
3€¦ · Web viewPara estudiar el efecto de las aguas residuales de las alcantarillas que...
59
3. Variables bidimensionales 3.2 introducción En lo estudiado anteriormente hemos podido aprender cómo a partir de la gran cantidad de datos que describen una muestra mediante una variable, X, se representan gráficamente los mismos de modo que resulta más intuitivo hacerse una idea de como se distribuyen las observaciones. Otros conceptos que según hemos visto, también nos ayudan en el análisis, son los estadísticos de tendencia central, que nos indican hacia donde tienden a agruparse los datos (en el caso en que lo hagan), y los estadísticos de dispersión, que nos indican si las diferentes modalidades que presenta la variable están muy agrupadas alrededor de cierto valor central, o si por el contrario las variaciones que presentan las modalidades con respecto al valor central son grandes. También sabemos determinar ya si los datos se distribuyen de forma simétrica a un lado y a otro de un valor central. En este capítulo pretendemos estudiar una situación muy usual y por tanto de gran interés en la práctica: Si Y es otra variable definida sobre la misma población que X, ¿será posible determinar si existe alguna relación entre las modalidades de X y de Y? Un ejemplo trivial consiste en considerar una población formada por alumnos de primero de Medicina y definir sobre ella las variables
Transcript of 3€¦ · Web viewPara estudiar el efecto de las aguas residuales de las alcantarillas que...

3. Variables bidimensionales
3.2 introducción En lo estudiado anteriormente hemos podido aprender cómo a partir de la gran cantidad de datos que describen una muestra mediante una variable, X, se representan gráficamente los mismos de modo que resulta más intuitivo hacerse una idea de como se distribuyen las observaciones.
Otros conceptos que según hemos visto, también nos ayudan en el análisis, son los estadísticos de tendencia central, que nos indican hacia donde tienden a agruparse los datos (en el caso en que lo hagan), y los estadísticos de dispersión, que nos indican si las diferentes modalidades que presenta la variable están muy agrupadas alrededor de cierto valor central, o si por el contrario las variaciones que presentan las modalidades con respecto al valor central son grandes.
También sabemos determinar ya si los datos se distribuyen de forma simétrica a un lado y a otro de un valor central.
En este capítulo pretendemos estudiar una situación muy usual y por tanto de gran interés en la práctica:
Si Y es otra variable definida sobre la misma población que X, ¿será posible determinar si existe alguna relación entre las modalidades de X y de Y?
Un ejemplo trivial consiste en considerar una población formada por alumnos de primero de Medicina y definir sobre ella las variables
ya que la relación es determinista y clara: Y=X/100. Obsérvese que aunque la variable Y, como tal puede tener cierta dispersión, vista como función de X, su dispersión es nula.
Un ejemplo más parecido a lo que nos interesa realmente lo tenemos cuando sobre la misma población definimos las variables

Intuitivamente esperamos que exista cierta relación entre ambas variables, por ejemplo,
dispersión
que nos expresa que (en media) a mayor altura se espera mayor peso. La relación no es exacta y por ello será necesario introducir algún termino que exprese la dispersión de Ycon respecto a la variable X.
Es fundamental de cara a realizar un trabajo de investigación experimental, conocer muy bien las técnicas de estudio de variables bidimensionales (y n-dimensionales en general). Baste para ello pensar que normalmente las relaciones entre las variables no son tan evidentes como se mencionó arriba. Por ejemplo:
¿Se puede decir que en un grupo de personas existe alguna relación entre X = tensión arterial e Y = edad?
Aunque en un principio la notación pueda resultar a veces algo desagradable, el lector podrá comprobar, al final del capítulo, que es bastante accesible. Por ello le pedimos que no se asuste. Al final verá que no son para tanto.
3.4 Tablas de doble entrada Consideramos una población de n individuos, donde cada uno de ellos presenta dos caracteres que representamos mediante las variables X e Y. Representamos mediante
las k modalidades que presenta la variable X, y mediante
las p modalidades de Y.
Con la intención de reunir en una sóla estructura toda la información disponible,
creamos una tabla formada por casillas, organizadas de forma que se tengan k filas
y p columnas. La casilla denotada de forma general mediante el hará referencia a los elementos de la muestra que presentan simultáneamente las modalidades xi e yj.
Y y1 y2 ... yj ... yp
X
x1 n11 n12 ... n1j ... n1p

x2 n21 n22 ... n2j ... n2p
... ... ... ... ... ... ... ...
xi ni1 ni2 ... nij ... nip
... ... ... ... ... ... ... ...
xk nk1 nk2 ... nkj ... nkp
... ...
De este modo, para , , se tiene que nij es el número de individuos o frecuencia absoluta, que presentan a la vez las modalidades xi e yj.
El número de individuos que presentan la modalidad xi, es lo que llamamos frecuencia
absoluta marginal de xi y se representa como . Es evidente la igualdad
Obsérvese que hemos escrito un símbolo `` '' en la ``parte de las jotas'' que simboliza que estamos considerando los elemento que presentan la modalidad xi, independientemente de las modalidades que presente la variable Y. De forma análoga se define la frecuencia absoluta marginal de la modalidad yj como
Estas dos distribuciones de frecuencias para , y para reciben el nombre de distribuciones marginales de X e Y respectivamente.
El número total de elementos de la población (o de la muestra), n lo obtenemos de cualquiera de las siguientes formas, que son equivalentes:

Las distribuciones de frecuencias de las variables bidimensionales también pueden ser representadas gráficamente. Al igual que en el caso unidimensional existen diferentes tipos de representaciones gráficas, aunque estas resultan a ser más complicadas (figura 3.1).
Figura: Algunos de las representaciones gráficas
habituales de distribuciones de frecuencias bidimensionales.
3.4.2 Distribuciones marginales A la proporción de elementos (tanto por uno) que presentan simultáneamente las modalidades xi e yj la llamamos frecuencia relativa fij
siendo las frecuencias relativas marginales las cantidades

Ni que decir tiene que
3.4.2.1 Observación
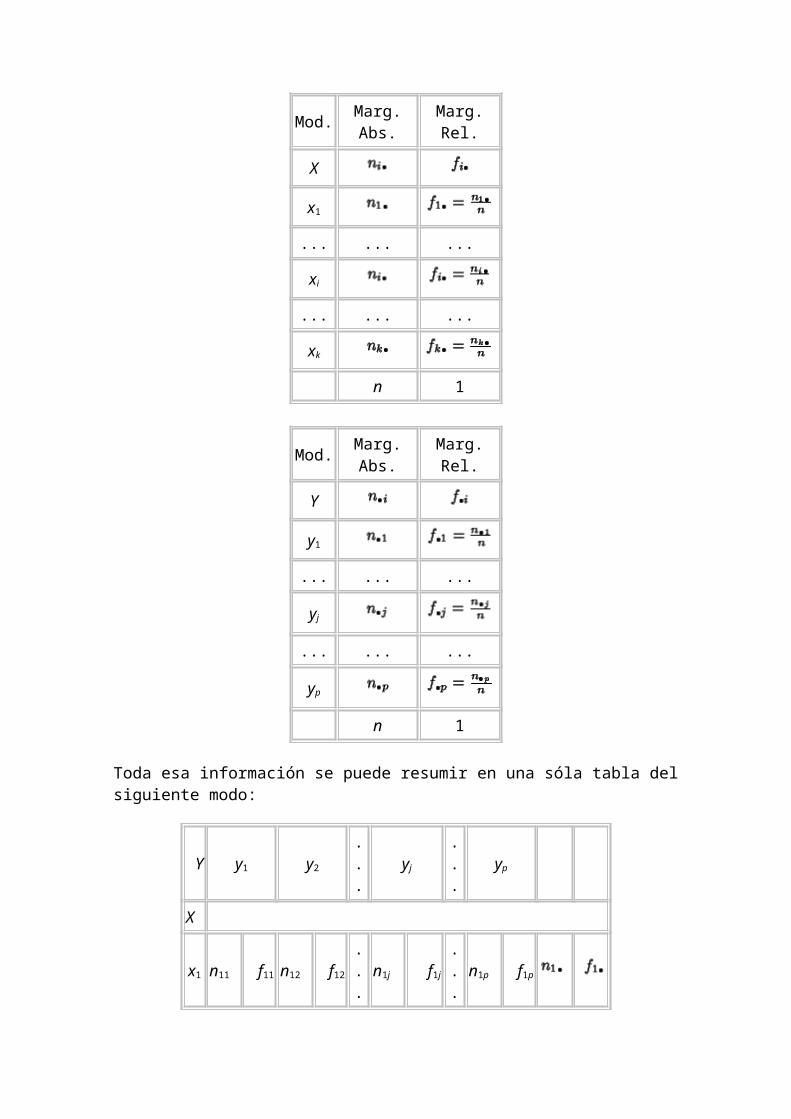
Es importante observar que las tablas bidimensionales aportan más información que las vistas anteriormente. De hecho, si quisiésemos estudiar la variable X y la Ypor separado, nos hubiese bastado con utilizar:
Mod. Marg. Abs. Marg. Rel.
X
x1
... ... ...
xi
... ... ...
xk
n 1
Mod. Marg. Abs. Marg. Rel.
Y

y1
... ... ...
yj
... ... ...
yp
n 1
Toda esa información se puede resumir en una sóla tabla del siguiente modo:
Y y1 y2 ... yj ... yp
X
x1 n11 f11 n12 f12 ... n1j f1j ... n1p f1p
x2 n21 f21 n22 f22 ... n2j f2j ... n2p f2p
... ... ... ... ... ... ... ... ... ... ... ... ...
xi ni1 fi1 ni2 fi2 ... nij fij ... nip fip
... ... ... ... ... ... ... ... ... ... ... ... ...
xk nk1 fk1 nk2 fk2 ... nkj fkj ... nkp fkp
... ...
3.4.4 Distribuciones condicionadas De todos los elementos de la población, n, podemos estar interesados, en un momento dado, en un conjunto más pequeño y que está formado por aquellos elementos que han
presentado la modalidad yj, para algún . El número de elementos de este
conjunto sabemos que es . La variable X definida sobre este conjunto se denomina
variable condicionada y se suele denotar mediante o bien . La distribución de frecuencias absolutas de esta nueva variable es exactamente la columna j de la tabla. Por tanto sus frecuencias relativas, que denominaremos frecuencias relativas condicionadas son
De la misma forma, es posible dividir la población inicial en ksubconjuntos, cada uno de ellos caracterizados por la propiedad de que el i-ésimo conjunto todos los elementos verifican la propiedad de presentar la modalidad xi. Sobre cada uno de estos conjuntos
tenemos la variable condicionada , cuya distribución de frecuencias relativas condicionadas es:
De este modo la distribución de cada una de las variables condicionadas se puede representar en tablas como sigue:
Mod. Fr. Abs. Fr. Rel.
X/yj nij fij
x1 n1j f1j
... ... ...
xi nij
... ... ...
xk nkj fkj
1
Mod. Fr. Abs. Fr. Rel.
Y/xi nij fji
y1 ni1 f1i
... ... ...
yj nij
... ... ...
yp nip fpi

1
3.4.4.1 Observación
Si interpretamos la relaciones
en términos de probabilidades, vemos que no es más que la definición de probabilidad condicionada:
lo que de forma abreviada representaremos normalmente como
3.6 Dependencia funcional e independencia La relación entre las variables X e Y, parte del objetivo de este capítulo y en general de un número importante de los estudios de las Ciencias Sociales, puede ser más o menos acentuada, pudiendo llegar ésta desde la dependencia total o dependencia funcional hasta la independencia.
3.6.2 Dependencia funcional

La dependencia funcional, que nos refleja cualquier fórmula matemática o física, es a la que estamos normalmente más habituados. Al principio del capítulo consideramos un ejemplo en el que sobre una población de alumnos definíamos las variables
Al tomar a uno de los alumnos, hasta que no se realice una medida sobre el mismo, no tendremos claro cual será su altura. Podemos tener cierta intuición sobre qué valor es más probable que tome (alrededor de la media, con cierta dispersión). Sin embargo, si la medida Xha sido realizada, no es necesario practicar la de Y, pues la relación entre ambas es exacta (dependencia funcional):
Y = X/100
Ello puede describirse como que conocido el valor X=xi, la distribución de sólo toma un valor con frecuencia del 100%. Esto se traduce en una tabla bidimensional de X e Y, del siguiente modo: La variable Y depende funcionalmente de la variable X si para
cada fila X=xi, existe un único tal que . Análogamente, tenemos dependencia funcional de X con respecto a Yhaciendo el razonamiento simétrico, pero por columnas, es decir, X depende funcionalmente de la variable Y si para cada columna Y=yj, existe
un único tal que .
Es claro que si la dependencia funcional es recíproca, la tabla es necesariamente cuadrada (k=p).
3.6.2.1 Ejemplo
Consideramos una población formada por 12 individuos, donde hay 3 franceses, 7 argentinos y 3 guineanos. Definimos las variables:
Entonces, sobre esta población, podemos construir las siguientes tablas:

Z Si No
X
Europa 0 3 3
América 7 0 7
África 2 0 2
9 3 12
Y Francés Guineano Argentino
X
Europa 3 0 0 3
América 0 0 7 7
África 0 2 0 2
3 2 7 12
y nos damos cuenta de que, según la definición
Z depende funcionalmente de X. X no depende funcionalmente de Z. X e Y depende funcionalmente la una de la otra de modo recíproco.
3.6.4 Independencia Hemos visto que la dependencia funcional implica una estructura muy particular de la tabla bidimensional, en la que en todas las filas (o en todas las columnas) existe un único elemento no nulo. Existe un concepto que de algún modo es el opuesto a la dependencia funcional, que es el de independencia. Se puede expresar de muchas maneras el concepto de independencia, y va a implicar de nuevo una estructura muy particular de la tabla bidimensional, en el que todas las filas y todas las columnas van a ser proporcionales entre sí.
Para enunciar lo que es la independencia de dos variables vamos a basarnos en el siguiente razonamiento: Si la variable Y es independiente de X, lo lógico es que la
distribución de frecuencias relativas condicionadas sea la misma que la de , ...,
. Esto se puede escribir diciendo que

Pues bien, diremos que la variable Y es independiente de Xsi la relación (3.3) es verificada. Hay otras formas equivalentes de enunciar la independencia: Cada una de las siguientes relaciones expresa por si sóla la condición de independencia:
3.6.4.1 Proposición (Independencia en tablas de doble entrada)
Cada una de las siguientes relaciones expresa por sí sóla la condición de independencia entre las variables Xe Y
3.6.4.2 Observación
Obsérvese que la relación (3.4) (o bien la (3.5)) implica que la independencia es siempre recíproca, es decir, si X es independiente de Y, entonces Y es independiente de X.
3.6.4.3 Ejemplo
Si tenemos dos variables que son

y están distribuidas en una tabla del modo:
Y
X
0 24 4 8 36
1 6 1 2 9
2 12 2 4 18
42 7 14 63
podemos decir que ambas variables son independientes. Obsérvese la proporcionalidad existente entre todas las filas de la tabla (incluidas la marginal) (figura 3.2). Lo mismo ocurre entre las columnas.
Figura: Cuando las variables son independientes, las diferencias entre las filas (o columnas) pueden
entenderse como cambios de escala.
3.8 Medias y varianzas marginales y condicionadas

Asociados a las distribuciones marginales y condicionadas definidas en las secciones anteriores, podemos definir algunos estadísticos de tendencia central o dispersión, generalizando los que vimos en los capítulos dedicados al análisis de una variable . Las medias marginales de la variable X e Y se definen del siguiente modo:
Las varianzas marginales respectivas son
Para cada una de las p variables condicionadas definimos sus respectivas media condicionada y varianza condicionada mediante:

y lo mismo hacemos para las k condicionadas
Es interesante observar que podemos considerar que las observaciones de la variable Xhan sido agrupadas en p subgrupos, cada uno de ellos caracterizados por la propiedad
de que Y=yj para algún . Así la proposición de la página nos permite afirmar que las medias de las marginales es la media ponderada de las condicionadas, y la proposición de la página 2.1, que la varianza de las marginales es la media ponderada de las varianzas condicionadas mas la varianza ponderada de las medias condicionadas (¡uff!). Vamos a enunciar de modo más preciso lo que acabamos de enunciar:
3.8.0.1 Proposición
Las medias y varianzas marginales de las variables X y Yse pueden escribir de modo equivalente como:

3.10 Covarianza y coeficiente de correlación Cuando analizábamos las variables unidimensionales considerábamos, entre otras medidas importantes, la media y la varianza. Ahora hemos visto que estas medidas también podemos considerarlas de forma individual para cada una de las componentes de la variable bidimensional.
Si observamos con atención los términos
vemos que las cantidades y van al cuadrado y por tanto no pueden ser negativas.
La covarianza , es una manera de generalizar la varianza y se define como:

Como se ve, la fórmula es muy parecida a las de las varianzas. Es sencillo comprobar
que se verifica la siguiente expresión de , más útil en la práctica:
3.10.0.1 Proposición
Si las observaciones no están ordenadas en una tabla de doble entrada, entonces se tiene que
o lo que es lo mismo
3.10.0.2 Ejemplo
Se han clasificado 100 familias según el número de hijos varones ( ) o hembras ( ), en la tabla siguiente:
0 1 2 3 4

0 4 6 9 4 1
1 5 10 7 4 2
2 7 8 5 3 1
3 5 5 3 2 1
4 2 3 2 1 01.
Hallar las medias, varianzas y desviaciones típicas marginales. 2.
¿Qué número medio de hijas hay en aquellas familias que tienen 2 hijos? 3.
¿Qué número medio de hijos varones hay en aquellas familias que no tienen hijas?
4. ¿Qué número medio de hijos varones tienen aquellas familias que a lo sumo tienen 2 hijas?
5. Hallar la covarianza
Solución:En primer lugar, definimos las variables X= número de hijos varones, e Y=número de hijas y construimos la tabla con las frecuencias marginales, y con otras cantidades que nos son útiles en el cálculo de medias y varianzas:
y1 y2 y3 y4 y5
0 1 2 3 4
4 6 9 4 1 24 0 0 0
5 10 7 4 2 28 28 28 44
7 8 5 3 1 24 48 96 62
5 5 3 2 1 16 48 144 63
2 3 2 1 0 8 32 128 40
23 32 26 14 5 100 156 396 209
0 32 52 42 20 146
0 32 104 126 80 342
de este modo, las medias marginales son

Calculamos después las varianzas marginales
que nos dan directamente las desviaciones típicas marginales,
El número medio de hijas en las familias con 2 hijos varones se obtiene calculando la
distribución condicionada de
n3j n3j yj
7 0
8 8
5 10
3 9
1 4
24 31

Del mismo modo, el número medio de hijos varones de las familias sin hijas, se calcula
con la distribución condicionada
ni1 ni1 xi
4 0
5 5
7 14
5 15
2 8
23 42
El número medio de hijos varones en las familias que a lo sumo tienen dos hijas, se calcula usando las marginales de la tabla obtenida a partir de las columnas y1, y2 e y3
ni1 ni2 ni3 ni1+ni2+ni3 (ni1+ni2+ni3) xi
4 6 9 19 19
5 10 7 22 22
7 8 5 20 40
5 5 3 13 39
2 3 2 7 28
81 129
La covarianza es:

3.10.2 Una interpretación geométrica de la covarianza Consideremos la nube de puntos formadas por las n parejas de datos (xi,yi). El centro de
gravedad de esta nube de puntos es , o bien podemos escribir simplemente si los datos no están ordenados en una tabla de doble entrada. Trasladamos los ejes XY
al nuevo centro de coordenadas . Queda así dividida la nube de puntos en cuatro cuadrantes como se observa en la figura 3.3. Los puntos que se encuentran en el primer
y tercer cuadrante contribuyen positivamente al valor de , y los que se encuentran en el segundo y el cuarto lo hacen negativamente.
Figura: Interpretación geométrica de
De este modo:
Si hay mayoría de puntos en el tercer y primer cuadrante, ocurrirá que , lo que se puede interpretar como que la variable Y tiende a aumentar cuando lo hace X;

Si la mayoría de puntos están repartidos entre el segundo y cuarto cuadrante
entonces , es decir, las observaciones Y tienen tendencia a disminuir cuando las de X aumentan;
Si los puntos se reparten con igual intensidad alrededor de , entonces se
tendrá que . Véase la figura 3.4 como ilustración.
Figura: Cuando los puntos se reparte de modo
más o menos homogéneo entre los cuadrantes primero y tercero, y segundo y cuarto, se tiene que
. Eso no quiere decir de ningún modo que no pueda existir ninguna relación entre las dos variables, ya que ésta puede existir como se aprecia
en la figura de la derecha.
LA COVARIANZA
Si las dos variables crecen o decrecen a la vez (nube de puntos creciente).
Si cuando una variable crece, la otra tiene tendencia a decrecer (nube de puntos decreciente).

Si los puntos se reparten con igual intensidad alrededor de , (no hay relación lineal).
De este modo podemos utilizar la covarianza para medir la variación conjunta (covariación) de las variables X e Y. Esta medida no debe ser utilizada de modo exclusivo para medir la relación entre las dos variables, ya que es sensible al cambio de unidad de medida, como se observa en el siguiente resultado:
3.10.2.1 Proposición
Demostración
Para simplificar las notaciones, vamos a considerar que los datos no están agrupados en una tabla estadística: Entonces
Así pues, es necesario definir una medida de la relación entre dos variables, y que no esté afectada por los cambios de unidad de medida. Una forma posible de conseguir este objetivo es dividir la covarianza por el producto de las desviaciones típicas de cada variable, ya que así se obtiene un coeficiente adimensional, r, que se denomina coeficiente de correlación lineal de Pearson
El coeficiente de correlación lineal posee las siguientes propiedades:

Estas propiedades sobre el coeficiente de correlación lineal son explicadas en la siguiente sección.
3.10.4 Interpretación geométrica de r Si los datos son observaciones que no están ordenadas en una tabla bidimensional, tendremos parejas de valores para cada sujeto o elemento
la fórmula de la covarianza, en este caso, es
Podemos a escribir las observaciones en forma de vectores de la siguiente manera:

Si denotamos al producto escalar de los vectores y , es inmediato comprobar que en realidad las definiciones de varianza y covarianza tienen una idea geométrica
muy simple: son productos escalares en los que intervienen los vectores e
Con esta descripción geométrica de las varianzas y covarianzas, podemos poner de manifiesto la existencia de paralelismo entre las desviaciones de las variables X e Y, con respecto a sus centros de gravedad ya que
donde es el ángulo entre los vectores e (véase la figura 3.5). Despejando:

Figura: Interpretación geométrica de r como el coseno del ángulo que forman los vectores de las
desviaciones con respecto a sus respectivas medias de X y de Y.
Si los vectores e son totalmente paralelos entonces . En este caso existirá una constante de proporcionalidad m tal que:
Esta es la ecuación de una recta (véase la figura 3.6). Es decir:
Figura: es lo mismo que decir que las observaciones de ambas variables están
perfectamente alineadas. El signo de r, es el mismo
que el de , por tanto nos indica el crecimiento o decrecimiento de la recta.

La magnitud que expresa el coseno del ángulo que forman los vectores e tiene un papel muy destacado como veremos más adelante en regresión lineal. La hemos denominado anteriormente como coeficiente de correlación lineal de Pearson y se representa mediante la letra r:
Son evidentes entonces las siguientes propiedades de r
Cualesquiera que sean los valores (xi,yi), , se tiene que , ya que r es el coseno del ángulo que forman las variaciones con respecto a sus valores medios de las observaciones xi e yi. Si cuando r es calculado en un caso práctico se obtiene un valor no comprendido en ese rango, es signo evidente de que se ha cometido un error de cálculo, que por tanto ha de ser revisado.
Si las desviaciones con respecto al valor central de las observaciones xi, son
proporcionales a las desviaciones de yi con respecto a su valor central ,

entonces los vectores e son paralelos y por tanto . En este caso se puede decir de modo exacto que conocido X lo es también Y, (y recíprocamente), gracias a la relación (3.8).
Por el contrario si no existe dicha relación, el ángulo que formen e
será mayor, siendo el caso extremo en que ambos sean perpendiculares (r=0). Cuando r=0 decimos que las variables X e Y son incorreladas.
Otra propiedad interesante de r es la siguiente:
3.10.4.1 Proposición
El coeficiente de correlación entre dos variables no se ve afectada por los cambios de unidades.
Demostración Consideramos la variable bidimensional (X,Y) y sometemos a Y a un cambio de unidad
. Entonces
Por tanto ambas variables XZ y XY tienen el mismo coeficiente de correlación.
3.12 Regresión Las técnicas de regresión permiten hacer predicciones sobre los valores de cierta variable Y (dependiente), a partir de los de otra X (independiente), entre las que intuimos que existe una relación. Para ilustrarlo retomemos los ejemplos mencionados al principio del capítulo. Si sobre un grupo de personas observamos los valores que toman las variables
no es necesario hacer grandes esfuerzos para intuir que la relación que hay entre ambas es:

Obtener esta relación es menos evidente cuando lo que medimos sobre el mismo grupo de personas es
La razón es que no es cierto que conocida la altura xi de un individuo, podamos determinar de modo exacto su peso yi (v.g. dos personas que miden 1,70 m pueden tener pesos de 60 y 65 kilos). Sin embargo, alguna relación entre ellas debe existir, pues parece mucho más probable que un individuo de 2 m pese más que otro que mida 1,20 m. Es más, nos puede parecer más o menos aproximada una relación entre ambas variables como la siguiente
A la deducción, a partir de una serie de datos, de este tipo de relaciones entre variables, es lo que denominamos regresión.
Figura: Mediante las técnicas de regresión de una
variable Y sobre una variable X, buscamos una función que sea una buena aproximación de una
nube de puntos (xi,yi), mediante una curva del tipo
. Para ello hemos de asegurarnos de
que la diferencia entre los valores yi e sea tan pequeña como sea posible.

Mediante las técnicas de regresión inventamos una variable como función de otra variable X (o viceversa),
Esto es lo que denominamos relación funcional. El criterio para construir , tal como citamos anteriormente, es que la diferencia entre Y e sea pequeña.
El término que hemos denominado error debe ser tan pequeño como sea posible (figura 3.7). El objetivo será buscar la función (también denominada modelo de regresión)
que lo minimice. Véase la figura 3.8.
Figura: Diferentes nubes de puntos y modelos de
regresión para ellas.

3.12.2 Bondad de un ajuste Consideremos un conjunto de observaciones sobre n individuos de una población, en los que se miden ciertas variables X e Y:
Estamos interesamos en hacer regresión para determinar, de modo aproximado, los
valores de Y conocidos los de X, debemos definir cierta variable , que debe tomar los valores
de modo que:

Ello se puede expresar definiendo una nueva variable E que mida las diferencias entre los auténticos valores de Y y los teóricos suministrados por la regresión,
y calculando de modo que E tome valores cercanos a 0. Dicho de otro modo, E debe
ser una variable cuya media debe ser 0 , y cuya varianza debe ser pequeña (en comparación con la de Y). Por ello se define el coeficiente de determinación de la
regresión de Y sobre X, , como
Si el ajuste de Y mediante la curva de regresión es bueno, cabe esperar que
la cantidad tome un valor próximo a 1.
Análogamente si nos interesa encontrar una curva de regresión para X como función de Y, definiríamos
y si el ajuste es bueno se debe tener que .
Las cantidades y sirven entonces para medir de qué modo las diferencias entre los verdaderos valores de una variable y los de su aproximación mediante una curva de regresión son pequeños en relación con los de la variabilidad de la variable que

intentamos aproximar. Por esta razón estas cantidades miden el grado de bondad del ajuste.
3.12.4 Regresión lineal La forma de la función f en principio podría ser arbitraria, y tal vez se tenga que la relación más exacta entre las variables peso y altura definidas anteriormente sea algo de la forma3.1
Por el momento no pretendemos encontrar relaciones tan complicadas entre variables, pues nos vamos a limitar al caso de la regresión lineal. Con este tipo de regresiones nos conformamos con encontrar relaciones funcionales de tipo lineal, es decir, buscamos cantidades a y b tales que se pueda escribir
con el menor error posible entre e Y, o bien
de forma que sea una variable que toma valores próximos a cero.
3.12.4.1 Observación
Obsérvese que la relación 3.12 explica cosas como que si X varía en 1 unidad, varía la cantidad b. Por tanto:
Si b>0, las dos variables aumentan o disminuyen a la vez; Si b<0, cuando una variable aumenta, la otra disminuye.
Por tanto, en el caso de las variables peso y altura lo lógico será encontrar que b>0.
El problema que se plantea es entonces el de cómo calcular las cantidades a y b a partir de un conjunto de n observaciones

de forma que se minimice el error. Las etapas en que se divide el proceso que vamos a desarrollar son de forma esquemática, las que siguen:
1. Dadas dos variables X, Y, sobre las que definimos
medimos el error que se comete al aproximar Y mediante calculando la suma de las diferencias entre los valores reales y los aproximados al cuadrado (para que sean positivas y no se compensen los errores):
2.
Una aproximación de Y, se define a partir de dos cantidades a y b. Vamos a calcular aquellas que minimizan la función
3. Posteriormente encontraremos fórmulas para el cálculo directo de a y b que sirvan para cualquier problema.
3.12.4.2 Regresión de Y sobre X
Para calcular la recta de regresión de Y sobre X nos basamos en la figura 3.9.

Figura: Los errores a minimizar son las
cantidades
Una vez que tenemos definido el error de aproximación mediante la relación (3.13) las cantidades que lo minimizan se calculan derivando con respecto a ambas e igualando a cero (procedimiento de los mínimos cuadrados):
La relación (3.15), no es más que otra manera de escribir la relación (3.14), que se denomina ecuaciones normales. La primera de (3.14) se escribe como

Sustituyendo se tiene que
Lo que nos da las relaciones buscadas:
La cantidad b se denomina coeficiente de regresión de Ysobre X.
3.12.4.3 Regresión de X sobre Y
Las mismas conclusiones se sacan cuando intentamos hacer la regresión de X sobre Y, pero ¡atención!: Para calcular la recta de regresión de X sobre Y es totalmente incorrecto despejar de
Pues esto nos da la regresión de X sobre , que no es lo que buscamos. La regresión de X sobre Y se hace aproximando X por , del modo

donde
pues de este modo se minimiza, en el sentido de los mínimos cuadrados, los errores
entre las cantidades xi y las (figura 3.10.)
Figura: Los errores a minimizar son las
cantidades
3.12.4.4 Ejemplo
En una muestra de 1.500 individuos se recogen datos sobre dos medidas antropométricas X e Y. Los resultados se muestran resumidos en los siguientes estadísticos:

Obtener el modelo de regresión lineal que mejor aproxima Y en función de X. Utilizando este modelo, calcular de modo aproximado la cantidad Y esperada cuando X=15.
Solución:
Lo que se busca es la recta, , que mejor aproxima los valores de Y (según el criterio de los mínimos cuadrados) en la nube de puntos que resulta de representar en un plano (X,Y) las 1.500 observaciones. Los coeficientes de esta recta son:
Así, el modelo lineal consiste en:
Por tanto, si x=15, el modelo lineal predice un valor de Y de:
En este punto hay que preguntarse si realmente esta predicción puede considerarse fiable. Para dar una respuesta, es necesario estudiar propiedades de la regresión lineal que están a continuación.
3.12.4.5 Propiedades de la regresión lineal

Una vez que ya tenemos perfectamente definida , (o bien ) nos preguntamos las relaciones que hay entre la media y la varianza de esta y la de Y (o la de X). La respuesta nos la ofrece la siguiente proposición:
3.12.4.6 Proposición
En los ajustes lineales se conservan las medias, es decir
En cuanto a la varianza, no necesariamente son las mismas para los verdaderos valores de las variables X e Y y sus aproximaciones y , pues sólo se mantienen en un factor de r2, es decir,
Demostración Basta probar nuestra afirmación para la variable Y, ya que para X es totalmente análogo:

donde se ha utilizado la magnitud que denominamos coeficiente de correlación, r, y que ya definimos anteriormente como
3.12.4.7 Observación
Como consecuencia de este resultado, podemos decir que la proporción de varianza
explicada por la regresión lineal es del .
Nos gustaría tener que r=1, pues en ese caso ambas variables tendrían la misma varianza, pero esto no es cierto en general. Todo lo que se puede afirmar, como sabemos, es que
y por tanto
La cantidad que le falta a la varianza de regresión, , para llegar hasta la varianza
total de Y, , es lo que se denomina varianza residual, que no es más que la varianza
de , ya que

El tercer sumando se anula según las ecuaciones normales expresadas en la relación (3.15):
Por ello
Obsérvese que entonces la bondad del ajuste es

Para el ajuste contrario se define el error como , y su varianza residual es también proporcional a 1-r2:
y el coeficiente de determinación (que sirve para determinar la bondad del ajuste de X en función de Y) vale:
lo que resumimos en la siguiente proposición:
3.12.4.8 Proposición
Para los ajustes de tipo lineal se tiene que los dos coeficientes de determinación son iguales a r2, y por tanto representan además la proporción de varianza explicada por la regresión lineal:
Por ello:
Si el ajuste es bueno (Y se puede calcular de modo bastante aproximado a partir de X y viceversa).
Si las variables X e Y no están relacionadas (linealmente al menos), por tanto no tiene sentido hacer un ajuste lineal. Sin embargo no es seguro que las dos variables no posean ninguna relación en el caso r=0, ya que si bien el ajuste lineal puede no ser procentente, tal vez otro tipo de ajuste sí lo sea.
3.12.4.9 Ejemplo

De una muestra de ocho observaciones conjuntas de valores de dos variables X e Y, se obtiene la siguiente información:
Calcule:
1. La recta de regresión de Y sobre X. Explique el significado de los parámetros.
2. El coeficiente de determinación. Comente el resultado e indique el tanto por ciento de la variación de Y que no está explicada por el modelo lineal de regresión.
3.
Si el modelo es adecuado, ¿cuál es la predicción para x=4.
Solución:
1. En primer lugar calculamos las medias y las covarianza entre ambas variables:
Con estas cantidades podemos determinar los parámetros a y b de la recta. La pendiente de la misma es b, y mide la variación de Ycuando X aumenta en una unidad:

Al ser esta cantidad negativa, tenemos que la pendiente de la recta es negativa, es decir, a medida que X aumenta, la tendencia es a la disminución de Y. En cuanto al valor de la ordenada en el origen, a, tenemos:
Así, la recta de regresión de Y como función de X es:
2. El grado de bondad del ajuste lo obtenemos a partir del coeficiente de determinación:
Es decir, el modelo de regresión lineal explica el de la variabilidad de Y en
función de la de X. Por tanto queda un de variabilidad no explicada.
3. La predicción que realiza el modelo lineal de regresión para x=4 es:

la cual hay que considerar con ciertas reservas, pues como hemos visto en el apartado anterior,hay una razonable cantidad de variabilidad que no es explicada por el modelo.
3.12.4.10 Ejemplo
En un grupo de 8 pacientes se miden las cantidades antropométricas peso y edad, obteniéndose los siguientes resultados:
Resultado de las mediciones
edad 12 8 10 11 7 7 10 14
peso 58 42 51 54 40 39 49 56
¿Existe una relación lineal importante entre ambas variables? Calcular la recta de regresión de la edad en función del peso y la del peso en función de la edad. Calcular la bondad del ajuste ¿En qué medida, por término medio, varía el peso cada año? ¿En cuánto aumenta la edad por cada kilo de peso?
Solución:
Para saber si existe una relación lineal entre ambas variables se calcula el coeficiente de correlación lineal, que vale:
ya que

Por tanto el ajuste lineal es muy bueno. Se puede decir que el ángulo entre el vector formado por las desviaciones del peso con respecto a su valor medio y el de la edad con respecto a su valor medio, , es:
es decir, entre esos vectores hay un buen grado de paralelismo (sólo unos 19 grados de desviación).
La recta de regresión del peso en función de la edad es
La recta de regresión de la edad como función del peso es
que como se puede comprobar, no resulta de despejar en la recta de regresión de Y sobre X.
La bondad del ajuste es

por tanto podemos decir que el de la variabilidad del peso en función de la edad es explicada mediante la recta de regresión correspondiente. Lo mismo podemos decir en cuanto a la variabilidad de la edad en función del peso. Del mismo modo puede
decirse que hay un de varianza que no es explicada por las rectas de regresión. Por tanto la varianza residual de la regresión del peso en función de la edad es
y la de la edad en función del peso:
Por último la cantidad en que varía el peso de un paciente cada año es, según la recta de regresión del peso en función de la edad, la pendiente de esta recta, es decir, b1=2,8367 Kg/año. Cuando dos personas difieren en peso, en promedio la diferencia de edad entre ambas se rige por la cantidad b2=0,3136 años/Kg de diferencia.
3.14 Problemas Ejercicio 3..1. Se realiza un estudio para establecer una ecuación mediante la cual se pueda utilizar la concentración de estrona en saliva(X) para predecir la concentración del esteroide en plasma libre (Y). Se extrajeron los siguientes datos de 14 varones sanos:
X 1,4 7,5 8,5 9 9 11 13 14 14,5 16 17 18 20 23
Y 30 25 31,5 27,5 39,5 38 43 49 55 48,5 51 64,5 63 681.
Estúdiese la posible relación lineal entre ambas variables. 2.
Obtener la ecuación que se menciona en el enunciado del problema. 3.
Determinar la variación de la concentración de estrona en plasma por unidad de estrona en saliva.
Ejercicio 3..2. Los investigadores están estudiando la correlación entre obesidad y la respuesta individual al dolor. La obesidad se mide como porcentaje sobre el peso ideal

(X). La respuesta al dolor se mide utilizando el umbral de reflejo de flexión nociceptiva (Y), que es una medida de sensación de punzada. Se obtienen los siguientes datos:
X 89 90 75 30 51 75 62 45 90 20
Y 2 3 4 4,5 5,5 7 9 13 15 141.
¿Qué porcentaje de la varianza del peso es explicada mediante un modelo de regeseión lineal por la variación del umbral de reflejo?
2. Estúdiese la posible relación lineal entre ambas variables, obteniendo su grado de ajuste.
3. ¿Qué porcentaje de sobrepeso podemos esperar para un umbral de reflejo de 10?
Ejercicio 3..3. Se lleva a cabo un estudio, por medio de detectores radioactivos, de la capacidad corporal para absorber hierro y plomo. Participan en el estudio 10 sujetos. A cada uno se le da una dosis oral idéntica de hierro y plomo. Después de 12 días se mide la cantidad de cada componente retenida en el sistema corporal y, a partir de ésta, se determina el porcentaje absorbido por el cuerpo. Se obtuvieron los siguientes datos:
Porcentaje de hierro 17 22 35 43 80 85 91 92 96 100
Porcentaje de plomo 8 17 18 25 58 59 41 30 43 581.
Comprobar la idoneidad del modelo lineal de regresión. 2.
Obtener la recta de regresión, si el modelo lineal es adecuado. 3.
Predecir el porcentaje de hierro absorbido por un individuo cuyo sistema corporal absorbe el 15% del plomo ingerido.
Ejercicio 3..4. Para estudiar el efecto de las aguas residuales de las alcantarillas que afluyen a un lago, se toman medidas de la concentración de nitrato en el agua. Para monitorizar la variable se ha utilizado un antiguo método manual. Se idea un nuevo método automático. Si se pone de manifiesto una alta correlación positiva entre las medidas tomadas empleando los dos métodos, entonces se hará uso habitual del método automático. Los datos obtenidos son los siguientes:
Manual 25 40 120 75 150 300 270 400 450 575
Automático 30 80 150 80 200 350 240 320 470 5831.
Hallar el coeficiente de determinación para ambas variables. 2.
Comprobar la idoneidad del modelo lineal de regresión. Si el modelo es apropiado, hallar la recta de regresión de Y sobre X y utilizarla para predecir la lectura que se obtendría empleando la técnica automática con una muestra de agua cuya lectura manual es de 100.

3. Para cada una de las observaciones, halle las predicciones que ofrece el modelo lineal de regresión para X en función de Y, e Y en función de X, es decir, e .
4. Calcule los errores para cada una de dichas predicciones, es decir, las variables
e . 5.
¿Que relación hay entre las medias de X y ? ¿Y entre las de Y e ? 6.
Calcule las medias de e . ¿Era de esperar el valor obtenido? 7.
Calcule las varianzas de X, , Y, , e . 8.
¿Qué relación existe entre y ¿Y entre y ? 9.
¿Que relación ecuentra entre y ? ¿También es válida para y
? 10.
Justifique a partir de todo lo anterior porqué se denomina r2 como grado de bondad del ajuste lineal.
Ejercicio 3..5. Se ha medido el aclaramiento de creatinina en pacientes tratados con Captopril tras la suspensión del tratamiento con diálisis, resultando la siguiente tabla:
Días tras la diálisis 1 5 10 15 20 25 35
Creatinina (mg/dl) 5,7 5,2 4,8 4,5 4,2 4 3,81.
Hállese la expresión de la ecuación lineal que mejor exprese la variación de la creatinina, en función de los dias transcurridos tras la diálisis, así como el grado de bondad de ajuste y la varianza residual.
2. ¿En qué porcentaje la variación de la creatinina es explicada por el tiempo transcurrido desde la diálisis?
3. Si un individuo presenta 4'1 mg/dl de creatinina, ¿cuánto tiempo es de esperar que haya transcurrido desde la suspensión de la diálisis?
Ejercicio 3..6. En un ensayo clínico realizado tras el posible efecto hipotensor de un fármaco, se evalúa la tensión arterial diastólica (TAD) en condiciones basales (X), y tras 4 semanas de tratamiento (Y), en un total de 14 pacientes hipertensos. Se obtienen los siguiente valores de TAD:

X 95 100 102 104 100 95 95 98 102 96 100 96 110 99
Y 85 94 84 88 85 80 80 92 90 76 90 87 102 891.
¿Existe relación lineal entre la TAD basal y la que se observa tras el tratamiento?
2. ¿Cuál es el valor de TAD esperado tras el tratamiento, en un paciente que presentó una TAD basal de 95 mm de Hg?
Ejercicio 3..7. Se han realizado 9 tomas de presión intracraneal en animales de laboratorio, por un método estándar directo y por una nueva técnica experimental indirecta, obteniéndose los resultados siguientes en mm de Hg:
Método estándar 9 12 28 72 30 38 76 26 52
Método experimental 6 10 27 67 25 35 75 27 531.
Hallar la ecuación lineal que exprese la relación existente entre las presiones intracraneales, determinadas por los dos métodos.
2. ¿Qué tanto por ciento de la variabilidad de Y es explicada por la regresión? Hállese el grado de dependencia entre las dos variables y la varianza residual del mismo.


















