Topicos de Estadistica Inferencial II ccesa007
16
Page 1 Demetrio Ccesa Rayme Araceli Chauca Zavaleta
-
Upload
demetrio-ccesa-rayme -
Category
Education
-
view
605 -
download
3
Transcript of Topicos de Estadistica Inferencial II ccesa007

Page 1
Demetrio Ccesa Rayme
Araceli Chauca Zavaleta
Page 2
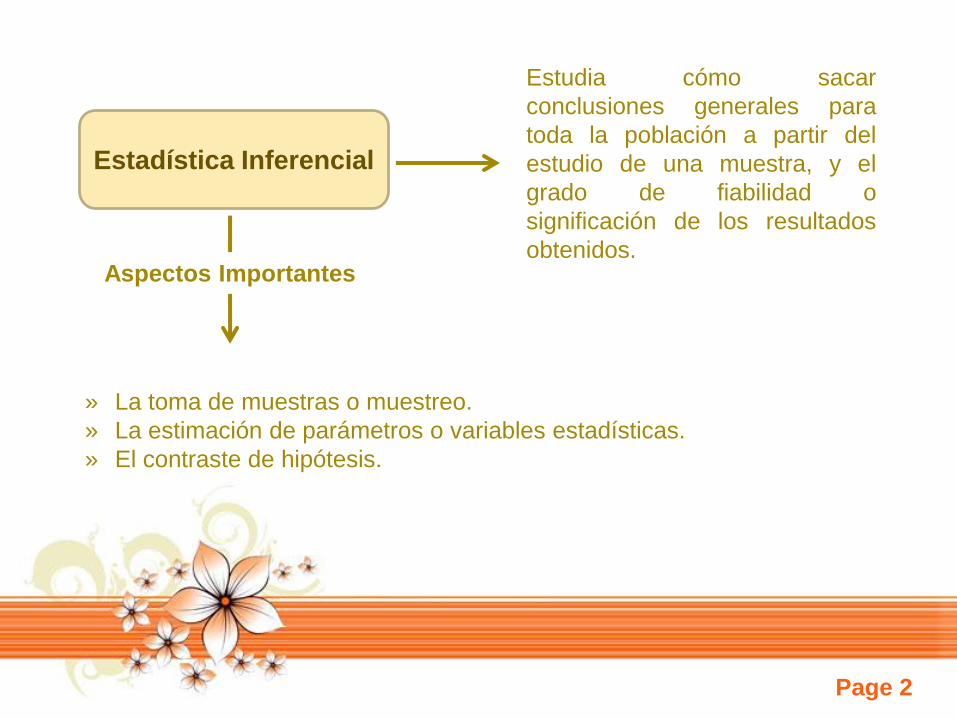
Estadística Inferencial
Estudia cómo sacar
conclusiones generales para
toda la población a partir del
estudio de una muestra, y el
grado de fiabilidad o
significación de los resultados
obtenidos.Aspectos Importantes
» La toma de muestras o muestreo.
» La estimación de parámetros o variables estadísticas.
» El contraste de hipótesis.
Page 3
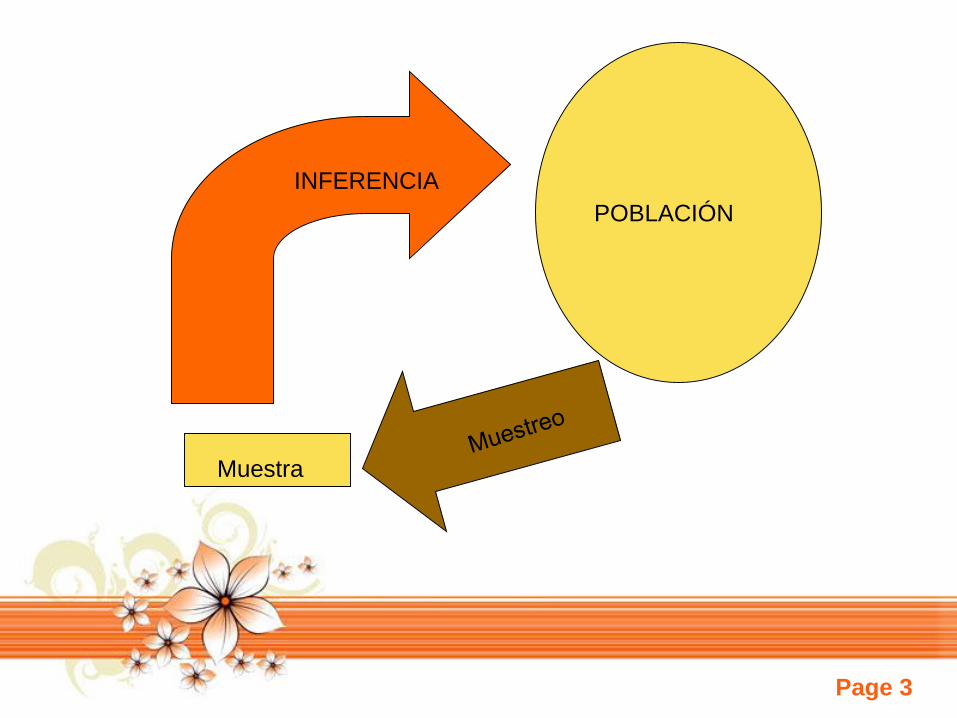
POBLACIÓN
Muestra
INFERENCIA
Page 4
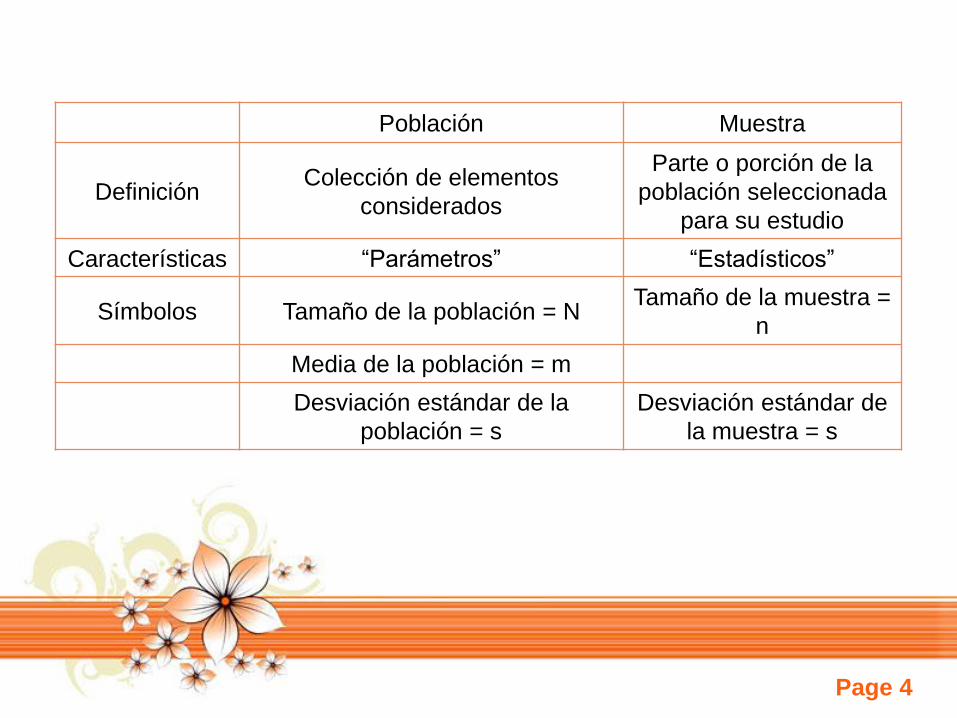
Población Muestra
Definición Colección de elementos
considerados
Parte o porción de la
población seleccionada
para su estudio
Características “Parámetros” “Estadísticos”
Símbolos Tamaño de la población = NTamaño de la muestra =
n
Media de la población = m
Desviación estándar de la
población = s
Desviación estándar de
la muestra = s
Page 5
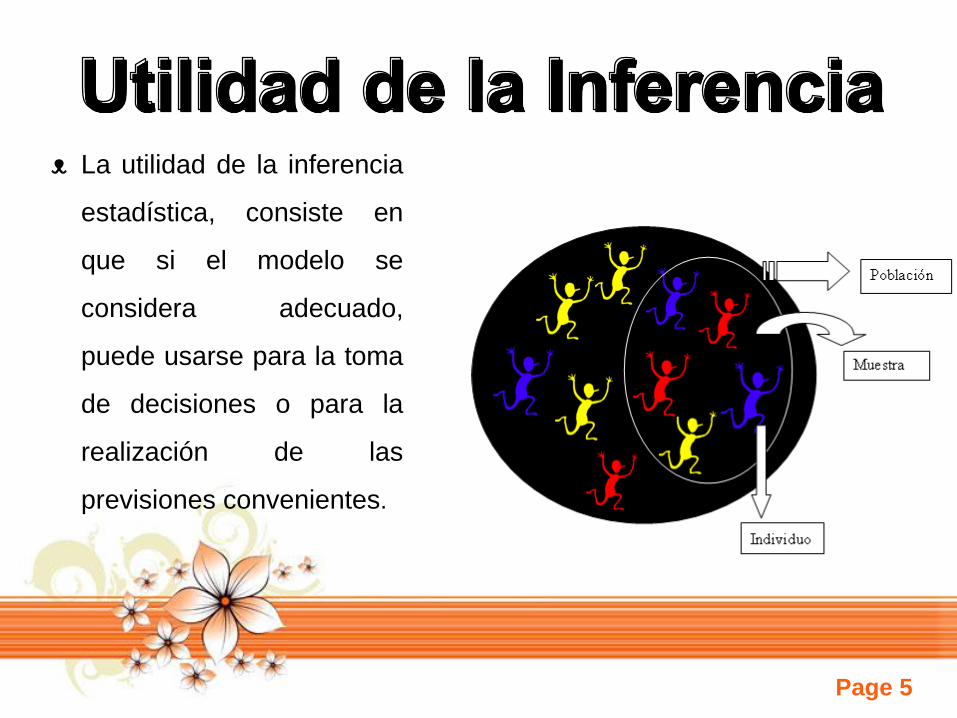
ᴥ La utilidad de la inferencia
estadística, consiste en
que si el modelo se
considera adecuado,
puede usarse para la toma
de decisiones o para la
realización de las
previsiones convenientes.

Page 6
ᴥ Métodos no probabilísticos.- Interviene la opinión del
investigador para obtener cada elemento de la muestra.
ᴥ Métodos probabilísticos.- Muestra que se selecciona de modo
que cada integrante de la población en estudio tenga una
probabilidad conocida (pero distinta de cero) de ser incluido en la
muestra.

Page 7
ᴥ Muestro aleatorio simple: Muestra seleccionada de manera que cada
integrante de la población tenga la misma probabilidad de quedar incluido.
Ejemplo: un bingo, introduzco los números en una ánfora y selecciono una
muestra al azar
ᴥ Muestreo aleatorio sistemático: Los integrantes o elementos de la
población se ordenan en alguna forma (Ejemplo: alfabéticamente) se
selecciona al azar un punto de partida y después se elige para la muestra
cada k-ésimo elemento de la población. Ejemplo: se desea establecer una
muestra 100 empleados de los 3000 que tiene una empresa, para lo cual
ordeno alfabéticamente a los empleados, divido 3000/100 = 30 y selecciona a
uno de cada treinta empleados.

Page 8
ᴥ Muestreo aleatoria estratificado: Una población se divide en subgrupos
denominados estratos y se selecciona una muestra de cada uno.
ESTRATO EDADESNº DE
EMPLEADOS% DEL TOTAL
CANTIDAD
MUESTREADA
1
2
3
4
5
MENOS DE 25 AÑOS
26-30AÑOS
31-35 AÑOS
36-40AÑOS
MÁS DE 41AÑOS
8
35
189
115
5
2
10
54
33
1
1
5
27
16
1
TOTAL 352 100 50
ᴥ Muestreo aleatorio por conglomerado: Se divide a la población en estratos
(subunidades) se selecciona con que subunidades se va a trabajar y de las
unidades seleccionadas, se toma una muestra aleatoriamente. EJEMPLO IPC
Guayaquil, Machala, Portoviejo, Quito, Ambato, Cuenca y, Manta, Esmeraldas
y Quevedo, Riobamba, Loja y Latacunga. Con estas ciudades se cubre el 67%
de la población urbana del país.

Page 9
Con una muestra aleatoria, de tamaño n, podemos efectuar una estimación de un
valor de un parámetro de la población; pero también necesitamos precisar un:
ᴥ Intervalo de confianza: se llama así a un intervalo en el que sabemos que está
un parámetro, con un nivel de confianza específico.
ᴥ Nivel de confianza: probabilidad de que el parámetro a estimar se encuentre
en el intervalo de confianza. El nivel de confianza (p) se designa mediante 1 − α.
ᴥ Error de estimación admisible: que estará relacionado con el radio del
intervalo de confianza.

Page 10
ᴥ El intervalo de confianza, para la media de una población, con un nivel de confianza
de 1 − α , siendo x la media de una muestra de tamaño n y σ la desviación típica de la
población, es:
ᴥ El error máximo de estimación es:
Cuanto mayor sea el tamaño de la muestra, n, menor es el error.
Cuanto mayor sea el nivel de confianza, 1-α, mayor es el error.
Tamaño de la muestra
Si aumentamos el nivel de confianza, aumenta el tamaño de la muestra.
Si disminuimos el error, tenemos que aumentar el tamaño de la muestra.

Page 11

Page 12
• Si en una población, una determinada característica se presenta en una
proporción p, la proporción p' , de individuos con dicha característica en
las muestras de tamaño n, se distribuirán según:
• Intervalo de confianza para una proporción:
• El error máximo de estimación es:

Page 13
ᴥ Hipótesis: Es una afirmación sobre una población, que puede someterse a
pruebas al extraer una muestra aleatoria.
ᴥ Prueba de hipótesis.- Formular una teoría y luego contrastarla.
Pasos para probar una hipótesis:
1.Prueba de hipótesis
2.Seleccionar el nivel de significancia
3.Calcular el valor estadístico de prueba
4.Formular la regla de decisión
5.Decidir

Page 14
Paso 1: plantear h0 y h1
Paso 2: Seleccionar el nivel de significancia
Generalmente son del 5% o 1% (Error de tipo I y Error de tipo II)
ERROR DE TIPO I.- Rechazar la hipótesis nula, H0 cuando es verdadera
ERROR DE TIPO II.- Aceptar la hipótesis nula, H0 cuando es Falsa
0:0
00 :
H
HHipótesis nula: Afirmación acerca del valor de un
parámetro poblacional
01
01
:
:
H
HHipótesis Alternativa: Afirmación que se aceptará si
los datos muéstrales aseguran que es falsa H 0
Page 15
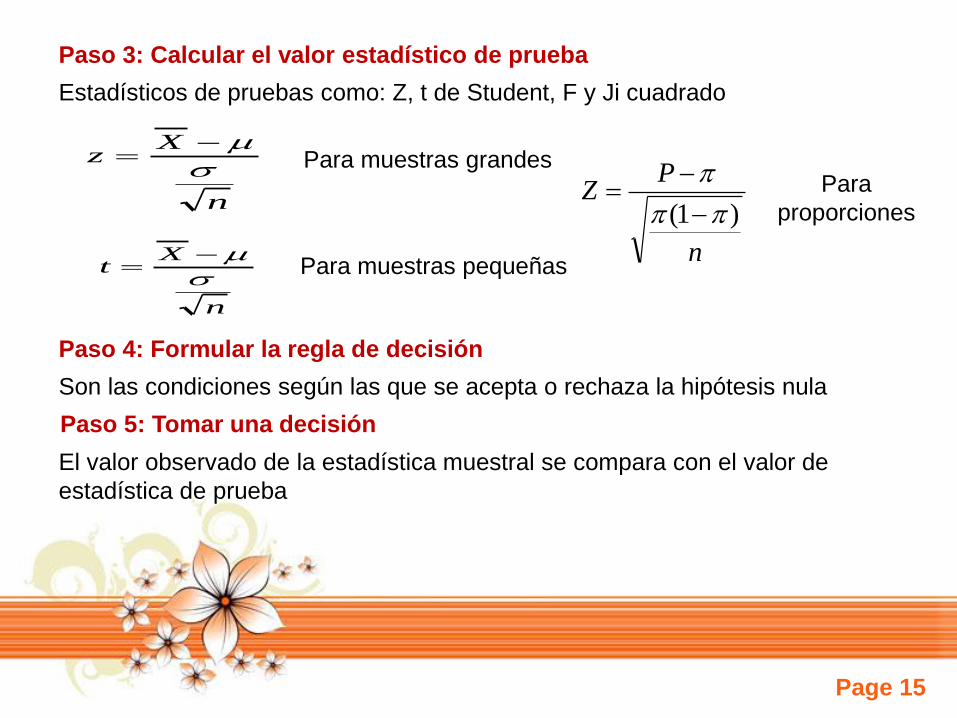
Paso 3: Calcular el valor estadístico de prueba
Estadísticos de pruebas como: Z, t de Student, F y Ji cuadrado
n
Xz
n
Xt
Para muestras grandes
Para muestras pequeñas
Paso 4: Formular la regla de decisión
Son las condiciones según las que se acepta o rechaza la hipótesis nula
Paso 5: Tomar una decisión
El valor observado de la estadística muestral se compara con el valor de
estadística de prueba
n
PZ
)1(
Para
proporciones

Page 16