
PROBABILIDAD Y ESTADÍSTICA CON MATLAB® PARA …
124
~1~ mean FACULTAD DE INGENIERヘA.PROGRAMA INGENIERヘA DE SISTEMAS 2010 PROBABILIDAD Y ESTADÍSTICA CON MATLAB® PARA INVESTIGADORES Curso básico Héctor José Pabón Ángel MSc. U NIVERSIDAD DE C UNDINAMARCA S ECCIONAL U BATノ
Transcript of PROBABILIDAD Y ESTADÍSTICA CON MATLAB® PARA …

~ 1 ~
meanFACULTAD DE INGENIERÍA. PROGRAMA INGENIERÍA DE SISTEMAS
2010
PROBABILIDAD Y ESTADÍSTICACON MATLAB® PARA
INVESTIGADORESCurso básico
Héctor José Pabón Ángel MSc.
U N I V E R S I D A D D E C U N D I N A M A R C A S E C C I O N A L U B A T É

2
PROBABILIDAD Y ESTADÍSTICACON MATLAB®
PARA INVESTIGADORES
POR:
HÉCTOR JOSÉ PABÓN ÁNGEL
MSc.
UNIVERSIDAD DE CUNDINAMARCA
SECCIONAL UBATÉ
PROGRAMA DE INGENIERÍA
2010

3
CONTENIDO
Pág.1. ELEMENTOS DE MATLAB® 81.1 INTRODUCCIÓN 81.2 ALGUNAS OPERACIONES BÁSICAS CON MATLAB® 81.3 LOS NÚMEROS EN MATLAB® Y LOS FORMATOS NUMÉRICOS 91.4 OPERACIONES ARITMÉTICAS 91.5 FUNCIONES MATEMÁTICAS DE MATLAB® 111.6 VECTORES 111.7 MATRICES 141.8 CREACIÓN DE MATRICES ESPECIALES 171.9 OPERACIONES CON MATRICES 211.10 CADENAS DE IMPRESIÓN 231.11 SOLUCIÓN DE ECUACIONES LINEALES 241.12 GRAFICACIÓN CON MATLAB® 271.13 SUBPLOT 291.14 DEFINICIÓN DE FUNCIONES 30
2. PROBABILIDAD 322.1 INTRODUCCIÓN 322.2 ESPACIO MUESTRAL 322.3 EVENTO 322.4 COMBINATORIA 332.5 PROBABILIDAD DE UN EVENTO 342.6 PROBABILIDAD CONDICIONAL 362.7 EVENTOS INDEPENDIENTES 372.8 VARIABLES ALETAORIAS 372.9 DISTRIBUCIONES DISCRETAS DE PROBABILIDAD 382.10 DISTRIBUCIÓN CONTINUA DE PROBABILIDAD 402.11 ESPERANZA MATEMÁTICA 412.12 VARIANZA 432.13 DISTRIBUCIONES DISCRETAS 452.13.1 Distribución binomial 452.13.2 Distribución hipergeométrica 472.13.3 Distribución de Poisson 482.14 DISTRIBUCIONES CONTINUAS 502.14.1 Distribución normal 502.14.2 Distribución 2 (o JI-cuadrado) 572.14.3 Distribución t de Student 582.14.4 Distribución F 59
3. ANÁLISIS ESTADÍSTICO 613.1 ESTADÍSTICA DESCRIPTIVA 613.1.1 Estadígrafos de posición 663.1.2 Estadígrafos de dispersión 66
4. TEORÍA DE MUESTREO 724.1 INFERENCIA ESTADÍSTICA 754.2 PRUEBA DE HIPÓTESIS 75

4
5. AJUSTES DE CURVAS Y REGRESIÓN 885.1 INTRODUCCIÓN 885.2 REGRESIÓN LINEAL SIMPLE 885.3 DIAGRAMAS DE DISPERSIÓN 89
APÉNDICE 1 98APÉNDICE 2 99APÉNDICE 3 100APÉNDICE 4 101GLOSARIO 103BIBLIOGRAFÍA 108FUENTES DE INFORMACIÓN ELECTRÓNICA 111

5
LISTA DE FIGURAS
Pág.
FIGURA 1.1 Gráfica de la función y = ex+10 27FIGURA 1.2 Gráfica de malla para la superficie Z = -3X + Y 28FIGURA 1.3 Gráfica de la superficie z = 28FIGURA 1.4 Varios gráficos en una misma ventana utilizando la función subplot 29FIGURA 1.5 Varios gráficos en una misma ventana utilizando la función
subplot30
FIGURA 1.6 Gráfica de la función f(x) = ex 2x/(1 + x3) 31FIGURA 2.1 (a) Diagrama de Venn de eventos mutuamente excluyentes (b)
(disyuntos)33
FIGURA 2.2 Diagrama de Venn de la variable aleatoria X del ejemplo 2.7 38FIGURA 2.3 Histograma de probabilidad 39FIGURA 2.4 Distribución acumulada discreta 39FIGURA 2.5 Distribución de Poisson con 48FIGURA 2.6 Función de densidad de la variable aleatoria normal X con = 0 y
= 150
FIGURA 2.7 Distribuciones normales con = -3, = 0 y = 3 y constante 51FIGURA 2.8 Distribuciones normales con igual media 0 y varianzas diferentes 52FIGURA 2.9 Histograma del ejemplo 2.27 52FIGURA 2.10 Histograma del ejemplo 2.28 53FIGURA 2.11 Función de distribución acumulada para la curva normal 57FIGURA 2.12 Distribución 2 con 2, 4, 6 y 8 grados de libertad con azul, verde,
rojo, azul claro, respectivamente58
FIGURA 2.13grados de libertad
59
FIGURA 2.14 Distribuciones F con 8 y 12 grados de libertad (azul), y 12 y 24grados de libertad (verde)
60
FIGURA 3.1 Gráfico de sectores (pie) 64FIGURA 3.2 Histograma de frecuencias con seis clases del ejemplo 3.2 64FIGURA 3.3 Diagrama de barras verticales 64FIGURA 3.4 Diagrama de barras horizontales 65FIGURA 3.5 Gráfico de racimo 65FIGURA 3.6 Polígono de frecuencias (rojo) 65FIGURA 3.7 Histograma y curva normal 67FIGURA 3.8 Histograma y curva normal 69FIGURA 3.9 Asimetrías 69FIGURA 3.10 Curtosis 70FIGURA 5.1 No existe relación entre los vectores de datos x e y 89FIGURA 5.2 Relación lineal positiva 89FIGURA 5.3 Relación lineal negativa 90FIGURA 5.4 Relación curvilínea 90FIGURA 5.5 Línea recta de ajuste por mínimos cuadrados 91FIGURA 5.6 Ajuste lineal y cuadrático 92FIGURA 5.7 Regresión lineal para la data del ejemplo 5.1 y límite de confianza
de y94
FIGURA 5.8 Gráfico de la distribución acumulativa normal de las desviacionesde la línea que aparece adecuada en la figura anterior
94

6
FIGURA 5.9 Recta de regresión estimada de las notas de Matemática Irespecto al puntaje de ingreso a la universidad
95
FIGURA 5.10 Gráfico de la distribución acumulativa normal de las desviaciones 96

7
LISTA DE TABLAS
Pág.
TABLA 2.1 Datos de estudiantes de la Universidad X 36TABLA 3.1 Clases vs frecuencias 64TABLA 5.1 Data de la variable independiente x, y la variable dependiente y 93

8
PROBABILIDAD Y ESTADÍSTICA CON MATLAB® PARAINVESTIGADORES
¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯1. ELEMENTOS DE MATLAB®
1.1 INTRODUCCIÓN
En esta sección se discutirán algunos tópicos de programación con MATLAB®. El nombrede MATLAB® Matrix Laboratory ® es un paquete paracomputación numérica extremadamente potente. Con MATLAB® se pueden darcomandos directos, como una calculadora de mano o se pueden escribir programas.
MATLAB® existe como un programa de aplicación primaria con una librería bastanteToolbox standard Toolbox de
MATLAB®, contienen una librería amplia para resolver muchos problemas prácticos deestadística, tales como interpolación, regresión, medidas de tendencia central, medidasde dispersión, inferencia estadística, graficación, entre otros muchos temas.
MATLAB® es un paquete de software matemático basado en matrices. Está altamenteoptimizado y es un sistema muy confiable. Muchas tareas numéricas pueden serexpresadas en forma concisa en el lenguaje del álgebra lineal sin mucha dificultad comoocurriría en otro lenguaje de programación no optimizado para matemáticas.
1.2 ALGUNAS OPERACIONES BÁSICAS CON MATLAB®
El prompt >> está dado por el sistema y se requiere dar <ENTER> para ejecutar uncomando MATLAB®
Es posible incluir comentarios en el espacio de trabajo de MATLAB® %después de la sentencia, para indicar que es un comentario.
Ejemplo 1.1
>>% este es un comentario que no es ejecutable.
Ejemplo 1.2 Para buscar ayuda en un tópico específico, se puede escribir:
>>help format %busca ayuda sobre format
Un punto y coma colocado al final de una expresión hace que la ejecución del comandono sea visible al usuario. Sin el punto y coma, se muestra el resultado de la ejecución.

9
Ejemplo 1.3 Uso del punto y coma.
>>A=[1 2 3;4 5 6;7 8 9]; % no muestra la matriz
>>A=[1 2 3;4 5 6;7 8 9] % muestra la matriz
1.3 LOS NÚMEROS EN MATLAB® Y LOS FORMATOS NUMÉRICOS
Las variables numéricas son almacenadas en MATLAB® en doble precisión, formato depunto flotante. Es posible forzar algunas variables a otros tipos, pero no de una manerafácil y esta capacidad no es necesaria por ahora.
Por defecto, la salida a la pantalla es de cuatro dígitos a la derecha del punto decimal.
Ejemplo 1.4 Para determinar el formato de salida de pantalla, se usa el comandoformat, así:
>>format short
>>pi
ans =
3.1416
>>format long % formato con 14 cifras decimales
>>pi
ans =
3.14159265358979
>>format short e
>>pi
ans =
3.1416e + 000
Como parte de su sintaxis y su semántica, MATLAB® está previsto para dar valoresexcepcionales. Más infinito (+ ) está representado por Inf, menos infinito (- ) por inf,
NAN (not a number). Estos valores excepcionales seencuentran a menudo a través de cálculos en MATLAB®.
1.4 OPERACIONES ARITMÉTICAS
La aritmética en MATLAB® sigue las reglas y uso de los símbolos de la computaciónestándar para los signos de las operaciones aritméticas.

10
Símbolo Efecto
+ Adición o suma- Substracción o resta* Multiplicación o producto/ División^ Potencia
Conjugada transpuestapi, e Constantes
En el presente contexto se considerarán estas operaciones como operaciones aritméticascon escalares.
Ejemplo 1.5
>>(4-2+3*pi)/2
ans =
5.7124
>>a=2;
>>b=sin(a);
>>2*b^2
ans =
1.6537
Las operaciones aritméticas con MATLAB® son mucho más potentes que éstas delejemplo 1.5, como se verá más adelante.
Hay algunas operaciones aritméticas que requieren gran cuidado. El orden en el cual lamultiplicación y la división se especifican es especialmente importante.
Ejemplo 1.6 El orden de ejecución de las operaciones siguen un orden estricto deacuerdo a la prioridad establecida por MATLAB®
>>a=2;
>>b=3;
>>c=4;
Aquí, ante la ausencia de paréntesis, las dos operaciones se ejecutan de izquierda aderecha como sigue:

11
>>a/b*c
ans =
2.6667
Las operaciones aritméticas ejecutadas es equivalente a (a/b)*c, que es diferente a:a/(b*c)
>> a/(b*c)
ans =
0.1667
1.5 FUNCIONES MATEMÁTICAS DE MATLAB®
Todas las funciones matemáticas estándar, llamadas funciones elementales que senecesitan en este curso están disponibles en MATLAB® usando sus nombresmatemáticos usuales.
Símbolo Efectoabs(x) Valor absoluto
sqrt(x) Raíz cuadrada
sin(x) Función seno
cos(x) Función coseno
tan(x) Función tangente
log(x) Función logaritmo natural
exp(x) Función exponencial
atan(x) Función tangente inversa
acos(x) Función coseno inversa
asin(x) Función seno inversa
cosh(x) Función coseno hiperbólico
sinh(x) Función seno hiperbólico
Nótese que las funciones trigonométricas su argumento debe estar en radianes (o númeropuro) y no en grados.
Ejemplo 1.7 Calcular cos(pi/3)

12
>> cos(pi/3)
ans =
0.5000
Como se dijo antes, las variables aparecen como escalares. De hecho, todas las variablesen MATLAB® son arreglos. Un aspecto importante de MATLAB® es que se trabaja muyeficientemente con arreglos y las tareas principales son mejor trabajadas con arreglos.
1.6 VECTORES
En MATLAB® la palabra vector puede ser realmente interpretada como una lista denúmeros. Estrictamente, podría ser una lista de otros objetos no numéricos, pero porahora, decir esto es más que suficiente y llena las expectativas del curso.
Hay dos clases básicas de vectores en MATLAB®: vector fila y vector columna.
Ejemplo 1.8 Definir un vector fila y un vector columna
>> x=[1 2 3 4 5] %define el vector x
x =
1 2 3 4 5
>> y=[1;2;3;4;5] %define el vector columna y
y =
1
2
3
4
5
>> x(3) %muestra el tercer elemento del vector x
ans =
3
>> y(5) %muestra el quinto elemento del vector columna
ans =
5
>> z=x(4)+3*x(2)+y(5)
z = 15

13
Los dos puntos tienen un especial y potente rol. Básicamente, permite una forma fácil dedefinir un vector de números igualmente espaciados. Hay dos formas básicas de definirun vector en MATLAB® con esta la notación, utilizando los dos puntos.
La primera se hace con dos argumentos separados por dos puntos, como sigue:
Ejemplo 1.9 Definir un vector x con elementos igualmente espaciados por una unidad.
>> x=-2:4 %crea un vector que empieza con -2 y termina con 4 con incrementos de a 1
x =
-2 -1 0 1 2 3 4
La segunda es con tres argumentos separados por dos veces los dos puntos y tiene elefecto de especificar el valor inicial : espaciamiento : valor final.
Ejemplo 1.10 Definir un vector espaciando igualmente sus elementos con incrementos
de 0.5
>> y=-2:0.5:4 %crea un vector que empieza con -2 y termina con 4 con incrementos de a 0.5
y =
-2.0000 -1.5000 -1.0000 -0.5000 0 0.5000 1.0000 1.5000 2.0000 2.5000
3.0000 3.5000 4.0000
Ejemplo 1.11 También se puede utilizar la notación con dos puntos como sigue:
>> z=x(2:6) %crea el vector z con los elementos desde x(2) hasta x(6)
z =
-1 0 1 2 3
>> w=y(2:6) %crea el vector w con los elementos desde y(2) hasta y(6)
w =
-1.5000 -1.0000 -0.5000 0 0.5000
MATLAB® tiene otros dos comandos para definir vectores de una manera adecuada. Laprimera se llama función linspace, que se usa para especificar un vector con un número
dado de elementos igualmente espaciados entre un punto inicial y un punto final.
Ejemplo 1.12 Definir un vector en un intervalo dado con elementos.
>> x=linspace(1,2,5) %crea el vector x con 5 elementos en el intervalo [1,2]

14
x =
1.0000 1.2500 1.5000 1.7500 2.0000
En el ejemplo 1.12, el vector tiene 5 elementos acomodados entre 1 y 2, igualmenteespaciados.
El otro comando es llamado función logspace, que es similar a la función linspace,excepto que los elementos crecen igualmente espaciados en forma logarítmica, y tambiénsegún 10valor inicial y 10valor final.
Ejemplo 1.13 Definir un vector en forma logarítmica con elementos
>> x=logspace(1,5,5)
x =
10 100 1000 10000 100000
Ejemplo 1.14 Se pueden usar vectores con MATLAB® para generar tablas de valores defunciones.
>> x=linspace(0,1,11);%crea el vector x con 11 valores entre 0 y 1
>> y=cos(x);%crea el vector y con los 11 valores de cos(x)
>> [x',y']%escribe los dos vectores x, y como columnas
ans =
0 1.0000
0.1000 0.9950
0.2000 0.9801
0.3000 0.9553
0.4000 0.9211
0.5000 0.8776
0.6000 0.8253
0.7000 0.7648
0.8000 0.6967
0.9000 0.6216
1.0000 0.5403

15
Nótese que se utilizó el apóstrofe para transponer los vectores, es decir, para convertirlas filas en columnas.
Ejemplo 1.15 Otra forma de usar los dos puntos es como sigue:
>> y=sqrt(4+2*(0:0.3:2.4)')
y =
2.0000
2.1448
2.2804
2.4083
2.5298
2.6458
2.7568
2.8636
2.9665
1.7 MATRICES
Una matriz es un arreglo bidimensional de valores numéricos que obedecen las reglas delálgebra lineal.
Para entrar una matriz, se listan todos los elementos de la matriz de la primera filaseparados por espacios en blanco o comas, separando la primera fila de la segunda porpunto y coma y así sucesivamente hasta la última fila, encerrando todos los elementoscon corchetes. Para entrar una matriz de 3x4 de números se procede así:
Ejemplo 1.16 Definir una matriz numérica de dimensión 3x4.
>> A=[1 2 3 4;5 6 7 8;8 10 11 12]%crea la matriz A de tres filas y 4 columnas
A =
1 2 3 4
5 6 7 8
8 10 11 12
Ejemplo 1.17 Si se quiere convertir un vector fila, en vector columna, se procede:
>> [1 2 3] %el ap strofe transpone el vector

16
ans =
1
2
3
Ejemplo 1.18 Los elementos de las matrices se pueden manipular de muchas maneras.
>> A
A =
1 2 3 4
5 6 7 8
8 10 11 12
>> A(2,3)%escribe el elemento localizado en la segunda fila y tercera columna
ans =
7
Ejemplo 1.19 Se puede seleccionar una submatriz, de la siguiente forma:
>> A([1 2 3],[1 2 3])
ans =
1 2 3
5 6 7
8 10 11
>> A([1:3],[1:3])
ans =
1 2 3
5 6 7
8 10 11
Ejemplo 1.20 Se puede borrar un elemento o un grupo de elementos de un vector o unamatriz, asignando a esos elementos la matriz nula (cero), [ ].
>> x=[1 2 3 4 5 6];

17
>> x(4)=[ ]
x =
1 2 3 5 6
>> A(:,1)=[ ]
A =
2 3 4
6 7 8
10 11 12
Ejemplo 1.21 Para intercambiar dos filas de una matriz A, se digita el siguiente script:
>> B=A([3 2 1])
B =
10 6 2
>> B=A([3 2 1],:)
B =
10 11 12
6 7 8
2 3 4
>> A
A =
2 3 4
6 7 8
10 11 12
Ejemplo 1.22 Para cambiar la segunda fila de una matriz A de 3x3 a [2 2 2], se ejecuta elsiguiente script:
>> A=[1 2 3;4 5 6;7 8 9]
A =
1 2 3
4 5 6
7 8 9

18
>> A(2,:)=[2 2 2]
A =
1 2 3
2 2 2
7 8 9
Ejemplo 1.23 seejecuta el siguiente script:
>> A=[1 2 3;4 5 6;7 8 9]
A =
1 2 3
4 5 6
7 8 9
>> A(:,2)=[1 1 1]
A =
1 1 3
4 1 6
7 1 9
1.8 CREACIÓN DE MATRICES ESPECIALES
Hay muchas funciones incorporadas en MATLAB® que se utilizan para crear vectores ymatrices especiales. Se tienen ejemplos como:
Ejemplo 1.24 Crear la matriz cero.
>> A=zeros(2,3)%crea la matriz A de 2 filas y tres columnas de ceros
A =
0 0 0
0 0 0
>> A=zeros(3)%crea la matriz cuadrada A de ceros de orden 3
A =
0 0 0
0 0 0

19
0 0 0
Ejemplo 1.25 Crear una matriz de unos
>> A=ones(2,3)
A =
1 1 1
1 1 1
>> A=ones(3)
A =
1 1 1
1 1 1
1 1 1
>> A=ones(2,3)'
A =
1 1
1 1
1 1
Ejemplo 1.26 Crear la matriz identidad
>> I3=eye(3)
I3 =
1 0 0
0 1 0
0 0 1
>> I5=eye(5)
I5 =
1 0 0 0 0
0 1 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1

20
Ejemplo 1.27 Crear una matriz diagonal
>> x=[1 2 3];
>> A=diag(x)
A =
1 0 0
0 2 0
0 0 3
>> A=diag([4 5 6])
A =
4 0 0
0 5 0
0 0 6
Ejemplo 1.28 Para extraer la diagonal de una matriz almacenada en memoria, se usa elnombre de la función diag, pero poniendo como entrada una matriz y presentando comosalida alternativa un vector.
>> A=diag([1 2 3])
A =
1 0 0
0 2 0
0 0 3
>> u=diag(A)
u =
1
2
3
Ejemplo 1.29 Crear la función length y la función size, la cual se usa para determinar elnúmero de elementos de un vector o una matriz. Estas funciones son muy útiles cuando

21
se trata de matrices de tamaño desconocido o tamaño variable especialmente cuando seescriben bucles (loops).
>> x=1:10 %crea el vector x de enteros entre 1 y 10
x =
1 2 3 4 5 6 7 8 9 10
>> length(x)%proporciona el n mero de elementos del vector x
ans =
10
Ejemplo 1.30 Ahora se define el comando size, el cual retorna dos valores,correspondientes a las filas y columnas de la matriz en cuestión, donde el primer númerocorresponde a las filas y el segundo a las columnas.
>> A=[1 2 3 4;5 6 7 8]
A =
1 2 3 4
5 6 7 8
>> size(A)
ans =
2 4
>> size(A')
ans =
4 2
Ejemplo 1.31 Crear la matriz de raíces cuadradas de una matriz A, usando la función sqrtpara obtener una matriz B cuyos elementos son las raíces cuadradas de los elementos dela matriz A.
>> A
A =
1 2 3 4
5 6 7 8
>> B=sqrt(A)
B =

22
1.0000 1.4142 1.7321 2.0000
2.2361 2.4495 2.6458 2.8284
Ejemplo 1.32 Crear una matriz triangular superior de una matriz dada A, usando la
función triu
>> A=[1 2 3;4 5 6;7 8 9]
A =
1 2 3
4 5 6
7 8 9
>> U=triu(A)
U =
1 2 3
0 5 6
0 0 9
>> U=triu(A,1)
U =
0 2 3
0 0 6
0 0 0
>> U=triu(A,2)
U =
0 0 3
0 0 0
0 0 0
Ejemplo 1.33 Crear una matriz triangular inferior, usando la función tril
>> U=tril(A)
U =
1 0 0
4 5 0

23
7 8 9
>> U=tril(A,-1)
U =
0 0 0
4 0 0
7 8 0
>> U=tril(A,-2)
U =
0 0 0
0 0 0
7 0 0
Ejemplo 1.34 Crear una matriz aleatoria nxn usando la función rand
>> R=rand(3) %siempre va a salir una matriz diferente por ser aleatoria
R =
0.8147 0.9134 0.2785
0.9058 0.6324 0.5469
0.1270 0.0975 0.9575
>> R=rand(2) %siempre va a salir una matriz diferente por ser aleatoria
R =
0.9649 0.9706
0.1576 0.9572
1.9 OPERACIONES CON MATRICES
Las operaciones básicas con matrices son la adición, substracción y multiplicación.Cuando dos matrices tienen el mismo tamaño, se pueden sumar y restar. También sepuede multiplicar una matriz por escalar.
Ejemplo 1.35
>> A=[-1 2 5 0; 1 -2 4 2; 1 2 3 4]
A =

24
-1 2 5 0
1 -2 4 2
1 2 3 4
>> B=[0 1 0 1; 2 -1 -4 3; 2 1 4 1]
B =
0 1 0 1
2 -1 -4 3
2 1 4 1
>> A+B
ans =
-1 3 5 1
3 -3 0 5
3 3 7 5
>> A-B
ans =
-1 1 5 -1
-1 -1 8 -1
-1 1 -1 3
>> 2*A-3*B
ans =
-2 1 10 -3
-4 -1 20 -5
-4 1 -6 5
>> B=B' % se hace B igual a B transpuesta por
B =
0 2 2
1 -1 1
0 -4 4
1 3 1
>> B*A %
a.
ans =

25
4 0 14 12
-1 6 4 2
0 16 -4 8
3 -2 20 10
>> A*B %en general A*B es diferente de B*A
ans =
2 -24 20
0 -6 18
6 0 20
Ejemplo 1.36 Matemáticamente la operación de división de matrices no está definida,mas sin embargo se pueden realizar algunas operaciones adicionales como sigue:
>> a=[1 2 3];
>> b=[2 -1 4];
>> c=a./b
c =
0.5000 -2.0000 0.7500
>> c=a.*b
c =
2 -2 12
>> c=a.^2
c =
1 4 9
>> c=a.^a
c =
1 4 27
>> c=a.^b
c =
1.0000 0.5000 81.0000
>> B=B'
B =
0 1 0 1

26
2 -1 -4 3
2 1 4 1
>> C=A.*B
C =
0 2 0 0
2 2 -16 6
2 2 12 4
>> C=C.^(1/2)
C =
0 1.4142 0 0
1.4142 1.4142 0.0000 + 4.0000i 2.4495
1.4142 1.4142 3.4641 2.0000
1.10 CADENAS DE IMPRESIÓN
Las cadenas son matrices cuyos elementos son caracteres. En aplicaciones másavanzadas tales como computación simbólica, la manipulación de cadenas es un tópicomuy importante. Para el presente propósito, sin embargo, se necesitarán algunasherramientas limitadas al manejo elemental de tales cadenas.
Ejemplo 1.37
>> nombre=' Hector';
>> apellido=' Pabon';
>> apellido=apellido'
apellido =
P
a
b
o
n
Ejemplo 1.38 Las matrices tipo string también pueden ser creadas como sigue:
>> nombres=['Hector';'Pabon '] %las dos cadenas deben ser de la misma longitud, o completarse
con blancos

27
nombres =
Hector
Pabon
Ejemplo 1.39 La función disp toma únicamente un argumento, el cual puede ser ambos, o
una matriz de caracteres o una matriz numérica.
>> x=0:0.5:2*pi;
>> y=cos(x);
>> disp([x' y'])
0 1.0000
0.5000 0.8776
1.0000 0.5403
1.5000 0.0707
2.0000 -0.4161
2.5000 -0.8011
3.0000 -0.9900
3.5000 -0.9365
4.0000 -0.6536
4.5000 -0.2108
5.0000 0.2837
5.5000 0.7087
6.0000 0.9602
Ejemplo 1.40 Se pueden imprimir cadenas más complicadas con la función fprintf.Esta es esencial en los comandos de programación C, que se usan para obtener unamplio rango de especificaciones de impresión.
>> fprintf('Mi nombre es: \n Hector Pabon \n') %donde \
Mi nombre es:
Hector Pabon
Ejemplo 1.41 La función fprintf tiene especificaciones del número de dígitos en el display

28
>> raiz2=fprintf('La raiz cuadrada de 2 es: %1.6f',(sqrt(2)))
La raiz cuadrada de 2 es: 1.414214
>> raiz2=fprintf('La raiz cuadrada de 2 es: %1.6e',(sqrt(2)))
La raiz cuadrada de 2 es: 1.414214e+000
1.11 SOLUCIÓN DE ECUACIONES LINEALES
Para resolver un sistema de ecuaciones lineales de la forma: Ax = b, se puede ejecutar uncomando de MATLAB®, de la siguiente manera:
>>x = A\b % con A como una matriz no singular.
Ejemplo 1.42 Resolver el siguiente sistema de ecuaciones lineales:
>> A=[1 1 1;2 3 1;1 -1 -2]; %matriz de los coeficientes de las variables
>> b=[2;3;-6]; %matriz de los terminos independientes
>> x=A\b
x =
-1
1
2
Hay un pequeño número de funciones que pueden ser mencionadas a continuación:
Ejemplo 1.43 Reducir una matriz A a la forma escalonada reducida por filas.>> rref(A)
ans =
1 0 0
0 1 0
0 0 1
Ejemplo 1.44 Encontrar el determinante de una matriz A, usando la función det.
>> det(A)
ans =
-5

29
Ejemplo 1.45 Encontrar el rango de una matriz, usando la función Rank.
>> rank(A)
ans =
3
Ejemplo 1.46 Encontrar la inversa de una matriz A no singular, usando la función inv.
>> format rat %formato de la forma p/q
>> inv(A)
ans =
1 -1/5 2/5
-1 3/5 -1/5
1 -2/5 -1/5
Ejemplo 1.47 Encontrar la matriz aumentada [A b], la cual es una combinación decoeficientes de la matriz A y el lado derecho es el vector b del sistema lineal Ax = b.
>> C=[A b] %escribe la matriz aumentada del sistema de ecuac. lineales
C =
1 1 1 2
2 3 1 3
1 -1 -2 -6
>> rref(C) %lleva a la forma escalonada reducida por filasans =
1 0 0 -10 1 0 10 0 1 2
Ejemplo 1.48 Descomposición LU de una matriz A, utilizando la función lu.
>> [L,U]=lu(A)
L =
1/2 1/5 1
1 0 0
1/2 1 0

30
U =
2 3 1
0 -5/2 -5/2
0 0 1
>> L*U
ans =
1 1 1
2 3 1
1 -1 -2
>> A
A =
1 1 1
2 3 1
1 -1 -2
Las raíces de un polinomio p(x) se pueden hallar utilizando la función roots, como
roots(p).
Ejemplo 1.49 Hallar las raíces del polinomio p(x) = 3x2 + 5x -6
>> p=[3 5 -6];
>> r=roots(p)
r =
-2.4748
0.8081
La función polyval se utiliza para evaluar un polinomio pn(x) en un punto particular x.
Ejemplo 1.50 Hallar el valor de la función polinómica p3(x) = x3 2x + 12, en el puntodado x = 1.5
>> coef=[1 0 -2 12];
>> sol=polyval(coef,1.5)
sol =
12.3750

31
1.12 GRAFICACIÓN CON MATLAB®
Con MATLAB® se pueden realizar gráficas de 2 o 3 dimensiones de curvas y superficies.El comando plot se utiliza para generar gráficos de funciones bidimensionales.
Primero se divide el intervalo en subintervalos de igual anchura. Luego se entra laexpresión para la variable dependiente y en términos de la variable independiente x, yfinalmente se crea el gráfico.
Ejemplo 1.51
>> x=-2:0.1:2;
>> y=exp(x)+10;
>> plot(x,y)
>> plot(x,y),grid %grid permite hacer las rejillas o cuadriculado
FIGURA 1.1 Gráfica de la función y = ex+10
Por defecto, la función plot conecta los puntos por medio de segmentos de línea sólida.Otras posibilidades que se pueden usar para cambiar la apariencia de la gráfica son:
>> plot(x,y,'o'),grid
>> plot(x,y,'*'),grid
>> plot(x,y,'x'),grid
>> plot(x,y,'.'),grid
>> plot(x,y,'+'),grid
32
>> plot(x,y,'-'),grid
>> plot(x,y,'.-'),grid
>> plot(x,y,'o-'),grid
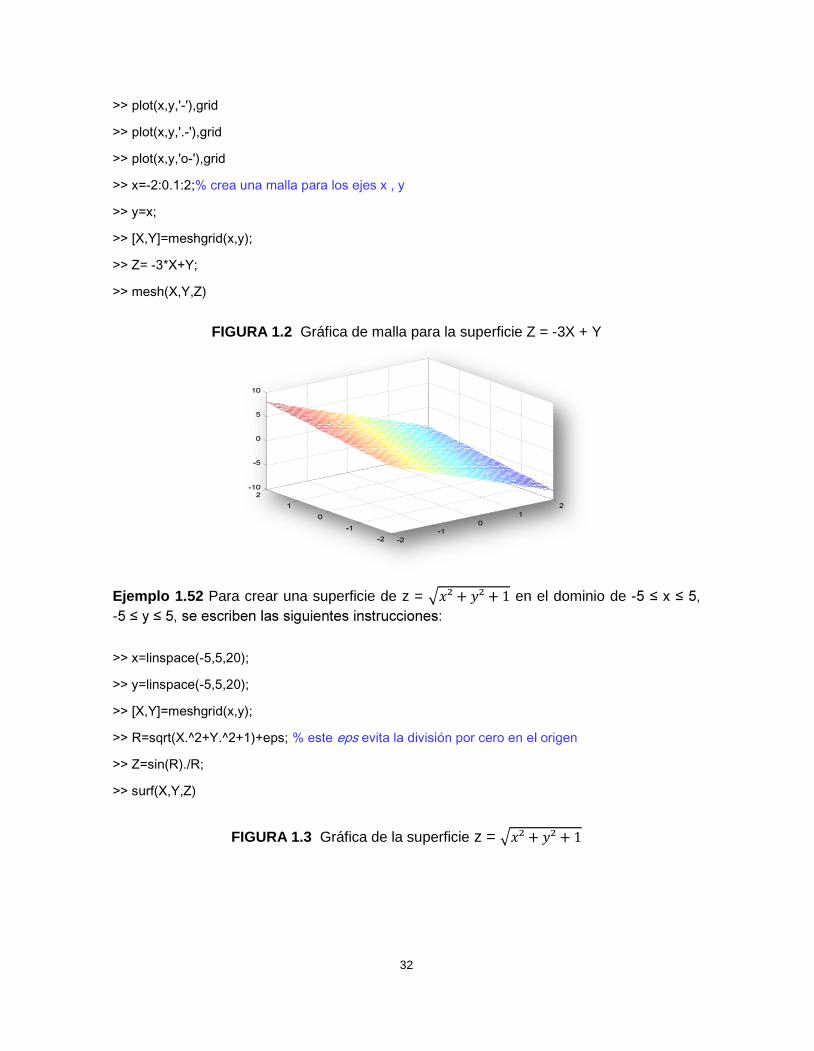
>> x=-2:0.1:2;% crea una malla para los ejes x , y
>> y=x;
>> [X,Y]=meshgrid(x,y);
>> Z= -3*X+Y;
>> mesh(X,Y,Z)
FIGURA 1.2 Gráfica de malla para la superficie Z = -3X + Y
Ejemplo 1.52 Para crear una superficie de z = en el dominio de --
>> x=linspace(-5,5,20);
>> y=linspace(-5,5,20);
>> [X,Y]=meshgrid(x,y);
>> R=sqrt(X.^2+Y.^2+1)+eps; % este evita la divisi
>> Z=sin(R)./R;
>> surf(X,Y,Z)
FIGURA 1.3 Gráfica de la superficie z =
33
1.13 SUBPLOT
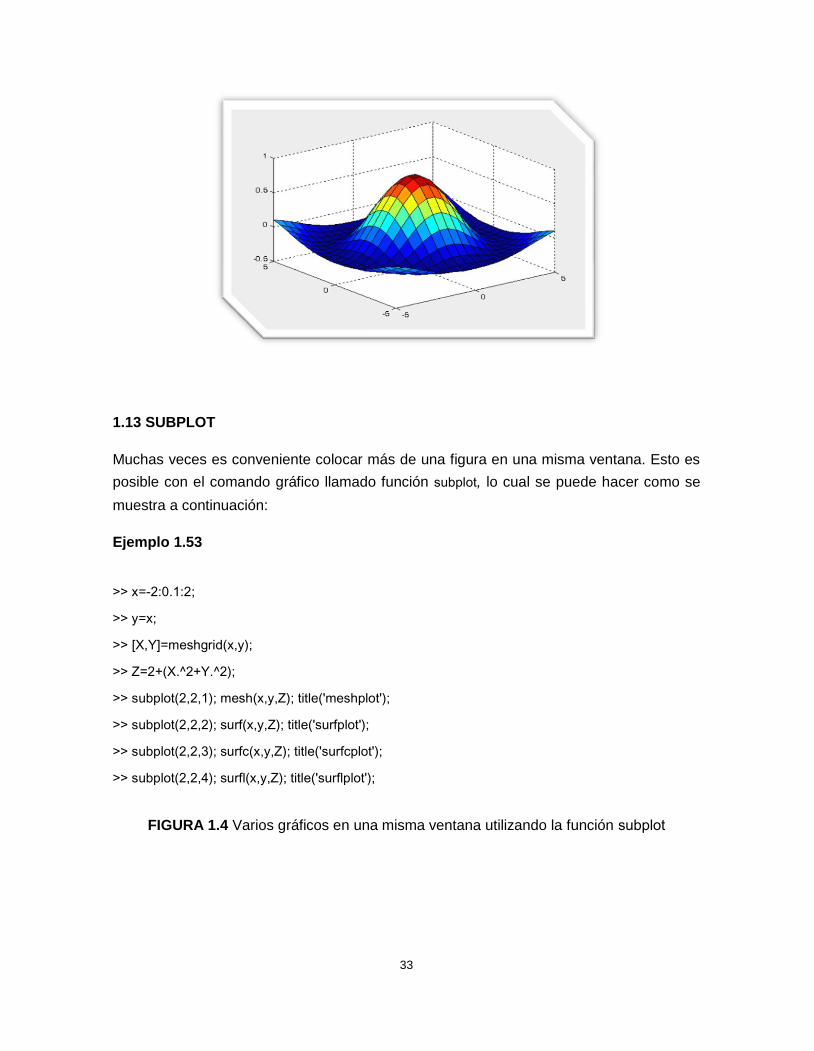
Muchas veces es conveniente colocar más de una figura en una misma ventana. Esto esposible con el comando gráfico llamado función subplot, lo cual se puede hacer como semuestra a continuación:
Ejemplo 1.53
>> x=-2:0.1:2;
>> y=x;
>> [X,Y]=meshgrid(x,y);
>> Z=2+(X.^2+Y.^2);
>> subplot(2,2,1); mesh(x,y,Z); title('meshplot');
>> subplot(2,2,2); surf(x,y,Z); title('surfplot');
>> subplot(2,2,3); surfc(x,y,Z); title('surfcplot');
>> subplot(2,2,4); surfl(x,y,Z); title('surflplot');
FIGURA 1.4 Varios gráficos en una misma ventana utilizando la función subplot

34
>> x=linspace(-2*pi,2*pi);
>> subplot(2,2,1);
>> plot(x,cos(x));axis([-6.5 6.5 -1.2 1.2]); title('cos(x)')
>> subplot(2,2,2);
>> plot(x,cos(2*x));axis([-6.5 6.5 -1.2 1.2]); title('cos(2x)')
>> subplot(2,2,3);
>> plot(x,cos(3*x));axis([-6.5 6.5 -1.2 1.2]); title('cos(3x)')
>> subplot(2,2,4);
>> plot(x,cos(4*x));axis([-6.5 6.5 -1.2 1.2]); title('cos(4x)')
FIGURA 1.5 Varios gráficos en una misma ventana utilizando la función subplot

35
1.14 DEFINICIÓN DE FUNCIONES
La sintaxis para definir funciones desde el editor de MATLAB®, tiene la siguiente forma:
function = nombre_funcion(entrada de argumentos)
Ejemplo 1.54 Para definir la función f(x) = ex 2x/(1 + x3), se escribe:
>> x=(0:0.2:2);
>> fx=fn2(x);
>> [x',fx'] %genera la siguiente tabla:
ans =
0 1.0000
0.2000 0.8246
0.4000 0.7399
0.6000 0.8353
0.8000 1.1673
1.0000 1.7183
1.2000 2.4404
1.4000 3.3073
1.6000 4.3251
1.8000 5.5227
2.0000 6.9446
36
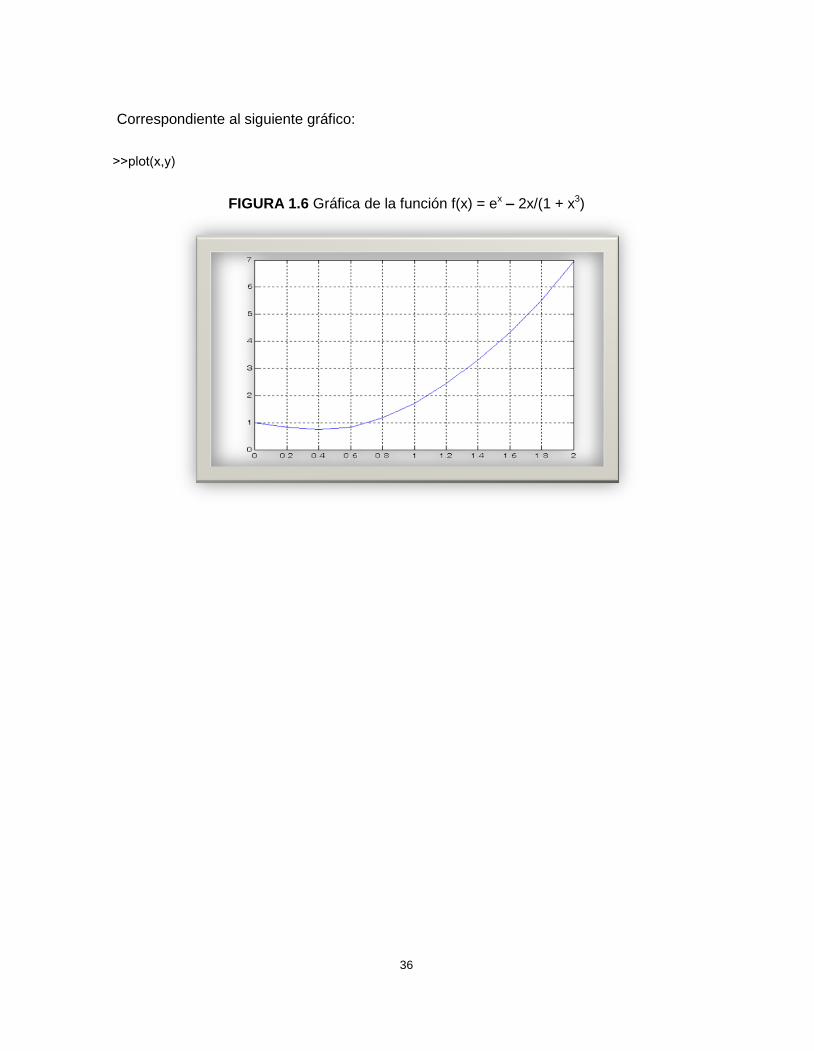
Correspondiente al siguiente gráfico:
>>plot(x,y)
FIGURA 1.6 Gráfica de la función f(x) = ex 2x/(1 + x3)

37
2. PROBABILIDAD
2.1 INTRODUCCIÓN
La probabilidad está asociada con muchas tendencias en eventos aleatorios naturalesque siguen una cierta regularidad si el proceso se repite un suficiente número de veces.Por ejemplo, se puede considerar el evento del lanzamiento de una moneda no cargada.Si el experimento se repite un número suficiente de veces, en forma continua en un grannúmero de ensayos, se puede esperar que se logren el mismo número de caras que desellos. Intuitivamente se puede decir que la probabilidad de obtener una cara es la mismaque la de obtener un sello en una moneda justa (no cargada) y que ésta es de 0.5 o del50%.
2.2 ESPACIO MUESTRAL
Al conjunto de todos los resultados posibles de un experimento estadístico se le llamaespacio muestral y generalmente se representa con la letra S.
A cada resultado en un espacio muestral se llama elemento o punto del espacio muestral.Por ejemplo, al lanzar una moneda el conjunto muestral S está conformado por doselementos: cara y sello.
Ejemplo 2.1 En un experimento de lanzar un dado cúbico (seis caras) el espacio muestralestá conformado por los puntos muestrales: S = {1, 2, 3, 4, 5, 6}
2.3 EVENTO
En cualquier experimento el hecho de que ocurra cierta circunstancia se llama evento, porejemplo al lanzar un dado corriente, un evento puede ser el hecho de obtener un númeropar, en cuyo caso está conformado por tres puntos muestrales: A = {2, 4, 6}
Matemáticamente se puede definir un evento A como un subconjunto de un espaciomuestral S.
También se puede definir el complemento de un evento A con respecto a S como elconjunto de todos los elementos de S que no pertenecen a A y se denota como: A .
En el ejemplo 2.1, el complemento está conformado por A = {1, 3, 5}
La intersección de dos eventos A1 y A2, se representa con los símbolos A1 A2, y es elevento que contiene todos los elementos comunes que pertenecen a A1 y A2.
Dos eventos A1 y A2 son mutuamente excluyentes o disyuntos si A1 A2 = , es decir,cuando no hay puntos muestrales comunes.

38
FIGURA 2.1 (a) Diagrama de Venn de eventos mutuamente excluyentes (disyuntos)
(b) Eventos que no son mutuamente excluyentes
La unión de dos eventos A1 y A2 se representa con el símbolo A1 A2 y es el evento queabarca a todos los elementos de A1 o A2 o a ambos.
2.4 COMBINATORIA
Una combinación es el número posible de seleccionar r objetos de un total de nelementos, sin importar el orden.
(1)
Ejemplo 2.2 Con MATLAB® se pueden generar combinaciones de un conjunto de nelementos tomados en partes de r elementos. Para el caso de un conjunto X = {1, 2, 3, 4,5}, tomando subconjuntos de a dos elementos, se procede de la siguiente forma:
>> v=[1 2 3 4 5]
>> c2=combnk(v,2)
c2 =
4 5
3 5
3 4
A1 A2
A1 A2

39
2 5
2 4
2 3
1 5
1 4
1 3
1 2
>> c4=combnk(v,4)
c4 =
1 2 3 4
1 2 3 5
1 2 4 5
1 3 4 5
2 3 4 5
Una permutación es un arreglo de todos o parte de un conjunto de objetos. Desde luegoque aquí sí importa el orden. Si se tienen tres letras diferentes como X = {v, e, a},permutadas todas tres aparecen palabras diferentes como VEA, AVE, EVA , que sonpalabras completamente diferentes.
(2)
>> v=['e' 'v' 'a'];
>> perms(v)
ans =
ave
aev
vae
vea
eva
eav
>> perms(0:2)%crea un vector con componentes 0, 1 y 2 y los permuta

40
ans =
2 1 0
2 0 1
1 2 0
1 0 2
0 1 2
0 2 1
2.5 PROBABILIDAD DE UN EVENTO
La probabilidad de un evento A es la suma de los pesos de todos los puntos muestralesde A. Así que:
P( ) = 0 ; P(S) = 1 ; P(Ak , (3)
Para una población consistente de K posibles resultados, solamente una de los cualespuede ocurrir, para cada ensayo del experimento, se puede deducir la siguiente relación:
P(A1) + P(A2) + P(A3 k) = 1, (4)
Ejemplo 2.3 Se lanza un dado (cúbico) una vez, ¿Cuál es la probabilidad de que caiga unnúmero par?
Solución. El espacio muestral para este experimento es: S = {1, 2, 3, 4, 5, 6}. Arepresenta el evento de que caiga un número par, A = {2, 4, 6}, entonces la probabilidadde A es, P(A)=número de casos favorables/número de casos posibles = n/N = 3/6 = 0.5 =50%.
Si A1 y A2 son dos eventos cualesquiera se tiene que:
P(A1 U A2) = P(A1) + P(A2) P(A1 A2) (5)
Pero si A1 y A2 son mutuamente excluyentes se tiene que:
P(A1 U A2) = P(A1) + P(A2) (6)
Ejemplo 2.4 ¿Cuál es la probabilidad de obtener al lanzar un dado un número par o unnúmero mayor que 3?
Solución. El espacio muestral es: S = {1, 2, 3, 4, 5, 6}, el evento A1 = {2, 4, 6} y A2 = {4, 5,
6}. A1 A2 = {4} por tanto P(A1 U A2) = 3/6 + 3/6 1/6 = 5/6, utilizando (2) para sucesosque no son mutuamente excluyentes.

41
Ejemplo 2.5. Se lanza un par de dados. ¿Cuál es la probabilidad de obtener 10 puntos u11 puntos?
Solución. El espacio muestral para este caso es:
S = {(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(2,1),(2,2),(2,3),(2,4),(2,5),(2,6),(3,1),(3,2),(3,3),(3,4),(3,5),(3,6),(4,1),(4,2),(4,3),(4,4),(4,5),(4,6),(5,1),(5,2),(5,3),(5,4),(5,5),(5,6),(6,1),(6,2), (6,3),(6,4),(6,5),(6,6)}
P(A1) = P({(4,6),(5,5),(6,4)} = 3/36P(A2) = P({(5,6),(6,5)}) = 2/36
Por tanto, P(A1UA2) = 3/36 + 2/36 = 5/36, aplicando (3), ya que A1 y A2 son mutuamenteexcluyentes.Ahora, si A1 y A2 son eventos complementarios, se tiene que:
P(A1) + P(A ) = 1 (7)
Ejemplo 2.6 Se lanza un dado. ¿Cuál es la probabilidad de no obtener un númeromúltiplo de 3?
Solución. La probabilidad de obtener un número múltiplo de 3 es: P({3,6}) = 2/6 = 1/3. Portanto, la probabilidad de no obtener un número múltiplo de 3 es: 1 - P({3,6}) = 1 - 1/3 = 2/3aplicando (4).
Ejemplo 2.7 Al lanzar tres monedas, se quiere determinar la probabilidad de obtenerexactamente dos caras.
Solución. El espacio muestral es: S = {ccc, ccs, csc, scc, css, scs, ssc, sss}. Laprobabilidad P({ccs, csc, scc}) = 3/8
2.6 PROBABILIDAD CONDICIONAL
La probabilidad condicional de A2 dado A1, que se denota por P(A2|A1), se define como:
P(A2|A1) = P(A1 A2) / P(A1), si P(A) > 0; (8)
De (5), se puede obtener: P(A1 A2) = P(A1) P(A2|A1); (9)
Ejemplo 2.8. Se tiene la siguiente tabla de estudiantes de la Universidad X
TABLA 2.1. Datos de estudiantes de la Universidad X

42
ESTUDIANTES DE ESTUDIANTES DE TOTAL
HOMBRES 70 80 150MUJERES 90 60 150TOTAL 160 140 300
Se va a seleccionar un estudiante al azar para ser becado. Los eventos son:
H: seleccionar a un hombreI: seleccionar a un estudiante de ingeniería
P(I) = 160/300 = 16/30
P(H I) = 70/300 = 7/30
P(H | I) = = 7/16, según (5)
Visto directamente desde la tabla 2.1 se obtiene el mismo resultado: P(H | I) = 70/160 =7/16
2.7 EVENTOS INDEPENDIENTES
Dados dos eventos A1 y A2, se dice que estos eventos son independientes siempre que:P(A1|A2) = P(A1), lo cual significa que la ocurrencia de A2 no incide en la ocurrencia de A1
Dicho de otra forma: dos eventos A1 y A2 son independientes sí y solo si:
P(A2|A1) = P(A2) y P(A1|A2) = P(A1) (10)
De otra forma A1 y A2 son dependientes.
Ejemplo 2.9 Suponga que se tiene una tula con 20 balotas, de las cuales 15 son rojas y 5azules. Se seleccionan dos balotas al azar una después de otra, sin reemplazamiento.¿Cuál es la probabilidad de obtener dos balotas azules?
Solución. Sea A1 el evento de obtener una balota azul en la primera extracción y A2 elevento de obtener una balota azul en la segunda extracción. P(A1 A2) es la probabilidadde obtener una balota azul en la primera extracción y otra balota azul en la segundaextracción. P(A2|A1), es la probabilidad de obtener una balota azul en la segundaextracción, dado que la primera extracción fue también una balota azul (sinreemplazamiento). Según (6) se tiene:
P(A1 A2) = P(A1) P(A2|A1) = (5/20)(4/19) = 1/19 = 5.26% aproximadamente.
Dos eventos son independientes sí y solo si P(A1 A2) = P(A1) P(A2);

43
2.8 VARIABLES ALETAORIAS
Una variable aleatoria es una función que asocia un número real con cada elemento delespacio muestral.
Ejemplo 2.10 Se tienen tres monedas. Se lanzan todas tres simultáneamente. El espaciomuestral es S = {ccc, ccs, csc, scc, ssc, scs, css, sss}, como en el ejemplo 2.7
Se define ahora variable aleatoria como una función que asocia un número real con cadaelemento del espacio muestral. En el ejemplo 2.7, si se asocia el número de caras paracada elemento del espacio muestral, se tiene:
FIGURA 2.2 Diagrama de Venn de la variable aleatoria X del ejemplo 2.7S X
Se ve en la figura 2.2 que, la variable aleatoria X tiene como elementos X={0, 1, 2, 3}. Siun espacio muestral S posee un número finito de posibilidades o un número infinito contantos elementos como números enteros positivos existen, se llama entonces, espaciomuestral discreto.
Si el anterior no fuese el caso, es decir, si S contiene un número infinito de posibilidadescon tantos elementos como números reales existen en un segmento de línea, se llamaespacio muestral continuo.
2.9 DISTRIBUCIONES DISCRETAS DE PROBABILIDAD
El conjunto de parejas ordenadas (x, f(x)) es una función de probabilidad o distribución deprobabilidad de la variable aleatoria X, si se cumple que para cada valor posible de x:
f(x) 0= 1
P(X = x) = f(x)
cccccscscsccsscscscsssss
0
1
2
3

44
Según el ejemplo 2.10, f(x) 0, ya que f(0) = 1/8, f(1) = 3/8, f(2) = 3/8, f(3) = 1/8.
>> x=[1/8 3/8 3/8 1/8];
>> y=[0 1 2 3]
>> bar(y,x, r )
Se ve también claramente que = 1/8 + 3/8 + 3/8 + 1/8 = 1
FIGURA 2.3 Histograma de probabilidad
La distribución acumulada F(x) de una variable aleatoria X con distribución deprobabilidad f(x) es:
, para - < x < ( )
Según el ejemplo 2.10
FIGURA 2.4 Distribución acumulada discreta

45
>> x=[1/8 4/8 7/8 8/8];
>> y=[0 1 2 3];
>> bar(y,x,'g')
2.10 DISTRIBUCIÓN CONTINUA DE PROBABILIDAD
La probabilidad de una función aleatoria continua tiene algunas particularidades a teneren cuenta, como por ejemplo que P(X=x) para un valor particular x de la variable aleatoriaX es cero, por tanto se toman intervalos para poder calcular su probabilidad. Si se deseacalcular la probabilidad de que un estudiante de Ingeniería de la Universidad deCundinamarca Seccional Ubaté tenga un índice de masa corporal1 de 20, la variablealeatoria se sabe que es continua y P(x=20) = 0, por propiedades de la integral definida.
La función de densidad de probabilidad de una variable aleatoria continua se define comosigue:
P(a < x < b) = (12)
Una función f(x) es una función de densidad de probabilidad para la variable aleatoriacontinua X, definida en el conjunto de los , si cumple las siguientes condiciones:
f(x) 0, para cada x= 1
P(a < x < b) =
1 Índice de masa corporal es igual a: peso(kg)/altura2 (m)

46
function y=fn(x)
y=(1/3)*x.^2;
La distribución acumulada F(x) de una VAC X (variable aleatoria continua X) con funciónde densidad f(x) es:
para - < x < (13)
Como consecuencia de la anterior definición se puede anotar que:
P(a < X < b) = F(b) - F(a) (14)
Ejemplo 2.11 Para la función de densidad definida como sigue:
, -1 < x < 2
f(x) =0, para cualquier otro valor en
Hallar:a) P(-1 < X < 2);b) P(-1 < X < 1);c) P(1 < X 2)Solución. Se utiliza el método de Simpson para calcular la integral de f(x), como ya sedefinió anteriormente.
a)>> simpsonR('fn',-1,2,10)
ans =
1
b)>> simpsonR('fn',-1,1,10)
function SN=simpsonR(fn,a,b,n)
%Regla trapezoidal compuesta
h=(b-a)/n;
s=(feval(fn,a)+feval(fn,b));
for k=1:2:n-1
s=s+4*feval(fn,a+k*h);
end;
for k=2:2:n-2
s=s+2*feval(fn,a+k*h);

47
ans =
0.2222
c)>> simpsonR('fn',1,2,10)
ans =
0.7778
2.11 ESPERANZA MATEMÁTICA
Sea X una VA con distribución de probabilidad f(x). La media o valor esperado de X es:
= E(X) = ; para X discreta (15)
= E(X) = ; para X continua (16)
Ejemplo 2.12. Al lanzar un dado (cúbico), la VAD se anota en la siguiente tabla, lo mismoque sus valores de probabilidad:
X 1 2 3 4 5 6P(X = x) 1/6 1/6 1/6 1/6 1/6 1/6
E(X) = 1(1/6) + 2(1/6) + 3(1/6) + 4(1/6) + 5(1/6) + 6(1/6) = 21/6 = 3.5Lo anterior se interpreta como que si se lanza un dado un gran número de veces y luegose promedia los distintos puntajes que se han obtenido entonces la media tiende a 3.5
Ejemplo 2.13 Supóngase que la variable aleatoria X se representa por el número depuntos que marca un dado corriente y la nueva VA como Y = 2x, los valores de estavariable son: {2, 4, 6, 8, 10, 12}. Los valores de probabilidad asociados son:
Y 2 4 6 8 10 12P(Y = y) 1/6 1/6 1/6 1/6 1/6 1/6
E(Y) = 2(1/6) + 4(1/6) + 6(1/6) + 8(1/6) + 10(1/6) + 12(1/6) = 42/6 = 7
E(X) = 3.5 implica 2E(X) = 2(3.5) = 7 = E(2X)
Ejemplo 2.14 Calcular E(X 3).
Solución. Aquí se tiene que E(X 3) = E(X) E(3) = 3.5 3 = 0.5, por propiedades delvalor esperado.
Propiedades del valor esperado:

48
E(c) = cE(cX) = cE(X)E(X + c) = E(X) + cE(X + Y) = E(X) + E(Y)E(aX + bY) = aE(X) + bE(Y)
Ejemplo 2.15 Sea X la VAC que define la vida en horas de cierta bombilla doméstica. Lafunción de densidad de probabilidad es:
, x > 100
f(x) =0, para cualquier otro valor en
= E(X) = = = = = =
= -20000(1/x)| = 200 horas
Si se quiere integrar utilizando el método de Simpson, se procede así:
>> SN=simpsonR('fn',100,100000,1000000)
SN =
1.0
Como se ve, f(x) cumple con la condición para la cual el área bajo la curva es 1.
>> SN=simpsonR('fn',100,100000,1000000)
SN =
199.8
Que es aproximadamente 200 horas como se calculó manualmente para esta integraldefinida que es realmente fácil de calcular.
2.12 VARIANZA
function y=fn(x)y=20000/x^3;
function y=fn(x)

49
Sea X una VA con distribución de probabilidad f(x) y media , la varianza de X, para Xdiscreta es:
2 = E[(X - )2] = (17)
Si X es continua se tiene:
2 = E[(X - )2] = (18)
La raíz cuadrada de la varianza 2 se denomina desviación estándar de X.
Ejemplo 2.16 Hallar la varianza para la VAD del del ejemplo 2.12.
Solución. Como ya se sabe en el ejemplo 2.12, = 3.5.
2 = E[(X - )2] = (1 - 3.5)²(1/6) + (2 - 3.5)²(1/6) + (3 - 3.5)²(1/6) + (4 - 3.5)²(1/6) + (5 -3.5)²(1/6) + (6 - 3.5)²(1/6) = 2.9167
La desviación estándar es: = 1.7078
>> E=((1-3.5)^2)/6 + ((2-3.5)^2)/6 +((3-3.5)^2)/6 +((4-3.5)^2)/6 +((5-3.5)^2)/6 +((6-3.5)^2)/6
E =
2.9167
>> s=sqrt(E)
s =
1.7078
Ejemplo 2.17 La demanda mensual de un cierto artículo en una cadena dehipermercados es una VAC que tiene densidad de probabilidad:
2(2x-1), 1 < x < 2f(x) =
0, para cualquier otro valor en
= E(X) = = = 2[ - ] = 5/3
E(X2) = = 17/6
Por tanto, teniendo en cuenta que la varianza también se puede escribir como:
2 = E(X2) - 2 (19)
Se obtiene: 17/8 (5/3)2 = 17/6 25/9 = 1/18

50
------------------------------
>> SN=simpsonR('fn',1,2,10)
SN =1
Ahora se calcula
>> SN=simpsonR('fn',1,2,10)
SN =
5/3
Ahora se calcula E(X2)
>> SN=simpsonR('fn',1,2,10)
SN =
17/6
>> s2=17/6 - (5/3)^2
s2 =
1/18
2.13 DISTRIBUCIONES DISCRETAS
2.13.1 Distribución binomial. Si p es la probabilidad de éxito y q la probabilidad defracaso, entonces la probabilidad P de que obtengan x éxitos en n ensayos, es el términodel desarrollo binomial de (p + q)n, así:
P(X=x) = px qn-x x, (20)
Ejemplo 2.18 La probabilidad de que un estudiante que ingresa a la universidad segradúe es de 0.6. Calcular la probabilidad de que 20 estudiantes que ingresan:
1. Ninguno se gradúe
function y=fn(x)
y=2*(x 1);
function y=fn(x)y=2*(x*(x 1));

51
2. Que se gradúen la mitad3. Que se gradúen todos
Solución. Se tiene que n = 20, p = 0.6 y por tanto q = 0.4, pues p + q = 1. Para n grandecomo en este caso es conveniente utilizar MATLAB® para agilizar los cálculos.
1. Que ninguno se gradúe
>> p=binopdf(0,20,0.6)
p =
1.0995e-008
Lo que es lo mismo que p = 1.0995 x 10-8 = 0.000000010995 un valor cercano a 0
2. Que se gradúen 10
>> p=binopdf(10,20,0.6)
p =
0.1171
La probabilidad de que se gradúen la mitad dada en porcentaje es 11.71%
3. Que se gradúen todos los 20
>> p=binopdf(20,20,0.6)
p =
3.6562e-005
Que es un valor bastante pequeño: p = 3.6562x10-5 = 0.000036562
Ejemplo 2.19 Encontrar la probabilidad de que diez personas que se encuentran en unareunión un sábado, a lo más 2 hayan nacido en este mismo día de la semana.Solución. El trabajo más dispendioso del cálculo de probabilidades es cuando estas sonacumuladas como en el presente ejemplo. En los libros aparecen al final, tablas quepermiten solucionar el problema pero con algunas limitaciones, por lo incompletas ydispendiosa la forma de encontrarlas.
En
Se tiene que p = 1/7, q = 6/7, x = 0, 1, 2, 3, 4.

52
>> p=binocdf(2,10,1/7)
p =
0.8384
Ejemplo 2.20 Encontrar la probabilidad de que diez personas que se encuentran en unareunión un sábado, por lo menos 2 hayan nacido en este mismo día de la semana.
Solución. Se tiene que p = 1/7, q = 6/7, x = 2, 3, 4, 5, 6, 7, 8, 9, 10.
>> p = 1-binocdf(1,10,1/7) %se calcula la probabilidad complementaria
p =
0.4292
O también utilizando la forma larga que es poco funcional, pero que sirve como prueba:
>> y = binopdf(2,10,1/7) + binopdf(3,10,1/7) + binopdf(4,10,1/7) + binopdf(5,10,1/7) +
binopdf(6,10,1/7) + binopdf(7,10,1/7) + binopdf(8,10,1/7) + binopdf(9,10,1/7) + binopdf(10,10,1/7)
y =
0.4292
n = 20 y p = 0.3, se procede de la siguiente manera:
>> p=binocdf(7,20,0.3)
p =
0.7723
Ejemplo 2.21 De 100 monedas que son extraídas de una alcancía y puestas sobre unamesa, ¿Cuál es la probabilidad de que entre 50 y 70 monedas inclusive se encuentrenmostrando cara?
Solución.
>> p=binocdf(70,100,0.5)- binocdf(49,100,0.5) %se supone p=0.5
p =
0.5398
La media y la varianza de la distribución binomial b(x; n, p) son:

53
= np y 2 = npq (21)
Ejemplo 2.22 Encuentre la media y la varianza del ejemplo 2.21
Solución. n = 100; p = ½ ; q = ½
= np = 100(1/2) = 502 = npq = 100(1/2)(1/2) = 25
2.13.2 Distribución hipergeométrica. La distribución de probabilidad aleatoriahipergeométrica X, el número de éxitos en una muestra aleatoria de tamaño n que seselecciona de m artículos de los que k se denominan éxito y m-k fracaso, es:
h(x, m, n, k) = , x (22)
Esta distribución se aplica cuando de un grupo de m artículos, de los cuales k tienencierta característica, son tomados n artículos, para saber el número de los seleccionadosque tienen la característica mencionada x.
Ejemplo 2.23 Se tienen 200 artículos de los cuales 50 son defectuosos. Si son tomados10 artículos al azar, calcular la probabilidad de que salgan: a) exactamente cincodefectuosos b) cinco o menos defectuosos.
Solución. m = 200; k = 50; n = 10.
Con MATLAB se utiliza el siguiente comando: h = hygepdf(x, m, k, n)
a) Para p(x = 5)
>> h=hygepdf(5,200,50,10)%m = 200; k = 50; n = 10.
h =0.0558
b) 5)
Se utiliza el siguiente comando: hc = hygecdf(x, m, k, n)>> hc = hygecdf(5,200,50,10)
hc =
0.9829
2.13.3 Distribución de Poisson. En una distribución binomial cuando n es grande, por logeneral mayor de 50, y p, la probabilidad de éxito de un evento, se acerca a 0, mientras
54
que q la probabilidad de fracaso se aproxima a 1 de tal manera que el producto np = , esmenor o igual a 5, debe utilizarse la distribución de Poisson. También puede considerarseel caso cuando p es bastante grande cercana a 1 y también > 5. En estos dos casos sepuede aplicar esta distribución.
P(x = k) = e- k / k! (23)
Donde e es la base de los logaritmos naturales e = 2.71828182, = np, k = número decasos favorables.
La distribución de Poisson es utilizada en las líneas de espera, número de bacterias en uncultivo, insectos por unidad de superficie, número de fallas de una máquina por unidad detiempo, entre otras.
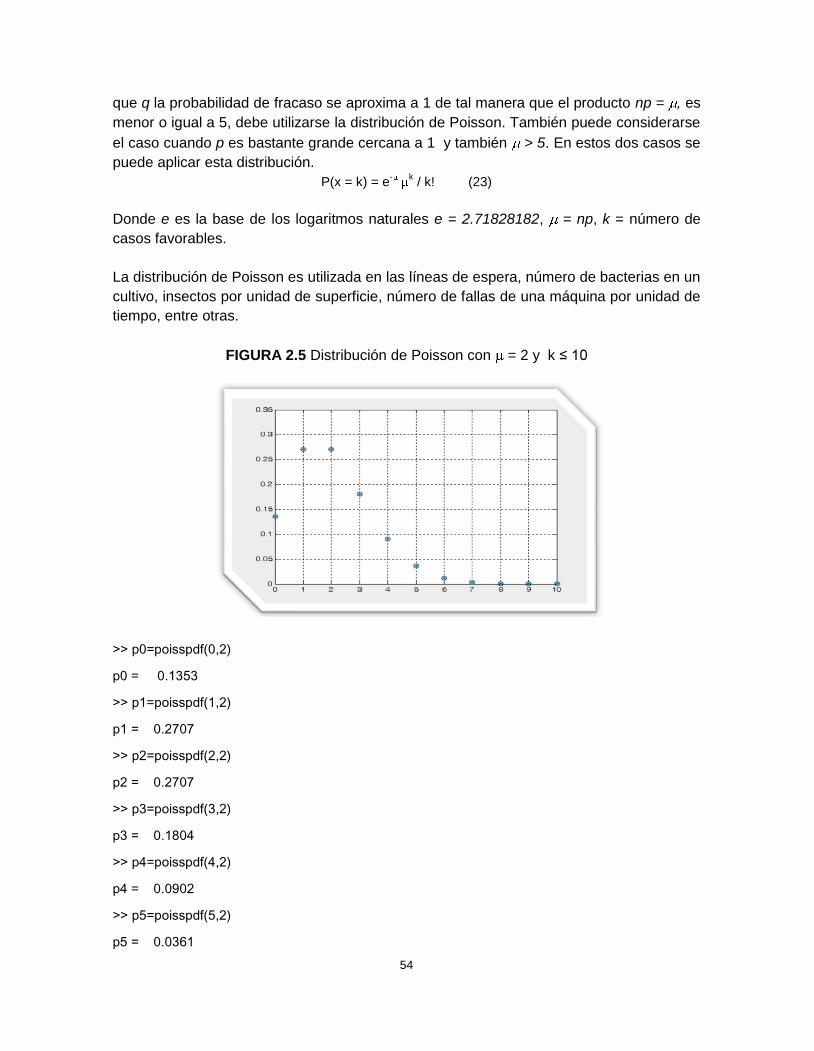
FIGURA 2.5 Distribución de Poisson con = 2 y k
>> p0=poisspdf(0,2)
p0 = 0.1353
>> p1=poisspdf(1,2)
p1 = 0.2707
>> p2=poisspdf(2,2)
p2 = 0.2707
>> p3=poisspdf(3,2)
p3 = 0.1804
>> p4=poisspdf(4,2)
p4 = 0.0902
>> p5=poisspdf(5,2)
p5 = 0.0361

55
>> p6=poisspdf(6,2)
p6 = 0.0120
>> p7=poisspdf(7,2)
p7 = 0.0034
>> p8=poisspdf(8,2)
p8 = 8.5927e-004
>> p9=poisspdf(9,2)
p9 = 1.9095e-004
>> p10=poisspdf(10,2)
p10 = 3.8190e-005
>> k=0:10
k = 0 1 2 3 4 5 6 7 8 9 10
>> p=[p0 p1 p2 p3 p4 p5 p6 p7 p8 p9 p10];
>> plot(k,p,'o',k,p,'*'),grid
Ejemplo 2.24 Si la probabilidad de que una persona se contagie debido a la aplicación deuna vacuna es de una en diez mil. ¿Cuál es la probabilidad de que se contagien con elvirus de la vacuna exactamente 5 personas en una población de 20,000 vacunados?¿Cuál es la probabilidad de que se contagien menos de 5 personas en la mismapoblación?
Solución. = np = 20000(1/10000) = 2
a) Exactamente 5 personas
>> p=poisspdf(5,2)
p =
0.0361
>> p=poisscdf(5,2)
p =
0.9834
b) Cinco o menos de 5 personas
>> p=poisscdf(5,2)
p =

56
0.9834
Ejemplo 2.25 Durante un experimento en un laboratorio de física, el número promedio departículas radiactivas que pasan a través de un contador en un milisegundo es 4. ¿Cuáles la probabilidad de que seis partículas entren al contador en un milisegundo dado?
Solución. k = 6; = 4;>> p4=poisspdf(6,4)
p4 =
0.1042
La media y la varianza de la distribución de Poisson p(k, ) tienen el valor .
2.14 DISTRIBUCIONES CONTINUAS
2.14.1 Distribución normal. La función de densidad de la variable aleatoria normal X(VAN), con media y varianza 2 es:
y = n(x, , ) = e-(x- )/2 ² (24)
Propiedades de la curva normal
La moda, ocurre donde la curva tiene el máximo, es decir en x =La curva es simétrica con respecto al eje verticalEl eje de las abscisas es asíntota horizontalEl área bajo la curva es igual a 1
En las variables continuas, no tiene sentido referirse a probabilidades de la forma p(x = k),de manera que sólo se tratarán probabilidades acumuladas.
Con MATLAB© la función y = normcdf(k, , ) calcula p(x < k) con media y desviaciónestándar
Ejemplo 2.26 Calcular p(x < 20) con = 25, y, = 3
>> y=normcdf(20,25,3)
y =
0.0478
FIGURA 2.6 Función de densidad de la variable aleatoria normal X con = 0 y = 1

57
>> nu=0;
>> ro=1;
>> x=linspace(-2.5,2.5,100);
>> y=(1/(sqrt(2*pi)*ro)*exp(-(x-nu).^2)/2*ro^2);
>> plot(x,y)
Una variable aleatoria continua (VAC) X que tiene su gráfica en forma de campana comola figura 2.6 se llama variable aleatoria normal (VAN).
La función matemática correspondiente a la figura 2.6 con = 1 y = 0, es:
f(x) = e-(x- )/2 ² (25)
f(x) depende de dos parámetros: 2 y que son la varianza y la media, respectivamente.
>> nu=-3;sigma=2;
>> y1=(1/(sqrt(2*pi)*sigma)*exp(-(x-nu).^2)/2*sigma^2);
>> nu=0;sigma=2;
>> y2=(1/(sqrt(2*pi)*sigma)*exp(-(x-nu).^2)/2*sigma^2);
>> nu=3;sigma=2;
>> y3=(1/(sqrt(2*pi)*sigma)*exp(-(x-nu).^2)/2*sigma^2);
>> plot(x,y1,x,y2,x,y3)
FIGURA 2.7 Distribuciones normales con = -3, = 0 y = 3 y constante
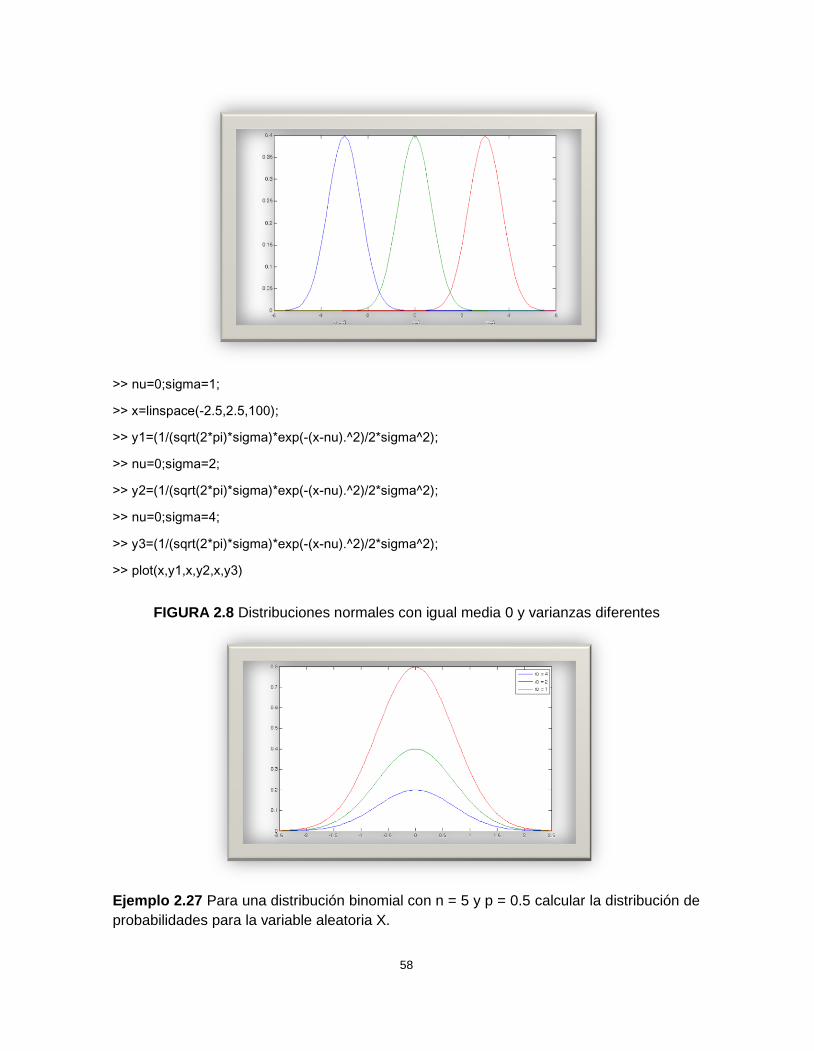
58
>> nu=0;sigma=1;
>> x=linspace(-2.5,2.5,100);
>> y1=(1/(sqrt(2*pi)*sigma)*exp(-(x-nu).^2)/2*sigma^2);
>> nu=0;sigma=2;
>> y2=(1/(sqrt(2*pi)*sigma)*exp(-(x-nu).^2)/2*sigma^2);
>> nu=0;sigma=4;
>> y3=(1/(sqrt(2*pi)*sigma)*exp(-(x-nu).^2)/2*sigma^2);
>> plot(x,y1,x,y2,x,y3)
FIGURA 2.8 Distribuciones normales con igual media 0 y varianzas diferentes
Ejemplo 2.27 Para una distribución binomial con n = 5 y p = 0.5 calcular la distribución deprobabilidades para la variable aleatoria X.
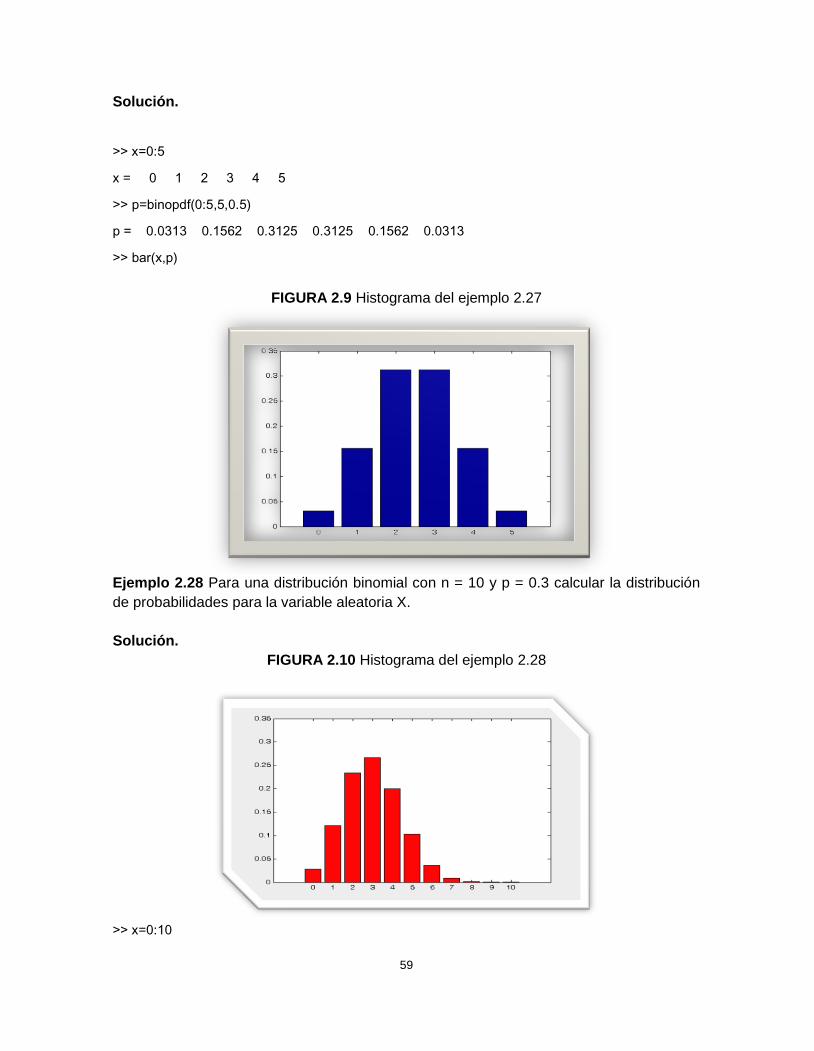
59
Solución.
>> x=0:5
x = 0 1 2 3 4 5
>> p=binopdf(0:5,5,0.5)
p = 0.0313 0.1562 0.3125 0.3125 0.1562 0.0313
>> bar(x,p)
FIGURA 2.9 Histograma del ejemplo 2.27
Ejemplo 2.28 Para una distribución binomial con n = 10 y p = 0.3 calcular la distribuciónde probabilidades para la variable aleatoria X.
Solución.FIGURA 2.10 Histograma del ejemplo 2.28
>> x=0:10

60
x =
0 1 2 3 4 5 6 7 8 9 10
>> p=binopdf(0:10,10,0.3)
p =
0.0282 0.1211 0.2335 0.2668 0.2001 0.1029 0.0368 0.0090 0.0014 0.0001
0.0000
>> bar(x,p,'r')
Ejemplo 2.29 Calcular la probabilidad de obtener 4, 5 o 6 caras en 9 lanzamientos de unamoneda, mediante aproximación binomial y mediante la normal.
Solución. p = 0.5; q = 0.5; n = 9; = np = 9(0.5) = 4.5; = = = 1.5
>> p=binopdf(4,9,0.5)+binopdf(5,9,0.5)+binopdf(6,9,0.5)
cuadro a cuadro
p =
0.6563
>> p=binocdf(6.5,9,0.5)-binocdf(3.5,9,0.5)
p =
0.6562
Ahora se calcula un valor aproximado utilizando la normal:
>> y=normcdf(6.5,4.5,1.5)-normcdf(3.5,4.5,1.5)
intervalo
y =
0.6563
Observe que utilizando MATLAB© no es necesario normalizar2, como se acostumbra demanera regular.
La distribución de una VAN con media 0 y varianza 1 se llama distribución normalestándar.
2 Z = (x - )/

61
Ejemplo 2.30 Hallar el área bajo la curva normal: Z = -1.20 y Z = 2.40
Solución.
>> y=normcdf(2.4,0,1)-normcdf(-1.2,0,1)% como Z est normalizada, se tiene que la media es 0 y
la desviaci n es 1
y =
0.8767
Ejemplo 2.31 Calcular el área bajo la curva normal, a la izquierda de Z = -1.78
Solución.
>> y=normcdf(-1.78,0,1)
y =
0.0375
Ejemplo 2.32 Calcular el área bajo la curva normal, a la derecha de Z = 1.78
Solución.
>> y=1-normcdf(1.78,0,1)
y =
0.0375
Ejemplo 2.33 Las estaturas de los varones de la Universidad de Cundinamarca seencuentran distribuidas normalmente con media 170 cm. y desviación estándar 4 cm.Calcular: a) ¿Cuál es la probabilidad de que un estudiante tenga una estatura superior a1.72 cm? b) ¿Qué porcentaje de estudiantes tendrá una estatura entre 160 cm. y 170 cm?
Solución.
a) Probabilidad de que un estudiante tenga una estatura superior a 172 cm.
>> y=1-normcdf(172,170,4)
y =
0.3085

62
En términos de porcentaje: 30.85% de los estudiantes miden más de 172 cm.
b) Porcentaje de estudiantes que miden entre 160 cm y 170 cm.
>> y=normcdf(170,170,4)- normcdf(160,170,4)
y =
0.4938
En términos de porcentaje, el 49.38% de los estudiantes miden entre 160 cm y 170 cm.
Ejemplo 2.34 En una distribución binomial de frecuencias, donde p = 0.2, encontrar laprobabilidad de obtener al menos 10 éxitos en 50 experimentos.
Solución. p = 0.2; q =0.8; n =50; = np = 50(0.2) = 10; = = =2.8284
>> yc=normcdf(10.5,10,2.8284)%c normal
yc =
0.5702
>> yc=binocdf(10,50,0.2)%c
yc =
0.5836
Ejemplo 2.35 Si una distribución normal tiene = 20 y = 3, encuentre la probabilidad deque una variable, seleccionada al azar, sea mayor de 30 o menor de 15.
Solución.
>> y30=normcdf(30,21,3)
y30 =
0.9987
>> y15=normcdf(15,21,3)
y15 =
0.0228
>> p=1-(y30-y15)
p =
0.0241
Expresado en porcentaje: p = 2.41%

63
Ejemplo 2.36 Se analizó una muestra de cinco bebidas gaseosas de un mismo sabor yuna misma marca y se encontró que su contenido de agua era, en mililitros: 20, 19, 22,18, 22. Obtener el intervalo de confianza al 0.95, para estimar el contenido medio de aguade todas las gaseosas de este tipo.
Solución.
>> [mediamuestral,destipicamuestral,interconfianza]=normfit(x,0.05)
mediamuestral =
20.2000
destipicamuestral =
1.7889
interconfianza =
17.9788
22.4212
Interconfianza (17.9788, 22.4212) representa el intervalo de confianza al 95% para lamedia poblacional.
>> [mediamuestral, destipicamuestral, interconfianza]=normfit(x,0.01)
mediamuestral =
20.2000
destipicamuestral =
1.7889
interconfianza =
16.5167
23.8833
Ahora, Interconfianza (16.5167, 23.8833) representa el intervalo de confianza al 99% parala media poblacional.
Si se desea calcular el intervalo de confianza al 95% de los valores de una distribuciónnormal (0, 1), la solución consiste en calcular los valores de la inversa de una normal enlos puntos 0.025 y 0.975, así:
>> x=norminv([0.025 0.975],0,1) %intervalo de confianza al 95 por ciento
x =
-1.9600 1.9600

64
>> x=norminv([0.01 0.99],0,1) %intervalo de confianza al 99 por ciento
x =
-2.3263 2.3263
>> x=norminv([0.1 0.9],0,1 %intervalo de confianza al 90 por ciento)
x =
-1.2816 1.2816
Más adelante se resolverá este mismo ejemplo, utilizando la distribución t-student paracomparar los resultados obtenidos.
FIGURA 2.11 Función de distribución acumulada para la curva normal
2.14.2 Distribución 2 (o JI-cuadrado). Una variable aleatoria continua X se dice quetiene distribución 2, con grados de libertad, si su función de densidad está definidacomo:
f(x) = x /2 e-x/2, x > 0; (26)
f(x) = 0, en cualquier otro caso, donde es un entero positivo.
La función 2, de distribución acumulada p = chi2cdf(x,v) en MATLAB® es la función quedevuelve la probabilidad acumulada p con v grados de libertad con valores en x.
Ejemplo 2.37 Hallar la probabilidad para x = 2, con una función de distribución acumulada2 y 3 grados de libertad, luego hacer el proceso inverso, es decir, calcular x dado p.
Solución.
>> v=3;
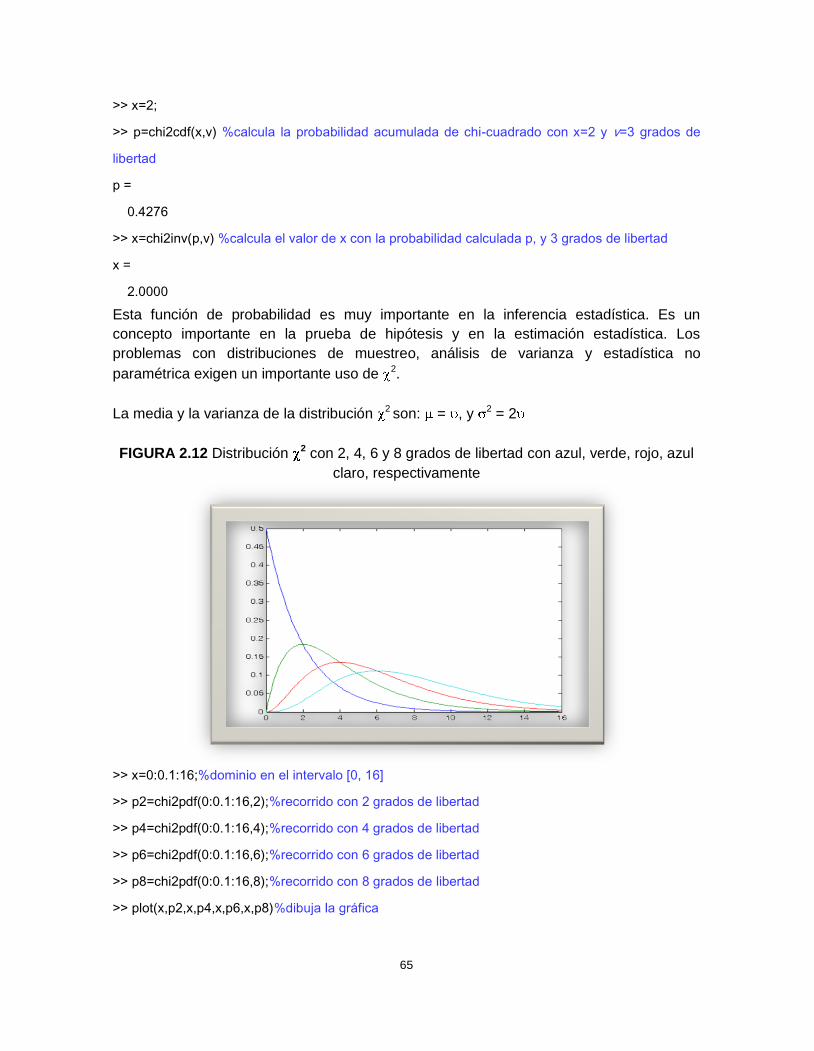
65
>> x=2;
>> p=chi2cdf(x,v) %calcula la probabilidad acumulada de chi-cuadrado con x=2 y =3 grados de
libertad
p =
0.4276
>> x=chi2inv(p,v) %calcula el valor de x con la probabilidad calculada p, y 3 grados de libertad
x =
2.0000
Esta función de probabilidad es muy importante en la inferencia estadística. Es unconcepto importante en la prueba de hipótesis y en la estimación estadística. Losproblemas con distribuciones de muestreo, análisis de varianza y estadística noparamétrica exigen un importante uso de 2.
La media y la varianza de la distribución 2 son: = , y 2 = 2
FIGURA 2.12 Distribución 2 con 2, 4, 6 y 8 grados de libertad con azul, verde, rojo, azulclaro, respectivamente
>> x=0:0.1:16;%dominio en el intervalo [0, 16]
>> p2=chi2pdf(0:0.1:16,2);%recorrido con 2 grados de libertad
>> p4=chi2pdf(0:0.1:16,4);%recorrido con 4 grados de libertad
>> p6=chi2pdf(0:0.1:16,6);%recorrido con 6 grados de libertad
>> p8=chi2pdf(0:0.1:16,8);%recorrido con 8 grados de libertad
>> plot(x,p2,x,p4,x,p6,x,p8)

66
2.14.3 Distribución t de Student. Se utiliza en las pruebas de hipótesis, cuando seconoce la desviación estándar poblacional , no importa el tamaño de la muestra ya seapequeña o grande. Una muestra es pequeña cuando n es menor o igual que 30 y seconsidera grande cuando n es mayor que 30.
Cuando se desconoce la desviación estándar poblacional , ésta se puede reemplazarpor la desviación estándar muestral s, siempre que la muestra sea grande, de acuerdo alas consideraciones anteriores.
cuando no se le ha hecho ningunacorrección. Generalmente es menor que , por lo tanto se hace necesario hacerlealgunas correcciones en su cálculo, con el fin de convertirla en un buen estimador de ,como se verá más adelante.Estas y otras consideraciones se tendrán en cuenta más tarde para el estudio de lainferencia estadística, en su debido momento.
con v grados de libertad está dada por:
h(t) = (1+t2/v)-(v+1)/2 , - < t < (27)
FIGURA 2.13 delibertad
>> x=-5:0.1:5;
>> t1=tpdf(x,1);
>> t2=tpdf(x,2);
>> t3=tpdf(x,5);
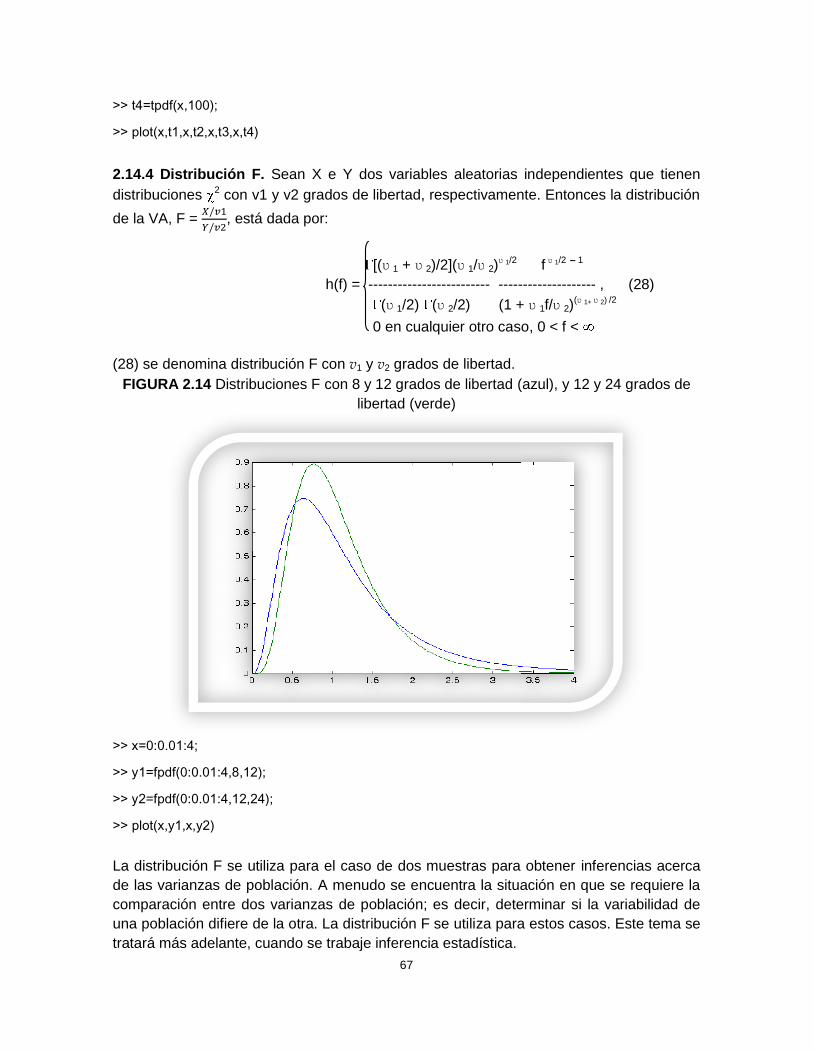
67
>> t4=tpdf(x,100);
>> plot(x,t1,x,t2,x,t3,x,t4)
2.14.4 Distribución F. Sean X e Y dos variables aleatorias independientes que tienendistribuciones 2 con v1 y v2 grados de libertad, respectivamente. Entonces la distribuciónde la VA, F = , está dada por:
[( 1 + 2)/2]( 1/ 2) 1/2 f 1/2 1
h(f) = ------------------------- -------------------- , (28)( 1/2) ( 2/2) (1 + 1f/ 2)( 1+ 2) /2
0 en cualquier otro caso, 0 < f <
(28) se denomina distribución F con v1 y v2 grados de libertad.FIGURA 2.14 Distribuciones F con 8 y 12 grados de libertad (azul), y 12 y 24 grados de
libertad (verde)
>> x=0:0.01:4;
>> y1=fpdf(0:0.01:4,8,12);
>> y2=fpdf(0:0.01:4,12,24);
>> plot(x,y1,x,y2)
La distribución F se utiliza para el caso de dos muestras para obtener inferencias acercade las varianzas de población. A menudo se encuentra la situación en que se requiere lacomparación entre dos varianzas de población; es decir, determinar si la variabilidad deuna población difiere de la otra. La distribución F se utiliza para estos casos. Este tema setratará más adelante, cuando se trabaje inferencia estadística.

68

69
3. ANÁLISIS ESTADÍSTICO
3.1 ESTADÍSTICA DESCRIPTIVA
Una de las etapas más importantes en el proceso de investigación se relaciona con lasistematización y análisis de la información y se denomina esta etapa como análisisestadístico de la información, y es una disciplina que se define como la ciencia de larecolección, análisis, interpretación y presentación de información que puede expresarseen forma numérica3.
Dada una serie de datos, se puede dibujar un histograma y calcular las medidas detendencia central: media, mediana, moda, media geométrica, media armónica y lasmedidas de dispersión como: rango, varianza, desviación estándar, desviación media,etc4.
La estadística como disciplina no debe confundirse con el concepto de
estadística, se refiere pues a algunas medidas calculadas con respecto a una muestracomo la media aritmética muestral o la desviación estándar muestral.
La primera es el proceso necesario para manejar y analizar información (data) con el finde apoyar de manera sistemática al investigador, para que identifique las leyes que guíano regulan los fenómenos o problemas estudiados. Una estadística es una característica oun resultado numérico a partir de una muestra de elementos. Relacionado con elconcepto de una estadística se encuentra el de parámetro (poblacional), que es el valorde una característica de una población total o Universo y ya no de una muestra de lamisma5.
La muestra se refiere a un subconjunto de elementos tomados del universo o poblaciónque a su vez incluye a todos los elementos6.
Ejemplo 3.1 Dados los siguientes datos de notas de un grupo de 10 estudiantes endeterminada asignatura, hallar la tabla de frecuencia absoluta y la frecuencia enporcentajes.
Solución.
>> x=[4.5 3.0 3.0 4.0 2.5 5.0 3.5 4.0 3.5 3.5];%data
3 VÉLEZ B. Eduardo. Análisis de la información. ICFES. Módulo 4. pp. 9.4 ARBOLEDA Q. Dairon y ÁLVAREZ J. Rafael. MATLAB®. Aplicaciones a las Matemáticas Básicas. Universidad deMedellín. pp. 30.5 VÉLEZ B. Eduardo. Op.Cit. pp.10.6 IBID. pp. 11.

70
>> x=sort(x)%ordena el vector ascendentemente
x =
2.5000 3.0000 3.0000 3.5000 3.5000 3.5000 4.0000 4.0000 4.5000 5.0000
>> tabla=tabulate(x)
tabla =
2.5000 1.0000 10.0000
3.0000 2.0000 20.0000
3.5000 3.0000 30.0000
4.0000 2.0000 20.0000
4.5000 1.0000 10.0000
5.0000 1.0000 10.0000
>> tabulate(x)
Value Count Percent
2.5 1 10.00%
3 2 20.00%
3.5 3 30.00%
4 2 20.00%
4.5 1 10.00%
5 1 10.00%
Ejemplo 3.2 Dada la siguiente serie de datos, calcular las medidas de tendencia central yde dispersión, además hacer la representación de datos agrupados.
Dado un examen de matemáticas de 60 estudiantes de dos cursos paralelos de la mismaasignatura, obtuvieron las siguientes calificaciones:
40, 33, 28, 25, 11, 21, 22, 17, 22, 19, 17, 16, 28, 26, 20, 15, 21, 20, 19, 24, 10, 29, 23, 34,24, 33, 26, 14, 13, 18, 28, 23, 28, 21, 29, 24, 11, 31, 25, 18, 25, 26, 20, 34, 22,30, 27, 32,35, 39, 18, 29, 16, 37, 28, 29, 10, 34, 29, 38
Solución.
function d=dataset11
d=[40 33 28 25 11 21 22 17 22 19 17 16 28 26 20 15 21 20 19 24 10 29 2334 24 33 26 14 13 18 28 23 28 21 29 24 11 31 25 18 25 26 20 34 22 30 2732 35 39 18 29 16 37 28 29 10 34 29 38];

71
>>data=dataset11; y los guarda en data
>> max(data) de data
ans =
40
>> min(data) de data
ans =
10
>> sum(data) %obtiene la suma de todos los elementos del vector data
ans =
1464
>> data=sort(data) % ordena en forma ascendente
data =
Columns 1 through 34
10 10 11 11 13 14 15 16 16 17 17 18 18 18 19 19 20 20 20 21
21 21 22 22 22 23 23 24 24 24 25 25 25 26 26 26
Columns 37 through 60
27 28 28 28 28 28 29 29 29 29 29 30 31 32 33 33 34 34 34 35
37 38 39 40
>> tabulate(data)
Value Count Percent
10 2 3.33%
11 2 3.33%
12 0 0.00%
13 1 1.67%
14 1 1.67%
15 1 1.67%
16 2 3.33%
17 2 3.33%
18 3 5.00%
19 2 3.33%
20 3 5.00%

72
21 3 5.00%
22 3 5.00%
23 2 3.33%
24 3 5.00%
25 3 5.00%
26 3 5.00%
27 1 1.67%
28 5 8.33%
29 5 8.33%
30 1 1.67%
31 1 1.67%
32 1 1.67%
33 2 3.33%
34 3 5.00%
35 1 1.67%
36 0 0.00%
37 1 1.67%
38 1 1.67%
39 1 1.67%
40 1 1.67%
TABLA 3.1 Clases vs frecuencias
Clases Clase 1 Clase 2 Clase 3 Clase 4 Clase 5 Clase 6Intervalos 10-15 16-20 21-25 26-30 31-35 36-40Frecuencia 7 12 14 15 8 4
>> y=[7 12 14 15 8 4]; % y es el vector de frecuencias de las 6 clases
>> pie(y) % hace el gr fico de sectores
FIGURA 3.1 Gráfico de sectores (pie)

73
FIGURA 3.2 Histograma de frecuencias de
con seis clases
FIGURA 3.3 Diagrama de barrasverticales
Código:>> hist(data,6)%histograma con seis clases
Código:>> bar(y,'g') %diagrama de barras verticales
FIGURA 3.4 Diagrama de barras horizontales FIGURA 3.5 Gráfico de racimo
Código: Código:

74
>> barh(y,'r')%diagrama de barras horizontales >> stem(y,'r')%gr fico de racimo
Ahora se escribe el script para un histograma con distribución acumulada, así:
>> data=dataset10;
n=length(data);
b=80:20:240;
nn=hist(data,b);
maxn=max(nn);
cs=cumsum(nn*maxn/n);
bar(b,nn,0.95,'y')
axis([70,250,0,maxn])
>> box off
>> hold on
>> plot(b,cs,'k-s')
FIGURA 3.6 Histograma de nueve clases, distribución acumulada de los datos dataset10
3.1.1 Estadígrafos de posición
>> xmedia=mean(data) %calcula la media aritm tica
xmedia =
24.4000
>> xmedian=median(data)%calcula la mediana

75
xmedian =
24.5000
>> xgeomed=geomean(data)%calcula la media geom trica
xgeomed =
23.1568
>> xarmedia=harmmean(data) %calcula la media arm nica
xarmedia =
21.7846
>> xmoda=mode(data)
moda =
28
MediaAritmética
Mediana MediaGeométrica
MediaArmónica
Moda
Posición de lamediana:
Md = xiSi ni = Max{ fj }j
Fuente: MAGRAB, Edward B. et al. ATLAB®.
3.1.2 Estadígrafos de dispersión
>> xmad=mad(data)%calcula la desviaci n media absoluta
xmad =
6.1000
>> xrango=range(data)%calcula el rango = max(data)-min(data)
rango =
30
>> xstd=std(data) %calcula la desviaci n est ndar
xstd =
7.4815
>> xcvar= var(data) %calcula la cuasivarianza
xcvar =
55.9729
>> xvar1=var(data,1)%calcula la varianza
Xvar1=

76
55.0400
>> riq=iqr(data) %rango intercuart lico q3-q1
riq = 10Desviación Media
AbsolutaCuasivarianza Varianza Desviación Estándar
Muestral
Fuente: http://es.wikipedia.org/wiki/Dispersi%C3%B3n_(matem%C3%A1ticas)
FIGURA 3.7 Polígono de frecuencias (rojo)
>> marcas=[8 13 18 23 28 33 38 43]; %marcas de clase
>> y=[0 7 12 14 15 8 4 0]; % frecuencias
>> hold on; bar(marcas,y); plot(marcas,y,'r')
Ejemplo 3.3 Con el mismo vector de datos, calcular: rango intercuartílico, cuartiles 1, 2 y3, percentiles 10, 25, 50 y 80, coeficiente de asimetría, kurtosis, momento de orden 2centrado en el origen, e interpretar los resultados.
Solución.
>> q1=quantile(data, 0.25)% calcula el cuartil 1
q1 =
19

77
>> q2=quantile(data,0.50) % mcalcula el cuartil 2
q2 =
24.5000
>> q3=quantile(data, 0.75)% calcula el cuartil 3
q3 =
29
El cuartil 1, indica que una cuarta parte de los estudiantes tienen notas por debajo de 19
El cuartil 2, indica que la mitad de los estudiantes tienen notas por debajo de 24.5. Nóteseque el cuartil dos, corresponde a la mediana.
El cuartil 3, muestra que las tres cuartas partes de los estudiantes tienen notas por debajode 29.
El rango intercuartílico corresponde a la diferencia entre el cuartil 3 y el cuartil 1, o sea, el50% de estudiantes están en ese rango, entre 19 y 29.
>> percentiles=prctile(data, [10 20 25 50 75 90]) %calcula los percentiles 10, 20, 25, 50, 75, y 90
percentiles =
14.5000 18.0000 19.0000 24.5000 29.0000 34.0000
El resultado anterior muestra:
p10 = 14.5 El 10% de los estudiantes tienen notas por debajo de 14.5p20 = 18.0 El 20% de los estudiantes tienen notas por debajo de 18.0p25 = 19.0 Observe que es el mismo cuartil 1p50 = 24.5 Observe que es la mediana, el cuartil 2 y el percentil 50p75 = 29.0 Observe que es el cuartil 3p80 = 34.0 El percentil 80 indica que el 80% de los estudiantes tienen notas por debajode 34.
>> coefasimetria = skewness(data)% calcula el coeficiente de asimetr a
coefasimetria =
0.0186
El coeficiente sesgo o de asimetría es un número que mediante su signo se puededeterminar si los datos tienen distribución simétrica o sesgada.

78
El coeficiente de sesgo o de asimetría, se interpreta del siguiente modo7:
Si es igual a cero, entonces los datos se distribuyen de manera simétrica.Si es mayor que cero, entonces los datos son sesgados a la derecha.Si es menor que cero, entonces los datos son sesgados a la izquierda.
Para el caso de estudio, los datos son sesgados ligeramente a la derecha, como se ilustraen la figura 3.8, mostrado a continuación.
FIGURA 3.8 Histograma y curva normal
>> histfit(data);colormap([1 1 0])
>> k=kurtosis(data)
k =
2.3859
FIGURA 3.9 Asimetrías
7 CHAO L. Lincoln. Estadística para las ciencias administrativas. McGraw Hill Latinoamericana. Bogotá, 1993. pp. 64-65

79
Fuente: http://www.tuveras.com/estadistica/estadistica02.htm
El coeficiente k de curtosis se interpreta de la siguiente manera8:
Si k = 3 implica que los datos presentan forma de una normal estandarizada (ver polígonode frecuencias y la curva normal).
Si k > 3 implica que los datos se presentan más empinados que los de la normalestandarizada.
Si k < 3 entonces los datos se presentan más aplanados que los de la curva normal, comoes el caso de estudio: k = 2.3859.
>> moment(data,2)% momento de orden 2
ans =
55.0400
>> s2=var(data,1)% calcula la varianza
S2 =
55.0400
Obsérvese que el momento de orden 2 es la misma varianza.
FIGURA 3.10 Curtosis
Leptocúrtica Mesocúrtica Platicúrtica
Coeficiente de variación. También es una medida relativa de dispersión. Determina elgrado de dispersión de un conjunto de datos relativo a su media aritmética.
Si se ha realizado un estudio estadístico en dos poblaciones diferentes, y se quierecomparar resultados, no se puede acudir a la desviación estándar para ver la mayor o
8 CHAO L. Lincoln. Op Cit. pp. 65-66

80
menor homogeneidad de los datos, sino a otro parámetro: el coeficiente de variación elcual se define como el cociente entre la desviación estándar y la media aritmética.
CV =
Ejemplo 3.4 En una exposición de ganado se estudia un conjunto de vacas con unamedia de 500 kilos y una desviación estándar de 50 kilos. Y se observa también unconjunto de ovejas con una media de 40 kilos y una desviación estándar de 10 kilos.¿Qué grupo de animales es más homogéneo?
Solución. Un razonamiento falso sería decir que el conjunto de ovejas es máshomogéneo porque su desviación estándar es más pequeña, pero si se calcula elcoeficiente de variación para ambos se notará que no es así:
CVV = 50/500 = 0.1 = 10%CVO = 10/40 = 0.25 = 25%Por tanto, es más homogéneo el conjunto de las vacas9.
Ejemplo 3.5 Quince estudiantes del grupo A de matemática I obtuvieron las siguientesnotas definitivas al final del periodo: 25 34 26 45 23 36 29 32 33 44 31 30 35 40 20 y elgrupo B de 20 estudiantes obtuvo las siguientes notas: 36 45 23 37 39 44 39 20 20 29 3946 28 30 35 36 28 29 40 38 de la misma asignatura. El docente desea averiguar cuál deestos dos grupos es más homogéneo (más parejo), teniendo en cuenta las notasdefinitivas obtenidas.
Solución
>> x=[25 34 26 45 23 36 29 32 33 44 31 30 35 40 20];
>> y=[36 45 23 37 39 44 39 20 20 29 39 46 28 30 35 36 28 29 40 38];
>> stdx=std(x)
stdx =
7.2230
>> stdy=std(y)
stdy =
7.8168
>> xmedia=mean(x)
xmedia =
32.2000
>> ymedia=mean(y)
9 http://recursostic.educacion.es/descartes/web/materiales_didacticos/unidimensional_lbarrios/parametros_est.htm

81
ymedia =
34.0500
>> CV1=std(x)/mean(x)
CV1 =
0.2243
>> CV2=std(y)/mean(y)
CV2 =
0.2296
Promedio aritmético del grupo 1 es: 32Promedio aritmético del grupo 2 es: 34
Coeficiente de variación del grupo 1 es 22.43%Coeficiente de variación del grupo 2 es 22.96%
Se puede observar que: el grupo 1 tiene un promedio más bajo que el grupo 2, pero elgrupo 1 es más homogéneo que el grupo 2.

82
4. TEORÍA DE MUESTREO
Tanto en las ciencias exactas como en las ciencias sociales, la mayoría del conocimientoexistente se debe a experiencias basadas en inferencias a partir de la observación y delanálisis de un número limitado de eventos.10
De la calidad y representatividad que ese número limitado de eventos (muestra) tenga,dependerá la bondad o el defecto (la precisión o el error) del conocimiento generado y,precisamente por esto, es relevante identificar cómo se debe seleccionar una buenamuestra11.
El primer paso para lograrlo, es tener claridad de que un muestreo es un proceso pormedio del cual se seleccionan probabilísticamente elementos de un universo o poblacióncon la finalidad de estimar, con un determinado grado de precisión, algunascaracterísticas de la población en su totalidad12.
De manera que, la lógica del muestreo consiste en estimar parámetros de la población apartir de estadísticos obtenidos de una muestra, aun cuando nunca se pueda afirmar conabsoluta seguridad cuáles son esos parámetros. Esto, que aparentemente es unproblema, realmente no lo es, ya que en la práctica lo importante es asegurar que elparámetro se encuentre dentro de cierto rango y esto lo permite la denominada teoría dela estimación que identifica la precisión de las estimaciones; es decir, identifica laprobabilidad de que el valor real del parámetro se encuentre dentro de unos límitesespecificados13.
Es necesario es entender que la teoría del muestreo permite estimar tamaños adecuadosde muestra, indispensables para obtener una estimación con cierto grado de precisión.Para lograrlo, es necesario definir qué es un intervalo de confianza, qué es un grado dede significancia y qué es una distribución muestral.
El grado de confianza se refiere a la probabilidad de que el valor real de un parámetro, seencuentre dentro de los límites especificados en la estimación que se quiere calcular14.
El intervalo de confianza corresponde a un intervalo de valores, dentro de los cuales se espera queesté el parámetro con cierto grado de confianza o con riesgo de error conocido; para ello esnecesario determinar primero la estimación puntual.
Cuando de una población de tamaño N se toman, por ejemplo, muestras de tamaño n unnúmero infinito de veces, la distribución de cualquier estadístico calculado, por ejemplo de
10 VÉLEZ, Eduardo B. El Análisis de la Información. ICFES, Módulo 4. Serie Aprender a Investigar. Bogotá D.C. 1990. pp.80.11 Ibid. pp. 8012 Ibid. pp. 8113 Ibid. pp. 8114 Ibid. pp. 81

83
su media aritmética, recibe el nombre de distribución de muestreo. Esto es importante,porque la distribución de muestreo de muchos estadísticos se aproxima a la curva normaly así se puede estudiarlos de manera adecuada15.
Un intervalo de confianza permite verificar las hipótesis planteadas acerca de parámetrospoblacionales. Existe intervalos de confianza bilaterales y unilaterales.
En el contexto de estimar un parámetro poblacional, un intervalo de confianza es un rangode valores (calculado en una muestra) en el cual se encuentra el verdadero valor delparámetro, con una probabilidad determinada.
La probabilidad de que el verdadero valor del parámetro se encuentre en el intervaloconstruido se denomina nivel de confianza, y se denota 1- . La probabilidad deequivocarse se llama nivel de significancia y se simboliza como . Generalmente, seconstruyen intervalos con confianza 1- = 95% (o significancia =5%). Menos frecuentesson los intervalos con = 10% o = 1%
Para construir un intervalo de confianza, se puede comprobar que la distribución normalestándar cumple:
p(-1.96 < z < 1.96) = 0.95
Luego, si una variable x tiene distribución N( , ), entonces el 95% de las veces secumple:
-
Despejando en la ecuación se tiene:
x - 1.96
El resultado es un intervalo que incluye a el 95% de las veces. Es decir, es un intervalode confianza al 95% para la media cuando la variable x es normal y es conocido16.
En cuanto a definición de población, el concepto de población o universo en estadística,va más allá de lo que comúnmente se conoce como tal. Una población, se precisa comoun conjunto finito o infinito de personas u objetos que presentan características comunes.También, una población es un conjunto de todos los elementos que se están estudiando,acerca de los cuales se intenta sacar conclusiones17.
Por ejemplo, si el elemento es una persona, se puede estudiar las características edad,peso, nacionalidad, sexo, etc. Los elementos que integran una población puedencorresponder a personas, objetos o grupos (por ejemplo, familias, fábricas, empresas,etc). Las características de la población se resumen en valores llamados parámetros.
15 VÉLEZ, Eduardo B. Op Cit. pp. 8216 http://escuela.med.puc.cl/recursos/recepidem/EPIANAL9.HTM17 http://www.scribd.com/doc/5181091/Estadistica-y-poblacio-y-muestra

84
En cuanto a la muestra, la mayoría de los estudios estadísticos, se realizan no sobre lapoblación, sino sobre un subconjunto o una parte de ella, llamado muestra, partiendo delsupuesto de que este subconjunto presenta el mismo comportamiento y característicasque la población. En general el tamaño de la muestra es mucho menor al tamaño de lapoblación, porque de esta manera ahorra un gran esfuerzo.
Los valores o índices que se concluyen de una muestra se llaman estadígrafos oestadísticos y estos mediante métodos inferenciales o probabilísticos, se aproximan a losparámetros poblacionales18.
A continuación se muestra la sintaxis de MATLAB con respecto a algunas funciones ocomandos relativos a los conceptos examinados anteriormente.
SINTAXIS MATLAB®
normfit19
[muhat,sigmahat] = normfit(data)[muhat,sigmahat,muci,sigmaci] = normfit(data)[muhat,sigmahat,muci,sigmaci] = normfit(data,alpha)[...] = normfit(data,alpha,censoring)
[...] = normfit(data,alpha,censoring,freq)[...] = normfit(data,alpha,censoring,freq,options
Descripción
>>[muhat,sigmahat] = normfit(data) %devuelve el estimativo de la media
>>[muhat,sigmahat,muci,sigmaci] = normfit(data) % devuelve el intervalo de confianza al 95%para los s estimados de la m s arreglos y ,respectivamente. La primera fila de contiene las cotas inferiores de los intervalos de
confianza para , la segunda fila contiene las cotas superiores. La primera fila decontiene las cotas inferiores de los intervalos de confianza para , y la segunda fila contiene lascotas superiores.
>>[muhat,sigmahat,muci,sigmaci] = normfit(datos,alpha) % devuelve el intervalo de confianza al100(1 - alfa)% stimado, donde alfa es un valor en el intervalo o rango [0 1],
18 http://www.scribd.com/doc/15268123/Conceptos-Basicos-de-Estadistica-I191984-2008 The MathWorks, Inc. MATLAB®

85
especificando el ancho del intervalo de confianza. Por defecto, alfa es 0.05, lo cual correspondea un intervalo de confianza del 95%.
Ejemplo 4.1 El contenido de siete contenedores similares de un ácido son 9.8, 10.2 10.4,9.8, 10, 10.2, 9.6 litros. Encuentre el intervalo de confianza del 95% para la media detodos los contenedores si se supone que la distribución es aproximadamente normal.Solución.
>> x=[9.8, 10.2 10.4, 9.8, 10, 10.2, 9.6 ]; %datos
>>alfa=0.05 %alfa por defecto es 0.05
>>[muhat,sigmahat,muci]=normfit(x,alfa) %
n-1 y muci: intervalo de confianza al 95%
muhat =
10
sigmahat =
0.2828
muci =
9.7384
10.2616
El intervalo en cuestión es: 9.7384 < < 10.2616
4.1 INFERENCIA ESTADÍSTICA
Se basa en las conclusiones a la que se llega por la ciencia experimental basándose eninformación incompleta (de una parte de la población). La inferencia estadística es unaparte de la Estadística que permite generar modelos probabilísticos a partir de un conjuntode observaciones. Del conjunto se observaciones que van a ser analizadas, se eligenaleatoriamente sólo unas cuantas, que es lo que se denomina muestra, y a partir de dichamuestra se estiman los parámetros del modelo, y se contrastan las hipótesis establecidas,con el objeto de determinar si el modelo probabilístico es el adecuado al problema realque se ha planteado.
La utilidad de la inferencia estadística, consiste en que si el modelo se consideraadecuado, puede usarse para la toma de decisiones o para la realización de lasprevisiones convenientes.
La inferencia estadística, parte de un conjunto de observaciones de una variable, y a partirde estos da infiere modelo probabilístico; por tanto, la inferencia

86
estadística es la consecuencia de la investigación empírica, cuando se está llevando acabo, y como consecuencia de la ciencia teórica, cuando se están generandoestimadores, o métodos, con tal o cual característica para casos particulares. Lainferencia estadística es, en consecuencia, un planteamiento inductivo20.
4.2 PRUEBA DE HIPÓTESIS
En ingeniería e investigación hay muchas situaciones donde uno tiene aceptar o negaruna hipótesis acerca de un parámetro. Una hipótesis estadística puede considerarsecomo una aseveración sobre los parámetros de una o más poblaciones. Una población esla totalidad de las observaciones de la cual se ocupa el investigador en el problema. Unamuestra es un subconjunto de una población. Desde que se utilizan distribuciones deprobabilidad para representar poblaciones, una hipótesis estadística puede considerarsecomo una aseveración sobre la distribución estadística de la población21.
Por ejemplo, supóngase que se tiene un parámetro que ha sido obtenido de n muestrasde una población, y se está interesado en determinar si este parámetro es igual a o. Elprocedimiento para la prueba de hipótesis requiere:
Formular una hipótesis, llamada hipótesis nula, HoLa forma de prueba estadística apropiada, qo.Seleccionar un nivel de confianza (tener en cuenta que: 100(1- )% es el nivel deconfianza para ).Comparar la prueba estadística para un valor que corresponde a la magnitud de laprueba que se puede esperar que ocurra naturalmente, q.
Basado en las respectivas magnitudes de qo y q, la hipótesis nula tiene dos posibilidades,ser aceptada o rechazada. Si la hipótesis nula es rechazada, entonces se acepta lahipótesis alternativa, la cual se denota como H1.
Hay tres casos posibles a considerar:
Ho : = o Ho : = o Ho : = o
Ha : o Ha : > o Ha : < o
Existen dos tipos de errores que se pueden cometer en la prueba de hipótesis:
Error tipo I : Rechazar la hipótesis nula Ho cuando es verdadera.
Error tipo II : Aceptar la hipótesis nula Ho cuando es falsa; esto es, cuando realmente =1.
20 http://www.mitecnologico.com/Main/InferenciaEstadistica21

87
SINTAXIS MATLAB®
ttest22
h = ttest(x)h = ttest(x,m)h = ttest(x,y)h = ttest(...,alfa)
h = ttest(...,alfa,tail)h = ttest(...,alfa,tail,dim)[h,p] = ttest(...)[h,p,ci] = ttest(...)[h,p,ci,stats] = ttest(...)
Descripción
>>h =ttest(x) %
varianza desconocida, frente a la
h = 0, indica unerror al rechazar la h
h=ttest(x,m)
y varianza desconocida, frente a laalternativa de que la media no sea .
h=ttest(x,y)es la diferencia x- rmal con media0 y varianza desconocida, frente a la alternativa de que la media no sea 0. Se debe tener en
a) %ejecuta la prueba en (100*alfa)% nivel de significancia. Por defecto, cuando no
se especifica alfa, esta es de 0.05.
h=ttest( ,alfa,tail)
22 1984-2008 The MathWorks, Inc. MATLAB®

88
m). Se realiza por defecto, cuando la cola no se especifica. (pruebade dos colas).
m) (prueba de cola derecha)m) (prueba de cola izquierda)
h ttest( ,alfa,cola,dim) -y para una prueba de parde variables. Usar [] para pasar por defecto valores predeterminados para m, alfa, o tail.[h,p] = ttest o la
t =
Donde m) es la media poblacional hipotética, s es la desviaciónestándar muestral, y n es el tamaño de la muestra. Bajo la hipótesis nula, la prueba estadísticatendrá una distribución t de Student con n - 1 grados de libertad.
[h,p,ci]=ttest(...) % retorna un intervalo de confianza de 100*(1 alpha)% de la media poblacionalo de la diferencia de medias poblacionales para una prueba apareada.
[h,p,ci,stats]=ttest(...) %devuelve la estructura con los siguientes campos:
tstat : Valor de la prueba estadística.df : Grados de libertad de la prueba.sd : Desviación estándar muestral.
Para probar la veracidad o no de una hipótesis acerca de la media poblacional, elMATLAB® asume la distribución normal cuando es conocida la media poblacional y ladistribución t-student cuando no se conoce . Según esto, se utilizan las funciones ztesto ttest para comprobar la hipótesis nula. La forma de utilizar estas funciones se hace dela siguiente manera:
Ejemplo 4.1 Considérese los datos de dataFci. Se quiere determinar si existe alguna
diferencia estadísticamente significativa entre las medias de estas muestras con un 95%de confianza. Así, la hipótesis es:
Ho: 1 = 2
H1: 2
Solución. Se usa ttest2 para determinar la validez de esta hipótesis. La función ttest2 es:
[h,p,ci]=ttest2(x1, x2, alfa)

89
Donde x1 y x2 son los datos, alfa = , h = 0 si Ho y h = 1 si H1, p = p-valor; esto es: p =2*(1-tcdf(t0,n-1))
Para un intervalo de confianza de dos colas; t0 = to está definido en la cuarta columna delcaso 4, y ci(1) = l y ci(2) = u son los límites de confianza inferior y superior,respectivamente. Así, el script es:
>> [x1,x2]=dataFci;
>> [h,p,ci]=ttest2(x1,x2,0.05)
h =
0
p =
0.6775
ci =
-0.7819 1.1724
Ejecutando el anterior script, se obtiene h = 0; esto es, que no se puede rechazar lahipótesis nula, p = 0.6645, ci(1) = -0.7550, y ci(2) = 1.1855 son los límites de confianzainferior y superior, respectivamente, de la diferencia entre las medias. Basado en el valorde p, se ve que están solamente 100(1-0.6445)=35.55% de confianza
Basado en el valor de p, se ve que se está a sólo 100(1-0.6445) = 35.55% de confianzaen que existe una diferencia estadísticamente significativa entre los medios, el cual essustancialmente inferior al valor deseado de nivel de confianza del 95%. Por tanto, lahipótesis nula no puede ser rechazada.
Ejemplo 4.2 El vendedor de cierta marca de automóvil afirma que el kilometraje medio delmodelo XW es de 45.425 Km por galón de gasolina. Un ente gubernamental de Pesas yMedidas, cree que el vendedor está generando falsas expectativas a los clientes. Nueveautomóviles de este modelo son sometidos a prueba con un galón de gasolina y dan elsiguiente resultado de kilómetros recorridos:
45.425 Km 41.640 Km 37.854 Km 39.747 Km 43.532 Km 41.640 Km 47.318 Km37.854 Km 39.747 Km.
¿Se rechazará o se aceptará la afirmación del vendedor? Utilizar un nivel de significanciade 0.01 ( = 1%).
Solución.
Ho = 45.425 Km/galón

90
Ha 45.425 Km/galón
Formato: [h,sig,ci] = ttest(x, , , tail)
Entrada:
x : data (si es menor que 30 se utiliza t-student como en este caso): media poblacional (44.425 Km/galón): significancia (0.01)
both 0
right > 0
left < 0
Salida:
Si h = 0, entonces se acepta la hipótesis nula.Si h = 1, entonces se rechaza la hipótesis nula.ci : intervalo de confianzasig : significancia
>> x= [45.425 41.640 37.854 39.747 43.532 41.640 47.318 37.854 39.747];
h =
1
sig =
0.0085
ci =
37.9730 45.3064
h = 1, significa que debe rechazarse la hipótesis nula, es decir, que lo que afirma elvendedor no es creíble bajo una certeza del 99%
sig = 0.0085 es menor que 0.01 o 1% , luego se rechaza la hipótesis nula.
ci = [37.9730 Km/galón , 45.3064 Km/galón] es el intervalo en el que puededesempeñarse el carro, respecto al kilometraje que afirma el vendedor del automóvil XW,con una significancia del 1%
Como la media poblacional es 45.425 km, no cae dentro del intervalo de confianza 0.99= 99% = (1- ), es así que se rechaza la hipótesis nula.

91
Ejemplo 4.3 Probar la hipótesis de que la distancia media requerida para poder frenar unautomóvil que va a 20 Km/h es de 25 metros. Con base en una muestra de 100conductores se obtiene que la distancia media es 27.3 metros, con una desviaciónestándar de s = 2.1 metros. Utilizar un nivel de significación de 5%.
Solución.
Entrada:
x: vector de 100 distancias con media 27.3= 0.05
s = 2.5761m = 25Ho : = 25Ha : 25
function d=dataset12d=[30 30 28 26 26 24 22 30 31 29 29 26 28 26 30 25 31 30 29 26 30 29 23 34 24 30 26 24 23 2828 23 28 31 27 24 31 28 25 28 25 26 30 24 27 30 27 32 35 29 28 29 26 27 28 29 30 24 29 28 2524 26 30 29 28 24 28 30 23 26 27 25 24 27 29 30 24 25 28 28 28 30 26 27 25 24 25 31 26 24 30
27 28 25 26 24 27 26 28];
>> data=dataset12;
>> sigma=2.1;
>> alfa=0.05;
>> m=25;
Salida:
>> h = ztest(data,m,sigma,alfa,'both')
h =
1
Como h = 1, se rechaza la hipótesis nula, es decir, que la distancia media requerida parafrenar es diferente de 25 metros, a un nivel de significancia del 5%.
SINTAXIS MATLAB
ztest23
23 The MathWorks, Inc. MATLAB® 1984-2008.

92
h = ztest(x,m,sigma)h = ztest(...,alpha)h = ztest(...,alpha,tail)h = ztest(...,alpha,tail,dim)[h,p] = ztest(...)
[h,p,ci] = ztest(...)[h,p,ci,zval] = ztest(...)
Descripción
h = ztest(x,m,sigma)
Ejecuta una prueba de hipótesis z (normal), donde la data proviene de una distribución conmedia m, y que devuelve el resultado de la prueba en términos de h. Cuando h = 0 indica que la
m5%. Los datos se supone que provienen de una distribución normal con desviación estándarsigma.
h=ztest(...,alpha) %Ejecuta una prueba de nivel de significancia del (100*alfa)%. Por defecto,
cuando no se especifica alfa da por sentado que alfa es 5% o 0.05.
h=ztest(...,alpha,tail) %Ejecuta la prueba contra la alternativa especificada por la string
Hay tres opciones para la string tail
both m (prueba de dos colas). Esto es por defecto, cuando la cola no seespecifica.
'right' : La media es más grande que m (prueba de cola derecha).
'left' : La media es más pequeña que m (prueba de cola izquierda).
La cola debe ser una cadena simple, incluso cuando x es una matriz o un arreglo n-dimensional.
>>h=ztest(...,alpha,cola,dim) % dim de x. Usar [] para pasar por
>>[h,p] = ztest(...) %devuelve el valor p de la prueba. El valor de p es la probabilidad, bajo la.
z=
Donde es la media muestral, es la media poblacional hipotética, es la desviaciónestándar, y n es el tamaño de la muestra. Bajo la hipótesis nula, la prueba estadística tendrá unadistribución normal estandarizada N(0,1).

93
[h,p,ci]=ztest(...) % devuelve un intervalo de confianza 100*(1 alfa)% de la media poblacional
[h,p,ci,zval]=ztest(...) % devuelve el valor de l
Ejemplo 4.3 De una población con distribución normal, constituida por 500 fichas que seencuentran en un archivador, se extrajo una muestra de 16 observaciones como sigue: 5645 46 37 56 41 43 36 45 56 49 62 43 60 49 72 56. Se sabe que ladesviación estándar poblacional =10, pero es desconocida la media poblacional ( = 50verdadera). Cometiendo un riesgo = 0.05 (nivel de significancia 5%), probar la hipótesisde que la media poblacional sea igual a: (a) 40, (b) 49, (c) 50, (d) 51 y (e) 60.
Solución.
(a) Ho : = 40Ha : 40
= 0.05
= 10
>> x=[56 45 46 37 56 41 43 36 45 56 49 62 43 60 49 72 56];
>> m=40;
>> sigma=10;
>> alfa=0.05;
>> h = ztest(x,m,sigma,alfa,'both') %
h =
1
Como h = 1 se rechaza la hipótesis nula, es decir, que no es cierto que = 40.
(b) Ho : = 49H1 : 49
= 0.05= 10
>> m=49;
>> sigma=10;
>> alfa=0.05;
>> h = ztest(x,m,sigma,alfa,'both')
h =
0

94
Como se sabe h = 0 significa que se acepta que = 49 y verdadera es 50, se estáaceptando algo falso que es un error tipo II.
(c) Ho : = 49H1 : 49
>> m=50;
>> h = ztest(x,m,sigma,alfa,'both')
h =
0
Aquí se acepta la hipótesis nula Ho = 50, lo cual es verdadero y no se está cometiendoningún error.
(d) Ho : = 51H1 : 51
>> m=51;
>> h = ztest(x,m,sigma,alfa,'both')
h =
0
Se acepta la hipótesis nula, por lo tanto se está cometiendo un error de tipo II porque sesabe que la media poblacional verdadera es 50.
(e) Ho : = 60H1 : 60
>> m=60;
>> h = ztest(x,m,sigma,alfa,'both')
h =
1
Como h = 1, se rechaza la hipótesis nula y por tanto no se comete ningún error, ya que serechaza algo falso.
Ejemplo 4.4 Encuentre el intervalo de confianza para la media muestral al 95% de nivel
de confianza, según los datos dados en dataset10.

95
Solución. Si se tiene el nivel de confianza del 95%, entonces el programa paradeterminar el intervalo de confianza de la media es:
function d=dataset10
d=[105 160 157 190 199 121 160 172 156 110 97 196 151 76 115 120 150 171 229 133 245 221175 101 193 181 181 237 158 123 163 154 201 142 167 160 168 170 148 146 207 228 183 149171 194 158 180 150 169 134 131 153 200 163 184 208 167 118 158 218 180 174 186 87 165133 176 143 135 199 178 154 174 176 145 135 158 141 149];
clcdisp([' '])meen=mean(dataset10);
L=length(dataset10);q=std(dataset10)*tinv(0.975,L-1)/sqrt(L);disp([' '])disp([' Media muestral = ' num2str(meen)])disp([' '])
disp(' Intervalo de confianza para la media muestral al 95% de nivel de confianza: ')disp([' '])disp([' ' num2str(meen-q) ' <= Media muestral <= ' num2str(meen+q)])disp([' '])
Considere los datos en dataset10. Se quiere saber si existe una diferenciaestadísticamente significativa entre la muestra y un valor promedio de 168 ( 0 = 168) enun 95% de nivel de confianza. Así, la hipótesis es:
Ho: = 168H1: 168
Se usa ttest para determinar la validez de la hipótesis.
[h,p,ci]=ttest(data,mucero,alfa)
Donde data son los datos, mucero = 0, alfa = , h = 0 si Ho y h = 1 si H1, p = valor de p;
esto es:

96
p = 2*(1-tcdf(t0,n-1));
>> [h,p,ci]=ttest(dataset10,168,0.05)
h =
0
p =
0.1614
ci =
155.1466 170.1784
Así, en el presente caso, tras la ejecución, se encuentra que h = 0; es decir, no se puederechazar la hipótesis nula, p = 0.1614, ci(1) = 155.1466, y ci(2)=170.1784. Se observa que
= 162.6625 dado atrás y que el intervalo de confianza para el valor de 168 en el 95% denivel de confianza es . Siendo que el valor hipotético de 168para la media está dentro de este intervalo de confianza, se debe esperar que lahipótesis nula no sea rechazada. De hecho, basado en su p-valor, se ve que se está asólo 100(1-0.1614) = 83,9% de confianza, que es menos que el nivel de confianza del95% deseado.
Ahora, si se ejecuta:
>> [h,p,ci]=ttest(dataset10,175,0.05)
h =
1
p =
0.0016
ci =
155.1466 170.1784
Se obtiene h = 1; esto es, se puede rechazar la hipótesis nula y aceptar H1; p = 0.0016,ci(1) = 155.1466, y ci(2) = 170.1784. En otras palabras, se puede tener 100(1-0.0016) =99.84% de confianza que la media de los datos en dataset10 son diferentes del valor de lamedia de 175.
Ejemplo 4.5 Determinar el intervalo de confianza para la razón de varianzas muestralesal 95% de nivel de confianza.
Solución. Se consideran los datos almacenados en , para desarrollar el ejemplo:
function [set1,set2]=dataFci

97
set1=[41.60 41.28 42.34 41.95 41.86 42.18 41.72 42.26 41.81 42.04];set2=[39.72 42.59 41.88 42.00 40.22 41.07 41.90 44.29];
clcdisp([' '])[data1,data2]=dataFci;
r=var(data1)/var(data2);L1=length(data1);L2=length(data2);q2=r*finv(.975,L2-1,L1-1);q1=r/finv(.975,L1-1,L2-1);
disp([' '])disp(['Razon de varianzas muestrales = ' num2str(r)])disp([' '])disp('Intervalo de confianza para la razon de varianzas muestrales al 95% de nivel de confianza:')disp([' '])
disp(['' num2str(q1) ' <= Razon de la varianza muestral <= ' num2str(q2)])disp([' '])
Después de la ejecución se obtiene:
Razon de varianzas muestrales = 0.051599
Intervalo de confianza para la razon de varianzas muestrales al 95% de nivel de confianza:
0.010698 <= Razon de la varianza muestral <= 0.21656
Ejemplo 4.6 Considere los datos de dataFci. Se quiere saber si existe alguna diferencia
estadísticamente significativa entre las variaciones de estas muestras con un 95% deconfianza. Así, la hipótesis es:
Ho : =H1 :
La prueba estadística es:
fo =

98
y el criterio de rechazo de la hipótesis nula es bien
f0 > f /2,n1-1,n2-1 ,Or, f0 < f1- /2,n1-1,n2-1
Solución. Se usa vartest2 para determinar la validez de esta hipótesis; esto es,
[h,p,ci] = vartest2(x1,x2,alfa)
Donde x1 y x2 son los datos, alfa = , h = 0 si Ho, y h = 1 si H1, p = valor de p, esto es:p=2*(1-fcdf(f0,n1,n2))
para un intervalo de confianza de dos colas; f0 = f0, y ci(1) = l y ci(2) = u son los límites deconfianza superior e inferior, respectivamente. El script es:
>> [x1,x2]=dataFci;
>> [h,p,ci]=vartest2(x1,x2,0.05)
h =
1
p =
6.5379e-005
ci =
0.0083 0.1674
Al ejecutar el anterior script, se encontró que h = 1; o sea, se niega la hipótesis nula, p =6.5379 x 10-5, ci(1) = 0.0083, y ci(2) = 0.1674 que son los límites de confianza inferior ysuperior, respectivamente en relación a las varianzas. Con base en el valor de p, seobserva que hay 100(1 - 6.5379 x 10-5) = 99.993 % de confianza que hay diferenciaestadísticamente significativa en sus varianzas.

99
5. AJUSTES DE CURVAS Y REGRESIÓN
5.1 INTRODUCCIÓN
Todas las fases científicas, y prácticas de ingeniería y servicios humanos implican laobtención, procesamiento, e interpretación de datos. La puesta de datos experimentales auna ecuación matemática se llama regresión. La regresión puede tener diferentesadjetivos, según la forma matemática que se utilice para el ajuste y el número de variablesutilizada. Por ejemplo, la regresión lineal consiste en utilizar una línea recta, o ecuaciónlineal para el ajuste requerido. Otro ejemplo puede ser, regresión múltiple que implica unafunción de más de una variable independiente.
La regresión y correlación son las dos herramientas estadísticas más poderosas yversátiles que se pueden utilizar para solucionar problemas comunes de investigación. Sedice que una variable depende de la otra, o como en este caso, que y depende de x,donde x e y son dos variables cualesquiera. Esto se puede escribir como: y = f(x). Se lee:y es función de x.
5.2 REGRESIÓN LINEAL SIMPLE
El primer caso a considerar es el de un conjunto de datos bidimensionales (puntos en elplano) en el que se selecciona la "mejor" línea recta o ecuación lineal que se ajuste, a losdatos correspondientes del problema. Esta recta podrá tener o no tener sentido para losdatos correspondientes, ello dependerá de su comportamiento en la realidad. Si estarelación es evidente desde una simple inspección en que la variación es drásticamentediferente de la de una ecuación lineal, el procedimiento puede dar resultados que tienenmuy poco sentido. Sin embargo, si la tendencia general de los datos parece aproximarsea una línea recta, el procedimiento puede arrojar resultados significativos.
En el caso expuesto, es la variable dependiente y es la variable independiente. Esimportante en su momento identificar cuál es la variable dependiente y cuál laindependiente.
La variable dependiente es la variable que se desea explicar o predecir. A la variableindependiente se le denomina también como variable explicativa.
Se debe diferenciar entre regresión simple y regresión múltiple. En la regresión simple, seestablece que y es función de una sola variable independiente. A veces se le llamaregresión bivariada porque intervienen dos variables. En un modelo de regresión múltiple,y es función de dos o más variables independientes y se nota: y = f(x1, x2, x3 n)donde hay n variables independientes.
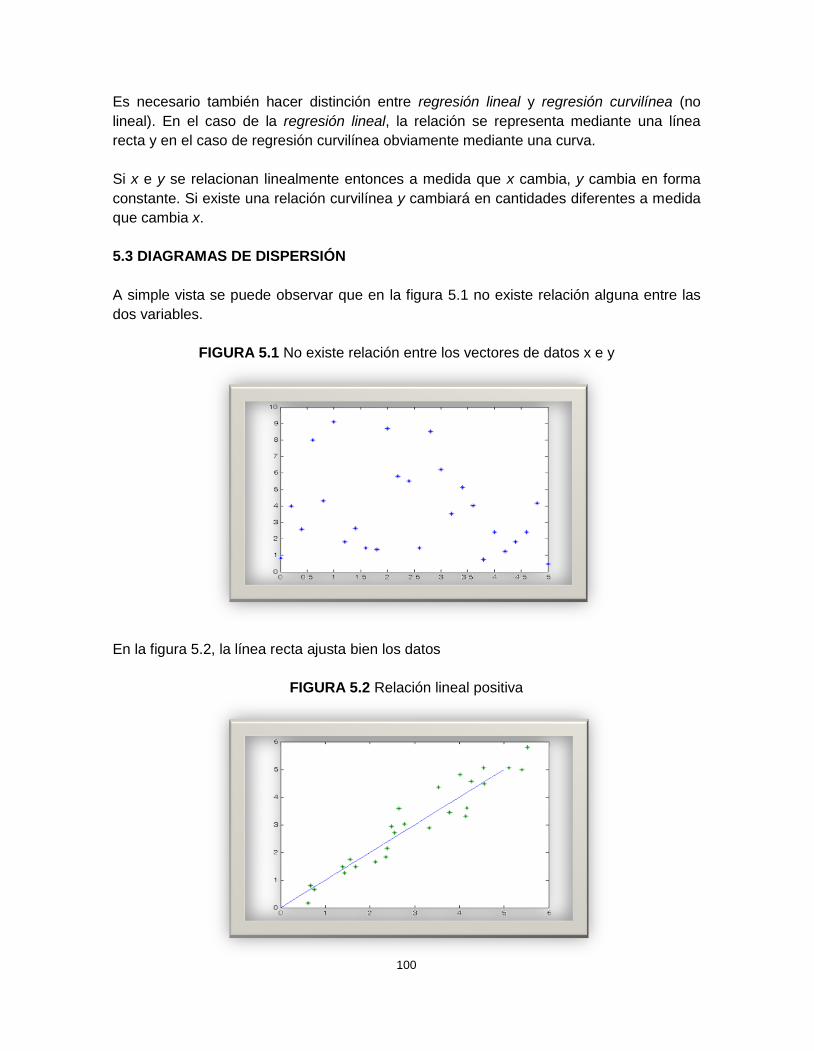
100
Es necesario también hacer distinción entre regresión lineal y regresión curvilínea (nolineal). En el caso de la regresión lineal, la relación se representa mediante una línearecta y en el caso de regresión curvilínea obviamente mediante una curva.
Si x e y se relacionan linealmente entonces a medida que x cambia, y cambia en formaconstante. Si existe una relación curvilínea y cambiará en cantidades diferentes a medidaque cambia x.
5.3 DIAGRAMAS DE DISPERSIÓN
A simple vista se puede observar que en la figura 5.1 no existe relación alguna entre lasdos variables.
FIGURA 5.1 No existe relación entre los vectores de datos x e y
En la figura 5.2, la línea recta ajusta bien los datos
FIGURA 5.2 Relación lineal positiva
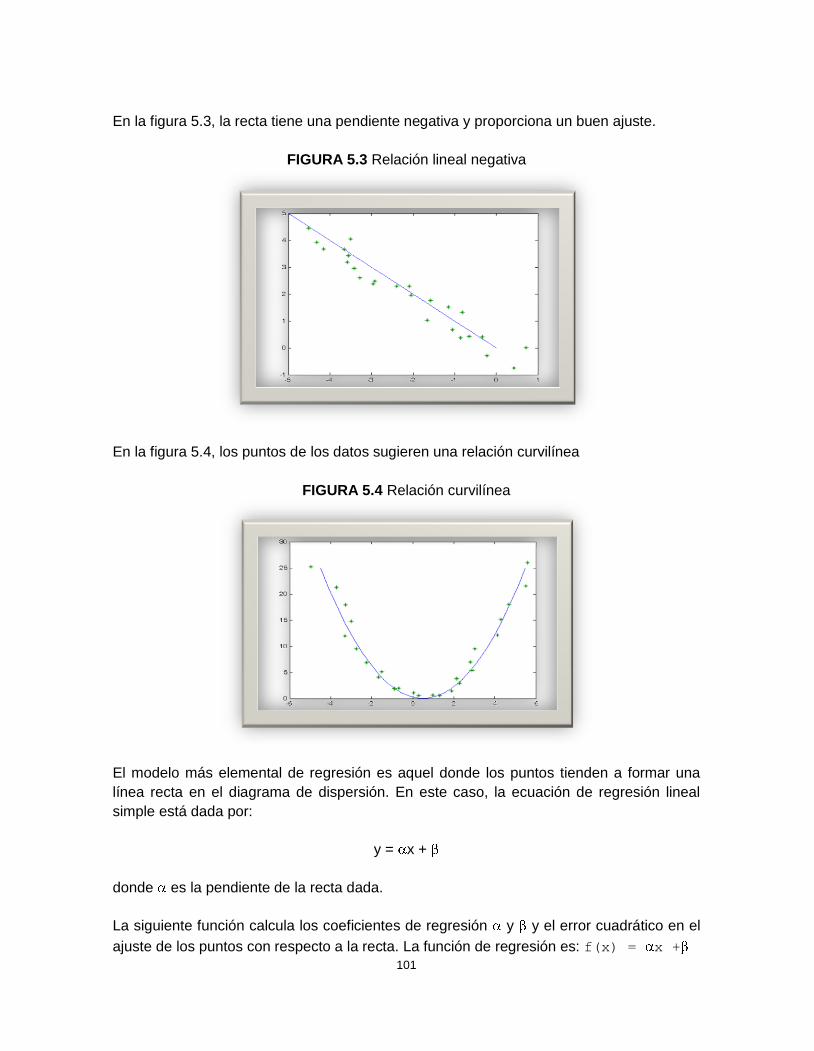
101
En la figura 5.3, la recta tiene una pendiente negativa y proporciona un buen ajuste.
FIGURA 5.3 Relación lineal negativa
En la figura 5.4, los puntos de los datos sugieren una relación curvilínea
FIGURA 5.4 Relación curvilínea
El modelo más elemental de regresión es aquel donde los puntos tienden a formar unalínea recta en el diagrama de dispersión. En este caso, la ecuación de regresión linealsimple está dada por:
y = x +
donde es la pendiente de la recta dada.
La siguiente función calcula los coeficientes de regresión y y el error cuadrático en elajuste de los puntos con respecto a la recta. La función de regresión es: f(x) = x +

102
function [a,b]=linefit(x,y)n=length(x);S1=sum(x);S2=sum(y);S3=sum(x.*x);S4=sum(x.*y);
a=(n*S4-S1*S2)/(n*S3-(S1)^2);b=(S3*S2-S4*S1)/(n*S3-(S1)^2);for k=1:n
p1=a+b*x(k);Error(k)=abs(p1-y(k));
endError=sum(Error.*Error)
Se entran primero los vectores x e y que deben ser de la misma dimensión y luego desdeel área de trabajo se llama de la siguiente manera:
>> x=[1 2 3 4 5];
>> y=[1 5 7 8 10]
>> [a b]=linefit(x,y)
Error =
147.9000
a =
2.1000
b =
-0.1000
>> z=a+b.*x;
>> plot(x,y,'*',x,z),grid
>> z=a.*x+b;
>> plot(x,y,'*',x,z),grid
FIGURA 5.5 Línea recta de ajuste por mínimos cuadrados

103
>> polyfit(x,y,1)
ans =
2.1000 -0.1000
>> x=[-3 -2 -1 0 1 2 3];
>> y=[8 5 2 0 1 3 10];
>> polyfit(x,y,1)%interpolaci n de MATLAB
ans =
0.0357 4.1429
>> [a b]=linefit(x,y) n lineal con la funci n creada
Error =
673.2232
a =
0.0357
b =
4.1429
>> z1=a.*x+b;
>> polyfit(x,y,2) %interpolaci n cuadr tica con la funci n de MATLAB
ans =
0.9643 0.0357 0.2857
>> z2=0.9643*x.^2+0.0357*x+0.2857 tica
z2 =
8.8573 4.0715 1.2143 0.2857 1.2857 4.2143 9.0715
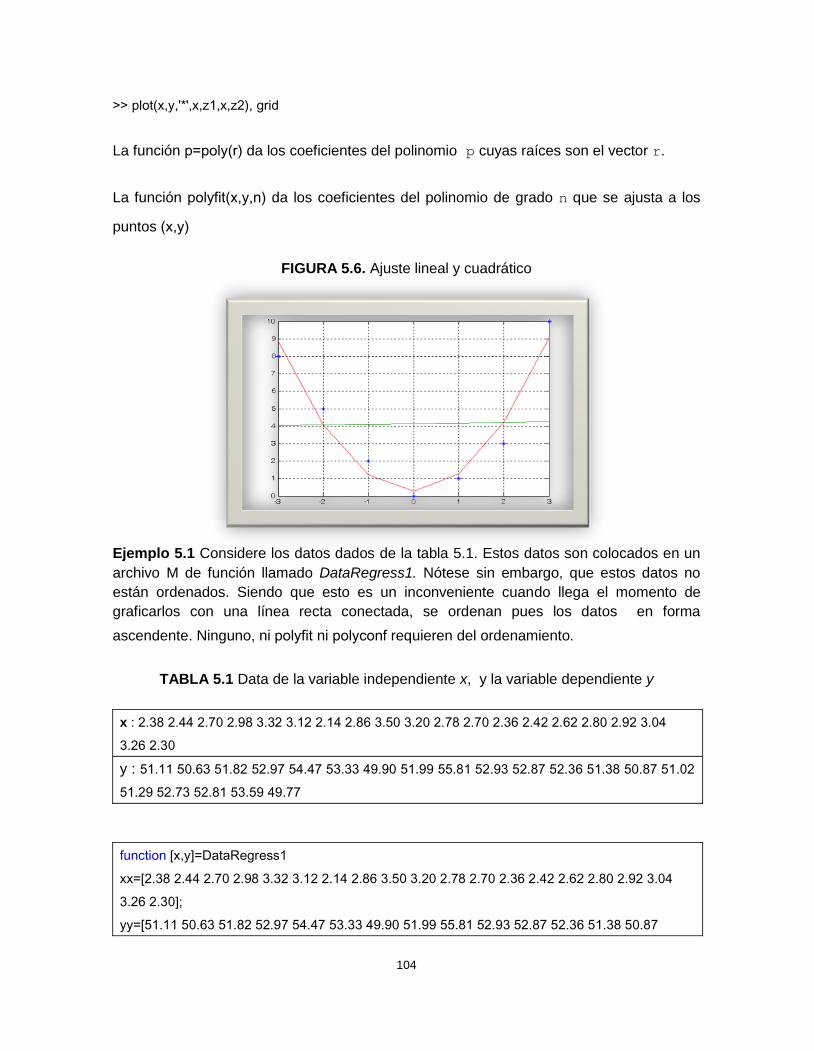
104
>> plot(x,y,'*',x,z1,x,z2), grid
La función p=poly(r) da los coeficientes del polinomio p cuyas raíces son el vector r.
La función polyfit(x,y,n) da los coeficientes del polinomio de grado n que se ajusta a los
puntos (x,y)
FIGURA 5.6. Ajuste lineal y cuadrático
Ejemplo 5.1 Considere los datos dados de la tabla 5.1. Estos datos son colocados en unarchivo M de función llamado DataRegress1. Nótese sin embargo, que estos datos noestán ordenados. Siendo que esto es un inconveniente cuando llega el momento degraficarlos con una línea recta conectada, se ordenan pues los datos en formaascendente. Ninguno, ni polyfit ni polyconf requieren del ordenamiento.
TABLA 5.1 Data de la variable independiente x, y la variable dependiente y
x : 2.38 2.44 2.70 2.98 3.32 3.12 2.14 2.86 3.50 3.20 2.78 2.70 2.36 2.42 2.62 2.80 2.92 3.043.26 2.30
y : 51.11 50.63 51.82 52.97 54.47 53.33 49.90 51.99 55.81 52.93 52.87 52.36 51.38 50.87 51.0251.29 52.73 52.81 53.59 49.77
function [x,y]=DataRegress1
xx=[2.38 2.44 2.70 2.98 3.32 3.12 2.14 2.86 3.50 3.20 2.78 2.70 2.36 2.42 2.62 2.80 2.92 3.043.26 2.30];yy=[51.11 50.63 51.82 52.97 54.47 53.33 49.90 51.99 55.81 52.93 52.87 52.36 51.38 50.87

105
51.02 51.29 52.73 52.81 53.59 49.77];[x,index]=sort(xx); %los datos se ordenan pero deben preservarse las parejasy=yy(index); %lo anterior se logra de esta manera
>> [x,y]=DataRegress1;
>> [c,s]=polyfit(x,y,1);
>> [yhat,w]=polyconf(c,x,s,0.005);
>> syy=sum(y.^2)-length(x)*mean(y)^2;
>> sse=syy-c(1)*(sum(x.*y)-length(x)*mean(x)*mean(y));
>> plot(x,yhat,'k-',x,yhat-w,'k--',x,yhat+w,'k--',x,y,'ks',[x;x],[yhat;y],'k-')
>> legend('Linea de regresion','95% intervalo de confianza de y','Location','SouthEast')
>> axis([2,3.6,48,57])
>> xlabel('x(Entrada)')
>> ylabel('y(Respuesta'))
>> coefdet=(1-sse/syy)
coefdet =
0.8774
El coeficiente de determinación está cerca de 1, lo cual refleja una correlación buena.
Se sabe que el coeficiente de determinación toma valores en el intervalo [-1,1]. Si el valores 1 existe una relación lineal positiva perfecta. Si es 0 indica que entre las dos variablesno existe relación lineal alguna (porque puede haber curvilínea). Si fuera negativa indicaque entre x e y existe una correlación lineal negativa perfecta.
FIGURA 5.7 Regresión lineal para la data del ejemplo 5.7 y límite de confianza de y
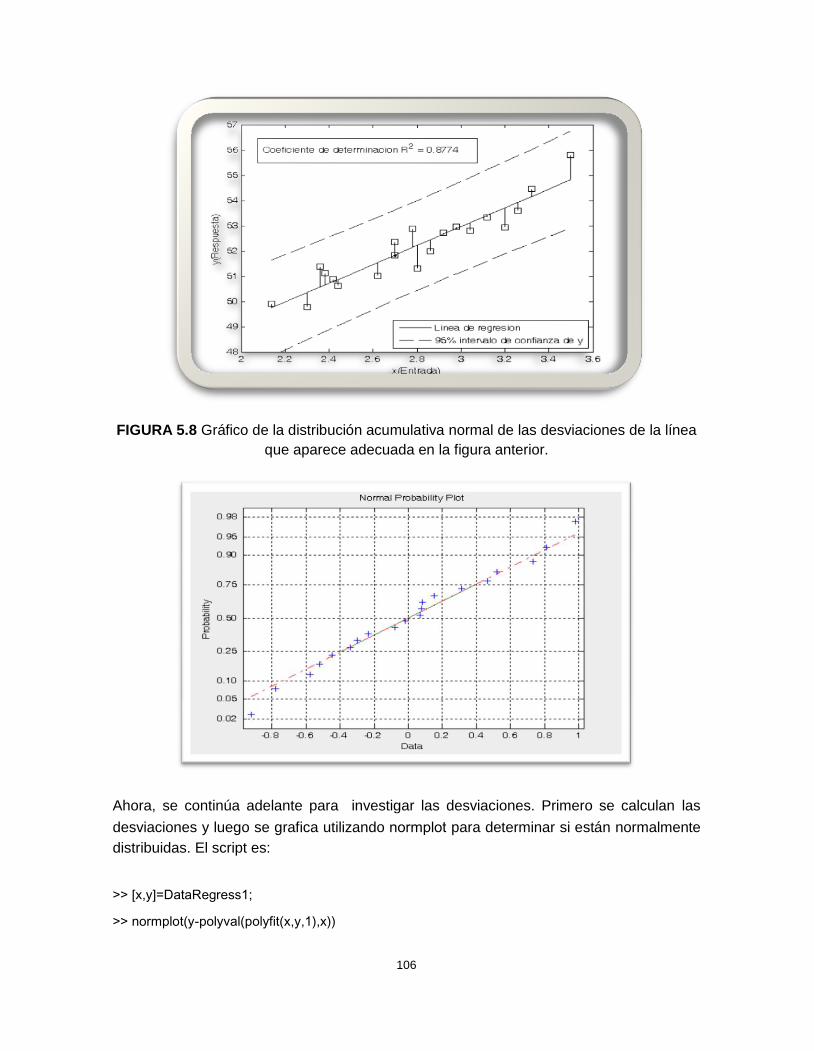
106
FIGURA 5.8 Gráfico de la distribución acumulativa normal de las desviaciones de la líneaque aparece adecuada en la figura anterior.
Ahora, se continúa adelante para investigar las desviaciones. Primero se calculan lasdesviaciones y luego se grafica utilizando normplot para determinar si están normalmentedistribuidas. El script es:
>> [x,y]=DataRegress1;
>> normplot(y-polyval(polyfit(x,y,1),x))

107
Siendo que las desviaciones están muy cerca de la línea que representa la distribuciónnormal, se puede decir que las desviaciones están muy cercanamente distribuidas deforma normal, por lo tanto, el modelo es adecuado.
Ejemplo 5.2 Una muestra de 10 estudiantes que ingresaron a la universidad con lossiguientes puntajes: 39, 43, 21, 64, 57, 47, 28, 75, 34, 52 sobre 100 obtuvieron lassiguientes notas en matemática I: 65, 78, 52, 82, 92, 89, 73, 98, 56, 75, respectivamente.
Solución.
function [x,y]=DataRegress2xx=[39 43 21 64 57 47 28 75 34 52];yy=[65 78 52 82 92 89 73 98 56 75];[x,index]=sort(xx); %los datos se ordenan pero deben preservarse las parejas
y=yy(index); %lo anterior se logra de esta manera
>> [x,y]=DataRegress2;
>> [c,s]=polyfit(x,y,1);
>> [yhat,w]=polyconf(c,x,s,0.005);
>> syy=sum(y.^2)-length(x)*mean(y)^2;
>> sse=syy-c(1)*(sum(x.*y)-length(x)*mean(x)*mean(y));
>> plot(x,yhat,'k-',x,yhat-w,'k--',x,yhat+w,'k--',x,y,'ks',[x;x],[yhat;y],'k-')
>> legend('Linea de regresion','95% intervalo de confianza de y','Location','SouthEast')
>> axis([15,80,10,140])
>> xlabel('x(Examen de Entrada)')
>> ylabel('y(Def. Matematica I)')
>> coefdet=(1-
coefdet =
0.7052
El coeficiente de determinación, muestra una buena relación lineal positiva entre lasvariables, porque está próximo a 1. Para el caso en cuestión, muestra que el puntajeobtenido por los estudiantes al ingresar a la universidad, se ha visto reflejado en las notasde matemática I.
Ahora, se se observan las desviaciones. Primero se calculan las desviaciones y luego segrafica utilizando normplot para determinar si están normalmente distribuidas. Ver figura5.10. El script es:

108
>> [x,y]=DataRegress2;
>> normplot(y-polyval(polyfit(x,y,1),x))
FIGURA 5.9 Recta de regresión estimada de las notas de Matemática I respecto alpuntaje de ingreso a la universidad
FIGURA 5.10 Gráfico de la distribución acumulativa normal de las desviaciones

109
Los datos se adaptan bien con los puntos de la normal.
(Curso II)
6. REGRESIÓN LINEAL MÚLTIPLE
7. SERIES DE TIEMPO
8. ANÁLISIS DE VARIANZA
9. PRUEBAS NO PARAMÉTRICAS

110
APÉNDICE 1
>> theta1=linspace(-2.0*pi,2.0*pi,35);
>> theta2=linspace(-2.0*pi,2.0*pi,35);
>> [T1,T2]=meshgrid(theta1,theta2);
>> F=T2.^2/2-cos(T1);
>> meshc(T1,T2,F)
>> axis([-2.0*pi,2.0*pi,-2.0*pi,2.0*pi,-5,20])
>> xlabel('\theta_1')
>> ylabel('F(\theta_1,\theta_2)')

111
APÉNDICE 2
>> t=linspace(0,2*pi);
>>fill(t,sin(t),'m')
>>hold on
>>fill(t,0.5*sin(2*t),'y')
>>axis off

112
APÉNDICE 3
>> x=linspace(0,6,100);
>> hc=plot(x,cos(x),'k-');
>> hold on
>> hch=plot(x,1./cosh(x),'k--');
>> hcl=plot([4.73,4.73],[-1,1],'k');
>> [a,b]=legend('cos(x)','1/cosh(x)','location','SouthWest');
>> xlabel('\it\bfx','FontSize',14,'FontName','Times')
>> ylabel('Value of function','FontSize',14)
>> ylabel('Valor de la funcion','FontSize',14)
>> title('\bfMuestra la interseccion de las dos curvas','FontName','Courier','FontSize',14)
>> text(4.8,-0.1,'\itx \rm= 4.73','FontName','Times','FontSize',12)
>> set(hc,'LineWidth',4)
>> set(hch,'LineWidth',2.5)
>> set(hcl,'LineWidth',0.25,'color','g')
>> set(gca,'FontSize',14,'LineWidth',1.5)
>> set(b(1),'FontSize',10)
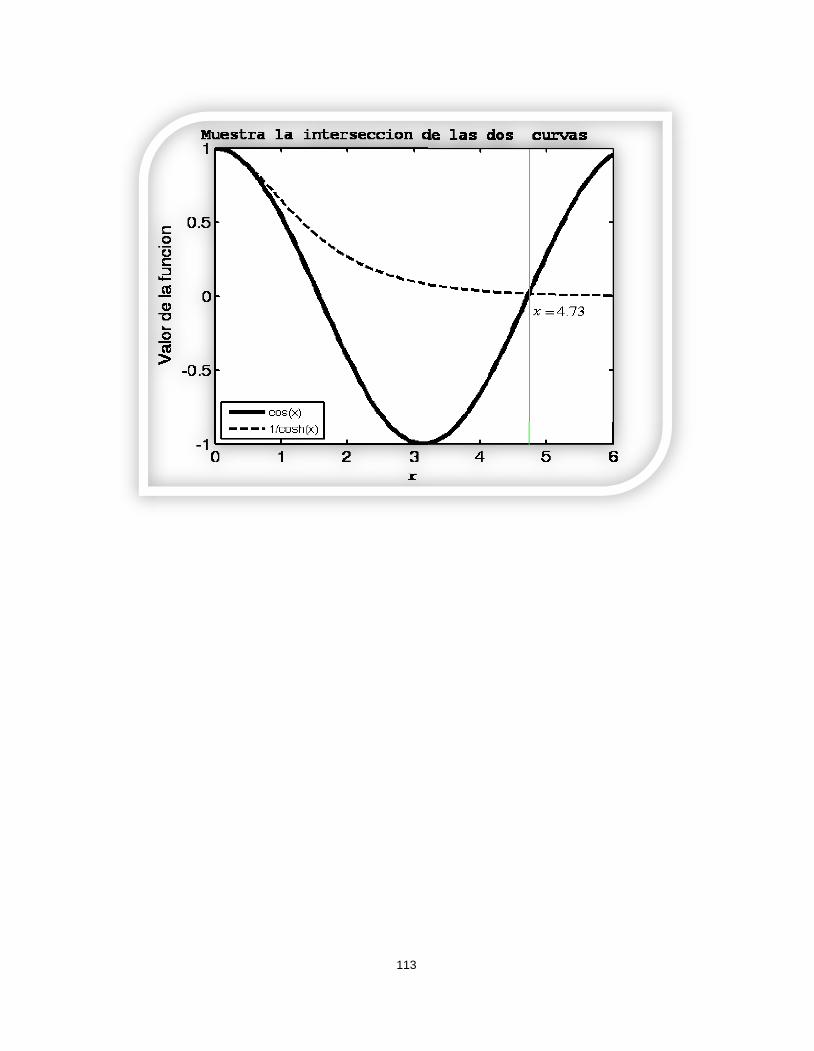
113

114
APÉNDICE 4
Modelo de Solución de problemas con MATLAB®
Se usan globos metereológicos para obtener datos de temperatura y presión a diferentesalturas en la atmósfera. El globo se eleva porque la densidad del helio en su interior esmenor que la del aire que rodea al globo. Al subir el globo, el aire circundante se vuelvemenos denso, y el ascenso se va frenando hasta que el globo alcanza un punto deequilibrio. Durante el día, la luz del Sol calienta el helio atrapado dentro del globo; el heliose expande y se vuelve menos denso, y el globo sube más. Durante la noche, en cambio,el helio del globo se enfría y se vuelve más denso, y el globo desciende a una alturamenor. El día siguiente, el Sol calienta el helio otra vez, y el globo sube. Este procesogenera una serie de mediciones de altura con el transcurso del tiempo que se puedenaproximar con una ecuación polinómica.
Suponga que el siguiente polinomio representa la altura en metros durante las primeras48 horas después del lanzamiento de un globo metereológico:
h(t) = -0.12t4 + 12t3 380t2 + 4100t + 220
donde las unidades de t son horas. Genere curvas para la altura, velocidad y aceleraciónde este globo usando unidades de metros, m/s y m/s2. Además, determine y exhiba laaltura máxima y su hora correspondiente.
Planteamiento del problema
Usando el polinomio dado, determine la velocidad y aceleración que corresponden a lainformación de altura. Grafique la altura, velocidad y aceleración. Además calcule la alturamáxima y su hora correspondiente.
Descripción de entradas/salidas
El siguiente diagrama de E/S muestra que el programa no tiene entradas externas. Lasalida consiste en las curvas y la altura máxima con su correspondiente tiempo.
* Gráfica de valores de altura
* Gráfica de valores de velocidad
* Gráfica de valores de aceleración
No hay datosexternos de
entrada

115
Ejemplo a mano
Solamente se necesita calcular la velocidad y la aceleración derivando a mano la funciónpolinómica dada de la altitud. Los datos se graficarán y se determinará el valor máximo.No obstante, es importante señalar que, al ser horas las unidades de t, se necesitaconvertir m/h en m/s sustituyendo el tiempo en horas por el tiempo en segundos.
Solución con MATLAB®
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%polinomico para la altura de un globo metereologico.%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
t=linspace(0,48,480);altitud=-0.12*t.^4+12*t.^3-380*t.^2+4100*t+220;velocidad=-0.48*t.^3+36*t.^2-760*t+4100;aceleracion=-1.44*t.^2+72*t-760;%
subplot(2,1,1),plot(t,altitud),title('Altura del globo')xlabel('t, horas'),ylabel('metros'),grid,pausesubplot(2,1,1),plot(t,velocidad/3600),title('Velocidad del globo')ylabel ('m/seg'),gridsubplot(2,1,2),plot(t,aceleracion/(3600*60)),title('Aceleracion del globo'),xlabel('t, horas')ylabel('metros/seg^2'),grid
%clcmaxima_altitud=max(altitud)for i=1:length(altitud)
if altitud(i)==maxima_altitud, t(i), break, end
endclcfprintf('La altura en metros es: %8.2f El tiempo en segundos es: %6.2f\n',maxima_altitud,t(i))

116
GLOSARIO
ANÁLISIS DE CORRELACIÓN. Es el conjunto de técnicas estadísticas empleado paramedir la intensidad de la asociación entre dos o más variables. El principal objetivo delanálisis de correlación consiste en determinar qué tan intensa es la relación entre dos omás variables. Normalmente, el primer paso es mostrar los datos en un diagrama dedispersión.
ANÁLISIS DE REGRESIÓN. Es una técnica estadística para el modelamiento e investigalas relaciones entre dos o más variables. El modelo de regresión lineal simple tieneúnicamente una variable independiente24. Es la técnica empleada para desarrollar laecuación y dar las estimaciones.
ANÁLISIS DE REGRESIÓN Y CORRELACIÓN MÚLTIPLE. Consiste en estimar unavariable dependiente, utilizando dos o más variables independientes.
ANÁLISIS ESTADÍSTICO DE LA INFORMACIÓN. Disciplina que se define como la ciencia de larecolección, análisis, interpretación y presentación de información que puede expresarse en formanumérica.
COEFICIENTE DE CONFIANZA. Es la probabilidad de que un intervalo de confianza contenga elparámetro que se estima.
COEFICIENTE DE CORRELACIÓN. Describe la intensidad de la relación entre dosconjuntos de variables de nivel de intervalo. Es la medida de la intensidad de la relaciónlineal entre dos variables.
El valor del coeficiente de correlación puede tomar valores desde -1 hasta 1, indicandoque mientras más cercano a 1 sea el valor del coeficiente de correlación, en cualquierdirección, más fuerte será la asociación lineal entre las dos variables. Mientras máscercano a 0 sea el coeficiente de correlación indicará más débil esta asociación entreambas variables. Si es igual a 0 se concluirá que no existe relación lineal alguna entreambas variables.
COVARIANZA. La covarianza de una variable bidimensional es la media aritmética de losproductos de las desviaciones de cada una de las variables respecto a sus medias respectivas.
DESVIACIÓN ESTÁNDAR. Se define como la raíz cuadrada de la varianza o como la desviacióncuadrática media.
DIAGRAMA DE DISPERSIÓN. Es aquel gráfico que representa la relación entre dosvariables.
24

117
ECUACIÓN DE REGRESIÓN. Es una ecuación que define la relación lineal entre dos
1x1 +b2x2 + b3x3
ECUACIÓN DE REGRESIÓN MÚLTIPLE. La forma general de la ecuación de regresiónmúltiple con dos variables independientes es:
= a + b1x1 + b2x2
x1 y x2 Variables independientes
a Coordenada del punto de intersección con el eje y
b1 Coeficiente de regresión (es la variación neta en y por cada unidad devariación en x1)
b2 Coeficiente de regresión (es el cambio neto en y para cada cambio unitarioen x2)
ESTADÍSTICA. La Estadística es la parte de las Matemáticas que se encarga del estudio de unadeterminada característica en una población, recogiendo los datos, organizándolos en tablas,representándolos gráficamente y analizándolos para sacar conclusiones de dicha población25.
ESTADÍSTICA DESCRIPTIVA. Realiza el estudio sobre la población completa, observando unacaracterística de la misma y calculando unos parámetros que den información global de toda lapoblación.
ESTADÍSTICA INFERENCIAL. Realiza el estudio descriptivo sobre un subconjunto de la poblaciónllamado muestra y, posteriormente, extiende los resultados obtenidos a toda la población26.
ESTADÍSTICO. Los datos o medidas que se obtienen sobre una muestra y por lo tanto unaestimación de los parámetros.
ESTIMADOR. Un estimador puntual utiliza un número único o valor para localizar una estimacióndel parámetro. Un intervalo de confianza denota un rango dentro del cual puede encontrarse elparámetro, y el nivel de confianza que el intervalo contiene del parámetro.
ESTIMADORES Y ESTIMACIONES. Un estimador es el proceso mediante el cual se obtiene laestimación. Una estimación es el resultado numérico del estimador.
Se dice que un buen estimador debe ser:
Insesgado, es decir, que no tenga sesgo o error, cuando el valor del estimador es igual aldel parámetro.Consistente, o sea, que al aumentar el tamaño de la muestra, converge en probabilidad alparámetro que se estima.
25 http://www.scribd.com/doc/15268123/Conceptos-Basicos-de-Estadistica-I26 http://recursostic.educacion.es/descartes/web/materiales_didacticos/unidimensional_lbarrios/parametros_est.htm

118
Eficiente, es decir, que el estimador tiene la menor varianza entre todos los estimadoresposibles.Suficiente, o sea, cuando incluye toda la información que la muestra puede proporcionaracerca del parámetro27.
ESTIMADOR INSESGADO. Un estimador es insesgado si la media de su distribución muestral esigual al parámetro correspondiente.
ESTIMADOR EFICIENTE. Dado un estimador insesgado, el estimador más eficiente es aquel quetenga la varianza más pequeña.
ESTIMADOR CONSISTENTE. Un estimador es consistente si, a medida que n aumenta, el valordel estadístico se aproxima al parámetro.
ESTIMADOR SUFICIENTE. Un estimador es suficiente si ningún otro estimador puedeproporcionar más información sobre el parámetro.
GRADO DE CONFIANZA. Se refiere a la probabilidad de que el valor real de un parámetro, seencuentre dentro de los límites especificados en la estimación que se quiere calcular.
GRADOS DE LIBERTAD. El número de observaciones menos el número de restriccionesimpuestas sobre tales observaciones.
GRÁFICO DE BARRAS. Son barras horizontales que representan el grado en que ciertascaracterísticas pueden existir a partir de la observación de casos o elementos.
GRÁFICOS CÍRCULARES O DE PASTEL (PIE). Son gráficas circulares divididas en sectores, querepresentan fracciones del círculo total y que están asociadas con una característica específica.
HISTOGRAMAS DE FRECUENCIA. Son gráficos que presentan la información contenida en unadistribución de frecuencia.
HIPÓTESIS ESTADÍSTICA. Puede considerarse como la afirmación acerca de una característicaideal de una población sobre la cual hay inseguridad en el momento de formularla y que, a la vez,es expresada de tal forma que puede ser rechazada.
INTERVALO DE CONFIANZA. Corresponde a un intervalo de valores, dentro de los cuales seespera que esté el parámetro con cierto grado de confianza o con riesgo de error conocido; paraello es necesario determinar primero la estimación puntual.
MEDIANA. Es la observación de la mitad después de que se han colocado la data en una serieordenada. Se usa en variables medidas en escala ordinal, intervalo o de razón. Si la data estáagrupada, la mediana se define como el valor dentro del intervalo que divide la distribución en dospartes iguales.
27 MARTÍNEZ B. Ciro. Op.Cit. pp. 315

119
MEDIA ARITMÉTICA. Se le llama también promedio. Es una medida de tendencia central queconsiste en la suma de las mediciones divididas por el total del número de mediciones. Se utilizaen variables medidas en escalas de intervalo o de razón.
MEDIA GEOMÉTRICA. Proporciona una medida precisa de un cambio porcentual promedio enuna serie de números28.
MEDIDA DE DISPERSIÓN. Miden qué tanto se dispersan las observaciones alrededor de sumedia29.
MÉTODO NO PARAMÉTRICO. O de distribución libre, es el análisis estadístico que no dependedel conocimiento de la distribución, ni de los parámetros poblacionales.
MODA. La moda de una distribución se define como el valor más frecuentemente encontrado, o lamayor frecuencia. Se usa con mediciones en escala nominal, ordinal, de intervalo o de razón. Si setrabaja con datos agrupados la moda se refiere al valor medio del intervalo que contiene la mayorfrecuencia.
MUESTRA. Es un subconjunto, extraído de la población (mediante técnicas de muestreo), cuyoestudio sirve para inferir características de toda la población.
MUESTREO. Es la técnica utilizada en la selección de una muestra a partir de una población.
MUESTREO NO PROBABILÍSTICO. Este tipo de muestreo, puede haber clara influencia de lapersona o personas que seleccionan la muestra o simplemente se realiza atendiendo a razones decomodidad. Salvo en situaciones muy concretas, en la que los errores cometidos no son grandes,debido a la homogeneidad de la población, en general no es un tipo de muestreo riguroso ycientífico, dado que no todos los elementos de la población pueden formar parte de la muestra. Porejemplo, si se hace una encuesta telefónica por la mañana, las personas que no tienen teléfono oque están trabajando, no podrán formar parte de la muestra.
MUESTREO PROBABILÍSTICO. En este tipo de muestreo, todos los individuos de la poblaciónpueden formar parte de la muestra, tienen probabilidad positiva de formar parte de la muestra. Porlo tanto es el tipo de muestreo que se debe utilizar en las investigaciones, por ser el más riguroso ycientífico.
M.A.S. Es un muestreo aleatorio simple, donde todos los individuos tienen la misma probabilidadde ser seleccionados. La selección de la muestre puede realizarse a través de cualquiermecanismo probabilístico en el que todos los elementos tengan las mismas opciones de salir.
PARÁMETROS ESTADÍSTICOS. Son las medidas que se obtienen sobre la distribución deprobabilidades de la población, tales como la media, la varianza, la proporción, etc.
Pueden ser de dos tipos:
28 WEBSTER, Allen L. Estadística Aplicada a los Negocios y la Economía. McGraw-Hill. Bogotá D.C. 2000. pp. 44.29 WEBSTER, Allen L. Op. Cit. pp. 47.

120
PARÁMETROS DE CENTRALIZACIÓN. Son datos que representan de forma global a toda lapoblación. Entre ellos se estudian: la media aritmética, la moda y la mediana.
PARÁMETROS DE DISPERSIÓN. Son datos que informan de la concentración o dispersión de losdatos respecto de los parámetros de centralización. Por ejemplo el rango, la desviación media, lavarianza y la desviación estándar30.
PERCENTILES. Es una medida de dispersión utilizada para calcular el valor que tiene P % de lasmediciones por debajo del percentil P y (100-P %) por encima.
POBLACIÓN. Es el conjunto de todos los elementos que son objeto del estudio estadístico.Algunos autores también le llaman Universo.
POLÍGONOS DE FRECUENCIA. Son gráficos en la forma de una serie de líneas rectasconectadas entre sí y que unen puntos medios de intervalos a lo largo del eje horizontal.
PRINCIPIO DE MÍNIMOS CUADRADOS. Es la técnica empleada para obtener laecuación de regresión, minimizando la suma de los cuadrados de las distancias verticales
PRUEBA DE HIPÓTESIS. Se denomina también prueba de significación que tiene por objetoprincipal evaluar suposiciones o afirmaciones acerca de los valores estadísticos de la población,denominados parámetros.
RANGO. Medida de dispersión que identifica la distancia entre el valor máximo y el menor valor dela distribución. O también se define como la diferencia entre el límite superior e inferior.
RANGO INTERCUARTÍLICO. Es otra medida de dispersión y se define como la diferencia entre elcuartil superior y el inferior.
TEOREMA DEL LÍMITE CENTRAL. Si de una población de tamaño N con media y varianza 2
se obtienen muestras al azar, la distribución de las medias de las muestras seleccionadas seránormal. Y más lo será en la medida en que se incremente el número de muestras seleccionadas ytendrá una media de y varianza 2/N31.
VARIABLE. Al hacer un estudio de una determinada población, se observa una característica opropiedad de sus elementos. Por ejemplo, con los y las estudiantes de la clase, se puede estudiarel lugar de residencia, el número de hermanos, la estatura, etc. Cada una de estas característicasestudiadas se llama variable estadística32.
Dependiendo de la característica se pueden distinguir varios tipos de variables:
VARIABLE CUALITATIVA. Es aquella característica que no se puede expresar con números y hayque expresarla con palabras. Por ejemplo, el lugar de residencia.
30 http://recursostic.educacion.es/descartes/web/materiales_didacticos/unidimensional_lbarrios/parametros_est.htm31 VÉLEZ, Eduardo B. El Análisis de la Información. ICFES, Módulo 4. Serie Aprender a Investigar. Bogotá D.C. 1990.32 http://recursostic.educacion.es/descartes/web/materiales_didacticos/unidimensional_lbarrios/parametros_est.htm

121
VARIABLE CUANTITATIVA. Es cualquier característica que se puede expresar con números. Porejemplo, el número de hermanos o la estatura. Dentro de esta variable se pueden distinguir dostipos:
VARIABLE CUANTITATIVA DISCRETA. Es aquella variable que puede tomar únicamente unnúmero finito de valores. Por ejemplo, el número de hermanos.
VARIABLE CUANTITATIVA CONTINUA. Es aquella variable que puede tomar cualquier valordentro de un intervalo real. Por ejemplo, la estatura.
VARIABLE DEPENDIENTE. Es la variable que se predice o calcula, cuya representaciónpuede ser y.
VARIABLE INDEPENDIENTE. Es la variable que proporciona las bases del cálculo, cuyarepresentación puede ser: x1, x2
VARIANZA. El promedio de las observaciones respecto a su media elevados al cuadrado.

122
BIBLIOGRAFÍA
ARAÚJO, Ulisses F. y SASTRE, Genoveva. El Aprendizaje Basado en Problemas. Una nuevaperspectiva de la enseñanza en la universidad. Gedisa Editorial. Barcelona, 2008.
ARBOLEDA Q. Dairon y ÁLVAREZ J. Rafael. MATLAB. Aplicaciones a las Matemáticas Básicas.Sello Editorial Universidad de Medellín, 2008.
BLAIR, Clifford R. and TAYLOR, Richard A. Bioestadística. Pearson Prentice Hall. México D.F.2008.
BOWERMAN, Bruce L. y otros. Pronósticos, Series de Tiempo y Regresión. Un enfoque Aplicado.CENGAGE Learning. México, 2007.
BROCKWELL, Peter J. and DAVIS, Richard A. Time Series: Theory and Methods. Springer Seriesin Statistics. Springer. New York, 2006.
CHAPMAN, Stephen J. MATLAB® Programming for Engineers. CENGAGE Learning. InternationalStudent Edition. Stanford, 2008
CHAO L. Lincoln. Estadística para las Ciencias Administrativas. Mc Graw-Hill. Bogotá D.C. 1998.
GIL RODRÍGUEZ, Manuel. Introducción Rápida a MATLAB y SIMULINK PARA CIENCIA EINGENIERÍA. Díaz de Santos. Madrid, 2003.
HAIR, ANDERSON et al. Análisis multivariante. Prentice Hall. Madrid, 2000.
HANSELMAN, Duane and LITTLEFIELD, Bruce. Mastering MATLAB 7. Pearson Prentice-Hall. NewJersey, 2005.
INSTITUTO DE NORMAS TÉCNICAS Y CERTIFICACIÓN. Trabajos escritos: presentación yreferencias bibliográficas. ICONTEC. Bogotá D. C. 2009.
KREYSZIG, Erwin. Introducción a la Estadística Matemática. Principios y Métodos. EditorialLIMUSA S. A. Méxido D.F. 1990.
MILLER, Irwin y FREUND, John E. Probabilidad y Estadística para Ingenieros. Prentice Hall.México D.F. 1990
PÉREZ, César. MATLAB® y sus aplicaciones en las Ciencias y la Ingeniería. Prentice Hall. Madrid,2002.
PÉREZ, César. Econometría de las Series Temporales. Pearson. Prentice Hall. Madrid, 2006.
Prentice Hall. New Jersey, 2010.
MARTÍNEZ BENCARDINO, Ciro. Estadística y Muestreo. ECOE Ediciones. Bogotá D.C. 2003.

123
SMITH, David M. Engineering Computation with MATLAB®. Addsison Wesley. Boston, 2010.
STANLEY, WillIam D. Technical Analysis and Applications with MATLAB®. THOMPSON DelmarLearning. Canada, 2005.
VÉLEZ, Eduardo B. El Análisis de la Información. ICFES, Módulo 4. Serie Aprender a Investigar.Bogotá D.C. 1990
WALPOLE, Ronald y otros. Probabilidad y Estadística para Ingenieros. Prentice Hall. PearsonEducación. Addison Wesley. México D.F. 1998.
WEBSTER, Allen L. Estadística Aplicada a los Negocios y la Economía. McGraw-Hill. Bogotá D.C.2000.
ZIMMERMANN, Francisco José P. Estadística para Investigadores. Universidad de la Sabana.Editorial Escuela Colombiana de Ingeniería. Bogotá D.C. 2004.

124
FUENTES DE INFORMACIÓN ELECTRÓNICA
Conceptos Básicos de Estadística [en línea]. http://www.scribd.com/doc/15268123/Conceptos-Basicos-de-Estadistica-I
Correlación [en linea]. <http://es. Wikipedia.org/wiki/Correlacion>
Coeficiente de Correlación de Pearson [en línea].<http://es.wikipedia.org/wiki/Coeficiente_de_correlación_de_Pearson>
Estadística Inferencial. [en línea] <http://es.wikipedia.org/wiki/Estadistica_inferencial >
Estadística, población y muestra. [en línea]. http://www.scribd.com/doc/5181091/Estadistica-y-poblacio-y-muestra
Hipótesis nula. [en línea]. <http://es.wikipedia.org/wiki/Hipótesis_nula>
Inferencia Estadística. [en línea]. http://www.mitecnologico.com/Main/InferenciaEstadistica
Intervalo de confianza. [en línea]. http://escuela.med.puc.cl/recursos/recepidem/EPIANAL9.HTM
Parámetros estadísticos. [en línea].http://recursostic.educacion.es/descartes/web/materiales_didacticos/unidimensional_lbarrios/parametros_est.htm
Pronóstico Estadístico. [en línea]. <http://es.wikipedia.org/wiki/Pronóstico_(Estadística)>


















