
CAPÍTULO 19 CORRELACIÓN Y REGRESIÓN...
48
Capítulo 19. Correlación y Regresión | 1 División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz 1CAPÍTULO 19 CORRELACIÓN Y REGRESIÓN 19.1 Introducción En los capítulos anteriores hemos tratado el caso en que observamos solamente una variable de los elementos de la muestra que sacamos de la población, tales como el peso, el tiempo, la proporción de votantes, la tasa medias de producción, etc.; por lo que podemos decir que hemos estudiado la inferencia estadística univariable. En este capítulo extenderemos el estudio de la inferencia a situaciones de dos o más variables al que llamaremos inferencia estadística multivariable que se aplica en problemas en que se observa más de una variable a los elementos de la muestra y el interés del investigador se centra fundamentalmente en estudiar la fuerza de asociación lineal entre las variables y la búsqueda de modelos matemáticos que reflejen las interrelación entre ellas para usarlos en la predicción. Algunos ejemplos que muestran la utilidad del análisis estadístico multivariable son las investigaciones médicas en las que se busca la interrelación existente entre el control de la azúcar de los pacientes con el ejercicio y la dieta; en investigaciones educativas en la Facultad de Ingeniería el interés puede enfocarse en la búsqueda un modelo que auxilie en la predicción del rendimiento académico de los alumnos causado por las calificaciones de las materias antecedentes seriadas; en ingeniería agrícola puede interesar si existe alguna asociación entre la cosecha de un fruto y la cantidad de fertilizantes y la profundidad de los surcos a la que se siembran las semillas; un ingeniero de computación puede interesarse en el tiempo de procesamiento y la cantidad de datos que se introducen al un procesador; o bien, un industrial desearía conocer la cantidad de artículos producidos en términos de las condiciones ambientales de la planta tales como temperatura, humedad y suciedad y, más aún, de las condiciones físicas y mentales de los trabajadores. Los ejemplos anteriores son suficientes para motivar el estudio de los conceptos que se desarrollarán en el presente capítulo que, en suma, son problemas que se estudian en el marco de los que se conoce como de correlación y regresión, e involucran las siguientes preguntas clave: ¿Vestiste una relación estadística que ofrezca alguna predictibilidad que al parecer parece existe entre las variables aleatorias de interés? ¿Qué tan fuerte es el grado aparente de la relación estadística en el sentido de la posible habilidad predictiva que ofrece la relación? ¿Es posible establecer un modelo para predecir una variable en términos de la otra u otras variables, y de ser afirmativo, que tan confiable es el modelo? La respuesta es estas preguntas se da a través de la correlación y la regresión. El estudio lo haremos considerando primeramente dos variables y en otro capítulo posterior el estudio se extenderá más de dos variables; para tal efecto, se sugiere ala lector repasar los conceptos de las variables aleatorias conjuntas analizados en la sección 9.3 del capítulo 9 y, particularmente, los conceptos de los mementos y de regresión y correlación de la teoría de la probabilidad de las secciones 10.7 a 10.12 del capítulo 10.
Transcript of CAPÍTULO 19 CORRELACIÓN Y REGRESIÓN...

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 1
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
1CAPÍTULO 19 CORRELACIÓN Y REGRESIÓN
19.1 Introducción En los capítulos anteriores hemos tratado el caso en que observamos solamente
una variable de los elementos de la muestra que sacamos de la población, tales como el peso, el tiempo, la proporción de votantes, la tasa medias de producción, etc.; por lo que podemos decir que hemos estudiado la inferencia estadística univariable. En este capítulo extenderemos el estudio de la inferencia a situaciones de dos o más variables al que llamaremos inferencia estadística multivariable que se aplica en problemas en que se observa más de una variable a los elementos de la muestra y el interés del investigador se centra fundamentalmente en estudiar la fuerza de asociación lineal entre las variables y la búsqueda de modelos matemáticos que reflejen las interrelación entre ellas para usarlos en la predicción.
Algunos ejemplos que muestran la utilidad del análisis estadístico multivariable son las investigaciones médicas en las que se busca la interrelación existente entre el control de la azúcar de los pacientes con el ejercicio y la dieta; en investigaciones educativas en la Facultad de Ingeniería el interés puede enfocarse en la búsqueda un modelo que auxilie en la predicción del rendimiento académico de los alumnos causado por las calificaciones de las materias antecedentes seriadas; en ingeniería agrícola puede interesar si existe alguna asociación entre la cosecha de un fruto y la cantidad de fertilizantes y la profundidad de los surcos a la que se siembran las semillas; un ingeniero de computación puede interesarse en el tiempo de procesamiento y la cantidad de datos que se introducen al un procesador; o bien, un industrial desearía conocer la cantidad de artículos producidos en términos de las condiciones ambientales de la planta tales como temperatura, humedad y suciedad y, más aún, de las condiciones físicas y mentales de los trabajadores.
Los ejemplos anteriores son suficientes para motivar el estudio de los conceptos que se desarrollarán en el presente capítulo que, en suma, son problemas que se estudian en el marco de los que se conoce como de correlación y regresión, e involucran las siguientes preguntas clave:
¿Vestiste una relación estadística que ofrezca alguna predictibilidad que al parecer parece existe entre las variables aleatorias de interés?
¿Qué tan fuerte es el grado aparente de la relación estadística en el sentido de la posible habilidad predictiva que ofrece la relación?
¿Es posible establecer un modelo para predecir una variable en términos de la otra u otras variables, y de ser afirmativo, que tan confiable es el modelo?
La respuesta es estas preguntas se da a través de la correlación y la regresión. El estudio lo haremos considerando primeramente dos variables y en otro capítulo posterior el estudio se extenderá más de dos variables; para tal efecto, se sugiere ala lector repasar los conceptos de las variables aleatorias conjuntas analizados en la sección 9.3 del capítulo 9 y, particularmente, los conceptos de los mementos y de regresión y correlación de la teoría de la probabilidad de las secciones 10.7 a 10.12 del capítulo 10.

2 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
19.2 Análisis de Correlación Por constituir la base teórica, es necesario repasar los conceptos de covarianza y el
coeficiente de correlación, estudiados en las secciones 10.8 y 10.9, puesto que son los indicadores que miden la interrelación entre dos variables aleatorias.
La covarianza es el momento de la distribución conjunta de las variables Y que refleja la fuerza de la dirección de la interrelación existente entre Y y se definió como
, = 10.47
Si Y son independientes
, 0 (10.53)
El signo de la covarianza proporciona la información sobre la dirección de la interrelación existente entre Y .
Si ,
2 (10.54) Y, si las VA son independientes se tiene
(10.56) 19.2.1 El Coeficiente de Correlación Como la covarianza tiene como unidades las correspondientes a Y es difícil
interpretar la fuerza de la relación entre Y , dificultad que se salva dividiendo la covarianza por el producto de sus desviaciones estándar ‐ y ‐ cuyo resultado es un parámetro adimensional conocido como el coeficiente de correlación y se define como
,
(10.57)
Puede demostrarse que 1 1 Este coeficiente corrige el escalamiento de Y y representa apropiadamente la
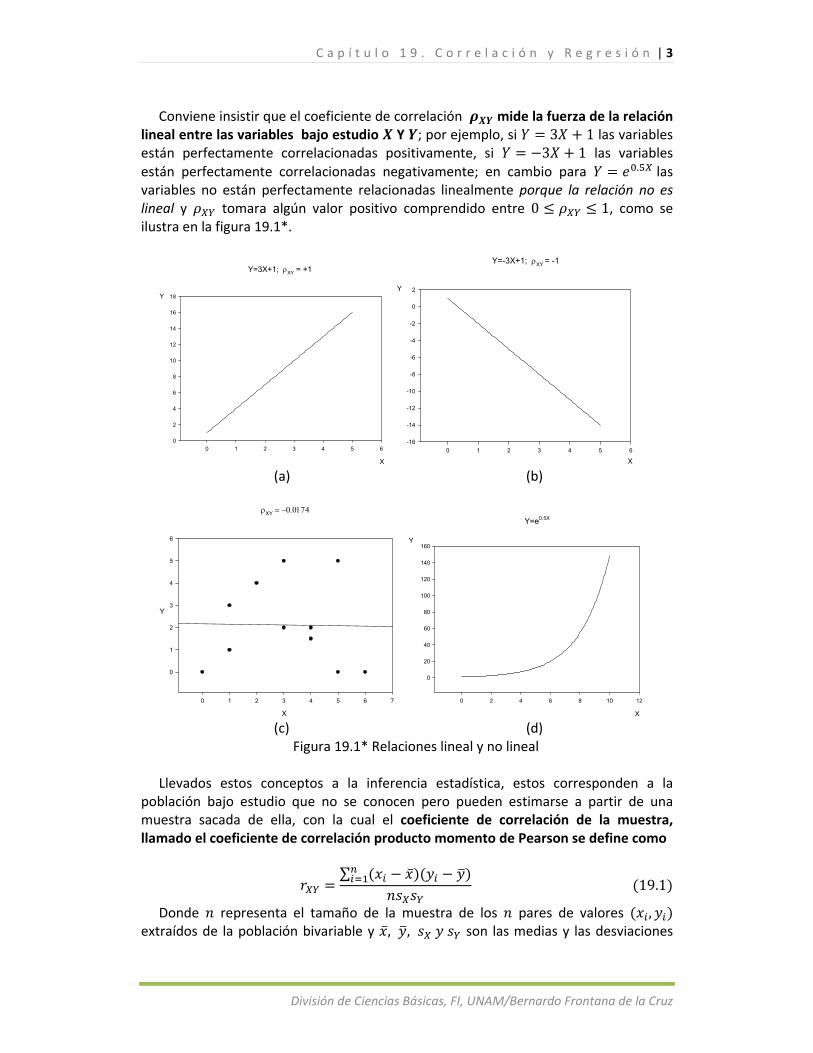
fuerza y la dirección de la relación que existe entre dichas variables. Si 1 los valores de las variables están perfectamente correlacionados o alineados positivamente como se muestra en la figura 19.1* (a); mientras que para 1 los valores de las variables estarán perfectamente correlacionados o alineados negativamente como se indica en la figura 19.1* (b); y si 0 las variables NO están correlacionadas como se ilustra en (c) de la figura. Para los demás valores si está cercano a 1 o a 1 se tiene una interrelación fuerte, en cambio si está cercano a 0 implica una fuerza de asociación lineal muy débil o inexistente.
C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 3
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Conviene insistir que el coeficiente de correlación mide la fuerza de la relación
lineal entre las variables bajo estudio Y ; por ejemplo, si 3 1 las variables están perfectamente correlacionadas positivamente, si 3 1 las variables están perfectamente correlacionadas negativamente; en cambio para . las variables no están perfectamente relacionadas linealmente porque la relación no es lineal y tomara algún valor positivo comprendido entre 0 1, como se ilustra en la figura 19.1*.
Y=3X+1; XY = +1
X
0 1 2 3 4 5 6
Y
0
2
4
6
8
10
12
14
16
18
Y=-3X+1; XY = -1
X
0 1 2 3 4 5 6
Y
-16
-14
-12
-10
-8
-6
-4
-2
0
2
(a) (b)
XY
X
0 1 2 3 4 5 6 7
Y
0
1
2
3
4
5
6
Y=e0.5X
X
0 2 4 6 8 10 12
Y
0
20
40
60
80
100
120
140
160
(c) (d)
Figura 19.1* Relaciones lineal y no lineal Llevados estos conceptos a la inferencia estadística, estos corresponden a la
población bajo estudio que no se conocen pero pueden estimarse a partir de una muestra sacada de ella, con la cual el coeficiente de correlación de la muestra, llamado el coeficiente de correlación producto momento de Pearson se define como
∑
19.1
Donde representa el tamaño de la muestra de los pares de valores , extraídos de la población bivariable y , , son las medias y las desviaciones

4 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
estándar de los valores de la muestra. Si se comparan las ecuaciones (10.57) y (19.1) pude verse que la covarianza de la muestra
∑ 19.2
es un estimador de la covarianza de la población. Una justificación teórica para usar como estimador del coeficiente consiste
en que si la población de donde se muestrea se comporta como una distribución normal bivariable, este coeficiente de correlación es un estimador de máxima verosimilitud del parámetro de la población; más aún, con referencia a la figura 19.2, si se saca la muestra aleatoria 1 de la población y se calcula su coeficiente de correlación se obtiene , si se saca la muestra 2 de la población y se calcula su coeficiente de correlación se obtiene , si se saca la muestra i de la población y se
calcula su coeficiente de correlación se obtiene , donde los superíndices significan los coeficientes de correlación calculados con las muestras 1, 2, …i respectivamente y, si teóricamente se saca un número infinito de muestras de la población⋯ lo que significa que realmente es una variable aleatoria o sea un estimador del verdadero coeficiente de correlación de la población ,con distribución muestral que definiremos más adelante.
Figura 19.2 La representación del coeficiente de correlación como estimador de
Con el propósito de obtener una expresión más sencilla para calcular el coeficiente
de correlación de la muestra , definimos por analogía con los momentos centrales estudiados en el capítulo 9 para las variables aleatorias, a los de la muestra
19.3

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 5
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
19.4
19.5
Si se sustituyen a con sus expresiones generales de los datos de la muestra
en la ecuación 19.1 y efectuando operaciones se tiene
√ 19.6
Con objeto de aplicar los conceptos y las expresiones correspondientes
desarrolladas, a lo largo del presente capítulo nos basaremos en el siguiente ejemplo. Los siguientes datos de la tabla 19.1 corresponden al tiempo de secado (en hrs) y el
contenido de un solvente (en %) de una muestra de hornadas para un recubrimiento experimental que se utilizará en la protección de la pintura en las zonas costeras con objeto de evitar la salinidad.
Tabla 19.1 Datos para el ejercicio por desarrollar
No de hornada Contenido de solvente (%) Tiempo de secado (hrs)
1 2.5 2.3
2 2.7 2.1 3 3 2.2 4 3.1 2.1 5 3.2 2 6 3.4 1.9
7 3.5 1.9 8 4 1.6 9 4.2 1.6 10 4.5 1.5
Aunque en el análisis de correlación no importa la relación causa‐efecto o sea
identificación de la variable dependiente y la independiente puesto que el resultado será el mismo, para fines del análisis de regresión que estudiaremos posteriormente en nuestro ejemplo es claro que el tiempo de secado del recubrimiento depende porcentaje de solvente que se agregue al recubrimiento; por lo que a la manera matemática usual hemos denotado al contenido de solvente con y al tiempo de secado con .
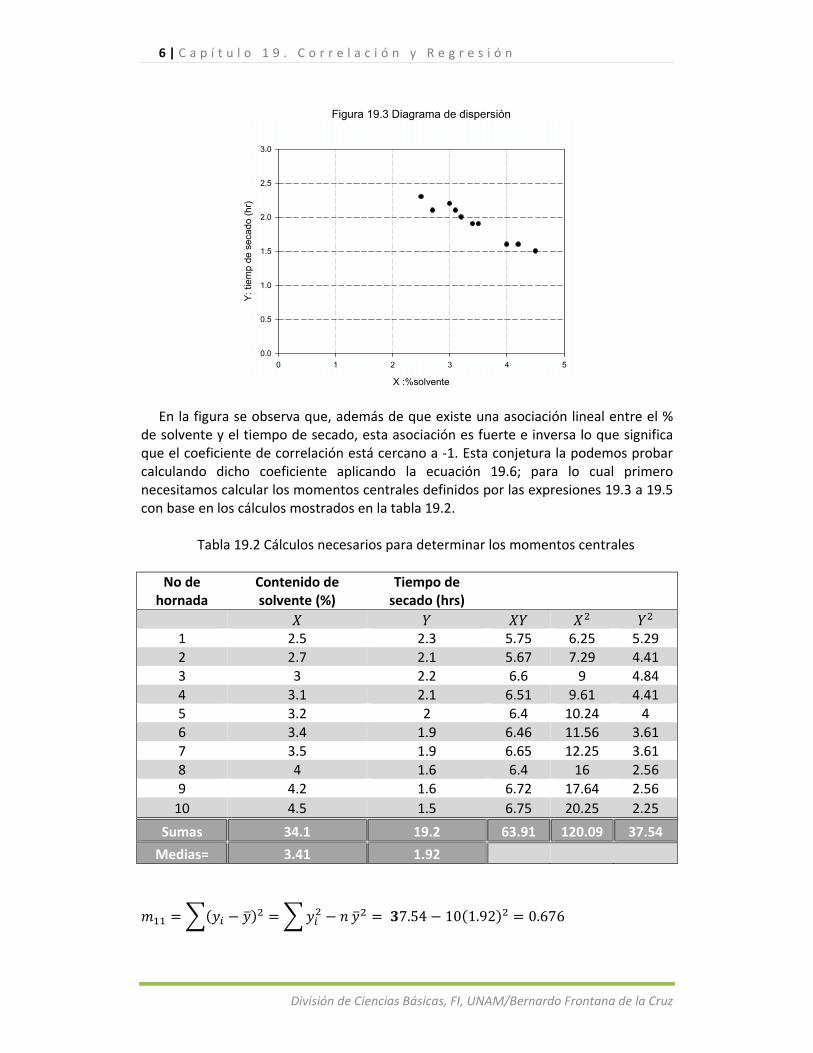
Para visualizar si existe una posible asociación lineal en los datos de la muestra, lo primero que se recomienda es dibujar el diagrama de dispersión que consiste en representar los puntos , en un plano con las coordenadas y . Para nuestro ejemplo, la figura 19.3 muestra dicho diagrama.
6 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.3 Diagrama de dispersión
X :%solvente
0 1 2 3 4 5
Y:
tiem
p de
sec
ado
(hr
)
0.0
0.5
1.0
1.5
2.0
2.5
3.0
En la figura se observa que, además de que existe una asociación lineal entre el % de solvente y el tiempo de secado, esta asociación es fuerte e inversa lo que significa que el coeficiente de correlación está cercano a ‐1. Esta conjetura la podemos probar calculando dicho coeficiente aplicando la ecuación 19.6; para lo cual primero necesitamos calcular los momentos centrales definidos por las expresiones 19.3 a 19.5 con base en los cálculos mostrados en la tabla 19.2.
Tabla 19.2 Cálculos necesarios para determinar los momentos centrales
No de hornada
Contenido de solvente (%)
Tiempo de secado (hrs)
1 2.5 2.3 5.75 6.25 5.29 2 2.7 2.1 5.67 7.29 4.41 3 3 2.2 6.6 9 4.84
4 3.1 2.1 6.51 9.61 4.415 3.2 2 6.4 10.24 4 6 3.4 1.9 6.46 11.56 3.61 7 3.5 1.9 6.65 12.25 3.61 8 4 1.6 6.4 16 2.56
9 4.2 1.6 6.72 17.64 2.56
10 4.5 1.5 6.75 20.25 2.25
Sumas 34.1 19.2 63.91 120.09 37.54
Medias= 3.41 1.92
7.54 10 1.92 0.676

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 7
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
120.09 10 3.41 3.809
63.91 10 1.92 3.41 1.562
Con los cuáles el coeficiente de correlación es
√
1.562
√0.676 3.8090.97
Este valor soporta la conjetura que habíamos establecido anteriormente por lo que
las variables se correlacionan negativamente en una línea recta, o con pendiente negativa.
19.2.2 Distribución Normal bivariable Para hacer inferencias sobre una variable, consideramos que la distribución de la
población era normal y utilizamos la distribución muestral del estadístico relacionado al parámetro; como ahora estamos en el caso de dos variables es necesario hacer algunas consideraciones de la distribución conjunta de dos variables de la población que estudiamos en los capítulos 12 y 13, a la que se llama la distribución bivariable.
Si recordamos, tales distribuciones de dos variables aleatorias y tienen como función masa de probabilidad , si son discretas; o función de densidad bivariable , si son continuas. Teóricamente, existen muchas distribuciones bivariables; sin embargo, la más estudiada es la distribución normal bivariable que se representa en la figura 19.3* cuya expresión matemática es
,1
2 1exp
22 1
19.7
Donde , ; por lo que para especificar completamente a la
función de densidad se deben definir los cinco parámetros , , , .

8 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
0
20
40
60
80
100
-5
0
5
10
15
-50
510
f(y|x)
X
E[Y|x]
FDP Normal Bivariable
f(y|x1)
f(y|x2)
f(y|x3)
Curva de regresión
x3
x2x1
E[Y|x]
f(x,y)
Figura 19.3* Función de densidad normal bivariable Componer
Esta distribución tiene varias características importantes entre la que destacan las
siguientes:
sus distribuciones marginales son normales;
sus distribuciones condicionales | | también son normales;
0 si y solo si y son independientes, implicado por la independencia estadística. Este resultado significa, para esta distribución, que cualquier interrelación entre dos variables es astrictamente lineal.
En otras distribuciones puede suceder que 0 aún cuando y no sean independientes, por lo que la mayoría de las inferencias que involucran correlación se desarrollan en términos de la suposición de que la distribución bivariable de la población es normal; en cuyo caso las inferencias sobre la correlación equivalen a las inferencias sobre la independencia o independencia de las variables y si se adopta restricciones más severas sobre la distribución bivariable de la población, se tendrán que plantear restricciones más severas sobre los resultados de las muestras.
Conviene destacar que el coeficiente de correlación definido por (19.1) es aplicable a datos se miden en las escalas de intervalos o de razones que se estudiaron en el

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 9
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
capítulo 4; sin embargo, para datos que se miden en las escalas nominales (que se miden con categorías) y ordinales (que se miden con el orden) se cuenta con otras técnicas para medir la asociación entre las dos variables como se verá en un capítulo posterior.
Finalmente, las nociones planteadas para la distribución normal bivariable pueden generalizarse para el caso de más variables, en cuyo caso se tiene la distribución normal multivariable; así, para variables aleatorias cada observación debe constar de valores , , , … , cuyos parámetros son las medias y las desviaciones estándar de cada variable y los coeficientes de correlación de cada par de ellas; para tal función, sus distribuciones marginales y condicionales son normales.
19.2.3 Distribución muestral del coeficiente de correlación ‐ ‐ Como nuestro interés está centrado en el coeficiente de correlación de la
población que usualmente se desconoce, el coeficiente de correlación de la muestra es el estadístico natural que se usa para hacer inferencias sobre su magnitud, bien sea calculando intervalos de confianza o haciendo pruebas de hipótesis; que es estudiaron en los dos capítulos precedentes. Para tal efecto conviene hacer algunas observaciones de la distribución muestral de que aparece en la figura 19.4.
Figura 19.4 Tres Distribuciones muestrales del coeficiente de correlación Como se observa en la figura, si 0 la densidad es simétrica respecto al origen,
de lo contrario, si 0 dicha densidad es asimétrica según el signo de . Ahora bien, si se muestrea de una población con densidad normal bivariable, la distribución muestral de se aproxima a una distribución normal si el tamaño de la muestra tiende a infinito. Para el caso en que 0 se utiliza la transformación
√ 2
1 19.8
Que corresponde al estadístico para la prueba que se distribuye conforme a la
distribución con 2 grados de libertad. 19.2.4 Inferencias respecto al coeficiente de correlación 19.2.4.1 Pruebas de hipótesis respecto al coeficiente de correlación

10 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Si hacemos la prueba
: 0 : 0
al ejemplo que nos ocupa, tenemos que se trata de una prueba de dos colas cuyos
valores críticos para 0.05 son . 2.306 y .2.306; el valor del estadístico es
0.97√10 2
1 0.9711.29
Lo que nos lleva a rechazar la hipótesis de que el coeficiente de correlación entre el
contenido de solvente y el tiempo de secado sea igual a cero con un nivel de significación estadística 0.05, indicando que sí existe una dependencia lineal entre ellos.
El valor‐p es igual a 0.00000211 ; es mucho menor que 0.025 indicando que es altamente improbable que 0
Obsérvese que al rechazar la hipótesis nula de la prueba, no es posible enunciar explícitamente el valor de la fuerza de la relación lineal entre las dos variables, porque la trasformación anterior solo se puede usar para 0, y no puede aplicarse para calcular intervalos de confianza ni probar hipótesis para valores de distintos de cero; no obstante, para poder hacerlo, Ronald Aymer Fisher, el creador de los métodos estadísticos modernos y del diseño de experimentos, demostró que es posible efectuarlas para valores de con muestras moderadamente grandes de una población normal bivariable.
Para tal efecto, se utiliza la función particular de conocida como la transformación de Fisher de a , que se define como
12
11
19.9
que es una función uno a uno en la cual para cada posible valor de existe uno y
solo un valor de y a la inversa, para cada valor de existe uno y solo un valor de ; lo que implica que es posible transformar el de la muestra en un valor ,
hacer inferencias en términos de y hacer la transformación inversa de estas inferencias en términos de .
Entonces, para cualquier valor de de la población la distribución muestral de es aproximadamente normal para muestras de tamaño moderado con valor esperado aproximado
12
11
19.10
Y varianza
13 19.11

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 11
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
La bondad de esta aproximación se incrementa para pequeños valores absolutos de
y cuando el tamaño de la muestra aumenta, y se utiliza para probar hipótesis : :
donde es igual a algún valor no tan cercano a ‐1 y +1, y el estadístico para la
prueba es
1 √ 3⁄ 19.12
donde
12
11
19.13
Que se distribuye aproximadamente ~ 0,1 . Conviene enfatizar que el uso de la
transformación de a implica la consideración de que y se comportan conforme una distribución normal bivariable en la población; tal suposición parece muy estricta y puede no ser razonable en algunas situaciones; sin embargo, las consecuencias si esta suposición no se cumple son desconocidas.
Finalmente, conviene mencionar que la tabla X da valores de para diferentes valores de r que sirve para facilitar los cálculos. La tabla solamente muestra valores positivos de y puesto que si es negativo el signo del valor de también será negativo.
Con las salvedades explicadas para nuestro ejemplo tenemos 10, 0.97 y con 0.05 deseamos probar la hipótesis
: 0.95 : 0.95
Como se trata de una prueba de dos colas de , se tienen ⁄ .
1.96 ⁄ . 1.96. Consultando la tabla o efectuando las operaciones de la función de transformación
se tiene Para 0.95 ⟹ 1.832 y para 0.97 ⟹ 2.092; con los
cuáles
.2.092 1.832
1 √10 3⁄0.688
Como 0.688 1.96, se acepta con un nivel de significación
estadística 0.05 que el coeficiente de correlación de la población entre el porcentaje de solvente y el tiempo de secado es 0.95.
Para : 0.95 y : 0.95

12 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
. 1.65
Por lo que se rechaza la hipótesis . Para : 0.80 y : 0.80 ⟹ 1.099 y para 0.97 ⟹
2.092; con los cuáles
/ . . 1.96; / . 1.96.
.2.092 1.099
1 √10 3⁄2.63
Por lo tanto se rechaza Ho. 19.2.4.2 Intervalos de confianza respecto al coeficiente de correlación Con los antecedentes anteriores y los conceptos básicos sobre intervalos de
confianza que se estudiaron en la sección 17.7 correspondiente al capítulo de estimación estadística de parámetros, el cálculo de los intervalos de confianza para el coeficiente de correlación consiste en determinar primero los correspondientes a y, después hacer la transformación inversa para determinar los de . Es decir, un intervalo del 1 100% de confianza para es
%
⁄ .⁄
√ 3 19.14
Donde ⁄ es el fractil 1 2⁄ de la distribución normal estándar. Calculado
este intervalo, con la ecuación (19.3) o con apoyo de la tabla se determinan los valores inversos para el intervalo de obteniéndose
% 19.15
Para nuestro ejemplo que venimos trabajando tenemos 10, 0.05,
2.092 y para determinar un intervalo de confianza del 95% tenemos que
⁄ . 1.96 y aplicando la ecuación (19.14) se obtiene
% 2.0921.96
√10 32.83, 1.35
Aplicando la transformación inversa se obtienen los valores de y del intervalo
(19.15)
% 0.992; 0.874

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 13
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
De manera similar, para un intervalo del 90% de confianza 0.10, 2⁄ 0.050 1 2⁄ 0.950 ⁄ . 1.65, con lo cual
% 2.0921.65
√10 32.72, 1.47
Y
% 0.991; 0.900
Obsérvese que ambos intervalos contienen a y el % es menor que el %
como era de esperarse. 19.3 Análisis de Regresión Como ya vimos, en el análisis de correlación nos interesa la fuerza de la asociación
lineal estadística de las variables y medida con el valor de este coeficiente, y en el análisis de regresión el investigador está interesado en predecir el valor de una de las variables dado el valor de la otra; así, un gerente de ventas desearía predecir el volumen de ventas de su producto en términos de su precio y el de la competencia, o en nuestro ejemplo nos gustaría predecir el tiempo de secado ( ) para algún valor diferente del porcentaje de solvente ( ) al margen de los observados en la muestra.
La pregunta que se plantea es ¿Cómo predecir ? Si se conoce la distribución marginal de podría utilizarse la media de la distribución sin embargo se ignora la información de ; pero como es un valor de la variable aleatoria la distribución que incluye esta información es la condicional de dado que y recordando estos conceptos estudiados en el capítulo 9, la Distribución condicional de dado
| , (9.18*)
Cabe observar que para el caso de las variables aleatorias continuas se tienen las
funciones marginales ‐ ‐, y un número infinito de funciones de densidad condicionales tanto para X como para Y puesto que estas variables tienen un número infinito de valores.
Si son independientes, se tiene
| O bien , (9.24*) Intuitivamente, Un estimador razonable también llamado predictor de es la
media de la distribución condicional |
| varía para cada valor de por lo que es una función que se llama la curva de regresión de sobre , la cual se representa en la figura 19.5 para tres valores de .

14 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.5 La curva de regresión
Cabe observar que para cada valor de se tiene una función de densidad condicional, así, para la figura se tienen representadas solamente | , | y
| cuyas medias | , | y | son tres del número infinito de puntos
que forman la curva de regresión. Al margen del ejemplo que venimos trabajando en este capítulo, es conveniente
hacer otro para fijar los conceptos desarrollando en esta sección. Ejemplo 19.1 Supóngase que el mercado compartido de de una compañía de
teléfonos celulares de una marca M es actualmente del orden de 2/3, y el gerente está preocupado porque la marca L incrementará los gastos de publicidad en 0.7 millones de dólares y desea conocer el impacto que tendrá en el porcentaje del mercado de sus producto. La interrelación que existe entre el incremento de los gastos de publicidad ( ) y el porcentaje del mercado compartido ( ) está dada por la función de densidad conjunta que se representa en la figura 19.6.
, 0 1,0 1
0

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 15
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
0.0
0.5
1.0
1.5
2.0
2.5
0.00.2
0.40.6
0.8
0.0
0.2
0.4
0.6
0.8
1.0
f(x,
y)
x
y
Figura 19.6 Función de densidad conjunta f(x,y) = x+y
La función marginal de es
12 0 1
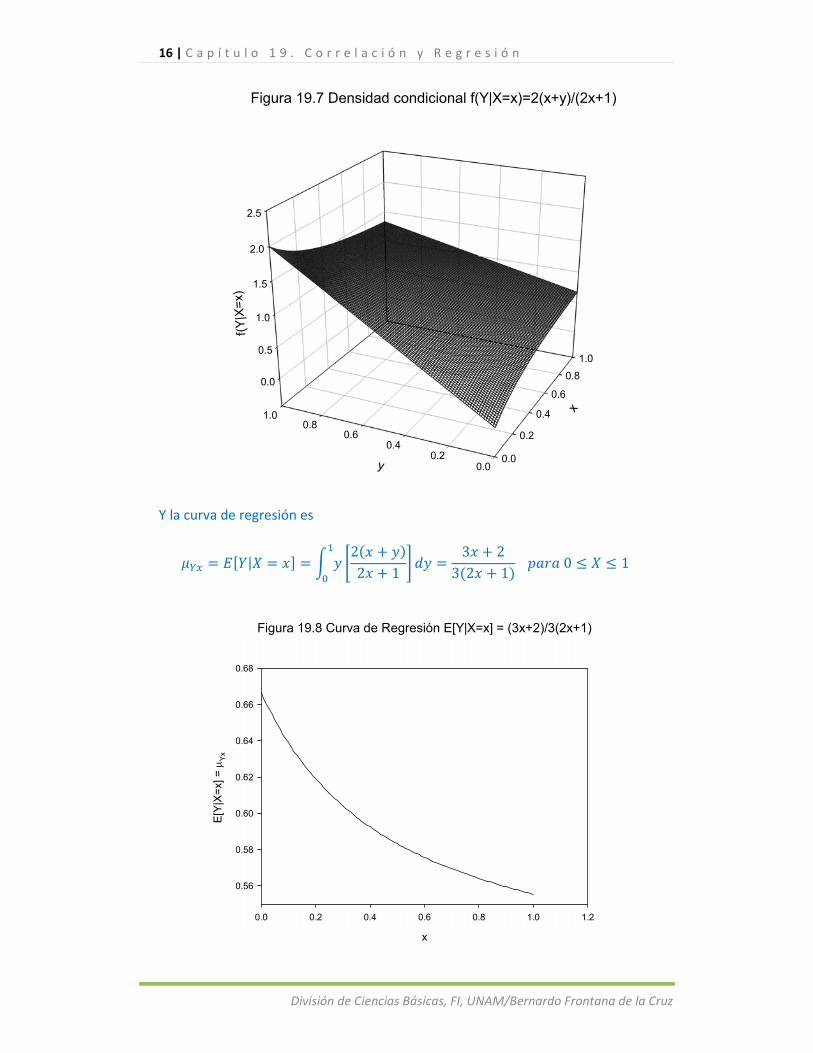
La función condicional de dado que aparece en la figura 19.7 es
|,
1 2⁄22 1
0 1
16 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
0.0
0.5
1.0
1.5
2.0
2.5
0.0
0.2
0.4
0.6
0.8
1.0
0.00.2
0.40.6
0.81.0
f(Y
|X=
x)
x
y
Figura 19.7 Densidad condicional f(Y|X=x)=2(x+y)/(2x+1)
Y la curva de regresión es
|22 1
3 23 2 1
0 1
Figura 19.8 Curva de Regresión E[Y|X=x] = (3x+2)/3(2x+1)
x
0.0 0.2 0.4 0.6 0.8 1.0 1.2
E[Y
|X=
x] =
Y
x
0.56
0.58
0.60
0.62
0.64
0.66
0.68

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 17
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Esta expresión muestra el comportamiento de los valores esperados de para cada valor de | , o sea que es la curva de las medias de todas las densidades condicionales como se muestra en las figura 19.5 por eso es la mejor curva predictiva de para los diferentes valores de ; e indica la los mejores predicciones del porcentaje del mercado compartido ( ) que existen para los posible incrementos de los gastos de publicidad ( ) de competidor; por ejemplo, para la compañía de teléfonos celulares de la marca M el marcado compartido es actualmente del orden de 2/3 y si la marca L incrementará los gastos de publicidad en 0.75 millones de dólares, entonces el mercado compartido será
| 0.753 0.75 23 2 0.75 1
0.57
O sea que el segmento de mercado de M disminuirá de 0.66 a 0.57; si la compañía
de la marca L decide no invertir en publicidad el segmento de M será
| 03 0 2
3 2 0 123
que es el que tiene actualmente; finalmente, si la marca competidora invierte todo
su capital disponible que es de 1 millón de dólares
| 13 1 2
3 2 1 10.55
Indicando que le quita a M el 11% del mercado. Es claro que los valores calculados anteriormente son valores esperados por no
tenemos la certeza a que; por ejemplo para 0.75, será igual a 0.57. Una medida nos da confianza de | puede obtenerse calculando la varianza de la distribución condicional que haremos a continuación.
| 2
| | |1
2 14 36
3 23 2 1
6 1 118 2 1
Ejemplo 19.2 Para los valores de utilizados en el ejemplo anterior las varianzas y
las desviaciones estándar son
|6 2 118 3
0.241 | 0.491

18 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
| .6 0.75 1.75 1 2 1
18 2.50.1972 | . 0.447
|118
0.056 | . 0.236
Se recomienda al lector verificar la expresión de la varianza condicional y los valores
de las varianzas así como los de las desviaciones estándar anteriores. 19.3.1 El papel de Distribución Normal bivariable en la curva de Regresión La distribución normal bivariable vista en la sección 19.2.2, representada en la
figura 19.3 y aplicada al análisis de regresión tiene varias características importantes entre la que destacan las siguientes:
sus distribuciones marginales son normales;
sus distribuciones condicionales | | también son normales;
0 si y solo si y son independientes, implicado por la independencia estadística. Este resultado significa, para esta distribución, que cualquier interrelación entre dos variables es estrictamente lineal.
19.3.2 La recta de regresión y el coeficiente de correlación La curva de regresión | depende de la forma de la densidad conjunta , y su modelo matemático puede ser razonablemente complicado, lo cual
generalmente se evita suponiendo que la población de donde se saca la muestra se distribuye conforme una normal bivariable en cuyo caso la curva de la población es lineal de la forma
| (19.16)
Donde es la ordenada al origen, la pendiente de la recta. En adelante
consideraremos esta suposición para analizar la recta de regresión por su facilidad para el estudio teórico. En la ecuación anterior y reciben el nombre de coeficientes o parámetros de regresión porque se asume que es la recta de la población, por lo que se expresan en términos de los parámetros de y , como sigue.
Calculando el valor esperado respecto a a (19.16)
(19.17) Multiplicando la ecuación por
(19.18) Aplicando el operador valor esperado

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 19
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
(19.19) Resolviendo las ecuaciones simultaneas (19.18) y (19.19) para y se obtiene
(19.20)
Y
(19.21)
Al sustituir las dos expresiones anteriores en el modelo original (19.16)
|
O bien
| (19.22)
Observe que si no existe relación lineal entre y entonces 0, como ya
vimos, la línea de regresión es simplemente | y ningún valor de sirve para predecir ; por el contrario cuando esta más cercano a ‐1 o +1 mayor es el efecto del término sobre la predicción | .
Más aún, el efecto preciso que tiene el coeficiente de correlación sobre la predicción se obtiene calculando la varianza condicional de | ; si y tienen distribución normal bivariable vale
∙ | 1 (19.23)
Donde . denota la varianza de dado algún valor de . Nuevamente
observamos que si no se tiene ningún conocimiento de se tiene simplemente
∙ | (19.24)
Despejando a de la ecuación (19.23) se tiene
∙ (19.25)
19.3.2.1 El coeficiente de determinación ‐ ‐
Como la varianza original es y la varianza restante ∙ es la varianza no
explicada por la regresión lineal, entonces el cuadrado del coeficiente de correlación dado por (19.25) se conoce como el coeficiente de determinación y representa la proporción de la varianza explicada por la recta de regresión. Regresaremos a este concepto al final del capítulo

20 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Ejemplo 19. 3 Si la varianza original es 81 y se tiene que 0 el conocimiento de no mejora en absoluto la predicción de , puesto que conforme a (19.23) ∙ 1 0 81, o bien con la ecuación (19.25) se tiene
∙ 81 y nada de la varianza es explicada por la regresión lineal; si por otro lado 1 se tiene que ∙ 81 81 0 en cuyo caso el conocimiento de nos permite predecir perfectamente a y toda la varianza es explicada por la regresión lineal.
Más aún, si 0.70, 0.49 es la proporción de la varianza explicada por la regresión lineal que vale 0.49 81 39.69 y la proporción de la no explicada es 1 1 0.49 0.51, cuya cantidad es ∙ 1
81 1 0.49 41.31; teniendo que la varianza total es 39.69 41.31 81. En suma, la varianza total consta de dos partes
∙ (19.26)
Donde
es la parte de la varianza total explicada por la regresión lineal y
∙ es la parte de la varianza total no explicada por la regresión lineal. Más adelante profundizaremos sobre este coeficiente de determinación. 19.3.3 Los errores En la sección anterior se vio que el conocimiento de permite predecir a
perfectamente sí y solo sí vale +1 o ‐1 Cuando se usa la curva de regresión para predecir , la diferencia entre los valores real y obtenido por la recta de regresión constituye el error de la predicción
|
Despejando a
| (19.26)
Si | es lineal, sustituyendo (19.16) en la ecuación anterior
(19.27) Este es el modelo probabilista general de la regresión lineal bivariable de la
población que liga a la variable dependiente o explicada con la variable independiente o explicativa , y consta de dos partes: la parte sistemática y la parte estocástica o aleatoria ; lo que enfatiza que el modelo es probabilista.

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 21
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
La naturaleza estocásticas del modelo indica que nunca puede predecirse como en el caso determinista puesto que la incertidumbre de se debe a la presencia de que es la variable aleatoria que le da aleatoriedad ; pero además también surge la aleatoriedad de , y por tanto la de , por la exclusión de otras variable explicativas en el modelo que no se conocen o, conociéndose, no se incluyen en el modelo lineal simple pero sí en la regresión lineal múltiple y; además, por errores en la medición de . Para una aplicación particular del análisis de regresión los múltiples factores
aleatorios son las causas plausibles de . En suma, este término refleja la variabilidad que hace que la parte sistemática no sea un predictor perfecto de .
Como es un valor dado, el modelo (19.27) no permite error de medición de , y la especificación completa del modelo incluye la forma de la ecuación de
regresión, la componente sistemática que es constante y la componente que es estocástica o aleatoria con su distribución de probabilidades. Tal especificación de este modelo llamado el modelo clásico de regresión lineal simple se basa en los siguientes supuestos.
Aunque hay una aparente contradicción de la noción fija con estocástica, los valores de la variable explicativa son fijos, cuyos valores son fijados o escogidos por el analista y el supuesto variable fija independiente indica que para cada valor fijo de existe una distribución de probabilidades de la variable aleatoria | llamada subpoblación de , como se observa en la figura 19.5; y para equilibrar la ecuación debe ser aleatorio.
Para , los primeros dos términos de (19.27) son constantes, y al aplicarle el operador valor esperado
| | | Sustituyendo (19.16) en la expresión anterior
| | | | 0 (19.28)
Lo que significa que para cada valor dado la media del error es cero. Aplicando el operador Varianza al modelo general y, por sus propiedades, se tiene
o | | | (19.30)
sea que la varianza condicional del término estocástico o error es constante, e idéntica a ∙ que es la varianza no explicada por la regresión, como era de esperarse.
En realidad, la varianza del error puede ser constante para cada subpoblación de correspondiente a en cuyo caso se dice que existe homoscedasticidad como se ilustra en la figura 19.9 (a), puede aumentar o disminuir conforme aumentan los valores de como se ilustra en las gráficas 19.9 (b.1) y (b.2) en cuyo caso se llama heteroscedasticidad; lo que podría suceder por ejemplo o si el gasto para consumo suntuario aumenta si se incrementa el nivel de ingresos.

22 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
. . . . .…. . . . .
. . . . .…. . . . .
. . . . .…. . . . .
. . . . .…. . . . .
(a)
(b.1) (b.2)
Figura 19.9 Homoscedasticidad (a) y Heteroscedasticidad (b.1) y (b.2)
El término estocástico es estadísticamente independiente de porque cada
valor de es una muestra aleatoria independiente de tamaño 1 y de una población normal que se distribuye conforme ~ 0, .
En resumen, se plantean las siguientes suposiciones en términos de los valores potenciales del término error:
La media de la población del término error es igual a cero para cualquier valor dado de .
La varianza de la población del término error es la misma para cualquier dada.
La población del término error se distribuye normalmente para cualquier valor dado de .
Los valores del término error son estadísticamente independientes, es decir, un valor del término error no depende de cualquier otro valor de o equivalentemente, valor de observado en un valor es independiente del observado en otro valor .
El análisis residual, que se verá posteriormente tiene por objeto comprobar la
validez de estas suposiciones basada en los residuos de la regresión.

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 23
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
19.4 Estimación de la recta de regresión En muchas aplicaciones la distribución conjunta se desconoce y no es posible
determinar la curva de regresión teórica | , salvo que dicha distribución se suponga normal bivariable, en cuyo caso se tiene la recta de regresión. Como no se conoce la recta de regresión de la población debemos estimarla; es decir, estimar los valores de los parámetros de regresión de la población y a partir de una muestra bivariable de tamaño , en la que el investigador ha seleccionado previamente cada valor de resultando las parejas de valores , ; con las se calcula la recta que mejor se ajuste a los datos. Si denotamos los coeficientes de regresión estimados por y , la línea de regresión estimada será
(19.31)
Donde indica un valor estimado de y no su valor real porque . Si denota el error estimado correspondiente a al término error de la población , el modelo general estimado es
(19.32)
Y el problema consiste en determinar los valores de y de la recta de regresión
(19.33)
correspondientes a y . Cabe observar que, en sentido estricto, esta ecuación debe ser donde son variables aleatorias y la recta de regresión es aleatoria, puesto que al sacar muestras aleatorias de la misma población los valores de los estimadores y cambian puesto que se tienen diferentes rectas como se ilustra en la figura 19.10
1
2
i
E[Y|x] = α+βx
E[Y|x] = a1+b1x
E[Y|x] = a2+b2x
E[Y|x] = a3+b3xy
x
y
x
y
x
y
x
Figura 19.10 La noción de recta de regresión aleatoria
24 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
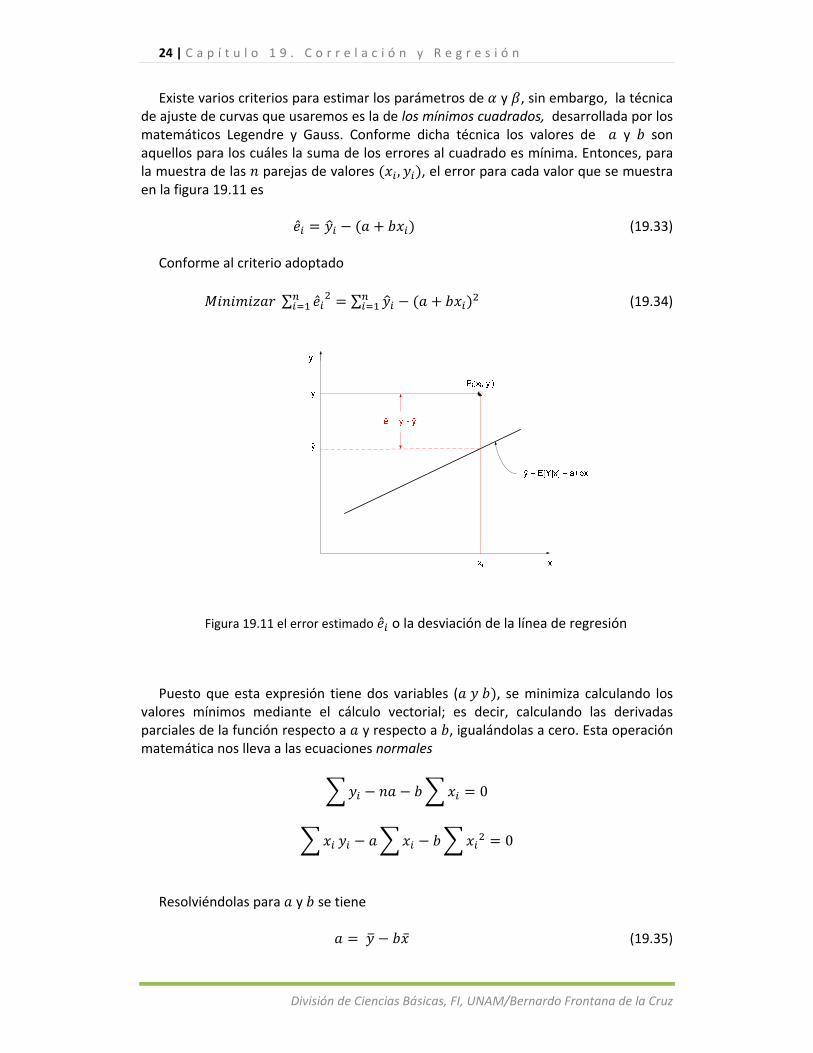
Existe varios criterios para estimar los parámetros de y , sin embargo, la técnica de ajuste de curvas que usaremos es la de los mínimos cuadrados, desarrollada por los matemáticos Legendre y Gauss. Conforme dicha técnica los valores de y son aquellos para los cuáles la suma de los errores al cuadrado es mínima. Entonces, para la muestra de las parejas de valores , , el error para cada valor que se muestra en la figura 19.11 es
(19.33)
Conforme al criterio adoptado
∑ ∑ (19.34)
Figura 19.11 el error estimado o la desviación de la línea de regresión
Puesto que esta expresión tiene dos variables ( , se minimiza calculando los
valores mínimos mediante el cálculo vectorial; es decir, calculando las derivadas parciales de la función respecto a y respecto a , igualándolas a cero. Esta operación matemática nos lleva a las ecuaciones normales
0
0
Resolviéndolas para y se tiene
(19.35)

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 25
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
∑ ∑ ∑∑ ∑
19.36
O bien, en analogía con los momentos centrales dados por las ecuaciones (19.3) a
(19.5)
19.36 ∗
Otra forma de estimar la recta de regresión consiste en estimar los valores de y
dados por las ecuaciones (19.20) y (19.21) en cuyo caso se tiene
(19.37)
Y
(19.38)
Al sustituir las dos expresiones anteriores en el modelo original (19.16) se tiene
| (19.39)
Calculemos la recta de regresión para el ejemplo del porcentaje de solvente y el
tiempo de secado en hrs de la pintura, que iniciamos en las secciones dedicadas al coeficiente de correlación, utilizando los momentos centrales ya calculados.
0.676; 3.809 y 1.562; además, de la tabla 19.2 se tiene
3.41 y 1.92. El estimador de lo encontramos con la ecuación (19.36*)
1.5623.809
0.41
Y el estimador de con la ecuación (19.35) conocido el valor de
1.92 0.41 3.41 3.3181 De (19.33), la ecuación de la recta de regresión estimada, que se muestra en la
figura 19.12, que representa la estimación del tiempo de secado para cada valor del porcentaje de solvente es
3.3181 0.41

26 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.12 Recta de regresión
X: % de solvente
0 1 2 3 4 5
Y :
Tie
mpo
de
seca
do (
hr)
1.0
1.5
2.0
2.5
3.0
3.5
4.0
3.41
1.92
ye 3.3181‐0.41x
Tal vez ahora sea más claro que, si se sacan otras muestras las rectas de regresión
obtenidas con ellas serán diferentes, de aquí su naturaleza aleatoria. Más aún, como la recta de regresión es la recta de los valores esperados de para cada valor de , es decir | ; entonces, para nuestro caso, el punto 3.41, 1.92 debe estar contenido en esta y todas las curvas de regresión estimadas por el método de mínimos cuadrados como se ilustra en la figura. Si dicho punto se sustituye en la ecuación de la recta de regresión calculada debe satisfacerla y es una manera de comprobarla; así, para nuestro ejemplo
. 3.3181 0.41 3.41 1.92 La interpretación de los coeficientes de la recta de regresión es la siguiente. Si el
porcentaje de solvente es igual a cero, el tiempo de secado será el máximo y es igual a 3.31.81 hrs y por cada unidad del porcentaje de solvente el tiempo de secado disminuye en 0.41.
Si la extrapolación es cercana al intervalo de los valores de y si el contexto del problema lo permite, se puede extrapolar con valores diferentes a los de la muestra sin alejarse mucho de este intervalo.
Con la ecuación de regresión de la muestra se obtienen los valores estimados de la
variable dependiente los cuáles aparecen en la tabla 19.3. Otra forma de comprobar la recta de regresión consiste en que debe satisfacer la ecuación ∑ ∑ ; como puede observarse en la parte inferior de las columnas y de la tabla.
Tabla 19.3 Cálculos para el análisis de los residuos
No de hornada Contenido de solvente (%) Tiempo de secado (hrs) Y
estimados residuales
1 2.5 2.3 2.2931 0.0069
2 2.7 2.1 2.2111 ‐0.1111
3 3 2.2 2.0881 0.1119
4 3.1 2.1 2.0471 0.0529
5 3.2 2 2.0061 ‐0.0061

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 27
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
6 3.4 1.9 1.9241 ‐0.0241
7 3.5 1.9 1.8831 0.0169
8 4 1.6 1.6781 ‐0.0781
9 4.2 1.6 1.5961 0.0039
10 4.5 1.5 1.4731 0.0269
Sumas 34.1 19.2 19.2 8.8818E‐16
Medias= 3.41 1.92
19.5 El análisis de residuos Este análisis se efectúa con el propósito de comprobar la validez de los supuestos
de la regresión lineal estipulados en la sección 19.3.3 y plantear algunas técnicas para corregir las violaciones.
Para cualquier valor particular observado de la variable explicada , el residuo se define la diferencia entre este valor y el pronosticado con la recta de regresión estimada
Donde, como ya vimos, es el valor de estimado con la regresión. Los residuos , que aparecen en la muestra, son estimaciones puntuales de los
errores , que están en la población, es decir, y si las suposiciones de la regresión se cumplen para cualquier valor dado de ,de se tiene que el término error se distribuye 0, ) con constante y los valores aleatorios de son estadísticamente independientes. En muchos casos dichas suposiciones no se satisfacen; no obstante si son muy pequeñas las desviaciones se pueden aceptar sin alterar de manera significativa los resultados de la regresión.
19.5.1 Gráficas de los residuos Una forma práctica de analizar los residuos es utilizando las gráficas de los residuos
cuyas abscisas pueden ser los valores de la variable explicativa, de la variable estimada o de los valores cronológicos de una serie de tiempo, como se verá en el capítulo correspondiente; todas tomando como ordenada los residuos.
La figura 19.13 muestra la gráfica para el primer caso del ejemplo del porcentaje de solvente contra los residuos. La pequeña cantidad de datos hace difícil conjeturar algo sobre la suposición de varianza constante; no obstante, al parecer se tiene forma de embudo por lo que posiblemente tenga Heteroscedasticidad y viola la suposición de varianza constante.
19.5.2 Suposición de normalidad Se cumple si la distribución de frecuencia de los residuos tiene una forma razonable
parecida a la normal (Ver figura 19.14) o bien si la gráfica de los residuos contra los valores de z calculados a partir de la frecuencia relativa acumulada dada por

28 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.13 % de Solvente Vs Residuos
% de solvente
2.0 2.5 3.0 3.5 4.0 4.5 5.0
Res
idu
os
-0.15
-0.10
-0.05
0.00
0.05
0.10
0.15
Á3 13 1
Aquí es el número consecutivo de los residuos ordenados deforma ascendente,
Á es la frecuencia relativa acumulada hasta el valor que equivale al área bajo la curva normal hasta el residuo y es el tamaño de la muestra; por ejemplo, para nuestro ejemplo se tiene 10,
Para 1 se tiene Á 0.064;
Para 5 tenemos Á 0.4516; etc.
A continuación se determinan los valores de correspondientes a las Á , que corresponden a las distribuciones acumuladas de la tabla de la distribución normal estándar por ejemplo
‐2.00
0.00
2.00
4.00
6.00
‐0.03 0.00 0.03
Frecuencia
Figura 19.14 Distribución de frecuencia de los residuos

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 29
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Para 1 se tiene Á 0.064 ⟹ 1.52;
Para 5 tenemos Á 0.4516 ⟹ 1.2; etc.
Con estos pares de valores se obtiene la gráfica 19.15 que, bajo la suposición de
normalidad, coincidirían sobre una recta, lo que no sucede en nuestro ejemplo.
Figura 19.15 Gráfica Normal
Residuos
-0.15 -0.10 -0.05 0.00 0.05 0.10 0.15
valo
r n
orm
aliz
ado
Zi
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
Otra forma más de analizar la suposición de normalidad consiste en dibujar la gráfica de los
residuos contra los valores correspondientes de ; que aparecen en la última columna de la tabla superior como se ilustra en la figura 19.16. Si hubiera normalidad, la gráfica debiera de asumir la forma de una distribución normal; lo que no es muy claro en la figura en la que se observa que el segundo residuo marca la diferencia.
Fig. 19.16 Distribución de Residuos VS f(Z)
Residuos
-0.15 -0.10 -0.05 0.00 0.05 0.10 0.15
Val
ore
s d
e f(
Z)
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
19.5.3 La suposición de la varianza constante Como ya se vio, esta suposición establece que la varianza de la regresión es
constante o sea que existe homoscedasticidad. Para nuestro ejemplo, la gráfica 19.13 es similar a la 19.9 (b) en forma de embudo lo que significa que, al parecer, existe varianza decreciente o sea heteroscedasticidad. Aunque la gráfica de dispersión nos da la misma información sobre la varianza como se ve en la gráfica 19.12, es preferible la de los residuos porque nos proporciona la información amplificada
Á
1 0.06 ‐0.1111 ‐1.52 0.13
2 0.16 ‐0.0781 ‐0.99 0.24
3 0.26 ‐0.0241 ‐0.65 0.32
4 0.35 ‐0.0061 ‐0.37 0.37
5 0.45 0.0039 ‐0.12 0.40
6 0.55 0.0069 0.12 0.40
7 0.65 0.0169 0.37 0.37
8 0.74 0.0269 0.65 0.32
9 0.84 0.0529 0.99 0.24
10 0.94 0.1119 1.52 0.12
30 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
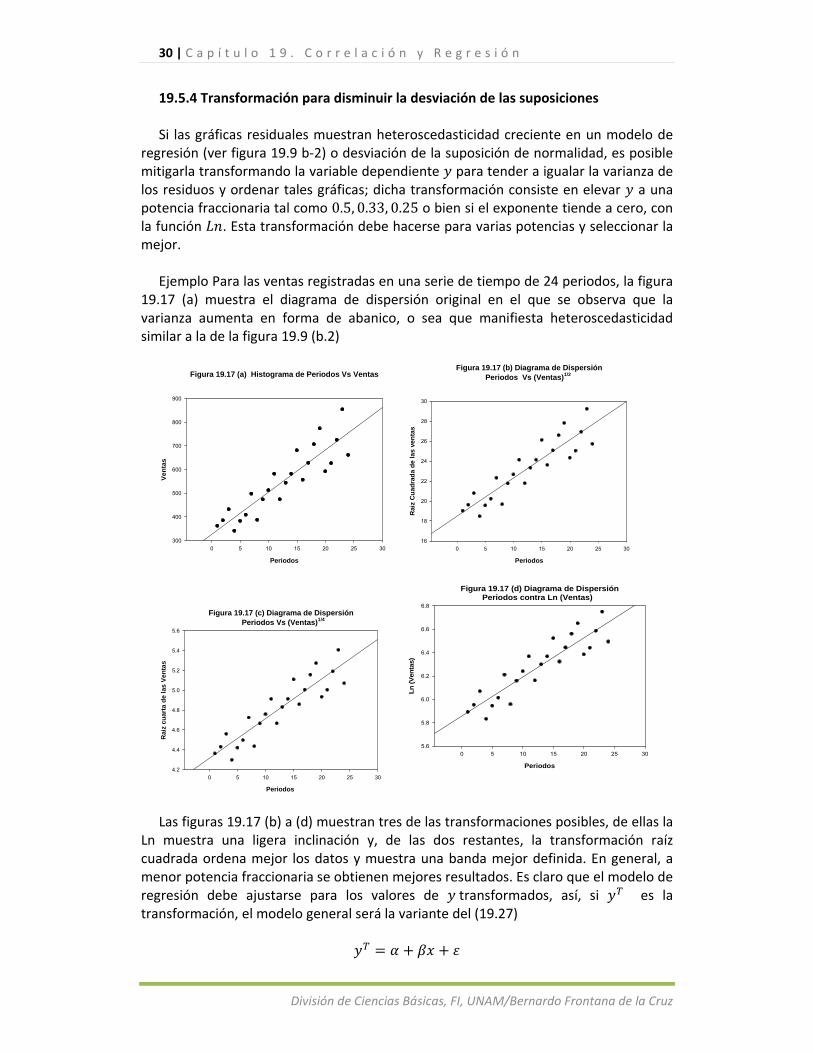
19.5.4 Transformación para disminuir la desviación de las suposiciones Si las gráficas residuales muestran heteroscedasticidad creciente en un modelo de
regresión (ver figura 19.9 b‐2) o desviación de la suposición de normalidad, es posible mitigarla transformando la variable dependiente para tender a igualar la varianza de los residuos y ordenar tales gráficas; dicha transformación consiste en elevar a una potencia fraccionaria tal como 0.5, 0.33, 0.25 o bien si el exponente tiende a cero, con la función . Esta transformación debe hacerse para varias potencias y seleccionar la mejor.
Ejemplo Para las ventas registradas en una serie de tiempo de 24 periodos, la figura
19.17 (a) muestra el diagrama de dispersión original en el que se observa que la varianza aumenta en forma de abanico, o sea que manifiesta heteroscedasticidad similar a la de la figura 19.9 (b.2)
Figura 19.17 (a) Histograma de Periodos Vs Ventas
Periodos
0 5 10 15 20 25 30
Ven
tas
300
400
500
600
700
800
900
Figura 19.17 (b) Diagrama de DispersiónPeriodos Vs (Ventas)1/2
Periodos
0 5 10 15 20 25 30
Rai
z C
uad
rad
a d
e la
s ve
nta
s
16
18
20
22
24
26
28
30
Figura 19.17 (c) Diagrama de Dispersión Periodos Vs (Ventas)1/4
Periodos
0 5 10 15 20 25 30
Rai
z c
ua
rta
de
las
Ve
nta
s
4.2
4.4
4.6
4.8
5.0
5.2
5.4
5.6
Figura 19.17 (d) Diagrama de DispersiónPeriodos contra Ln (Ventas)
Periodos
0 5 10 15 20 25 30
Ln
(V
enta
s)
5.6
5.8
6.0
6.2
6.4
6.6
6.8
Las figuras 19.17 (b) a (d) muestran tres de las transformaciones posibles, de ellas la
Ln muestra una ligera inclinación y, de las dos restantes, la transformación raíz cuadrada ordena mejor los datos y muestra una banda mejor definida. En general, a menor potencia fraccionaria se obtienen mejores resultados. Es claro que el modelo de regresión debe ajustarse para los valores de transformados, así, si es la transformación, el modelo general será la variante del (19.27)

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 31
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
19.6 Varianza de la regresión lineal La principal función de la recta de regresión consiste en predecir el valor de o asociada a un valor particular de ; pero es necesario conocer el grado de la
predicción puede conocerse, en parte, estudiando la variabilidad del valor real obtenida con el valor estimado por la regresión para un valor específico . Para muestro ejemplo, la figura 19.13 muestra las dispersiones de los valores reales de la muestra respecto a los estimados: y, se observa que estas son muy pequeñas como era de esperarse ya que 0.97; sin embargo, la medida numérica de tales desviaciones se encuentra calculando el estimador insesgado de la varianza de los errores o residuos, que es la varianza de la regresión.
∙∑
2∑
2
Desarrollando el cuadrado de esta ecuación y utilizando los momentos centrales se
obtiene
∙⁄
2 19.40
Cabe observar que el denominador tiene 2 grados de libertad puesto que se
pierden 2 debido a los coeficientes de regresión; cuya desviación estándar de la regresión es la raíz cuadrada.
Para nuestro ejemplo, con 0.676; 3.809 y 1.562 esta la variabilidad de la regresión es
∙0.676 1.562 3.809⁄
10 20.0044
Y la desviación estándar de la regresión para la muestra es
√0.0044 0.0666 hrs de secado para todos los valores de | . Así pues tanto como son medidas del grado de ajuste de la relación lineal
entre el tiempo de secado y el porcentaje de solvente y nuevamente, como era de esperarse, la variabilidad de la regresión es muy pequeña como puede constatarse con las líneas verticales que van de los puntos observados en la muestra a la línea de regresión en la figura 19.13.

32 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.13 Análisis de los residuos o errores
X: % de solvente
0 1 2 3 4 5Y
: T
iem
po d
e se
cado
(hr
)1.0
1.5
2.0
2.5
3.0
3.5
4.0
ye 3.3181‐0.41x
Por lo anterior, puede concluirse que en la medida en que el valor de la varianza de la
regresión sea menor, la ecuación de regresión de la muestra será más precisa como herramienta de predicción y, en el límite e idealmente, cuando todos los puntos de la muestra se alineen perfectamente dicha varianza será igual a cero lo cual es prácticamente imposible por los errores aleatorios del muestreo. Con muestras más grandes se puede tener mejor precisión en la determinación de la recta de regresión; sin embargo, esto no ayuda a mejorar su varianza.
Otra indicación del análisis de regresión se tiene comparando las desviaciones estándar de la regresión y de sin tomar en cuenta los valores de , es decir que se ilustra en la figura 19.15 donde se observa que esta variabilidad es mayor.
Como sabemos
∑
1 1
Para el ejemplo que venimos desarrollando tenemos
10.6769
0.274
Como se anticipó, al ignorar este resultado es más de cuatro veces el valor de ;
por lo tanto, las variaciones de por el conocimiento de a través de la regresión lineal ayuda significativamente a la estimación porque dicha curva es la de valores esperados dado .

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 33
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.14 Dispersiones respecto a la media
X :%solvente
0 1 2 3 4 5
Y:
tiem
p de
se
cad
o (
hr)
0.0
0.5
1.0
1.5
2.0
2.5
3.0
19.7 Inferencias respecto a los problemas de regresión En la sección 19.4 no hicimos ninguna consideración respecto a la distribución
conjunta de la población, solamente usamos la técnica de los mínimos cuadrados y asumimos que la recta es la que se ajusta mejor a los datos porque es la que minimiza el cuadrado de los errores. Si suponemos que las variables aleatorias y tienen distribución normal bivariable, se tiene otra justificación para los resultados de esa sección por lo que se vio en la sección 19.2.2 donde se analizo esta distribución y se estableció que la curva de regresión es estrictamente lineal. Bajo esta suposición no es necesario considerar modelos de regresión no lineal.
Más aún, bajo la misma suposición anterior, se puede determinar la función de verosimilitud por el método estudiado en el capítulo 17 cuyos resultados apoyan los estimadores dados por las ecuaciones (19.35) y (19.36) y se llega a ellas por dos métodos diferentes; con la salvedad de que si la distribución d la población es diferente, los resultados obtenidos por los dos métodos serán diferentes.
En problema de regresión el interés está en la predicción de dado un valor de por lo cual no es necesario hacer ninguna suposición sobre la distribución de la
variable independiente porque, en sentido estricto no es una variable aleatoria; por ejemplo, en un experimento de elementos estructurales, el investigador puede interesarse en la resistencia de una viga sometida a una tensión , en cuyo caso, el investigador tiene un control total sobre la tensión y no es una variable aleatoria. En lo que sigue continuaremos considerando a la variable independiente como una variable aleatoria recordando que no es necesario para el estudio de las inferencias respecto a los problemas de regresión.
Para la regresión lineal de sobre si se supone la distribución conjunta normal bivariable conviene recordar que:
Para cualquier valor de , la distribución de es normal.
La varianza condicional | tiene distribución normal.
El proceso de muestreo es independiente. Como está fija, la variabilidad de se debe exclusivamente a los factores
aleatorios manifestados en los errores o residuos, con lo cual las proposiciones

34 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
anteriores pueden plantearse como sigue, recordando al lector que, para nuestro caso, los términos errores, residuales o residuos son equivalentes.
Para cualquier valor de , los errores se distribuyen normalmente.
La varianza de los errores es la misma para toda .
Los errores son independientes. Estos supuestos se representan gráficamente en la figura 19.15.
Figura 19.15 Distribuciones iguales de los errores
En contraparte, si no se cumple el supuesto de la igualdad de varianzas para los errores
como se ilustra en la figura 19.16, entonces la varianza se incrementa al aumentar como suele suceder cuando se desea predecir los montos de los gastos suntuarios cuando aumenta el ingreso o bien los gastos en publicidad u otras cosas si aumentan las ganancias de las empresas. Así pues las suposiciones anteriores deben tenerse presentes cuando apliquemos las técnicas de inferencia que se presentarán en las siguientes secciones.
Figura 19.16 Violación del supuesto de varianzas del error iguales
19.7.1 Inferencias respecto a los Coeficientes de Regresión Determinada la ecuación de regresión lineal de la muestra y analizadas las varianzas
y las desviaciones estándar de la regresión; ∙ , y de la variable dependiente , , supuestamente favorables; podría pensarse que la recta de regresión se utilizaría animosamente para la predicción, no obstante, aún si la recta de regresión de la muestra es idéntica a la de la población la predicción contiene errores causados por el muestreo o porque la relación entre de la población puede no ser perfecta,

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 35
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
recuérdese que la magnitud de este error se mide con ∙ y que si se sacan varias muestras de la misma población las rectas de regresión son, en lo general, diferentes como se puso de manifiesto en la figura 19.10.
19.7.2 Pruebas de hipótesis respecto a los Coeficientes de Regresión Como se ha visto desde el capítulo 17, las inferencia sobre cualquier parámetro
requieren de sus distribuciones muéstrales correlativas por lo cual, para hacer inferencias sobre los parámetros de la recta de regresión se necesitan conocer las distribuciones muestrales de sus estimadores y .
Los errores de los estimadores de mínimos cuadrados y se miden con base en sus distribuciones muestrales respectivas.
Estos coeficientes son insesgados por lo cual y ; como y forman combinaciones lineales para y conforme a los supuestos anteriores se distribuye normalmente se sigue que y también deben distribuirse normalmente; y se puede demostrar que para estos estimadores lineales insesgados sus varianzas se definen como:
∙ ∑∑ ∙
∑ 19.41
∙
∑ ∙1
19.42
Con las expresiones anteriores, si el tamaño de la muestra es grande ‐ 30‐ y ∙ se conoce los estadísticos para las pruebas de hipótesis sobre y son las
estandarizaciones ya conocidas
19.43
19.44
Por el contrario, si el tamaño de la muestra es pequeña ‐ 30‐ y ∙ se
desconoce los estadísticos para las pruebas de hipótesis sobre y los estadísticos y se distribuyen aproximadamente conforme la distribución t de Student con
2 grados de libertad, en cuyo caso los estadísticos para las pruebas de hipótesis son
19.43
19.44

36 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Para nuestro ejemplo sobre el porcentaje de solvente y el tiempo de secado para las pinturas tenemos que 10, la recta de regresión es 3.3181 0.41 , con un nivel de significación estadística 0.01 probemos la hipótesis
: 0 Contra la alternativa : 0.
Como nuestra muestra es pequeña, entonces usamos el estadístico (19.43). El valor
crítico es ⁄ . , 3.355; para calcular el valor del estadístico es necesario calcular con la ecuación 19.41 habiendo calculado en la sección 19.5
∙ 0.0044 y previamente 3.809 y de la tabla 19.2, ∑ 120.09
∙∑
0.0044120.09
10 3.8090.0139
√0.0139 0.118 Entonces
3.31810.118
28.12
Por lo tanto se rechaza la hipótesis de que el parámetro de la población sea
menor o igual a cero con un nivel de significación estadística 0.01 a favor de la hipótesis alternativa que sea mayor que cero. Si se calcula el valor‐p se verá que es altamente improbable.
De manera similar probemos la hipótesis con el mismo nivel de significancia estadística 0.01.
: 0 Contra la alternativa : 0.
El valor crítico es ⁄ . , 3.355 Para ello, el estadístico para la prueba está dado por la ecuación (19.44) para el cual
∙1
0.00441
3.8090.0012
√0.0012 0.034 Por lo tanto
0.41 00.034
12.06
Por lo que se rechaza la hipótesis de que el parámetro de la población sea mayor
o igual a cero con un nivel de significación estadística 0.01 a favor de la hipótesis alternativa que sea menor que cero. Si se calcula el valor‐p nuevamente se verá que este valor es altamente improbable.

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 37
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Si se determina que la pendiente de la recta de regresión es significativa, entonces la recta puede utilizarse como instrumento de predicción, de lo contrario debe rechazarse.
19.7.3 Intervalos de confianza respecto a los Coeficientes de Regresión Los conceptos estudiados en el capítulo 17 relacionados con los intervalos de
confianza, son aplicables a la determinación de los mismos para los parámetros y de la regresión de la población.
En general, un intervalo de confianza para la ordenada al origen de la regresión de la población se determina mediante la expresión
% 19.45
Y un intervalo de confianza para la pendiente de la regresión de la población se
determina mediante la expresión
% 19.46
Donde en ambos casos es el fractil 1 2⁄ de la distribución con
2 grados de libertad; y son los valores de la ordenada al origen y de la pendiente obtenidos para la recta de regresión y y son las desviaciones estándar estimadas con la muestra para y , respectivamente.
Para el ejemplo que venimos trabajando calculemos un intervalo de confianza del 99% para .
De la recta de regresión 3.3181;del ejemplo anterior ⁄ . ,
3.355 y 0.118; aplicando (19.45) se obtiene
% 3.3181 3.355 0.118 2.922,3.714 Con el mismo nivel de confianza, un intervalo para se obtiene aplicando (19.46)
para lo cual 0.41 y 0.034.
% 0.41 3.355 0.034 0.524, 0.296
19.7.4 Predicción y pronosticación (Bandas de confianza) Como hemos insistido anteriormente, el objetivo del análisis de regresión es la
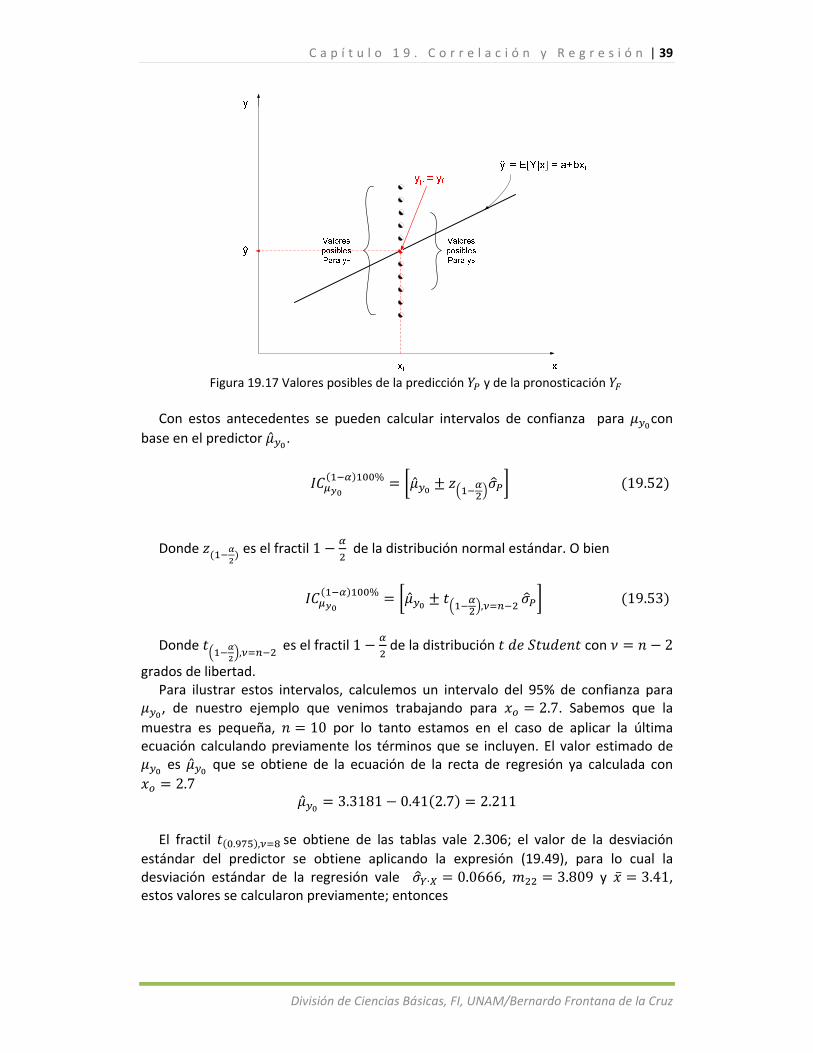
estimación del | ∙ por la asociación dictada por la recta de regresión; sin embargo, existen dos tipos de estimación, a saber, la predicción y la pronosticación que se estudiarán a continuación.
La predicción es el procedimiento para estimar ∙ , dado un valor específico . Obsérvese que la predicción re relaciona con la precisión de TODA la recta de
regresión, su estimador asociado se denota con , | que se llama el

38 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
predictor; De las notaciones anteriores, para mejorar la presentación usaremos la primera y como esta definición alude a la recta de regresión, su valor es
19.47
Para determinar la distribución muestral de este estimador; primero como
es una combinación lineal de las variables que se distribuyen normalmente, se sigue que este estimador también se distribuye normalmente; como vimos que es
un estimador insesgado de su valor esperado es
19.48 Para determinar la varianza del predictor observamos que el error al determinar el
valor | , que en adelante lo denotaremos por para simplificar la notación, proviene de las variaciones aleatorias de , y el error de la predicción que denotaremos con será
(
Si se eleva al cuadrado esta expresión y se calcula su valor esperado se obtiene su
varianza, que es igual a
∙1
∑ 19.49
Y la desviación estándar es
∙1
∑
O bien, en términos de los momentos centrales
∙1
19.50
Conviene recordar que ∙ es la varianza de la regresión, La dispersión de los
valores posibles de se muestran en la figura 19.17. Estandarizando , que como vimos es el valor de | tenemos que
19.51
que se distribuye ~ 0,1 si se conoce ∙ o 30; de lo contrario, tiene una
distribución con 2 grados de libertad.
C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 39
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.17 Valores posibles de la predicción y de la pronosticación
Con estos antecedentes se pueden calcular intervalos de confianza para con
base en el predictor .
% 19.52
Donde es el fractil 1 de la distribución normal estándar. O bien
% , 19.53
Donde , es el fractil 1 de la distribución con 2
grados de libertad. Para ilustrar estos intervalos, calculemos un intervalo del 95% de confianza para , de nuestro ejemplo que venimos trabajando para 2.7. Sabemos que la
muestra es pequeña, 10 por lo tanto estamos en el caso de aplicar la última ecuación calculando previamente los términos que se incluyen. El valor estimado de
es que se obtiene de la ecuación de la recta de regresión ya calculada con
2.7 3.3181 0.41 2.7 2.211
El fractil . , se obtiene de las tablas vale 2.306; el valor de la desviación
estándar del predictor se obtiene aplicando la expresión (19.49), para lo cual la desviación estándar de la regresión vale ∙ 0.0666, 3.809 y 3.41, estos valores se calcularon previamente; entonces

40 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
∙1
0.0666110
2.7 3.413.809
0.0321
Con los valores anteriores calculamos el intervalo mediante la ecuación (19.52)
%, 2.211 2.306 0.0321 2.14, 2.29
Este intervalo de confianza aparece en la figura 19.18 para 2.7 con la línea
sólida vertical en dicho punto. Los intervalos de confianza para los demás puntos de la muestra se obtienen siguiendo el procedimiento descrito y los resultados se muestran en la tabla 19.4.
Tabla 19.4 Cálculos de los intervalos de confianza de la regresión para la predicción
Núm. Hornada Raíz límite Inferior
limite Superior
1 2.5 2.29 0.56 0.04 2.21 2.38
2 2.7 2.21 0.48 0.03 2.14 2.29
3 3 2.09 0.38 0.03 2.03 2.15
4 3.1 2.05 0.35 0.02 1.99 2.10
5 3.2 2.01 0.33 0.02 1.95 2.06
6 3.4 1.92 0.32 0.02 1.88 1.97
7 3.5 1.88 0.32 0.02 1.83 1.93
8 4 1.68 0.44 0.03 1.61 1.75
9 4.2 1.60 0.51 0.03 1.52 1.67
10 4.5 1.47 0.64 0.04 1.37 1.57
Finalmente, si se dibujan estos intervalos en la figura 19.18 y se unen sus extremos,
se obtiene la banda de confianza de la recta de regresión, , también llamada la
banda de confianza de la predicción del porcentaje de solvente y el tiempo de secado de la pintura que se está investigando que se muestra en dicha figura con líneas a trazos. Al igual que los intervalos de confianza para los parámetros, el nivel de confianza del 95% que fijamos, significa que cada 100 bandas de confianza que calculemos; en 95 de ellas está atrapada la recta de regresión de la población. Más aún, ahora debe ser claro que si aumentamos el nivel de confianza la banda de confianza será más ancha, y si disminuimos el nivel de confianza se estrechará. Una observación final de la figura consiste en que en el punto , la banda de confianza es más estrecha como se muestra en la gráfica citada con líneas rojas discontinuas, y la banda se va ampliando a medida que nos alejamos en los demás; por lo que debe tenerse precaución cuando se hacen predicciones más allá del intervalo de los valores de la muestra.

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 41
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
Figura 19.18 Bandas de confianza de la predicción y pronosticación
% solvente
2.0 2.5 3.0 3.5 4.0 4.5 5.0
Tie
mpo
s de
sec
ado
1.2
1.4
1.6
1.8
2.0
2.2
2.4
2.6
1.92
3.41
La pronosticación es la valoración de un solo valor de para un valor ,
y al estimador se le llama pronosticador, designado como y es
19.54
El problema consiste en determinar el valor del pronosticador que es una
variable aleatoria cuyos valores se encuentran alrededor del punto de la regresión para como se muestra en llas figuras 19.15 a 19.17 en la que esta última aclara la diferencia entre la predicción y la pronosticación.
En este caso el error del pronóstico es la diferencia o sea
( Que es una variable aleatoria distribuida normalmente con media
0 Y, observando la figura 19.18, la varianza es igual a la varianza de la predicción más
la varianza debida a los factores aleatorios del muestreo, por ello
∙ Sustituyendo (19.49) en la expresión anterior se obtiene

42 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
∙1
∑ ∙ ∙ 11
∑
Y la desviación estándar es
∙ 11
∑ ∙ 11
19.55
Cuando 30 y se conoce ∙ de la población se tiene que la estandarización
19.56
se distribuye ~ 0, 1 ; y en caso contrario, cuando 30 y se desconoce ∙
estonces
19.57
se tiene una distribución 2 grados de libertad. Con las dos ecuaciones anteriores y por lo visto en el capítulo 17, podemos calcular
intervalos de confianza para el valor individual pronosticado
% 19.58
Donde es igual al fractil 1 2⁄ de la distribución normal estándar; o bien
%
⁄ , 19.59
Donde ⁄ , es igual al fractil 1 2⁄ de la distribución
2 grados de libertad. Para ilustrar estos intervalos, calculemos un intervalo del 95% de confianza para ,
de nuestro ejemplo para 4.2. Como 10 se aplica la ecuación (19.59) calculando previamente los términos que se incluyen. El valor estimado de es , que corresponde al valor del pronosticador que se obtiene de la ecuación de la recta de regresión ya calculada con 4.2
3.3181 0.41 4.2 1.60
El fractil . , se obtiene de las tablas vale 2.306; el valor de la desviación
estándar del pronosticador se obtiene aplicando la expresión (19.59), para lo cual la desviación estándar de la regresión vale ∙ 0.0666, 3.809 y 3.41, estos valores se calcularon previamente; entonces la desviación estándar del pronosticador, aplicando (19.55) vale

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 43
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
∙ 11
0.0666 1110
4.2 3.413.809
0.07
Con los valores anteriores calculamos el intervalo mediante la ecuación (19.52)
%, 1.60 2.306 0.07 1.42,1.77
Este intervalo de confianza aparece en la figura 19.8 para 4.2 con la línea
sólida vertical en dicho punto. Los intervalos de confianza para los demás puntos de la muestra para la pronosticación, se obtienen siguiendo el procedimiento anterior y los resultados se muestran en la tabla 19.5.
Tabla 19.5 Cálculos de los intervalos de la pronosticación de
Núm. Hornada Raíz límite Inferior
limite Superior
1 2.5 2.29 1.15 0.08 2.12 2.47
2 2.7 2.21 1.11 0.07 2.04 2.38
3 3 2.09 1.07 0.07 1.92 2.25
4 3.1 2.05 1.06 0.07 1.88 2.21
5 3.2 2.01 1.05 0.07 1.84 2.17
6 3.4 1.92 1.05 0.07 1.76 2.09
7 3.5 1.88 1.05 0.07 1.72 2.04
8 4 1.68 1.09 0.07 1.51 1.85
9 4.2 1.60 1.12 0.07 1.42 1.77
10 4.5 1.47 1.19 0.08 1.29 1.66
Al igual que se hizo para la predicción, al unir los puntos extremos de estos
intervalos se obtiene la banda de confianza para la pronosticación de los valores individuales de que aparece en la figura 19.18 y se interpreta como de cada 100 bandas de confianza que calculemos 95% de ellas contendrán a los verdaderos valores de del pronosticador ; además, si se aumenta el nivel de confianza las bandas se harán más grandes y si se disminuye las bandas se angostarán.
Cabe observar que las bandas de confianza para la predicción y la
pronosticación siguen el mismo patrón con su ancho mínimo en el punto , y va aumentando a medida que los valores se alejan de este punto, por lo que a medida que nos alejamos tanto la predicción como la pronosticación son más inciertas.
19.8 El análisis de varianza en la regresión lineal y el coeficiente de determinación En las secciones 19.3.2.1 estudiamos el coeficiente de determinación, y en la 19.5 la
varianza de la regresión; sin embargo, es necesario reunir estos dos conceptos para aclarar el significado de la varianza de la regresión ∙ y del coeficiente de correlación
. El indicador que sirve para ambas aclaraciones es el coeficiente de determinación
. Analicemos la varianza descomponiendo el error total de de una observación de
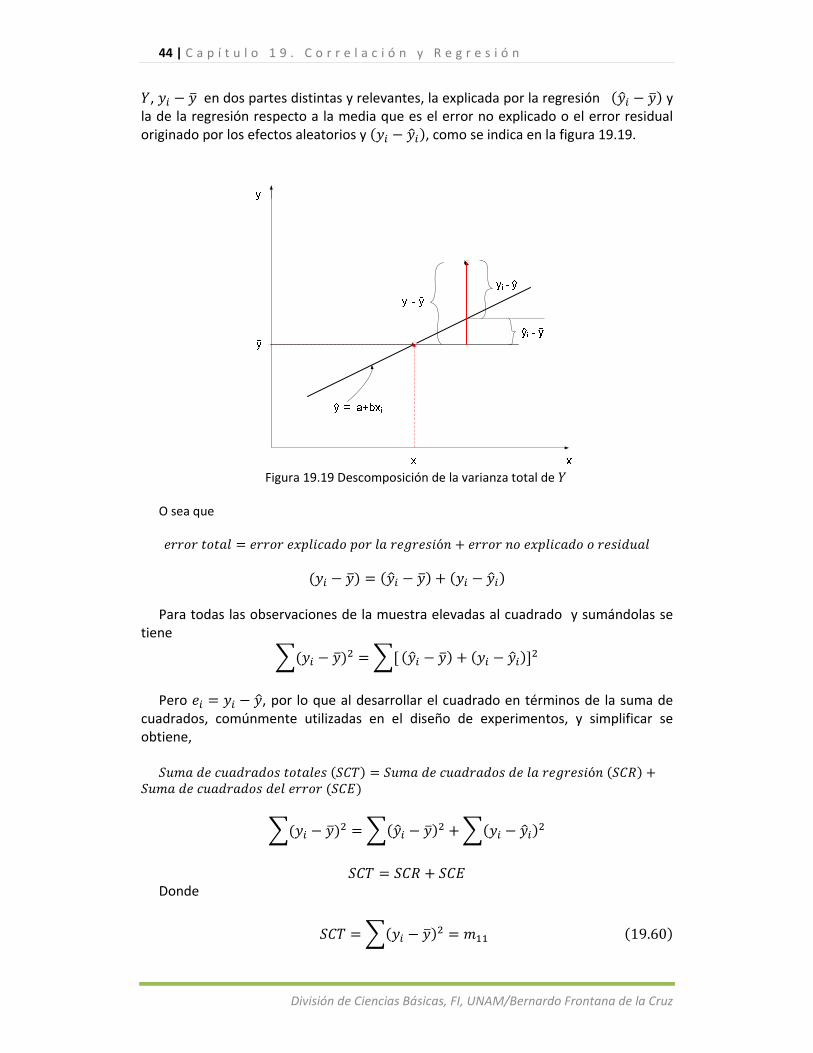
44 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
, en dos partes distintas y relevantes, la explicada por la regresión y la de la regresión respecto a la media que es el error no explicado o el error residual originado por los efectos aleatorios y , como se indica en la figura 19.19.
Figura 19.19 Descomposición de la varianza total de
O sea que
ó
Para todas las observaciones de la muestra elevadas al cuadrado y sumándolas se tiene
Pero , por lo que al desarrollar el cuadrado en términos de la suma de
cuadrados, comúnmente utilizadas en el diseño de experimentos, y simplificar se obtiene,
ó
Donde
19.60

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 45
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
19.61
Y
19.62 Dividiendo cada término de por se tiene
1
De donde
1
Que es el coeficiente de determinación que estudiamos en el apartado 19.3.2.1 y
justifica que es la varianza explicada por la regresión puesto que
ó
Que es un estimador de máxima verosimilitud de . Con base en la figura anterior, siempre se cumple , por lo tanto, si
0, 0 lo que indica que el ó es cero y las variables y son estadísticamente independientes y la recta de regresión será horizontal en como la mostrada en la figura citada; en otros términos . En este caso 0 implica que la pendiente de la regresión sea cero; pero también puede esto si los puntos de la muestra se dispersan completamente al azar que es evidente; que se ajusten perfectamente a una línea horizontal si ∀ en este caso no hay variación que deba explicarse y la descomposición de pierde sentido; o que los puntos sigan algún patrón no lineal y el ajuste también sea una línea horizontal, lo que indica que el ajuste es muy malo y está indeterminado. Por lo anterior, el coeficiente de determinación puede verse como el valor de mejoría debido a la regresión, una medida del grado de ajuste de la regresión o la potencia de linealidad de los puntos de la muestra.
Por otro lado, si se tiene que el coeficiente de determinación 1; en cuyo caso se tiene que , ∀ , lo que significa que todos los puntos de la muestra están perfectamente localizados en la recta de regresión de la muestra y como los 0se tiene y el ó
. Para nuestro ejemplo del tiempo desecado y el % de solvente de la pintura
obtuvimos 0.676; 3.809,aplicando (19.60) a (19.62) tenemos
0.676

46 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
0.41 3.809 0.64
0.676 0.41 3.809 0.0357
Comprobación
0.64 0.0357 0.6757 Por lo tanto
0.640.6757
0.947
Por otro lado calculamos el coeficiente de correlación 0.97 por lo que el
coeficiente de determinación es
0.97 0.941 La diferencia de las milésimas se debe a los errores por redondeo. Este coeficiente indica que más de 94% de la varianza total de los datos del tiempo
desecado se explica por las variaciones que tiene el % de solvente que se la pone a la pintura y el 6% restante de la variación total no lo explica la regresión sino que se debe a los factores aleatorios del muestreo. Si se tuviera 1 nos indicaría que hay una reducción del 100% del error total y toda la variación se debe a la regresión.
Una forma de presentar los resultados del análisis de varianza consiste en escribir la recta de regresión y a bajo de sus términos colocar, entre paréntesis, sus correspondientes errores estándar y a la derecha el coeficiente de determinación que es más representativo que el de regresión. Para nuestro ejemplo tenemos
3.3181 0.41 0.941
0.118 0.034 19.9 El Análisis de varianza para la pendiente con el estadístico F. Para terminar este capítulo, veremos el fundamento de las pruebas de de análisis
de varianza, conocidas en la literatura de los análisis estadísticos de experimentos como ANOVA, con la prueba de la relación de varianzas de la regresión y del error para la pendiente de la regresión ; utilizando el estadístico F. Para ello, es necesario comentar brevemente algunos conceptos básicos del diseño estadístico de experimentos.
Como se anticipó en la sección 19.2.4.1, Ronald Aymer Fisher fue el creador de los diseños estadísticos experimentales que los publicó en 1935 su libro The Design of Experiments y, desde entonces todas las contribuciones sobre este campo han venido en aumento al grado que, a la fecha, forman una rama especializada de la estadística.
Se parte de la idea de que los datos pueden clasificarse en datos observacionales y datos experimentales que se distinguen porque los primeros son las medidas de las unidades observadas de la muestra que permanecen fijos durante el estudio y son incontrolables, como hasta ahora lo hemos hecho; en contraste, los datos

C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n | 47
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
experimentales que se observan de una muestra en la que ciertas variables si son controlables o modificables para analizar la respuesta de los factores variables; es decir, son el resultado de experimentos diseñados para probar las relaciones causa‐ efecto.
En la jerga de de esta teoría, a las variables independientes se les llama tratamientos o factores sobre los que se establece el control y a la variable independiente se le llama respuesta. Así, para nuestro ejemplo la respuesta sería el tiempo de secado y los tratamientos o factores pueden ser el mismo % de solvente de marcas diferentes, la misma marca pero a diferentes niveles de % de solvente o bien una combinación de ambos marcas y % de solvente. Obsérvese que todos estos diseños deben estar rigurosamente controlados en los que varían los factores o tratamientos.
Pero cuando se trabaja experimentalmente, salvo para los factores controlados, es difícil controlar otros, bien sea que no se conozcan, que se dejen sin control a propósito o porque siempre existen factores incontrolables aleatorios; por lo anterior, en un trabajo experimental siempre existe el error experimental que es la variación en la respuesta causada por la falta de control ineludible y se define como la varianza residual que no puede ser explicada por las varianzas de los tratamientos.
El método comúnmente utilizado para estudiar los datos de los diseños experimentales se llama análisis de varianza que consiste en analizar la varianza total de una respuesta como una función lineal de de las varianzas de los tratamientos participantes en el experimento mas la varianza y la varianza residual.
Para tal efecto, se acostumbra a construir la tabla de Análisis de Varianza que por sus siglas en inglés se llama ANOVA como se muestra en la tabla 19.6.
Tabla 19.6 Tabla de Análisis de varianza: ANOVA
Fuente de variación
Suma de cuadrados
(SC)
Grados de libertad ( )
Media de cuadrados
(MC)
Fuente 1 Fuente 2
…. Error
Total
Apliquemos este método de análisis de varianza para probar la significancia de la
pendiente de la recta de regresión de nuestro ejemplo, con las aclaraciones pertinentes.
1) Por lo que toca a las fuentes de variación que contribuyen a la varianza total, se tienen las de la regresión y las del error, cuya suma debe ser la total como se observa en la figura 10.19.
2) Las Sumas de Cuadrados (SC) para las fuentes se calcularon en la sección previa y sus valores son 0.676, 0.64 y 0.0357.
3) Los grados de libertad son: a. Para la fuente de variación total 1 10 1 9.

48 | C a p í t u l o 1 9 . C o r r e l a c i ó n y R e g r e s i ó n
División de Ciencias Básicas, FI, UNAM/Bernardo Frontana de la Cruz
b. Para la regresión donde es el número de variables independientes o el número de pendientes , por lo que para nuestro ejemplo 1 de donde 1.
c. Para los errores o residuos, se pierden 1 grado de libertad por la ordenada al origen y debido a , todos los coeficientes de regresión; por ello 1; y para nuestro caso 101 1 8.
4) Las medias de los cuadrados MC son los valores esperados de las sumas de cuadrados y se obtienen dividiendo las SC entre los grados de libertad correspondientes; por ello son estimadores de las varianzas de las fuentes.
5) Los valores son los cocientes de las de las fuentes entre la del
error o sea el cociente de varianzas que definen a los estadísticos
6) Comparando estos valores con las se hacen las pruebas de significancia de las fuentes.
Con la información anterior podemos construir la tabla de análisis de varianza o la
tabla ANOVA con los resultados de nuestro ejemplo.
Tabla 19.6 ANOVA para la del ejemplo
Fuente de variación
Suma de cuadrados
(SC)
Grados de libertad ( )
Media de cuadrados (MC)
Regresión 0.64 1 0.64/1=0.64 0.64/0.0045
142.22 Error 0.0357 n – k – 1 = 8 0.0357/8=0.0045
Total 0.676 1 9 0.676 9⁄ 0.0751
Ahora bien, para la prueba : 0 si es cierta, los valores de Y son
independientes de los valores de X,y solamente se explican por las variaciones de los errores aleatorios del muestreo; por el contrario, si los valores de Y son altamente
dependientes de los valores de Xel cociente sería diferente de 0 por
las variaciones del muestreo, y como los términos del cociente se distribuyen conforme la Ji‐Cuadrada, corresponde a la distribución ; ; para la
hipótesis alterna : 0.Los valores críticos son
. ; ; . ; ; .
0.001 Y
. ; ; 7.57 Como 142.22 entonces el rechazo de que la pendiente de la regresión sea
igual a cero es altamente significativo.









![EdIeM.ppt [Modo de compatibilidad]dcb.fi-c.unam.mx/Academicos/FPPC/Ponencias/EdIeM.pdf · Físicos: Osborne Reynolds, Niels Bohr, Ernest Rutherford, James Chadwick, Arthur Schuster,](https://static.fdocuments.co/doc/165x107/5cc243ca88c993110a8da1e2/ediemppt-modo-de-compatibilidaddcbfi-cunammxacademicosfppcponenciasediempdf.jpg)








