
Unidad 3 - Cómo se administran los datos: Archivos y bases...
34
1 Unidad 3 - Cómo se administran los datos: Archivos y bases de datos Cómo se administran los datos Material desarrollado por Carola Jones y Francisco Gatti, 2006 1. Presentación Este capítulo tiene como objetivo examinar las tecnologías para administrar los datos, que deben ser tenidas en cuenta para implementar con éxito los sistemas de administración de bases de datos. En particular se describe la arquitectura tradicional de archivos y cómo esta tecnología ha evolucionado hacia los actuales sistemas de administración de bases de datos. Representación de los datos en las computadoras Para ser almacenados y procesados por un sistema de computación, los datos deben estar reducidos a una cadena de dígitos binarios. Un dígito binario se representa a través de un bit que sólo puede contener dos valores posibles: 0 o 1. Como se puede apreciar con un bit no es posible almacenar demasiada información útil. Pero si se forma una cadena de ocho bits, cada uno de los cuales puede contener dos valores posibles, entonces se tendrá una combinación de 256 valores posibles ( 2 8 = 256 ). A esta cadena de 8 bits se la denomina byte. Con un byte es posible representar una letra, un número o, en general, un carácter. Se necesita además una codificación estándar para poder identificar cada carácter con una determinada combinación de 8 bits. Un ejemplo de esta codificación es el “Código Estándar Estadounidense para el Intercambio de Información – ASCII” Por ejemplo con el número binario 01000001, en la codificación ASCII, es posible representar la letra “A” y con el número binario 00110101, se puede representar el número “5”. La agrupación de varios bytes nos permiten formar palabras, frases, fechas o números largos, con decimales o enteros. Esta agrupación recibe el nombre de campo y permite representar, por ejemplo, el nombre de una persona, su edad o número de teléfono. Un grupo de campos relacionados, como el nombre de un estudiante, la materia en la que está inscripto y la fecha de inscripción constituye un registro. Una colección de registros del mismo tipo se denomina archivo.
Transcript of Unidad 3 - Cómo se administran los datos: Archivos y bases...

1
Unidad 3 - Cómo se administran los datos: Archivos y bases de datos
Cómo se administran los datos
Material desarrollado por Carola Jones y Francisco Gatti, 2006
1. Presentación
Este capítulo tiene como objetivo examinar las tecnologías para administrar los datos, que
deben ser tenidas en cuenta para implementar con éxito los sistemas de administración de bases de
datos.
En particular se describe la arquitectura tradicional de archivos y cómo esta tecnología ha
evolucionado hacia los actuales sistemas de administración de bases de datos.
Representación de los datos en las computadoras
Para ser almacenados y procesados por un sistema de computación, los datos deben estar
reducidos a una cadena de dígitos binarios. Un dígito binario se representa a través de un bit que
sólo puede contener dos valores posibles: 0 o 1. Como se puede apreciar con un bit no es posible
almacenar demasiada información útil. Pero si se forma una cadena de ocho bits, cada uno de los
cuales puede contener dos valores posibles, entonces se tendrá una combinación de 256 valores
posibles ( 28 = 256 ).
A esta cadena de 8 bits se la denomina byte. Con un byte es posible representar una letra,
un número o, en general, un carácter.
Se necesita además una codificación estándar para poder identificar cada carácter con una
determinada combinación de 8 bits. Un ejemplo de esta codificación es el “Código Estándar
Estadounidense para el Intercambio de Información – ASCII”
Por ejemplo con el número binario 01000001, en la codificación ASCII, es posible
representar la letra “A” y con el número binario 00110101, se puede representar el número “5”.
La agrupación de varios bytes nos permiten formar palabras, frases, fechas o números
largos, con decimales o enteros. Esta agrupación recibe el nombre de campo y permite representar,
por ejemplo, el nombre de una persona, su edad o número de teléfono.
Un grupo de campos relacionados, como el nombre de un estudiante, la materia en la que
está inscripto y la fecha de inscripción constituye un registro. Una colección de registros del mismo
tipo se denomina archivo.

2
En el siguiente ejemplo se muestra un archivo de LIBROS:
Titulo autor isbn editorial
El Código Da Vinci Dan Brown 8495618605 Umbriel
El Asir Paulo Coelho 8408059688 Planeta
La Conspiración Dan Brown 8495618826 Umbriel
Los Mitos de la Historia Argentina Felipe Pigna 9875451495 Norma
Todo registro de un archivo debe tener al menos un campo cuyo valor identifique en forma
única ese registro, a fin de poder recuperar o modificar los campos de ese registro en particular. Ese
campo identificador recibe el nombre de campo clave.
Por ejemplo, en el archivo de LIBROS precedente, el campo clave es isbn, que nos permite
identificar en forma única cada uno de los libros.
2. Organización Tradicional de Archivos
La mayor parte de las organizaciones que implementaron sus sistemas entre las décadas
de los 70 y los 80, lo hicieron bajo el concepto del ambiente tradicional de archivos. Las necesidades
de información que surgían en distintas áreas funcionales o bien en diferentes unidades de negocio,
se resolvían por medio de distintos sistemas de información independientes. Las distintas áreas
crearon sus propios sistemas y archivos de datos.
A nivel gerencial los administradores de la organización tenían que lidiar con reportes e información
proveniente de sistemas distintos, que en algunos casos eran incongruentes entre sí, generando en
los directivos desconfianza acerca de la verosimilitud de la información proporcionada por los
sistemas.
Almacenamiento y Recuperación de los Archivos en el Ambiente Tradicional
Los archivos que generan y manipulan los sistemas de información se guardan en
dispositivos de almacenamiento secundario, típicamente discos duros o cintas magnéticas.
Existen distintas técnicas para el almacenamiento y posterior recuperación de los archivos:
Acceso Secuencial
Bajo esta técnica los registros de un archivo se recuperan, uno a uno, en el mismo orden
físico en que fueron almacenados. Un ejemplo de acceso secuencial podría ser un sistema de
Campo “autor” Registro correspondiente al libro “El Zahir”

3
nómina, donde los registros correspondientes a los recibos de sueldos se deben acceder, uno por
uno, generando el medio de pago respectivo.
Acceso Directo
Con este método se puede localizar directamente un registro determinado a través de su
campo clave. Existen dos formas de llevar a cabo el acceso directo:
• Acceso Directo por Indices: consiste en mantener una tabla, a modo de índice, que
relaciona los valores de los campos clave con la posición física en la que está ubicado el
registro en el archivo. Se puede hacer una analogía entre el índice de un archivo y el índice
de un libro.
• Acceso Directo con Algoritmo de Transformación: consiste en aplicar un algoritmo o fórmula
matemática al valor del campo clave de un registro, obteniendo como resultado la posición
física donde se encuentra almacenado el registro.
Problemas con el Ambiente Tradicional de Archivos
Los principales problemas del ambiente tradicional de archivos son:
• Redundancia de Datos: La redundancia de datos se produce por la existencia de los
mismos datos en diferentes archivos. Por ejemplo un sistema de cuentas corrientes de
ventas seguramente tendrá un archivo maestro de clientes; paralelamente el área de
marketing podría tener también un archivo con los mismos clientes. Suele ocurrir en estos
casos que un mismo cliente archivado en ambas áreas, cuentas corrientes y marketing,
tenga un código de identificación distinto en cada una de éstas. Un cliente que cambia de
domicilio es posible que en un momento dado tenga registrado distintos domicilios, según
se consulte en el área de cuentas corrientes o en marketing.
• Dependencia programas-datos: Consiste en la estrecha relación entre los archivos de datos
y los programas que acceden a éstos. El conocimiento de la organización de los datos y de
las técnicas para acceder a ellos forma parte del código con el que están escritos los
programas que los utilizan. En esta situación es imposible alterar la estructura de los
archivos (por ejemplo la cantidad de campos, su tamaño o tipo de dato que puede contener)
o la técnica de acceso a ellos (por ejemplo secuencial, indexado, directo, etc.) sin tener que
modificar todos los programas que utilizan estos archivos.
• Falta de Flexibilidad: Los sistemas cuyos datos se organizan en un ambiente tradicional sólo
pueden brindar los reportes de rutina que están programados de antemano. Si un usuario
del sistema requiere un nuevo informe que reúna los datos en una forma no prevista con

4
anterioridad se deberá construir un programa que lo genere, insumiendo horas de trabajo de
los programadores.
• Pobre Seguridad: La diseminación de los archivos en distintas áreas trae como
consecuencia que no exista un control unificado sobre el acceso que pueden tener los
usuarios a los mismos. Los controles de acceso deben implementarse en cada uno de los
programas que los acceden. Por ejemplo el archivo de clientes del área cuentas corrientes
puede tener fuertes restricciones en cuanto al acceso al mismo, por otro lado puede ser
muy fácil acceder al mismo archivo que existe en el área de marketing.
• Dificultad para Compartir y Disponer de los Datos: La falta de una administración
centralizada de los datos que provoca los problemas mencionados ut supra hace que sea
difícil acceder a los datos. Por otra parte, dado que los archivos tienen distinta estructura y
codificación resulta muy difícil y complejo compartir datos entre los distintos sistemas.
3. Arquitectura de Base de Datos
Una base de datos es una colección de datos organizados de tal forma que sirvan a
muchas aplicaciones con eficiencia, centralicen los datos y minimicen los datos redundantes.1
Podríamos mencionar además que las bases de datos se caracterizan por organizar los
datos en forma independiente de los programas que lo utilizan. Los datos se pueden acceder en
tiempo real y en forma concurrente por distintos usuarios con distintas necesidades de información.
Sistemas de Administración de Bases de Datos
Un sistema de administración de bases de datos (DBMS – database management
system) es un software encargado de centralizar los datos de una base de datos, administrar en
forma eficiente el almacenamiento físico de los mismos y proveer a los programas de aplicación un
medio de acceso a éstos.
El DBMS actúa como una interfase entre los archivos de datos y los programas que los
requieren. Esto contrasta con el entorno tradicional de archivos, donde cada programa debe
describir con precisión la forma en que deben obtenerse los datos desde el dispositivo de
almacenamiento.
1 LAUDON KENNETH C. LAUDON JANE P. Sistemas de Información Gerencial. Editorial Prentice-Hall, 2002. Capítulo 8,
pag. 234

5
El siguiente esquema muestra la relación entre las aplicaciones, el DBMS y la base de datos:
Los elementos de un DBMS son:
• Lenguaje de definición de datos: es el lenguaje a través del cual es posible definir o
declarar los objetos de la base de datos.
• Lenguaje de manipulación de datos: es aquel que permite a los usuarios manipular los
datos, insertarlos, modificarlos y/o consultarlos.
• Diccionario de datos: Son los archivos que almacenan información acerca de la estructura
de los datos. Podríamos decir que el diccionario de datos contiene datos acerca de los
datos. Por ejemplo contienen la forma de uso de un dato, su representación física (de tipo
numérico, carácter, fecha, etc.) y quién está autorizado a usarlo.
Entre los principales administradores de bases de datos encontramos Oracle, de Oracle
Corporation, DB2 e Informix de IBM y SQL Server de Microsoft.
También existen DBMS desarrollados bajo la filosofía de “software libre” como MySQL o
Postgres, que son muy utilizados en aplicaciones para la Web.
Personas responsables de la administrar datos y bases de datos
Resulta oportuno aclarar las diferencias entre las funciones del administrador de datos
(DA, data administrator) y las del administrador de base de datos (DBA, database
administrator).
Sistema de Compras
Sistema de Stock
Sistema de Pagos
DBMS (SABD)
BASE DE
DATOS

6
La labor del administrador de datos es decidir cuáles datos deben almacenarse en la base
de datos y establecer políticas para mantener y manejar los datos una vez almacenados. Por
ejemplo determinar quién puede realizar cuáles operaciones sobre cuáles datos y en qué
circunstancias, es decir, una política de seguridad de la información. Es importante señalar que el
administrador de datos es un gerente, no un técnico (aunque ciertamente sí necesita conocer las
posibilidades de los sistemas de bases de datos en un nivel técnico).
El técnico responsable de poner en práctica las decisiones del administrador de datos es el
administrador de bases de datos. Este, a diferencia del administrador de datos, es un profesional
en sistemas de información. La tarea del DBA es crear la base de datos en sí y poner en
funcionamiento los controles técnicos necesarios para apoyar las políticas dictadas por el
administrador de datos. El DBA debe garantizar el funcionamiento adecuado del sistema de base de
datos y proporcionar otros servicios de índole técnica relacionados.
¿Por qué utilizar una base de datos?
La principal ventaja de utilizar un entorno de base de datos es que ofrece a la empresa un
control centralizado de su información. Esta situación presenta un fuerte contraste con respecto a la
de una empresa sin un entorno de base de datos, donde cada aplicación tiene sus propios archivos
privados de manera que los datos están muy dispersos y son difíciles de controlar en cualquier
forma sistemática.
Ventajas del enfoque de base de datos
• Disminución de la redundancia de datos: Al centralizar el almacenamiento de los datos es
posible eliminar los datos repetidos de modo que un mismo dato, como por ejemplo el
código de un cliente, sea igual para el área de cuentas corrientes y para el área de
marketing. De todos modos, en ciertas ocasiones, suelen existir motivos válidos de
negocios o técnicos para mantener copias redundantes de los mismos datos, en esos casos
se deberá tener extremo cuidado y asumir la responsabilidad de “propagar las
actualizaciones”.
• Independencia de los datos: es posible modificar la estructura de almacenamiento y/o la
técnica de acceso sin tener que modificar las aplicaciones ya existentes. Por ejemplo
podrían agregarse datos de otro tipo a una base de datos; podrían adoptarse normas
nuevas; podrían surgir nuevos tipos de dispositivos de almacenamiento; etc. Si las
aplicaciones dependen de los datos, tales cambios requerirían modificaciones
correspondientes en los programas. Podemos definir entonces la independencia de los
datos como la inmunidad de los programas ante los cambios en la estructura de
almacenamiento y en la técnica de acceso a los datos.

7
• Flexibilidad para obtener informes: Esto se logra a través de la utilización de un lenguaje de
manipulación de datos estándar, como por ejemplo SQL, el cual permite sin necesidad de
modificar programas, obtener reportes ad hoc en forma oportuna, ante necesidades
inesperadas de información.
• Posibilidad de aplicar restricciones de seguridad: el DBA puede asegurar que el acceso a la
base de datos sea sólo a través de los canales apropiados y por lo tanto definir las
verificaciones que se deben realizar cuando se intente acceder a información delicada. Se
pueden establecer restricciones de acceso para consulta, modificación o eliminación a cada
elemento de información (tabla, registro, campo). Debe advertirse, que dada la naturaleza
centralizada de la arquitectura de base de datos, ante la ausencia de este tipo de
verificaciones, la seguridad de la información podría estar en mayor peligro que un sistema
de archivos tradicionales (disperso).
• Posibilidad de compartir datos: Al tener un control centralizado, se pueden establecer
normas para la representación de los datos. Estas normas hacen posible que distintas
aplicaciones y distintos usuarios tengan reglas claras sobre la forma en que pueden acceder
a los datos. Esto implica no sólo que las aplicaciones ya existentes puedan compartir la
información de la base de datos, sino también que se pueden desarrollar aplicaciones
nuevas para trabajar con los mismos datos almacenados.
Las tablas
En un ambiente de base de datos relacionales, los datos se organizan en tablas. Las tres
principales características de las tablas son: registros, campos y nombre de la tabla. Por
convención, en este material utilizaremos mayúsculas para las tablas y minúsculas para los
nombres de los campos.
En el siguiente ejemplo se ilustra la tabla VENDEDORES:
id_vendedor apellido_vendedor nombre_vendedor fecha_ingreso telefono_vend
3 López Manuel y Claudi 01/12/1995 4821729
2 Rodríguez Miguel 08/01/1995 4526584
1 Martínez Carlos José 01/01/1994 4245166
4 Pérez Daniel 01/05/1996 156555111
5 Ríos Gabriel 06/01/1996 156555112
6 Castellanos José 02/01/2000 4333111
7 Gonzalez Juan 11/01/2000 4222111
8 Barrionuevo Carlos 11/01/2000 4255222
9 Paz Daniel 11/01/2000 4255441
La tabla del ejemplo tiene cinco campos: id_vendedor, apellido_vendedor, nombre_vendedor,
fecha_ingreso y telefono_vend.
El campo “apellido_vendedor” Registro correspondiente al vendedor Rodríguez

8
4. El diagrama de entidad-relación
Dado que las estructuras de datos y las relaciones entre ellos suelen ser complejas, los
analistas utilizan herramientas gráficas para diseñarlas y examinarlas. El diagrama de entidad-
relación (DER) es un modelo de notación gráfica para describir los datos almacenados en una base
de datos y sus relaciones, independientemente de los procesos del sistema que los utilizan.2
Conocer el diagrama de entidad-relación de un sistema nos permite responder a preguntas
tales como: ¿en qué forma se almacenan los datos requeridos para manejar nuestro negocio; para
mantener una correcta contabilidad o para cumplir con normas legales? ¿Quién los tiene? ¿Quién
tiene acceso a ellos?
El siguiente es el diagrama de entidad-relación correspondiente a la base de datos de una empresa
distribuidora mayorista de repuestos para automóviles:
CLIENTES
id_cliente
SECTORES
id_sector
CTACTE
nro_movim_ctacte
VENDEDORES
id_vendedor
PROVINCIAS
id_provincia
DETALLE_MOVIM_CTACTE
nro_movim_ctacte
id_producto
TIPOS_MOVIMIENTOS
id_tipo_movim
INVENTARIO
id_producto
Diagrama de entidad-relación que refleja el diseño lógico de la base de datos
2 Otros ejemplos de estas herramientas gráficas son: el Diagrama de Flujo de Datos, que modela las
funciones que lleva a cabo un sistema; el Diagrama de Transición de Estados, que modela el comportamiento en distintos momentos de un sistema.
Relación uno a muchos Mientras que un VENDEDOR puede atender a varios CLIENTES, cada cliente es atendido por un solo VENDEDOR.
Campo clave o principal Id_producto es el campo clave de la tabla INVENTARIO
Entidad CLIENTES.

9
Los rectángulos se utilizan para identificar entidades. Las entidades representan un tipo o
clase de objetos (cosas) del mundo real, cuyos miembros individuales (o instancias) se identifican
de manera única por algún medio y cada una de las instancias puede describirse por uno o más
datos. Por ejemplo un cliente en particular puede describirse por medio de datos tales como
nombre, domicilio o límite de crédito y se identifica de manera única a través un código tal como su
DNI, su CUIT o simplemente por un código interno del sistema como por ejemplo “id_cliente”.
Generalmente las entidades serán la representación en el sistema de elementos materiales
del mundo real. Por ejemplo: clientes, artículos de inventario, empleados, partes manufacturadas,
etc. son entidades típicas. Sin embargo, una entidad también puede representar algo inmaterial, por
ejemplo: horarios, planes, estándares, estrategias y áreas.
Las entidades, al momento de crear una base de datos, se asimilan a las “tablas” descriptas
ut-supra.
Las líneas, en el diagrama de entidad-relación, se usan para indicar una relación entre
entidades. Cuando una línea partida en tres señala a un objeto, existe la posibilidad de que haya
varios casos para ese objeto, por ejemplo un vendedor puede atender varios clientes3.
Los cuadros que representan las entidades en el diagrama, muestran los campos claves
subrayados. Una clave es un campo cuyos valores identifican registros. Normalmente todas las
tablas tienen una clave principal 4definida. Una clave principal es un campo (o combinación de
campos) que permite identificar de forma inequívoca cada registro de la tabla, por lo que no pueden
haber en una tabla dos registros con el mismo valor para el campo definido como clave principal.
Por otra parte, ningún registro de la entidad puede contener un valor nulo en ese campo ni tampoco
se pueden repetir valores en el campo.
Por ejemplo, id_vendedor es el campo clave o clave principal de la tabla VENDEDORES,
por lo que el DBMS no permitirá que un usuario introduzca más de un registro con el mismo valor en
ese campo.
Una clave foránea es un campo (o combinación de campos) que contiene un valor que
hace referencia a una registro de otra entidad (en algunos casos puede ser la misma entidad) y
que es clave principal en ésta última.
Una entidad tiene una única clave primaria y puede contener cero o más claves foráneas.
Al momento de hacer consultas a la base de datos, cierta información sólo puede obtenerse
consultando las dos entidades. Por ejemplo, ¿cuáles son los clientes atendidos por el vendedor de
apellido López? Las entidades CLIENTES y VENDEDOR son completamente independientes. Cada
una contiene su propia información en registros y campos, pero tienen en común el campo
3 Más información en Oz, pág. 303-304

10
id_vendedor y esto hace que la consulta sea posible. Así, para cada código de vendedor
(id_vendedor) en la entidad CLIENTES hay uno idéntico en la tabla VENDEDOR, como se ilustra
seguidamente.
id_vendedor = id_vendedor
CLIENTES
id_cliente
id_vendedor
id_sector
id_provincia
nombre_cliente
tipo_iva
cuit
nro_ing_brutos
calle_y_nro_cli
barrio_cl i
ciudad_cli
cod_postal_cl itelefono_cl i
saldo_actual
ctacte_suspendida
l imite_credito
VENDEDORES
id_vendedor
apell ido_vendedor
nombre_vendedor
fecha_ingreso
calle_y_nro_vend
barrio_vend
ciudad_vend
cod_postal_vend
telefono_vend
5. Lenguaje estructurado de consultas (SQL)
El propósito de este apartado es abordar temas prácticos concretos relacionados con bases
de datos; así, partiendo de los conceptos teóricos y la bibliografía5 propuesta en el programa de la
materia, el alumno aprenderá a trabajar en un ambiente estándar de base de datos, utilizando el
lenguaje SQL (Structured Query Language) para manipular, controlar y consultar datos.
El caso sobre el que trabajaremos es el de una empresa distribuidora mayorista de
repuestos para automóviles. Haremos de cuenta que usted es asistente de auditoría de un estudio
contable nacional y ha sido asignado a un grupo de trabajo que está auditando los estados
contables y el control interno de la empresa mencionada. La Gerencia de Sistemas de la firma ha
entregado un diagrama de Entidad Relación, la definición de registros de cada una de las tablas (ver
Anexo) que conforman la base de datos de la empresa y también los permisos de acceso a la base
de datos para que usted pueda realizar consultas utilizando el lenguaje SQL.
Antes de comenzar con la ejercitación, consideramos conveniente conocer algunos
conceptos básicos sobre base de datos y SQL.
4 Oz, pág. 301
5 LAUDON KENNETH C. LAUDON JANE P. Sistemas de Información Gerencial. Capítulo 8. Editorial Prentice-Hall, 2002;
OZ, EFFY. Administración de Sistemas de Información. Cap.8 Editorial Thomson International, 2000
campos de la entidad CLIENTES
campos de la entidad VENDEDORES

11
El lenguaje estructurado de consultas SQL es una herramienta eficaz para la definición y
manipulación de datos en un ambiente de Base de Datos Relacional. Ofrece la ventaja de que no
se necesitan conocimientos previos de programación para usarlo, ya que sigue reglas de gramática
y sintaxis (del inglés) que se entienden fácilmente.
SQL consta de distintas “sentencias” o instrucciones, cada una de ellas demanda una
acción específica al DBMS, tal como la creación de una tabla, la recuperación de datos o la
inserción de nuevos datos en la base de datos.
Todas las sentencias SQL tienen la misma forma básica: comienzan con un verbo, por
ejemplo: CREATE, INSERT, DELETE; continúan con una o más cláusulas y terminan con un punto
y coma (;).
5.1 Sentencias SQL para definición de datos
Las principales sentencias para la definición de datos son:
• CREATE TABLE
• DROP TABLE
• ALTER TABLE
Debe aclararse que estas sentencias no forman parte de las que tiene acceso un auditor.
La sentencia CREATE TABLE se usa para crear las tablas de una base de datos
especificando sus columnas o campos. A cada campo se le da un nombre, un tipo de datos y
algunas restricciones, por ejemplo:
CREATE TABLE VENDEDORES ( id_vendedor CHAR(2) NOT NULL, apellido_vendedor VARCHAR(20) NOT NULL, nombre_vendedor VARCHAR (20) NOT NULL, fecha_ingreso DATE NOT NULL, calle_y_nro_vend CHAR(35), barrio_vend CHAR (30), ciudad_vend CHAR (30), cod_postal_vend CHAR (4), telefono_vend CHAR (12), PRIMARY KEY (id_vendedor) );
La sentencia DROP TABLE y ALTER TABLE se usan para eliminar y modificar tablas
respectivamente.

12
Tipos de datos
Los campos son caracterizados por: nombre, tipo y tamaño. Existen distintos tipos de
campo, según la clase de datos que contienen. En general podemos agrupar los tipos de datos en
tres categorías: numéricos; de fecha y hora; y de cadenas de caracteres. La notación de los tipos de
datos difiere ligeramente según el sistema de administración de base de datos (DBMS) utilizado. A
continuación se muestran algunos tipos de datos que acepta el administrador de base de datos
MySQL:
TIPOS DE CAMPO DESCRIPCIÓN
CHAR(n) Cadena de caracteres de longitud fija. El motor de base de datos reserva espacio de almacenamiento para “n” caracteres. Ej: número de CUIT, código postal, etc.
VARCHAR(n) Cadena de caracteres de longitud variable. El motor de base de datos no reserva espacio de almacenamiento fijo, pero limita la cantidad máxima de datos que puede contener el campo a “n” caracteres. Ej. Nombres, apellidos, direcciones, etc.
INTEGER Números enteros. Ej: números de clientes, edad, número de empleado, etc
NUMERIC(n,d) Números decimales. Ej: porcentajes, tasas, importes monetarios. Donde “n” es la cantidad total de dígitos (incluyendo el signo y la punto decimal) y “d” es la cantidad de decimales.
DECIMAL(n,d) Sinónimo de NUMERIC
DATE Una fecha. En MySQL las fechas tienen formato ‘aaaa-mm-dd’. Ej 2003-11-26
DATETIME Una combinación de fecha y hora. En MySQL en formato ‘aaaa-mm-dd hh-mm-ss’. Ej. 2003-11-26 22:55:30
TEXT Cadenas de texto de hasta 65535 caracteres.
LONGTEXT Cadenas de texto de hasta 4294967295 caracteres.
Es posible además definir que un campo pueda aceptar o no valores “nulos”. Para esto se
utiliza la palabra “NULL” o “NOT NULL”. Un campo al cual no se le ha insertado ningún dato tendrá
un valor “nulo” o “vacío” que es incluso diferente del cero o de una cadena de caracteres vacía.
Consulta de la estructura de las tablas
La sentencia DESCRIBE permite ver los campos que componen una tabla y sus
características. Por ejemplo, para obtener la estructura de la tabla VENDEDORES la sentencia es:
DESCRIBE VENDEDORES

13
El resultado obtenido es:
Field Type Null Key
id_vendedor char(2) PRI apellido_vendedor varchar(20) nombre_vendedor varchar(20) fecha_ingreso date calle_y_nro_vend varchar(35) YES barrio_vend varchar(30) YES ciudad_vend varchar(30) YES cod_postal_vend varchar(4) YES telefono_vend varchar(12) YES
5.2 Sentencias para la manipulación de datos
Existen cuatro sentencias en SQL para manipulación de datos:
• SELECT: Permite hacer consultas a una o varias tablas. • INSERT: Permite agregar registros de datos a una tabla. • DELETE: Permite eliminar registros de una tabla que cumplan con determinada condición. • UPDATE: Permite modificar datos de uno o varios registros de una tabla.
En particular, en este curso, se describirá la sentencia SELECT.
Consultas de datos: SELECT
SQL provee tres cláusulas para obtener información de las tablas de una base de datos
que se usan junto a la sentencia SELECT, estas son: FROM, WHERE y ORDER BY.
La sentencia SELECT le indica al DBMS las columnas que se desean seleccionar6 y
FROM le indica la o las tablas dónde se encuentran esas columnas. Con la cláusula WHERE se
establecen las restricciones que debe cumplir la información solicitada. Por ejemplo, la siguiente es
una consulta a la tabla CLIENTES. Cabe notar que los nombres de las columnas están separados
por comas(,) y que una sentencia SQL finaliza normalmente con un punto y coma(;):
6 Si se desea seleccionar la totalidad de las columnas, se utiliza el comando SELECT seguido de un asterisco
(*). Por ejemplo: SELECT * FROM CLIENTES

14
SELECT id_cliente, id_sector, cuit, nombre_cliente
FROM CLIENTES
WHERE id_sector = 1
id_cliente id_sector cuit nombre_cliente
C0011 1 20-07975234 CARUSA JUAN C0018 1 23-06518228 COLOMBINI ANGEL C0027 1 30-68096311 INDIOS S.R.L. F0011 1 30-69847710 FABREZIO REPUESTOS SA G0003 1 20-07889169 GARCIA REPUESTOS S.A. R0011 1 30-58503469 RIGATUSSO E HIJOS A0105 1 20-13535715 ALBERTI DIESEL S.A. C0066 1 30-69301577 CORDOBA CENTRO S.A. C0021 1 20-12645848 GARCIA JUAN
En este caso, el DBMS examina cada fila de la tabla CLIENTES y devuelve sólo aquellas
donde el contenido de la columna id_sector es 1.
Por otra parte, si se necesita que la información se muestre en un determinado orden se
utiliza la cláusula ORDER BY seguida del nombre del campo por el que se desea ordenar. Por
ejemplo, para ordenar los datos por el nombre del cliente:
SELECT id_cliente, id_sector, cuit, nombre_cliente
FROM CLIENTES
WHERE id_sector = 1
ORDER BY nombre_cliente
id_cliente id_sector cuit nombre_cliente
A0105 1 20-13535715 ALBERTI DIESEL S.A. C0011 1 20-07975234 CARUSA JUAN C0018 1 23-06518228 COLOMBINI ANGEL C0066 1 30-69301577 CORDOBA CENTRO S.A. F0011 1 30-69847710 FABREZIO REPUESTOS SA C0021 1 20-12645848 GARCIA JUAN G0003 1 20-07889169 GARCIA REPUESTOS S.A. C0027 1 30-68096311 INDIOS S.R.L. R0011 1 30-58503469 RIGATUSSO E HIJOS
En forma predeterminada el ordenamiento se realiza en forma ascendente. También se
pueden solicitar los datos en orden inverso al predeterminado agregando la palabra DESC
(descendente) en la cláusula ORDER BY, a continuación del nombre del campo.
Por ejemplo, para ordenar los clientes del sector 1 por el nombre en forma descendente,
se escribe la siguiente sentencia SQL:

15
SELECT id_cliente, id_sector, cuit, nombre_cliente
FROM CLIENTES
WHERE id_sector = 1
ORDER BY nombre_cliente des
id_cliente id_sector Cuit nombre_cliente
R0011 1 30-58503469 RIGATUSSO E HIJOS C0027 1 30-68096311 INDIOS S.R.L. G0003 1 20-07889169 GARCIA REPUESTOS S.A. C0021 1 20-12645848 GARCIA JUAN F0011 1 30-69847710 FABREZIO REPUESTOS SA C0066 1 30-69301577 CORDOBA CENTRO S.A. C0018 1 23-06518228 COLOMBINI ANGEL C0011 1 20-07975234 CARUSA JUAN A0105 1 20-13535715 ALBERTI DIESEL S.A.
Para ordenar el resultado de la consulta por más de un campo se los coloca separados
por coma después de la cláusula ORDER BY.
La sentencia SELECT más simple es la que permite obtener todos los registros de una
tabla mostrando el valor de todos los campos lo cual se indica con el carácter asterisco. Por
ejemplo:
SELECT *
FROM CLIENTES
Consultas específicas usando la cláusula WHERE
La cláusula WHERE permite hacer consultas más específicas “filtrando” los registros que
cumplen con una determinada condición lógica.
Operadores de Comparación (Igual, mayor que, menor que, distinto de)
saldo_actual = 800 El saldo actual es igual a 800
saldo_actual > 800 El saldo actual es mayor que 800
saldo_actual >= 800 El saldo actual es mayor o igual que 800
saldo_actual < 800 El saldo actual es menor que 800
saldo_actual <= 800 El saldo actual es menor o igual que 800
saldo_actual != 800 El saldo actual es distinto de 800
saldo_actual <> 800 El saldo actual es distinto de 800

16
El siguiente es un ejemplo en el que se solicitan los saldos de los clientes que sean
mayores a 800 pesos. Sólo se devuelven las filas que cumplen esta condición.
SELECT id_cliente, nombre_cliente, cuit, saldo_actual
FROM CLIENTES
WHERE saldo_actual > 800
id_cliente nombre_cliente cuit saldo_actual C0009 CAROL OMAR 20-06445715 855.35 F0011 FABREZIO REPUESTOS SA 30-69847710 1997.64 C0021 GARCIA JUAN 20-12645848 1390.96
Uso de la cláusula LIKE
La cláusula LIKE se utiliza para realizar operaciones de comparación entre una cadena de
caracteres y un patrón determinado. El patrón es una cadena de caracteres y/o espacios que puede
incluir uno o más “comodines”. El signo de porcentaje (%) es un comodín que se corresponde con
cualquier secuencia de caracteres y/o espacios. El guión bajo (_) es un comodín que representa un
solo caracter o espacio. El patrón debe escribirse entre comillas simple. Los siguientes ejemplos
ilustran el uso del comando like:
nombre_cliente LIKE 'Mo%' El nombre comienza con las letras “Mo".
nombre_cliente LIKE '_ _i%' El nombre tiene una “i” en la tercera posición.
nombre_cliente LIKE '%o%o%' El nombre tiene dos letras “o” en su interior.
nombre_cliente LIKE '%Perez' El nombre termina con las letras “Perez”.
Valores nulos y no nulos
NULL se usa para ver las filas de una columna que están vacías (la palabra "IS" se debe
usar con NULL y NOT NULL) Los signos igual, mayor y menor no se utilizan con esta sentencia.
Ejemplos:
saldo_actual IS NULL El saldo es nulo o vacío
saldo_actual IS NOT NULL El saldo no es nulo (es decir, tiene algún valor)

17
Comparaciones lógicas con secuencias e intervalos de valores
Así como hay operadores lógicos que comparan valores discretos, existe también la
posibilidad de realizar comparaciones con listas de valores (números o letras).
Para esto se utilizan las cláusulas IN y BETWEEN, como se indica en los siguientes ejemplos:
id_vendedor IN (1,2,3) "el campo id_vendedor asume uno de los valores de la lista
(1,2,3)"
id_vendedor NOT IN (1,2,3) "el campo id_vendedor no asume ninguno de los valores de
la lista (1,2,3)"
id_vendedor BETWEEN 6 AND 8 "el campo id_vendedor asume un valor comprendido entre 6
y 8 inclusive"
id_vendedor NOT BETWEEN 6 AND 8 "el campo id_vendedor asume un valor inferior a 6 o
superior a 8"
Por ejemplo, para seleccionar los clientes que se encuentran en los sectores 4 y 5:
SELECT id_cliente, nombre_cliente, id_sector
FROM CLIENTES
WHERE id_sector IN (4,5)
id_cliente nombre_cliente id_sector M0005 MANZURI JORGE 5 O0008 OCHOA JOSE 5 R0003 RECALDE JORGE 5 T0007 TRANSPORTES CARRETA SA 4
Para seleccionar los clientes cuyo saldo actual es entre 700 y 1000:
SELECT id_cliente, nombre_cliente, saldo_actual
FROM CLIENTES
WHERE saldo_actual BETWEEN 700 AND 1000
id_cliente nombre_cliente Saldo_actual C0009 CAROL OMAR 855.35 G0003 GARCIA REPUESTOS S.A. 763.56
Operadores lógicos (AND, OR, NOT)
El operador AND se usa para combinar una o más expresiones lógicas y requiere que

18
cualquier fila examinada de la base de datos cumpla con todas las condiciones planteadas. Por
ejemplo, para seleccionar los clientes del sector 1 cuyo saldo actual sea mayor que 700:
SELECT id_sector, nombre_cliente, saldo_actual
FROM CLIENTES
WHERE id_sector = 1
AND saldo_actual > 700
id_sector nombre_cliente saldo_actual 1 FABREZIO REPUESTOS SA 1997.64 1 GARCIA REPUESTOS S.A. 763.56 1 GARCIA JUAN 1390.96
La sentencia selecciona sólo las filas que cumplen con las dos condiciones: "id_sector = 1
y saldo_actual > 700"
Por otra parte, se usa el operador OR para solicitar las filas que cumplan, al menos, una
de las condiciones planteadas. Por ejemplo:
SELECT nombre_cliente, ciudad_cli, cod_postal_cli
FROM CLIENTES
WHERE cod_postal_cli = 5870
OR cod_postal_cli = 5889
nombre_cliente ciudad_cli cod_postal_cli MANZURI JORGE VILLA DOLORES 5870 OCHOA JOSE VILLA DOLORES 5870 RECALDE JORGE MINA CLAVERO 5889
En este caso, vemos que fueron seleccionadas las filas que cumplen al menos con una de
las condiciones (cod_postal_cli = 5870 ó cod_postal_cli = 5889).
Tanto AND como OR se pueden combinar, pero hay que tener presente el orden en que
se los usa y el empleo de paréntesis, ya que el resultado en cada caso es diferente.
Suponiendo tres condiciones A, B y C, veamos los distintos casos:
A OR B AND C

19
En este caso primero se evaluará la expresión B AND C. Luego, el resultado se evaluará
con la condición A. Si queremos modificar ese orden utilizamos paréntesis:
(A OR B) AND C
En este caso primero se evaluará la expresión encerrada entre paréntesis (A OR B).
Luego el resultado se evaluará con la condición C.
Supongamos que se quieren encontrar los clientes con saldo actual mayor que 700 que
pertenezcan a los sectores 1 o 3. La forma correcta de efectuar la consulta sería de la siguiente
forma (observe la ubicación de los paréntesis):
SELECT id_sector, nombre_cliente, saldo_actual
FROM CLIENTES
WHERE ( id_sector=1 OR id_sector=3 ) AND saldo_actual>700
id_sector nombre_cliente saldo_actual 3 CAROL OMAR 855.35 1 FABREZIO REPUESTOS SA 1997.64 1 GARCIA REPUESTOS S.A. 763.56 1 GARCIA JUAN 1390.96
Si escribimos la sentencia omitiendo los paréntesis:
SELECT id_sector, nombre_cliente, saldo_actual
FROM CLIENTES
WHERE id_sector=1 OR id_sector=3 AND saldo_actual>700
Obtendremos el siguiente resultado:
id_sector nombre_cliente saldo_actual 3 CAROL OMAR 855.35 1 CARUSA JUAN 0.00 1 COLOMBINI ANGEL 0.00 1 INDIOS S.R.L. 664.45 1 FABREZIO REPUESTOS SA 1997.64 1 GARCIA REPUESTOS S.A. 763.56 1 RIGATUSSO E HIJOS 0.00 1 ALBERTI DIESEL S.A. 0.00 1 CORDOBA CENTRO S.A. 0.00 1 GARCIA JUAN 1390.96
El resultado que se obtiene no es el deseado ya que se han incluido clientes cuyo saldo es
menor que 700.
Si se coloca "AND saldo_actual>700" al medio de la cláusula WHERE, el resultado es
diferente pero también erróneo:

20
SELECT id_sector, nombre_cliente, saldo_actual
FROM CLIENTES
WHERE id_sector=1 AND saldo_actual>700 OR id_sector=3
id_sector nombre_cliente saldo_actual 3 CAROL OMAR 855.35 1 FABREZIO REPUESTOS SA 1997.64 1 GARCIA REPUESTOS S.A. 763.56 3 MUSSOLINI ATILIO RODOLFO 0.00 3 ROMARIO CARLOS E HIJOS 0.00 3 MARCCHIAVO RUBEN JOSE 0.00 3 PERLAROTA DOMINGO 0.00 3 ROSTIGATO S.A. 0.00 1 GARCIA JUAN 1390.96
Lo que sucede es que aunque tanto AND como OR son conectores lógicos, AND se
ejecuta primero y se relaciona con la cláusula contigua. Este comportamiento se puede romper
usando paréntesis para rodear aquellas expresiones que se quieren interpretar juntas.
Funciones: suma(SUM), promedio(AVG), máximo(MAX), mínimo(MIN),
contar(COUNT)7
SQL permite obtener información utilizando funciones. Describiremos algunos ejemplos de
las funciones más elementales:
SUM calcula la suma algebraica de un campo o columna. Por ejemplo, para obtener el
saldo total adeudado por todos los clientes:
SELECT SUM(saldo_actual)
FROM CLIENTES
AVG calcula el valor promedio de un campo o columna. Por ejemplo, para obtener el saldo
promedio de los clientes (se excluyen del promedio los clientes que no adeudan):
SELECT AVG(saldo_actual)
FROM CLIENTES
WHERE saldo_actual>0
7 GUNDERLOY MIKE y CHIPMAN MARY, SQL Server7. Editorial Anaya Multimedia, 1999.

21
MIN encuentra el valor más pequeño de un campo. Por ejemplo, para conocer cuál es el
deudor con menor saldo (se excluyen los clientes que no adeudan):
SELECT MIN(saldo_actual) FROM CLIENTES WHERE saldo_actual>0
MAX encuentra el valor máximo de un campo. Para conocer cuál es el cliente que más
adeuda:
SELECT MAX(saldo_actual) FROM CLIENTES WHERE saldo_actual>0
COUNT cuenta la cantidad de valores de un campo que cumplan una condición. Para
conocer cuántos clientes tienen saldo en su cuenta:
SELECT COUNT(id_cliente) FROM CLIENTES WHERE saldo_actual>0
Consultas agrupadas: cláusulas GROUP BY y HAVING8
Las consultas descriptas anteriormente permiten obtener totales. Por otra parte, la
cláusula GROUP BY nos permite obtener subtotales agrupando por uno o más campos. Veamos
algunos ejemplos:
Para obtener la suma de los saldos de clientes, agrupados por los vendedores que los
atienden:
SELECT id_vendedor, SUM(saldo_actual) FROM CLIENTES GROUP BY id_vendedor
id_vendedor sum(saldo_actual) 1 2818.97 2 0.00 3 2852.99 4 0.00 5 0.00 6 0.00 7 0.00 8 0.00

22
GROUP BY no implica ORDER BY; para garantizar que el resultado aparezca en un
determinado orden se debe especificar también la cláusula ORDER BY.
Cuando, en la misma sentencia, se utiliza la cláusula GROUP BY y alguna de las
funciones (ej. SUM, AVG, etc.), los campos que se pueden incluir en la sentencia SELECT son los
mismos que se utilizan para realizar la agrupación. Los demás campos sólo pueden incluirse en el
SELECT como argumentos de las funciones.
Por ejemplo, si se quiere obtener el total de ventas netas de IVA de cada cliente se
debería hacer:
SELECT id_cliente, SUM(importe_total - iva) FORM CTACTE GROUP BY id_cliente
Por lo tanto la siguiente sentencia sería incorrecta:
SELECT id_cliente, fecha_comprobante, SUM(importe_total - iva) FROM CTACTE GROUP BY id_cliente
Es incorrecta debido que el GROUP BY ya efectuó el agrupamiento por id_cliente y por lo tanto no
se puede determinar cuál fecha_comprobante se debe mostrar.
La cláusula HAVING se utiliza para introducir una condición para seleccionar grupos, de la
misma manera que la cláusula WHERE se utiliza para introducir una condición cuando se
seleccionar registros. En el ejemplo anterior, para seleccionar los vendedores cuyo total de ventas
netas de IVA es mayor que 700, la sentencia SQL sería:
SELECT id_vendedor, SUM(importe_total - iva) FROM CTACTE GROUP BY id_vendedor HAVING SUM(importe_total - iva) > 700
id_vendedor sum(importe_total - iva)
1 6400.14 3 7223.73 4 730.51
Reunión de tablas (Table Join)
Probablemente se necesiten combinar dos o más tablas para obtener cierta información.
Supongamos que se desea identificar el código y apellido de los vendedores cuyos
clientes tienen saldo mayor que 700. La información que se necesita se encuentra en las tablas
CLIENTES y VENDEDORES. Haciendo las consultas a las tablas mencionadas por separado no se
8 Ibid, Pag

23
obtendría una vista integral de la información que se necesita.
Para remediar esta situación se puede solicitar que las columnas seleccionadas de las dos
tablas se muestren juntas. Esto será posible siempre que las tablas tengan algún campo en común
y se debe usar la cláusula WHERE para indicar cuál es ese campo común. Para nuestro ejemplo el
campo común es id_vendedor que es la clave primaria de la tabla VENDEDORES:
SELECT id_cliente, saldo_actual, CLIENTES.id_vendedor, VENDEDORES.apellido_vendedor FROM CLIENTES, VENDEDORES WHERE CLIENTES.id_vendedor = VENDEDORES.id_vendedor AND saldo_actual>700
id_cliente saldo_actual id_vendedor apellido_vendedor C0009 855.35 3 López F0011 1997.64 3 López G0003 763.56 1 Martínez C0021 1390.96 1 Martínez
La cláusula SELECT escoge las columnas de las dos tablas que se quieren ver. Las
columnas que no se han nombrado, simplemente se ignoran. Cuando el nombre de una columna
seleccionada se repite en las dos tablas, debe indicarse a qué tabla pertenece, precediendo el
nombre del campo por el nombre de la tabla separado por un punto, por ejemplo:
“CLIENTES.id_vendedor” para el campo id_vendedor de la tabla CLIENTES. Sin esa aclaración el
DBMS respondería que el nombre de la columna id_vendedor es ambiguo ya que se encuentra en
ambas tablas.
Asimismo, cabe notar que los únicos registros que aparecen como resultado del Join
(reunión) son los comunes a ambas tablas. Si un vendedor estuviera sólo en una de las tablas no
sería seleccionado. Este tipo de operación se conoce como Inner Join a diferencia del Outer Join
que permite obtener todos los registros de ambas tablas.

24
Subconsultas
Las subconsultas permiten combinar dos o más consultas en una. La ventaja de utilizar
subconsultas se relaciona con la rapidez de la respuesta ya que en este caso, el DBMS resuelve en
primer lugar la subconsulta y luego de esta primera selección de datos, se ejecuta el resto de la
consulta.
Por ejemplo, si se quiere consultar los vendedores que tienen algún cliente cuyo saldo
actual sea mayor que 300:
SELECT VENDEDORES.id_vendedor, VENDEDORES.apellido_vendedor
FROM VENDEDORES
WHERE id_vendedor IN (SELECT id_vendedor
FROM CLIENTES
WHERE saldo_actual > 300);
El DBMS selecciona en primer lugar, los registros que cumplen la condición entre
paréntesis (llamada “subconsulta”) y luego ejecuta el resto de la sentencia verificando sólo entre los
registros seleccionados en la subconsulta. En el ejemplo traerá solamente los datos de los
vendedores cuyo id_vendedor se encuentre en el resultado de la subconsulta.
Vistas
Las vistas son “tablas virtuales” que no existen físicamente y que se crean en base a
operaciones sobre una o más tablas. El usuario percibe una vista como si fuera una tabla y puede
manipularla y realizar las mismas operaciones que puede hacer con las tablas.
Las sentencias CREATE VIEW, DROP VIEW y ALTER VIEW se utilizan para crear,
eliminar y modificar una vista, respectivamente.
Las vistas son útiles porque proporcionan un mecanismo de seguridad al permitir ocultar
determinadas columnas a ciertos usuarios. También se pueden crear vistas que se adapten a las
necesidades específicas de cada usuario.
Las vistas son dinámicas porque los cambios que se realizan en las tablas base se reflejan
inmediatamente sobre la vista.
Se utilizan para construir informes complejos y/o restringir a grupos o individuos
específicos el acceso a parte de la información de una tabla. Por ejemplo, se podría permitir a cada
vendedor tener acceso sólo a los datos de los clientes que atiende, restringiéndole la vista sólo a los

25
campos: id_cliente, nombre_cliente, limite_credito y saldo_actual.
Así, la vista para el vendedor 1 se crearía de la siguiente manera:
CREATE VIEW CLIENTESVENDEDOR1 AS
SELECT id_vendedor, apellido_vendedor, id_cliente, nombre_cliente, limite_credito, saldo_actual
FROM CLIENTES, VENDEDORES
WHERE CLIENTES.id_vendedor=VENDEDORES.id_vendedor
AND VENDEDORES.id_vendedor =’1’;
5.3 Sentencias para modificar datos (DML): INSERT, UPDATE y DELETE
Estos comandos están diseñados para introducir nuevas filas o registros (INSERT),
modificar los valores de las columnas en las filas (UPDATE) y borrar filas (DELETE).
La sentencia INSERT
Se usa para agregar registro directamente en una tabla.
Así, para agregar un registro a la tabla VENDEDORES, primero vemos la estructura de la
tabla con el comando DESCRIBE:
DESCRIBE VENDEDORES;
Field Type Null Key
id_vendedor char(2) PRI apellido_vendedor varchar(20) nombre_vendedor varchar(20) fecha_ingreso date calle_y_nro_vend varchar(35) YES barrio_vend varchar(30) YES ciudad_vend varchar(30) YES cod_postal_vend varchar(4) YES telefono_vend varchar(12) YES
Luego agregamos una fila o registro a la tabla con el comando INSERT:
INSERT INTO VENDEDOR
(id_vendedor, apellido_vendedor, nombre_vendedor, fecha_ingreso)
VALUES ('10', ‘Mir’,’Raúl’,'2003-01-15');
La cláusula VALUES debe ir delante de la lista de datos que se quiere insertar. Cabe notar

26
que cada dato debe ir entre comillas simples (salvo que sean numéricos), respetando el tipo y el
orden de los campos.
En el ejemplo no hemos insertado datos en algunos campos que, según indica la
estructura de la tabla admiten valores nulos o vacíos.
La sentencia DELETE
DELETE es la sentencia SQL que se encarga de borrar filas de una tabla. La cláusula
WHERE es esencial para eliminar sólo las filas que se desee. DELETE sin la cláusula WHERE
borra todos los registros de una tabla.
DELETE FROM CLIENTES WHERE id_cliente = 'C0034';
Para comprobar el efecto del DELETE, hacemos una simple consulta intentando ver la fila
cuyo número de cliente (id_cliente) es ‘C0034’:
SELECT *
FROM CLIENTES
WHERE id_cliente = 'C0034';
Veremos que no aparece ningún registro seleccionado.
La sentencia UPDATE
UPDATE modifica los valores de una o varias columnas dentro de una o varias filas y
permite especificar a qué fila o filas se desee que afecte, usando la cláusula WHERE. Por ejemplo,
para aumentar el límite de crédito a $500 al cliente ‘C0018’, se hace:
UPDATE CLIENTES
SET limite_credito = 800
WHERE id_cliente = ‘C0018';
Al actualizar los datos se pueden utilizar también funciones. Por ejemplo, para incrementar
en 300 el límite de crédito de aquellos clientes cuyo saldo actual sea menor a 200:
UPDATE CLIENTES
SET limite_credito = limite_credito + 300
WHERE saldo_actual < 200;
27
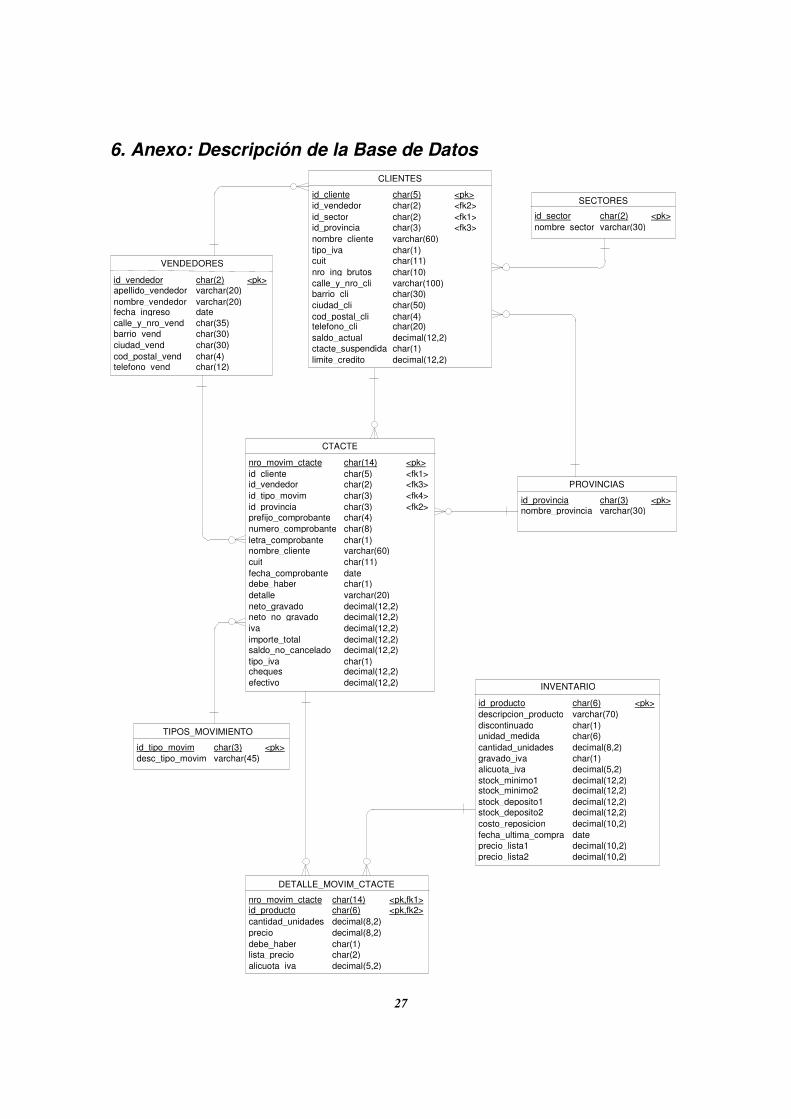
6. Anexo: Descripción de la Base de Datos
CLIENTES
id_cliente id_vendedor
id_sectorid_provincia
nombre_cliente
tipo_ivacuit
nro_ing_brutos
calle_y_nro_clibarrio_cli
ciudad_cli
cod_postal_clitelefono_cli
saldo_actualctacte_suspendida
limite_credito
char(5) char(2)
char(2)char(3)
varchar(60)
char(1)char(11)
char(10)
varchar(100)char(30)
char(50)
char(4)char(20)
decimal(12,2)char(1)
decimal(12,2)
<pk> <fk2>
<fk1><fk3>
SECTORES
id_sector
nombre_sector
char(2)
varchar(30)
<pk>
CTACTE
nro_movim_ctacte
id_clienteid_vendedor
id_tipo_movim
id_provinciaprefijo_comprobante
numero_comprobante
letra_comprobantenombre_cliente
cuit
fecha_comprobantedebe_haber
detalle
neto_gravadoneto_no_gravado
iva
importe_totalsaldo_no_cancelado
tipo_ivacheques
efectivo
char(14)
char(5)char(2)
char(3)
char(3)char(4)
char(8)
char(1)varchar(60)
char(11)
datechar(1)
varchar(20)
decimal(12,2)decimal(12,2)
decimal(12,2)
decimal(12,2)decimal(12,2)
char(1)decimal(12,2)
decimal(12,2)
<pk>
<fk1><fk3>
<fk4>
<fk2>
VENDEDORES
id_vendedor apellido_vendedor
nombre_vendedorfecha_ingresocalle_y_nro_vendbarrio_vend
ciudad_vend
cod_postal_vendtelefono_vend
char(2) varchar(20)
varchar(20)datechar(35)char(30)
char(30)
char(4)char(12)
<pk>
PROVINCIAS
id_provincia nombre_provincia
char(3) varchar(30)
<pk>
DETALLE_MOVIM_CTACTE
nro_movim_ctacte id_producto
cantidad_unidades
precio
debe_haberlista_precio
alicuota_iva
char(14) char(6)
decimal(8,2)
decimal(8,2)
char(1)char(2)
decimal(5,2)
<pk,fk1> <pk,fk2>
TIPOS_MOVIMIENTOS
id_tipo_movim desc_tipo_movim
char(3) varchar(45)
<pk>
INVENTARIO
id_producto
descripcion_producto
discontinuadounidad_medida
cantidad_unidadesgravado_ivaalicuota_iva
stock_minimo1stock_minimo2
stock_deposito1stock_deposito2
costo_reposicion
fecha_ultima_compraprecio_lista1precio_lista2
char(6)
varchar(70)
char(1)char(6)
decimal(8,2)char(1)decimal(5,2)
decimal(12,2)decimal(12,2)
decimal(12,2)decimal(12,2)
decimal(10,2)
datedecimal(10,2)decimal(10,2)
<pk>

28
6.1. Definición de registro de las tablas del sistema
1 Table CLIENTES 1.1 Card of the table CLIENTES
Name CLIENTES
DBMS MySQL 3.23
Comment Tabla que contiene el padrón de clientes
1.2 Column list of the table CLIENTES
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
id_cliente X char(5) Identificador único del
cliente
id_vendedor X char(2) Identificador único del
vendedor
id_sector X char(2) Identificador único de
cada sector comercial
id_provincia X char(3) Identificador único de
cada provincia
nombre_cliente varchar(60)
tipo_iva char(1) Condición del cliente
frente al IVA:
I : Responsable Inscripto
N : Responsable No
Inscripto
M : Monotributista
E : Exento
cuit char(11)
nro_ing_brutos char(10)
calle_y_nro_cli varchar(100)
barrio_cli char(30)
ciudad_cli char(50)
cod_postal_cli char(4)
telefono_cli char(20)
saldo_actual decimal(12,2) Saldo actual de la cuenta
del cliente
ctacte_suspendida char(1) Indica si el cliente tiene
su cuenta suspendida
S : Si
N : No
limite_credito decimal(12,2) Límite de crédito a
otorgar al cliente

29
2 Table SECTORES 2.1 Card of the table SECTORES
Name SECTORES
DBMS MySQL 3.23
Comment Sectores de comercialización
2.2 Column list of the table SECTORES
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
id_sector X char(2) Identificador único de cada
sector comercial
nombre_sector varchar(30)
3 Table CTACTE 3.1 Card of the table CTACTE
Name CTACTE
DBMS MySQL 3.23
Comment Movimientos en la cuenta corriente del cliente
3.2 Column list of the table CTACTE
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
nro_movim_ctacte X char(14) Identificador único del
movimiento en cuenta
corriente
id_cliente X char(5) Identificador único del
cliente
id_vendedor X char(2) Identificador único del
vendedor
id_tipo_movim X char(3) Identificador único del
movimiento en cuenta
corriente
id_provincia X char(3) Identificador único de
cada provincia
prefijo_comproba
nte
char(4) Prefijo del comprobante
(Punto de Venta)
numero_comprob
ante
char(8)
letra_comprobante char(1) A, B, C, E o M

30
nombre_cliente varchar(60)
Cuit char(11)
Fecha_comproban
te
Date
Debe_haber char(1) Indica si el movimiento
se debita o se acredita
en la cuenta corriente.
D : Debe
H: Haber
Detalle varchar(20) Puede ser:
- FACTURA
- N.CREDITO
- PAGO
Neto_gravado decimal(12,2) Importe neto gravado en
IVA
Neto_no_gravado decimal(12,2) Importe no gravado en
IVA
Iva decimal(12,2) Importe del IVA
Importe_total decimal(12,2) Importe total del
comprobante
Saldo_no_cancela
do
decimal(12,2) Saldo sin cancelar del
comprobante
Tipo_iva char(1) Condición del cliente
frente al IVA:
I : Responsable
Inscripto
N : Responsable No
Inscripto
M : Monotributista
E : Exento
Cheques decimal(12,2) Importe cancelado con
cheques o valores
Efectivo decimal(12,2) Importe cancelado en
efectivo

31
4 Table VENDEDORES 4.1 Card of the table VENDEDORES
Name VENDEDORES
DBMS MySQL 3.23
Comment Padrón de Vendedores
4.2 Column list of the table VENDEDORES
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
id_vendedor X char(2) Identificador único del
vendedor
apellido_vendedor varchar(20)
nombre_vendedor varchar(20)
fecha_ingreso Date
calle_y_nro_vend char(35)
barrio_vend char(30)
ciudad_vend char(30)
cod_postal_vend char(4)
telefono_vend char(12)
5 Table PROVINCIAS 5.1 Card of the table PROVINCIAS
Name PROVINCIAS
DBMS MySQL 3.23
Comment
5.2 Column list of the table PROVINCIAS
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
id_provincia X char(3) Identificador único de cada
provincia
nombre_provincia varchar(30)
32
6 Table DETALLE_MOVIM_CTACTE 6.1 Card of the table DETALLE_MOVIM_CTACTE
Name DETALLE_MOVIM_CTACTE
DBMS MySQL 3.23
Comment Detalle o renglones de cada movimiento en cuenta corriente.
Esta tabla tiene clave compuesta, relacionando los movimientos
en cuenta corriente con cada uno de los artículos o productos
contenidos en su detalle.
6.2 Column list of the table DETALLE_MOVIM_CTACTE
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
nro_movim_ctacte X X char(14) Identificador único del
movimiento en cuenta
corriente
id_producto X X char(6) Identificador único del
producto
cantidad_unidades decimal(8,2) Cantidad de unidades
existentes en stock
precio decimal(8,2) Precio de Venta
debe_haber char(1) Indica si el movimiento se
debita o se acredita en la
cuenta corriente.
D : Debe
H: Haber
lista_precio char(2)
alicuota_iva decimal(5,2)
7 Table TIPOS_MOVIMIENTOS 7.1 Card of the table TIPOS_MOVIMIENTOS
Name TIPOS_MOVIMIENTOS
DBMS MySQL 3.23
Comment Tipos de movimientos en cuenta corriente
7.2 Column list of the table TIPOS_MOVIMIENTOS
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
id_tipo_movim X char(3) Identificador único del
movimiento en cuenta
corriente
desc_tipo_movim varchar(45)

33
8 Table INVENTARIO 8.1 Card of the table INVENTARIO
Name INVENTARIO
DBMS MySQL 3.23
Comment Padrón de artículos
8.2 Column list of the table INVENTARIO
Name P
ri
m
ar
y
F
or
ei
g
n
K
ey
Data Type Comment
id_producto X char(6) Identificador único del producto
descripcion_produ
cto
varchar(70)
discontinuado char(1) Indica si un artículo está
discontinuado
S - N
unidad_medida char(6) Unidad de Medida en la que se
expresan las cantidades físicas
del artículo
cantidad_unidades decimal(8,2) Cantidad de unidades existentes
en stock
gravado_iva char(1) Indica si la compra venta del
artículo está o no gravado en el
IVA
alicuota_iva decimal(5,2)
stock_minimo1 decimal(12,2) Stock mínimo del depósito 1
(pto. de reposición)
stock_minimo2 decimal(12,2) Stock mínimo del depósito 2
(Pto. de reposición)
stock_deposito1 decimal(12,2) Stock existente en el depósito 1
stock_deposito2 decimal(12,2) Stock existente en el depósito 2
costo_reposicion decimal(10,2) Costo de reposición
fecha_ultima_com
pra
Date
precio_lista1 decimal(10,2) Precio de la lista 1
precio_lista2 decimal(10,2) Precio de la lista 2

34
7. Bibliografía
CASTELLO, RICARDO. “Manual sobre base de datos relacionales”. Material inédito, 1993.
GUNDERLOY MIKE y CHIPMAN MARY, SQL Server7. Editorial Anaya Multimedia, 1999.
LAUDON KENNETH C. LAUDON JANE P. Sistemas de Información Gerencial. Editorial Capítulo 8.
Prentice-Hall, 2002.
OZ, EFFY. Administración de Sistemas de Información. Cap.8 Editorial Thomson International, 2000
DATE, C. J. Introducción a los Sistemas de Bases de Datos. 5ta. Edición. Addison-Wesley
Iberoamericana. 1993


















