
material teoria1 2011-12 - Alojamientos Universidad de ... · PDF filePrimera parte Esquemas...
57
Material Docente de Econometría Curso 2011-2012. Primera parte Esquemas de teoría Cuarto curso de Economía Cuarto curso de Administración y Dirección de Empresas Cuarto curso de Derecho y A.D.E Profesores: Jesús Cavero Álvarez Helena Corrales Herrero Yolanda González González Carmen Lorenzo Lago Mercedes Prieto Alaiz Pilar Zarzosa Espina
Transcript of material teoria1 2011-12 - Alojamientos Universidad de ... · PDF filePrimera parte Esquemas...

Material Docente de
Econometría Curso 2011-2012. Primera parte
Esquemas de teoría
Cuarto curso de Economía Cuarto curso de Administración y Dirección de Empre sas
Cuarto curso de Derecho y A.D.E
Profesores: Jesús Cavero Álvarez
Helena Corrales Herrero Yolanda González González
Carmen Lorenzo Lago Mercedes Prieto Alaiz Pilar Zarzosa Espina


Material Docente de Econometría
Primera parte
Curso 2011-2012
Introducción............................................................................................... 1
Tema 1.- El modelo de regresión lineal clásico I ..................................... 5
Tema 2.- El modelo de regresión lineal clásico II ................................... 17
Tema 3.- Predicción .................................................................................. 21
Tema 4.- Variables ficticias ...................................................................... 25
Tema 5.- Errores de especificación ........................................................... 31
Tema 6.- Multicolinealidad ..................................................................... 41
Anexo ........................................................................................................ 47


Econometría Curso 2011-2012
1
INTRODUCCIÓN Concepto de Econometría En sentido literal “Econometría” significa “medición de la economía”.
A lo largo del tiempo se han formulado diversas definiciones del concepto de Econometría. La primera, formulada por Frisch a finales de los años 20, definía la Econometría como la ciencia que combina la Tª Económica, las Matemáticas y la Estadística, con el objeto de medir los fenómenos económicos. Entre las más recientes podríamos quedarnos con la de Maddala que define la Econometría como “la aplicación de métodos estadísticos y matemáticos al análisis de los datos económicos, con el propósito de dar un contenido empírico a las teorías económicas y verificarlas o refutarlas”.
Podemos considerar que los objetivos de la Econometría son: • Explicar el comportamiento de una o de varias variables económicas en función
de otras. • Predecir el comportamiento de las variables económicas. • Contrastar hipótesis de interés económico.
Modelos Económicos y Modelos Econométricos Un modelo económico es la expresión matemática simplificada de una determinada teoría económica. Ejemplos:
- Si queremos especificar que la cantidad demandada de un bien depende del precio de dicho bien, podremos formular una función matemática, lineal o no, entre la cantidad demandada y el precio. Así, si la relación es lineal la función de demanda será : Dt = α + βPt.
- El consumo según la teoría keynesiana es función de la renta por lo que la función de consumo podría expresarse: Ct = α + βRt.
Estos modelos son deterministas.
Un modelo econométrico es un modelo económico con las especificaciones necesarias para su tratamiento empírico. Así, en el ejemplo de la función de demanda el modelo econométrico sería Dt = α + βPt + εt y en la de consumo Ct = α + βRt+ εt, donde εt es una variable aleatoria. Con su introducción el fenómeno económico se concibe como un fenómeno aleatorio. Esta variable que llamaremos perturbación aleatoria dota al modelo de un mayor realismo ya que con ella aceptamos la incertidumbre existente en cualquier comportamiento social.
Otros motivos adicionales para incorporar la perturbación aleatoria son:
1) Es imposible especificar todos los factores causales que intervienen en el fenómeno. En el ejemplo del consumo: número de hijos, lugar de residencia, nivel cultural, etc.
2) En ocasiones, aunque conozcamos todos los factores causales, algunos no serán cuantificables o serán de cuantificación difícil. En el ejemplo del consumo, los gustos constituyen un factor que influye en el consumo, pero es de difícil cuantificación.
3) Para recoger los posibles errores de observación que podríamos cometer.

Econometría Curso 2011-2012
2
Elementos constitutivos de un modelo econométrico La forma general de presentar un modelo econométrico será: Yt =β0 +β1X1t +β2X2t +β3X3t +…..+βkXkt +εt
Los elementos constitutivos de un modelo econométrico son por tanto: parámetros y variables.
Parámetros: son las constantes del modelo que nos permiten cuantificar las relaciones entre las variables y que trataremos de estimar mediante métodos estadísticos. Son los coeficientes del modelo y recogen la estructura del modelo.
Variables: pueden ser de dos tipos: variables observables y variables no observables.
• Variables observables: (Yt, X1t, X2t, X3t,…..Xkt). Pueden ser endógenas o predeterminadas
* Variables endógenas: son aquellas cuyo comportamiento se pretende explicar con el modelo. (Yt). En el ejemplo del consumo sería Ct. En los modelos uniecuacionales hay una sola variable endógena, que figura como variable dependiente o “regresando”. En los modelos multiecuacionales hay tantas variables endógenas como ecuaciones.
* Variables predeterminadas: son las variables explicativas del modelo. (X1t, X2t, X3t,…..Xkt). En el ejemplo del consumo sería Rt. En los modelos uniecuacionales figuran como variables independientes y se suelen llamar regresores. Pueden ser variables exógenas puras o variables endógenas retardadas.
o Variables exógenas puras: son las que se determinan fuera del modelo. En el ejemplo Rt.
o Variables endógenas retardadas: son variables endógenas pero que aparecen en periodos de tiempo anteriores al del modelo. En el ejemplo Ct-1.
{ { tttt CRC εβββ +++= −
retardada endógena V.
pura exógena V.
1210
• Variables no observables: son variables para las cuales no podemos obtener observaciones. Son variables aleatorias con propiedades probabilísticas bien definidas, que se denominan “perturbaciones aleatorias” y recogen aquéllo que no es posible especificar explícitamente dentro de las variables explicativas del modelo.
Etapas en la elaboración de un modelo econométrico 1) Especificación del modelo: se trata de expresar la relación propuesta por la Teoría Económica en un lenguaje matemático, determinando las variables a introducir y la función que las relaciona, así como las distintas hipótesis sobre todas las variables del modelo. 2) Elección y tratamiento de los datos Estas dos etapas van muy unidas pues especificamos el modelo y elegimos los datos pero también la disposición de los datos nos permite especificar mejor el modelo.

Econometría Curso 2011-2012
3
3) Estimación: consiste en obtener estimadores de los parámetros a partir de los datos disponibles. 4) Evaluación y Contrastación: En esta fase se realizan diferentes contrastes con el fin de conocer si tanto las hipótesis estadísticas, como las económicas son coherentes con los datos disponibles. 5) Predicción: en esta fase se obtienen valores futuros de la variable dependiente, en base a valores conocidos de las variables explicativas. Clasificación de los modelos econométricos
Según los diferentes criterios que se pueden utilizar, existen múltiples clasificaciones de modelos econométricos. Entre ellas las siguientes:
1er criterio: según el número de ecuaciones • Modelos uniecuacionales. Ejemplo: Ct = α + βRt+ εt • Modelos multiecuacionales. Ejemplo: si al modelo uniecuacional de consumo
añadimos otra ecuación como por ejemplo Rt = Ct + It donde It
sería la inversión, tendremos un modelo multiecuacional: 2º criterio: atendiendo a la forma funcional • Modelos lineales. Ejemplo: Ct = α + βRt+ εt • Modelos no lineales. Ejemplo: la función de producción de Cobb-Douglas Pt =
teKAL ttεββ 21
3er criterio: atendiendo al periodo de tiempo al que estén referidas las variables • Modelos estáticos: están especificados para un momento de tiempo determinado.
Ejemplo: Ct = α + βRt+ εt • Modelos dinámicos: en ellos aparece alguna variable retardada. Ejemplo: Ct =
β0 + β1Rt + β2Ct-1 + εt
Clasificación de los datos Para que el modelo econométrico sea operativo necesitamos conocer los valores numéricos de sus parámetros y para ello hemos de disponer de un conjunto de datos sobre las variables.
Los datos pueden ser de tres tipos: datos temporales, datos de corte transversal y datos de panel.
• Datos temporales o series temporales: son observaciones de una variable, para una unidad económica a lo largo del tiempo. Ejemplos: datos de la Contabilidad Nacional, indicadores de coyuntura mensuales o trimestrales, ventas de una empresa a lo largo del tiempo, etc.
• Datos atemporales o de corte transversal: son observaciones de una variable, para distintas unidades económicas en un momento de tiempo dado. Ejemplo: Encuesta de Presupuestos Familiares (INE) en el período 90-91, en la que se ha entrevistado a más de 20.000 familias.
• Datos de panel: son observaciones de una variable para distintas unidades económicas a lo largo del tiempo, es decir, es la combinación de datos temporales y de corte transversal.
Ct = α + βRt+ εt
Rt = Ct + It
Econometría Curso 2011-2012
4

Econometría Curso 2011-2012
5
TEMA 1.-EL MODELO DE REGRESIÓN LINEAL CLÁSICO I
1.1.- Especificación del modelo
• Forma escalar : ikikioi XXY εβββ ++++= .....11 para i =1….N
iii XY εβ += '
• Forma matricial: εβ += XY
Donde: Y=
NY
Y
Y
.
.2
1
, X=
kNN
k
k
XX
XX
XX
..1
.....
.....
..1
..1
1
212
111
,
=
Nε
εε
ε.
.2
1
Hipótesis Clásicas:
• Linealidad en los parámetros
• ( )IN 2,0 σε → o ( )IXNY 2,σβ→ por tanto ε o Y son variables iid
• X no aleatoria
• rg(X) = k+1 < N
1.2.- Estimación Mínimo Cuadrática Ordinaria
Objetivo: Obtener estimadores de los parámetros 2σβ y
Método: Mínimos Cuadrados Ordinarios
• Función Objetivo a minimizar: )ˆ(')ˆ('2 ββ XYXYeeei −−==∑
βββββββ ˆ''ˆˆ'2'ˆ''ˆ''ˆˆ''' XXXYYYXXYXXYYYee +−=+−−=
• Condiciones de mínimo:
1ª Condición : 0ˆ' =
∂∂
βee
2ª Condición : 'ˆˆ
'2
ββ ∂∂
∂ eesea definida positiva
• Obtención del estimador MCO:
0ˆ'2'2ˆ
'=+−=
∂
∂β
βXXYX
ee ⇒ YXXX 'ˆ' =β Sistema de ecuaciones normales
⇒ ( ) YXXX ''ˆ 1−=β

Econometría Curso 2011-2012
6
XXee
'2'ˆˆ
'2
=∂∂
∂
ββ matriz definida positiva
Por tanto: ⇒ ( ) YXXXMCO ''ˆ 1−=β
1.3.- Propiedades del estimador de β
• Finitas
- Lineal en Y y en ε : por ser X no aleatoria
- Insesgado: ( ) ββ =ˆE por ser X no aleatoria y ( ) 0=εE
( ) ( ) ( )εββ EXXXE ''ˆ 1−+=
- Òptimo: de mínima varianza dentro de la familia de estimadores lineales e insesgados. Cuya matriz de varianzas covarianzas es:
( ) ( )( ) ( )( )'ˆˆ'ˆˆ ˆˆ)ˆ(ˆ ββββββ ββββ −−=∑ −−= EEEE =
= ( ) ( ) ( ) 1211 ''''' −−− = XXXXXXXXE σεε
Teorema de Gauss Markov demuestra que:
∑ +∑ = ββ σββ ˆˆ '~~ 2 DD donde ( ) XXXCD ′−= −1'''
siendo C’ una matriz cualquiera no aleatoria y DD' una matriz semidefinida positiva.
- Eficiente: de mínima varianza entre los insesgados. Alcanza la cota de Cramer Rao.
- Distribución finita: ( )( )12 ',ˆ −→ XXNMCO σββ
• Asintóticas
- Consistente : Si se cumple P= XXΣ = 0;'
lim ≠∞→ PN
XXN y finita, entonces:
- ββ → ..ˆ pcMCO o bien ββ =∞→
ˆlim Np
βεββ =
+= ∞→
−
∞→∞→∞→ N
Xp
N
XXppp NNNN
'lim
'limlimˆlim
1
ya que: 0'
lim =∞→ N
Xp N
ε
- Asintóticamente normal : ( )
→−−
∞→
12 'lim,0ˆ
N
XXNN N
a σββ
- Asintóticamente eficiente : La varianza asintótica alcanza la cota de Cramer-Rao.

Econometría Curso 2011-2012
7
1.4.- Estimador de 2σ y sus propiedades
Denotamos por S2 el estimador de la varianza de las perturbaciones σ2
• Definimos 1
'2
−−=
KN
eeS
• Propiedades:
- Insesgado: E(S2) = σ2
Consistente: 22lim σ=∞→ SpN
• Propiedades del estimador de ∑ ββ ˆˆ
( ) 12ˆˆ ' −= XXSS
ββ
- Insesgado : ( ) ∑== −ββββˆˆ
12ˆˆ ' XXSESE
1.5.- Características de los residuos mínimo cuadráticos
• Poblacionales: e=Mε
Ya que: εβ MMYXYYYe ==−=−= ˆˆ
βˆ XY =
( ) '1' XXXXIM −−= matriz no aleatoria, simétrica e idempotente
- E(e)=0
- ( ) IMee MMEEee 22' ''' σσεε ≠=∑ == si N→∞ M→I
- ( ) 0' =eXE
- ( )MNe 2,0→ σ
• Muestrales:
- 0' =eX ⇒
( ) YXYXYYX ˆ''ˆ −=−′ ⇒ YY ˆ= si XNx(k+1)
∑ ==
N
i ie1
0 ⇒ 0=e si XNx(k+1)
kjeX iji ....10 =∑ ∀= ⇒ cov(e, Xj)=0 ⇒ 0=jexr
- 0'ˆ =eY ⇒ cov( 0),ˆ =eY ⇒ 0ˆ =Ye
r

Econometría Curso 2011-2012
8
1.6.- Descomposición de la varianza
( )∑ ∑ −=−222
YNYYiY i
( ) ( )∑ +=++== eeYYeYeYYYYi 'ˆ'ˆˆ'ˆ'2
Restando a ambos lados : 2
YN
( ) ( ) ( )∑ ∑ −+−∑ =−222 ˆˆ eeYYYY iii si YY ˆ=
SCT=SCE+SCR
Coeficientes de determinación R2 y de determinación ajustado
SCT
SCE
SCT
SCRR =−= 12 1 R 0 2 ≤≤
1/
1/1
2
−−−−=
NSCT
kNSCRR
1.7.- Estimadores máximo verosímiles de los parámetros
El método de máxima verosimilitud consiste en hallar los estimadores que maximizan la función de verosimilitud.
La función de verosimilitud de la muestra es, simplemente, la función de densidad conjunta de la muestra haciéndola depender de los parámetros desconocidos.
Puesto que Y es una variable normal N-dimensional : ( )IXNY 2,σβ→
su función de densidad y, por lo tanto, la función de verosimilitud es:
=
−−−−
))`((22
1
222)(
ββσπσ
XYXY
eN
Yf
dado que max ( )2,σβL es lo mismo que max ( )2,ln σβL
( ) ( ) ( )ββσ
σπσβ XYXYNNL −−−−−=
'
2
1ln2
2ln2
,ln2
22
( )
+−−−−=
βββ
σσπσβ XXXYYYNNL '''2'
2
1ln2
2ln2
,ln2
22
Condiciones de máximo:
1ª condición: Se igualan a cero las primeras derivadas
• ( ) 0ˆ'2'2ˆ2
1ln2
=+−−=∂
∂MV
MV
XXYXL β
σβ ⇒
MVXXYX β'' =
por tanto ( )MCOMV
YXXX ββ ˆ''ˆ 1 == −

Econometría Curso 2011-2012
9
• 0)ˆ(2
)ˆ(')ˆ(2
ˆ2
ln22222
=−−
+−=∂
∂
MV
MVMV
MV
XYXYNL
σ
ββ
σσ
⇒ Nee
MV
'ˆ 2 =σ
2ª condición: Se cumple que el hessiano evaluado en el máximo es una matriz definida negativa.
Propiedades de los estimadores
Bajo condiciones de regularidad se demuestra que los EMV tienen las siguientes propiedades:
• Asintóticamente insesgados
• Consistentes
• Asintóticamente eficientes
• Asintóticamente normal
• Invarianza
1.8.- Criterios de bondad del ajuste basados en la función de verosimilitud
1) Análisis de la función de verosimilitud evaluada en los EMV de los parámetros
( ) ( ) ( )MVMV
MV
MVXYXYNNL ββ
σσπσβ ˆ'ˆ
ˆ2
1ˆln2
2ln2
,ln2
22 −−−−−=
( )2
ln2
2ln2
,ln2
2 N
N
eNNL i −−−=
∑πσβ
No está acotado y está influido por el número de variables explicativas que introduzcamos en el modelo.
2) Criterio de Akaike AIC y Criterio de información bayesiano de Schwartz SBIC
AIC = N
kL
N
)1(2ln
2 ++−
SBIC =N
NkL
N
ln)1(ln
2 ++−
Cuanto menor sean estos estadísticos mejor será la estimación del modelo.

Econometría Curso 2011-2012
10
1.9.- Diferencias entre la regresión simple y la regresión múltiple
1) Los coeficientes son diferentes
• ikikioi XXY εβββ ++++= .....11
• *ii1
*1
*0i XY εββ ++=
En el primer modelo,1β mide en cuánto varía la variable endógena cuando varía X1 en una
unidad, manteniendo constante el resto de las variables. En el segundo modelo, *1β mide en cuánto varía la variable endógena cuando varía X1 en una unidad
2) Los coeficientes estimados por MCO son diferentes La información que proporciona un regresor, por ejemplo X1, sobre la variable endógena puede ser parecida a la que tienen el resto de las variables. De hecho, la información de X1 puede ser genuina de la propia variable o compartida con el resto de las variables explicativas. Cuando estimamos por mínimos cuadrados ordinarios un modelo de regresión simple el estimador asociado a X1 solamente recoge el efecto de la información propia de X1, ya que no están incluidos otros regresores. La importancia de la regresión múltiple es que el estimador por mínimos cuadrados ordinarios asociado a X1 es capaz de medir el efecto de X1 una vez descontada la información que comparte con el resto de los regresores.
3) Las varianzas estimadas de los coeficientes son diferentes
Existen dos casos especiales en los que el coeficiente estimado por MCO asociado a X1 será el mismo en la regresión simple que en la regresión conjunta.
1) Cuando no exista información compartida (regresores ortogonales) 2) Cuando los coeficientes asociados al resto de los regresores sean cero.
Econometría Curso 2011-2012
11
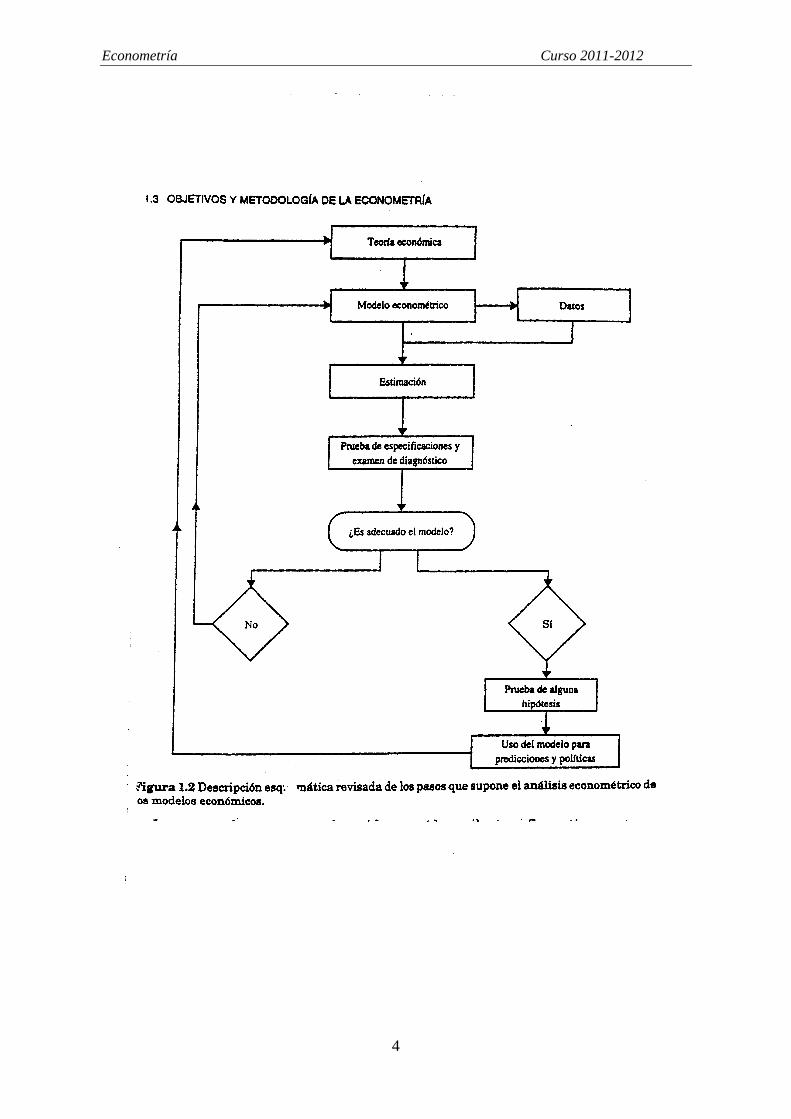
Apéndice 1.- Gráfico de algunas hipótesis del modelo

Econometría Curso 2011-2012
12
Apéndice 2.- Modelo de regresión sin término constante
Yi = β1X1i +β2X2i +β3X3i +…..+βkXki +εi con i=1,2,3,....N
Matricialmente se podría expresar:
Y = X*β* + εεεε donde X* es la matriz de orden Nxk
X =
4444 34444 21L
MMMM
L
L
M
*
21
22212
12111
1
1
1
X
kNNN
k
k
XXX
XXX
XXX
*ˆMCOβ = YXXX '
*1
*'* )( − tiene buenas propiedades y no hay ningún problema por lo que
respecta a las propiedades de los estimadores, pero se dejan de cumplir algunas características que se daban en el modelo con término constante.
ββ ˆˆS = S2( *'* XX )-1 donde
kN
eeS
−= '2
*ˆMCOβ =
=
∑
∑
∑
∑∑∑
∑∑∑
∑∑∑
=
=
=
−
===
===
===
*
*2
*1
1
12
11
1
1
2
12
11
12
1
22
112
11
121
1
21
ˆ
ˆ
ˆ
kN
iiki
N
iii
N
iii
N
iki
N
iiki
N
iiki
N
ikii
N
ii
N
iii
N
ikii
N
iii
N
ii
YX
YX
YX
XXXXX
XXXXX
XXXXX
β
ββ
MM
L
MMMM
L
L
Particularidades de estos modelos:
1) Los estimadores obtenidos con datos centrados no coinciden con los obtenidos con datos sin centrar ya que si trabajamos con datos centrados en un modelo sin término constante obtenemos los mismos estimadores que si trabajásemos con datos centrados en el modelo con término constante. Lo más correcto en estos modelos es trabajar con datos sin centrar.
2) Ya no se cumple que YY =ˆ pues al no disponer X* de una columna de unos no se
cumple que ∑∑==
=N
ii
N
ii YY
11
ˆ y por lo tanto YY ≠ˆ
3) Aunque se sigue cumpliendo que los regresores son ortogonales a los residuos '*X e = 0,
ya no se cumple que los errores estén linealmente incorrelacionados porque no se cumple que ∑ = 0ie .
4) No se cumple la descomposición de la varianza y por lo tanto el R2 no tiene sentido porque nunca estaría acotado SCT ≠ SCR+SCE
Sí se sigue cumpliendo Y’Y = Y ’ Y + e’e

Econometría Curso 2011-2012
13
En este caso lo único que se puede hacer es definir un 2*R como:
Y'Y
Y'Y
Y'Y
e'e1R2
* =−= que
sí estará acotado, pero que en realidad no medirá la variabilidad de Y porque Y’Y no es la SCT, simplemente nos dará una idea de como ha sido el ajuste. El R2 de un modelo con término constante y el 2*R del modelo sin término constante no son comparables.
Apéndice 3.- Cambios de origen y escala en las variables En ocasiones nos interesa cambiar las unidades de una, varias o todas las variables del modelo para hacer sus valores numéricos comparables con las demás variables o para que su manejo sea menos engorroso.
Otras veces necesitamos hacer un cambio de origen en los valores de las variables.
Analizaremos, a continuación, los efectos que, sobre la estimación de un modelo, generan esos cambios.
Cambio de escala
Sea el modelo: Yi = β0 +β1X1i +β2X2i +β3X3i +…..+βkXki +εi con i=1,2,3,....N
Supongamos que hacemos un cambio de escala en todas las variables pasando a tener:
ii aYY ='
ii XaX 11'1 =
................
kikki XaX ='
Ahora el modelo será: ikikii XXY εβββ ++++= '''1
'1
'0
' ...
Sustituyendo: ikikkii XaXaaY εβββ ++++= '11
'1
'0 ...
a
Xa
aX
a
a
aY i
kik
kiiεβββ
++++= '1
1'1
'0 ...
donde aiε
cumple las hipótesis clásicas.
Luego 0'0
'0 ββββ a
ao =⇒=
11
'1
1'1
1 ββββa
a
a
a=⇒=
.........................................
kk
kkk a
a
a
a ββββ =⇒= '1
'
Estos son los cambios que experimentan los coeficientes cuando hacemos un cambio de escala en todas las variables.
Por lo tanto:

Econometría Curso 2011-2012
14
• Si hacemos un cambio de escala sólo en Yi ( kaa ,...,1 serán igual a 1) los nuevos
coeficientes son los originales multiplicados por la constante por la que hayamos multiplicado los valores de Y.
• Si hacemos un cambio de escala sólo en Xjt sólo cambia el coeficiente que acompaña a Xjt y lo hace dividiendo el original entre ja .
Otros resultados que también cambian son:
• La SCR. La nueva es eeaee '2**' = .
• La SCT. La nueva es SCT*=2a SCT.
• La varianza estimada de los jβ : 2ˆ2
2*2
ˆ *jj
Sa
aS
jββ =
2ˆ
2*2ˆ
0*0 ββ SaS =
Cambio de origen
Sea el modelo: Yi = β0 +β1X1i +β2X2i +β3X3i +…..+βKXKi +εi con i=1,2,3,....N
Supongamos que hacemos un cambio de origen en todas las variables pasando a tener:
aYY ii +='
11'1 aXX ii +=
................
kkiki aXX +='
Ahora el modelo será: ikikii XXY εβββ ++++= '''1
'1
'0
' ...
Sustituyendo: ( ) ( ) ikkikii aXaXaY εβββ ++++++=+ '11
'1
'0 ...
ikikikki XXaaaY εβββββ ++++++++−= '1
'1
'1
'1
'0 ......
1'1 ββ =
...................
kk ββ ='
kkaaa '1
'1
'00 ... ββββ ++++−= ⇒ kk aaa ββββ ++++−= ...11
'00 ⇒
kk aaa ββββ −−−+= ...110'0
Luego los cambios de origen en alguna o en todas las variables del modelo sólo afectan al término independiente.
El único resultado que también cambia es la varianza estimada de 0β .

Econometría Curso 2011-2012
15
Apéndice 4.- Coeficientes Beta1
Los parámetros estimados de un modelo lineal son valores absolutos y dependen de las unidades de medida en las que se expresen las variables del modelo.
Una variable no es más importante que otra por tener un parámetro mayor. Esto ocurre cuando, siendo ambos parámetros significativos, ambas variables están medidas en las mismas unidades.
Una solución a este problema es calcular unos coeficientes estandarizados o coeficientes beta a partir de la normalización de las variables (restarles su media y dividirles por su desviación típica)
i
k
uS
XX
S
XX
S
YY
X
kkik
X
i
Y
i +−
++−
=− *11*
1 ...1
ββ
donde la relación entre los coeficientes beta y los coeficientes estimados originales es:
Y
Xjj S
Sjββ ˆˆ * = .
1 Pulido (2001): Modelos econométricos. Pirámide.

Econometría Curso 2011-2012
16

Econometría Curso 2011-2012
17
TEMA 2. EL MODELO DE REGRESIÓN LINEAL CLÁSICO II
2.1.- Contrastes de restricciones lineales sobre los parámetros. Forma general
Hipótesis a contrastar:
rRH o =β:
rRH ≠β:1
Partiendo de la distribución de las perturbaciones y de los estimadores, obtenemos la de
βR :
( )( )'',ˆ 12 RXXRRNR −→ σββ
A partir de aquí, se demuestra que, si la hipótesis nula es cierta:
( ) ( )[ ] ( ) HkNF
HS
rRRXXRrR12
1'1 ˆ''ˆ−−
−−→−− ββ
Otra forma alternativa de realizar el contraste es introduciendo las restricciones en el modelo y comparando el modelo restringido con el modelo sin restringir, ya que la expresión anterior coincide con la siguiente:
HkN
rr FHS
eeee12
''−−→
−
Donde rr XYe β−=
2.2.- Contrastes de restricciones lineales sobre los parámetros. Casos particulares
A) Contraste de significación individual de un regresor:
0: =joH β
0:1 ≠jH β
1ˆ
ˆ−−→ kN
Hj tS
o
jβ
β
B) Contraste de significación conjunta de los regresores:

Econometría Curso 2011-2012
18
⋅⋅
=
⋅⋅
0
0
:
1
k
oH
β
β
≠:1H
kkN
H FkS
SCEo
12 −−→ o bien ( )k
kNH F
kR
kNRo
12
2
1
)1(−−→
−−−
2.3.- Estimación restringida. Propiedades del estimador restringido
Sea la restricción lineal sobre los parámetros: Rβ=r. Intentaremos encontrar el estimador
del vector paramétrico β que satisfaga la restricción. En definitiva, vamos a elegir rβ de forma que minimice
)ˆ()'ˆ('rrrr XYXYee ββ −−= sujeto a la restricción rR r =β
Para obtener dicho estimador restringido habría que formar la función lagrangiana. El proceso de minimización da como resultado el estimador restringido siguiente:
[ ] )ˆ(')'(')'(ˆˆ 111 βββ RrRXXRRXXr −+=−−−
En la práctica este estimador se puede obtener introduciendo las restricciones en el modelo inicial y estimando dicho modelo, denominado modelo restringido, por mínimos cuadrados ordinarios.
Ejemplo:
Su pongamos el siguiente modelo
tttt XXY εβββ +++= 22110
Las variables Y, X1 y X2 toman los siguientes valores
Yt X1t X2t
3 1 8 2 2 14 4 2 10 5 3 9 5 4 7 7 5 6 6 5 8 8 9 4 8 9 3 12 15 1
Si queremos estimar bajo las dos siguientes restricciones 5.01 =β y 02 21 =+ ββ podemos proceder de las dos formas siguientes:

Econometría Curso 2011-2012
19
En primer lugar, se puede aplicar mínimos cuadrados restringidos
[ ] )ˆ(')'(')'(ˆˆ 111 βββ RrRXXRRXXr −+= −−−
=0,2672-
0,4471
5,4118
β ;
−−
−−=−
0315.00235.03497.0
0235.00235.02941.0
3497.02941.01654.4
)'( 1XX ;
{32143421
r
o
R
rR
=
=
0
5.0
210
010;
2
1
β
βββ
β
−−=
−−
−−=−
0865.0
0706.0
993.0
0235.0
0235.0
294.0
2
1
0
0
1
0
0315.00235.03497.0
0235.00235.02941.0
3497.02941.01654.4
')'( 1RXX
=− ')'( 1RXXR
=
−−
−−
2435.00706.0
0706.00235.0
2
1
0
0
1
0
0315.00235.03497.0
0235.00235.02941.0
3497.02941.01654.4
210
010
[ ] 11 ')'(−− RXXR =
−−
=
−
5.315.94
5.94326
2435.00706.0
0706.00235.01
)ˆ( βRr − =
−
0.2672-
0.4471
5.4118
210
010
0
5.0=
=
−−
0874.0
0.0529
0874.0
0.4471
0
5.0
[ ] )ˆ(')'(')'(ˆˆ 111 βββ RrRXXRRXXr −+= −−− =
=
+
=
−−
−−+
0.25-
0.5
5
0,0172
0,0529
0,4118-
0.2672-
0.4471
5.4118
0874.0
0.0529
5.315.94
5.94326
0865.0
0706.0
993.0
0235.0
0235.0
294.0
0.2672-
0.4471
5.4118
En segundo lugar, se puede introducir la restricción en el modelo:
tttttttttt YXXYXXY εβεβεβ +=⇒+=++−⇒+−+= 0*
021210 25.05.025.05.0
57*25.05.5*5.0625.05.0ˆ21
* =+−=+−== XXYYoβ

Econometría Curso 2011-2012
20
=rβ
0.25-
0.5
5
Los residuos restringidos se pueden obtener a partir del modelo original con los estimadores restingidos o a través del modelo restringido:
Propiedades del estimador restringido:
Las propiedades del estimador restringido dependen de si la restricción es cierta o no. Así, el siguiente cuadro enumera las propiedades en ambos casos.
Restricción cierta
Rβ=r
1. rβ es insesgado
2. rβ es consistente
3. rβ es más eficiente que MCOβ
Qrr
−Σ=Σ ββββ ˆˆˆˆ donde Q es semidefinida
positiva
4. 2rS es insesgado y consistente
Error en la restricción
Rβ≠r
1. rβ es sesgado
2. rβ es inconsistente
3. Qrr
−Σ=Σ ββββ ˆˆˆˆ
AECMECMr
=− ββ ˆˆ donde A es semidef.
posit. o semidef. negat.
4. 2rS es sesgado e inconsistente
Primera forma
Y Y re
3 3,5=5+0.5*1-0.25*8 -0,5=3-3.5 2 2,5=5+0.5*2-0.25*14 -0,5=2-2.5 4 3,5 0,5 5 4,25 0,75 5 5,25 -0,25 7 6 1 6 5,5 0,5 8 8,5 -0,5 8 8,75 -0,75 12 12,25 -0,25
Segunda forma
*Y *Y re
4,5=3-0.5*1+0.25*8 5 -0,5 4,5=2-0.5*2+0.25*14 5 -0,5
5,5 5 0,5 5,75 5 0,75 4,75 5 -0,25
6 5 1 5,5 5 0,5 4,5 5 -0,5
4,25 5 -0,75 4,75 5 -0,25

Econometría Curso 2011-2012
21
TEMA 3.- PREDICCIÓN 3.1.- Predicción
Objetivo: Obtener valores de observaciones fuera de la muestra que se ha utilizado en la estimación de la variable endógena. Para ello se requieren tres condiciones: 1) Buen comportamiento del modelo a lo largo del período muestral 2) Conocer lo más exactamente posible los valores que tomarán las variables
explicativas en el período de predicción. 3) Que el modelo mantenga la misma estructura en el período de predicción que en el
muestral. Punto de partida: Sea el modelo: iii XY εβ += ' que cumple las hipótesis clásicas
βˆ 'ii XY =
Si esa relación se mantiene para el período de predicción : ppp XY εβ += '
siendo 'pp XyY los valores que toma la variable endógena fuera de la muestra y el
vector fila formado por los valores que toman las variables explicativas, respectivamente.
Donde: ( ) ( ) ( ) ( ) NjECovVarE pjpjpp ....10,,0 2 =∀==== εεεεσεε
Definimos:
Predictor: βˆpp XY ′= un estimador del valor a predecir.
Error de predicción: f diferencia entre el predictor y lo que queremos predecir.
f es una variable aleatoria con media cero ( ) 0=fE y varianza: ( )22 )( fEfEf −=σ
Propiedades del predictor:
• pY es un estimador sesgado de pY , por tanto, para analizar su precisión calculamos su
ECM:
( ) ( ) ( ) 222ˆˆfppp fEYYEYECM σ==−=
donde podemos comprobar que: ( ) ( ) ( ) pppppp XXXXXYYf εεεββ −′=−−=−= − ''ˆ'ˆ 1
Y, por tanto:
( ) ( )( ) ( ) )''1('ˆˆˆ 122
ppppppfp XXXXYYYYEYECM −+=−−== σσ
( ) )''1( 122ppf XXXXSS −+=

Econometría Curso 2011-2012
22
Queremos predecir Predictor Esperanza ECM
Valor individual
Yp= β'pX +εp βXY '
pp = 'pX β [ ]p
1'p
2 X)X'X(X1 −+σ
3.2.- Intervalos de confianza y test de hipótesis para un valor individual
( )2,0 fNf σ→
( )1,0Nf
f→
σ
1
21
2
2
−−→ −−
kN
S kNχσ
como ( )
121
1
1,0−−
−−
=
−−
kN
kN
t
kN
N
χ
tenemos: 1 f
−−→ kNf
tS
donde :
pp YYf −= ˆ y ( ) ppf XXXXSS 1''1 −+=
• Intervalo de confianza para la predicción de un valor individual:
ααα −=
≤
−≤− 1
ˆ2/2/ t
S
YYtP
f
pp
Por tanto, el I. C. de pY vendrá dado por: [ ]fp StY ⋅± 2/ˆ
α
• Test de Hipótesis para la predicción de un valor individual:
oppo YYH =:
opp YYH ≠:1
Si la Ho es cierta: 1
opp Y-Y
−− → kNo
f
tH
S
3.3.- Evaluación de la capacidad predictiva del modelo: La capacidad predictiva se puede evaluar a partir de varios estadísticos. Los estadísticos que computa EViews, suponiendo que el tamaño del periodo de predicción es n, son:
• Raíz del error cuadrático medio: n
f
RECM
n
jj∑
== 1
2

Econometría Curso 2011-2012
23
• Error absoluto medio: n
f
EAM
n
jj∑
== 1
• Error absoluto medio del porcentaje de error: ∑=
=n
j j
j
Y
f
nEAMP
1
1
• Coeficiente de desigualdad de Theil:
( )
∑∑
∑ −
==
=
+
=n
jj
n
jj
n
jjj
nYnY
nYY
U
1
2
1
2
1
2
//
/
ˆ
ˆ
0 ≤ U ≤ 1
Todos los estadísticos descritos hasta ahora indican una mejor capacidad predictiva
del modelo cuanto más cercanos a cero sean, lo que permite comparar un determinado modelo con otros alternativos.
• Descomposición del error cuadrático medio de predicción:
( ) ( ) ( )44 344 21321321arianzacomponente
SSr
ianzacomponente
SS
sesgocomponente
YYYYn YYYY
n
jYYjj
cov
12
var
ˆˆ1ˆˆ
1
2
ˆ
22
−+
∑ −+−=−
=
El cociente entre cada uno de los componentes en la suma total se denomina proporción del sesgo, proporción de la varianza y proporción de la covarianza. Cada una de estas proporciones varía entre cero y uno, siendo su suma la unidad como es de esperar. Los dos primeros miden, respectivamente, las diferencias entre la media y la varianza de la serie predicha ($Y ) y las de la serie observada (Y) en el periodo de predicción. Por tanto, lo deseable es que su valor sea pequeño. La última proporción mide la parte residual o no sistemática de los errores de predicción, en donde debería recaer la mayor parte del error total cometido.

Econometría Curso 2011-2012
24

Econometría Curso 2011-2012
25
TEMA 4. VARIABLES FICTICIAS
1.- Introducción
Las variables que hemos introducido como regresores en los temas precedentes son variables de tipo cuantitativo. Sin embargo, en ocasiones existen factores de tipo cualitativo que pueden ser relevantes para explicar el comportamiento de la variable endógena.
La inclusión de estos factores en un modelo econométrico se realiza a partir de la construcción de lo que se conoce como variables ficticias, variables dicotómicas o variables dummy que toman dos valores arbitrarios, normalmente 1 y 0, que corresponden a las modalidades del factor, aunque no necesariamente ya que podrán tomar otros valores o más de dos.
Pueden utilizarse para recoger:
• Efectos temporales:
• Efectos espaciales:
• Efectos de tipo puramente cualitativo.
• Otro tipo de efectos: efectos estacionales, funciones escalonadas, etc
Ejemplo: Queremos explicar el salario de los empleados de varias empresas (Yi) en función del número de años de experiencia laboral (X i) y del género (factor cualitativo con dos modalidades: hombre/mujer).
=mujer
breDi 1
hom0
2.- Formas de introducir un factor cualitativo en el modelo de regresión
Las variables ficticias se pueden construir e incorporar de forma que actúen en el modelo de tres modos distintos. En el caso de un modelo de dos variables tendríamos:
1º.- Que afecte sólo a la ordenada en el origen (Variables ficticias aditivas)
Si tenemos dos ecuaciones con la misma pendiente y diferente ordenada:
Y i=α1 +βXi+εi
Y i=α2 +βXi+εi
las dos ecuaciones se pueden expresar en una sola por medio de una variable ficticia:
Y i= α1 +β Xi +δDi +εi
donde cuando
++=
+++==
iii
iii
i
XY
XY
D
εβα
εβδαα
1
1
0
)(1
2
321
α1+δ = α2 ⇒ δ = α2-α1

Econometría Curso 2011-2012
26
El coeficiente de la variable ficticia δ nos mide el efecto diferencial entre las dos
ordenadas en el origen, es decir, el efecto diferencial del valor esperado de la variable
dependiente por presentar una de las características del factor cualitativo respecto al hecho
de no presentarla.
2º.- Que afecte sólo a la pendiente (Variables multiplicativas o compuestas)
Si tenemos dos modelos con la misma ordenada en el origen y distinta pendiente:
Y i=α +β1Xi+εi
Y i=α +β2Xi+εi
las dos ecuaciones se pueden expresar en una sola por medio de una variable ficticia de la forma:
Y i= α +β1 Xi +γ 321iZ
ii DX +εi
donde cuando
==
=00
1
i
iii Z
XZD
por tanto cuando
++=
+++==
iii
iii
i
XY
XY
D
εβα
εγβαβ
1
1
0
)(1
2
321
β1+γ = β2 ⇒ γ = β2-β1
El coeficiente de la variable ficticia γ nos mide el efecto diferencial entre las pendientes en los dos grupos, es decir, la diferencia de la influencia de la variable explicativa sobre la variable endógena por presentar una característica respecto de no presentarla.
3º.- Que afecte a ambas (ordenada y pendiente)
Si tenemos dos modelos con diferente ordenada en el origen y diferente pendiente:
Y i=α1 +β1X i+εi
Y i=α2 +β2X i+εi
las dos ecuaciones se pueden expresar en una sola por medio de una variable ficticia de la forma:
Y i= α1 +β1 Xi +δDi+ γ 321iZ
ii DX +εi
donde cuando
++=
++++==
iii
iii
i
XY
XYD
εβα
εγβδαβα
11
11
0
)()(1
22
321321
Todos estos casos podrían generalizarse para un modelo de k variables.
Para el caso de Variables ficticias que afectan al término independiente:

Econometría Curso 2011-2012
27
Y i =α1 +δDi +∑=
k
jjij X
1
β +εi
Para el caso de variables ficticias que afectan a la pendiente dependerá de la variable con la que se relacione la ficticia. Si es X1:
Y i =α +β1X1i +∑=
k
jjij X
2
β +γDiX1i +εi
¿Cómo introducir en el modelo un factor cualitativo con m modalidades?
Como regla general si tenemos “m” modalidades deberíamos introducir “m-1” variables ficticias.
1) Si las variables ficticias afectan a la ordenada, el número de variables ficticias a introducir dependerá de que el modelo tenga o no término constante. Si el modelo tiene término constante e incluimos tantas variables ficticias aditivas como modalidades tiene el factor, caemos en la “trampa de las variables ficticias” que consiste en que la primera columna de la matriz X será combinación lineal exacta de las columnas que contienen las observaciones de las variables ficticias, por tanto, rg(X)<k+1 ⇒ |X’X|=0 y no se puede invertir la matriz X’X.
La regla para evitar la trampa es la siguiente: si el factor posee “m” modalidades incluimos “m-1” variables ficticias en el modelo (si hay varios factores cualitativos la regla se aplica para cada uno de ellos). En caso de que el modelo no tenga término constante, el número de variables ficticias sería igual al número de modalidades que tuviésemos.
2) Si las variables ficticias afectan a la pendiente del modelo también hay que utilizar esa regla para no caer en la trampa de las variables ficticias, pero en ese caso independientemente de que el modelo tenga término constante o no, ya que es la columna de la variable X la que es combinación lineal de las columnas de las ficticias.
Contrastes de hipótesis en modelos con variables ficticias
El estudio de la importancia de uno o varios factores cualitativos en un modelo econométrico se realiza mediante el análisis de la significación de las variables ficticias que utilizamos. Teniendo en cuenta los modelos considerados antes, podemos concretar dicho análisis en los siguientes contrastes:
1º.- En modelos con variables ficticias que afectan al término independiente
H0: δ=0
H1: δ≠0
estaríamos contrastando si los dos modelos tienen la misma ordenada.
2º.- En modelos con variables ficticias que afectan a la pendiente
H0: γ=0
H1: γ≠0
En este caso estaríamos contrastando si los dos modelos tienen la misma pendiente.

Econometría Curso 2011-2012
28
3º.- En modelos con variables ficticias que afectan a pendiente y ordenada
≠
=
0
0:
0
0:
1
0
γδγδ
H
H
y estaríamos contrastando si los dos modelos tienen tanto la misma ordenada en el origen como la misma pendiente.
3.- Formas de introducir varios factores cualitativos en el modelo de regresión
En el modelo también podemos introducir a la vez varios factores cualitativos, cada uno con diversas modalidades, y podemos analizar además las interacciones que se producen entre esos factores cualitativos.
La forma de introducir más factores cualitativos es similar a la introducción de uno de ellos y se aplican también las reglas vistas acerca de cuántas variables ficticias introducir para un factor con m modalidades y de cómo realizar los contrastes de hipótesis.
Ejemplo: Supongamos que queremos estimar un modelo de determinación de salarios, para lo cual disponemos de una muestra de N trabajadores e información sobre el salario que reciben, su categoría profesional (empleado, técnico y directivo) y el género.
Y i =β0+ β1E1i + β2E2i+ β3Si +εi
donde Yi es el salario
= hombre esr trabajadoel si0
mujer esr trabajadoel si1iS
= caso otroen 0
técnicoesr trabajadoel si11iE
= caso otroen 0
directivo esr trabajadoel si12iE
de esta forma el valor esperado de Yi en cada caso es:
Empleado Técnico Directivo
Mujer β0+β3 β0+β3+β1 β0+β3+β2
Hombre β0 β0+β1 β0+β2
La diferencia salarial entre hombres y mujeres viene dada por β3 independientemente de su categoría profesional. Está claro que si β3 es <0 implica que el salario de los hombres es superior al de las mujeres para la misma categoría profesional.
Por otro lado, un contraste de discriminación salarial respecto al género sería:
H0: β3 = 0
H1: β3 ≠ 0

Econometría Curso 2011-2012
29
Un contraste de diferencias salariales respecto a la categoría profesional sería:
≠
=
0
0:
0
0:
2
11
2
10
ββββ
H
H
Efectos interacción
El modelo que acabamos de plantear recoge que el hecho de ser hombre o mujer no influye en la diferencia salarial según la categoría profesional. Sin embargo, podríamos estar interesados en estudiar el efecto que tiene sobre el salario recibido el hecho de ser mujer o hombre con cierta categoría profesional. En este caso, el modelo tendría que incluir lo que se llama efectos interacción entre variables ficticias y se especificaría de la siguiente forma:
Y i =β0+ β1E1i + β2E2i+ β3Si +β4E1iSi+β5E2iSi +εi
Ahora, el valor esperado de Yi en cada caso es:
Empleado Técnico Directivo
Mujer β0+β3 β0+β3+β1+β4 β0+β3+β2+β5
Hombre β0 β0+β1 β0+β2
La diferencia salarial entre hombres y mujeres ya no viene dada únicamente por β3, sino también por β4 o β5, dependiendo de su categoría profesional.

Econometría Curso 2011-2012
30

Econometría Curso 2011-2012
31
TEMA 5: ERRORES DE ESPECIFICACIÓN
Un error de especificación es cualquier error que se pueda producir en la especificación del modelo econométrico. La especificación de un modelo de regresión consta de la formulación de la ecuación de regresión y de las afirmaciones o supuestos acerca de los regresores y del término de perturbación. En sentido amplio, existirá un error de especificación siempre que sea incorrecta la formulación de la ecuación o uno de los supuestos subyacentes (Kmenta, p.467).
Podemos mencionar los siguientes errores de especificación:
1. Formulación de la ecuación:
1.1. Forma funcional. Representaciones gráficas y contraste RESET. 1.2. Permanencia estructural. Contraste de estabilidad estructural y estimación
recursiva.
2. Especificación de la matriz X:
• Omisión • Inclusión • X no estocástica. Contraste de exogeneidad. • Rango de X menor que K+1. Multicolinealidad.
3. Especificación de la perturbación
• Perturbaciones no esféricas: Varianzas no constantes: heteroscedast. Convarianzas no nulas: Autocorrelación • Perturbaciones no normales. Contraste Jarque-Bera.
1.-Formulación de la ecuación
1.1. Errores de especificación en la forma funcional
Una de las hipótesis clásicas que se realizan en el modelo de regresión es el de la
forma funcional lineal. La Teoría Económica a veces nos indica como es la relación entre
las variables, pero otras veces tienen que ser los datos los que nos ayuden a decidir. La
especificación incorrecta en la forma funcional genera estimadores sesgados e
inconsistentes.

Econometría Curso 2011-2012
32
Hay que tener en cuenta que hay varios tipos de modelos no lineales. Algunos
pueden ser tratados con las técnicas vistas hasta ahora realizando algunas transformaciones
y teniendo en cuenta algunas diferencias2.
Detección de no linealidades en el modelo econométrico:
• Contraste Reset de Ramsey:
Ramsey propuso una prueba general de errores de especificación que puede ser aplicada para la detección de no linealidades.
El contraste se basa en especificar un nuevo modelo alternativo al modelo inicial
(Y=Xβ+ε ) de la forma:
Y=Xβ+Zγ+u
y contrastar la restricción γ=0.
Ramsey sugiere incluir en Z potencias de los valores estimados de la variable dependiente (los cuales son, por supuesto, combinaciones lineales de potencias y productos
cruzados de las variables explicativas), de modo que: Z=( ,..Y,Y,Y 432 )
No se incluye Y porque existe correlación perfecta de esta variable con la matriz X y, por lo tanto, el modelo no se podría estimar.
1.2. Permanencia estructural3
Hasta ahora hemos supuesto que en el modelo de regresión especificado los coeficientes se mantienen constantes para todo el periodo muestral. Sin embargo, es posible que existan submuestras para las que el comportamiento del modelo sea diferente, es decir, exista cambio estructural.
Detección de cambio estructural:
a).- Contraste de estabilidad estructural de Chow
Si no hay cambio estructural (modelo restringido)
ikikii XXY εβββ ++++= ...110 i=1...N
Si hay cambio estructural a partir del periodo N1
ikikii XXY 11
111
10 ... εβββ ++++= i=1...N1
ikikii XXY 22
12
120 ... εβββ ++++= i=N1+1...N (total N2 )
2 Ver el apéndice 1 de este tema. Si las variables están todas en logaritmos, los parámetros miden elasticidades. En general, la elasticidad de Y respecto a X recoge la variación porcentual de Y ante una
variación porcentual de X: Y
X
X
YE
∆∆=
3 Basado en Carrascal, U. y otros (2001). Análisis econométrico con Eviews. Ed. RAMA.

Econometría Curso 2011-2012
33
Hipótesis del contraste
=
=
2
21
20
1
11
10
0
kk
H
β
ββ
β
ββ
MM
=
1
11
10
1
k
H
β
ββ
M≠
2
21
20
kβ
ββ
M
Estadístico de contraste
12-2-
212'21
'1
2'21
'1
'
212-2-/)(
1/))(-( ++→
++++ k
kNNrr F
kNNeeee
keeeeee
Nota 1: Es necesario que las observaciones de ambas submuestras sean suficientes para estimar los modelos, es decir, N1>k+1 y N2>k+1. No obstante, el contraste se puede hacer aunque en una de las dos muestras no haya suficientes grados de libertad, asignando cero a la SCR correspondiente a esa muestra (Johnston, 1989, pág. 264 y ss.)
Nota 2: Una forma alternativa de llevar a cabo este contraste de Chow es mediante la incorporación de variables ficticias que recojan el cambio en los coeficientes del modelo.
b).- Estimación recursiva
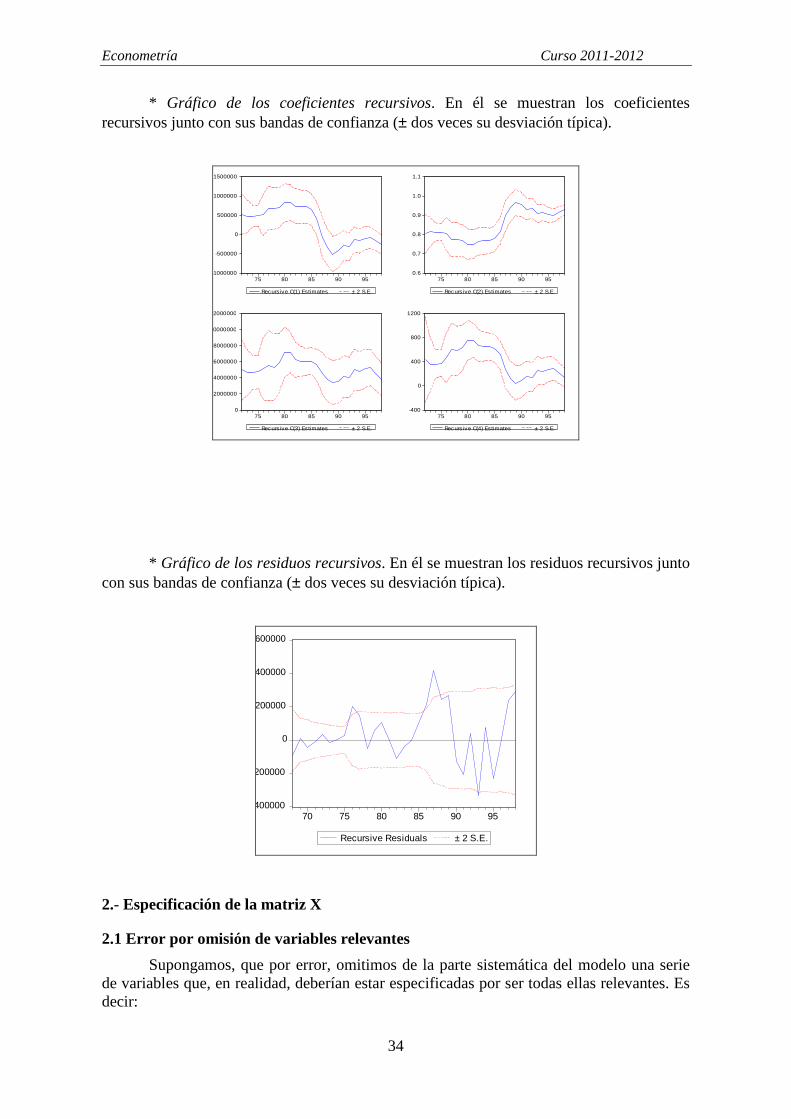
Esta técnica es adecuada cuando trabajamos con datos temporales y se desconoce el momento en el que se ha producido un cambio estructural. Consiste en la estimación secuencial del modelo especificado para distintos tamaños muestrales. Con cada estimación obtenemos un vector de estimadores (coeficientes recursivos), con el que podemos calcular la predicción de Y en el periodo siguiente, el error de predicción correspondiente y los llamados residuos recursivos. Si no existe un cambio estructural los coeficientes recursivos se mantendrán constantes al ir aumentando la muestra secuencialmente y los residuos recursivos no se desviarán de cero. Estos comportamientos se analizan mediante los siguientes gráficos:
Econometría Curso 2011-2012
34
* Gráfico de los coeficientes recursivos. En él se muestran los coeficientes recursivos junto con sus bandas de confianza (± dos veces su desviación típica).
-1000000
-500000
0
500000
1000000
1500000
75 80 85 90 95
Recursive C(1) Estimates ± 2 S.E.
0.6
0.7
0.8
0.9
1.0
1.1
75 80 85 90 95
Recursive C(2) Estimates ± 2 S.E.
0
2000000
4000000
6000000
8000000
10000000
12000000
75 80 85 90 95
Recursive C(3) Estimates ± 2 S.E.
-400
0
400
800
1200
75 80 85 90 95
Recursive C(4) Estimates ± 2 S.E.
* Gráfico de los residuos recursivos. En él se muestran los residuos recursivos junto con sus bandas de confianza (± dos veces su desviación típica).
-400000
-200000
0
200000
400000
600000
70 75 80 85 90 95
Recursive Residuals ± 2 S.E.
2.- Especificación de la matriz X
2.1 Error por omisión de variables relevantes
Supongamos, que por error, omitimos de la parte sistemática del modelo una serie de variables que, en realidad, deberían estar especificadas por ser todas ellas relevantes. Es decir:

Econometría Curso 2011-2012
35
Modelo correctamente especificado: [1] Y=X1β1+ X2β2+ ε
Modelo estimado (con omisión): [2] Y=X1β1+ u donde u = X2β2+ ε
En realidad, cuando cometemos un error de especificación por omisión estamos planteando un modelo restringido (bajo la restricción 02 =β ) en el que la restricción es falsa.
Consecuencias:
a) El estimador restringido es sesgado (salvo la excepción de que los dos bloques de regresores sean ortogonales, es decir, que 2
'1XX = 0) e inconsistente. Aunque tiene menor
varianza que el estimador del modelo correctamente especificado, como es sesgado, la varianza no mide la precisión del estimador sino que la mediría el ECM, que puede ser mayor o menor (recordar propiedades del estimador restringido).
b) El estimador de la varianza de las perturbaciones, S2, también es sesgado e inconsistente.
c) Al ser S2 sesgado el estimador de la matriz de varianzas y covarianzas de 1β : 11bbS
también será sesgado: E(11bbS ) ≠ σ2 1
1'1 )XX( −
d) Los contrastes de hipótesis habituales sobre 1β no son válidos porque la distribución de
1β no es la habitual, ya que es sesgado.
e) El predictor pY es un estimador sesgado de β'pX .
2.2. Error por inclusión de variables irrelevantes
Supongamos ahora, que por error, incluimos en la parte sistemática del modelo una serie de variables que no son significativas. Es decir:
Modelo correctamente especificado: [1] Y=X1β1+ ε
Modelo estimado (con inclusión): [2] Y=X1β1+ X2β2+ ε
En este caso se estima un modelo donde no se incluye la restricción cierta β2 = 0. Los estimadores del modelo estimado seguirán siendo ELIO y consistentes y también lo será S2. El problema, por tanto, no está en las propiedades de los estimadores sino en su eficiencia comparada con los estimadores del modelo correctamente especificado. Como ya sabemos, el estimador mínimo cuadrático restringido tiene siempre varianza más pequeña que el mínimo cuadrático ordinario sin restringir y, por lo tanto, en este caso será más eficiente. Además, los test de hipótesis son válidos y el predictor es un estimador insesgado del valor medio.
La detección de error de omisión o de inclusión consiste en aplicar los criterios de selección del modelo adecuado.
2.3. Regresores estocásicos
La existencia de regresores estocásticos en el modelo econométrico rompe conla hipótesis clásica de que la matriz X es determinista. El tratamiento de estos modelos se basa fundamentalmente en analizar la relación entre los regresores y la perturbación. Existen pruebas de hipótesis como el contraste de exogeneidad para su estudio.

Econometría Curso 2011-2012
36
2.4. Rango de X menor que K+1
El incumplimiento de la hipótesis de rango sobre X implica la existencia de combinaciones lineales exactas sobre las variables explicativas, es decir, presencia de multicolinealidad perfecta. Esta situación, así como la presencia de relaciones entre los regresores que no sean exactas se estudiarán en el tema “Multicolinealidad”.
3.- Especificación de la perturbación
3.1 Perturbaciones esféricas
La hipótesis de que IE 2)'( σεε = es necesaria en la propiedad de optimalidad del estimador de β por MCO. Su incumplimiento genera estimadores insesgados, pero no óptimos ni eficientes. El tratamiento de un modelo econométrico en el que se incumple dicha hipótesis se realizará en los temas 7 y 8 del programa.
3.2. Perturbaciones no normales
La hipótesis de normalidad de la perturbación aleatoria no se utiliza para la obtención de los estimadores MCO, por lo que dichos estimadores seguirán cumpliendo sus propiedades aunque la perturbación no sea normal. Sin embargo, bajo dicha hipótesis, los estimadores de MCO coinciden con los estimadores MV, y también bajo dicha hipótesis se construye todo el proceso inferencial sobre los modelos econométricos analizados.
El inclumplimiento de la hipótesis de normalidad hace que el estimador MCO no sea el más eficiente ni cumpla las propiedades adicionales de los EMV. Además, los estadísticos utilizados para realizar los contrastes de hipótesis, que seguían distribuciones derivadas de la normal, como la t o la F, ya no seguirán, en general, distribuciones conocidas. No obstante, asintóticamente los contrastes habituales mantienen su validez.
Test de normalidad de Jarque-Bera
Este contraste analiza la normalidad de las perturbaciones a partir de la forma de la distribución de los residuos puesto que las perturbaciones son variables no observables. Concretamente, examina sus discrepancias respecto a la curva campaniforme característica del modelo normal (distribución simétrica y de kurtosis igual a 3).
Así, se definen los coeficientes de asimetría g1 y de kurtosis g2::
Asimetría Kurtosis
2/3
1
2
1
3
1
/
/
=
∑
∑
=
=
Ne
Neg
N
ii
N
ii
2
1
2
1
4
2
/
/
=
∑
∑
=
=
Ne
Neg
N
ii
N
ii
g1=0⇒ Distribución simétrica g2=3⇒ Distribución mesocúrtica
g1>0⇒ Distrib. con asimetría positiva g2>3⇒ Distrib. Leptocúrtica
g1<0⇒ Distrib. con asimetría negativa g2<3⇒ Distrib. Platicúrtica

Econometría Curso 2011-2012
37
El contraste plantea en la hipótesis nula la normalidad de la perturbación, siendo el estadístico de Jarque-Bera:
( ) 22
2
221 3
4
1
6
1 χ→
−+−−= ggkN
dJB
Este estadístico adoptará valores pequeños si la distribución observada de los residuos es aproximadamente simétrica y mesocúrtica (valores de g1 y g2-3 cercanos a cero). En otro caso, a medida que se detectan asimetrías (positivas o negativas) o desviaciones en la kurtosis, aumenta su valor. Por lo tanto, aceptaremos H0 cuando dJB <
)(22 αχ y rechazaremos en caso contrario.
TABLA RESUMEN Error de especificación ¿cómo detectarlo? 1. Formulación del modelo
a) Forma funcional b) Forma estructural Cambio/permanencia
Test RESET de Ramsey
* Test de Chow * Estimación recursiva
2. Especificación de la matriz de regresores
a)Omisión de variable relevante b)Inclusión de variable irrelevante c)Rango de la matriz X (Multicolinealidad)
d) X no estocástica
En general, el test RESET de Ramsey puede detectar cualquier tipo de error de especificación en un modelo
*E-views (test Wald de omisión de v. relevante) *E-views (test Wald de inclusión de v. irrelevante) *Indicios de multicolinealidad (tema 6)
3. Hipótesis sobre las perturbaciones
a)Normalidad b)Homoscedasticidad c)Incorrelación
Test Jarque-Bera Varios contrastes (tema 7) Varios contrastes (tema 8)

Econometría Curso 2011-2012
38

Econometría Curso 2011-2012
39
Apéndice 1.- Modelos no lineales
A) No linealidad en las variables:
* En las variables explicativas Ej: t
2t22
X10t XeY t1 ε+β+β+β= . Basta con definir nuevas variables de la forma:
t1Xt1 eZ = y 2
t2t2 XZ =
* En las variables explicadas Ej: YtXt + β1lnYt = β2Xt + εt. Sería imposible expresar Y como función de los vectores X y β.
B) No linealidad en los parámetros:
1.b) Modelos intrínsecamente lineales Son modelos fácilmente linealizables mediante sencillas transformaciones.
Ejs: Yt = β01
tX β εt ⇒ lnYt = lnβ0 +β1lnXt +lnεt ⇒ **1
*0
*ttt XY εββ ++=
Función de producción Cobb-Douglas: tttt LAKQ εβα= ⇒
lnQt = lnA +αlnKt +βlnLt+lnεt ⇒****tttt LKQ εβαγ +++=
Se estima el modelo transformado y una vez conocidos los estimadores, se deshacen los cambios. Así:
*0
ˆeˆlogantiˆˆlnˆ *
000*0
β=β=β⇒β=β
1β no hay que realizar ningún cambio
Interpretación de los parámetros en los modelos no lineales
La hipótesis de linealidad del MRLC supone la existencia de una relación lineal en los parámetros que unen a las variables, pero no significa que esa linealidad tenga que darse entre las variables. En Economía, las relaciones entre las variables no siempre son lineales. Así, por ejemplo, la demanda de un producto no tiene porque estar en relación lineal directa con la renta, si el incremento en la renta no supone un incremento equivalente en el consumo del producto. Otras formas funcionales
Modelo Pendiente Elasticidad4
Lineal en logaritmo ttt XY εββ ++= 110 lnln XY /1β
1β
Semilog en Y ttt XY εββ ++= 110ln Y1β X1β (*)
Semilog en X ttt XY εββ ++= 110 ln X/11β Y/11β (*)
Recíprocos ttt XY εββ ++= 110 /1 21 /1 Xβ− XY/11β− (*)
(*) Indica que el coeficiente de la pendiente varía dependiendo del valor asumido para X, Y o ambas. Cuando no se especifica ningún valor de X o Y, las elasticidades suelen medirse en los valores medios de las variables.
Fuente: Gujarati (2006): Principios de Econometría, pág. 275.
4 La elasticidad de Y respecto a X recoge la variación porcentual de Y ante una variación porcentual de X,
Y
X
X
YE
∆∆= .

Econometría Curso 2011-2012
40
Propiedades de los estimadores a) Si los parámetros no sufren transformación, los estimadores conservan las propiedades de MCO. b) Si sufren transformaciones lineales (sumas y restas) los estimadores conservan las propiedades de los estimadores de MCO pues la esperanza es un operador lineal. c) Si se realizan transformaciones logarítmicas, los estimadores no conservan las propiedades finitas, pero dado que los estimadores de MCO coinciden con los de MV y estos tienen la propiedad de la invarianza, se mantendrían las asintóticas.
Problemas con el coeficiente de determinación a) Si el regresando no sufre modificación, el R2 encontrado para el modelo transformado sirve también para medir la bondad del ajuste. b) Pero si existe transformación en el regresando, el R2 nos medirá la bondad del ajuste del modelo transformado, es decir, no nos medirá la variabilidad de Y sino por ejemplo del lnY. b.2) Modelos intrínsecamente no lineales Son aquellos modelos que no se pueden linealizar mediante transformaciones sencillas. Son de la forma: Ejs. Yt = β1
2tX β + εt
Función de producción CES: [ ] pnppt KLY
/)1( −− −+= δδα

Econometría Curso 2011-2012
41
TEMA 6: MULTICOLINEALIDAD
6.1.- Ortogonalidad versus multicolinealidad perfecta
Una cuestión importante que debe analizarse al estudiar los resultados de un modelo de regresión es el grado de relación lineal existente entre las observaciones de las variables explicativas, siendo tres las situaciones posibles con las que nos podemos encontrar.
Ortogonalidad: supone la ausencia de relación lineal entre algunos o todos los regresores incluidos en el modelo, es decir, implica incorrelación entre los regresores.
Multicolinealidad perfecta: se da cuando existe una relación lineal exacta entre algunos o todos los regresores incluidos en el modelo.
Multicolinealidad imperfecta: consiste en la existencia de una relación lineal fuerte entre los regresores del modelo.
A continuación vamos a analizar las consecuencias de estas tres situaciones centrándonos sobre todo en la multicolinealidad imperfecta que es la situación más frecuente.
Ortogonalidad : Se dice que dos regresores son ortogonales cuando están linealmente incorrelacionados, es decir, cuando su coeficiente de correlación lineal, o su covarianza es cero. Así, Xh y Xj son ortogonales si 0=
jhxxr .
Dos grupos de regresores son ortogonales si 02'1 =XX , lo que significa que cada
regresor del primer bloque está incorrelacionado con cada regresor del segundo bloque.
Particularidades del modelo con regresores ortogonales:
Sea el modelo particionado: εββ ++= 2211 XXY
• Los EMCO de los parámetros de este modelo coinciden con los que obtendríamos efectuando la regresión individual de Y sobre cada uno de los bloques:
Los estimadores de los parámetros del modelo particionado en la regresión
21 XXY R→ son:
Los estimadores de los parámetros de las regresiones individuales son:
1XY R→ uXY += 11β ( ) YXXXb '1
1
1'11
−=
2XY R→ vXY += 22β ( ) YXXXb '2
1
2'22
−=
Por lo tanto, se obtienen los mismos resultados.
Sin embargo, si los regresores no son ortogonales, no se obtienen los mismos resultados, sino que en la regresión conjunta, cada uno de los dos estimadores depende de toda la matriz X, por tanto de X1 y de X2, debido a que 02
'1 ≠XX
( )( )
=
=
=
= −
−−−
YXXX
YXXX
YX
YX
XX
XX
YX
YX
XXXX
XXXX'2
1
2'2
'1
1
1'1
'2
'1
1
2'2
1'1
'2
'1
1
2'21
'2
2'11
'1
2
1
0
0ˆ
ˆˆ
βββ

Econometría Curso 2011-2012
42
• Las varianzas de los estimadores también coinciden con las calculadas al hacer las regresiones individuales pero no los estimadores de esas varianzas:
1
2'2
1'1
ˆˆ2
0
0−
=∑
XX
XXββ
σ ,
1
2'2
1'12
ˆˆ0
0−
=
XX
XXSS ββ siendo
1
'2
−−=
KN
eeS
Haciendo las regresiones individuales:
( ) 1
1'1
2
11
−∑ = XX
bbσ ( ) 1
2'2
2
22
−∑ = XX
bbσ
( ) 1
1'1
2111
−= XXSS bb siendo
1
ˆˆ
1
'2
1 −−=
KN
uuS
( ) 1
2'2
2222
−= XXSS bb siendo
1
ˆˆ
2
'2
2 −−=
KN
vvS
Multicolinealidad Perfecta: Cuando la relación que liga a dos o más variables explicativas es una relación lineal exacta, es decir, las columnas de la matriz X son linealmente dependientes. En este caso se deja de cumplir la hipótesis clásica Rg(X) = k+1, de modo que:
Rg(X) < k+1 ⇒X’X = 0
Y por tanto los estimadores mínimos cuadrados ordinarios no se pueden calcular.
Es, en definitiva un grave problema pero fácilmente detectable, así que si conocemos la relación lineal entre las variables es muy fácil de corregir, bastará con eliminar una cualquiera de las variables correlacionadas sin sufrir ninguna disminución en la capacidad explicativa o predictiva del modelo
La multicolinealidad normalmente, es un problema meramente muestral.
Multicolinealidad Imperfecta o fuerte: cuando la relación entre las variables es muy fuerte pero no perfecta, es decir, los coeficientes de correlación lineal no son igual a 1 o -1 pero se aproximan bastante. En este caso X’X ≠0 por lo tanto no existen razones, a priori, para no poder estimar el modelo.
Los estimadores serán ELIO siempre que el modelo cumpla las hipótesis clásicas y coincidirán con los máximo verosímiles, aunque en la práctica esto puede tener poco valor debido a las consecuencias que este problema genera.
Causas de la multicolinealidad imperfecta:
• Existencia de alguna relación causal entre dos variables explicativas (o más).
• En economía, la mayoría de las variables explicativas están, de alguna manera correlacionadas. Cuando trabajamos con series temporales, la mayoría de las variables económicas tienen una tendencia creciente, Granger y Newold demostraron que basta con introducir una tendencia lineal en dos series temporales independientes para que su correlación aumente considerablemente, por tanto, la existencia de esa tendencia puede ser la causa de un problema de multicolinealidad.

Econometría Curso 2011-2012
43
• Existencia de una variable explicativa con escasa variabilidad en su serie. Es decir, si iXX jji ∀≅ en un modelo con término constante, esto implicaría que la
columna correspondiente a Xj sería proporcional al regresor falso (Xoi=1):
joiji XXX ≅
• Existencia de variables explicativas retardadas.
6.2.- Consecuencias de la multicolinealidad imperfecta
1) Dificultad para interpretar los coeficientes, y por tanto, sus estimaciones. Los coeficientes de regresión (jβ ) se interpretan como el cambio que se produce en Yi
al variar Xji en una unidad, permaneciendo el resto de variables explicativas constantes. Cuando existe multicolinealidad imperfecta carece de sentido suponer que, cuando una variable explicativa se modifica, el resto de las variables permanecen constantes, al existir altas correlaciones entre ellas. Por este motivo, los parámetros pierden este significado y, por lo tanto, también sus estimaciones.
2) La multicolinealidad afecta a la precisión de los estimadores ya que sus varianzas toman valores grandes. Se puede ver, por un lado, a partir del determinante de X’X, que es relativamente pequeño y, por otro, analizando la varianza de un estimador de la siguiente manera: Planteamos un modelo particionado en el que el 2º bloque está formado por un único regresor: εββ ++= 2211 XXY
En ese caso: ( ) 22
2
2
2121
ˆXXX SNR
Var•−
= σβ
Y su estimador: ( ) 22
22ˆ
212
2 1 XXX SNR
SS
•−=β
Las varianzas de los estimadores pueden ser grandes como consecuencia de:
• Valores grandes del S2
• Fuerte correlación entre X2 y X1 : valores grandes de 212 XXR •
• Poca variabilidad en X2: 2
2XS pequeña
• Tamaño muestral pequeño
Esto implica que no siempre que las varianzas de los estimadores sean grandes será como consecuencia de la multicolinealidad, aunque cuando la haya las varianzas pueden tomar valores más grandes de lo que serían si no la hubiese.
3) Valores muestrales de los estadísticos t pequeños, lo que implica que es muy dificil rechazar cualquier contraste de no singnificación de las variables
4) No afecta al R2 ya que éste mide el efecto conjunto de todos los regresores sobre el regresando y la multicolinealidad afecta a los valores individuales de los regresores, por tanto la regresión podrá ser significativa a pesar de la existencia de multicolinealidad.
5) Los puntos 3 y 4 nos pueden llevar a rechazar la significación individual de todos los regresores y sin embargo no rechazar la significación conjunta de todos ellos.

Econometría Curso 2011-2012
44
6) Sensibilidad de los EMC a los pequeños cambios en las muestras, como la incorporación o eliminación de unas pocas observaciones o a la eliminación de una variable aparentemente no significativa.
7) No afecta a las predicciones
6.3.- Procedimientos para detectar la multicolinealidad
• La simple lógica permite, algunas veces, saber si existe o no una relación causal entre ellas. Por ejemplo, si dos variables explicativas son la población y el empleo, el presupuesto nacional y el PNB, etc.
• Grandes varianzas. Indicio poco fiable por sí solo.
• Altos coeficientes de correlación lineal. Si el modelo tiene 2 regresores este coeficiente es un buen indicio pero si tiene más de dos regresores, los coeficientes de correlación altos son una condición suficiente para la existencia de multicolinealidad pero no necesaria, ya que ésta puede existir aunque los coeficientes de correlación sean comparativamente bajos.
• Coeficientes de correlación múltiple entre los regresores grandes: 2 ....1XX jR •
Estos coeficientes miden la correlación que existe entre un regresor y todos los demás. Se puede calcular como coeficiente de determinación en la regresión auxiliar de cada regresor frente a los otros.
• Estadísticos t pequeños y F grandes
• Factor de inflación de la varianza: FIV
Este factor se define como el cociente: 2
.....11
1
XXj
jR
FIV•−
=
Como 110 2....1
≥⇒≤≤ • jXX FIVRj
Si las variables fuesen ortogonales 102....1
=⇒=• FIVR XX j
Cuando ∞→⇒→• FIVR XX j12
....1
Si expresamos la varianza del estimador de un parámetro cualquiera como vimos antes
( ) 22...
2
11
ˆ
jkj XXXXj SNR
Var•−
= σβ , el factor de inflación de la varianza mide la influencia que
tiene la relación entre Xj y las demás variables sobre la varianza de jβ . Cuanto mayor sea
este factor, mayor es la varianza del estimador.
El factor de inflación de la varianza se puede interpretar como cociente de dos varianzas del estimador:
o Su varianza real 2ˆ
jβσ
o La varianza que tendría si hubiera ortogonalidad ( )ortogj
2
βσ

Econometría Curso 2011-2012
45
Si hay ortogonalidad, el FIV vale uno, luego ( )2
22ˆ
j
jX
ortog SN
σσ β =
Si hacemos el cociente entre las dos varianzas tenemos
( )( )
( ) FIVR
SN
SNR
kj
j
jkj
j
j
XXX
X
XXXX
ortog
=−
=−
=•
•
2...
2
2
22...
2
2ˆ
2ˆ
1
1
1
11
σ
σ
σ
σ
β
β
Esto nos permite interpretar este factor de la siguiente forma:
Supongamos que 25.02....1
=→=• FIVR XX j, es decir, la varianza de jβ es el doble del
valor que tomaría en el caso de ortogonalidad entre los regresores.
Si 1000999.02....1
=→=• FIVR XX j, la varianza es 1000 veces mayor que la que se
tendría en caso de ortogonalidad (con el mismo 22 ,,jXSyN σ ).
6.4.- Soluciones a la multicolinealidad
Las soluciones más frecuentes aunque no las únicas son:
1) Aumentar el tamaño de la muestra. Esta podría ser una solución siempre que la multicolinealidad fuera un problema muestral.
2) Eliminación de variables: Eliminar aquella o aquellas variables colineales. El inconveniente de este método es que podríamos caer en graves problemas de errores de especificación por omisión. Este error sería tanto menor cuanto mayor fuese la correlación lineal entre la variable omitida y las incluidas y por tanto también será menor el sesgo de los estimadores.
3) Utilización de información a priori: Consiste en incorporar al modelo algún tipo de información estableciendo restricciones sobre los parámetros del modelo.
4) Transformación de variables: Si la multicolinealidad se presenta en modelos con una muestra de series temporales la tendencia aproximadamente común en los regresores podría ser la principal causa del problema. En este caso una forma de eliminar esa tendencia es trabajar con la series en primeras diferencias y de esa forma no solo se eliminaría la tendencia sino que la correlación entre los regresores disminuiría. También se podría trabajar con ratios.

Econometría Curso 2011-2012
46

Econometría Curso 2011-2012
47
ANEXO . INSTRUMENTOS MATEMÁTICOS Y ESTADÍSTICOS BÁSICOS
ELEMENTOS DE ÁLGEBRA MATRICIAL
MATRIZ.- Se llama matriz a una agrupación rectangular de números ordenados en filas y columnas (aij) donde el primer subíndice indica la fila y el segundo la columna.
=
mnmm
n
n
aaa
aaa
aaa
A
.......
.......
.
.
.
.......
......
21
22221
11211
En Econometría, por comodidad, la notación que seguiremos será: (xij) donde el primer subíndice indica la columna y el segundo la fila a la que pertenece.
=
kTTT
k
k
xxx
xxx
xxx
X
.......
.......
.
.
.
.......
......
21
22212
12111
ORDEN de una matriz.- Una matriz con T filas y K columnas se dice que es de orden T por K, (TxK).
RANGO de una matriz.- Se define como el máximo número de columnas o filas, de X, linealmente independientes. Corrientemente se dice que es el ORDEN del mayor MENOR no nulo. Donde los MENORES son los determinantes (nxn) que se puede formar.
PROPIEDADES: Si A es una matriz nxm de rango m<n, entonces A'A es definida positiva y AA' es semidefinida positiva. (Johnston, p. 182).
Si A es una matriz nxm de rango m<n, entonces A' es de rango m y la matriz resultante de premultiplicar a A por su transpuesta (A'A) también es de rango m.
MATRIZ CUADRADA.- Es aquella que tiene el mismo número de filas y de columnas.
MATRIZ DIAGONAL.- Aquélla cuyos únicos elementos distintos de cero están en la diagonal principal.
MATRIZ NO SINGULAR.- Aquélla matriz cuadrada cuyo determinante es distinto de cero.
MATRIZ IDENTIDAD.- Aquélla cuyos elementos de la diagonal principal son la unidad y el resto ceros. Se cumple que A·I = I.A = A.
OPERACIONES CON MATRICES
SUMA DE MATRICES.- Para sumar dos matrices deben tener el mismo orden. Se suma cada elemento de la primera con su correspondiente elemento en la segunda.
PROPIEDADES: Conmutativa: A+B=B+A; Asociativa: A+(B+C)=(A+B)+C
MULTIPLICACIÓN POR UN ESCALAR: Se multiplica el escalar por todos los elementos de la matriz. Admite la propiedad distributiva: a(A+B)= aA+aB

Econometría Curso 2011-2012
48
MULTIPLICACIÓN DE MATRICES.- Tiene que guardar la condición de orden, es decir, el número de columnas de la primera ha de ser igual al número de filas de la segunda. Se multiplican filas por columnas.
PROPIEDADES.- No cumple la propiedad conmutativa, A·B ≠ B·A, pero sí la distributiva A·(B·C)=(A·B)·C
MATRIZ TRASPUESTA.- Es la que se obtiene cambiando filas por columnas y columnas por filas.
PROPIEDADES.- (A’)’ = A ; (A+B)’ = A’ + B’ ; (A·B·C)’ = C’·B’·A’
MATRIZ SIMÉTRICA.- Aquélla que es igual a su traspuesta A = A’
MATRIZ IDEMPOTENTE.- Aquélla que al multiplicarla por sí misma se reproduce A·A=A
MATRIZ INVERSA.- Dada una matriz A, llamamos matriz inversa de A y la denotamos como A-1, a aquélla que cumple A·A-1 = I y A-1·A= I
A tiene inversa si y sólo si el determinante de A es distinto de cero.
CÁLCULO DE LA MATRIZ INVERSA: En primer lugar se calcula la matriz de adjuntos de los elementos de A, y luego se divide por el valor del determinante.
La matriz adjunta es la traspuesta de la formada por los adjuntos (valor del determinante suprimida la fila y la columna correspondiente, con el signo más o menos dependiendo de que la suma de lo subíndices sea par o impar).
PROPIEDADES DE LA MATRIZ INVERSA: (A-1) -1 = A ; (A·B)-1 = B-1· A-1 ; (A·B·C)-1 = C-1·B-1·A-1 siempre que las matrices sean invertibles.
TRAZA DE UNA MATRIZ.- Es la suma de sus elementos diagonales.
PROPIEDADES:
tr(A+B) = tr(A) + tr(B) ; tr(d·A) = d·tr(A)
tr(A) = tr A’ ; tr(A·B) = tr(B·A)
tr(A·B·C) = tr(C·A·B) = tr(B·C·A) ; [ ] [ ])()( AEtrAtrE =
MATRIZ DEFINIDA POSITIVA.- Dada una matriz cuadrada A de orden nxn y un vector x de orden nx1, decimos que A es definida positiva si x’Ax es mayor que cero.
PROPIEDAD: Los elementos de la diagonal principal de A son mayores que cero.
MATRIZ DEFINIDA NO NEGATIVA O SEMIDEFINIDA POSITIVA.- Dada una matriz cuadrada A de orden nxn y un vector x de orden nx1, decimos que A es semidefinida positiva si x’Ax son mayores o iguales a cero.
PROPIEDAD: Los elementos de la diagonal principal de A son mayores o iguales que cero.
SISTEMA DE ECUACIONES LINEALES.- Si tenemos una serie de ecuaciones lineales
que podemos expresar en términos matriciales )1()()1(
·mxnxmnxxAY = entonces 'A
x
Y =∂∂
.
FORMA CUADRÁTICA DE ECUACIONES.- Si tenemos una forma cuadrática como
)1()()1()11(··'
mxmxmxmx
xAxy = entonces se cumple que Axx
y2=
∂∂
.

Econometría Curso 2011-2012
49
CONCEPTOS BÁSICOS DE ESTADÍSTICA DESCRIPTIVA
Dados n datos x1, x2,…,xn de una variable X
Media aritmética: n
xX
n
ii∑
== 1
Varianza muestral: ( )
n
Xnx
n
Xx
S
n
ii
n
ii
x
2
1
2
1
2
2∑∑==
−=
−=
Cuasivarianza muestral: ( )
11
2
1
2
1
2
2
−
−=
−
−=
∑∑==
n
Xnx
n
Xx
S
n
ii
n
ii
x
Desviación típica muestral: 2xx SS +=
Covarianza muestral:( )( )
n
YXnyx
n
YyXx
S
n
iii
n
iii
xy
∑∑==
−=
−−= 11
Donde y1, …yn son n datos de la variable Y
Coeficiente de correlación lineal yx
xyxy SS
Sr =
DISTRIBUCIONES DE FORMAS LINEALES Y CUADRÁTICAS EN VECTORES NORMALES
1) Supongamos una forma lineal Y=CX+b
donde: C es una matriz , X un vector normal T dimensional y b un vector de constantes
si ),( Σ→ µNX ⇒ )',( CCbCNY Σ+→ µ
2) Supongamos una forma cuadrática idempotente X’AX en vectores normales
donde A es una matriz idempotente lo que implica que rango(A)=traza A y X es un vector normal
a) si ),0( INX → y el rango(A) =r,
la forma cuadrática idempotente 2' rAXX χ→
b) si ),0( 2 INX σ→ y el rango(A) =r,
la forma cuadrática idempotente 22' rAXX χσ→
c) si ),( Σ→ µNX siendo µ la media y Σ la matriz de varianzas –covarianzas
la forma cuadrática 2)(
1' )()( Σ− →−Σ− rgXX χµµ
cuando 0=µ la forma cuadrática 2)(
1'Σ
− →Σ rgXX χ
INDEPENDENCIA ENTRE FORMAS LINEALES Y CUADRÁTICAS E N VECTORES NORMALES
a) Independencia entre una forma lineal y una forma cuadrática en el mismo vector normal

Econometría Curso 2011-2012
50
Sea X un vector: ),0( INX → o bien ),0( 2 INX σ→
A una matriz idempotente y simétrica tal que rango(A)=r y B una matriz cualquiera
Bajo estos supuestos, la forma lineal BX y la forma cuadrática idempotente X’AX son independientes si se verifica que BA=0.
b) Independencia entre formas cuadráticas idempotentes en el mismo vector normal
Sea: ),0( INX → o bien ),0( 2 INX σ→
A y B dos matrices simétricas e idempotentes y por tanto X’AX y X’BX dos formas cuadráticas idempotentes en el vector X. Ambas formas son independientes si: AB=BA=0
DISTRIBUCIONES χχχχ2 DE PEARSON, T DE STUDENT Y F DE SNEDECOR
Distribución χ2 de Pearson
Sea X→N(0,1). Decimos que Y=X2 sigue una distribución 21χ de Pearson.
Propiedad: Si X1,...Xn v.a.i.i.d con distribución N(0,1), entonces 2n
2n
21 X...XX χ→++=
Distribución t de Student
Sean X, X1,X2,...,Xn n+1 v.a.i.i.d con distribución N(0,1). Entonces
n
n
t
n
XX
XT →
++=
221 ...
se distribuye como una t de Student.
Distribución F de Snedecor
Sean X1,X2,...,Xn, e Y1,Y2,...,Yn n1+n2 v.a.i.i.d con distribución N(0,1). Entonces
21
2
1
,
2
221
1
221
...
...
nnn
n
F
n
YY
n
XX
U →++
++
= se distribuye como una F con n1 y n2 grados de libertad.
Propiedad: Sean X e Y v.a.i. tal que 2n1
X χ→ e 2n2
Y χ→ , entonces 21 n,n
2
1 F
n
Yn
X
U →=
CONVERGENCIAS Y TEOREMA DEL LÍMITE
Convergencia en probabilidad: Una sucesión }{ ∞=1nnX converge en probabilidad hacia la
variable X, XX pcn → .. , si para cualquier δ>0,
[ ] 0lim =>−∞→
δXXp nn
, o bien si XXp n =lim .
Propiedades
1.- XX pcn → .. ⇔ 0..→− pc
n XX
2.- XX pcn → .. y g una función continua ⇒ ( ) ( )XgXg pc
n → ..

Econometría Curso 2011-2012
51
Convergencia en media cuadrática: Una sucesión }{ ∞=1nnX converge en media cuadrática
hacia la variable X, XX cmn → .. , si
[ ] 0lim2 =−
∞→XXE n
n
Propiedades
1) Una condición suficiente pero no necesaria para la convergencia en probabilidad es que se dé la convergencia en media cuadrática. Es decir , si XX cm
n → .. ⇒ XX pcn → .. .
2) }{ ∞=1nnX converge en media cuadrática a X si y sólo si el XXE n =)(lim y el
0)(lim =nXVar .
Convergencia en ley o en distribución: Una sucesión }{ ∞=1nnX converge en ley o en
distribución hacia la variable X, XX Ln → , si
)()(lim xFxFnn
=∞→
∀x en los que la función de distribución F sea continua.
Propiedades
1) Si XX Ln → decimos que Xn se distribuye asintóticamente como X, es decir,
XX an → .
3) Si XX cmn → .. ⇒ XX pc
n → .. ⇒ XX Ln →
Ley de los grandes números
Los momentos muestrales de una sucesión de variables aleatorias independientes e igualmente distribuidas convergen en probabilidad a los correspondientes momentos poblacionales.
Teorema del límite central
Sea }{ ∞=1nnX una sucesión de v.a.i.i.d. con E(Xi)=µ y Var(Xi)=σ2. Entonces
)1,0(1
1
11 Nn
nX
XVar
XEXL
n
ii
n
ii
n
ii
n
ii
→−
=
− ∑
∑
∑∑=
=
==
σ
µ
o lo que es lo mismo, ),(n
NX an
σµ→ .
ÁLGEBRA DE LOS LIMITES EN PROBABILIDAD (PLIM)
Sean XT e YT dos sucesiones de variables aleatorias tales que plim XT = c, plim YT = d.
1.- plim (XT + YT) = plim XT + plim YT = c + d.
2.- plim XT.YT = plim XT . plim YT = c .d.

Econometría Curso 2011-2012
52
3.- d
c
Yp
Xp
Y
Xp
T
T
T
T ==lim
limlim si 0lim ≠TYp
4.- ( ) ( )ST
ST XpXp limlim =
5.- Si plim (XT - YT ) = 0 y plim XT = c, entonces plim YT = c.
Teorema de Slutsky
Sea XT una sucesión de variables aleatorias tales que plim XT = c, e YT = Ψ (XT) una función continua en c que no depende de T, entonces plim YT = Ψ (c).
Ejemplo: Si 11
´lim,
´lim −
−
=
= PT
XXpP
T
XXp siempre que P sea una matriz no singular.
ELEMENTOS BÁSICOS SOBRE CONTRASTES
Hipótesis estadística: Es un enunciado sobre los valores de algunos de los parámetros en la población hipotética de la cual se toma la muestra.
Hipótesis puntual: es aquella en la que se plantea contrastar un valor específico para un parámetro.
Hipótesis de intervalo: es aquella en la que se plantea contrastar si el parámetro se encuentra en un intervalo específico.
Contraste de hipótesis: es la regla que nos permite dilucidar la validez de una hipótesis en base a la evidencia empírica.
Hipótesis nula: es la hipótesis sometida a análisis y se designa por Ho.
Hipótesis alternativa: es la hipótesis contra la que suele probarse la hipótesis nula y se designa por H1 o HA.
Al contrastar una hipótesis cabe adoptar dos decisiones: por un lado, podemos rechazarla o no rechazarla y, por otro, dicha hipótesis puede ser cierta o falsa. Por ello, las consecuencias de la decisión se pueden esquematizar de la siguiente forma:
Ho cierta Ho falsa
No Rechazar Decisión correcta Error de II tipo
Rechazar Error de I tipo Decisión correcta
Nivel de significación del contraste: Se denota con la letra α (también se denomina tamaño del contraste) y se define como la probabilidad de rechazar la Ho siendo cierta, lo que ocurrirá cuando la observación muestral pertenezca a la región crítica.
α= P{error de I tipo}=P{rechazar Ho| si Ho es cierta}
Potencia del contraste: se denota como (1-β), siendo β la probabilidad de cometer el error de tipo II y se define como la probabilidad de no rechazar la hipótesis nula cuando ésta es falsa. Así, una vez fijado α, de todas las regiones críticas con el mismo nivel de significación, elegiremos aquella donde la potencia del contraste sea mayor, es decir que β sea menor.
β= P{error de II tipo}=P{No rechazar Ho| si Ho es falsa}

Econometría Curso 2011-2012
53
Región crítica: es aquella zona del espacio muestral donde se rechaza Ho. Si la observación muestral realizada pertenece a ella, entonces se rechaza la Ho.
Región de aceptación: es la complementaria a la región crítica, es decir donde no se rechaza la Ho.
Valor crítico: es el valor de la distribución obtenido en las correspondientes tablas, fijado un nivel de significación, que separa la región crítica de la región de aceptación.
La técnica de los contrastes consiste en delimitar estas dos regiones y ver donde cae el valor muestral obtenido.
P-valor: es el valor de probabilidad y describe el nivel de significación exacto asociado con un resultado econométrico particular. Por tanto es la probabilidad de rechazar de forma incorrecta una hipótesis nula que es cierta. Cuanto menor sea el valor p más seguros estaremos al rechazar la hipótesis nula.
Nivel de confianza (1-α): nos indica la proporción aproximada de veces que el parámetro βi se encontraría en el intervalo si calculásemos el intervalo con muchas muestras diferentes.
Intervalo de confianza: es un intervalo numérico en el que creemos que se encontraría el parámetro con un cierto grado (nivel) de confianza.
Intervalo de Probabilidad: es un intervalo aleatorio que se concreta en un intervalo de confianza cuando disponemos de una realización muestral.


















