
ESTADÍSTICA - · PDF fileSi la variable toma muchos valores realizaremos una tabla de...
13
1 ESTADÍSTICA La estadística tiene por objeto el desarrollo de técnicas para el conocimiento numérico de un conjunto de datos empíricos (recogidos mediante experimentos o encuestas). Según el colectivo a partir del cual se obtenga la información y el objetivo que se persiga a la hora de analizar esos datos, la estadística se llama descriptiva o inferencial. ESTADÍSTICA DESCRIPTIVA E INFERENCIAL La estadística descriptiva trata de describir y analizar algunos caracteres de los individuos de un grupo dado (población) sin extraer conclusiones para un grupo mayor. La estadística inferencial trabaja con muestras y pretende a partir de ellas “inferir” caracaterísticas de toda la población. Es decir, se pretende tomar como generales propiedades que sólo se han verificado para casos particulares. Conceptos básicos de estadística Población. Es el conjunto de todos los elementos (personas, objetos, animales, etc.) cuyo conocimiento nos interesa y que serán objeto de nuestro estudio. Por ejemplo, si estudiamos el precio de la vivienda en una ciudad, la población será el total de las viviendas. Muestra. Es un subconjunto extraído de la población, cuyo estudio sirve para inferir características de toda la población. Individuo. Es cada uno de los elementos que forman la población o muestra. Caracteres. Son los apectos que deseamos estudiar en los individuos de una población. Cada carácter puede tomar distintos valores o modalidades. Una variable estadística recorre todos los valores de un cierto carácter. Las variables estadísticas pueden ser: Cuantitativas si toman valores numéricos. • Discretas: solo toman valores aislados. (Ejemplo: número de hermanos, empleados de una fábrica) • Continuas: pueden tomar cualquier valor de un intervalo. (Ejemplo: temperaturas registradas en una habitación cada hora) Cualitativas si toman valores no numéricos. (color de ojos, bondad de una persona, profesión de una persona) Tablas de frecuencias Tras la recogidad de datos, la elaboración de una tabla de frecuencias es el siguiente paso. Cuando la variable toma pocos valores, la elaboración de la tabla es sumamente sencilla, no hay más que hacer el recuento de datos.
-
Upload
nguyenkiet -
Category
Documents
-
view
224 -
download
0
Transcript of ESTADÍSTICA - · PDF fileSi la variable toma muchos valores realizaremos una tabla de...

1
ESTADÍSTICA La estadística tiene por objeto el desarrollo de técnicas para el conocimiento
numérico de un conjunto de datos empíricos (recogidos mediante experimentos o encuestas). Según el colectivo a partir del cual se obtenga la información y el objetivo que se persiga a la hora de analizar esos datos, la estadística se llama descriptiva o inferencial.
ESTADÍSTICA DESCRIPTIVA E INFERENCIAL
La estadística descriptiva trata de describir y analizar algunos caracteres de los individuos de un grupo dado (población) sin extraer conclusiones para un grupo mayor. La estadística inferencial trabaja con muestras y pretende a partir de ellas “inferir” caracaterísticas de toda la población. Es decir, se pretende tomar como generales propiedades que sólo se han verificado para casos particulares.
Conceptos básicos de estadística
Población. Es el conjunto de todos los elementos (personas, objetos, animales, etc.) cuyo conocimiento nos interesa y que serán objeto de nuestro estudio. Por ejemplo, si estudiamos el precio de la vivienda en una ciudad, la población será el total de las viviendas. Muestra. Es un subconjunto extraído de la población, cuyo estudio sirve para inferir características de toda la población.
Individuo. Es cada uno de los elementos que forman la población o muestra.
Caracteres. Son los apectos que deseamos estudiar en los individuos de una población. Cada carácter puede tomar distintos valores o modalidades.
Una variable estadística recorre todos los valores de un cierto carácter. Las variables estadísticas pueden ser:
Cuantitativas si toman valores numéricos.
• Discretas: solo toman valores aislados. (Ejemplo: número de hermanos, empleados de una fábrica)
• Continuas: pueden tomar cualquier valor de un intervalo. (Ejemplo: temperaturas registradas en una habitación cada hora)
Cualitativas si toman valores no numéricos. (color de ojos, bondad de una persona, profesión de una persona)
Tablas de frecuencias
Tras la recogidad de datos, la elaboración de una tabla de frecuencias es el siguiente paso. Cuando la variable toma pocos valores, la elaboración de la tabla es sumamente sencilla, no hay más que hacer el recuento de datos.

2
Si la variable toma muchos valores realizaremos una tabla de frecuencias agrupándolos en intervalos. Para ello:
• Localizamos los valores extremos, a y b, y se halla su diferencia,
€
r = b − a (llamada rango o recorrido). • Se decide el número de intervalos que se quiere formar dependiendo de
los datos que se poseen. El número de intervalos no debe ser inferior a 6 ni superior a 15.
• Se toma un intervalo r’, de longitud algo mayor que el recorrido r y que sea múltiplo del número de intervalos, con objeto de que estos tengan una longitud entera.
• Se forman los intervalos, de modo que el extremos inferior del primero sea algo menor que a y el extremo superior del último sea algo superior a b. Los extremos de los intervalos no deberían de coincidir con ninguno de los datos. El punto medio de cada intervalo se llama marca de clase. Es el valor que representa a todo el intervalo para el cálculo de parámetros.
Frecuencias
Frecuencia absoluta: fi
Se llama frecuencia absoluta fi de un valor xi, al número de veces que se repite dicho valor.
Frecuencia absoluta acumulada: Fi
Se llama frecuencia absoluta acumula Fi de un valor xi, a la suma de las frecuencias absolutas de todos los valores anteriores a xi, más la frecuencia absoluta de xi.
€
Fi = f1 + f2 + .+ f i
Frecuencia relativa: hi
Se llama frecuencia relativa hi de un valor xi, al cociente entre la frecuencia absoluta de
xi y el número total de datos N que intervienen en la distribución.
€
hi =xiN
Frecuencia relativa acumulada:
€
Hi = h1 + h2 ++ hi
Gráficos. Utilizaremos los gráficos para expresar los resultados obtenidos: Diagramas de barras, histogramas, polígono de frecuencias, diagrama de sectores, pictogramas…
Ejemplo de una variable cuantativa discreta.
Las notas de un examen de matemáticas de 30 alumnos de una clase son las siguientes:
5, 3, 4, 1, 2, 8, 9, 8, 7, 6, 6, 7, 9, 8, 7, 7, 1, 0, 1, 5, 9, 9, 8, 0, 8, 8, 8, 9, 5, 7.
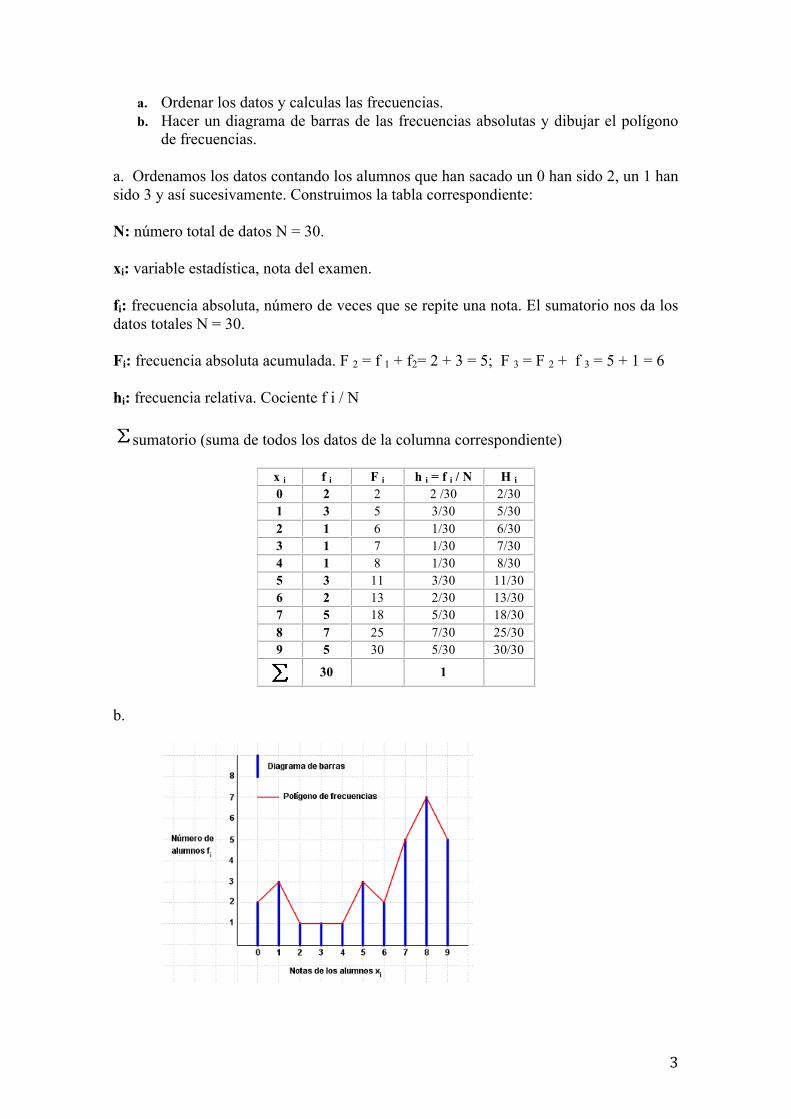
3
a. Ordenar los datos y calculas las frecuencias. b. Hacer un diagrama de barras de las frecuencias absolutas y dibujar el polígono
de frecuencias.
a. Ordenamos los datos contando los alumnos que han sacado un 0 han sido 2, un 1 han sido 3 y así sucesivamente. Construimos la tabla correspondiente:
N: número total de datos N = 30.
xi: variable estadística, nota del examen.
fi: frecuencia absoluta, número de veces que se repite una nota. El sumatorio nos da los datos totales N = 30.
Fi: frecuencia absoluta acumulada. F 2 = f 1 + f2= 2 + 3 = 5; F 3 = F 2 + f 3 = 5 + 1 = 6
hi: frecuencia relativa. Cociente f i / N
sumatorio (suma de todos los datos de la columna correspondiente)
x i f i F i h i = f i / N H i 0 2 2 2 /30 2/30 1 3 5 3/30 5/30 2 1 6 1/30 6/30 3 1 7 1/30 7/30 4 1 8 1/30 8/30 5 3 11 3/30 11/30 6 2 13 2/30 13/30 7 5 18 5/30 18/30 8 7 25 7/30 25/30 9 5 30 5/30 30/30
30 1
b.

4
Ejemplo de una variable cuantativa continua.
Se ha controlado el peso de 50 recién nacidos, obteniéndose los siguientes resultados:
Peso ( en kg) Número de niños
[2,5 - 3) 6
[3 - 3,5) 23
[3,5 - 4) 12
[4 - 4,5) 9
a) Formar la tabla de frecuencias.
b) Representar gráficamente la distribución.
a) Tabla de frecuencias
Peso ( en kg) Número de niños f i F i h i H i [2,5 - 3) 6 6 0,120 0,120 [3 - 3,5) 23 29 0,460 0,580 [3,5 - 4) 12 41 0,240 0,820 [4 - 4,5) 9 50 0,180 1
50 1
b) Gráfica: Histograma
Por ser una distribución continua obtenemos áreas de cada intervalo, no hay separación entre los intervalos.
Ejemplo de un diagrama de sectores
En un hipermercado se han producido las siguientes ventas en euros: juguetes 125, plantas 175, discos 250, alimentación 450.
a) Calcular las frecuencias, porcentajes y ángulo correspondiente.

5
b) Realizar un diagrama de sectores.
a) Colocamos los datos en una tabla. Las variable xi son los productos vendidos. Las frecuencias absolutas fi son las ventas en euros de cada producto. Las frecuencias relativas hi se obtienen dividiendo las frecuencias absolutas entre el total de euros 1000 €. El porcentaje se calcula multiplicando la frecuencia relativa por 100. Para realizar el diagrama de sectores necesitamos conocer el ángulo. Para hallar el ángulo multiplicamos la frecuencia relativa por 360 º que se corresponden con el total. . * Para hallar el ángulo a partir del porcentaje, dividimos entre 100 y multiplicamos por 360º
Variable xi fi hi = fi /1000 Porcentaje % = hi x 100 Ángulo = hi x 360 º Juguetes 125 0,125 12,5 0,125 x 360 º = 45 º Plantas 175 0,175 17,5 0,175 x 360 º = 63 º Discos 250 0,250 25 0,250 x 360 º = 90 º
Alimentación 450 0,450 45 0,450 x 360 º = 162 º
1000 1 100 360 º
b) Diagrama de sectores
PARÁMETROS ESTADÍSTICOS
MEDIDAS DE CENTRALIZACIÓN
Media aritmética:
€
x =xi ⋅ fi∑N

6
Moda Mo: Valor de una variable estadística xi que representa mayor frecuencia absoluta fi.
Si la variable es continua aplicamos la fórmula:
€
Mo = Li + c ⋅ D1D1 + D2
€
Li : es el límite inferior de la clase mediana.
c: amplitud de los intervalos.
€
D1: Diferencia entre la frecuencia absoluta de la clase modal y la de la clase anterior.
€
D2 : Diferencia entre la frecuencia absoluta de la clase modal y la de la clase siguiente.
Mediana M: Si los individuos de una población están colocados en orden creciente según la variable que estudiamos, el que ocupa el valor central se llama individuo mediano, y su valor, mediana. La mediana, Me, está situada de modo que antes de ella está el 50% de la población y detrás el otro 50%.
Por ejemplo : 6, 7, 7, 7, 8, 9, 10,12, 15
€
⇒ Me=8
Si el número de datos es par, la mediana es el valor medio de los dos centrales.
Por ejemplo: 6, 7, 7, 7, 8, 9, 10,12, 15, 16
€
⇒ Me=8,5
Si la variable a estudio es continua aplicamos la siguiente fórmula:
€
Me = Li + c ⋅
N2− Fi−1f i
€
Li : es el límite inferior de la clase mediana.
c: amplitud de los intervalos.
N: número total de datos.
€
Fi−1 : Frecuencia absoluta acumulada de la clase anterior a la clase mediana.
€
fi: Frecuencia absoluta de la clase mediana.
Cuartiles: Si en lugar de partir la totalidad de los individuos en dos mitades, lo hacemos en cuatro partes iguales (todas ellas con el mismo número de individuos), los dos nuevos puntos de separación se llaman cuartiles.

7
Cuartil inferior, Q1, es un valor de la variable que deja por debajo de él al 25% de la población, y por encima, al 75%.
Cuartil inferior, Q3, deja por debajo de él al 75%, y por encima, al 25%.
Se designan por Q1 y Q3, porque la mediana sería el Q2.
Ejemplo, en la siguiente distribución:
1, 2, 2 , 3, 4, 5 , 5, 5, 6 , 8, 9, 10
Q1 = 2,5; M=Q1 = 5; Q3 = 7
Centiles o Percentiles: Si partimos la población en 100 partes y señalamos el lugar que deja debajo k de ellas, el valor de la variable correspondiente a ese lugar se designa por pk y se denomina centil k o percentil k.
La mediana es Me=p50, y los cuartiles, Q1 = p25, Q3 = p75.
MEDIDAS DE DISPERSIÓN
Rango o recorrido: diferencia entre el mayor valor y el menor valor de la variable estadística.
Varianza
€
σ 2:
€
σ 2 =xi − x( )
2⋅ fi∑
N
€
σ 2 =xi( )2 ⋅ fi∑N
− x( )2
Desviación típica:
€
σ
€
⇒ var ianza⇒σ =xi( )2 ⋅ f i∑N
− x( )2
Coeficiente de variación:
€
C.V =σx
Ejemplo de una variable discreta
Se ha preguntado a 40 personas el número de personas que forman el hogar familiar obteniéndose los siguientes resultados:
Número de personas en el hogar 2 3 4 5 6 7 Frecuencia 4 11 11 6 6 2
• Calcula la media, la mediana, la moda y la desviación típica.
• Haz el diagrama correspondiente.
Construimos la tabla:
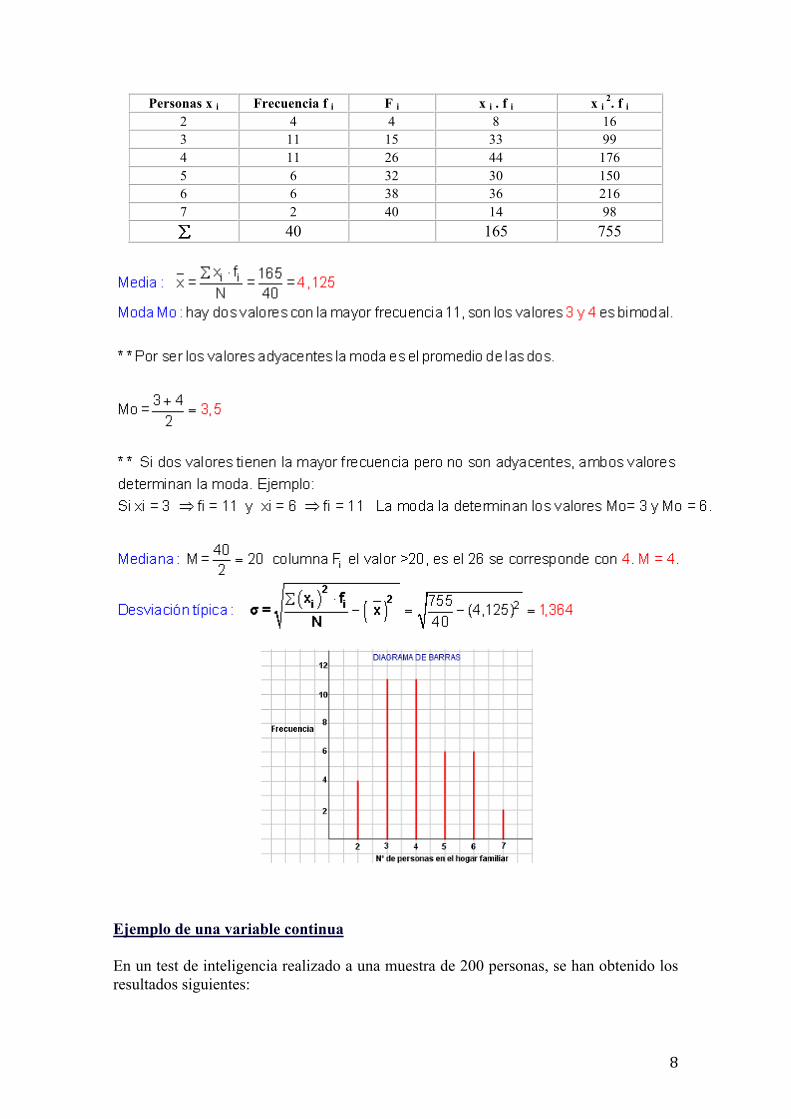
8
Personas x i Frecuencia f i F i x i . f i x i 2. f i 2 4 4 8 16 3 11 15 33 99 4 11 26 44 176 5 6 32 30 150 6 6 38 36 216 7 2 40 14 98
40 165 755
Ejemplo de una variable continua
En un test de inteligencia realizado a una muestra de 200 personas, se han obtenido los resultados siguientes:
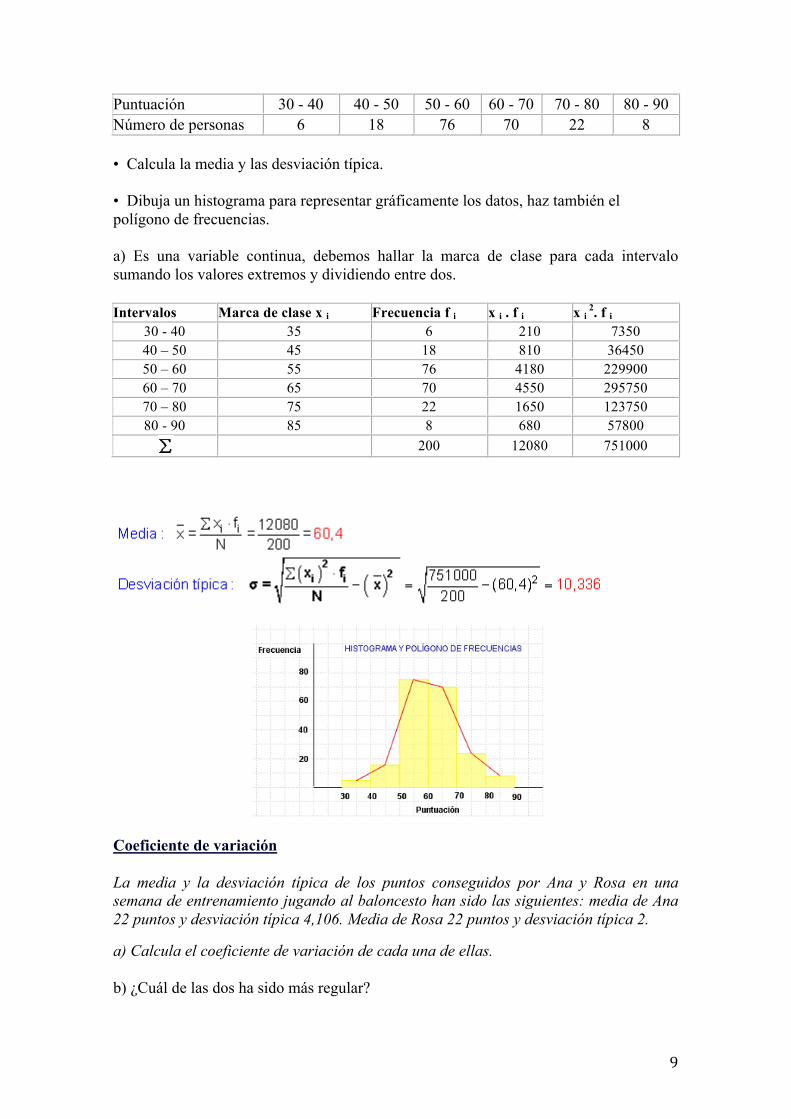
9
Puntuación 30 - 40 40 - 50 50 - 60 60 - 70 70 - 80 80 - 90 Número de personas 6 18 76 70 22 8
• Calcula la media y las desviación típica.
• Dibuja un histograma para representar gráficamente los datos, haz también el polígono de frecuencias.
a) Es una variable continua, debemos hallar la marca de clase para cada intervalo sumando los valores extremos y dividiendo entre dos.
Intervalos Marca de clase x i Frecuencia f i x i . f i x i 2. f i 30 - 40 35 6 210 7350 40 – 50 45 18 810 36450 50 – 60 55 76 4180 229900 60 – 70 65 70 4550 295750 70 – 80 75 22 1650 123750 80 - 90 85 8 680 57800
200 12080 751000
Coeficiente de variación
La media y la desviación típica de los puntos conseguidos por Ana y Rosa en una semana de entrenamiento jugando al baloncesto han sido las siguientes: media de Ana 22 puntos y desviación típica 4,106. Media de Rosa 22 puntos y desviación típica 2.
a) Calcula el coeficiente de variación de cada una de ellas.
b) ¿Cuál de las dos ha sido más regular?
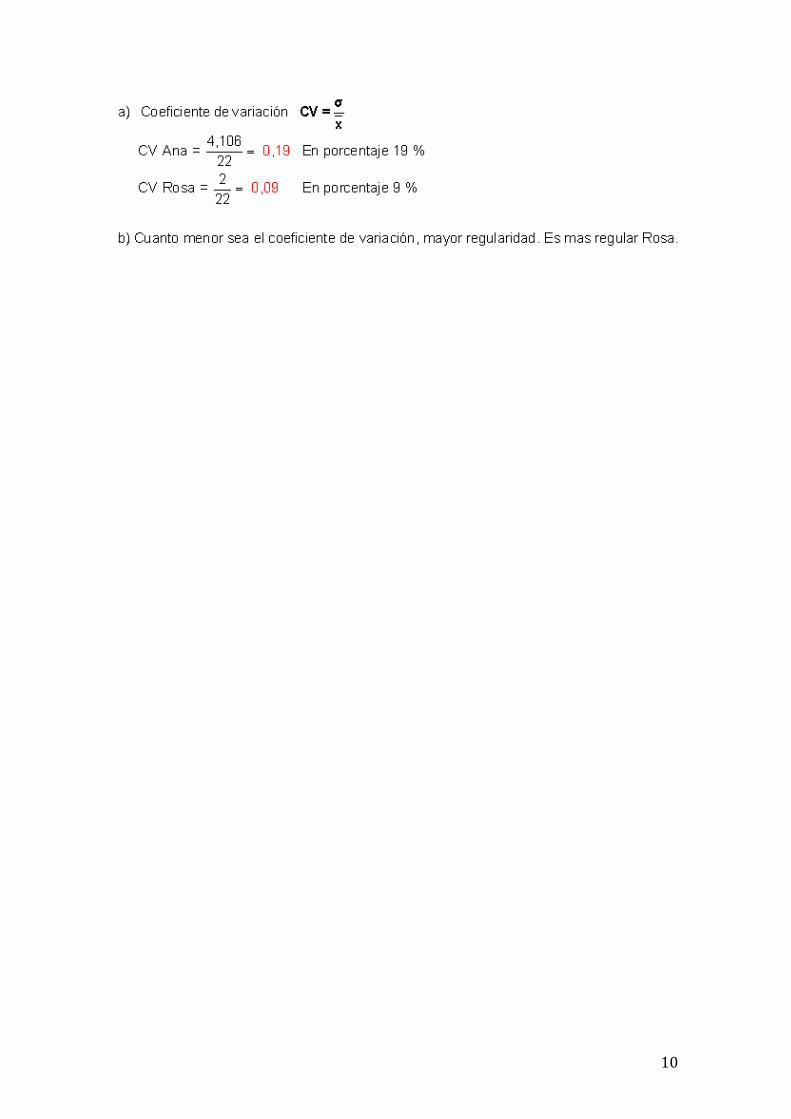
10

11
DISTRIBUCIONES BIDIMENSIONALES
CORRELACIÓN
Tenemos un colectivo de n individuos. Estudiamos en ellos dos variables, x, y. Conocemos los valores de las variables para cada uno de los individuos.
El conjunto de pares de valores
€
x1,y1( ),
€
x2,y2( ),
€
xn ,yn( ) se llama distribución bidimensional. Si interpretamos cada par de valores como las coordenadas de un punto, el conjunto de todos ellos se llama nube de puntos o diagrama de dispersión.
La correlación viene a representar la relación que existe entre esas dos variables para los n individuos. Puede ser más o menos fuerte según lo apretados que estén los puntos de la nube en torno a una recta que marca la tendencia y se llama recta de regresión. Si la pendiente de la recta de regresión es positiva o negativa la correlación se llama positiva o negativa, respectivamente.
Ejemplos:
• Horas de estudio – Horas de televisión • Estatura media de los padres – Estatura media de los hijos • Nota de matemáticas – Nota de física
Estas son las notas de 12 estudiantes en Matemáticas y en Física.
ALUMNO a b c d e f g h i j k l
MATEMÁTICAS 2 3 4 4 5 6 6 7 7 8 10 10
FÍSICA 1 3 2 4 4 4 6 4 6 7 9 10
Es una distribución bidimensional porque a cada individuo le corresponden dos valores de dos variables. Si tomamos esos dos valores como las coordenadas de un punto, la distribución puede ser representada mediante 12 puntos: nube de puntos.
Se aprecia una relación entre las dos variables: a mejor nota en Matemáticas, mejor nota en Física y a peor nota en Matemáticas peor nota en Física, pero solo a grandes rasgos. Se dice que existe correlación entre esas dos variables.
Medida de la correlación
Vamos a indicar la expresión que nos servirá para obtener su valor de forma numérica e inequívoca.

12
Centro de gravedad de una distribución bidimensional
Media de la variable
€
x→ x =xi∑n
Media de la variable
€
y→ y =yi∑n
El punto
€
x,y( ) se llama centro de gravedad de la distribución.
Covarianza
Se llama covarianza al parámetro :
€
σ xy =xi − x( ) ⋅∑ yi − y( )
n=
x i⋅yi∑n
− x ⋅ y
Ambas expresiones, como es lógico, coinciden. La segunda de ellas es más cómoda para obtener numéricamente la covarianza.
Correlación
El valor de la correlación entre las dos variables de una distribución bidimensional viene dado por la expresión:
€
r =σ xy
σ x ⋅σ y
€
σ xy es la covarianza;
€
σ x,σ y son las desviaciones típicas de cada variable
El coeficiente de correlación, r, tiene las siguientes propiedades:
• No tiene dimensiones. Es decir, no depende de las unidades en las que se expresen los valores de las dos variables. Por tanto, si se realiza un cambio de unidades, el valor de r no varía.
• El valor de r está comprendido entre -1 y 1. Si la correlación es perfecta (puntos de la nube alineados), entonces
€
r =1. Si la correlación es fuerte,
€
r es próximo a 1. Si la correlación es débil,
€
r es próximo a 0.

13
Recta de regresión
Tenemos una distribución bidimensional y representamos la nube de puntos correspondiente. La recta que mejor se ajusta a esta nube de puntos recibe el nombre de recta de regresión.
Consideramos todas las rectas posibles
€
y = A + Bx y nos quedaremos con aquella para la cual los cuadrados de las distancias, di (de los puntos a las rectas), sumen lo menos posible. La recta buscada pasa por el centro de gravedad de la distribución y su
pendiente es
€
myx =σ xy
σ x2 .
La recta tiene por ecuación:
€
y = y +σ xy
σ x2 ⋅ x − x( )
Se llama recta de regresión de Y sobre X. A la pendiente,
€
σ xy
σ x2 ,se le llama coeficiente
de regresión.
La recta de regresión de X sobre Y es:
€
x = x +σ xy
σ x2 ⋅ y − y( )
Al número,
€
σ xy
σ y2 ,se le
llama coeficiente de regresión de X sobre Y. No es la pendiente de la recta, sino su inversa.
La recta de regresión para hacer estimaciones: Se amolda a la nube de puntos y describe, grosso modo, su tendencia. Por eso, a partir de la recta de regresión obtenemos, de forma aproximada, el valor esperado de y para un cierto valor x, o viceversa. A estos valores se les llama estimaciones.
€
ˆ y xo( ) es el valor estimado de y correspondiente a
€
x = xo sobre la recta de regresión.
€
ˆ x yo( ) es el valor estimado de x correspondiente a
€
y = yo sobre la recta de regresión.
• Las estimaciones siempre se realizan aproximadamente y en términos de probabilidad: es probable que si
€
x = xo, entonces y valga, aproximadamente,
€
ˆ y xo( ) . • La aproximación es tanto mejor cuanto mayor sean
€
r , pues para valores de r próximos a 1 o a -1, los puntos están próximos a la recta.
• Las estimaciones solo deben hacerse dentro del intervalo de valores utilizados o muy cerca de ellos.


















