le support d’une mesure µ sur R est par definition,l’ensemble des points x de R tels que µ(Vx) 6= 0 pour tout voisinage de x.
Lemme 6.7.1 Soit µ une probabilite sur R telle queR|x| dµ(x) < +1,
Rx dµ(x) =
0. Si µ n’est pas portee par deux points il existe une probabilite ⌫ equivalente a µ maisdi↵erente telle que
R|x| d⌫(x) < +1,
Rx d⌫(x) = 0
Preuve: Si le support de µ a plus de deux points il y en a au moins un positifx1
> 0 et un negatif x2
< 0 puisqueRx dµ(x) = 0. Choisissons aussi un troisieme
x3
, di↵erent de ces 2 la. On peut trouver trois voisinages I, J,K de x1
, x2
, x3
tels telsque
RI x dµ(x) < 0,
RJ x dµ(x) > 0. Pour ↵,�, � > 0 posons
⌫(dx) = [↵1I(x) + �1J(x) + �1K(x) + 1L(x)]µ(dx)
ou L est le complementaire de I [ J [K. C’est une probabilite centree siZ
[↵1I(x) + �1J(x) + �1K(x)]µ(dx) =
Z[1I(x) + 1J(x) + 1K(x)]µ(dx)
Zx[↵1I(x) + �1J(x) + �1K(x)]µ(dx) =
Zx[1I(x) + 1J(x) + 1K(x)]µ(dx)
donc si
(↵� 1)
Z
Iµ(dx) + (� � 1)
Z
Jµ(dx) + (� � 1)
Z
Kµ(dx) = 0,
(↵� 1)
Z
Ixµ(dx) + (� � 1)
Z
Jxµ(dx) + (� � 1)
Z
Kxµ(dx) = 0.

6.7 Appendice: Preuve de la proposition 6.5.5 79
Le determinantRI µ(dx)
RJ xµ(dx)�
RJ µ(dx)
RI xµ(dx) est strictement positif donc
non nul. Pour tout � tres proche de 1 on peut donc trouver ↵,� > 0 solutions.
Preuve: [de la proposition 6.5.5](Bn = 1 sans perte de generalite) Par recurrencesur N . La propriete est triviale pour N = 0. Pour s’entrainer un peu, traitons le casN = 1: Il existe par hypothese une seule probabilite P pour laquelle S
0
, S1
est unemartingale. Cette propriete s’ecrit, pour a = S
0
,
a = E(S1
|F0
) = E(S1
)
Notons µ l’image de P par S1
� a. La probabilite µ sur R est centree. Si S1
prend aumoins 3 valeurs, on a vu au lemme qu’il existe ⌫ equivalente a µ centree et di↵erentede ⌫. Si � = d⌫/dµ on a, pour tout g : R ! R mesurable positive,
E(g(S1
� a)�(S1
� a)) =
Zg(x)�(x) dµ(x) =
Zg(x) d⌫(x)
Posons dQ = �(S1
� a)dP. Prenant d’abord g = 1 puis g(x) = x on voit que Q estune probabilite et que Z
S1
dQ = a
Donc S0
, S1
est aussi une martingale sous Q. Absurde. Ceci montre l’hypothese derecurrence pour N = 1.
Supposons maintenant le resultat vrai a l’ordre N�1. Comme on l’a note, ceci en-traine que (S
0
, · · · , SN�1
) ne prend qu’un nombre fini de valeurs. La loi conditionnelleest donc facile a calculer. Sur S
0
= a0
, · · · , SN�1
= aN�1
,
E(f(SN )|�(S0
, · · · , SN�1
)) = E(f(SN )|{S0
= a0
, · · · , SN�1
= aN�1
),
pour tout f mesurable borne. Si il existe (a0
, · · · , aN�1
) pour lesquels la loi condi-tionnelle de SN prend au moins 3 valeurs, par le lemme, on construit alors commeau dessus une fonction � telle que �
(a0,··· ,aN�1)(SN ) pour laquelle
E(SN � aN�1
)�(a0,··· ,aN�1)
(SN � aN�1
)|{S0
= a0
, · · · , SN�1
= aN�1
) = 0
En posant (S
0
, · · · , SN ) = �(SN � aN�1
)
si S0
= a0
, · · · , SN�1
= aN�1
et 1 sinon, on voit que pour dQ = (S0
, · · · , SN )dP,on a encore une martingale, ce qui est absurde.

80 Marches a temps discret, AOA, completude

Chapitre 7
Theorie du Portefeuille deMarkowitz
7.1. La notion d’Utilite
Considerons une experience aleatoire ! 2 ⌦, dependant d’un parametre (controle)u 2 C et donnant le gain Gu(!). En l’absence d’aleatoire la question: ”que signifiemaximiser le gain ?” est claire. On cherche maxu2C Gu.
Meme si l’on se restreint a des criteres bases sur l’esperance (et les mathematiquesde la finance montrent justement que ce n’est pas forcement ce qu’il faut faire...), laquestion n’est pas si claire. Que choisir entre maxu2C E(Gu) et maxu2C E(�(Gu)) ou �est une fonction croissante ? Par exemple, si Gu � 0 doit on preferer maxu2C E(
pGu)
? maxu2C E(Gu)? maxu2C E(G2
u) ?Dans le cas deterministe les controles u optimaux sont les memes car � est crois-
sante mais pas dans la cas aleatoire.La question se pose du choix de cette fonction � ? Elle doit evidemment etre
croissante, mais il est souvent naturel aussi de la supposer concave. Rappelons
Definition 7.1.1 Une fonction � : R ! R est convexe si
�(↵x+ (1� ↵)y) ↵�(x) + (1� ↵)�(y)
pour tout ↵ 2 [0, 1] et x, y 2 R. Elle est dite concave si �� est convexe.
Considerons un critere de choix base sur l’esperance d’une fonction � du gain G.Une telle fonction � est appelee utilite en economie. On dit qu’une fonction � traduitl’aversion pour le risque si elle favorise un gain sur par rapport a un gain aleatoirede meme esperance. On veut donc que, si G est un gain aleatoire, le critere favorisele gain X = �(E(G)) au gain Y = �(G), autrement dit E(Y ) E(X) c’est a dire
E(�(G)) �(E(G))

82 Theorie du Portefeuille de Markowitz
Proposition 7.1.2 L’inegalite precedente est vraie pour toute variable aleatoire reelleG si et seulement si � est concave.
Preuve: Si cette propriete est vraie, en prenant la v.a. G egale a x avec probabilite↵ et y avec probabilite 1� ↵, ou 0 ↵ 1, on voit que
↵�(x) + (1� ↵)�(y) = E(�(G)) �(E(G)) = �(↵x+ (1� ↵)y))
donc � est concave. Reciproquement si � est concave, pour toute probabilite µ sur Rd’esperance finie,
�(
Zx dµ(x))
Z�(x) dµ(x)
En e↵et, ceci decoule de l’inegalite de Jensen que l’on va montrer en utilisant le lemmesuivant.
Lemme 7.1.3 Une fonction continue conxexe f : R ! R est l’enveloppe superieured’une famille de droites. Plus precisement si E(f) = {(a, b) 2 R; f(x) � ax+ b, 8x 2R} alors, pour tout x 2 R,
f(x) = max{ax+ b; (a, b) 2 E(f)}
Preuve: L’ensemble C = {(x, y) 2 R2; y � f(x)} etant un ensemble convexe ferme,le resulte du theoreme de projection.
Proposition 7.1.4 (Inegalite de Jensen) Si f : R ! R est convexe, pour toutev.a. X telle que X et f(X) sont integrables, ou positives,
f(E(X)) E(f(X)).
Preuve: Si (a, b) 2 E(f), f(X) � aX + b donc E(f(X)) � aE(X) + b donc
E(f(X)) � max{aE(X) + b; (a, b) 2 E(f)} = f(E(X))
On montre exactement de la meme facon
Proposition 7.1.5 (Inegalite de Jensen pour l’esperance conditionnelle) Sif : R ! R est convexe, pour toute v.a. X telle que X et f(X) sont integrables, oupositives,
f(E(X|F)) E(f(X)|F).
On voit donc qu’une fonction d’utilite sera en general choisie croissante et concave.Un exemple typique est donne pour x � 0 par
�(x) = x↵
avec 0 < ↵ 1 ou bien �(x) = log(x).

7.2 Multiplicateurs de Lagrange 83
7.2. Multiplicateurs de Lagrange
La cadre naturel de cette section serait celui des varietes, mais on se contente ici ducas simple. Etant donne une fonction
g : Rn ! R
et des fonctions f1
, · · · , fd : Rn ! R il s’agit de regarder, localement,
max{g(x);x 2 Rd, f1
(x) = f2
(x) = · · · = fd(x) = 0}.
Rappelons qu’une fonction f : Rn ! R est dite di↵erentiable en x si il existe uneforme lineaire dfx sur Rn telle que
f(x+ h) = f(x) + dfx(h) + o(khk)
ou o(khk)/khk ! 0 quand h ! 0. Si on note rf le vecteur gradient de composantes(rf)i =
@f@xi
on a dfx(h) = hrf(x), hi.
Theoreme 7.2.1 Si g a sur l’ensemble V = {x 2 Rn; f1
(x) = f2
(x) = · · · = fd(x) =0} un extremum local en x
0
2 V , si g et f1
, · · · , fd sont di↵erentiables au voisinagede x
0
2 Rn et si les vecteurs rf1
(x0
), · · · ,rfd(x0) sont lineairement independants,il existe �
1
, · · · ,�d 2 R, appeles multiplicateurs de Lagrange, tels que
rg(x0
) =dX
k=1
�krfk(x0).
Preuve: La preuve n’est pas triviale et utilise un argument de calcul di↵erentiel(genre theoreme des fonctions implicites): L’idee de la preuve est la suivante: si il ya un extremum sur V en x
0
, la di↵erentielle de g en x0
s’annule sur l’espace tangenta V en x
0
. Or cet espace est exactement {v 2 Rn; hrfk(x0), vi = 0, k = 1, · · · , d}.Donc rg(x
0
) doit etre orthogonal a l’orthogonal de l’espace vectoriel engendre parrfk(x0), k = 1, · · · , d. Il est donc dans cet espace.⇤
Pour calculer des extremas d’esperances, on peut etre amene a deriver sous lesigne somme.
Theoreme 7.2.2 (thm de derivation sous l’integrale) Soit O un (petit) inter-valle ouvert convexe de Rd, f : O ⇥ E ! R ou (E, E , µ) est un espace mesure. Onsuppose que pour tout y 2 E, la fonction x 2 O 7! f(x, y) est di↵erentiable et qu’ilexiste une fonction g : E ! R integrable telle que
supx2O
krxf(x, y)k g(y).
Si y 7! f(x, y) est integrable, alors, x 7!Rf(x, y) dµ(y) est diferentiable et
rx
Zf(x, y) dµ(y) =
Zrxf(x, y) dµ(y)

84 Theorie du Portefeuille de Markowitz
Preuve: Par le theoreme de la moyenne (ou accroissements finis), pour tout x 2 Osi x+ h 2 O
|f(x+ h, y)� f(x, y)| sup0t1
| ddtf(x+ th, y)| g(y)khk
On a donc,
1
khk |Z
f(x+ h, y) dµ(y)�Z
f(x, y) dµ(y)�Zhrxf(x, y), hi dµ(y)|
Z
1
khk |f(x+ h, y)� f(x, y)� hrxf(x, y), hi| dµ(y)
Le terme sous la deuxieme integrale est majore par 2g(y), donc tend vers 0 par letheoreme de Lebesgue domine.
7.3. Theorie du portefeuille de Markowitz
Un investisseur dispose d’une fortune V0
a l’instant 0, qu’il veut ”placer” jusqu’al’instant 1 (l’unite de temps est ici par exemple le mois ou l’annee). Il a acces ad + 1 actifs aleatoires, A
0
, A1
, · · · , Ad de rendement R0
, R1
, · · · , Rd (qui sont doncdes v.a.), par exemple des actions, des obligations, etc... Par definition un produit ale rendement R sur une periode de temps donnee, si la somme x au temps 0 donnex(1+R) a la fin de cette periode. Pour des raisons qui vont apparaitre bientot, il estcommode de supposer que l’actif A
0
est sans risque, autrement dit que R0
est constant(pas aleatoire). L’investisseur cherche a faire, sur une seule periode de temps (doncpas de dynamique pour l’instant), un portefeuille avec ces di↵erents actifs. C’est, pardefinition, une combinaison lineaire
V0
= ↵0
A0
+ ↵1
A1
+ · · ·+ ↵dAd
de ces actifs. Le portefeuille vaut donc au temps 1,
V1
= ↵0
A0
(1 +R0
) + ↵1
A1
(1 +R1
) + · · ·+ ↵dAd(1 +Rd)
et le rendement G du portefeuille est donc
G =V1
� V0
V0
=↵0
A0
R0
+ ↵1
A1
R1
+ · · ·+ ↵dAdRd
V0
.
On note xk = ↵kAk/V0
la proportion de la fortune V0
investie dans l’actif k. On adonc
1 = x0
+ x1
+ · · ·+ xd
etG = x
0
R0
+ x1
R1
+ · · ·+ xdRd.

7.3 Theorie du portefeuille de Markowitz 85
On posera x = (x1
, · · · , xd)⇤, attention sans x0
.Par definition le portefeuille de Markowitz est celui qui minimise la variance du
rendement du portefeuille, pour une esperance de ce rendement fixee.Dans la suite on note R = (R
1
, · · · , Rd)⇤ donc R est un vecteur colonne (attentionla aussi que R
0
n’apparait pas) et on introduit le vecteur d’esperance et la matricede covariance
E(R),� = E((R� E(R))(R� E(R))⇤
On note 1 le vecteur de Rd dont toutes les composantes sont egales a 1, 1 =(1, · · · , 1)⇤, et on pose
R = E(R), S = E(R)�R0
1.
7.3.1. Cas sans taux fixe
Commencons par considerer le cas ou il n’y a pas d’actif A0
au taux fixe R0
. On aalors
x1
+ x2
+ · · ·+ xd = 1
donc x⇤1 = 1. On a R = E(R), G = x⇤R, donc
E(G) =dX
i=1
xiE(Ri) = x⇤R, V ar(G) = x⇤�x.
On supposera que � est inversible, ce qui signifie que les produits sont diversifies(aucun n’est combinaison lineaire des autres). On pose
a = 1⇤��1R, b = R⇤��1R, c = 1⇤��11, d = bc� a2
(remarque b, c > 0 et par Cauchy Schwarz d � 0 ).
Proposition 7.3.1 Si � est inversible et d > 0, a esperance fixee E(G) = m, et sanstaux fixe, le portefeuille de variance V ar(G) minimale est obtenu pour
x = ���1R+ µ��11
et est de variance
�2 = �m+ µ
avec
� =cm� a
d, µ =
b� am
d.
Preuve: Nous cherchons donc
minx⇤�x, x⇤R = m,x⇤1 = 1.

86 Theorie du Portefeuille de Markowitz
Pour l’esthetique, pour g(x) = x⇤�x2
, f1
(x) = x⇤R � m, f2
(x) = x⇤1 � 1, on cherchemin g sur {f
1
= f2
= 0}. Si le minimum est atteint en x, il existe des multiplicateursde Lagrange � et µ tels que
rg(x) = �rf1
(x) + µrf2
(x)
Ce qui s’ecrit�x = �R+ µ1
d’oux = ���1R+ µ��11.
On a de plus x⇤R = m et x⇤1 = 1, donc la variance mimum est
x⇤�x = x⇤(�R+ µ1) = �m+ µ.
Etm = x⇤R = �R⇤��1R+ µ1⇤��1R = �b+ µa
avec1 = x⇤1 = �R⇤��11 + µ1⇤��11 = �a+ µc
ce qui donne � = cm�ad , µ = b�am
d .
7.3.2. Frontiere de Markowitz
Regardons la courbe obtenue par les couples (Ecart type,Esperance) de tous les porte-feuilles optimaux. On a
E(G) = m = x⇤R, V ar(G) = x⇤�x
avecx⇤�x = x⇤(�R+ µ1) = �m+ µ.
Donc, en posant �2 = V arG,
�2 =cm� a
dm+
b� am
d=
cm2 � 2am+ b
d
ce que l’on peut reecrire sous la forme
c�2 � c2(m� a/c)2
d= 1.
Dans le plan de coordonnees (�,m), c’est l’equation d’une hyperbole de centre (0, a/c)et d’asymptotes
m =a
c+
rd
c�,m =
a
c�
rd
c�.
L’ensemble des portefuilles optimaux, appellee frontiere e�cace, est la branche superieurede l’hyperbole.

7.3 Theorie du portefeuille de Markowitz 87
7.3.3. Avec un actif sans risque, a taux fixe, Theorie de Tobin
On considere le cas ou x0
n’est pas necessairement nul. Pour tout choix de x =(x
1
, · · · , xd) on peut alors constituer un portefeuille en posant
x0
= 1�dX
k=1
xk.
Il n’y a donc plus la contrainte x⇤1 = 1.Puisque
G = x0
R0
+ x1
R1
+ · · ·+ xdRd
on a
E(G) = x0
R0
+ x⇤E(R) = (1� x⇤1)R0
+ x⇤E(R) = R0
+ x⇤(E(R)�R0
1)
donc (rappelons que S = E(R)�R0
1),
E(G) = R0
+ x⇤S.
Par ailleurs, puisque R0
est constant,
V ar(G) = x⇤�x.
Theoreme 7.3.2 Le portefeuille G d’esperance E(G) = m fixee et de variance min-imum �2 est donne par
x = ���1S,� =m�R
0
S⇤��1S,�2 =
(m�R0
)2
S⇤��1S.
Preuve: Nous cherchons donc minx⇤�x sur l’ensemble x⇤S�m+R0
= 0. Comme audessus, il existe un multiplicateur de Lagrange � tel que, au point x ou le minimumest atteint,
�x = �S, x⇤S = m�R0
donc,x = ���1S.
En remplacant, �S⇤��1S = m�R0
donc
� =m�R
0
S⇤��1S
La variance du portefeuille optimal est
V ar(G) = �2 = x⇤�x = x⇤�S = �(m�R0
)

88 Theorie du Portefeuille de Markowitz
donc
�2 =(m�R
0
)2
S⇤��1S.
On voit donc que
m = R0
+ �pS⇤��1S
C’est l’equation d’une droite. Un seul parametre donc: �.Sur un dessin, dans le plan, (ecart type, esperance) on peut voir que l’on parcoure
la droite passant par (0, R0
) et tangente a la frontiere e�ciente.
On voit qu’un seul portefeuille d’actifs risques (le portefeuille tangent) intervientdans la solution du probleme.
Figure 7.1: Dessin de J.P. Desquilbet, avec rf = R0
Definition 7.3.3 Un portefeuille est dit MV e�cace si il n’existe pas d’autre porte-feuille de meme esperance et de variance plus petite.

7.3 Theorie du portefeuille de Markowitz 89
Il resulte du theoreme qu’un portefeuille est MV e�cace ssi il est de la forme���1R.
Question: Un portefeuille est-il MV e�cace si il n’existe pas d’autre portefeuillede meme variance et d’esperance plus grande ?

90 Theorie du Portefeuille de Markowitz

Chapitre 8
Controle et filtrage lineaireoptimal
8.1. Le cadre du controle lineaire
L’un des modeles les plus utilises est celui du controle lineaire quadratique avec bruitsgaussiens (Linear Quadratic Gaussian, Linear Regulator Gaussian). On considere lesysteme:
Xn+1
= AXn +BUn +Wn, n 2 N, X0
= x,
ou
1. Xn 2 Rd,
2. A est une matrice reelle d⇥ d ,
3. U 2 Rp, B est une matrice reelle d⇥ p et
4. Wn, n 2 N, est une suite de variable aleatoires gaussiennes independantes dememe loi N(0, V ), c’est a dire centrees de matrice de covariance V .
Les vecteurs sont identifies a des matrices colonnes.
Pour le controle, on utilisera essentiellement le fait que les variables aleatoires Wn
sont de carre integrable, centrees non correlees, de meme matrice de covariance V ,c’est a dire en notant W ⇤ le transpose de W , que
E(Wn) = 0,
E(WnW⇤n) = V, et E(WnW
⇤m) = 0 si m 6= n.
En particulier, V peut etre nul, auquel cas Wn = 0 identiquement et on traite alorsle cas du controle lineaire deterministe. Le cout est
E(N�1X
k=0
c(Xk, Uk) + �(XN )),

92 Controle et filtrage lineaire optimal
ou c et � sont des formes quadratiques de la forme suivante:
c(x, u) = x⇤Qx+ u⇤Ru,
�(x) = x⇤�x,
ou Q et � sont donc des matrices d ⇥ d symetriques semi-definies positives et R estune matrice symetrique p⇥ p definie positive.
Profitons en pour faire un bref rappel sur les matrices symetriques.
8.2. Matrices symetriques
Definition 8.2.1 Une matrice reelle M de taille d ⇥ d, est dite symetrique si elleest egale a sa transposee M⇤. Elle est, de plus, semi-definie positive si,
x⇤Mx � 0, pour tout x 2 Rd,
et definie positive si
x⇤Mx > 0, pour tout x 6= 0, x 2 Rd.
On note Pd l’ensemble des matrices semi-definies positives d’ordre d.
Toute matrice d’ordre d symetrique M est diagonalisable: plus precisement ilexiste une matrice orthogonale U d’ordre d (c’est a dire verifiant U⇤ = U�1) et unematrice diagonale D (c’est a dire que Di,j = 0 si i 6= j) telle que
M = UDU⇤.
Les valeurs propres �1
, · · · ,�d, de M sont les elements de la diagonale de D et sontreels.
La matrice symetrique M est semi-definie positive si
�1
� 0, · · · ,�d � 0,
et M est definie positive si et seulement
�1
> 0, · · · ,�d > 0.
On voit donc qu’une matrice symetrique semi-definie positive est definie positivesi et seulement si elle est inversible. Nous allons utiliser:
Lemme 8.2.2 Soit S une matrice symetrique definie positive d’ordre p et y 2 Rp
fixe. Le minimum sur u 2 Rp, de la forme quadratique
2u⇤y + u⇤Su
est egal a �y⇤S�1y et est atteint en u = �S�1y.

8.3 Programmation dynamique 93
Preuve: Il su�t de calculer la di↵erentielle. On peut aussi proceder directement:Pour tout h 2 Rp on a (en remarquant que u⇤Sh = h⇤Su car ce sont des reels)
2(u+ h)⇤y + (u+ h)⇤S(u+ h) = 2u⇤y + u⇤Su+ h⇤Sh+ 2h⇤(Su+ y).
En remplacant h par th ou t est reel on voit que ceci est une fonction de h minimaleen h = 0 si pour tout t 2 R,
t2h⇤Sh+ 2th⇤(Su+ y) � 0
donc si et seulement si h⇤(Su+y) = 0 pour tout h 2 Rp donc Su+y = 0 et u = �S�1yet alors
2u⇤y + u⇤Su = �2y⇤S�1y + (S�1y)⇤S(S�1y) = �y⇤S�1y.
Lemme 8.2.3 Si W est un vecteur centre de matrice de covariance V , on a
E(W ⇤�W ) = tr(�V ).
Preuve: Puisque W ⇤�W est un reel, il est egal a sa trace et donc,
E(W ⇤�W ) = E(tr(W ⇤�W )) = E(tr(�WW ⇤)) = tr�E(WW ⇤) = tr(�V )
8.3. Programmation dynamique
Nous cherchons
J(x) = min⌫
E⌫x(N�1X
k=0
c(Xk, Uk) + �(XN )),
le minimum etant pris sur toutes les strategies ⌫ = (⌫0
, · · · , ⌫N�1
).On est dans le cadre de la programmation dynamique, en notant P (u)(x, .) la loi
de Ax+Bu+W ou W est une v.a. de loi N(0, V ). Dans cette situation, l’algorithmeadmet une solution explicite. En e↵et, tout d’abord,
JN (x) = x⇤�x = x⇤�Nx
en posant �N = �. Par le lemme 8.2.3
E(JN (Ax+Bu+WN�1
)) = (Ax+Bu)⇤�N (Ax+Bu) + tr(�NV ).
Ensuite,
JN�1
(x) = minu
{x⇤Qx+ u⇤Ru+
ZJN (y)P (u)(x, dy)}
= minu
{x⇤Qx+ u⇤Ru+ E(JN (Ax+Bu+WN�1
))}
= minu
{x⇤Qx+ u⇤Ru+ (Ax+Bu)⇤�N (Ax+Bu) + tr(�NV )}.
= minu
{x⇤(Q+A⇤�NA)x+ u⇤(R+B⇤�NB)u+ 2u⇤B⇤�NAx+ tr(�NV )}
= tr(�NV ) + x⇤(Q+A⇤�NA)x+minu
{u⇤(R+B⇤�NB)u+ 2u⇤B⇤�NAx}.

94 Controle et filtrage lineaire optimal
En appliquant le lemme avec S = R + B⇤�NB, et y = B⇤�NAx on voit que ceminimum est egal a
JN�1
(x) = x⇤�N�1
x+ tr(�NV )
pour�N�1
= Q+A⇤�NA� (A⇤�NB)(R+B⇤�NB)�1(B⇤�NA)
et est atteint enu = KN�1
x
pourKN�1
= �(R+B⇤�NB)�1(B⇤�NA).
Remarquons que, en utilisant l’expression de JN�1
(x) en fonction du u optimal, eten remplacant u par sa valeur, on obtient que
x⇤�N�1
x = x⇤(Q+A⇤�NA)x+ u⇤(R+B⇤�NB)u+ 2u⇤B⇤�NAx
pour u = KN�1
x donc que
�N�1
= Q+K⇤N�1
RKN�1
+ (A+BKN�1
)⇤�N (A+BKN�1
) (8.1)
Ceci montre que �N�1
est semi definie positive, car c’est la somme de matrices semidefinies positives. Comme a une constante pres, JN�1
est de la meme forme que JN ,on peut reprendre le meme calcul pour obtenir JN�2
, etc... (ou plus rigoureusementen faisant une recurrence retrograde) Finalement on obtient
Theoreme 8.3.1 Posons (Transformation de Riccati)
⇢(�) = Q+A⇤�A� (A⇤�B)(R+B⇤�B)�1(B⇤�A)
On considere la suite de matrices definies par les equations (retrogrades) suivantes,�N = � puis, pour n < N ,
�n = ⇢(�n+1
)
Alors
Jn(x) = x⇤�nx+NX
k=n+1
tr(�kV )
et le controle optimal est Un = KnXn ou
Kn = �(R+B⇤�n+1
B)�1(B⇤�n+1
A).
Si, par exemple, d = p = 1, on obtient donc, pour tout 0 n < N ,
Un = � ba�nR+ b2�n
Xn, Jn(x) = �nx2 +
NX
k=n+1
�kV,
ou �n est definie par l’equation sur R+
�n =QR+ (b2Q+Ra2)�n+1
R+ b2�n+1
+R, 0 n < N,
et �N = �. Remarquons l’apparition d’une transformation homographique a coe�-cients positifs.

8.4 Variantes 95
8.4. Variantes
8.4.1. Coe�cients dependant du temps
De nombreuses variantes sont possibles. Deja on peut supposer que les matricesA,B,Q,R, V et donc c dependent de n. On aura le meme type de resultat avecla meme demonstration. Il su�ra de remplacer l’equation �n = ⇢(�n+1
) par �n =⇢n(�n+1
) ou
⇢n(�) = Qn +A⇤n�An � (A⇤
n�Bn)(Rn +B⇤n�Bn)
�1(B⇤n�An)
et chaque terme tr(�nV ) par tr(�nVn�1
).
8.4.2. Correction de trajectoire
Une autre variante utile est la suivante. Imaginons que l’on veut que Xn soit proched’un vecteut ⇠n connu a l’avance (par exemple une trajectoire nominale ...). Dans cecas on cherchera a rendre Xn � ⇠n petit, donc a minimiser le critere
E(N�1X
k=0
ck(Xk, Uk) + �(XN � ⇠N ))
ou ck(x, u) = (x�⇠k)⇤Q(x�⇠k)+u⇤Ru. On veut se ramener a la situation precedente.Pour cela on pose Xk = Xk � ⇠k. Le critere est bien de la forme
E(N�1X
k=0
ck(Xk, Uk) + �(XN ))
mais maintenant, on a
Xn+1
= AXn +BUn +Wn +A⇠n � ⇠n+1
Une facon de faire est d’augmenter de un la dimension de l’espace des etats, en posant
Xn =
✓Xn
1
◆
En e↵et introduisons les matrices
An =
✓A vn0 1
◆, B =
✓B
0 · · · 0
◆, Wn =
✓Wn
0
◆
ou vn = A⇠n � ⇠n+1
. Cette equation s’ecrit
Xn+1
= AnXn + BUn + Wn
on est donc ramene au cas precedent.Application a la poursuite...

96 Controle et filtrage lineaire optimal
8.5. Le probleme du filtrage
8.5.1. Gaussiennes
Une famille gaussienne est une famille Zi, i 2 I, de variables aleatoires telle que toutecombinaison lineaire finie
Pnk=1
�kZik suit une loi normale. On parlera de vecteur oude processus gaussien.
Travaillons dans Rd et considerons les vecteurs comme des vecteurs colonnes. Soitm 2 Rd et Q une matrice symetrique semi-definie positive d’ordre d. Un vecteurgaussien X 2 Rd de loi N(m,Q) est un vecteur aleatoire dont la transformee deFourier verifie
E(ei�⇤X) = ei�⇤me�
�⇤Q�2
pour tout � 2 Rd. AlorsE(X) = m
etVar(X) = Q
ou l’on note Var(X) la matrice de covariance de X definie par
Var(X) = E((X � E(X))(X � E(X))⇤)
Reciproquement si X est un vecteur d’esperance m et de matrice de covariance Qtel que toutes les combinaisons lineaires �⇤X,� 2 Rd, des composantes de X ont deslois gaussiennes, la formule precedente montre que X est un vecteur gaussien de loiN(m,Q). Ecrivons X = (U, V ) ou U 2 Rp et V 2 Rq. Supposons que, pour toutk, j, 1 k p, 1 j q,
Cov(Uk, Vj) = E((Uk � E(Uk))(Vj � E(Vj)) = 0
ou Uk, Vj sont les composantes de U et V . Alors,
Q =
✓Var(U) 0
0 Var(V )
◆
et donc, si mU = E(U) et mV = E(V ) et si a 2 Rp, b 2 Rq, puisque
(a, b)⇤X = (a, b)⇤(U, V ) = a⇤U + b⇤V
on a
E(ei(a⇤U+b⇤V )) = ei�⇤me�
�⇤Q�2
= ei(a⇤mU+b⇤mV )e�
a⇤Var(U)a2 e�
b⇤Var(V )b2
= eia⇤mU e�
a⇤Var(U)a2 eib
⇤mV e�b⇤Var(V )b
2
= E(eia⇤U )E(eib⇤V )
La transformee de Fourier du couple (U, V ) est donc le produit des transformees deFourier de U et de V , donc U et V sont independantes. On a donc montre la partienon triviale du theoreme fondamental suivant:

8.5 Le probleme du filtrage 97
Theoreme 8.5.1 Si le vecteur (U, V ) est gaussien une condition necessaire et su↵-isante pour que U et V soient independantes est que toutes leur composantes verifient
Cov(Uk, Vj) = 0
Considerons maintenant un grand vecteur gaussien
(X1
, X2
, · · · , Xn, Z)
et cherchons la loi conditionnelle de Z sachant �(X1
, · · · , Xn). Les v.a. X1
, · · · , Xn, Zsont de carre integrable (car gaussiennes) donc dans L2(⌦,A,P). Notons H le sousespace de L2 de dimension finie engendre par les fonctions X
1
, · · · , Xn et la fonctionconstante 1 et notons Z la projection orthogonale de Z sur H (dans l’espace deHilbert L2 muni du produit scalaire hU, V i = E(UV )).
Lemme 8.5.2 La variable aleatoire Z � Z est independante de (X1
, · · · , Xn) de loigaussienne centree et
Z = E(Z|�(X1
, · · · , Xn)).
Preuve: Par definition de la projection dans L2, Z est le seul vecteur de la formeZ = �
0
+P
k=1
�kXk tel que
hZ � Z, 1i = E(Z � Z) = 0
et pour tout k = 1, · · · , n
hZ � Z,Xki = E((Z � Z)Xk) = 0
donc, vu la ligne precedente
Cov(Z � Z,Xk) = 0.
Il su�t donc d’appliquer le theoreme pour obtenir l’independance, enfin
E(Z|�(X1
, · · · , Xn) = E(Z � Z|�(X1
, · · · , Xn) + E(Z|�(X1
, · · · , Xn) = Z.
Proposition 8.5.3 La loi conditionnelle de Z sachant �(X1
, · · · , Xn) est la loi gaussi-enne d’esperance (conditionnelle) la projection orthogonale de Z sur l’espace vectorielengendre par 1, X
1
, · · · , Xn.
Preuve: Par exemple en utilisant la transformee de Fourier; en ecrivant que Z =Z + Z � Z
E(ei�Z |�(X1
, · · · , Xn)) = ei�ˆZE(ei�(Z� ˆZ)|�(X
1
, · · · , Xn)) = ei�ˆZE(ei�(Z� ˆZ))
puique Z est mesurable par rapport a �(X1
, · · · , Xn) alors que Z�Z est independantde cette tribu. Par ailleurs Z � Z est gaussienne comme combinaison lineaire duvecteur gaussien (X
1
, · · · , Xn, Z). Enfin, Zn+1
�Xn+1
= A(Zn�Xn)+BUn est bienFn mesurable. ⇤
Tout ceci s’etend au cas vectoriel en projetant sur les composantes des vecteursXk.

98 Controle et filtrage lineaire optimal
8.6. Le Filtre de Kalman Bucy
8.6.1. Le Probleme
On considere les equations, pour n � 0,
Xn+1
= AXn + "n+1
,
Yn = CXn + ⌧n,
ou Xn, "n sont des v.a. de Rd, Yn et ⌧n des v.a. de Rp, A est une matrice d⇥ d et Cune matrice p⇥ d. On suppose que
• X0
, "1
, "2
, · · · , ⌧0
, ⌧1
, · · · sont des vecteurs gaussiens independants,
• "n est un vecteur centre de matrice de covariance Q,
• ⌧n est centre de matrice de covariance R inversible,
• Les matrices A et C sont deterministes.
Le but du filtre de Kalman Bucy est de calculer
Xn = E(Xn|�(Y0, · · · , Yn))
etPn = Var(Xn � Xn),
ou on note Var la matrice de covariance, en utilisant Xn�1
, Pn�1
et Yn, donc de faconrecursive.
Remarquons que les vecteurs
(⌧0
, X0
, Y0
, "1
, ⌧1
, X1
, Y1
, "2
, ⌧2
, X2
, Y2
, · · · , "n, ⌧n, Xn, Yn)
sont gaussiens.
8.6.2. Decomposition a l’aide de l’innovation
On introduit
• La meilleure approximation X�n qu’on peut faire de Xn au temps n� 1:
X�n = E(Xn/�(Y0, . . ., Yn�1
)),
• La matrice P�n de la covariance de l’erreur estimee
P�n = Var(Xn � X�
n ),

8.6 Le Filtre de Kalman Bucy 99
• L’innovation Jn apportee par la connaissance de Yn :
Jn = Yn � E(Yn|�(Y0, · · · , Yn�1
)).
Par le lemme suivant Jn mesure bien la partie de Yn qui apporte une nouvelle infor-mation, donc qui ”innove”).
Lemme 8.6.1 Jn est independant de Y0
, · · · , Yn�1
et gaussienne.
On verifie tres facilement les relations suivantes,
Lemme 8.6.2X�
n = AXn�1
, (8.2)
Jn = Yn � CX�n = C(Xn � X�
n ) + ⌧n, (8.3)
P�n = APn�1
A⇤ +Q. (8.4)
Remarquons que Jn est orthogonal aux vecteurs 1, Y0
, . . ., Yn�1
et que
�(Y0
, · · · , Yn�1
, Yn) = �(Y0
, · · · , Yn�1
, Jn).
On en deduit (en utilisant le lemme qui suit) que Xn est la somme de la projec-tion orthogonale de Xn sur le sous espace de L2 engendre par les composantes desvecteurs 1, Y
0
, · · · , Yn�1
, c’est a dire X�n , et de sa projection sur celui engendre par
les composantes de Jn. Autrement dit il existe une matrice Kn, d’ordre d⇥p, appeleela matrice de gain de Kalman, telle que
Xn = X�n +KnJn,
et X�n et KnJn sont orthogonaux (Jn est donc bien une ”innovation”).
Lemme 8.6.3 Soient H1
et H2
deux sous espaces vectoriels fermes orthogonaux d’unespace de Hilbert H et H = H
1
+H2
. Notons ⇡,⇡1
,⇡2
les projections orthogonales surH,H
1
et H2
. Alors⇡ = ⇡
1
+ ⇡2
.
Preuve: Soit x 2 H. Verifions que ⇡1
(x) + ⇡2
(x) est bien la projection de x sur H.D’abord il est clair que ⇡
1
(x) + ⇡2
(x) 2 H1
+H2
= H. Ensuite, pour tout h1
2 H1
hx� ⇡1
(x) + ⇡2
(x), h1
i = hx� ⇡1
(x), h1
i+ h⇡2
(x), h1
i = 0
car hx� ⇡1
(x), h1
i = 0 puisque ⇡1
(x) est la projection de x sur H1
et h⇡2
(x), h1
i = 0car H
1
et H2
sont orthogonaux. De meme hx � ⇡1
(x) + ⇡2
(x), h2
i = 0 pour touth2
2 H2
. Donchx� ⇡
1
(x) + ⇡2
(x), h1
+ h2
i = 0
ce qui prouve bien que ⇡1
(x) + ⇡2
(x) = ⇡(x).

100 Controle et filtrage lineaire optimal
8.6.3. Calcul de la matrice de gain
Puisque KnJn est la projection orthogonale de Xn sur Jn,
E((Xn �KnJn)J⇤n) = 0
doncE(XnJ
⇤n) = KnE(JnJ⇤
n). (8.5)
Comme Jn est centre et independant de �(Y0
, · · · , Yn�1
), avec (8.3)
E(XnJ⇤n) = E((Xn � X�
n )J⇤n) = E((Xn � X�
n )(C(Xn � X�n ) + ⌧n)
⇤) = P�n C⇤
doncKnE(JnJ⇤
n) = P�n C⇤. (8.6)
On a aussi
E(JnJ⇤n) = E((C(Xn � X�
n ) + ⌧n)(C(Xn � X�n ) + ⌧n)
⇤)
= CE((Xn � X�n )(Xn � X�
n ))C⇤ + E(⌧n⌧⇤n) = CP�n C⇤ +R.
On en tire Kn (rappelons que l’on a suppose R inversible):
Kn = E(XnJ⇤n)E(JnJ⇤
n)�1 = P�
n C⇤(CP�n C⇤ +R)�1. (8.7)
Pour terminer, calculons Pn :
Pn = E((Xn � Xn)(Xn � Xn)⇤)
= E((Xn � X�n �KnJn)(Xn � X�
n �KnJn)⇤)
= E((Xn � X�n ))(Xn � X�
n )⇤)� 2E((Xn � X�n )(KnJn)
⇤) + E(KnJn(KnJn)⇤)
= E((Xn � X�n ))(Xn � X�
n )⇤)� 2E(Xn(KnJn)⇤) + E(KnJn(KnJn)
⇤)
= P�n �KnE(JnJ⇤
n)K⇤n
= P�n �KnCP�
n
ou l’on a utilise que X�n et KnJn sont orthogonaux, les relations (8.5) et (8.6).
8.6.4. L’algorithme
En resume, l’algoritme est le suivant:
Theoreme 8.6.4 (Kalman-Bucy)
P�n = APn�1
A⇤ +Q (Calcul de la covariance de l’erreur estimee)
Kn = P�n C⇤(CP�
n C⇤ +R)�1 (Calcul de la matrice de gain de Kalman )
Pn = P�n �KnCP�
n (Calcul de la covariance de l’erreur )
Xn = AXn�1
+Kn(Yn�CAXn�1
) ( Utilisation de la nouvelle information)
Il faut disposer d’une condition initiale. Les trois premieres etapes sont deterministeset peuvent etre preprogrammees.

8.7 Controle avec information imparfaite 101
8.6.5. Equation de Riccati
Rappelons l’equation de Riccati du controle:
�n = Q+A⇤�n+1
A� (A⇤�n+1
B)(R+B⇤�n+1
B)�1(B⇤�n+1
A)
Posons, pour R et Q fixes,
%(A,B)
(�) = Q+A⇤�A� (A⇤�B)(R+B⇤�B)�1(B⇤�A).
Regardons l’equation satisfaite par P�n ,
P�n+1
= APnA⇤ +Q = A(P�
n �KnCP�n )A⇤ +Q
= Q+AP�n A⇤ �AKnCP�
n A⇤
avecKn = P�
n C⇤(CP�n C⇤ +R)�1
ce qui s’ecrit aussi, puisque P�n est symetrique,
P�n+1
= Q+AP�n A⇤ �AP�
n C⇤(CP�n C⇤ +R)�1CPnA
⇤
C’est donc de la formeP�n+1
= %(A⇤,C⇤
)
(P�n ).
On obtient donc l’equation de Riccati en remplacant A par A⇤ et B par C⇤.
8.7. Controle avec information imparfaite
On considere le systeme suivant, pour n � 0,
Zn+1
= AZn +BUn + "n+1
,
Tn = CZn + ⌧n,
ou Un 2 Rr, B est une matrice reelle d⇥ r avec Z0
= x0
, (ou x0
est une constante),Zn 2 Rd, Tn 2 Rp, A est une matrice d⇥d et C une matrice p⇥d . "
1
, "2
, · · · , ⌧1
, ⌧2
, · · ·sont des vecteurs gaussiens independants, "n est centre de matrice de covariance Q,⌧n est centre de matrice de covariance R inversible. On cherche a determiner
minE(N�1X
k=0
(Z⇤kSZk + U⇤
k⌃Uk) + �(ZN )),
ou S est une matrice d ⇥ d symetrique semi-definie positive et ⌃ est une matricesymetrique r ⇥ r definie positive, le minimum etant pris sur l’ensemble des vecteursU0
, · · · , UN�1
tels que U0
est constant et Un est Fn mesurable ou
Fn = �(T0
, · · · , Tn),

102 Controle et filtrage lineaire optimal
pour n � 0. La raison pour laquelle on suppose que Un est Fn-mesurable, est quel’on observe seulement Fn et il est naturel de ne pouvoir utiliser que l’observation.
On considere aussi les equations, X0
= x0
et, pour n � 0,
Xn+1
= AXn + "n+1
, Yn = CXn + ⌧n
ou Xn, "n sont des v.a. de Rd, Yn et ⌧n des v.a. de Rp, avec les memes v.a. ("n, ⌧n)qu’au dessus. On a vu que
Xn = E(Xn|�(Y0, · · · , Yn)), Pn = Var(Xn � Xn),
verifie
Pn = P�n �KnCP�
n , ou P�n = APn�1
A⇤ +Q,Kn = P�n C⇤(CP�
n C⇤ +R)�1.
Lemme 8.7.1 Zn �Xn est Fn�1
mesurable et Fn = �(Y0
, · · · , Yn).
Preuve: Remarquons que
Zn �Xn = A(Zn�1
�Xn�1
) +BUn�1
Tn � Yn = C(Zn �Xn) = CA(Zn�1
�Xn�1
) + CBUn�1
On a donc T0
� Y0
= C(Z0
�X0
) = 0. Donc �(T0
) = �(Y0
). Ensuite, supposons parrecurrence que
Fn�1
= �(T0
, · · · , Tn�1
) = �(Y0
, · · · , Yn�1
)
et que Zn �Xn est Fn�1
-mesurable. Alors
Tn � Yn = C(Zn �Xn) = A(Zn�1
�Xn�1
) +BUn�1
est aussi Fn�1
mesurable, donc Tn 2 �(Fn�1
, Yn), ce qui montre que �(T0
, · · · , Tn) ⇢�(Y
0
, · · · , Yn) et Yn 2 �(Fn�1
, Tn), ce qui montre que �(Y0
, · · · , Yn) ⇢ �(T0
, · · · , Tn).Enfin, Zn+1
�Xn+1
= A(Zn �Xn) +BUn est bien Fn mesurable. ⇤
On pose
Zn = E(Zn|Fn).
Lemme 8.7.2 Les v.a. Jn = Yn � CAXn�1
sont gaussiennes independantes et
Zn = AZn�1
+BUn�1
+KnJn.

8.7 Controle avec information imparfaite 103
Preuve: D’abord,
Zn = Xn + (Zn �Xn)
car Zn = E(Zn|Fn) = E(Xn + (Zn � Xn)|Fn) = Xn + E((Zn � Xn)|Fn) et on dejaremarque que Zn �Xn est Fn�1
mesurable, donc Fn mesurable. Puisque les Jn sontles innovations du cours, on sait qu’elles sont gaussiennes et independantes. On a
Xn = AXn�1
+KnJn
donc
Zn = AXn�1
+KnJn + (Zn �Xn).
or
Zn �Xn = A(Zn�1
�Xn�1
) +BUn�1
On a donc la relation voulue. ⇤
Lemme 8.7.3
E(N�1X
k=0
Z⇤kSZk + U⇤
k⌃Uk + �(ZN ))� E(N�1X
k=0
Z⇤kSZk + U⇤
k⌃Uk + �(ZN ))
ne depend pas des valeurs de U0
, U1
, · · · , UN�1
En e↵et,
E(Z⇤kSZk � Z⇤
kSZk) = E((Xk � Xk)⇤S(Xk � Xk))
car
Z⇤kSZk = (Zk + (Zk � Zk))
⇤S(Zk + (Zk � Zk))
= Z⇤kSZk + Z⇤
kS(Zk � Zk) + (Zk � Zk)⇤SZk + (Zk � Zk)
⇤S(Zk � Zk)
Or
E(Z⇤kS(Zk � Zk)) = E(E(Z⇤
kS(Zk � Zk)|Fk) = 0
Donc
E(Z⇤kSZk) = E(Z⇤
kSZk) + E((Xk � Xk)⇤S(Xk � Xk))
Et on montre de la meme facon que E�(ZN )) = E(�(ZN )).
Theoreme 8.7.4 Le probleme de minimisation de
minE(N�1X
k=0
Z⇤kSZk + U⇤
k⌃Uk + �(ZN )),
a une solution.

104 Controle et filtrage lineaire optimal
Preuve: Par le lemme precedent, trouver ce minimum revient a trouver le minimum
minE(N�1X
k=0
Z⇤kSZk + U⇤
k⌃Uk + �(XN ))
avec des Uk, Fk-mesurables, lorsque
Zn = AZn�1
+BUn�1
+KnJn.
Ceci est obtenu par la theorie du controle du debut de ce chapitre. On obtient Un
comme une fonction lineaire de Zn, et Zn s’obtient par recurrence par les relations
Xn = AXn�1
+Kn(Yn � CAXn�1
),
Yn = Tn � CA(Zn�1
� Xn�1
)� CBUn�1
,
Zn = Xn +A(Zn�1
� Xn�1
) +BUn�1
.

Chapitre 9
Filtrage Markovien non lineaire:Cas fini
9.1. Introduction
Dans ce chapitre on veux decrire rapidement l’algorithme utilise dans le filtrage deschaines de Markov. Il s’agit de l’algorithme de Baum-Welsh employe pour les chainesde Markov cachees (HMM=Hidden Markov chains) par exemple dans la reconnais-sance de la parole.
On se place d’abord dans un cadre general: Etant donne une chaine de MarkovXn a valeurs dans un espace a priori arbitraire E, on cherche a approcher le mieuxpossible Xn au vu d’une observation Y
0
, · · ·Yn bruitee de X0
, · · ·Xn et ce de faconrecursive pour pouvoir l’implanter en temps reel. Autrement dit on veut pouvoirpasser facilement de cette approximation a celle de Xn+1
, au vu de Y0
, · · · , Yn+1
.Mathematiquement il s’agit de calculer e↵ectivement et rapidement (temps reel) laloi conditionnelle de Xn sachant Y
0
, · · · , Yn, c’est a dire par definition, l’ensembledes
E(f(Xn))|�(Y0, · · · , Yn))ou f est mesurable positive.
9.2. Le modele
On ne va considerer que le cas le plus important en pratique. Celui a espace d’etatfini. On considere donc une chaıne de Markov homogene Xn, n � 0, a valeurs dans Efini de probabilite de transition P , donc
E(f(Xn+1
)|�(X0
, · · · , Xn) = Pf(Xn)
pour tout f positif. L’obseravtion est donne par une suite Yk de variables aleatoiresa valeurs dans un espace fini F . Pour simplifier, on se place dans l’exemple usuelsuivant:
Yn = h(Xn) + Vn

106 Filtrage Markovien non lineaire: Cas fini
ou h : E ! F , et les variables aleatoires Vn sont independantes et de meme loi etindependantes des Xn.
9.3. Les equations du filtrage
Introduisons les notations suivantes, tres utilisees par les ingenieurs, qui considerentplus les Y
0
, · · · , Yn observes comme des donnees que comme des variables aleatoires(assimilation des variables aleatoires a des ... variables).
On introduit les notations suivantes: pour toute fonction f : E ! R+
Zf dµn = E(f(Xn)|�(Y0, · · · , Yn))
et Zf dµ�
n = E(f(Xn)|�(Y0, · · · , Yn�1
))
On fera attention que µn et µ�n dependent de Y
0
, · · · , Yn. Ce sont simplement desprobabilites dependant de ce ”parametre” Y
0
, · · · , Yn, que nous pourrons considerercomme ”fixe”, car connu a l’instant n.
Le filtrage va se faire en deux etapes: l’etape de prediction et celle de correction(ou mise a jour).
9.3.1. L’etape de prediction
Lemme 9.3.1
E(f(Xn)|�(Y0, · · · , Yn�1
, Xn�1
)) = Pf(Xn�1
)
Preuve:On a
E(f1
(Xn)f2(Xn�1
)�(Y0
, · · · , Yn�1
))
= E(Pf1
(Xn�1
)f2
(Xn�1
)�(Y0
, · · · , Yn�1
))
ce qui prouve le lemme. ⇤En general, si ⌫ est une probabilite sur E, on note ⌫P la probabilite sur E definie
par
(⌫P )(A) =
ZP (x,A) d⌫(x)
Pour toute fonction f : E ! R+
Zf d(⌫P ) =
ZPf d⌫.
La proposition suivante nous dit ce que l’on peut predire sur Xn a l’instant n�1.

9.3 Les equations du filtrage 107
Proposition 9.3.2µ�n = µn�1
P
Preuve: Avec le lemme precedent,Z
f dµ�n = E(f(Xn)|�(Y0, · · · , Yn�1
)) =
= E(E(f(Xn)|�(Y0, · · · , Yn�1
, Xn�1
))|�(Y0
, · · · , Yn�1
))
= E(Pf(Xn�1
)|�(Y0
, · · · , Yn�1
))
=
ZPf dµn�1
9.3.2. L’etape de mise a jour ou correction
Lemme 9.3.3 Si v(x) = P(Vn = x), posons
g(x, y) = v(y � h(x))
Alors
E(f(X0
, · · · , Xn)1{Y0=y0,··· ,Ym=ym}) = E(f(X0
, · · · , Xn)mY
k=1
g(Xk, yk))
Preuve: Il su�t d’ecrire que
E(f(X0
, · · · , Xn)1{Y0=y0,··· ,Ym=ym}) =
E(f(X0
, · · · , Xn)1{h(X0)+V0=y0,··· ,h(Xm)+Vm=ym}).
En utilisant le lemme 9.3.3, on a
Zf dµn = E(f(Xn)|�(Y0, · · · , Yn)) =
E(f(Xn)Qn
k=0
gk(Xk, yk))
E(Qn
k=0
gk(Xk, yk))
=E(f(Xn)gn(Xn, yn)
Qn�1
k=0
gk(Xk, yk))
E(Qn
k=0
gk(Xk, yk))
sur l’ensemble Y0
= y0
, · · · , Yn = yn. De la meme facon on obtient que
E(f(X0
, · · · , Xn)|�(Y0, · · · , Yn�1
)) =E(f(X
0
, · · · , Xn)Qn�1
k=0
gk(Xk, yk))
E(Qn�1
k=0
gk(Xk, yk))
et en particulier, pour toute fonction l sur E,Z
l dµ�n = E(l(Xn)|�(Y0, · · · , Yn�1
)) (9.1)

108 Filtrage Markovien non lineaire: Cas fini
donc avec (9.1) applique a la fonction l(x) = f(x)gn(x, yn),
Zf dµn =
Zf(x)gn(x, yn) dµ
�n (x)
E(Qn�1
k=0
gk(Xk, yk))
E(Qn
k=0
gk(Xk, yk))
ce qui s’ecrit aussi, de facon plus agreable (prendre f = 1 pour identifier la constante):
Proposition 9.3.4
Zf dµn =
Rf(x)gn(x, yn) dµ�
n (x)Rgn(x, yn) dµ
�n (x)
Pour resume
Theoreme 9.3.5 Le filtre est donne par
µn�1
prediction�! µ�n = µn�1
Pmise a jour�! µn(x) =
gn(x, Yn)µ�n (x)P
z2E gn(z, Yn)µ�n (z)
C’est l’algorithme du filtrage de Baum Welsh des chaines de Markov cachees.

Partie II
Modeles a temps continu


Chapitre 10
Calcul stochastique a tempscontinu, par rapport aubrownien
10.1. Mouvement Brownien
10.1.1. Famille gaussienne
Donnons nous un espace de probabilite (⌦,F ,P). Rappelons qu’une famille {Xi, i 2 I}de variables aleatoires est dite gaussienne si toute combinaison lineaire finie de cesv.a. suit une loi normale. La loi globale de cette famille (c’est a dire par definition,la loi de toute sous famille finie que l’on appelle vecteur gaussien) est determineepar les esperances E(Xi), i 2 I, et les covariances Cov (Xi, Xj), i, j 2 I. La loi duvecteur gaussien X = (X
1
, · · · , Xn) est caracterisee par sa transformee de Fourier ousa transformee de Laplace: pour � 2 Cn,
E(exp�⇤X) = exp(�⇤E(X) +�⇤Var(X)�
2)
ou X est considere comme un vecteur colonne, E(X) est le vecteur de composantesE(X
1
), · · ·E(Xn) et Var(X) la matrice de covariance de X definie par
Var(X) = E((X � E(X))(X � E(X)⇤).
Si I1
et I2
sont deux parties de I, l’independance de {Xi, i 2 I1
} et {Xi, i 2 I2
} estequivalente au fait que Cov (Xi, Xj) = 0 si i 2 I
1
et j 2 I2
. Un processus gaussienest par definition un processus dont les elements forment une famille gaussienne.
10.1.2. Definition du mouvement brownien
Definition 10.1.1 On appelle mouvement brownien le processus Wt, t 2 R+, a tra-jectoires continues, tel que W
0
= 0 et pour tout 0 s t,

112 Calcul stochastique a temps continu, par rapport au brownien
• Wt �Ws a une loi N(0, t� s)
• Wt �Ws est independant de Wr, r s.
Si on ne le supposait pas dans la definition, on pourrait montrer que le processusconsidere est a trajectoires continues presque surement.
Proposition 10.1.2 Un processus (continu) {Wt, t 2 R+} est un mouvement brown-ien si et seulement si c’est un processus gaussien verifiant
E(Wt) = 0, E(WtWs) = min(s, t), pour tout t, s � 0.
Preuve: Supposons d’abord que Wt, t 2 R+, est un mouvement brownien. Alors Wt
est centre donc E(Wt) = 0. De plus, si 0 s t, on sait que Wt�Ws est independantde �(Wr, r s), donc en particulier de Ws. Il en resulte que
E(WtWs) = E((Wt �Ws +Ws)Ws) = E(Wt �Ws)E(Ws) + E(W 2
s ) = s.
Reciproquement, supposons les relations vraies et montrons qu’alors Wt, t 2 R+, estun mouvement brownien. Il faut montrer d’abord que si 0 s t, Wt � Ws estindependant de �(Wr, r s). Puisque la famille des Wt, t � 0, est gaussienne, il su�tde verifier que Cov(Wt �Ws,Wr) = 0, si r s t. Or
Cov(Wt �Ws,Wr) = E(WtWr)� E(WsWr) = min(t, r)�min(s, r) = 0.
Ensuite, il faut voir que, si 0 s t, loi de Wt �Ws ne depend que de t � s: cetteloi est gaussienne centree et sa variance est
E((Wt �Ws)2) = E(W 2
t ) + E(W 2
s )� 2E(WtWs) = t+ s� 2s = t� s.
Enfin, Wt est bien centre de variance t.
Corollaire 10.1.3 (Scaling) Soit {Wt, t 2 R+} un mouvement brownien. Alors
1. pour tout a > 0, {Wt+a �Wa, t 2 R+},
2. pour tout ↵ 2 R⇤, {↵W↵�2t, t 2 R+},
3. {tW1/t, t 2 R+},
sont des mouvements browniens.
Preuve: Les trois assertions se montrent de la meme facon. Traitons par exemplela seconde. Posons Xt = ↵W↵�2t. Tout d’abord, toute combinaison lineaire des v.a.Xt est une combinaison lineaire de certains Ws donc est gaussienne. Ceci montreque le processus {Xt, t � 0} est gaussien. Il est continu comme Wt. Il est clair queE(Xt) = 0, et
E(XtXs) = ↵2E(W↵�2tW↵�2s) = ↵2min(t
↵2
,s
↵2
) = min(s, t).
Par la proposition precedente, {Xt, t � 0} est un brownien.

10.1 Mouvement Brownien 113
Theoreme 10.1.4 (Theoreme de Donsker) Soit X1
, X2
, · · · , Xn, · · · des variablesaleatoires independantes et de meme loi centree, de variance 1. On pose Sn =Pn
k=1
Xk. Alors les processus
{ 1pnS[nt], t 2 R+}
s’approchent en loi d’un mouvement brownien quand n ! +1.
Preuve: (Indication) Montrons seulement que si 0 s t, le couple ( 1pnS[ns],
1pnS[nt] � 1p
nS[ns]) converge en loi vers la loi de deux v.a. gaussiennes independantes
centrees de variance s et t � s. D’abord il est clair que les deux v.a. 1pnS[ns] et
1pn(S
[nt] � S[ns]) sont independantes. Il su�t donc de les etudier separement. Or
1pnS[ns] =
p[ns]pn
X1
+X2
+ · · ·+X[ns]p
[ns]
donc il resulte du theoreme central limite usuel que ceci tend en loi vers la loi depsX ou X a une loi normale centree reduite. Le second terme a la meme loi que1pnS[nt]�[ns] et se traite donc de la meme maniere.
10.1.3. Quelques proprietes
Le resultat technique suivant va nous permettre de decrire quelques proprietes nontriviales du mouvement brownien.
Lemme 10.1.5 Si {Wt, t 2 R+} est un mouvement brownien,
lim supt!+1
Wtpt= +1, p.s.
Preuve: Posons R = lim supWt/pt. Montrons d’abord que R est constant presque
surement. Pour tout s > 0, on a
R = lim supt!+1
Ws+t �Wspt
donc est independant de �(Wr, r s). Ceci etant vrai pour tout s > 0, R est indep-endant de �(Wr, r � 0). Par ailleurs, R est mesurable par rapport a cette tribu. DoncR est une v.a. independante d’elle meme. Il en resulte que soit R = +1, soit il existeune constante ↵ telle que R = ↵, p.s. Ce dernier cas est impossible car il entraine queP(Wtp
t� ↵+ 1) ! 0 quand t ! +1 alors que P(Wtp
t� ↵+ 1) = P(W
1
� ↵+ 1) 6= 0.

114 Calcul stochastique a temps continu, par rapport au brownien
Proposition 10.1.6 Pour preque tout !, la trajectoire t 7! Wt(!),
1. passe une infinite de fois par chaque point de R;
2. n’est nulle part derivable.
Preuve: Il resulte du lemme precedent que, p.s.,
lim supt!+1
Wt = +1.
Comme {�Wt, t � 0} est aussi un mouvement brownien, on a aussi
lim inft!+1
Wt = �1.
Ces deux relations assurent, par continuite, que presque toute trajectoire passe partout point une infinite de fois. En ce qui concerne la non derivabilite, nous allonsseulement etablir que les trajectoires ne sont pas derivables en t = 0. Posons Bt =tW
1/t. Comme Bt, t � 0, est un mouvement brownien, on peut lui appliquer le lemme:presque surement,
lim supt!+1
Btpt= +1.
Donc, en posant s = t�1,
lim sups!0
1psWs = lim sup
s!0
psB
1/s = +1,
ce qui entraine que la trajectoire n’est pas derivable en 0, p.s.. Puisque Wt+a�Wa, t �0 est aussi un brownien, W n’est pas derivable en a, p.s. (ce p.s. a priori depend dea). Nous admettrons qu’en fait p.s., W n’est pas derivable en a.⇤
La fin de la preuve precedente montre aussi que la trajectoire oscille enormementau moment ou elle part de 0, puisqu’elle arrive a traverser une infinite de fois l’axe{x = 0} avant chaque instant fixe.
10.2. Propriete de Markov forte du Brownien
Lemme 10.2.1 Soit ⌧ un temps d’arret. Il existe une suite decroissante {⌧n, n 2 N}de temps d’arret tel que ⌧n est a valeurs dans {k/2n, k 2 N} [ {+1}.
Preuve: On peut prendre ⌧n = [2
n⌧ ]+1
2
n .
Theoreme 10.2.2 Soit {Bt, t � 0} un (Ft)–mouvement brownien. Alors, pour touttemps d’arret ⌧ , conditionnellement a {⌧ < +1}, le processus {Bt+⌧ � B⌧ , t 2 R+}est un brownien, independant de F⌧ .

10.2 Propriete de Markov forte du Brownien 115
Preuve: Il faut montrer que pour toute v.a. Z, F⌧ -mesurable bornee et F : Rd ! R,continue bornee,
E(Z1{⌧<+1}F (Bt1+⌧ �B⌧ , Bt2+⌧ �B⌧ , · · · , Btd+⌧ �B⌧ )) =
= E(Z1{⌧<+1})E(F (Bt1 , · · · , Btd))
On considere d’abord le cas ou ⌧ prend toutes ses valeurs dans l’ensemble denombrable{sk = k2�n, k 2 N}. Alors, puisque ⌦ est la reunion denombrable des ensemblesdisjoints {⌧ = sk}, on peut ecrire:
E(Z1{⌧<+1}F (Bt1+⌧ �B⌧ , · · · , Btd+⌧ �B⌧ )) =
=+1X
k=0
E(ZF (Bt1+⌧ �B⌧ , · · · , Btd+⌧ �B⌧ )1{⌧=sk})
=+1X
k=0
E(Z1{⌧=sk}F (Bt1+sk �Bsk , · · · , Btd+sk �Bsk))
=+1X
k=0
E(Z1{⌧=sk})E(F (Bt1 , · · · , Btd))
= E(Z1{⌧<+1})E(F (Bt1 , · · · , Btd))
ou l’on a utilise que Z1{⌧=sk} est Fsk mesurable et que B est un Ft–brownien. Dansle cas general, on approche ⌧ par une suite decroissante ⌧n de temps d’arret a valeursdenombrables, donnee par le lemme. Puisque F⌧ est contenu dans F⌧n on a encore
E(Z1{⌧<+1}F (Bt1+⌧n �B⌧n , · · · , Btd+⌧n �B⌧n)) = E(Z1{⌧<+1})E(F (Bt1 , · · · , Btd))
et on fait tendre n vers l’infini pour conclure, en utilisant la continuite des trajectoires.
Proposition 10.2.3 (Principe de reflexion) Soit {Bt, t � 0} un mouvement brown-ien. Pour a > 0, on pose Ta = inf{t � 0;Bt = a}. Alors
P(Ta t) = 2P(Bt � a).
La densite de Ta est f(s) = a(2⇡s3)�1/2e�a2/2s1R+(s). En particulier E(Ta) = 1.
Preuve: En utilisant la propriete de Markov forte du brownien, on sait que Wt =Bt+Ta �BTa est un brownien independant de FTa donc en particulier de Ta. On peutdonc ecrire, puisque BTa = a que
P(Bt � a) = P(Ta t, Bt � a)
= P(Ta t, (Bt �BTa) +BTa � a)
= P(Ta t,Wt�Ta � 0)
=
Z1{st}P(Wt�s � 0)dPTa(s)
=1
2P(Ta t).

116 Calcul stochastique a temps continu, par rapport au brownien
On en deduit, avec le changement de variable x = apt/s,
P(Ta t) =p2/⇡t
Z 1
ae�x2/2t dx = a
Z t
0
(2⇡s3)�1/2e�a2/2s ds.
Donc la densite de Ta est f(s) = a(2⇡s3)�1/2e�a2/2s, ce qui permet de calculerl’esperance.
On voit donc que, bien que le brownien passe une infinite de fois par tout lespoints, il met un temps d’esperance infinie pour atteindre un point donne. La proprietesuivante est assez etonnante !
Corollaire 10.2.4 La loi de sup0stBs est la meme que celle de |Bt|.
Preuve: P(sup0stBs � a) = P(Ta t) = 2P(Bt � a) = P(|Bt| � a).
10.2.1. Martingales et mouvement brownien
Theoreme 10.2.5 Si (Wt) est un mouvement brownien, les trois processus suivantssont des martingales:
• Wt, t � 0.
• W 2
t � t, t � 0.
• e�Wt��2
2 t, t � 0.
Preuve: Pas di�cile: mettre en evidence les accroissements.
Proposition 10.2.6 (Ruine du joueur) Soit ⌧a = inf{t � 0,Wt = a}. Alors poura < 0 < b
P(⌧a < ⌧b) =b
b� a,
etE(⌧a ^ ⌧�a) = a2.
Preuve: Posons � = ⌧a ^ ⌧b. C’est un temps d’arret donc W � est une martingale parle theoreme d’arret. On a donc, pour tout t � 0,
E(W �t ) = E(W �
0
) = 0
Remarquons que |W �t | max(�a, b) qui est integrable fixe. On peut donc appliquer
le theoreme de convergence dominee pour faire tendre t ! +1 et obtenir que
E(W �1) = 0
Puisque � est fini p.s. (pourquoi ?) on a donc a la fois
0 = E(W�) = aP(⌧a < ⌧b) + bP(⌧b < ⌧a)
et1 = P(⌧a < ⌧b) + P(⌧b < ⌧a)
ce qui donne le premier resultat. Pour montrer le second utiliser la martingale W 2
t �t.

10.3 Integrale stochastique 117
10.3. Integrale stochastique
Nous allons imiter la construction de l’integrale de Riemann pour integrer un proces-sus continu ”contre” le mouvement brownien. Remarquons d’abord que si f : R+ ! Rest une fonction continue et si 0 = t(n)
0
< t(n)1
< · · · < t(n)n = T est une suite de sub-divisions de [0, T ] donc le pas tend vers 0, quand n ! +1, pour tout 0 t T , laconstruction de Riemann nous dit que
Z T
0
f(s) ds = limn!+1
n�1X
i=0
f(t(n)i )(t(n)i+1
� t(n)i )
et plus generalement, si 0 < t < T ,
Z t
0
f(s) ds = limn!+1
n�1X
i=0
f(t(n)i )(t(n)i+1
^ t� t(n)i ^ t)
On se donne un Ft-mouvement brownien (Wt) sur (⌦,F ,P).
Definition 10.3.1 On appelle processus adapte etage un processus Xt s’ecrivant
Xt =kX
i=0
Xti1[ti,ti+1[(t)
ou Xti est Fti-mesurable,
Si X est un processus adapte etage, on pose
Mt =
Z t
0
Xs dWs =kX
i=0
Xti(Wti+1^t �Wti^t) (10.1)
Theoreme 10.3.2 La formule se prolonge a tout processus adapte continu borne Xet definit un processus
Mt =
Z t
0
Xs dWs
qui est une martingale continue et telle que
M2
t �Z t
0
X2
s ds
est aussi une martingale. Pour tout t � 0
E( sup0st
M2
s ) 4E(M2
t ) = 4E(Z t
0
X2
s ds) (10.2)

118 Calcul stochastique a temps continu, par rapport au brownien
Preuve: Etape 1. Montrons deja que Mt a ces proprietes de martingales dans le casde la formule (10.1). Si ti s t ti+1
,
Mt �Ms = Xti(Wt �Ws)
doncE(Mt �Ms|Fs) = E(Xti(Wt �Ws)|Fs) = XtiE(Wt �Ws|Fs) = 0.
En particulier E(Mt|Fti) = Mti et si ti�1
s ti,
E(Mt|Fs) = E[E(Mt|Fti)|Fs)] = E[Mti |Fs)] = Ms
De proche en proche on obtient que cette relation est vraie pour tout s t. De lameme facon, si ti s t ti+1
, (Mt �Ms)2 = X2
ti(Wt �Ws)2 donc
E((Mt �Ms)2|Fs) = E(X2
ti(Wt �Ws)2|Fs) = X2
tiE(Wt �Ws)2|Fs) = X2
ti(t� s).
Remarquons que E(MsMt|Fs) = M2
s donc
E((M2
t �M2
s )|Fs) = E((Mt �Ms)2|Fs) = X2
ti(t� s) =
Z t
sX2
u du
a nouveau, de proche en proche on en deduit que M2
t �R t0
X2
s ds est une martingale.La relation (10.3) est consequence de l’inegalite de Doob.
Etape 2. Considerons le cas ou X est continu borne. Alors, pour tout T > 0, lasuite de processus
Xnt =
nX
k=0
XkT/n1[kT/n,(k+1)T/n[(t)
converge vers X, en dehors des points de sauts de X. Si on pose
Mnt =
Z t
0
Xns dWs
on a Mnt �Mm
t =R t0
(Xns �Xm
s ) dWs, donc par (10.3),
E( sup0sT
(Mns �Mm
s )2) 4E(Z t
0
(Xns �Xm
s )2 ds)
Le terme de droite tend vers 0 quand n,m ! +1. On peut donc construire parrecurrence une suite nk telle que
EZ t
0
(Xnk+1s �Xnk
s )2 ds 1/2k
Posons alors
Mt = limk!+1
Mnks = Mn0
s +1X
k=0
[Mnk+1s �Mnk
s ]
Cette serie converge, dans L2 et uniformement ... Une limite dans L1 de martingalesetant une martingale (Lemme 10.4.4) on conclut facilement.

10.4 Processus arrete, martingale locale 119
10.4. Processus arrete, martingale locale
Un temps d’arret ⌧ est une v.a. a valeurs dans R+[{+1} telle que, pour tout t � 0,
{⌧ t} 2 Ft.
Remarquons que ceci est equivalent au fait que le processus t 7! 1[0,⌧ [(t) est adapte.
Pour tout processus continu adapte, on montre comme au dessus queR t0
Xs1[0,⌧ [(s)dWs
est bien defini et queZ t^⌧
0
XsdWs =
Z t
0
Xs1[0,⌧ [(s)dWs.
Corollaire 10.4.1 Soit ⌧ un temps d’arret, X continu borne, et M =R t0
Xs dWs.Alors M ⌧
t = M⌧^t est une martingale.
Definition 10.4.2 Un processus adapte continu M est une martingale locale si ilexiste une suite croissante de temps d’arrets ⌧n ! +1, p.s., telle que M ⌧n �M
0
soitune martingale. On dit alors que la suite {⌧n, n � 0} reduit M .
Soit X un processus adapte continu nul en 0, on pose ⌧n = inf{t � 0, |Xt| � n}.Alors X⌧n est un processus adapte continu borne. Si t ⌧n posons
Mt =
Z t
0
Xs dWs =
Z t
0
X⌧ns dWs.
Il n’y a pas d’ambiguite car si t ⌧n ⌧mZ t
0
X⌧ms dWs =
Z t^⌧n
0
X⌧ms dWs =
Z t
0
X⌧ns dWs.
Si X est un processus adapte continu arbitraire, on poseZ t
0
Xs dWs =
Z t
0
(Xs �X0
) dWs +X0
Wt.
Alors M est une martingale locale puisque M ⌧n est une martingale et, de meme,M2
t �R t0
X2
sds est une martingale locale :
Theoreme 10.4.3 Pour tout processus continu adapte Xt, t � 0,, les processus
Mt =
Z t
0
Xs dWs, t � 0,
et
(
Z t
0
Xs dWs)2 �
Z t
0
X2
s ds, t � 0,
sont des martingales locales. De plus
E( sup0st
M2
s ) 4E(Z t
0
X2
s ds). (10.3)

120 Calcul stochastique a temps continu, par rapport au brownien
Preuve: Pour montrer l’inegalite, on utilise le fait que puisque (Mt) est un martingalelocale, Il existe une suite ⌧n croissant vers +1 pour laquelle M ⌧n
t est une martingale.On a, par Doob,
E( sup0st
(M ⌧ns )2) 4E((M ⌧n
t )2) 4E(Z t^⌧n
0
X2
s ds) 4E(Z t
0
X2
s ds)
et on fait tendre n vers l’infini (avec Lebesgue monotone). ⇤
Contrairement au cas du temps discret, il n’est pas vrai qu’une martingale localeintegrable est une martingale. Il est donc tres utile d’avoir des criteres permettant devoir si une martingale est une martingale locale.
Lemme 10.4.4 Si (M (n)t , t 2 R+) est une suite de martingales et si M (n)
t ! Mt
dans L1 quand n ! +1, alors Mt, t 2 R+ est aussi une martingale
Preuve: Continuite de l’esperance conditionnelle dans L1.
Proposition 10.4.5 1. Une martingale locale bornee est une martingale.
2. SI X est un processus adapte continu tel que, pour tout t � 0
E(Z t
0
X2
s ds) < +1
alors
Mt =
Z t
0
Xs dWs et M2
t �Z t
0
X2
s ds
sont des martingales.
Preuve: 1. Si (Zt) est une martingale locale bornee et (⌧n) reduit Z, la suite Z⌧nt con-verge vers Z dans L1 par le theoreme de Lebesgue domine. Z est donc une martingalepar le lemme 10.4.4.
2. Par le theoreme precedent,
E( sup0st
M2
s ) 4E(M2
t ) E(Z t
0
X2
sds)
qui est fini par hypothese. Si ⌧n reduit M , M ⌧nt converge vers Mt dans L1 et donc,
par le lemme 10.4.4, M est une martingale. De meme M2
t^⌧n �R t^⌧n0
X2
sds est majoreepar une fonction integrable fixe. C’est donc une suite de martingale convergeant dansL1 vers M2
t �R t0
X2
s ds qui est donc une martingale.

10.5 Formule d’Ito pour le Brownien 121
10.5. Formule d’Ito pour le Brownien
Theoreme 10.5.1 Si f : R ! R est de classe C2,
f(Wt) = f(0) +
Z t
0
f 0(Ws) dWs +1
2
Z t
0
f 00(Ws) ds
Preuve: Quitte a remplacer d’abord t par t ^ ⌧ ou ⌧ = inf{t; |Wt| � M , on peutsupposer f 0 et f 00 bornes. Soit 0 < tn
1
< tn2
< · · · < tnn = t une suite de partitions de[0, t]dont le pas sup
0<i<n�1
tni+1
� tni tend vers 0 quand n ! +1. Utilisons la formulede Taylor sous la forme
f(y)� f(x) = f 0(x)(y � x) +1
2f 00(z)(y � x)2
pour un z entre x et y pour ecrire que
f(Wt) = f(W0
) +n�1X
i=0
f(Wti+1)� f(Wti)
= f(W0
) +n�1X
i=0
f 0(Wti)(Wti+1 �Wti) +1
2
n�1X
i=0
f 00(zi)(Wti+1 �Wti)2
ou zi est entre Wti et Wti+1 . On a
n�1X
i=0
f 0(Wti)(Wti+1 �Wti) =
Z t
0
n�1X
i=0
f 0(Wti)1[ti,ti+1[(s) dWs
donc
E([n�1X
i=0
f 0(Wti)(Wti+1 �Wti)�Z t
0
f 0(Ws)dWs]2)
E(Z t
0
[n�1X
i=0
(f 0(Wti)� f 0(Ws))1[ti,ti+1[
(s)]2 ds)
qui tend vers 0 par continuite et Lebesgue domine. Pour traiter le dernier terme onutilise le lemme suivant.
Lemme 10.5.2 Soit f : R+ ! R une fonction continue, si t(n)k = kT2
n , alors, presquesurement,
2
n�1X
k=0
f(t(n)i )(Wt(n)i+1
�Wt(n)i
)2 !Z t
0
f(s)ds
quand n ! +1.

122 Calcul stochastique a temps continu, par rapport au brownien
Preuve: N’ecrivons pas l’exposant (n) pour simplifier les notations. Puisque Wt+s �Wt a la meme loi que
pt� sW
1
on a
E((Wti+1 �Wti)2) = ti+1
� ti
V ar((Wti+1 �Wti)2) = a(ti+1
� ti)2
ou a = V ar(W 2
1
). Donc, en utilisant l’independance des accroissements,
E([2
n�1X
i=0
(Wti+1 �Wti)2 � (ti+1
� ti)]2) =
XV ar(Wti+1 �Wti)
2 = aX
(ti+1
� ti)2
a(X
(ti+1
� ti)) supk(tk+1
� tk) aTT
2n
On voit donc que+1X
n=0
E[2
n�1X
i=0
(Wt(n)i+1
�Wti(n))2 � T ]2 < +1
ce qui entraıne que, presque surement,
2
n�1X
i=0
(Wt(n)i+1
�Wti(n))2 ! T
De la meme facon, on voit que pour tout 0 t T , presque surement,
2
n�1X
i=0
(Wt(n)i+1^t
�Wti(n)^t)2 ! t
Si f = 1[0,t] clair, donc plus generalement pour les fonctions etagees, par linearite.
Ensuite toute fonction continue f est limite uniforme sur [0, T ] de fonctions etageesfr et donc
|X
f(ti)(Wti+1 �Wti)2 �
Xfr(ti)(Wti+1 �Wti)
2| sup|f � fr|X
(Wti+1 �Wti)2
et on conclut alors facilement.
10.5.1. Generalisation unidimensionnelle
Definition 10.5.3 On appelle processus d’Ito (unidimensionnel) un processus Xt
s’ecrivant
Xt = X0
+
Z t
0
asds+
Z t
0
�s dWs
ou a et � sont des processus adaptes continus.

10.5 Formule d’Ito pour le Brownien 123
Lorsque at et �t sont des processus adaptes etages, on montre facilement, enadaptant la preuve de la formule d’Ito pour le brownien, que le theoreme suivant estvrai. On l’obtient ensuite pour tout a et � continus adaptes par approximation etlocalisation.
Theoreme 10.5.4 (Formule d’Ito) Si X est un processus d’Ito unidimensionnel,et f : R ! R est de classe C2,
f(Xt) = f(X0
) +
Z t
0
f 0(Xs) dXs +1
2
Z t
0
f 00(Xs)�2
s ds
On a utilise la notation intuitive suivante: si �t est un processus continu adapte,Z t
0
�s dXs =
Z t
0
�sas ds+
Z t
0
�s�s dWs
Autrement dit, formellement
dXt = at dt+ �t dWt.
On ecrit souvent la formule d’Ito sous la forme condensee
d(f(Xt)) = f 0(Xt) dXt +1
2f 00(Xt)�
2
t dt.
ou encore
d(f(Xt)) = f 0(Xt) dXt +1
2f 00(Xt)dhX,Xit
en posantdhX,Xit = �2t dt.
10.5.2. Cas multidimensionnel
Soit W (1)
t ,W (2)
t , · · · ,W (n)t n Ft-mouvements browniens independants. Un processus
Xt = (X(1)
t , · · · , X(d)t ) a valeurs dans Rd est appele un processus d’Ito si, pour tout
i = 1, · · · , d,
X(i)t = X
0
+
Z t
0
a(i)s ds+nX
j=1
Z t
0
�(i,j)s dW (j)s
ou a(i)s et �(i,j)s sont des processus continus adaptes. On ecrira pour simplifier
dX(i)t = a(i)t dt+
nX
j=1
�(i,j)t dW (j)t .
Posons
hX(i), X(j)it =Z t
0
nX
k=0
�(i,k)s �(j,k)s ds

124 Calcul stochastique a temps continu, par rapport au brownien
ce que l’on ecrit aussi
dhX(i), X(j)it =nX
k=0
�(i,k)t �(j,k)t dt.
Theoreme 10.5.5 (Formule d’Ito multidimensionnelle) Si X est un processusd’Ito a valeurs dans Rd, et f : Rd ! R est de classe C2,
f(Xt) = f(X0
) +dX
i=1
Z t
0
@f
@xi(Xs) dX
(i)s +
1
2
dX
i,j=1
Z t
0
@2f
@xi@xj(Xs)dhX(i), X(j)is
Un cas particulier important est le suivant. Il s’obtient en appliquant la formuleprecedente a la fonction f(x
1
, x2
) = x1
x2
.
Theoreme 10.5.6 (Formule d’integration par parties) Si X1, X2 est un pro-cessus d’Ito
dX(1)
t X(2)
t = X(1)
t dX(2)
t +X(2)
t dX(1)
t + dhX(1), X(2)it
Comme cas particulier de la formule d’Ito on obtient:
Theoreme 10.5.7 (Formule d’Ito pour fonction dependant du temps) Si Xest un processus d’Ito unidimensionnel, et f : R+ ⇥ R ! R est de classe C2,
f(t,Xt) = f(0, X0
) +
Z t
0
@f
@t(s,Xs) ds+
Z t
0
@f
@x(s,Xs) dXs +
1
2
Z t
0
@2f
@x2(s,Xs)�
2
s ds
Preuve: On remarque que le couple (t,Xt) est lui meme un processus d’Ito bidimen-sionnel auquel on on peut applique la formule d’Ito precedente.
10.6. Exemples
La plupart des calculs sur l’integrale stochastique se font avec la formule d’Ito. Ex-emple:
Z t
0
WsdWs =1
2(W 2
t � t)
e�Wt��2
2 t = 1 + �
Z t
0
e�Ws��2
2 sdWs

10.7 Theoreme de Girsanov 125
Proposition 10.6.1 Soit Mt =R t0
�s dWs, ou � est continu adapte. Alors
Zt = eMt� 12
R t0 �
2s ds
verifie
Zt = 1 +
Z t
0
Zs�s dWs
C’est en particulier une martingale locale.
Preuve: On applique la formule d’Ito au processus d’Ito
Xt = �1
2
Z t
0
�2s ds+
Z t
0
�s dWs = Mt �1
2
Z t
0
�2s ds
pour lequel < X,X >t=R t0
�2s ds et a la fonction f(x) = ex.
Proposition 10.6.2 Si f est deterministe continue, Mt =R t0
f(s)dWs est un pro-cessus gaussien centre de covariance
cov(Mt,Ms) =
Z s^t
0
f(s)2ds
Preuve: On applique la proposition precedente pour calculer la transformeee deFourier de Mt.
10.7. Theoreme de Girsanov
Soit Mt =R t0
�s dWs, ou � est continu adapte et
Zt := eMt� 12
R t0 �
2s ds
Jusqu’a present nous travaillons sur un espace de probabilite (⌦, (Ft),P). FixonsT > 0 et supposons que Zt, 0 t T, soit une vraie martingale (il existe des criterespermettant de le verifier) donc que E[ZT ] = 1. Sur (⌦, (FT )) on peut definir uneprobabilite P equivalente a P en posant, par
dP = ZT dP
(autrement dit
E(X) :=
ZX dP =
ZXZT dP = E(XZT )
pour toute v.a. posiitve X, FT -mesurable.)Le theoreme suivant est du a Cameron et Martin quand � est deterministe.

126 Calcul stochastique a temps continu, par rapport au brownien
Theoreme 10.7.1 (Girsanov) Sur (⌦, (FT ), P), le processus
Wt := Wt �Z t
0
�s ds
est un mouvement brownien pour t T .
Preuve: Montrons seulement que Wt a bien la loi N(0, t). (La preuve generale con-siste a calculer la loi de
Pnk=1
�kWtk exactement de la meme facon). Calculons latransformee de Laplace ou de Fourier,
E(e� ˜Wt) = E(ZT e� ˜Wt) = E(Zte
� ˜Wt) car(Zt) est une martingale,
= E(eMt� 12
R t0 �
2s dse�(Wt�
R t0 �s ds))
Remarquons alors que
Mt + �Wt =
Z t
0
(�s + �)dWs
donc, par la proposition
eMt+�Wt� 12
R t0 (�s+�)
2 ds
est une martingale locale. Admettons que c’est une martingale. Donc
E[eMt+�Wt� 12
R t0 �
2s ds�
R t0 ��s ds� 1
2
R t0 �
2 ds] = 1
On en deduit bien que
E(e� ˜Wt) = e�2t2 .
10.7.1. Une application
Comme application du theoreme de Girsanov, calculons la loi du temps d’atteinted’un niveau a > 0 par un brownnien avec drift �. Soit Wt, t � 0 un Brownien. Onpose
Zt = exp(�Wt ��2
2t)
Sur FT on posedP = ZT dP.
Par Girsanov, sur (⌦,FT , P), Wt = Wt � �t est un brownien usuel. Autrement dit,
Wt = Wt + �t
est sous P un brownien avec drift �. Soit ⌧a = inf{t � 0,Wt = a}. On a, pour t T ,en utilisant que Zt est une martingale sous P,
P(⌧a T ) = E(1⌧aTZT ) = E(1⌧aTZ⌧a)

10.8 Equations di↵erentielles stochastiques 127
= E(1⌧aT exp(�a� �2
2⌧a))
=
Z t
0
exp(�a� �2
2s)f(s)ds
ou
f(t) =|a|p2⇡t3
e�a2/2t
par la proposition 10.2.3. Donc ⌧a a sous P la densite
f(t) =|a|p2⇡t3
e�(a��s)2/2t.
Si t ! +1 on en deduit que, si a < 0,� > 0,
P(⌧a < +1) = e2�a.
10.8. Equations di↵erentielles stochastiques
On se limite au cas unidimensionnel. Soient � : R+ ! R et b : R+R ! R deux fonc-tions continues. Pour x, on considere l’equation di↵erentielle stochastique (E.D.S.)
dXt = �(Xt) dBt + b(Xt) dt, X0
= x 2 Rp; (10.4)
Etant donne un mouvement Brownien sur (⌦, (Ft),P), muni de sa filtration, on appellesolution (forte) de cette equation un processus adapte continu Xt tel que, pour toutt � 0,
Xt = X0
+
Z t
0
b(Xs) ds+
Z t
0
�(Xs) dBs
On considere l’equation (10.4). On dit que b et � sont lipschitziennes en x si ilexiste K > 0 tels que, pour tous x, y 2 R
|b(x)� b(y)| K|x� y|, |�(x)� �(y)| K|x� y|.
Le theoreme fondamental est le suivant:
Theoreme 10.8.1 Soit Bt, t � 0, un mouvement brownien. On suppose que b et �sont lipschitziennes en x et bornees sur les compacts. Etant donne x 2 R il existe unet un seul processus continu adapte X tel que pour tout t � 0,
Xt = x+
Z t
0
b(Xs) ds+
Z t
0
�(Xs) dBs.

128 Calcul stochastique a temps continu, par rapport au brownien
Preuve:1. Unicite: admise. 2. Existence: on utilise ce qu’on appelle le schema de Picard. Onpose, pour tout t � 0, X0
t = x puis par recurrence
Xnt = x+
Z t
0
b(Xn�1
s ) ds+
Z t
0
�(Xn�1
s ) dBs
On a
Xn+1
t �Xnt =
Z t
0
(b(Xns )� b(Xn�1
s ) ds+
Z t
0
(�(Xns )� �(Xn�1
s ) dBs
Posonsgn(u) = E(sup
tu[Xn+1
t �Xnt ]
2).
Si 0 u T ,
gn(u)
2E(suptu
[
Z t
0
(b(Xns )� b(Xn�1
s )) ds]2) + 2E(suptu
[
Z t
0
(�(Xns )� �(Xn�1
s )) dBs]2)
2E(TZ u
0
(b(Xns )� b(Xn�1
s ))2 ds) + 8E([Z u
0
(�(Xns )� �(Xn�1
s ))2 ds)
2(T + 4)K2
Z u
0
E(|Xns �Xn�1
s |2) ds
2(T + 4)K2
Z u
0
E(supsv
|Xns �Xn�1
s |2) dv = C
Z u
0
gn�1
(v) dv
pour C = 2(T + 4)K2. On en deduit par recurrence que,
gn(t) Cntn
n!g0
(t)
or
g0
(t) E(supsT
[X1
s � x]2) E(supsT
(sb(x) +
Z s
0
�(x)dBr)2)) Cte
On a donc
E(1X
n=0
suptT
[Xn+1
t �Xnt ]
2) =1X
n=0
gn(T ) < +1.
On en deduit que Xn converge p.s. vers une solution X de l’equation.
10.8.1. Estimees
Lemme 10.8.2 (Gronwall) Soit g : [0, T ] ! R une fonction borelienne bornee telleque, pour a, b � 0,
g(t) a+ b
Z t
0
g(s) ds, pour tout 0 t T.
Alors g(t) aebt sur [0, T ].

10.8 Equations di↵erentielles stochastiques 129
Preuve: On pose G(t) = a+ bR t0
g(s) ds. Alors g(t) G(t). Si g est continue, G estune fonction derivable et
(e�btG(t))0 = �be�btG(t) + e�btG0(t) = �be�btG(t) + be�btg(t) 0
donc e�btg(t) e�btG(t) G(0) = a.Si g est seulement mesurable bornee, G est continue et verifie
G(t) = a+ b
Z t
0
g(s) ds a+ b
Z t
0
G(s) ds
donc la meme conclusion est vraie. ⇤
Theoreme 10.8.3 Sous les hypotheses du theoreme 10.8.1 Pour tout m,T > 0,
E(suptT
kXtkm) < +1.
Preuve: Sous ces hypotheses, il existe K > 0 tel que, pour tout x 2 Rp,
||�(x)||+ ||b(x)|| K(1 + ||x||) (10.5)
Soit⌧ = inf{t � 0; kXtk � n}
avec n � kx0
k. Pour simplifier les notations, en dimension 1, en prenant p pair pourque kXtkp = Xp
t , par Ito,
dXpt = pXp�1
t dXt +p(p� 1)
2Xp�2
t dhX,Xit
donc
Xpt^⌧ = xp
0
+
Z t^⌧
0
[p(X⌧s )
p�1b(X⌧s ) +
p(p� 1)
2�(X⌧
s )2(X⌧
s )p�2]ds
+
Z t^⌧
0
p(X⌧s )
p�1�(X⌧s )dBs
Puisque (a+ b+ c)2 4(a2 + b2 + c2) on en deduit que
X2pt^⌧ 4x2p
0
+ 4(
Z t^⌧
0
[p(X⌧s )
p�1b(X⌧s ) +
p(p� 1)
2�(X⌧
s )2(X⌧
s )p�2]ds)2
+4(
Z t^⌧
0
p(X⌧s )
p�1�(X⌧s )dBs)
2
donc par Doob, et par Cauchy Schwarz, si 0 r T , pour un T > 0 fixe,
E(suptr
X2pt^⌧ )

130 Calcul stochastique a temps continu, par rapport au brownien
4x2p0
+ 4T (
Z r
0
|p(X⌧s )
p�1b(X⌧s ) +
p(p� 1)
2�(X⌧
s )2(X⌧
s )p�2]|2ds)
+16E(Z r
0
[p(X⌧s )
p�1�(X⌧s )]
2ds
On peut trouver deux constantes ↵,� > 0 telles que, pour tout x 2 R,
4T (|pxp�1b(x)|+ |p(p� 1)
2�(x)2xp�2]|)2 + 16|pxp�1�(x)|2 ↵+ �|x|2p
On a donc, en posant � = 4x2p0
+ T↵,
E(suptr
X2pt^⌧ ) � + �
Z r
0
E(X2ps^⌧ )ds
donc
E(suptr
X2pt^⌧ ) � + �
Z r
0
E(supts
X2pt^⌧ )ds
et par Gronwall,E(sup
trX2p
t^⌧ ) �e�r.
Comme les constantes ne dependent pas de n (qui a defini ⌧) on peut faire tendre nvers l’infini pour obtenir que
E(suptr
X2pt ) �e�r.
10.8.2. Propriete de Markov
Reprenons les hypotheses precedentes mais supposons que b et � ne dependent pasdu temps t. Notons Xx
t la solution de l’E.D.S. (10.4) verifiant Xx0
= x. PrenonsFt = �(Bs, s t). Il existe une application mesurable
� : R⇥ C([0, T ],R) ! C([0, T ],R)
telle queXx = �(x,B).
Pour tout temps d’arret ⌧ , fini p.s., par la propriete de Markov forte du Brownien leprocessus Bt = Bt+⌧ � B⌧ est un mouvement brownien independant de F⌧ , donc deX⌧ . On voit facilement en prenant d’abord pour H des fonctions etagees que, pourtout H de L0(B), Z t+⌧
⌧Hs dBs =
Z t
0
Hs+⌧ dBs
La relation
X⌧+t = X⌧ +
Z t+⌧
⌧b(Xs) ds+
Z t+⌧
⌧�(Xs) dBs

10.9 Processus de Markov 131
= X⌧ +
Z t
0
b(X⌧+s) ds+
Z t
0
�(X⌧+s) dBs
montre que, si on pose ⌧Xt = X⌧+t, pour tout t � 0, alors
⌧X = �(X⌧ , B).
Puisque B est independant de F⌧ , on en deduit:
Theoreme 10.8.4 (Propriete de Markov forte) Pour tout temps d’arret ⌧ fini p.s.,pour toute fonction mesurable positive F definie sur C(R+,Rp),
E(F (⌧X)|F⌧ ) = Ey(F (X)), pour y = X⌧
ou le symbole Ey signifie que l’on considere la solution X telle que X0
= y (c’est adire X(y)).
10.9. Processus de Markov
Posons, pour f mesurable positive sur Rp, Ptf(x) = Ex(f(Xt)). En prenant F (X) =f(Xt) et ⌧ = s dans le theoreme precedent on voit que
E(f(Xt+s)|Fs) = Ey(f(Xt)) = Ptf(y), pour y = Xs,
donc, en prenant l’esperance,
Pt+sf(x) = Ex(f(Xt+s)) = Ps(Ptf)(x)
c’est la propriete dite de semigroupe. On dit que X est un processus de Markov desemigroupe (Pt). Par continuite des trajectoires en t = 0,
limt!0
Ptf(x) = f(x)
si f est continue bornee.
Definition 10.9.1 On appelle generateur du semigroupe (Pt) l’operateur Lf definipar
Lf(x) = limt!0
Ptf(x)� f(x)
tpour les f pour lesquels cette limite a un sens.
Theoreme 10.9.2 Soit X solution de l’E.D.S.,
dXt = �(Xt) dBt + b(Xt) dt
Alors X est un processus de Markov dont le generateur est donne par
Lf(x) =1
2�(x)2
@2f
@x2+ b(x)
@f
@x(x)
lorsque f est C2 a support . On dit que X est une di↵usion.

132 Calcul stochastique a temps continu, par rapport au brownien
Preuve: Si on applique la formule d’Ito a f(Xt), on obtient,
f(Xt) = f(X0
) +
Z t
0
@f
@x(Xs)�(Xs) dBs +
Z t
0
Lf(Xs) ds
Puisque f est a support compact , @f@x (Xs)�(Xs) est borne, donc l’integrale stochas-tique est une martingale, d’esperance nulle. On a alors
Ptf(x) = f(x) + Ex(
Z t
0
Lf(Xs) ds) = f(x) +
Z t
0
PsLf(x) ds
Donc
Lf(x) = limt!0
Ptf(x)� f(x)
t= lim
t!0
1
t
Z t
0
PsLf(x) ds = P0
Lf(x) = Lf(x).
10.9.1. Feynman-Kac
On considere a nouveau,
Lf(x) =1
2�(x)2
@2f
@x2+ b(x)
@f
@x(x)
On se donne �, c : R ! R avec c � 0 et on considere une solution u bornee a deriveesbornees de l’equation
@u
@t(t, x) = (L� c(x))u(t, x), u(0, x) = �(x). (10.6)
Theoreme 10.9.3 La solution u(t, x) de (10.6) verifie:
u(t, x) = Ex[�(Xt) exp(�Z t
0
c(Xs) ds)]
ou X est la di↵usion associee a (10.4)
Preuve: On pose, t > 0 etant fixe,
v(s, x) = u(t� s, x), Zs = exp(�Z s
0
c(Xu) du).
Appliquant la formule d’Ito, on a
d(v(s,Xs)Zs) = �v(s,Xs)c(Xs)Zs ds+ Zs dv(s,Xs)
= Z{@v@s
+ (L� c)v} ds+ Z@v
@x� dBs.

10.9 Processus de Markov 133
Vu que @v@x est bornee et que 0 Zs 1, E(
R t0
Zs@v@x �(Xs) dBs) = 0. D’autre part
@v@s (s, x) = �@u
@s (t� s, x) et donc
@v
@s(s, x) + (L� c)v(s, x) = �@u
@s(t� s, x) + (L� c)u(t� s, x) = 0
On a doncE(v(t,Xt)Zt) = E(v(0, X
0
)Z0
)
mais, puisque u(0, Xt) = �(Xt),
E(v(t,Xt)Zt)� E(v(0, X0
)Z0
) = E(u(0, Xt)Zt)� u(t, x) = E(�(Xt)Zt)� u(t, x)
et l’on obtientu(t, x) = E(�(Xt)Zt).

134 Calcul stochastique a temps continu, par rapport au brownien

Chapitre 11
Black et Scholes
11.1. Introduction
Nous allons maintenant etudier l’evaluation d’actifs derives en temps continu, en nousconcentrant sur le modele de loin le plus important, le modele de Black et Scholes.On va voir qu’il s’applique dans un cadre plus large que celui du temps discret, etqu’il donne souvent des formules explicites.
11.2. Le modele
On considere le modele classique de Black et Scholes: un horizon T , deux actifsSt, Bt, 0 t T, ou
Bt = ert, donc dBt = rBt dt
dSt = µSt dt+ �St dWt
et W est un mouvement brownien sur un espace (⌦,F ,P), ou P est une probabilite.En fait ce P va jouer exactement le role de la mesure de reference m que l’on avaitintroduite dans le cas discret (⌦ est forcement un tres gros espace puisqu’on peuty definir le mouvement brownien. En un sens, il contient l’ensemble des fonctionscontinues, et sur ce dernier il n’y a pas de mesure de reference canonique, P va jouerce role).
Pour garder la tradition financiere on appelle B l’actif non risque (B pour Bondou Banque), a ne pas confondre avec un mouvement brownien.
L’introduction de l’equation donnant St vient du fait que, intuitivement dSt/St
est le rendement du spot, et qu’il est a peu pres constant egal a µdt a une (petite)perturbation aleatoire �dWt. L’ ”amplitude” de cette perturbation est mesuree par�, parametre tres important qu’on appelle la volatilite de l’actif St.

136 Black et Scholes
11.2.1. Le spot
Le spot St est un processus continu adapte defini par l’equation stochastique
dSt = µSt dt+ �St dWt,
autrement dit
St = S0
+
Z t
0
µSu du+
Z t
0
�Su dWu.
Lemme 11.2.1 Pour tout a 2 R on note S(a)t la solution de
dS(a)t = aS(a)
t dt+ �S(a)t dWt, S(a)
0
= S0
Alors, pour tout a, b 2 R S(a)t = et(a�b)S(b)
t .
Preuve: Appliquons la formule d’Ito a f(t, x) = et(a�µ)x au processus d’Ito St:
et(a�µ)St = f(t, St) = S0
+
Z t
0
(a� µ)et(a�µ)Su du+
Z t
0
et(a�µ)dSu
Donc dS(a)t = (a+ µ)S(a)
t dt+ �S(a)t dWt. ⇤
Si on choisit a = 0 on obtient
dS(0)
t = �S(0)
t dWt
(qui est une martingale locale, comme integrale stochatique). On a deja vu que leprocessus
S0
e�Wt��2
2 t
verifiait cette equation et c’est la seule (car coe�cient lipschitzien, par exemple).Remarquons que c’est une vraie martingale (martingale exponentielle du brownien).On obtient donc
Proposition 11.2.2 Pour tout a 2 R,
S(a)t = S
0
e(a��2
2 )t+�Wt
en particulier,
St = S0
e(µ��2
2 )t+�Wt . (11.1)
Comme dans les chapitres precedents on considere les prix reactualises par Bt, en lessurmontant d’un tilde. On a
St = e�rtSt
Il resulte du lemme, en prenant a = �r que
dSt = (µ� r)St dt+ �St dWt. (11.2)

11.3 Portefeuille autofinance 137
11.3. Portefeuille autofinance
Par analogie avec le cas discret,
Definition 11.3.1 On appelle portefeuille un processus Vt s’ecrivant
Vt = ↵tSt + �tBt
avec ↵,� adaptes continus. Il est dit autofinance si
dVt = ↵t dSt + �t dBt.
Remarquons qu’en temps continu, dans le cadre des processus continus, il n’y a pasde distinction intuitive entre previsible et adapte.
Lemme 11.3.2 Si V est un portefeuille autofinance dans la marche (S,B), alorsVt = e�rtVt autofinance dans la marche (S, 1)
dVt = ↵t dSt (11.3)
Preuve: Puisque Vt = ↵tSt+�t, il su�t de montrer la formule (11.3). En appliquantla formule d’Ito a f(t, x) = e�rtx comme au-dessus
d(e�rtVt) = d(f(t, Vt)) = �re�rtVt dt+ e�rtdVt
= �re�rt(↵tSt + �tert) dt+ e�rt(↵t dSt + �t re
rt dt)
= ↵t(�re�rtSt dt+ e�rt dSt)
= ↵t dSt
puisque, par Ito,
dSt = �re�rtSt dt+ e�rtdSt.
11.4. AOA et l’univers risque neutre
Nous ne reprenons pas la discussion sur l’absence d’opportunite d’arbitrage que nousavons developpe en temps discret. Comme dans ce cas elle est equivalente a l’existenced’une mesure martingale P equivalente a P, ou
Definition 11.4.1 On appelle mesure martingale une probabilite P sur FT pourlaquelle St, 0 t T, est une martingale locale.

138 Black et Scholes
et on dit que le marche est viable si elle existe. Posons Wt = Wt � r�µ� t, alors, par
(11.2),
dSt = �St dWt (11.4)
avec Wt = Wt � r�µ� t. Par le theoreme de Girsanov, on sait que si on choisit, sur FT ,
dP = ecWT� c2
2 T dP
pour c = r�µ� , alors Wt, 0 t T, est un brownien sur (⌦,Ft, P). Alors, par (11.4),
St = S0
e�ˆWt��2t
2 (11.5)
est bien une martingale sous P . Donc,
Theoreme 11.4.2 Le marche est viable de mesure martingale P.
11.5. Marche complet
On vient de voir que le marche est viable. En fait, et c’est le point clef,
Theoreme 11.5.1 Le marche est complet.
Par definition, ceci signifie que tout actif (donc toute variable aleatoire FT mesurableest replicable). Cela resulte du theoreme de representation des martingales du a Ito.Contentons nous de montrer (ce qui nous su�ra pour Black et Scholes) que
Theoreme 11.5.2 Tout actif de la forme ZT = �(ST ) pour lequel ZT est P integrableest replicable.
Preuve analytique. On cherche donc un processus adapte continu ↵t tel que leprocessus defini par
dVt = ↵t dSt
verifie VT = �(ST ), ce qui s’ecrit
VT = e�rTVT = e�rT�(erT ST ) = (ST )
en posant (x) = e�rT�(erTx). Cherchons V sous la forme
Vt = f(t, St)
ou f est une fonction de classe C2. Par la formule d’Ito
dVt = d(f(t, St)) =@f
@t(t, St) dt+
@f
@x(t, St) dSt +
1
2
@2f
@x2(t, St)�
2S2
t dt.

11.5 Marche complet 139
Il “su�t” donc de choisir f de telle sorte que
@f
@t(t, x) +
�2
2
@2f
@x2(t, x)x2 = 0
f(T, x) = (x) = e�rT�(erTx)
(cette equation est appelee parfois l’EDP du produit, elle et ses generalisations fontle lien entre les mathematiques financieres et l’analyse numerique). Alors
dVt =@f
@x(t, St) dSt
et on peut prendre
↵t =@f
@x(t, St).
Preuve probabiliste. Plutot que de resoudre cette EDP nous allons proceder defacon probabiliste. Soit P la mesure martingale introduite au dessus. On a vu (11.4)que
dSt = �St dWt
et que Wt est un mouvement brownien sous P. On cherche dVt = ↵t dSt donc on veutque Vt soit une martingale (en tout cas locale) avec VT = (ST ). Le candidat est
Vt = E( (ST )|Ft)
en notant E l’esperance pour la probabilite P. Utilisons alors l’expression explicite11.5 pour ecrire que, pour 0 t T ,
ST = S0
e�ˆWT��2T
2 = S0
e�(ˆWt+ ˆWT� ˆWt)��2T
2
= S0
e�ˆWt��2t
2 eˆWT� ˆWt��2(T�t)
2
donc
ST = SteˆWT� ˆWt��2(T�t)
2
Puisque St est Ft mesurable et WT �Wt independant de Ft de meme loi que GpT � t
ou G est une variable gaussienne N(0, 1) on a donc
Vt = E( (ST )|Ft) = f(t, St)
si on pose
f(t, x) =1p2⇡
Z+1
�1 (xe�y
pT�t��2(T�t)
2 )e�y2/2 dy.
donc
f(t, x) =1p2⇡
Z+1
�1e�rT�(xerT e�y
pT�t��2(T�t)
2 )e�y2/2 dy.

140 Black et Scholes
On a donc trouve l’expression de f . (Remarque il n’y a qu’une martingale prenantla valeur (ST ) en T on a donc bien le meme portefeuille que dans l’approche ana-lytique).
On appelle delta de l’option la part ↵t du portefeuille dans l’actif. Il est importantcar il permet de constituer explicitement ce portefeuille.
Theoreme 11.5.3 En particulier le prix de l’option est
V0
= V0
= f(0, S0
)
et le delta de l’option est
↵t =@f
@x(t, St).
11.6. Formules de Black et Scholes
On applique ce qui precede dans le cas des Call et des Put europeens. La valeur deces actifs (derives) a l’instant final T est
(ST �K)+
pour un Call et(K � ST )
+
pour un Put. On obtient par un calcul fastidieux mais facile, pour un Call
C = S0
N(d1
)�Ke�rT N(d2
)
ou
N(x) =1p2⇡
Z x
�1e�u2/2 du
et
d1
=log(S
0
/K) + T (r + �2
2
)
�pT
d2
= d1
� �pT
Pour un putP = �S
0
N(�d1
) +Ke�rT N(�d2
)
Remarquons la relation de parite Call-Put qui s’obtient aussi directement ainsi(puisque (x+)� (�x)+ = x),
C � P = e�rT E((ST �K)+)� e�rT E((K � ST )+) = e�rT E(ST �K)
= e�rT E(ST )� e�rTK = S0
� e�rTK
puisque St est une martingale sous P.Dans ce cadre, on a comme on l’a vu en temps discret: Call americain=Call
europeen, mais pas d’analogue pour les put ou il faut utiliser l’arret optimal.

11.7 Implementation 141
11.7. Implementation
11.7.1. Volatilite implicite
11.7.2. Gestion Delta neutre
11.8. Generalisations du modele de Black et Scholes
Afin de traiter les options sur futures, devises, actions avec dividendes, etc.. on intro-duit la notion de cout de portage de l’actif S.
On suppose que le fait de detenir l’actif coute pendant un temps court dt, lasomme St dt. Nous verrons plus bas les exemples principaux. Si a l’instant t, unportefeuille est comme d’habitude
Vt = ↵tSt + �tBt
a l’instant t+ dt il vaudra (si il n’y a aucun apport ni retrait d’argent)
Vt+dt = ↵tSt+dt � ↵tSt dt+ �tBt+dt
doncdVt = ↵tdSt � ↵tStdt+ �tdBt.
Si on pose St = e�tSt on a
dSt = e�tdSt � e�tSt dt
doncVt = ↵te
tSt + �tBt
etdVt = ↵te
tdSt + �tdBt.
autrement dit, si on pose �t = ↵tet,
Vt = �tSt + �tBt
etdVt = �tdS
t + �tdBt.
On voit donc que la notion de portefeuille autofinance est un peu di↵erente, il fautremplacer St par St .
On obtient donc pour un Call, puisque
(ST �K)+ = (eTST �K)+ = eT (ST �Ke�T )+
C = eTS0
N(d1
)�Ke�rT N(d2
)

142 Black et Scholes
ou
N(x) =1p2⇡
Z x
�1e�u2/2 du
et
d1
=log(S
0
eT /K) + T (r + �2
2
)
�pT
=log(S
0
/K) + T (r + + �2
2
)
�pT
=
d2
= d1
� �pT
11.8.1. Cas particulier
• Formule de Black Scholes Merton: Cas avec dividende: = �dividende
• Formule de Black: Cas d’option sur future (on peut placer la valeur de l’actifcar il n’est pas mobilise): = �r
• Formule de Garman Kohlagen: Cas d’option sur devise (on peut placer la valeurde l’actif car il n’est pas mobilise): = �taux de la devise etrangere
Options sur denree, etc...

Chapitre 12
Controle et gestion deportefeuille en temps continu
Ce court chapitre est une introduction au modele de gestion de portefeuille de Merton.On ne donne que les idees, sans les preuves.
12.1. Le cadre du controle de di↵usions
On considere une equation di↵erentielle stochastique en dimension 1 (pour simplifier)s’ecrivant
dXt = b(t,Xt, ⌫(t,Xt))dt+ �(t,Xt, ⌫(t,Xt))dWt
ou W est un brownien, et (t, x, u) 7! b(t, x, u) et (t, x, u) 7! �(t, x, u) sont au moinscontinues (en fait lipschitzien en x uniformement pour t, u dans un compact). Ici lafonction ⌫ va jouer le role du controle, on la prendra au moins continue egalement.Pour T > 0 fixe, on pose, si 0 s T
J(s, x, ⌫) = E(Z T
sc(t,Xt, ⌫(t,Xt)) + �(XT )|Xs = x)
et on cherche
max⌫
J(0, x, ⌫)
le maximum etant pris sur toutes les fonctions ⌫ a valeurs dans un ouvert O.
12.2. L’equation HJB
Posons, pour 0 s T
J(s, x) = max⌫
J(s, x, ⌫)

144 Controle et gestion de portefeuille en temps continu
Definition 12.2.1 L’equation de Hamilton Jacobi Bellman (HJB) associee est
0 =@J
@t(t, x) + max
u2O[c(t, x, u) + b(t, x, u)
@J
@x(t, x) +
1
2�2(t, x, u)
@2J
@x2(t, x)] (12.1)
avec la condition frontiereJ(T, x) = �(x).
Donnons une approche heuristique de cette equation. Pour un entier n > 0 fixe,posons tk = kT/n, et considerons l’approximation discrete du probleme:
X(n)tk+1
= X(n)tk
+b(tk, X(n)tk
, ⌫(tk, X(n)tk
))(tk+1
�tk)+�(tk, X(n)tk
, ⌫(tk, X(n)tk
))(Wtk+1�Wtk)
avec les criteres
J (n)(tk, x, ⌫) = E(Tn
n�1X
r=k
c(tr, X(n)tr , ⌫(tr, X
(n)tr )) + �(X(n)
tn )|X(n)tk
= x)
On poseJ (n)(tk, x) = max
⌫J (n)(tk, x, ⌫)
La programmation dynamique en temps discret du modelemarkovien s’applique acette situation et l’algorithme de Bellman nous dit que, pour
J (n)(tn, x) = �(x),
si 0 k < n,
J (n)(tk, x) = maxu2O
[T
nc(tk, x, u) + E(J (n)(tk+1
, X(n)tk+1
)|X(n)tk
= x)]
que l’on reecrit
0 = maxu2O
[T
nc(tk, x, u) + E(J (n)(tk+1
, X(n)tk+1
)� J (n)(tk, x)|X(n)tk
= x)]
Imaginons, ce qui est beaucoup demande..., que J (n) est tres proche de sa limite J , queX(n) est tres proche de sa limite X, donc qu’on remplace chacun par sa limite et queJ est su�sament reguliere pour appliquer la formule d’Ito, alors, approximativement,
J (n)(tk+1
, X(n)tk+1
)� J (n)(tk, X(n)tk
) ⇠
J(tk+1
, Xtk+1)� J(tk, Xtk) =
=
Z tk+1
tk
@
@tJ(s,Xs)ds+
@
@xJ(s,Xs)dXs +
1
2
@2
@x2J(s,Xs)�
2(s,Xs)ds ⇠

12.3 Le modele de consommation investissement de Merton 145
=T
n[@
@tJ(tk, Xtk) +
1
2
@2
@x2J(tk, Xtk)�
2(tk, Xtk)] +@
@xJ(tk, Xtk)(Xtk+1 �Xtk).
En utilisant que
X(n)tk+1
= X(n)tk
+b(tk, X(n)tk
, ⌫(tk, X(n)tk
))(tk+1
�tk)+�(tk, X(n)tk
, ⌫(tk, X(n)tk
))(Wtk+1�Wtk)
on en deduit que
E(J (n)(tk+1
, X(n)tk+1
)� J (n)(tk, x)|X(n)tk
= x) ⇠
=T
n[@
@tJ(tk, x) +
1
2
@2
@x2J(tk, x)�
2(tk, x) +@
@xJ(tk, x)b(t, x, u)]
d’ou l’equation HJB
0 = maxu2O
[c(tk, x, u) +@
@tJ(tk, x) +
1
2
@2
@x2J(tk, x)�
2(tk, x) +@
@xJ(tk, x)b(tk, x, u)]
Faute de temps, nous n’irons pas plus loin dans la justification. Montrer que la con-dition est su�sante (et c’est l’important pour les applications) ne serait pas tresdi�cile).
12.3. Le modele de consommation investissement de Mer-ton
Reprenons le modele a deux actifs de Black et Scholes, donc un actif sans risqueBt = ert et un actif risque St satisfaisant a
dSt = µStdt+ �StdWt
ou W est un brownien. On considere un portefeuille
Vt = ↵tSt + �tBt
et l’on suppose ↵t et �t positifs. On note Ut la proportion du portefeuille investiedans l’actif risque, donc
Ut =↵tSt
Vt,
On a 0 � Ut 1. Si le portefeuille est autofinance, alors
dVt = ↵tdSt + �tdBt.
puisque�tdBt = r�tBtdt = r(Vt � ↵tSt)dt = r(Vt � UtVt)dt
et↵tdSt = ↵tSt(µdt+ �dWt) = UtVt(µdt+ �dWt),

146 Controle et gestion de portefeuille en temps continu
on a
dVt = (1� Ut)Vtrdt+ UtVt(µdt+ �dWt)
Supposons maintenant que l’on veuille consommer une partie de ce portefeuille. Sion note Yt la consommation a l’instant t par unite de temps, le portefeuille n’est plusautofinance et on on obtient la nouvelle equation,
dVt = (1� Ut)Vtrdt+ UtVt(µdt+ �dWt)� Ytdt
On considere le couple (Ut, Yt) comme le controle a valeurs dans [0, 1] ⇥ R+, et oncherche a maximiser
E(Z T
0
Y t + ✓VT )
ou 0 < < 1 et ✓ 2 R, noter que ce cout est concave. L’equation HJB s’ecrit
0 =@J
@t(t, x) + max
(u,y)2O[y + (1� u)xr + uxµ� y)
@J
@x(t, x) +
1
2�2x2u2
@2J
@x2(t, x)]
ou O =]0, 1[⇥R+
⇤ et J(T, x) = ✓x. Regardons ou la di↵erentielle en (u, y) est nulle,pour (t, x) fixe.
@
@u[y + ((1� u)xr + uxµ� y)
@J
@x(t, x) +
1
2�2x2u2
@2J
@x2(t, x)] = 0
donc
(�xr + xµ)@J
@x(t, x) + �2x2u
@2J
@x2(t, x) = 0
et@
@y[y + (1� u)xr + uxµ� y)
@J
@x(t, x) +
1
2�2x2u2
@2J
@x2(t, x)] = 0
donc
y�1 � @J
@x(t, x) = 0.
On en deduit que
u =r � µ
�2xJxx, y = (
Jx)1/�1
Si, par la suite on verifie que ceci est dans O, on aura reussi a resoudre le probleme.Pour cela on remplace u et y par ces valeurs dans l’equation HJB. On obtient
0 = Jt + (Jx/)(/�1) + xrJx �
(µ� r)2J2
x
2�2Jxx� (1/)1/�1(Jx)
/�1
On cherche une solution sous la forme
J(t, x) = (t)1�x

12.3 Le modele de consommation investissement de Merton 147
On trouve en remplacant que 0 = � � 1 ou
� =
� 1(r +
(µ� r)2
2�2(1� )).
On en deduit que (t) = (✓1/1� � 1/)e�(t�T ) + 1/�
ce qui donne J puisy = x/ (t), u = (µ� r)/�2(1� ).
N’oublions pas que se placer dans l’univers risque neutre revient a prendre µ = r,mais que l’on veut peut etre maximiser l’esperrance dans le monde reel !









![abc 1 [1] - Instituto Nacional de Saúde Dr. Ricardo Jorge€¦ · – Paris : V.ve Ch. Dunod et P. Vicq, 1894. (Encyclopédie chimique, tome x) INSA 1173 Capa 20. BELÉM, António](https://static.fdocuments.co/doc/165x107/5ec604de5638540e6d6ee54f/abc-1-1-instituto-nacional-de-sade-dr-ricardo-a-paris-vve-ch-dunod.jpg)