
Estadística 2009 Maestría en Finanzas Universidad del CEMA
32
Estadística 2010 Clase 5 Maestría en Finanzas Universidad del CEMA Profesor: Alberto Landro Asistente: Julián R. Siri
Transcript of Estadística 2009 Maestría en Finanzas Universidad del CEMA

Estadística2010
Clase 5
Maestría en FinanzasUniversidad del CEMA
Profesor: Alberto Landro
Asistente: Julián R. Siri
Clase 5
4. Propiedades de los estimadores de MCO
5. Test de Hipótesis e Intervalos de Confianza
1. Análisis de Regresión
2. Especificación y Estimación
3. Supuestos del modelo de regresión lineal
6. Bondad de Ajuste
7. Test de significatividad global
8. Ejercicios

• A pesar de que el análisis de regresión tiene que ver con la dependencia de una variable respecto a otras variables, esto no implica causalidad necesariamente. La misma viene dada por consideraciones a priori o teóricas.
•A diferencia del análisis de correlación, en donde el principal objetivo es medir el grado de asociación linealentre dos variables, aquí estamos interesados en estimar o predecir el valor promedio de una variable sobre la base de valores fijos de otras variables.
1. Análisis de Regresión
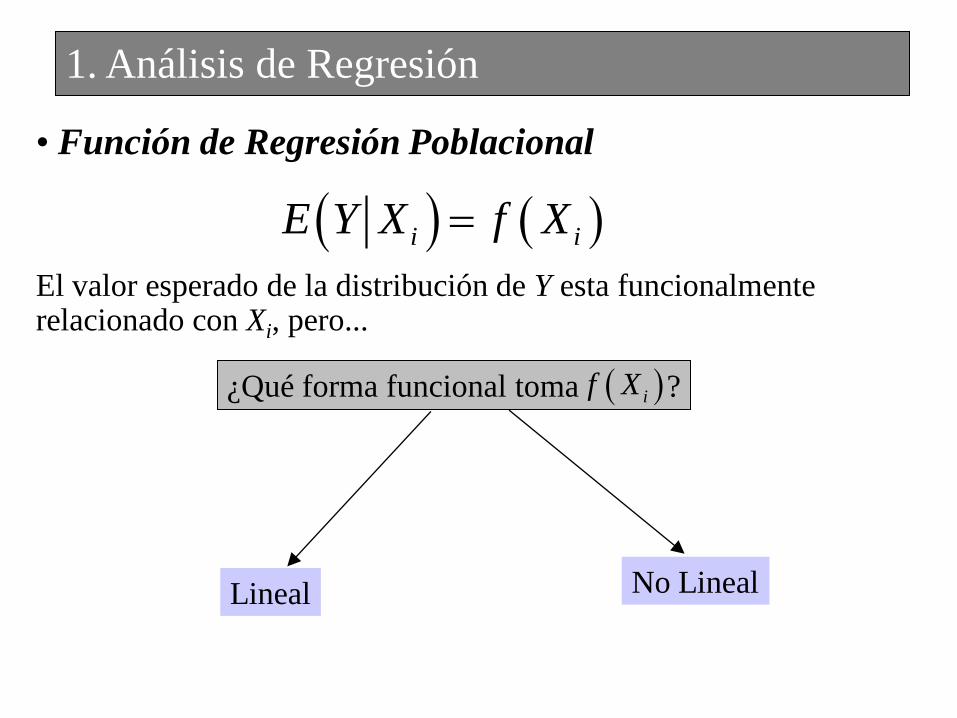
• Función de Regresión Poblacional
El valor esperado de la distribución de Y esta funcionalmente relacionado con Xi, pero...
1. Análisis de Regresión
i iE Y X f X
¿Qué forma funcional toma ? if X
Lineal No Lineal

• En cuanto a linealidad, le pedimos a las regresiones que sean
lineales en los parámetros, y no necesariamente en las variables.
•Entre las formas funcionales lineales se destacan:
1. Análisis de Regresión
.
.
exp( . )
Y X
Y X
Y X

• La primer ecuación es lineal en Y y en X.
• La segunda ecuación se puede trasformar en:
La cual es lineal en log Y y en log X
• La tercer ecuación se puede transformar en
La cual es lineal en log Y y en X.
• Veamos la interpretación de cada coeficiente
1. Análisis de Regresión
log log logY X
logY X

• : parte determinística
• : perturbación estocástica (o parte aleatoria).
2. Especificación y Estimación
componentecomponente
no sistemáticosistemático
i i iY E Y X u
iE Y X
iu

• Perturbación Estocástica
–El término incluye todas las variables omitidas por el modelo pero que, en
conjunto, influencian al valor de Y. También incluye información no disponible
(variables no cuantificables), problemas de representación de las variables
(errores de medición) y/o una falla en la forma funcional del modelo.
•Modelo inicial
–Introduciremos el análisis de regresión con un modelo de dos variables, del
tipo:
–En donde:
2. Especificación y Estimación
iu
1 2Y X u
1
2
= variable dependiente
= ordenada al origen de la recta de regresión
= pendiente de la recta de regresión
= variable independiente
= perturbación estocástica
Y
X
u
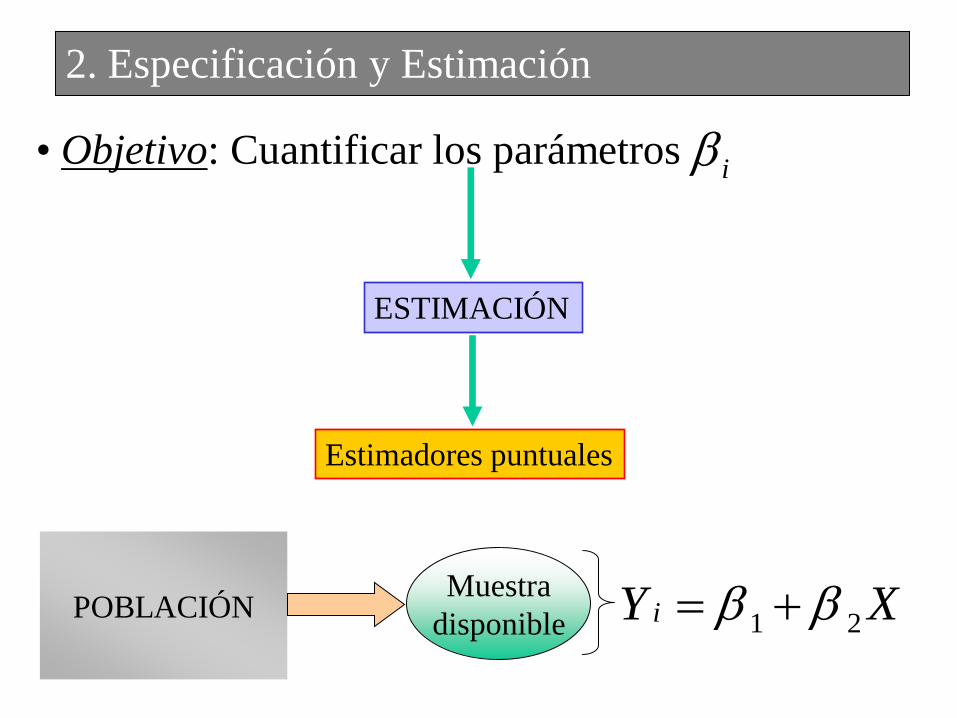
• Objetivo: Cuantificar los parámetros
2. Especificación y Estimación
i
ESTIMACIÓN
Estimadores puntuales
POBLACIÓNMuestra
disponible 1 2iY X

•Podemos reexpresar la recta de regresión poblacional como:
•El último término es el error de estimación, , que análogamente
podría calcularse de la siguiente manera:
2. Especificación y Estimación
1 2 ii iY X u
iu
1 2
i ii
ii i
Y Y u
Y X u

•Existen diversos métodos de estimación. El idea es aquél que genere
una recta de regresión para la cual los residuos de estimación sean
iguales a 0. En términos prácticos esto es imposible, por lo que nos
conformamos con minimizar la magnitud de dichos residuos. El
criterio que utilizaremos en esta reunión es el de Mínimos Cuadrados
Ordinarios (MCO o MCC, por Mínimos Cuadrados Clásicos).
2. Especificación y Estimación
2 22
1 2
1 1 1
minn n n
ii i i i
i i i
u Y Y Y X

•Desarrollando el cuadrado y minimizando (derivando respecto a
ambos parámetros) obtenemos las siguientes ecuaciones normales:
y resolviendo ambas simultáneamente llegamos a que:
2. Especificación y Estimación
1 2
2
1 2
0
0
i i
i i i i
Y n X
Y X X X
2 22
i i i i
i i
n X Y X Y
n X X
2
1 22
1 2
i i i i i
i i
X Y X X Y
n X X
Y X
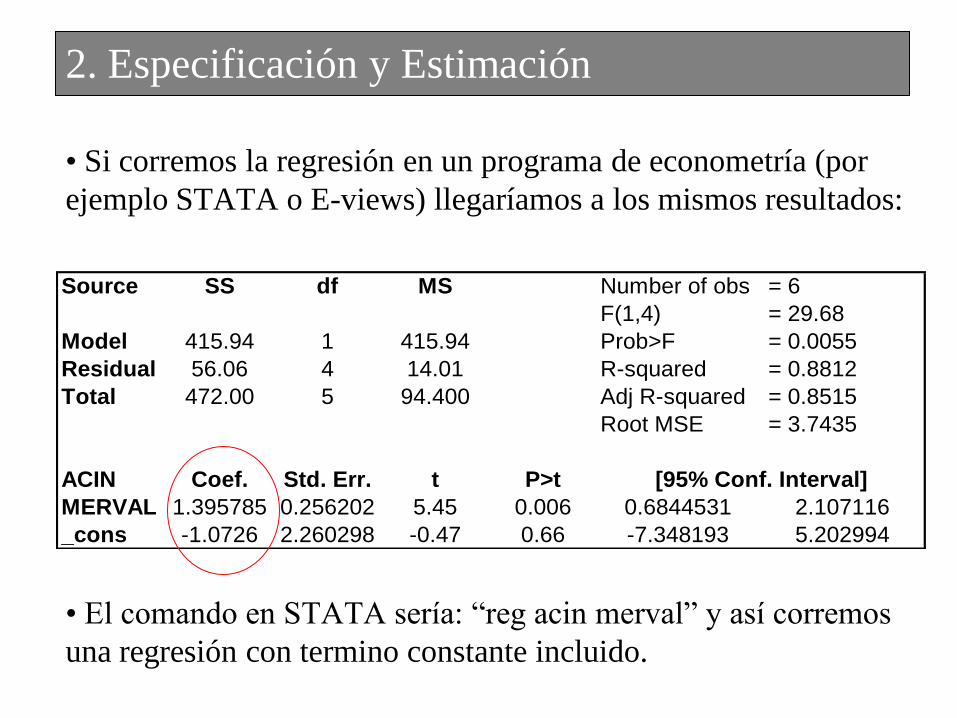
• Si corremos la regresión en un programa de econometría (por
ejemplo STATA o E-views) llegaríamos a los mismos resultados:
• El comando en STATA sería: “reg acin merval” y así corremos
una regresión con termino constante incluido.
2. Especificación y Estimación
Source SS df MS Number of obs = 6
F(1,4) = 29.68
Model 415.94 1 415.94 Prob>F = 0.0055
Residual 56.06 4 14.01 R-squared = 0.8812
Total 472.00 5 94.400 Adj R-squared = 0.8515
Root MSE = 3.7435
ACIN Coef. Std. Err. t P>t
MERVAL 1.395785 0.256202 5.45 0.006 0.6844531 2.107116
_cons -1.0726 2.260298 -0.47 0.66 -7.348193 5.202994
[95% Conf. Interval]

• El modelo clásico de regresión lineal, surgido de la aplicación
de los MCO, necesita de ciertos supuestos para poder realizar
inferencia estadística sobre la variable dependiente, así como
sobre los parámetros poblacionales.
– Los supuestos son 10, destacando los siguientes:
3. Supuestos del modelo de regresión lineal
2 2
I. 0
II. var
III. cov , 0
IV. cov , 0
i i
i i i i u
i j
i j
E u X
u X E u X
u u j i
u X j i

•Entonces, en base a estos supuestos, cada estimador de MCO es
MELI (Mejor Estimador Lineal Insesgado):
–Es lineal (función lineal de una variable aleatoria)
–Es insesgado (su valor promedio es igual al verdadero valor del parámetro)
–Es eficiente (tiene varianza mínima dentro de todos los estimadores lineales
insesgados del parámetro)
Cabe destacar que éstas son propiedades de muestra finita, o sea, se
mantienen independiente del tamaño de la muestra sobre la cual estén
basados los estimadores.
4. Propiedades de los estimadores de MCO

•Los estimadores de MCO, además, presentan las siguientes
propiedades deseables:
–El valor de la media de los residuos es cero.
–Los residuos no están correlacionados con el valor predicho de Y, :
–Los residuos no están correlacionados con Xi.:
4. Propiedades de los estimadores de MCO
ˆiu
iY
0i iE Y u
ˆiu
0iiE X u
ˆiu

• es un estimador insesgado de . Es decir,
•La varianza de es,
•Mientras que la varianza de es,
4. Propiedades de los estimadores de MCO
i i
iiE
1
2
2
2
1 2var
i
u
i
X
n x
2
2 2var u
ix

En donde,
Y como desconocemos , lo reemplazamos por la estimación
muestral, . La misma se estima a partir del siguiente cálculo:
Y agregándole el supuesto de que las perturbaciones se distribuyen
normalmente, obtenemos que:
4. Propiedades de los estimadores de MCO
variable centradai ix X X
2
2
2
i
u
uS
n
2
u2
uS
2 22
1 21 22 2, ,
i uu
i i
XN N
n x x

•Ya definidas las distribuciones de los estadísticos, podemos realizar
test individuales sobre los parámetros , de la siguiente manera:
5. Test de Hipótesis e Intervalos de Confianza
i
Caso I Caso II Caso III
Prueba Estadística
Regla de Decisión
Rechazar Rechazar Rechazar
si tcal<-t(,n-2) si |tcal |>t(/2,n-2) si tcal>t(,n-2)
1
*
11
( 2)2
2
~ n
i
u
i
t tX
Sn x
*
0
*
1
:
:
H
H
*
0
*
1
:
:
H
H
*
0
*
1
:
:
H
H
0H 0H 0H
2
*
22
( 2)2
~ n
u i
t tS x

•Y el intervalo de confianza, con un nivel de significación, para los
parámetros poblacionales, quedan definidos de la siguiente manera:
5. Test de Hipótesis e Intervalo de Confianza
%
2 2
2 2
2 1 21 12 2
2 2 2 2
2 2 22 2
i i
n u n u
i i
n u i n u i
X XIC t S t S
n x n x
IC t S x t S x
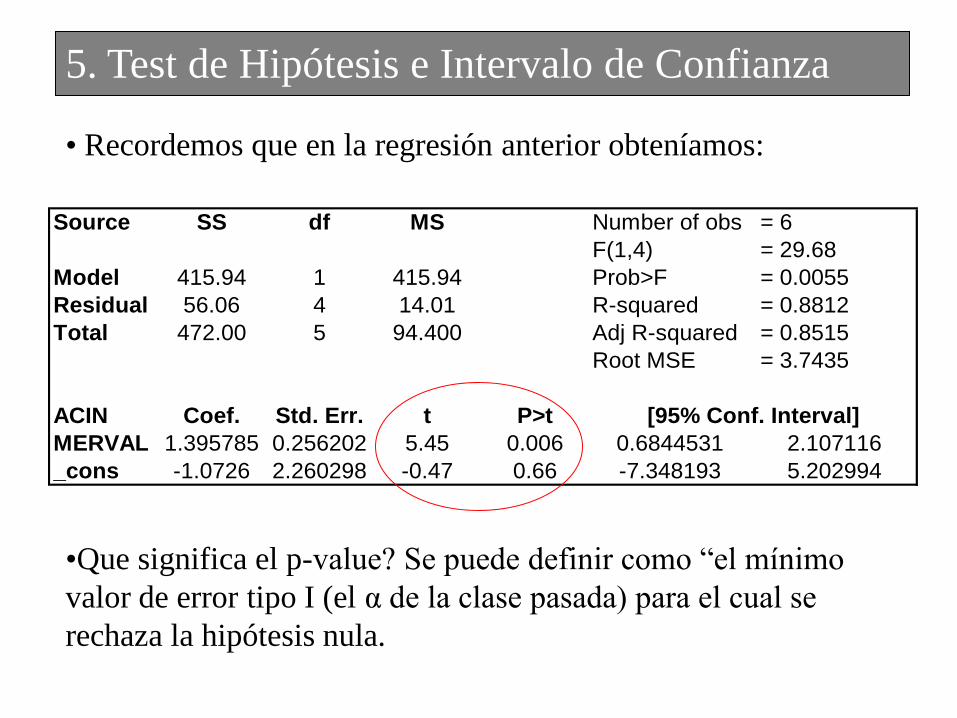
• Recordemos que en la regresión anterior obteníamos:
•Que significa el p-value? Se puede definir como “el mínimo
valor de error tipo I (el α de la clase pasada) para el cual se
rechaza la hipótesis nula.
5. Test de Hipótesis e Intervalo de Confianza
Source SS df MS Number of obs = 6
F(1,4) = 29.68
Model 415.94 1 415.94 Prob>F = 0.0055
Residual 56.06 4 14.01 R-squared = 0.8812
Total 472.00 5 94.400 Adj R-squared = 0.8515
Root MSE = 3.7435
ACIN Coef. Std. Err. t P>t
MERVAL 1.395785 0.256202 5.45 0.006 0.6844531 2.107116
_cons -1.0726 2.260298 -0.47 0.66 -7.348193 5.202994
[95% Conf. Interval]

• La bondad de ajuste de la recta de regresión es equivalente a
determinar cuán bien se ajusta la recta de regresión a los datos
muestrales. Como medida de esto surge el coeficiente de determinación
(ó R2):
•En el contexto de la regresión, es una medida de la proporción de la
variación en la variable dependiente explicada por la/s variable/s
explicativa/s.
6. Bondad de Ajuste
2
2 2cov ,
x y
x yR

• Coeficiente de Correlación: Determina el grado de relación
lineal que existe entre distintas variables. Dicho coeficiente toma
valores entre –1 y 1. De aquí en mas lo llamaremos r o ρ.
• Si el coeficiente de correlación lineal es igual a +1 o –1
podemos afirmar que la relación lineal entre ambas variables es
perfecta. Es decir “ambas variables se mueven juntas”.
• En el caso de dos variables que no tienen relación lineal alguna,
tendremos un ρ igual a cero.
6. Bondad de Ajuste
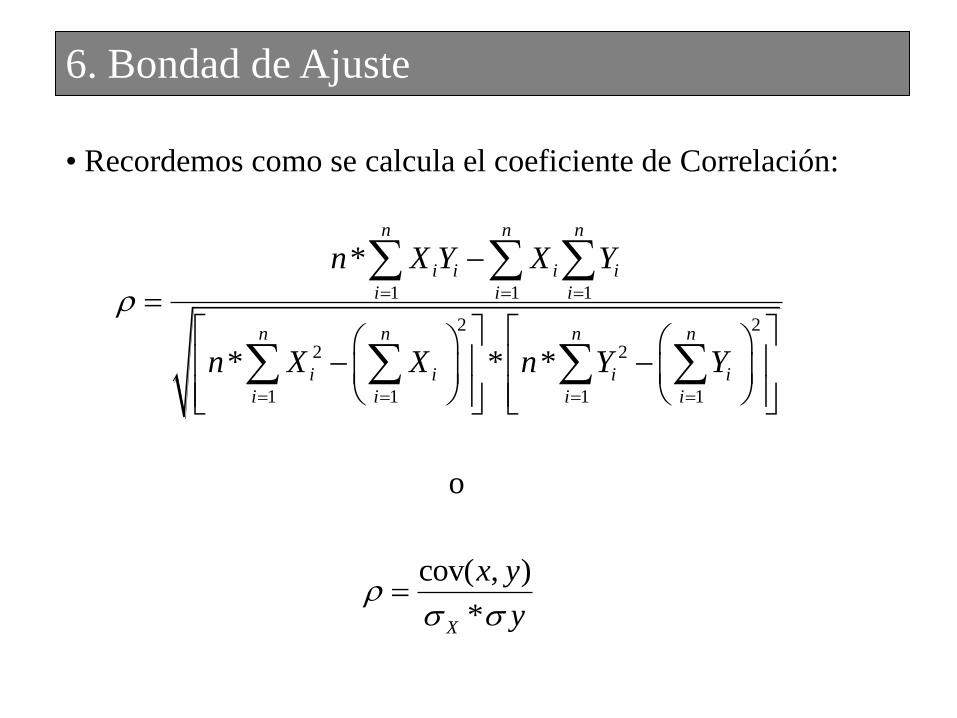
• Recordemos como se calcula el coeficiente de Correlación:
o
6. Bondad de Ajuste
1 1 1
2 2
2 2
1 1 1 1
*
* * *
n n n
i i i i
i i i
n n n n
i i i i
i i i i
n X Y X Y
n X X n Y Y
cov( , )
*X
x y
y

• Vamos a testear con un nivel de significatividad del 5% si el
coeficiente de correlación lineal entre ambas variables es o no
significativamente distinto de cero.
Planteamos las hipótesis: H0: ρ=0 y H1: ρ≠0
•A fin de realizar nuestro test, utilizaremos el siguiente
estadístico
•En donde si reemplazamos por los datos del ejercicio tenemos
que:
t=(0.94*(6-2)0.5)/(1-(0.942)0.5=5.51
6. Bondad de Ajuste
22
* 2:
1n GL
r nt t
r

Uno podría plantear, en base a que , lo siguiente:
Donde:
6. Bondad de Ajuste
ii iy y u
2 22
ii iy y u
2
2
2
Suma de los cuadrados totales (STC)
Suma de los cuadrados explicados (SEC)
Suma de los cuadrados residuales (SRC)
i
i
i
y
y
u

• Dividiendo a todo por SCT tenemos que:
•Ahora bien, definiendo al coeficiente de determinación como
•Podemos expresarlo también como:
6. Bondad de Ajuste
1SCE SCR
SCT SCT
22
2
2 2
ii
ii
Y Y y SCER
y SCTY Y
22
2
2 21 1
i i
ii
u u u SCRR
y SCTY Y

Podemos hacer otro análisis sobre la varianza de la regresión conocido
como el test F. Su popularidad radica en que es fácilmente calculada para
regresiones simples y múltiples:
Entonces, plantenado como hipótesis nula que los estimadores no son
conjuntamente significativos, , se realiza el test de
hipótesis.
7. Test de significatividad global
, 11
k n k
SCE kF F
SCR n k
0 : 0iH

• E1.Sea n=10, ∑X=40,∑Y=90, el estimador de a1=2 y ρ=0.5
¿Cuáles de las siguientes afirmaciones son ciertas?
I.El coeficiente de determinación es igual a 0.25
II.El estimador de a0=1
III.Si X fuera 5, entonces Y sería 11.
IV.La pendiente de la recta de regresión es ascendente hacia la
derecha.
A.Sólo I y IV.
B.Sólo II y III.
C.Sólo I y II
D.Todas son correctas.
•E2.Si una regresión lineal simple tiene un R2 = 0.45. ¿Cuál es el
coeficiente de correlación entre las variables dependiente e
independiente? A. 0.20 B. 0.37 C. 0.55 D. 0.67
8. Ejercicios

• E3. De una muestra de 200 pares de observaciones se han
calculado las siguientes cantidades:
∑X=11.34, ∑Y=20.72, ∑X2=12.16, ∑Y2=84.96,
∑XY=22.13
Estimar y
•E4.Si una regresión lineal simple tiene un R2 = 0.45. ¿Cuál es el
coeficiente de correlación entre las variables dependiente e
independiente? A. 0.20 B. 0.37 C. 0.55 D. 0.67
8. Ejercicios
XY .
YX .

• E4. Una muestra de 20 observaciones correspondiente al
modelo de regresión
Donde u se distribuye normalmente con media cero y varianza
desconocida, dio los siguientes datos:
∑X=186.2,
∑Y=21.9,
Estimar α y β y calcular las estimaciones de las varianzas.
8. Ejercicios
4,106))((
4,215)(
9,86)(
2
2
YYXX
XX
YY

Me pueden escribir a:
Las presentaciones estarán colgadas en:
www.cema.edu.ar/u/jrs06
FIN


















