







Idiomas
Páginas
Jurídico


UNIVERSIDAD POLITÉCNICA ESTATAL DEL CARCHI
INGENIERÍA EN COMERCIO EXTERIOR Y NEGOCIACIÓN
COMERCIAL INTERNACIONAL
MÓDULO:
ESTADÍSTICA INFERENCIAL
DOCENTE:
MSC. JORGE POZO
NOMBRE:
STALIN GOYES
NIVEL:
SEXTO “A”
FECHA DE ENTREGA:
28/JUL/2012

1. TEMA
Manejo del SPSS Statistics en la Estadística Inferencial
2. PROBLEMA
El mal manejo del SPSS Statistics no le ha permitido al estudiante
utilizarlo para resolver de forma rápida problemas estadísticosaplicados al
Comercio Exterior.
3. ABSTRACT
CORRELATION AND REGRESSION
The correlation and linear regression are closely related. Both involve the
relationship between two or more variables. The correlation is concerned
primarily to establish whether a relationship exists and determining its
magnitude and direction, whereas the regression is primarily responsible
to the ratio used to make a prediction. (Spiegel, 1992)
HYPOTHESIS TESTING
It is also called hypothesis testing or hypothesis dócima are procedures
used to determine whether it is reasonable or correct, accept that the
statistic obtained in the sample population may come with a parameter,
the formulation in Ho.
As a result of hypothesis testing to accept or reject Ho. If we accept Ho,
we agree that the sampling error (random), by itself, can lead to the value
of the statistic that causes the difference between this and the parameter.
If we reject Ho, we agree that the difference is so great that we are the

result of sampling error (random) and conclude that the statistical sample
from a population that has the parameter studied. (Levin, 2010)
• Null hypothesis: It is a hypothesis that says the opposite of what you
want to try. It assumes that the parameter of the population being studied,
has a certain value. (Levin, 2010)
• Alternative hypothesis: It is a hypothesis different from the null
hypothesis. Express what we really believe is feasible, ie, is the research
hypothesis. Is designated by the symbol H1. (Levin, 2010)
• Error type 1: It consists in rejecting the null hypothesis when in fact it
should be rejected. Because it is true. The probability of committing Type I
error is called alpha. (Levin, 2010)
• Error Type 2:consists nonrejection not reject Ho when it should be
rejected as false. The probability of making type two error is called beta.
(Levin, 2010)
STUDENT T TEST.
In probability and statistics, distribution (Student t) is a probability
distribution that arises from the problem of estimating the mean of a
normally distributed population when the sample size is small.
Occurs naturally when performing the Student t test to determine
differences between two sample means and to build the confidence
interval for the difference between the means of two populations is
unknown when the standard deviation of a population and it must be
estimated from data of a sample. (Spiegel, 1992)

CHI SQUARE
It is a statistic that provides a basis for a nonparametric test called chi-
square test that is used especially for qualitative variables, ie variables that
lack of unity and therefore their values can not be expressed numerically.
The values of these variables are categories that only serve to classify the
elements of the universe of study. Can also be used for quantitative
variables, transforming previously by qualitative ordinal variables. (Spiegel,
1992)
VARIANCE
In probability theory, the variance (which is usually represented as) of a
random variable is a measure of dispersion defined as the expectation of
the square of the deviation of that variable from its mean.
Is measured in units other than those of the variable. For example, if the
variable measuring a distance in meters, the variance is expressed in
meters squared. The standard deviation is the square root of the variance,
is an alternative measure of dispersion expressed in the same units of
data from the variable under study. The variance is the minimum value 0.
Keep in mind that the variance can be strongly influenced by outliers and
are not recommended for use when the distributions of the random
variables have heavy tails. In such cases we recommend the use of other
more robust measures of dispersion.

4. OBJETIVOS
4.1. OBJETIVO GENERAL
Utilizar el SPSS Statisticspararesolver problemas aplicando métodos
estadísticos como la correlación y regresión lineal, prueba de hipótesis, t
de student, chi cuadrado y varianza.
4.2. OBJETIVOS ESPECÍFICOS
Investigar la utilizacióndel SPSS Statistics para resolver problemas
estadísticos
Analizar las opciones que tiene SPSS Statistics que se puedan
utilizar en la Estadística Inferencial.
Resolver problemas de Comercio Exterior a través delSPSS
Statistics utilizandométodos estadísticos como la correlación y
regresión lineal, prueba de hipótesis, t de student, chi cuadrado y
varianza.
5. JUSTIFICACIÓN
La presente tarea es realizada con la finalidad de conocer la importancia
del manejo adecuado delSPSS Statistics para resolución de problema del
contexto en la Estadística Inferencial en la cual se pueden utilizar
diferentesmétodos como la correlación y regresión lineal, prueba de
hipótesis, t de student, chi cuadrado y varianza; de esta manera se
podrán realizar conclusiones o inferencias de una forma más rápida para
la toma de decisiones, como también un análisis de datos reales donde
se pondrá en evidencia las relaciones que existen entre las variables
Es decir con el estudio de diferentes estadísticos en programas
informáticos el estudiante podrá realizar análisis simultáneos de una

manera ágil, en donde las dos variables bidimensionales pueden ser:
producción y consumo; ventas y utilidades; gastos en publicidad y valor en
ventas; salarios altos y horas de trabajo; salarios y productividad; ingresos
y gastos; etc.
Además el optimismo sobre el afortunado futuro basado en la Introducción
de la Tecnologías de la Información y la Comunicación (TIC) en el entorno
educativo está plenamente justificado, porque esta introducción es un
objetivo educacional en sí mismo, para lograr la inmersión de varias
ciencias que hoy están presentes en todas las dimensiones de la vida
humana: científica, económica, social y como lo es en este caso las TICS
han sido de gran ayuda para resolver problemas de la Estadística
Inferencial, siendo esta una rama de la matemática.
6. MARCO TEÓRICO:
LA CORRELACIÓN Y REGRESIÓN LINEAL
La correlación y regresión lineal están muy relacionadas entre sí. Ambas
implican la relación entre dos o más variables. La correlación se ocupa,
principalmente de establecer si existe una relación, así como de
determinar su magnitud y dirección, mientras que la regresión se encarga
principalmente de utilizar a la relación para efectuar una
predicción.(Spiegel, 1992)
PRUEBA DE HIPÓTESIS
Se llama también ensayo de hipótesis o dócima de hipótesis son
procedimientos que se usan, para determinar si es razonable o correcto,

aceptar que el estadístico obtenido en la muestra, puede provenir de la
población que tiene como parámetro, el formulado en Ho.
Como resultado de la prueba de hipótesis aceptamos o rechazamos Ho.
Si aceptamos Ho, convenimos en que el error de muestreo (al azar), por si
solo, puede dar lugar al valor del estadístico que origina la diferencia entre
este y el parámetro. Si rechazamos Ho, convenimos que la diferencia es
tan grande, que nos es fruto del error de muestreo (al azar) y concluimos
que el estadístico de la muestra no proviene de una población que tenga
el parámetro estudiado.(Levin, 2010)
Hipótesis nula: Es una hipótesis que afirma lo contrario de lo que se
quiere probar. En ella se supone que el parámetro de la población que
se esta estudiando, tiene determinado valor.(Levin, 2010)
Hipótesis alternativa: Es una hipótesis diferente de la hipótesis nula.
Expresa lo que realmente creemos es factible, es decir, constituye la
hipótesis de investigación. Se le designa por el símbolo H1.(Levin,
2010)
Error tipo 1: Consiste en rechazar la hipótesis nula cuando en
realidad no debe ser rechazado. Por ser verdadera. La probabilidad de
cometer el error tipo, se llama alfa.(Levin, 2010)
Error tipo 2: Consiste en no rechazar en no rechazar la Ho, cuando
debería ser rechazada por ser falsa. La probabilidad de cometer el
error tipo dos se llama beta. (Levin, 2010)
T DE STUDENT.
En probabilidad y estadística, la distribución (T de Student) es una
distribución de probabilidad que surge del problema de estimar la media
de una población normalmente distribuida cuando el tamaño de la
muestra es pequeño.

Aparece de manera natural al realizar la prueba t de Student para la
determinación de las diferencias entre dos medias muestrales y para la
construcción del intervalo de confianza para la diferencia entre las medias
de dos poblaciones cuando se desconoce la desviación típica de una
población y ésta debe ser estimada a partir de los datos de una
muestra.(Spiegel, 1992)
CHI CUADRADO
Es un estadístico que sirve de base para una prueba no paramétrica
denominada prueba de chi cuadrado que se utiliza especialmente para
variables cualitativas, esto es, variables que carecen de unidad y por lo
tanto sus valores no pueden expresarse numéricamente. Los valores de
estas variables son categorías que solo sirven para clasificar los
elementos del universo de estudio. También puede utilizarse para
variables cuantitativas, transformándolas, previamente, en variables
cualitativas ordinales.(Spiegel, 1992)
VARIANZA
En teoría de probabilidad, la varianza (que suele representarse como ) de
una variable aleatoria es una medida de dispersión definida como la
esperanza del cuadrado de la desviación de dicha variable respecto a su
media.
Está medida en unidades distintas de las de la variable. Por ejemplo, si la
variable mide una distancia en metros, la varianza se expresa en metros
al cuadrado. La desviación estándar, es la raíz cuadrada de la varianza,
es una medida de dispersión alternativa expresada en las mismas
unidades de los datos de la variable objeto de estudio. La varianza tiene
como valor mínimo 0.

Hay que tener en cuenta que la varianza puede verse muy influida por los
valores atípicos y no se aconseja su uso cuando las distribuciones de las
variables aleatorias tienen colas pesadas. En tales casos se recomienda
el uso de otras medidas de dispersión más robustas.(Spiegel, 1992)
DESCARGA E INSTALACIÓN DEL SPSS STATISTICS
1) Ir al link http://ibm-spss-statistics.softonic.com/descargar y hacer clic
en descargar
2) La descarga comenzará tras la lectura y aceptación del acuerdo, se
debe hacer clic en aceptar.

3) Se debe esperar diez minutos aproximadamente mientras se descarga
el SPSS Statitics
4) Aparece el cuadro de dialogo donde se debe hacer clic en “Ejecutar”
para proseguir con la ejecución de este archivo.
5) En escritorio se ha descargado el archivo comprimido, hay que
descomprimirlo y aparecerá una carpeta con el nombre “SPSS PASW”
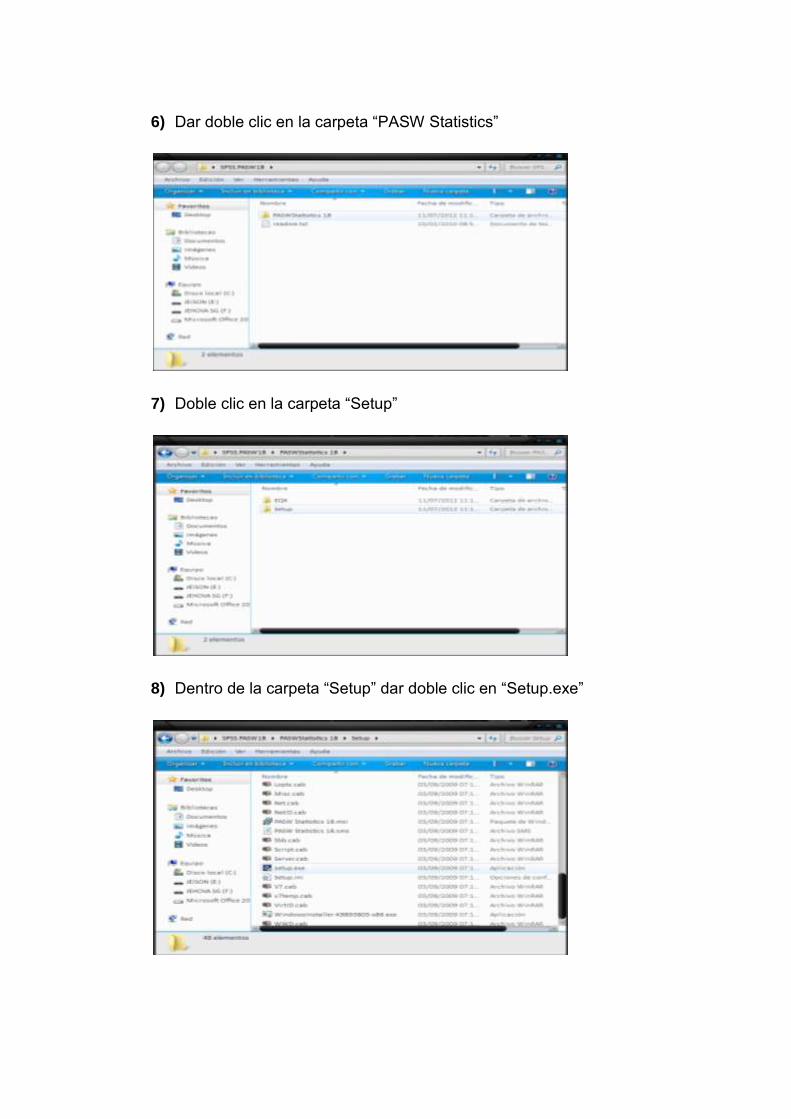
6) Dar doble clic en la carpeta “PASW Statistics”
7) Doble clic en la carpeta “Setup”
8) Dentro de la carpeta “Setup” dar doble clic en “Setup.exe”

9) Aparece el cuadro “InstallShieldWizard” y para continuar hacer clic en
siguiente.
10) Seleccionar la opción modificar y dar clic en “siguiente”.
11) Hacer clic en “ instalar” para comenzar la instalación y en
aproximadamente cinco minutos ya se podrá acceder a las bondades
del SPSS Statitics.

BREVE EXPLICACIÓN DE LA UTLILIZACIÓN DEL SPSS STATISTICS
Creación de variable
Para una mejor comprensión este link te ayudará:
http://www.youtube.com/watch?v=k8tmAvyCLq0&feature=BFa&list=LL
uAhA915jTWjdZEcZEh-3jA
Miramos la ventana que muestra las columnas y las filas denominada
data new donde se ingresan los datos, en la parte inferior izquierda se
encuentran vista de datos y vista de variables, en la de variables como
su nombre lo indica permite las variables que el usuario desee y en la
de datos se pondrán las características de dichas variables.
Ingreso de datos

Entonces construimos una base de datos y nos dirigimos a variables e
ingresamos las datos en el primer casillero de la primera columna
ingresamos el nombre de la variable sin espacios no tilde, en tipo
pondremos el tipo de datos ingresados como son fecha, cadena,
numérico entre otras, y llenamos los caracteres, vamos a utilizar
depende cuantas letras tenga la palabra a utilizar o números que
ingresemos.
Link de ayuda:
http://www.youtube.com/watch?v=otg0RqQ68sk&feature=BFa&list=LL
uAhA915jTWjdZEcZEh-3jA
Valorar variables
En valor de la variable se la realiza de la siguiente manera, damos un
clic en valor y se despliega una ventana que se puede mirar en la
imagen, en el primer casillero se coloca el código y en el segundo la
descripción y añadir y esta listo para ser usada.
Link de ayuda:
http://www.youtube.com/watch?v=WQ7RMtYkJC4&feature=BFa&list=L
LuAhA915jTWjdZEcZEh-3jA

Analizar datos
Podemos comenzar a ingresar los datos que se hayan obtenido en la
encuesta o entrevista depende del medio de recolección de datos que
utiliza el encuestador, la herramienta más utilizada es analizar ya que
esta cuenta con todas las herramientas del programa que permite
determinar el análisis correspondiente
Link de ayuda:
http://www.youtube.com/watch?v=vVPr_Oylc3s&feature=BFa&list=LLu
AhA915jTWjdZEcZEh-3jA.
EJERCICIOS EN EL SPSS E INTERPRETACIÓN DE RESULTADOS:
CORRELACIÓN Y REGRESIÓN LINEAL
Al ingresar al SPSS Statistics en la parte izquierda inferior aparece la
opción “Vista de variables” en donde se debe hacer clic para crear la
plantilla con datos año, mes, importaciones petroleras e importaciones no
petroleras que se investigaron del Banco Central del Ecuador:
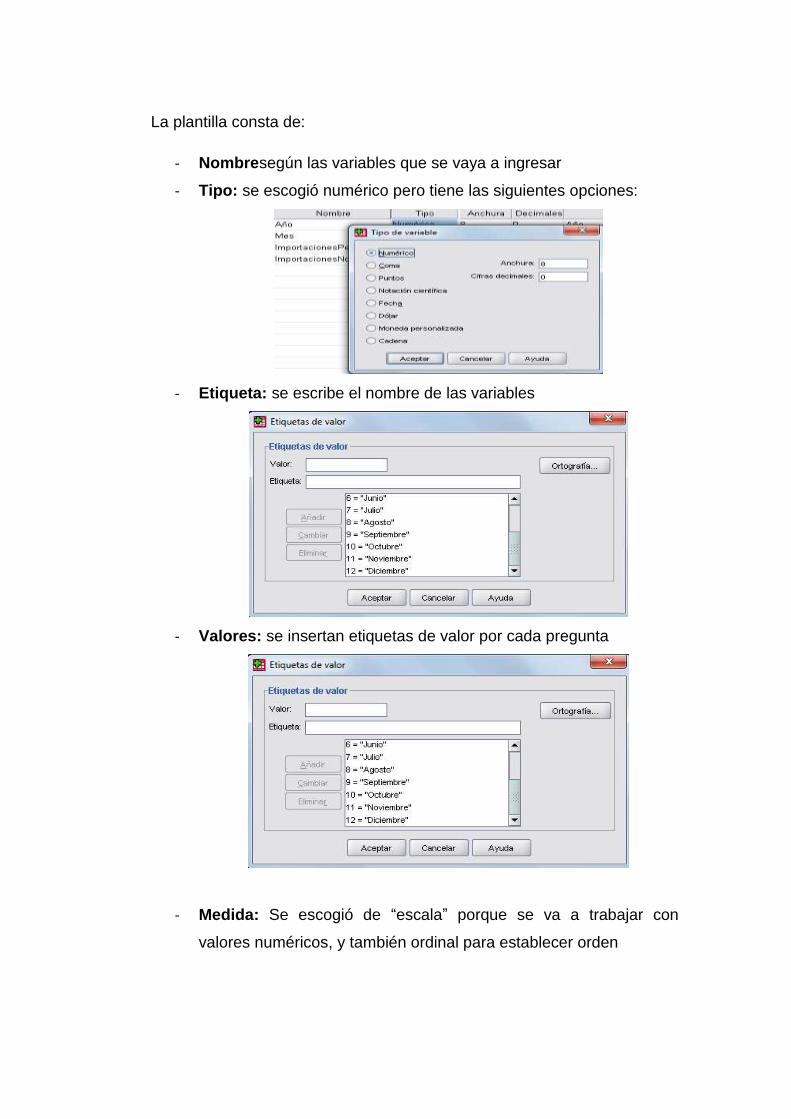
La plantilla consta de:
- Nombresegún las variables que se vaya a ingresar
- Tipo: se escogió numérico pero tiene las siguientes opciones:
- Etiqueta: se escribe el nombre de las variables
- Valores: se insertan etiquetas de valor por cada pregunta
- Medida: Se escogió de “escala” porque se va a trabajar con
valores numéricos, y también ordinal para establecer orden

Luego de haber insertado todos los datos en la parte inferior izquierda del
SPSS Statistics se escoge la opción “Vista de datos” donde se pueden
observar todas las variables insertadas y se procede a ingresar los datos
Regresión lineal
Se debe seleccionar la opción “Analizar”, luego “Regresión” y “Lineales”
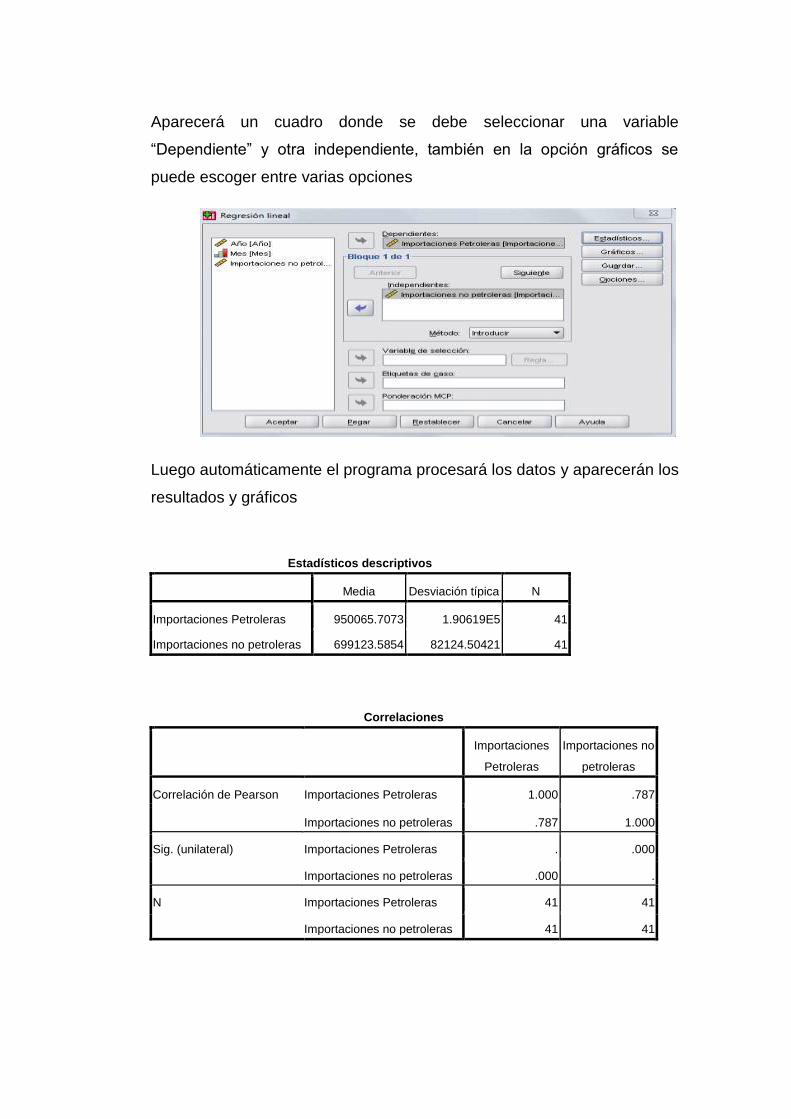
Aparecerá un cuadro donde se debe seleccionar una variable
“Dependiente” y otra independiente, también en la opción gráficos se
puede escoger entre varias opciones
Luego automáticamente el programa procesará los datos y aparecerán los
resultados y gráficos
Estadísticos descriptivos
Media Desviación típica N
Importaciones Petroleras 950065.7073 1.90619E5 41
Importaciones no petroleras 699123.5854 82124.50421 41
Correlaciones
Importaciones
Petroleras
Importaciones no
petroleras
Correlación de Pearson Importaciones Petroleras 1.000 .787
Importaciones no petroleras .787 1.000
Sig. (unilateral) Importaciones Petroleras . .000
Importaciones no petroleras .000 .
N Importaciones Petroleras 41 41
Importaciones no petroleras 41 41

Correlación
Se selecciona la opción “Analizar”, “Correlación” y “Bivariadas”
Aparecerá el cuadro de Correlaciones bivariadas, en donde se deberán
insertar las dos variables de importaciones petrolera y no petroleras

Los datos se procesarán automáticamente y aparecerán los resultados
Correlaciones
Importaciones
Petroleras
Importaciones no
petroleras
Importaciones Petroleras Correlación de Pearson 1 .787**
Sig. (bilateral) .000
N 41 41
Importaciones no petroleras Correlación de Pearson .787** 1
Sig. (bilateral) .000
N 41 41
**. La correlación es significativa al nivel 0,01 (bilateral).
Interpretación de datos:
Según los datos obtenidos en la tabla anterior se observa que el
coeficiente de Pearson es de 0,787 lo que indica que hay una relación
casi perfecta entre las variables y además los puntos están poco
dispersos.
PRUEBA DE HIPÓTESIS
Seleccionar “Analizar”, luego “Comparar medias” y “Prueba T”; las
variables deben tener más de 30 datos
En el cuadro de la Prueba T se insertarán las variables a contrastar

Luego el programa procesa los datos:
Prueba para una muestra
Valor de prueba = 0
95% Intervalo de confianza para
la diferencia
t gl Sig. (bilateral)
Diferencia de
medias Inferior Superior
Importaciones
Petroleras
31.914 40 .000 9.50066E5 889898.9933 1.0102E6
Importaciones no
petroleras
54.510 40 .000 6.99124E5 673201.8934 725045.2774
Interpretación de datos:
De acuerdo a los resultados el nivel de significación de la prueba es del
5% y teniendo en cuenta los grados de libertad (40) se tiene que el
resultado de la prueba es de 31,914 para las importaciones petroleras y
de 54,510 para las importaciones no petroleras, la prueba es unilateral.

T DE STUDENT
Se debe realizar el mismo procedimiento que la Prueba de Hipótesis pero
con menos de 30 datos, seleccionar “Analizar”, luego “Comparar medias”
y “Prueba T”.
En el cuadro de la Prueba T se insertarán las variables a contrastar
Luego el programa procesa los datos:
Prueba para una muestra
Valor de prueba = 0
99% Intervalo de confianza para la
diferencia
t gl Sig. (bilateral)
Diferencia de
medias Inferior Superior
Importaciones
Petroleras
48.557 22 .000 8.09530E5 762536.8821 856523.9874
Importaciones no
petroleras
101.888 22 .000 6.36014E5 618418.2343 653609.1570

Interpretación de datos:
De acuerdo a los resultados el nivel de significación de la prueba es del
1% y teniendo en cuenta los grados de libertad (22) se tiene que el
resultado de la prueba es de 48,557 para las importaciones petroleras y
de 101,888 para las importaciones no petroleras, la prueba es unilateral.
CHI - CUADRADO
Seleccionar la opción “Analizar”, “Pruebas no paramétricas” y elegir “Chi-
cuadrado”
En el cuadro de la “Prueba Chi-cuadrado” insertar las variables de las
importaciones petroleras y no petroleras.
Los datos serán procesados automáticamente:

Estadísticos de contraste
Petrolera No petrolera
Chi-cuadrado 27.488a 29.829
a
gl 23 23
Sig. asintót. .236 .154
Sig. exacta .251 .165
Probabilidad en el punto .046 .033
a. 24 casillas (100,0%) tienen frecuencias esperadas
menores que 5. La frecuencia de casilla esperada mínima
es 1,7.
Interpretación de datos:
De acuerdo a la tabla anterior se acepta la hipótesis alternativa es decir
que los datos son independientes porque el resultado de la prueba es
petrolera 27,488 y no petrolera 29,829; estos datos se encuentran en la
zona de rechazo porque el valor de z es de 0,251 y 0,165.
VARIANZA
Seleccionar la opción “Analizar”, “Estadísticos descriptivos” y elegir
“Descriptivos”

Aparecerá un cuadro denominado “Descriptivos” en donde se debe
insertar las dos variables de importaciones petroleras y no petroleras y se
hace clic en “Opciones”
En el cuadro de “Descriptivos: Opciones” se debe seleccionar “Varianza” y
hacer clic en “Continuar”
El SPSS procesa automáticamente los datos:
Estadísticos descriptivos
N Varianza
Petrolera 41 3.634E10
No petrolera 41 6.744E9
N válido (según lista) 41
Análisis de datos:
La varianza nos indica la distancia que hay entre la media y los puntos de
dispersión en este ejemplo los datos de las exportaciones petroleras
varían 3.63 y las exportaciones no petroleras en 6,74

7. CONCLUSIONES
Mediante el presente trabajo hemos podido conocer y aplicar sobre el
manejo y la forma correcta del SPSS permitiendo aprender
conocimientos básicos para su utilización
En estadística inferencial existen muchos riesgos de que se produzca
errores humanos de cálculo o de decisión, mas el SPSS facilita este
trabajo el cual ofrece información completa e enriquecedora para que
se efectué una razonable conclusión
Con el desarrollo de varios problemas con respecto al tema hemos
podido practicar y aprender las relaciones entre la utilización del SPSS
y la practicar a mano, es decir, realizar la resolución de problemas en
una hoja de papel, podemos decir que es importante conocer todo
referente al tema para aplicarlo por cualquier método de resolución
que se desee aplicar.
Al momento de interpretar la información entregada por el SPSS se
debe considerar muy cuidadosamente los valores como la media,
frecuencias, r de Pearson, entre otros y compararlos con los que
tenemos a mano para determinar una correcta decisión. Al aplicar
todos los métodos que se utiliza en la estadística Inferencial en el
SPSS se pudo observar que se ahorro tiempo, riesgos de error, y se
obtuvo el máximo de datos para ser analizados.
8. RECOMENDACIONES
Tener en cuenta que cuando se realice el análisis en el SPSS ir
determinando en el orden que se quiera obtener porque se acumulan
las tabla y no se comprenden los datos.
Basado en la H0 y H1 decidir de acuerdo a los datos que se
obtengan tomando en cuenta de las reglas que nos menciona cada
método

Una lógica bien desarrollada va acompañada de un conocimiento
amplio por esta razón se recomienda aprender muy bien los métodos
estadísticos con sus respectivos procesos.
Lo más importante del programa SPSS no es aprender aunque si es
indispensable pero si se recomienda que se enfoquen en la
interpretación de datos, saber de donde provienen y para qué sirven.
9. BIBLIOGRAFÍA
Levin, R. (2010). Estadística para Administración y Economía. En R.
Levin, Estadística para Administración y Economía.
Spiegel, M. R. (1992). Estadística II. En M. R. Spiegel, Estadística II.
México DF: Mcgraw Hill.
10. CRONOGRAMA DE ACTIVIDADES
Actividades Fecha de realización Duración
Planteamiento del tema y problema Martes (10/jul/2012) 10 min
Realización de objetivos Martes (10/jul/2012) 10 min
Justificación de la investigación Martes (10/jul/2012) 10 min
Realización del marco teórico Martes (10/jul/2012) 2:30 h
Conclusiones y recomendaciones Martes (10/jul/2012) 10 min