
TÉCNICAS DE MUESTREO -...
54
TÉCNICAS DE MUESTREO
Transcript of TÉCNICAS DE MUESTREO -...

TÉCNICAS DE MUESTREO

TÉCNICAS DE MUESTREO
2
I. CONCEPTOS GENERALES DE MUESTREO
El objetivo de la teoría de muestras es proporcionar una serie de técnicas que permitan
conocer características o valores referidas al total de unidades de un conjunto,
estudiando sólo una parte de las unidades del conjunto.
Población o Universo es el conjunto total de unidades de las que se desea información o
conjunto total de unidades objeto de estudio:
{ }P u u uN= 1 2, ,...,
Muestra es una parte de la población sobre la que se mide la información:
{ }S u u uj j j jn=
1 2, ,...,
Tamaño de la población es el número de unidades N que forman la población. Tamaño
de la muestra es el número de unidades n seleccionadas para la muestra.
El término muestreo se refiere al conjunto de técnicas utilizadas para seleccionar una
muestra de una población. Representamos por Yi el valor numérico de una característica
o variable en la unidad ui. Esta variable y se denomina variable de estudio.
Valor poblacional es una expresión θ ϑ= ( )y que sintetiza los valores de la variable en
estudio en las N unidades de la población completa:
Total Y Yii
N
==∑
1
Media Y YN
=
Valor muestral es una estimación !( )θ s del valor poblacional θ que se calcula a partir de
las n unidades de la muestra.
El valor poblacional es una constante, en general desconocida, que depende sólo de los
N valores Yi. La estimación es un valor calculado y único en cada muestra particular,
pero el valor varía de muestra a muestra.

TÉCNICAS DE MUESTREO
3
Si dado un procedimiento de muestreo podemos definir el conjunto de muestras posibles
o espacio muestral y la selección de la muestra se hace de acuerdo a una función de
probabilidad P definida sobre el espacio muestral, diremos que el muestreo es
probabilístico. Es decir, para cada muestra posible, Sj, está definida una probabilidad
P(Sj) > 0 con P( S jj
∑ =) 1, y la selección de la muestra respeta esta probabilidad.
En el muestreo probabilístico la estimación !ϑ se convierte para una muestra particular
en el valor observado de una variable aleatoria !( )θ S j que se llama estimador cuya
función de probabilidad corresponde a la definida en el espacio muestral, es decir
[ ]P S P( Sj j! ( ) )ϑ =
Esta función de probabilidad del estimador sobre el espacio muestral se denomina
distribución de muestreo del estimador y corresponde, por tanto, al conjunto de
estimaciones de todas las muestras posibles con su probabilidad de materializarse.
En la práctica podemos asignar probabilidades de selección a las N unidades de la
población. En tal caso la probabilidad de selección de una muestra será:
P( S P( u P( u u P( u u u uj j j j j j j jn n) ) ) , ,..., )= ⋅ ⋅ ⋅ ⋅ ⋅
−1 2 1 1 2 1
De esta forma en el muestreo probabilístico, cada unidad de la población tiene una
probabilidad conocida y no nula de ser seleccionada.
El muestreo probabilístico es sin reposición o sin reemplazamiento si toda muestra Sj
está formada por n unidades distintas, es decir, las muestras con alguna unidad repetida
tienen probabilidad cero de ser seleccionadas. En caso contrario, si en la muestra puede
haber unidades repetidas, se dice que el muestreo es con reposición o con
reemplazamiento.
La selección con reposición responde al hecho físico de hacer n selecciones sucesivas de
elementos, restituyendo a la población cada unidad elegida antes de proceder a la
siguiente selección.En la selección sin reposición cada unidad elegida no se restituye a
la población y, por tanto, una misma unidad sólo puede estar presente en la misma
muestra una sola vez. En lo que sigue nos referiremos siempre al muestreo sin
reemplazamiento.
TÉCNICAS DE MUESTREO
4
Suele hablarse de muestra aleatoria cuando todas las unidades de la población tienen la
misma probabilidad de ser seleccionadas. En éste caso todas las posibles muestras son
también equiprobables.
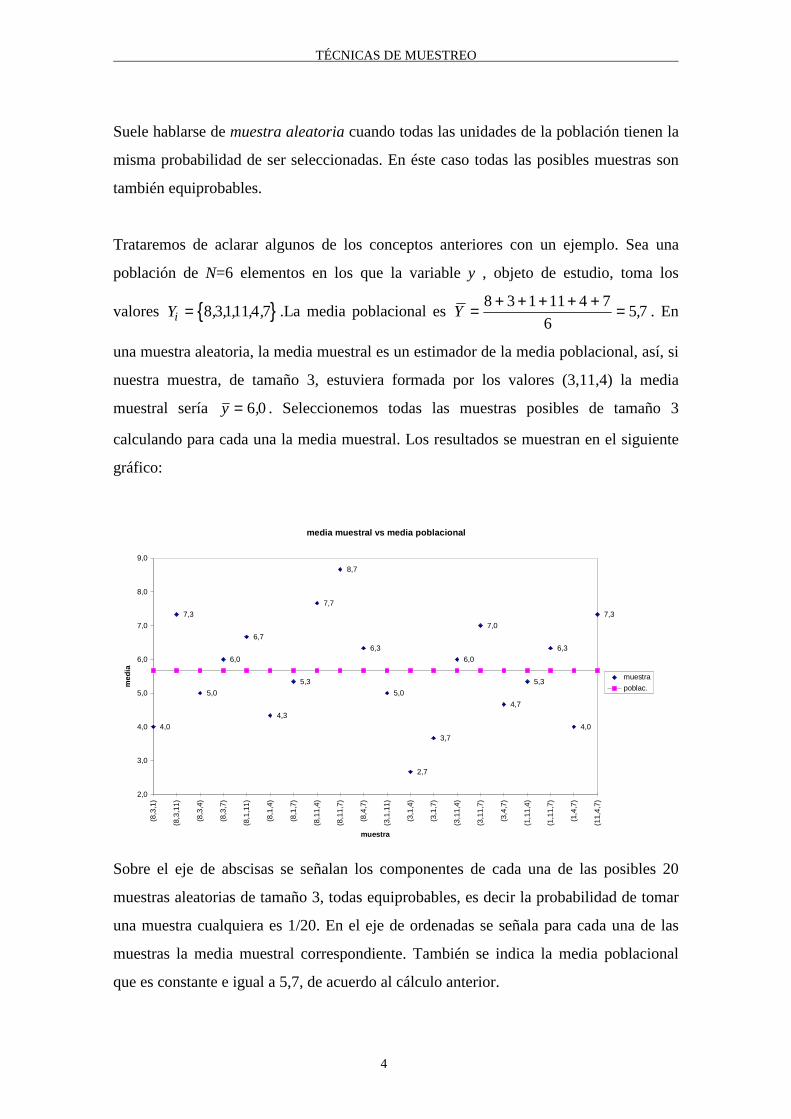
Trataremos de aclarar algunos de los conceptos anteriores con un ejemplo. Sea una
población de N=6 elementos en los que la variable y , objeto de estudio, toma los
valores { }Yi = 8 31114 7, , , , , .La media poblacional es Y = + + + + + =8 3 1 11 4 7
65 7, . En
una muestra aleatoria, la media muestral es un estimador de la media poblacional, así, si
nuestra muestra, de tamaño 3, estuviera formada por los valores (3,11,4) la media
muestral sería y = 6 0, . Seleccionemos todas las muestras posibles de tamaño 3
calculando para cada una la media muestral. Los resultados se muestran en el siguiente
gráfico:
media muestral vs media poblacional
4,0
7,3
5,0
6,0
6,7
4,3
5,3
7,7
8,7
6,3
5,0
2,7
3,7
6,0
7,0
4,7
5,3
6,3
4,0
7,3
2,0
3,0
4,0
5,0
6,0
7,0
8,0
9,0
(8,3
,1)
(8,3
,11)
(8,3
,4)
(8,3
,7)
(8,1
,11)
(8,1
,4)
(8,1
,7)
(8,1
1,4)
(8,1
1,7)
(8,4
,7)
(3,1
,11)
(3,1
,4)
(3,1
,7)
(3,1
1,4)
(3,1
1,7)
(3,4
,7)
(1,1
1,4)
(1,1
1,7)
(1,4
,7)
(11,
4,7)
muestra
med
ia
muestrapoblac.
Sobre el eje de abscisas se señalan los componentes de cada una de las posibles 20
muestras aleatorias de tamaño 3, todas equiprobables, es decir la probabilidad de tomar
una muestra cualquiera es 1/20. En el eje de ordenadas se señala para cada una de las
muestras la media muestral correspondiente. También se indica la media poblacional
que es constante e igual a 5,7, de acuerdo al cálculo anterior.

TÉCNICAS DE MUESTREO
5
El gráfico refleja cómo el valor poblacional (la media) es una constante pero su
estimador (la media muestral) presenta valores diferentes según las unidades que
componen la muestra, es decir, el valor del estimador, estimación, varía de muestra a
muestra. Puede observarse también como las distintas estimaciones se sitúan alrededor
del verdadero valor que se quiere estimar.
Puesto que cada muestra en el ejemplo tiene una probabilidad de 1/20 de ser
seleccionada, cada uno de los 20 valores muestrales tiene también una probabilidad de
1/20 de ser obtenido, es decir, denotando por y la media muestral (el estimador) resulta
( ) ( ) ( )P y P y P y= = = = = =2 7 3 7 8 7 1 20, , ," . Este conjunto de posibles valores del
estimador junto con la probabilidad de obtener cada valor constituye la distribución en
el muestreo del estimador. En base a esta distribución puede calcularse la probabilidad
de que el estimador tome valores en un cierto intervalo; así, el intervalo (4,5; 6,5)
comprende 9 de las 20 muestras. Es decir, la probabilidad de que la media muestral
tome valores comprendidos entre 4,5 y 6,5 es de 9/20.
Siendo el estimador una variable aleatoria pueden estudiarse distintas características del
mismo, como son su media o esperanza matemática, la varianza y su raiz cuadrada o
desviación típica, y el coeficiente de variación, esto es, el cociente entre la desviación
típica del estimador y su esperanza matemática. En particular, la desviación típica del
estimador se llama error de muestreo o error estándar.
Sobre el ejemplo anterior fácilmente podemos comprobar que el promedio de las 20
estimaciones es 5,7 que coincide con la media poblacional. Esto no es casualidad, es
debido a que en el muestreo aleatorio de unidades elementales la media muestral es un
estimador insesgado de la media poblacional, es decir, la esperanza matemática del
estimador coincide con el verdadero valor que se quiere estimar: ( )E y Y= . En caso
contrario el estimador se dice sesgado y a la diferencia entre la esperanza matemática o
valor medio del estimador y el valor a estimar se le llama sesgo. En ocasiones puede ser
preferible la utilización de un estimador sesgado si ello implica una sensible reducción
del error de muestreo y el tamaño del sesgo es pequeño respecto al error estándar. En

TÉCNICAS DE MUESTREO
6
caso de estimadores sesgados es deseable la propiedad de consistencia que se cumple
cuando el sesgo tiende a cero al aumentar el tamaño de la muestra.
Calculemos a continuación la desviación típica del estimador en nuestro ejemplo.
Recordemos que dado un conjunto de valores x x xn1 2, , ," , la desviación típica se
define como la raiz cuadrada de la varianza, es decir
( )σ =
−∑ x x
n
i
n2
1
donde xx
ni= ∑ es el valor medio. En nuestro caso xi son las 20 estimaciones del
gráfico y x es su valor medio por lo que
( ) ( ) ( )σ =
− + − + + −=
2 7 5 7 3 7 5 7 8 7 5 720
152 2 2, , , , , ,
,"
Así pues, el error de muestreo en el ejemplo es 1,5 y nos da una medida de la
variabilidad de las estimaciones individuales alrededor de su media. La desviación típica
se expresa en la misma unidad de medida que la variable en estudio, por lo que,
dividiendo por la media se obtiene el coeficiente de variación, que es una medida
relativa de la variabilidad, sin unidad de medida. En nuestro caso el coeficiente de
variación de las estimaciones sería
CV = = →155 7
0 264 26 4,,
, , %
El coeficiente de variación del estimador se denomina error de muestreo relativo.
Veremos posteriormente que no es necesario tomar todas las posibles muestras para
calcular el error de muestreo, lo cuál en la práctica sería irrealizable.
II. POBLACIÓN, MARCO Y MUESTRA. UNIDADES DE
MUESTREO

TÉCNICAS DE MUESTREO
7
Conviene distinguir entre unidad elemental y unidad de muestreo. La unidad elemental
o unidad de estudio es todo elemento o individuo miembro de la población objetivo. Las
variables objeto de estudio en una investigación por muestreo se miden sobre las
unidades elementales.
Las unidades de muestreo son aquellas que forman parte del proceso de selección de la
muestra. La unidad de muestreo puede coincidir con la unidad elemental, en cuyo caso
hablamos de muestreo de unidades elementales, o puede referirse a un conjunto de
unidades elementales, que se denominan conglomerados. Así, para seleccionar una
muestra de la población española para estudiar cualquier característica, por ejemplo la
talla, podemos seleccionar la muestra a partir de una lista de todos los individuos. Aquí
la unidad de muestreo es la persona física y coincide con la unidad elemental. Pero si no
disponemos de la lista de individuos sino sólo de una lista de viviendas, podemos
seleccionar una muestra de viviendas y recoger información de todos los individuos que
habitan en las viviendas seleccionadas. En este caso la unidad elemental sigue siendo el
individuo pero la unidad de muestreo es la vivienda, formada por un conjunto de
unidades elementales.
El concepto de población establecido anteriormente como conjunto total de unidades de
las que se desea información, se refiere a la población objetivo y constituye un modelo
ideal. En la práctica, la muestra se selecciona a partir de un material soporte,
denominado marco, que coincide en mayor o menor grado con la población objetivo. En
sentido estricto, el marco de muestreo se define como la lista de unidades de muestreo a
partir de la cual se selecciona la muestra. Es decir que el marco equivale a la población
que va a ser muestreada y por tanto el marco o “población marco” será tanto mejor
cuanto mas equivalga a la población objeto de estudio. Como idea intuitiva, un marco
sería aceptable cuando obteniendo a partir de él información exhaustiva (del 100% de
las unidades del marco), ésta cubriese aceptablemente los objetivos propuestos.
En sentido amplio, el marco de muestreo comprende no solo listas de unidades de
muestreo, sino que incluye todo el material e información previa que disponemos sobre
la población y su agrupación en unidades de muestreo, y que es útil para la
estratificación y formación de estimadores.

TÉCNICAS DE MUESTREO
8
Dada la importancia del marco en una investigación por muestreo, hay que pretender
trabajar con marcos perfectos, es decir marcos en los que todas las unidades de la
población objetivo estén incluidas una sola vez y sólo incluya unidades de la población.
El muestreo de unidades elementales aunque tiene gran interés teórico, no es muy
utilizado en la práctica por dos graves inconvenientes:
a) Imposibilidad práctica en muchas ocasiones de obtener una lista de unidades
elementales en la cuál basar la selección de la muestra.
b) La selección de unidades elementales proporciona en general una muestra muy
esparcida de unidades a entrevistar con el consiguiente incremento de coste y tiempo.
Para evitar estos inconvenientes surge, de forma natural, el muestreo de conglomerados,
agrupando las unidades elementales próximas en un conglomerado que se constituye en
la nueva unidad de muestreo, más grande que la unidad elemental. Los conglomerados
deben estar perfectamente definidos, lo cuál significa que no haya solapamiento entre
ellos (una unidad elemental pertenece sólo a un conglomerado) y que el conjunto de
todos los conglomerados contiene a la población objeto de estudio.
La agrupación de unidades elementales en unidades de muestreo mas amplias tiene
ventajas e inconvenientes. Entre las ventajas podemos citar el ahorro de coste y tiempo,
y la mayor facilidad de preparar listas (sólo se necesitan para los conglomerados de la
muestra). De los inconvenientes hay que destacar la menor precisión derivada de una
mayor homogeneidad de las unidades elementales dentro de un conglomerado respecto a
la característica de estudio.
Si en el proceso de muestreo investigamos todas las unidades elementales contenidas en
los conglomerados seleccionados en la muestra, el muestreo se denomina en una etapa o
monoetápico. Ahora bien, para evitar el inconveniente apuntado (homogeneidad dentro
del conglomerado) podemos investigar no todas las unidades elementales del
conglomerado, sino seleccionar a su vez una muestra probabilística de las mismas.
Estaríamos así ante un muestreo en dos etapas: las unidades de primera etapa o

TÉCNICAS DE MUESTREO
9
unidades primarias de muestreo serían los conglomerados y las unidades de segunda
etapa serían las unidades elementales.
Este proceso puede generalizarse llevándonos así al muestreo multietápico o
polietápico. Obsérvese que en muestreo por etapas se definen distintas unidades de
muestreo y que la “lista” de unidades de muestreo en una etapa dada, sólo es necesario
disponerla para las unidades seleccionadas en la etapa inmediatamente anterior. Se
constituye así una jerarquía entre las distintas unidades de muestreo de acuerdo a las
etapas del proceso.
Para precisar mejor las ideas anteriores, consideremos la selección de una muestra de
individuos de la población española. En un muestreo de unidades elementales
necesitamos disponer de una lista de todas las personas. Podemos optar por un muestreo
de conglomerados y tomar como unidad de 1ª etapa la sección censal, con lo cual solo
necesitamos la lista de secciones. Podemos tomar como unidad de 2ª etapa las
manzanas, para lo cual necesitamos una lista de manzanas de las secciones previamente
seleccionadas. Finalmente en una 3ª etapa podemos tomar como unidad de muestreo la
vivienda, necesitando una lista de viviendas de las manzanas seleccionadas en la 2ª
etapa.
III. MUESTREO PROBABILÍSTICO Y OTROS TIPOS DE
MUESTREO
Al estudiar una población la primera posibilidad es obtener la información necesaria de
todas y cada una de las unidades que forman la población. Estaríamos así ante un
estudio censal o censo. El censo se caracteriza por obtener información de toda la
población, mientras que en el muestreo se estudia una parte de la población.
En general hay tres principales ventajas en el muestreo respecto a la investigación total
de la población o censo:
1) Menor coste, derivado de obtener información solo de una parte de la población.
2) Mayor rapidez, por el mismo motivo anterior.

TÉCNICAS DE MUESTREO
10
3) Mayor calidad. Al reducirse el volumen de trabajo se puede emplear personal
especialista mejor preparado y entrenado. Igualmente los procesos de supervisión y
proceso de datos están mejor controlados, lo que redunda en una mejor calidad de
trabajo y una disminución de errores (no de muestreo) respecto al censo total.
Ya hemos indicado que el muestreo probabilístico se caracteriza porque cada unidad de
la población tiene una probabilidad no nula y conocida de ser seleccionada en la
muestra. El conocimiento de esta probabilidad permite calcular errores de muestreo, y
los sesgos de selección, no respuesta y estimación pueden ser virtualmente eliminados o
contenidos dentro de límites conocidos.
Un muestreo probabilístico se lleva a cabo con un plan estadístico de selección
totalmente rígido y fijado de antemano de acuerdo a esas probabilidades y donde ni los
entrevistadores ni otras personas que intervengan en el muestreo toman decisión alguna
sobre qué unidad elegir para la muestra. También hay que notar que los procedimientos
para formar estimadores están fijados de antemano como parte del diseño muestral y no
dependen de la muestra particular que se ha seleccionado.
En las muestras que denominamos intencionales o de juicio (judgment samples según
Deming), el procedimiento de selección no es probabilístico y, en consecuencia, los
errores de muestreo y posibles sesgos no pueden ser calculados, sino que son
determinados por el buen juicio y experiencia del investigador que diseña y calcula los
resultados muestrales.
En una muestra intencional las unidades muestrales se seleccionan de forma que a juicio
del diseñador las unidades sean “típicas” o “representativas” respecto a la información
que se desea obtener. Un ejemplo típico de muestreo intencional es el muestreo por
cuotas, donde se fija de antemano, de acuerdo a características poblacionales conocidas,
los porcentajes o cuotas de las unidades muestrales que deben reunir esas características.
El entrevistador deberá seleccionar las unidades de la muestra de forma que el conjunto
de unidades seleccionadas verifiquen las cuotas que se le han fijado.

TÉCNICAS DE MUESTREO
11
En una muestra por cuotas los porcentajes muestrales de las características
poblacionales fijadas como cuotas pueden corresponder exactamente a las proporciones
poblacionales, lo que lleva a decir que la muestra es perfectamente representativa
transversalmente. Sin embargo, ello no evita el riesgo de sesgos en la representación de
las características que se van a medir en la muestra, no coincidentes con las establecidas
como cuotas. Únicamente una muestra probabilística evita estos riesgos.
Si la experiencia y el conocimiento de la población a muestrear es importante en un
muestreo intencional, no lo es menos en muestreo probabilístico. Este conocimiento de
la población, particularmente en aspectos relacionados con variables objeto de estudio
deben ser utilizados de la mejor manera posible en el diseño de muestras probabilísticas.
Por ejemplo, nos puede ayudar a definir el tamaño y el tipo de las unidades de muestreo
en distintas etapas, en la formación de estratos y en el uso de variables auxiliares
conocidas en la población que ayuden a mejorar las estimaciones, en el establecimiento
de las propias probabilidades de selección de las unidades muestrales, etc. No hay límite
a la cantidad de información que puede utilizarse en un proceso probabilístico de
muestreo. El único límite que existe es que la selección sea matemática, respetando las
probabilidades asignadas.
IV. LA HIPÓTESIS DE NORMALIDAD
Admitiremos que una población finita sigue una distribución normal si su distribución
de frecuencias se ajusta a las correspondientes frecuencias teóricas de la distribución
normal.
Si el estimador está formado por una combinación lineal de variables cuya población
base es normal, sabemos que el estimador tiene una distribución normal en el muestreo.
Si la población base no es normal, está demostrado que en condiciones muy generales,
un estimador lineal sigue una distribución convergente a la normal a medida que
aumenta el tamaño de la muestra. El error de muestreo, que indica en que forma las
estimaciones procedentes de muestras de igual tamaño y diseño se distribuyen alrededor
del verdadero valor poblacional (estimador insesgado), en el supuesto de que tuviéramos

TÉCNICAS DE MUESTREO
12
miles de tales muestras, corresponde a la desviación típica de la distribución normal del
estimador.
Es importante recalcar que el error estándar no nos dice nada acerca del tamaño o
dirección de la diferencia entre nuestras estimaciones y el valor verdadero. Cuando
estamos ante una muestra en particular, no sabemos en que parte de la distribución de
frecuencias de las estimaciones nos encontramos (no sabemos si estamos cerca o lejos
del verdadero valor, que por otra parte no conocemos). Sin embargo las propiedades de
la distribución normal, nos permiten la construcción de intervalos de la forma
( )! , !ϑ ϑ− +E E dentro del cual y con un determinado nivel de confianza (probabilidad),
se encuentra el verdadero valor. E se calcula a partir del error estándar en la forma
( )E k e e= ⋅ . . . El multiplicador k del error estándar nos proporciona el nivel de confianza
que deseemos y se puede obtener a partir de unas tablas de la normal. Hay que indicar
que el e.e. está definido por el tamaño y el diseño de la encuesta. Conocido su valor, el
usuario de los datos de una encuesta puede manejarlos con el nivel de confianza que
desee. Algunos valores típicos de k y su confianza asociada son:
k nivel de confianza
0.6745 50%
1 68.26%
1.6 89.04%
2 95.44%
3 99.73%
!ϑϑ

TÉCNICAS DE MUESTREO
13
En la práctica, es habitual encontrarse con poblaciones normales o muy simétricas en su
distribución de frecuencias, por lo que la hipótesis de normalidad de los estimadores es
razonable incluso para tamaños de muestra moderados. Pero también es muy frecuente
encontrarse con poblaciones muy asimétricas, con una gran concentración de
frecuencias en valores moderados de la variable y una marcada cola a la derecha
correspondiente a frecuencias bajas de valores muy altos de la variable. En estos casos
debe tenerse en cuenta que cuanto mayor sea la asimetría de la población, mayor es el
tamaño de la muestra requerido para admitir la distribución normal del estimador. Si el
tamaño de la muestra no es suficiente, la distribución del estimador muestra cierta
asimetría por la derecha, tanto mayor cuanto menor es el tamaño de la muestra:
Los tamaños muestrales que se utilizan en la práctica suelen ser lo suficientemente
grandes para admitir la hipótesis de normalidad sin mayores problemas. Además, la
práctica, muy frecuente en muestreo, de incluir con certeza en la muestra las unidades
muy grandes contribuye a facilitar la validez de la aproximación normal, ya que la
eliminación de las unidades extremas de la población a muestrear, además de reducir la
variabilidad de la muestra y aumentar la precisión de los estimadores, reduce la
asimetría y mejora la aproximación normal.
Como ejemplo de la aproximación normal a la distribución del estimador vamos a
considerar una población de N=2959 supermercados de 400 m2 y más de superficie de
venta que presentan la distribución por superficie que refleja el gráfico:
DISTRIBUCIÓN DE SUPERMERCADOS POR SUPERFICIE
DE VENTA (%)
!ϑ

TÉCNICAS DE MUESTREO
14
Superficie
400-599
600-799
800-999
1000-1499
1500-2499
2500-4999
5000-9999
10000y m as
1,72,5
7,2
2,4
13,612,2
22,7
37,7
La superficie media poblacional es de Y = 1165 2m , con una desviación típica de
1793m2. De este Universo de supermercados se han seleccionado 100 muestras
aleatorias de tamaño n=100, calculándose la superficie media de cada muestra. El
siguiente gráfico muestra la distribución de medias muestrales obtenida:
DISTRIBUCIÓN DE MEDIAS MUESTRALES DE 100 MUESTRAS
ALEATORIAS (n=100)

TÉCNICAS DE MUESTREO
15
5
11
28
33
4
19
3
12
27
32
19
7
< 900 1050-1200 1350-1500
superficie m edia estim ada
frec. obs.
frec. teor.
Junto a la distribución observada de medias muestrales aparece la distribución teórica
que se obtendría de acuerdo a la hipótesis de distribución normal del estimador. Puede
observarse como la distribución de medias muestrales está muy próxima a la
distribución normal teórica, a pesar del alto grado de asimetría de la distribución
original de superficies de venta.
V. PRINCIPALES FASES DEL DISEÑO DE UNA ENCUESTA
POR MUESTREO
1. Establecer los objetivos. Es clave establecer unos objetivos claros y precisos de la
encuesta. Esta fase puede incluir una revisión de la información existente en relación
con los objetivos perseguidos y un análisis de la utilidad final de la encuesta, con el fin
de revelar que la información a recoger sea realmente necesaria.
2. Definir la población a ser muestreada. Las definiciones deben ser claras de forma
que los inspectores de Campo no tengan dificultad para decidir si una unidad pertenece
o no a la población. La definición de la población incluye el marco de muestreo y la
división del mismo en unidades de muestreo.
3. Cuestionario. Se incluye aquí la lista de datos que deben ser recogidos, la forma de
medición y la estructura y organización de todo ello en un cuestionario. Establecer un

TÉCNICAS DE MUESTREO
16
primer plan de tabulación puede ser de ayuda también en el diseño del cuestionario,
sobre todo para eliminar preguntas que no se van a utilizar. Debe tenerse presente que el
cuestionario puede ser fuente de errores y sesgos y causa de falta de cooperación de los
entrevistados. Un cuestionario demasiado largo puede bajar la calidad de las respuestas,
tanto a las preguntas importantes como a las de poca importancia.
Entre los aspectos a tener en cuenta al preparar el cuestionario citaremos:
-Forma de presentar las preguntas.
-Redacción correcta de las mismas.
-Orden de las preguntas.
-Evitar preguntas tendenciosas.
4. Nivel de precisión - coste y selección de la muestra. Será útil disponer de diseños
muestrales alternativos que muestren los costes aproximados para distintos grados de
precisión, que ayuden a tomar la decisión sobre el grado de precisión y tamaños
muestrales. Debe tenerse presente que el coste de una encuesta por muestreo está muy
relacionado con el tamaño de muestra.
5. Elaboración de instrucciones de campo y planes de supervisión. Deben ser claras e
inteligibles por la gente que va a trabajar. Los objetivos de la encuesta ayudarán a
entender mejor las instrucciones. Debe incluirse el calendario de realización de la
encuesta y planes de envío a la central.
6. Encuesta piloto o prueba. Sirve para testar sobre el terreno el cuestionario y los
métodos de campo a pequeña escala. Puede resultar en mejoras del cuestionario y
soluciones de otros problemas, que descubiertos a mayor escala, podrían incluso
invalidar la encuesta.
7. Preparación de planes de inspección de resultados, análisis de datos y tabulación.
Inspección de datos, depuración de errores. Primeros resultados para datos importantes
basados en una submuestra. Planes para manejar la no respuesta. Los métodos de
control de calidad utilizados en la industria pueden aplicarse en la encuesta para
determinar la calidad del trabajo de campo y de otras operaciones realizadas en la
oficina.

TÉCNICAS DE MUESTREO
17
8. Interpretación y publicación de resultados finales. Es una buena práctica la de
informar de los errores de muestreo esperados para las estimaciones mas importantes.
VI. MUESTREO DE UNIDADES ELEMENTALES CON
PROBABILIDADES IGUALES
También llamado muestreo aleatorio simple, corresponde al caso de seleccionar las
unidades elementales o de estudio con igual probabilidad. La probabilidad de que la
unidad ui esté en la muestra es n/N y el número de muestras posibles corresponde a las
combinaciones de N elementos tomados de n en n, siendo todas las muestras
equiprobables. Antes de entrar en el estudio de estimadores y errores de muestreo vamos
a recordar el concepto de varianza, ya apuntado anterormente.
Sea una población { }P u u uN= 1 2, ,..., y sean { }Y Y YN1 2, ,..., los valores de la variable en
estudio. La media y el total poblacional vienen dados por :
YY
N
i
N
=∑
1 Y Yi
N
= ∑1
El promedio de los cuadrados de las desviaciones de cada valor individual a la media es
la varianza:
( )σ2
2
1=−∑ Y Y
N
i
N
Su raiz cuadrada, ( )
σ =−∑ Y Y
N
i
N 2
1 , se denomina desviación típica o estándar y es
una medida de la dispersión o variabilidad de los valores individuales alrededor de su
media: cuanto mayor es la desviación típica mayor variabilidad, es decir, menos
concentrados estan los valores alrededor de la media. En cualquier distribución, al
menos el 75% de los valores, se encuentran comprendidos entre la media y ± dos veces
la desviación típica.

TÉCNICAS DE MUESTREO
18
Tanto la media como la desviación estándar se expresan en la misma unidad de medida
que la variable en estudio, es decir, si estamos considerando ventas de empresas,
tendremos una venta media por empresa expresada en pesetas y su correspondiente
desviación típica expresada también en pesetas. En la práctica es frecuente utilizar como
medida de dispersión el coeficiente de variación, que es el cociente entre la desviación
típica y la media: C VY
. = σ , y en el cuál la unidad de medida de la variable desaparece
al dividir por la media: el CV es la desviación estandar en términos relativos (expresable
en % sin mas que multiplicar por 100) y es comparable para distintas variables y
poblaciones.
Con frecuencia estaremos interesados en conocer el número de unidades que cumplen
una condición o poseen una característica (% de votantes de un determinado partido, %
de personas que han visto un cierto programa de televisión, etc). En este caso la variable
Yi toma el valor 1 si la unidad posee la característica y el valor 0 si no la posee. Se dice
que estamos estudiando una variable cualitativa o de atributos.Llamaremos C al número
total de elementos de la población que poseen el atributo o característica en estudio. C
se denomina total de clase y P CN
= es la proporción de clase, expresable en %. En este
caso tenemos:
Yu Cu Ci
i
i
=∈∉
10
sisi
por lo que
C Yi
N
= ∑1
P YY
NCN
i
N
= = =∑
1
corresponden al total y la media de una variable cualitativa. Hay que indicar que todas
las fórmulas que se obtienen para varibles cuantitativas Yi son igualmente válidas para
variables cualitativas o dicotómicas.De ahí que no siempre se obtengan las fórmulas en
el caso dicotómico. Como ejemplo, para la varianza tenemos

TÉCNICAS DE MUESTREO
19
( ) ( ) ( )σ2
2
1
2
12 22
=−
=−
=− +
=∑ ∑ ∑Y Y
N
Y P
N
Y PY P
N
i
N
i
N
i i
( )=− +
= − + = − = − =∑∑Y P Y NPN
P P P P P P P PQi i2 2
2 2 222 1
dónde se ha tenido en cuenta que
YN
YN
Pi i2∑ ∑= =
VI.A. Estimadores y varianzas
Designaremos por y Yi
n= ∑
1 el total muestral correspondiente a una muestra de tamaño
n. La media muestral
y yn
Y
n
i
n
= =∑1
es el estimador insesgado de la media poblacional Y , mientras que para el total
poblacional Y, el estimador insesgado es
!Y N y Nn
Y Nn
yi
n= ⋅ = =∑
1
De la misma forma la proporción muestral pY
n
i
n
=∑1 y !C N p= ⋅ son los estimadores
insesgados de la proporción poblacional P y del total de clase C respectivamente.
La relación f nN
= se llama fracción de muestreo y expresa la relación que existe entre
el tamaño de la muestra y el de la población. Su inverso Nn
se llama factor de
expansión, factor por el que se multiplica cada valor muestral para obtener la estimación
del total.

TÉCNICAS DE MUESTREO
20
La varianza de la media muestral es
( ) ( )V y N nN n
N nN
Sn
f Sn
= −−
= − = −1
12 2 2σ
dónde
( )S N
N
Y Y
N
i
N
2 2
2
1
1 1=
−=
−
−
∑σ
es la cuasivarianza poblacional. A partir de aquí se obtiene
( ) ( )V Y N V y! = 2
( )V p N nN
PQn
= −−1
( ) ( )V C N V p! = 2
La raiz cuadrada de las varianzas de los estimadores son su desviación típica o error de
muestreo. Puede comprobarse cómo en la población del ejemplo del epígrafe I, resulta
S2 = 13,47 y el error estándar es ( )1 0 5 13 473
1 5− =, , , , coincidente con el allí calculado
a partir de todas las muestras posibles.
El problema práctico con las fórmulas anteriores es que en las mismas intervienen los
parámetros poblacionales σ2 o S2, en general desconocidos, por lo que necesitan ser
estimados. Como estimador insesgado de S2 se toma la cuasivarianza muestral
( )s
Y y
n
i
n
2 1
1=
−
−
∑
que, para el caso de proporciones, resulta en
s nn
pq2
1=
−
En consecuencia los estimadores insesgados de las varianzas de los estimadores son
( ) ( )!V y f sn
= −12
( ) ( )! ! !V Y N V y= 2

TÉCNICAS DE MUESTREO
21
( ) ( )!V p f pqn
= −−
11 ( ) ( )! ! !V C N V p= 2
En la práctica, si exceptuamos el caso de proporciones, suele trabajarse con errores de
muestreo relativos, que se obtienen al dividir los valores absolutos por el valor de los
estimadores. También en la práctica la fracción de muestreo n/N suele ser próxima a
cero y se prescinde del factor (1-f), llamado factor de corrección por población finita.
Con ello el error estándar en términos relativos resulta
ee Knr =
dónde K sy
= es el coeficiente de variación estimado a partir de los datos muestrales.
Para calcular el tamaño de muestra necesario para obtener un determinado error estándar
no hay mas que despejar n, obteniéndose
n Keer
0
2
2=
En el caso de que la fracción de muestreo no sea próxima a cero, se tiene
ee f Knr = −1 ( )n
nn N
=+
0
01
En el caso de proporciones si se sustituye K por pq se obtiene una aproximación al
error estándar en términos absolutos. Si no se tiene ninguna idea aproximada del valor
de P, puede utilizarse p=q=0,50 ya que en éste caso pq es máximo y estamos ante el
caso mas desfavorable. Al trabajar con errores absolutos en proporciones debe tenerse
presente que, por ejemplo, 1 punto de error para P=50% es un 2% de error relativo y se
convierte en un 10% de error si P=10%.
Conviene notar que el error estándar es inversamente proporcional a la raiz cuadrada del
tamaño de muestra. Esto significa, por ejemplo, que para reducir el error estándar a la
mitad es necesario tomar un tamaño de muestra cuatro veces superior. El siguiente

TÉCNICAS DE MUESTREO
22
gráfico relaciona el coeficiente de variación de la población, el error estándar y el
tamaño de muestra:
Tamaño de muestra según CV y error estándar
2025
1600
1225
900
625
400
225100
1111
900
711
544
400278
178
625506
400306
225
0
500
1000
1500
2000
2500
1 0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2COEFICIENTE DE VARIACION
TAM
AÑ
O D
E M
UES
TRA
2%3%4%
err. est
Ya se ha mencionado la influencia del error estándar en el tamaño de muestra. El gráfico
revela también la influencia del coeficiente de variación de la población en el tamaño de
muestra: cuanto más homogénea sea la población tanto menor será el tamaño de muestra
requerido. De ahí la importancia que tiene el conocimiento de la población a muestrear
para tratar de reducir la variabilidad original de la misma. Existen dos principales
técnicas de muestreo con éste objetivo: el muestreo estratificado y la técnica del
estimador de razón.
VII. MUESTREO ESTRATIFICADO
VII.A. Definición y objetivos
El muestreo estratificado consiste en :
1º) Dividir la población de N unidades en un cierto número de subpoblaciones llamadas
estratos, de forma que las unidades que componen cada estrato sean lo más homogéneas

TÉCNICAS DE MUESTREO
23
posibles en cuanto a la variable objeto de estudio. Cada unidad de la población ha de
pertenecer a uno y sólo uno de los estratos formados. El número de unidades que
pertenecen a un estrato dado es el tamaño del estrato.
L = número de estratos
Nh = tamaño del estrato h. N Nhh
L
∑ =
W NNh
h= = tamaño relativo del estrato h (peso del estrato h)
2º) Seleccionar una muestra probabilística en cada estrato. La muestra de cada estrato es
independiente de la muestra de cualquier otro estrato. Si la muestra en cada estrato es
una muestra aleatoria simple (probabilidades iguales) tenemos el muestreo aleatorio
estratificado que es el que vamos a estudiar (sin reemplazamiento).
nh = tamaño de la muestra en el estrato h
n = tamaño de la muestra total: n nhh
L
= ∑
f nNh
h
h
= = fracción de muestreo en el estrato h
f nN
= = fracción de muestreo global o total
Los principales objetivos del muestreo estratificado son:
a) Ganancia en precisión respecto al muestreo no estratificado. Es el objetivo
fundamental y en poblaciones muy asimétricas pueden conseguirse excelentes
resultados. Para precisar mas la idea vamos a considerar la población de supermercados
de 400 m2 y más de superficie de venta citada anteriormente. Tomaremos como variable
de estudio el personal empleado. Los datos del Universo son:
Número de establecimientos: N = 2959
Personal medio por establecimiento: Y = 29 8,
Coeficiente de variación poblacional: CV= 2,16

TÉCNICAS DE MUESTREO
24
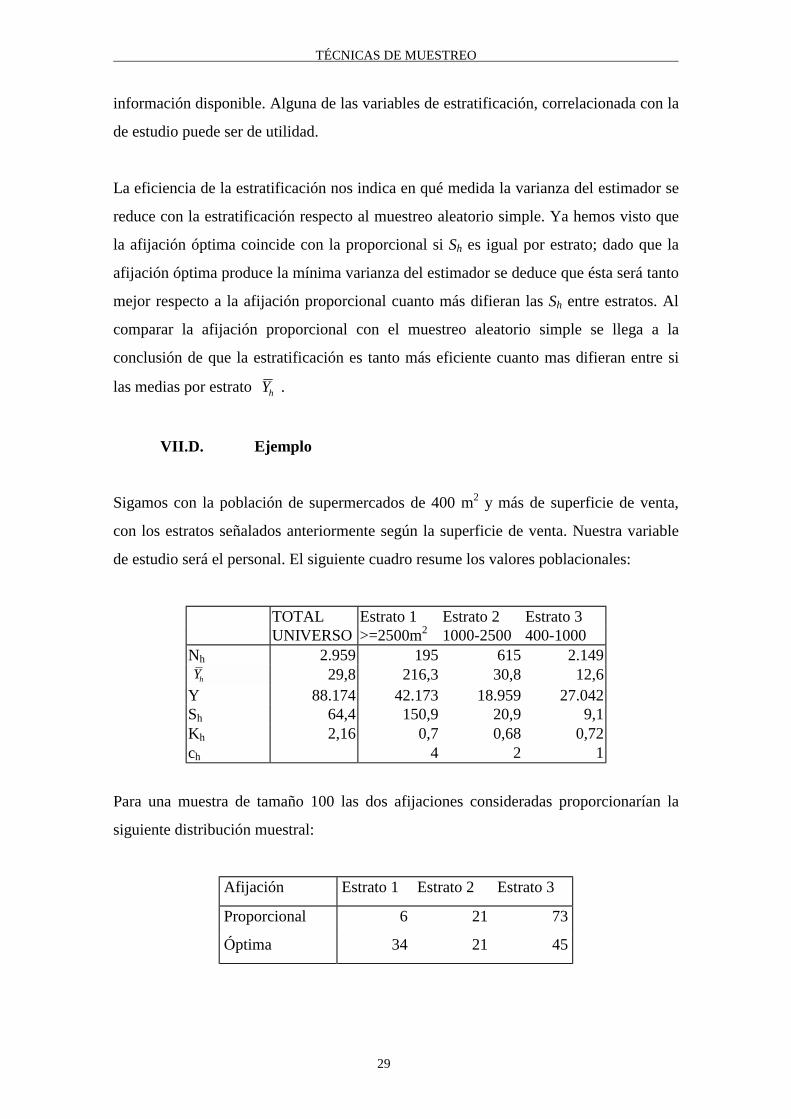
Vamos a dividir el Universo en tres estratos tomando como variable de estratificación la
superficie de venta, que, intuitivamente, debe estar correlacionada con el personal. Los
resultados que se obtienen son:
estrato1
>= 2500m2
estrato2
1000-2500 m2
estrato3
400-1000 m2
Núm. establ (Nh) 195 615 2149
media person. ( )Yh216.3 30.8 12.6
coefic. de variac. 0.70 0.68 0.72
Fijémonos como el coeficiente de variación del personal, que en la población global es
de 2,16, se reduce a la tercera parte, alrededor de 0,70 en cada estrato. Si recordamos la
fórmula del error estándar resulta intuitivo que éste experimentará sensibles reducciones
al tomar muestras independientes en cada estrato.
Ésta es la clave de la estratificación: formar estratos que reduzcan la variabilidad de la
población original. Cuanto más reduzcamos la variabilidad dentro de cada estrato
respecto a la variabilidad total de la población, mayor será la ganancia en precisión ( o al
revés, menor muestra necesitaremos para una precisión prefijada).
b) Posibilidad de obtener estimadores separados para cada estrato o agrupación de
estratos, lo que proporciona una información mas rica y detallada.
c) Más eficacia en la organización administrativa, al poder considerar como variables de
estratificación provincias o regiones geográficas, que permiten una mayor
descentralización de la organización de Campo y de tareas administrativas.
d) Los problemas de muestreo pueden diferir marcadamente en diferentes partes de la
población. Al ser el proceso de muestreo independiente en cada estrato, pueden
aplicarse métodos diferentes de muestreo por estrato de acuerdo a la información de que
se disponga.
Respecto a las variables o criterios de estratificación, su número y el número de estratos,
dependen de los objetivos concretos de cada caso, de la información disponible y de la

TÉCNICAS DE MUESTREO
25
estructura de la población; las variables utilizadas en la estratificación, deberán estar
correlacionadas con las variables objeto de investigación, aunque tambien pueden
incluirse criterios “administrativos” (regiones geográficas).
En general, un número moderado de variables de estratificación y de estratos es
suficiente para obtener ganacias de precisión; ésta es, en general, decreciente al
aumentar el número de estratos.
Puesto que en cada estrato vamos a seleccionar una muestra aleatoria simple de
unidades, recordemos que la media muestral y es estimador insesgado de la media
poblacional, con varianza, ( )V y f Sn
( ) = −12
, estimada por ( ) ( )!V y f sn
= −12
y
varianza relativa estimada = ( ) ( )!V x fknry= −1
2
.
VII.B. Estimadores insesgados y varianzas
La formación de estimadores se basa en la selección independiente de muestras
aleatorias en cada estrato. Ello lleva a elegir el correspondiente estimador insesgado en
cada estrato y, posteriormente, mediante combinaciones lineales adecuadas de los
estimadores insesgados de cada estrato, obtener el estimador insesgado global de toda la
población. Para el cálculo de varianzas de los estimadores no hay mas que tener en
cuenta la regla de aditividad de varianzas de combinaciones lineales de variables
aleatorias (en este caso estimadores) independientes.
Sean:
Yhi = valor de la variable de estudio en la unidad i del estrato h
YY
NYNh
hii
N
h
h
h
h
= = =∑
media poblacional del estrato h
Y N Yh h h= = total poblacinal del estrato h
Y Yhh
L
= =∑ total poblacional

TÉCNICAS DE MUESTREO
26
YY
NN Y
NW Y
hh
L
h h
h
L
h hh
L
= = = =∑
∑ ∑ media poblacional
( )S
Y Y
Nh
hi hi
N
h
h
2
2
1=
−
−=
∑ cuasivarianza poblacional del estrato h
Los estimadores y sus varianzas son ya inmediatos de obtener:
Media:
!Y W yst h h= ∑ ( ) ( )E Y W E y W Y Yst h hh
L
h hh
L! = = =∑ ∑
( ) ( ) ( )V Y W V y W f Snst h h
h
L
h hh
hh
L! = = −∑ ∑2 2
2
1
( ) ( ) ( )! ! !V Y W V y W f snst h h
h
L
h hh
hh
L
= = −∑ ∑2 22
1
dónde ( )
sY y
nh
hi hi
n
h
h
2
2
1=
−
−
∑ es la cuasivarianza muestral del estrato h.
Total:
! ! !Y NY N W y N y Yst st h hh
L
h hh
L
hh
L
= = = =∑ ∑ ∑
( ) ( ) ( ) ( )V Y N V Y N V y V Yst st h hh
L
hh
L! ! != = =∑ ∑2 2
( ) ( ) ( )! ! ! !V Y N V Y N f snst st h hh
hh
L
= = −∑2 22
1
Proporción:
En este caso estamos ante una variable cualitativa que sólo toma los valores, Yhi = 1 si la
unidad uhi posee la característica en estudio, y Yhi = 0 si no la posee. Tenemos:
!P W pst h hh
L
= ∑

TÉCNICAS DE MUESTREO
27
( ) ( )V P W V p W N nN
P Qnst h h
h
L
hh h
h
h h
hh
L! = =
−−∑ ∑2 2
1
( ) ( ) ( )! ! !V P W V p W N nN
p qn
W f p qnst h h
h
L
hh h
h
h h
hh
L
h hh h
hh
L
= =−
−= −
−∑ ∑ ∑2 2 2
11
1
Total de clase:
! !C NPst st= ( ) ( )V C N V Pst st! != 2 ( ) ( )! ! ! !V C N V Pst st= 2
Debe observarse que el cálculo de estimadores de la varianza, requiere al menos dos
unidades en la muestra por cada estrato.
VII.C. Afijación
Se denomina afijación al método de distribuir las n unidades de la muestra total entre los
diferentes estratos. Supondremos que el tamaño de muestra total, n, está dado. En
principio, el tamaño de muestra en cada estrato puede fijarlo el diseñador a su buen
juicio y criterio. Esta forma de distribución de la muestra entre estratos puede
denominarse afijación subjetiva. Sin embargo, en la práctica es habitual utilizar algún
criterio formulable para hacer la afijación. Los tipos de afijación más comunes son:
1. Afijacion proporcional. Consiste en repartir la muestra proporcionalmente a los
tamaños de los estratos:
n n NNh
h= , h = 1,2, ...., L ; nN
nN
h
h
= ; fh = f
Las fracciones de muestreo resultan idénticas en todos los estratos y cada unidad de la
población tiene la misma probabilidad de pertenecer a la muestra, originando una
muestra autoponderada en la que los factores de expansión por estrato para la

TÉCNICAS DE MUESTREO
28
estimación de totales son todos iguales. Ello se traduce en una notable simplificación en
el cálculo de estimaciones y sus varianzas.
2. Afijación óptima. Introducimos una función de coste de la forma C c c nh hh
L
= +∑0 ,
dónde c0 representa un costo general, mientras que ch correspondería a un coste por
unidad de muestreo en el estrato h. La afijación óptima proporciona la mínima varianza
del estimador para un coste prefijado. La fórmula que se obtiene es
n nN S c
N S chh h h
h h hh
=∑
y utilizando los coeficientes de variación por estrato K SX
S K Xhh
hh h h= → = , se
obtiene
n nY K c
Y K chh h h
h h hh
=∑
Resulta, pues, que la muestra en cada estrato es proporcional a la variabilidad del estrato
(Sh) e inversamente proporcional a la raiz cuadrada del coste por unidad.
Si no se consideran costes o ch es igual por estrato se obtiene
n n N SN S
n Y KY Kh
h h
h hh
h h
h hh
= =∑ ∑
Si además Sh es igual por estrato se obtiene la afijación proporcional, mientras que si Kh
es igual por estrato se obtiene una afijación proporcional a la importancia que tiene en
cada estrato la variable en estudio.
Obsérvese que en las fórmulas anteriores pueden utilizarse los valores absolutos de Nh,
Yh o los relativos NN
h , YY
h (no habría mas que dividir numerador y denominador por N
y Y respectivamente). Los valores relativos pueden utilizarse también en forma de
porcentaje. Los valores de Sh o Yh deberán ser, en la práctica, estimados a partir de la
TÉCNICAS DE MUESTREO
29
información disponible. Alguna de las variables de estratificación, correlacionada con la
de estudio puede ser de utilidad.
La eficiencia de la estratificación nos indica en qué medida la varianza del estimador se
reduce con la estratificación respecto al muestreo aleatorio simple. Ya hemos visto que
la afijación óptima coincide con la proporcional si Sh es igual por estrato; dado que la
afijación óptima produce la mínima varianza del estimador se deduce que ésta será tanto
mejor respecto a la afijación proporcional cuanto más difieran las Sh entre estratos. Al
comparar la afijación proporcional con el muestreo aleatorio simple se llega a la
conclusión de que la estratificación es tanto más eficiente cuanto mas difieran entre si
las medias por estrato Yh .
VII.D. Ejemplo
Sigamos con la población de supermercados de 400 m2 y más de superficie de venta,
con los estratos señalados anteriormente según la superficie de venta. Nuestra variable
de estudio será el personal. El siguiente cuadro resume los valores poblacionales:
TOTAL Estrato 1 Estrato 2 Estrato 3UNIVERSO >=2500m2 1000-2500 400-1000
Nh 2.959 195 615 2.149Yh 29,8 216,3 30,8 12,6
Y 88.174 42.173 18.959 27.042Sh 64,4 150,9 20,9 9,1Kh 2,16 0,7 0,68 0,72ch 4 2 1
Para una muestra de tamaño 100 las dos afijaciones consideradas proporcionarían la
siguiente distribución muestral:
Afijación Estrato 1 Estrato 2 Estrato 3
Proporcional 6 21 73
Óptima 34 21 45

TÉCNICAS DE MUESTREO
30
Con los datos anteriores estamos ya en situación de calcular el error estándar del
estimador de la media. Los resultados se resumen a continuación (se prescinde del factor
1-f):
Tipo de muestreo Tamaño de
muestra
Varianza del
estimador
error de
muestreo
error relativo
de muestreo
muestra aleatoria 100 41,47 6,4 21,6%
m. estr. proporcional 100 17,98 4,2 14,2%
m. estr. óptima 100 4,78 2,2 7,3%
Vemos que el muestreo estratificado con afijación óptima produce una sensible
disminución del error de muestreo, a la tercera parte, respecto al muestreo aleatorio
simple, y también respecto a la afijación proporcional debido a los diferentes valores de
Sh, según se apuntó anteriormente. En forma gráfica se tiene:
COMPARACIÓN DE ERRORES ESTÁNDAR (n = 100)
21,6%
14,2%
7,3%
mtra aleat m. estr. prop. m. estr. ópt.
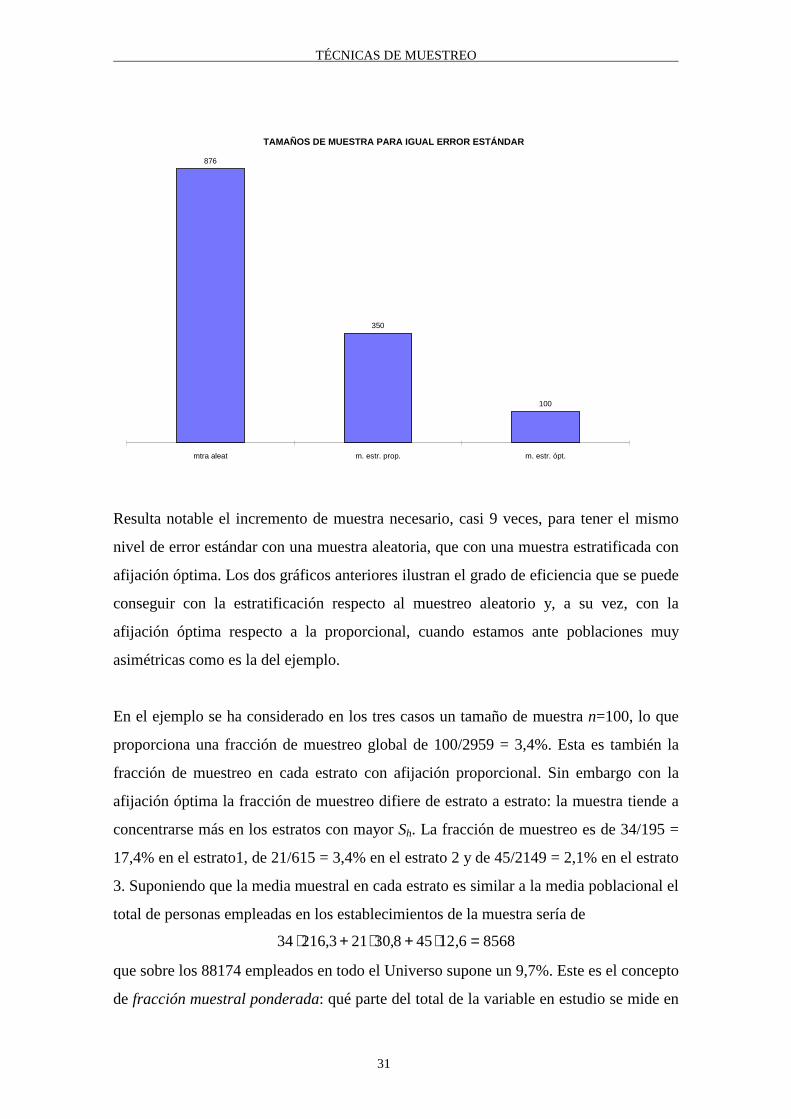
Otra forma de ver los resultados anteriores es comparar los tamaños de muestra que para
los distintos diseños muestrales proporciona el mismo nivel de error estándar, según
muestra el gráfico siguiente:
TÉCNICAS DE MUESTREO
31
TAMAÑOS DE MUESTRA PARA IGUAL ERROR ESTÁNDAR
876
350
100
mtra aleat m. estr. prop. m. estr. ópt.
Resulta notable el incremento de muestra necesario, casi 9 veces, para tener el mismo
nivel de error estándar con una muestra aleatoria, que con una muestra estratificada con
afijación óptima. Los dos gráficos anteriores ilustran el grado de eficiencia que se puede
conseguir con la estratificación respecto al muestreo aleatorio y, a su vez, con la
afijación óptima respecto a la proporcional, cuando estamos ante poblaciones muy
asimétricas como es la del ejemplo.
En el ejemplo se ha considerado en los tres casos un tamaño de muestra n=100, lo que
proporciona una fracción de muestreo global de 100/2959 = 3,4%. Esta es también la
fracción de muestreo en cada estrato con afijación proporcional. Sin embargo con la
afijación óptima la fracción de muestreo difiere de estrato a estrato: la muestra tiende a
concentrarse más en los estratos con mayor Sh. La fracción de muestreo es de 34/195 =
17,4% en el estrato1, de 21/615 = 3,4% en el estrato 2 y de 45/2149 = 2,1% en el estrato
3. Suponiendo que la media muestral en cada estrato es similar a la media poblacional el
total de personas empleadas en los establecimientos de la muestra sería de
34 216 3 21 30 8 45 12 6 8568⋅ + ⋅ + ⋅ =, , ,
que sobre los 88174 empleados en todo el Universo supone un 9,7%. Este es el concepto
de fracción muestral ponderada: qué parte del total de la variable en estudio se mide en

TÉCNICAS DE MUESTREO
32
las unidades muestrales. Tanto en muestreo aleatorio como en muestreo estratificado
con afijación proporcional la fracción muestral ponderada es similar o igual a la fracción
de número. Pero con la afijación óptima, con un 3,4% de muestra se está “observando”
el 9,7% de la variable en estudio, siendo ésta última, con frecuencia, un mejor indicador
del tamaño de muestra que el simple número n.
Hay que destacar también que siendo el factor de expansión el inverso de la fracción de
muestreo, la afijación óptima origina factores de expansión diferentes por estrato, tanto
menores cuanto mayor es la varianza del estrato: obsérvese que el factor de expansión
más pequeño corresponde a las unidades muestrales más grandes.
VIII. ESTIMADOR DE RAZON
El estimador de razón trata de mejorar la precisión de un estimador utilizando la
información que se posee, para la población investigada, de una variable auxiliar que se
supone correlacionada con la variable de estudio. Sea Yi la variable de estudio y sea Xi
la variable auxiliar conocida para el Universo o población en estudio.
Supongamos que se desea estimar la producción de trigo mediante una muestra aleatoria
de explotaciones agrarias, y poseemos información sobre la superficie cultivada:
explotación prod. trigo (Yi) superf. cultivada (Xi)
1 Y1 X1
2 Y2 X2
...... ....... ......
n Yn Xn
total muestral y x
El estimador insesgado lineal de la producción de trigo es
!Y Nn
Y Nn
yi
n
= =∑1

TÉCNICAS DE MUESTREO
33
Puesto que poseemos información de la superficie cultivada Xi y conocemos su total
poblacional X, podemos, además, estimarlo con los datos de la muestra
!X Nn
X Nn
xi
n
= =∑1
El cociente XX!
constituye una cierta medida de la representatividad de la muestra: si
XX!
> 1 , indicaría que en la muestra hay una mayor representación de explotaciones
pequeñas, mientras que si XX!
< 1 , tendríamos una mayor representación de
explotaciones grandes. Habiendo correlación entre ambas variables parece lógico
utilizar la desviación XX!
, cometida en la estimación de la variable conocida para
corregir la estimación de Y. Esto nos lleva al estimador
! !!
!
!!Y Y X
XYX
X RXR = = =
!!
!R Y
Xyx
= = , se llama estimador de razón, !YR es el estimador del total por el método
de razón. !YR lo podemos escribir como
!Y Nn
y XNn
x
Xx
YR i
n
= = ∑1
es decir, el estimador del total por razón equivale a la expansión de los datos muestrales
mediante el factor X x , relación entre el valor poblacional y el valor muestral de la
variable auxiliar Xi , en lugar de utilizar la expansión N/n de número o expansión
simple. Al factor X x le llamamos factor-X.
La media Y se estima por !!
! !Y YN
R XN
RXRR= = = .
La razón R YX
YX
= = se llama razón poblacional, y su estimador !R es sesgado, es
decir, la esperanza matemática de !R o media sobre todas las posibles muestras no
coincide con R. Una acotación para el sesgo ( )B E R R= −! viene dada por

TÉCNICAS DE MUESTREO
34
BX
C Knx
xx
x
σσ
≤ = ≈
que expresa que la razón del sesgo al error estandar de x es menor o igual al coeficiente
de variación Cx o error de muestreo relativo de la media muestral x . En la práctica si
Cx es menor de 0,20 el sesgo puede ignorarse. También se observa que la razón del
sesgo al error de muestreo es del orden de magnitud de 1 n y, por tanto, disminuye
con el tamaño de muestra. En el caso particular de que la línea de regresión poblacional
de y respecto a x sea una recta que pasa por el origen, el estimador de razón !R es
insesgado.
La varianza del estimador de razón es
( ) ( )V R fnX
S R S RSy x yx! = − + −
1 222 2 2
con
( )( )S
Y Y X X
Nyx
i i
N
=− −
−
∑1
1
y se estima sustituyendo los valores poblacionales por los muestrales:
( ) ( )! ! ! !V R fnX
s R s Rsy x yx= − + −1 22
2 2 2
Para el total ! !Y RXR = y la media ! !Y RXR = , la varianza es
( ) ( )! ! ! !V Y X V RR = 2 ( ) ( )! ! ! !V Y X V RR = 2
Al comparar ( )V YR! con la varianza del total en muestreo aleatorio simple,
( ) ( )V YN f
nSas y
! =−2
21
resulta que ( ) ( )V Y V YR as! !< si se verifica
ρ >12
CC
x
y
dónde ( )( )( )ρ =
− −
−=
∑ Y Y X X
N S SS
S S
i i
N
y x
yx
y x
1
1 es el coeficiente de correlación entre Yi y Xi.

TÉCNICAS DE MUESTREO
35
Se deduce entonces, que el estimador de razón puede ser más o menos preciso que el de
simple expansión dependiendo del tamaño del coeficiente de correlación entre Yi, Xi y
de la relación de sus coeficientes de variación. Si Cx > 2Cy el estimador de razón es
siempre menos preciso ya que ρ no puede ser superior a 1. Cuando Xi es el valor de Yi
en alguna ocasión previa, Cx y Cy pueden ser aproximadamente iguales y el estimador de
razón es superior si ρ > 0 5, . Siendo Xi el valor de Yi en alguna ocasión anterior, es
frcuente que R ≈ 1 y S Sx y≈ , con lo cuál tenemos
( ) ( ) ( ) ( ) ( ) ( )V YN f
nS S S
N fn
S VR y y y y as! =
−+ − =
−⋅ − = ⋅ −
22 2 2
221
21
2 1 2 1ρ ρ ρ
( )2 1− ρ indica la ganacia en precisión respecto al estimador de simple expansión. Así,
si ρ = 0 8, , ( )V Y VR as= ⋅0 4, , ( )V Y VR as= ⋅0 63, . Vemos que con correlaciones altas
se obtienen reducciones importantes en el error de muestreo.
En el muestreo estratificado la variabilidad de la población se reduce por la formación
de estratos relativamente homogéneos. Con el estimador de razón la variabilidad se
reduce por medio de la correlación existente entre la variable de estudio y, y la variable
auxiliar x. Resulta entonces, que la utilización de muestreo estratificado junto con
estimador de razón puede producir importantes aumentos en la precisión de los
estimadores.
IX. MUESTREO DE CONGLOMERADOS SIN SUBMUESTREO.
El muestreo de unidades elementales tiene dos principales inconvenientes de tipo
práctico:
a) Imposibilidad en muchas ocasiones de obtener una lista de unidades elementales en la
cuál basar la selección de la muestra.
b) La selección de unidades elementales proporciona, en general, una muestra muy
esparcida de unidades a entrevistar con el consiguiente incremento de coste y tiempo.
Para evitar estos inconvenientes surge de forma natural la idea de agrupar unidades
elementales próximas entre si en una unidad mayor que se denomina conglomerado,

TÉCNICAS DE MUESTREO
36
constituyéndose el conjunto de conglomerados en las nuevas unidades de muestreo. Los
conglomerados deben estar perfectamente definidos, lo cuál significa que no haya
solapamiento entre ellos -una unidad elemental pertenece sólo a un conglomerado- y
que el conjunto de todos los conglomerados contiene a la población objeto de estudio.
Así pues, en el muestreo de conglomerados se selecciona una muestra de
conglomerados. Si posteriormente, investigamos todas las unidades elementales
contenidas en los conglomerados seleccionados en la muestra, el muestreo se dice de
conglomerados sin submuestreo o muestreo en una etapa, que es el que vamos a estudiar
aquí.
Se denomina tamaño del conglomerado al número de unidades elementales que
contiene. Supondremos que todos los conglomerados son de igual tamaño M .
Supondremos también que la selección de la muestra se hace con probabilidades iguales
y sin reemplazamiento (muestreo aleatorio simple):
N = número de conglomerados en la población.
M NM0 = = número total de unidades elementales en la población.
n = número de conglomerados en la muestra.
nM = número de unidades elementales en la muestra.
Para la variable en estudio tenemos:
Yij = valor de y en la unidad j del conglomerado i.
Y Yi ijj
M
= =∑ total del conglomerado i.
Y Y Yii
N
ijj
M
i
N
= = =∑ ∑∑ total general.
Y YMi
i= = media por elemento del conglomerado i.
YY
N
ii
N
= =∑
total medio de conglomerados, es decir, media de los totales de
conglomerados (media entre conglomerados).

TÉCNICAS DE MUESTREO
37
YY
NM
Y
NMYM
Y
N
ijj
M
i
N
ii
N
ii
N
= = = = =∑∑ ∑ ∑
media general por elemento.
La media muestral por elemento puede expresarse por :
y ynM
Y
nM
Y
nM
ijj
M
i
n
ii
n
= = =∑∑ ∑
y es un estimador insesgado de la media poblacional por elemento Y con varianza
dada por
( )V y fnM
Sb= −1 2
dónde
( ) ( )S
Y Y
N
M Y Y
Nb
ij
M
i
N
ii
N
2
2 2
1 1=
−
−=
−
−
∑∑ ∑
es decir, la varianza de la media muestral por elemento proviene en su totalidad de la
varianza de las medias por elemento entre los conglomerados, lo cuál es lógico ya que
dentro de cada conglomerado de la muestra no hay submuestreo: todas las unidades
elementales del conglomerado seleccionado forman parte de la muestra. Si hubiera
submuestreo, habría que añadir un componente de variabilidad debido al submuestreo
dentro de cada conglomerado.
Si consideramos una muestra aleatoria simple de nM elementos, la varianza de la
media muestral sería:
( )( )
( )V y NM nMNM nM
Y Y
NMf
nMS V yas
ijj
M
i
N
= −−
−= − ≠
∑∑11
1
2
2
La relación entre ambas puede aproximarse por
( ) ( ) ( )[ ]V y V y Mas≈ + −1 1 δ (1)
dónde

TÉCNICAS DE MUESTREO
38
( )( )( ) ( )
( )( )( )( )δ =
− −
− −=
− −
− −≠ ≠∑∑
∑∑
∑∑Y Y Y Y
M Y Y
Y Y Y Y
M NM S
ij ikj k
M
i
N
ijj
M
i
N
ij ikj k
M
i
N
1 1 12 2
define la correlación existente entre todos los posibles pares de unidades distintas dentro
de cada conglomerado. δ se denomina coficiente de correlación intraconglomerados y
constituye una medida de la homogeneidad existente entre las unidades elementales
dentro de cada conglomerado.
A la razón ( ) ( )V y V yas entre la varianza del estimador en un diseño particular y la
varianza del estimador en una muestra aleatoria simple, con el mismo tamaño muestral
en unidades elementales, se denomina efecto de diseño. En el caso de muestreo por
conglomerados, el efecto de diseño es ( )1 1+ −M δ , y corresponde al factor por el que
hay que multiplicar la varianza del estimador por usar conglomerados en lugar de una
muestra aleatoria simple de unidades elementales.
Así pues, siempre que δ > 0 , que es lo más habitual, el muestreo por conglomerados
tiene menos prcisión que el muestreo aleatorio simple para el mismo tamaño de muestra
en unidades elmentales. Si δ < 0 , el muestreo por conglomerados es mas eficiente y si
δ = 0 , ambos son equivalentes. En el caso de M = 1, el muestreo por conglomerados
coincide con el muestreo aleatorio simple.
De (1) se obtiene una expresión aproximada para el coeficiente de correlación
intraconglomerados:
( )δ ≈−
−S SM S
b2 2
21
Según el valor de Sb2 en relación a S2 el, el coeficiente de correlación
intraconglomerados podrá tomar valores positivos o negativos. Vamos a distinguir los
siguientes casos:

TÉCNICAS DE MUESTREO
39
a) Sb2 = 0 . Entonces δ = −
−1
1M , su valor mínimo, y ( )V y = 0 . Estamos ante el caso
ideal para la utilización de muestreo por conglomerados. Todas las Yi son iguales a Y
y por tanto, un solo conglomerado en la muestra suministra toda la información. En
otras palabras, toda la variabilidad procede de dentro de los conglomerados y todos los
conglomerados son iguales entre si. Aún cuando δ no alcance su valor mínimo, siempre
que δ < 0 , que no es usual en la práctica, resultará ventajoso utilizar muestreo por
conglomerados.
b) Sb2 = S2 . Entonces δ = 0 y V Vc as= . La variación entre conglomerados es igual a la
variación entre unidades elementales en la población. Yi varía de conglomerado a
conglomerado como podría esperarse si los conglomerados hubiesen sido formados
agrupando aleatoriamente las unidades elementales. Sb2 = S2 . Con δ = 0 da igual
utilizar muestreo de conglomerados o de unidades elementales en lo que a precisión se
refiere.
c) Sb2 > S2 . Entonces δ > 0 y V Vc as> . Es el caso mas común. La varianza entre
conglomerados es mayor que la varianza de las unidades elementales en la población, es
decir, Yi varía de conglomerado a conglomerado más que varían las unidades
elementales en la población. Esto equivale a decir que las unidades dentro de los
conglomerados son más homogéneas que lo son en la población. Cuanto mayor sea Sb2,
mayor será δ y mayor el efecto de diseño o efecto conglomerado, y mayor la varianza
del estimador respecto al muestreo aleatorio simple. El caso mas desfavorable será aquel
en que toda la variabilidad de la población procede de la variabilidad entre
conglomerados, es decir, existiese homogeneidad absoluta dentro de los conglomerados.
En este caso δ tomaría su valor máximo: δ =1 .
X. MUESTREO SISTEMÁTICO
Sea una población { }u u uN1 2, , ,# . La selección sistemática de una muestra de n
unidades se realiza en la siguiente forma: sea k N n= (suponemos N divisible por n),

TÉCNICAS DE MUESTREO
40
tomamos un número i al azar 1 ≤ ≤i k con probabilidad 1 k y la muestra sistemática
queda formada por las n unidades
( ){ }u u u ui i k i k i n k, , , ,+ + + −2 1#
Como vemos, la selección de la primera unidad determina la muestra completa. El
espacio muestral está formado por las siguientes k muestras posibles, dónde se indica el
valor de la variable en estudio en cada unidad seleccionada:
Muestra
1 2 ...... i ...... k
X1 X2 Xi Xk
X1+k X2+k Xi+k X2k
...... ...... ...... ......
X1+(n-1)k X2+(n-1)k Xi+(n-1)k Xnk
Media x1 x2 xi xk
Las k muestras posibles son equiprobables (prob. = 1 k ) y la probabilidad de que la
unidad ui esté en la muestra es 1 k n N= . La media muestral
xn
Xi ijj
n= ∑1
es el estimador insesgado de la media poblacional. Observar que al utilizar dos
subíndices, el primero i hace referencia a la muestra sistemática y el segundo j a la
unidad elemental dentro de la muestra.
El muestreo sistemático es de fácil aplicación práctica y asegura además que la muestra
se extiende a toda la población. Podemos considerar la población dividida en n estratos,
los cuales consisten de las primeras k unidades, las segundas k unidades, etc., es decir, al
contemplar el cuadro de muestras posibles en horizontal, cada fila sería un estrato. La
muestra sistemática correspondería a una muestra estratificada con una unidad por
estratos
conglomerados

TÉCNICAS DE MUESTREO
41
estrato, por lo que sería esperable una mayor precisión respecto al muestreo aleatorio
simple.
La diferencia con el muestreo estratificado está en que con la muestra sistemática, las
unidades seleccionadas ocupan la misma posición relativa en cada estrato, mientras que
en el muestreo estratificado la selección es independiente en cada estrato, por lo que
también es esperable que el muestreo sistemático sea menos preciso que el muestreo al
azar estratificado.
Observando el cuadro de muestras posibles, el muestreo sistemático es equivalente a
considerar la población dividida en k grupos o conglomerados (columnas del cuadro),
cada uno de n unidades, de los cuales se selecciona uno al azar. Es decir, una muestra
sistemática es una muestra aleatoria de una unidad conglomerada de una población de k
conglomerados de tamaño n.
El comportamiento del muestreo sistemático respecto al estratificado o el muestreo
aleatorio simple, depende en gran medida de las propiedades de la población. En
poblaciones en las cuales la numeración de las unidades puede considerarse al azar
respecto a la característica que se mide, cabría esperar que el muestreo sistemático fuera
equivalente al muestreo aleatorio simple y que tuviera la misma varianza.
Cuando la población presenta una tendencia lineal como en la figura que sigue,
ui
Xi
muestra aleatoria estratif.
muestra sistemática
intuitivamente se ve que la muestra sistemática es más efectiva que la muestra aleatoria
simple ya que asegura presencia en la muestra de todas las zonas de tendencia, pero es

TÉCNICAS DE MUESTREO
42
menos efectiva que la muestra estratificada ya que si la muestra sistemática es muy baja
en un estrato, es muy baja en todos, mientras que la estratificación da oportunidad para
que los errores dentro de los estratos se compensen. El comportamiento de la muestra
sistemática podría mejorarse usando una muestra centralmente ubicada.
Para una población con tendencia periódica, por ejemplo una curva sinoidal, la
efectividad de la muestra sistemática depende del valor de k, como puede verse en la
A A A B
B B
B B
figura, dónde la altura de la curva es la observación Yi. Los puntos A de la muestra,
representan el caso menos favorable y suceden si k es igual al periodo de la curva o a un
múltiplo entero del periodo. Toda observación dentro de la muestra sistemática
proporciona la misma información y la muestra no es más precisa que una sola
observación tomada al azar de la población.
El caso más favorable (muestra B) ocurre cuando k es un múltiplo impar del medio-
periodo. Toda muestra sistemática tiene una media exactamente igual a la media
verdadera. Entre estos dos casos extremos, la muestra sistemática tiene varios grados de
efectividad, dependiendo de la relación entre k y el periodo de la curva.
Poblaciones con tendencia más o menos periódica se encuentran en la práctica con
relativa frecuencia. Ejemplos son el flujo de tránsito por un punto de una carretera
durante las 24 horas del día y las ventas de una tienda durante los dias de la semana.
Para estimar un promedio sobre un periodo de tiempo, una muestra sistemática diaria a
las 6 p. m. o cada martes, no sería obviamente juicioso. La estrategia correcta es girar la
muestra sobre la curva periódica, por ejemplo, viendo que cada día de la semana esté
igualmente representado, en el caso de las ventas de una tienda.

TÉCNICAS DE MUESTREO
43
A partir de los resultados de una muestra aletoria simple podemos calcular un estimador
insesgado de la varianza de la media muestral siempre que n > 1. Este estimador es
insesgado cualquiera que sea la forma de la población. Dado que una muestra
sistemática corresponde a una muestra aleatoria simple de tamaño n = 1, seleccionada de
entre k conglomerados en la población, no resulta posible construir un estimador de la
varianza de la media muestral. En la práctica si la población está ordenada al azar puede
utilizarse la estimación de la varianza que proporcionaría una muestra aleatoria simple
del mismo tamaño.
XI. OTROS ASPECTOS DEL MUESTREO
Habrá ocasiones en que el conocimiento previo que se dispone del Universo objeto de
estudio es muy limitado e insuficiente para proceder a una estratificación eficiente o
para la utilización de estimadores del tipo de razón que nos permitan importantes
reducciones del error estándar. En estos casos puede ser conveniente la realización de
una primera muestra, relativamente amplia, con el objeto de estimar aquellas
características básicas que nos sirvan para la utilización posterior de muestreo
estratificado o de estimadores de razón. Una vez determinadas las características del
Universo que sean de interés, se selecciona en una segunda fase una submuestra de la
primera sobre la que ya se estudian propiamente las variables objeto de estudio. Este
proceso se conoce como muestreo doble o muestreo en dos fases. El proceso se justifica
si la información obtenida en la primera fase permite una reducción de muestra en la
segunda fase que compense costes.
La muestra correspondiente a la primera fase se denomina también muestra censal,
muestra maestra o censo muestral. Estas denominaciones indican un primer proceso de
muestreo sustitutivo de un censo completo, es decir, cuyo fin es conocer características
poblacionales, incluso el propio tamaño del Universo N, necesarios para el posterior
diseño de la muestra. Este procedimiento censal en base a una muestra no debe
sorprender: es práctica habitual en grandes operaciones censales proporcionar resultados
basados en una muestra de los cuestionarios censales en lugar de utilizar la información
completa del censo total. La muestra en segunda fase puede denominarse muestra

TÉCNICAS DE MUESTREO
44
principal o muestra de estudio, ya que es la muestra sobre la que se miden las variables
objeto de estudio.
Cuando se estudia la teoría de muestras siempre se habla de la variable de estudio Yi.
Sin embargo cuando se selecciona una muestra van a ser muchas variables Yi las que se
estudien en cada unidad muestral, lo que significa que la muestra va a proporcionar
multitud de estimaciones cada una con su propio nivel de error estándar, es decir, no
puede hablarse de la calidad global de una muestra, sino que cada estimación que
proporcione, tendrá su propio error de muestreo. Previamente habrá que haber definido
un tamaño de muestra en función de un cierto error estándar. Si quisiéramos el mismo
nivel de error estándar para cada variable en estudio resultarían tamaños de muestra
diferentes para cada una, lo cuál, desde un punto de vista práctico no tiene sentido. Lo
normal será que entre las variables a estudiar haya unas pocas de mayor importancia y
sean éstas las que predominen en la determinación del tamaño de muestra, llegándose a
una solución de compromiso. Un problema similar surge al establecer la distribución
óptima de una muestra estratificada para distintas variables a estudiar: cada variable nos
puede proporcionar afijaciones diferentes y debe llegarse a una solución única.
El concepto de error de muestreo surge porque al tomar cientos o miles de muestras
independientes de una población para estimar un parámetro, las estimaciones presentan
una variabilidad aleatoria que puede aproximarse por la distribución normal. En una
forma análoga se puede pensar que cuando una muestra proporciona cientos, miles de
estimaciones se pueden aplicar las propiedades de la distribución normal y pensar que,
por ejemplo, un 5% de las estimaciones quedan fuera de su intervalo de confianza ( ± 2
veces el error estándar), es decir, alejadas de la realidad, sin que pueda saberse cuales
son: es el analista de los resultados el que con su conocimiento y experiencia puede
separar, quizá no totalmente, aquellos datos que reflejen la realidad de aquellos otros
que pueden ser debidos a variaciones extremas de muestreo o a sesgos introducidos en
la muestra, no importantes para muchas de las variables investigadas pero que sí lo son
para otras.
En la actualidad es práctica común la de utilizar muestras para recoger series de datos
sobre la misma población que se publican a intervalos regulares de tiempo. Ejemplos de

TÉCNICAS DE MUESTREO
45
ello los tenemos en las encuestas de población activa o de fuerza de trabajo que realizan
los paises desarrollados, los paneles de audiencia de televisión, muestras contínuas de
hogares o de tiendas para medir el consumo, etc.
Cuando la misma población se muestrea repetidamente en el tiempo, estamos en una
posición ideal para obtener estimadores realistas de costes y varianzas y, en
consecuencia, para aplicar técnicas que conducen a una utilización óptima del muestreo.
Una cuestión importante en muestreo repetido es con qué frecuencia y de qué manera
debe cambiarse la muestra a lo largo del tiempo. Podemos optar entre las siguientes
alternativas:
a) Utilizar la misma muestra, llamada panel, en cada repetición del muestreo o
periodo.
b) Mantener en cada periodo una proporción πc de muestra común con el
periodo anterior, renovando el resto de la muestra.
c) Utilizar en cada periodo muestras independientes.
Hay muchas consideraciones que afectan a la decisión. Los entrevistados pueden
negarse a dar la misma información una y otra vez. Los que responden pueden influirse
por la información que reciben durante las entrevistas lo que contribuye a introducir
paulatinamente sesgos en la muestra y suele decirse que la muestra se contamina con el
tiempo. Otras veces puede haber mejor cooperación en segunda y sucesivas tomas de
información. Si conseguir la colaboración de una unidad muestral implica un coste
relativamente alto respecto a la toma de información puede ser aconsejable utilizar la
misma muestra o una alta proporción de muestra común.
Con los datos de muestras sucesivas de la misma población hay tres clases de cantidades
a estimar y, en cada caso, la política de renovación de la muestra es diferente si
deseamos maximizar la precisión:
1. Si deseamos estimar el cambio en Y de un periodo al siguiente o de un año al mismo
periodo del año anterior, es mejor retener la misma muestra.
2. Para estimar el valor promedio Y sobre varios periodos, es mejor tomar muestras
independientes en cada periodo.

TÉCNICAS DE MUESTREO
46
3. Si nuestro interés se centra en el valor promedio Y para el periodo más reciente,
entonces se obtiene la misma precisión conservando la misma muestra o cambiándola
en cada periodo; el cambio parcial de parte de la muestra puede ser mejor que cualquiera
de estas alternativas.
Lo anterior es consecuencia de la correlación positiva ρ entre las medidas de la misma
unidad en dos periodos consecutivos. Al mantener la muestra constante en periodos
consecutivos, existe una alta correlación entre los datos de las unidades muestrales en
ambas ocasiones, lo que hace que los errores en las estimaciones tiendan a permanecer
en la misma dirección (es decir, si el error es + 2,5% en el primer periodo, puede ser
+1,5% en el siguiente, pero dificílmente será -3%), lo que hace que los cambios se
midan con menor error absoluto que las estimaciones individuales de cada periodo.
Si suponemos muestreo aleatorio simple y que la varianza poblacional es la misma en
los dos periodos t1, y t2 se tiene que la varianza de la media en cada periodo es
( ) ( )V y V y Sn1 2
2
= =
y la varianza de la diferencia resulta ser
( ) ( )V y y Sn c2 1
22 1− = − ρπ
obteniéndose la mayor precisión cuando la parte común de la muestra es πc = 1 ,
mientras que si el cambio se estima a partir de muestras independientes la varianza
resulta en
( )V y y Sn2 1
22− =
Al estimar la media de los dos periodos resulta
( )V y y Sn c
2 12
2 21+
= + ρπ
y si las muestras son independientes
V y y Sn
2 12
2 2+
=

TÉCNICAS DE MUESTREO
47
Hay que notar que en el caso de πc = 1 y ρ = 1, sería V y y Sn
2 12
2+
= , es decir, igual
a la varianza de la media de cualquiera de los periodos. Significa esto que utilizando la
misma muestra en cada periodo, siempre que ρ < 1 la media de dos periodos tiene algo
más de precisión que la de un periodo individual aunque, desde luego, mayor que si se
utilizaran muestras independientes.
En muestreo repetido de la misma población puede tener total sentido la dedicación de
parte de los recursos a lo que anteriormente se ha indicado como primera fase del
muestreo o censo muestral ya que su coste se amortiza sobre varias realizaciones de la
muestra objetivo. En estudios periódicos en el tiempo esta primera fase censal se vuelve
imprescindible si el Universo que se pretende estudiar cambia en el tiempo y no se
dispone de información sobre su evolución: en estos caso resulta necesario realizar
estudios censales periódicos (cada cinco, dos años, o de forma contínua) para preservar
de sesgos a la muestra de estudio. Lógicamente, la muestra de estudio, aunque se
pretenda constante en el tiempo, estará afectada por la propia evolución del Universo y
será necesario introducir cambios paulatinos en la misma para su adaptación al carácter
cambiante y evolutivo del Universo.
Cuando se muestrean poblaciones con un alto grado de asimetría ya se vió la
importancia del muestreo estratificado para la precisión. En estos casos la varianza por
estrato suele aumentar con el valor de la variable de estudio (tamaño de la unidad) de
forma que la afijación óptima es la única garantía para que el factor de expansión de las
unidades grande o muy grandes se mantenga dentro de límites razonables. Pensemos
que en cualquier proceso de muestreo, el total poblacional se estima aplicando a cada
unidad muestral un factor de expansión Fi, de forma que el total estimado es
!Y Y Fi
n
i= ∑1
. La cantidad Y FYi i
! es la contribución de la i-ésima unidad muestral a la
estimación y es la misma para la estimación del total que para la media. Con muestreo
aleatorio o con afijación proporcional Fi es igual para todas las unidades muestrales y la
contribución depende del valor Yi: valores muy altos van a resultar en contribuciones
muy altas y estimaciones con alto error de muestreo y, por tanto, poco fiables. Resulta
intuitivo que cuanto mayor es Yi menor debe ser Fi con el fin de preservar a la

TÉCNICAS DE MUESTREO
48
estimación final de contribuciones extremas debidas a una sola o unas pocas unidades:
no parecería muy fiable una estimación obtenida con una muestra de 100 unidades (100
sumandos) , de las cuales una sola de ellas represente el 80% del total estimado, cuando
cada sumando en promedio contribuya con un 1%. La afijación óptima es la única
garantía para evitar estos problemas.
XII. ERRORES NO DE MUESTREO
Hasta ahora hemos supuesto que 1) la población marco coincide con la población
objetivo, 2) que la muestra real alcanzada se corresponde con la muestra inicialmente
planificada y seleccionada probabilísticamente y 3) que la información obtenida en cada
unidad muestral es correcta. En estas condiciones la única fuente de error del estimador
es el error de muestreo que es la variación aleatoria que se presenta cuando se miden n
de las unidades en lugar de la población completa N. Lamentablemente esta situación
ideal no se da con frecuencia en la práctica y debemos asumir la presencia de otros
errores, que se presentan cuando no se cumple cualquiera de los tres supuestos
mencionados y que se agrupan bajo el nombre de errores no de muestreo o errores
ajenos al muestreo.
Cuando la población marco no coincide con la población objetivo tenemos los llamados
errores de cobertura. Recordemos que la población marco es la población que sirve de
base para la selección de la muestra. Podemos pensar en un listado del que se selecciona
la muestra: puede haber unidades de la población objetivo no contenidas en el listado
(omisiones) o puede haber unidades en el listado que no se corresponden con la
población objetivo (unidades vacias), incluso el listado puede contener unidades
duplicadas:
(1)+(2) = población marco
(1)
(2)
(3)

TÉCNICAS DE MUESTREO
49
(1)+(3) = población objetivo
Con la muestra seleccionada de la población marco podremos estimar la proporción de
unidades (1) y hacer que los resultados estimados se refieran al Universo (1), parte
coincidente entre la población marco y la población objetivo, pero no a la parte (3),
conjunto de unidades omitidas en el listado. Una solución para disminuir errores de
cobertura puede ser la utilización de varios listados. No obstante, si las proporciones (2)
y (3) son altas será necesario utilizar conjuntamente una muestra de la lista junto con
otro procedimiento de selección, por ejemplo áreas, que nos permita acceder a la parte
(3). Una muestra en primera fase nos puede servir para determinar estimaciones de (1) y
(3) y por tanto de la población objetivo.
Los problemas de cobertura no son exclusivos de la utilización de listas. Pensemos en
un muestreo por áreas en una ciudad en el que se parte de planos o mapas incompletos:
manzanas, urbanizaciones o barrios de reciente construcción pueden quedar omitidos
del marco.
Cuando la muestra real alcanzada no se corresponde con la muestra inicialmente
planificada, es decir, no se obtiene información en todas las unidades de la muestra,
decimos que existe falta de respuesta o no respuesta. Aparte la no respuesta por
unidades omitidas en el marco, ya mencionada, la falta de respuesta puede agruparse en
dos principales tipos:
a) No localizado o falta de contacto, que puede ser debido a:
a1) Ausencia temporal durante las horas de entrevista (no-en-casa). Es conocido que
familias en las cuales ambos padres trabajan y las familias sin niños son más difíciles de
alcanzar que familias con niños pequeños o con personas jubiladas.
a2) Viaje, vacaciones.
a3) Enfermedad.
a4) Problemas de lenguaje.
a5) Movilidad gegráfica: cambio de dirección o domicilio, cambio de ciudad.
a6) Falta de motivación o experiencia en el entrevistador para contactar con el
entrevistado. Está comprobado que las tasas de no respuesta varían por entrevistador.

TÉCNICAS DE MUESTREO
50
a7) Barrio o vecindad “dificil”.
b) Negativa a colaborar, debido a:
b1) Falta de tiempo.
b2) Falta de motivación o de interés por el tema de la encuesta.
b3) No desea que el entrevistador conozca sus respuestas u opiniones.
b4) No desea estar “registrado”.
b5) Cansancio de las entrevistas.
b6) Cuestionario demasiado largo, preguntas complicadas, preguntas que rozan la
intimidad.
b7) Los “hueso duro”. Personas que cerradamente rechazan ser entrevistadas o están
sistemáticamente fuera de casa durante el tiempo disponible para el trabajo de campo.
b8) Falta de habilidad del entrevistador para conseguir la colaboración. Vale aquí el
comentario de a6): hay entrevistadores que consiguen mejores tasa de respuesta que
otros.
b9) La colaboración es, finalmente, voluntaria: “Busque a otro que yo no puedo ahora”.
A estos dos grupos de no respuesta puede añadirse la falta de respuesta parcial: el
entrevistado no responde a parte de las preguntas porque no tiene la información o,
simplemente, no está dispuesto a facilitarla.
Para evaluar los efectos de la falta de respuesta conviene pensar en la población dividida
en dos estratos: en el primero se incluyen todas las unidades para las cuales se
obtendrían mediciones si caen en la muestra y en el segundo se incluyen las unidades
para las que no se obtendrían mediciones. La muestra no proporciona información del
estrato 2, lo cuál no sería un problema si se pudiera suponer que las características que
se miden en el muestreo son las mismas, en promedio, en el estrato 2 que en el estrato1.
Desde el momento que esto no sea así estaremos en presencia de un sesgo causado por
la falta de respuesta.
Suponiendo muestreo aleatorio simple, sean N1 y N2 el número de unidades en el
Universo en cada uno de los dos estratos y W N N1 1= , W N N2 2= , es decir, W2 es la
proporción de no respuesta en toda la población y W1 la proporción de respuesta.

TÉCNICAS DE MUESTREO
51
Terminado el trabajo de campo tenemos datos del estrato 1 pero no del estrato 2 y
siendo la media muestral y1 estimador insesgado de la media poblacional del estrato 1,
Y1 , la cantidad de sesgo en la media de la muestra es
( ) ( ) ( )E y Y Y Y Y W Y W Y W Y Y1 1 1 1 1 2 2 2 1 2− = − = − + = −
es decir, el sesgo es el producto de la proporción de no respuesta y la diferencia entre las
medias de los dos estratos. Al no disponer de información de Y2 , el tamaño del sesgo es
desconocido.
La falta de respuesta no debe ignorarse o pensar que se corrige sustituyendo en la
muestra a los que no responde por otros que sí colaboren, ya que ello no va eliminar el
sesgo, simplemente nos mantiene el tamaño de muestra. Por el contrario hay que ser
conscientes de que la no respuesta va a ocurrir y asignar, en lo posible, algunos recursos
y disponer de algunas estrategias para reducir su proporción. Algunos procedimientos
para reducir la no respuesta son:
1) Cartas y llamadas telefónicas por adelantado.
2) Dar algún incentivo por la colaboración.
3) Programar visitas repetidas puede ser de gran efectividad para reducir los no-en-casa.
4) Mejora de los procedimientos de recogida de información. Si la información se
recoge por entrevista personal el entrenamiento del entrevistador es fundamental: la
interacción positiva entrevistador-entrevistado es básica para el éxito de la entrevista, lo
cuál puede requerir que el entrevistador disponga de distintas estrategias para afrontar la
entrevista en función de ciertas características observables de los encuestados. Preservar
la intimidad del entrevistado puede favorecer el dejarle el cuestionario para que lo
rellene y envíe posteriormente por correo, aunque se haya tenido un primer contacto
personal para obtener la colaboración. Otro aspecto a tener en cuenta es que cuanto más
activa (más tiempo requiere) sea la colaboración de la unidad muestral menor es su
disposición a colaborar: pensemos en un panel de audiencia de TV en el que el hogar
debe rellenar y enviar por correo un largo y tedioso cuestionario sobre qué ha visto cada
día en relación con la instalación de un audímetro conectado al televisor que registra y
transmite lo que el televisor emite en cada momento; la colaboración del hogar en el
caso del audímetro es mucho más pasiva (menos molestia), lo cuál favorece la
colaboración.

TÉCNICAS DE MUESTREO
52
En la práctica y a pesar de las medidas que se tomen será imposible, en general, reducir
la no respuesta a cero por lo que se hace imprescindible su medición y control. Un
primer aspecto en este sentido es cuantificar la tasa de no respuesta según distintas
causas. Ello puede ayudar para reducir las tasas de no respuesta en encuestas
posteriores. En ocasiones será posible recoger ciertas características observables de las
unidades no respuesta que puedan ser utilizadas posteriormente en procedimientos de
ajuste para remover los sesgos de no respuesta en las estimaciones finales.
Normalmente, además de las variables que hayan servido para la estratificación del
Universo se dispone de información poblacional de otras características que pueden
servir para controlar la “microrrepresentatividad” final de la muestra obtenida,
comparando los valores poblacionales de estas variables conocidas con los estimados
por la muestra. Éste control de microrrepresentatividad es fundamental en presencia de
falta de respuesta y nos puede ayudar a determinar ciertas características del estrato de
no respuesta Las desviaciones que se producen pueden utilizarse para modificar los
factores de expansión originales de cada unidad muestral, en un proceso iterativo, hasta
conseguir que los valores “estimados” coincidan con los conocidos en el Universo para
las distintas variables incluidas en el proceso. Este proceso iterativo de ajuste en los
factores originales de expansión se conoce también como equilibraje de la muestra y
puede contribuir a remover sesgos introducidos en la muestra final, en la medida en que
las variables objeto de investigación puedan estar correlacionadas con las variables que
intervienen en el proceso de equilibraje.
Un tercer tipo de error no de muestreo se produce por errores de medición y errores que
se introducen en la producción de los resultados de una encuesta. Estos errores suceden
cuando el valor medido Yi* (o el utilizado para la estimación) no se corresponde con el
valor real Yi. Se conocen también por errores de respuesta y pueden ser varias las
causas que los producen:
1) Instrumentos de medición inadecuados o sujetos a error.
2) Fallos de memoria. El entrevistado responde lo que él cree que hizo, pero no lo qué
realmente hizo.

TÉCNICAS DE MUESTREO
53
3) El entrevistado dá una respuesta falsa, bién inducido por el entrevistador (quizá por el
cuestionario), o bién porque no desea que “su verdad” quede registrada (“qué dirán...”).
4) Olvido. Por ejemplo en un panel de hogares el hogar colaborador olvida anotar
algunas compras en el diario o en un panel de audímetros una persona olvida
identificarse.
5) Falta de información. El informante no dispone de toda la información para contestar
y da una respuesta aproximada.
6) Errores de codificación y grabación que introducen en el proceso un valor erróneo
con independencia de que el valor original fuera correcto o no.
Si suponemos que las mediciones Yi estan sujetas a un sesgo constante B Y Yi i= −* cuya
magnitud se desconoce, entonces la media muestral está también sujeta al sesgo,
mientras que la estimación del error de muestreo no se ve afectado por el sesgo ya que
se deriva de una suma de cuadrados de los términos ( )Y yi − 2 . Este hecho puede
desvirtuar los límites de confianza, al aplicar a una cantidad sesgada una variabilidad
que no contempla el sesgo. Con sesgo constante, estimadores de cambio de un periodo a
otro o de un estrato a otro permanecen sin sesgo, precísamente por la constancia del
mismo.
Si los errores de medición son independientes de unidad a unidad dentro de la muestra y
promedian cero sobre toda la población la media muestral sigue siendo estimador
insesgado y los errores de medición son tenidos en cuenta en el cálculo de errores
estándar. La precisión de las estimaciones disminuye. Si los errores de medición no son
independientes la formula usual de error estándar es un subestimador, debido a que en la
práctica la correlación intramuestra de los errores será positiva.
Una técnica útil para para el estudio de errores correlacionados es el de submuestras
mutuamente penetrantes. En forma simple consistiría en dividir una muestra aleatoria de
n unidades en k submuestras de n/k unidades cada una. El trabajo de campo y
procesamiento se planean de forma que no hay correlación entre los errores de medición
de dos unidades cualesquiera en submuestras diferentes. Por ejemplo si la correlación
que hay que tratar proviene solo de sesgos imputables a los entrevistadores se puede

TÉCNICAS DE MUESTREO
54
asignar cada submuestra a un entrevistador. Un análisis de varianza posterior “entre
submuestras” y “dentro de submuestras” ayuda a determinar el efecto del entrevistador.
Con datos cuantitativos se mencionó anteriormente el concepto de contribución de una
unidad muestral al total estimado. El análisis cuidadoso de las contribuciones puede
ayudar en la detección de datos especialmente extremos que pueden tener efectos fuertes
en las estimaciones y provenir de errores de medición.
Como comentario final hay que decir que al planear un estudio por muestreo debe
prestarse especial atención a los errores no de muestreo que pueden presentarse en
cualquier fase del trabajo y, si son importantes, incluso invalidar los resultados. Por otra
parte detectarlos y cuantificarlos no es tarea fácil. Sólo la anticipación y el análisis
cuidadoso de cada paso en el proceso de muestreo y de los resultados pueden ayudar.
Los errores de muestreo desde el momento que pueden ser evaluados y estimados dejan
de tener importancia. El error de muestreo se constituye en una medida de la calidad del
diseño teórico de la muestra pero no mide la calidad real, afectada por los errores no de
muestreo.


![PROPIEDADES FÍSICAS Y MECÁNICAS DE … · tomada de la NTC 4017, Métodos para muestreo y ensayos de unidades de mampostería y otros productos de arcilla [16], en donde se expone,](https://static.fdocuments.co/doc/165x107/5bbf81a809d3f28c0d8c2b29/propiedades-fisicas-y-mecanicas-de-tomada-de-la-ntc-4017-metodos-para-muestreo.jpg)















