
Regresión lineal en spss para ciencias agrarias y forestales
84
-
Upload
marcelo-rodriguez-gallardo -
Category
Education
-
view
12.955 -
download
9
Transcript of Regresión lineal en spss para ciencias agrarias y forestales

Correlación y Regresión
Marcelo Rodríguez, MScIngeniero Estadístico
Universidad Católica del Maule
Facultad de Ciencias Básicas
Diseño de Experimentos y Modelos de Regresión lineal: Aplicaciones en SPSS.MÓDULO 5 y 6
26 de noviembre de 2010
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 1 / 84

Introducción
Comúnmente, cuando se realiza un estudio estadístico, se miden a unamisma unidad de análisis, más de una variable.
De�nición (Variable Dependiente)
Es la variable por predecir (o por modelar) y se denota con la letra Y .
De�nición (Variable Independiente)
Son las variables que se utilizan para predecir y se denota con la letra X.
De�nición (Relación entre variables)
Se dice que dos variables están relacionadas, si cambios producidos (causa)en la variable independiente producen un efecto en la variable dependiente.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 2 / 84

Relación entre las variables
De�nición (Covarianza)
La covarianza entre dos variables cuantitativas, nos indica si la posiblerelación entre dos variables es directa o inversa. La covarianza muestral secalcula de la siguiente manera:
covxy =
n∑i=1
(xi − x)(yi − y)
n− 1=
Sxyn− 1
Si la covarianza es negativa, entonces la relación es inversa.
Si la covarianza es positiva, entonces la relación es directa.
Si la covarianza es cero, entonces la relación es nula (no relacionados).
El signo de la covarianza nos dice si el aspecto de la nube de puntos escreciente o no, pero no nos dice nada sobre el grado de relación entre lasvariables.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 3 / 84
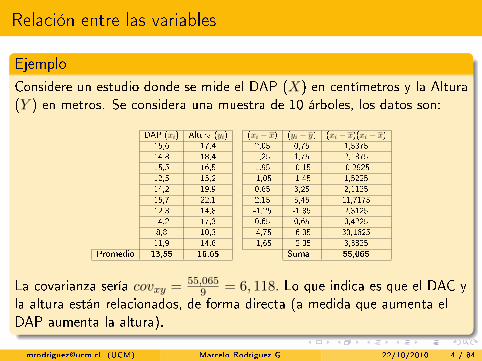
Relación entre las variables
Ejemplo
Considere un estudio donde se mide el DAP (X) en centímetros y la Altura(Y ) en metros. Se considera una muestra de 10 árboles, los datos son:
DAP (xi) Altura (yi) (xi − x) (yi − y) (xi − x)(xi − x)15,6 17,4 2,05 0,75 1,537514,8 18,4 1,25 1,75 2,187515,5 16,5 1,95 -0,15 -0,292512,5 15,2 -1,05 -1,45 1,522514,2 19,9 0,65 3,25 2,112515,7 22,1 2,15 5,45 11,717512,3 14,8 -1,25 -1,85 2,312514,2 17,3 0,65 0,65 0,42258,8 10,3 -4,75 -6,35 30,162511,9 14,6 -1,65 -2,05 3,3825
Promedio 13,55 16,65 Suma 55,065
La covarianza sería covxy =55,065
9 = 6, 118. Lo que indica es que el DAC yla altura están relacionados, de forma directa (a medida que aumenta elDAP aumenta la altura).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 4 / 84

Grado de relación entre las variablesCoe�ciente de correlación de Pearson
De�nición (Correlación)
El coe�ciente de correlación de Pearson, indica la fuerza y la dirección deuna relación lineal entre dos variables aleatorias. Se considera que dosvariables cuantitativas están correlacionadas cuando los valores de una deellas varían sistemáticamente con respecto a los valores de la otra.
r =
n∑i=1
(xi − x)(yi − y)√√√√ n∑i=1
(xi − x)2 ·n∑i=1
(yi − y)2=
Sxy√SxxSyy
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 5 / 84
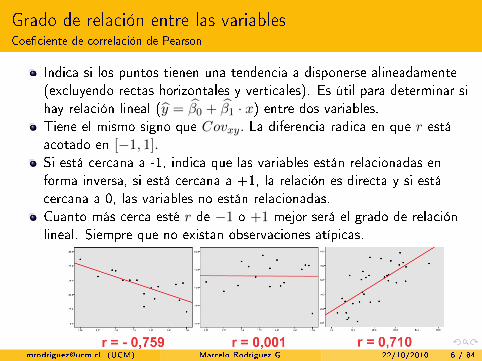
Grado de relación entre las variablesCoe�ciente de correlación de Pearson
Indica si los puntos tienen una tendencia a disponerse alineadamente(excluyendo rectas horizontales y verticales). Es útil para determinar sihay relación lineal (y = β0 + β1 · x) entre dos variables.Tiene el mismo signo que Covxy. La diferencia radica en que r estáacotado en [−1, 1].Si está cercana a -1, indica que las variables están relacionadas enforma inversa, si está cercana a +1, la relación es directa y si estácercana a 0, las variables no están relacionadas.Cuanto más cerca esté r de −1 o +1 mejor será el grado de relaciónlineal. Siempre que no existan observaciones atípicas.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 6 / 84

Grado de relación entre las variablesCoe�ciente de correlación de Pearson
Ejemplo
Con los datos anteriores, calcule e interprete la correlación.
DAP (xi) Altura (yi) (xi − x)2 (yi − y)215,6 17,4 4,2025 0,562514,8 18,4 1,5625 3,062515,5 16,5 3,8025 0,022512,5 15,2 1,1025 2,102514,2 19,9 0,4225 10,562515,7 22,1 4,6225 29,702512,3 14,8 1,5625 3,422514,2 17,3 0,4225 0,42258,8 10,3 22,5625 40,322511,9 14,6 2,7225 4,2025
Promedio 13,55 16,65 Suma 42,985 94,385
La correlación sería r = 55,065√42,985·94,385 = 0, 865. Lo que indica es que el
DAC y la altura están relacionados, de forma directa casi perfecta (rcercana a 1).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 7 / 84

Grado de relación entre las variablesPrueba de hipótesis para probar si la correlación es signi�cativa
Para probar la hipótesis de que la correlación es signi�cativamente distinta(mayor o menor) que cero, se debe seguí el siguiente procedimiento.Comúnmente cuando el valor−p es menor que 0,05 se dice que essigni�cativa, si es menor que 0,01 es altamente signi�cativa.
Estadística de prueba: tc =r ·√n− 2√
1− r2
Hip. Nula Hip. Alternativa Rechace H0 si Valor−pH0 : ρ = 0 H1 : ρ 6= 0 |tc| > t1−α/2(n− 2) 2[1− P(T < |tc|)]H0 : ρ = 0 H1 : ρ > 0 tc > t1−α(n− 2) 1− P(T < |tc|)H0 : ρ = 0 H1 : ρ < 0 tc < −t1−α(n− 2) 1− P(T < |tc|)
T se distribuye t−student con n− 2 grados de libertad.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 8 / 84

Grado de relación entre las variablesPrueba de hipótesis para probar si la correlación es signi�cativa
Ejemplo
Pruebe la hipótesis de que la correlación es signi�cativa.
Hipótesis: H0 : ρ = 0 v/s H1 : ρ 6= 0
Estadístico de prueba: tc =0, 865 ·
√8√
1− 0, 8652= 4, 865.
Región de Rechazo: Si α = 0, 05. Entonces rechace H0, si|tc| > t0,975(8) = 2, 306.
Signi�cancia:valor−p = 2[1− P(T < |4, 865|)] ∼= 2[1− 0, 99925] = 0, 0015
Conclusión: Como |tc| = 4, 865 > 2, 306 o equivalentementevalor−p < 0, 05. Entonces, existe su�ciente evidencia muestral paraa�rmar que el DAP y la altura están signi�cativamente correlacionadas(en rigor estricto es altamente signi�cativa, pues el valor−p < 0, 01).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 9 / 84
Grado de relación entre las variablesPrueba de hipótesis para probar si la correlación es signi�cativa en SPSS
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 10 / 84
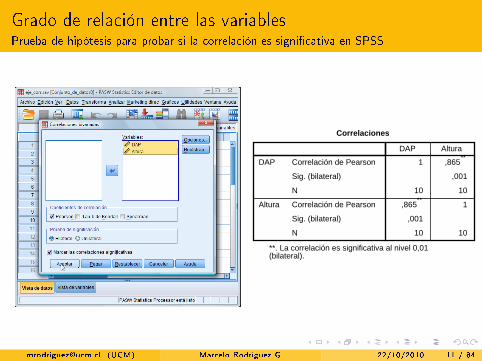
Grado de relación entre las variablesPrueba de hipótesis para probar si la correlación es signi�cativa en SPSS
AlturaDAP
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral)
N
DAP
Altura
1010
,001
1,865**
1010
,001
,865**
1
Correlaciones
**. La correlación es significativa al nivel 0,01 (bilateral).
Página 1
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 11 / 84

Regresión Lineal SimpleIntroducción
(Regresión Lineal Simple)
El término regresión fue introducido por Galton en su libro �Naturalinheritance� (1889) re�riéndose a la �ley de la regresión universal�.
Se supone que se tiene una muestra (x1, y1), (x2, y2), . . . , (xn, yn)correspondiente a la observación conjunta de las variables X e Y .
El objetivo será encontrar una relación entre ambas variables, estarelación podría estar dada por una recta (ecuación de regresión:y = β0 + β0 · x).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 12 / 84
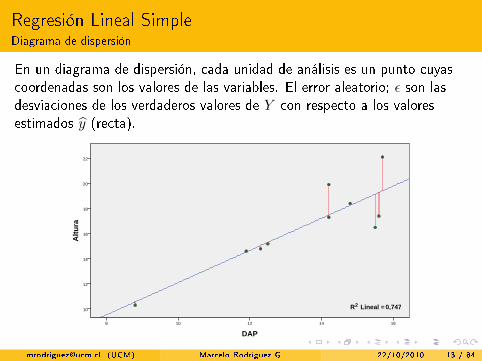
Regresión Lineal SimpleDiagrama de dispersión
En un diagrama de dispersión, cada unidad de análisis es un punto cuyascoordenadas son los valores de las variables. El error aleatorio; ε son lasdesviaciones de los verdaderos valores de Y con respecto a los valoresestimados y (recta).
Resultados creados
Comentarios
Datos
Conjunto de datos activo
Filtro
Peso
Segmentar archivo
Núm. de filas del archivo de trabajo
Sintaxis
Tiempo de procesador
Tiempo transcurrido
Entrada
Recursos
00:00:00,530
00:00:00,500
GRAPH /SCATTERPLOT(BIVAR)=DAP WITH Altura /MISSING=LISTWISE.
10
<ninguno>
<ninguno>
<ninguno>
Conjunto_de_datos1
D:\Archivos de Marcelo\Proyectos 2010\Diseño Experimental y Modelos de Regresión Lineal (Aplicaciones en SPSS 18.0)\Módulo 5 ( Correlación y Regresión Lineal Simple)\datos\eje_corr.sav
19-nov-2010 13:31:28
Notas
[Conjunto_de_datos1] D:\Archivos de Marcelo\Proyectos 2010\Diseño Experimental
y Modelos de Regresión Lineal (Aplicaciones en SPSS 18.0)\Módulo 5 ( Correlac
ión y Regresión Lineal Simple)\datos\eje_corr.sav
DAP
161412108
Alt
ura
22
20
18
16
14
12
10 R2 Lineal = 0,747
Página 3
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 13 / 84

Regresión Lineal SimpleLa ecuación de regresión
La ecuación de predicción esperada está dada por
y = β0 + β1 · x.
Donde, las estimaciones de los parámetros β1 y β0 son:
β1 =SxySxx
; y β0 = y − β1x
Intercepto (β0): es la estimación de y cuando x = 0.
Pendiente (β1): es la estimación de la pendiente de la recta (magnituddel incremento (o decremento) de y por cada unidad de incremento enx.)
Además, se de�ne el coe�ciente de determinación r2, como el porcentajede la variabilidad total que explica el modelo.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 14 / 84

Regresión Lineal SimpleLa ecuación de regresión
Ejemplo
Considerando los datos del problema anterior, encuentre la ecuación deregresión entre el DAP y la altura.La ecuación de predicción esperada está dada por
y = β0 + β1x,
Altura = β0 + β1 · DAP,
Donde, las estimaciones de los parámetros β1 y β0 son:
β1 =55, 065
42, 985= 1, 281; y β0 = 16, 65− 1, 281 · 13, 55 = −0, 708.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 15 / 84

Regresión Lineal SimpleLa ecuación de regresión
Ejemplo
Entonces, la ecuación sería:
Altura = −0, 708 + 1, 281 · DAP,
Pendiente: Por cada centímetro que se incrementa el DAP, la altura seincrementa en 1,281 metros.
Intercepto: Un árbol con un DAP muy pequeño (0), se estima que suAltura será de -0,708. En este caso no tiene sentido.
Esta recta, puede servir para predecir, suponga que tiene un árbol con unDAP=8cm, entonces se estima que su altura sería deAltura = −0, 708 + 1, 281 · 8 = 9, 54 metros.Además el porcentaje de la variabilidad total que explica el modelo es de74,7% (r2 = 0, 8652 = 0, 747).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 16 / 84

Regresión Lineal SimplePrueba de hipótesis para la pendiente
Para probar la hipótesis de que la pendiente es signi�cativamente distinta(mayor o menor) que cero, se debe seguí el siguiente procedimiento. Al serla pendiente distinta de cero, esto indicaría que las variables estánrelacionadas.
Estadística de prueba: tc =β1 ·√Sxx
se
Hip. Nula Hip. Alternativa Rechace H0 si Valor−pH0 : β1 = 0 H1 : β1 6= 0 |tc| > t1−α/2(n− 2) 2[1− P(T < |tc|)]H0 : β1 = 0 H1 : β1 > 0 tc > t1−α(n− 2) 1− P(T < |tc|)H0 : β1 = 0 H1 : β1 < 0 tc < −t1−α(n− 2) 1− P(T < |tc|)
T se distribuye t−student con n− 2 grados de libertad. Además
sε =√∑n
i=1(yi−yi)2n−2 =
√Syy−β1Sxy
n−2 es la desviación estándar del error,también llamado, error estándar (típico) de la estimación.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 17 / 84

Regresión Lineal SimplePrueba de hipótesis para la pendiente
Ejemplo
Pruebe la hipótesis de que la pendiente es distinta de cero.
Hipótesis: H0 : β1 = 0 v/s H1 : β1 6= 0
Estadístico de prueba: tc =1, 281 ·
√42, 985
1, 726= 4, 865.
Región de Rechazo: Si α = 0, 05. Entonces rechace H0, si|tc| > t0,975(8) = 2, 306.
Signi�cancia:valor−p = 2[1− P(T < |4, 865|)] ∼= 2[1− 0, 99925] = 0, 0015
Conclusión: Como |tc| = 4, 865 > 2, 306 o equivalentementevalor−p < 0, 05. Entonces, existe su�ciente evidencia muestral paraa�rmar que el DAP y la altura están signi�cativamente relacionadas.(Esta prueba es equivalente a la prueba de hipótesis para lacorrelación).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 18 / 84
Regresión Lineal SimpleRegresión Lineal Simple en SPSS
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 19 / 84
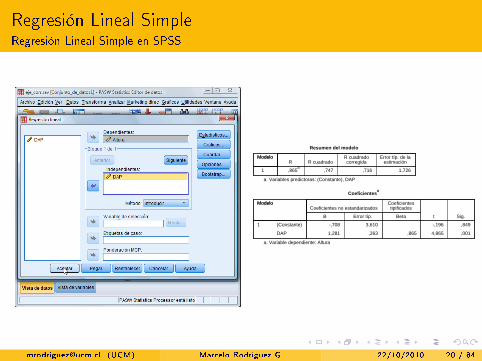
Regresión Lineal SimpleRegresión Lineal Simple en SPSS
[Conjunto_de_datos1] D:\Archivos de Marcelo\Proyectos 2010\Diseño Experimental
y Modelos de Regresión Lineal (Aplicaciones en SPSS 18.0)\Módulo 5 ( Correlac
ión y Regresión Lineal Simple)\datos\eje_corr.sav
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 1,726,716,747,865a
ModeloModelo
Resumen del modelo
a. Variables predictoras: (Constante), DAP
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
DAP
1
,0014,865,865,2631,281
,849-,1963,610-,708
ModeloModelo
Coeficientesa
a. Variable dependiente: Altura
Página 1
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 20 / 84
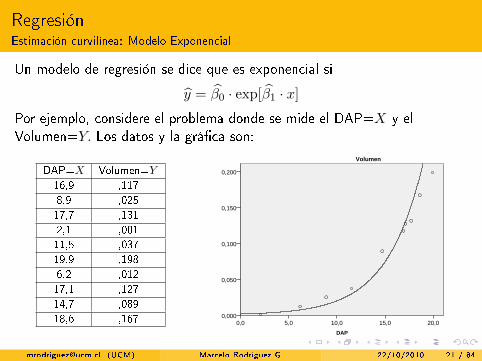
RegresiónEstimación curvilínea: Modelo Exponencial
Un modelo de regresión se dice que es exponencial si
y = β0 · exp[β1 · x]Por ejemplo, considere el problema donde se mide el DAP=X y elVolumen=Y. Los datos y la grá�ca son:
DAP=X Volumen=Y16,9 ,1178,9 ,02517,7 ,1312,1 ,00111,5 ,03719,9 ,1986,2 ,01217,1 ,12714,7 ,08918,6 ,167
b1Constante
Estimaciones de los parámetros
Exponencial ,266,001
EcuaciónEcuación
Resumen del modelo y estimaciones de los parámetros
La variable independiente esDAP.
Variable dependiente:Volumen
DAP
20,015,010,05,00,0
0,200
0,150
0,100
0,050
0,000
Volumen
Página 8
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 21 / 84

RegresiónEstimación curvilínea: Modelo Exponencial
(Modelo exponencial)
El modelo exponencial, se puede solucionar mediante una regresiónlineal simple.
Aplicar el logaritmo natural a la ecuación
y = β0 · exp[β1 · x]
.
Tendríamosw = ln[y] = ln[β0] + β1 · x
.
Encuentre la ecuación de regresión lineal simple entre X y W .
Luego se debe aplicar la exponencial a w para despejar y.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 22 / 84
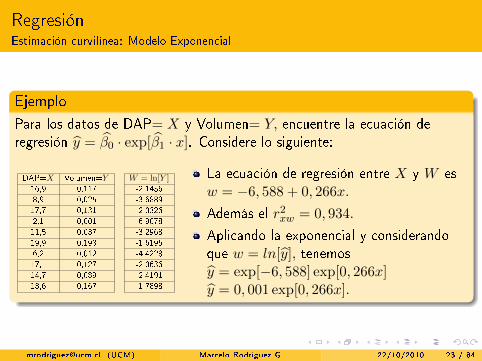
RegresiónEstimación curvilínea: Modelo Exponencial
Ejemplo
Para los datos de DAP= X y Volumen= Y, encuentre la ecuación deregresión y = β0 · exp[β1 · x]. Considere lo siguiente:
DAP=X Volumen=Y W = ln[Y ]16,9 0,117 -2,14568,9 0,025 -3,688917,7 0,131 -2,03262,1 0,001 -6,907811,5 0,037 -3,296819,9 0,198 -1,61956,2 0,012 -4,422817,1 0,127 -2,063614,7 0,089 -2,419118,6 0,167 -1,7898
La ecuación de regresión entre X y W esw = −6, 588 + 0, 266x.
Además el r2xw = 0, 934.
Aplicando la exponencial y considerandoque w = ln[y], tenemosy = exp[−6, 588] exp[0, 266x]y = 0, 001 exp[0, 266x].
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 23 / 84

RegresiónEstimación curvilínea: Modelo Exponencial
Ejemplo
También podemos encontrar la ecuación de regresión lineal simpleentre X e Y. La cual sería, y = −0, 055 + 0, 011x, con r2xy = 0, 890.
El modelo exponencial es y = 0, 001 exp[0, 266x], con r2xw = 0, 934.
En los datos existe un árbol con DAP= 14, 7 y Volumen= 0, 089. Siutilizamos estos dos modelos para predecir el volumen de un árbol conDAP=14,7, tenemos
Con el modelo de regresión lineal simple:
y = −0, 055 + 0, 011 · 14, 7 = 0, 105.Con el modelo exponencial:
y = 0, 001 exp[0, 266 · 14, 7] = 0, 068.
Ambas estimaciones del volumen están cercanas a 0, 089, pero la delmodelo exponencial (0,068), está más cercana. Además, el r2 delmodelo exponencial está más cercano al 100%.
En conclusión, entre estos dos modelos el mejor es el [email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 24 / 84
RegresiónEstimación curvilínea: Modelo Exponencial en SPSS
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 25 / 84
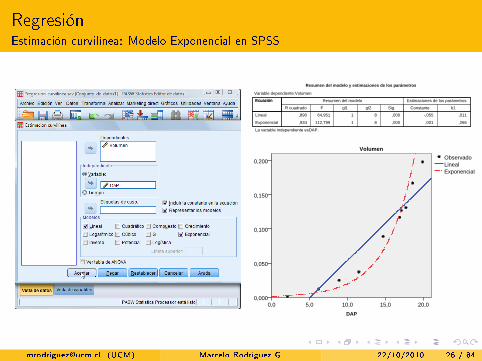
RegresiónEstimación curvilínea: Modelo Exponencial en SPSS
Sig.gl2gl1FR cuadrado b1Constante
Estimaciones de los parámetrosResumen del modelo
Lineal
Exponencial ,266,001,00081112,799,934
,011-,055,0008164,951,890
EcuaciónEcuación
Resumen del modelo y estimaciones de los parámetros
La variable independiente esDAP.
Variable dependiente:Volumen
DAP
20,015,010,05,00,0
0,200
0,150
0,100
0,050
0,000
Volumen
ExponencialLinealObservado
Página [email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 26 / 84
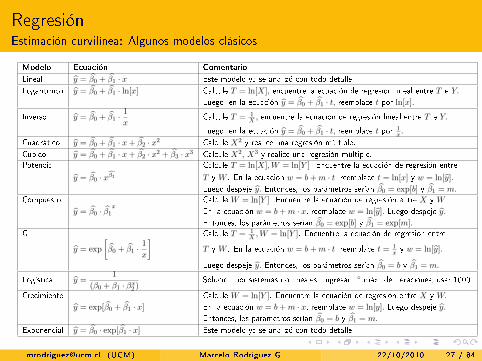
RegresiónEstimación curvilínea: Algunos modelos clásicos
Modelo Ecuación Comentario
Lineal y = β0 + β1 · x Este modelo ya se analizó con todo detalle.Logarítmico y = β0 + β1 · ln[x] Calcule T = ln[X], encuentre la ecuación de regresión lineal entre T e Y.
Luego, en la ecuación y = β0 + β1 · t, reemplace t por ln[x].
Inverso y = β0 + β1 ·1
xCalcule T = 1
X , encuentre la ecuación de regresión lineal entre T e Y.
Luego, en la ecuación y = β0 + β1 · t, reemplace t por 1x .
Cuadrático y = β0 + β1 · x+ β2 · x2 Calcule X2 y realice una regresión múltiple.Cúbico y = β0 + β1 · x+ β2 · x2 + β3 · x3 Calcule X2, X3 y realice una regresión múltiple.Potencia Calcule T = ln[X],W = ln[Y ]. Encuentre la ecuación de regresión entre
y = β0 · xβ1 T y W . En la ecuación w = b+m · t, reemplace t = ln[x] y w = ln[y].
Luego despeje y. Entonces, los parámetros serían β0 = exp[b] y β1 = m.
Compuesto Calcule W = ln[Y ]. Encuentre la ecuación de regresión entre X y W .y = β0 · β1
xEn la ecuación w = b+m · x, reemplace w = ln[y]. Luego despeje y.Entonces, los parámetros serían β0 = exp[b] y β1 = exp[m].
G Calcule T = 1X ,W = ln[Y ]. Encuentre la ecuación de regresión entre
y = exp
[β0 + β1 ·
1
x
]T y W . En la ecuación w = b+m · t, reemplace t = 1
x y w = ln[y].
Luego despeje y. Entonces, los parámetros serían β0 = b y β1 = m.
Logística y =1
(β0 + β1 · βx2 )Solución por sistemas no lineales. Ingresar n◦ máx. de iteraciones, usar 1000.
Crecimiento Calcule W = ln[Y ]. Encuentre la ecuación de regresión entre X y W.y = exp[β0 + β1 · x] En la ecuación w = b+m · x, reemplace w = ln[y]. Luego despeje y.
Entonces, los parámetros serían β0 = b y β1 = m.
Exponencial y = β0 · exp[β1 · x] Este modelo ya se analizó con todo detalle.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 27 / 84
RegresiónEstimación curvilínea: Algunos modelos clásicos en SPSS
Encontraremos todos losmodelos de regresión quepropone SPSS.
Un modelo es bueno si elvalor−p < 0, 05.
El mejor modelo es el que tieneel menor valor−p, mayor r2,mayor F y menor número deparámetros.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 28 / 84
RegresiónEstimación curvilínea: Algunos modelos clásicos en SPSS
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 29 / 84
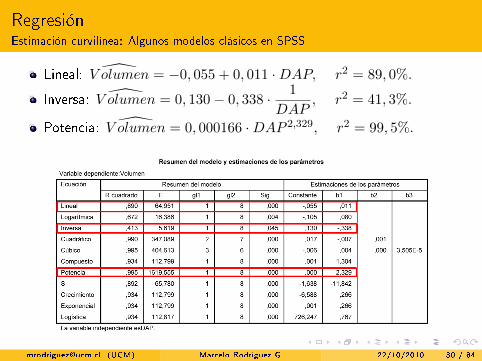
RegresiónEstimación curvilínea: Algunos modelos clásicos en SPSS
Lineal: V olumen = −0, 055 + 0, 011 ·DAP, r2 = 89, 0%.
Inversa: V olumen = 0, 130− 0, 338 · 1
DAP, r2 = 41, 3%.
Potencia: V olumen = 0, 000166 ·DAP 2,329, r2 = 99, 5%.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 30 / 84

RegresiónEstimación curvilínea: Algunos modelos clásicos en SPSS
Lineal: V olumen = −0, 055 + 0, 011 ·DAP, r2 = 89, 0%.
Inversa: V olumen = 0, 130− 0, 338 · 1
DAP, r2 = 41, 3%.
Potencia: V olumen = 0, 000166 ·DAP 2,329, r2 = 99, 5%.
DAP
20,015,010,05,00,0
0,200
0,150
0,100
0,050
0,000
Volumen
PotenciaInversoLinealObservado
Página 20
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 31 / 84
Regresión Lineal MúltipleIntroducción
Arena
50,045,0
40,035,0
30,0
Índ
ice
de
siti
o
28,0
26,0
24,0
22,0
20,0
18,0
Densidad 1,501,45
1,401,35
1,301,25
1,20
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT IS
/METHOD=ENTER Arena Densidad.
Regresión
Página 8
Técnica de dependencia que puedeutilizarse para analizar la relación entreuna única variable dependiente (Y ) yvarias variables independientes x1, x2,. . . , xk.
Cada variable independiente esponderada (βj), de forma que lasponderaciones indican su contribuciónrelativa a la predicción conjunta.
El objetivo es usar las variablesindependientes cuyos valores sonconocidos para predecir la únicavariable dependiente seleccionada porel investigador.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 32 / 84

Regresión Lineal MúltipleEl modelo lineal general
El modelo de regresión lineal sería
yi = β0 + β1 · xi1 + β2 · xi2, . . . , βk · xik + εi.
Donde
Y =
y1y2...yn
, X =
1 x11 x12 . . . x1n1 x21 x22 . . . x2k...
......
...1 xn1 xn2 . . . xnk
, β =
β0β1...βk
, ε =
ε1ε2...εn
,
βj , son los parámetros desconocidos, j = 1, . . . , k. El n◦ total deparámetros es p = k + 1.
εi es el i−ésimo error aleatorio asociado con yi, i = 1, . . . , n.
El objetivo es estimar βj , a esta estimación la llamaremos βj .
La estimación se los parámetros sería β = (XTX)−1XTY. Entoncesel modelo estimado sería yi = β0 + β1 · xi1 + β2 · xi2, . . . , βk · xik.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 33 / 84

Regresión Lineal MúltipleEjemplo de estimación de los parámetros.
Ejemplo
Se desea conocer la tasa de crecimiento de un cultivo bajo diferentescondiciones de sitio y manejo. En el caso del Eucaliptus Globulus esprácticamente desconocida, es por ello que se toman muestras de suelo decada rodal, midiendo el y = índice de sitio (altura promedio alcanzadapor árboles dominantes a una edad determinada), x1 = % de arena, x2 =% de arcilla y la x3 = densidad aparente (gr/cc).
Índice de sitio (y) 25,4 24,0 22,9 25,3 21,4 24,5 22,1 19,6 26,9 24,0 20,3 23,6 23,4 24,0 23,1 21,2% Arena (x1) 40,5 45,8 47,6 47,2 40,4 38,9 45,3 32,7 41,5 42,9 40,2 46,1 45,0 48,9 41,3 46,2% Arcilla (x2) 34,3 37,5 27,4 32,9 33,8 38,7 28,4 34,0 30,1 34,4 46,9 35,4 34,3 25,7 32,3 32,5Densidad (x3) 1,29 1,32 1,40 1,30 1,41 1,25 1,38 1,50 1,20 1,34 1,38 1,49 1,47 1,36 1,42 1,48
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 34 / 84

Regresión Lineal MúltipleEjemplo de estimación de los parámetros.
Se propone el siguiente modelo
y = β0 + β1 · x1 + β2 · x2 + β3 · x3 + ε.
Se desea estimar los parámetros del modelo (βj). Por ejemplo, si laestimación del parámetro β2 es muy cercano a 0, quiere decir que el %de arcilla (x2) no in�uye en la predicción del índice de sitio (y).
Los parámetros estimados serían:β0 = 43, 037, β1 = 0, 121, β2 = −0, 066, y β3 = −16, 604.Entonces el modelo estimado sería
y = 43, 037 + 0, 121 · x1 − 0, 066 · x2 − 16, 604 · x3.
Índice de sitio = 43, 037+0, 121·Arena−0, 066·Arcilla−16, 604·Densidad.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 35 / 84

Regresión Lineal MúltiplePrueba de hipótesis para los parámetros.
(Prueba de hipótesis para los parámetros del modelo)
Hipótesis:H0 : β0 = β1 = · · · = βk = 0 v/s H1 : βj 6= 0, para algún j.
Estadístico de prueba:
Modelo Suma de Grados de Media Fccuadrados libertad cuadrática
Regresiónn∑i=1
(yi − y)2 p− 1SCReg(p− 1)
MCRegMCRes
Residualn∑i=1
(yi − yi)2 n− p SCRes(n− p)
Totaln∑i=1
(yi − y)2 n− 1
Región de rechazo: Rechace H0 si Fc > F1−α(p− 1, n− p).Signi�cancia: Valor-p = 1− P(F < Fc). Donde F se distribuyeFisher con p− 1 y n− p grados de libertad.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 36 / 84
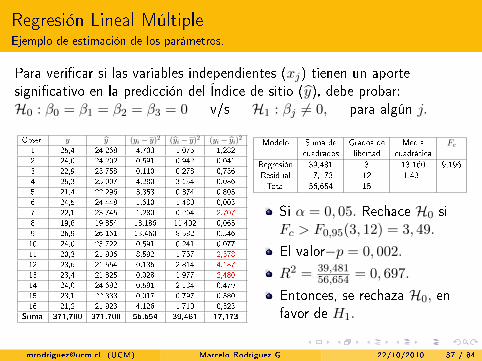
Regresión Lineal MúltipleEjemplo de estimación de los parámetros.
Para veri�car si las variables independientes (xj) tienen un aportesigni�cativo en la predicción del Índice de sitio (y), debe probar:H0 : β0 = β1 = β2 = β3 = 0 v/s H1 : βj 6= 0, para algún j.
Obser. y y (yi − y)2 (yi − y)2 (yi − yi)21 25,4 24,268 4,703 1,075 1,2822 24,0 24,202 0,591 0,942 0,0413 22,9 23,758 0,110 0,278 0,7364 25,3 25,007 4,280 3,154 0,0865 21,4 22,296 3,353 0,874 0,8036 24,5 24,448 1,610 1,480 0,0037 22,1 23,745 1,280 0,264 2,7078 19,6 19,854 13,186 11,402 0,0659 26,9 26,161 13,460 8,582 0,54610 24,0 23,722 0,591 0,241 0,07711 20,3 21,906 8,592 1,757 2,57812 23,6 21,554 0,136 2,814 4,18713 23,4 21,825 0,028 1,977 2,48014 24,0 24,692 0,591 2,134 0,47915 23,1 22,338 0,017 0,797 0,58016 21,2 21,923 4,126 1,710 0,523
Suma 371,700 371,700 56,654 39,481 17,173
Modelo Suma de Grados de Media Fccuadrados libertad cuadrática
Regresión 39,481 3 13,160 9,196Residual 17,173 12 1,431Total 56,654 15
Si α = 0, 05. Rechace H0 siFc > F0,95(3, 12) = 3, 49.
El valor−p = 0, 002.
R2 = 39,48156,654 = 0, 697.
Entonces, se rechaza H0, enfavor de H1.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 37 / 84

Regresión Lineal MúltipleBondad de ajuste
(Coe�ciente de Determinación (R2))
Expresa la proporción de varianza de la variable dependiente que estáexplicada por las variables independientes.
R2 =SCRegSCT
.
R2 corregida es una corrección a la baja de R2 que se basa en el númerode casos y de variables independientes:
R2correjida = R2 −
[k(1−R2)
(n− k + 1)
].
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 38 / 84

Regresión Lineal MúltipleBondad de ajuste
(Coe�ciente de correlación múltiple (R))
Es la raíz de R2. Si tenemos dos variables el Coe�ciente de correlaciónmúltiple es el valor absoluto del coe�ciente de correlación de Pearson, esdecir, R = |r|.
(Error (residuo) estándar de la estimación)
Es la desviación media que existe entre la variable dependiente y y suestimación y (el residuo es εi = yi − yi).
sε =
√√√√√√n∑i=1
(yi − yi)2
n− p=√MCRes.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 39 / 84

Regresión Lineal MúltiplePrueba de hipótesis para cada uno de los parámetros
Hipótesis: H0 : βj = 0 v/s H1 : βj 6= 0, para j = 0, 1, . . . , k.
Estadística de prueba: tc =βj
s(βj)
Hip. Nula Hip. Altern. Rechace H0 si Valor−pH0 : βj = 0 H1 : βj 6= 0 |tc| > t1−α/2(n− p) 2[1− P(T < |tc|)]H0 : βj = 0 H1 : βj > 0 tc > t1−α(n− p) 1− P(T < |tc|)H0 : βj = 0 H1 : βj < 0 tc < −t1−α(n− p) 1− P(T < |tc|)
T se distribuye t−student con n− p grados de libertad. Ademáss(βj) =
√cj+1 · sε, donde cj+1 es el elemento (j + 1) de la diagonal de
(XTX)−1.
Un intervalo de con�anza del 100(1− α)% para el parámetro βj es
βj ± t1−α/2(n− p) · s(βj)
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 40 / 84

Regresión Lineal MúltipleParámetros estandarizados (coe�cientes tipi�cados)
1 Los coe�cientes tipi�cados, se obtienen de la ecuación de regresióntras estandarizar las variables originales. Es decir, debe a cada variablerestarle su promedio y dividirlo por su desviación estándar, y luegoencontrar los parámetros de la ecuación de regresión con esas nuevasvariables.
2 Permiten valorar la importancia relativa de cada variable independientedentro de la ecuación. En general, una variable independiente tienetanto más peso (importancia) en la ecuación de regresión cuantomayor (en valor absoluto) es su coe�ciente de regresión estandarizado.
3 Indican la cantidad de cambio, en puntuaciones estándar, que seproducirá en la variable dependiente por cada cambio de una unidaden la correspondiente variable independiente (manteniendo constantesel resto de variables independientes).
4 En regresión simple, el coe�ciente estandarizado, coincide con elcoe�ciente de correlación de Pearson.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 41 / 84
Regresión Lineal MúltipleRegresión Lineal Múltiple en SPSS
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 42 / 84
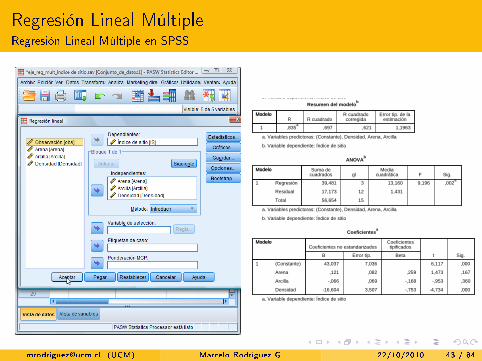
Regresión Lineal MúltipleRegresión Lineal Múltiple en SPSS
MétodoVariables
eliminadasVariables
introducidas
1 Introducir.Densidad, Arena, Arcilla
a
ModeloModelo
Variables introducidas/eliminadasb
a. Todas las variables solicitadas introducidas.
b. Variable dependiente: Índice de sitio
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 1,1963,621,697,835a
ModeloModelo
Resumen del modelob
a. Variables predictoras: (Constante), Densidad, Arena, Arcilla
b. Variable dependiente: Índice de sitio
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
1
1556,654
1,4311217,173
,002a
9,19613,160339,481
ModeloModelo
ANOVAb
a. Variables predictoras: (Constante), Densidad, Arena, Arcilla
b. Variable dependiente: Índice de sitio
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Arena
Arcilla
Densidad
1
,000-4,734-,7533,507-16,604
,360-,953-,168,069-,066
,1671,473,259,082,121
,0006,1177,03643,037
ModeloModelo
Coeficientesa
a. Variable dependiente: Índice de sitio
Página 2
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 43 / 84

Regresión Lineal MúltipleRegresión Lineal Múltiple en SPSS
No existe su�ciente evidencia muestral, para a�rmar que el % de arena(t = 1, 473, valor−p = 0, 167) o el % de arcilla (t = −0, 953,valor−p = 0, 360), in�uyen en la estimación del índice de sitio.
La muestra proporciona evidencia para a�rmar que la densidad incideen la estimación del índice de sitio (t = −4, 734, valor−p = 0, 000).
La relación entre la densidad y el índice de sitios es inversa (signo delestadístico de prueba).
Según los coe�cientes estadarizados, la variable independiente másimportante en la predicción del índice de sitios, es la densidad, luego elporcentaje de arena y por último el porcentaje de arcilla.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 44 / 84

Regresión Lineal MúltipleCorrelaciones parciales y semiparciales
(Correlaciones parciales)
Es la correlación lineal entre dos variables mientras se mantienen constantesotras variables. En el contexto del análisis de regresión, los coe�cientes decorrelación parcial expresan el grado de relación existente entre cadavariable independiente y la variable dependiente tras eliminar de ambas elefecto debido al resto de variables independientes incluidas en la ecuación.El coe�ciente de correlación parcial de primer orden, anotado aquí rAB/C ,permite conocer el valor de la correlación entre dos variables A y B, si lavariable C había permanecido constante para la serie de observacionesconsideradas.
rAB/C =rAB − rAC · rBC√1− r2AC ·
√1− r2BC
.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 45 / 84

Regresión Lineal MúltiplePuntos de in�uencia
La distancia de Cook (1977) mide el cambio que se produce en lasestimaciones de los coe�cientes de regresión al ir eliminando cada caso dela ecuación de regresión. Una distancia de Cook grande indica que ese casotiene un peso considerable en la estimación de los coe�cientes de regresión.Para evaluar estas distancias puede utilizarse la distribución F con p yn− p grados de libertad. En general, un caso con una distancia de Cooksuperior a 1 debe ser revisado.
Di =
n∑j=1
[yj − yj(i)
]2p ·MCRes
.
Donde yj(i), es una estimación sin considerar el dato i−ésimo.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 46 / 84
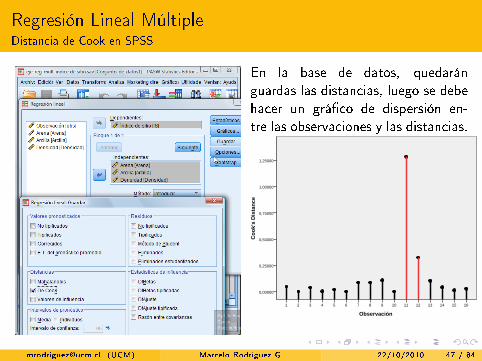
Regresión Lineal MúltipleDistancia de Cook en SPSS
En la base de datos, quedaránguardas las distancias, luego se debehacer un grá�co de dispersión en-tre las observaciones y las distancias.
Observación
16151413121110987654321
Co
ok'
s D
ista
nce
1,25000
1,00000
0,75000
0,50000
0,25000
0,00000
SAVE OUTFILE='D:\Archivos de Marcelo\Proyectos 2010\Diseño Experimental y Mode
los de Regresión '+
'Lineal (Aplicaciones en SPSS 18.0)\Módulo 5 ( Correlación y Regresión Lin
eal '+
'Simple)\datos\eje_reg_mult_indice de sitio.sav'
/COMPRESSED.
Página 8
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 47 / 84

Regresión Lineal MúltipleSupuestos del Modelo
(Supuestos del Modelo de Regresión)
Los supuestos de un modelo estadístico se re�eren a una serie decondiciones que deben darse para garantizar la validez del modelo.
Linealidad: La variable dependiente es la suma de un conjunto deelementos: el origen de la recta, una combinación lineal de variablesindependientes y los residuos.
Independencia: Los residuos son independientes entre sí.
Homocedasticidad: Para cada valor de la variable independiente, lavarianza de los residuos es constante.
Normalidad: Para cada valor de la variable independiente, losresiduos se distribuyen normalmente con media cero.
No-colinealidad: No existe relación lineal exacta entre ninguna de lasvariables independientes.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 48 / 84
Regresión Lineal MúltipleSupuestos del Modelo: Linealidad
Los diagramas de regresión parcialpermiten examinar la relación exis-tente entre la variable dependiente ycada una de las variables independi-entes por separado, tras eliminar deellas el efecto del resto de las vari-ables independientes incluidas en elanálisis. Estos diagramas son sim-ilares a los de dispersión ya estu-diados, pero no están basados enlas puntuaciones originales de lasdos variables representadas, sino enlos residuos obtenidos al efectuar unanálisis de regresión con el resto delas variables independientes.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 49 / 84
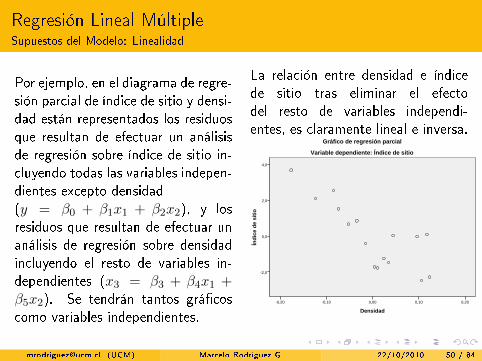
Regresión Lineal MúltipleSupuestos del Modelo: Linealidad
Por ejemplo, en el diagrama de regre-sión parcial de índice de sitio y densi-dad están representados los residuosque resultan de efectuar un análisisde regresión sobre índice de sitio in-cluyendo todas las variables indepen-dientes excepto densidad(y = β0 + β1x1 + β2x2), y losresiduos que resultan de efectuar unanálisis de regresión sobre densidadincluyendo el resto de variables in-dependientes (x3 = β3 + β4x1 +β5x2). Se tendrán tantos grá�coscomo variables independientes.
La relación entre densidad e índicede sitio tras eliminar el efectodel resto de variables independi-entes, es claramente lineal e inversa.
Densidad
0,200,100,00-0,10-0,20
Índ
ice
de
siti
o
4,0
2,0
0,0
-2,0
Gráfico de regresión parcial
Variable dependiente: Índice de sitio
Página 12
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 50 / 84

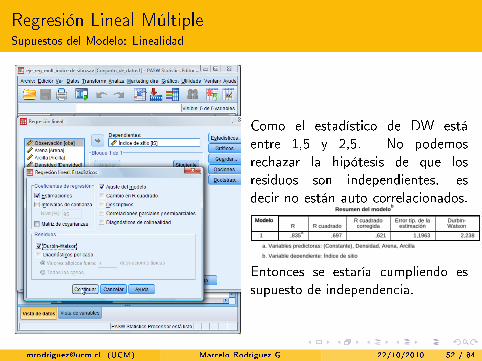
Regresión Lineal MúltipleSupuestos del Modelo: Independencia
Para veri�car el supuesto de independencia entre los residuos εi = yi − yiuse el estadístico de Durbin-Watson (DW ), el cual está dado por:
DW =
n∑i=1
(εi − εi−1)2
n∑i=1
ε2i
.
El estadístico DW toma el valor 2 cuando los residuos sonindependientes, valores menores que 2 indican autocorrelación positivay los mayores que 2 autocorrelación negativa.
Podemos asumir independencia entre los residuos cuando DW tomavalores entre 1,5 y 2,5.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 51 / 84
Regresión Lineal MúltipleSupuestos del Modelo: Linealidad
Como el estadístico de DW estáentre 1,5 y 2,5. No podemosrechazar la hipótesis de que losresiduos son independientes, esdecir no están auto correlacionados.
MétodoVariables
eliminadasVariables
introducidas
1 Introducir.Densidad, Arena, Arcilla
a
ModeloModelo
Variables introducidas/eliminadasb
a. Todas las variables solicitadas introducidas.
b. Variable dependiente: Índice de sitio
Durbin-Watson
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 2,2381,1963,621,697,835a
ModeloModelo
Resumen del modelob
a. Variables predictoras: (Constante), Densidad, Arena, Arcilla
b. Variable dependiente: Índice de sitio
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
1
1556,654
1,4311217,173
,002a
9,19613,160339,481
ModeloModelo
ANOVAb
a. Variables predictoras: (Constante), Densidad, Arena, Arcilla
b. Variable dependiente: Índice de sitio
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Arena
Arcilla
Densidad
1
,000-4,734-,7533,507-16,604
,360-,953-,168,069-,066
,1671,473,259,082,121
,0006,1177,03643,037
ModeloModelo
Coeficientesa
a. Variable dependiente: Índice de sitio
NDesviación
típicaMediaMáximoMínimo
Valor pronosticado
Residual
Valor pronosticado tip.
Residuo típ. 16,894,0001,710-1,375
161,000,0001,806-2,081
161,0700,00002,0461-1,6452
161,622423,23126,16119,854
Estadísticos sobre los residuosa
a. Variable dependiente: Índice de sitio
Página 14
Entonces se estaría cumpliendo essupuesto de independencia.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 52 / 84
Regresión Lineal MúltipleSupuestos del Modelo: Normalidad
Los residuos (o los residuos tipi�-cados) deben cumplir el supuestode normalidad. El recuadro Grá�-cos de los residuos tipi�cados (es-tandarizados) contiene dos opcionesgrá�cas que informan sobre el gradoen el que los residuos tipi�cados seaproximan a una distribución normal:El histograma (debe ser simétrico)y el grá�co de probabilidad nor-mal (deben estar los puntos sobrela recta). También con los residuosse puede realizar una prueba de nor-malidad como Kolmogorov-Smirnov(n > 50) o Shapiro-Wilk (n ≤ 50).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 53 / 84
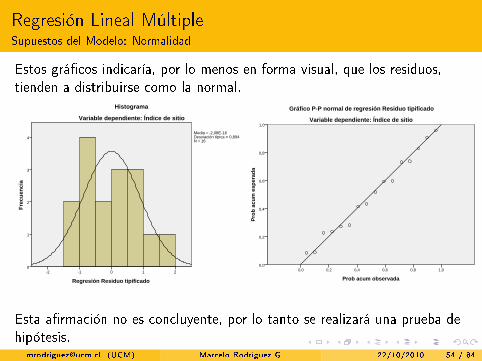
Regresión Lineal MúltipleSupuestos del Modelo: Normalidad
Estos grá�cos indicaría, por lo menos en forma visual, que los residuos,tienden a distribuirse como la normal.Gráficos
Regresión Residuo tipificado
210-1-2
Fre
cuen
cia
4
3
2
1
0
Histograma
Variable dependiente: Índice de sitio
Media = -2,08E-16Desviación típica = 0,894N = 16
Página 4
Prob acum observada
1,00,80,60,40,20,0
Pro
b a
cum
esp
erad
a
1,0
0,8
0,6
0,4
0,2
0,0
Gráfico P-P normal de regresión Residuo tipificado
Variable dependiente: Índice de sitio
Página 5
Esta a�rmación no es concluyente, por lo tanto se realizará una prueba dehipótesis.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 54 / 84
Regresión Lineal MúltipleSupuestos del Modelo: Normalidad
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 55 / 84
Regresión Lineal MúltipleSupuestos del Modelo: Normalidad
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 56 / 84

Regresión Lineal MúltipleSupuestos del Modelo: Normalidad
No existe su�ciente evidencia muestral para rechazar que los residuos seencuentra distribuidos como la normal (SW = 0, 972, valor−p = 0, 871).
Unstandardized Residual
3,00000
2,00000
1,00000
0,00000
-1,00000
-2,00000
EXAMINE VARIABLES=RES_1
/PLOT BOXPLOT NPPLOT
/COMPARE GROUPS
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.
Explorar
Página 16
PD: Si el n > 50, se puede utilizar KS, en este caso ambos estadísticos,nos indican que se cumple el supuesto de normalidad.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 57 / 84
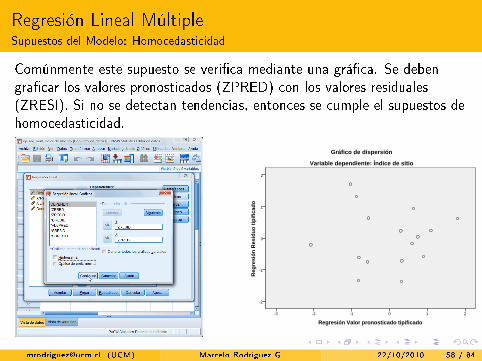
Regresión Lineal MúltipleSupuestos del Modelo: Homocedasticidad
Comúnmente este supuesto se veri�ca mediante una grá�ca. Se debengra�car los valores pronosticados (ZPRED) con los valores residuales(ZRESI). Si no se detectan tendencias, entonces se cumple el supuestos dehomocedasticidad.
Gráficos
Regresión Valor pronosticado tipificado
210-1-2-3
Reg
resi
ón
Res
idu
o t
ipif
icad
o
2
1
0
-1
-2
Gráfico de dispersión
Variable dependiente: Índice de sitio
Página 9
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 58 / 84

Regresión Lineal MúltipleSupuestos del Modelo: No-colinealidad
Existe colinealidad perfecta cuando una de las variables independientesse relaciona de forma perfectamente lineal con una o más del resto devariables independientes de la ecuación.Hablamos de colinealidad parcial o, simplemente, colinealidad, cuandoentre las variables independientes de una ecuación existencorrelaciones altas.En términos generales, cuantas más variables hay en una ecuación,más fácil es que exista colinealidad (aunque, en principio, bastan dosvariables).Es un problema porque, en el caso de colinealidad perfecta, no esposible estimar los coe�cientes de la ecuación de regresión; y en elcaso de colinealidad parcial, aumenta el tamaño de los residuostípi�cados y esto produce coe�cientes de regresión muy inestables:pequeños cambios en los datos (añadir o quitar un caso, por ejemplo)produce cambios muy grandes en los coe�cientes de regresión.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 59 / 84

Regresión Lineal MúltipleSupuestos del Modelo: No-colinealidad
El nivel de tolerancia de una variable se obtiene restando a 1 elcoe�ciente de determinación (R2) que resulta al regresar esa variablesobre el resto de variables independientes. Valores de tolerancia muypequeños indican que esa variable puede ser explicada por unacombinación lineal del resto de variables, lo cual signi�ca que existecolinealidad.
Los factores de in�ación de la varianza (FIV) son los inversos de losniveles de tolerancia. Cuanto mayor es el FIV de una variable, mayores la varianza del correspondiente coe�ciente de regresión. De ahí queuno de los problemas de la presencia de colinealidad (toleranciaspequeñas, FIVs grandes) sea la inestabilidad de las estimaciones de loscoe�cientes de regresión.
Como regla se puede utilizar: Las variables independientes soncolineales si FIV> 10. Las variables que tienen FIV alto y parecidosestán altamente correlacionadas.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 60 / 84

Regresión Lineal MúltipleSupuestos del Modelo: No-colinealidad
Como los FVI's son menoresque 10, entonces se cumpleel supuesto de no-colinealidad.
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Arena
Arcilla
Densidad
1
,000-4,734-,7533,507-16,604
,360-,953-,168,069-,066
,1671,473,259,082,121
,0006,1177,03643,037
ModeloModelo
Coeficientesa
a. Variable dependiente: Índice de sitio
FIVTolerancia
Estadísticos de colinealidad
(Constante)
Arena
Arcilla
Densidad
1
1,0001,000
1,229,814
1,229,814
ModeloModelo
Coeficientesa
a. Variable dependiente: Índice de sitio
Índice de condiciónAutovalores DensidadArcillaArena(Constante)
Proporciones de la varianza
1
2
3
4
1
,58,25,37,9955,226,001
,41,24,53,0128,401,005
,00,51,10,0013,781,021
,00,00,00,001,0003,973
Modelo DimensiónModelo Dimensión
Diagnósticos de colinealidada
a. Variable dependiente: Índice de sitio
Página 3
Si se detecta la presencia de colinealidad hay que i) aumentar el tamaño dela muestra; ii) crear indicadores múltiples combinando variables; iii) excluirvariables redundantes, quedándonos con las que consideremos másimportantes.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 61 / 84

Regresión Lineal MúltipleRegresión por pasos: Qué variables debe incluir la ecuación de regresión
La regresión por pasos (stepwise) es una método para seleccionar lasvariables independientes que debe incluir un modelo de regresión. Seseleccionan de acuerdo al siguiente criterio estadístico.Criterio de entrada: El valor−p < 0, 05 y se debe seleccionar las variablescon menor valor−p en la ANOVA.Método Hacia adelante:
Las variables se incorporan al modelo de regresión una a una.
En el primer paso se selecciona la variable independiente que, ademásde superar los criterios de entrada, tiene la más alta correlación.
En los siguientes pasos se utiliza como criterio de selección elcoe�ciente de correlación parcial: van siendo seleccionadas una a unalas variables que, además de superar los criterios de entrada, poseen elcoe�ciente de correlación parcial más alto en valor absoluto.
La selección de variables se detiene cuando no quedan variables quesuperen el criterio de entrada.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 62 / 84

Regresión Lineal MúltipleRegresión por pasos: Qué variables debe incluir la ecuación de regresión
En el ejemplo anterior, se realizarán todas las regresiones posible,identi�cando, las variables independientes, el R2, estadístico de prueba F, yel valor−p. El mejor modelo es el que tiene, menos variables, mayor R2,mayor F y menor valor−p.
Variables R2 F valor−px1 0,112 1,773 0,20427x2 0,711 1,072 0,31799x3 0,564 18,096 0,00080
x1, x2 0,131 0,978 0,40227x1, x3 0,674 13,436 0,00069
x2, x3 0,642 11,662 0,00126x1, x2, x3 0,697 9,196 0,00196
El mejor modelo sería y = β0 + β3 · x3.Aunque y = β0 + β1 · x1 + β3 · x3, también es un muy buen modelo.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 63 / 84
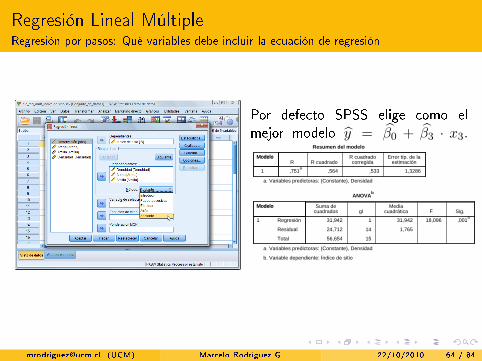
Regresión Lineal MúltipleRegresión por pasos: Qué variables debe incluir la ecuación de regresión
Por defecto SPSS elige como elmejor modelo y = β0 + β3 · x3.
Sintaxis
Tiempo de procesador
Tiempo transcurrido
Memoria necesaria
Memoria adicional requerida para los diagramas de residuos
Recursos
0 bytes
1972 bytes
00:00:00,031
00:00:00,031
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT IS /METHOD=FORWARD Densidad Arena Arcilla.
Notas
[Conjunto_de_datos1] D:\Archivos de Marcelo\Proyectos 2010\Diseño Experimental
y Modelos de Regresión Lineal (Aplicaciones en SPSS 18.0)\Módulo 5 ( Correlac
ión y Regresión Lineal Simple)\datos\eje_reg_mult_indice de sitio.sav
MétodoVariables
eliminadasVariables
introducidas
1 Hacia adelante (criterio: Prob. de F para entrar <= ,050)
.Densidad
ModeloModelo
Variables introducidas/eliminadasa
a. Variable dependiente: Índice de sitio
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 1,3286,533,564,751a
ModeloModelo
Resumen del modelo
a. Variables predictoras: (Constante), Densidad
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
1
1556,654
1,7651424,712
,001a
18,09631,942131,942
ModeloModelo
ANOVAb
a. Variables predictoras: (Constante), Densidad
b. Variable dependiente: Índice de sitio
Página 30
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 64 / 84

Regresión Lineal MúltipleRegresión por pasos: Qué variables debe incluir la ecuación de regresión
Para que coincida con los cálculos efectuados antes, debemos ser menosrestrictivos con el valor−p. Fíjese que la arena es signi�cativa para valoressuperiores a 0,056. Utilizaremos el valor de 0,06.
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Densidad
1
,001-4,254-,7513,894-16,566
,0008,5785,36245,999
ModeloModelo
Coeficientesa
a. Variable dependiente: Índice de sitio
Correlación parcialSig.tBeta dentro Tolerancia
Estadísticos de
colinealidad
Arena
Arcilla
1
1,000-,424,116-1,686-,280a
1,000,503,0562,096,332a
ModeloModelo
Variables excluidasb
a. Variables predictoras en el modelo: (Constante), Densidad
b. Variable dependiente: Índice de sitio
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.06) POUT(.10)
/NOORIGIN
/DEPENDENT IS
/METHOD=FORWARD Densidad Arena Arcilla.
Regresión
Página 31
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 65 / 84
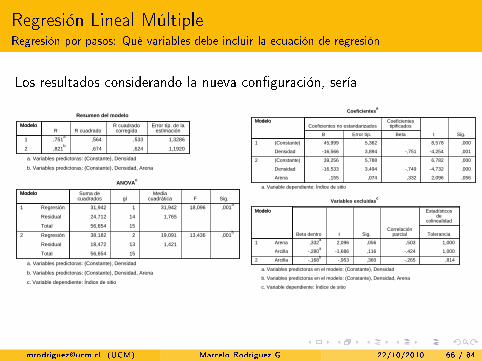
Regresión Lineal MúltipleRegresión por pasos: Qué variables debe incluir la ecuación de regresión
Los resultados considerando la nueva con�guración, sería
MétodoVariables
eliminadasVariables
introducidas
1
2 Hacia adelante (criterio: Prob. de F para entrar <= ,060)
.Arena
Hacia adelante (criterio: Prob. de F para entrar <= ,060)
.Densidad
ModeloModelo
Variables introducidas/eliminadasa
a. Variable dependiente: Índice de sitio
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1
2 1,1920,624,674,821b
1,3286,533,564,751a
ModeloModelo
Resumen del modelo
a. Variables predictoras: (Constante), Densidad
b. Variables predictoras: (Constante), Densidad, Arena
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
Regresión
Residual
Total
1
2
1556,654
1,4211318,472
,001b
13,43619,091238,182
1556,654
1,7651424,712
,001a
18,09631,942131,942
ModeloModelo
ANOVAc
a. Variables predictoras: (Constante), Densidad
b. Variables predictoras: (Constante), Densidad, Arena
c. Variable dependiente: Índice de sitio
Página 33
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Densidad
(Constante)
Densidad
Arena
1
2
,0562,096,332,074,155
,000-4,732-,7493,494-16,533
,0006,7825,78839,256
,001-4,254-,7513,894-16,566
,0008,5785,36245,999
ModeloModelo
Coeficientesa
a. Variable dependiente: Índice de sitio
Correlación parcialSig.tBeta dentro Tolerancia
Estadísticos de
colinealidad
Arena
Arcilla
Arcilla
1
2 ,814-,265,360-,953-,168b
1,000-,424,116-1,686-,280a
1,000,503,0562,096,332a
ModeloModelo
Variables excluidasc
a. Variables predictoras en el modelo: (Constante), Densidad
b. Variables predictoras en el modelo: (Constante), Densidad, Arena
c. Variable dependiente: Índice de sitio
Página 34
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 66 / 84

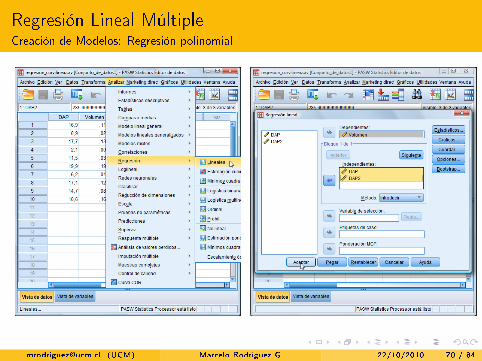
Regresión Lineal MúltipleCreación de Modelos: Regresión polinomial
(Polinomio de grado k)
Un polinomio de grado k, con una variable independiente, sería
y = β0 + β1 · x1 + β2 · x21 + β3 · x31 + . . .+ βk · xk1.
Basándonos en la regresión lineal múltiple, podemos ajustar cualquiermodelo lineal, por ejemplo un polinomio.Considerando el ejemplo anterior del DAP= x y Volumen= y,podemos ajustar el siguiente modelo:
y = β0 + β1 · x1 + β2 · x21Mediante la regresión curvilínea, ya encontramos la estimación de losparámetros. También podemos solucionar este problema con laregresión multiple. Basta tan solo crear una nueva variable x2 = x21.Luego se debe ajustar una regresión lineal múltiple.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 67 / 84
Regresión Lineal MúltipleCreación de Modelos: Regresión polinomial
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 68 / 84
Regresión Lineal MúltipleCreación de Modelos: Regresión polinomial
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 69 / 84
Regresión Lineal MúltipleCreación de Modelos: Regresión polinomial
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 70 / 84
Regresión Lineal MúltipleCreación de Modelos: Regresión polinomial
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 ,007777,987,990,995a
ModeloModelo
Resumen del modelo
a. Variables predictoras: (Constante), DAP2, DAP
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
1
9,042
,0007,000
,000a
347,089,0212,042
ModeloModelo
ANOVAb
a. Variables predictoras: (Constante), DAP2, DAP
b. Variable dependiente: Volumen
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
DAP
DAP2
1
,0008,3601,555,000,001
,017-3,111-,579,002-,007
,1601,573,011,017
ModeloModelo
Coeficientesa
a. Variable dependiente: Volumen
Página 3
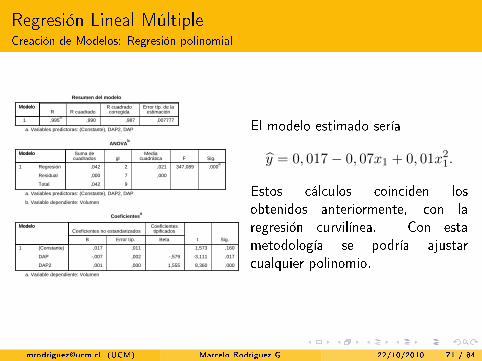
El modelo estimado sería
y = 0, 017− 0, 07x1 + 0, 01x21.
Estos cálculos coinciden losobtenidos anteriormente, con laregresión curvilínea. Con estametodología se podría ajustarcualquier polinomio.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 71 / 84

Regresión Lineal MúltipleCreación de Modelos: Modelo con interacción
(Modelo de interacción de segundo orden)
Un Modelo de interacción de segundo orden, con dos variablesindependientes, sería
y = β0 + β1 · x1︸ ︷︷ ︸Efecto principal
+ β2 · x2︸ ︷︷ ︸Efecto principal
+ β3 · x1 · x2︸ ︷︷ ︸Interacción
.
Ejemplo
Considere un problema donde se mide a 16 plantas, la Biomasa Total (y),el DAC (x1) y la Altura (x2). Los datos son:DAC 2,64 2,92 2,72 2,63 2,77 2,83 2,63 2,62 2,89 2,62 2,17 2,17 1,89 3,25 3,64 2,82Altura 10,5 16,1 16,1 13,8 14,8 16,2 14,6 15,9 12,1 14,0 10,9 11,5 10,9 11,9 18,3 9,0BT 3,18 4,30 3,86 4,09 3,84 4,33 4,26 4,06 3,76 3,83 3,25 2,89 3,08 3,94 3,98 3,64
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 72 / 84
Regresión Lineal MúltipleCreación de Modelos: Modelo con interacción
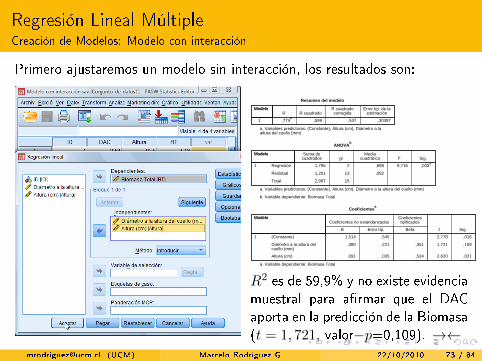
Primero ajustaremos un modelo sin interacción, los resultados son:
Regresión
Resultados creados
Comentarios
Datos
Conjunto de datos activo
Filtro
Peso
Segmentar archivo
Núm. de filas del archivo de trabajo
Definición de perdidos
Casos utilizados
Sintaxis
Tiempo de procesador
Tiempo transcurrido
Memoria necesaria
Memoria adicional requerida para los diagramas de residuos
Entrada
Tratamiento de los datos perdidos
Recursos
0 bytes
1652 bytes
00:00:00,000
00:00:00,000
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT BT /METHOD=ENTER DAC Altura.
Los estadísticos se basan en los casos sin valores perdidos para ninguna variable de las utilizadas.
Los valores perdidos definidos por el usuario se tratarán como perdidos.
16
<ninguno>
<ninguno>
<ninguno>
Conjunto_de_datos1
D:\Archivos de Marcelo\Proyectos 2010\Diseño Experimental y Modelos de Regresión Lineal (Aplicaciones en SPSS 18.0)\Módulo 5 ( Correlación y Regresión Lineal Simple)\datos\Modelo con interacción.sav
01-dic-2010 18:43:05
Notas
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 ,30397,537,599,774a
ModeloModelo
Resumen del modelo
a. Variables predictoras: (Constante), Altura (cm), Diámetro a la altura del cuello (mm)
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
1
152,997
,092131,201
,003a
9,716,89821,795
ModeloModelo
ANOVAb
a. Variables predictoras: (Constante), Altura (cm), Diámetro a la altura del cuello (mm)
b. Variable dependiente: Biomasa Total
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Diámetro a la altura del cuello (mm)
Altura (cm)
1
,0212,620,534,035,091
,1091,721,351,221,380
,0162,778,5451,514
ModeloModelo
Coeficientesa
a. Variable dependiente: Biomasa Total
Página 1
R2 es de 59,9% y no existe evidenciamuestral para a�rmar que el DACaporta en la predicción de la Biomasa(t = 1, 721, valor−p=0,109). →←
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 73 / 84
Regresión Lineal MúltipleCreación de Modelos: Modelo con interacción
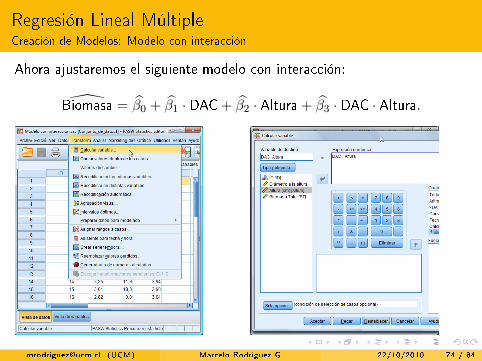
Ahora ajustaremos el siguiente modelo con interacción:
Biomasa = β0 + β1 · DAC+ β2 · Altura+ β3 · DAC · Altura.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 74 / 84
Regresión Lineal MúltipleCreación de Modelos: Modelo con interacción
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 75 / 84
Regresión Lineal MúltipleCreación de Modelos: Modelo con interacción
El modelo estimado sería
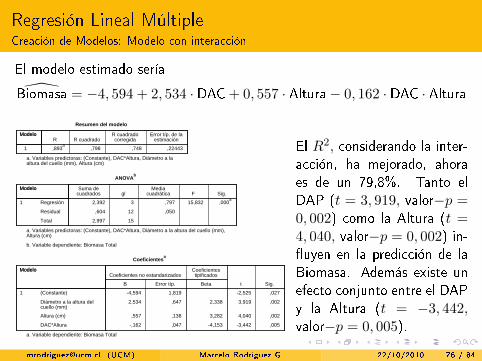
Biomasa = −4, 594 + 2, 534 · DAC+ 0, 557 · Altura− 0, 162 · DAC · Altura
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 ,22443,748,798,893a
ModeloModelo
Resumen del modelo
a. Variables predictoras: (Constante), DAC*Altura, Diámetro a la altura del cuello (mm), Altura (cm)
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
1
152,997
,05012,604
,000a
15,832,79732,392
ModeloModelo
ANOVAb
a. Variables predictoras: (Constante), DAC*Altura, Diámetro a la altura del cuello (mm), Altura (cm)
b. Variable dependiente: Biomasa Total
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Diámetro a la altura del cuello (mm)
Altura (cm)
DAC*Altura
1
,005-3,442-4,153,047-,162
,0024,0403,282,138,557
,0023,9192,338,6472,534
,027-2,5251,819-4,594
ModeloModelo
Coeficientesa
a. Variable dependiente: Biomasa Total
Página 2
El R2, considerando la inter-acción, ha mejorado, ahoraes de un 79,8%. Tanto elDAP (t = 3, 919, valor−p =0, 002) como la Altura (t =4, 040, valor−p = 0, 002) in-�uyen en la predicción de laBiomasa. Además existe unefecto conjunto entre el DAPy la Altura (t = −3, 442,valor−p = 0, 005).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 76 / 84

Regresión Lineal MúltipleCreación de Modelos: Modelo con variables indicadoras
(Modelos con variables indicadoras)
Los modelos con variables indicadoras se utilizan cuando una de lasvariables independientes es cualitativa, la metodología trata de recodi�caresta variable en variables que tomen el valor 0 o 1 (ausencia o presencia deuna característica).
Ejemplo
Considere un problema donde se mide a 16 plantas, la Biomasa Total, elDAC y el origen (1=Central, 2=Precordillera y 3=valle central). Los datosson:DAC (x1) 2,64 2,92 2,72 2,63 2,77 2,83 2,63 2,62 2,89 2,62 2,17 2,17 1,89 3,25 3,64 2,82BT (y) 3,18 4,30 3,86 4,09 3,84 4,33 4,26 4,06 3,76 3,83 3,25 2,89 3,08 3,94 3,98 3,64Origen 1 1 1 1 1 2 2 2 2 2 2 3 3 3 3 3
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 77 / 84

Regresión Lineal MúltipleCreación de Modelos: Modelo con variables indicadoras
Dado que se tienen tres orígenes, se de�nen dos variables indicadoras x2 yx3 tales, que
x2 =
{1, Si la semilla provenia de la Costa0, En otro caso.
x3 =
{1, Si la semilla provenia de la Precordillera0, En otro caso.
El modelo sería
y = β0 + β1 · x1 + β2 · x2 + β3 · x3 + β4 · x1 · x2 + β5 · x1 · x3
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 78 / 84
Regresión Lineal MúltipleCreación de Modelos: Modelo con variables indicadoras
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 79 / 84
Regresión Lineal MúltipleCreación de Modelos: Modelo con variables indicadoras
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 80 / 84
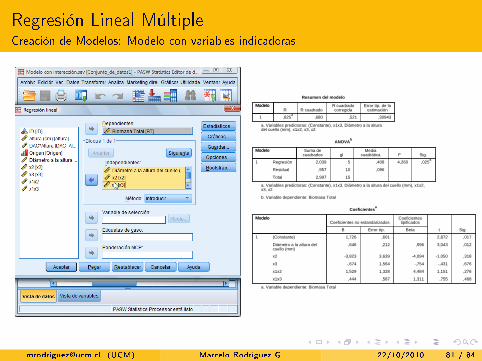
Regresión Lineal MúltipleCreación de Modelos: Modelo con variables indicadoras
Resultados creados
Comentarios
Datos
Conjunto de datos activo
Filtro
Peso
Segmentar archivo
Núm. de filas del archivo de trabajo
Definición de perdidos
Casos utilizados
Sintaxis
Tiempo de procesador
Tiempo transcurrido
Memoria necesaria
Memoria adicional requerida para los diagramas de residuos
Entrada
Tratamiento de los datos perdidos
Recursos
0 bytes
2748 bytes
00:00:00,000
00:00:00,000
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT BT /METHOD=ENTER DAC x2 x3 x1x2 x1x3.
Los estadísticos se basan en los casos sin valores perdidos para ninguna variable de las utilizadas.
Los valores perdidos definidos por el usuario se tratarán como perdidos.
16
<ninguno>
<ninguno>
<ninguno>
Conjunto_de_datos1
D:\Archivos de Marcelo\Proyectos 2010\Diseño Experimental y Modelos de Regresión Lineal (Aplicaciones en SPSS 18.0)\Módulo 5 ( Correlación y Regresión Lineal Simple)\datos\Modelo con interacción.sav
02-dic-2010 00:56:41
Notas
Error típ. de la estimación
R cuadrado corregidaR cuadradoR
1 ,30943,521,680,825a
ModeloModelo
Resumen del modelo
a. Variables predictoras: (Constante), x1x3, Diámetro a la altura del cuello (mm), x1x2, x3, x2
Sig.FMedia
cuadráticaglSuma de
cuadrados
Regresión
Residual
Total
1
152,997
,09610,957
,025a
4,260,40852,039
ModeloModelo
ANOVAb
a. Variables predictoras: (Constante), x1x3, Diámetro a la altura del cuello (mm), x1x2, x3, x2
b. Variable dependiente: Biomasa Total
Error típ.B Beta Sig.t
Coeficientes tipificadosCoeficientes no estandarizados
(Constante)
Diámetro a la altura del cuello (mm)
x2
x3
x1x2
x1x3
1
,468,7551,311,587,444
,2761,1514,4841,3281,529
,676-,431-,7541,564-,674
,318-1,050-4,0943,639-3,823
,0123,043,596,212,646
,0172,872,6011,726
ModeloModelo
Coeficientesa
a. Variable dependiente: Biomasa Total
Página 1
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 81 / 84
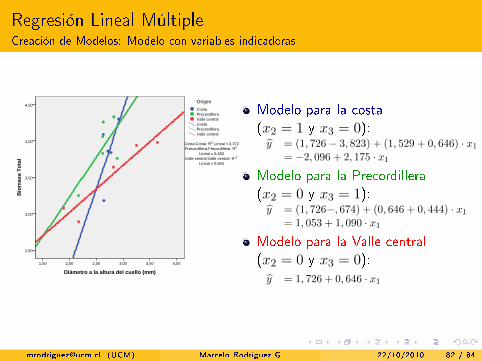
Regresión Lineal MúltipleCreación de Modelos: Modelo con variables indicadoras
Diámetro a la altura del cuello (mm)
4,003,503,002,502,001,50
Bio
mas
a T
ota
l
4,50
4,00
3,50
3,00
2,50
Valle centralPrecordilleraCostaValle centralPrecordilleraCosta
Origen
Costa;Costa: R2 Lineal = 0,372Precordillera;Precordillera: R2
Lineal = 0,483Valle central;Valle central: R 2
Lineal = 0,894
Página 7
Modelo para la costa(x2 = 1 y x3 = 0):y = (1, 726− 3, 823) + (1, 529 + 0, 646) · x1
= −2, 096 + 2, 175 · x1Modelo para la Precordillera(x2 = 0 y x3 = 1):y = (1, 726−, 674) + (0, 646 + 0, 444) · x1
= 1, 053 + 1, 090 · x1Modelo para la Valle central(x2 = 0 y x3 = 0):y = 1, 726 + 0, 646 · x1
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 82 / 84

Regresión Lineal MúltipleProceso de decisión para el análisis de regresión múltiple
Paso 1: Objetivos. El investigador debe considerar tres asuntosfundamentales: la conveniencia del programa de investigación, laespeci�cación de una relación estadística y la selección de las variablesdependientes e independientes.
Paso 2: Diseño de la investigación. El investigador debe considerarasuntos tales como el tamaño muestral, el R2, la naturaleza de lasvariables independientes y la posible creación de nueva variables pararepresentar las especiales relaciones entre las variables dependientes eindependientes.
Paso 3: Supuestos del modelo. Veri�car que cumplen las variablesindividuales los supuestos de: Normalidad, Linealidad,Homocedasticidad e Independencia.
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 83 / 84

Regresión Lineal MúltipleProceso de decisión para el análisis de regresión múltiple
Paso 4: Estimación del modelo de regresión y valoración. (1)Seleccionar un método para especi�car el modelo de regresión aestimar, (2) evaluar la signi�cación estadística del modelo conjunto enla predicción de la variable criterio y (3) determinar si cualquiera de lasobservaciones ejerce una indebida in�uencia sobre los resultados.Paso 5: Interpretación del valor teórico de la regresión. (1)Evaluar la ecuación de predicción con los coe�cientes de regresión, (2)Evaluar la importancia relativa de las variables independientes con loscoe�cientes beta estandarizados y (3) Valoración de lamulticolinealidad y sus efectos.Paso 6: Validación de los resultados. Después de identi�carnuestro mejor modelo de regresión, el paso �nal consiste en asegurarsede que represente a la población general (generalización) y que seaapropiada para situaciones en las cuales será utilizada(transferibilidad).
[email protected] (UCM) Marcelo Rodríguez G. 22/10/2010 84 / 84


















