
INFORME TAREA N°3 - U-Cursos · multiplicadores de Lagrange en la formulación final del...
28
Universidad de Chile Facultad de Ciencias Físicas y Matemáticas Departamento de Ingeniería Eléctrica EL4106 – Inteligencia Computacional INFORME TAREA N°3 DETECTOR DE DÍGITOS CON SVM Nombre Alumno : Sebastián Gálvez Profesor : Javier Ruiz del Solar Profesor Auxiliar : Daniel Herrmann Felipe Valdés Fecha : 12/05/2014 Santiago, Chile.
Transcript of INFORME TAREA N°3 - U-Cursos · multiplicadores de Lagrange en la formulación final del...

Universidad de Chile
Facultad de Ciencias Físicas y Matemáticas
Departamento de Ingeniería Eléctrica
EL4106 – Inteligencia Computacional
INFORME TAREA N°3
DETECTOR DE DÍGITOS CON SVM
Nombre Alumno : Sebastián Gálvez
Profesor : Javier Ruiz del Solar
Profesor Auxiliar : Daniel Herrmann
Felipe Valdés
Fecha : 12/05/2014
Santiago, Chile.

Contenido
Contenido ............................................................................................. II
Índice de Figuras y Tablas ............................................................................... III
1. Introducción .................................................................................... 1
2. Desarrollo ..................................................................................... 2
2.1. Teoría ........................................................................................................ 2
2.2. División de Base de Datos ...................................................................... 6
2.3. Detector de dígito ‘8’ ................................................................................ 8
Clasificador SVM con Kernel Lineal .......................................................... 8
Clasificador SVM con Kernel Polinomial ................................................. 11
Clasificador con Kernel Gaussiano ......................................................... 13
3. Conclusiones ..................................................................................16
4. Anexos ...........................................................................................17
5. Bibliografía .....................................................................................25

Índice de Figuras y Tablas
Figura 1: Hiperplano separador generado entre los vectores de soporte por el método
SVM. .................................................................................................................................. 2
Figura 2: Ejemplo de caso no separable, con variable de holgura . .................................. 5
Figura 3: Curvas ROC del SVM con Kernel lineal para distintos valores del parámetro C. 9
Figura 4: Curva ROC del clasificador para C=1, mejor clasificador con Kernel lineal. ...... 10
Figura 5: Curvas ROC de SVM con orden= 2, C=1, mejor clasificador polinomial logrado.
........................................................................................................................................ 11
Figura 6: Curvas ROC para distintos valores de C, para Kernel polinomiales de distinto
orden. .............................................................................................................................. 12
Figura 7: Curvas ROC del clasificador SVM con Kernel Gaussiano, para distintos valores
de y C. .......................................................................................................................... 14
Figura 8: Comparación entre rendimientos según las curvas ROC de los mejores SVM
logrados para las distintas funciones Kernel probadas. ................................................... 15

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~1~
Introducción
1. Introducción
El objetivo general de esta tarea consiste en la implementación de un
clasificador de dígitos trazados en la pantalla táctil de un Tablet. En particular, se
tiene como objetivo implementar este clasificador utilizando la metodología de
clasificación estadística Support Vector Machine (SVM), analizando su rendimiento
para distintos tipos de Kernels.
La base de datos a utilizar es Pen-Based Recognition of Handwritten Digits
Data Set, tomada del UC Irvine Machine Learning Repository. La cual contiene
información de 10992 muestras y consiste en dos matrices: La primera, “trazos”,
contiene las mediciones de presión en la pantalla táctil de 8 puntos (x,y) equi-
espaciados en longitud de arco, las cuales se traducen 16 características medidas
para cada muestra, cuyos valores fueron ajustados para ser enteros dentro del
rango [0,100]. En esta matriz cada columna corresponde a una muestra. La
segunda matriz “numeros”, que en realidad es un vector columna de tamaño
10992, contiene información sobre qué dígito fue representado en cada muestra,
en cada fila se observa el valor correspondiente al dígito representado por dicha
muestra.
Si se desea tener más detalles sobre cómo se obtuvo la información de la base
de datos la información la puede encontrar en la página del repositorio:
http://archive.ics.uci.edu/ml/datasets/Pen-Based+Recognition+of+Handwritten+Digits
En el desarrollo de esta tarea se explicará a grandes rasgos la teoría de los
clasificadores SVM, y los parámetros de diseño que se deben escoger. También
se debe separar la base de datos en un conjunto de entrenamiento y un conjunto
de prueba, utilizando cantidades de muestras con una razón de 4:1. Finalmente se
implementará el detector de un dígito elegido usando el toolbox de SVM de Matlab
para dos tipos distintos de kernels, para posteriormente analizar las diferencias en
el rendimiento.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~2~
Desarrollo
2. Desarrollo
2.1. Teoría a) Clasificador Support Vector Machine (SVM)
Al igual que todo clasificador, un SVM debe realizar una separación del espacio de características para diferenciar los distintos objetos en base a ellas. En el caso de un SVM, sólo se permite realizar una separación con un hiperplano, por lo que su capacidad de clasificación está limitada únicamente a dos clases. Sin embargo, se pueden utilizar varios clasificadores SVM en cascada para realizar clasificación de múltiples clases. El funcionamiento de un SVM se basa en encontrar los vectores de soporte que definen la frontera del conjunto de datos de cada clase. Considerando una
clasificación para dos clases “ ” y “ ”, un vector de soporte de la clase “ ” es
aquel dato perteneciente a la clase “ ” del conjunto de entrenamiento que, ubicado en el espacio característico, se encuentra más cercano a la clase “ ”. Con esto, se tiene que cada clase posee al menos un vector de soporte. En la Figura 1 se muestra como ejemplo un caso linealmente separable, ya que los
vectores de soporte y definen fronteras en las cuales no se incluyen elementos de la otra clase.
Figura 1: Hiperplano separador generado entre los vectores de soporte por el método SVM.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~3~
Desarrollo
En el caso mostrado, el vector representa el vector normal del hiperplano, que indica su dirección, mientras que el coeficiente indica su distancia al origen, con esto la ecuación del plano separador es la que se muestra en la figura. Lo que
hace el método SVM es determinar los valores de y , con tal de generar la separación entre las clases que produzca el mayor margen entre ellas. Por lo tanto, se debe resolver un problema de optimización. Suponiendo un caso más general, es probable que alguno de los vectores de soporte de una clase defina una frontera que incluya miembros de la otra clase en su interior, por lo que es imposible definir un hiperplano separador de las clases. En estos casos se debe definir lo que se conoce como un margen suave (soft margin), entrando en un juego de tradeoff entre cuánto se desea maximizar el margen entre las clases y cuánto se desea realizar correctamente la clasificación de los datos. Para esto se define un parámetro que controla el tradeoff.
Finalmente, considerando un conjunto de entrenamiento * + , donde
es un vector de características de una muestra, e es la clase de esa muestra. Al ser resuelto el problema de maximización de margen utilizando resolución del problema dual del Lagrangiano, sujeto a las condiciones de que a cada lado del hiperplano se encuentren miembros de la misma clase, considerando cuánto interesa realizar correctamente la clasificación de los datos, se obtienen las siguientes ecuaciones para los parámetros del hiperplano:
∑ , , para algún vector de soporte.
Se da que los multiplicadores de Lagrange son nulos para todo vector de características que no pertenezca al conjunto de vectores de soporte (VS). Luego, queda que:
∑
, , con
Finalmente, para clasificar se puede utilizar la función signo, que determina a
qué lado del hiperplano se encuentra una muestra :
( ) ( + b)
Cabe destacar que para que el método funcione correctamente debe existir un cierto grado en que las clases sean linealmente separables, ya que se admiten unos cuantos datos “fuera” de la frontera definida finalmente, pero cuando se cuenta con un problema que claramente no es linealmente separable, se debe recurrir a un método que considera aumentar la dimensión del espacio de características a un nivel en que sí se pueden separar las clases con un hiperplano.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~4~
Desarrollo
Este método permite implementar un SVM No-lineal, mediante una separación lineal en una dimensionalidad mayor a la del problema original. Dado que el objetivo es realizar la clasificación, existe una técnica que permite trabajar el problema de maximización en una dimensión superior sin necesidad de saber en qué dimensionalidad se está trabajando. Como la técnica considera una propiedad de las funciones definidas como “kernels”, se conoce como el “Kernel trick”. Y
consiste en que dado un mapeo del espacio de características original al espacio de dimensión aumentada, se puede calcular el producto punto entre los vectores de característica en el espacio de dimensión aumentada utilizando la
propiedad ( ) ( ) ( ) , evaluando la función Kernel en los vectores. Para que esta propiedad se cumpla, el Kernel debe cumplir la condición de Mercer. Con esto, en el espacio aumentado se resuelve el problema de maximización de manera análoga al caso visto anteriormente, generando las ecuaciones:
∑ ( ) , ( ) , ( ) ( ( ) )
Así, al reemplazar en las otras ecuaciones, y utilizar la propiedad del Kernel
para calcular los productos punto, el nuevo clasificador está dado por:
( ) ( ∑ ( )
) ∑ ( )
Cabe destacar que en esta formulación final no se requiere conocer
efectivamente el mapeo utilizado para aumentar la dimensionalidad, por lo que el método no identifica cuántas dimensiones se agregan para lograr encontrar una
separación lineal del espacio de características. Tampoco se requiere calcular , lo cual sería imposible sin conocer el mapeo. Además, el rendimiento del clasificador dependerá de qué Kernel se escoja para utilizar el “Kernel trick” y de los parámetros asignados al mismo. Las funciones Kernel más utilizadas para SVM No-lineales son:
Finalmente, cuando se desea diseñar un clasificador SVM, se debe escoger una función Kernel, calibrar sus parámetros, y ajustar el parámetro C de tradeoff entre la clasificación correcta de los datos y maximización del rango.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~5~
Desarrollo
b) Efecto de mover el parámetro C
Tal como se explicó en la sección anterior, existe un parámetro de diseño para el clasificador SVM, conocido como “penalización”, o “parámetro C”, que realiza un tradeoff entre la clasificación correcta de los datos y la maximización del rango que existe entre las clases y el hiperplano separador. Este parámetro se utiliza en la resolución del problema de maximización del rango, afectando únicamente los multiplicadores de Lagrange en la formulación final del clasificador SVM. Para una mayor comprensión sobre cómo afecta el parámetro C, en la Figura 2 se muestra un caso donde existe un vector de características que se escapa del conjunto de su clase, transformando el problema en uno no linealmente
separable. Se definen las variables de holgura , que indican una medida de cuánto se debe alejar el margen de la clase respectiva para poder clasificar correctamente esa muestra, y se incluyen estas variables en el problema de maximización.
En base a esto, el parámetro C, con valores reales positivos, indica cuánta importancia se le da a las variables de holgura, teniendo un efecto de que cuando C disminuye, se acerca el plano separador a donde se encontraría si no se considera el dato que se encuentra en el lado incorrecto del margen. Mientras que si C aumenta, es porque se le da mucha importancia a los datos de la clase que se encuentran al otro lado del margen, acercando el hiperplano separador a estos datos, alejándolo de la clase correspondiente.
Figura 2: Ejemplo de caso no separable, con variable de holgura .

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~6~
Desarrollo
2.2. División de Base de Datos El programa generado en el archivo “basededatos.m” contiene una función
“[entren,clases_entren,prueba,clases_prueba]=basededatos(data,clases)”, que tiene como objetivo dividir la base de datos en los conjuntos de entrenamiento y prueba, para retornarlos en las matrices respectivas. El
argumento “data” contiene en cada fila las mediciones sobre las distintas
características correspondientes a las columnas. El argumento “clases” es un vector columna que en cada fila contiene el número correspondiente al dígito representado en cada muestra. Luego de cargar la base de datos de los dígitos trazados en una Tablet
utilizando “load BaseDatosTarea3”, se puede separar invocando la función de la
forma “[en en_c pr pr_c]=basededatos(trazos,numero);”
Para construir esta función, primero se revisó que todos los datos en la matriz “trazos” estuvieran efectivamente entre 0 y 100, y que en la matriz “numero” no contuviera números que no corresponden a un dígito. Luego, se procedió a juntar ambas matrices en una sola para poder trabajar separando tanto datos como información de la clase al mismo tiempo. Se prosigue ordenando las filas según la clase a la que pertenecen mediante el comando “sortrows(…)”, gracias a la columna agregada. Finalmente se calculan los límites de los índices que corresponden a cada clase y la cantidad de datos por clase.
N=length(data(:,1)); nfeats=length(data(1,:)); % n° de caracteristicas nc=10; % n° de clases
%Uno los datos con las clases en una sola matriz, para asociar los %índices de las filas a cada clase distinta. newdata=[data,clases];
%ordeno y obtengo los índices de las muestras de cada clase. [aux ind]=sortrows(newdata,17); szs=zeros(1,nc); ind_bord=zeros(1,nc); %debo encontrar los indices de los que efectivamente pertenecen a cada %clase, para guardarlos en una matriz y luego separarlos. for i=1:nc auxaux=(aux(:,nfeats+1)==i-1); ind_aux=find(auxaux,1,'last'); ind_bord(i)=ind_aux; szs(i)=sum(auxaux(:)); %también calculo cuántos hay por clase. end
Posteriormente, teniendo información sobre cuántas muestras hay por cada clase, se calcula el 20% de la cantidad de muestras a utilizar en el conjunto de prueba, y luego extraer ese número de datos aleatoriamente por cada clase.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~7~
Desarrollo
%Se quiere 20% de los datos por cada clase para el conjunto de prueba pr_szs=round(szs.*0.2); ind_bord_pr=cumsum(pr_szs);%esto me sirve para saber cuántos datos
seleccionar por cada clase en las iteraciones. sz_prueba=sum(pr_szs); %tamaño total del conjunto de prueba. prueba=zeros(sz_prueba,nfeats+1); r_vec=zeros(sz_prueba,1); %vector que tendrá los indices seleccionados.
%Selección de datos de prueba (20% por cada clase)
%primera iteración for i=1:ind_bord_pr(1) r=randi([1 ind_bord(1)]); while(find(r_vec==ind(r))) %selecciono un indice al azar dentro
del rango de la clase '0'. % y me aseguro que sea distinto a
alguno seleccionado. r=randi([1 ind_bord(1)]); end prueba(i,:)=newdata(ind(r),:); %guardo los datos y la clase a la que
pertenece el dato elegido en el conjunto de prueba r_vec(i)=ind(r); %guardo el indice para luego borrar ese dato del
conjunto y que lo que quede sea el de entrenamiento end % repito para el resto de las clases. for j=2:nc for i=(ind_bord_pr(j-1)+1):ind_bord_pr(j) r=randi([(ind_bord(j-1)+1) ind_bord(j)]); while(find(r_vec==ind(r))) r=randi([(ind_bord(j-1)+1) ind_bord(j)]); end prueba(i,:)=newdata(ind(r),:); r_vec(i)=ind(r); end end prueba2 = prueba(randperm(length(prueba(:,1))),:); %desordeno las
filas prueba=prueba2;
Con esto, ya se tiene listo el conjunto de prueba, por lo que para generar el conjunto de entrenamiento basta extraer del conjunto original los datos utilizados para el conjunto de prueba.
%extraigo del conjunto original los datos utilizados para el conjunto de
prueba entren=newdata; entren(r_vec,:)=[]; sz_entren=length(entren(:,1));
Finalmente, se verificó la representatividad de ambos conjuntos visualizando la razón de datos de cada clase respecto el tamaño del conjunto, y se comparó con la proporción en el conjunto original, logrando un error máximo en algunas clases del 0.0003%, lo cual se consideró totalmente aceptable.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~8~
Desarrollo
2.3. Detector de dígito „8‟ Arbitrariamente, se eligió detectar el dígito „8‟, por lo que el clasificador SVM
diseñado debe clasificar entre las clases „8‟ y „{0,1,2,3,4,5,6,7,9}‟. A continuación
se muestran los procedimientos utilizados para entrenar un SVM con Kernel
lineal, Kernel polinomial y un Kernel Gaussiano, mostrando las curvas ROC
obtenidas para la clasificación tanto de datos de entrenamiento como de los
datos del conjunto de prueba para evaluar si existe sobreajuste. Las curvas ROC
se generaron para distintos „bias‟ (parámetro „b‟ del hiperplano separador
generado por el SVM) cercanos al „bias‟ encontrado en el entrenamiento.
Clasificador SVM con Kernel Lineal
En el primer caso se utilizó una función Kernel de la forma ( ) ,
por lo que el único parámetro de diseño existente corresponde a la penalización
C.
En el script “svm_lin.m” se comienza cargando la base de datos con el
comando load BaseDatosTarea3 .Una vez separada la base de datos con el
comando “[en en_c pr pr_c]=basededatos(trazos,numero);” se procede a adaptar los vectores de clase de cada conjunto para que tengan un valor „1‟ si la clase corresponde a la del dígito „8‟, y un valor „0‟ si corresponde a cualquier otro dígito. Para esto se utilizó la operación booleana „ == ‟ , de la siguiente manera:
%digito escogido: 8 pr_salida=(pr_c==8); %muestra un 1 si la salida corresponde al
digito 8 y un 0 si no en_salida=(en_c==8);
Para entrenar el SVM se utilizó la función “svmtrain(…)”, fijando un valor del parámetro C, mediante el valor de propiedad „BoxConstraint‟. Se fijó que la función Kernel a utilizar fuera lineal ajustando el campo „Kernel_function‟ a „linear‟, finalmente se probaron los distintos métodos de optimización, siendo el único que convergió el método de “Least Squares”, por lo que se utilizó el valor de la propiedad „method‟ igual a „LS‟.
%entreno el detector para kernel lineal, fijando el C. Método de %optimización "Least Squares" C=1; svmStruct= svmtrain(en,en_salida,'kernel_function','linear',…
'BoxConstraint',C,'method','LS');
Luego se obtiene el „bias‟ (parámetro b del hiperplano separador) obtenido en
el entrenamiento con el comando “b=svmStruct.Bias;”. Finalmente, se recorre un arreglo de valores alrededor del „bias‟ original (entre b-5 y b+5) para evaluar el rendimiento en distintos puntos de operación mediante las tasas de
EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~9~
Desarrollo
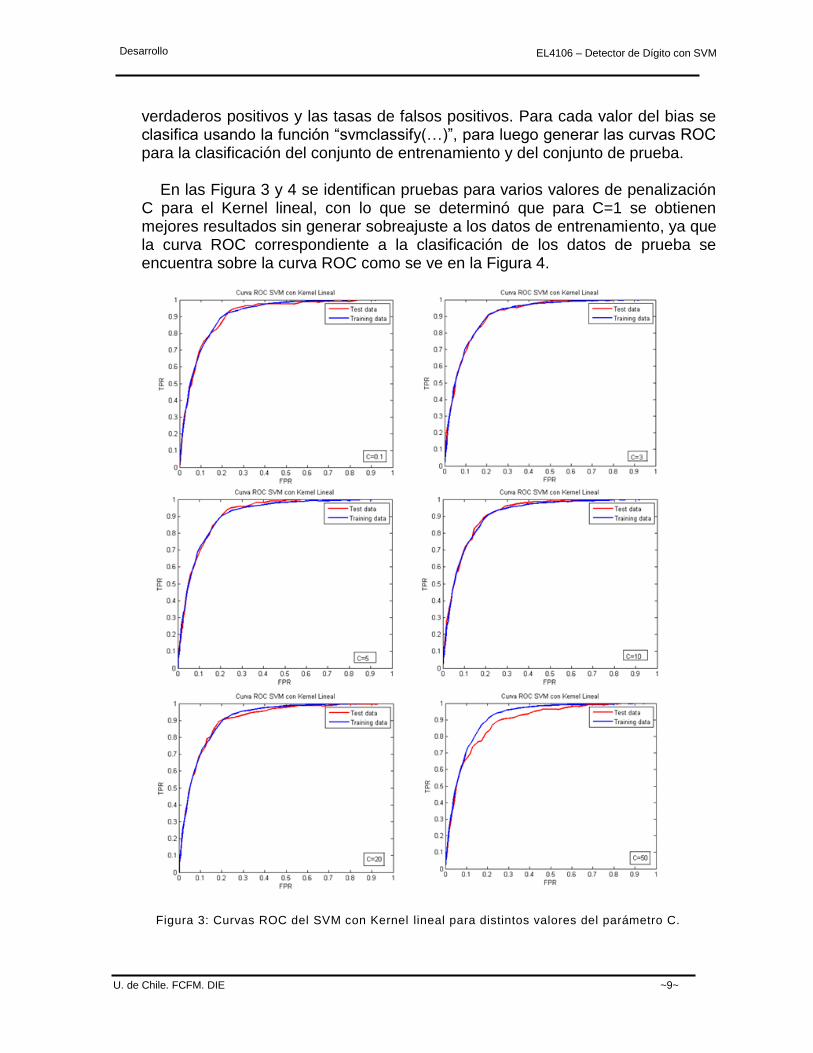
Figura 3: Curvas ROC del SVM con Kernel lineal para distintos valores del parámetro C.
verdaderos positivos y las tasas de falsos positivos. Para cada valor del bias se clasifica usando la función “svmclassify(…)”, para luego generar las curvas ROC para la clasificación del conjunto de entrenamiento y del conjunto de prueba. En las Figura 3 y 4 se identifican pruebas para varios valores de penalización C para el Kernel lineal, con lo que se determinó que para C=1 se obtienen mejores resultados sin generar sobreajuste a los datos de entrenamiento, ya que la curva ROC correspondiente a la clasificación de los datos de prueba se encuentra sobre la curva ROC como se ve en la Figura 4.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~10~
Desarrollo
Para realizar la clasificación se utilizaron los comandos:
salida=svmclassify(svmStruct,pr); %clasifico datos de prueba salida_en=svmclassify(svmStruct,en); %clasifico datos del conjunto de
entrenamiento
Donde las funciones “svmclassify(…)” utilizan la estructura SVM entrenada
“svmStruct” para clasificar los datos en “pr” o “en”, respectivamente, y retornan
vectores con valor 1 para la muestra que se identifica como un dígito „8‟, y un
valor 0 para las muestras que se identifican como un dígito distinto de „8‟.
Figura 4: Curva ROC del clasificador para C=1, mejor clasificador con Kernel lineal .

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~11~
Desarrollo
Clasificador SVM con Kernel Polinomial
La función Kernel polinomial tiene la forma ( ) ( ) , lo que
permite tener un nuevo parámetro de diseño, además del parámetro C, el cual
corresponde al orden del polinomio „d‟. Cabe destacar que la función Kernel
lineal es un caso particular donde d=1.
En el archivo “svm_pol.m” se repite el proceso realizado para el clasificador
con kernel lineal, con excepción del comando utilizado para entrenar el SVM. En
este caso se utiliza el siguiente bloque de instrucciones.
%entreno el detector para kernel lineal, fijando el C y el orden del
polinomio (d). Método de %optimización "Least Squares" C=1; d=2; %debe ser entero positivo svmStruct=
svmtrain(en,en_salida,'kernel_function','polynomial','BoxConstraint',C,'met
hod','LS','Polyorder',d);
Donde se deben cambiar los valores C y d para probar distintos diseños del
SVM y probar el rendimiento mediante las curvas ROC, tal como se hizo en la
parte anterior. La parte principal del proceso de selección de los parámetros
óptimos se muestra en la Figura 6, donde se identifica que para d=4, se produce
un sobreajuste al conjunto de entrenamiento, mientras que para d=3 y d=2 se
logra un mejor rendimiento en comparación con el caso lineal. El mejor
clasificador SVM logrado corresponde a la combinación d=2, C=1, y sus curvas
ROC se muestran en la Figura 5.
Figura 5: Curvas ROC de SVM con orden= 2, C=1, mejor clasificador polinomial logrado.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~12~
Desarrollo
Figura 6: Curvas ROC para distintos valores de C, para Kernel polinomiales de distinto orden.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~13~
Desarrollo
Clasificador con Kernel Gaussiano
Finalmente, se entrenó un clasificador con un Kernel de función de base radial
(rbf) de la forma ( ) ‖ ‖
, donde el parámetro extra para diseño es .
Así, repitiendo el proceso iterativo de los casos anteriores, en el archivo
“svm_gauss.m” se cambia el bloque de entrenamiento del SVM por:
%entreno el detector para kernel gaussiano, fijando el C y el sigma. Método
de %optimización "Least Squares" C=1; sigma=2; svmStruct=svmtrain(en,en_salida,'kernel_function','rbf',…
'BoxConstraint',C,'method','LS','RBF_Sigma',sigma);
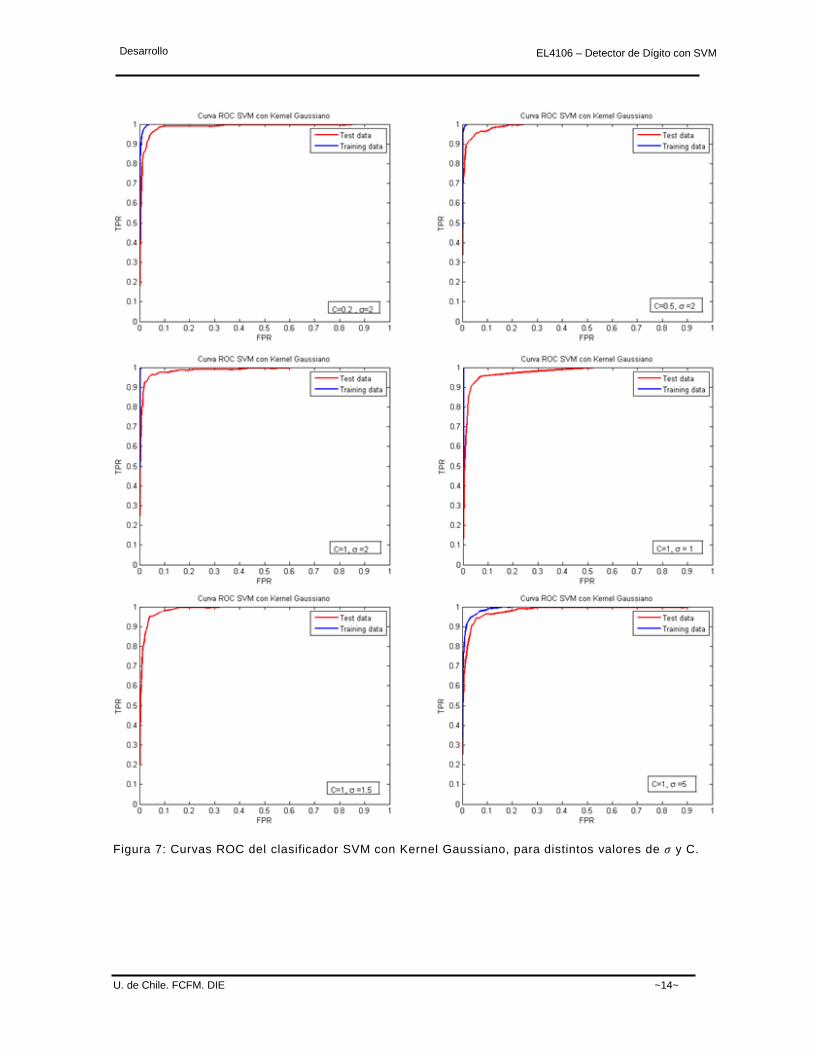
En este caso no existe una clara diferencia que permita identificar los
parámetros más convenientes. Sin embargo, en base a lo que se observa en la
Figura 7, se podría afirmar que para =2, C=1 se logra tener un punto de
operación con un TPR más elevado para un FPR pequeño, lo cual sería
conveniente en el caso de detección de dígitos. Por otro lado esta afirmación no
es imperativa, ya que la aleatoriedad de las muestras a clasificar pueden generar
variaciones que hagan ver más convenientes, según las curvas ROC, la
combinación de parámetros , C=0.2, o alguna otra.
Cabe destacar que en cualquiera de estos casos se observa una superioridad
respecto de los Kernel polinomiales, sin embargo los tiempos de entrenamiento
para el clasificador con Kernel Gaussiano aumentan considerablemente respecto
a los otros. En el caso de que se desease realizar una búsqueda más exhaustiva
de los parámetros de diseño, se requeriría mucho más tiempo en este último
caso, pero se lograrían mejores resultados.
EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~14~
Desarrollo
Figura 7: Curvas ROC del clasificador SVM con Kernel Gaussiano, para distintos valores de y C.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~15~
Desarrollo
Luego de observar los rendimientos para el clasificador SVM que permite
detectar el dígito „8‟ utilizando distintas funciones Kernel, se escoge como mejor
clasificador aquel con Kernel Gaussiano, ya que se obtiene una curva ROC para
los datos de prueba más cercana al caso de un clasificador ideal, logrando
mejores resultados de clasificación con una menor tasa de falsos positivos y
mayor tasa de verdaderos positivos.
En la Figura 8 se comparan los mejores clasificadores logrados para cada
función Kernel. Si bien el Kernel gaussiano en general supera el rendimiento de
los otros, el SVM con Kernel polinomial de orden 2 genera una curva ROC
bastante cercana al rendimiento del clasificador con Kernel gaussiano, y en un
tiempo de entrenamiento bastante menor, lo cual tiene ventajas en ciertas
aplicaciones. El clasificador con Kernel lineal posee un rendimiento claramente
menor, pero con una gran velocidad para el entrenamiento.
Figura 8: Comparación entre rendimientos según las curvas ROC de los mejores SVM logrados para
las distintas funciones Kernel probadas.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~16~
Conclusiones
3. Conclusiones
En primer lugar, luego de realizar exitosamente la implementación del detector del dígito „8‟ con la herramienta de SVM de Matlab, según las muestras de la base de datos utilizada, se puede concluir que el método estadístico de clasificación binaria Support Vector Machine, es una forma eficaz y sencilla de solucionar problemas de clasificación de dos clases. En segundo lugar, se observa que el rendimiento de una SVM está directamente relacionado con los parámetros de diseño fijados, los cuales corresponden al parámetro C de penalización, el tipo de función Kernel a utilizar y los parámetros de la misma. Se logró identificar un mejor clasificador en cada uno de los casos de SVM implementados con funciones Kernel tipo lineal, polinomial y gaussiana, identificando como la con mejor rendimiento la de tipo gaussiana, y la de mayor rapidez de entrenamiento a la de tipo lineal. Se concluye además que dependiendo de los parámetros escogidos se puede dar sobreajuste, el cual se puede observar al comparar las curvas ROC de la clasificación del conjunto de entrenamiento y del conjunto de prueba, ya que si el rendimiento del clasificador para el conjunto de prueba es menor que el de entrenamiento, se detecta el caso de sobre-entrenamiento. Finalmente, el mejor clasificador logrado durante el desarrollo de esta tarea corresponde a un SVM con función Kernel tipo gaussiana, para parámetros C=1,
, logrando una curva ROC de los datos de prueba bastante cercana al caso de un clasificador ideal.

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~17~
Anexos
4. Anexos
A continuación se muestran los códigos contenidos en cada uno de los archivos
entregados en la tarea.
“basededatos.m”
function [entren, clases_entren, prueba, clases_prueba]=
basededatos(data,clases) %[entren clases_entren, prueba, clases_prueba]= basededatos(data,clases)
recibe la matriz 'data' con los datos de %los trazos de los digitos y genera dos conjuntos representativos 'entren'
con el 80% de los datos y %'prueba' con el 20%, y dos conjuntos ('clases_entren' y 'clases_prueba')
que llevan información sobre la clase verdadera de cada muestra.
N=length(data(:,1)); nfeats=length(data(1,:)); % n° de caracteristicas nc=10; % n° de clases
%Uno los datos con las clases en una sola matriz, para asociar los %índices de las filas a cada clase distinta. newdata=[data,clases];
%ordeno y obtengo los índices de las muestras de cada clase. [aux ind]=sortrows(newdata,17); szs=zeros(1,nc); ind_bord=zeros(1,nc); %debo encontrar los indices de los que efectivamente pertenecen a cada %clase, para guardarlos en una matriz y luego separarlos. for i=1:nc auxaux=(aux(:,nfeats+1)==i-1); ind_aux=find(auxaux,1,'last'); ind_bord(i)=ind_aux; szs(i)=sum(auxaux(:)); %también calculo cuántos hay por clase. end clear auxaux;
%Se quiere 20% de los datos por cada clase para el conjunto de prueba pr_szs=round(szs.*0.2); ind_bord_pr=cumsum(pr_szs);%esto me sirve para saber cuántos datos
seleccionar por cada clase en las iteraciones. sz_prueba=sum(pr_szs); %tamaño total del conjunto de prueba. prueba=zeros(sz_prueba,nfeats+1); r_vec=zeros(sz_prueba,1); %vector que tendrá los indices seleccionados.
%Selección de datos de prueba (20% por cada clase)
%primera iteración

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~18~
Anexos
for i=1:ind_bord_pr(1) r=randi([1 ind_bord(1)]); while(find(r_vec==ind(r))) %selecciono un indice al azar dentro
del rango de la clase '0'. % y me aseguro que sea distinto a
alguno seleccionado. r=randi([1 ind_bord(1)]); end prueba(i,:)=newdata(ind(r),:); %guardo los datos y la clase a la que
pertenece el dato elegido en el conjunto de prueba r_vec(i)=ind(r); %guardo el indice para luego borrar ese dato del
conjunto y que lo que quede sea el de entrenamiento end % repito para el resto de las clases. for j=2:nc for i=(ind_bord_pr(j-1)+1):ind_bord_pr(j) r=randi([(ind_bord(j-1)+1) ind_bord(j)]); while(find(r_vec==ind(r))) r=randi([(ind_bord(j-1)+1) ind_bord(j)]); end prueba(i,:)=newdata(ind(r),:); r_vec(i)=ind(r); end end prueba2 = prueba(randperm(length(prueba(:,1))),:); %desordeno las
filas prueba=prueba2; clear prueba2;
%extraigo del conjunto original los datos utilizados para el conjunto de
prueba entren=newdata; entren(r_vec,:)=[]; sz_entren=length(entren(:,1));
%Verificar representatividad
%calculo cantidad de datos por clase en cada conjunto [aux ind]=sortrows(prueba,17); [aux2 ind2]=sortrows(entren,17); ver_szs_prueba=zeros(1,nc); ver_szs_entren=zeros(1,nc); for i=1:nc auxaux=(aux(:,nfeats+1)==i-1); auxaux2=(aux2(:,nfeats+1)==i-1); ver_szs_prueba(i)=sum(auxaux(:)); %calculo cuántos datos hay por clase
en el conjunto de prueba construido. ver_szs_entren(i)=sum(auxaux2(:)); %y cuántos por clase en el conjunto
de entrenamiento end clear auxaux; clear auxaux2; %verifico proporciones parecidas por clase en ambos conjuntos. (DESCOMENTAR %PARA VERIFICAR)

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~19~
Anexos
% repr_total=szs./N % repr_prueba=ver_szs_prueba./sz_prueba % repr_entren=ver_szs_entren./sz_entren
%verifico proporción 80/20 de los datos en cada conjunto.
% sz_entren/N % sz_prueba/N
%Separo datos de información sobre la clase a la que pertenece cada uno.
clases_entren = entren(:,17); entren(:,17)=[]; clases_prueba = prueba(:,17); prueba(:,17)=[];

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~20~
Anexos
“svm_lin.m”
close all; clear all; load BaseDatosTarea3 [en en_c pr pr_c]=basededatos(trazos,numero);
%digito escogido: 8 pr_salida=(pr_c==8); %muestra un 1 si la salida corresponde al
digito 8 y un 0 si no en_salida=(en_c==8);
%entreno el detector para kernel lineal, fijando el C. Método de %optimización "Least Squares" C=1; svmStruct=
svmtrain(en,en_salida,'kernel_function','linear','BoxConstraint',C,'method'
,'LS');
%obtengo el bias generado por el metodo svmtrain b=svmStruct.Bias;
%realizo clasificaciones para distintos bias cercanos al inicial bias=b-5:0.05:b+5; true1=zeros(length(bias),1); true0=zeros(length(bias),1); TPR=zeros(length(bias),1); FPR=zeros(length(bias),1); true1_en=zeros(length(bias),1); true0_en=zeros(length(bias),1); TPR_en=zeros(length(bias),1); FPR_en=zeros(length(bias),1);
for j=1:length(bias) svmStruct.Bias=bias(j); %asigno el nuevo bias a la estructura
SVM salida=svmclassify(svmStruct,pr); %clasifico datos de prueba salida_en=svmclassify(svmStruct,en); %clasifico datos del conjunto
de entrenamiento for i=1:length(salida) %calculo total de verdaderos
positivos y negativos if pr_salida(i)==1 true1(j)=true1(j)+1; end if pr_salida(i)==0 true0(j)=true0(j)+1; end if salida(i)==1 && pr_salida(i) ==1 %calculo TPR y FPR para cada
caso TPR(j)=TPR(j)+1; end if salida(i)==1 && pr_salida(i) == 0 FPR(j)=FPR(j)+1;

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~21~
Anexos
end end for i=1:length(salida_en) %repito para clasificacion de datos
de entrenamiento if en_salida(i)==1 true1_en(j)=true1_en(j)+1; end if en_salida(i)==0 true0_en(j)=true0_en(j)+1; end if salida_en(i)==1 && en_salida(i) ==1 TPR_en(j)=TPR_en(j)+1; end if salida_en(i)==1 && en_salida(i) == 0 FPR_en(j)=FPR_en(j)+1; end end end
%calculo las tasas TPR y FPR TPR=TPR./true1; FPR=FPR./true0; TPR_en=TPR_en./true1_en; FPR_en=FPR_en./true0_en; %grafico curvas ROC figure plot(FPR,TPR,'r','LineWidth',1.5) title('Curva ROC SVM con Kernel Lineal') xlabel('FPR') ylabel('TPR') hold on plot(FPR_en,TPR_en,'LineWidth',1.5) legend('Test data','Training data')
“svm_pol.m”
close all; clear all; load BaseDatosTarea3 [en en_c pr pr_c]=basededatos(trazos,numero); %digito escogido: 8 pr_salida=(pr_c==8); en_salida=(en_c==8);
%entreno el detector para kernel lineal, fijando el C y el orden del
polinomio (d). Método de %optimización "Least Squares" C=1; d=2; %debe ser entero positivo svmStruct=
svmtrain(en,en_salida,'kernel_function','polynomial','BoxConstraint',C,'met
hod','LS','Polyorder',d); %obtengo el bias generado por el metodo svmtrain

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~22~
Anexos
b=svmStruct.Bias;
%realizo clasificaciones para distintos bias cercanos al inicial bias=b-5:0.05:b+5; true1=zeros(length(bias),1); true0=zeros(length(bias),1); TPR=zeros(length(bias),1); FPR=zeros(length(bias),1); true1_en=zeros(length(bias),1); true0_en=zeros(length(bias),1); TPR_en=zeros(length(bias),1); FPR_en=zeros(length(bias),1);
for j=1:length(bias) svmStruct.Bias=bias(j); %asigno el nuevo bias a la estructura
SVM salida=svmclassify(svmStruct,pr); %clasifico datos de prueba salida_en=svmclassify(svmStruct,en); %clasifico datos del conjunto
de entrenamiento for i=1:length(salida) %calculo total de verdaderos
positivos y negativos if pr_salida(i)==1 true1(j)=true1(j)+1; end if pr_salida(i)==0 true0(j)=true0(j)+1; end if salida(i)==1 && pr_salida(i) ==1 %calculo TPR y FPR para cada
caso TPR(j)=TPR(j)+1; end if salida(i)==1 && pr_salida(i) == 0 FPR(j)=FPR(j)+1; end end for i=1:length(salida_en) %repito para clasificacion de datos
de entrenamiento if en_salida(i)==1 true1_en(j)=true1_en(j)+1; end if en_salida(i)==0 true0_en(j)=true0_en(j)+1; end if salida_en(i)==1 && en_salida(i) ==1 TPR_en(j)=TPR_en(j)+1; end if salida_en(i)==1 && en_salida(i) == 0 FPR_en(j)=FPR_en(j)+1; end end end
%calculo las tasas TPR y FPR TPR=TPR./true1;

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~23~
Anexos
FPR=FPR./true0; TPR_en=TPR_en./true1_en; FPR_en=FPR_en./true0_en; %grafico curvas ROC figure plot(FPR,TPR,'r','LineWidth',1.5) title('Curva ROC SVM con Kernel Polinomial') xlabel('FPR') ylabel('TPR') hold on plot(FPR_en,TPR_en,'LineWidth',1.5) legend('Test data','Training data')
“svm_gauss.m”
close all; clear all; load BaseDatosTarea3 [en en_c pr pr_c]=basededatos(trazos,numero); %digito escogido: 8 pr_salida=(pr_c==8); en_salida=(en_c==8);
%entreno el detector para kernel gaussiano, fijando el C y el sigma. Método
de %optimización "Least Squares" C=1; sigma=2; svmStruct=
svmtrain(en,en_salida,'kernel_function','rbf','BoxConstraint',C,'method','L
S','RBF_Sigma',sigma);
%obtengo el bias generado por el metodo svmtrain b=svmStruct.Bias;
%realizo clasificaciones para distintos bias cercanos al inicial bias=b-5:0.05:b+5; true1=zeros(length(bias),1); true0=zeros(length(bias),1); TPR=zeros(length(bias),1); FPR=zeros(length(bias),1); true1_en=zeros(length(bias),1); true0_en=zeros(length(bias),1); TPR_en=zeros(length(bias),1); FPR_en=zeros(length(bias),1); for j=1:length(bias) svmStruct.Bias=bias(j); %asigno el nuevo bias a la estructura
SVM salida=svmclassify(svmStruct,pr); %clasifico datos de prueba salida_en=svmclassify(svmStruct,en); %clasifico datos del conjunto
de entrenamiento

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~24~
Anexos
for i=1:length(salida) %calculo total de verdaderos
positivos y negativos if pr_salida(i)==1 true1(j)=true1(j)+1; end if pr_salida(i)==0 true0(j)=true0(j)+1; end if salida(i)==1 && pr_salida(i) ==1 %calculo TPR y FPR para cada
caso TPR(j)=TPR(j)+1; end if salida(i)==1 && pr_salida(i) == 0 FPR(j)=FPR(j)+1; end end for i=1:length(salida_en) %repito para clasificacion de datos
de entrenamiento if en_salida(i)==1 true1_en(j)=true1_en(j)+1; end if en_salida(i)==0 true0_en(j)=true0_en(j)+1; end if salida_en(i)==1 && en_salida(i) ==1 TPR_en(j)=TPR_en(j)+1; end if salida_en(i)==1 && en_salida(i) == 0 FPR_en(j)=FPR_en(j)+1; end end end
%calculo las tasas TPR y FPR TPR=TPR./true1; FPR=FPR./true0; TPR_en=TPR_en./true1_en; FPR_en=FPR_en./true0_en; %grafico curvas ROC figure plot(FPR,TPR,'r','LineWidth',1.5) title('Curva ROC SVM con Kernel Gaussiano') xlabel('FPR') ylabel('TPR') hold on plot(FPR_en,TPR_en,'LineWidth',1.5) legend('Test data','Training data')

EL4106 – Detector de Dígito con SVM
U. de Chile. FCFM. DIE ~25~
Bibliografía
5. Bibliografía
Presentación “EL4106 - Inteligencia Computacional - SVMJRS”- Otoño 2014.
Presentación “EL4106 – Inteligencia Computacional – Performance
Evaluation” – Otoño 2014.
Centro de documentación de Mathworks, Sección de Support Vector
Machine: http://www.mathworks.com/help/stats/support-vector-machines-
svm.html
















![T5ICISis0506.ppt [Modo de compatibilidad]ma1.eii.us.es/miembros/narro/icis/diario_archivos/T5ICISis0506.pdf · Método de los multiplicadores de Lagrange. ... Una de las aplicaciones](https://static.fdocuments.co/doc/165x107/5baacca909d3f215608d07ae/modo-de-compatibilidadma1eiiusesmiembrosnarroicisdiarioarchivost5icisis0506pdf.jpg)

