
Estadística Descriptiva
26
Fundación Universitaria Católica del Norte 1 Unidad 1 NOMBRE DE LA ASIGNATURA: ESTADÍSTICA DESCRIPTIVA NOMBRE DE LA UNIDAD: ORGANIZACIÓN DE LA INFORMACIÓN DATOS GENERALES DE LA UNIDAD Introducción: En la estadística es de vital importancia el manejo de la información, ya que normalmente se manejan grandes volúmenes de la misma. El manejo de la información en gran parte depende de la habilidad del que la administra, como también de la forma como esté organizada, pues información mal organizada nos puede llevar a cometer errores de apreciación e inclusive en los cálculos matemáticos. Temas: TEMA 1: CONCEPTOS BÁSICOS 1.1 Definición 1.2 Conceptos básicos TEMA II. ORGANIZACIÓN Y REPRESENTACIÓN DE DATOS 2.1 Tablas de frecuencias simples 2.2 Tabla de frecuencia para datos agrupados. TEMA III MEDIDAS DESCRIPTIVAS 3.1. Medidas de tendencia central 3.2. Medidas de dispersión 3.3. Medidas de posición Bibliografía:
-
Upload
concentracion-educativa-del-sur-de-montelib -
Category
Education
-
view
2.465 -
download
0
Transcript of Estadística Descriptiva

Fundación Universitaria Católica del Norte
1
Unidad 1
NOMBRE DE LA ASIGNATURA: ESTADÍSTICA DESCRIPTIVA NOMBRE DE LA UNIDAD: ORGANIZACIÓN DE LA INFORMACIÓN
DATOS GENERALES DE LA UNIDAD
Introducción:
En la estadística es de vital importancia el manejo de la información, ya que normalmente se manejan grandes volúmenes de la misma.
El manejo de la información en gran parte depende de la habilidad del que la administra, como también de la forma como esté organizada, pues información mal organizada nos puede llevar a cometer errores de apreciación e inclusive en los cálculos matemáticos.
Temas:
TEMA 1: CONCEPTOS BÁSICOS 1.1 Definición
1.2 Conceptos básicos
TEMA II. ORGANIZACIÓN Y REPRESENTACIÓN DE DATOS
2.1 Tablas de frecuencias simples 2.2 Tabla de frecuencia para datos agrupados.
TEMA III MEDIDAS DESCRIPTIVAS
3.1. Medidas de tendencia central 3.2. Medidas de dispersión 3.3. Medidas de posición
Bibliografía:

Fundación Universitaria Católica del Norte
2
Bejarano Barrera, Hernán. Estadística Descriptiva. Unisur.
Chow, Ya-Lun Análisis estadístico. 2 edi. México: Interamericana 1977
Douglas A. Lind, Robert D. Mason, William G. Marchal, Estadística para
Guarín Salazar Norberto estadística descriptiva/ Norberto Guanín Salazar Medellín: Lealon 1987
Hoggy Craig. Introducción a la estadística Matemática.
TEMA 1 CONCEPTOS BASICOS
1.1 DEFINICIÓN
La Estadística es la ciencia que trata de la recopilación, el análisis, la interpretación y la presentación de una gran cantidad de datos. Su uso es fundamental en el diseño de experimentos en los cuales se requiera recolectar información y obtener conclusiones sobre una población. Es la ciencia que mas se utiliza como herramienta en la mayoría de disciplinas, ya que se relaciona directamente con el método científico utilizado en el desarrollo de una investigación
Se clasifica en dos grandes ramas de acuerdo con la necesidad de cada situación: la estadística descriptiva y la estadística inferencial.
Estadística descriptiva: Describe, analiza y representa un grupo de datos utilizando métodos numéricos, gráficos y tablas que resumen y presentan la información contenida en ellos.
Estadística inferencial: Apoyándose en el cálculo de probabilidades y a partir de datos muéstrales, efectúa estimaciones, decisiones, predicciones u otras generalizaciones sobre un conjunto mayor de datos.
1.2 CONCEPTOS BÁSICOS
Individuo: cualquier elemento que porte información sobre el fenómeno que se estudia. Así, si estudiamos la altura de los niños de una clase, cada alumno es un individuo; si estudiamos el precio de la vivienda, cada vivienda es un individuo.

Fundación Universitaria Católica del Norte
3
Población: conjunto de todos los individuos (personas, objetos, animales, entre otros.) que porten información sobre el fenómeno que se estudia. Por ejemplo, si estudiamos el precio de la vivienda en una ciudad, la población será el total de las viviendas de dicha ciudad. La cantidad de elementos de la población se representa con la letra N
Muestra: subconjunto que seleccionamos de la población. Así, si se estudia el precio de la vivienda de una ciudad, lo normal será no recoger información sobre todas las viviendas de la ciudad (sería una labor muy compleja), sino que se suele seleccionar un subgrupo (muestra) que se entienda que es suficientemente representativo. La cantidad de elementos de la muestra se representa con la letra n
La muestra es más pequeña que la población
Variable estadística
Una variable es una característica que va a ser estudiada en una población. Puede tomar diferentes valores en personas, animales o cosas
Una variable es estadística, si puede ser escrita como una pregunta cuyas respuestas pueden ser tabuladas o clasificadas dentro de determinados rangos.
Las variables estadísticas se construyen de acuerdo con el objetivo del estudio y apuntan a recolectar la información de manera eficaz y efectiva
Las variables pueden ser de dos tipos: Variables Cualitativas y Variables Cuantitativas
Variables cualitativas o atributos: no se pueden medir numéricamente (por ejemplo: nacionalidad, color de la piel, sexo).
Variables cuantitativas: tienen valor numérico (edad, precio de un producto, ingresos anuales).
Las variables cuantitativas se pueden clasificar en discretas y continuas:
Discretas: sólo pueden tomar valores enteros (1, 2, 8, -4, etc.). Por ejemplo: número de hermanos (puede ser 1, 2, 3...., etc. Por ejemplo, nunca podrá ser 3,45).
Continuas: pueden tomar cualquier valor real dentro de un intervalo. Por ejemplo, la velocidad de un vehículo puede ser 80,3 Km./h, 94,57 Km./h...etc.

Fundación Universitaria Católica del Norte
4
TEMA II. ORGANIZACIÖN Y REPRESENTACIÓN DE DATOS
Para ordenar y estudiar los datos de una variable estadística se utilizan tablas de frecuencias. Se pueden elaborar tablas de frecuencias dependiendo del número de datos que se van a estudiar y el tipo de variables que se van a tener en cuenta.
2.1 TABLAS DE FRECUENCIAS SIMPLES
Se utiliza para datos no agrupados, cuando la variable x , toma pocos valores, estos se registran en una tabla de dos columnas. En la primera columna se escriben los valores de la variable en forma creciente y en la segunda columna se escribe el número de veces que aparece cada uno de ellos. Este número se llama frecuencia absoluta y se representa por in . La suma de las frecuencias absolutas de la tabla debe ser el total de la muestra. La cantidad de elementos de la muestra se representa con la letra n
k: Datos diferentes entre el total de n datos
Al dividir las frecuencias absolutas in entre el número total de datos n , se obtiene
la frecuencia relativa ih :
n
nh i
i
Al multiplicar los valores de la frecuencia relativa por 100, se obtiene la frecuencia relativa porcentual que se representa por el símbolo % (por ciento).
Es decir, 100% ih La suma de las frecuencias porcentuales de la tabla es igual 100%
iN : Frecuencia absoluta acumulada Es la suma de las i frecuencias absolutas anteriores
iH : Frecuencia relativa acumulada Es la suma de las i frecuencias relativas anteriores

Fundación Universitaria Católica del Norte
5
i
jjii hhhhH
121 ....
Ejemplo, se tomo una muestra de 20 alumnos del programa de agropecuaria cuyas edades y sexo son:
Mujeres: 20 años, 20 años, 20 años, 20 años, 22 años, 21 años, 21 años, 20 años, 21 años, 21 años, 22 años, 22 años, 20 años
Hombres: 20 años, 21 años, 22 años, 22 años, 20 años, 21 años, 21 años
En estos datos se identifican dos variables: el sexo, que es una variable cualitativa, y la edad, que es una variable cuantitativa discreta.
Para organizar la información se elabora una tabla de frecuencias para la edad y otra para el sexo
Tabla de frecuencias para datos sin agrupar La edad de los estudiantes
x
in iN ih % iH %
20 8 8 40 40 21 7 15 35 75 22 5 20 25 100
Total 20
Tabla de frecuencia para el sexo
x
in iN ih % iH %
Femenino
13 13 65 65 masculino
7 20 35 100 Total 20
De las tablas anteriores se puede concluir que en el grupo de estudiantes hay más mujeres que hombres, que los alumnos de menor edad tienen 20 años y equivalen al 40%; que el menor número de alumnos tiene 22 años y equivale al 25% del total.

Fundación Universitaria Católica del Norte
6
2.2 TABLA DE FRECUENCIA PARA DATOS AGRUPADOS.
Cuando el número de datos es grande y la variable toma muchos valores distintos, conviene agruparlos en intervalos de la misma amplitud, llamados intervalos de clase.
Mediante un ejemplo veremos como se agrupa una muestra y como se representa mediante una tabla de frecuencias.
Pasos para su construcción:
Paso 1. Elección del número de clases (k) No existen reglas y la elección se hace teniendo en cuenta el tamaño de la muestra. Existen varias formas de cálculo:
La formula propuesta por STURGES es nk log32.31
Otra formula es nk
El número de intervalos también se puede calcular de acuerdo a la experiencia del investigador
Paso 2. Rango de los datos (R) El rango es la diferencia entre el valor máximo y el valor mínimo
Rango = MX - mX
Paso 3.Se calcula la amplitud (A) Se divide el rango entre el número de intervalos definidos.
A = ervalosdenúmero
XX mM
int..
en otras palabras A = k
R
Si el resultado anterior no es un número entero, se redondea al entero Superior.
Paso 4. Limites de los intervalos de clase
Los limites deben escogerse en tal forma que ellos incluyan los valores máximos y mínimos mediante la formula
Lo primero que se hace es calcular el rango kAR ,

Fundación Universitaria Católica del Norte
7
Para establecer los límites de los intervalos trabajaremos con este nuevo rango
Llamado rango ampliado ( ,R ) el cual ampliaremos de tal forma que la diferencia
de rangos ( RR , ) se reparta mas o menos en partes iguales en los dos extremos (en los valores máximo y mínimo de la serie de datos)
En estadística, los intervalos usados son de la forma ba, , que incluyen todos los números mayores o iguales que a y menores que b
Al número a se llama límite inferior del intervalo ( il ) y al número b se llama límite
superior del intervalo ( sl ). Los límites de los intervalos se trabajan con los valores del rango ampliado El limite inferior del primer intervalo es el valor mínimo del rango ampliado, a este valor mínimo se le suma A (amplitud) y se obtiene el valor del limite superior del primer intervalo que es también el limite inferior del segundo intervalo.
Para construir los otros intervalos se toma como límite inferior, el límite superior del intervalo anterior y para el límite superior se le suma la amplitud del intervalo hallado
Paso 5. Calculo de la marca de clase ( cM ) El punto medio de cada intervalo se llama marca de clase y se usa para identificar el intervalo en donde se encuentra ese dato, evitando nombrar cada uno de los
valores que entran en él, se simboliza cM y su valor es, 2
baM c
Paso 6 conteos de datos y construcción de la tabla de frecuencias teniendo en cuenta que en la columna de in se escribe el número de datos que agrupa cada intervalo.
Ejemplo
Los datos siguientes corresponden a la estatura de 40 alumnos en centímetros. Después de ordenarlos en forma creciente, los resultados fueron: 147, 148, 149, 149, 150, 150, 151, 151, 152, 153, 153,154, 156, 157, 157, 158, 158, 158, 158, 158, 159, 159, 160, 162, 162, 163, 163, 164, 165, 165, 166, 168, 170, 170, 170, 171, 173, 173, 176, 179.
a. Representar los datos en una tabla de frecuencias. b. Realizar un análisis de la información.
Solución

Fundación Universitaria Católica del Norte
8
a. La variable estatura es continua; como en este ejemplo la variable toma
muchos valores diferentes, se debe trabajar con tabla de frecuencias para datos agrupados.
Paso 1. Es necesario agrupar los datos en intervalos. Para este caso se usarán 5 intervalos.
K = 5 Paso 2. Se halla el rango
R = 179 147 = 32
Paso 3. Se halla la amplitud del intervalo
Amplitud del intervalo A = ;4,65
32 como el resultado no es un número entero se
redondea al entero superior, en este caso se redondea al entero 7 por lo tanto, la amplitud del intervalo es 7 A = 7 Paso 4. Se hallan los límites de los intervalos de clase
Para establecer los límites de los intervalos trabajaremos con este nuevo rango
Llamado rango ampliado ( ,R )
kAR , = 5 3575,R
La diferencia de rangos ( RR , ) 35 -32=3
El cual ampliaremos de tal forma que la diferencia de rangos ( RR , )se reparta mas o menos en partes iguales en los dos extremos (en los valores máximo y mínimo de la serie de datos ) como la diferencia es 3 ampliamos un numero a la izquierda y dos números a la derecha, queda así:
147-1= 146 Limite inferior 179+2 = 181 Limite inferior
Se hallan los intervalos: Primer intervalo: 153,1467146,146
Segundo intervalo 160,1537153,153
Tercer intervalo 167,1607160,160

Fundación Universitaria Católica del Norte
9
Para construir los otros intervalos se toma como límite inferior, el límite superior del intervalo anterior y para el límite superior se le suma la amplitud del intervalo hallado
Paso 5. Se halla la marca de clase de cada intervalo. Así, en el primer intervalo.
5,1492
153146cM
Paso 6. Finalmente se construye la tabla de frecuencias, teniendo en cuenta que en la columna de in se escribe el número de datos que agrupa cada intervalo.
Tabla de frecuencias para datos agrupados k x ( si ll ) cM in iN ih % iH %
1 153,146 149,5 9 9 22.5 22.5
2 160,153 156,5 13 22 32.5 55
3 167,160 163,5 9 31 22.5 77.5
4 174,167 170,5 7 38 17.5 95
5 181,174 177,5 2 40 5 100
Total 40
b. De la tabla se puede concluir que la mayoría de los alumnos miden entre153 y 160 cm. El porcentaje de los alumnos de mayor estatura es 5% y el de los de menor estatura es 22.5%. El total de la población es de 40 alumnos. El 22.5% de los alumnos miden entre 160 y 167 cm.
TEMA III MEDIDAS DESCRIPTIVAS
Las principales medidas son: medidas de tendencia central y medidas de dispersión.
3.1 MEDIDAS DE TENDENCIA CENTRAL
Las principales medidas de tendencia central son: la media aritmética o promedio, la mediana y la moda.

Fundación Universitaria Católica del Norte
10
MEDIDAS DE TENDENCIA CENTRAL PARA DATOS SIN AGRUPAR
Media aritmética La media de un conjunto de datos es el promedio aritmético de ellos.
Generalmente, se nota por X si nxxx ,......,, 21 es un conjunto de datos, entonces
n
xxx
n
x
X n
k
ii
.....211 La media se interpreta como el individuo o dato típico
de un grupo, y se puede considerar como el dato que mejor representa al conjunto
Ejemplo 1 si tenemos el conjunto de números siguientes 2, 3, 5, 6
44
16
4
6532
n
xx i
Ejemplo 2 Para el conjunto de números siguientes hallar la media aritmética
10, 13, 10, 13, 14, 10, 13, 10, 15
Media Aritmética Ponderada
Si los valores que toma x en una serie de datos, no todos tienen la misma importancia, es valido asignar "pesos" o "ponderaciones" de acuerdo a la importancia de cada dato.
En la serie del ejemplo anterior aparecen los números; pero cada uno con diferente frecuencia. Si cada uno de estos datos se multiplica por su respectiva frecuencia o ponderación y se suman estos productos, se obtendrá la misma suma que si se hubieran sumado uno por uno.
Formula de la media ponderada n
nxnxnx
n
nx
X kn
k
iii
.....22111

Fundación Universitaria Católica del Norte
11
Dato
ix Frecuencia absoluta
in
Producto
ii nx
10 4 40
13 3 39
14 1 14
15 1 15
Total
9 108
129
151439401
n
nx
X
k
iii
Mediana
La mediana es el dato que divide un conjunto de datos en dos partes porcentualmente iguales. Es notada por X
~.
Para calcular la mediana se ordena el conjunto de datos de menor a mayor y luego, se ubica el punto o valor que esta en el centro de ellos. Para encontrar la mediana se tienen dos casos
Caso uno si el número de datos n es impar 2
1
~nxX
Recordar que en ix i es la posición del dato
Ejemplo 2, 3, 4, 5, 6
3
2
15
~xxX Que corresponde a la posición 3 de la serie de datos en este caso
el valor es 4
Caso dos: si el número de datos n es par 2
~ 122
nn xx
X
Ejemplo dada en la siguiente serie de datos 3, 4, 5, 6, 7, 8, 9, 10

Fundación Universitaria Católica del Norte
12
22
~ 541
2
8
2
8xx
xx
X La posición 4 corresponde al número 6 y la posición 5
corresponde al 7; luego 5.62
13
2
76~X
Ejemplo 2 Calcular la mediana de las siguientes series de datos
7, 8, 8, 10, 12, 19, 23
10~
4
2
17
2
1 xxxX n
4x Corresponde a la posición 4 de la serie ordenada si miras esta posición corresponde al número 10
Ejemplo 3
3, 4, 4, 5, 16, 19, 25, 30
22~ 54
12
8
2
8xx
xx
X La posición 4 corresponde al número 5 y la posición 5
corresponde al 16; luego 5.102
21
2
165~X
Moda
La moda es el valor que aparece con mayor frecuencia en la serie de datos. Así por ejemplo, de la serie {14, 15, 17, 17, 21, 21, 21, 33, 36, 40}, la moda es 21.
La moda es una medida muy natural para describir un conjunto de datos; su concepto se adquiere fácilmente: es la altura más corriente, es la velocidad más común, etc. Además tiene la ventaja de que no se ve afectada por la presencia de valores altos o bajos.
La principal limitación esta en el hecho de que requiere un número suficiente de observaciones para que se manifieste o se defina claramente.
Otros inconvenientes son que puede darse el caso de que una determinada serie no tenga moda o que tenga varias modas.
Por ejemplo:
L, K, M, O, N (no hay moda)
5, 6, 10, 5, 8, 6, 7, 4 (2 modas 5 y 6)
Fundación Universitaria Católica del Norte
13
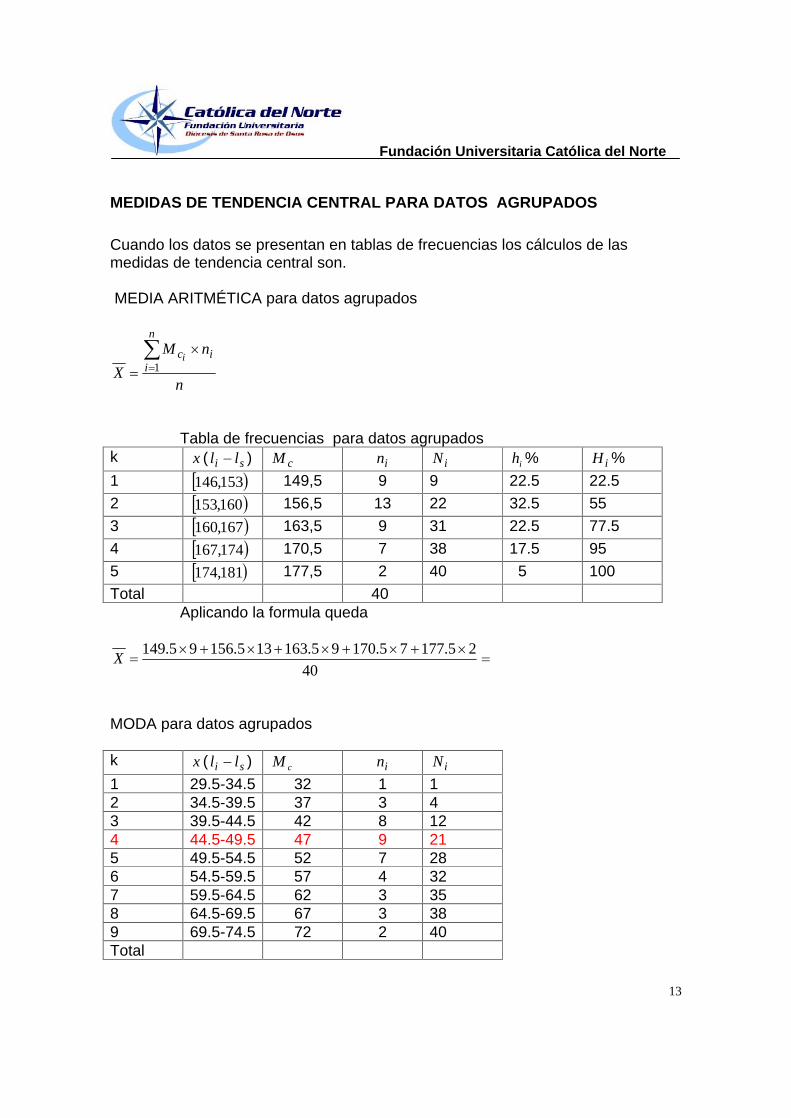
MEDIDAS DE TENDENCIA CENTRAL PARA DATOS AGRUPADOS
Cuando los datos se presentan en tablas de frecuencias los cálculos de las medidas de tendencia central son.
MEDIA ARITMÉTICA para datos agrupados
n
nM
X
n
iici
1
Tabla de frecuencias para datos agrupados k x ( si ll ) cM in iN ih % iH %
1 153,146 149,5 9 9 22.5 22.5
2 160,153 156,5 13 22 32.5 55
3 167,160 163,5 9 31 22.5 77.5
4 174,167 170,5 7 38 17.5 95
5 181,174 177,5 2 40 5 100
Total 40 Aplicando la formula queda
40
25.17775.17095.163135.15695.149X
MODA para datos agrupados
k x ( si ll ) cM in iN
1 29.5-34.5
32 1 1 2 34.5-39.5
37 3 4 3 39.5-44.5
42 8 12 4 44.5-49.5
47 9 21 5 49.5-54.5
52 7 28 6 54.5-59.5
57 4 32 7 59.5-64.5
62 3 35 8 64.5-69.5
67 3 38 9 69.5-74.5
72 2 40 Total

Fundación Universitaria Católica del Norte
14
La formula es:
21
1
dd
dALM io
Donde: iL = Limite inferior de la clase modal.
d1 = Diferencia entre la frecuencia del intervalo que contiene la moda y la frecuencia del intervalo anterior al que contiene la moda.
d2 = Diferencia entre la frecuencia del intervalo que contiene la moda y la frecuencia del intervalo posterior al que contiene la moda.
A =Amplitud del Intervalo.
Para ubicar el intervalo que contiene la moda se busca el intervalo que mayor frecuencia tiene y este es el intervalo que contiene la moda
y luego aplicar la formula.
21
1
dd
dALM io
El intervalo que mayor frecuencia tiene es : 44.5 - 49.5 Entonces:
1d =9 - 8 = 1
2d = 9 7 = 2
17.4621
155.44oM
MEDIANA (para datos agrupados) La formula es:
Mei
a
i n
Nn
ALx 2~

Fundación Universitaria Católica del Norte
15
1L : limite inferior del intervalo que contiene la mediana
n : Número de datos
aN : Frecuencia absoluta acumulada anterior al intervalo que contienen la mediana
Mein : Frecuencia absoluta del intervalo mediano
A: amplitud del intervalo
Pasos: Lo primero que debes hacer es hallar el intervalo que contiene la mediana y se
halla de la siguiente manera el valor medio 2
n se halla y se busca en la
frecuencia absoluta acumulada y en el intervalo que este, es donde se encuentra el intervalo que contiene la mediana, luego se aplica la formula.
Para el ejercicio anterior el intervalo que contiene la mediana es el 4
94.489
122
40
55.44~x
3.2 MEDIDAS DE DISPERSIÓN
Son medidas que indican que tan espaciados o distanciados están los datos con referencia de un valor particular.
Las medidas más usadas de la dispersión de un conjunto de datos son: el rango, la desviación media de la varianza, la desviación típica y el coeficiente de variación.
MEDIDAS DE DISPERSIÓN PARA DATOS SIN AGRUPAR
RANGO: es igual a la diferencia entre el valor máximo y el valor mínimo de la muestra.
Solo da una idea general de la variabilidad de los datos es poco informativo por que tiene en cuenta únicamente los valores externos.

Fundación Universitaria Católica del Norte
16
R = valor máximo valor medio
LA DESVIACIÓN MEDIA
Para que una medida sea indicativa de la variabilidad debe tener en cuenta el valor de cada una de los datos, una forma de media la variabilidad consiste en elegir un valor central y observar que tan alejados están los datos de ese valor central.
Si los datos están muy alejados la variabilidad es grande, en el caso continúan la variabilidad sea pequeña.
La distancia de cada dato al valor central se llama desviación o error. Si el valor central es la media entonces se llama desviación del dato ix a la diferencia
xxi
, la suma de estas desviaciones es siempre cero ya que unas serán positivas y otras negativas y la suma total se anula. Por lo tanto la suma de las desviaciones no puede ser una medida de la dispersión. Si tomamos los valores absolutos de la desviación y los sumamos y esta suma la dividimos por el número de datos obtenemos la desviación media.
DM (desviación media) = n
ii xx
n 1
1
La desviación media es difícil de manejar matemáticamente por lo que su uso es muy limitado en estadística
VARIANZA
La varianza es una medida que pretende establecer la cercanía de cada uno de los datos con respecto a la media.
Para calcular la varianza es necesario determinar la desviación o distancia entre cada uno de los datos y la media.
Se tiene que si el valor de la desviación es negativo, entonces el dato correspondiente es menor que el promedio, y si la desviación es positiva, entonces, el dato correspondiente es mayor que el promedio. La suma de las desviaciones es cero.
La varianza de un conjunto de datos nxxx ,......,, 21 , se nota por 2S y su formula es

Fundación Universitaria Católica del Norte
17
11
2
2
n
xx
S
n
ii
Donde xxi es la desviación del ésimoi dato
Ejemplo tenemos el conjunto de números siguientes 2, 3, 5, 6
Lo primero que tienes que hallar es la media
44
16
4
6532
n
xx i
Luego calculamos la varianza 1
1
2
2
n
xxS
n
ii
Luego calculamos las desviaciones de cada término y la sumamos
104114
2112
464543422222
2222
Luego se reemplaza en la formula recuerda que 4n
33.33
102S
OTRA FORMULA DE LA VARIANZA (para datos sin agrupar) es:
11
2
1
2
2
nn
xxn
S
k
i
k
iii

Fundación Universitaria Católica del Norte
18
DESVIACIÓN ESTÁNDAR
La desviación estándar, notada como S , es la raíz cuadrada positiva de la varianza. Es la más utilizada y representa la concentración de los datos alrededor de un valor central
2SS
En el ejemplo anterior 82.133.32SS
La desviación estándar representa un dato que al sumarlo y restarlo, dos veces a la media, proporciona un intervalo en el cual se concentra el 95% de los datos. Si el intervalo es grande, los datos están muy alejados entre si y el promedio no representa bien al grupo. Si el intervalo es pequeño se tendrán la mayoría de los datos cercanos y la media será un buen representante del grupo.
Ejemplo
Calcular la varianza y la desviación estándar de los siguientes datos que son los puntajes obtenidos en las pruebas de admisión, por 25 aspirantes a ingresar en una universidad de la ciudad:
55, 78, 50, 41, 55, 44, 41, 42, 51, 54, 64, 56, 41, 54, 76, 76, 75, 47, 62, 59, 75, 46, 49, 54, 57
Solución: primero calculamos la media 5625
57.....78551
n
xX
n
ii
Luego podemos construir la tabla siguiente
Dato
Desviación
xxi
2Desviacion
2xxi
55 -1 1 78 22 484 50 -6 36

Fundación Universitaria Católica del Norte
19
41 -15 225 55 -1 1 44 -12 144 41 -15 225 42 -14 196 51 -5 25 54 -2 4 64 8 64 56 0 0 41 -15 225 54 -2 4 76 20 400 76 20 400 75 19 361 47 -9 81 62 6 36 59 3 9 75 19 361 46 -10 100 49 -7 49 54 -2 4 57 1 1
Así, la varianza es 22 16.143125
14....364841puntosS
La desviación estándar es puntosSS 96.1116.1432
Teniendo el valor de S = 11.96 se construye el intervalo de extremos SX 2
y SX 2
así: 96.11256
y 96.11256 ; es decir, 92.7908.32
dentro de este intervalo se encuentra el 95% de los puntajes. Como el intervalo es muy grande la variación entre los puntajes es muy alta es decir, en esta caso la media no es una medida que representa bien los datos

Fundación Universitaria Católica del Norte
20
COEFICIENTE DE VARIACION
Coeficiente de variación es una medida relativa de la variabilidad de un conjunto de datos y se denota por CV y es el cociente entre la desviación típica y la media
aritmética 100X
SCV (expresada en porcentaje)
El CV permite comparar varios conjuntos de datos expresados en diferentes unidades o en las mismas unidades pero con diferente orden de magnitud
Este coeficiente se emplea cuando se desea comparar dos o más distribuciones con el fin de determinar cual de ellos tienen mayor o menor dispersión.
MEDIDAS DE DISPERSIÓN PARA DATOS AGRUPADOS
Rango es la diferencia entre el límite superior del último intervalo y el límite inferior del primer intervalo
DM (desviación media)= i
n
ii nxx
n 1
1
Varianza para datos agrupados 2S = ii nxx
n
2
1
1
OTRA FORMULA DE LA VARIANZA (para datos agrupados)
11
2
1
2
2
nn
nxnixn
S
k
i
k
iiii
Ejemplo
Datos agrupados correspondientes a las estaturas de 98 estudiantes
Intervalos en mts
Marca de clase
ix in ii nx 2ix ii nx 2
1.47-1.53 1.50 9 13.50 2.25 20.2500 1.53-159 1.56 18 28.08 2.43 43.8048 1.59-1.65 1.62 20 32.40 2.62 52.4880

Fundación Universitaria Católica del Norte
21
1.65-1.71 1.68 16 26.88 2.82 45.1584 1.71-1.77 1.74 19 33.06 3.03 57.5244 1.77-1.83 1.80 8 14.40 3.24 25.9200 1.83-1.89 1.86 5 9.30 3.46 17.2980 1.89-1.95 1.92 3 5.76 3.69 11.0592
98 163.38 273.5028
R = 1.95 1.47 = 0.48
mtsn
nxx ii 67.1
98
38.163
11
2
1
2
2
nn
nxnixn
S
k
i
k
iiii
mtsS 0116.09798
38.1635028.27398 22
2SS
11.00116.0 2S
3.3 MEDIDAS DE POSICIÓN
Medidas de posición
Las medidas de posición permiten conocer otros puntos característicos de la distribución que no son los valores centrales. Entre otros indicadores, se suelen utilizar una serie de valores que dividen la muestra en tramos iguales: Así como la mediana divide el conjunto de datos en dos partes iguales, es decir, la mitad de los valores son inferiores a la mediana y la otra mitad son superiores
Cuartiles: son 3 valores que distribuyen la serie de datos, ordenada de forma creciente o decreciente, en cuatro tramos iguales, en los que cada uno de ellos concentra el 25% de los resultados. Se denota por Q

Fundación Universitaria Católica del Norte
22
Q1cuartil 1 equivale al 25%, Q2 equivale al 50%, Q3 equivale al 75%,
Deciles: son 9 valores que distribuyen la serie de datos, ordenada de forma creciente o decreciente, en diez tramos iguales, en los que cada uno de ellos concentra el 10% de los resultados. se denota por D
D1:decil 1 equivale al 10%, D2 . decil 2 equivale al 20%, .........D9. decil 9 equivale al 90%,
Percentiles: son 99 valores que distribuyen la serie de datos, ordenada de forma creciente o decreciente, en cien tramos iguales, en los que cada uno de ellos concentra el 1% de los resultados.
P1:percentil 1 equivale al 1%,...... P10:percentil 10 equivale al 10%, .........P90:percentil 90 equivale al 90%,
Tanto la mediana, como los cuartiles y los deciles pueden expresarse como percentiles. Se denota por P
Por ejemplo:
Me = P50; Q3 = P75; D4 = P40
Así que conociendo los percentiles se puede averiguar cualquier valor.
Para el cálculo de los percentiles, el conjunto de datos debe estar ordenado, luego se aplica la siguiente formula:
1npX p
Donde p: representa el orden del percentil, varía entre 0 y 1. Por ejemplo el
percentil 43 es igual a 43.0100
43 de donde p = 0.43,
El valor de p debe estar entre 0 y 1
pX : Representa el percentil de orden p ejemplo 43.0X
n : Número de datos (número total de observaciones)
Calcular el percentil 77 de los siguientes datos:
32, 35, 36, 37, 40, 40, 41, 41, 42, 43, 43, 44, 45, 45,
46, 46, 47, 47, 48, 49, 49, 50, 51, 51, 52, 53, 53, 54,
55, 56, 57, 59, 60, 60, 62, 66, 67, 68, 70, 74.

Fundación Universitaria Católica del Norte
23
57.314177.077.0X
El percentil 77 (P77) será el valor que este ubicado en la 31. 57 posición del conjunto de datos.
CALCULO DE MEDIDAS DE POSICIÓN PARA DATOS AGRUPADOS
Se calcula mediante los percentiles
La formula es:
pXi
aip n
NnpALX
Donde
pX : Representa el percentil de orden p
p: representa el orden del percentil, varía entre 0 y 1
1L : limite inferior del intervalo que contiene el percentil
n : Número de datos (número total de observaciones)
aN : Frecuencia absoluta acumulada anterior al intervalo que contienen el percentil
Mein : Frecuencia absoluta del intervalo que contiene el percentil
A: amplitud del intervalo
Pasos: Lo primero que debes hacer es hallar el intervalo que contiene el percentil, se halla de la siguiente manera se calcula ( pn ) y este valor ubica en la frecuencia absoluta acumulada y en este intervalo es donde se encuentra el intervalo que contiene el percentil, luego se aplica la formula.
Lo ilustraremos con un ejemplo

Fundación Universitaria Católica del Norte
24
Ejemplo: Vamos a calcular el percentil 72 de la serie de datos siguientes
k x ( si ll ) cM in iN
1 29.5-34.5
32 1 1 2 34.5-39.5
37 3 4 3 39.5-44.5
42 8 12 4 44.5-49.5
47 9 21 5 49.5-54.5
52 7 28 6 54.5-59.5
57 4 32 7 59.5-64.5
62 3 35 8 64.5-69.5
67 3 38 9 69.5-74.5
72 2 40 Total
Donde
pX : 72X
p = 0.72
Lo primero que se hace es ubicar el intervalo que contiene el percentil, se calcula ( pn ) = ( 72.040 )= 28.8, se ubica en la frecuencia acumulada absoluta, para este caso 28.8 se encuentra en el sexto intervalo (28.8 no esta en el intervalo quinto porque en este están hasta el 28 y en el sexto esta hasta el 32)
1L = 54.5
n = 40
aN =28
Mein = 4
A =5
Reemplazando en la formula tenemos

Fundación Universitaria Católica del Norte
25
4
288.2855.5472.0X 55.5

This document was created with Win2PDF available at http://www.daneprairie.com.The unregistered version of Win2PDF is for evaluation or non-commercial use only.




