
UNIVERSIDAD CENTRAL DEL ECUADOR · 2018-06-14 · ii DERECHOS DE AUTOR Yo, Yahaira Karina...
65
UNIVERSIDAD CENTRAL DEL ECUADOR FACULTAD DE INGENIERÍA, CIENCIAS FÍSICAS Y MATEMÁTICA CARRERA DE INGENIERÍA MATEMÁTICA Enfoque de máxima entropía para la modelación de la distribución del Paludismo en Ecuador Trabajo de titulación modalidad proyecto integrador, previo a la obtención del Título de Ingeniera Matemática Yahaira Karina Rivadeneira Maya TUTOR: Ing. Mat. Guillermo Alexis Albuja Proaño Quito, 2017
Transcript of UNIVERSIDAD CENTRAL DEL ECUADOR · 2018-06-14 · ii DERECHOS DE AUTOR Yo, Yahaira Karina...

UNIVERSIDAD CENTRAL DEL ECUADOR
FACULTAD DE INGENIERÍA, CIENCIAS FÍSICAS Y
MATEMÁTICA
CARRERA DE INGENIERÍA MATEMÁTICA
Enfoque de máxima entropía para la modelación de la distribución del Paludismo en Ecuador
Trabajo de titulación modalidad proyecto integrador, previo a la
obtención del Título de Ingeniera Matemática
Yahaira Karina Rivadeneira Maya
TUTOR: Ing. Mat. Guillermo Alexis Albuja Proaño
Quito, 2017

ii
DERECHOS DE AUTOR
Yo, Yahaira Karina Rivadeneira Maya en calidad de autor y titular de los
derechos morales y patrimoniales del trabajo de titulación ENFOQUE DE
MÁXIMA ENTROPÍA PARA LA MODELACIÓN DE LA DISTRIBUCIÓN
DEL PALUDISMO EN ECUADOR, modalidad Proyecto Integrador, de
conformidad con el Art. 114 del CÓDIGO ORGÁNICO DE LA ECONOMÍA
SOCIAL DE LOS CONOCIMIENTOS, CREATIVIDAD E INNOVACIÓN,
concedo a favor de la Universidad Central del Ecuador una licencia gratuita,
intransferible y no exclusiva para el uso no comercial de la obra, con fines
estrictamente académicos.
Conservo a nuestro favor todos los derechos de autor sobre la obra,
establecidos en la normativa. Así mismo, autorizo a la Universidad Central
del Ecuador para que realice la digitalización y publicación de este trabajo
de titulación en el repositorio virtual, de conformidad a lo dispuesto en el
Art. 144 de la Ley Orgánica de Educación Superior.
El autor declara que la obra objeto de la presente autorización es original
en su forma de expresión y no infringe el derecho de autor de terceros,
asumiendo la responsabilidad por cualquier reclamación que pudiera
presentarse por esta causa y liberando a la Universidad de toda
responsabilidad.
Firma:
Yahaira Karina Rivadeneira Maya
CC.0401639455

iii
APROBACIÓN DEL TUTOR
En mi calidad de Tutor del Trabajo de Titulación, presentado por Yahaira Karina Rivadeneira Maya, para optar por el Grado de Ingeniera Matemática; cuyo título es: ENFOQUE DE MÁXIMA ENTROPÍA PARA LA MODELACIÓN DE LA DISTRIBUCIÓN DEL PALUDISMO EN ECUADOR, considero que dicho trabajo reúne los requisitos y méritos suficientes para ser sometido a la presentación pública y evaluación por parte del tribunal examinador que se designe. En la ciudad de Quito, a los 21 días del mes de Julio de 2017. Matemático. Guillermo Alexis Albuja Proaño DOCENTE-TUTOR C.C. 1712454063 [email protected]

iv
AGRADECIMIENTOS
La necesidad de realizar este proyecto se generó en el centro EpiSIG
del Instituto Nacional de Investigación en Salud Pública INSPI - Dr.
Leopoldo Izquieta Pérez, por lo que quiero agradecer en especial a
Emmanuelle Quentin, Ph.D, y a mi grupo EpiSIG por el apoyo brindado
cada día, de igual manera a Varsovia Cevallos, Ph.D, quien dirigió el
proyecto “Sistema de Alerta Temprana para el Control de Vectores de
Malaria y Leishmaniasis (FASE 1)” y apoyó mi vida profesional inicial,
además implanto en mi la motivación para realizar este proyecto.
A mis profesores y compañeros de ingeniería matemática, con quien
compartí tanto tiempo para tener la formación matemática y forjar un
pensamiento lógico que se aplica cada día de nuestra vida, les manifiesto
el más sincero agradecimiento.

v
DEDICATORIA
Dedico a mis padres Yahaira y Gustavo, por forjarme como la mujer
que estoy tan orgullosa de ser, por permitirme creer en el amor mediante
su ejemplo.
A mis hermanos David y Pablo, su ayuda y existencia fueron
fundamentales para no caer en los momentos difíciles.
A ti compañero, el mejor amigo que encontré para caminar juntos
cada vivencias, a ti Byron por creer en mí capacidad, por siempre tratar de
hacerme sonreír y buscar el lado bueno de las peores situaciones, a ti por
levantarme cuando me caí, a ti por amarme.
Se las dedico porque “todos necesitamos hacer nuestra vida como
un árbol, necesitamos personas que son nuestras raíces, para vivir y poder
tener ramas, flores y frutos”, así todos ustedes se convirtieron en las raíces
de mi vida.
Y al resto de mi familia, amigos y amigas porque todos aportaron a
mi crecimiento; sobre todo aportaron con momentos de felicidad.
Karina Rivadeneira
Quito, Ecuador

vi
CONTENIDO
DERECHOS DE AUTOR ............................................................................................... ii
APROBACIÓN DEL TUTOR ........................................................................................ iii
AGRADECIMIENTOS ................................................................................................... iv
DEDICATORIA ................................................................................................................ v
CONTENIDO ................................................................................................................... vi
LISTA DE FIGURAS .................................................................................................... viii
RESUMEN ......................................................................... ¡Error! Marcador no definido.
ABSTRACT ....................................................................... ¡Error! Marcador no definido.
INTRODUCCIÓN ............................................................................................................. x
CAPÍTULO 1 .................................................................................................................... 3
DESARROLLO DEL PROBLEMA ........................................................................... 3
1.1. Planteamiento del problema ..................................................................... 3
1.2. Formulación del problema ........................................................................ 3
1.3. Objetivos...................................................................................................... 3
1.3.1. Objetivos General .................................................................................. 3
1.3.2. Objetivos Específicos ............................................................................ 4
1.4. Justificación ................................................................................................ 4
CAPÍTULO 2 .................................................................................................................... 5
MARCO TEÓRICO...................................................................................................... 5
2.1. Antecedentes .............................................................................................. 5
2.2. Teoría de la Información (TI) .................................................................... 7
2.2.1. El concepto de información .................................................................. 7
2.2.2. Expresión cuantitativa de información ................................................ 8
2.2.3. Cadenas de Markov ............................................................................ 10
2.2.4. Entropía ................................................................................................. 12
2.3. Fundamentos de análisis convexo ........................................................ 13
2.3.1. Igualdad de la conjugada Legendre y la conjugada convexa ........ 13
2.3.2. Proyección Legendre - Bregman ....................................................... 17
2.3.3. Relaciones básicas entre 𝐷𝜙,ℒ𝜙 y ℓ𝜙 .............................................. 18
2.3.4. La extensión continua ......................................................................... 19
2.3.5. Conjuntos Factibles y familia de proyecciones Legendre -
Bregman .............................................................................................................. 20
CAPÍTULO 3 .................................................................................................................. 22
APROXIMACIÓN DE MÁXIMA ENTROPÍA ......................................................... 22

vii
3.1. Dualidad .................................................................................................... 22
3.2. Enfoque de máxima entropía ................................................................. 25
3.3. Regularización .......................................................................................... 27
3.4. Algoritmo de actualización secuencial y prueba de convergencia .... 30
CAPÍTULO 4 .................................................................................................................. 35
MODELADO DE LA DISTRIBUCIÓN DE LOS CASOS DE PALUDISMO EN
ECUADOR CONTINENTAL UTILIZANDO MaxEnt en TerrSet ........................ 35
4.1. Introducción .............................................................................................. 35
4.2. Determinación de variables explicativas y preparación de capas ..... 36
4.2.1. Predictores medioambientales ........................................................... 37
4.2.2. Características topográficas ............................................................... 38
4.2.3. Determinantes sociales ....................................................................... 38
4.4. Aplicación del modelo .............................................................................. 42
4.4.1. Parametrización de MaxEnt, Ganancia y Formato de Salida ........ 42
4.5. Validación de la capacidad predictora del modelo .............................. 46
4.5.1. Creación de una matriz de confusión (o contingencia)................... 46
4.5.2. AUC (Area Under The Curve) del modelo bajo la curva ROC
(Receiver Operating Characteristic) ................................................................ 48
CONCLUSIONES Y RECOMENDACIONES ............................................................ 51
6.1. Conclusiones ............................................................................................ 51
6.2. Recomendaciones ................................................................................... 52
BIBLIOGRAFÍA ............................................................................................................. 53

viii
LISTA DE FIGURAS
Figura 1. Tendencia de egresos hospitalarios y muertes por paludismo (CIE10 B50 – B54);
existe un aumento de egresos hospitalarios aproximadamente por el año 2000 mientras
que hay una baja de defunciones. ............................................................................................ 5 Figura 2. Índice Oceánico “El Niño”; datos obtenidos y procesados en EpiSIG del INSPI.
En el eje “Y” muestra el índice de anomalías de la temperatura de superficie del mar en
la región Niño del océano pacifico y en el eje “X” el periodo por año (1950 - 2017). .......... 6 Figura 3. Ciclo de transmisión de la malaria ........................................................................... 7 Figura 4. Proceso de Markov .................................................................................................. 11 Figura 5. Curva de variación de la entropía H en función de p en el intervalo 0,1 de la
variable. Con una probabilidad de 0.5 se alcanza el mayor valor de entropía. .................. 13 Figura 6. Proceso para aplicar MaxEnt .................................................................................. 36 Figura 7. Dimensión para Ecuador continental a 100 metros. Rejilla de 6800
columnas por 7400 filas............................................................................................................ 37 Figura 8. Distancia a los cultivos de arroz (m). El color rojo indica mayor distancia a los
cultivos, conforme cambia de tonalidad a negro la distancia disminuye. ............................ 38 Figura 9. Distancia a pantanos (m). El color rojo indica mayor distancia a los pantanos,
conforme cambia de tonalidad a negro la distancia disminuye. ........................................... 38 Figura 10. Distancia a vías (m). El color rojo indica mayor distancia a las vías, conforme
cambia de tonalidad a negro la distancia disminuye. ............................................................ 38 Figura 11. Zonas que se consideran con viviendas hacinadas ....................................................... 39 Figura 12. Altitud (m). El color rojo indica mayor altitud, conforme cambia de tonalidad a
negro la altitud baja. .................................................................................................................. 39 Figura 13. Anomalía de la precipitación, T-Mode PCA Componente 1 (mm). Mide una
aproximación de la cantidad de lluvia que se acumula sobre la superficie de la tierra. El
color rojo indica mayor cantidad acumulada de lluvia. .......................................................... 40 Figura 14. Anomalía de la precipitación, T-Mode PCA Componente 2 (mm). Mide una
aproximación de la cantidad de lluvia que se acumula sobre la superficie de la tierra. El
color rojo indica mayor cantidad acumulada de lluvia. .......................................................... 40 Figura 15. Anomalía de la temperatura, T-Mode PCA Componente 1 (°). Mide la
aproximación de la temperatura en grados, la intensidad del color rojo indica la
temperatura más alta. ............................................................................................................... 40 Figura 16. Anomalía de la temperatura, T-Mode PCA Componente 2 (°). Mide la
aproximación de la temperatura en grados, la intensidad del color rojo indica la
temperatura más alta. ............................................................................................................... 40 Figura 17. Anomalía del índice de vegetación, T-Mode PCA Componente 1. Mide la
densidad de vegetación............................................................................................................ 40 Figura 18. Anomalía del índice de vegetación, T-Mode PCA Componente 2. Mide la
densidad de vegetación............................................................................................................ 40 Figura 19. Distancia a pantanos (m). Indica la distancia en metros desde cada pixel
hasta el pantano más cercano. ................................................................................................ 41 Figura 20. Distancia a cultivos de arroz (m). Indica la distancia en metros desde cada
pixel hasta el cultivo de arroz más cercano. .......................................................................... 41 Figura 21. Distancia a vías (m). Indica la distancia en metros desde cada pixel hasta la
vía más cercana. ....................................................................................................................... 41 Figura 22. Pendiente del terreno (°). Mide el grado de inclinación del terreno. ................. 41 Figura 23. Hacinamiento. Indica la cantidad de personas por dormitorio. Se considera
hacina ......................................................................................................................................... 41 Figura 24. Analfabetismo. Indica la proporción del total de dormitorio para el total de
personas. ................................................................................................................................... 41 Figura 25. Ganancia del modelo; comienza en 0 y se incrementa hacia una asíntota
mientras dura la ejecución del programa................................................................................ 44

ix
Figura 26. Salida Logística de MaxEnt .................................................................................. 45 Figura 27. Salida Logística de MaxEnt. Mapa de Ecuador con nombres de provincias que
representa la probabilidad relativa de encontrar casos de paludismo en Ecuador
continental con una probabilidad máxima de 0,76. ............................................................... 46 Figura 28. Matriz de confusión ................................................................................................ 47 Figura 29. Umbrales de presencia ......................................................................................... 48 Figura 30. Curva operacional ROC y el AUC del modelo. ................................................... 48 Figura 31. Curva de respuesta de las variables predictoras que se utiliza para el
modelado de la distribución de paludismo en el Ecuador continental. ................................ 50

x
TITULO: Enfoque de máxima entropía para la modelación de la distribución
del Paludismo en Ecuador
Autora: Yahaira Karina Rivadeneira Maya Tutor: Ing. Mat. Guillermo Alexis Albuja Proaño
RESUMEN
El paludismo es una enfermedad potencialmente mortal que se monitorea
en Ecuador por el Sistema De Vigilancia Epidemiológica, el cual reportó
cantidades altas de casos desde 1961 hasta 2001 a partir de este año se
observa una disminución en los datos de reportes, según expertos del
Centro Nacional de Referencia e Investigación de Vectores del Instituto
Nacional De Investigación en Salud Pública, comentaron que no hay una
explicación por lo que se puede sospechar que cualquier instante en el
tiempo, estos casos puedan aumentar de la misma forma, por lo que es
viable saber las zonas de riesgo para apoyar a los organismos pertinentes
para su vigilancia y control. Según Merow (2013), un software muy utilizado
en la actualidad es MaxEnt, que usa la técnica de máxima entropía que
combina estadística, modelos bayesianos, análisis convexo, permitiendo
hacer predicciones de las zonas de riesgo utilizando información incompleta
(Philips et al., 2006, 2008); MaxEnt tiene como principio estimar una
distribución de probabilidades de máxima entropía sujeta a restricciones.
Esta investigación presenta los conceptos básicos, teoremas,
proposiciones de análisis convexo para comprender la metodología seguida
por MaxEnt; metodología que ayuda a resolver un problema de
programación lineal en el campo de la optimización matemática, que se
encarga de maximizar la entropía o minimizar la distancia de Bregman
(funciones lineales). Las variables de la función objetivo están sujetas a un
conjunto de restricciones de diferentes ámbitos. La modelación solo
necesita registros de presencia de paludismo los cuales fueron reportados
y confirmados por laboratorios en el año 2014 y se usó variables predictoras
medio-ambientales, topográficas, socioeconómicas. Los resultados indican
que aunque el modelo tenga pocos casos de presencia, este presenta una
predicción muy buena (AUC de 0.91), siendo representada mediante un
mapa de las zonas de riesgo, en el cual se resalta la zona costera y
amazonita de Ecuador Continental.
PALABRAS CLAVES: PALUDISMO / MAXENT / INSPI / SATVEC / EPISIG
/ ECUADOR / SALUD / MODELOS DE DISTRIBUCIÓN DE ESPECIES.

xi
TITLE: Approach of maximum entropy for the modeling of the distribution of
Malaria (or Paludismo) in Ecuador
ABSTRACT
Malaria is a life-threatening disease that is monitored in Ecuador by the Epidemiological Surveillance System, which reported high numbers of cases from 1961 to 2001, since 2001 there is a decrease in the reporting data, according to experts from the National Center of Reference and Research of Vectors of the National Institute of Public Health Research, they commented there is no explanation for this decreasing and it can be suspected that any moment in time, these cases can increase in the same way, so it is viable to know the risk zones to support the relevant organisms for their surveillance and control. According to Merow (2013), a software widely used today is MaxEnt, which uses the maximum entropy technique that combines statistics, Bayesian models, convex analysis, making predictions of risk areas using incomplete information (Philips et al., 2006, 2008); MaxEnt has as its principle to estimate a probability distribution of maximum entropy subject to restrictions. This research presents the basic concepts, theorems, propositions of convex analysis to understand the methodology followed by MaxEnt; methodology that helps solve a linear programming problem in mathematical optimization, which is responsible for maximizing entropy or minimizing Bregman distance (linear functions). The variables of the objective function are subject to a set of restrictions from different areas. The process of modeling only needs records of the occurrences of malaria which were reported and confirmed by laboratories in 2014 plus environmental, topographic, socioeconomic predictor variables. The results show that although the model has few cases of presence, it presents a very good prediction (AUC of 0.91), being represented by a map of the risk zones, in which the coastal and Amazonian zone of Continental Ecuador is highlighted.
KEYWORDS: MALARIA / MAXENT / INSPI / SATVEC / EPISIG /
ECUADOR / HELTH / SPECIES DISTRIBUTION MODELS.

1
INTRODUCCIÓN
Ecuador es uno de los países con la ubicación geográfica que favorece a
muchas enfermedades tropicales por tener distintos climas (cálido,
húmedo) y por ser un país fronterizo con países que poseen las mismas
enfermedades como paludismo (o malaria), dengue, chikungunya y zika1.
El paludismo no es reportado en toda la extensión del Ecuador, pero existen
las zonas tropicales y subtropicales donde la causa predominante de fiebre
ha sido históricamente esta enfermedad (Cifuentes et al., 2013), en estas
zonas el riesgo de contraer dicha enfermedad es alto y siempre está latente,
por esta razón, Ecuador es un país endémicos.
En Ecuador la incidencia de paludismo ha disminuido considerablemente
desde el año 2001, el dengue en 2011 fue identificado en el 42% de los
pacientes febriles en el noroeste del Ecuador y paludismo en ninguno
(Cifuentes et al., 2013). Sin embargo, se han reportado cada año casos de
paludismo esporádicos que han sido confirmados por laboratorios.
El Ministerio de Salud Pública (MSP), rector de la vigilancia en Ecuador,
necesita de metodologías actuales, útiles y robustas matemáticamente para
usar, que aporten al estudio una vigilancia permanente de las
enfermedades en el transcurso del tiempo; metodologías que tomen en
cuenta factores que están involucrados en la transmisión de la enfermedad
como cambios ambientales (Índice oceánico de “El Niño”), control larval
(abatización), control vectorial (fumigación), vacunación y más. Y estos
sean integrados para predecir zonas de riesgo.
El MSP usa sistemas de información geográfica (SIG) para la toma de
decisiones, vigilancia, control y prevención de la enfermedad, sin embargo,
el uso de estos sistemas pueden ir acompañados con modelos de
distribución de especies.
Los modelos de distribución de especies pueden estimar que áreas dentro
de una región satisfacen los requerimientos para desarrollar a una especies
(Anderson & Martínez-Meyer, 2004).
La modelación mediante el enfoque de máxima entropía es un modelo de
distribución de especies el cual se basa en sitios donde la especie fue
observada, es decir, puntos georreferenciados solamente de presencia de
la enfermedad y variables que proporcionen información sobre la
enfermedad (socioeconómicas y bioclimáticas).
El desarrollo de este proyecto el cual trabaja el modelo de máxima entropía
para la modelación de la distribución de paludismo o paludismo en Ecuador,
esta seccionado de la manera siguiente:
1 OMS | Enfermedades tropicales, 2017

2
En el capítulo 1, se desarrolla el problema; tratando el planteamiento del
problema, la formulación del problema, el objetivo general y los objetivos
específicos y la justificación.
En el capítulo 2, se habla sobre los antecedentes del paludismo en Ecuador,
de modelaciones de distribución de especies y conceptos base que se
utilizará del análisis convexo.
En el capítulo 3, se trata el enfoque de máxima entropía, la dualidad, la
regularización y el algoritmo de actualización secuencial y prueba de
convergencia.
En el capítulo 4, se da resume una breve lectura acerca del software MaxEnt, se determinan los diferentes tipos de variables predictoras que restringirán a la distribución junto a como es la preparación de capas, además se indica la parametrización, la aplicación e interpretación de los resultados obtenidos de la predicción del modelo y finalmente la validación de la capacidad predictora del modelo.

3
CAPÍTULO 1
DESARROLLO DEL PROBLEMA
1.1. Planteamiento del problema
En Ecuador, la carga de paludismo decreció en un 99% (Krisher et al.,
2016), es uno de los países en América que presenta la tendencia más
marcada en reducción del paludismo, después de haber alcanzado a
reportar cifras sobre los 100,000 casos anuales al inicio de la
década(Krisher et al., 2016).
Según datos reportados por el MSP, el paludismo reporta disminución en
sus registros a partir del 2001 hasta la actualidad, esta disminución fue
resultado de una estabilización observada después del fenómeno
meteorológico "El Niño" y de las epidemias2. El Paludismo en Ecuador
progresó desde la fase de "control" hasta la fase de "pre-eliminación",
basada en los criterios de la Organización Mundial de la Salud (OMS)
(Cifuentes et al., 2013).
La información recopilada acerca de paludismo en el Ecuador son puntos
georreferenciados de los casos reportados, gacetas epidemiológicas,
además, con la disminución de casos, la atención se dirigió a otras
enfermedades vectoriales como dengue, chikunguña y zika por lo tanto no
se ha generado mayor información pública sobre su distribución geográfica
actual.
1.2. Formulación del problema
La pregunta que persigue resolver este proyecto de investigación es:
Mediante la técnica de máxima entropía que se basa en la relación entre
los datos de casos registrados en el sistema de Vigilancia Epidemiológica
(ViEpi) del MSP y variables predictoras (información socioeconómica
recogida por el Instituto Nacional de Estadísticas y Censos (INEC) en el
último Censo del 2010 de todo Ecuador, datos entomológicos de CIREV del
INSPI, imágenes satelitales de la NASA, entre otros) ¿Es factible en
Ecuador, inferir zonas de riesgo de paludismo en sitios donde la información
de la enfermedad es inexistente?
1.3. Objetivos
1.3.1. Objetivos General
2 OPS/OMS | Situación del Programa del Paludismo en las Américas (2000)

4
Modelar los sitios de riesgo mediante un riguroso método matemático
de máxima entropía para obtener la estimación de la densidad de
casos de paludismo en Ecuador continental mediante factores
predictores.
1.3.2. Objetivos Específicos
Explicar los fundamentos matemáticos del enfoque de máxima
entropía para la modelación de la distribución de especies.
Definir las variables determinantes con la transformación
matemática si es necesario, la temporalidad, espacialidad y
resolución con los cuales se aplicará el modelo
Aplicar la metodología y validar el resultado de distribución
espacial del paludismo en Ecuador
1.4. Justificación
En el Ecuador, la pobreza es uno de los principales factores que afecta a
las poblaciones y es un potencial causante del aumento de reportes de
casos y muertes provocadas por enfermedades transmitidas al humano
mediante vectores. En los últimos años, las epidemias por los virus de zika,
dengue, chikunguña y sus complicaciones que afectaron a grandes
cantidades de población, resaltaron a las enfermedades tropicales como un
campo nuevo e interesante para explorar a nivel nacional e internacional
enfocando sus estudios a las enfermedades como dengue, chikunguña y
zika3.
En la actualidad, la disminución casi total de reportes de paludismo en el
Ecuador (Krisher et al., 2016), restó prioridad a la investigación de esta
enfermedad.
Por tal motivo la generación de información sobre la distribución de
paludismo en el Ecuador continental mediante técnicas matemáticas, no
solo traerá consigo generar información histórica para próximas
investigaciones científicas sino mostrará posibles patrones que mantenga
la enfermedad, y es que dicha enfermedad a breves rasgos en los últimos
años ha presentado tendencias de decrecimiento muy interesantes, y más
aún cuando el control se lo ha puesto en su mayoría a otras enfermedades
tropicales antes mencionadas.
3 OMS | Respuesta mundial para el control de vectores 2017 – 2030

5
CAPÍTULO 2
MARCO TEÓRICO
2.1. Antecedentes
Desde mediados del año 1980 hasta principios del año 2000, las zonas
tropicales y subtropicales del Ecuador, experimentaron una alta tasa de
transmisión de paludismo, los expertos atribuyeron a una ineficaz
combinación de tratamiento antipalúdico, factores socioeconómicos y
factores políticos (Krisher et al., 2016).
En los últimos años, los egresos hospitalarios y muertes por paludismo
(CIE10 B50 – B54)4 según los datos del INEC, han tenido una tendencia
decreciente.
Figura 1. Tendencia de egresos hospitalarios y muertes por paludismo (CIE10 B50 – B54); existe un aumento de egresos hospitalarios aproximadamente por el año 2000 mientras que hay una baja de defunciones.
Cabe mencionar que el país participa en la “Estrategia técnica mundial contra el paludismo 2016 – 2030” de la OMS, esta tiene como objetivo: que continentes enteros eliminen la enfermedad y que con el tiempo esta sea erradicada del planeta, para esto es necesario un compromiso político inquebrantable, una financiación considerable y previsible, aumento de la colaboración regional, la inversión constante en investigación y desarrollo5.
4 MSSSI, URL: http://eciemaps.msssi.gob.es/ecieMaps/browser/index_10_mc.html 5 OMS | Estrategia Técnica Mundial contra la Malaria 2016-2030 URL: http://www.who.int/malaria/publications/atoz/9789241564991/es/
0102030405060708090100
19
98
19
99
20
00
20
01
20
02
20
03
20
04
20
05
20
06
20
07
20
08
20
09
20
10
20
11
20
12
20
13
20
14
20
15
20
16
20
17/0
2
0
1000
2000
3000
4000
5000
6000
7000
8000
De
fun
cio
ne
s (I
NEC
)
Periodo
Egre
sos
ho
spit
alar
ios
(IN
EC)
Paludismo - Ecuador1998 - Feb 2017
INEC_pld_EgrHsp INEC_pld_Dfn

6
Ecuador, también ha pertenecido a varios proyectos nacionales e internacionales que tienen como objetivo investigar y vigilar el paludismo para reducir la incidencia, proyectos como “Control de la malaria en las zonas fronterizas de la región andina: Un enfoque comunitario” (PAMAFRO)6, “Servicio Nacional de Control de Enfermedades Transmitidas por Vectores Artrópodos” (SNEM) del MSP, “Sistema de alerta temprana para el control de vectores de malaria y leishmaniasis (fase 1)” del INSPI7, ser parte de esto ha sido favorable, puesto que hoy es reconocido como uno de los tres "Campeones de Malaria de las Américas"(Mateo, Felicísimo, & Muñoz, 2011) y los avances en la vigilancia ha aportado información relevante e histórica para el país. Un reto para Ecuador, es mantener los logros de reducción en la transmisión de paludismo, pero se dificulta por ser una enfermedad de recurrencia cíclica, que se expone al aparecimiento de determinantes o combinaciones de ellos. Un determínate que puede influir en la tendencia creciente de reportes, es la reducción marcada de casos confirmados que se presenta en la actualidad, puesto que la enfermedad deja de ser prioridad y se debilita su vigilancia. Además, históricamente hay otros factores que han determinado un comportamiento epidémico cíclico del paludismo, como fenómenos sociales, económicos (por ejemplo, la minería, aumento del flujo migratorio8, reducción de recursos y cambios en la gestión), fenómenos ambientales (por ejemplo, El Niño, cultivo de arroz, construcción de reservorios, cambios climáticos) (Mateo et al., 2011; S. J. Phillips & Dudík, 2008), que han presentado alteraciones los últimos años, probablemente, son causantes que el país reporte a la OMS un aumento de casos en 2017(Fithian & Hastie, 2013).
Figura 2. Índice Oceánico “El Niño”; datos obtenidos y procesados en EpiSIG del INSPI. En el eje “Y” muestra el índice de anomalías de la temperatura de superficie del mar en la región Niño del océano pacifico y en el eje “X” el periodo por año (1950 - 2017).
6 PAMAFRO, URL: http://www.orasconhu.org/pamafro/presentaci%C3%B3n 7 INSPI | CIREV, URL: http://www.investigacionsalud.gob.ec/webs/cirev/satvec-malaria/ 8 Movimiento migratorio en ecuador se incrementó en un 20%
-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
19
50-D
JF1
951
-DJF
19
52-D
JF1
953
-DJF
19
54-D
JF1
955
-DJF
19
56-D
JF1
957
-DJF
19
58-D
JF1
959
-DJF
19
60-D
JF1
961
-DJF
19
62-D
JF1
963
-DJF
19
64-D
JF1
965
-DJF
19
66-D
JF1
967
-DJF
19
68-D
JF1
969
-DJF
19
70-D
JF1
971
-DJF
19
72-D
JF1
973
-DJF
19
74-D
JF1
975
-DJF
19
76-D
JF1
977
-DJF
19
78-D
JF1
979
-DJF
19
80-D
JF1
981
-DJF
19
82-D
JF1
983
-DJF
19
84-D
JF1
985
-DJF
19
86-D
JF1
987
-DJF
19
88-D
JF1
989
-DJF
19
90-D
JF1
991
-DJF
19
92-D
JF1
993
-DJF
19
94-D
JF1
995
-DJF
19
96-D
JF1
997
-DJF
19
98-D
JF1
999
-DJF
20
00-D
JF2
001
-DJF
20
02-D
JF2
003
-DJF
20
04-D
JF2
005
-DJF
20
06-D
JF2
007
-DJF
20
08-D
JF2
009
-DJF
20
10-D
JF2
011
-DJF
20
12-D
JF2
013
-DJF
20
14-D
JF2
015
-DJF
20
16-D
JF2
017
-DJF
ON
I
Periodo

7
Una reciente recomendación de la OPS y de la OMS es restablecer una vigilancia proactiva(Gwitira, Murwira, Zengeya, Masocha, & Mutambu, 2015). Los métodos matemáticos vinculados con los SIG son utilizados como herramientas para analizar patrones temporales de presencia y/o ausencia de la enfermedad, esto modelos son más conocidos como modelos de distribución de especies (Capurro Rafael, 2003). Hace 50 años aproximadamente se dieron los primeros acercamiento a la modelación de la distribución de especies, partiendo de su relación con factores ambientales, la celeridad con la que avanza los estudios permiten desarrollar varias técnicas de modelación que mejoran los resultados, buscando superar algunos problemas como la colinearidad entre variables independientes, sesgos de muestreo o inclusión de variables nominales (Mateo et al., 2011; Phillips & Dudík, 2008). Existen modelos estadísticos de datos solamente de presencia que están siendo usados en gran cantidad de artículos de literatura ecológica, se sospecha que sea por la poca información que es necesitada con respecto a la localización de la especie, permitiendo tener modelaciones muy certeras. Estos modelos incluyen métodos como por ejemplo el de máxima entropía (Maxent) (Fithian & Hastie, 2013). Las escazas aplicaciones en nuestro país, ha sido para modelar la distribución geográfica del vector Anopheles de distintas especies que son potenciales portadores del parásito (por ejemplo, Anopheles arabiensis) (Basu, 2002).
Figura 3. Ciclo de transmisión de la malaria
2.2. Teoría de la Información (TI)
2.2.1. El concepto de información
La noción de información tiene raíces en latín Informatio igual dar forma,
pero este pierde su relevancia en la modernidad definiéndose como “decir
algo a alguien”. Un concepto de información que está más relacionado en

8
la TI, es el concepto de inteligencia dada o instrucción9, que indica el acto
de moldear o dar forma a lo que se va a decir a alguien que probablemente
ignora el contenido de un mensaje, provocando incertidumbre en el
argumento que trae consigo.
Las primeras referencias del uso del término “informo” se dieron en el
ambiente biológico, cuando se expresó que: un feto está siendo informado
por cabeza y columna vertebral; en el contexto intangible se hacía uso en
aspectos morales o pedagógicos, es decir, era usado por personas
dedicadas a la educación o moldeadores de pensamiento (por ejemplo:
pensadores como Platón, Aristóteles).
Luego Fritz Machlup, manifestó que la información es un fenómeno
solamente humano, refiriéndose a información como "el algo que se está
diciendo en un mensaje, dirigido a las mentes humanas y recibido por las
mentes humanas" encontrándose en desacuerdo con el uso del término en
el contexto de la transmisión de señales (Basu, 2002; Taylor & Karlin, 2010).
La controversia se generó particularmente con Hartley, con su artículo
"Transmisión de la información" que como sistemas de transmisión ya no
implicaba solamente a seres humanos, si no, a sistemas de transmisión
eléctrica como máquinas y recomendó <<eliminar los factores psicológicos
implicados y establecer una medida de información en términos de
cantidades puramente físicas>> (Basu, 2002). Cuando se desarrolló la
teoría matemática de la comunicación por Claude Shannon y Warren
Weaver, se pretendía eliminar los conceptos tradicionales involucrados con
información y señalaban que este término no debe ser confundido con el
contenido de un mensaje. Por ejemplo, existen dos mensajes, el primero
tiene mucho significado y el otro es un mensaje sin sentido, sin embargo,
estos pueden ser exactamente equivalente desde el presente punto de
vista. Sin duda, esto es lo que Shannon quiere decir con "los aspectos
semánticos de la comunicación son irrelevantes para los aspectos de
ingeniería". Pero, esto no significa que los aspectos de ingeniería sean
necesariamente irrelevantes para los aspectos semánticos (Basu, 2002).
2.2.2. Expresión cuantitativa de información
Según Hartley (1928), en una selección hay 𝑠 símbolos disponibles, que
pueden ser seleccionados 𝑛1 veces para crear 𝑠𝑛1 diferentes secuencias.
Se llama a
𝑠2 = 𝑠𝑛1 ( 1)
Es decir, 𝑠2 caracteres, se pueden representar de 𝑠𝑛1 formas.
9 S. Johnson: A Dictionary of the English Language. London, 1755. Repr. Olms, Hildesheim 1968

9
Ahora, se supone que puede haber uno o más caracteres que conforman
un mensaje; 𝑛2 es el representante del número total caracteres de este
mensaje.
Recordemos que 𝑠2 es el número de caracteres a ser representados
mediante 𝑠𝑛1 secuencias, entonces podemos tener 𝑠2𝑛2 mensajes como
vaya variando 𝑛2, así se tendrá 𝑠2 mensajes si el tamaño del mensaje es
un carácter, 𝑠22 el tamaño del mensaje son dos caracteres y así
sucesivamente, luego
𝑠2𝑛2 = (𝑠𝑛1)𝑛2 𝑐𝑜𝑛 𝑛 = 𝑛1𝑛2
𝑠2𝑛2 = 𝑠𝑛 ( 2)
Se llamará 𝑠𝑛 al número de posibles secuencias que podemos encontrar
para representar un mensaje.
Un ejemplo es el sistema telegráfico de impresión de Baudot, consiste en
una máquina con una salida de 5 bits, capaz de representar hasta 32
caracteres distintos. 𝑠 puede tomar dos estados y representar un símbolo
en 5 posiciones 𝑠2 = 𝑠𝑛1 = 25 = 32 𝑐𝑎𝑟𝑎𝑐𝑡𝑒𝑟𝑒𝑠.
Recordemos que tenemos por objetivo establecer una medida
independiente de factores humanos como comprensión del mensaje, sino
una medida que dependa únicamente de lo que se quiere decir una medida
que cuantifique la cantidad de información que aporta el mensaje.
La medida como un valor práctico en ingeniería, debe ser de tal forma que
la información sea proporcional al número de selecciones así, que solo, el
número de posibles secuencias no es el valor óptimo para ser usado
directamente como medida de información, pero puede ser usado como
base que cumple los requisitos prácticos para definir la expresión que
cuantifique la información.
Para un sistema particular, se elige la cantidad de información de forma
arbitraria que debe ser proporcional al número de selecciones por un factor
de proporcionalidad (a cantidades iguales de información hace equivalente
números iguales de posibles secuencias), definiendo,
𝐻 = 𝐾𝑛
𝑛: 𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑠𝑒𝑙𝑒𝑐𝑐𝑖𝑜𝑛𝑒𝑠
𝐾: Cualquiera constante que depende de 𝑠 símbolos disponibles en la
selección
( 3)
Ahora se toma dos sistemas cualesquiera, donde 𝑠 puede tomar los valores
de 𝑠 = {𝑠1, 𝑠2} y sus correspondientes factores de proporcionalidad 𝐾 ={𝐾1, 𝐾2}, que cumplen con la condición: que cuando el número de
selecciones 𝑛1 y 𝑛2 sean iguales al número de posibles secuencias de los

10
dos sistemas, entonces la cantidad de información para ambos sistemas es
el mismo, esto se dice cuándo,
𝑠1𝑛1 = 𝑠2
𝑛2 ( 4)
aplicando logaritmo a la igualdad se tiene
log 𝑠1𝑛1 = log 𝑠2
𝑛2
𝑛1log 𝑠1 = 𝑛2log 𝑠2
𝑛1
log 𝑠2=
𝑛2
log 𝑠1 ( 5)
luego,
𝐻 = 𝐾1𝑛1 𝑦 𝐻 = 𝐾2𝑛2 ( 6)
de donde 𝑛1 =𝐻
𝐾1 y 𝑛2 =
𝐻
𝐾2
reemplazamos estos valores en (5) y obtenemos
𝐾1
log 𝑠1=
𝐾2
log 𝑠2
esta relación se cumple para todos los valores posibles de s si y solo si K
esta conectado con s por la relación
𝐾 = 𝐾0 log 𝑠, ( 7)
𝐾0 es el mismo para todo los sistemas y por ser arbitrario puede ser omitido
si y solo si la base del logaritmo es arbitraria (el tamaño de la unidad de
información es dada por la base seleccionada del logaritmo).
Se reemplaza 𝐾 en (3)
𝐻 = 𝑛 𝐾0 log 𝑠 ( 8)
𝐻 = 𝑛 log 𝑠
y definimos como información a,
𝐻 = log 𝑠𝑛. ( 9)
2.2.3. Cadenas de Markov
2.2.3.1. Proceso estocástico
Es la descripción matemática de un fenómeno aleatorio que cambia en el
tiempo (Basu, 2002).
Los modelos estocásticos (o no determinísticos) desempeñan un
importante rol en la explicación de eventos en áreas de la naturaleza y la

11
ingeniería, en muchas ocasiones los modelos no deterministas son más
realistas que los determinísticos (Basu, 2002).
Definición Es una familia de variables aleatorias {Xn: n ∈ T ⊂ ℝ}, donde n
es un parámetro que corre sobre un conjunto de índices T llamado espacio
parametral o conjunto de tiempo, en donde las variables toman valores en
un conjunto S llamado espacio de estados (Basu, 2002).
Si 𝑇 es contable entonces el proceso estocástico es una secuencia
estocástica (o un proceso estocástico parametrizado discreto)
(Grinstead & Snell, 2007).
Si 𝑆 es contable entonces el proceso estocástico es un proceso de
estados discretos (Grinstead & Snell, 2007).
Si 𝑆 ⊂ ℝ el proceso estocástico es llamado proceso a valor real
(Rincón, 2012; Taylor & Karlin, 2010).
Si 𝑇 toma continuamente un número incalculable de valores
comprendidos en (0, ∞) 𝑜 (−∞, ∞) el proceso estocástico es un
proceso de tiempo continuo (Basu, 2002).
2.2.3.2. Cadena de Markov
Sea 𝑆 un conjunto finito de estados 𝑆1, 𝑆2, …, 𝑆𝑛 de un sistema, el proceso
empieza en un estado aleatorio y continúa moviéndose de un estado a otro
(Shannon, 1948).
Si la cadena está en el estado 𝑆𝑖 y en el siguiente paso se mueve al estado
𝑆𝑗 tendrá una probabilidad 𝑝𝑖𝑗, esta probabilidad no depende en qué estado
la cadena se encontraba antes del estado actual, además el siguiente paso
puede permanecer en el mismo estado que se encontraba, con una
probabilidad 𝑝𝑖𝑖. Las probabilidades 𝑝𝑖𝑗 son llamadas como probabilidad de
transición (Grinstead & Snell, 2007).
Definición Una cadena de Markov {Xn: n ≥ 0} es un proceso estocástico a
tiempo discreto, con un espacio de estados discretos S = {S1, S2, … , Sn}, que
cumple la propiedad de Markov, esta es, para cualquier entero n y para
cualquier estado S0, … , Sn+1, se cumple
𝑃(𝑋𝑛+1 = 𝑆𝑛+1|𝑋1 = 𝑆1, 𝑋2 = 𝑆2, … , 𝑋𝑛 = 𝑆𝑛) = 𝑃(𝑋𝑛+1 = 𝑆𝑛+1|𝑋𝑛 =𝑆𝑛).
( 10)
𝑆𝑖 𝑆𝑗
𝑝𝑖𝑗
𝑝𝑗𝑖
𝑝𝑖𝑖 𝑝𝑗𝑗
Figura 4. Proceso de Markov

12
(Rincón, 2012; Taylor & Karlin, 2010).
2.2.4. Entropía
Al haber definido una cadena de Markov, se generan preguntas como
¿Qué tasa de información es producida?
¿Podemos definir alguna medida que permita calcular cuanta información
es producida por una cadena de Markov?
¿Podemos encontrar la medida de lo dudosos que estamos del resultado?
Según Shannon (1948) hay un conjunto de eventos posibles con
probabilidades de ocurrencia 𝑝1, 𝑝2, … , 𝑝𝑛, si existe tal medida
𝐻(𝑝1, 𝑝2, … , 𝑝𝑛), es sensato suponer que cumpla las siguientes
propiedades:
1. 𝐻 debería ser continua en todo 𝑝𝑖
2. Si todo los 𝑝𝑖 son iguales, 𝑝𝑖 =1
𝑛, entonces 𝐻 debería ser una función
monótona creciente de 𝑛. Con eventos igualmente probables hay más
elecciones o incertidumbre, cuando hay más posibles eventos.
3. Si una elección es averiada dentro de dos elecciones sucesivas el 𝐻
original debería ser la suma ponderada de los valores individuales de 𝐻.
Teorema 2.1. (Aliprantis & Border, 2006) El H único que satisface las tres
anteriores propiedades es de la forma
𝐻 = −𝐾 ∑ 𝑝𝑖 𝑙𝑜𝑔 𝑝𝑖
𝑛
𝑖=1
( 11)
donde K es una contante positiva (K ≥ 0).
Demostración. Ver en el apéndice 2 de (Rockafellar, 1970).
Un ejemplo particular de fuente de información binaria. Es cuando el
alfabeto se reduzca a {0,1}. La entropía en el caso de dos posibilidades con
probabilidades 𝑝 y 𝑞 = 1 − 𝑝 es
𝐻(𝑝) = −(𝑝 log 𝑝 + 𝑞 log 𝑞)
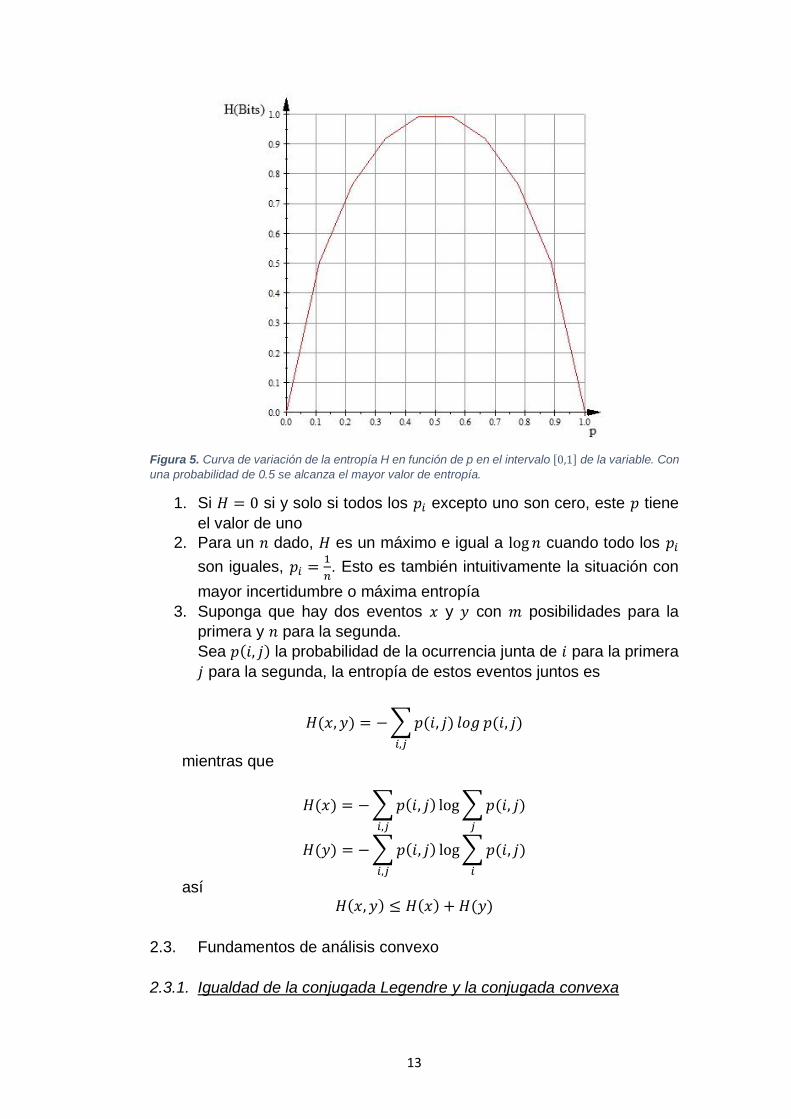
13
Figura 5. Curva de variación de la entropía H en función de p en el intervalo [0,1] de la variable. Con
una probabilidad de 0.5 se alcanza el mayor valor de entropía.
1. Si 𝐻 = 0 si y solo si todos los 𝑝𝑖 excepto uno son cero, este 𝑝 tiene
el valor de uno
2. Para un 𝑛 dado, 𝐻 es un máximo e igual a log 𝑛 cuando todo los 𝑝𝑖
son iguales, 𝑝𝑖 =1
𝑛. Esto es también intuitivamente la situación con
mayor incertidumbre o máxima entropía
3. Suponga que hay dos eventos 𝑥 y 𝑦 con 𝑚 posibilidades para la
primera y 𝑛 para la segunda.
Sea 𝑝(𝑖, 𝑗) la probabilidad de la ocurrencia junta de 𝑖 para la primera
𝑗 para la segunda, la entropía de estos eventos juntos es
𝐻(𝑥, 𝑦) = − ∑ 𝑝(𝑖, 𝑗) 𝑙𝑜𝑔 𝑝(𝑖, 𝑗)𝑖,𝑗
mientras que
𝐻(𝑥) = − ∑ 𝑝(𝑖, 𝑗)
𝑖,𝑗
log ∑ 𝑝(𝑖, 𝑗)
𝑗
𝐻(𝑦) = − ∑ 𝑝(𝑖, 𝑗)
𝑖,𝑗
log ∑ 𝑝(𝑖, 𝑗)𝑖
así 𝐻(𝑥, 𝑦) ≤ 𝐻(𝑥) + 𝐻(𝑦)
2.3. Fundamentos de análisis convexo
2.3.1. Igualdad de la conjugada Legendre y la conjugada convexa

14
Teorema 2.2. (Rockafellar, 1970) Sean los conjuntos 𝐶 = 𝑖𝑛𝑡(∆𝑓), 𝐶∗ =
𝑖𝑛𝑡(∆𝑓∗) y una función cerrada convexa 𝑓 entonces (𝐶, 𝑓) es una función
convexa de tipo Legendre si y solo (𝐶∗, 𝑓∗) es una función convexa de tipo
Legendre. Así, esto se cumple
la conjugada Legendre de (𝐶, 𝑓) es (𝐶∗, 𝑓∗)
la conjugada Legendre de (𝐶∗, 𝑓∗) es (𝐶, 𝑓)
𝛻𝑓 (gradiente de f) es una biyección desde el conjunto convexo abierto
𝐶 sobre el conjunto convexo abierto 𝐶∗
𝛻𝑓 es continuo en ambas direcciones
𝛻𝑓∗ = (𝛻𝑓)−1
Demostración. Ver en (Rockafellar, 1970).
Conceptos Básicos:
2.3.1.1. Función convexa
Definición. Sea un conjunto convexo 𝐶 ⊂ 𝑋. Una función 𝑓: 𝐶 → ℝ se llama
convexa cuando, para cualquier 𝑥1, 𝑥2 ∈ 𝐶 y 𝑡 ∈ [0,1], entonces
𝑓((1 − 𝑡)𝑥1 + 𝑡𝑥2) ≤ (1 − 𝑡)𝑓(𝑥1) + 𝑡𝑓(𝑥2).
Conjunto convexo: Un conjunto 𝐶 ⊂ 𝑋, es convexo cuando el segmento
de recta que une dos de sus puntos cualesquiera está enteramente
contenida en 𝐶, es decir,
𝑎, 𝑏 ∈ 𝐶, 0 ≤ 𝑡 ≤ 1 ⇒ (1 − 𝑡)𝑎 + 𝑡𝑏 ∈ 𝐶.
2.3.1.2. Función convexa extendida
Para trabajar con funciones convexas se ha visto que es más útil definirlas
en todas partes del dominio. Basándose en la definición de función convexa
se puede extenderla a todo el espacio vectorial 𝑋 definiendo como ∞ lo que
esta fuera del conjunto convexo 𝐶 (Aliprantis & Border, 2006).
Definición. Una función real extendida 𝑓: 𝑋 → ℝ ∪ {+∞, −∞} sobre un
espacio vectorial 𝑋, es convexa si su epígrafo
𝑒𝑝𝑖 𝑓 = {(𝑥, 𝜇) ∈ 𝑋 × ℝ ∶ 𝑓(𝑥) ≤ 𝜇}
es un subconjunto convexo del espacio vectorial 𝑋 × ℝ.
Epígrafo: Es el conjunto de todos los puntos que están situados en y sobre
la función.
El epígrafo de una función 𝑓: 𝑋 → ℝ está definido por
𝑒𝑝𝑖 𝑓 = {(𝑥, 𝜇) ∈ 𝑋 × ℝ |𝑓(𝑥) ≤ 𝜇} ⊆ 𝑋 × ℝ.

15
2.3.1.3. Dominio efectivo
Definición. Sea 𝑓: 𝑋 → ℝ ∪ {+∞, −∞} una función convexa, su dominio
efectivo está definido por el conjunto
∆𝑓= {𝑥 ∈ 𝑋 | 𝑓(𝑥) < +∞}.
Hecho posible:
El dominio efectivo de una función real extendida 𝑓 es la proyección
sobre 𝑋 de su epígrafo, es decir, 𝑥 ∈ ∆𝑓 si y solo si (𝑥, 𝑓(𝑥)) ∈ 𝑒𝑝𝑖 𝑓.
Función convexa propia: Una función convexa 𝑓: 𝑋 → ℝ ∪ {+∞, −∞} es
propia si el dominio efectivo es no vacío (∆𝑓≠ ∅) y además este nunca
asume el valor de −∞, es decir, 𝑓(𝑥) > −∞ para cada 𝑥 ∈ 𝑋.
Función convexa semi-continua inferiormente: Una función convexa
propia extendida 𝑓 sobre un espacio vectorial topológico es una función
convexa semi-continua inferiormente si y solo si su epígrafo es un cerrado
subconjunto de 𝑋 × ℝ.
Función convexa cerrada: Una función convexa propia 𝑓 es cerrada si es semi-continua inferiormente.
2.3.1.4. Conjugada de una función convexa
La conjugada convexa es una generalización de la transformada de Legendre, también llamada como transformada de Legendre – Fenchel o transformada de Fenchel.
Definición. Sea 𝑋 un espacio vectorial topológico real y sea 𝑋∗ el espacio
dual de 𝑋. Dado 𝑓: 𝑋 → ℝ ∪ {+∞} una función convexa, semi-continua
inferiormente y propia, su conjugada convexa es la función 𝑓∗: 𝑋∗ → ℝ ∪
{+∞} definida por
𝑓∗(𝑥∗) = sup𝑥∈𝑋
{⟨𝑥, 𝑥∗⟩ − 𝑓(𝑥)}
Función afín: Una función 𝑓: 𝑋 → ℝ sobre un espacio vectorial es afín si
esta es de la forma ℎ(𝑥) = ⟨𝑥, 𝑥∗⟩ + 𝜇∗ para alguna función lineal 𝑥∗ ∈ 𝑋 y
algún real 𝜇∗.
Teorema 2.3. (Rockafellar, 1970) Una función convexa cerrada 𝑓 es el
supremo puntual de la colección de todas las funciones afín ℎ tal que ℎ(𝑥) ≤𝑓(𝑥). Demostración. Ver en Rockafellar (1970); Teorema 12.1. Hay una manera dual de describir 𝑓(𝑥) (de acuerdo al teorema 2.3.): Se puede describir el conjunto 𝐹∗ que consiste en todos los pares (𝑥∗, 𝜇∗) en

16
𝑋 × ℝ tal que la función afín ℎ(𝑥) = ⟨𝑥, 𝑥∗⟩ − 𝜇∗ es mayorada por 𝑓(𝑥), así
ℎ(𝑥) ≤ 𝑓(𝑥) para cada 𝑥 si y solo si 𝑠𝑢𝑝{⟨𝑥, 𝑥∗⟩ − 𝑓(𝑥)|𝑥 ∈ 𝑋} ≤ 𝜇∗.
De este modo 𝐹∗ es el epígrafo de la función 𝑓∗ sobre X definida por
𝑓∗(𝑥∗) = 𝑠𝑢𝑝{⟨𝑥, 𝑥∗⟩ − 𝑓(𝑥)|𝑥 ∈ 𝑋}
= −𝑖𝑛𝑓{𝑓(𝑥) − ⟨𝑥, 𝑥∗⟩|𝑥 ∈ 𝑋}
es llamada la conjugada convexa de 𝑓(𝑥) (Rockafellar, 1970).
2.3.1.5. Conjugada Legendre
La conjugada de Legendre es una transformación de una función convexa
diferenciable 𝑓 a una función que depende sobre la familia de tangentes
∇𝑓(𝑥).
Definición. Sea 𝑓 una función diferenciable a valor real, sobre un
subconjunto abierto 𝐶 ⊂ 𝑋. El par (𝐷, 𝑔) es la conjugada Legendre del par
(𝐶, 𝑓) donde 𝐷 es la imagen de 𝐶 bajo la función gradiente ∇𝑓 (para una
función de una variable ∇𝑓(𝑥) es la derivada) y 𝑔 es la función sobre 𝐷,
dada por la fórmula
𝑔(𝑥∗) = ⟨(∇𝑓)−1(𝑥∗), 𝑥∗⟩ − 𝑓((∇𝑓)−1(𝑥∗))
Transformada de Legendre: Si la conjugada (𝐷, 𝑔) del par (𝐶, 𝑓) está bien
definida es llamada transformada de Legendre.
Función suave: Sea una función real extendida 𝑓 sobre 𝑋, es suave solo
si es finita y diferenciable a través de 𝑋.
Estas funciones tienen la primera derivada definida única (la pendiente o
gradiente) en cada punto de 𝑋.
Función esencialmente suave: Una función convexa propia 𝑓 es una función esencialmente suave si 𝑓 satisface las siguientes condiciones para
𝐶 = 𝑖𝑛𝑡(∆𝑓):
a. 𝐶 es no vacío b. 𝑓 es diferenciable en 𝐶 c. Si lim
𝑖→∞|𝛻𝑓(𝑥𝑖)| = +∞ cuando 𝑥1, 𝑥2, … es una secuencia en 𝐶
convergiendo a un punto límite 𝑥 de 𝐶
Función convexa esencialmente estricta: Una función convexa cerrada
y propia 𝑓 sobre 𝑋, será esencialmente estricta si 𝑓 es estrictamente convexa en cada subconjunto convexo de
∆𝜕𝑓= {𝑥|𝜕𝑓(𝑥) ≠ ∅}
con 𝜕 el sub-diferencial de 𝑓.

17
Función convexa de tipo Legendre: Suponga 𝑓 es una función convexa
cerrada y propia sobre 𝑋 entonces 𝑓 es de tipo Legendre, si 𝑓 es a la vez función esencialmente suave y esencialmente estricta.
Teorema 2.4. (Rockafellar, 1970) Sea 𝑓 una función convexa propia, cerrada tal que el conjunto 𝐶 = 𝑖𝑛𝑡(∆𝑓) es no ∅ y 𝑓 es diferenciable en 𝐶.
La conjugada Legendre (𝐷, 𝑔) de (𝐶, 𝑓) está bien definida. Además, 𝐷 (específicamente el rango de ∇𝑓) es un subconjunto de ∆𝑓∗, y 𝑔 es la
restricción de 𝑓∗ a 𝐷.
Demostración. Ver en Rockafellar, 1970; Teorema 26.4.
2.3.2. Proyección Legendre - Bregman
Proposición 2.1. (Della Pietra, Della Pietra, & Lafferty, 2001) Sea 𝜙: 𝑋 →
ℝ ∪ {+∞} una función de tipo Legendre luego para 𝑞 ∈ 𝑖𝑛𝑡(∆𝜙) y 𝑣 ∈
(𝑖𝑛𝑡(∆𝜙∗) − ∇𝜙(𝑞)), la proyección Legendre - Bregman es dada
explícitamente por
ℒ𝜙(𝑞, 𝑣) = ∇𝜙∗(∇𝜙(𝑞) + 𝑣)
Además, para el hiperplano 𝐻 = {𝑝 ∈ 𝑋|⟨𝑝, 𝑣⟩ = 𝑏} con 𝑏 = ⟨ℒ𝜙(𝑞, 𝑣), 𝑣⟩,
ésta proyección puede ser escrita como una proyección de Bregman
ℒ𝜙(𝑞, 𝑣) = arg min𝑝∈∆𝜙∩𝐻
𝐷𝜙(𝑝, 𝑞)
Demonstración. Ver en Della Pietra, Della Pietra, & Lafferty, 2001;
Proposicion 2.6.
Distancia o divergencia de Bregman: Esta distancia es semejante a una
métrica, pero la desigualdad triangular, ni la simetría no cumple.
Definición. Sea 𝜙: 𝑋 → ℝ ∪ {+∞} una función convexa propia cerrada
definida sobre un conjunto 𝑆 ⊂ 𝑋, tal que 𝜙 es diferenciable en el 𝑖𝑛𝑡 (∆𝜙) ≠
∅. La distancia de Bregman denotada por 𝐷𝜙: ∆𝜙 × 𝑖𝑛𝑡(∆𝜙) ⟶ [0, +∞) esta
dada por:
𝐷𝜙(𝑝, 𝑞) = 𝜙(𝑝) − 𝜙(𝑞) − ⟨∇𝜙(𝑞), 𝑝 − 𝑞⟩
Se escribirá 𝜙(𝑝) y 𝜙(𝑞) teniendo en cuenta las distribuciones de
probabilidad 𝑝 y 𝑞.
La distancia de Bregman puede ser interpretada como una medida de la
convexidad de 𝜙 (Della Pietra, Della Pietra, & Lafferty, 2001).
Al definir a 𝜙: ℝ+𝑚 → ℝ como:
𝜙(𝑝) = ∑ (𝑝𝑖 ln 𝑝𝑖 + (1 − 𝑝𝑖) ln(1 − 𝑝𝑖)),𝑚𝑖=1 la distancia de Bregman
asociada a 𝜙 está dada por

18
𝐷𝜙(𝑝, 𝑞) = ∑ (𝑝𝑖 ln (𝑝𝑖
𝑞𝑖)
𝑚
𝑖=1
+ (1 − 𝑝𝑖) ln (1 − 𝑝𝑖
1 − 𝑞𝑖)) 𝐸𝑛𝑡𝑟𝑜𝑝𝑖𝑎 𝑅𝑒𝑙𝑎𝑡𝑖𝑣𝑎 (𝐵𝑖𝑛𝑎𝑟𝑖𝑎)
𝜙(𝑝) = ∑ (𝑝𝑖 ln 𝑝𝑖)𝑚𝑖=1 note que se refiere a la entropía negativa entonces
la distancia de Bregman asociada a 𝜙 está dada por
𝐷𝜙(𝑝, 𝑞) = ∑ (𝑝𝑖 ln (𝑝𝑖
𝑞𝑖) + 𝑞𝑖 − 𝑝𝑖) 𝐸𝑛𝑡𝑟𝑜𝑝í𝑎 𝑅𝑒𝑙𝑎𝑡𝑖𝑣𝑎 (𝑛𝑜 𝑛𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑎𝑑𝑎)
𝑚
𝑖=1
𝜙(𝑝) = ∑ (𝑝𝑖 ln 𝑝𝑖)𝑚𝑖=1 con ∑ (𝑝𝑖)𝑚
𝑖=1 = ∑ (𝑞𝑖)𝑚𝑖=1 =1, la distancia de Bregman
asociada a 𝜙 está dada por
𝐷𝜙(𝑝, 𝑞) = ∑ (𝑝𝑖 ln (𝑝𝑖
𝑞𝑖))
𝑚
𝑖=1
𝐸𝑛𝑡𝑟𝑜𝑝í𝑎 𝑅𝑒𝑙𝑎𝑡𝑖𝑣𝑎 (𝑛𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑎𝑑𝑎)
También se la llama como divergencia de Kullback – Leibler, esta es
usada para medir la distancia entre distribuciones de probabilidad 𝑝 y 𝑞
se notará como:
𝑅𝐸(𝑝, 𝑞) = ∑ (𝑝𝑖 ln (𝑝𝑖
𝑞𝑖))
𝑚
𝑖=1
= 𝐷𝜙(𝑝, 𝑞)
Ya que 𝑞 ∈ 𝑖𝑛𝑡(∆𝜙), la aplicación 𝑝 → ⟨∇𝜙(𝑞), 𝑝 − 𝑞⟩ + 𝜙(𝑞) es una función
lineal afín, la función 𝑝 → 𝐷𝜙(𝑝, 𝑞) es una función de tipo Legendre con
dominio ∆𝜙 y con un dominio conjugado ∆𝜙∗ − ∇𝜙(𝑞).
Conjugada Legendre – Bregman: Para una función convexa de tipo
Legendre ϕ se define la conjugada Legendre – Bregman denotada por
ℓ𝜙: 𝑖𝑛𝑡(∆𝜙) × X → ℝ ∪ {+∞} como
ℓ𝜙(𝑞, 𝑣) = sup𝑝∈∆𝜙
(⟨𝑣, 𝑝⟩ − 𝐷𝜙(𝑝, 𝑞))
Proyección Legendre – Bregman: se denota por ℒ𝜙: 𝑖𝑛𝑡(∆𝜙) × ℝ𝑚 → ∆𝜙
y se define como:
ℒ𝜙(𝑞, 𝑣) = arg max𝑝∈∆𝜙
(⟨𝑣, 𝑝⟩ − 𝐷𝜙(𝑝, 𝑞))
2.3.3. Relaciones básicas entre 𝐷𝜙,ℒ𝜙 y ℓ𝜙
Relaciones básicas para establecer los aspectos geométricos de la
dualidad.

19
Proposición 2.2. Sea 𝜙 de tipo Legendre con ∆𝜙∗= ℝ𝑚. Para un fijo 𝑝 ∈
∆𝜙, 𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑣)) es continua en 𝑞 ∈ 𝑖𝑛𝑡(∆𝜙) y convexa en 𝑣. Con todo
esto, la conjugada Legendre-Bregman y la proyección satisfacen:
𝐷𝜙(𝑝, 𝑞) − 𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑣)) = ⟨𝑣, 𝑝⟩ − ℓ𝜙(𝑞, 𝑣)
= 𝐷(ℒ𝜙(𝑞, 𝑣), 𝑞) + ⟨𝑣, 𝑝 −
ℒ𝜙(𝑞, 𝑣)⟩
∀𝑝 ∈ ∆𝜙, 𝑞 ∈ 𝑖𝑛𝑡(∆𝜙) y 𝑣 ∈ ℝ𝑚.
Proposición 2.3. Sea 𝜙 de tipo Legendre, con 𝑝 ∈ ∆𝜙 y 𝑞 ∈ 𝑖𝑛𝑡(∆𝜙)
entonces para 𝑣 ∈ ℝ𝑚, el mapeo 𝑡 ⟼ 𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑡𝑣)) es diferenciable en
𝑡 = 0, con derivada
𝑑
𝑑𝑡|
𝑡=0𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑡𝑣)) = ⟨𝑣, 𝑞⟩ − ⟨𝑣, 𝑝⟩
2.3.4. La extensión continua
Los resultados antes dados en términos de distancia de Bregman, usando
su definición estándar como una función sobre ∆𝜙 × 𝑖𝑛𝑡(∆𝜙). Se hará
suposiciones que permitirán trabajar con 𝐷𝜙 como una función extendida a
valor real sobre ∆𝜙 × ∆𝜙.
Según Della Pietra (2001) esto permite formular un resultado muy natural y
general de dualidad. Informalmente, se asume que:
𝐷𝜙 continuamente extendida desde ∆𝜙 × 𝑖𝑛𝑡(∆𝜙) a ∆𝜙 × ∆𝜙 y
ℒ𝜙 continuamente extendida desde 𝑖𝑛𝑡(∆𝜙) × ℝ𝑚 a ∆𝜙 × ℝ𝑚
Además, se requiere un tipo de compacidad que asegure la existencia de
ciertos minimizadores, para simplificar la presentación, se asume que el
rango de ∇𝜙 es todo ℝ𝑚. Suposiciones sobre 𝜙:
A1 𝜙 es de tipo Legendre;
A2 ∆𝜙∗= ℝ𝑚;
A3 𝐷𝜙 extendida a una función 𝐷𝜙: ∆𝜙 × ∆𝜙→ [0, ∞] tal que 𝐷𝜙(𝑝, 𝑞) es
conjuntamente continua en 𝑝 y 𝑞 y satisface 𝐷𝜙(𝑝, 𝑞) = 0 si y solo si 𝑝 = 𝑞;
A4 ℒ𝜙 extendida a una función ℒ𝜙: ∆𝜙 × ℝ𝑚 → ∆𝜙 tal que ℒ𝜙(𝑞, 𝑣) es
conjuntamente continua en 𝑞 y 𝑣 y satisface ℒ𝜙(𝑞, 0) = 𝑞;
A5 𝐷𝜙(𝑝,∙) es coerciva para cada 𝑝 ∈ ∆𝜙\𝑖𝑛𝑡(∆𝜙);
Juntas las propiedades A1-A5 implican que 𝜙 es una función Legendre –
Bregman.
De la definición de conjugada de Legendre – Bregman, para 𝑞 ∈ 𝑖𝑛𝑡(∆𝜙)

20
ℓ𝜙(𝑞, 𝑣) = ⟨𝑣, ℒ𝜙(𝑞, 𝑣)⟩ − 𝐷𝜙(ℒ𝜙(𝑞, 𝑣), 𝑞)
Las propiedades A4 y A5 permiten definir a ℓ𝜙: ∆𝜙 × ℝ𝑚 → ℝ como la
extensión continua de ℓ𝜙: 𝑖𝑛𝑡(∆𝜙) × ℝ𝑚 → ℝ, satisfaciendo la misma
identidad.
Luego la conjugada Legendre – Bregma es continua en 𝑞, continua y
convexa en 𝑣 y satisface ℓ𝜙(𝑞, 0) = 0.
Las relaciones básicas se generalizan a la extensión continua, así:
Proposición 2.4. (Della Pietra, Della Pietra, & Lafferty, 2001) Sea 𝜙 que
satisface A1 - A4, para un fijo 𝑝 ∈ ∆𝜙, 𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑣)) es continua en 𝑞 y
convexa en 𝑣. Juntas, la conjugada Legendre-Bregman y la proyección
satisfacen:
𝐷𝜙(𝑝, 𝑞) − 𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑣)) = ⟨𝑣, 𝑝⟩ − ℓ𝜙(𝑞, 𝑣)
= 𝐷(ℒ𝜙(𝑞, 𝑣), 𝑞) + ⟨𝑣, 𝑝 −
ℒ𝜙(𝑞, 𝑣)⟩
∀𝑝, 𝑞 ∈ ∆𝜙 y 𝑣 ∈ ℝ𝑚.
Demostración. Ver en Della Pietra, Della Pietra, & Lafferty, 2001;
Proposición 2.9.
Proposición 2.5. (Merow, Smith, & Silander, 2013) Sea 𝜙 que satisface A1
- A4 y sea 𝑝, 𝑞 ∈ ∆𝜙 con 𝐷𝜙(𝑝, 𝑞) < ∞, entonces para 𝑣 ∈ ℝ𝑚, el mapeo
𝑡 ⟼ 𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑡𝑣)) es diferenciable en 𝑡 = 0, con derivada
𝑑
𝑑𝑡|
𝑡=0𝐷𝜙 (𝑝, ℒ𝜙(𝑞, 𝑡𝑣)) = ⟨𝑣, 𝑞⟩ − ⟨𝑣, 𝑝⟩
Demostración. Ver en (Elith et al., 2011).
2.3.5. Conjuntos Factibles y familia de proyecciones Legendre - Bregman
Definición. Para un elemento dado 𝑝0 ∈ ∆𝜙 el conjunto factible para 𝑝0 y
𝐹 es definido por
𝒫(𝑝0, 𝐹) = {𝑝 ∈ ∆𝜙| ⟨𝑝, 𝑓(𝑗)⟩ = ⟨𝑝0, 𝑓(𝑗)⟩, 𝑗 = 1, . . . , 𝑛}
Para un 𝑞0 ∈ ∆𝜙 dado, la familia de proyecciones Legendre - Bregman
para 𝑞0 y 𝐹 está definido por
𝒬(𝑞0, 𝐹) = {𝑞 ∈ ∆𝜙| 𝑞 = ℒ𝜙(𝑞0, 𝐹𝜆), 𝑝𝑎𝑟𝑎 𝑎𝑙𝑔ú𝑛 𝜆 ∈ ℝ𝑛}.
Note que los conjuntos son no serán vacíos ya que 𝑝0 ∈ 𝒫(𝑝0, 𝐹) y 𝑞0 ∈
𝒬(𝑞0, 𝐹).

21
Ya que 𝑝0, 𝑞0 y 𝐹 son fijos en los posterior nos referiremos a los conjuntos
como 𝒫, 𝒬 y �̅� para denotar a la clausura de 𝒬 como un subconjunto de
ℝ𝑚.
Relacionamos dualmente la proyección sobre 𝒫 a la proyección sobre �̅�.

22
CAPÍTULO 3
APROXIMACIÓN DE MÁXIMA ENTROPÍA
3.1. Dualidad
Proposición 3.1. (Elith et al., 2011) Sea 𝜙 (satisface A1 - A5) y suponga
que 𝑝0, 𝑞0 ∈ ∆𝜙 con 𝐷𝜙(𝑝0, 𝑞0) < ∞ entonces existe un 𝑞⋆ ∈ ∆𝜙 único que
satisface las cuatro propiedades:
1. 𝑞⋆ ∈ 𝒫 ∩ �̅�
2. 𝐷𝜙(𝑝, 𝑞) = 𝐷𝜙(𝑝, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞) para cualquier 𝑝 ∈ 𝒫 y 𝑞 ∈ �̅�
3. 𝑞⋆ = arg min𝑝∈𝒫
𝐷𝜙(𝑝, 𝑞0)
4. 𝑞⋆ = arg min𝑞∈�̅�
𝐷𝜙(𝑝0, 𝑞)
Además, cualquiera de estas propiedades determina la unicidad de 𝑞⋆.
Demostración. Para probar este teorema antes debemos probar dos lemas.
El primero demuestra que hay al menos un elemento en común entre 𝒫 y �̅�;
la segunda muestra que la igualdad Pitagórica es válida para cualquier
miembro.
Lema 3.1. Si 𝐷𝜙(𝑝0, 𝑞0) < ∞ entonces 𝒫 ∩ �̅� es no vacío.
Demostración lema 3.1.
PD: 𝑞⋆ ∈ �̅�
Note que:
𝐷𝜙(𝑝0, 𝑞0) < ∞ en �̅�;
el mapeo 𝜆 ↦ 𝐷𝜙(𝑝0, ℒ𝜙(𝑞0, 𝐹𝜆)) es continuo y convexo;
el conjunto de nivel ℛ = {𝑞 ∈ ∆𝜙|𝐷𝜙(𝑝0, 𝑞) ≤ 𝐷𝜙(𝑝0, 𝑞0)} por A5
(pag.24) sabemos que es acotado
luego 𝐷𝜙(𝑝0, 𝑞) alcanza su mínimo en un punto, este puede o no ser único
𝑞⋆ ∈ 𝒬 ∩ ℛ̅̅ ̅̅ ̅̅ ̅̅ ⊂ �̅�.
PD: 𝑞⋆ ∈ 𝒫
Sea �̅� ∈ �̅� y sea 𝑢𝑗 ∈ ℝ𝑛 tal que
�̅� = 𝑙𝑖𝑚𝑗→∞
ℒ𝜙(𝑞0, 𝐹𝑢𝑗)
entonces por continuidad de ℒ𝜙(∙,∙) tenemos

23
ℒ𝜙(�̅�, 𝐹𝜆) = 𝑙𝑖𝑚𝑗→∞
ℒ𝜙(ℒ𝜙(𝑞0, 𝐹𝑢𝑗), 𝐹𝜆)
luego
ℒ𝜙(ℒ𝜙(𝑞, 𝑤), 𝑣) = (∇𝜙)−1 (∇𝜙 (ℒ𝜙(𝑞, 𝑤)) − 𝑣)
= (∇𝜙)−1(∇𝜙((∇𝜙)−1(∇𝜙(𝑞) − 𝑤)) − 𝑣)
= (∇𝜙)−1(∇𝜙(𝑞) − 𝑤 − 𝑣) = (∇𝜙)−1(∇𝜙(𝑞) − (𝑣 + 𝑤))
= ℒ𝜙(𝑞, 𝑣 + 𝑤)
entonces
ℒ𝜙(�̅�, 𝐹𝜆) = 𝑙𝑖𝑚𝑗→∞
ℒ𝜙(𝑞0, 𝐹(𝑢𝑗 + 𝜆)) ∈ �̅�
luego �̅� es cerrado bajo el mapeo 𝑞 ↦ ℒ𝜙(𝑞, 𝐹𝜆) para 𝜆 ∈ ℝ𝑚 y ℒ𝜙(𝑞⋆, 𝐹𝜆)
está en �̅� para algún 𝜆. Por definición de 𝑞⋆, se sigue que 𝜆 = 0 es un
mínimo de la función 𝜆 ↦ 𝐷𝜙(𝑝0, ℒ𝜙(𝑞⋆, 𝐹𝜆)). Tomando derivadas con
respecto a 𝜆 y usando proposición 2 pag.24 se concluye que
⟨𝑞⋆, 𝑓⟩ = ⟨𝑝0, 𝑓⟩ así 𝑞⋆ ∈ 𝒫.
3.□
Lema 3.2. Si 𝑞⋆ ∈ 𝒫 ∩ �̅� entonces la igualdad Pitagórica
𝐷𝜙(𝑝, 𝑞) = 𝐷𝜙(𝑝, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞)
se cumple para cualquier 𝑝 ∈ 𝒫 y 𝑞 ∈ �̅�.
Demostración lema 3.2.
Suponga 𝑞⋆ ∈ 𝒫 que 𝑝1, 𝑝2, 𝑞1, 𝑞2 ∈ ∆𝜙 con 𝑞2 = ℒ𝜙(𝑞1, 𝐹𝜆) de la proposición
(pag.25) se tiene que
𝐷𝜙(𝑝1, 𝑞1) − 𝐷𝜙(𝑝1, 𝑞2) = ⟨𝑝1, 𝐹𝜆⟩ − ℓ𝜙(𝑝1, 𝐹𝜆)
𝐷𝜙(𝑝2, 𝑞1) − 𝐷𝜙(𝑝2, 𝑞2) = ⟨𝑝2, 𝐹𝜆⟩ − ℓ𝜙(𝑝2, 𝐹𝜆)
por lo tanto
𝐷𝜙(𝑝1, 𝑞1) − 𝐷𝜙(𝑝1, 𝑞2)
− (𝐷𝜙(𝑝2, 𝑞1) − 𝐷𝜙(𝑝2, 𝑞2))
= ⟨𝑝1, 𝐹𝜆⟩ − ℓ𝜙(𝑞1, 𝐹𝜆)
− (⟨𝑝2, 𝐹𝜆⟩
− ℓ𝜙(𝑞1, 𝐹𝜆))
= ⟨𝑝1, 𝐹𝜆⟩ − ℓ𝜙(𝑞1, 𝐹𝜆) − ⟨𝑝2, 𝐹𝜆⟩
+ ℓ𝜙(𝑞1, 𝐹𝜆)
= ⟨𝑝1, 𝐹𝜆⟩ − ⟨𝑝2, 𝐹𝜆⟩
= ∑ 𝜆𝑗(⟨𝑝1, 𝑓(𝑗)⟩ − ⟨𝑝2, 𝑓(𝑗)⟩)
𝑛
𝑗=1
de esta identidad y de la continuidad de 𝐷𝜙 se tiene que
𝐷𝜙(𝑝1, 𝑞1) − 𝐷𝜙(𝑝1, 𝑞2) − 𝐷𝜙(𝑝2, 𝑞1) + 𝐷𝜙(𝑝2, 𝑞2) = 0.

24
Si 𝑝1, 𝑝2 ∈ 𝒫 y 𝑞1, 𝑞2 ∈ �̅�, el lema sigue de tomar 𝑝1 = 𝑞1 = 𝑞⋆ pues
𝐷𝜙(𝑝1, 𝑝1) − 𝐷𝜙(𝑝1, 𝑞2) − 𝐷𝜙(𝑝2, 𝑞1) + 𝐷𝜙(𝑝2, 𝑞2) = 0
−𝐷𝜙(𝑝2, 𝑞1) − 𝐷𝜙(𝑝1, 𝑞2) = −𝐷𝜙(𝑝2, 𝑞2)
−𝐷𝜙(𝑝2, 𝑞⋆) − 𝐷𝜙(𝑞⋆, 𝑞2) = −𝐷𝜙(𝑝2, 𝑞2)
𝐷𝜙(𝑝2, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞2) = 𝐷𝜙(𝑝2, 𝑞2)
□
Demostración de la proposición de dualidad.
Propiedad (1)
PD: 𝑞⋆ ∈ 𝒫 ∩ �̅�
Por lema 3.1 existe 𝑞⋆ ∈ 𝒫 ∩ �̅�.
Propiedad (2)
PD: 𝐷𝜙(𝑝, 𝑞) = 𝐷𝜙(𝑝, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞), ∀𝑝 ∈ 𝒫 y 𝑞 ∈ �̅�
Por lema 3.2 se ha demostrado.
Propiedad (3)
PD: 𝑞⋆ = 𝑎𝑟𝑔 𝑚𝑖𝑛𝑞∈�̅�
𝐷𝜙(𝑝0, 𝑞) 𝑦
Sea 𝑞 ∈ �̅� entonces
𝐷𝜙(𝑝0, 𝑞) = 𝐷𝜙(𝑝0, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞) ≥ 𝐷𝜙(𝑝0, 𝑞⋆)
Propiedad (4)
PD: 𝑞⋆ = 𝑎𝑟𝑔 𝑚𝑖𝑛𝑝∈𝒫
𝐷𝜙(𝑝, 𝑞0)
Sea 𝑝 ∈ 𝒫 entonces
𝐷𝜙(𝑝, 𝑞0) = 𝐷𝜙(𝑝, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞0) ≥ 𝐷𝜙(𝑞⋆, 𝑞0).
Faltaría probar que las cuatro propiedades determinan que 𝑞⋆ es único, es
decir, si 𝑚 ∈ ∆𝜙 y satisface cualquiera de las propiedades, entonces 𝑚 =
𝑞⋆.
Propiedad (1)
Suponga que 𝑚 ∈ 𝒫 ∩ �̅� entonces con 𝑝 = 𝑞 = 𝑚 implica que
𝐷𝜙(𝑚, 𝑚) = 𝐷𝜙(𝑚, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑚)
puesto que 𝐷𝜙(𝑚, 𝑚) = 0 entonces 𝐷𝜙(𝑚, 𝑞⋆) = 0 luego 𝑚 = 𝑞⋆.
Propiedad (2)
Si 𝑚 satisface

25
𝐷𝜙(𝑚, 𝑞) = 𝐷𝜙(𝑚, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞)
como 𝑚, 𝑞 ∈ 𝒫 ∩ �̅� se tiene que
𝐷𝜙(𝑞⋆, 𝑞⋆) = 𝐷𝜙(𝑚, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑚)
𝐷𝜙(𝑚, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑚) = 0
por lo tanto 𝑚 = 𝑞⋆.
Propiedad (3)
Suponga que 𝑚 satisface
𝑞⋆ = arg min𝑚∈�̅�
𝐷𝜙(𝑝0, 𝑚)
entonces
𝐷𝜙(𝑝0, 𝑚) = 𝐷𝜙(𝑝0, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑚) ≤ 𝐷𝜙(𝑝0, 𝑞⋆)
la segunda desigualdad sigue de la propiedad 2 para 𝑞⋆ luego
𝐷𝜙(𝑝0, 𝑞⋆) − 𝐷𝜙(𝑝0, 𝑞⋆) ≥ 𝐷𝜙(𝑞⋆, 𝑚)
0≥ 𝐷𝜙(𝑞⋆, 𝑚)
por lo tanto m= 𝑞⋆.
Propiedad (4)
Suponga que 𝑚 satisface
𝑞⋆ = arg min𝑚∈𝒫
𝐷𝜙(, 𝑞0)
entonces
𝐷𝜙(𝑚, 𝑞0) = 𝐷𝜙(𝑚, 𝑞⋆) + 𝐷𝜙(𝑞⋆, 𝑞0) ≤ 𝐷𝜙(𝑞⋆, 𝑞0)
y análogamente al punto anterior 𝑚 = 𝑞⋆.
□
3.2. Enfoque de máxima entropía
Según Dudík (2004), el objetivo es estimar una distribución de probabilidad
𝜋 sobre una espacio muestral finito 𝑋.
Dado:
Un conjunto de muestras 𝑥1, … , 𝑥𝑚 ∈ 𝑋 ubicadas independientemente al
azar de acuerdo a 𝜋, la correspondiente distribución empírica �̃� definida por,
�̃�(𝑥) =1
𝑚|{1 ≤ 𝑖 ≤ 𝑚 ∣ 𝑥𝑖 = 𝑥}| o
�̃�(𝑥) =1
𝑚𝑐𝑎𝑟𝑑({1 ≤ 𝑖 ≤ 𝑚 ∣ 𝑥𝑖 = 𝑥}) 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑐𝑖ó𝑛 𝑒𝑚𝑝í𝑟𝑖𝑐𝑎

26
Un conjunto de características (features) 𝑓 = (𝑓1, … , 𝑓𝑛) donde 𝑓𝑗: 𝑋 → ℝ; el
valor esperado de 𝑓 bajo la distribución 𝜋 o esperanza de 𝑓 se denota por
𝜋[𝑓] = ∑ 𝜋(𝑥)𝑓(𝑥)𝑥∈𝑋
Se usará esta notación (a veces) cuando 𝜋 no sea necesariamente una
distribución de probabilidad
Por otra parte, dada una función 𝑓 se espera que �̃�[𝑓] el promedio empírico
de 𝑓, sea bastante cercano a su verdadero valor esperado 𝜋[𝑓]
�̃�[𝑓] ≈ 𝜋[𝑓]
para esto es necesario buscar una aproximación 𝑝 bajo la cual la esperanza
de 𝑓𝑗 sea igual a �̃�[𝑓𝑗] para cada 𝑓𝑗, es decir, 𝑝[𝑓𝑗] = �̃�[𝑓𝑗].
Habrá muchas distribuciones que satisfacen estas restricciones pero, el
principio de maxent sugiere que de entre todas las distribuciones que
satisfacen las restricciones se elija la que tenga máxima entropía, es decir,
la que sea más cercana a la distribución Uniforme.
La entropía 𝐻 de una distribución 𝑝 sobre 𝑋 está definida como
𝐻(𝑝) = − ∑ 𝑝(𝑥) ln 𝑝(𝑥)
𝑥∈𝑋
𝐸𝑛𝑡𝑟𝑜𝑝í𝑎
Otra manera es considerando todas las distribuciones de Gibbs donde
𝜆 = (𝜆1, … , 𝜆𝑛) ∈ ℝ𝒏 y 𝑍𝝀 = ∑ 𝑒𝝀⋅𝒇(𝒙)𝑥∈𝑋 una constante de normalización se
define como
𝑞𝝀(𝑥) =𝑒𝝀⋅𝒇(𝒙)
𝑍𝝀 𝐷𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑐𝑖𝑜𝑛𝑒𝑠 𝑑𝑒 𝐺𝑖𝑏𝑏𝑠
La distribución de máxima entropía es la distribución de máxima
verosimilitud de Gibbs, así
o Función verosimilitud
𝑙( 𝝀) = ∏ 𝑞𝜆(𝑥𝑖; 𝝀)
𝑚
𝑖=1
o Función log-verosimilitud
𝐿�̃�(𝝀) = log(𝑙( 𝝀))
= ∑ log 𝑞𝜆(𝑥𝑖; 𝝀)
𝑚
𝑖=1
= −
1
𝑚∑ ln 𝑞𝝀(𝑥𝑖)
𝑚
𝑖=1

27
= −�̃�[ln 𝑞𝝀]
Nótese que solo difieren por la constante entropía 𝐻(�̃�), así:
Entropía Relativa o Divergencia de Kullback-Leibler
Función log-verosimilitud
(log-loss)
𝑅𝐸(�̃�||𝑞𝝀) = ∑ �̃�(𝑥𝑖) ln (�̃�(𝑥𝑖)
𝑞𝝀(𝑥𝑖))
𝑚
𝑖=1
= ∑ �̃�(𝑥𝑖)(ln(�̃�(𝑥𝑖)))
𝑚
𝑖=1
− ∑ �̃�(𝑥𝑖)(ln(𝑞𝝀(𝑥𝑖)))
𝑚
𝑖=1
𝐿�̃�(𝝀)
= −1
𝑚∑ ln 𝑞𝝀(𝑥𝑖)
𝑚
𝑖=1
= −𝐻(�̃�) − �̃�[ln 𝑞𝝀] = −�̃�[ln 𝑞𝝀]
= 𝐿�̃�(𝝀) − 𝐻(�̃�) = 𝐿�̃�(𝝀)
Estas dos serán usadas como funciones objetivo. Los programas convexos
correspondientes a los dos problemas de optimización son:
𝓟: 𝐦𝐚𝐱𝒑∈∆
𝑯(𝒑) 𝓠: 𝒎𝒊𝒏𝝀∈ℝ𝒏
𝑳�̃�(𝝀)
sujeto a
𝒑[𝒇𝒋] = �̃�[𝒇𝒋]
∆: es el conjunto de todas las distribuciones de probabilidad
sobre 𝑿
3.3. Regularización
Este enfoque básico calcula la distribución 𝑝 de máxima entropía, para que
𝑝[𝑓𝑗] = �̃�[𝑓𝑗].
Sin embargo, no se espera el cumplimiento de la igualdad �̃�[𝑓𝑗] = 𝜋[𝑓𝑗] pero
si la cercanía �̃�[𝑓] ≈ 𝜋[𝑓]. Por lo tanto, se suavizan las restricciones a la
forma:
|𝑝[𝑓𝑗] − �̃�[𝑓𝑗]| ≤ 𝛽𝑗
donde 𝛽𝑗 es una estimación de cuan cercano �̃�[𝑓𝑗] (siendo un promedio
empírico) debe estar a su valor verdadero 𝜋[𝑓𝑗],
�̃�[𝑓𝑗] − 𝛽𝑗 ≤ 𝑝[𝑓𝑗] ≤ �̃�[𝑓𝑗] + 𝛽𝑗.
Así, el problema se puede expresar como:
Este corresponde al problema o programa convexo:
𝓟: 𝐦𝐚𝐱𝒑∈∆
𝑯(𝒑) 𝓟′ : 𝐦𝐚𝐱𝒑∈(ℝ+)𝑿
𝑯(𝒑)

28
sujeto a
∀𝒋: |𝒑[𝒇𝒋] − �̃�[𝒇𝒋]| ≤ 𝜷𝒋
∆: es el conjunto de todas las distribuciones de probabilidad sobre
𝑿
sujeto a
∑ 𝑝(𝑥) = 1𝑥∈𝑋 (𝜆0)
∀𝑗: �̃�[𝑓𝑗] − 𝑝[𝑓𝑗] ≤ 𝛽𝑗 (𝜆𝑗+)
∀𝑗: 𝑝[𝑓𝑗] − �̃�[𝑓𝑗] ≤ 𝛽𝑗 (𝜆𝑗−)
Para calcular el dual convexo, se crea el Lagrangiano (las variables duales
son indicadas a continuación de las restricciones) para obtener el programa
dual:
min𝜆0∈ℝ
𝜆𝑗−,𝜆𝑗
+∈ℝ+
max𝑝∈(ℝ+)𝑋
[𝐻(𝑝) − 𝜆0(∑ 𝑝(𝑥) − 1𝑥∈𝑋 ) − ∑ 𝜆𝑗+
𝑗 (�̃�[𝑓𝑗] − 𝑝[𝑓𝑗] − 𝛽𝑗) − ∑ 𝜆𝑗−
𝑗 (𝑝[𝑓𝑗] − �̃�[𝑓𝑗] − 𝛽𝑗)]
min𝜆0∈ℝ
𝜆𝑗−,𝜆𝑗
+∈ℝ+
max𝑝∈(ℝ+)𝑋
[𝐻(𝑝) − 𝜆0 (∑ 𝑝(𝑥) − 1
𝑥∈𝑋
) + ∑ 𝜆𝑗+
𝑗
(𝑝[𝑓𝑗] − �̃�[𝑓𝑗] + 𝛽𝑗) − ∑ 𝜆𝑗−
𝑗
(𝑝[𝑓𝑗] − �̃�[𝑓𝑗] − 𝛽𝑗)]
min𝜆0∈ℝ
𝜆𝑗−,𝜆𝑗
+∈ℝ+
max𝑝∈(ℝ+)𝑋
[𝐻(𝑝) − 𝜆0 (∑ 𝑝(𝑥) − 1
𝑥∈𝑋
) + ∑ 𝜆𝑗+
𝑗
(𝑝[𝑓𝑗] − �̃�[𝑓𝑗]) − ∑ 𝜆𝑗−
𝑗
(𝑝[𝑓𝑗] − �̃�[𝑓𝑗]) + ∑ 𝜆𝑗+
𝑗
𝛽𝑗 − ∑ −𝜆𝑗−
𝑗
𝛽𝑗]
min𝜆0∈ℝ
𝜆𝑗−,𝜆𝑗
+∈ℝ+
max𝑝∈(ℝ+)𝑋
[𝐻(𝑝) − 𝜆0(∑ 𝑝(𝑥) − 1𝑥∈𝑋 ) + ∑ (𝜆𝑗+ − 𝜆𝑗
−)𝑗 (𝑝[𝑓𝑗] − �̃�[𝑓𝑗]) + ∑ (𝜆𝑗+ − 𝜆𝑗
−)𝑗 𝛽𝑗], con 𝜆𝑗 = 𝜆𝑗+ − 𝜆𝑗
−
min𝜆0∈ℝ
𝜆0,𝜆𝑗∈ℝ+
max𝑝∈(ℝ+)𝑋
[𝐻(𝑝) − 𝜆0 (∑ 𝑝(𝑥) − 1
𝑥∈𝑋
) + ∑ 𝜆𝑗
𝑗
(𝑝[𝑓𝑗] − �̃�[𝑓𝑗]) + ∑|𝜆𝑗|𝛽𝑗
𝑗
]
𝐻(𝑝) − 𝜆0 (∑ 𝑝(𝑥) − 1𝑥∈𝑋
) + ∑ 𝜆𝑗
𝑗
(𝑝[𝑓𝑗] − �̃�[𝑓𝑗]) + ∑|𝜆𝑗|𝛽𝑗
𝑗
Esta expresión es diferenciable y cóncava en 𝑝(𝑥). El cálculo de las derivadas parciales con respecto a 𝑝(𝑥) e igualando a 0
da lugar a que 𝑝 pueda ser una distribución de Gibbs, con parámetros
correspondientes a las variables duales 𝜆𝑗 y 𝑍𝝀 = 𝜆0 + 1.
Convirtiéndose el programa en:
min𝜆∈ℝ𝑛
[𝐻(𝑞𝝀(𝑥)) + 𝝀 ⋅ (𝑞𝝀[𝒇(𝒙)] − �̃�[𝒇(𝒙)]) + ∑|𝜆𝑗|𝛽𝑗
𝑗
]
con
𝐻(𝑞𝝀(𝑥)) = − ∑ 𝑞𝝀(𝑥) ln 𝑞
𝝀(𝑥)
𝑥∈𝑋
= − ∑ 𝑞𝝀(𝑥) ln (
𝑒𝝀⋅𝒇(𝒙)
𝑍𝝀)
𝑥∈𝑋
= − ∑ 𝑞𝝀(𝑥)(ln( 𝑒𝝀⋅𝒇(𝒙)) − ln (𝑍𝝀))
𝑥∈𝑋

29
= − ∑ 𝑞𝝀(𝑥)(𝝀 ⋅ 𝒇(𝒙) − ln (𝑍𝝀))
𝑥∈𝑋
= − ∑ 𝑞𝝀(𝑥)(𝝀 ⋅ 𝒇(𝒙))
𝑥∈𝑋
− (− ln(𝑍𝝀))
= − 𝝀 ⋅ 𝑞𝝀[𝒇(𝒙)] + ln (𝑍𝝀)
Ahora
𝐻(𝑞𝝀) + 𝝀 ⋅ (𝑞𝝀[𝒇] − �̃�[𝒇])
+ + ∑|𝜆𝑗|𝛽𝑗
𝑗
= − 𝝀 ⋅ 𝑞𝝀[𝒇] + ln (𝑍𝝀) + 𝝀⋅ (𝑞𝝀[𝒇] − �̃�[𝒇])
+ ∑|𝜆𝑗|𝛽𝑗
𝑗
= − 𝝀 ⋅ 𝑞𝝀[𝒇] + ln (𝑍𝝀) + 𝝀 ⋅ 𝑞𝝀[𝒇] − 𝝀
⋅ �̃�[𝒇] + ∑|𝜆𝑗|𝛽𝑗
𝑗
= −𝝀 ⋅ �̃�[𝒇] + ln (𝑍𝝀) + ∑|𝜆𝑗|𝛽𝑗
𝑗
= −�̃�[𝝀 ⋅ 𝒇 − ln (𝑍𝝀)] + ∑|𝜆𝑗|𝛽𝑗𝑗
= − ∑ �̃�
𝒎
𝒊=𝟏
(ln (𝑒𝝀.𝒇
𝑍𝝀)) + ∑|𝜆𝑗|𝛽
𝑗𝑗
= − ∑ �̃�
𝒎
𝒊=𝟏
ln(𝑞𝝀) + ∑|𝜆𝑗|𝛽𝑗𝑗
= −�̃�[ln(𝑞𝝀)] + ∑|𝜆𝑗|𝛽𝑗
𝑗
= 𝐿�̃�(𝝀) + ∑|𝜆𝑗|𝛽𝑗
𝑗
= 𝐿�̃�𝛽 (𝝀)
Versión final del programa dual:
𝓠′ : 𝒎𝒊𝒏𝝀
𝑳�̃�𝜷(𝝀)
entonces se demuestra que maxent con restricciones relajadas es
equivalente a minimizar 𝐿�̃�𝛽(𝜆). Esta función objetivo modificada consiste de
un terminó empírico de la log-verosimilitud 𝐿�̃�(𝝀) más un término adicional
∑ |𝜆𝑗|𝛽𝑗𝑗 que puede ser interpretado como una forma de regularización,
limitando cuán grande los pesos 𝜆𝑗 pueden convertirse.
Maximizar la entropía con restricciones relajadas es equivalente a
minimizar 𝑳�̃�𝜷(𝝀)
𝓟′ : 𝐦𝐚𝐱𝒑∈(ℝ+)𝑿
𝑯(𝒑) 𝒬′ : min𝝀
𝐿�̃�𝛽 (𝝀)

30
sujeto a
∑ 𝒑(𝒙) = 𝟏𝒙∈𝑿 (𝝀𝟎)
∀𝒋: �̃�[𝒇𝒋] − 𝒑[𝒇𝒋] ≤ 𝜷𝒋 (𝝀𝒋+)
∀𝒋: 𝒑[𝒇𝒋] − �̃�[𝒇𝒋] ≤ 𝜷𝒋 (𝝀𝒋−)
3.4. Algoritmo de actualización secuencial y prueba de convergencia
Según Dudík (2004), hay muchos algoritmos para encontrar la distribución
de maxent, se revisará el algoritmo de escalamiento iterativo y sus
variantes.
Se describirá a continuación el algoritmo de actualización secuencial que
modifica un peso 𝝀𝒋 a la vez para la optimización de la log-verosimilitud (log
loss) regularizada
Entrada:
𝑋 es un dominio finito características 𝑓1, … , 𝑓𝑛 donde 𝑓𝑗: 𝑋 → [0,1]
muestras 𝑥1, … , 𝑥𝑚 ∈ 𝑋
parámetros de regularización no negativos 𝛽1, . . . , 𝛽𝑛
Salida:
𝝀𝟏, 𝝀𝟐, … minimizando 𝐿�̃�𝛽 (𝝀)
sea 𝝀𝟏 = 𝟎
para 𝑡 = 1,2, … Sea (𝑗, 𝛿) = arg min
(𝑗,𝛿)𝐹𝑗(𝝀𝒕, 𝛿); 𝐹𝑗(𝝀𝒕, 𝛿) se indica a continuación
𝜆𝑡+1,𝑗′ = {𝜆𝑡,𝑗+𝛿 𝑠𝑖 𝑗′=𝑗
𝜆𝑡,𝑗′ 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟𝑎𝑟𝑖𝑜
Recordemos el objetivo es encontrar 𝝀 que minimice la función objetivo
𝐿�̃�𝛽(𝝀).
El algoritmo trabaja iterativamente ajustando (o actualizando) un solo peso
𝜆𝑗 que maximizará (una aproximación de) el cambio en 𝐿�̃�𝛽(𝝀), es decir,
supongamos que se añade 𝛿 a 𝜆𝑗, así resulta 𝝀′ el vector de pesos que es
idéntico a 𝝀 excepto en la coordenada 𝑗, 𝜆𝑗′ = 𝜆𝑗 + 𝛿 entonces con
𝑍𝝀′ =∑ 𝑒𝝀⋅𝒇(𝒙)+𝜹𝒇𝒋(𝒙)𝑥∈𝑋
=∑ 𝑒𝝀.𝒇(𝒙)𝑥∈𝑋 𝑒𝜹𝒇𝒋(𝒙), por definición de 𝑞𝝀(𝑥)
=𝑍𝝀 ∑ 𝑞𝝀(𝑥)𝑒𝜹𝒇𝒋𝑥∈𝑋
=𝑍𝝀𝑞𝝀[𝑒𝜹𝒇𝒋]
el cambio en 𝐿�̃�𝛽
es
𝐿�̃�𝛽(𝝀′) − 𝐿�̃�
𝛽(𝝀) = −𝝀′ ⋅ �̃�[𝒇] + 𝝀 ⋅ �̃�[𝒇] + ln(𝑍𝝀′) − ln(𝑍𝝀) + 𝛽𝑗|𝜆𝑗′| − 𝛽𝑗|𝜆𝑗|

31
= 𝝀 ⋅ �̃�[𝒇] − 𝝀′ ⋅ �̃�[𝒇] + ln (
𝑍𝝀′
𝑍𝝀) + 𝛽𝑗(|𝜆𝑗 + 𝛿| − |𝜆𝑗|)
= −𝛿�̃�[𝑓𝑗] + ln(𝑞𝝀[𝑒𝜹𝒇𝒋]) + 𝛽𝑗(|𝜆𝑗 + 𝛿| − |𝜆𝑗|),
puesto que ∀𝑥 ∈ [0,1] se cumple 𝑒𝛿𝑥 ≤ 1 + (𝑒𝛿 − 1)𝑥
≤ −𝛿�̃�[𝑓𝑗] + ln(𝑞𝝀[1 + (𝑒𝛿 − 1)𝑓𝑗]) + 𝛽𝑗(|𝜆𝑗 + 𝛿| − |𝜆𝑗|)
=−𝛿�̃�[𝑓𝑗] + ln(1 + (𝑒𝛿 − 1)𝑞𝝀[𝑓𝑗]) + 𝛽𝑗(|𝜆𝑗 + 𝛿| − |𝜆𝑗|)
=𝐹𝑗(𝝀, 𝛿)
𝐹𝑗(𝝀, 𝛿) puede ser minimizada sobre todas las elecciones de 𝛿 ∈ ℝ mediante
un simple caso de análisis de signo de 𝜆𝑗 + 𝛿 particularmente si vemos la
necesidad de usar
𝛿 = −𝜆𝑗, o
𝛿 = ln ((�̃�[𝑓𝑗]−𝛽𝑗)(1−𝑞𝝀[𝑓𝑗])
(1−�̃�[𝑓𝑗]+𝛽𝑗)𝑞𝝀[𝑓𝑗]) cuando 𝜆𝑗 + 𝛿 ≥ 0, o
𝛿 = ln ((�̃�[𝑓𝑗]−𝛽𝑗)(1−𝑞𝝀[𝑓𝑗])
(1−�̃�[𝑓𝑗]−𝛽𝑗)𝑞𝝀[𝑓𝑗]) cuando 𝜆𝑗 + 𝛿 ≤ 0
este caso de análisis es repetido para toda características 𝑓𝑗 .
El par (𝑗, 𝛿) que minimiza 𝐹𝑗(𝝀, 𝛿) es seleccionado y se suma 𝛿 a 𝜆𝑗.
Ahora se demuestra un teorema que garantiza que el algoritmo generar una
sucesión de 𝝀𝒕’s que minimizan la función objetivo 𝐿�̃�𝛽(𝝀) donde todos los
𝛽𝑗’s son positivos.
Teorema (Dudík, Phillips, & Schapire, 2004; Teorema 2) Asuma que todas
las 𝛽𝑗 son estrictamente positivas, entonces el algoritmo citado
anteriormente produce una secuencia 𝝀𝟏, 𝝀𝟐, … para la cual
lim𝑡→∞
𝐿�̃�𝛽 (𝝀𝑡) = min
𝝀𝐿�̃�
𝛽(𝝀)
Demostración. Sean los vectores 𝝀+ y 𝝀− en términos de 𝝀 como sigue:
∀𝑗 𝑠𝑖 𝜆𝑗 ≥ 0 entonces 𝜆𝑗+ = 𝜆𝑗 y 𝜆𝑗
− = 0
∀𝑗 𝑠𝑖 𝜆𝑗 ≤ 0 entonces 𝜆𝑗+ = 0 y 𝜆𝑗
− = −𝜆𝑗
Los vectores �̂�+, �̂�−, �̂�𝑡+, �̂�𝑡
−, etc. Son definidos análogamente.
Se reescribe la función 𝐹𝑗:
∀ 𝜆, 𝛿, se tiene |𝜆 + 𝛿| − |𝜆| = 𝑚𝑖𝑛{𝛿+ + 𝛿−|𝛿+ ≥ −𝜆+, 𝛿− ≥ −𝜆−, 𝛿+ − 𝛿− =
𝛿}.

32
Esto puede ser visto como un simple caso de análisis de signo de 𝜆 y 𝜆 +
𝛿.
Añadiendo esto a la definición de 𝐹𝑗 se da:
𝐹𝑗(𝝀, 𝛿) = 𝑚𝑖𝑛{𝐺𝑗(𝝀, 𝛿+, 𝛿−)|𝛿+ ≥ −𝜆+, 𝛿− ≥ −𝜆−, 𝛿+ − 𝛿− = 𝛿}
donde
𝐺𝑗(𝝀, 𝛿+, 𝛿−) = (𝛿− − 𝛿+)�̃�[𝑓𝑗] + 𝑙𝑛(1 + (𝑒𝛿+−𝛿−− 1)𝑞𝝀[𝑓𝑗]) + 𝛽𝑗(𝛿+ + 𝛿−).
Combinando con 𝐹𝑗(𝝀, 𝛿) y nuestra elección de 𝑗 y 𝛿, queda esto
𝐿�̃�𝛽(𝝀𝑡+1) − 𝐿�̃�
𝛽 (𝝀𝑡) ≤ 𝑚𝑖𝑛𝑗
𝑚𝑖𝑛𝛿
𝐹𝑗(𝝀𝑡, 𝛿)
= 𝑚𝑖𝑛𝑗
𝑚𝑖𝑛{𝐺𝑗(𝝀𝑡, 𝛿+, 𝛿−)|𝛿+ ≥ −𝜆𝑡,𝑗+ , 𝛿− ≥ −𝜆𝑡,𝑗
− }
= 𝑚𝑖𝑛 𝐺(𝝀𝒕)
Desde que 𝐺𝑗(𝝀, 0, 0) = 0, sigue que la función 𝑚𝑖𝑛 𝐺𝑗(𝜆𝑡) no es positiva y
por lo tanto 𝐿�̃�𝛽(𝝀𝑡) no es creciente en 𝑡.
Desde que la función log-verosimilitud no es negativa se tiene que
∑ 𝛽𝑗|𝜆𝑡,𝑗|
𝑗
≤ 𝐿�̃�𝛽(𝝀1)
< ∞ Pues
𝐿�̃�𝛽(𝝀𝑡+1) = 𝐿𝜋(𝝀𝑡+1) + ∑ 𝛽𝑗|𝜆𝑡+1,𝑗|
𝑗
≤ 𝐿�̃�𝛽(𝝀𝑡)
= 𝐿𝜋(𝝀𝑡) + ∑ 𝛽𝑗|𝜆𝑡,𝑗|
𝑗
En particular para 𝑡 > 1 se tiene que
∑ 𝛽𝑗|𝜆𝑡,𝑗|
𝑗
≤ 𝐿𝜋(𝝀𝑡) + ∑ 𝛽𝑗|𝜆𝑡,𝑗|
𝑗
≤ 𝐿�̃�
𝛽(𝝀1)
< ∞
Por lo tanto usando la suposición que todos los 𝛽𝑗 > 0, se tiene que los 𝜆𝑡
son elementos de un espacio compacto.
Luego, como 𝝀𝒕 son elementos de un espacio compacto entonces en la
ecuación
𝑚𝑖𝑛 𝐺(𝝀𝒕) = 𝑚𝑖𝑛𝑗
𝑚𝑖𝑛{𝐺𝑗(𝝀𝑡, 𝛿+, 𝛿−)|𝛿+ ≥ −𝜆𝑡,𝑗+ , 𝛿− ≥ −𝜆𝑡,𝑗
− }

33
Es suficiente considerar las actualizaciones 𝛿+ y 𝛿− que vienen de un
espacio compacto.
Las funciones 𝐺𝑗 son uniformemente continuas sobre espacios
compactos, por lo tanto la función 𝑚𝑖𝑛 𝐺 es continua.
El hecho que 𝝀𝒕 sean elementos de un espacio compacto también implica
que estos deben tener una subsucesión convergente a un vector �̂�.
Se puede ver que 𝐿�̃�𝛽
es no negativa, y ya se ha notado que 𝐿�̃�𝛽
es no
creciente, por lo tanto
𝑙𝑖𝑚𝑡→∞
𝐿�̃�𝛽 (𝝀𝒕) existe
Y por continuidad
𝑙𝑖𝑚𝑡→∞
𝐿�̃�𝛽 (𝝀𝒕) = 𝐿�̃�
𝛽(�̂�)
Además, las diferencias 𝐿�̃�𝛽 (𝝀𝑡+1) − 𝐿�̃�
𝛽(𝝀𝑡) deben converger a cero,
entonces la función 𝑚𝑖𝑛 𝐺(𝝀𝒕), la cual es no positiva, también debe
converger a cero.
Por continuidad, esto significa que 𝑚𝑖𝑛 𝐺(�̂�) = 0, en particular para cada 𝑗,
se tiene
𝑚𝑖𝑛{𝐺𝑗(�̂�, 𝛿+, 𝛿−)|𝛿+ ≥ −𝜆𝑗+, 𝛿− ≥ −𝜆𝑗
−} = 0 (7)
Resta probar que (7) implica que �̂�+y �̂�− junto con 𝑞�̂� satisfacen las
condiciones Kuhn-Tucker para el programa convexo 𝒫′y así forma una
solución a este problema asi como también a su dual 𝒬′.
Para 𝑝 = 𝑞�̂� las condiciones son las siguientes, para todo 𝑗
�̂�𝑗+ ≥ 0, �̃�[𝑓𝑗] − 𝑞�̂�[𝑓𝑗] ≤ 𝛽𝑗, �̂�𝑗
+(�̃�[𝑓𝑗] − 𝑞�̂�[𝑓𝑗] − 𝛽𝑗) = 0 (8)
�̂�𝑗− ≥ 0, 𝑞�̂�[𝑓𝑗] − �̃�[𝑓𝑗] ≤ 𝛽𝑗, �̂�𝑗
−(𝑞�̂�[𝑓𝑗] − �̃�[𝑓𝑗] − 𝛽𝑗) = 0 (9)
Se sabe que 𝐺𝑗(�̂�, 0, 0) = 0, así por (7):
Si �̂�𝑗+ > 0 entonces 𝐺𝑗(�̂�, 𝛿+, 0) es no negativo en una vecindad de
𝛿+ = 0 y entonces tiene un mínimo local en este punto, esto es,
0 =𝜕𝐺𝑗(�̂�, 𝛿+, 0)
𝜕𝛿+|
𝛿+=0
= −�̃�[𝑓𝑗] + 𝑞�̂�[𝑓𝑗] + 𝛽𝑗
Si �̂�𝑗+ = 0, entonces por (7) se tiene que 𝐺𝑗(�̂�, 0, 0) ≥ 0 para todo
𝛿+ ≥ 0
Asi, 𝐺𝑗(�̂�, 𝛿+, 0) no puede ser decreciente en 𝛿+ = 0.
Por lo tanto la derivada parcial evaluada arriba debe ser no
negativa

34
Con todos estos argumentos se prueba que la primera condición (8),
análogamente se prueba (9)
Así se ha probado que
𝑙𝑖𝑚𝑡→∞
𝐿�̃�𝛽 (𝝀𝒕) = 𝐿�̃�
𝛽(�̂�) = 𝑚𝑖𝑛𝜆
𝐿�̃�𝛽(𝝀)
□

35
CAPÍTULO 4
MODELADO DE LA DISTRIBUCIÓN DE LOS CASOS
DE PALUDISMO EN ECUADOR CONTINENTAL
UTILIZANDO MaxEnt en TerrSet
4.1. Introducción
TerrSet es un sistema integrado de software geoespacial para monitorear y
modelar el sistema de tierra para el desarrollo sostenible. Una de las
características de TerrSet es una aplicación vertical denominada Hábitat
and Biodiversity Modeler que tiene como propósito la evaluación del hábitat,
el análisis de patrones espaciales y el modelado de biodiversidad (Clark
Labs, 2017).
Es necesario mencionar que TerrSet brinda una interfaz para MaxEnt que
es un programa desarrollado en el lenguaje JAVA (es un programa fácil de
usar), para modelar datos de la especie presente, escrito por Steven
Phillips, Miroslav Dudík y Robert Schapire, con el apoyo de AT&T Labs-
Investigación de la Universidad de Princeton, y el centro para la
biodiversidad y conservación, museo americano de historia natural.
El algoritmo de MaxEnt es un algoritmo de aprendizaje automático que
utiliza el principio de máxima entropía. El algoritmo usa solo datos de
presencia (reportes de paludismo) y variables predictoras, proporcionando
buenos resultados (Elith et al., 2011) con pocos datos. Esto es importante
en salud pública puesto que por presupuesto no siempre se puede
conseguir todos los datos necesarios para correr un modelo.
MaxEnt asume una distribución de la especie en cada celda de la cuadricula
luego mediante una transformación se incluyen variables predictoras al
modelo llamadas características que restringen la distribución. En la
parametrización de entrada del modelo, se puede manejar el factor de
regularización y las funciones de ajuste de cada variable.
El área de estudio comprende a Ecuador continental esta área contiene
algunas zonas que poseen las características climáticas y/o geográficas y/o
socio-económica favorables para la distribución del paludismo.
A continuación se esquematiza la forma en que se organizará este
capítulo.

36
Figura 6. Proceso para aplicar MaxEnt
4.2. Determinación de variables explicativas y preparación de capas
Según Merow (2013), MaxEnt se usa para abordar problemas con mayor
complejidad no solo para simples análisis exploratorios por esto es
importante asegurar de que las decisiones de modelado sean basadas
biológicamente por hipótesis específicas, objetivos de estudio y
consideraciones específicas de la enfermedad.
La transmisión del paludismo se ocasiona principalmente por la picadura
del mosquito infectado Anopheles hembra, pero se relaciona con otros
factores relacionados al paracito, al vector, al huésped humano o al medio
ambiente. Estos mosquitos sobreviven en agua dulce de poca profundidad
(ej. cultivos de arroz) o aguas pantanosas; también es importante el
desarrollo del vector que está ligado a las condiciones climáticas
(precipitación, temperatura, índice de vegetación) y condiciones socio-
económicas pueden ser no tan relacionadas como con el vector de
transmisor de Dengue pero se ha visto algunas relaciones.
Se usan 10 variables determinantes o capas que se encuentran en el mismo
formato matricial (o formato raster), este consta de celdas (o pixeles)
organizadas en filas y columnas, cada celdas contienen un valor que
representa la información de la variable (temperatura, precipitación,
densidad de población, etc.) estas capas tienen una resolución de 100
metros (7400 filas y 6800 columnas).
Determinar variables
explicativas
Obtener registros de casos reportados por
paludismo Aplicar MaxEnt
Validar el resultado

37
Preparación de capas
4.2.1. Predictores medioambientales
La preparación de las capas precipitación, temperatura y el índice de vegetación consiste en calcular la anomalías estandarizadas con respecto al ciclo anual,
𝑎𝑛𝑜𝑚𝑎𝑙í𝑎 𝑒𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑖𝑧𝑎𝑑𝑎 =𝑥 − �̅�
𝑠𝑥
como resultado obtenemos gran cantidad (por el periodo elegido) de patrones irregulares pero repetitivos en espacio y tiempo, por esta razón se aplica un análisis de componentes principales (PCA) del cual se toma las dos primeras componentes que resumen la información obteniendo así por cada predictor medioambiental dos entradas (excepto la altura); la altura no necesita una preparación especial (EpiSIG, 2017).
Análisis en componentes principales:
Precipitación Componente % de variación
1 20,361446
7400 fila
s
6800 columnas
Pixel 100m
100m
Figura 7. Dimensión para Ecuador continental a 100 metros. Rejilla de 6800 columnas por 7400 filas.

38
2 13,387565
Temperatura Componente % de variación
1 11,074243
2 9,000597
Índice de vegetación Componente % de variación
1 3,217588
2 2,676063
4.2.2. Características topográficas
Las capas topográficas son categóricas por lo que se convierten en
continuas, mediante un cálculo de la distancia Euclidiana entre cada celda
y la más cercana de un conjunto de características objetivo (TerrSet, 2017).
Figura 8. Distancia a los cultivos de arroz (m). El color rojo indica mayor distancia a los cultivos, conforme cambia de tonalidad a negro la distancia disminuye.
Figura 9. Distancia a pantanos (m). El color rojo indica mayor distancia a los pantanos, conforme cambia de tonalidad a negro la distancia disminuye.
Figura 10. Distancia a vías (m). El color rojo indica mayor distancia a las vías, conforme cambia de tonalidad a negro la distancia disminuye.
4.2.3. Determinantes sociales
Se toman dos variables del censo de población y vivienda 2010 del INEC:

39
El hacinamiento (número de habitante por dormitorio) se calcula como:
la relación entre el número de personas habitando la vivienda sobre el
número de dormitorios que hay en la vivienda (sin contar la cocina, el
baño y cuartos de negocio) (EpiSIG, 2017). Según INEC se considera
que una casa esta hacinada cuando hay más de 3 personas promedio
por dormitorio.
Figura 11. Zonas que se consideran con viviendas hacinadas
Y el analfabetismo. La tasa de analfabetismo se calcula como la división
entre el número de personas que no saben leer ni escribir para la
población (EpiSIG, 2017).
Resumen de las variables seleccionadas:
MEDIOAMBIENTALES
# Temática Periodo Fuente de
procesamiento
01 Altitud 2000 EpiSIG
02 Precipitación 2004-2015 por mes EpiSIG
03 Temperatura 2004-2015 por mes EpiSIG
04 Vegetación 2004-2015 por mes EpiSIG
Figura 12. Altitud (m). El color rojo indica mayor altitud, conforme cambia de tonalidad a negro la altitud baja.
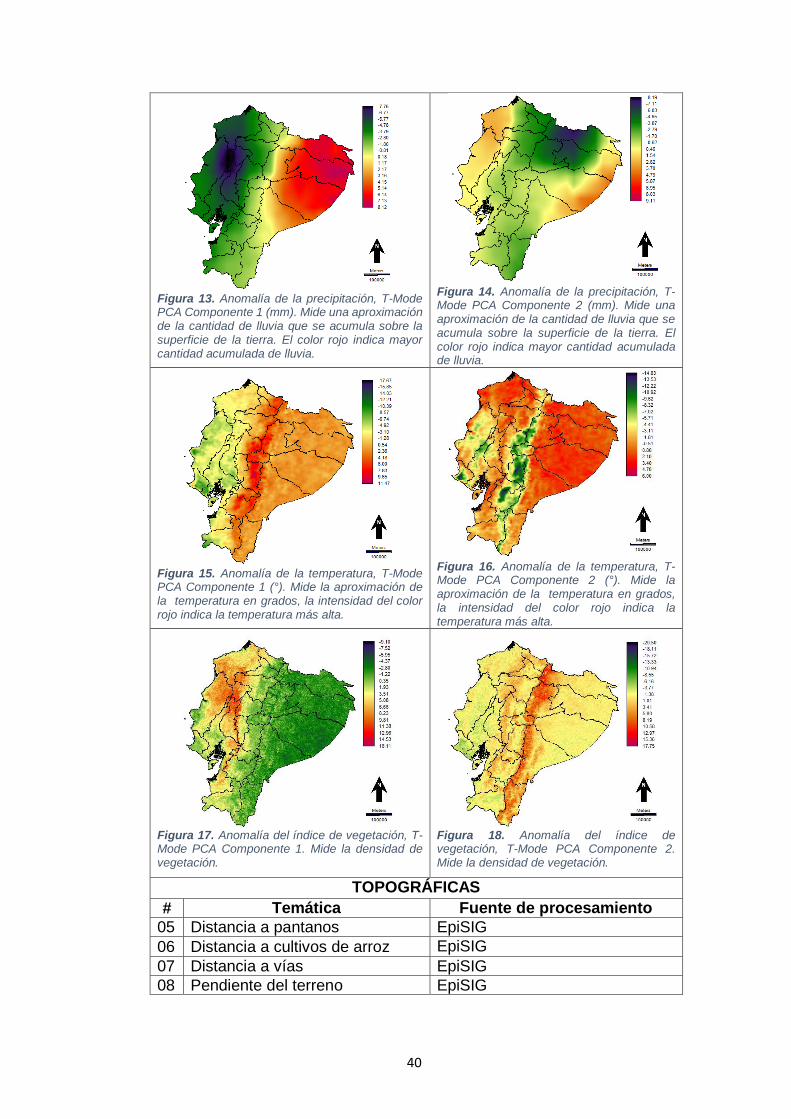
40
Figura 13. Anomalía de la precipitación, T-Mode PCA Componente 1 (mm). Mide una aproximación de la cantidad de lluvia que se acumula sobre la superficie de la tierra. El color rojo indica mayor cantidad acumulada de lluvia.
Figura 14. Anomalía de la precipitación, T-Mode PCA Componente 2 (mm). Mide una aproximación de la cantidad de lluvia que se acumula sobre la superficie de la tierra. El color rojo indica mayor cantidad acumulada de lluvia.
Figura 15. Anomalía de la temperatura, T-Mode PCA Componente 1 (°). Mide la aproximación de la temperatura en grados, la intensidad del color rojo indica la temperatura más alta.
Figura 16. Anomalía de la temperatura, T-Mode PCA Componente 2 (°). Mide la aproximación de la temperatura en grados, la intensidad del color rojo indica la temperatura más alta.
Figura 17. Anomalía del índice de vegetación, T-Mode PCA Componente 1. Mide la densidad de vegetación.
Figura 18. Anomalía del índice de vegetación, T-Mode PCA Componente 2. Mide la densidad de vegetación.
TOPOGRÁFICAS
# Temática Fuente de procesamiento
05 Distancia a pantanos EpiSIG
06 Distancia a cultivos de arroz EpiSIG
07 Distancia a vías EpiSIG
08 Pendiente del terreno EpiSIG

41
Figura 19. Distancia a pantanos (m). Indica la distancia en metros desde cada pixel hasta el pantano más cercano.
Figura 20. Distancia a cultivos de arroz (m). Indica la distancia en metros desde cada pixel hasta el cultivo de arroz más cercano.
Figura 21. Distancia a vías (m). Indica la distancia en metros desde cada pixel hasta la vía más cercana.
Figura 22. Pendiente del terreno (°). Mide el grado de inclinación del terreno.
SOCIO-ECONÓMICAS
# Temática Periodo Fuente de
procesamiento
09 Hacinamiento (habitantes por dormitorio)
2010 EpiSIG
10 Analfabetismo 2010 EpiSIG
Figura 23. Hacinamiento. Indica la cantidad de personas por dormitorio. Se considera hacina
Figura 24. Analfabetismo. Indica la proporción del total de dormitorio para el total de personas.
4.3. Registros de casos reportados por paludismo
La base ViEpi no cuenta con la ubicación donde el paciente fue infectado
por paludismo, se cuenta con un valor totalizado de casos por unidad

42
operativa donde fueron atendidos, estos datos no dan información espacial
real por tal motivo los datos han sido desagregados por sector censal (el
método en proceso de publicación por EpiSIG). Por criterios médicos sería
de mayor aportación al modelo filtrar los casos por fecha de inicio de
síntomas, que hayan sido registrados en el año 2014.
Solo presencia
Variables Tipo Fuente de
procesamiento Periodo
Resolución espacial
Paludismo Booleana EpiSIG 2014 (Fecha de inicio de síntomas)
Parroquia (domicilio)
4.4. Aplicación del modelo
4.4.1. Parametrización de MaxEnt, Ganancia y Formato de Salida
Usualmente la parametrización predeterminada da como resultado un buen
modelo según Phillips (2008), sin embargo por varias simulaciones hechas,
se ha cambiado ciertos parámetros de la configuración para tener un
modelo que se ajusta mejor a la realidad.
Los siguientes parámetros se dejan por default:
Pestaña Básica: Random Seed, Write clamp grid when projecting, Do
MESS analysis when projecting.
Pestaña avanzada: Extrapolate, Do clamping, Apply threshold rule, Bias file.
Configuración de parámetros: Selección de características (o features), es la selección de la forma en
que MaxEnt va a tratar cada característica.
La opción elegida es “características automáticas”. Esta opción automatiza
el trabajo de elegir el tipo de característica utilizando un algoritmo, toma una
combinación de los distintos tipos de características para cuando se ajusta
al modelo:
Linear features = datos brutos no transformados
Quadratic features = valores de datos al cuadrado
Product features = producto de dos diferentes variables
Threshold features = 0 cuando la variable es menos que el umbral y 1
cuando es mayor o igual que el umbral.
Ejemplo según Merow (2013), con la precipitación como predictor:
Linear features: se asegura que el valor promedio de la precipitación donde
se predice la aparición de la especie sea aproximado al valor promedio del
predictor en los lugares donde se registró la especie.

43
Quadratic features: restringe la variación de la precipitación donde se
predijo la aparición de la especie que coincida con la observada.
Product features: restringe a ser aproximado el valor de su covarianza de
una variable predictora con las demás variables
Threshold features: crea un predictor binario continuo que al generar una
característica cuyo valor es 0 si esta debajo del umbral y 1 arriba.
Hinge features: son como Threshold features, excepto que se utiliza una
función lineal, en lugar de una función por partes.
El rango de todas las características se transforman en [0,1] para poder ser
coeficientes comparables (Merow, Smith, & Silander, 2013).
Datos de “trasfondo” (background), MaxEnt los usa para medir la
Entropía Relativa Mínima (Elith et al., 2011). Merow (2013), menciona que
estos datos que son usados para generar una hipótesis nula, erróneamente
son confundidos con pseudo-ausencias los cuales conceptualmente son
distintos. El número máximo de puntos de background utilizado en el
modelo es de 1000 datos, añadiendo las muestras a esta selección.
Para obtener una solución MaxEnt maximiza una función llamada ganancia
(Gain), una función de máxima verosimilitud penalizada, que es una medida
de precisión de ajuste comienza en 0 e incrementa hacia una asíntota
durante la corrida. Se la define como probabilidad logarítmica promedio de
la muestras de presencia menos una constante que hace que la distribución
uniforme tenga 0 ganancia.
Definida por:
Ganancia =1
𝑚∑ 𝒛(𝑥𝑖)𝝀
𝑀
𝑖=1
suma de valores predichos en los lugares de presencia
− log ∑ 𝑄(𝑥𝑖)𝑒𝒛(𝑥𝑖)𝝀
𝑁
𝑖=1
suma de valores predichos en los lugares de background (probabilidad en todas las ubicaciones de background)
− ∑|𝜆𝑗| ∗ 𝛽 ∗ √𝑠2[𝓏𝑗]
𝑀
𝐽
𝑗=1
regularización del sobreajuste (overfitting)
𝛽: Coeficiente de regularización
𝑠2[𝓏𝑗]: Varianza de la característica 𝑗 en un lugar de presencia
𝑀: Lugares de presencia
(Merow et al., 2013).

44
La ganancia representa cuantas veces un modelo resultante de los puntos
de presencia es mejor que el modelo resultante de los puntos de trasfondo.
exp(𝑔𝑎𝑛𝑎𝑛𝑐𝑖𝑎) = máximo de 𝑣𝑒𝑐𝑒𝑠
Cuando la “Ganancia”= 0,97
exp(0,97) = 2, 6379
Figura 25. Ganancia del modelo; comienza en 0 y se incrementa hacia una asíntota mientras dura la ejecución del programa.
Hay 3 formatos de salida en MaxEnt: Logistic, Raw, Cumulative.
Merow (2013), aconseja que para obtener la probabilidad de presencia de
una especie se tome la salida logística (Logistic output), definida por
Pr (𝑦 = 1|𝑧) =𝜏𝑒𝒛𝜆−𝑟
1 + 𝜏 + 𝜏𝑒𝒛𝜆−𝑟
𝑟: Entropía relativa entre 𝑃∗(𝒛(𝑥𝑖)) y distribución empírica 𝑄(𝒛(𝑥𝑖))
𝜏: Probabilidad de presencia en los sitios con “típicas” condiciones para la
especie (𝜏 = 0,5 es el valor predeterminado) (Elith et al., 2011)
𝑧: Vector de características
𝜆: Vector (buscado) de coeficientes de regresión
En la siguiente figura se observa el mapa de probabilidad de presencia de
Paludismo en Ecuador Continental mediante la salida Logística de MaxEnt:

45
Figura 26. Salida Logística de MaxEnt
Se identifica con una división administrativa a las zonas que están divididas,
es decir, se incluye los nombres de provincias para poder identificar las
zonas.
El color rojo muestra las áreas con mejores condiciones para contraer
paludismo; Esmeraldas es la zona que presenta la coloración más intensa,
es decir, la alta probabilidad predicha de las mejores condiciones para tener
mayores reportes de paludismo; para tener una mejor ubicación de esta
zona se nombra las parroquias que están pintadas más fuerte, San
Lorenzo, Ancon, Mataje, Tululbi, Pampanal de Bolívar, Tambillo, Calderón,
Carondelet, Santa Rita, conforme se degrada el color rojo la probabilidad
va disminuyendo hasta llegar al color blanco que indica una probabilidad
de 0, como se nota con mayor cantidad la sierra tiene dicha probabilidad.
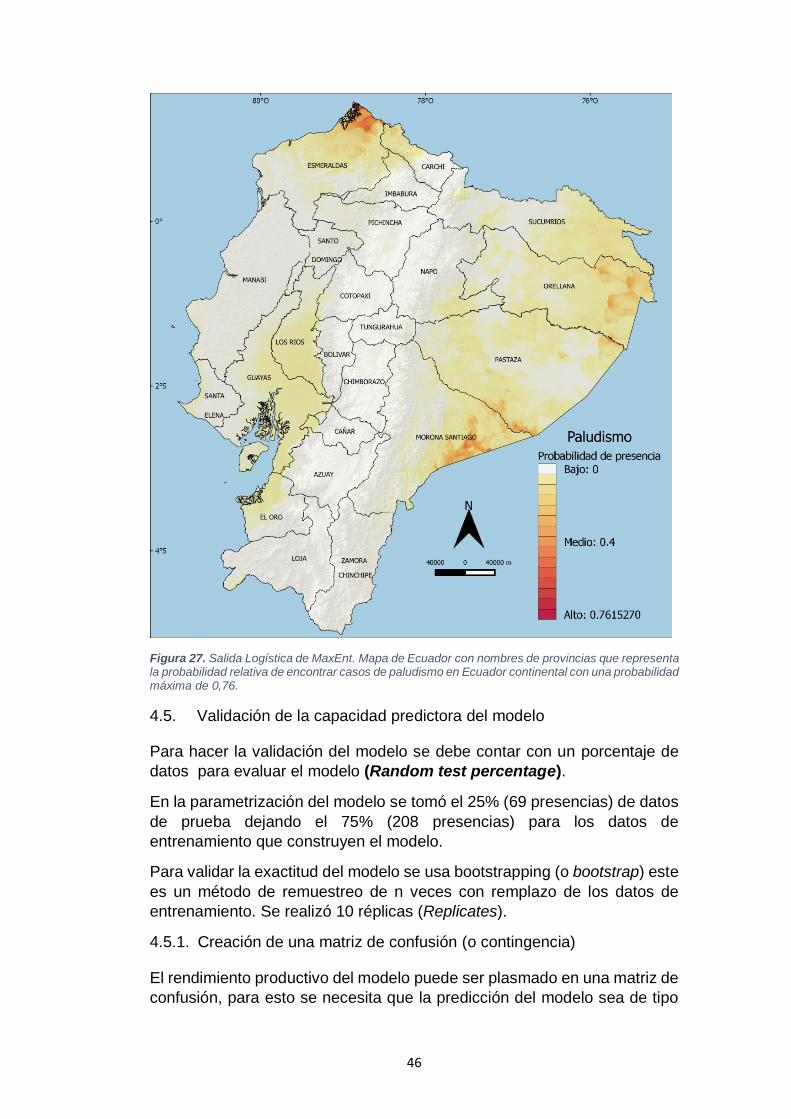
46
Figura 27. Salida Logística de MaxEnt. Mapa de Ecuador con nombres de provincias que representa la probabilidad relativa de encontrar casos de paludismo en Ecuador continental con una probabilidad máxima de 0,76.
4.5. Validación de la capacidad predictora del modelo
Para hacer la validación del modelo se debe contar con un porcentaje de
datos para evaluar el modelo (Random test percentage).
En la parametrización del modelo se tomó el 25% (69 presencias) de datos
de prueba dejando el 75% (208 presencias) para los datos de
entrenamiento que construyen el modelo.
Para validar la exactitud del modelo se usa bootstrapping (o bootstrap) este
es un método de remuestreo de n veces con remplazo de los datos de
entrenamiento. Se realizó 10 réplicas (Replicates).
4.5.1. Creación de una matriz de confusión (o contingencia)
El rendimiento productivo del modelo puede ser plasmado en una matriz de
confusión, para esto se necesita que la predicción del modelo sea de tipo

47
binario, así, 1 para zonas adecuadas y 0 para zonas no adecuadas, para
hacer esta categorización se usa un umbral de presencia.
Datos de prueba
+ -
Datos de entrenamiento
Especie predicha
+ Verdadero
positivo (a)
Falso positivo
(b)
Especie no predicha
- Falso
negativo (c)
Verdadero negativo
(d)
Figura 28. Matriz de confusión
La matriz de confusión trabaja con las frecuencias de cada una de las 4
posibles predicciones y nos calcula el error que el modelo cometió en su
predicción. Los errores son:
El error por comisión es dado por los falsos positivos (b) este puede ser real
o fingido puesto que puede ser un sitio idóneo para la aparición o una sobre-
estimación del modelo.
El erro por omisión es dado por los falsos negativos (c) este es el más
importante puesto que puede predecir no presencia en lugares donde las
condiciones son idóneas para la especie.
Al usar solo puntos de presencia se puede calcular:
𝑆𝑒𝑛𝑠𝑖𝑏𝑖𝑙𝑖𝑑𝑎𝑑 =𝑎
(𝑎 + 𝑐) (Fracción de verdaderos
positivos) ( 12)
𝑇𝑎𝑠𝑎 𝑑𝑒 𝑜𝑚𝑖𝑠𝑖ó𝑛 =𝑎
(𝑎 + 𝑐) (Fracción de falsos positivos) ( 13)
𝑆𝑒𝑛𝑠𝑖𝑏𝑖𝑙𝑖𝑑𝑎𝑑 + 𝑇𝑎𝑠𝑎 𝑑𝑒 𝑜𝑚𝑖𝑠𝑖ó𝑛 = 1
El cálculo de la Especificidad es importante en la selección del umbral y en el análisis de la curva ROC:
𝐸𝑠𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑑𝑎𝑑 =𝑑
(𝑏 + 𝑑)
(Fracción de verdaderos negativos)
( 14)
Hay diferentes métodos para la selección del umbral de presencia:

48
Figura 29. Umbrales de presencia
Una de las réplicas nos da el umbral “Equal test sensitivity and specificity”
con el valor más alto y el valor más pequeño se obtiene con el umbral “Fixed
cumulative value 1” para clasificar la presencia.
4.5.2. AUC (Area Under The Curve) del modelo bajo la curva ROC
(Receiver Operating Characteristic)
Como la predicción es de tipo binarias no cuenta con toda la información
por esta razón es mejor tener una solo medida de la asertividad de la
predicción, dentro de todo el rango de umbrales posibles.
Esta medida es el AUC bajo la curva ROC es representada en la siguiente
figura:
Figura 30. Curva operacional ROC y el AUC del modelo.
Frac
ció
n d
e ve
rdad
ero
s p
osi
tivo
s
Fracción de falsos positivos
Clasificación
perfecta
Mejor
Peor

49
representa la relación entre el porcentaje correcto de presencia predicha
versus 1 menos el porcentaje correcto de ausencias predichas (Hanley,
Mcneil, & Ph, 1982). 1 − 𝐸𝑠𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑑𝑎𝑑 es un arreglo para que la
𝑆𝑒𝑛𝑠𝑖𝑏𝑖𝑙𝑖𝑑𝑎𝑑 y la 𝐸𝑠𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑑𝑎𝑑 varíen en la misma dirección cuando se
ajusta el umbral. Mientras más se acerque la curva ROC al eje de las 𝑌 la
modelación es mejor y caso contrario se acercara a la línea de color negro
(Random prediction).
El promedio ROC de entrenamiento para las iteraciones es 0,914 y la
desviación estándar es 0,009. Según la clasificación la precisión del test es
muy bueno por encontrarse en el rango de 0,9 a 0,97.
La dependencia de la predicción con las variables predictoras se lo puede
ver con las curvas de respuesta de MaxEnt. En el eje "𝑋" indica la
variación de la variable predictora y en el eje "𝑌" representa la probabilidad
predicha de presencia de paludismo en las condiciones idóneas, con las
variables predictoras de acuerdo al cálculo de su valor promedio.
Curva de respuesta del hacinamiento; la probabilidad de presencia de reportes de la enfermedad es más alta en 2 por ser lo un número común en zonas urbanas. Se presenta un decrecimiento al contar con viviendas hacinadas (>3 habitantes por dormitorio) que tiene mayor probabilidad de ser encontrado en zonas rurales.
Curva de respuesta del analfabetismo; la probabilidad de reportar paludismo se presenta mayormente en zonas con más cantidad de personas de edad mayor a 15 años, que saben leer y escribir, esto se pueden interpretar como zonas urbanas, mientras que en zonas rurales no se ve una probabilidad marcada de reportes.
Curva de respuesta de la pendiente; entre menos sea la inclinación es decir en zonas planas (no laderas) mayor es la probabilidad de presencia de casos reportados.
Curva de respuesta de la distancia a cultivos de arroz; la probabilidad de encontrar reportes de paludismo es más alta, cuando más alejado se encuentre de los cultivos de arroz.

50
Curva de respuesta de la distancia a vías; mientras más cercano se encuentre a las vías la probabilidad de reportes de paludismo aumenta.
Curva de respuesta de la altitud; la probabilidad de aparición de la enfermedad reportada aumenta con valores bajos de altitud, es decir, en zonas bajas del Ecuador se reportan más casos de paludismo.
Figura 31. Curva de respuesta de las variables predictoras que se utiliza para el modelado de la distribución de paludismo en el Ecuador continental.

51
CONCLUSIONES Y RECOMENDACIONES
6.1. Conclusiones
La Entropía en teoría de la información es una medida de incertidumbre o
la medida de la información promedio por cada símbolo proporcionado de
una fuente de información.
El análisis convexo y la solución del problema de optimización en la familia
de distancias de Bregman sujeto a ciertas restricciones lineales conduce a
un modelo matemático específicamente a un modelo estadístico el cual es
de principal interés en aplicaciones de estadística o machine learning. La
demostración del teorema de dualidad conecta el problema primal al
problema dual, lo que permite que la solución se la pueda expresar en
términos geométricos.
Basándose en conocimiento de profesionales de salud que han sido
adquiridos académica o empíricamente en relación a la enfermedad se
definió las variables predictoras de diferentes ámbitos medio-ambientales
como la altura, precipitación y temperatura, socio-económicos como el
hacinamiento, el analfabetismo, topográficos como la pendiente del terreno,
distancia a los pantanos y cultivos de arroz, que se encuentran relacionadas
con las características óptimas para la aparición de la enfermedad, dando
un modelo muy certero comparable con la realidad.
El vector Anopheles es un vector rural es decir su hábitat se encuentra
alejado de las sitios con mayor población por lo que se justifica una
resolución espacial de 100 metros.
El análisis del modelo presenta que las variables ambientales y topográficas
influyen en la propagación de la enfermedad, pero a pesar que el vector no
tenga un comportamiento urbano las variables socioeconómicas de igual
manera aportan información para poder reconocer los sitios donde se
puede dar un reporte masivo de casos autóctonos o importados, que por lo
general son sitios ubicados en las zonas urbanas; cabe mencionar que por
otras simulaciones hechas se descartó la variable de ”densidad
poblacional” porque alteraba el modelo sesgando la predicción en base a
la población.
Esta modelación sirve como ayuda para tomar decisiones al distribuir
recursos humanos o económicos, para la prevención del paludismo; incluso
para tener una idea donde ubicar centros de atención médica.
El mapa de riego de paludismo no nos indica la población que está en
riesgo, puesto que algunas zonas favorables para la presencia de la
enfermedad no están habitadas por lo que con dificultad el paludismo se
pueda convertir en una epidemia.

52
Se observa que las provincias con mayor probabilidad de presencia
cuentan con pequeñas zonas habitadas, pero se debe tomar medidas de
prevención en las provincias con mayor densidad poblacional que cuenten
con las condiciones óptimas para contraer la enfermedad (Los Ríos,
Guayas, El Oro y partes de las provincias aledañas) convirtiéndose en
zonas de cuidado epidemiológico.
6.2. Recomendaciones
La disponibilidad libre de los geodatos, datos socio-económicos, imágenes
satelitales, el software MaxEnt, facilita el uso a profesionales de la salud
para que mantengan un monitoreo constante de cualquier enfermedad,
pero se necesita contar con acceso a las bases de datos de salud de forma
libre sin perder la confidencialidad del paciente, puesto que se necesita
campos específicos para la modelación en los cuales no intervienen ningún
dato de identificación del paciente.
Las bases de salud para el análisis espacial deberían incluir coordenadas
de la ubicación del trabajo, escuela, vivienda, en general de sitios donde el
paciente puede haber estado la mayor cantidad de su tiempo y un campo
donde almacene las coordenadas donde el paciente responda donde cree
que pudo haberse contagiado de la enfermedad esto ayudará a una
dispersión espacial más real.
El modelamiento puede ser mejorado en su parametrización en un futuro
para encontrar una predicción más precisa, pues al cambiar las diferentes
configuraciones del programa se obtienen diferentes escenarios del
fenómeno a modelar, hay que tener en cuenta que estos escenarios
dependen del objetivo de estudio que se persigue. Sin embargo hay que
recalcar que las opciones por defecto modelan y persiguen la probabilidad
de presencia en este caso del Paludismo en el Ecuador.
Esta modelación se podría mejorar su resolución espacial (10 metros), y de
igual manera contar con mayor información temporal en los datos de
presencia, es decir, contar con más datos de distintos años de reportes de
paludismo.
Encontrar una manera para difundir resultados de las modelaciones de una
forma rápida y fácil a las autoridades pertinentes de salud pública
encargadas de tomar decisiones.

53
BIBLIOGRAFÍA
Aliprantis, C., & Border, K. (2006). Infinite Dimensional Analysis, 251–309. https://doi.org/10.1007/3-540-29587-9_7
Anderson, R. P., & Martínez-Meyer, E. (2004). Modeling species’ geographic distributions for preliminary conservation assessments: An implementation with the spiny pocket mice (Heteromys) of Ecuador. Biological Conservation, 116(2), 167–179. https://doi.org/10.1016/S0006-3207(03)00187-3
Basu, A. (2002). Introduction To Stochastic Process, 432.
Capurro Rafael. (2003). The Concept of Information. Retrieved July 23, 2017, from http://www.capurro.de/infoconcept.html
Cifuentes, S. G., Trostle, J., Trueba, G., Milbrath, M., Baldeón, M. E., Coloma, J., & Eisenberg, J. N. S. (2013). Transition in the cause of fever from malaria to dengue, Northwestern Ecuador, 1990-2011. Emerging Infectious Diseases, 19(10), 1642–1645. https://doi.org/10.3201/eid1910.130137
Della Pietra, S., Della Pietra, V., & Lafferty, J. (2001). Duality And Auxiliary Functions For Bregman Distances.
Dudík, M., Phillips, S. J., & Schapire, R. E. (2004). Performance Guarantees for Regularized Maximum Entropy Density Estimation, 472–486. https://doi.org/10.1007/978-3-540-27819-1_33
Elith, J., Phillips, S. J., Hastie, T., Dudík, M., Chee, Y. E., & Yates, C. J. (2011). A statistical explanation of MaxEnt for ecologists. Diversity and Distributions, 17(1), 43–57. https://doi.org/10.1111/j.1472-4642.2010.00725.x
Fithian, W., & Hastie, T. (2013). Finite-sample equivalence in statistical models for presence-only data. Annals of Applied Statistics, 7(4), 1917–1939. https://doi.org/10.1214/13-AOAS667
Grinstead, C. M., & Snell, J. L. (2007). Introduction to Probability. Swarthmore College, 1–520. https://doi.org/http://dx.doi.org/10.1016/S1363-
4127(97)81322-2
Gwitira, I., Murwira, A., Zengeya, F. M., Masocha, M., & Mutambu, S. (2015). Modelled habitat suitability of a malaria causing vector (Anopheles arabiensis) relates well with human malaria incidences in Zimbabwe. Applied Geography, 60, 130–138. https://doi.org/10.1016/j.apgeog.2015.03.010
Hanley, a, Mcneil, J., & Ph, D. (1982). under a Receiver Characteristic. Radiology, 143, 29–36. https://doi.org/10.1148/radiology.143.1.7063747
Hartley, R. V. L. (1928). Transmission of Information. Bell System Technical Journal. https://doi.org/10.1002/j.1538-7305.1928.tb01236.x
Krisher, L. K., Krisher, J., Ambuludi, M., Arichabala, A., Beltrán-Ayala, E., Navarrete, P., … Stewart-Ibarra, A. M. (2016). Successful malaria elimination in the Ecuador–Peru border region: epidemiology and lessons learned. Malaria Journal, 15(1), 573. https://doi.org/10.1186/s12936-016-1630-x
Mateo, R. G., Felicísimo, Á. M., & Muñoz, J. (2011). Modelos de distribución de especies: Una revisión sintética. Revista Chilena de Historia Natural, 217–

54
240. https://doi.org/10.4067/S0716-078X2011000200008
Merow, C., Smith, M. J., & Silander, J. A. (2013). A practical guide to MaxEnt for modeling species’ distributions: What it does, and why inputs and settings matter. Ecography, 36(10), 1058–1069. https://doi.org/10.1111/j.1600-0587.2013.07872.x
OMS. (n.d.). OPS/OMS Ecuador - ECUADOR GANA PREMIO al “Campeón de la malaria en las Américas.” Retrieved June 17, 2017, from http://www.paho.org/ecu/index.php?option=com_content&view=article&id=188:ecuador-gana-premio-campeon-malaria-americas&Itemid=360
OMS. (2017a). Alerta Epidemiológica Aumento de casos de malaria. Retrieved from http://www.paho.org/hq/index.php?option=com_docman&task=doc_view&Itemid=270&gid=38148&lang=es
OMS, A. R. . (2017b). Respuesta mundial para el control de vectores 2017 – 2030, 2030. Retrieved from http://apps.who.int/gb/ebwha/pdf_files/WHA70/A70_26Rev1-sp.pdf
Phillips, S. (2008). A Brief Tutorial on Maxent. AT&T Research, 1–38. https://doi.org/10.4016/33172.01
Phillips, S. J., & Dudík, M. (2008). Modeling of species distribution with Maxent: new extensions and a comprehensive evalutation. Ecograpy, 31(December 2007), 161–175. https://doi.org/10.1111/j.2007.0906-7590.05203.x
Rincón, L. (2012). Introducción a los procesos estocásticos , 1–328. Retrieved from http://users/Natch- Nacht/Documents/Bibliotecas/Mendeley/Rinc%7B’o%7Dn/Unknown/Rinc%7B’o%7Dn - 2012 - Introducci%7B’o%7Dn a los procesos estoc%7B’a%7Dsticos.pdf
Rockafellar, R. (1970). Convex Analysis, 472. https://doi.org/10.1515/9781400873173
Shannon, C. E. (1948). A mathematical theory of communication. The Bell System Technical Journal, 27(July 1928), 379–423.
https://doi.org/10.1145/584091.584093
Shannon, C. E., & Weaver, W. (1964). THE MATHEMATICAL THEORY OF COMMUNICATION. Retrieved from http://www.magmamater.cl/MatheComm.pdf
Taylor, H. M., & Karlin, S. (2010). An Introduction to Stochastic Modeling. Star. https://doi.org/10.1016/B978-0-12-684880-9.50006-X
Tyrrell Rockafellar, R. (1970). Convex Analysis, 472. https://doi.org/10.1515/9781400873173












