
Capítulo 3 EAP Agronomia
59
Capítulo 3 INTRODUCCIÓN A LA INFERENCIA ESTADÍSTICA El proceso de Inferencia Estadística permite extraer conclusiones científicamente válidas acerca de la población a partir de los resultados muéstrales (obtenidos a través de la estadística descriptiva). El propósito de la inferencia estadística es realizar: - Estimación de Parámetros - Contraste de Hipótesis
-
Upload
adriannoel1995 -
Category
Documents
-
view
322 -
download
31
description
Inferencia Estadistica
Transcript of Capítulo 3 EAP Agronomia

Capítulo 3
INTRODUCCIÓN
A LA
INFERENCIA ESTADÍSTICA
El proceso de Inferencia Estadística permite extraer conclusiones científicamente
válidas acerca de la población a partir de los resultados muéstrales (obtenidos a
través de la estadística descriptiva).
El propósito de la inferencia estadística es realizar:
- Estimación de Parámetros
- Contraste de Hipótesis

Estimación de Parámetros
El método de estimación de un parámetro puede ser puntual o por intervalo.
Estimación puntual de µ
En base al resultado de la muestra particular de tamaño n, una estimación puntual de µ
sería el valor numérico que toma en dicha muestra.
En nuestro ejemplo, a partir de una muestra de n=50 planchas de acero. Daríamos como
estimación del peso medio poblacional o teórico, = 215 Kg.
Inconveniente(s):
La estimación puntual depende de la muestra particular que se obtenga. Existe una incertidumbre total, acerca de la proximidad (lejanía) del valor puntual a la
media poblacional o teórica.
Sin embargo
Conocemos la distribución de la medias muéstrales bajo ciertas condiciones sobre la población de partida.
DISTRIBUCIÓN DE LA MEDIA MUESTRAL
a) Si asumimos que X → N (µ, σ), σ → conocida
Las (infinitas) medias muéstrales obtenidas con muestras de tamaño n se distribuyen según una distribución normal (campana de Gauss):
Donde: es el error típico o desviación estándar de la media muestral.
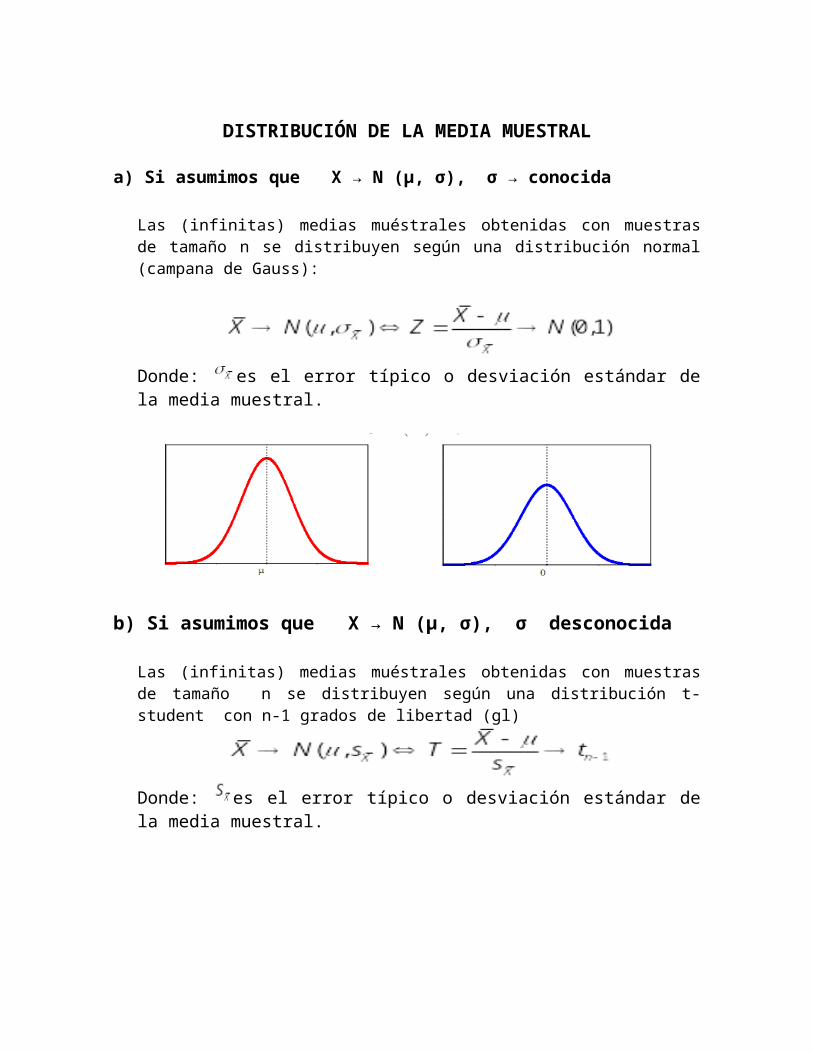
b) Si asumimos que X → N (µ, σ), σ desconocida
Las (infinitas) medias muéstrales obtenidas con muestras de tamaño n se distribuyen según una distribución t-student con n-1 grados de libertad (gl)
Donde: es el error típico o desviación estándar de la media muestral.
0
Nota: (Error estándar o Error típico de la media)
conocida Tamaño de población (N) demasiado grande o
infinita.
conocida Tamaño de población (N) conocido o finita.
desconocida, entonces Tamaño de población (N) demasiado grande o
infinita.
desconocida, entonces Tamaño de población (N) conocida o finita.
Estimación por Intervalo de confianza para µ
Supongamos que de una población normal con media desconocida y varianza conocida
o desconocida se extrae una muestra de tamaño n, entonces de la distribución de la
media muestral se obtiene que, lleva asociado un error típico de dicho estadístico de lo que ha de tenerse en cuenta para valorar la precisión de una estimación puntual.
Idea

Construir intervalos de confianza, basado , que contenga “con alta probabilidad” el parámetro µ.Caso I: X → N (µ, σ), σ conocida
El Intervalo de confianza para µ es:
Con un nivel de confianza del .
Caso II: X → N (µ, σ), σ desconocida
El intervalo de confianza para µ es:
Con un nivel de confianza del .
Tamaño de muestra
Se puede determinar que tan grande debe ser el tamaño de la muestra, n, de manera que si
se estima por , el error de estimación no sea mayor que un valor dado e. En efecto:
Tamaño de población (N) demasiado grande o infinita.
Si la desviación estándar ( ) es desconocida, se estima por la desviación estándar muestral (S) hallado a partir de una muestra piloto.
Tamaño de población (N) conocida o finita
Si la desviación estándar ( ) es desconocida, se estima por la desviación estándar muestral (S) hallado a partir de una muestra piloto.
Ejemplo 1: Una encuesta realizada a 25 empleados de un sector dio como resultados que el tiempo medio de empleo era de 5,3 años con una desviación típica de 1,2 años.

a) Estimar, al 90% de confianza, el tiempo medio de empleo para el sector, suponiendo Normalidad.
b) Si el margen de error hubiera sido de 1 año ¿qué grado de confianzase tendría?c) ¿Qué tamaño muestral es necesario si se quisiera el margen de error del apartado
primero y el grado de confianza del apartado segundo?Solución: a)
Estimar, al 90% de confianza, el tiempo medio de empleo para el sector, suponiendo Normalidad.
Datos: X: Tiempo de empleo supuestamente NormalTamaño de muestra : n = 25 empleados
Tiempo medio de empleo : = 5,3 añosDesviación típica muestral : S = 1,2 años ( desconocido)
Confianza : = 0,90 = 0,10
En base a los datos corresponde al CASO II, donde su intervalo es:
Entonces:
= 5,3 (Buscar tabla) Reemplazando en la fórmula:
5,3 – 1,711*0,24 5,3 + 1,711*0,245,3 – 0,411 5,3 + 0,4114,889 5,711
Interpretación: El tiempo medio de empleo de todos los empleados del sector se estima en 4,9 a 5,7 años, con una confianza del 90%.
Solución:b)Si el margen de error hubiera sido de 1 año ¿qué grado de confianza se tendría?
Error de estimación: e =
1 = 1 =
(Buscando en la tabla estadística)

Por lo tanto el grado de confianza es:
Solución: c)
¿Qué tamaño muestral es necesario si se quisiera el margen de error del apartado primero y el grado de confianza del apartado segundo?
Tamaño de muestra con margen de error de 0,411 yGrado de confianza 0,99998N=Tamaño de población de empleados desconocido de la entidad
Entonces la formula que le corresponde es:
Ejemplo 2: El número de horas diarias que los empleados de cierta entidad bancaria de ámbito nacional trabajan delante del ordenador es una variable aleatoria normal con varianza 1,5. Se toma una muestra al azar de 10 empleados y se anota el número de horas que cierto día trabajaron con el ordenador:6 3,4 5,6 6,3 6,4 5,3 5,4 5 5,2 5,5a) Determina el intervalo de confianza al 95% para el número medio de horas diarias que se
trabaja en el ordenador en esa entidad. Explica claramente el resultado comentando que significa el 95% de confianza.
b) ¿Qué tamaño muestral es necesario si se quisiera el margen de error del apartado primero y el grado de confianza de 90%?
Solución:a)Datos: X: Número de horas diarias variable Normal
Varianza poblacion : = 1,5 conocido Desviación estándar = 1,225Tamaño de muestra : n = 10 empleadosNúmero promedio de horas diarias se halla a partir de los valores numéricos registrados de
los 10 empleados : = 5,41 horas

Confianza : = 0,95 = 0,05
En base a los datos corresponde al CASO I, cuyo intervalo es:
= 5,41 (Buscar tabla) 5,41 – 1,96*0,387 5,41 + 1,96*0,3875,41 – 0,759 5,41 + 0,7594,651 6,169Interpretación: El número medio de horas diarias que trabajan delante del ordenador todos los empleados de cierta entidad bancaria se estima en 4,6 a 6,2horas, con una confianza del 95%; el cual significa que de 100 muestras de empleados seleccionados de toda la entidad bancaria, 95 de ellas estiman dicho parámetro.
Solución:b)Datos: Margen de error : e = 0,759
Varianza poblacional : = 1,5Confianza : = 0,90 = 0,10Tamaño de la población : N desconocidoEn base a los datos corresponde utilizar la formula:
Ejercicios Propuestos
Ejercicio 1: La duración aleatoria de las unidades producidas de un artículo, se distribuye según la ley normal, con desviación típica igual a seis minutos. Elegidas al azar cien unidades, resulto ser la duración media de 14,35 minutos. Elaborar el intervalo de confianza del 99% para la duración media de las unidades producidas.
Ejercicio 2: Se analizan 9 zumos de fruta y se ha obtenido un contenido medio de fruta de 22 mg por 100 cc de zumo. La varianza poblacional es desconocida, por lo que se ha calculado la cuasi desviación típica de la muestra que ha resultado ser 6,3 mg de fruta por cada 100 cc de zumo. Suponiendo que el contenido de fruta del zumo es normal, estimar el contenido medio de fruta de los zumos tanto puntualmente como por intervalos al 95% de confianza.

Ejercicio 3: Se desea estimar el número medio de libros que los estudiantes de cierta titulación adquieren en el último curso de sus estudios. Suponiendo conocida la dispersión (varianza igual a 36) y siendo Normal el comportamiento de la variable, a) ¿qué tamaño muestral hace falta para alcanzar un grado de confianza del 95% y
un margen de error no superior a 2 unidades?b) ¿Cuál sería el tamaño muestral si queremos reducir el intervalo a la mitad sin
perder fiabilidad?
Ejercicio 4: Queremos ajustar una máquina de refrescos de modo que el promedio del líquido dispensado quede dentro de cierto rango. La cantidad de líquido vertido por la máquina sigue una distribución normal con desviación estándar 0.15 decilitros. Deseamos que el valor estimado que se vaya a obtener comparado con el verdadero no sea superior a 0.2 decilitros con una confianza del 95%. ¿De qué tamaño debemos escoger la muestra?Ejercicio 5: Es necesario estimar entre 10000 establos, el número de vacas lecheras por establo con un error de estimación de 4 y un nivel de confianza del 95%.Sabemos que la varianza es 1000. ¿Cuántos establos deben visitarse para satisfacer estos requerimientos?
Intervalo de Confianza para la varianza
La varianza como medida de dispersión es importante dado que nos ofrece una mejor visión de dispersión de datos. Nuevamente consideramos que la población sigue una distribución de probabilidad normal.
Otro campo del conocimiento donde la varianza se ocupa en gran medida es en control de calidad; cuando un producto se elabora el área de control de calidad busca que los productos esté dentro de ciertos límites de tolerancia, pero también que la variabilidad de un producto sea lo menor posible.
El Intervalo de confianza para la varianza poblacional ( ) es:
Con un nivel de confianza del .
Ejemplo 1: Se han recogido muestras de aire para estudiar su contaminación, obteniéndose las siguientes cantidades de impurezas en Kg/m3

2.2; 1.8; 3.1; 2.0; 2.4; 2.0; 2.1; 1.2Construir un intervalo de confianza al 98% para la desviación estándar de impurezas contenidas en el aire.
Solución:Datos: Calculando la cantidad media de impurezas a partir de los valores numéricos
registrados en las 8 muestras de aire :
Calculando la varianza muestral obtenido de los valore numéricos :
= 0,288
Confianza : = 0,98 = 0,02Entonces el intervalo es:
Por lo tanto:
Interpretación: La variabilidad de impurezas con respecto a su media que contiene el
aire se estima en 0,109 a 1,627 Kg./ , con una confianza del 98%.
Ejercicios Propuestos
Ejercicio 1: Se sabe por experiencia que el tiempo que tarda el servicio de caja de una empresa prestadora del servicio de agua de una región para atender a los clientes que llegan a efectuar el pago mensual del servicio se distribuye normalmente. Se pide estimar el intervalo de confianza para la desviación estándar poblacional del tiempo requerido para atender los pagos que efectúan los clientes, con un nivel de confianza del 95%, si para el efecto se tomó una muestra aleatoria de 25 clientes que arrojó una desviación estándar de 1.8 minutos.

Ejercicio 2: El tiempo que transcurre para los obreros de una gran compañía entre el momento del ingreso a la planta y el momento en que están listos para recibir las orientaciones de su jefe inmediato, se distribuye normalmente. Una muestra de 20 obreros arroja una desviación estándar de 3.5 minutos. Se pide calcular el intervalo de confianza del 99% para la desviación estándar del tiempo transcurrido para todos los obreros de la compañía.
Intervalo de Confianza para la diferencia de medias ( )
Supongamos que se tiene dos poblaciones distribuidas normalmente con medias
desconocidas y , respectivamente. Se puede aplicar una prueba z o t de Student para comparar las medias de dichas poblaciones basándonos en dos muestras independientes
tomadas de ellas. La primera muestra es de tamaño , con media y la segunda muestra
es de tamaño , tiene media . Donde las varianzas poblacionales pueden ser conocidas
( y ) o desconocidas (≈
y ≈
).
Caso I: Muestras independientes, Varianzas poblacionales conocidas
( y )
El intervalo de confianza es:
Donde:
Caso IIA: Normal-Muestras independientes, Varianzas poblacionales
desconocidas pero iguales ( )
El intervalo de confianza es:

Donde: es el grado de libertad.
Caso IIB: Normal-Muestras independientes, Varianzas poblacionales
desconocidas y diferentes ( )
El intervalo de confianza es:
Donde:
Es el grado de libertad, que toma un valor numérico redondeado entero.
Ejemplo 1: En el departamento de control de calidad de una empresa, se quiere determinar si ha habido un descenso significativo de la calidad de su producto entre las producciones de dos semanas consecutivas a consecuencia de un incidente ocurrido durante el fin de semana. Deciden tomar una muestra de la producción de cada semana, si la calidad de cada artículo se mide en una escala de 100, obtienen los resultados siguientes:Semana 1: 93 86 90 90 94 91 92 96Semana 2: 93 87 97 90 88 87 84 93Construye un intervalo de confianza para la diferencia de medias al nivel de 95%.Interpreta los resultados obtenidos.

Solución:Suponiendo normalidad las producciones de las dos semanasCada semana son muestras independientes
Varianzas poblacionales desconocidas ( , )Ahora
¿Cómo saber si las varianzas son iguales o diferentes?
Se realiza la prueba de homogeneidad de varianzas, que consiste en lo siguiente:
Formular las hipótesis
Hipótesis nula :
Hipótesis alterna :
Fijar nivel de significancia
Estadístico de prueba
Semana 1:
Calculo de la media
Calculo de la varianza
Semana 2:
Calculo de la media

Calculo de la varianza
Reemplazando en el estadístico de prueba
Regiones críticas
0,200 4,99 ZR/-------------------Zona------------------/--------Zona--------- Aceptación Rechazo
La zona de aceptación para un nivel de significación del 5% está delimitada por 0,200 y 4,990, correspondientes a las probabilidades /2 y (1 - /2) respectivamente. DecisiónComo = 1,951 se ubica en la zona de aceptación cuyo intervalo es (0,200; 4,99) se
acepta : 12= 2
2
Luego se concluye que no hay diferencias entre las varianzas poblacionales, lo que indica el cumplimiento del supuesto de homogeneidad de varianzas
Entonces el intervalo de confianza para la diferencia de medias es el CASO IIA:

Diferencia de medias muestrales : = 91,50 – 89,88 = 1,62
Coeficiente de confianza : = 0,95 = 0,05
Grados de libertad : = 8 + 8 – 2 = 14
= 2,145
= 1,8365
Reemplazando en la formula del intervalo se tiene:
1,62 – 2,145*1,8365 1,62 + 2,145*1,8365
-2,319 5,559
Interpretación: La diferencia promedio de producciones de artículos en las dos semanas se estima entre -2,319 a 5,559, con una confianza del 95%. Esto significa que la producción promedio de artículos entre las dos semanas es igual.
Ejercicios Propuestos
Ejercicio 1: Un profesor de estadística realiza un idéntico cuestionario a dos grupos de estudiantes de dos universidades diferentes de la misma ciudad. En una muestra aleatoria de 9 estudiantes de la universidad A, el promedio de notas fue de 7.5 y desviación estándar de 0.4. En otra muestra aleatoria de 9 estudiantes de la universidad B la media de las notas fue de 6.7 y desviación estándar de 0.6. Calcular los límites de confianza del 95% para la diferencia de medias de las notas entre las dos universidades. Se sabe que la escala de calificación es de 0 a 10.
Ejercicio 2: Se quiere estimar la diferencia de los promedios de los salarios entre la industria metalmecánica y la industria de los muebles en una ciudad. Para tal fin se toma una muestra aleatoria de 200 operarios en la primera industria la cual arroja un salario promedio de $535000 mensuales y desviación estándar de $128000, mientras que una muestra de 120 operarios en la segunda industria arroja un salario promedio de $492000 y desviación estándar de $75000. Se pide estimar el intervalo de confianza para la diferencia de salarios entre las dos industrias con un nivel de confianza del 90%.

Ejercicio 3: En una compañía se quiere estimar la diferencia de los promedios de los rendimientos para producir cierta pieza por parte de los obreros en dos turnos diferentes. Para tal fin el Jefe de producción de la empresa toma muestras de 32 obreros para el turno 1 y encuentra que la media en la misma es de 20 minutos mientras que la desviación estándar es de 2.8 minutos. Por otra parte tomó una muestra de 35 obreros del turno 2 y encuentra que la media de la misma es de 22 minutos mientras que la desviación estándar es de 1.9 minutos. Se pide calcular el intervalo de confianza de la diferencia de las medias de los rendimientos en los dos turnos con un nivel de confianza del 98%.
Ejercicio 4: Para comparar el contenido promedio de aceites de las semillas de dos variedades de maní, se diseña un ensayo en el que para cada variedad se obtienen los contenidos de aceite de 10 bolsas de 1 kg de semillas de maní, extraídas aleatoriamente de distintos productores de semillas.Los resultados del ensayo son los siguientes:
Variedad n1 10 160,4 65,32 10 165,6 67,9
Distribución de la proporción muestral
Vamos a considerar que tenemos una población de modo que en cada una de ellas estudiamos una v.a. dicotómica (Bernoulli) de parámetro respectivo . De la población vamos a extraer una muestra de tamaño .Entonces,
y la proporción de éxito en la muestra es
Luego se cumple:
a)
b)
c) Si el tamaño muestral n es grande, el Teorema Central del Límite nos asegura que:

Nota: (Error estándar o Error típico de la proporción muestral)
p y q conocidosTamaño de población (N) demasiado grande o infinita.
p y q conocidosTamaño de población (N) conocido o finita.
p y q desconocidos, entonces y Tamaño de población (N) demasiado grande o infinita.
p y q desconocidos, entonces y Tamaño de población (N) conocida o finita.
Intervalo de Confianza para una Proporción
En este caso, interesa construir un intervalo de confianza para una proporción o un porcentaje poblacional (por ejemplo, el porcentaje de personas con hipertensión, fumadoras, etc.)
Donde, p es el porcentaje de personas u objetos con la característica de interés en la
población (o sea, es el parámetro de interés) y es su estimador puntual muestral.
Luego, procediendo en forma análoga al caso de la media, podemos construir un intervalo
de confianza para la proporción poblacional p, con una confianza de .
Donde:

Ejemplo 1: Una compañía que fabrica pastelillo desea estimar la proporción de consumidores que prefieran su marca. Los agentes de la compañía observan a 450 compradores, del número total observado 300 compraron los pastelillos. Calcule un intervalo de confianza del 95% para la venta de la proporción de compradores que prefieren la marca de esta compañía.
Solución:x: Número de consumidores que prefieren los pastelillos.n = 450 tamaño de muestra grandex = 300 son los que prefieren los pastelillos en la muestra
Es la proporción puntual muestral que prefieren los pastelillos
Es la proporción puntual muestral de los que no prefieren los pastelillos.
Coeficiente de confianza = 0,95 = 0,05
= 1,96
Reemplazando en el intervalo de confianza se tiene:
0,67 – 1,96 * 0,022 0,67 + 1,96 * 0,0220,63 0,71
Interpretación: La proporción de pastelillos que prefieren la marca de la compañía por
parte de los consumidores se estima entre 0,63 a 0,71, con una confianza del 95%.
Tamaño de muestra
Se puede determinar que tan grande debe ser el tamaño de la muestra, n, de manera que si p
se estima por , el error de estimación no sea mayor que un valor dado e. En efecto:
Tamaño de población (N) demasiado grande o infinita.
Si p y q son desconocidas, se estima por
y hallados a partir de una muestra

piloto. En últimos de los casos si no se tiene
ninguna información de p y q se asume el máximo riesgo de p = 0,5 y q = 0,5.
Tamaño de población (N) conocida o finita
Si p y q son desconocidas, se estima por
y hallados a partir de una muestra piloto.
En últimos de los casos si no se tiene ninguna información de p y q se asume el máximo riesgo de p = 0,5 y q = 0,5.
Ejercicios Propuestos
Ejercicio 1: Una compañía quiere conocer la proporción de consumidores que adquieren su producto. Encarga a una empresa un estudio de mercado para obtener un intervalo de confianza al 99% de su proporción de clientes a partir de una muestra de tamaño 1000. Los resultados muestral es arrojaron que 740 de los entrevistados eran clientes de su producto.Ejercicio 2: En un experimento para determinar la toxicidad de una sustancia se administra una dosis de esta a cada uno de 300 conejos, y se registra el número de muertos, que resulta ser de 192. a) Calcule el estimador de p.b) la probabilidad de que un conejo elegido al azar muera a causa de una dosis de la
sustancia. c) Calcule la desviación estándar. d) Construya un intervalo de confianza al 98%.
Distribución de la diferencia de proporciones muestrales
Vamos a considerar que tenemos dos poblaciones de modo que en cada una de ellas
estudiamos una v.a. dicotómica (Bernoulli) de parámetros respectivos y . De cada
población vamos a extraer muestras de tamaño y .Entonces
Luego se cumple:

a)
b)
c) Si el tamaño muestral n es grande, el Teorema Central del Límite nos asegura que:
N (0,1)
Intervalo de Confianza para la diferencia de dos proporciones
Si las muestras son suficientemente grandes ocurre que una aproximación para un intervalo
de confianza al nivel para la diferencia de proporciones de dos poblaciones es:
Dónde:
Ejemplo 1: En un estudio sobre las relaciones prematrimoniales se encontró en la zona A que, de 200 personas, 124 estaban a favor y en la zona B, de 266 personas, 133 también lo estaban. Estimar la diferencia de proporciones de ambas zonas al 90% de confianza comentando el resultado.
Solución:Zona A
: Número de personas que están a favor de las relaciones prematrimoniales
= 124
= 200
= 0,62 = 0,38
Zona B
: Número de personas que están a favor de las relaciones prematrimoniales
= 133
= 266

= 0,50 = 0,50
= 0,90 = 0,10
= 1,645
Reemplazando en la formula se tiene:
(0,62 – 0,50) – 1,645 * 0,046 (0,62 – 0,50) + 1,645 * 0,046
0,044 0,196
Interpretación: La diferencia de proporciones de personas que están a favor de las relaciones prematrimoniales en las dos zonas se estima entre 0,044 a 0,196, con una confianza del 90%. Esto significa que la proporción de personas de la zona A son las que están mayormente a favor de las relaciones prematrimoniales respecto a la zona B.
Ejercicios Propuestos
Ejercicio 1: Se está considerando cambiar el procedimiento de manufactura de partes. Se toman muestras del procedimiento actual así como del nuevo para determinar si este último resulta mejor. Si 75 de 1000 artículos del procedimiento actual presentaron defectos y lo mismo sucedió con 80 de 2500 partes del nuevo, determine un intervalo de confianza del 90 % para la verdadera diferencia de proporciones de partes defectuosas.Ejercicio 2: Un productor decide cultivar dos variedades de tomate, valencia y perita. De la variedad valencia planta 230 semillas y de la variedad perita planta 358. Luego de tres semanas de cultivadas ambas variedades el productor recorre el campo y registra que cantidad de semillas emergieron para cada variedad. Los resultados son los siguientes:Variedad Cultivadas EmergieronValenciano 230 126Perita 358 293

a). Que modelo teórico de probabilidad considera apropiado si la variable aleatoria es "numero de plantas que emergieron de una variedad en el total que se cultivo de la misma"? ¿Cuales son los parámetros para cada una de las variedades?
b). Estime para cada variable la proporción de emergencia.c). Construya un intervalo de confianza al 95 % para la probabilidad de emergencia
de las plantas de cada variedad e interprete en términos del problemad). Que supuesto fue necesario para que el intervalo anterior sea valido?e). Si comparamos ambas variedades con el tomate americano que tiene una
probabilidad de emergencia de 0.65, .que puede decir viendo los intervalos de confianza?
f). Si el productor quiere saber si el tomate valenciano tiene la misma probabilidad de emergencia que el tomate americano. ¿Cual es el procedimiento a seguir? Explíquelo y concluya con el mismo.
Inferencia basada en pruebas de hipótesis para una y dos muestras
Hipótesis Estadística es una afirmación, conjetura que se hace acerca de un parámetro poblacional.
Tipos de Hipótesis
Hipótesis nula, es la afirmación que está establecida y que se espera sea rechazada después de aplicar una prueba estadística y se representa por Ho.
Hipótesis alterna, es la afirmación que se espera sea aceptada después de aplicar una
prueba estadística y se representa por .
Nivel de significación, representada por , es la probabilidad de cometer error tipo I, y por lo general se asume que tiene un valor de 0,05 ó 0,01.
Prueba estadística o Estadístico de prueba, es una fórmula, basada en la distribución del estimador puntual del parámetro que aparece en la hipótesis y que va a permitir tomar una decisión acerca de aceptar o rechazar una hipótesis nula.
Contraste de Hipótesis para la media “µ”
Formas de contraste de las hipótesis:

Depende del planteamiento de la hipótesis alterna
Prueba bilateral Prueba unilateral superior Prueba unilateral inferior
Fijar nivel de significancia: = 0,05; 0,01 etc.
Seleccionar el estadístico de prueba:
Caso I: X→ N (µ, σ), σ conocida
El estadístico de prueba es:
Prueba Z- Normal estándar para una muestra.
Usualmente la varianza es desconocida
Caso II: X→ N (µ, σ), σ desconocida
El estadístico de prueba es:
Prueba T- Student para una muestra con n - 1 grados de libertad (gl.)
Regiones Críticas:Depende de las formas de contraste de las hipótesis.
Contraste Bilateral Contraste unilateral superior Contraste unilateral inferior
-- ZR-- /-------------ZA--------------/--ZR-- ----------------ZA---------------/----ZR---- ----ZR-----/-------------ZA----------------
Decisión:

Forma TabularSi el valor numérico del estadístico de prueba se ubica en la Zona de Aceptación (ZA) se
acepta la Hipótesis nula .Si el valor numérico del estadístico de prueba se ubica en la Zona de Rechazo (ZR) se
rechaza la Hipótesis nula .
Forma Método “p”Si el valor numérico de “p” es superior que el nivel de significancia fijado “ ” se acepta
la Hipótesis nula .Si el valor numérico de “p” es inferior que el nivel de significancia fijado “ ” se rechaza
la Hipótesis nula .
Ejemplo 1. Un fabricante de lámparas eléctricas está ensayando un nuevo método de producción que se considerará aceptable si las lámparas obtenidas por este método dan lugar a una población normal de duración media 2400 horas, con una desviación típica igual a 300. Se toma una muestra de 100 lámparas producidas por este método y esta muestra tiene una duración media de 2320 horas. ¿Se puede aceptar la hipótesis de validez del nuevo proceso de fabricación con un riesgo igual o menor al 5%? Solución:
Formulación de Hipótesis
Nivel de significancia
Estadístico de Prueba
Caso I: X → N (µ, σ), σ = 300 conocida
La población N de la producción de lámparas es desconocida, así que puede ser que sea demasiado grande.

Regiones críticas
-- ZR-- /----------------ZA---------------/---ZR--
-1,96 1,96
DecisiónEn vista que el valor del estadístico de prueba (Z = -2,67) es inferior que el valor tabular (
= -1,96) ubicándose en la zona de rechazo, entonces se rechaza la hipótesis nula . Esto significa que el nuevo proceso de fabricación no es aceptable.
Ejemplo 2. Un fabricante de aparatos de TV afirma que se necesita a lo sumo 250 microamperes de corriente para alcanzar cierto grado de brillantez con un tipo de televisor en particular. Una muestra de 20 aparatos de TV produce un promedio muestral de corriente de 257,3 microemperes. Denotemos por m el verdadero promedio de corriente necesaria para alcanzar la brillantez deseada con aparatos de este tipo, y supongamos que m es la media de una población con s = 15. Pruebe al nivel de significación del 2,5% la hipótesis nula de que m es a lo sumo 250 microamperes. Solución:Formulación de Hipótesis
Nivel de significancia
Estadístico de Prueba
Caso II: X → N (µ, σ), = 15 desconocida

Regiones críticas
----------------ZA---------------/-----ZR-----
2,093
Decisión
Dado que el valor del estadístico de prueba ( ) es superior que el valor tabular
(t = 2,093) , entonces se ubica en la zona de rechazo, rechazando la hipótesis nula . Esto demuestra que no se necesita a lo sumo 250 micro amperes, en forma significativa.
Ejercicios Propuestos
Ejercicio 1: La tasa actual para producir fusibles de 5 amp en Neary Electric Co. Es 250 por hora. Se compró e instaló una máquina nueva que, según el proveedor, aumentará la tasa de producción. Una muestra de 20 horas seleccionadas al azar el mes pasado indica que la producción media por hora en la nueva máquina es 256, con desviación estándar de 6 por
hora. Con de nivel de significancia, ¿Puede Neary Electric concluir que la nueva máquina es más rápida?Ejercicio 2: Un fabricante de lámparas eléctricas sostiene que la duración media de las mismas (horas) es en promedio superior a 1300 h. Se toma una muestra de 17 lámparas siendo el resultado de la inspección el siguiente:980 1 350 1 020 1 140 1 520 1 390 1 205 1 180 970 1 420 1 850 1 300 1 305 1 040 1 050 1 520 1 320Verificar el Ho del fabricante con un coeficiente de riesgo del 5% (suponiendo la distribución normal).Ejercicio 3: Una empresa desea concursar para ganar un contrato con el gobierno como proveedor de concreto; uno de los requisitos es la resistencia a la compresión del concreto a los 28 días de haberse preparado la mezcla. La empresa ganadora dice que mantiene excelentes controles de calidad en su concreto y como tal hay una varianza muy baja en

resistencias a la compresión, del orden de 16 / ; pero al hacerle en la UNAM unas
pruebas de resistencia se detecta una varianza mas elevada de 25 /a) ¿hay evidencia estadística suficiente para considerar que el proveedor está mintiendo y
en realidad la desviación estándar es DIFERENTE a 16 / ?b) Redacción de la prueba de hipótesis, indicando si debe ser prueba de una o dos colas
para responder la pregunta.Ejercicio 4: Un vendedor de neumáticos dice que la vida media de sus neumáticos es de 28000 Km. Admitiendo para la desviación típica el valor 1348 Km. diseñar un test de hipótesis al 99% de confianza, basado en muestras de 40 elementos que permita contrastar la hipótesis nula de ser μ = 28000Km usando como hipótesis alternativa μ < 28000KmEjercicio 5: Se pretende diseñar una prueba de hipótesis con una muestra de 74 automóviles para comprobar su capacidad de frenado. Para ello se medirá en todos ellos la distancia de frenado si el automóvil parte de una velocidad inicial de 100 Km/h. Se quiere saber si, tras un frenazo brusco, la distancia media recorrida antes de pararse es de 110 metros. Se supone que la distancia de frenado sigue una distribución normal con desviación típica conocida σ = 3 m. Supongamos ahora que hemos realizado efectivamente la prueba a los 74 automóviles y hemos obtenido las siguientes distancias de frenado.
Distancias 98 102 105 113 123 126
Num. de autos 15 10 12 8 16 13 Total 74
¿Se acepta la hipótesis de que la distancia media de frenado es de 110 m, con un nivel de significación α = 0.05?Ejercicio 6: Un fabricante asegura que sus fusibles, con una sobrecarga del 20%, se fundirán por promedio al cabo de 12.40 min. Una muestra de 20 fusibles se sobrecarga un 20%, obteniéndose una media de 10.63 y una cuasi desviación de 2.48 min. ¿Confirma la muestra la afirmación del fabricante para el promedio?
Prueba de hipótesis para la varianza
La varianza como medida de dispersión es importante dado que nos ofrece una mejor visión de dispersión de datos. Nuevamente consideramos que la población sigue una distribución de probabilidad normal.
Formulación de las hipótesis
Depende del planteamiento de la hipótesis alterna
Prueba bilateral Prueba unilateral derecho Prueba unilateral inferior

Fijar nivel de significancia: = 0,05; 0,01 etc.
Estadístico de prueba:
Si X → N (µ, σ), σ conocida
El estadístico de prueba es:
Prueba Chi cuadrado ( ) para una muestra con n-1 grados de libertad (gl.)Regiones críticasDepende de las formas de contraste de las hipótesis.
Contraste Bilateral Contraste unilateral inferior Contraste unilateral superior
---ZR--/----------ZA---------/--------ZR---------- ----ZR--/-------------------ZA---------------------- ------------------ZA---------/----------ZR----------
Decisión:
Forma TabularSi el valor numérico del estadístico de prueba se ubica en la Zona de Aceptación (ZA) se
acepta la Hipótesis nula .Si el valor numérico del estadístico de prueba se ubica en la Zona de Rechazo (ZR) se
rechaza la Hipótesis nula .
Ejemplo 1: Un negocio debe pagar horas extra dada la demanda incierta de su producto, por lo cual en promedio se pagan 50 horas extra a la semana; el gerente de recursos humanos considera que siempre se ha tenido una varianza de 25 en las horas extras demandadas. Si se toma una muestra de 16 semanas se obtiene una varianza muestral de 28,1.

Determine con alfa = 0,10 si la varianza poblacional de las horas extras demandadas a la semana puede considerarse igual a 25.Solución:
Formulación de hipótesis
Nivel de significancia
Estadístico de prueba
= 16,86
Regiones críticas
----ZR----/---------------ZA------------/-------------ZR-------------
7,261 24,996
DecisiónComo que el valor del estadístico de prueba se ubica entre los valores tabulares (7,261
= 16,86 24,996), es decir dentro de la zona de aceptación, entonces se acepta la
hipótesis nula . Efectivamente se puede concluir con una confianza del 90% que la varianza poblacional de las horas extras demandadas a la semana es igual a 25.
Ejercicios propuestos

Ejercicio 1: Un supervisor de control de calidad en una enlatadora sabe que la cantidad exacta en cada lata varía, pues hay ciertos factores imposibles de controlar que afectan a la cantidad de llenado. El llenado medio por lata es importante, pero igualmente importante es
la variación de la cantidad de llenado. Si es grande, algunas latas contendrán muy poco, y otras, demasiado. A fin de estimar la variación del llenado en la enlatadora, el supervisor escoge al azar 10 latas y pesa el contenido de cada una, obteniendo el siguiente pesaje (en onzas):7,96 7,90 7,98 8,01 7,97 7,96 8,03 8,02 8,04 8,02Suponga que las agencias reguladoras especifican que la desviación estándar de la cantidad de llenado debe ser menor que 0,1 onzas. ¿Esta información proporciona pruebas suficientes de que la desviación estándar de las mediciones de llenado es menor que 0,1 onzas si el nivel de significación queda fijado en un 5%?Ejercicio 2: Se supone que los diámetros de cierta marca de válvulas están distribuidos
normalmente con una varianza poblacional de 0,2 , pero se cree que últimamente ha aumentado. Se toma una muestra aleatoria de válvulas a las que se les mide su diámetro, obteniéndose los siguientes resultados en pulgadas: 5,5 5,4 5,4 5,6 5,8 5,4 5,5 5,4 5,6 5,7 Con ésta información pruebe si lo que se cree es cierto.
Prueba de Hipótesis para la diferencia de medias ( )
Supongamos que se tiene dos poblaciones distribuidas normalmente con medias
desconocidas y , respectivamente. Se puede aplicar una prueba z o t de Student para comparar las medias de dichas poblaciones basándonos en dos muestras independientes
tomadas de ellas. La primera muestra es de tamaño , con media y la segunda muestra
es de tamaño , tiene media . Donde las varianzas poblacionales pueden ser conocidas
( y ) o desconocidas ( y ).
Formulación de las hipótesis para muestras independientes
Depende del planteamiento de la hipótesis alterna
Prueba bilateral Prueba unilateral superior Prueba unilateral inferior
Fijar el nivel de significancia: = 0,05; 0,01 etc.
Estadístico de prueba

Caso I: Muestras independientes, Varianzas poblacionales conocidas ( y )
El estadístico de prueba es:
Donde:
Caso IIA: Normal-Muestras independientes, Varianzas poblacionales iguales (
) y desconocidas
El estadístico de prueba es:
Donde: es el grado de libertad.
Caso IIB: Normal-Muestras independientes, Varianzas poblacionales diferentes (
) y desconocidas
El estadístico de prueba es:
Donde:
Es el grado de libertad, que toma un valor numérico redondeado entero.
Usualmente las varianzas son desconocidas
Regiones críticas
Contraste Bilateral Contraste unilateral superior Contraste unilateral inferior
-- ZR-- /-------------ZA--------------/--ZR-- ----------------ZA---------------/----ZR---- ----ZR-----/-------------ZA----------------
Decisión:
Forma TabularSi el valor numérico del estadístico de prueba se ubica en la Zona de Aceptación (ZA) se
acepta la Hipótesis nula .Si el valor numérico del estadístico de prueba se ubica en la Zona de Rechazo (ZR) se
rechaza la Hipótesis nula .
Forma Método “p”Si el valor numérico de “p” es superior que el nivel de significancia fijado “ ” se acepta
la Hipótesis nula .Si el valor numérico de “p” es inferior que el nivel de significancia fijado “ ” se rechaza
la Hipótesis nula .
Ejemplo 1: Para comparar el contenido promedio de aceites de las semillas de dos
variedades de maní, se plantean las hipótesis H0: m1= m2 vs. H1: m1 ¹ m2Se diseña un ensayo en el que para cada variedad se obtienen los contenidos de aceite de 10 bolsas de 1 kg de semillas de maní, extraídas aleatoriamente de distintos productores de semillas. Usar = 0,05.Los resultados del ensayo son los siguientes:
Variedad n
1 10 160,4 65,3

2 10 165,6 67,9
Solución:Según los datos corresponden al CASO II: Muestras independientes, varianzas
poblacionales desconocidas ( , ). Ahora el problema es; ¿Cómo saber si las varianzas son iguales o diferentes?
Suponiendo normalidad para las observaciones de las muestras, se realiza la prueba de homogeneidad de varianzas, que consiste en lo siguiente:
Formulación de hipótesis
vs.
Nivel de significancia = 0,05.
Estadístico de prueba
Regiones críticas
0.0 1.5 3.0 4.5 6.00.248 4.03
Distribución F de Snedecor
-ZR-/--------------------------ZA-------------------------/-----------ZR--------------
Decisión:
La región de aceptación para un nivel de significación del 5% está delimitada por 0,248 y 4,03, correspondientes a las probabilidades /2 y (1 - /2) respectivamente.

Como F = 0,96 está en el intervalo (0,248; 4,03), es decir en la zona de aceptación, se
acepta : 12= 2
2 , lo cual significa el cumplimiento del supuesto de homogeneidad de
varianzas.
Entonces aplicaremos CASO IIA: Prueba T para la diferencia de medias con
varianzas poblacionales ( ) y desconocidas
Formulación de hipótesis
H0: m1= m2 vs. H1: m1 ¹ m2
Nivel de significancia = 0,05.
Estadístico de prueba
Regiones críticas
-4.0 -2.7 -1.3 0.0 1.3 2.7 4.0-2.101 2.101
Distribución T de Student
---------ZR-------/---------------------ZA-------------------/--------ZR---------

Decisión
La región de aceptación para un nivel de significación del 5% está delimitada por -2,101 y 2,101, correspondientes a los probabilidades /2 y (1 - /2) respectivamente y 18 grados de libertad
Como T = -1,42 está en el intervalo (-2,101; 2,101), es decir en la zona de aceptación, se acepta H0: m1= m2
Entonces se concluye que no hay diferencias entre el contenido promedio de aceites de las semillas de dos variedades de maní.
Ejemplo 2. Un constructor está considerando dos lugares alternativos para construir un centro comercial. Como los ingresos de los hogares de la comunidad son una consideración importante en ésta selección, desea probar que el ingreso promedio de la primera comunidad excede al promedio de la segunda comunidad en cuando menos $1,5 diarios. Con la información de un censo realizado el año anterior sabe que la desviación estándar del ingreso diario de la primera comunidad es de $1,8 y la de la segunda es de $2,4Para una muestra aleatoria de 30 hogares de la primera comunidad, encuentra que el ingreso diario promedio es de $35,5 y con una muestra de 40 hogares de la segunda comunidad el ingreso promedio diario es de $34,6. Pruebe la hipótesis con un nivel de confianza del 95 por ciento. Solución:DatosPrimera comunidad Segunda comunidad
= $ 1,8 = $ 2,4
= 30 = 40
= $ 35,5 = $ 34,6 Formulación de hipótesis
Nivel de significancia = 0,05
Estadístico de pruebaSegún los datos corresponden al CASO I: Muestras independientes con varianzas poblacionales conocidas. Entonces:

= - 1,195
Regiones críticas
----ZR-----/-------------ZA-----------------
- -1,645
DecisiónLa región de aceptación para un nivel de significación del 5% está delimitada por -1,645 y + , correspondientes a la probabilidad (1 - ).
Como Z = -1,195 está en el intervalo (- ;-1,645), es decir en la zona de echazo, se rechaza H0
Entonces se concluye que el ingreso promedio de la primera comunidad no excede al promedio de la segunda comunidad en cuando menos $1,5 diarios, con un nivel de confianza del 95%.
Ejercicios propuestos
Ejercicios 1. Un investigador desea averiguar si una industria está contaminando el agua de un arroyo al cual evacua sus efluentes. A tal fin toma muestras de agua en dos sitios: 1) aguas arriba del establecimiento y 2) aguas abajo del mismo. Los siguientes son valores de concentración de uno de los metales pesados encontrados en cada sitio.
Aguas arriba8 10 6 9 4 7 5 12 8 7 8 7 12 5 6 96 4 5 9 8 11 8 6 12 9 8 10 6 9 4 78 7 12 5 6 9 7 10 6 8 6 4 5 9 8 118 6 12 9 5 12 8 7 7 10 6 8
Aguas abajo9 12 8 15 12 10 7 12 10 14 12 13 10 12 9 129 14 10 10 13 12 12 15 11 9 9 12 8 15 12 1012 13 10 12 9 12 7 13 15 10 9 14 10 10 13 1212 15 11 9 7 12 10 14 7 13 15 10

¿Cree Ud. que existen diferencias en la concentración de este metal pesado entre uno y otro sitio? Evalúe su respuesta para un α = 0,02Ejercicio 2. Un fabricante que usa dos líneas de producción 1 y 2 hizo un ligero ajuste a la línea 2 con la esperanza de reducir tanto la variabilidad como la cantidad promedio de impurezas en la sustancia química. Muestras aleatorias en cada línea arrojaron las siguientes mediciones:
Línea n Promedio Varianza1 16 3,2 1,042 16 3,0 0,51
¿Los datos aportan suficiente evidencia para concluir que la cantidad promedio de impurezas de la línea 1 es menor que la línea 2?Ejercicio 3. Una muestra de 80 alambres de acero producidos por la fábrica A presenta una resistencia promedio a la ruptura de 1.230 lbs. con una desviación estándar de 120 lbs Una muestra de 100 alambres de acero producidos por la fábrica B presenta una resistencia promedio a la ruptura de 1.110 lbs . con una desviación estándar de 90 lbs .. Con base en ésta información pruebe si la resistencia promedio a la rotura de los alambres de acero de la marca A es significativamente mayor que la de los alambres de acero de la marca B. Asuma un nivel de confianza del 99 por ciento.Ejercicio 4. El jefe de personal de una gran empresa afirma que la diferencia de los promedios de antigüedad entre los obreras y obreros de la compañía es de 3.5 años. El presidente de la compañía considera que ésta diferencia es superior. Para comprobar dicha situación, se toma una muestra aleatoria de 40 obreras cuyo promedio de antigüedad es de 12.4 años con desviación estándar de 1.5 años y de un grupo de 45 obreros cuyo promedio de antigüedad es de 8.3 años con desviación estándar de 1.7 años. Comprobar la hipótesis con un nivel de significación del 5%.Caso III: Normal- Muestras dependientes
Los datos se obtienen de muestras que están relacionadas, es decir, los resultados del primer grupo no son independientes de los del segundo.
Por ejemplo, esto ocurre cuando se mide el nivel de un metabolito en cada uno de los individuos de un grupo experimental antes y después de la administración de una droga.
El objetivo es comprobar si la droga produce efectos en el nivel del metabolito
Los pares de observaciones (antes y después) obtenidas en cada individuo no son independientes ya que el nivel posterior a la administración de la droga depende del nivel inicial.
Ejemplo
ANTES DESPUES DIF 8,69 7,24 1,45 7,13 7,10 0,03 7,79 7,80 -0,01

7,93 7,95 -0,02 7,59 7,50 0,09 7,86 7,79 0,07 9,06 9,00 0,06 9,59 9,48 0,11
Formulación de Hipótesis
Prueba bilateral Prueba unilateral inferior Prueba unilateral superior
Fijar nivel de significancia = 0,05; 0,01 etc.
Estadístico de prueba
Regiones críticas
-- ZR-- /-------------ZA--------------/--ZR--
- -2,365 2,365
Fijando = 0.05, la región de aceptación es el intervalo (t/2= -2,365, t1- /2 = 2,365),
con 7 grados de libertad
Como T = 1,26 es menor que t1- /2= 2,365, se ubica en la zona de aceptación, por lo
tanto se acepta

Se concluye que la droga no causo efectos significativos, es decir que no existe diferencias observadas entre los niveles de metabolitos por uno u otro individuo en forma significativa.
Prueba de hipótesis para la proporción (de éxitos) de una sola población
Vamos a considerar que tenemos una población de modo que en cada una de ellas estudiamos una v.a. dicotómica (Bernoulli) de parámetro respectivo . De la población vamos a extraer una muestra de tamaño .Entonces,
En este caso, interesa contrastar hipótesis para una proporción o un porcentaje poblacional (por ejemplo, el porcentaje de personas con hipertensión, fumadoras, etc.)
Si el tamaño muestral n es grande, el Teorema Central del Límite nos asegura que:
O bien:
Donde:
p es la proporción o el porcentaje de personas u objetos con la característica de
interés en la población (o sea, es el parámetro de interés) y es su estimador puntual muestral.
Formulación de Hipótesis
Prueba Bilateral Prueba unilateral superior Prueba unilateral inferior
Fijar nivel de significancia

= 0,05; 0,01 etc.
Estadística de prueba
Donde:
p : Proporción muestral de éxitos
Regiones críticas
Contraste Bilateral Contraste unilateral superior Contraste unilateral inferior
-- ZR-- /-------------ZA--------------/--ZR-- ----------------ZA---------------/----ZR---- ----ZR-----/--------------ZA----------------
Decisión
Forma TabularSi el valor numérico del estadístico de prueba se ubica en la Zona de Aceptación (ZA) se
acepta la Hipótesis nula .Si el valor numérico del estadístico de prueba se ubica en la Zona de Rechazo (ZR) se
rechaza la Hipótesis nula .
Forma Método “p”Si el valor numérico de “p” es superior que el nivel de significancia fijado “ ” se acepta
la Hipótesis nula .Si el valor numérico de “p” es inferior que el nivel de significancia fijado “ ” se rechaza
la Hipótesis nula .
Ejemplo 1. En una gran compañía, el 18% o más de los trabajadores están de acuerdo con un proyecto de ley que modifica el código laboral Peruano. La gerencia de la compañía selecciona una muestra aleatoria de 120 trabajadores, donde el 30% están de acuerdo con dicho proyecto de ley. ¿Cual es la conclusión del gerente?

Solución:
Formulación de hipótesis
Nivel de significancia= 1%
Estadístico de prueba
= 3,43
Regiones críticas
------------------ZA--------------/----ZR-----
2,33
Decisión
Fijando = 0.01, la región de aceptación es el intervalo (- ; = 2,33)
Como el estadístico de prueba Z = 3,43 es mayor que = 2,33, es decir se ubica en la zona de rechazo, se rechaza H0
El gerente concluye que efectivamente el 18% o más de los trabajadores están de acuerdo con un proyecto de ley que modifica el código laboral Peruano.
Ejercicios propuestos
Ejercicio 1. Se conoce por experiencia que el 14% de la producción de cierto artículo resulta defectuosa. Se introducen algunos correctivos en el proceso y luego mediante una muestra de 360 artículos escogidos aleatoriamente, se encuentra que el 13.33% resultan defectuosos. Comprobar si los cambios mejoraron la calidad con un nivel de significación del 5%.

Ejercicio 2. Un propietario de un gran taller de reparación de artículos electrodomésticos, asegura que por lo menos en el 30% de las reparaciones se hacen posteriores reclamos. Uno de sus empleados piensa que dicha proporción es mayor y para probarlo toma una muestra aleatoria de 120 órdenes de reparación efectuadas anteriormente y encuentra que el 39.17% de las mismas fueron objeto de reclamos. ¿Quién tiene la razón? Nivel de significación del 1%.Ejercicio 3. Una compañía estima que tiene una participación en el mercado de un 80% para su producto estrella. Mediante una muestra aleatoria de 400 posibles consumidores se encuentra que el 75% de los mismos consumen el referido producto. ¿Con un nivel de significación del 1%, puede concluirse a través de los resultados que dicha proporción es menor?
Ejercicio 4. Se quiere comprar una maquina troqueladora y se adquirirá si la proporción de piezas defectuosas producidas por la máquina es 10% o menos. Se examina una muestra aleatoria de 40 piezas y se encuentra que 7.5% resultaron defectuosas. ¿Con un nivel de significación del 5%, puede concluirse que la máquina satisface los requerimientos?
Prueba de hipótesis para la diferencia entre las proporciones de dos poblaciones
Vamos a considerar que tenemos dos poblaciones de modo que en cada una de ellas
estudiamos una v.a. dicotómica (Bernoulli) de parámetros respectivos y . De
cada población vamos a extraer muestras de tamaño y .Entonces
Si las muestras son suficientemente grandes ocurre que una aproximación para la prueba de hipótesis al nivel de significancia “ ” para la diferencia de proporciones
de dos poblaciones es:
Formulación de Hipótesis
Prueba bilateral Prueba unilateral inferior Prueba unilateral superior
Fijar nivel de significación = 0,05; 0,01 etc.
Estadística de prueba
Regiones críticas
Contraste Bilateral Contraste unilateral superior Contraste unilateral inferior
-- ZR-- /-------------ZA--------------/--ZR-- ----------------ZA---------------/----ZR---- ----ZR-----/--------------ZA----------------
Decisión
Forma TabularSi el valor numérico del estadístico de prueba se ubica en la Zona de Aceptación (ZA) se
acepta la Hipótesis nula .Si el valor numérico del estadístico de prueba se ubica en la Zona de Rechazo (ZR) se
rechaza la Hipótesis nula .
Forma Método “p”Si el valor numérico de “p” es superior que el nivel de significancia fijado “ ” se acepta
la Hipótesis nula .Si el valor numérico de “p” es inferior que el nivel de significancia fijado “ ” se rechaza
la Hipótesis nula .
Ejemplo 1. Una firma distribuye dos marcas de detergente. En una encuesta se encuentra que 56 de 200 amas de casa prefieren el detergente de la marca A y que 29 de 150 amas de casa prefieren la marca B. ¿Se puede concluir al nivel de significación del 5% que la marca A tiene mayor preferencia que la marca B? Solución:

Marca A Marca B
: Número de amas de casa que : Número de amas de casa que prefieren detergente marca A prefieren detergente marca B
= 56 = 29
= 200 = 150
= 0,28 = 0,72 = 0,19 = 0,81
Formulación de hipótesis
Nivel de significancia = 5%
Estadístico de prueba
= 1,96
Calculando
= 0,24 = 0,76
Regiones críticas
----------------ZA---------------/-----ZR----
1,645
Decisión
Fijando = 0.05, la región de aceptación es el intervalo (- ; = 1,645)
Como el estadístico de prueba Z = 1,96 es mayor que = 1,645, es decir se ubica en la zona de rechazo, se rechaza H0
Se concluye que efectivamente la marca A tiene mayor preferencia que la marca B con un nivel de confianza del 95%.
Ejercicios propuestos
Ejercicio 1. Dos máquinas A y B, producen un mismo artículo. La máquina A produce como término medio una proporción de 14% de artículos defectuosos, mientras que la máquina B, produce en término medio una proporción de 20% de artículos defectuosos. Si se obtiene una muestra aleatoria de 200 unidades del artículo que provengan de la máquina A y una muestra aleatoria de 100 unidades provenientes de la máquina B. Demostrar que la máquina B tenga una proporción de defectuosos 8% o más que A. Se supone que la población es infinita.Ejercicio 2. Se seleccionó una muestra aleatoria de 100 hombres y 100 mujeres de un departamento de Colombia; se halló que de los hombres 60 estaban a favor de una ley de divorcio y de las mujeres 55 estaban a favor de dicha ley. Con base en ésta información, pruebe que la proporción de hombres que favorece ésta ley es mayor que la proporción de mujeres. Asuma un nivel de confianza del 99 por ciento. Ejercicio 3. La maqueta del nuevo automóvil propuesto se mostró a dos grupos de 150 personas cada uno. Un grupo constó de personas entre 18 y 25 años de edad, y el otro de personas mayores de 50 años. El 80% de los integrantes del grupo más joven aprobó el modelo, mientras que sólo el 50% del grupo mayor en edad lo aprueba. Dentro de un 95% de confiabilidad, ¿puede decirse que ambos grupos tienen opiniones diferentes?Ejercicio 4. Un profesor de Estadística desea comparar el porcentaje de aprobados de la sección “A” contra el porcentaje de aprobados de la sección “B”. En la sección “A” se tomó una muestra de 26 estudiantes, de los cuales 16 habían aprobado, de la sección “B” una muestra de 28 estudiantes reveló 25 aprobados. Utilice un 99% de confiabilidad para comprobar si el porcentaje de aprobados de la sección “B” es superior al de la sección “A”.


















