
Teide - istac.webs.ull.es · Todos los institutos de estadística necesitan depurar los datos que...
105
Teide Técnicas de Edición e Imputación de Datos Estadísticos 15 de Julio de 2004 Proyecto “Depuración de encuestas estadísticas” Entre el ISTAC y la ULL a través de la FEU Desarrollado desde el 1 de Agosto de 2003 al 31 de Julio de 2004 http://webpages.ull.es/users/istac Responsable en la ULL: Juan José Salazar González ([email protected]) Desarrollador en la ULL: Sergio Delgado Quintero ([email protected])
Transcript of Teide - istac.webs.ull.es · Todos los institutos de estadística necesitan depurar los datos que...

Teide
Técnicas de Edición e Imputación de Datos Estadísticos15 de Julio de 2004
Proyecto “Depuración de encuestas estadísticas”Entre el ISTAC y la ULL a través de la FEU
Desarrollado desde el 1 de Agosto de 2003 al 31 de Julio de 2004http://webpages.ull.es/users/istac
Responsable en la ULL: Juan José Salazar González ([email protected])Desarrollador en la ULL: Sergio Delgado Quintero ([email protected])

2

Índice general
Prólogo 5
1. Introducción 71.1. Los pasos previos a la imputación . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2. Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3. Definición . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.4. Tipos de edición . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.5. Software existente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2. Instituto Canario de Estadística 212.1. El Instituto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2. Experiencias previas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.3. EICVHC 2004 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3. Metodología General 293.1. Problema de localización del errores . . . . . . . . . . . . . . . . . . . . . . . . . 293.2. Paradigma de Fellegi-Holt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.3. Fellegi-Holt para datos categóricos . . . . . . . . . . . . . . . . . . . . . . . . . . 403.4. Fellegi-Holt para datos numéricos y mixtos . . . . . . . . . . . . . . . . . . . . . . 45
4. Metodología Aplicada 494.1. Edits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 494.2. Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 504.3. El proceso de edición . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 504.4. El proceso de imputación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5. Implementación práctica 555.1. Ámbito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.2. Flujo de Programa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.3. Estructuras de Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.4. Estructuras de Clases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 615.5. Problemas prácticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3

4 ÍNDICE GENERAL
6. Manual de usuario 736.1. Inicio de la aplicación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 736.2. Manejo de Metafiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 746.3. Modelo de pestañas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 766.4. Pestaña de Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 776.5. Pestaña de Microdatos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 786.6. Pestaña de Edits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 806.7. Pestaña de Rangos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 836.8. Pestaña de Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 876.9. Pestaña de Imputación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 916.10. Pestaña de Estadísticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
7. Experiencias computacionales 957.1. Descripción del conjunto de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 957.2. Evaluación de rangos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 967.3. Evaluación de edits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 977.4. Imputación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 977.5. Comentarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
8. Conclusiones y Futuro 103
Bibliografía 105

Prólogo
Todos los institutos de estadística necesitan depurar los datos que reciben a través de susencuestas antes de proceder a extraer conclusiones de tales datos. Este proceso de depuraciónconsiste en verificar si los valores de cada encuesta satisfacen un conjunto de reglas de consis-tencias, típicamente conocidas como edits. Por ejemplo, un edit puede ser “si el campo ‘estadocivil’ contiene ‘divorciado’ entonces el campo ‘edad’ debe contener un valor no menor de 14”.Los registros de la encuestas que cumplan todas (o casi todas) las reglas se consideran válidos,mientras que cuando un registro no cumple todas (o casi todas) las reglas se considera incorrecto.Cuando un registro incorrecto no cumple muchas reglas (quizás ninguna) entonces el institutode estadística puede considerar la opción de eliminarlo o sustituirlo por otro registro en unasegunda fase de la encuesta. Sin embargo, cuando un registro no cumple todas las reglas perosí un número suficiente de ellas (quizás las más importantes) entonces el instituto de estadísticase plantea el problema de localizar qué campos en tal registro pueden ser los causantes de loserrores, y qué valores habría que re-asignarles a tales campos para que el registro modificadosea válido y que la perturbación de los datos no afecte a las conclusiones que se extraigan de laencuesta. Este problema se conoce como Edición e Imputación: “edición” es localizar los camposa modificar e “imputación” es determinar los nuevos valores para tales campos.
Dada la importancia de este problema en todos los institutos de estadística, y dada la varie-dad de formas en las que se podría interpretar y afrontar, durante los últimos 50 años se hanrealizado estudios científico-técnicos buscando fijar unos fundamentos que puedan ser válidospara el mayor número posible de encuestas, y por tanto que puedan ser aceptados por el mayornúmero posible de institutos de estadística. Entre esos estudios cabe destacar el artículo de Fe-llegi y Holt publicado en 1979 en la revista “Journal of the American Statistical Association”, yen el que se proponen las principales pautas con las características anteriores. Principalmente sedice que un método para depurar un registro incorrecto debe pretender siempre cambiar el menornúmero posible de campos de manera que luego existan unos valores imputables. Esto plantea laprimera parte del problema (la edición) como un problema combinatorio de los que se trabajanen Investigación Operativa. Una vez determinados los campos a cambiar, la segunda parte (laimputación) debe tratar de mantener las propiedades estadísticas de los registros correctos, ypara ello se han desarrollado varios mecanismos en los últimos años. Quizás el más conocido esel llamado donante y que consiste en buscar un oportuno registro correcto del que extraer losvalores para los campos a modificar. Principalmente esta segunda parte cae dentro de diversostrabajos en el campo de la Estadística. Ahora bien, las dos partes del problema no pueden (o nodeben) resolverse aisladamente y, dada la cantidad de registros con los que hay que trabajar, esnecesario un mecanismo automático que ayude al técnico del instituto de estadística. Por tanto,es fundamental en todo este proceso el aprovechar los avances de la tecnología, y en particular las
5

6 ÍNDICE GENERAL
herramientas modernas del campo de la Computación (ordenadores, lenguajes de programación,bases de datos, entornos gráficos,etc.).
El Instituto Canario de Estadística (ISTAC) ha motivado y apoyado en todo momento eldesarrollo e implementación de Teide. De hecho, el trabajo que se expone en esta memoria,realizado en el Departamento de Estadística, Investigación Operativa y Computación (DEIOC),fue fruto de un convenio previo firmado entre el ISTAC y la Universidad de La Laguna (ULL).Además de financiar económicamente el trabajo, el ISTAC ha contribuido con personal suyoque ha ido sugiriendo ideas y evaluando diversas versiones preliminares sobre datos próximos areales. Concretamente se está usando Teide en el ISTAC para depurar la encuesta de ingresos ycondiciones de vida de los hogares canarios, una encuesta de sanidad y una encuesta de turismo.Lamentablemente ninguna de estas experimentaciones ha concluido, pero se sigue trabajando enellas.
La presente memoria resume un trabajo iniciado en agosto de 2003 a través de siete capí-tulos. El capítulo 1 presenta el contexto en el que nace la edición e imputación, e introduce laterminología básica que se usarán en el resto de la memoria. En el capítulo 2 se exponen algunasnecesidades prácticas que llevaron al ISTAC a interesarse por el desarrollo y apoyo de este traba-jo. El capítulo 3 describe el problema de la edición e imputación mediante modelos matemáticosde Optimización y mediante las pautas introducidas por Fellegi y Holt. La metodología pararesolver los problemas prácticos que se han usado se muestra en el capítulo 4, mientras que losdetalles técnicos sobre la implementación realizada aparece en el capítulo 5. El capítulo 6 descri-be con detalle los procedimientos automáticos que ofrece Teide. El capítulo 7 expone algunosresultados computaciones usando Teide sobre una de las experiencias piloto desarrollada por elISTAC, y que es la Encuesta de Ingresos y Condiciones de Vida de los Hogares Canarios 2004.La memoria termina con unas conclusiones y futuras posibilidades de este proyecto.
El presente trabajo ha sido implementado por Sergio Delgado Quintero a través de una becafinanciada por este convenio entre el ISTAC y la ULL. Al presente trabajo han contribuido deforma notable varias personas del ISTAC. Agradecemos de forma especial las numerosas ideasaportadas por Fayna Alamo Santana, José Molina González, Rafael Betancort Villalba y AlbertoGonzález Yánez, todos funcionarios del ISTAC. También agradecemos la colaboración de lasbecarias Rosana García García y Yolanda Ramallo Farina, que con su trabajo nos han ayudadoa usar Teide sobre muestras iniciales de la encuesta de ingresos y condiciones de vida y de laencuesta de sanidad. Finalmente también queremos expresar nuestro agradecimiento al Directordel ISTAC, Álvaro Dávila González, por su constante confianza en la investigación científico-técnica que hacemos en la ULL. También agradecemos al DEIOC y a la ETSII (ambos en laULL) por habernos permitido desarrollar este proyecto en sus instalaciones, y al “Ministerio deCiencia y Tecnología” por su apoyo a través del proyecto de investigación TIC-2002-00895.

Capıtulo 1Introducción
En este capítulo se pretende dar una visión general de la edición e imputación de datosestadísticos (también llamada “depuración de datos”), partiendo de la necesidad y la motivaciónque lleva a los institutos de estadística a realizar estas operaciones hasta la descripción delsoftware existente para automatizar dichas tareas.
1.1. Los pasos previos a la imputación
Una de las tareas principales de los institutos de estadística es la obtención de datos para lasatisfacción de necesidades de información de la sociedad. Para ello realizan trabajos estadísticosrecogiendo datos muestrales, censales, o aprovechando datos administrativos.
El esquema de trabajo en una operación estadística, consta de la siguientes etapas:
1. Planificación.
2. Diseño y realización.
3. Ejecución.
4. Validación del resultado.
5. Difusión.
A continuación se explican de forma general cada una de estas etapas.
1.1.1. Planificación
En esta etapa se fijan los objetivos y se establecen las definiciones básicas, además de analizarla información disponible en el dominio de estudio y de diseñar un plan de acción.
1.1.2. Diseño y realización
En esta etapa se establecen los métodos y se elaboran los procedimientos que permitiráncumplir los objetivos fijados. Se diseña el marco de muestreo, el plan de muestreo, el cuestionario,el método de recogida, el método de verificación manual, la codificación y la grabación, el métodode detección de errores con corrección manual, el método de imputación automática, el métodode estimación, los sistemas informáticos de soporte y los manuales de procedimientos.
7

8 CAPÍTULO 1. INTRODUCCIÓN
1.1.3. Ejecución
En esta etapa se obtienen y tratan los datos, siguiendo los procedimientos establecidos en laanterior.
1.1.4. Validación del resultado
En esta etapa se analiza la realización de las tareas de ejecución y los datos obtenidos, convistas a decidir si los resultados tienen un nivel de calidad aceptable. Se analizan y evalúan lacobertura obtenida, el nivel de no respuesta, la precisión de las respuestas, los errores produ-cidos durante la grabación, el nivel y distribución de los errores detectados y las imputacionesrealizadas.
La calidad del trabajo estadístico se logra extremando el cuidado en la realización de lasetapas descritas anteriormente. Dado que hay una gran variedad de investigaciones estadísticas,que se realizan en muy diferentes contextos y bajo organizaciones muy distintas, no hay normaso métodos prefijados sobre cómo realizar cada una de las tareas necesarias en cada una de lasetapas.
En el proceso de recoger y tratar los datos estadísticos se pueden producir distintos tipos deerrores. No hablamos de errores de muestreo, sino los errores en los datos de la encuesta; es decir,los errores ajenos al muestreo, que clasificamos en errores en las identificaciones y errores en losdatos propiamente dichos. Los errores en las identificaciones son importantes porque afectan atodo el proceso de manipulación y clasificación de la información.
1.1.5. Difusión
En esta etapa se hacen llegar los resultados estadísticos obtenidos a la sociedad. A través delacceso a los medios de comunicación, de folletos informativos o revistas especializadas, el granpúblico tiene acceso a los datos y conclusiones que realizan los institutos de estadística. Estaetapa es muy importante, ya que el acierto en el acceso a la sociedad permite que se conozca eltrabajo efectuado y se valore es su justa medida.
1.2. Motivación
La toma de decisiones hoy en día es un asunto de prioridad máxima para directores, políti-cos, empresarios, etc. Estas personas necesitan de información de alta calidad que les produzcadatos estadísticos sobre aspectos sociales, demográficos, industriales, económicos, financieros,culturales, etc. para llevar a cabo sus tareas.
Los institutos de estadística desempeñan un papel fundamental en proveer dichos datos esta-dísticos a la sociedad y a los decisores. El trabajo de los institutos de estadística no es fácil. Lasociedad cambia con una rapidez insospechada, así como todos sus aspectos, y además de ello,el usuario de a pie, puede – en gran medida, gracias a la potencia de los ordenadores personales– realizar tratamientos de gran cantidad de datos, sacando sus propias conclusiones. Por ello, losusuarios finales de datos estadísticos exigen una alta calidad y un gran detalle en los trabajoselaborados por los institutos de estadística. Y no sólo esto. El trabajo de los institutos de es-tadística debe ser realizado en períodos de tiempo muy pequeños y con unos recursos – por logeneral – bastante escasos.
El hecho de producir datos de alta calidad en períodos cortos de tiempo es bastante difícil,sobre todo si pensamos que los datos recogidos normalmente contienen errores. La etapa derecolección de datos es, en sí misma, una fuente de posibles errores. Y el resto de procesos que se

1.2. MOTIVACIÓN 9
dan en una producción de datos introducen de igual manera, posibles pérdidas o incoherenciasde información. Así, desde el momento en el que el informante responde, puede darse el error (demanera voluntaria o no), pasando por los errores que se pueden producir cuando se transcribenlos datos de los cuestionarios en papel a los ordenadores, etc. Es necesario, por tanto, llevar acabo un largo proceso de imputación de datos sobre la información recogida, poniendo otrosdatos coherentes.
La edición de datos ha sido un aspecto que tradicionalmente las agencias de estadística hancuidado mucho y han potenciado, ya que se considera un elemento básico en la publicación deresultados estadísticos fiables y de calidad. En el procesamiento tradicional de datos, la ediciónera principalmente una tarea interactiva, en la cual los errores y las inconsistencias detectadas semostraban al técnico en la pantalla del ordenador y éste tomaba decisiones al respecto, pudiéndoseen su caso repetir el contacto con el informante para aclarar las posibles incoherencias que sehubieran encontrado.
En varios estudios realizados por técnicos estadísticos se ha demostrado que esta tarea tanminuciosa de intentar corregir todos los datos a un nivel muy grande de detalle no siempre esnecesario a la hora de publicar resultados estadísticos. Los principales productos generados porlos institutos de estadística son tablas de datos agregados, basados en muestras de la población.Debido a esto, pequeños errores en los individuos son aceptables en los resultados globales. Enprimer lugar esto es así porque los pequeños errores en registros individuales tienden a cancelarse(errores que suman y que restan) y en segundo lugar – debido a que los datos provienen de unamuestra de la población – siempre habrá un error de muestreo en los resultados publicados,incluso cuando todos los datos recogidos sean correctos. Si intentamos obtener datos de calidad,normalmente es suficiente con intentar eliminar los errores más influyentes de la muestra. Estasconclusiones han sido confirmadas durante muchos años mediante experiencias prácticas porvarios institutos de estadística.
A menudo, tanto en el pasado como – incluso – en el presente, los institutos de estadísticahan dedicado mucho esfuerzo a la corrección de datos que no tienen un impacto notable en elresultado de los informes estadísticos producidos. Esto se conoce como “over-editing”. Esta técnicano solamente consume recursos innecesarios, sino también mucho tiempo lo que provoca que elperíodo de tiempo entre la recogida de los datos y la publicación final de los resultados estadísticossea muy grande, lo que conlleva una pérdida importante de eficiencia y productividad. Incluso,en muchas ocasiones, suele aplicarse otra técnica posterior al “over-editing” que se conoce como“creative-editing”. Estos procesos consumen tiempo innecesariamente y provocan, en muchoscasos, alteraciones injustificadas en la calidad de datos. La creciente potencia de los ordenadoresactuales permite a los institutos de estadística plantearse nuevos proyectos y, en su caso, poderabordarlos con garantías de resolución. Uno de estos proyectos es el de la edición e imputaciónautomática de datos, es decir, intentar conseguir datos de alta calidad en un espacio de tiemponormalmente bastante corto usando ordenadores. De esta manera, lo que se intenta es mejorarlos procesos tradicionales de depuración de datos llevándolos al plano computacional. Existenmuchas técnicas, que aunque modernas, son bastante bien conocidas. Se podrían nombrar el“selective-editing”, el “(graphical) macro-editing” y el “automatic-editing”.
El “selective-editing” intenta dividir el conjunto de datos en dos partes: una que probable-mente contenga errores de influencia notable y otra que no los contenga. Posteriormente, sólola primera parte de los datos se edita utilizando el enfoque tradicional interactivo. En “macro-editing” se contrasta la plausibilidad de los agregados. Solamente cuando los agregados son noplausibles es cuando los datos se editan de la manera tradicional. La técnica más moderna deedición es el “automatic-editing”. Esta técnica está opuesta al enfoque tradicional, donde cadaregistro es editado manualmente. Con el “automatic-editing” todos los registros son procesados

10 CAPÍTULO 1. INTRODUCCIÓN
mediante un ordenador. Estas modernas técnicas consumen menos tiempo y dinero que el métodointeractivo tradicional, y normalmente suelen dar resultados de mayor calidad.
El “automatic-editing” es una técnica que, como se ha comentado, ofrece grandes prestacionesen términos de tiempo y recursos. Uno de los problemas más complicados que existen dentro deestas técnicas es el problema de la localización de los datos erróneos, o mejor dicho, de los datosimplausibles. La manera de abordar este problema es desarrollar un algoritmo general que puedaser aplicado a una gran variedad de conjuntos de datos sin necesidad de que el usuario debatener conocimiento específico sobre la encuesta y los detalles del conjunto en el que se trabaja,más que la especificación de las reglas de coherencia que van a ser usadas.
1.3. Definición
Los errores en los datos pueden ser detectados especificando ciertas restricciones que debenser satisfechas por los registros individuales, es decir, los datos de los informantes individuales.Estas restricciones se llaman reglas de coherencia, pero en la mayoría de los casos se usa lapalabra inglesa edits para referirse a ellos. Los edits son especificados por un técnico estadísticoconocedor de la encuesta sobre la que se está trabajando y sobre las restricciones que deben tenerlos datos. Por ejemplo, una persona no puede estar divorciada si no tiene al menos 10 años deedad. Cuando un registro no cumple un edit, se considera erróneo. Cuando un registro satisfacetodos los edits se considera correcto. Los valores de un registro erróneo deben ser modificados detal manera que el registro resultante sea la mejor aproximación a las respuestas verdaderas delinformante.
Para modificar un registro erróneo se deben llevar a cabo dos etapas. En primer lugar, sedeben localizar los valores incorrectos dentro del registro. Esto es lo que se llama el problema delocalización del error ó problema de edición. En segundo lugar, una vez que se tengan identificadoslos campos que son erróneos dentro del registro, hay que pasar a imputarlos, es decir, los valores deestos campos deben ser reemplazados por otros mejores, preferiblemente por los valores correctos.Esto se conoce como el problema de imputación. El problema de la localización del error debe serresuelto de manera que los campos que se consideran erróneos puedan ser imputados de maneraconsistente para lograr que el registro modificado satisfaga todos los edits.
Tradicionalmente, el problema de la localización del error ha sido resuelto por personas sinayudarse de un ordenador. Algunas maneras de resolver el problema de la localización del errorpodrían ser las siguientes: recontacto con el informante, comparación de los datos del informantecon sus datos en anteriores años, comparación de los datos del informante con otros informantesque sean similares a él y el uso del conocimiento y la experiencia de los expertos. El mayorinconveniente del enfoque tradicional es que conlleva un gran consumo de tiempo.
Sobre un registro erróneo, el problema de la localización del error y el problema de impu-tación están fuertemente relacionados. A menudo es difícil distinguir dónde termina la fase delocalización del error y dónde empieza la fase de imputación. Cuando los humanos llevan a ca-bo la edición de datos, frecuentemente buscan maneras de imputar un registro incluso antes determinar con la fase de localización del error.
1.4. Tipos de edición
1.4.1. Edición asistida por ordenador
El uso de ordenadores en la edición de datos empezó hace varios años. En los primeros añosla función de los ordenadores estaba limitada a contrastar qué edits se violaban. Los especialistas

1.4. TIPOS DE EDICIÓN 11
introducían los datos en el ordenador y a continuación éste contrastaba si los datos satisfacíantodos los edits. Luego, para cada registro, el ordenador listaba todos los edits que eran violados, ya partir de ahí, el especialista usaba estas listas para corregir los registros, es decir, se dedicaba arecuperar todos los cuestionarios en papel que no pasaban todos los edits y a corregirlos. Despuésde corregir los datos, estos eran de nuevo introducidos en el ordenador que volvía a contrastarsi se cumplían todos los edits. Este proceso iterativo se repetía hasta que todos los registrossatisfacían todos los edits.
El principal problema de este enfoque es que durante el proceso de corrección manual, noexistía un contraste de consistencia en los registros. Esto daba como resultado, que un registroque se consideraba “correcto” podía incluso fallar en uno o varios edits. Por lo tanto, este registronecesitaría volver a entrar en el proceso de corrección alargándose el tiempo y el costo de laedición. Se estimaba que del 25 al 40% del presupuesto total se dedicaba a la edición.
La introducción de los ordenadores personales y de los sistemas automatizados introdujouna mejora sustancial en la eficiencia de los procesos de edición. Los sistemas automatizadosincorporaban en un solo paso el contraste de edits erróneos y la corrección de los mismos, de talmanera que se aseguraba la consistencia de los datos, y tras un paso se llegaba a converger.
En la misma línea que los sistemas automatizados de edición de datos, nos encontramoscon sistemas denominados CAPI (Computer Assisted Personal Interviewing) y CATI (ComputerAssisted Telephone Interviewing). Estos sistemas permiten, en tiempo de entrevista, detectarciertos errores que pueden ser corregidos in-situ, preguntando de nuevo al informante. Estossistemas parecen ser los mejores a la hora de recoger datos, pero también tienen sus desventajas.La primera desventaja es que estos sistemas son muy caros. Enviar un cuestionario en papel esmucho más fácil y barato que utilizar esta tecnología. La segunda desventaja, y muy importante,es que tanto CAPI como CATI están mucho menos preparados para cuestionarios en empresasque para cuestionarios a personas o a viviendas. Un prerrequisito de estos sistemas, es que elinformante debe ser capaz de responder las preguntas durante la entrevista. Para un cuestionarioen hogares o personas, los informantes suelen ser rápidos en la contestación a las preguntas, peroen una empresa, las respuestas no son tan inmediatas y se necesita tiempo para poder dar unainformación fiable. A menudo, se necesita recoger información de varios departamentos de unaempresa para completar un cuestionario para un instituto de estadística, y esto lleva tiempo.
Por estos motivos y muchos otros, la mayoría de los institutos de estadística se decantan porsistemas CAPI o CATI para realizar entrevistas en encuestas a personas o viviendas, pero nopara realizar entrevistas en empresas. Una alternativa para llevar a cabo los cuestionarios enlas empresas, es, por ejemplo, utilizar Internet. Las empresas pueden rellenar electrónicamentedichos cuestionarios, y cuando los tengan terminados, enviarlos al instituto de estadística corres-pondiente. Esto permite incorporar ciertos edits dentro del software que recoge la informaciónpor Internet, para poder realizar ciertos contrastes que descarguen las posteriores fases de laedición. El uso de Internet parece una herramienta muy atractiva a la hora de recoger datos,aunque , como todo, tiene también ciertos inconvenientes de tipo tecnológico: el software usado ylas comunicaciones deben ser rápidas y fiables; se debe mantener la seguridad y confidencialidadde los datos; el software debe ser flexible para permitir al informante no tener que rellenar todoslos campos de una vez, y poder retomarlo posteriormente. Este ultimo punto es muy importante,ya que si un informante rellena un cuestionario y existen preguntas que no sabe responder yel programa le obliga a responder sin tener la posibilidad de continuar, posiblemente dejará derellenar el cuestionario y no se obtendrá información al respecto.
La edición asistida por ordenador es, hoy en día, la manera estándar de realizar la edición dedatos. Puede ser usada tanto para datos categóricos como para datos numéricos. El número devariables, edits y registros, puede en principio ser alto, ya que el procesamiento automático por

12 CAPÍTULO 1. INTRODUCCIÓN
parte del ordenador puede manejar grandes volúmenes de información.La principal ventaja que tiene la edición interactiva de datos usando ordenadores personales
y sistemas automatizados ante la edición de los primeros años es que el contraste y la correcciónpueden realizarse al mismo tiempo. Cada registro debe ser editado sólo una vez, con lo quedespués de ese proceso el registro cumplirá todos los edits.
En la edición selectiva y la macro-edición se describen técnicas que tienen como objetivointentar descubrir los errores más influyentes de una manera rápida. Esto implica que estastécnicas son más adecuadas para análisis de datos numéricos que categóricos, ya que es mássencillo definir el término “más influyente” sobre datos numéricos que categóricos. Se consideraque un error numérico es influyente si la diferencia entre el valor almacenado y el valor ideales grande. Sólo queda por especificar que quiere decir eso de grande. En datos categóricos sinembargo, a menudo no existe un concepto de desviación grande entre el valor almacenado y elvalor ideal.
Por otro lado, aunque las técnicas que se van a describir son más apropiadas para datosnuméricos que para datos categóricos, algunas versiones de estas técnicas también son aplicablesa datos categóricos.
1.4.2. Edición selectiva
Ya se ha comentado con anterioridad que no es necesario que un registro sea totalmentecorrecto. Los institutos de estadística publican datos agregados generalmente basados en muestrasde la población, así que pequeños errores en registros individuales son aceptables siempre quelos pesos que tengan estos registros no sean muy altos comparados con los pesos de los otrosregistros.
La edición selectiva es un conjunto de varios métodos que se dedican a identificar los erroresinfluyentes, es decir, los errores que tienen un impacto sustancial en la publicación de los resulta-dos estadísticos. El objetivo de la edición selectiva es dividir el conjunto de datos en dos flujos: elflujo crítico y el flujo no crítico. El flujo crítico consiste en registros que parecen contener erroresinfluyentes, y el flujo no crítico consiste en registros que parecen no contener errores influyentes.Los registros del flujo crítico, los registros críticos, se editan de la manera tradicional de ediciónasistida por ordenador. Los registros del flujo no crítico, los registros no críticos, no son editadosde la manera tradicional de edición asistida por ordenador. Serán más tarde editados de maneraautomática.
Actualmente, no existe una teoría aceptada para los métodos de edición selectiva. Por ello,muchos de estos métodos son simples y están basados en el sentido común. Sería engorrosodescribir todos los métodos que se han desarrollado durante estos años sobre edición selectiva, yno es necesario para comprender el concepto general de la metodología.
La edición selectiva es una técnica relativamente nueva. Se está convirtiendo gradualmenteen un método popular para editar datos comerciales (numéricos). Cada vez más y más institutosde estadística usan la edición selectiva para depurar sus datos, o experimentar con ella.
El alcance de los métodos de edición selectiva está limitado a los datos de negocio (numéricos).En estos datos algunos informantes pueden ser más importantes que otros, simplemente porque lamagnitud de sus contribuciones es mucho mayor. Los datos sociales (categóricos) son datos dondelos informantes contribuyen más o menos de la misma manera. Por lo tanto, en datos sociales esdifícil distinguir entre distintos tipos de informantes. En datos de negocio, esa diferenciación deinformantes es mucho más fácil de realizar.
En la edición selectiva, los datos del período actual pueden ser fácilmente comparados con losdatos en períodos anteriores. No hay límite para el número de edits. Un problema que plantea

1.4. TIPOS DE EDICIÓN 13
la edición selectiva por el momento es que el número de variables no puede ser muy grande.Actualmente, no se disponen de buenas técnicas para combinar alcances locales, por ejemploaquellos basados en la distancia entre los valores almacenados y los valores esperados para cadavariable, dentro de un alcance global para cada registro si existen muchas variables. Esto puedeser un mero problema técnico que se resolverá en su debido momento, pero puede ser un problemafundamental para la edición selectiva. Se necesita mayor investigación sobre este aspecto paradar respuesta.
1.4.3. Macro-edición (gráfica)
La macro-edición ofrece algunas soluciones a los problemas de la micro-edición. Particular-mente, la macro-edición se puede tratar con tareas de edición relacionadas al aspecto de ladistribución. Se distinguen dos formas de macro-edición. La primera forma se llama a veces mé-todo de agregación. Formaliza y sistematiza lo que todo instituto de estadística debería hacerantes de la publicación de resultados estadísticos: verificar si los resultados estadísticos a publi-car parecen plausibles. Esto se lleva a cabo comparando cantidades en las tablas de publicacióncon las mismas cantidades en publicaciones previas. Solamente si se observa un valor inusual seaplican técnicas de micro-edición a los registros individuales y a los campos que contribuyen aese error.
Una segunda forma de macro-edición se denomina método de distribución. Los datos dispo-nibles son usados para caracterizar la distribución de las variables. Entonces, todos los valoresindividuales se comparan con la distribución. Típicamente, se computan medidas de localizacióny extensión. Los registros que contienen valores que podrían ser considerados no comunes (dadala distribución) son candidatos para posteriores inspecciones y posiblemente para editarlos.
Existe un área en el campo de la estadística que provee técnicas para el análisis de la distri-bución de las variables llamada análisis exploratorio de datos. Muchas de estas técnicas puedenser usadas en macro-edición. Estas técnicas hacen uso de gráficas, que son capaces de mostrarpropiedades inesperadas que no se podrían haber deducido de los datos numéricos directamente.
La macro-edición siempre ha sido utilizada de alguna forma en los institutos de estadística.Las técnicas no gráficas de macro-edición pueden ser usadas tanto para datos de negocio (numé-ricos) como para datos sociales (categóricos). El uso de técnicas gráficas parece estar restringidoa datos de negocio (numéricos).
1.4.4. Edición automática
El objetivo de la edición automática es que el ordenador realice todo el trabajo. El papeldel humano en estas técnicas es la de proveer al ordenador con metadatos, tales como edits,modelos de imputación y reglas para guiar el problema de la localización de errores. Despuésde que estos metadatos hayan sido proporcionados, el ordenador edita los datos y todo lo quedebe hacer el humano es examinar la salida generada por el ordenador. En el caso de la calidadde los datos editados se considere demasiado baja, los metadatos deben ser ajustados o algunosregistros deben ser editados de otra manera.
En los años 60 y 70, la edición automática estaba basada en reglas predeterminadas delsiguiente tipo: si una cierta combinación de edits se violan de una cierta manera entonces sedeben llevar a cabo ciertas acciones para corregir los datos. Hay algunos problemas con esteenfoque determinístico. En primer lugar, a menudo es difícil desarrollar reglas predeterminadasque aseguren que todos los datos cumplirán todos los edits después de que hayan sido editados.Esto puede llevar a un proceso iterativo complejo donde los registros editados que todavía no

14 CAPÍTULO 1. INTRODUCCIÓN
cumplen algunos edits son de nuevo editados. Más aún, para algunos registros este proceso puedeser no convergente.
En segundo lugar, el conjunto de reglas predeterminadas a desarrollar será muy grande ymuy difícil de tratar, y basar un programa de ordenador en este complejo conjunto de reglas seráincluso más difícil.
Freund y Hartley (1967) propusieron un enfoque alternativo basado en la minimización de ladesviación total entre los valores originales de un registro y los valores correctos más la violacióntotal los edits (cuanto mayor sea un edit violado, más contribuye este edit a la función objetivo).En este sentido, sólo tienen que ser especificados los edits. Los valores correctos son determinadosminimizando una función cuadrática. Este enfoque nunca llegó a ser popular entre la comunidadcientífica, probablemente porque los edits suelen seguir estando violados después de la correcciónde los datos.
En 1976 Fellegi y Holt publicaron un artículo en el Journal of the American Statistical As-sociation que fue un punto y aparte. En su artículo, Fellegi y Holt describen un paradigma parala localización de errores en un registro de forma automática. De acuerdo a este paradigma, losdatos de un registro deberían satisfacer todos los edits cambiando los valores del menor númeroposible de variables. Este paradigma generalizado es la base de varios algoritmos y programasde ordenador para localizar errores en registros de manera automática. Es el estándar de factopara los sistemas modernos de edición automática.
La edición automática ya se usaba en los años 60 y 70. Sin embargo, nunca llegó a serdemasiado popular. Esto se debía a varias razones. En primer lugar, en aquellos tiempos losordenadores eran máquinas demasiado lentas para realizar la edición automática. En segundolugar, el desarrollo de un sistema para edición automática era considerado demasiado complicadoy demasiado costoso para los institutos de estadística. En tercer lugar, muchos institutos deestadística asumían que los datos editados automáticamente eran de una calidad muy baja. Estoes un punto importante.
La edición automática puede ser usada tanto para datos categóricos como para datos numé-ricos. Sin embargo, la mayoría de los sistemas automáticos de edición suelen tratar o bien condatos categóricos o bien con datos numéricos.
En la edición automática, los datos de un período actual pueden ser comparados con datos deun período anterior. Una manera simple de hacer esto es, por ejemplo, combinar el registro de uninformante en el período actual con el registro del mismo informante en un período anterior en unsolo registro más grande, el registro combinado. Los datos del período anterior son etiquetadoscomo fijos, indicando que en el proceso de edición automática no deben ser cambiados.
Cuando la edición automática es usada para depurar datos, la imputación puede ser llevadaa cabo a través de gran variedad de métodos de automáticos. El hecho de que un modelo seamejor depende de que el modelo se ajuste más o menos a las características del conjunto de datosque tenemos entre manos.
1.5. Software existente
Dentro de los sistemas automáticos de edición no existen demasiadas herramientas desarro-lladas hoy en día para su tratamiento. En este punto se hará mención de algunas de las másimportantes.

1.5. SOFTWARE EXISTENTE 15
1.5.1. Sistema DIA
DIA (Depuración e Imputación Automática) es un sistema generalizado para la depuraciónautomática de datos cualitativos. Desarrollado en el Instituto Nacional de Estadística De España(INE) en 1985, trata tanto los errores sistemáticos como los aleatorios. El tratamiento de loserrores aleatorios se realiza siguiendo la metodología de Fellegi y Holt. El tratamiento de loserrores sistemáticos es una característica específica de DIA. Para estos errores, DIA tiene unsubsistema de imputación determinística, que utiliza reglas de imputación con un formato similara los edits. DIA tiene un analizador de reglas que garantiza la consistencia lógica y sintáctica delos conjuntos de edits, de reglas de imputación determinística y la consistencia mutua de los editsy de las reglas determinísticas. De esta forma, el sistema trata los errores sistemáticos y aleatoriosen un proceso único. Cada campo se modifica una vez a lo sumo, evitándose imputacionesinnecesarias y dejando los registros consistentes.
DIA tiene las funciones siguientes:
Especificación de reglas de conflicto (edits).
Especificación de reglas de imputación determinística.
Análisis de las reglas.
Detección de errores.
Identificación de las variables a imputar.
Imputación probabilística.
Imputación determinística.
Informes sobre el proceso de depuración.
DIA se basa en la metodología de Fellegi y Holt. Sin embargo tiene extensiones respectoa la misma que conviene justificar. La metodología de Fellegi y Holt es satisfactoria para eltratamiento de los errores aleatorios; sin embargo no da un tratamiento adecuado a los erroressistemáticos.
DIA trabaja a partir de una descripción de variables con sus valores válidos, un conjunto dereglas de conflicto (edits en forma normal típicos de la metodología de Fellegi-Holt) y un conjuntode reglas de imputación determinística si se quieren llevar a cabo imputaciones determinísticas.
En un edit normal sólo pueden aparecer código válidos mientras que en una regla de impu-tación determinística se pueden especificar valores inválidos, ya que estos son errores a los quetal vez se quiera imputar determinísticamente.
DIA dispone de un analizador de reglas, una pieza clave en la metodología de trabajo delsistema. Tiene como objetivo garantizar que la depuración realizada con DIA satisface los requi-sitos de consistencia establecidos. Para ello examina las reglas especificadas (edits y/o reglas deimputación determinística [rid]) asegurando que darán lugar a un proceso de depuración consis-tente en los datos y ayudando a los expertos en la tarea de especificar reglas tan precisas comosea posible, mostrándoles cuales son sus interrelaciones. El analizador tiene tres componentes quefuncionan secuencialmente: el analizador de rid, el analizador de edit y el analizador de rid-edit.
El analizador de rid tiene dos funciones. La primera es eliminar redundancias en el conjuntode rid y la segunda es detectar conflictos en el conjunto de rid que requieran la actuación de losexpertos. El analizador de edit tiene también dos funciones. La primera es eliminar redundanciasentre los edits, tratando de conseguir un conjunto equivalente lo más reducido posible. Y la

16 CAPÍTULO 1. INTRODUCCIÓN
segunda es detectar inconsistencias. El analizador de rid-edit se encarga de detectar las posiblesincoherencias derivadas del hecho de trabajar con dos sistemas separados, y tratar de resolverlasde la mejor manera posible.
Una vez que las reglas pasan satisfactoriamente el analizador, estas son válidas para operar conlos datos. DIA procesa los datos modularmente según el caso ya que, hay distintas posibilidadesentre las que el usuario puede elegir. El proceso de datos consta de tres fases: la detección, laimputación determinística y la imputación probabilística.
La fase de detección tiene la función de separar los registros con algún error de los registrossin error. Además se obtiene toda la información necesaria para el proceso posterior o paralos informes finales. La fase de imputación determinística se realiza únicamente cuando se hanespecificado rid. Para todo registro que haya fallado alguna rid se realiza un proceso iterativo enel que se localiza la rid fallada; si la rid debe actual entonces recibirá imputación probabilística,y si no se imputa por último. La fase de imputación probabilística entra en funcionamiento paratodo registro que después de la imputación determinística todavía tenga algún error. Esta faseprocede en dos pasos: la selección del conjunto mínimo de campos a imputar y la selección deun código en dichos campos.
Finalmente, DIA produce como salida un fichero depurado, un listado de los registros erróneosseguidos de una cola con información de sus errores e información referente al proceso y suimpacto sobre los datos.
1.5.2. Sistema SPEER
SPEER (Structured Program for Editing and Referral) es un sistema general para la depu-ración de datos cuantitativos que aplica la metodología de Fellegi y Holt con edits de razón.SPEER. El sistema, modular, ha sido programado en Fortran. Operan en grandes sistemas, enmicros y ordenadores personales y soporta modos de operación en batch (Main-frames) y Batche Interactiva (Micros y ordenadores personales).
SPEER en su actual implementación no está completamente generalizado. Son generales losmódulos de generación del conjunto completo de edits, detección y localización de errores. No songenerales los módulos de definición de la aplicación o los módulos de imputación. Los módulosgenerales de SPEER son una aplicación elegante y eficaz de la metodología que implementan. Eltiempo de ejecución del sistema es bueno, (evidentemente es función del número de campos enlos registros y del número de registros de las encuestas).
Los módulos interactivos de SPEER son una de sus características más interesantes. Ellospermiten adaptar SPEER a distintas etapas del proceso de una encuesta. Así, SPEER puedeemplearse como un sistema para la entrada de datos y para el análisis y la corrección manual delos registros seleccionados para estudio en una fase de depuración previa.
Los edits utilizados en SPEER son los llamados edits de la razón. Hay que tener en cuentaque en este sistema, los edits explícitos generan un conjunto de edits implícitos. La unión de losedits explícitos y los edits implícitos es lo que da lugar al conjunto completo de edits.
Un registro se considera con error si falla cualquiera de los edits del conjunto completo deedits. Después de la fase de contraste de edits, el problema consiste en localizar el númeromínimo (ponderado) de campos a eliminar, de forma tal que los campos restantes del registrosean mutuamente consistentes. Este problema ya se ha citado anteriormente y se conoce comoel problema de localización de errores.
SPEER utiliza un procedimiento altamente eficiente para la localización de errores. Utiliza unprocedimiento heurístico derivado de la teoría de grafos. Cada campo de un registro es un nodopara SPEER. Cada edit traza un arco que une los (campos) nodos activos del edit. La localización

1.5. SOFTWARE EXISTENTE 17
de errores es un problema de desconexión del grafo de los edits fallados por un registro. Es decir,para cada registro que falla un subconjunto de edits, SPEER dibuja el grafo correspondienteenlazando los nodos en los edits fallados. Para desconectar el grafo trazado, SPEER borra unoa uno y con un criterio definido, tales nodos hasta que no haya más nodos enlazados, o lo que eslo mismo, más edits fallados.
Como se indicó al anteriormente, SPEER no provee procedimientos generales de imputación.Estos deben programarse a medida para la encuesta. El sistema facilita los medios para garantizarque los resultados de la imputación no vulneren el conjunto de edits previamente definidos.
1.5.3. Sistema GEIS
GEIS (Generalized Editing and Imputation System) es un sistema general para la depura-ción y la imputación de datos numéricos. El sistema GEIS se basa en técnicas de investigaciónoperativa, de programación lineal, el problema del “matching” y la técnica de imputación tipodonor. La elegancia del sistema está en la sencillez conceptual de los métodos utilizados. Lo cualno significa, sin embargo, que carezca de problemas importantes en la implementación de talesmétodos y el deseo de conseguir un sistema eficiente desde el punto de vista operacional.
La primera característica de GEIS es su portabilidad lo que le permite operar en distintasarquitecturas de sistemas. La segunda característica es su modularidad. Las funciones del siste-ma han sido programadas en módulos separados que se ejecutan de forma independiente; parafunciones específicas, GEIS puede suministrar más de un módulo, que implementan metodologíasalternativas. Esta modularidad permite su adaptación a las necesidades específicas de una en-cuesta y ofrece además la posibilidad de programar módulos adicionales cuando las encuestas lorequieren. Todo esto aumenta la flexibilidad del sistema para adaptarse a los futuros desarrollostecnológicos del hardware y del software.
El sistema es un conjunto integrado por siete funciones principales que se utilizan para:definir y analizar los conjuntos de edits especificados por el usuario, contrastar los registros dela encuesta, y aplicar procedimientos múltiples de imputación. Estas funciones están basadas enlos supuestos de linealidad de los edits y la no negatividad de los datos.
La primera entrada al sistema GEIS son los edits definidos por los expertos. Los edits sonlimitaciones lógicas de los datos que permiten bien aceptar o rechazar el registro que le satisface.A este conjunto de edits se le denomina conjunto de edits originales. Por lo tanto, los edits sondesigualdades o igualdades lineales que expresan condiciones de fallo o de aceptación.
El análisis de los edits consta de tres módulos que son: contraste de edits, generación deedits implícitos y generación de puntos extremos. El contraste de edits consiste en determinar elconjunto mínimo de edits que definen la región de aceptación de los registros, comprobando almismo tiempo si existe tal región. Para la generación de edits implícitos, GEIS utiliza el algoritmode Chernikova.
El módulo de aplicación de los edits evalúa cada registro en el sistema. El resultado de estafunción de contraste de los registros es un conjunto de tablas de diagnóstico. Además de loserrores detectados por la aplicación de edits, GEIS comprueba los registros con valores outliers.Un valor es outlier si se halla fuera de los límites definidos por k veces la primera y la terceradistancia intercuartílica.
La función de localización de errores resuelve el problema de localizar los campos a imputar.Es decir, el problema de identificar para cada registro el menor número ponderado de campos aimputar.
La imputación de datos es un proceso de estimación de los valores identificados como erró-neos. GEIS ofrece tres módulos diferentes de imputación automática: imputación determinística,

18 CAPÍTULO 1. INTRODUCCIÓN
imputación del estimador e imputación donor. La imputación determinística comprueba si existeun valor único que satisfaga todos los edits. Para cada registro a imputar, el sistema define elsubsistema de edits activos en el registro, y a partir de él, define el sistema reducido al númerode variables a imputar. La imputación donor es otra de las funciones interesantes de GEIS. Elmétodo consiste en casar un registro con campos a imputar con un registro del conjunto de regis-tros aceptados en la fase de detección de errores, y en asignar a los campos del registro candidatolos valores de los campos correspondientes en el registro donor. De este modo, el procedimientoasegura, primero, que el registro candidato pase todos los edits y segundo, que se mantenga laestructura de correlación entre las variables.
1.5.4. Sistema SOLAS
SOLAS es una aplicación informática desarrollada por Statistical Solutions (http://www.statsol.ie/solas/solas.htm) para el análisis de datos perdidos y la imputación múltiple, queactualmente está en la versión 3.0.
Esta versión ofrece un lenguaje de guión propio y un conjunto de 6 técnicas de imputación,incluyendo dos de tipo múltiple, basadas en los estudios del profesor Donald B. Rubin. Los datospueden ser importados en un gran variedad de formatos, como SAS, SPSS, Splus, Stata y otros.Una vez que los datos son importados, se muestra un patrón de los valores perdidos (véase figura1.1) junto con la opción de elegir el método de imputación más apropiado. Una vez que se haconcluído con la imputación, se puede llevar a cabo un análisis de los resultados o exportarlos aotros formatos.
Figura 1.1: Patrón de datos perdidos (SOLAS).
El lenguaje de guión que se ofrece en SOLAS permite el procesamiento de distintos conjuntosde datos a través de un mismo código en el que se especifican las opciones de imputación. Cuando

1.5. SOFTWARE EXISTENTE 19
se realiza la imputación de un conjunto de datos, la aplicación guarda todas aquellos parámetrosescogidos a través de este lenguaje de guión, para que luego pueda ser usado posteriormente,obteniendo los mismos resultados, e incluso poder modificar el código a través de un editor paraincorporar nuevas opciones.
La imputación múltiple consiste en imputar varios conjuntos de datos simultáneamente, através de variables que los relacionen. Las técnicas de imputación múltiple usadas en la aplicaciónson las siguientes:
Modelo predictivo: Sus características son las siguientes:
Algoritmo de mínimos cuadrados por regresión múltiple totalmente configurable.Los valores imputados están basados en información extraída de variables comunes.Se preserva la correlación entre las variables.
Cuenta de propensión: Sus características son las siguientes:
Algoritmo por regresión logística totalmente configurable.Usa información contenida en un conjunto de variables comunes para predecir valoresperdidos en la variable que se va a imputar.Aprovecha variables adicionales en el modelo de selección donor, para preservar larelación entre variables. variables.
Las técnicas de imputación simple usadas en la aplicación son las siguientes:
Imputación Hot Deck: El usuario especifica el criterio de emparejamiento a través de varia-bles del conjunto de datos para poder localizar ciertos registros donantes, de los cualesextraer los valores a imputar. Se lleva a cabo una ordenación de los registros y las variablesprevia al proceso de imputación.
Imputación por la media: Los valores imputados se predicen usando un algoritmo ordinariode mínimos cuadrados por regresión múltiple, o un modelo discriminante si los datos soncategóricos.
Último valor llevado hacia adelante: Los valores imputados se basan en valores previamen-te observados. Sólo se usa para variables longitudinales.
Grupo de medias: Los valores imputados son un conjunto del grupo de medias de variables(o la moda en el caso de variables categóricas).
Después del proceso de imputación se pueden llevar a cabo varios análisis sobre los datos.Son los siguientes:
1. Estadística descriptiva.
2. t-Test.
3. ANOVA.
4. Regresión.
5. Tablas de frecuencia.
La aplicación no necesita grandes recursos mínimos para ser ejecutada. Se recomienda pro-cesador Pentium, con 32Mb. de RAM, 14Mb. de disco duro libre y un sistema Windows95 osuperior.

20 CAPÍTULO 1. INTRODUCCIÓN

Capıtulo 2Instituto Canario de Estadística
Este trabajo es un proyecto informático que se desarrolla en la Universidad de La Laguna(ULL) con la colaboración del Instituto Canario de Estadística (ISTAC) y su desarrollo estáorientado al trabajo con la encuesta EICVHC 2004. Por ello, en este capítulo se van a explicarestos dos elementos. En primer lugar una descripción del instituto, con sus objetivos y organiza-ción, y posteriormente una descripción de la encuesta, a nivel de diseño y recogida de datos.
2.1. El Instituto
El ISTAC es el órgano estadístico de la Comunidad Autónoma de Canarias. Es un organismoautónomo de carácter administrativo, con personalidad jurídica y patrimonio propios y estáadscrito a la Consejería de Economía y Hacienda del Gobierno de Canarias.
En materia de estadística de interés para la Comunidad Autónoma de Canarias, el Instituto hade constituir, mantener y promover el desarrollo del sistema estadístico de la Comunidad Autóno-ma de Canarias, impulsando, coordinando, centralizando y organizando la actividad estadísticade los diferentes órganos que lo componen. Para ello son de su competencia las funciones que sedetallan en el artículo 5 de la Ley 1/1991, de 28 de enero. Los objetivos finales del instituto sonconstituir, mantener y promover el desarrollo del sistema estadístico de la Comunidad Autónomade Canarias, impulsando, coordinando, centralizando y organizando la actividad estadística delos diferentes órganos que la componen.
Los objetivos instrumentales del instituto son los siguientes. En primer lugar elaborar elAnteproyecto del Plan Estadístico Anual y los programas estadísticos anuales. En segundo lugarcolaborar en materia estadística con las Entidades Locales de Canarias, las demás ComunidadesAutónomas y la Administración Central. En tercer lugar promover la normalización metodológicapara la actividad estadística; la investigación y formación estadística; la obtención, conocimientoy difusión de las estadísticas referidas a Canarias; la creación y mantenimiento de bancos dedatos de carácter estadístico.
Los objetivos operativos son los siguientes. Desarrollar un sistema de cuentas económicasregionales integradas que facilite información estadística macroeconómica y sectorial sobre laeconomía canaria. Desarrollar un sistema integrado de gestión demográfica que aporte informa-ción periódica y actualizada sobre la población canaria. Promover y coordinar el desarrollo dela información estadística de origen administrativo en el ámbito de la Comunidad Autónoma deCanarias. Organizar y gestionar la información estadística, así como su difusión, en torno a unbanco de datos estadístico propio.
21

22 CAPÍTULO 2. INSTITUTO CANARIO DE ESTADÍSTICA
La vinculación de este proyecto con el ISTAC viene determinada por la encuesta de ingresosy condiciones de vida de los hogares canarios para el año 2004 (EICVHC 2004).
2.2. Experiencias previas
El ISTAC sólo ha tenido una experiencia previa similar a la encuesta de ingresos y condicionesde vida de los hogares canarios para el 2004 que ha sido la estadística de condiciones socialeselaborada en el año 2001. A continuación se desarrolla una síntesis del contenido de esta encuestapionera en Canarias por sus dimensiones y resultados obtenidos.
La Estadística de Condiciones Sociales de la Población Canaria constituye un tipo de inves-tigación estadística que ofrece múltiples posibilidades de análisis, ya que proporciona una visiónglobal de amplios aspectos de la vida y permite establecer conexiones entre diversos campos deconocimiento (ingresos, equipamientos de los hogares, problemas en el hogar, etc.). Los objetivosprioritarios que se persiguen son los siguientes. En primer lugar conocer la estructura y compo-sición de la población residente en viviendas familiares para determinar el volumen, ubicaciónespacial, y las características y condiciones socioeconómicas de los distintos estratos sociales dela población canaria, haciendo una especial prospección de las situaciones más vulnerables desdeel punto de vista de las políticas y servicios sociales. En segundo lugar, aportar informaciónpara determinar las diferencias sociales y económicas entre los diferentes estratos sociales de lapoblación canaria. Y en tercer lugar, establecer comparaciones entre los niveles socioeconómicosde la población canaria y el resto del territorio español y europeo.
En cuanto a las características estudiadas se aplican dos cuestionarios distintos, uno dirigidoa los hogares y otro a los individuos de 16 y más años que forman parte de esos hogares. Lasunidades básicas de la encuesta son los hogares. Además cada hogar proporciona informaciónsobre los miembros que los conforman. La población de estudio son todos los miembros de loshogares privados, que residen en las viviendas familiares seleccionadas. El tipo de muestreo esestratificado por islas y en cada una de ellas se aplica un muestreo bietápico de conglomeradoscon estratificación de las unidades de primera etapa. El tamaño de la muestra ejecutada fuede 9758 hogares y 31193 personas. La ejecución del trabajo de campo fue llevada a cabo porPrice WaterHouse Coopers Auditores y la mecanización de los datos por ODEC, S.A. (Centrode Cálculo y Aplicaciones Informáticas, S.A.). El proceso de edición e imputación de los datosrecogidos en esta encuesta fue desarrollado por ODEC, una empresa especializada en la prestaciónde servicios informáticos para proceso de datos desde 1965. Para más información visitar http://www.odec.es.
2.3. EICVHC 2004
La Encuesta de Ingresos y Condiciones de Vida de los Hogares Canarios (EICVHC) basa susestudios en la medición de la pobreza. En el plano internacional existe una creciente preocupaciónpor la pobreza y la exclusión social. Para poder manejar el concepto de pobreza existen variosenfoques entre los que se encuentran la pobreza vista como necesidad, la pobreza vista comoestándar de vida o la pobreza vista como insuficiencia de recursos. La medición de la pobreza noes tarea sencilla porque no nos podemos basar sólo en los ingresos, ya que las condiciones de vidatambién son un factor importante en ella; véase educación, sanidad, vivienda, empleo o entornosocial.

2.3. EICVHC 2004 23
2.3.1. Objetivo y dimensiones de estudio
El objetivo del estudio es poner a disposición del Gobierno de Canarias un instrumentode observación estadística para el estudio y seguimiento del nivel de vida, las condiciones delmercado de trabajo y la cohesión social en relación con los requerimientos de información de laspolíticas activas del Gobierno en éstos y otros ámbitos reflejadas en sus diversos programas deactuación.
Por lo tanto, se pretende medir el volumen, composición, ubicación espacial, características ycondiciones socio-económicas de los distintos estratos sociales de la población canaria, haciendouna especial prospección de las situaciones más vulnerables desde el punto de vista de las políticasy servicios sociales.
Las unidades de análisis son los hogares residentes en Canarias que habitan en viviendasfamiliares: conjunto de personas que ocupan en común una vivienda familiar y comparten unpresupuesto común para alimentos y gastos de la vivienda, y los individuos mayores de 16 añosmiembros del hogar.
En cuanto a las dimensiones del estudio existen tres grandes bloques: el entorno, el hogary la población. Dentro del entorno encontramos equipamientos y problemas. Dentro del hogarencontramos estructura, situación económica, características de la vivienda, equipamiento delhogar y problemas. Dentro de la población encontramos demografía, empleo, ingresos, formacióny estudios, salud y discapacidades, uso del tiempo y migración.
2.3.2. Cuestionario
Para la normalización de conceptos y clasificaciones la encuesta hace uso de varios estándaresentre los que podemos encontrar el panel de hogares de la Unión Europea (marco de referencia),la encuesta de población activa (ocupados, parados e inactivos), el Sistema Europeo de Cuen-tas Nacionales (ingreso disponible del hogar), el Sistema de Estadísticas de Protección Social(prestaciones sociales), la clasificación de funcionamiento, discapacidades y salud de la OMS(discapacidades), la clasificación nacional de ocupaciones (tipo de ocupación) o la clasificaciónnacional de actividades económicas (tipo de actividad).
El cuestionario del hogar dispone de la siguiente estructura:
Composición del hogar.
• Relación de miembros.
• Relación de parentesco.
• Tipo de familia.
Características de la vivienda.
• Variación la vivienda.
• Características principales.
• Régimen de tenencia.
• Equipamiento.
Entorno.
• Entorno social.
• Medio ambiente.

24 CAPÍTULO 2. INSTITUTO CANARIO DE ESTADÍSTICA
• Equipamiento.
Situación económica.
• Valoración subjetiva.
• Ingresos del hogar.
Problemas en el hogar.
• Situaciones problemáticas.
El cuestionario individual dispone de la siguiente estructura:
Demografía.
• Edad y sexo.
• Estado civil.
• Nacionalidad.
Empleo.
• Ocupación y actividad.
• Características del empleo.
• Condiciones en el trabajo.
• Búsqueda de empleo.
• Experiencia profesional.
• Ingresos y prestaciones.
Formación y estudios.
• Características de formación.
Uso del tiempo.
• Ocio.
• Vacaciones.
• Participación en el hogar.
• Participación ciudadana.
Salud.
• Cobertura sanitaria.
• Discapacidades.
Migraciones.
• Variaciones residenciales.

2.3. EICVHC 2004 25
2.3.3. Diseño muestral
El diseño muestral que se utiliza como guía es la Encuesta General de Población (EGP) delInstituto Nacional de Estadística (INE). La EGP no es una encuesta en sí misma sino un diseñomuestral válido para encuestas dirigidas a la población y hogares. Su objetivo es mantener undiseño muestral actualizado que permita investigar características de los hogares y la poblaciónespañola en todos aquellos aspectos que interesen a la Administración del Estado. La EGP se usaen la Encuesta de Población Activa (EPA), la Encuesta de Presupuestos Familiares, las Encuestasde Fecundidad, la Encuesta sobre Discapacidad, Deficiencias y Estado de Salud o en el Panel deHogares de la Unión Europea entre otras.
El tipo de muestreo utilizado es un estudio periódico de carácter bienal con solapamientoparcial tipo ab-bc del 50% de las unidades muestrales. El dominio del análisis son 28 comarcasbásicas para uso estadístico. En cada dominio se aplica un muestreo bietápico de conglomeradoscon estratificación de la primera etapa. En la primera etapa encontramos las secciones, quese estratifican según criterio geográfico y socioeconómico y seleccionadas con repetición segúnmétodo proporcional al tamaño, medido en número de viviendas (PPT). Se seleccionan 313secciones en toda Canarias. En la segunda etapa tenemos las viviendas, que se seleccionan segúnmuestreo sistemático con arranque aleatorio, ordenando previamente el marco de viviendas porcriterios de entidad de población, núcleo de población, calle y número. Se seleccionan 25 viviendaspor sección. Se entrevistan aproximadamente 7825 hogares y 25040 personas.
Las comarcas básicas del dominio de análisis son las siguientes:
La Palma.
• LP-Noroeste.
• LP-Noreste.
• LP-Valle de Aridane.
• LP-Capitalina.
El Hierro.
• EH-El Hierro.
• La Gomera.
• LG-Norte.
• LG-Sur.
Tenerife.
• TF-Daute.
• TF-Icod.
• TF-Valle Orotava.
• TF-Acentejo.
• TF-Área Metropolitana.
• TF-Valle de Güimar.
• TF-Abona.
• TF-Suroeste.

26 CAPÍTULO 2. INSTITUTO CANARIO DE ESTADÍSTICA
Gran Canaria.
• GC-Oeste.• GC-Noroeste.• GC-Centro Norte.• GC-Área Metropolitana.• GC-Sureste.• GC-Sur.
Fuerteventura.
• FV-Sur.• FV-Centro.• FV-Norte.
Lanzarote.
• LZ-Suroeste.• LZ-Este.• LZ-Norte.
En la primera etapa existe una estratificación primaria (geográfica) que distingue entre mu-nicipios atendiendo al número de habitantes, y una estratificación secundaria (socioeconómica)en la que se utiliza la metodología de estratificación social, que clasifica cada hogar de acuerdoa la relación con la actividad, ocupación y estudios.
2.3.4. Recogida de datos
La recogida de datos se realiza mediante entrevista personal asistida por ordenador (ComputerAssisted Personal Interviewing, CAPI). La localización de las viviendas a entrevistar se realizamediante GPS con el apoyo del programa basado en el motor cartográfico del programa Mapde Grafcan y adaptado a las necesidades de la operación estadística. Se dispone de un softwareespecífico y parametrizable (CAPI - ISTAC) para la gestión de la agenda del encuestador, lacumplimentación de los cuestionarios y las comunicaciones seguras entre los pen-tables y elservidor del ISTAC.
2.3.5. Edición e imputación de datos
Es aquí donde aparece nuestra aportación en la Encuesta de Ingresos y Condiciones de Vida delos Hogares Canarios 2004. Una vez recogidos los datos y pasados a formato digital, el programainformático desarrollado en este trabajo toma esos datos, junto con las reglas de edición y ladefinición de las variables para llevar a cabo la edición e imputación de los mismos. Más adelantese explicará con detenimiento todas las funcionalidades y características del programa llamadoTeide.
2.3.6. Organización de la encuesta
Para el trabajo de campo existe un jefe de operación que controla a dos jefes de campo, unopor cada provincia canaria. Los jefes de campo disponen de tres jefes de zona que a su vez tienena su cargo a tres o cuatro entrevistadores. Esto hace un total de 1 jefe de operación, 2 jefes decampo, 6 jefes de zona y 20 entrevistadores en la Comunidad Autónoma de Canarias.

2.3. EICVHC 2004 27
2.3.7. Calidad
La guía de calidad está basada en la metodología del Statistics Canada Quality Guidelines,Guía Esomar para la Armonización de las Normas sobre el Trabajo de Campo y la Metodologíay Tratamiento de la no respuesta del Instituto Vasco de Estadística. El análisis de errores decontenido y cobertura se han llevado a cabo mediante el modelo matemático elaborado porla Oficina de Censos de EE.UU.: repetición de entrevistas en una submuestra y análisis deconcordancia para investigar inconsistencias cuantificando errores mediante índices de calidad.

28 CAPÍTULO 2. INSTITUTO CANARIO DE ESTADÍSTICA

Capıtulo 3Metodología General
Este capítulo trata sobre la metodología general que se aplica a la imputación desde el puntode vista teórico, centrado fundamentalmente en datos categóricos, aunque también citaremosel caso numérico. Es decir, la formulación matemática que tiene el problema, y el método deFellegi-Holt como principio de resolución del mismo.
3.1. Problema de localización del errores
En este punto se va a dar una formulación del problema de localización de errores tanto paradatos categóricos como para datos numéricos.
3.1.1. Formulación matemática
Vamos a empezar introduciendo alguna notación y terminología. Una variable se llama cate-górica o discreta, cuando solo puede asumir un número finito de valores, categorías, y no tienenuna estructura aritmética. Ejemplos de variables categóricas son “sexo” y “profesión”. La variable“sexo” sólo puede tomar los valores “varón” y “hembra”. La variable “profesión” puede tener unnúmero finito de valores. Estos valores dependen del esquema de clasificación usado. Los datosnuméricos son datos que poseen una estructura aritmética. Los datos numéricos normalmente seentienden como datos numéricos continuos, es decir, que los datos pueden tomar cualquier valorreal en un intervalo. Un ejemplo de variable numérica es “salario”, que es un valor no negativo.
Denotamos las variables categóricas por vi (i = 1, . . . , m) y las variables numéricas por xi (i =1, . . . , n). Para los datos categóricos denotamos el dominio, es decir, el posible conjunto de valores,de la variable i por Di. Denotamos los edits, es decir, las restricciones que tienen que satisfacerlos datos correctos, por Ej (j = 1, . . . , p). Asumimos que son escritos de la siguiente forma: editEj es satisfecho por un registro (v1, . . . , vm, x1, . . . , xn) si se cumple la siguiente sentencia:
IF vi ∈ F ji for i = 1, . . . , m
THEN (x1, . . . , xn) ∈ x/a1jx1 + . . . + anjxn + bj ≥ 0 (3.1)
o
IF vi ∈ F ji for i = 1, . . . , m
THEN (x1, . . . , xn) ∈ x/a1jx1 + . . . + anjxn + bj = 0 (3.2)
29

30 CAPÍTULO 3. METODOLOGÍA GENERAL
Los valores aij se asumen como números racionales. F ji ⊆ Di ∀i, j. Nótese que, sin perder
generalidad, todas las expresiones numéricas vistas en (3.1) y en (3.2) pueden ser asumidascomo desigualdades, porque cualquier igualdad se puede expresar como dos desigualdades. Noharemos esta suposición aquí porque más adelante trataremos ocasionalmente las igualdades ylas desigualdades de manera distinta por razones de eficiencia.
Los edits dados en (3.1) y en (3.2) son condiciones numéricas lineales que se cumplen a travésde ciertas combinaciones de valores categóricos. Las condiciones numéricas no lineales se danraramente en la práctica. Además estos edits no lineales son bastantes difíciles de especificar yde manejar. En principio, para cada combinación de valores categóricos se pueden especificardiferentes condiciones numéricas. Se puede especificar incluso una condición numérica contra-dictoria, como 0 ≥ 1 para una combinación de valores categóricos. Este edit significa que esacombinación particular de valores categóricos no puede aparecer.
Todos los edits dados en (3.1) y en (3.2) se tienen que satisfacer simultáneamente. Se asumeque los edits se pueden satisfacer simultáneamente, es decir, que el conjunto de edits es consis-tente. Sin perder generalidad, se puede asumir que el conjunto de edits no puede ser dividido envarios subconjuntos disjuntos, o sea, subconjuntos sin variables superpuestas. Si un conjunto deedits puede ser dividido en subconjuntos disjuntos, se asume que el problema de localización deerrores se resuelve sobre cada subconjunto de manera independiente.
La condición después de la sentencia IF (vi ∈ F ji for i = 1, . . . ,m) se llama el antecedente
del edit. La condición después de la sentencia THEN se llama el consecuente. Una variable categó-rica vi se dice que entra en el edit Ej dado en (3.1) y en (3.2) si F j
i ⊂ Di y F ji 6= Di, es decir, si
F ji está estrictamente contenido en el domino de la variable i. Se dice que ese edit está envuelto
por una variable categórica. Una variable numérica xi se dice que entra el consecuente del editEj dado en (3.1) y en (3.2) y aij 6= 0. Esta condición ENTONCES se dice que está envuelta poresta variable numérica.
Se asume que ninguno de los valores de las variables entrantes en los edits puede tener valor“missing”, es decir, que el valor tiene que contener un dato válido. Cualquier campo para el quesu valor sea “missing” se considerará erróneo.
El conjunto en el consecuente en (3.1) y en (3.2) puede ser el conjunto vacío o el espaciovectorial real n-dimensional. Si el conjunto en el consecuente en (3.1) y en (3.2) es el espaciovectorial real n-dimensional, entonces el edit se satisface siempre. Así que el edit puede serdescartado. Si el conjunto en el consecuente de (3.1) y (3.2) es el conjunto vacío, entonces el editfalla para cualquier registro cuyo antecedente sea verdadero, es decir, por cualquier registro parael que vi ∈ F j
i for i = 1, . . . , m. Así mismo, F ji en (3.1) y en (3.2) puede ser el conjunto vacío
o igual a Di . Si un conjunto F ji = ∅ (para algún i = 1, . . . , m), el edit se satisface siempre, y
puede ser descartado. Si el antecedente no es verdadero para un registro particular, el edit essatisfecho, indistintamente de los valores de las variables numéricas.
Para cada registro (v01, . . . , v
0m, x0
1, . . . , x0n) en el conjunto de datos que va a ser editado auto-
máticamente, se debe determinar la existencia de un registro sintético (v1, . . . , vm, x1, . . . , xn)que satisface todos los edits j = 1, . . . , p tal que:
m∑
i=1
wiδ(v0i , vi) +
n∑
i=1
wm+iδ(x0i , xi) (3.3)
sea minimizado. Aquí wi es el peso de fiabilidad de la variable i, δ(y0, y) = 1 si y0 6= yy δ(y0, y) = 0 si y0 = y. El peso de fiabilidad expresa cómo de confiable es el valor de lacorrespondiente variable. A mayor peso de fiabilidad, más fiable es el valor de la variable. Lafunción objetivo (3.3) es simplemente el número de variables pesadas que tienen que cambiar. Las

3.1. PROBLEMA DE LOCALIZACIÓN DEL ERRORES 31
variables para las que las que los valores originales eran “missing” forman una solución óptimaal problema de localización de errores.
El problema de localización de errores puede ser formulado de manera sencilla como sigue:Dado (v0
1, . . . , v0m , x0
1, . . . , x0n), buscar (v1, . . . , vm, x1, . . . , xn) minimizando la función objetivo
(3.3) y de tal manera que se satisfagan todos los edits en (3.1) y en (3.2).Nótese que la formulación hecha es una formulación matemática del paradigma generalizado
de Fellegi-Holt. Nótese también que pueden haber varias soluciones óptimas a una instanciaespecífica del problema de localización de errores.
Un objetivo en la literatura es encontrar y enumerar todas las posibles soluciones óptimas alproblema de localización de errores. Para un problema de optimización, este objetivo es bastanteantinatural. La razón de perseguir este objetivo es que el problema estadístico actual de la ediciónautomática es más comprensible que el problema de optimización anteriormente descrito. Esteproblema estadístico es “simplemente” el problema de obtener datos de alta calidad a partir deun conjunto de datos con errores de una manera eficiente. Resolver el problema de localizaciónde errores es sólo uno de los pasos en este proceso. Después de identificar los campos erróneos,estos deben ser imputados. Para resolver el problema estadístico efectivamente no es suficientecon resolver solamente el problema de optimización. En concreto, durante la fase de localizaciónde errores, uno debería tener en cuenta que los errores identificados pueden ser imputados detal manera que los registros resultantes sean de suficiente calidad. También se debería tener encuenta que el conjunto de datos finales imputados sea de suficiente calidad. Es necesario teneren cuenta los problemas estadísticos relacionados con la fase de imputación durante la fase delocalización de errores. Estos problemas son, por lo menos, tan importantes y difíciles de resolvercomo el problema antes mencionado de la localización de errores.
Generando todas las posibles soluciones óptimas al problema matemático de localización deerrores, se pretende ofrecer la posibilidad más tarde de seleccionar una de estas soluciones, usandoun criterio secundario más estadístico. Se ha visto que en los peores casos, los registros tienenvarias miles de soluciones óptimas, pero en la mayoría de los casos no es así.
Los pesos son fijos para cada registro que va a ser editado, pero pueden ser diferentes paradistintos registros. En la práctica, los pesos se pueden calcular antes de que un registro se editeautomáticamente. De esta manera, es necesario tener en cuenta la probabilidad de que un valorparticular en un registro particular sea incorrecto.
El problema de localización de errores es NP-Completo ya que el problema de la satisfaci-bilidad puede ser transformado a un problema de localización de errores en tiempo polinomial.Por lo tanto, el objetivo no es desarrollar algoritmos que resuelvan el problema de localizaciónde errores de manera eficiente en los peores casos, sino desarrollar algoritmos que resuelvan elproblema de manera eficiente para casos promedio.
3.1.2. Una primera aproximación
Está claro que al menos se debería cambiar un valor por cada edit violado. Vamos a asumirpor un momento que es suficiente con cambiar cualquier valor por cada edit violado. En esecaso el problema de localización de errores se reduce al problema asociado de cubrimiento deconjuntos. Para formalizarlo, definimos las variables yi (i = 1, . . . , n), donde es igual a 1 si lavariable i hay que modificarla. Para un conjunto general de edits el problema de cubrimiento deconjuntos viene dado por: Minimizar la función objetivo dada por:
n∑
i=1
wiyi (3.4)

32 CAPÍTULO 3. METODOLOGÍA GENERAL
sujeto a la condición de que se cambie una variable en cada edit violado.Se define:
aij =
1, si la variable i está envuelta en el edit j.0, en otro caso.
(3.5)
Entonces las restricciones se pueden escribir de la siguiente manera:
n∑
i=1
aijyi ≥ 1 (3.6)
para cada edit violado j por el registro bajo esta consideración.Desafortunadamente, no basta con cambiar cualquier valor por edit violado, ya que el cambio
de una variable puede alterar la validez de otro edit, quizás inicialmente correcto. La solución alproblema asociado de cubrimiento de conjuntos no es normalmente una solución al correspon-diente problema de localización de errores. Esto se puede ver en el siguiente ejemplo.
Ejemplo 3.1.1. Supongamos que el conjunto de edits explícitamente especificados son:
T = P + C (3.7)
0,5 ≤ C
T≤ 1,1 (3.8)
0 ≤ T
N≤ 550 (3.9)
T ≥ 0 (3.10)C ≥ 0 (3.11)N ≥ 0 (3.12)
La variable T denota el volumen de ventas de una empresa, P su beneficio, C sus costes, yN el número de empleados. El volumen de ventas, beneficio y costes se dan en miles de euros. Eledit (3.7) dice que el volumen de ventas de una empresa debería ser igual a la suma del beneficioy los costes. El edit (3.8) pone cotas a los costes de una empresa en términos de su volumen deventas, el edit (3.9) pone cotas al volumen de ventas en términos del número de empleados, ylos edits del (3.10) al (3.12) dicen que el volumen de ventas, los costes y el número de empleadosdeben ser valores no negativos. Los edits (3.7), (3.10), (3.11) y (3.12) son edits que se puedenderivar lógicamente, y mantener para toda empresa. Los edits (3.8) y (3.9) no se pueden derivarlógicamente, y sólo se mantendrán para alguna clase de empresas.
Consideramos un registro específico con valores T=100, P=40, C=60 y N=5. Los edits del(3.9) al (3.12) se satisfacen, mientras que los edits (3.7) y (3.8) se violan. Asumimos que los pesosde fiabilidad de las variables T, P y C son iguales a 1, y que el peso de fiabilidad de la variable Nes igual a 2. Esto es, el valor de la variable N, el número de empleados, se considera más creíbleque los valores de las variables financieras T, P y C.
El problema del cubrimiento de conjuntos asociado al problema de localización de errorestiene su solución óptima en cambiar el valor de T, porque esta variable cubre los edits violadosy tiene el mínimo peso de fiabilidad. El valor óptimo de la función objetivo del problema decubrimiento de conjuntos es igual a 1. Sin embargo, para satisfacer el edit (3.7) cambiando elvalor de T, el valor imputado debería ser igual a 100, pero en ese caso (3.9) sería violado. Lasolución óptima al problema del cubrimiento de conjuntos no es una solución factible al problemade localización de errores, porque la variable T no puede ser imputada de manera consistente.

3.1. PROBLEMA DE LOCALIZACIÓN DEL ERRORES 33
El problema de localización de errores tiene su solución óptima en cambiar las variables P y C.El valor óptimo de la función objetivo para el problema de localización de errores es 2. Esto esmayor que el valor óptimo para la función objetivo del problema asociado de cubrimiento deconjuntos. Una posible imputación para estas variables es P=40 y C=60. El registro imputadoresultante pasa todos los edits. Nótese que en este ejemplo el informante probablemente se olvidóque los valores P y C se daban en miles de euros.
Una solución factible al problema de localización de errores es una solución factible al proble-ma asociado de cubrimiento de conjuntos, pero no viceversa. Por lo tanto, el valor de la soluciónóptima para el problema de localización de errores es al menos igual al valor de la solución óptimapara el problema asociado del cubrimiento de conjuntos.
3.1.3. Una formulación de programación entera mixta
En este punto se asume, por conveniencia de notación, que todos los edits son del tipo(3.1). Una igualdad puede ser representada por dos desigualdades, así que la simplicidad de estemodelo no limita esa posibilidad. También se asume que los valores de las variables numéricasestán acotados. Esto es, se asume que para la i-ésima variable numérica (i = 1, . . . , n) existendos constantes tales que:
αi ≤ xi ≤ βi (3.13)
En la práctica, estos valores αi y βi existen siempre, porque las variables numéricas que sedan en datos estadísticos están acotadas. Si el valor de la i-ésima variable es “missing”, se asignaráa xi un valor menor que αi o un valor mayor que βi.
El número de categorías de la i-ésima variable categórica es gi (i = 1, . . . , m), es decir,gi = |Di|. Para el k-ésimo valor cik de la variable categórica i se introduce una variable binariaγik tal que:
γik =
1, si el valor de la variable categórica i es igual a cik.0, en otro caso.
(3.14)
A la i-ésima variable categórica le corresponde un vector (γi1, . . . , γigi) tal que γik = 1 si ysolo si el valor de esta variable categórica es igual a cik, en otro caso γik = 0. Para cada variablecategórica i se debe cumplir la relación:
∑
k
γik = 1 (3.15)
Denotaremos también el vector (γi1, . . . , γigi) por γi. Si el valor de la i-ésima variable categó-rica i es “missing”, se fijan todos los γik iguales a cero (k = 1, . . . , gi). Un edit j puede ser escritoen términos de las variables binarias γik de la siguiente manera:
a1jx1 + . . . + anjxn + bj ≥ M
m∑
i+1
∑
cik∈F ji
γik − 1
(3.16)
donde M es un número entero positivo suficientemente grande. Si el antecedente del edit (3.1) esverdadero, la parte derecha de (3.1) es igual a cero. Por lo tanto, el consecuente de (3.1) tiene queser verdadera para las variables numéricas. Si el antecedente de (3.1) no es verdadero, la parte

34 CAPÍTULO 3. METODOLOGÍA GENERAL
derecha de (3.16) es igual a un valor negativo grande. Consecuentemente, (3.16) es verdaderoindependientemente de los valores de las variables numéricas.
Alternativamente, la desigualdad (3.16) puede ser reemplazada por:
m∑
i=1
∑
cik∈F ji
γik − 1
≤ −u
2(3.17)
teniendo en cuenta la siguiente relación:
a1jx1 + . . . + anjxn + bj ≥ u
n∑
i=1
aijαi (3.18)
donde u es una variable binaria. Si vi ∈ F ji for i = 1, . . . , m, entonces u tiene que ser igual a
cero, y se tiene que cumplir el consecuente de (3.1). Si u es igual a 1, entonces (3.18) se satisfacesiempre.
Si (3.1) no es satisfecho por un registro (v01, . . . , v
0m, x0
1, . . . , x0n) o de manera equivalente
si (3.17) no es satisfecho por (γ01 , . . . , γ0
m, x01, . . . , x
0n), entonces buscamos los valores eP
ik(k =1, . . . , gi; i = 1, . . . , m), eN
ik(k = 1, . . . , gi; i = 1, . . . , m), zPi (i = 1, . . . , m) y zN
i (i = 1, . . . , m).Los valores eP
ik y zPi corresponden a cambios positivos en el valor de γ0
ik y x0i , respectivamente.
Así mismo, los valores eNik y zN
i corresponden a cambios negativos en el valor de γ0ik y x0
i ,respectivamente. El vector (eP
i1, . . . , ePig) también se denota por eP
i , y el vector (eNi1 , . . . , e
Nig) por
eNi .
Los valores antes descritos tienen que ser calculados de tal manera que:
m∑
i=1
(∑
k
eNik
)+
n∑
i=1
wm+i
(δ(zPi
)+ δ
(zNi
))(3.19)
donde wi es el peso de fiabilidad de la variable i, δ(x) = 1 si y solo si x 6= 0 y δ(x) = 0 en otrocaso, sea minimizado sujeto a las restricciones siguientes:
ePik, e
Nik ∈ 0, 1 (i = 1, . . . , m) (3.20)
zPi , zN
i ≥ 0 (i = 1, . . . , n) (3.21)
ePik + eN
ik ≤ 1 (i = 1, . . . , m) (3.22)∑
k
ePik ≤ 1 (i = 1, . . . ,m) (3.23)
eNik = 0 if γ0
ik = 0 (i = 1, . . . ,m) (3.24)∑
k
(γ0ik + eP
ik − eNik) = 1 (i = 1, . . . , m) (3.25)
αi ≤ x0i + zP
i − zNi ≤ βi (i = 1, . . . , n) (3.26)
n∑
i=1
aij(x0i + zP
i − zNi ) + bj ≥ M
m∑
i+1
∑
cik∈F ji
(γ0ik + eP
ik − eNik)− 1
(3.27)
para todos los edits j = 1, . . . ,K.

3.1. PROBLEMA DE LOCALIZACIÓN DEL ERRORES 35
La relación (3.22) expresa que no se puede aplicar la misma corrección positiva y negativa auna variable categórica. La relación (3.23) expresa que como mucho solo uno de los valores puedeser imputado, es decir, estimado y rellenado, para una variable categórica, y la relación (3.24)expresa que se puede aplicar una corrección negativa a una variable categórica si el valor originalno es igual a la correspondiente categoría. La relación (3.25) asegura que cada variable categóricaes rellenada con una valor, incluso si el valor original era “missing”. La relación (3.26) dice queel valor de una variable numérica debe estar acotada por constantes apropiadas. En concreto, larelación (3.26) especifica que el valor de una variable numérica no puede ser “missing”. Finalmente,la relación (3.27) expresa que el registro modificado debería satisfacer todos los edits dados por(3.1).
Después de resolver este problema de optimización, el registro resultante modificado quedacomo sigue: (γ0
1 + eP1 − eN
1 , . . . , γ0m + eP
m − eNm, x0
1 + zP1 − zN
1 , . . . , x0n + zP
n − zNn ).
Una solución al problema matemático anterior corresponde a una solución para el problemade localización de errores. Una solución para el problema de localización de errores es simplementedar los nombres de las variables que tienen que cambiar sus valores, sin especificar cuáles sonsus nuevos valores. Teniendo el registro modificado correspondiente a una solución óptima alproblema anterior, la solución correspondiente al problema de localización de errores viene dadapor las variables para las que los valores en este registro modificado difiere del valor original.Como ya se ha dicho, el objetivo es encontrar todas las soluciones óptimas.
El problema de optimización anterior es una traducción del paradigma generalizado de Fellegi-Holt en términos matemáticos. La función objetivo (3.19) es la suma de los pesos de fiabilidadde las variables cuyos valores originales deben ser cambiados. Nótese que la minimización de lafunción objetivo (3.19) es equivalente a minimizar:
m∑
i=1
wi
(∑
k
ePik
)+
n∑
i=1
wm+i
(δ(zPi
)+ δ
(zNi
))(3.28)
La función objetivo (3.28) es la suma de los pesos de fiabilidad de las variables que deben serimputadas con un nuevo valor. Para ser precisos, el valor de esta función objetivo es igual al valorde la función objetivo (3.19) más la suma de los pesos de fiabilidad de las variables categóricasque tienen valor “missing”.
3.1.4. Usando algoritmos estándar
Quizás, los algoritmos tipo branch & bound sean la clase más conocida de algoritmos paraminimizar funciones objetivo lineales sujetas a restricciones lineales donde algunas de las variablesenvueltas son variables binarias. Antes de aplicar un algoritmo estándar de branch&bound alproblema general de localización de errores, primero tenemos que introducir algunas variablesadicionales.
La función objetivo (3.19) contiene una función no lineal, llamada δ. Se intentará reescribiresta función objetivo introduciendo variables binarias adicionales. Estas variables son dP
i y dNi
for (i = 1, . . . , n) que satisfacen las siguientes relaciones:
dPi , dN
i ∈ 0, 1 (3.29)
dPi ≤ MzP
i (3.30)
MdPi ≥ zP
i (3.31)
dNi ≤ MzN
i (3.32)

36 CAPÍTULO 3. METODOLOGÍA GENERAL
MdNi ≥ zN
i (3.33)
donde M es de nuevo un número positivo suficientemente grande.La reescritura de (3.19) quedaría de la siguiente manera:
m∑
i=1
wi
(∑
k
eNik
)+
m+n∑
i=m+1
wi
(dP
i + dNi
)(3.34)
Esta función objetivo debería minimizarse sujeta a las restricciones de (3.20) a (3.27) y de(3.29) a (3.33). Las relaciones (3.30) y (3.31) expresan que dP
i = 1 si y solo si zPi 6= 0, si no
dPi = 0. De manera similar, las relaciones (3.32) y (3.33) expresan que dN
i = 1 si y solo si zNi 6= 0,
si no dNi = 0. Si y solo si una variable continua es distinta de cero, la variable binaria asociada es
igual a uno. El hecho de que una variable continua difiera o no difiera de cero se incorpora en lafunción objetivo a través de la variable binaria asociada. En este esquema, el problema generalde localización de errores se convierte en un problema de programación entera mixta.
Un algoritmo de branch&bound es un algoritmo iterativo para resolver problemas de progra-mación entera (mixta). Consiste básicamente en tres pasos: ramificar, acotar y explorar. Estostres pasos se ejecutan en cada iteración.
Durante la fase de ramificación, un problema de programación lineal (LP) se divide en dossubproblemas lineales separados fijando una variable binaria a cero o a uno. Para cada uno deestos subproblemas se determina una cota durante la fase de acotación. Esta cota se determinaresolviendo el subproblema lineal relajado, es decir, resolviendo el problema lineal sin tener encuenta que las variables binarias que no han sido fijadas todavía solo pueden tomar los valorescero o uno. Finalmente, durante la fase de exploración se determina si los subproblemas tienenque ser divididos en subproblemas más pequeños. Un subproblema no tiene que ser dividido ensubproblemas más pequeños a) si la solución óptima al problema LP relajado es una soluciónal subproblema en sí (en ese caso la solución óptima al problema LP relajado es también unasolución óptima al subproblema); b) si la cota obtenida del problema LP relajado es peor quela cota obtenida de una solución anterior al problema de programación entera (mixta); c) si elproblema LP relajado no tiene solución factible.
La aplicación de un algoritmo de branch&bound para resolver el problema general de locali-zación de errores es, en principio, posible. Los modernos resolutores comerciales para problemasde programación entera mixta (MIP), como ILOG CPLEX, son lo suficientemente potentes paradeterminar una solución óptima para algunos modelos de programación entera. Sin embargo, haypocos problemas relacionados con el problema de localización de errores a los que se les puedaaplicar un resolutor comercial de MIP.
Un problema técnico es que se necesitarían generar todas las posibles soluciones óptimasal problema de localización de errores. Los resolutores estándar de MIP parecen estar menospreparados para esta tarea. Un algoritmo de propósito específico diseñado para encontrar todaslas soluciones óptimas al problema de localización de errores podría dar mejores resultados quelos resolutores comerciales.
También hay varios problemas no técnicos cuando se usa un resolutor comercial de MIP. Enprimer lugar, el problema de localización de errores es sólo una parte de un proceso estadísticopara depurar registros. A los institutos de estadística les interesa tener un control completosobre cómo trabaja este proceso estadístico. Quieren ser capaces de incorporar el problema delocalización de errores en el resto del proceso de producción estadístico. No quieren que losresolutores comerciales restrinjan sus acciones.
En segundo lugar, los institutos de estadística no quieren depender de vendedores de softwarecomercial en general. Los cambios en el software de los vendedores de software comercial tienen

3.2. PARADIGMA DE FELLEGI-HOLT 37
un importante impacto en los sistemas de los institutos de estadística. El software es difícilde mantener, especialmente si el software comercial adquirido es matemáticamente complicado,como es el caso de los resolutores de MIP.
Y en tercer lugar, los resolutores comerciales de MIP son bastante caros. En un instituto deestadística hay muchos usuarios potenciales de un sistema de edición automática de datos. Estosería más acusado todavía si el sistema de edición automática de datos estuviera integrado en elsoftware para edición asistida por ordenador. Esta integración permitiría al humano preguntar ala máquina cómo depurar un determinado registro. A partir de ahí, se podría aceptar un consejoo desestimarlo.
3.2. Paradigma de Fellegi-Holt
El paradigma de Fellegi-Holt dice que un registro erróneo debería satisfacer todos los editscambiando el valor del menor número posible de variables.
En su artículo, Fellegi y Holt no solo proponían este paradigma, también proponían uninteresante método para resolver el problema matemático resultante. Este método puede seraplicado tanto para datos categóricos como para datos numéricos. Aunque posteriormente se handesarrollado otros algoritmos, este artículo sigue siendo la referencia clave de cualquier trabajosobre localización de errores.
3.2.1. La idea básica de Fellegi-Holt
El método desarrollado por Fellegi-Holt está basado en generar lo que se denominan editsimplícitos (o edits implicados). Estos edits implícitos están lógicamente derivados de los editsexplícitos especificados. Los edits implícitos pueden ser definidos tanto para datos categóricoscomo para datos numéricos.
Aunque los edits implícitos son redundantes, pueden revelar información importante sobre laregión factible definida por los edits explícitos. Los edits implícitos algunas veces permiten verrelaciones entre variables más claramente. Veamos esto con un simple ejemplo.
Ejemplo 3.2.1. En una pequeña encuesta, se les pide a los informantes que elijan entre una delas posibles alternativas para las siguiente tres cuestiones:
1. ¿Cuál es la razón más importante por la que compras azúcar?
2. ¿Bebes café con azúcar?
3. ¿Cuál es la media de azúcar que consumes en una taza de café?
Las alternativas para la primera cuestión son:
“Consumo azúcar en mi café”.
“Uso azúcar para hacer tarta de cereza”.
“Nunca compro azúcar”.
“Otra razón”.
Las alternativas para la segunda cuestión son:
“Sí”.

38 CAPÍTULO 3. METODOLOGÍA GENERAL
“No”.
Las alternativas para la tercera cuestión son:
“0 gramos”.
“Más de 0 gramos pero menos de 10 gramos”.
“Más de 10 gramos”.
Se han definido los siguientes edits explícitos:
1. La principal razón para comprar azúcar no es tomarlo en el café para alguien que no bebecafé con azúcar.
2. La cantidad media de azúcar consumido en una taza de café por alguien que bebe café conazúcar no es igual a 0 gramos.
3. Alguien que nunca compra azúcar no consume más de 0 gramos de azúcar en el café demedia.
4. Alguien que nunca compra azúcar no consume azúcar en el café. (Edit implícito)
Este edit está derivado del segundo y tercer edit explícito (ya que el segundo edit explícitoimplica que alguien que bebe azúcar en el café debe consumir más de 0 gramos por taza de cafécomo media y el tercer edit explícito dice que alguien que bebe más de 0 gramos de azúcar portaza de café de media alguna vez compra azúcar).
El edit 4 es, por definición, un edit redundante, porque su información ya está presente en elsegundo y tercer edit explícito. Sin embargo, este edit hace que la relación entre comprar azúcar yconsumir azúcar se vea más claramente. Esta relación es menos clara si uno sólo mira el segundoy el tercer edit explícito. Los beneficios de generar edits implícitos se verán más adelante en esteejemplo.
Para datos numéricos, el conjunto de edits que se derivan lógicamente de los edits explícitoscontiene infinitos elementos. Veamos un ejemplo simple de esto.
Ejemplo 3.2.2. Si x ≥ 1 es un edit, entonces λx ≥ λ es un edit implicado para todo λ ≥ 0.Generar todos los edits implícitos está fuera de lugar para los datos numéricos, y es un
desperdicio de tiempo y memoria para los datos categóricos.El método propuesto por Fellegi-Holt empieza generando un conjunto de edits implícitos y
explícitos bien definido y lo suficientemente grande. Este conjunto de edits se denomina conjuntocompleto de edits. Se denomina así no porque todos los posibles edits implícitos estén generadossino porque es el conjunto de edits (implícitos y explícitos) suficiente y necesario para convertirel el problema del cubrimiento de conjuntos en el problema de localización de errores.
Una vez que el conjunto completo de edits ha sido generado, es suficiente para encontrar unconjunto de variables S que cubran los edits (implícitos y explícitos) que son violados, es decir,en cada edit violado al menos una variable de S debería estar presente.
Ejemplo 3.2.3. El conjunto de edits viene dado por los siguientes:
1. La principal razón para comprar azúcar no es tomarlo en el café para alguien que no bebecafé con azúcar.
2. La cantidad media de azúcar consumido en una taza de café por alguien que bebe café conazúcar no es igual a 0 gramos.

3.2. PARADIGMA DE FELLEGI-HOLT 39
3. Alguien que nunca compra azúcar no consume más de 0 gramos de azúcar en el café demedia.
4. Alguien que nunca compra azúcar no consume azúcar en el café.
5. La cantidad media de azúcar consumida por taza de café por alguien cuya principal razónpara comprar azúcar es consumirlo con café no es igual a 0 gramos.
Veamos en el siguiente ejemplo porqué es necesario definir el conjunto completo de edits deforma matemática.
Ejemplo 3.2.4. Supongamos que el conjunto de edits explícitos vienen dados de nuevo porlos edits explícitos especificados en el ejemplo 3.2.1. Supongamos también que las respuestasobtenidas por uno de los informantes son:
1. La razón más importante por la que compra azúcar: Nunca compro azúcar.
2. ¿Bebe café con azúcar?: Sí.
3. ¿Cuál es la cantidad media de azúcar por taza de café?: 0 gramos.
Nótese que este registro no satisface el segundo edit explícito. Obviamente la respuesta ala segunda cuestión o la respuesta a la tercera cuestión deben ser cambiadas. Cambiar sólo larespuesta a la primera cuestión no puede generar un registro consistente.
Una manera de ver qué valor se puede cambiar es simplemente usar la idea de “prueba yerror”. Una posibilidad es cambiar la tercera respuesta a “más de 0 pero menos de 10 gramos”.Como consecuencia, el segundo edit explícito se cumplirá, pero desafortunadamente el tercer editexplícito no se cumplirá. Así que, cambiar la tercera respuesta a “más de 0 pero menos de 10gramos” no parece una buena idea.
Vamos a intentar cambiar la tercera respuesta a “más de 10 gramos”. Esto no es una buenaidea, porque el segundo edit explícito se cumplirá a través de este cambio, pero de nuevo el terceredit explícito no se cumplirá.
Ahora, supongamos que la respuesta a la segunda cuestión la cambiamos a “No”, mientrasla tercera respuesta se fija a su valor original. Ahora todos los edits son satisfechos y se haencontrado una solución al problema de la localización de errores. En este pequeño ejemplo se haencontrado una solución después de unos pocos pasos usando en enfoque de prueba y error. Peropara problemas grandes este enfoque de prueba y error no es eficiente. En el peor caso todos losposibles registros
∏mi=1 |Di| han de ser contrastados para buscar todas las soluciones óptimas.
Aquí los edits implícitos muestran su importancia y lo ilustramos a continuación.Consideremos el edit 4 del ejemplo 3.2.1, el que dice: “Alguien que nunca compra azúcar
no consume azúcar en el café”. Nótese que para determinar si este edit es satisfecho o no, sólotenemos que considerar las respuestas a las dos primeras preguntas. Esto es, el hecho de queel edit sea satisfecho o no, no depende de la respuesta a la tercera pregunta. Nótese tambiénque este edit no se cumple para el registro bajo esta consideración. Cambiando la respuesta ala tercera cuestión no conseguimos que este edit sea satisfecho. Así que no sólo tenemos quecambiar el valor de la respuesta a la tercera cuestión.
Este edit está implicado por el segundo y el tercer edit, así que es obviamente redundante.Sin embargo, como se ha visto, contiene información útil que ayuda a identificar los valores másimplausibles.

40 CAPÍTULO 3. METODOLOGÍA GENERAL
3.3. Fellegi-Holt para datos categóricos
Para datos puramente categóricos, los edits que se van a considerar son del tipo siguiente:
IF vi ∈ F ji (for i = 1, . . . , m) THEN ∅ (3.35)
Un edit del tipo (3.35) es violado si vi ∈ F ji para todo i = 1, . . . ,m. En otro caso, el edit es
satisfecho.Alternativamente, un edit categórico Ej dado en (3.35) se puede escribir de la siguiente forma:
P (Ej) =m∏
i=1
F ji (3.36)
donde∏
denota el producto cartesiano. Es decir, el edit Ej falla si y solo si los valores vi delregistro que se esté considerando mienten en el espacio dado por la parte derecha de (3.36).Fellegi y Holt llaman a (3.36) la forma normal de los edits categóricos.
Un conjunto de edits es satisfecho si todos los edits dados en (3.36) son satisfechos, es decir, unconjunto de edits falla si al menos un edit falla. Si denotamos el conjunto de edits Ej(j = 1, . . . , J)por E, entonces un registro v falla este conjunto de edits si y sólo si
v ∈ P (E) (3.37)
donde
P (E) =J⋃
j=1
P (Ej) (3.38)
Si el conjunto de valores F ji es un subconjunto propio del dominio Di de la variable i, entonces
se dice que la variable i entra en el edit Ej , y el edit Ej se dice que envuelve la variable i. Fellegiy Holt demostraron que cualquier sistema de edits categóricos pueden ser expresados en formanormal de manera equivalente.
A continuación se muestra un pequeño ejemplo para ilustrar estos conceptos.
Ejemplo 3.3.1. Supongamos que tenemos tres variables: “Edad”, “Estado civil” y “Sexo”. Lavariable “Edad” toma tres valores: 1, 2 y 3 (es decir, D1 = 1, 2, 3), que representan respec-tivamente: “Edad=0-14", “Edad=15-80 2“Edad>80”. La variable “Estado civil” solo toma dosposibles valores: 1 y 2 (es decir, D2 = 1, 2), representando “Casado” y “Soltero”. La variable“Sexo” toma dos posibles valores: 1 y 2 (es decir, D3 = 1, 2), representando respectivamente“Varón” y “Mujer”.
La sentencia “IF (Edad<15) THEN (Estado civil=Soltero)” es falsa si (Edad=0-14) y (Estadocivil=Casado), independientemente del valor de la variable “Sexo”. De una manera más matemá-tica: F 1
1 = 1, F 12 = 1 y F 1
3 = 1, 2, y el edit vendría dado en forma normal de la siguientemanera P (E1) = 1 × 1 × 1, 2.
“Edad” y “Estado civil” entran este edit porque F 11 es un subconjunto propio de D1 y F 1
2 esun subconjunto propio de D2, pero el edit no envuelve a “Sexo” ya que F 1
3 no es un subconjuntopropio de D3.
Ejemplo 3.3.2. Los edits explícitos definidos en el ejemplo 3.1.1 vendrían dados en forma normalde la siguiente manera

3.3. FELLEGI-HOLT PARA DATOS CATEGÓRICOS 41
P (E1) = 1 × 1 × 1, 2 (3.39)
P (E2) = 1, 2, 3, 4 × 1 × 1 (3.40)
P (E2) = 3 × 1, 2 × 2, 3 (3.41)
En la sección anterior ya se ha ilustrado el concepto de edits implícitos. En el algoritmode Fellegi y Holt se tiene que generar un subconjunto con todos los posibles edits implícitos yexplícitos, que se denomina el conjunto completo de edits. El siguiente lema de Fellegi y Holt esla base de los edits implícitos generados.
Lema 3.3.1. Sea Eg un conjunto arbitrario de edits, explícitos o implícitos ya generados, queenvuelven un campo g ∈ 1, . . . , m. Sea E∗ el edit definido por
F ∗j =
⋂
k,Ek∈Eg
F kj j ∈ 1, . . . ,m, j 6= g
F ∗g =
⋂
k,Ek∈Eg
F kj
Si F ∗j 6= ∅ para todo j ∈ 1, . . . , m, entonces E∗ es un edit implícito en forma normal.
Fellegi y Holt (1976) demostraron que todos los edits implícitos requeridos para sus conjuntoscompletos de edits podían ser generados a través de la aplicación repetitiva de este lema. Nóteseque este lema implica que, en general, los edits pueden ser deducidos desde uno, dos, tres, cuatroo incluso más edits explícitos o implícitos.
El subconjunto Eg se denomina conjunto contributivo y contiene los edits contributivos, o losedits que implican a E∗. El campo g se denomina el campo generador del edit E∗.
Ejemplo 3.3.3. En el ejemplo 3.1.1 el edit (implícito) 4, denotado como E4, se puede obtenera través del lema 3.3.1 con el tercer campo como el campo generador y conjunto contributivoEg = E2, E3, es decir, el segundo y el tercer edits.
Además de E4 hay otros dos edits implícitos: E5 con P (E5) = 1 × 1, 2 × 1 y E6, conP (E6) = 1, 3 × 2 × 2, 3. El edit E5 se puede obtener usando el lema 3.3.1 con conjuntocontributivo E1, E2 y campo generador 2. El edit E4 se puede obtener usando el lema 3.3.1con campo generador 1 y conjunto contributivo E1, E2. De hecho, E6 y E4 se podrían tambiéncombinar, usando la variable 2 como campo generador pero el edit resultante sería idéntico a E3.
Fellegi y Holt mostraron que no es necesario generar todos los edits implícitos a través dellema 3.3.1 para resolver el problema de localización de errores. En este punto se introduce elconcepto de edit implícito esencialmente nuevo. Un edit implícito esencialmente nuevo E∗ es unedit implícito que no envuelve a sus campos generadores (es decir, F ∗
g = Dg). El conjunto deedits explícitos junto con el conjunto de todos los edits implícitos esencialmente nuevos formanel conjunto completo de edits.

42 CAPÍTULO 3. METODOLOGÍA GENERAL
Ejemplo 3.3.4. En el ejemplo 3.3.3 es fácil ver que tanto E4 como E5 son edits implícitos esen-cialmente nuevos, pero E6 no. El conjunto completo de edits EC viene dado por E1, E2, E3, E4, E5.
Un edit implícito esencialmente nuevo E∗ puede ser interpretado como la proyección de losedits Eg sobre sus campos entrantes excepto sobre el campo generador g. Esto es, define unarelación que debe cumplirse para los campos entrantes excepto para el campo generador g. Algenerar los edits implícitos esencialmente nuevos, se pueden clarificar relaciones ocultas entrevarias variables. Una vez que las relaciones ocultas se han hecho explícitas, resolver el problemade localización de errores es relativamente directo.
Después de la generación del conjunto completo de edits, se seleccionan todos los edits que nose cumplen para cada registro. De acuerdo con Fellegi y Holt, se debe encontrar un conjunto devariables S que cubra el conjunto de edits que fallan (es decir, al menos una variable contenidaen S está envuelta en cada edit falso).
Teorema 3.3.1. Si S es cualquier conjunto de variables que cubre el conjunto completo de editsfallados, entonces existe un conjunto de valores para las variables en S que junto con los valoresoriginales para el resto de variables darán como resultado un registro consistente. Esto es, lasvariables en S pueden ser imputadas de manera consistente.
Este teorema dice que el conjunto de variables S es una solución (posiblemente suboptimal)al problema de localización de errores si S cubre el conjunto de edits que fallan. Nótese que paraobtener un registro consistente al menos uno de los campos entrantes de cada edit incumplidotiene que ser imputado. Por lo tanto, se mantiene la afirmación de que un conjunto de variablesS no puede ser imputado de manera consistente si S no cubre el conjunto de edits que fallan.Consecuentemente, todas las soluciones al problema de localización de errores se pueden encon-trar buscando todos los conjuntos de cubrimiento de variables. De acuerdo con el paradigmageneralizado de Fellegi y Holt, las soluciones óptimas al problema de localización de errores sontodos los conjuntos con una suma de pesos de fiabilidad mínima entre los conjuntos de variablesque cubren los edits violados.
Ejemplo 3.3.5. Supongamos que en el ejemplo 3.1.1 los pesos de fiabilidad son 1 para el primercampo, 2 para el segundo campo y 1 para el tercer campo. Ahora consideremos el registro v delejemplo 3.2.3. Los edits E2 y E5 son violados por este registro. Nótese que el segundo campo entraen ambos edits violados. En otras palabras, el campo 2 cubre el conjunto de edits incumplidosE2, E4. Esto implica que los conjuntos de variables v1, v2, v2, v3 y v1, v2, v3 tambiéncubren el conjunto completo de edits que fallan. Sin embargo, de acuerdo con el paradigmageneralizado de Fellegi y Holt estos últimos conjuntos de variables no deberían ser imputados.
Hay un conjunto de variables que también cubre E2, E4, llamado v1, v3. La suma de lospesos de fiabilidad de las dos variables en este conjunto es igual a dos, exactamente el mismoque el peso de fiabilidad del segundo campo. Esto significa que v2 y v1, v3 son las solucionesóptimas al problema de localización de errores.
Nótese que el teorema 3.3.1 implica que si las variables en un subconjunto S no pueden serimputadas de manera consistente entonces hay un edit (explícito o implícito) que no se cumpleen el cual ninguna de las variables del conjunto S están envueltas.
Para demostrar este teorema, Fellegi y Holt aplicaron un principio conocido como principiode elevación. Se define ΩK como el subconjunto del conjunto completo de edits que envuelve sóloa los campos 1, . . . , K. El principio de elevación dice lo siguiente:
Teorema 3.3.2. Si v0i (i = 1, . . . , K − 1) son valores para las primeras K − 1 variables que
satisfacen todos los edits en ΩK−1, entonces existen algunos valores v0K tales que los valores
v0i (i = 1, . . . , K) satisfacen todos los edits en ΩK .

3.3. FELLEGI-HOLT PARA DATOS CATEGÓRICOS 43
Este teorema establece que si los valores para K − 1 variables satisfacen todos los corres-pondientes edits (explícitos y implícitos esencialmente nuevos), entonces existe un valor para laK-ésima variable tal que todos los edits correspondientes a las primeras K variables son satisfe-chos. En otras palabras, la posibilidad de satisfacer todos los edits envolviendo K − 1 variablesse eleva a K variables. El principio de elevación es un principio muy importante.
Nótese que por aplicación repetida del teorema 3.3.1 de la página 42 se puede obtener elsiguiente corolario, donde m denota el número de variables categóricas.
Corolario 3.3.1. Si v0i (i = 1, . . . ,K − 1) son valores para las primeras K − 1 variables que
satisfacen todos los edits en ΩK−1, entonces existen valores vi (i = K, . . . , m) tal que los valoresv0i (i = 1, . . . , m) satisfacen todos los edits en el conjunto completo de edits.
3.3.1. Mejoras en el método de Fellegi-Holt para datos categóricos
En la sección anterior se ha dicho que el subconjunto de edits implícitos es suficiente pararesolver el problema de localización de errores, llamándolo el subconjunto de los edits implícitosesencialmente nuevos. Este subconjunto de edits implícitos esencialmente nuevos es mucho máspequeño que el conjunto de los edits implícitos. Sin embargo, el problema práctico del método deFellgi y Holt es que el número de edits implícitos (esencialmente nuevos) puede ser muy grande.Como resultado, el método puede ser muy lento en la práctica, o incluso peor, el número de editsimplícitos (esencialmente nuevos) puede ser tan grande que no sea manejable por un computador.
Supongamos que aplicamos el lema 3.3.1 para generar todos los edits implícitos esencialmentenuevos con el campo j como campo generador. Es importante recordar que los edits implícitosse deducen desde - al menos - dos edits. Así que, si Nj denota el número de edits (los explícitosy los implícitos ya creados) que envuelven al campo j (j = 1, . . . , m) entonces existe una cotasuperior al número de edits implícitos esencialmente nuevos que se puedan generar. Esta cota esla siguiente:
Nj∑
i=2
(Nj
i
)= 2Nj −Nj − 1 (3.42)
Por lo tanto, la generación de todos los edits implícitos esencialmente nuevos crece expo-nencialmente con el número de campos entrantes en los edits originales. Winkler (1999) inclusopropuso que la cantidad de computación requerida para generar el conjunto completo de editspara J edits explícitos es del orden exp(exp(J)). Además, informaba que el conjunto completode edits no puede ser siempre generado en la práctica, debido a limitaciones de memoria y decómputo.
El conjunto completo de edits puede ser extremadamente grande. Hay dos razones que expli-can esto. La primera razón es que para generar el conjunto completo de edits, uno debería - enprincipio - considerar todos los posibles subconjuntos de variables. Cada uno de estos conjuntosdebería ser eliminado de los edits para obtener el conjunto completo de edits. El número total desubconjuntos de variables de un conjunto de variables es 2m, donde m es el número de variables.
La segunda razón es que el número de edits nuevos que se obtienen después de que unavariable (o subconjunto de variables) han sido eliminadas puede ser muy grande. Por ejemplo,supongamos que hay s edits, donde s es par. Supongamos, incluso, que el dominio de la variableque se va a editar, variable g, es Dg = 1, 2. Si F j
g = 1 for j = 1, . . . , s/2 y F jg = 2 for j =
s/2 + 1, . . . , s, entonces el número total de edits nuevos podría ser en el peor caso igual a s2/4.

44 CAPÍTULO 3. METODOLOGÍA GENERAL
Por lo tanto, los aspectos más importantes en la implementación de un algoritmo basado enFellegi-Holt es reducir el tiempo de computación y la memoria requerida.
El problema de localización de errores puede verse como un problema de cubrimiento deconjuntos. Denotamos el conjunto de edits explícitos por EE . Supongamos que tenemos queeditar un registro v0 ∈ P (EE). Denotamos por v la versión consistente de v0 (en el sentido deque es el registro correcto) y por zi (i = 1, . . . , m) una variable binaria tal que
zi =
1 si vi 6= v0
i
0 en otro caso(3.43)
El modelo de programación entera, equivalente al problema de localización de errores, parav viene dado por:
Minimizarm∑
i=1
wizi (3.44)
Sujeto a: v ∈ D − P (EE) (3.45)
Aquí m denota, como es normal, el número de variables categóricas.Como se citó anteriormente, una condición necesaria para un vector v para resolver el proble-
ma de localización de errores es que resuelva el siguiente problema de cubrimiento de conjuntos:
Minimizarm∑
i=1
wiyi (3.46)
Sujeto a:m∑
i=1
ajiyi ≥ 1 for Ej ∈ EF (x0) (3.47)
yi ∈ 0, 1 for i = 1, . . . , m (3.48)
donde
aji =
1 si el campo i entra en Ej
0 en otro caso(3.49)
EF (v0) : conjunto de edits explícitos violados por v0 (3.50)
Las desigualdades dicen que si un edit es violado, entonces el valor de al menos una variableenvuelta por ese edit tiene que cambiar.

3.4. FELLEGI-HOLT PARA DATOS NUMÉRICOS Y MIXTOS 45
3.4. Fellegi-Holt para datos numéricos y mixtos
En las secciones anteriores se ha explicado cómo trabaja el método de Fellegi-Holt para datoscategóricos. El método trabaja de manera similar para datos numéricos. La única diferencia esla manera en la que se generan los edits implícitos esencialmente nuevos. En esta sección vamosa empezar explicando cómo se generan los edits implícitos para datos numéricos. A partir deahí, se describirá el método de Fellegi-Holt para datos mixtos de una manera muy breve segúnlo describe Tom de Wall.
Para datos puramente numéricos, los edits pueden venir dados a través de desigualdades o deigualdades. Para generar un edit implícito, primero seleccionamos un campo generador. Luego,básicamente se aplica la eliminación de Fourier-Motzkin para eliminar la variable generadoradesde el conjunto de edits.
Consideremos todos los edits que envuelven a la variable seleccionada x. Supongamos que eledit s viene dado por alguna de las dos formas siguientes
a1sx1 + . . . + ansxn + bs = 0 (3.51a)a1sx1 + . . . + ansxn + bs ≥ 0 (3.51b)
y el edit t viene dado por alguna de las dos formas siguientes
a1tx1 + . . . + antxn + bt = 0 (3.52a)a1tx1 + . . . + antxn + bt ≥ 0 (3.52b)
Ahora construimos un edit implícito. Si (3.51) es una igualdad, usamos la igualdad
xr = −bs − 1ars
( n∑
i=1, i 6=r
aisxi
)(3.53)
para eliminar xr desde (3.52).Si (3.51) es una desigualdad y (3.52) es una igualdad, entonces podemos usar la igualdad en
(3.52) para eliminar xr. Si (3.51) y (3.52) son desigualdades, hay que contrastar si los coeficientesde xr en esas desigualdades tienen signos opuestos. Esto es, hay que contrastar si ars × art < 0.Si ése es el caso, generamos el siguiente edit implícito que no envuelve a xr:
a1x1 + . . . + anxn + b ≥ 0 (3.54)
donde
ai = |ars|ait + |art|ais for all i = 1, . . . , m (3.55)
y
b = |ars|bt + |art|bs (3.56)

46 CAPÍTULO 3. METODOLOGÍA GENERAL
Dejando a un lado la manera en la que se generan los edits implícitos, el método de Fellegi-Holtpara datos numéricos es el mismo que el método de Fellegi-Holt para datos categóricos. De nuevo,el conjunto completo de edits se genera seleccionando un campo generador de manera repetida.Por lo tanto, se consideran todos los pares de edits (explícitos o implícitos), y se contrasta silos edits implícitos (esencialmente nuevos) se pueden obtener eliminando los campos generadoresseleccionados desde esos pares de edits. Este proceso continua hasta que no se generen más editsimplícitos (esencialmente nuevos) nuevos, cualquiera que sea el campo generador seleccionado.En ese instante, el conjunto completo de edits ha sido determinado.
Para ilustrar esto, veamos un ejemplo. Este ejemplo está extraído básicamente de Fellegi-Holt,excepto en el hecho de que en su informe los edits indican una condición de un edit que falla (esdecir, si una condición numérica es verdad, el edit se viola), mientras que aquí los edits indicanla condición opuesta del edit de consistencia (es decir, si una condición numérica es verdad, eledit es satisfecho).
Ejemplo 3.4.1. Supongamos que tenemos cuatro variables numéricas xi (i = 1, . . . , 4). Los editsexplícitos vienen dados por:
x1 − x2 + x3 + x4 ≥ 0 (3.57)
−x1 + 2x2 − 3x3 ≥ 0 (3.58)
Los edits implícitos vienen dados por:
x2 − 2x3 + x4 ≥ 0 (3.59)
x1 − x3 + 2x4 ≥ 0 (3.60)
2x1 − x2 + 3x4 ≥ 0 (3.61)
Los cinco edits descritos forman el conjunto completo de edits como no se pueden generarningún edit implícito (esencialmente nuevo).
Ahora, supongamos que estamos editando un registro con valores (3, 4, 6, 1), y supongamosque todos los pesos de fiabilidad son iguales a 1. Examinando los edits explícitos vemos que elprimer edit se satisface, mientras que el segundo edit se viola. A partir de los edits explícitosno está claro cuál de los campos debe cambiar. Si examinamos los edits implícitos, sin embargo,se puede ver que los edits (3.59), (3.60) y (3.61) fallan. La variable x3 está presente en los tresedits violados. Así que podemos satisfacer todos los edits cambiando el valor de x3, por ejemplo,x3 podría ser igual a 1. Cambiar el valor de x3 es la única solución óptima a este problema delocalización de errores.
Fellegi y Holt no demuestran que su método funciona con datos numéricos. En concreto, nodemuestran que una solución al problema de cubrimiento de conjuntos basada en todos los editsexplícitos y los edits implícitos esencialmente nuevos es también una solución al problema delocalización de errores. Afortunadamente, es sencillo encontrar una demostración de este estilo

3.4. FELLEGI-HOLT PARA DATOS NUMÉRICOS Y MIXTOS 47
si se recurre a los resultados standard de la eliminación de Fourier-Motzkin. Supongamos quese obtiene una solución al problema de cubrimiento de conjuntos basado en todos los edits ex-plícitos y los edits implícitos esencialmente nuevos. Entonces eliminamos las variables envueltasen esta solución a partir de los edits explícitos. El conjunto resultante de edits (implícitos) sesatisface si los valores originales son colocados para todas las variables que no están envueltas enla solución al problema de cubrimiento de conjuntos. Los edits violados (explícitos e implícitos)corresponden a restricciones para el problema de cubrimiento de conjuntos. Un resultado stan-dard de la eliminación de Fourier-Motzkin dice que los edits (explícitos) pueden ser satisfechosdando valores apropiados a las variables envueltas en la solución al problema de cubrimiento deconjuntos. Una solución al problema de cubrimiento de conjuntos es, por lo tanto, también unasolución al problema de localización de errores.
Un importante problema práctico del método de Fellegi-Holt para datos numéricos es queel número de edits implícitos puede ser muy grande. Ya se ha comentado este mismo hechopara datos categóricos. Las razones de que existan potencialmente tantos edits implícitos paradatos numéricos es que - de nuevo - existe una enorme cantidad de subconjuntos del conjuntode variables tienen que ser eliminados, y el número de edits crece cuando una variable (o unconjunto de ellas) es eliminada.
El tamaño del conjunto completo de edits aparece normalmente como un problema más seriopara datos numéricos que para datos categóricos. Para la mayor parte de los problemas de la vidareal el número de edits implícitos es extremadamente grande incluso para un número moderadoo pequeño de edits explícitos. Debido a los fracasos obtenidos en la teoría y en la práctica sobreesta situación, este camino basado en el método de Fellegi-Holt se ha abandonado rápidamentepara abordar el tratamiento de datos numéricos.
La excepción a la regla de que el número de edits implícitos crece hasta un tamaño extre-madamente grande son los edits de ratio, es decir, ratios de dos variables numéricas que estánacotados por cotas superiores e inferiores. Para los edits de ratio, el número de edits implícitoses bajo, y el método de Fellegi-Holt se puede aplicar en la práctica.
Para datos mixtos, se puede (en principio) usar también el método de Fellegi-Holt pararesolver el problema de localización de errores. Sin embargo, la lógica para generar los editsimplícitos se vuelve bastante compleja. Esta lógica se vuelve compleja porque a la hora de generarel conjunto completo de edits, las variables categóricas frecuentemente tienen que ser eliminadasde los edits en los cuales hay alguna variable numérica envuelta. Los edits resultantes son bastantecomplicados. Por esta razón, y porque el número de edits implícitos puede llegar a ser muy grande,el método de Fellegi-Holt quizás no sea el más adecuado para abordar este tipo de datos.

48 CAPÍTULO 3. METODOLOGÍA GENERAL

Capıtulo 4Metodología Aplicada
En este apartado, se intentará abordar la metodología de edición e imputación general expli-cada en el capítulo 3 aplicada al caso concreto del sistema Teide con sus particularidades.
4.1. Edits
Teide trabaja con el conjunto total de edits dividido en tres subconjuntos:
1. Edits de Rango.
2. Edits de Filtro.
3. Edits Explícitos.
4.1.1. Edits de Rango
Un edit de rango no es más que la especificación del rango que puede tomar una determinadavariable. Por ejemplo, podríamos tener algo como: xi ∈ 0, 10, donde xi es una variable discretaen el rango especificado.
4.1.2. Edits de Filtro
Un edit de filtro aparece por la necesidad de poner ciertas “llaves” a cuestiones dependientes.Por ejemplo, si una persona está en el paro, no puede responder a la pregunta “cuál es su nóminamensual”. Por lo tanto, estar o no en el paro es un filtro para la variable de nómina mensual. Deesta manera, los edits de filtro están diseñados con la siguiente estructura. Existe una condición,tal que si no se cumple, la variable sólo puede tomar un valor, y ese valor es “No Procede”.
Por ejemplo, si la variable que dice si una persona está en el paro la denominamos xi yla variable que almacena la nómina mensual de la persona la denominamos xj , existiría unedit de filtro para la variable xj . Supongamos que los edits de rango fueran: xi ∈ 0, 1 yxj ∈ 600, 10000, con xi variable discreta y xj variable continua. Pues bien, el edit de filtropara xj se escribiría tal que: IF (xi = 0) THEN (xj = “No Procede”).
49

50 CAPÍTULO 4. METODOLOGÍA APLICADA
4.1.3. Edits Explícitos
Un edit explícito sí que viene a corresponder con la definición general de edit, aunque suescritura, en el sistema Teide, se basa principalmente en estructuras del tipo IF - THEN. Esdecir, siguiendo con el ejemplo anterior, supongamos que existe otra variable xt que indica eltramo de retención que se practica sobre el sueldo bruto de una persona. Esta variable tieneasociado un edit de rango que es xt ∈ 0, 5. Con todo ello, podríamos definir un edit explícitotal que: IF ((xj ≥ 1000) Y (xj ≤ 1500)) THEN (xt = 2).
4.2. Variables
Las variables que utiliza Teide son de tipo numérico, y dentro de éstas, básicamente laherramienta está diseñada para trabajar con variables cualitativas. El fundamento de la metodo-logía aplicada se asienta en el trabajo con variables discretas, con valores estratificados y en lamayoría de los casos, representando distintas alternativas de respuesta social, aunque no quieredecir que no se puedan tratar variables contínuas.
4.3. El proceso de edición
El proceso de edición para Teide se divide en dos fases que se realizan de manera secuencial,una detrás de otra. La primera de estas fases es la edición de rangos y la segunda es la edición deedits explícitos. Esta división en fases, viene derivada de la división de edits que ya se ha citado,y naturalmente, las fases están relacionadas entre sí.
4.3.1. Edición de rangos
En esta fase de edición intervienen dos de los tres conjuntos de edits: el conjunto de editsde rango y el conjunto de edits de filtro. Esto es así, porque estos dos conjuntos de edits estáníntimamente relacionados.
Supongamos que existen n registros y m variables. Los registros vienen dados por el conjuntoM = mi | i = 1, . . . , n. Las variables vienen dadas por el conjunto V = vj | j = 1, . . . , m.Cada variable vj tiene asociado un edit de rango γj(mi) y un edit de filtro δj(mi). Estos editsson funciones que devuelven true ó false dependiendo de si la variable cumple los edits o nopara los valores de esa variable en el registro. La función que expresa la evaluación del rango esrj(mi).
El proceso de edición de rangos sería el siguiente:∀i = 1, . . . , n
∀j = 1, . . . , mrj(mi) = true ⇔ γj(mi) = true y δj(mi) = true
Esto genera un subconjunto M1 ⊆M tal que M1 = mi | rj(mi) = true ∀i = 1, . . . , n,∀j =1, . . . , m. Es decir, este subconjunto M1 es el subconjunto de aquellos registros que tienen todoslos rangos correctos.
A su vez, el conjunto complementario M ′1 es el conjunto de registros que tienen algún error.
Existe un conjunto de variables erróneas asociadas a cada registro en M ′1. Denotaremos por
ver(i) a la función que devuelve la lista de variables erróneas en rango para el registro mi, coni = 1, . . . , n.

4.4. EL PROCESO DE IMPUTACIÓN 51
4.3.2. Edición de edits explícitos
En esta fase de edición, como su nombre lo indica, sólo intervienen los edits explícitos. Elobjetivo es evaluar todos los edits explícitos sobre todos los registros.
Supongamos que existen p edits explícitos. El conjunto de edits explícitos viene dado por elconjunto E = ek | k = 1, . . . , p. Cada edit tiene asociado una función ψk(mi), que determina siel registro mi cumple el edit explícito ek. Denotaremos por tk(mi) a la función final de evaluaciónde edits explícitos.
El proceso de edición de edits explícitos sería el siguiente:∀i = 1, . . . , n
∀k = 1, . . . , ptk(mi) = true ⇔ ψk(mi) = true
Esto genera un subconjunto M2 ⊆M tal que M2 = mi | tk(mi) = true ∀i = 1, . . . , n,∀k =1, . . . , p. Es decir, este subconjunto M2 es el subconjunto de aquellos registros que cumplen contodos los edits explícitos.
A su vez, el conjunto complementario M ′2 es el conjunto de registros que tienen algún error.
Existe un conjunto de edits erróneos asociados a cada registro. La función que devuelve el con-junto unión de todas las variables presentes en el conjunto de edits erróneos para un registro ila denotaremos por vet(i), con i = 1, . . . , n.
4.4. El proceso de imputación
El proceso de imputación en Teide opera partiendo de la información generada por el procesode edición. El método general de actuación es la imputación por registro donante, basado en lateoría de Fellegi-Holt, ya vista en el capítulo 3.
4.4.1. Grafo de edits
El proceso de imputación hace uso de un grafo de edits. Este grafo viene dado por G = (N, A),donde N = V y A = aij | ∃e ∈ S : vi, vj ∈ e; i, j = 1, . . . , m, con S = Γ ∪∆ ∪ E, donde Γ es elconjunto de edits de rango y ∆ es el conjunto de edits de filtro. Es decir, el conjunto de vérticesde este grafo es el conjunto de variables y existe una arista que enlaza dos vértices (variables)siempre que esas dos variables existan en un mismo edit.
4.4.2. Registros donantes
Para llevar a cabo la imputación, es necesario contar con un conjunto de registros donantes,es decir, un conjunto de registros totalmente correctos, que han cumplido todos los edits, tantode rango, filtro como explícitos.
Este conjunto de registros viene dado por Md ⊆M tal que Md = M1 ∩M2.
4.4.3. Variables básicas y extendidas a imputar
Como contraposición al caso anterior, existe un conjunto de registros que contienen algúnerror. Estos registros deben entrar en el proceso de imputación y ser “arreglados”. Este conjuntode registros viene dado por Me ⊆M tal que Me = M ′
1 ∩M ′2.
Cada registro que pertenece a este conjunto tiene asociado un conjunto de variables básicas aimputar. Las variables básicas a imputar son las que salen directamente de la edición de rangos

52 CAPÍTULO 4. METODOLOGÍA APLICADA
y de edits explícitos, es decir, aquellas variables erróneas directamente desde la fase de edición.Para un registro mi, el conjunto de variables básicas viene dado por:
vbas(i) = ver(i)⋃
vet(i)
Las variables extendidas a imputar son aquellas variables que salen de la unión de las com-ponentes conexas de las variables básicas a imputar. Con esto se consigue tener en un conjuntotodas las variables que están relacionadas entre sí, algo muy importante para el algoritmo deimputación que se verá más adelante. Supongamos que la función cc(j) devuelve el conjuntode variables de la componente conexa para la variable vj . Para un registro mi, el conjunto devariables extendidas viene dado por:
vext(i) =⋃
vj∈vbas(i)
cc(vj)
4.4.4. Distancia interior y exterior
Se hace necesario definir una medida de distancia para poder comparar la cercanía de unregistro. En este caso, se han definido dos distancias, derivadas de los conceptos de variablesbásicas a imputar y de variables extendidas a imputar.
La distancia interior es el número de campos que difiere un registro de otro teniendo encuenta las variables básicas de imputación. Si denotamos por dint(i, j) la función que devuelvela distancia interior entre los registros mi y mj :
dint(i, j) = |vbas(i)| −∑
vk∈vbas(i)
eq(mi(vk),mj(vk))
donde la función eq(x, y) devuelve un 1 si x e y son iguales, y devuelve un 0 en otro caso.La distancia exterior es el número de campos que difiere un registro de otro teniendo en cuenta
las variables extendidas de imputación. Si denotamos por dext(i, j) la función que devuelve ladistancia exterior entre los registros mi y mj :
dext(i, j) = |vext(i)| −∑
vk∈vext(i)
eq(mi(vk),mj(vk))
donde la función eq(x, y) devuelve un 1 si x e y son iguales, y devuelve un 0 en otro caso.
4.4.5. Algoritmo de imputación
Vamos a estudiar el algoritmo de imputación para un registro mi. En primer lugar, y dadoque queremos imputar mi, se debe cumplir que mi ∈ Me.
Después de haber calculado componentes conexas y distancias interior y exterior para todoslos registros, tenemos que buscar un registro mj que será nuestro donante para el registro mi.El registro donante cumple que mj ∈ Md, además debe cumplir que su distancia sea la mínimahacia el registro mi. En la implementación actual se está utilizando la distancia exterior, peroeste criterio puede variar. Es decir, el registro donante mj sería:

4.4. EL PROCESO DE IMPUTACIÓN 53
mj = mınmk∈Md
dext(mi,mk)
Ya tenemos el registro que “donará” los valores a nuestro registro incorrecto. Ahora el proble-ma que se plantea es: ¿Cuántos valores debe donar el registro donante para hacer que el registroincorrecto cumpla las restricciones impuestas?
La donación se puede dividir en dos fases. En una primera fase, se intentará arreglar elregistro incorrecto probando con todas las combinaciones de donación de variables básicas aimputar. Es importante señalar que estas combinaciones sólo se llevarán a cabo si el número devariables básicas a imputar está por debajo de un umbral definido. Con esto, si para el registromi tenemos un número de variables básicas a imputar t = |vbas(i)|, probaremos a donar lascombinaciones siguientes:
(t1
)(t2
)(t3
). . .
(tt
)
Si en alguna de estas combinaciones el registro cumple con todos los edits definidos, salimoscon éxito. Si no es así, pasamos a la segunda fase del algoritmo.
En la segunda fase vamos a ir donando una a una el resto de variables extendidas a imputarque se han calculado para el registro mi. Pero el orden en el que se van donando estas variablesno es aleatorio, sino que están ordenadas de mayor a menor aparición en los edits. Es decir, sila función ed(j) devuelve el conjunto de edits en los que aparece la variable vj , intenta donar encada iteración la variable que cumpliera la siguiente condición:
maxvk∈vext(i)
|ed(vk)|
En el peor de los casos, este proceso terminará donando todo el conjunto de variables básicasa imputar y todo el conjunto de variables extendidas a imputar, con lo que se asegura que elregistro incorrecto tendrá todas sus variables conflictivas donadas, y por lo tanto, el registro serácorrecto.

54 CAPÍTULO 4. METODOLOGÍA APLICADA

Capıtulo 5Implementación práctica
La implementación es la manera en que se trasladan los conceptos teóricos a una realidadpráctica. Este capítulo está enfocado a describir los procesos más importantes que se dan lugaren la aplicación, mediante las funcionalidades que proporciona una estructura de clases biendefinida, y el uso de estructuras de datos concretas.
5.1. Ámbito
Teide es una aplicación informática orientada al proceso de edición e imputación de datosestadísticos, aunque no deja de ser igualmente una herramienta importante de debug para losconjuntos de datos obtenidos en encuestas por parte de institutos de estadística.
Además de su vertiente de edición e imputación, permite al usuario una visualización completade todos los elementos que forman parte del proceso, así como la toma de decisiones sobre losparámetros influyentes en la depuración.
La aplicación trabaja fundamentalmente con los siguientes tres elementos:
1. Variables.
2. Microdatos.
3. Edits.
Estos elementos conforman la entrada de datos que la aplicación necesita para funcionar y lasalida principal que proporciona son los datos imputados.
El problema de edición e imputación de datos estadísticos trabaja fundamentalmente con doselementos: una lista de edits y un conjunto de microdatos. El hecho de que exista aquí el elementovariables, es debido a que existen implícitamente edits definidos dentro del elemento variablesreferentes a los rangos de las variables y a los filtros (concepto que se explicará más adelante).Lo que se ha hecho básicamente es dividir el conjunto de edits total en varios subconjuntos quepermitan una manipulación más lógica y sencilla de los mismos.
La filosofía de desarrollo de Teide ha sido básicamente la Programación orientada a objetos(POO), aunque no totalmente pura, es decir, con ciertos trazos de programación estructurada.El lenguaje de desarrollo escogido ha sido C++ con una interface amigable de ventanas con elaspecto visual muy potenciado.
La aplicación no tiene unos requerimientos software y hardware específicos. La aplicaciónfunciona sobre plataforma windows, y las pruebas realizadas se han efectuado en un ordenador
55

56 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
personal con procesador Intel Pentium 2.4Ghz y 512Mb. de memoria RAM. Trabaja en modolocal y monousuario. Está optimizada para trabajar en resolución de pantalla de 1024 × 768píxeles.
5.2. Flujo de Programa
Teide es una aplicación que trabaja por fases. Esto significa que existe un flujo del programabien definido a través del cual se llega a los datos imputados a partir de los datos de entrada. Enuna primera fase el programa se encarga de cargar la información de entrada, llevando a cabouna serie de verificaciones de integridad y completitud. En la segunda fase se llevaría a cabo laevaluación de rangos de las variables. Una vez hecho esto, la tercera fase consiste en la evaluaciónde los edits. La cuarta fase viene a ser el propio proceso de imputación de datos. La quinta fasesería la generación de estadísticas. Y la última fase vendría a ser el volcado de la informaciónimputada.
5.2.1. Fase I: Carga de datos
Esta fase, como su nombre indica, es la encargada de cargar los datos de entrada a la apli-cación. Como ya se ha mencionado en la introducción, existen tres elementos básicos con losque trabaja Teide, que son: las variables, los microdatos y los edits. Por lo tanto Teide debecargar estos tres elementos en esta fase, pero se hace necesario disponer de un metafile (ficherocon información sobre ficheros) que permita conocer dónde están esos elementos, cuáles son susnombres y sus características. No entraremos en detalle de momento en la estructura de estosmetafiles, pero sí que diremos que son ficheros estilo XML (Extensible Markup Language: Unlenguaje de descripción de datos) que permiten obtener valores a partir de tags.
La aplicación pide al usuario un nombre de metafile para cargar la información de entraday va a buscarla a la base de datos especificada. Por lo tanto, al menos se necesita especificaren el mentafile las tablas que hacen referencia a las variables, a los microdatos y a los edits.Durante la fase de carga se hacen comprobaciones de coherencia entre los distintos registros, sehace comprobaciones de completitud y corrección de las variables y también verificaciones de losedits.
Una vez finalizado el proceso de carga y de verificaciones, la información estará almacenadaen memoria y también colocada en sus correspondientes controles para la visualización en lainterface de usuario.
5.2.2. Fase II: Evaluación de Rangos
En esta fase, se lleva a cabo la edición de los rangos de las variables, es decir, se compruebaque todos los microdatos estén en dentro de los rangos definidos en las variables. Además, en estafase se tienen en cuenta los filtros para controlar que los microdatos cumplen las restriccionesimpuestas por las variables.
El resultado de esta fase es una tabla con verdaderos y falsos, indicando qué variables cumpleno no los rangos sobre qué registros. En esta fase es posible controlar también una serie deparámetros adicionales, entre los que se destaca el porcentaje de exclusión de registros y variables.Es decir, es posible que el usuario quiera excluir del proceso posterior de imputación ciertasvariables o registros que por su elevado porcentaje de error se consideren anómalos y no setengan en cuenta.

5.2. FLUJO DE PROGRAMA 57
5.2.3. Fase III: Evaluación de Edits
Esta fase es análoga a la fase II, pero ahora estaremos trabajando con los edits que llamamosexplícitos, es decir, una serie de reglas definidas que no tienen que ver con la definición de rangosni con la definición de filtros.
Es necesario que antes de llevar a cabo esta fase se haya completado la fase II, ya que en laevaluación de los edits explícitos se hace uso de información que proviene de la fase anterior. Deahí el concepto de que Teide es una aplicación que trabaja con un claro flujo de ejecución.
Durante esta fase, se evalúan los edits explícitos que existan en el sistema sobre los microdatosde entrada. Esto genera de nuevo una tabla con respuestas afirmativas y negativas sobre elresultado de la evaluación de todos los valores de cada registro.
De igual modo, una vez calculados los porcentajes de error de todos los edits y de todos losregistros, el usuario puede volver a excluir los elementos que considere necesarios, para que luegono sean tenidos en cuenta en el proceso de imputación.
5.2.4. Fase IV: Imputación
Esta fase es el núcleo de la aplicación y es donde se lleva a cabo el proceso de imputaciónpropiamente dicho. Con los resultados obtenidos en las fases II y III, los algoritmos diseñadosintentarán imputar los microdatos incorrectos de manera que puedan ser corregidos con el menornúmero de cambios posibles.
La imputación asigna valores nuevos a aquellas variables que hayan tenido evaluaciones in-correctas para conseguir que la evaluación total del registro sobre el conjunto total de edits (véaseedits de rango, edits de filtro y edits explícitos) sea correcta.
La salida de esta fase consiste en un conjunto de microdatos convenientemente imputados, yademás mucha otra información referente al proceso de imputación llevado a cabo. De esta ma-nera, el usuario podrá comprobar la bondad del proceso y podrá también realizar modificacionesen la imputación, a través de asignaciones manuales de valores a registros.
5.2.5. Fase V: Generación de Estadísticas
Una vez que han concluido todas las fases anteriores, la aplicación lleva a cabo un proceso derecolección de toda aquella información relevante que se ha generado. Así, se hace un resumencuantitativo de aspectos que van desde el número de registros, edits y variables, hasta un listadode las variables que han fallado para algún registro pasando por los porcentajes de exclusiónaplicados o el número de registros imputados.
Este informe permite disponer de un documento muy importante a la hora de evaluar la bon-dad del proceso de imputación y de discutir y comentar posteriormente los resultados obtenidos.
5.2.6. Fase VI: Volcado de información
Todo este proceso no tendría sentido si luego toda esta información no fuera almacenada endisco. El proceso de volcado de información lleva a cabo esta tarea, almacenando el conjuntode microdatos imputados en el mismo formato de entrada que tenían los microdatos originales.Además de ello se da la posibilidad de volcar la estadísticas generadas durante todas las fasespara disponer de un respaldo a las decisiones.

58 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
5.3. Estructuras de Datos
La organización interna de los datos parte del metafile como elemento principal, además decontar con toda la información almacenada en la base de datos. A continuación vamos a ver estosaspectos con mayor detalle.
5.3.1. Metafile
El metafile es un fichero de texto plano ASCII que contiene atributos de los datos que se vana cargar en el sistema Teide. Este fichero tiene una estructura similar a la de un fichero XMLen el sentido de que hace uso de tags para encapsular los valores, aunque la sintaxis es propia.Principalmente se encarga de especificar el nombre de la base de datos con la que se va a trabajary posteriormente los atributos del conjunto de datos.
El fichero está formado por tags que permiten agrupar la información de manera coherentey sin importar el orden en el que se especifiquen. La sintaxis de cada línea del fichero metafilevendría a ser la siguiente:
<TAG> “valor del tag” .A continuación se muestra un listado de los posibles tags que pueden aparecer en el metafile:<NOM> : Nombre del conjunto de datos. Este nombre será asignado al conjunto de datos dentro
de la aplicación cada vez que haya que hacer referencia a elementos propios.<RBD> : Ruta de la base de datos. Es la ruta completa junto con el nombre del fichero de base
de datos que se quiera cargar en la aplicación.<VAR> : Nombre de la tabla de variables. Es el nombre de la tabla en la que se especifican
las propiedades de las variables que entran en juego en el proceso de edición e imputación. Estatabla debe estar en la base de datos definida previamente.
<MD1> : Nombre de la tabla 1 de microdatos.<MD2> : Nombre de la tabla 2 de microdatos.<MD3> : Nombre de la tabla 3 de microdatos.<MD4> : Nombre de la tabla 4 de microdatos.. . .<MDN > : Nombre de la tabla N de microdatos.Puede existir más de una tabla de microdatos debido a que los conjuntos suelen ser tan
grandes que se hace necesario una división de las mismas para poder gestionarlas de mejormanera. Por lo tanto, aquí se van especificando las diferentes tablas que deben estar en la basede datos, don de la aplicación debe ir a buscar los microdatos. Es recomendable seguir un ordenlógico tanto en la división de las tablas como en el orden. Por ejemplo, si se tiene una encuestalo suficientemente grande, sería conveniente separar en varias tablas de acuerdo con las distintasdimensiones que se quieran medir, y hacer uso del orden para fijar primero aquellas tablas deidentificación para luego ir añadiendo el resto de dimensiones.
<EDT> : Nombre de la tabla de edits. Es el nombre de la tabla que contendrá todas aquellas“reglas” que se quieren introducir en el sistema. Esta tabla también tendrá que estar contenidaen la base de datos especificada con anterioridad.
<MIS> : Nombre de la tabla de valores “missing”. Esta tabla especifica los valores que seránconsiderados “missing” y su relación con la respuesta correspondiente. Por ejemplo, un caso deespecificación de esta tabla podría ser la siguiente:

5.3. ESTRUCTURAS DE DATOS 59
Codigo Literal-1 No procede-3 No sabe-7 No contesta-9 No sabe ó No contesta
5.3.2. Base de Datos
La base de datos conforma el soporte principal para el almacenamiento tanto de los datos deentrada al programa como para los datos de salida. Las tablas que forman la base de datos sepueden agrupar de la siguiente manera:
Tablas de descripción de variables.
Tablas de descripción de microdatos.
Tablas de descripción de edits explícitos.
Tablas de información auxiliar.
Los tres primeros grupos de tablas ya los conocemos, pero se detallarán con mayor detalle acontinuación. Las tablas de información auxiliar son principalmente tablas de mapping, queasocian códigos numéricos de variables con sus literales de cadena correspondientes. En esteúltimo conjunto de tablas también existen otras sobre información general de los conjuntos dedatos.
5.3.3. Tabla de Variables
La tabla de variables, como se ha dicho, sirve para especificar todos los atributos que tienenlas mismas, de una manera ordenada y con una estructura definida. Los campos que contieneesta tabla se detallan a continuación:
ID: Identificador de cada variable (clave principal).
NOMBRE: Nombre de la variable (cadena sin espacios en blanco; suele ser un nombrecodificado).
TIPO: Tipo de la variable. Existen 4 posibles valores para este atributo:
• Valor “0”: Indica que la variable es de tipo continuo.
• Valor “1”: Indica que la variable es de tipo discreto en lista, es decir, que toma unaserie de valores concretos dentro de una lista.
• Valor “2”: Indica que la variable es de tipo discreto en rango, es decir, que toma valoresdiscretos(enteros) dentro de un rango.
• Valor “3”: Indica que la variable es de tipo alfanumérico, es decir, variable de cadena.
RANGO: Rango de la variable. Este atributo es una cadena que representa los distintosvalores que puede tomar la variable, y está vinculado al atributo TIPO que se ha definidoanteriormente. En función del TIPO, el rango se debe expresar de la siguiente manera:
• Si TIPO = 0. El rango debe ser expresado como: Vmin : Vmax.

60 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
• Si TIPO = 1. El rango debe ser expresado como: V1, V2, V3, V4, . . . , Vn.• Si TIPO = 2. El rango debe ser expresado como: Vmin : Vmax.• Si TIPO = 3. El rango es vacío.
NO_PROCEDE: Indica si se quieren imputar aquellos valores de los microdatos que seaniguales al valor correspondiente a NO_PROCEDE.
NO_SABE: Indica si se quieren imputar aquellos valores de los microdatos que sean igualesal valor correspondiente a NO_SABE.
NO_CONTESTA: Indica si se quieren imputar aquellos valores de los microdatos que seaniguales al valor correspondiente a NO_CONTESTA.
NS_NC: Indica si se quieren imputar aquellos valores de los microdatos que sean igualesal valor correspondiente a NS_NC.
FILTRO: Filtro de la variable. Regla que permite que la variable tome un valor en funciónde si se cumple esta regla o no.
DESCRIPCION: Comentario libre sobre la variable.
IMPUTABLE: Indica si la variable se puede imputar o no.
PI: Peso de imputación. Valor usado por los algoritmos de imputación para dar mayorimportancia a unas variables que a otras.
MAPPING: Nombre de la tabla que contiene las referencias cruzadas entre valores numé-ricos y sus correspondientes literales para esta variable.
Aquellas variables que se definan de TIPO=3, es decir, de tipo cadena, serán obviadas entodos los procesos de edición e imputación realizados en la aplicación. Únicamente serán cargadaspara visualizarlas aparte del resto de variables numéricas. Aquellas variables que se definan detipo no imputable, aún no pudiéndose imputarles un valor, sí que serán tenidas en cuenta en losprocesos de búsqueda de registros donantes y demás, siempre y cuando estén definidas de tiponumérico, es decir, un tipo entre 0 y 2, inclusive.
5.3.4. Tabla de Microdatos
La tabla de microdatos contiene todos los registros que se quieren tener en cuenta en elproceso de edición e imputación. Realmente no tiene porqué tratarse de una única tabla demicrodatos. Como se ha visto, se pueden especificar en el metafile varias tablas de microdatos,que posteriormente serán fusionadas para trabajar con una única tabla en la aplicación.
Las tablas de microdatos tienen como atributos las variables que se han definido en la tablaanterior. Por ejemplo si trabajamos con 3 variables como x1, x2, x3, y hubiéramos realizado 5encuestas, la tabla que tendríamos sería algo como:
x1 x2 x3
r1
r2
r3
r4
r5
Por supuesto, existe un campo ID en la tabla que es clave primaria y que identifica unívoca-mente a cada registro.

5.4. ESTRUCTURAS DE CLASES 61
5.3.5. Tabla de Edits
La tabla de edits almacena el conjunto de edits explícitos que van a ser considerados enla aplicación. Estos edits tienen la forma IF condición THEN conclusión . La tabla contienesolamente tres campos:
ID: Identificador de cada edit (clave primaria).
CONDICION: Cadena que contiene el propio edit.
DESCRIPCION: Descripción de la función del edit.
5.3.6. Tablas de Mapping
Las tablas de mapping son las que contienen la relación entre los valores numéricos y lascadenas de literales de cada variable. Estas tablas tienen una estructura muy sencilla, constandode dos campos: Codigo que indica el valor numérico y Literal que indica el valor de cadena. Laestructura es la misma que la indicada en la página 58 para la tabla de “missing”.
5.4. Estructuras de Clases
Prácticamente todos los procesos que tienen lugar en la aplicación están gestionados a travésde objetos. Dado que la aplicación tiene un funcionamiento secuencial, donde las tareas se vanrealizando en un orden concreto, el diseño de las clases se ha hecho pensando en este punto, ypor lo tanto, la creación de las mismas también responde a esta estructura.
La clase base de todo el sistema es la clase de variables, a partir de la cual se van construyendoel resto de clases de una manera bastante homogénea. Una vez que está construida la clase devariables, ésta es pasada como parámetro al constructor de la clase de microdatos. Una vez ahí,la clase de microdatos se pasa a la clase de edits para su construcción y así sucesivamente. Elorden de construcción y por lo tanto, de paso de clases como parámetros, es el siguiente:
1. Clase de Variables.
2. Clase de Microdatos.
3. Clase de Edits.
4. Clase de Rangos.
5. Clase de Test.
6. Clase de Imputacion.
7. Clase de Estadisticas.
5.4.1. Clase de Variables
Esta clase almacena el conjunto de variables con todos sus atributos. Es la clase base parael resto de clases del sistema y posee métodos para responder a cualquier pregunta sobre lasvariables que almacena.

62 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
Constructor
En el constructor se llevan a cabo una serie de tareas que se pasan a detallar a continuación:
Realizar la consulta de las variables sobre la base de datos.
Fijar la cantidad de datos sobre la que se va a trabajar.
Cargar la información leída desde base de datos sus correspondientes controles para suvisualización en la interface.
Generar las listas de los rangos de las variables realizando un parsing de las cadenas espe-cificadas en las tablas.
Contrastar la coherencia de los rangos en relación a los tipos especificados.
Extraer de los filtros todas sus variables para almacenar una lista con ellas.
Contrastar la completitud de los atributos de la tabla y validar sintáctica y léxicamentelos filtros definidos.
Crear las distintas estructuras de datos y guardar en memoria toda aquella informaciónleída desde la tabla de base de datos.
Métodos principales
Consultar las distintas tablas de mapping de variables y mostrar una visualización de lasmismas en pantalla.
Devolver la existencia de una variable.
Decir si una determinada variable es imputable o no lo es, o si es alfanumérica o no lo es.
Devolver tanto la lista de variables no alfanuméricas como la lista de variables alfanuméri-cas.
Devolver el índice de una variable a partir de su nombre o el nombre de la variable a partirde su índice.
Devolver el tipo de una variable.
Devolver el valor de cualquier atributo de una variable especificada.
Devolver el rango de una variable.
Devolver la cadena de un valor “missing” o el valor de una cadena “missing”.
Devolver el índice de un atributo de variable.
Devolver valores absolutos y porcentajes tanto de número de filtros, de número de variablesimputables, de tipos de variables o de admisión de valores “missing”.
Devolver el identificador (Id) de una variable. Este identificador se refiere al identificadorque existe en la tabla de la base de datos, no al identificador interno utilizado por laaplicación.

5.4. ESTRUCTURAS DE CLASES 63
Devolver una cadena con todos los nombres de las variables tanto numéricas como alfanu-méricas.
Devolver los filtros en los que aparece una determinada variable o las variables que aparecenen un determinado filtro.
Validar el rango a partir de un valor sobre una determinada variable.
5.4.2. Clase de Microdatos
Esta clase almacena el conjunto de microdatos sobre los que va a trabajar la aplicación. Losmicrodatos están dispuestos en registros, y cada registro está compuesto de variables. La claseprincipalmente sirve como contenedor de datos y como visualización de los mismos.
Constructor
Para construir la clase de microdatos se pasa como parámetro fundamental la clase de varia-bles, de la que se obtendrán, entre otras muchas cosas, la lista de variables que hay que leer dela base de datos. En este constructor se realizan las siguientes tareas:
Fijar la cantidad de datos sobre la que se va a trabajar.
Realizar la consulta de los microdatos sobre la base de datos y cargar esos datos tanto enlas rejillas de visualización correspondientes como en estructuras de memoria.
Contrastar la completitud de los registros de microdatos y las posibles incoherencias, indi-cando cualquier error encontrado.
Métodos principales
Devolver un registro concreto a partir de su índice en el conjunto de datos.
Devolver un valor concreto a partir de una variable y un registro determinados.
Devolver valores absolutos y porcentajes de la presencia de valores “missing” en los micro-datos.
Devolver el identificador de un registro (identificador de base de datos).
5.4.3. Clase de Edits
Esta clase contendrá el conjunto de edits, incluyendo un módulo de edición de edits y va-lidación de los mismos. Prácticamente de manera análoga al caso anterior, esta clase serviráfundamentalmente de repositorio de los edits explícitos que se van a utilizar, así como de visua-lización y de editor de los mismos.
Constructor
En este caso, el parámetro que viene a parar al constructor es la clase de microdatos. En esteconstructor se llevan a cabo las siguientes operaciones:
Cargar los edits desde su tabla en la base de datos hasta memoria, además de presentarlosen una rejilla para la visualización en la interface.

64 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
Fijar la cantidad de datos sobre la que trabaja la clase y el resto del sistema.
Llevar a cabo la validación de los edits que se han cargado en busca de posibles erroresléxicos o sintácticos.
Métodos principales
Insertar un nuevo edit.
Borrar un edit.
Modificar un edit.
Actualizar la validación de cualquier edit nuevo que se introduzca en el sistema.
Devolver si un determinado edit es correcto o no.
Devolver si el conjunto de edits es vacío.
Devolver si el conjunto de edits está validado.
Devolver si un determinado edit es factible o no.
Devolver las variables que pertenecen a un determinado edit.
Devolver valores absolutos y porcentajes del número de edits validados.
Devolver la cadena que representa a un edit a partir de su índice.
Devolver el identificador (Id) de un edit - el que aparece en la base de datos -.
Devolver el número de edits en los que aparece una determinada variable.
Devolver si una determinada variable pertenece o no a un edit concreto.
5.4.4. Clase de Rangos
Esta clase es la encargada de llevar a cabo la verificación de los rangos de las variables,almacenando los resultados obtenidos para que posteriormente sean usados en la imputación.Básicamente, realiza un procesamiento para cada microdato en cada variable, evaluando el rangoespecificado y devolviendo verdadero o falso en función del resultado de la evaluación. Ademásde ello, se pueden llevar a cabo operaciones de exclusión de variables o registros que superendeterminados porcentajes de error.
Constructor
Fijar la cantidad de datos con la que se va a trabajar.
Inicializar las estructuras de datos correspondientes a la evaluación de los rangos y alalmacenamiento de porcentajes y valores absolutos.

5.4. ESTRUCTURAS DE CLASES 65
Métodos principales
Llevar a cabo la evaluación del conjunto de microdatos enfrentados al conjunto de variables.
Métodos de interface para permitir al usuario buscar en todo el conjunto de la evaluaciónel siguiente error detectado tanto para variables como para registros.
Realizar la exclusión de un registro.
Realizar la exclusión de una variable.
Realizar la exclusión de un filtro.
Devolver los porcentajes de error y asociados a la evaluación tanto para el caso de variablescomo para el caso de registros.
Devolver la evaluación únicamente del rango de una variable sobre un registro.
Devolver la evaluación únicamente del filtro de una variable sobre un registro.
Devolver la evaluación conjunta del rango y el filtro de una variable sobre un registro.
Devolver el conjunto de variables excluidas y de registros excluidos.
Decir si un determinado registro o si una determinada variable están totalmente libre deerrores.
5.4.5. Clase de Test
Esta clase es totalmente análoga a la clase anterior pero en este caso la evaluación se realiza,no sobre las variables y sus rangos, sino sobre el conjunto de edits explícitos definidos. La interfacede usuario es prácticamente la misma salvando la diferencia de las variables por los edits. Hayalgo importante, y es que en la construcción de esta clase, la clase de Rangos es un parámetro deentrada. Esto es así porque la clase de Test necesita conocer toda esa información de variables yregistros excluidos, así como variables y registros erróneos para llevar a cabo su evaluación.
Constructor
Fijar la cantidad de datos con la que se va a trabajar.
Inicializar las estructuras de datos correspondientes a la evaluación de los edits explícitosy al almacenamiento de porcentajes y valores absolutos.
Métodos principales
Llevar a cabo la evaluación del conjunto de microdatos enfrentados al conjunto de editsexplícitos.
Métodos de interface para permitir al usuario buscar en todo el conjunto de la evaluaciónel siguiente error detectado tanto para edits como para registros.
Realizar la exclusión de un registro.
Realizar la exclusión de un edit.

66 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
Devolver los porcentajes de error y asociados a la evaluación tanto para el caso de editscomo para el caso de registros.
Devolver la evaluación de un edit sobre un determinado registro.
Devolver el conjunto de edits excluidos y de registros excluidos.
Decir si un determinado registro o si un determinado edit están totalmente libre de errores.
5.4.6. Clase de Imputación
Como su nombre bien indica, esta clase es la encargada de llevar a cabo la imputación delos microdatos, el fin último de la aplicación. Por supuesto, toma como parámetro de entradala clase de Test, y a través de ella, accede al resto de clases vistas hasta ahora. En esta claseestán dispuestos los mecanismos necesarios para llevar a cabo el proceso de imputación a travésdel registro donante. La información necesaria es principalmente la evaluación de rangos y laevaluación de edits explícitos. Los métodos de la clase de imputación se apoyan en la informaciónque proporcionan estas dos últimas clases.
Constructor
Fijar la cantidad de datos con la que se va a trabajar.
Inicializar las estructuras de la interface de usuario, con bastante información relevante.
Inicializar las estructuras necesarias para el proceso de imputación.
Crear el grafo de variables a través de los edits definidos en el sistema.
Calcular las componentes conexas de las variables sobre el grafo creado.
Métodos principales
Realizar la imputación sobre el conjunto de microdatos originales.
Métodos de interface para permitir al usuario buscar en todo el conjunto de imputaciónaquellos valores que han sido imputados.
Obtener el registro donante para un registro a imputar en función de distintos criterios.
Buscar la mejor donación para un registro a imputar a través de su registro donante.
Devolver el registro donante asociado a un determinado registro.
Devolver el número de registros donantes, excluidos, correctos e incorrectos.
Explorar enumerativamente las distintas combinaciones que existen para imputar variosvalores sobre un registro hasta encontrar alguna que satisfaga.
Volcar la imputación a la base de datos.

5.5. PROBLEMAS PRÁCTICOS 67
5.4.7. Clase de Estadísticas
Esta es la última clase de la jerarquía y se encarga de hacer resumen y extraer ciertos valoresestadísticos que permitan un análisis más completo del proceso de imputación. A esta clase lellega la clase de Imputación, y lo que eso conlleva es que le llega toda la información que ha sidogenerada durante la aplicación hasta ese momento. Dicho de otra manera, esta clase dispone detodos los datos necesarios para poder desarrollar su cometido.
Constructor
Fijar la cantidad de datos con la que se va a trabajar.
Inicializar las estructuras de datos de estadística descriptiva que se van a utilizar.
Realizar un resumen estadístico a priori sobre los datos de entrada.
Métodos principales
Generar las estadísticas asociadas al conjunto de variables.
Generar las estadísticas asociadas al conjunto de microdatos.
Generar las estadísticas asociadas al conjunto de edits.
Generar las estadísticas asociadas al proceso de evaluación de rangos.
Generar las estadísticas asociadas al proceso de evaluación de edits explícitos.
Generar las estadísticas asociadas al proceso de evaluación de imputación.
Generar un listado completo de edits incluyendo edits de rango, de filtro y explícitos.
Generar un listado con todos los registros y aquellos edits que incumplían.
Generar un listado con todas las variables y a qué edits pertenecían.
Generar un listado con todos los registros, variables y edits que han sido excluidos duranteel proceso.
Generar una estadística descriptiva de las frecuencias de las variables antes y después delproceso de imputación.
5.5. Problemas prácticos
En la implementación de Teide, han aparecido una serie de problemas en los que se han teni-do que tomar decisiones para su resolución. En las siguientes secciones se describen los principalesproblemas junto con las soluciones tomadas.

68 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
5.5.1. Almacenamiento de datos
El primer problema práctico que surgió en la fase de análisis y diseño de la aplicación, fuela necesidad de elegir el medio de almacenamiento de datos, llámese variables, microdatos yedits. En un primer momento, la aplicación trabajó con ficheros de texto plano. Esto daba laventaja de tener un formato extremadamente sencillo y fácil de entender por cualquier sistema,pero con la desventaja de no tener la información bien organizada y estructurada, y de hacerlas modificaciones más costosas. Por ello se pensó en una base de datos, que podría paliar estasdesventajas.
El sistema de base de datos elegido fue Access. Esto permitía un acceso sencillo, incluso entiempo de ejecución, al fichero de base de datos especificado en el metafile, y además era unabase de datos que no necesitaba grandes sistemas gestores trabajando para ella, sino que másbien se podía utilizar en monousuario y de modo local, que eran las características básicas de laaplicación.
5.5.2. Carga de datos
Una vez elegida la base de datos que se iba a utilizar, la primera fase que tiene la aplicaciónes la carga de datos para su manejo en memoria. Tras unas cuantas ejecuciones de la aplicación,se pudo observar, que el trabajo directamente sobre la base de datos era muy costoso, ya quelos accesos a un determinado registro suponían ir desplazando el puntero secuencialmente, y esoconsumía excesivo tiempo. Por lo tanto, se hacía necesario cargar la información en memoriapara trabajar con ella.
De este modo, una vez que se arranca la aplicación, y el usuario especifica el metafile, y portanto, la base de datos a cargar, el primer proceso es el de recuperar la información existenteen dicha base de datos y almacenarla en estructuras de datos más eficientes (llámese arraysbidimensionales) en memoria. Teide trabajará con estas estructuras hasta el final de la ejecución,para posteriormente volcar la imputación efectuada en el mismo formato que el de entrada.
5.5.3. Número de variables
Con estos procesos funcionando en una primera experiencia, la aplicación se enfrentó a lacarga de una pequeña muestra de prueba de la encuesta EICVHC 2004, en la que existían unnúmero de variables superior a 255. Esto suponía un problema en el almacenamiento de lastablas, y viene derivado del hecho de que Access no permite tablas con más de 255 variables.
Se pensó en cambiar el sistema de base de datos para trabajar, por ejemplo con Oracle oMySql, pero al final se decidió seguir utilizando el sistema que se tenía, pero dividiendo las tablasde microdatos en varias subtablas más pequeñas, es decir, con un número de variables menorde 255. Esto suponía un cambio en la manera de cargar los datos en memoria, ya que ahora sedebía recoger la información de varias tablas, y no era tan sencillo como utilizar una senteciaSQL para recoger los datos entre las distintas tablas, porque, al seguir siendo un acceso a unabase de datos access, la consulta tampoco permitía tener un número de variables superior a 255.Por lo tanto, este proceso se tuvo que implementar de manera manual, e ir cargando tabla atabla en memoria, además de tener que realizar un conjunto de contrastes grande, debido a lacoherencia de los registros.
Al tener el conjunto de microdatos subdividido en varias tablas, esto hace que se tenga queasegurar que cada porción de registro está almacenado en una tabla, que no hay duplicados, queno hay pérdidas de información, etc.

5.5. PROBLEMAS PRÁCTICOS 69
Además de esto, la filosofía de carga de datos sufrió un cambio, ya que hasta estos momentos,la tabla de variables era la base de todo el resto de información. Es decir, la aplicación conocíalas variables que se iban a utilizar a través de una consulta a todas las variables existentes enla tabla correspondiente de la base de datos. Pero, con la necesaria subdivisión del conjunto demicrodatos, esto cambia, y ahora las variables que se van a utilizar en el sistema son aquellasque están recogidas en las distintas tablas de microdatos que se especifican en el metafile. Así,el conjunto de variables se extrae de los microdatos, pero su información asociada se conocepor la tabla de variables. Esto supone otro conjunto de contrastes adicionales, intentando evitarvariables duplicadas, variables inexistentes, incoherencia entre la especificación de los microdatosy de las variables, etc.
5.5.4. Evaluación de edits
Un punto crítico del sistema es la evaluación de los edits. Como se ya ha comentado, un primerpaso en la edición e imputación de datos estadísticos es conocer cuáles son los errores existentesen los microdatos, y para esto se deben evaluar los edits establecidos sobre los microdatos.
Evaluar un edit viene a ser equivalente a obtener el resultado de una operación lógica en laque intervienen variables. El evaluador fue implementado a través de dos herramientas conocidaspara estos fines, como son flex y bison. Estas herramientas permiten desarrollar analizadoresgenerales para cualquier propósito. Lo único que es necesario es definir bien el léxico que se va autilizar y la sintaxis permitida. flex es la herramienta encargada de procesar el fichero léxico ybison es la herramienta encargada de procesar el fichero sintáctico.
Estas herramientas fueron desarrolladas para sistemas Unix-Linux, y su funcionamiento sebasa en darles como entrada unos ficheros léxicos y sintácticos en un formato concreto en el queno entraremos, y generan como salida un fichero en lenguaje ANSI C que luego puede ser incluídoen un proyecto. El problema es que, debido a esa orientación Unix-Linux, el código hace uso dealguna librería complicada de exportar a sitemas Windows. Por lo tanto, la dificultad estuvo ahí,es decir, en trasladar ese código para que fuera “aceptado” por el compilador en Windows.
La elección de usar estas herramientas para la escritura de los evaluadores, tiene sus ventajas ysus incovenientes, como casi todas las decisiones. Estas herramientas proporcionan un mecanismomuy potente y muy flexible para especificar el léxico y la sintaxis de tus analizadores, pero porcontra generan un código relativamente “grande” y “pesado”, ya que su uso es bastante general.La otra posible opción para escribir los evaluadores podría haber sido codificarlo directamente amano. Esto tiene la ventaja de que amoldas el código a tus necesidades y tienes la posibilidad deafinar y optimizar más tus procesos, pero tiene la desventaja de ser algo mucho más complicadode realizar y menos flexible o escalable.
5.5.5. Flexibilidad y escalibidad
Estos dos conceptos se han querido implantar de manera especial en el diseño y desarrollode la aplicación. La filosofía de Teide es la de una aplicación capaz de asumir la imputación decualquier conjunto de microdatos que cumplan una serie de condiciones básicas de completitud,corrección de formatos, etc.
Estos conceptos llevan asociado una serie de problemas que se derivan del hecho de quecuanto más general planteas un programa, hay una mayor pérdida de eficiencia y los procesos sevuelven más complicados por la necesidad de mantener esa generalidad. Esto se hace patente envarias cuestiones implementadas en la aplicación, pero sobre todo en la necesidad de crear unainfraestructura de clases bien organizada y una estructura en las variables bien definida.

70 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA
Se ha hecho un gran esfuerzo en establecer el formato de entrada en el que deben estar lasvariables. También los microdatos y los edits, pero en menor medida. La tabla de variables actuales el resultado de muchos cambios, que intentan buscar por una lado una flexibilidad de cara aotras encuestas, y por otro lado, dar respuesta a necesidades de información para la aplicación.Como ya se ha visto, la tabla de variables consta de bastantes campos de obligado cumplimiento,pero que permiten manejar cualquier encuesta, al menos, de momento.
La flexibilidad y la escalabilidad también han sido tenidas en cuenta en el desarrollo dela estructura de clases. De alguna manera, era necesario que cada clase conociera a todas lasanteriores que se habían creado ya. Por lo tanto, se pensó en una estructura jerárquica, empezandopor las variables y terminando por las estadísticas. Si pensamos que Ci es una clase y Ci+1 esla siguiente clase en la jerárquica, es decir, que se crea a continuación, lo que tendríamos es queCi sería un parámetro que se pasaría a la clase Ci+1 en su constructor. Con esto, se crearía unentramado de punteros, dando como resultado que en cada clase se conoce a las anteriores.
5.5.6. Factibilidad de edits
El problema que se planteó en este punto era el de intentar proponer algún mecanismo quesirviera para conocer si un edit era factible o no lo era, es decir, si a priori admite que exista algúnregistro que lo verifique o no. En muchos casos, la escritura de los edits es una tarea complejay tediosa, y puede llevar a situaciones imposibles de resolver, y por ello, una herramienta quedetectara estos casos, era de gran ayuda.
Aunque este proceso está todavía en desarrollo, actualmente la factibilidad de edits estáfuncionando para aquellos edits que hacen uso de variables discretas. De este modo, lo que seimplementó fue un algoritmo recursivo que realiza una enumeración exhaustiva de todos losposibles valores de las variables discretas existentes en la regla, intentando averiguar si todas susevaluaciones dan falso. Si esto es así, se puede concluir que dicho edit no es factible, y por lotanto no se tiene en cuenta en el proceso de imputación.
5.5.7. Escritura de edits
Teide se basa en el trabajo con los edits, y su escritura debe seguir unas normas biendefinidas. Por ello, uno de los problemas que se tuvieron que abordar desde un principio fue lasintaxis y los operadores que se iban a permitir utilizar. Los edits no son otra cosa que expresioneslógicas con un resultado de verdadero o falso, pero deben permitir expresar aquellas operacionesdemandadas en las reglas de coherencia de una encuesta.
Los edits de filtro tienen la forma general siguiente: IF NOT(condicion) THEN (variable= "No procede"). Por lo tanto, en la especificación de los mismos, se omite la parte derechadel edit, y sólamente hay que especificar lo que nosotros hemos llamado condicion, teniendo encuenta la forma general que tienen y que lo que se está haciendo es negando la condición.
De esta manera, lo que hemos llamado condicion corresponde con el campo Filtro en la tablade variables de la base de datos. La sintaxis que se admite en este campo es una expresión conlos elementos que se verán a continuación.
Los edits explícitos pueden contener cualquier expresión con las reglas definidas a continua-ción, aunque suelen tener la forma IF (condicion) THEN (conclusion).
5.5.8. Operadores
Los operadores permitidos son los siguientes (todos los operadores que sean cadenas de textoadmiten todas las combinaciones de mayúsculas y minúsculas que generen la cadena apropiada.

5.5. PROBLEMAS PRÁCTICOS 71
Los operadores no son sensitivos a mayúsculas y minúsculas):Operador Explicación Operador Explicación
< Menor que > Mayor que<= Menor o igual que >= Mayor o igual que!= <> Distinto + Suma- Resta * Multiplicación/ División and y & Operador yor o | Operador o not no ! Operador noxor % Operador xor ( Abrir paréntesis) Cerrar paréntesis if si Cláusula sithen entonces Cláusula entonces # Resto
5.5.9. Variables y valores
Dentro de los edits se pueden especificar nombres de variables y valores numéricos, nuncaconstantes de cadena. Las variables deben responder a la siguiente expresión regular:
[a-zA-Z][a-zA-Z0-9_]*Los valores numéricos especificados deben responder a la siguiente expresión regular:[+-]?[0-9]+([0-9]+)?([eE][+-]?[0-9]+)?
5.5.10. Sintaxis
Para definir la posible sintaxis de los edits vamos a definir algunos términos. Denotamos porei cualquier expresión que se pueda escribir, por b cualquier operador binario de los que se hanvisto, por u cualquier operador unario de los que se han visto, por ( y ) los paréntesis, por n unvalor numérico y por if y then las cláusulas vistas.
Con todo esto, las expresiones que se pueden escribir vienen reflejadas en el siguiente listado:
e1 = n
e1 = ( e2 )
e1 = e2 b e3
e1 = u e2
e1 = if e2 then e3
Es importante hacer notar que en la sintaxis no se habla de variables y sólo de valoresnuméricos porque, al final, toda variable es traducida a su valor numérico correspondiente cuandoes evaluada sobre un registro concreto.

72 CAPÍTULO 5. IMPLEMENTACIÓN PRÁCTICA

Capıtulo 6Manual de usuario
Como cualquier otra aplicación informática, el manual de usuario es un elemento básico paralograr utilizar la herramienta de manera correcta y para poder sacarle el máximo partido a lamisma. En este capítulo se verá una explicación detallada del manual de usuario, que consisteen la descripción exhaustiva de la interface de usuario, así como de todas las funcionalidadessubyacentes.
6.1. Inicio de la aplicación
6.1.1. Pantalla de bienvenida
En primer lugar, una vez que se ha ejecutado la aplicación, aparece una pantalla de bienvenidacon el nombre de la aplicación y de los autores. Esta pantalla está presente durante aproximada-mente 2 segundos. También es posible cerrarla a través de la tecla ESC o pulsando con el ratónsobre ella. Ver figura 6.1.
Figura 6.1: Pantalla de bienvenida
73

74 CAPÍTULO 6. MANUAL DE USUARIO
6.1.2. Situación inicial
Una vez que desaparece la pantalla de bienvenida aparece la interface principal de la aplicaciónen la que únicamente tenemos a nuestra disposición un escueto menú principal.
Este menú contiene dos submenús principales como son Principal y Ayuda. Dentro del menúPrincipal encontramos las siguientes opciones:
Nuevo Metafile. . .Abrir Metafile. . .Cerrar Metafile. . .Proceder. . .Salir. . .
Las tres primeras opciones reflejan las acciones que se pueden llevar a cabo con los metafiles.En el inicio de la aplicación sólo están activas las opciones de Nuevo Metafile y de Abrir Metafile.Una vez que se haya cargado un metafile en el sistema, el resto de opciones saldrán activas. Laopción de Proceder se verá más adelante pero su cometido es de servir como punto de arranquede cada uno de los procesos que se van a realizar. Y por supuesto la opción Salir representa loque su nombre indica.
En cuanto al menú de Ayuda sólo hay que reseñar que dispone de dos opciones que son lassiguientes:
Ayuda de TEIDE. . .Acerca De. . .
La opción de Ayuda de TEIDE despliega la ayuda sobre la aplicación y la opción de AcercaDe muestra una pequeña ventana al estilo de la de bienvenida en la que figuran los créditos dela aplicación así como una dirección web para conocer los desarrollos del proyecto Teide. Verfigura 6.2.
Figura 6.2: Acerca de...
6.2. Manejo de Metafiles
6.2.1. Crear un nuevo metafile
Si elegimos la opción de Nuevo Metafile se nos abrirá un pequeño editor en el que podremosescribir un texto libre para formar nuestro metafile y luego guardarlo en la misma ventana conun nombre en disco. Ver figura 6.3.
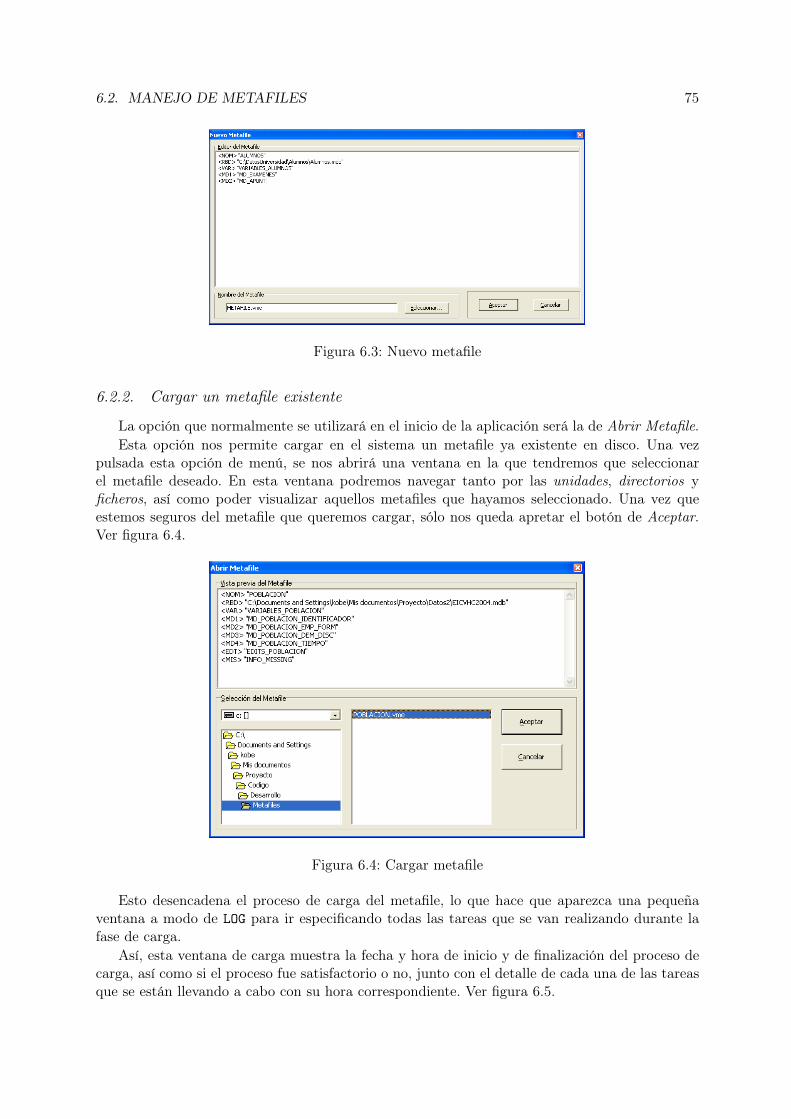
6.2. MANEJO DE METAFILES 75
Figura 6.3: Nuevo metafile
6.2.2. Cargar un metafile existente
La opción que normalmente se utilizará en el inicio de la aplicación será la de Abrir Metafile.Esta opción nos permite cargar en el sistema un metafile ya existente en disco. Una vez
pulsada esta opción de menú, se nos abrirá una ventana en la que tendremos que seleccionarel metafile deseado. En esta ventana podremos navegar tanto por las unidades, directorios yficheros, así como poder visualizar aquellos metafiles que hayamos seleccionado. Una vez queestemos seguros del metafile que queremos cargar, sólo nos queda apretar el botón de Aceptar.Ver figura 6.4.
Figura 6.4: Cargar metafile
Esto desencadena el proceso de carga del metafile, lo que hace que aparezca una pequeñaventana a modo de LOG para ir especificando todas las tareas que se van realizando durante lafase de carga.
Así, esta ventana de carga muestra la fecha y hora de inicio y de finalización del proceso decarga, así como si el proceso fue satisfactorio o no, junto con el detalle de cada una de las tareasque se están llevando a cabo con su hora correspondiente. Ver figura 6.5.

76 CAPÍTULO 6. MANUAL DE USUARIO
Figura 6.5: Cargando metafile
6.2.3. Cerrar un metafile cargado
Una vez que haya sido cargado un metafile en la aplicación, la opción de Cerrar Metafileestará activa. El cometido de esta opción es simplemente cerrar el metafile cargado, liberandotodos sus recursos y volviendo a la situación originaria de la aplicación para que se pueda volvera cargar un nuevo metafile.
6.3. Modelo de pestañas
Esta aplicación está diseñada basándose en el modelo de pestañas. Esto quiere decir que lamayoría de sus componentes son pestañas en vez de ventanas independientes. Una pestaña noes más que una “ventana” pero con un anclaje permanente e inamovible. En la implementacióndesarrollada, existe una estrecha relación entre los conceptos de clase, proceso y pestaña, ya quecada clase implementada está situada en una pestaña, y su vez, cada proceso que se realiza generauna nueva pestaña, y por lo tanto, una nueva clase.
6.3.1. Flujo
En cualquier caso, cuando un metafile se carga en el sistema, y el proceso ha sido satisfactorio,aparecen tres pestañas principales en la interface, que son: la pestaña de variables, la pestaña demicrodatos y la pestaña de edits. Una vez con estas pestañas en la interface, podremos empezara desarrollar el propio proceso de edición e imputación.
A través de la opción de menú Proceder, podremos ir generando el resto de pestañas quequedan en la aplicación de una manera ordenada y con un flujo determinado.
Para proceder con cada operación es necesario estar situado en la pestaña correspondienteen cada momento. Una vez situados sobre esa pestaña, podremos poner en marcha su procesoasociado. Cada operación sólo se podrá realizar una vez, y en el momento de pulsar la opciónProceder aparecerá una pequeña ventana indicando el progreso de la operación. Esta ventanacontiene una barra de progreso típica de Windows, así como el nombre de la operación que se estállevando a cabo, el porcentaje completado y el número de elementos procesados, que en todoslos casos que vamos a ver se corresponden con el número de registros. Una vez que la ventanade progreso ha llegado a su fin, ésta se cerrará automáticamente, mostrando la propia pestañacorrespondiente a la operación. Para ver un ejemplo de ventana de progreso puede dirigirse a la

6.4. PESTAÑA DE VARIABLES 77
figura 6.6.
Figura 6.6: Progreso de evaluación de rangos
En la tabla que hay a continuación se muestra la pestaña fuente sobre la que aplicaremos laopción Proceder para obtener la pestaña destino.
Pestaña de Origen Pestaña de DestinoVariables RangosEdits Test
Microdatos ImputacionImputacion Estadisticas
En las siguientes secciones, iremos explicando la estructura y funcionalidades de cada una delas pestañas que se han citado.
6.4. Pestaña de Variables
Esta pestaña contiene toda la información relevante de las variables que se han cargado.Su objetivo es servir de referente para extraer cualquier información que se necesite sobre unadeterminada variable, y dentro de ella, sobre algún atributo en concreto. Ver figura 6.7.
6.4.1. Rejilla principal
Esta rejilla contiene toda la información de las variables en forma tabular. Cada fila representauna variable y cada columna representa un atributo. La rejilla muestra directamente lo que hayen la tabla de variables de la base de datos ya explicada en la sección 5.3.3, con la única diferenciade que el tipo no está visualizado mediante códigos numéricos, sino con su literal asociado, parahacer más fácil su comprensión.
Se ha implementado una funcionalidad dentro de esta rejilla, que permite el acceso a los map-pings de las variables. Si hacemos doble click sobre alguna de las columnas de valores “missing”,véase “No procede”, “No sabe”, “No contesta”, “No sabe, No contesta, aparecerá una pequeñaventana indicando la relación entre los códigos numéricos y los literales asociados. Este tambiénocurre si hacemos doble click sobre el campo Mapping, con lo que también tendremos esta mismaventana indicando el mapping de la variable actual. Véanse las figuras 6.8 y 6.9.
6.4.2. Navegadores
En la parte inferior de la pestaña, justo debajo de la rejilla principal, existe un panel conunos navegadores que nos permiten acceder de forma rápida a las variables y a los atributos.
6.4.3. Barra de estado
Al pie de la pestaña, nos encontramos con una típica barra de estado, subdividida en dosregiones. Una primera región a la izquierda indica el número de variables y el número de atributosde cada variable. El número de variables sólo se refiere a las variables no alfanuméricas. Las
78 CAPÍTULO 6. MANUAL DE USUARIO
Figura 6.7: Pestaña de variables
variables alfanuméricas son separadas y no intervienen en los procesos de edición e imputación.Y una segunda región a la derecha indica en qué variable nos encontramos actualmente. En estepunto hay que reseñar un aspecto. Este puntero de la barra de estado indica el número ordinalde la variable dentro del conjunto total. Sin embargo el campo ID de la rejilla principal no tieneporqué coincidir con este valor ordinal, ya que, como se ha comentado, estos valores de la rejillason extraídos directamente de la base de datos.
6.5. Pestaña de Microdatos
Esta pestaña contiene el conjunto de microdatos que han sido cargados a partir del metafileen el sistema. Esta pestaña es algo más compleja que la anterior aunque sigue manteniendo prác-ticamente la misma estructura. Su objetivo fundamental es visualizar los microdatos y permitiruna navegación por los mismos de manera sencilla. Ver figura 6.10.
6.5.1. Rejilla principal
Esta rejilla contiene toda la información de los microdatos de manera tabular. Cada filarepresenta un registro y cada columna representa una variable. Los microdatos se muestran demanera numérica aunque ya veremos que se dispone de una funcionalidad para acceder a losliterales asociados.

6.5. PESTAÑA DE MICRODATOS 79
Figura 6.8: Mapping de valores “missing”
Figura 6.9: Mapping de variable
6.5.2. Rejilla auxiliar
Junto con la rejilla principal de microdatos, existe una pequeña rejilla debajo que contieneaquellas variables que son de tipo alfanumérico y que por lo tanto han sido separadas del restopara darles otro tratamiento. Esta pequeña rejilla sólo muestra los valores de estas variablesalfanuméricas para el registro actual, de tal manera que si vamos cambiando de registro estosvalores se actualizan.
6.5.3. Rejilla de variable
A continuación de la rejilla de visualización de variables alfanuméricas, viene otra pequeñarejilla. Esta rejilla muestra los valores de los distintos atributos para la variable que está activaen la rejilla de microdatos, es decir, que cuando nos desplazamos por el conjunto de microdatos,esta rejilla actualiza sus valores en función del lugar en el que se encuentre la celda activa.
6.5.4. Navegadores
En la parte inferior de la pestaña podemos encontrar un pequeño navegador, con la posibilidadde acceder a un determinado registro a través de su número ordinal y también la posibilidad deir a una determinada variable a través de su nombre.
6.5.5. Cuadro de Mapping
Como se citó anteriormente, los valores existentes en la rejilla principal no dejan de servalores numéricos, pero a través de este cuadro de mapping podemos visualizar el valor literalcorrespondiente al valor numérico. Este valor del cuadro se va actualizando en función de dóndeesté la celda activa en la rejilla principal. Para aquellas variables que no disponen de tablas demapping, este cuadro muestra un mensaje de error.

80 CAPÍTULO 6. MANUAL DE USUARIO
Figura 6.10: Pestaña de microdatos
6.5.6. Barra de estado
Al pie de la pestaña, nos encontramos con una típica barra de estado, subdividida en dosregiones. Una primera región a la izquierda indica el número de registros, el número de variablesnuméricas y el número de variables alfanuméricas. La región derecha indica en qué registro nosencontramos actualmente. Igual que en el caso de las variables, aquí también ocurre lo mismocon el caso del identificador y del puntero ordinal.
6.6. Pestaña de Edits
La pestaña de edits permite la visualización y la gestión de los edits que existen en el sistema.La estructura de la pestaña está también basada en una rejilla principal de visualización perocon ciertas funciones añadidas. Sus objetivos principales son los de permitir una validación delos edits cargados, la actualización de los mismos y la consulta. Ver figura 6.11.
6.6.1. Rejilla principal
En la rejilla principal están recogidos los edits que hay cargados en el sistema. En ella, cadafila representa un edit y cada columna un atributo de ese edit. Estos atributos están descritos enla sección 5.3.5. A medida que nos movemos por cada una de las filas (edits), toda la informaciónde la pestaña se actualiza en función de esto.

6.6. PESTAÑA DE EDITS 81
Figura 6.11: Pestaña de edits
Cuando algún edit tiene errores de validación, la fila correspondiente en la rejilla se pintaráde color destacado.
6.6.2. Módulo de gestión de edits
Este módulo está localizado en un panel en la parte inferior de la pestaña, donde podemosencontrar un cuadro de edición para el edit actual, tres botones correspondientes a las tareasbásicas de gestión, que son modificación (MOD.), inserción (INS.) y borrado (BOR.), y tambiénencontramos dos listas desplegables, una para las variables y otra para los operadores.
A la hora de insertar un nuevo edit, hay que pulsar el botón INS. para crear una nuevaentrada, escribir el edit en el cuadro de edición y pulsar la tecla ENTER para completar elproceso. Sería interesante rellenar el resto de atributos que componen el edit, sobre todo elcampo de descripción ya que es de mucha ayuda para el posterior análisis. Pero este proceso tieneasociado unas funcionalidades de ayuda a la escritura del edit, ya que en las listas desplegablespodremos seleccionar la variable que queremos introducir y el operador necesario.
En cuanto al borrado, sólo tenemos que situarnos en la rejilla principal sobre aquel edit quequeramos eliminar y pulsar el botón BOR.
Para actualizar un edit, seguimos la misma estructura que en el borrado, es decir, nos situamossobre aquel edit que vaya a ser modifcado, luego cambiamos lo que sea necesario sobre el cuadrode edición, para luego pulsar el botón MOD. o bien pulsar la tecla ENTER, para que los cambiostengan efecto.

82 CAPÍTULO 6. MANUAL DE USUARIO
6.6.3. Rejilla de variable
Esta rejilla está íntimamente relacionada con el módulo de gestión de edits, ya que nos sirvepara lo siguiente. Cuando seleccionamos una variable en la lista desplegable a la hora de insertaro modificar un edit, toda la información referente a esa variable se visualiza en esta rejilla,permitiendo conocer al usuario, sus posibles valores, rangos, etc.
6.6.4. Módulo de validación
Este módulo de validación está compuesto prácticamente por dos elementos, una validaciónléxica y una validación sintáctica. Vienen representados por unos pequeños bitmaps, en formade flecha verde si todo fue correcto, o de cruz roja si hubieron problemas. Por supuesto, tienenuna vinculación directa con el módulo de gestión de edits, y también con la navegación por larejilla principal.
Cada vez que nos movemos entre edits, o modificamos o insertamos edits, las validaciones seactualizan en función del edit actual.
La validación léxica de un edit indica si el edit es léxicamente correcto, o sea, si todos suselementos son correctos, véase que los operadores son adecuados y que los nombres de variablesestán en el sistema. Por otro lado, la validación sintáctica de un edit indica si la estructura en laque se ha creado el edit es correcta, véase matching de paréntesis, estructuras IF - THEN, etc.
Existe otro elemento que es la factibilidad. Este elemento está todavía en desarrollo, perointenta descubrir si un determinado edit puede llegar a ser no factible. Realizando una evaluaciónexhaustiva de todos los posibles valores de las variables del edit, puede verse si un determinadoedit no va a poder ser nunca factible. Este elemento funciona con variables discretas y sigue enestudio.
6.6.5. Navegadores
A un lado de los controles de validación, existen una serie de navegadores para movernos porla rejilla principal de manera más eficiente. Existe un navegador que permite ir a un determinadoedit a través de su número ordinal, y también tenemos un botón a través del cual podemos irnosmoviendo por todos aquellos edits que están incorrectos.
6.6.6. Filtrado de edits
En la misma posición en la que se encuentran los navegadores, existe un cuadro de ediciónpara filtrar edits. Colocando un nombre de variable n el cuadro, y pulsando la tecla ENTERpodremos ir accediendo de manera contínua a todos aquellos edits que contengan la variableespecificada.
6.6.7. Barra de estado
Por último, indicar que esta pestaña también dispone de una pequeña barra de estado quepermite conocer el número total de edits, junto con los edits que han sido validados y los queno, y también un puntero que indica el número ordinal del edit que estamos visualizando enla rejilla, teniendo en cuenta los mismos aspectos comentados anteriormente sobre el campo deidentificación presente en la rejilla principal.

6.7. PESTAÑA DE RANGOS 83
6.7. Pestaña de Rangos
Esta pestaña se genera a partir de proceder desde la pestaña de variables. Como su nombreindica, esta pestaña presenta la información asociada a la evaluación de los rangos de las variablessobre los microdatos. Debe ser la primera pestaña generada por el usuario en la aplicación, y suobjetivo es mostrar los resultados obtenidos en distintos formatos y permitir ciertas operacionesde exclusión, que ya se verán. Ver figura 6.12.
Figura 6.12: Pestaña de evaluación de rangos
6.7.1. Rejilla principal
La rejilla principal dispone los registros por filas y las variables por columnas. Los valoresque se pueden observar en la rejilla son valores "True" y "False" (estos en color rojo), corres-pondientes a verdadero y falso, respectivamente.
Si partimos de un registro i y una variable j, la función de evaluación R(i, j) indicaría elvalor existente en la celda [i, j] de la rejilla principal, y vendría definida de la siguiente manera:
R(i, j) =
True Si el registro i cumple el rango j
False en otro caso(6.1)
La rejilla dispone en su segunda fila y columna, de los valores absolutos y relativos de erroresencontrados durante la evaluación.

84 CAPÍTULO 6. MANUAL DE USUARIO
Si partimos de un registro i, la función E(i) sería el valor absoluto que veríamos en la fila ide la rejilla principal, y vendría definida de la siguiente manera:
E(i) =m∑
h=1
(R(i, h) = False
)(6.2)
donde m representa el número de variables.Si partimos de una variable j, la función E(j) sería el valor absoluto que veríamos en la
columna j de la rejilla principal, y vendría definida de la siguiente manera:
E(j) =n∑
h=1
(R(h, j) = False
)(6.3)
donde n representa el número de registros.Los porcentajes asociados que aparecen junto con los valores absolutos, se calculan simple-
mente como el tanto por cien del valor de estas funciones.La rejilla principal dispone de un código de colores, para permitir identificar de manera más
rápida registros y variables. La leyenda sería la siguiente:Color ExplicaciónNaranja Registros o variables excluídos/asAzul Registros o variables correctos/as
Una funcionalidad que ha sido implementada en la rejilla principal pensando en la navegaciónpor la misma, es la de acceder de una manera rápida a aquellas evaluaciones falsas de los rangos.Situados sobre cualquier celda, podemos ir moviendonos a derecha, izquierda, arriba o abajo,hacia los valores incorrectos, pulsando la tecla ALT y los cursores correspondientes. Cuando lacelda activa no se mueva más indicará que no existen más valores incorrectos en esa dirección.
6.7.2. Histograma de porcentajes de error
En la zona central de la pestaña, existe un histograma en el que se visualizan los porcentajesde error comentados anteriormente. El histograma puede visualizar dos gráficas alternativas, queson las siguientes:
1. Histograma de porcentajes de error sobre registros.
2. Histograma de porcentajes de error sobre variables.
Para cambiar de un histograma a otro, basta con hacer doble click en el título Porcentajesde Error del cuadro que contiene al histograma.
Debido a la gran cantidad de datos que se manejan fue necesario paginar los histogramas, detal manera que en cada momento en pantalla sólo se muestran 100 valores. Para acceder a lossiguientes valores basta con hacer click en la zona derecha del histograma y para acceder a losanteriores valores basta con hacer click en la zona izquierda del histograma.
El histograma de porcentajes de error viene a reflejar de manera gráfica los valores relativoscalculados en la rejilla principal, pero lo hace de una manera indirecta. Es decir, en la gráfica,para cada valor en el eje X, existen dos barras de porcentajes. Una de ellas es el valor originaldel porcentaje de error (representado en color verde), y la otra es el valor actual del porcentajede error después de haber llevado a cabo un proceso de exclusión tanto de variables como de

6.7. PESTAÑA DE RANGOS 85
registros que se verá en próximos apartados. En cualquier caso, el histograma sigue manteniendoel código de colores usado por la rejilla principal.
Por último, comentar que la escala en el eje Y del histograma es de autoajuste, es decir, quesitúa su máximo en el máximo valor de todos los porcentajes de error que existen en la serieactual.
6.7.3. Sistema de Exclusión
Justo debajo de la rejilla principal, aparece un pequeño panel con la funcionalidad de permitirla exclusión de registros y variables. El usuario debe introducir un porcentaje de umbral, de talmanera, que cuando se presione el botón Aplicar Exclusión, todos aquellos registros que tenganun porcentaje de error mayor que el umbral de registros serán excluidos, y todos aquellas variablesque tengan un porcentaje de error mayor que el umbral de variables serán excluidas.
Antes de haber realizado ningún tipo de exclusión, es posible que aparezcan los llamadosregistros excluidos a priori. Estos registros aparecen excluídos ya que contienen alguna variablecuyo rango es erróneo, y además esa variable está fijada como no imputable. De esta manera, elsistema detecta este hecho, y coloca el registro en cuestión como excluído, ya que no se puedearreglar un registro si la variable erróneo no es imputable.
Además de esto, es posible excluir de manera individual, tanto los registros como las variables.Una vez situados sobre una celda [i, j] en la rejilla principal, podemos hacer click con el botónderecho del ratón, y tendremos un menú emergente para excluir el registro i o la variable j.
Una vez que un registro o variable ha sido excluido, se recalculan los porcentajes del restode registros y variables, pudiéndose en su caso, entrar en un proceso en el que otros registroso variables vayan disminuyendo sus porcentajes de error gracias a la exclusión de anteriores.Es muy importante indicar lo siguiente. Cuando una variable es excluida, todos los edits enlos aparezca dicha variable son excluidos, por lo que se debe tener un cierto cuidado en estosprocesos, ya que no sólo están siendo afectados edits explícitos, sino también edits de filtro.
En la figura 6.12 se puede ver que no se ha aplicado ningún tipo de exclusión, mientras queen la figura 6.13 se observa que se ha aplicado una exclusión con un porcentaje del 20% tantoen registros como en variables.
6.7.4. Rejilla de variable
Esta rejilla es análoga a las rejillas de variable vistas con anterioridad, salvo en un detalle quees el filtro. Como ya se ha citado, la evaluación de rangos comprende el uso de los filtros para sucometido, por lo que son un elemento fundamental y deben ser tratados particularmente.
La peculiaridad de esta rejilla de variable con respecto a otras, es que existe un código decolores para el campo Filtro. Este código de colores representa la evaluación del filtro sobre elmicrodato actual en la variable actual de la rejilla principal. El código de colores usado para elfiltro es el siguiente:
Color ExplicaciónBlanco El filtro es correctoRojo El filtro es incorrectoNaranja La condición del filtro es incorrecta, pero el filtro completo es correctoAzul El filtro está excluído, es decir, es correcto

86 CAPÍTULO 6. MANUAL DE USUARIO
Figura 6.13: Pestaña de evaluación de rangos
6.7.5. Rejilla de registro
Esta rejilla funciona de manera similar a la rejilla de variable, pero en este caso, a medidaque nos movemos por la rejilla principal, en esta rejilla se actualizan los valores de los microdatospara el registro actual.
Esta rejilla también dispone de un código de colores para indicar la vinculación de las variablescon el resto de estructuras. El código de colores utilizado es el siguiente:
Color ExplicaciónAzul Variable actual en la rejilla principal con rango correctoRojo Variable actual en la rejilla principal con rango incorrectoAmarillo Variable incluida en el filtro de la variable actual
6.7.6. Navegadores
Debajo de estas últimas rejillas, existe un panel en el que hay navegadores tanto de variablescomo de registros. Para acceder a un registro, lo hacemos a través de un cuadro de edición en elque introducimos el número ordinal del registro que queremos ver. Para acceder a una variable lopodemos hacer tanto a través del nombre como a través de su número ordinal (posición) dentrodel conjunto de variables.

6.8. PESTAÑA DE TEST 87
6.7.7. Indicadores de edits involucrados
En la parte izquierda del panel que contiene a los navegadores podemos encontrar los cua-dros de edición que pretenden ser una referencia del número de edits en los que aparece unadeterminada variable.
Cuando nos movemos por la rejilla principal cambiando de variable, estos valores se actuali-zan, y nos permiten ver el número de filtros y el número de edits explícitos en los que aparecela variable actual. No se incluyen aquí los edits de rangos, puesto que es sabido que todas lasvariables poseen un único edit de rango que les afecta.
Estos datos le permiten al usuario hacerse una idea de lo importante que es una variable ode lo extendida que está, para cuando vaya a realizar tareas de exclusión.
6.7.8. Barra de estado
La barra de estado se encuentra situada en la parte inferior de la pestaña, y se basa enmostrar el número ordinal de registro que tenemos activo, dentro del total, así como el ordinalde la variable que hay activa.
6.8. Pestaña de Test
Esta pestaña se genera a partir de proceder desde la pestaña de edits. El objetivo de estapestaña es mostrar los resultados obtenidos durante la fase de edición de edits explícitos, con unformato totalmente análogo al visto en el apartado anterior, es decir, una rejilla principal con losresultados de la evaluación y una serie de controles que facilitan las operaciones de seguimientoy análisis. Ver figura 6.14.
6.8.1. Rejilla principal
La rejilla principal dispone los registros por filas y los edits por columnas. Los valores que sepueden observar en la rejilla son valores "True" y "False" (estos en color rojo), correspondientesa verdadero y falso, respectivamente.
Si partimos de un registro i y un edit j, la función de evaluación T (i, j) indicaría el valorexistente en la celda [i, j] de la rejilla principal, y vendría definida de la siguiente manera:
T (i, j) =
True Si el registro i cumple el edit jFalse en otro caso
(6.4)
La rejilla dispone en su segunda fila y columna, de los valores absolutos y relativos de erroresencontrados durante la evaluación.
Si partimos de un registro i, la función E(i) sería el valor absoluto que veríamos en la fila ide la rejilla principal, y vendría definida de la siguiente manera:
E(i) =m∑
h=1
(R(i, h) = False
)(6.5)
donde m representa el número de edits.Si partimos de un edit j, la función E(j) sería el valor absoluto que veríamos en la columna
j de la rejilla principal, y vendría definida de la siguiente manera:

88 CAPÍTULO 6. MANUAL DE USUARIO
Figura 6.14: Pestaña de evaluación de edits explícitos
E(j) =n∑
h=1
(R(h, j) = False
)(6.6)
donde n representa el número de registros.Los porcentajes asociados que aparecen junto con los valores absolutos, se calculan simple-
mente como el tanto por cien del valor de estas funciones.La rejilla principal dispone de un código de colores, para permitir identificar de manera más
rápida registros y variables. La leyenda sería la siguiente:Color ExplicaciónNaranja Registros o edits excluídos/asAzul Registros o edits correctos/as
Una funcionalidad que ha sido implementada en la rejilla principal pensando en la navegaciónpor la misma, es la de acceder de una manera rápida a aquellas evaluaciones falsas de los test.Situados sobre cualquier celda, podemos ir moviendonos a derecha, izquierda, arriba o abajo,hacia los valores incorrectos, pulsando la tecla ALT y los cursores correspondientes. Cuando lacelda activa no se mueva más indicará que no existen más valores incorrectos en esa dirección.
6.8.2. Histograma de porcentajes de error
En la zona central de la pestaña, existe un histograma en el que se visualizan los porcentajesde error comentados anteriormente. El histograma puede visualizar dos gráficas alternativas, que

6.8. PESTAÑA DE TEST 89
son las siguientes:
1. Histograma de porcentajes de error sobre registros.
2. Histograma de porcentajes de error sobre edits.
Para cambiar de un histograma a otro, basta con hacer doble click en el título Porcentajesde Error del cuadro que contiene al histograma.
Debido a la gran cantidad de datos que se manejan, fue necesario paginar los histogramas,de tal manera que en cada momento en pantalla sólo se muestran 100 valores. Para acceder a lossiguientes valores basta con hacer click en la zona derecha del histograma y para acceder a losanteriores valores basta con hacer click en la zona izquierda del histograma.
El histograma de porcentajes de error, viene a reflejar de manera gráfica los valores relativoscalculados en la rejilla principal, pero lo hace de una manera indirecta. Es decir, en la gráfica,para cada valor en el eje X, existen dos barras de porcentajes. Una de ellas es el valor originaldel porcentaje de error (representado en color verde), y la otra es el valor actual del porcentajede error después de haber llevado a cabo un proceso de exclusión tanto de variables como deregistros que se verá en próximos apartados. En cualquier caso, el histograma sigue manteniendoel código de colores usado por la rejilla principal.
Por último, comentar que la escala en el eje Y del histograma es de autoajuste, es decir, quesitúa su máximo en el máximo valor de todos los porcentajes de error que existen en la serieactual.
6.8.3. Sistema de Exclusión
Justo debajo de la rejilla principal, aparece un pequeño panel con la funcionalidad de permitirla exclusión de registros y edits. El usuario debe introducir un porcentaje de umbral, de talmanera, que cuando se presione el botón Aplicar Exclusión, todos aquellos registros que tenganun porcentaje de error mayor que el umbral de registros serán excluidos, y todos aquellos editsque tengan un porcentaje de error mayor que el umbral de edits serán excluidos.
De manera similar al caso de la exclusión en rangos, aquí también aparecen registros excluídosa priori, pero también edits excluídos a priori. El conjunto de registros excluídos a priori es elconjunto de registros excluídos en la evaluación de rangos, y el conjunto de edits excluídos apriori, es el conjunto que resulta de excluir todos aquellos edits que contengan alguna variableque ha sido excluída en el proceso de evaluación de rangos.
Además de esto, es posible excluir de manera individual, tanto los registros como los edits.Una vez situados sobre una celda [i, j] en la rejilla principal, podemos hacer click con el botónderecho del ratón, y tendremos un menú emergente para excluir el registro i o el edit j.
Una vez que un registro o edit ha sido excluido, se recalculan los porcentajes del resto deregistros y edits, pudiéndose en su caso, entrar en un proceso en el que otros registros o editsvayan disminuyendo sus porcentajes de error gracias a la exclusión de anteriores.
En la figura 6.14 se puede ver que no se ha aplicado ningún tipo de exclusión, salvo la queviene implícita desde la evaluación de rangos, mientras que en la figura 6.15 se observa que seha aplicado una exclusión con un porcentaje del 20% tanto en registros como en edits.
6.8.4. Rejilla de registro
Esta rejilla está situada justo debajo del histograma del porcentajes de error, y permite lavisualización en cada momento de todos los valores del registro actual, es decir, del registro conla celda activa de la rejilla principal.

90 CAPÍTULO 6. MANUAL DE USUARIO
Figura 6.15: Pestaña de evaluación de edits explícitos
6.8.5. Cuadro de edit
En la parte inferior de la pestaña, al lado de los navegadores, tenemos un cuadro de texto quenos permite conocer el cada momento el edit completo que estamos seleccionando en la rejillaprincipal. A medida que nos movemos por los distintos edits, este cuadro se va actualizando conel propio texto del edit.
6.8.6. Navegadores
Debajo de la rejilla de registro, existe un panel en el que hay navegadores tanto de registroscomo de edits. Para acceder a un registro, lo hacemos a través de un cuadro de edición en elque introducimos el número ordinal del registro que queremos ver. Para acceder a una variableel procedimiento es igual, aunque ahora lo haremos mediante el ordinal del edit al que queramosacceder.
6.8.7. Barra de estado
La barra de estado se encuentra situada en la parte inferior de la pestaña, y se basa enmostrar el número ordinal de registro que tenemos activo, dentro del total, así como el ordinaldel edit que hay activo.

6.9. PESTAÑA DE IMPUTACIÓN 91
6.9. Pestaña de Imputación
Esta pestaña se genera a partir de proceder desde la pestaña de microdatos. Esta pestañaes la pestaña más compleja que existe en el sistema, tanto por la cantidad de información quese muestra al usuario, como por la importancia que tiene. El fin último del sistema es llevar acabo la imputación, y es aquí dónde se nos muestran los resultados de la misma, así como otrosmuchos datos cuantitavos del proceso. Ver figura 6.16
Figura 6.16: Pestaña de imputación
6.9.1. Rejilla principal
La rejilla principal es idéntica a la rejilla principal que existe en la pestaña de microdatos,es decir, dispone los registros por filas y las variables por columnas. Cada celda tiene el valordel microdato para un registro y una variable concretos, pero la diferencia radica en que en estarejilla están ya presentes los valores que se han imputado.
La rejilla principal dispone de un código de colores para permitir identificar de manera másrápida cuál ha sido el tratamiento que se le ha dado al microdato que se visualiza. Este códigoes el siguiente:
Color ExplicaciónBlanco Microdato originalAmarillo Microdato imputadoAzul Registro donante
Naranja Registro/variable excluído/a

92 CAPÍTULO 6. MANUAL DE USUARIO
Una funcionalidad que ha sido implementada en la rejilla principal pensando en la navega-ción por la misma, es la de acceder de una manera rápida a aquellos microdatos que han sidoimputados. Situados sobre cualquier celda, podemos ir moviéndonos a derecha, izquierda, arribao abajo, hacia los valores imputados, pulsando la tecla ALT y los cursores correspondientes.Cuando la celda activa no se mueva más indicará que no existen más valores imputados en esadirección.
6.9.2. Leyenda
Debajo de la rejilla principal, existe un pequeño panel, con el código de colores que se haexplicado en el apartado anterior, para facilitar la interpretación de los resultados.
6.9.3. Sistema de volcado
A un lado de la leyenda, encontramos unos controles orientados al volcado de los microda-tos imputados sobre la base de datos. Dado que los microdatos originales de entrada han sidocargados a partir de una o varias tablas, el sistema intenta volcar los microdatos imputados enel mismo formato. O sea, generando el mismo número de tablas que en la entrada, y respetandolos formatos de esas tablas.
Para llevar a cabo el volcado sólo hay que especificar en el cuadro de Sufijo de volcadouna cadena que será añadida a los nombres de las tablas de entrada, y dónde se volcarán losmicrodatos imputados una vez que se pulse el botón Volcar Imputación.
6.9.4. Registros donantes
Debajo de este panel que contiene la leyenda y el sistema de volcado, nos encontramos conuna serie de controles destinados a la gestión y análisis de los distintos registros donantes.
En primer lugar, tenemos un navegador de registros donantes, que nos permite ir accediendoa los distintos registros donantes que existen en el sistema, pero que está inicialmente fijado alregistro donante para el registro actual que hay seleccionado en la rejilla principal.
A través de una rejilla de registro, podemos ir visualizando los valores de cada registrodonante, a medida que nos desplazamos con el navegador. Esta rejilla utiliza el color azul paramostrar la variable activa en la rejilla principal.
En el sitema de registros donantes, también existe un contador que indica el número ordinal deregistro donante que estamos visualizando en función del número total. En próximos apartadosse hablará de la metodología de registro donante aplicada en el sistema, y se hablará de losregistros donantes y de su tratamiento.
En cualquier caso, a través del navegador nos movemos por los distintos registros donantesexistentes, y podemos cambiar el registro donante a otro distinto pulsando el botón CambiarRegistro Donante. Cuando se lleva a cabo esta operación, se pone en marcha el proceso dedonación que se explicará más adelante, para que el registro incorrecto tome sus valores.
Por último, en este sistema existen dos medidas que relacionan el registro donante con elregistro incorrecto al que le han sido donados determinados valores. Estas medidas son la distanciaexterior y la distancia interior que son conceptos que se verán en la metodología aplicada.
6.9.5. Rejilla de variable
Para permitir un mayor seguimiento y análsis, la pestaña dispone de una rejilla de variablesituada justo debajo del sistema de registros donantes, que muestra los atributos de la variable

6.10. PESTAÑA DE ESTADÍSTICAS 93
activa en la rejilla principal. De esta manera, a medida que vamos cambiando de variable en larejilla principal, veremos cómo se van actualizando los datos en la rejilla de variable.
6.9.6. Cuadro de microdato original
En la parte inferior derecha de la pestaña, nos encontramos con un cuadro que sirve paravisualizar el valor original que tenía una determinada variable sobre un registro, para aquellosvalores que han sido imputados. De esta manera, existe un mecanismo rápido para acceder alvalor original de una variable imputada.
6.9.7. Información de registro imputado
Justo al lado del cuadro de microdato original, el panel cuenta con tres cuadros de edición,que permiten conocer ciertos datos referentes a la imputación que se le ha practicado al registroactual de la rejilla principal. Estos datos son: el número de variables básicas a imputar, el númerode variables extendidas a imputar y el número de variables imputadas. Todos estos conceptos seaclararán más adelante.
6.9.8. Navegadores
De igual modo que en todas las pestañas anteriores, en la parte inferior izquierda de lapestaña, existe un navegador para acceder al registro deseado a través de su número ordinal yun navegador para acceder a la variable deseada a través de su nombre.
6.9.9. Barra de estado
Al pie de la pestaña, nos encontramos con una típica barra de estado, subdividida en dosregiones. Una primera región a la izquierda indicando el número de registros y el número devariables numéricas. La región derecha indica en qué registro nos encontramos actualmente.
6.10. Pestaña de Estadísticas
Una vez que los microdatos han sido imputados, podemos proceder sobre la pestaña deimputación para obtener esta pestaña de estadísticas. Esta pestaña recoge toda la informacióngenerada durante el proceso completo de edición e imputación de datos, para servir como respaldocuantitativo a las decisiones tomadas y por tomar. La pestaña se basa en un informe tipo textoplano, separado por secciones, donde se va haciendo referencia a los distintos procesos que se hanrealizado hasta llegar a la imputación final. Ver figura 6.17.
6.10.1. Informe
Prácticamente en su totalidad, la pestaña está tomada por un cuadro de texto que recoge lainformación derivada de los procesos ejecutados. A continuación se muestra una pequeña tablaen la que se recogen las secciones descritas en el informe y un pequeño resumen de su contenido.

94 CAPÍTULO 6. MANUAL DE USUARIO
Figura 6.17: Pestaña de estadísticas
Sección ExplicaciónVariables Información a priori del conjunto de variables cargadas en el sistemaMicrodatos Información a priori del conjunto de microdatos cargados en el sistemaEdits Información a priori del conjunto de edits cargados en el sistemaRangos Información sobre el proceso de edición de rangosTest Información sobre el proceso de edición de edits explícitosImputación Información sobre el proceso de imputación de microdatosListado Rangos Listado de todos los edits de rango en notación matemáticaListado Filtros Listado de todos los edits de filtro en notación completaListado Edits Listado de todos los edits explícitos en notación completaIncumplimiento Edits Relación de los edits erróneos en cada registroEdits en Variables Relación de las variables que presentan los editsExclusión Listado de variables, edits y registros excluídosComparativa estadística Frecuencias de variables antes y después de la imputación
6.10.2. Panel de guardar informe
El otro elemento que queda pendiente en la pestaña, es un panel que permite almacenar elinforme en un fichero de disco. Podemos seleccionar el fichero que queremos pulsando el botónSelccionar Fichero, para luego salvar los datos en el fichero elegido a través del botón Guardar.

Capıtulo 7Experiencias computacionales
Aunque Teide no ha sido probado aún con datos reales de encuestas, sí que ha sido probadoy depurado con de datos “casi reales”, que representaba una muestra muy pequeña de la ecuestaEICVHC 2004, explicada en el capítulo 2.
En este apartado daremos una descripción de las variables, microdatos y edits que constituyeneste conjunto de muestra, así como los resultados computacionales de la edición e imputacióngenerada por la aplicación.
Es importante reseñar que este conjunto de datos casi reales contiene un alto grado de errores,lo que provoca dos consecuencias contrapuestas: por un lado nos permite detectar errores en elsistema e irlos depurando, pero por otro lado no permite un análisis fiable de los resultados quegenera la aplicación, dado el elevado número de incoherencias que presentan los microdatos.
Los resultados computacionales se han obtenido utilizando un ordenador personal con unprocesador Intel Pentium a 2.4Ghz y 512Mb de memoria RAM. La aplicación ha sido ejecutadasobre un sistema Windows XP (2002).
7.1. Descripción del conjunto de datos
En esta sección vamos a dar una descripción cuantitativa del conjunto de datos sobre el queestamos trabajando, mostrando detalles del conjunto de variables, de microdatos y de edits.
7.1.1. Variables
1. Número de variables numéricas = 247.
2. Número de variables alfanuméricas = 8.
3. Número de atributos = 12.
4. Tipos de variables.
a) Continuas = 29 (11.74%).
b) Discretas en rango = 90 (36.44%).
c) Discretas en lista = 128 (51.82%).
d) Alfanuméricas = 8 (3.24%).
5. Admisión de valores “missing”.
95

96 CAPÍTULO 7. EXPERIENCIAS COMPUTACIONALES
a) No procede = 228 (92.31%).
b) No sabe = 2 (0.81%).
c) No contesta = 6 (2.43%).
d) No sabe/No contesta = 2 (0.81%).
6. Existencia de filtros = 255 (91.09%).
7. Variables imputables = 234 (94.74%).
7.1.2. Microdatos
1. Número de registros = 73.
2. Número de registros x Número de variables = 18031.
3. Existencia de valores “missing”.
a) No procede = 11104 (61.58%).
b) No sabe = 3 (0.02%).
c) No contesta = 261 (1.45%).
d) No sabe/No contesta = 6 (0.03%).
7.1.3. Edits
1. Número de edits = 57.
2. Edits validados = 57 (100%).
3. Edits no validados = 0 (0%).
4. Edits factibles = 57 (100%).
5. Edits no factibles = 0 (0%).
7.2. Evaluación de rangos
Una vez descritos los elementos de entrada a la aplicación, vamos a continuación a mostrarlos datos obtenidos en la evaluación de rangos sobre el conjunto de microdatos.
1. Tiempo de proceso = 1.81s.
2. Porcentaje de exclusión de variables aplicado = 20%.
3. Porcentaje de exclusión de registros aplicado = 20%.
4. Registros.
a) Número de registros excluidos a priori = 3 (4.10%).
b) Número de registros excluidos a posteriori = 1 (1.36%).
c) Número de registros correctos = 28 (38.35%).
d) Número de registros incorrectos = 41 (56.14%).

7.3. EVALUACIÓN DE EDITS 97
5. Variables.
a) Número de variables excluidas a priori = 0 (0%).
b) Número de variables excluidas a posteriori = 7 (2.83%).
c) Número de variables correctas = 161 (65.18%).
d) Número de variables incorrectas = 79 (31.98%).
7.3. Evaluación de edits
De manera análoga a la sección anterior, vamos a mostrar los resultados computacionalesobtenidos en la evaluación de edits explícitos sobre el conjunto de microdatos:
1. Tiempo de proceso = 0.71s.
2. Porcentaje de exclusión de edits aplicado = 20%.
3. Porcentaje de exclusión de registros aplicado = 20%.
4. Registros.
a) Número de registros excluidos a priori = 4 (1.61%).
b) Número de registros excluidos a posteriori = 0 (0%).
c) Número de registros correctos = 57 (23.07%).
d) Número de registros incorrectos = 12 (4.85%).
5. Edits.
a) Número de edits excluidos a priori = 30 (52.63%).
b) Número de edits excluidos a posteriori = 2 (3.50%).
c) Número de edits correctos = 17 (29.82%).
d) Número de edits incorrectos = 8 (14.03%).
7.4. Imputación
Una vez realizadas las fases de evaluación de rangos y edits explícitos, a continuación semuestran los resultados computacionales obtenidos de la imputación propiamente dicha. Paramostrar los distintos resultados que se obtienen, vamos a utilizar dos criterios de ordenación deregistros donantes: ordenación por distancia interior y ordenación por distancia exterior.
7.4.1. Ordenación por distancia interior
En este caso, el algoritmo de imputación toma como registro donante aquel registro que seencuentre más cercano a uno dado teniendo en cuenta la distancia de las variables básicas deimputación, es decir, la distancia interior. Los resultados son los siguientes:
1. Tiempo de proceso = 6.20s.
2. Número de registros donantes = 27 (36.98%).

98 CAPÍTULO 7. EXPERIENCIAS COMPUTACIONALES
3. Número de registros excluídos = 4 (5.47%).
4. Número de registros correctos = 42 (57.53%).
5. Número de registros incorrectos = 0 (0%).
6. Número medio de variables imputadas por registro = 8.40.
A continuación se muestra una tabla resumen de todos los registros que intervienen en elproceso, indicando varios parámetros en cada caso.
Cuadro 7.1: Resultados con distancia interior
mi mj |vbas(i)| |vext(i)| dint(i, j) dext(i, j) |vimp(i)|1 2 1 221 1 32 12 Registro Donante3 28 10 212 9 60 14 Registro Excluido5 Registro Donante6 28 3 219 2 39 17 28 3 219 2 41 18 19 10 212 9 105 39 2 1 221 1 46 110 2 1 221 1 44 111 Registro Donante12 Registro Donante13 2 5 217 2 55 114 Registro Donante15 2 3 219 3 39 116 Registro Donante17 2 2 220 2 43 118 Registro Donante19 Registro Donante20 Registro Donante21 2 2 220 2 47 122 Registro Donante23 Registro Donante24 Registro Donante25 2 3 219 2 73 126 Registro Donante27 Registro Donante28 Registro Donante29 22 5 217 4 68 7230 22 5 217 3 74 131 2 6 216 6 46 132 2 3 219 3 42 133 24 4 218 3 67 134 Registro Excluido35 Registro Donante36 2 4 218 4 43 137 2 5 217 3 46 138 Registro Excluido
Continua en la siguiente página. . .
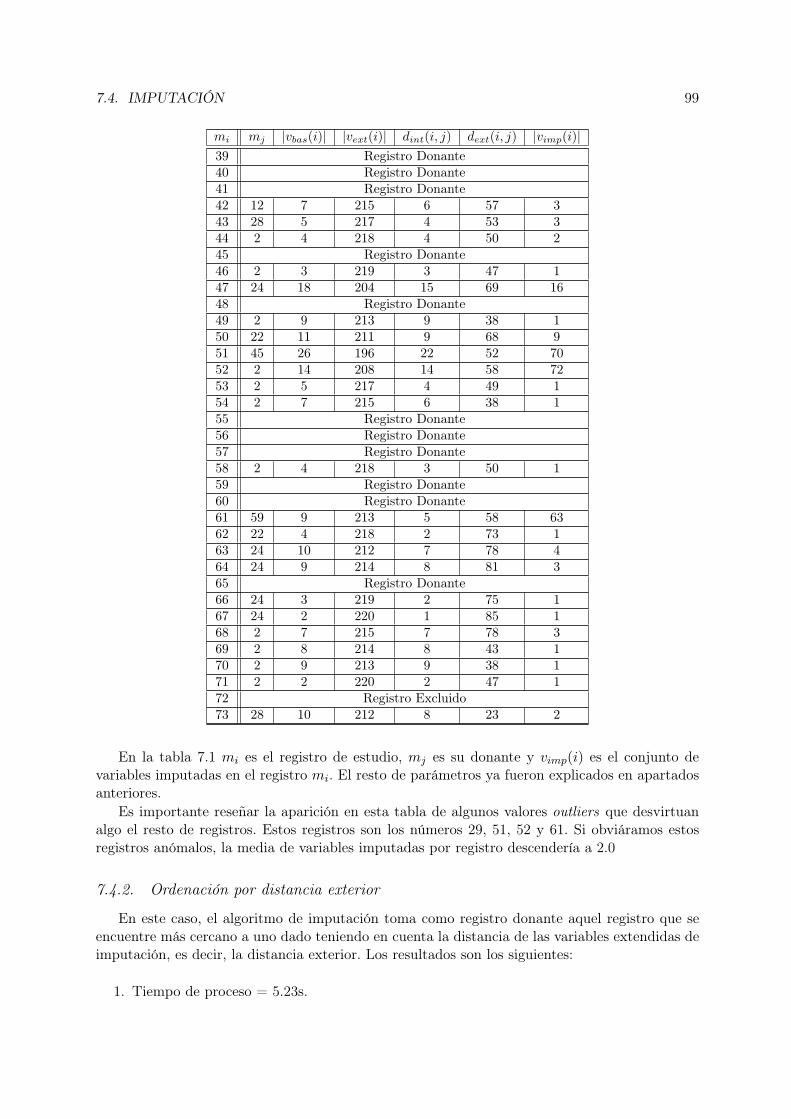
7.4. IMPUTACIÓN 99
mi mj |vbas(i)| |vext(i)| dint(i, j) dext(i, j) |vimp(i)|39 Registro Donante40 Registro Donante41 Registro Donante42 12 7 215 6 57 343 28 5 217 4 53 344 2 4 218 4 50 245 Registro Donante46 2 3 219 3 47 147 24 18 204 15 69 1648 Registro Donante49 2 9 213 9 38 150 22 11 211 9 68 951 45 26 196 22 52 7052 2 14 208 14 58 7253 2 5 217 4 49 154 2 7 215 6 38 155 Registro Donante56 Registro Donante57 Registro Donante58 2 4 218 3 50 159 Registro Donante60 Registro Donante61 59 9 213 5 58 6362 22 4 218 2 73 163 24 10 212 7 78 464 24 9 214 8 81 365 Registro Donante66 24 3 219 2 75 167 24 2 220 1 85 168 2 7 215 7 78 369 2 8 214 8 43 170 2 9 213 9 38 171 2 2 220 2 47 172 Registro Excluido73 28 10 212 8 23 2
En la tabla 7.1 mi es el registro de estudio, mj es su donante y vimp(i) es el conjunto devariables imputadas en el registro mi. El resto de parámetros ya fueron explicados en apartadosanteriores.
Es importante reseñar la aparición en esta tabla de algunos valores outliers que desvirtuanalgo el resto de registros. Estos registros son los números 29, 51, 52 y 61. Si obviáramos estosregistros anómalos, la media de variables imputadas por registro descendería a 2.0
7.4.2. Ordenación por distancia exterior
En este caso, el algoritmo de imputación toma como registro donante aquel registro que seencuentre más cercano a uno dado teniendo en cuenta la distancia de las variables extendidas deimputación, es decir, la distancia exterior. Los resultados son los siguientes:
1. Tiempo de proceso = 5.23s.
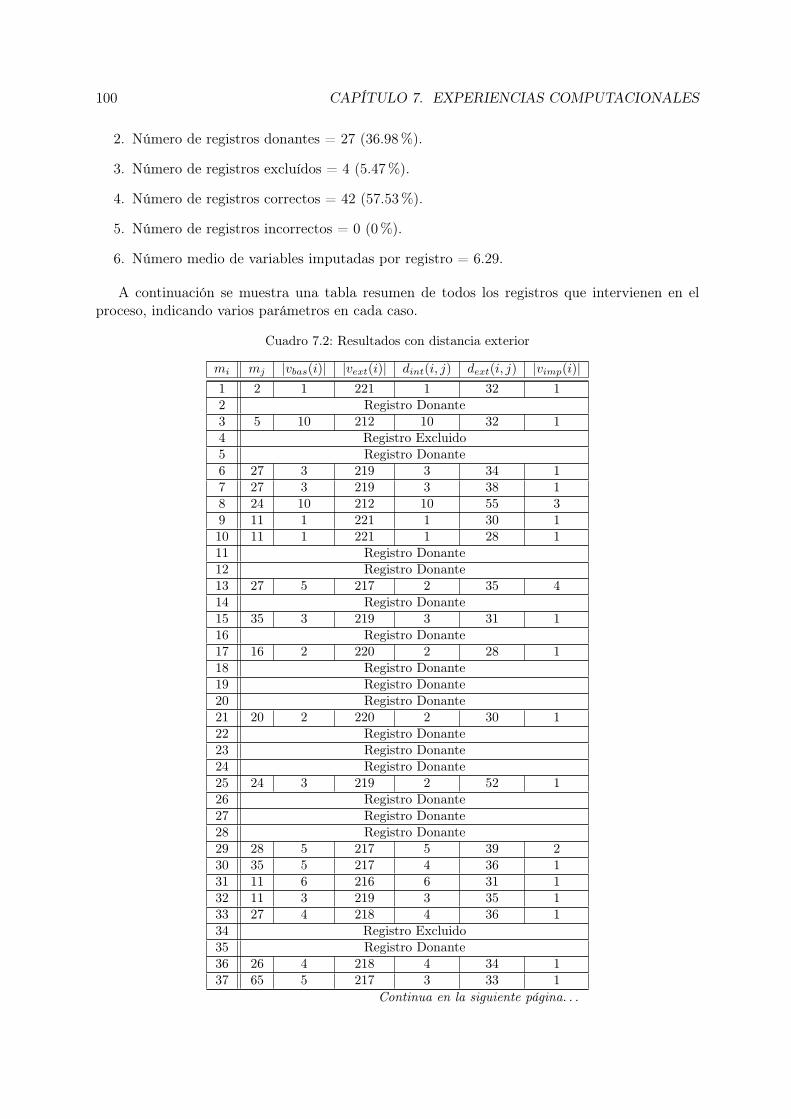
100 CAPÍTULO 7. EXPERIENCIAS COMPUTACIONALES
2. Número de registros donantes = 27 (36.98%).
3. Número de registros excluídos = 4 (5.47%).
4. Número de registros correctos = 42 (57.53%).
5. Número de registros incorrectos = 0 (0%).
6. Número medio de variables imputadas por registro = 6.29.
A continuación se muestra una tabla resumen de todos los registros que intervienen en elproceso, indicando varios parámetros en cada caso.
Cuadro 7.2: Resultados con distancia exterior
mi mj |vbas(i)| |vext(i)| dint(i, j) dext(i, j) |vimp(i)|1 2 1 221 1 32 12 Registro Donante3 5 10 212 10 32 14 Registro Excluido5 Registro Donante6 27 3 219 3 34 17 27 3 219 3 38 18 24 10 212 10 55 39 11 1 221 1 30 110 11 1 221 1 28 111 Registro Donante12 Registro Donante13 27 5 217 2 35 414 Registro Donante15 35 3 219 3 31 116 Registro Donante17 16 2 220 2 28 118 Registro Donante19 Registro Donante20 Registro Donante21 20 2 220 2 30 122 Registro Donante23 Registro Donante24 Registro Donante25 24 3 219 2 52 126 Registro Donante27 Registro Donante28 Registro Donante29 28 5 217 5 39 230 35 5 217 4 36 131 11 6 216 6 31 132 11 3 219 3 35 133 27 4 218 4 36 134 Registro Excluido35 Registro Donante36 26 4 218 4 34 137 65 5 217 3 33 1
Continua en la siguiente página. . .

7.5. COMENTARIOS 101
mi mj |vbas(i)| |vext(i)| dint(i, j) dext(i, j) |vimp(i)|38 Registro Excluido39 Registro Donante40 Registro Donante41 Registro Donante42 11 7 215 6 37 343 35 5 217 5 47 344 11 4 218 4 29 245 Registro Donante46 65 3 219 3 40 147 28 18 204 16 37 1748 Registro Donante49 48 9 213 9 31 150 35 11 211 10 36 1051 48 26 196 26 45 6852 27 14 208 14 31 1453 16 5 217 4 33 154 16 7 215 6 35 155 Registro Donante56 Registro Donante57 Registro Donante58 57 4 218 3 19 159 Registro Donante60 Registro Donante61 28 9 213 9 42 5062 35 4 218 3 35 163 48 10 212 8 35 364 27 9 214 9 35 265 Registro Donante66 27 3 219 3 37 167 65 2 220 2 35 168 12 7 215 7 48 5469 57 8 214 8 30 170 11 9 213 9 32 171 65 2 220 2 40 172 Registro Excluido73 27 10 212 9 21 2
En la tabla 7.2 mi es el registro de estudio, mj es su donante y vimp(i) es el conjunto devariables imputadas en el registro mi. El resto de parámetros ya fueron explicados en apartadosanteriores.
Es importante reseñar la aparición en esta tabla de algunos valores outliers que desvirtuanalgo el resto de registros. Estos registros son los números 51, 61 y 68. Si obviáramos estos registrosanómalos, la media de variables imputadas por registro descendería a 2.42
7.5. Comentarios
Algunos comentarios sobre los datos obtenidos son los siguientes:
1. La ordenación de los registros donantes por la distancia exterior da mejores resultados quepor la distancia interior. Esto se puede comprobar tanto en tiempo de proceso como en

102 CAPÍTULO 7. EXPERIENCIAS COMPUTACIONALES
número medio de variables imputadas por registro.
2. El proceso de evaluación de edits explícitos toma menos de la mitad de tiempo que tomala evaluación de rangos, y esto se debe en gran medida a que un número elevado de losedits han sido eliminados, ya que fueron eliminadas algunas variables en la evaluación derangos, y por tanto se eliminan los edits asociados.
3. Sin tener en cuenta los outliers, la gran mayoría de registros se arreglan mediante imputa-ción de aproximadamente 2 variables, un valor significativo. El valor óptimo sería conseguirtocar sólo 1 variable para arreglar el registro, aunque esto no es siempre posible.
4. El cardinal de las componentes conexas de la mayoría de las variables es un valor muy alto(ver tablas 7.1 y 7.2), próximo al número de variables, y esto hace que la resolución delproblema sea más compleja ya que hay una mayor interconexión y las perturbaciones quese introducen en las variables pueden afectar en mayor medida a otros edits.
5. Fue necesario aplicar un 20% de exclusión en variables y edits para poder ampliar el númerode registros donantes. Dejando el porcentaje original, el número de registros donanteshubiera sido cuatro, mientras que con este porcentaje de exclusión hemos conseguido 27 (unvalor aceptable). Esto se debe a que esta encuesta piloto contiene determinadas variablescon un alto grado de presencia en edits pero a la vez con un alto grado de errores.

Capıtulo 8Conclusiones y Futuro
La edición e imputación de datos estadísticos es un proceso necesario en cualquier instituto deestadística que consume bastantes recursos si no está dotado de una herramienta que automaticeparte de este proceso. El desarrollo e implementación de un software informático no es tampocotarea fácil, y debe ir enriqueciéndose con la experiencia que proporciona su tratamiento dedistintos conjuntos de datos. Éste ha sido el eje básico de trabajo para este proyecto.
El desarrollo de Teide ha estado basado en todo momento en el método de imputaciónpor el registro donante. Esto implica que se tiene asegurado que los datos imputados van amantener ciertas características estadísticas básicas, ya que no se están incorporando combina-ciones artificiales de valores. Sin embargo, a través de las experiencias computacionales que sehan ido desarrollando, como la que está detallada en el capítulo 7, se puede observar que haydeterminados casos para los que esta metodología no ofrece buenos resultados porque cambia ungran número de valores en algunos registros. Por lo tanto, es necesario tener en cuenta que losalgoritmos de imputación basados en el registro donante que se están utilizando deben contem-plar ciertos aspectos heurísticos que eviten la casuística que generan determinados registros enalgunos conjuntos de datos. Este aspecto abre nuevas líneas de trabajo para el futuro inmediato.
Como se ha citado en este documento, la edición e imputación de datos estadísticos es unproblema difícil de resolver. De forma breve, la solución a este problema estaría en poder conocer“qué es lo que quiso responder el informante en aquella pregunta”. Partiendo de esta base, Tei-de pretende ser un sistema informático que busca la respuesta en vecinos parecidos al susodichoinformante. Este sistema informático es más que un depurador de datos, ya que permite al técnicoestadístico un estudio pormenorizado de cada caso a través de las reglas definidas en la entradaal programa. Su filosofía se basa en ser un sistema flexible, capaz de admitir a trámite cualquierencuesta siempre y cuando sus elementos estén correctamente definidos en un formato específico.
Teide se ha beneficiado mucho de la colaboración con el ISTAC. Esta colaboración ha sidoimprescindible ya que el contacto con una organización que cada día se enfrenta a nuevos retosde carácter estadístico y que maneja un volumen de datos tan grande, nos ha planteado nuevasmetas y nos ha inspirado nuevos mecanismos de resolución, lo que ha repercutido en una mejorade la aplicación. La transformación que ha ido experimentando el programa Teide en funciónde las nuevas aportaciones que iba generando el tratamiento de los datos ha sido enorme.
El futuro de Teide es seguir enriqueciéndose de la colaboración entre técnicos de la uni-versidad y técnicos del ISTAC. Estamos ante un proyecto necesario y ambicioso que requierede tiempo de desarrollo y aplicación porque es una herramienta útil y compleja para cualquierencuesta. Aunque por una parte creemos que Teide es ya una sofisticada herramienta, por otra
103

104 CAPÍTULO 8. CONCLUSIONES Y FUTURO
se es consciente de que necesita mejorar en muchos aspectos. Por un lado, la aplicación debeintentar reducir los tiempos de procesamiento. Para ello habrá que pensar en mejoras en losalgoritmos de evaluación de las expresiones y en las estructuras de datos. Por otro lado, hayque simplificar los formatos de entrada de datos para que el sistema pueda ser utilizado por unaamplia mayoría de usuarios. Y por último, mejorar poco a poco los procedimientos de imputa-ción que se están utilizando. La experiencia y el conocimiento de gran variedad de casos va apermitir ir añadiendo nuevas funcionalidades que cubran los nuevos aspectos que se presentan.En resumen, el objetivo es buscar una aplicación más rápida, más flexible y más fiable.

Bibliografía
[1] Álamo Santana, F. y González Yánez, A. (2004). “Planificación y diseño de encuestas: En-cuesta de Ingresos y Condiciones de Vida de los Hogares Canarios”. ISTAC.
[2] Aparicio, F., Feito J. M., Quesada, J. y Revilla P. (2003). “Curso de depuración de datoscuantitativos”. INE.
[3] Fellegi, I. P. y D. Holt (1976). “A systematic approach to automatic edit and imputation”.Journal of the American Statistical Association.
[4] García Rubio, E. (1995). “DIA v.2”. INE.
[5] Garfinkel, R. S., A. S. Kunnathur y G. E. Liepins (1986). “Optimal imputation of erroneousdata: continuous data, linear constraints”. Operations Research.
[6] Puerta Goicoechea, A. (2002). “Imputación basada en árboles de ramificación”. EUSTAT.
[7] Riera, J. y Salazar J.J. (2004). “A Branch-and-Cut Algorithm for the Editing-and-Imputation Problem”. Documento de trabajo. Universidad de La Laguna.
[8] Villán Criado, I. y Bravo Cabria, M. S. (1990). “Procedimiento de depuración de datosestadísticos”. EUSTAT.
[9] de Waal, A. G. (2003). “Processing of Erroneous and Unsafe Data”. Ph.D. Erasmus Univer-sity Rotterdam.
[10] Winkler, W. (1999). “State of statistical data editing and current research problems”. Procee-dings of the Conference of European statisticians, UNECE work session on statistical DataEditing.
Este documento fue elaborado utilizando LATEX.
105


















