
SEMINARIO DE MATEMÁTICAS
36
1 SEMINARIO DE MATEMÁTICAS Mag. Carlos Alberto Ardila Albarracín 4.2. MEDIDAS DE RESUMEN Y TIPOS DE DISTRIBUCIONES
Transcript of SEMINARIO DE MATEMÁTICAS

1
SEMINARIO DE
MATEMÁTICASMag. Carlos Alberto Ardila Albarracín
4.2. MEDIDAS DE RESUMEN Y TIPOS DE DISTRIBUCIONES
Departamento de Sistemas - Maestría en Computación 2
Seminario de Matemáticas
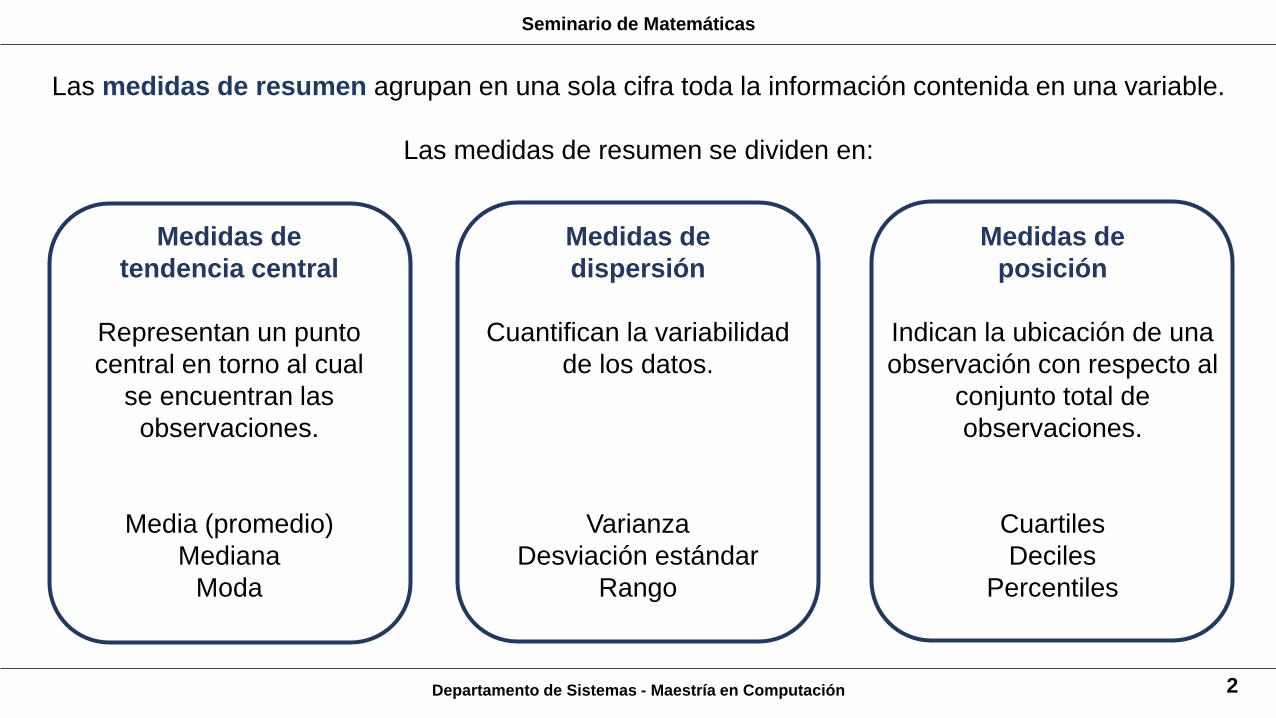
Las medidas de resumen agrupan en una sola cifra toda la información contenida en una variable.
Las medidas de resumen se dividen en:
Medidas de
tendencia central
Representan un punto
central en torno al cual
se encuentran las
observaciones.
Media (promedio)
Mediana
Moda
Medidas de
dispersión
Cuantifican la variabilidad
de los datos.
Varianza
Desviación estándar
Rango
Medidas de
posición
Indican la ubicación de una
observación con respecto al
conjunto total de
observaciones.
Cuartiles
Deciles
Percentiles

Departamento de Sistemas - Maestría en Computación 3
Seminario de Matemáticas
Medidas de tendencia central
M O D A
La moda es la observación que más se repite o en otras palabras la de mayor frecuencia.
Se usa principalmente para variables categóricas y corresponde a la categoría de mayor frecuencia.
Observemos que la categoría de mayor
frecuencia es "vacaciones" con 3.952.000
observaciones.
Es decir la moda o categoría modal es
Vacaciones.
No suele usarse para variables cuantitativas
ya que en estos casos puede que haya
varias modas o que no haya ninguna.
Departamento de Sistemas - Maestría en Computación 4
Seminario de Matemáticas
Medidas de tendencia central
M E D I A N A
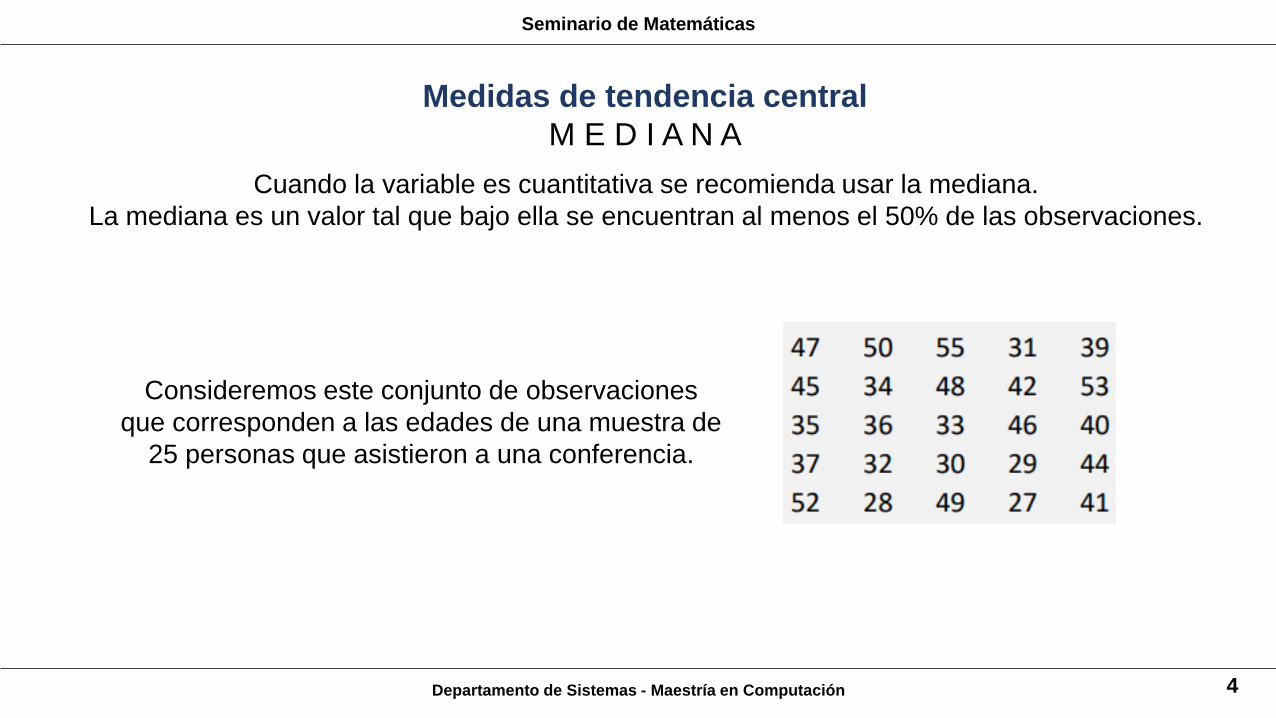
Cuando la variable es cuantitativa se recomienda usar la mediana.
La mediana es un valor tal que bajo ella se encuentran al menos el 50% de las observaciones.
Consideremos este conjunto de observaciones
que corresponden a las edades de una muestra de
25 personas que asistieron a una conferencia.

Departamento de Sistemas - Maestría en Computación 5
Seminario de Matemáticas
Medidas de tendencia central
M E D I A N A
Para calcular la mediana lo primero que debemos hacer ordenar los datos de menor a mayor:
Como hay un número impar de observaciones,
la mediana es justo el valor que se encuentra en la mitad de los datos.
Dicho de otra forma, la mediana es el valor que se encuentra en la posición (n+1)/2
donde n es la cantidad de observaciones.
¿Cómo se interpreta? Esto quiere decir que el 50% de los asistentes tenía a lo más 40 años.

Departamento de Sistemas - Maestría en Computación 6
Seminario de Matemáticas
Medidas de tendencia central
M E D I A N A
Si hubiera un número par de observaciones,
la mediana es el promedio de las dos observaciones centrales.
En este caso sería (40+41)/2 = 40.5.
Esto quiere decir que el 50% de los asistentes tenía a lo más 40.5 años.
El cálculo aquí realizado solo fue hecho con fin ilustrativo ya que la mediana,
al igual que la media, se puede calcular usando software estadístico o Excel.

Departamento de Sistemas - Maestría en Computación 7
Seminario de Matemáticas
Medidas de tendencia central
Hay casos en que es más recomendable usar la media y otros la mediana.
Razón: la media es sensible a la presencia de datos atípicos o extremos
en tanto que la mediana no.
Como dato atípico o extremo se entiende a aquel que se aleja,
ya sea por que es mucho más grande o mucho más chico, del resto de los datos.

Departamento de Sistemas - Maestría en Computación 8
Seminario de Matemáticas
Medidas de tendencia central
Por ejemplo, si 21, 22; 22; 23 y 23 son las edades de 5 alumnos de un curso,
en este caso la mediana es 22 y el promedio 22.2.
¿Qué pasa si se integra un nuevo alumno mucho mayor, digamos de 55 años?
La mediana ahora sería 22,5 (observe que casi no varió con respecto al valor anterior),
pero el promedio ahora sería 27.67.
Por lo que en este caso la mediana es la medida de tendencia central más apropiada
para representar este conjunto de datos.
Cuando hay presencia de datos extremos se recomienda utilizar la mediana
como medida de tendencia central pues esta será más representativa que la media.
La media, en relación a la mediana, sufrió una mayor variación, pero además,
¿podemos decir que 27,67 representa la edad de los alumnos de ese curso?
La respuesta es NO, ya que la mayoría de las edades están entre los 21 y 23 años.

Departamento de Sistemas - Maestría en Computación 9
Seminario de Matemáticas
Medidas de dispersión
V A R I A N Z A Y D E S V I A C I Ó N E S T Á N D A R
Como mencionamos en un inicio las medidas más usadas de dispersión son:
el rango, la varianza y la desviación estándar.
El rango es la diferencia entre
el valor máximo observado y el valor mínimo observado.
La varianza y la desviación estándar miden
qué tan dispersos están los datos en torno a la media.

Departamento de Sistemas - Maestría en Computación 10
Seminario de Matemáticas
Medidas de dispersión
V A R I A N Z A Y D E S V I A C I Ó N E S T Á N D A R
Consideremos las siguientes series de datos:
Ambas series tienen el mismo promedio,
sin embargo la segunda es mucho más variable que la primera
pues su desviación estándar es mayor.
Departamento de Sistemas - Maestría en Computación 11
Seminario de Matemáticas
Medidas de dispersión
V A R I A N Z A Y D E S V I A C I Ó N E S T Á N D A R
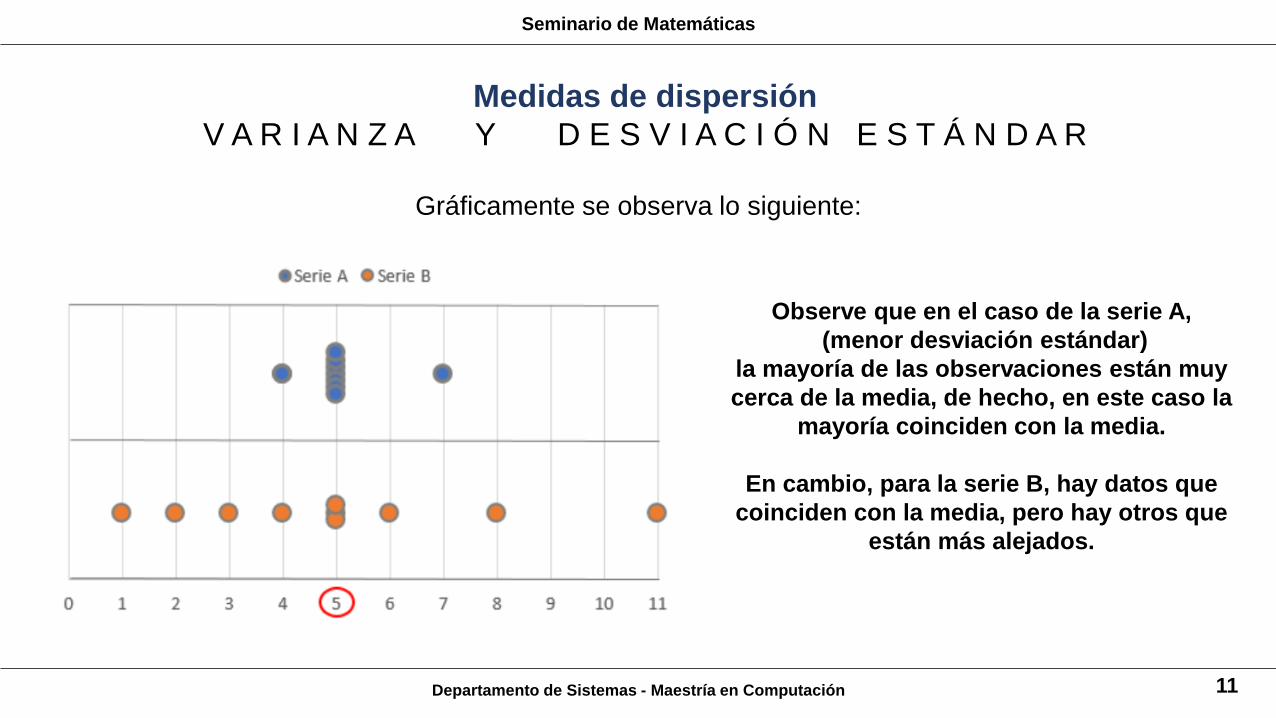
Gráficamente se observa lo siguiente:
Observe que en el caso de la serie A,
(menor desviación estándar)
la mayoría de las observaciones están muy
cerca de la media, de hecho, en este caso la
mayoría coinciden con la media.
En cambio, para la serie B, hay datos que
coinciden con la media, pero hay otros que
están más alejados.
Departamento de Sistemas - Maestría en Computación 12
Seminario de Matemáticas
Medidas de dispersión
V A R I A N Z A Y D E S V I A C I Ó N E S T Á N D A R
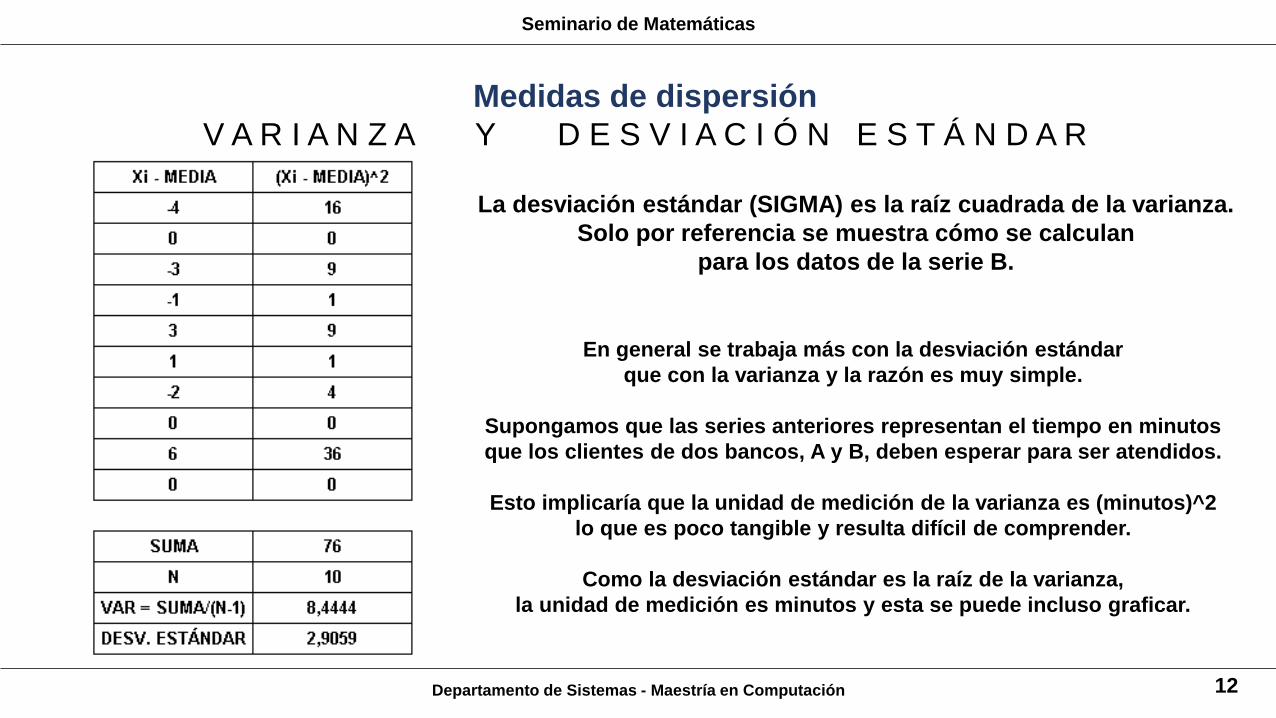
La desviación estándar (SIGMA) es la raíz cuadrada de la varianza.
Solo por referencia se muestra cómo se calculan
para los datos de la serie B.
En general se trabaja más con la desviación estándar
que con la varianza y la razón es muy simple.
Supongamos que las series anteriores representan el tiempo en minutos
que los clientes de dos bancos, A y B, deben esperar para ser atendidos.
Esto implicaría que la unidad de medición de la varianza es (minutos)^2
lo que es poco tangible y resulta difícil de comprender.
Como la desviación estándar es la raíz de la varianza,
la unidad de medición es minutos y esta se puede incluso graficar.
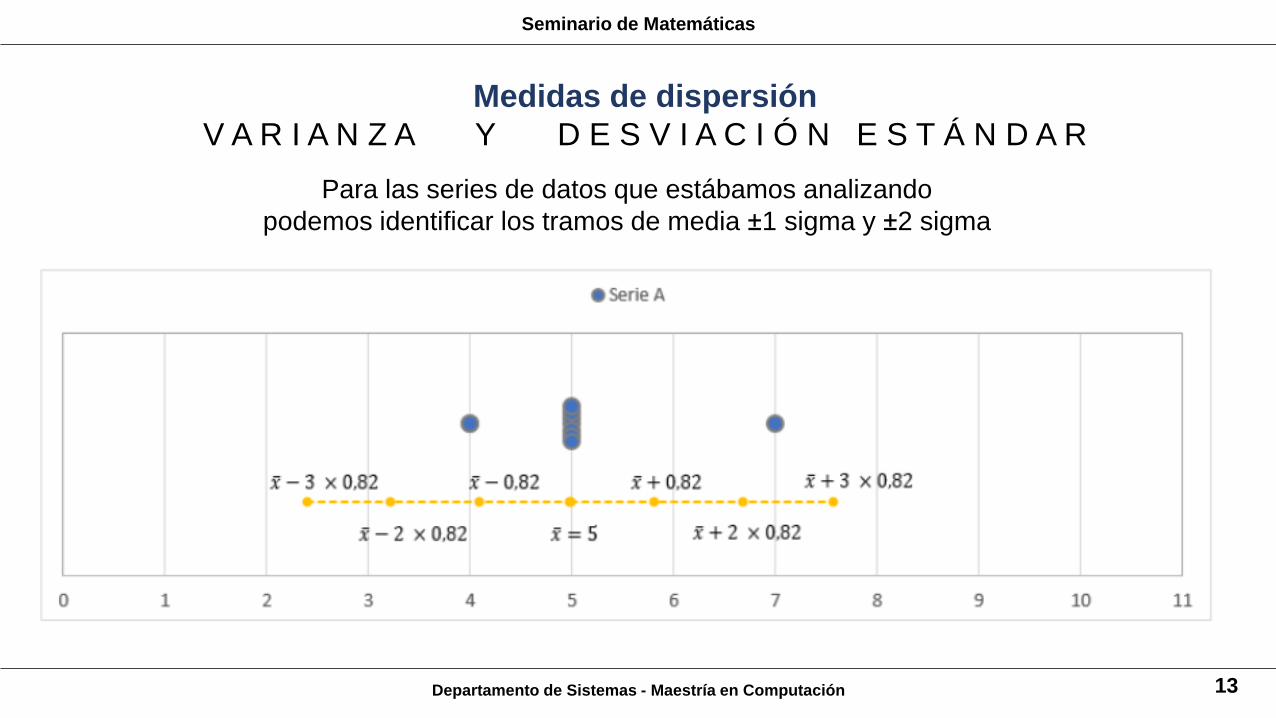
Departamento de Sistemas - Maestría en Computación 13
Seminario de Matemáticas
Medidas de dispersión
V A R I A N Z A Y D E S V I A C I Ó N E S T Á N D A R
Para las series de datos que estábamos analizando
podemos identificar los tramos de media ±1 sigma y ±2 sigma
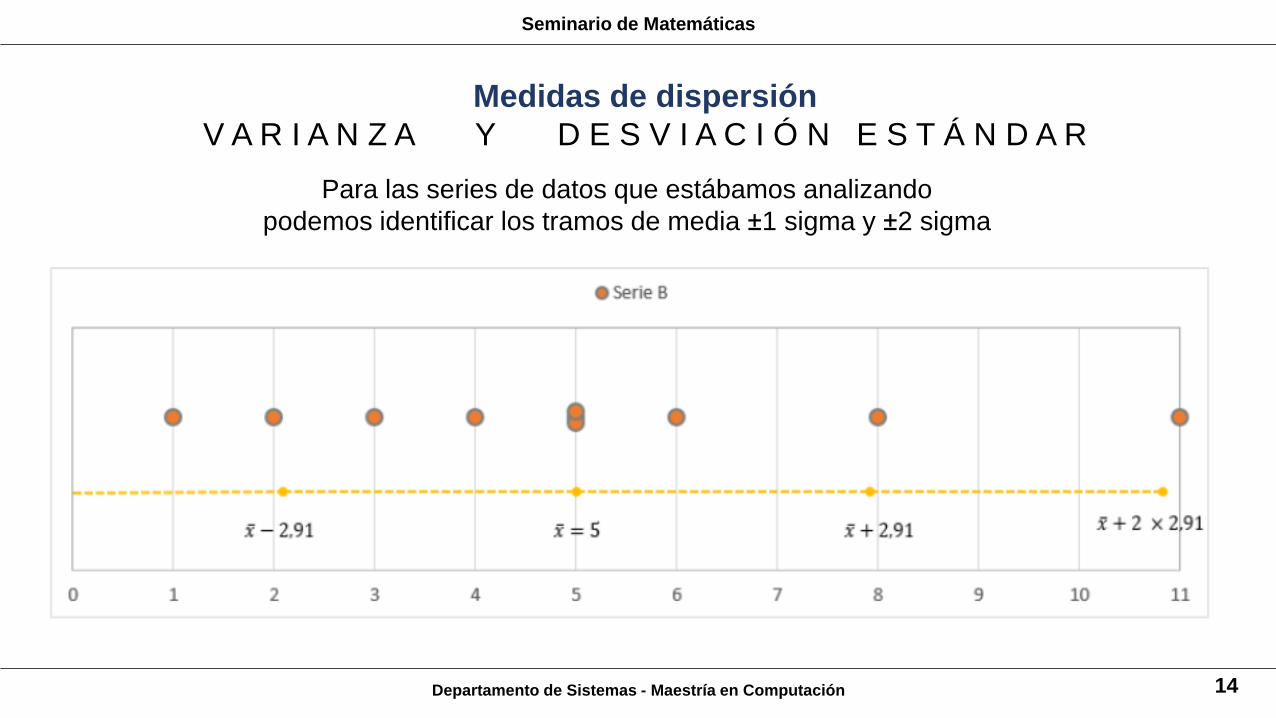
Departamento de Sistemas - Maestría en Computación 14
Seminario de Matemáticas
Medidas de dispersión
V A R I A N Z A Y D E S V I A C I Ó N E S T Á N D A R
Para las series de datos que estábamos analizando
podemos identificar los tramos de media ±1 sigma y ±2 sigma

Departamento de Sistemas - Maestría en Computación 15
Seminario de Matemáticas
Medidas de posición
Las medidas de posición son valores que permiten dividir el
conjunto de datos en partes porcentuales iguales y se usan para
clasificar una observación dentro de una población o muestra.
Las medidas de posición más usuales son:
los cuartiles, los deciles y los percentiles.
A continuación, una pequeña descripción de cada uno de ellos.
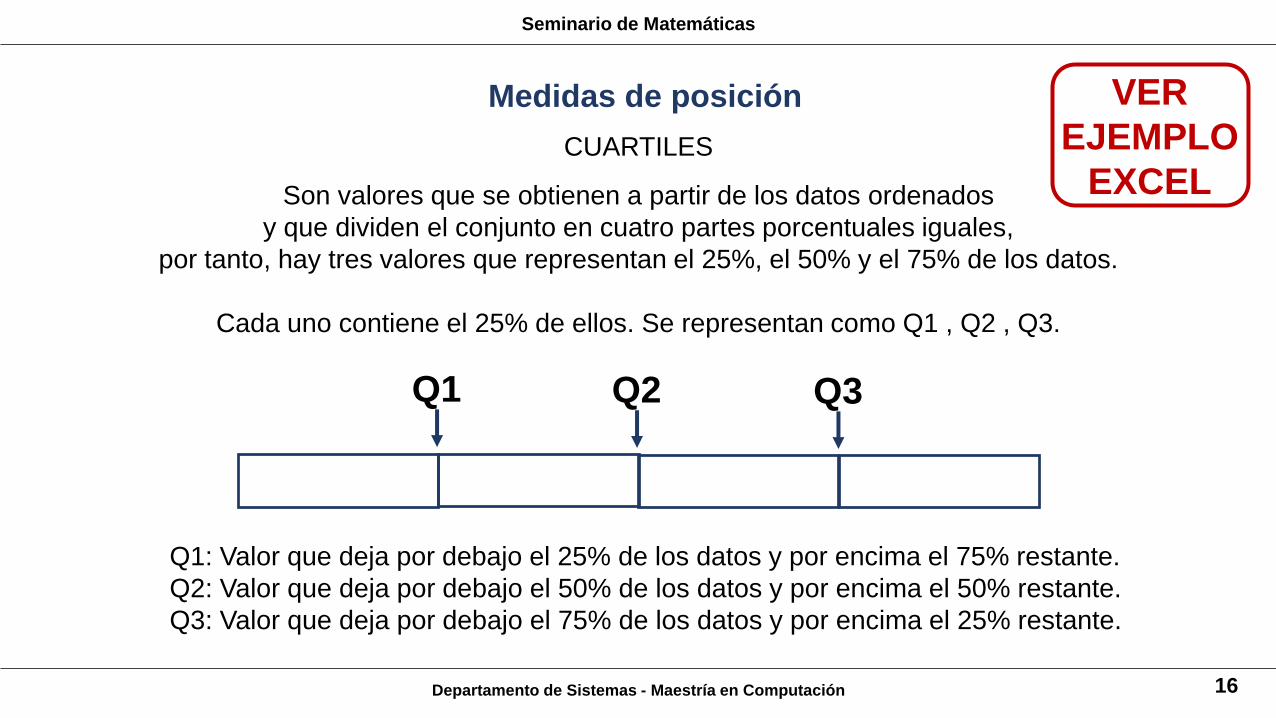
Departamento de Sistemas - Maestría en Computación 16
Seminario de Matemáticas
Medidas de posición
CUARTILES
Son valores que se obtienen a partir de los datos ordenados
y que dividen el conjunto en cuatro partes porcentuales iguales,
por tanto, hay tres valores que representan el 25%, el 50% y el 75% de los datos.
Cada uno contiene el 25% de ellos. Se representan como Q1 , Q2 , Q3.
Q1: Valor que deja por debajo el 25% de los datos y por encima el 75% restante.
Q2: Valor que deja por debajo el 50% de los datos y por encima el 50% restante.
Q3: Valor que deja por debajo el 75% de los datos y por encima el 25% restante.
Q1 Q2 Q3
VER
EJEMPLO
EXCEL
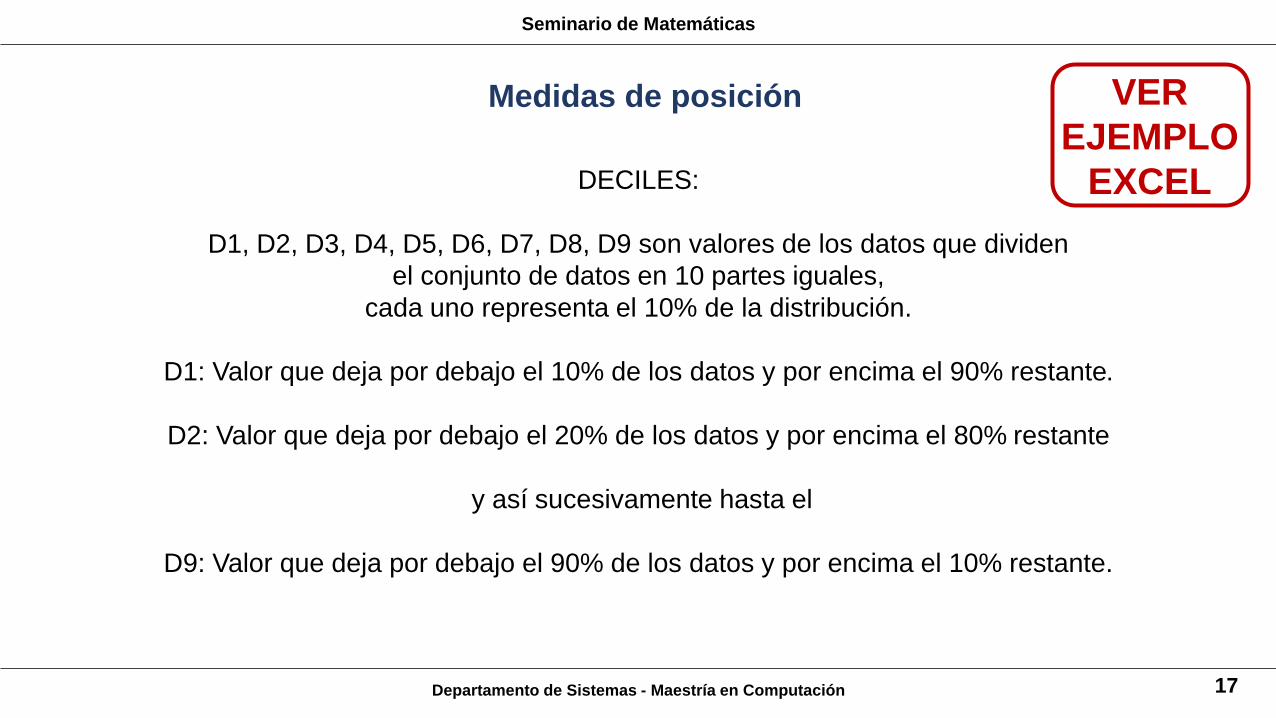
Departamento de Sistemas - Maestría en Computación 17
Seminario de Matemáticas
Medidas de posición
DECILES:
D1, D2, D3, D4, D5, D6, D7, D8, D9 son valores de los datos que dividen
el conjunto de datos en 10 partes iguales,
cada uno representa el 10% de la distribución.
D1: Valor que deja por debajo el 10% de los datos y por encima el 90% restante.
D2: Valor que deja por debajo el 20% de los datos y por encima el 80% restante
y así sucesivamente hasta el
D9: Valor que deja por debajo el 90% de los datos y por encima el 10% restante.
VER
EJEMPLO
EXCEL
Departamento de Sistemas - Maestría en Computación 18
Seminario de Matemáticas
Medidas de posición
PERCENTILES:
P1, P2,…,Pk,…, P99 son los valores de los datos
que dividen el conjunto de datos en 100 partes iguales.
P1: Valor que deja por debajo el 1% de los datos y por encima el 99% restante.
P8: Valor que deja por debajo el 8% de los datos y por encima el 92% restante.
Pk: Percentil k es el valor que deja por debajo el k% de la distribución.

Departamento de Sistemas - Maestría en Computación 19
Seminario de Matemáticas
Distribución de probabilidad discreta
B I N O M I A L
Con frecuencia un experimento consta de pruebas repetidas,
cada una con dos resultados posibles que se pueden denominar éxito o fracaso.
La aplicación más evidente tiene que ver
con la prueba de artículos a medida que salen de una línea de ensamble,
donde cada prueba o experimento puede indicar si un artículo está o no defectuoso.
O con la prueba de la eficacia de un nuevo fármaco a varios pacientes,
donde cada prueba puede indicar si un paciente se curó o no.
Esto se conoce como proceso de Bernoulli
y cada ensayo se denomina experimento de Bernoulli.

Departamento de Sistemas - Maestría en Computación 20
Seminario de Matemáticas
En términos estrictos el proceso de Bernoulli se caracteriza por lo siguiente:
1. El experimento consta de ensayos repetidos.
2. Cada ensayo produce un resultado que se puede clasificar como éxito o fracaso.
3. La probabilidad de un éxito, que se denota con p, permanece constante de un ensayo a otro.
4. Los ensayos repetidos son independientes.
El número X de éxitos en n experimentos de Bernoulli se denomina variable aleatoria binomial.
Distribución de probabilidad discreta
B I N O M I A L

Departamento de Sistemas - Maestría en Computación 21
Seminario de Matemáticas
La distribución de probabilidad de esta variable aleatoria discreta
se llama distribución binomial y sus valores se denotarán como b(x; n, p),
ya que dependen del número de ensayos y de la probabilidad de éxito en un ensayo dado.
Distribución de probabilidad discreta
B I N O M I A L
Un experimento de Bernoulli puede tener como resultado
un éxito con probabilidad p y un fracaso con probabilidad q = 1 – p.
Entonces, la distribución de probabilidad de la variable aleatoria binomial X,
el número de éxitos en n ensayos independientes, es
VER
EJEMPLO
EXCEL

Departamento de Sistemas - Maestría en Computación 22
Seminario de Matemáticas
Distribución de probabilidad discreta
P O I S S O N
Los experimentos que producen
valores numéricos de una variable aleatoria X,
el número de resultados que ocurren durante un intervalo de tiempo determinado
o en una región específica,
se denominan experimentos de Poisson.
El intervalo de tiempo puede ser de cualquier duración,
como un minuto, un día, una semana, un mes o incluso un año.
Como la distribución binomial, la distribución de Poisson se utiliza para
control de calidad, aseguramiento de calidad y muestreo de aceptación.

Departamento de Sistemas - Maestría en Computación 23
Seminario de Matemáticas
Distribución de probabilidad discreta
P O I S S O N
Por ejemplo, un experimento de Poisson podría generar observaciones para la variable aleatoria X
que representa:
el número de llamadas telefónicas por hora que recibe una oficina,
el número de días que una escuela permanece cerrada debido al invierno,
el número de juegos suspendidos debido a la lluvia durante la temporada de béisbol.
La región específica podría ser:
un segmento de recta, una área, un volumen o quizá una pieza de material.
En tales casos X podría representar:
el número de ratas de campo por metro cuadrado,
el número de bacterias en un cultivo dado
el número de errores mecanográficos por página.

Departamento de Sistemas - Maestría en Computación 24
Seminario de Matemáticas
Distribución de probabilidad discreta
P O I S S O N
El número X de resultados que ocurren durante un experimento de Poisson
se llama variable aleatoria de Poisson
y su distribución de probabilidad se llama distribución de Poisson.
El número medio de resultados se calcula a partir de μ = λt,
Donde t es el “tiempo”, la “distancia”, el “área” o el “volumen” específicos de interés.
Como las probabilidades dependen de λ,
denotaremos la tasa de ocurrencia de los resultados con p(x; λt).

Departamento de Sistemas - Maestría en Computación 25
Seminario de Matemáticas
Distribución de probabilidad discreta
P O I S S O N
La distribución de probabilidad
de la variable aleatoria de Poisson X,
la cual representa el número de resultados
que ocurren en un intervalo de tiempo dado o región específicos
y se denota con t , es:
Donde:
λ es el número promedio de resultados por unidad de tiempo, distancia, área o volumen
e = 2.71828...
VER
EJEMPLO
EXCEL
Departamento de Sistemas - Maestría en Computación 26
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
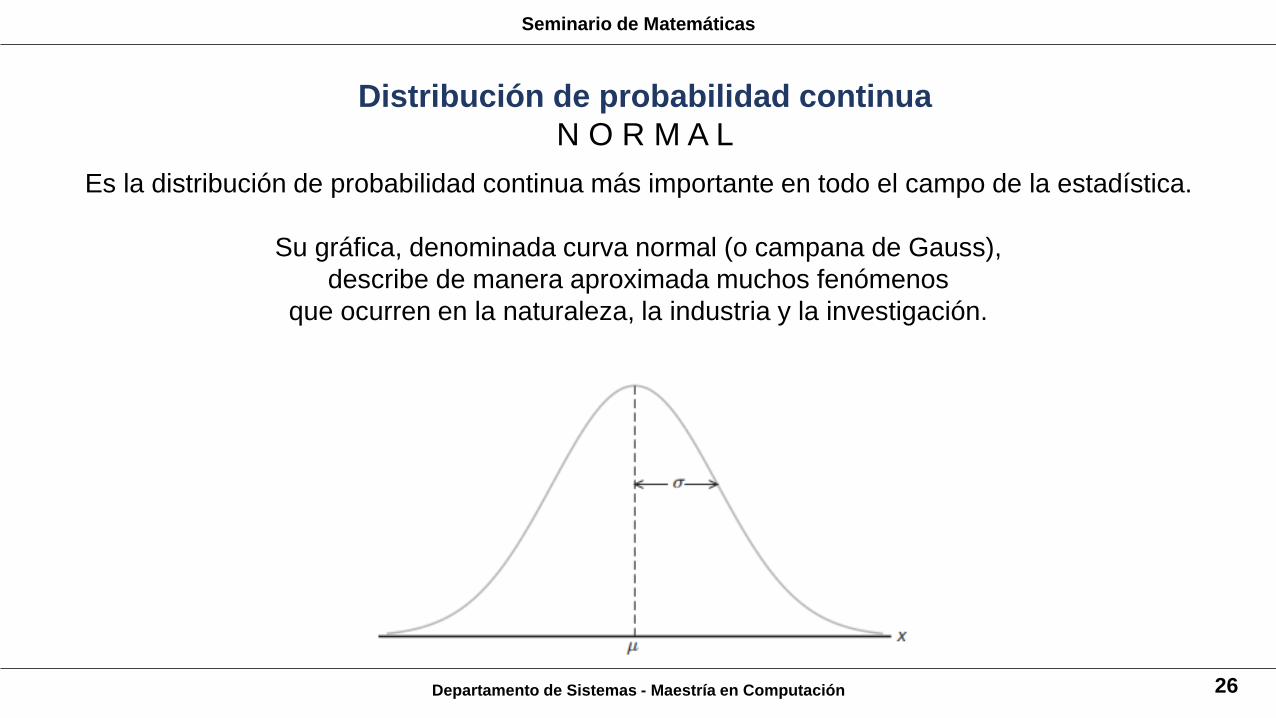
Es la distribución de probabilidad continua más importante en todo el campo de la estadística.
Su gráfica, denominada curva normal (o campana de Gauss),
describe de manera aproximada muchos fenómenos
que ocurren en la naturaleza, la industria y la investigación.
Departamento de Sistemas - Maestría en Computación 27
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
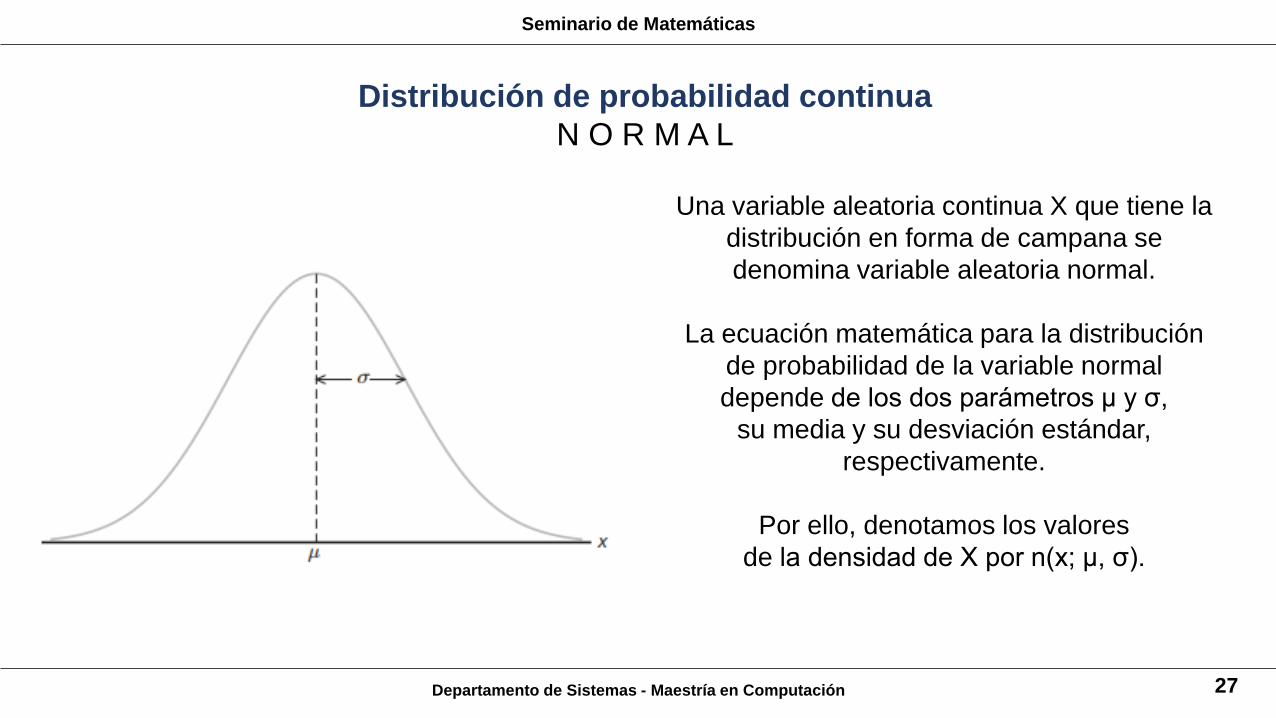
Una variable aleatoria continua X que tiene la
distribución en forma de campana se
denomina variable aleatoria normal.
La ecuación matemática para la distribución
de probabilidad de la variable normal
depende de los dos parámetros μ y σ,
su media y su desviación estándar,
respectivamente.
Por ello, denotamos los valores
de la densidad de X por n(x; μ, σ).

Departamento de Sistemas - Maestría en Computación 28
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
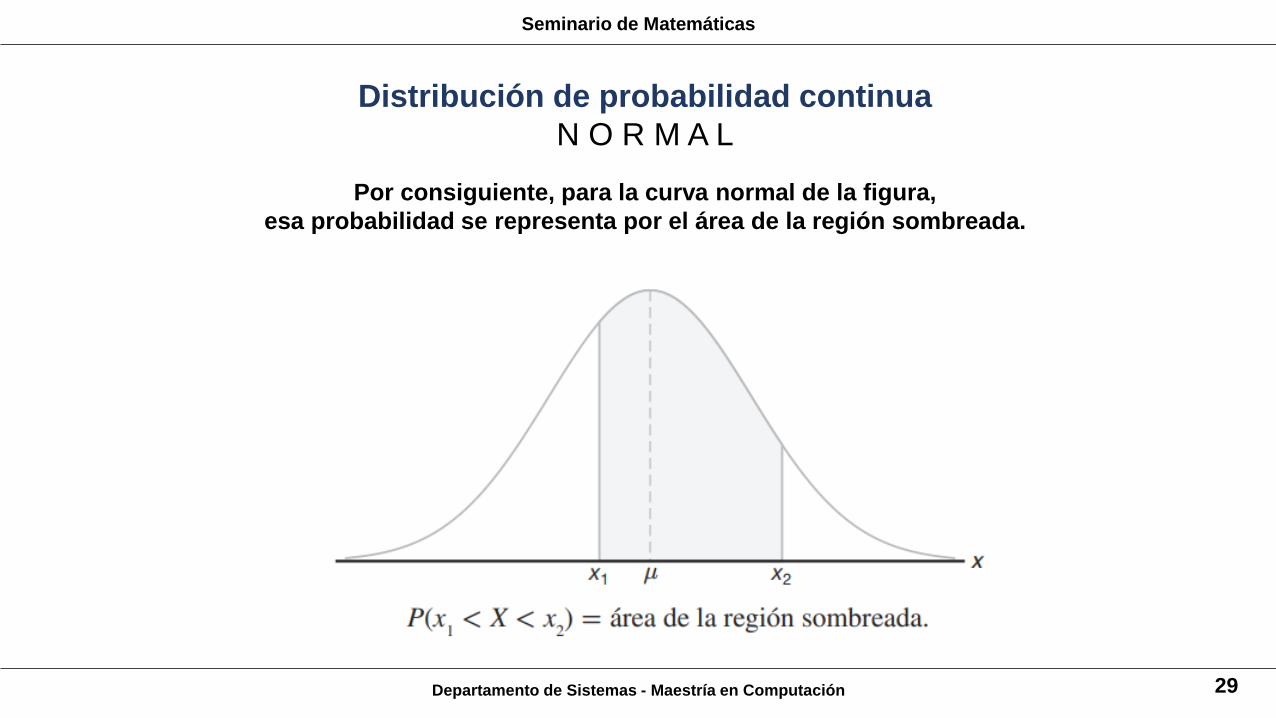
La curva de cualquier distribución continua de probabilidad o función de densidad
se construye de manera que el área bajo la curva limitada por las dos ordenadas x = x1 y x = x2
sea igual a la probabilidad de que la variable aleatoria X tome un valor entre x = x1 y x = x2.
Departamento de Sistemas - Maestría en Computación 29
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
Por consiguiente, para la curva normal de la figura,
esa probabilidad se representa por el área de la región sombreada.

Departamento de Sistemas - Maestría en Computación 30
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
Existen muchos tipos de programas estadísticos que sirven para calcular el área bajo la curva normal.
La dificultad que se enfrenta al resolver las integrales de funciones de densidad normal exige tabular
las áreas de la curva normal para una referencia rápida.
Sin embargo, sería inútil tratar de establecer tablas separadas para cada posible valor de μ y σ.
Por fortuna, podemos transformar todas las observaciones de cualquier variable aleatoria normal X
en un nuevo conjunto de observaciones de una variable aleatoria normal Z con media 0 y varianza 1.
Esto se puede realizar mediante la transformación

Departamento de Sistemas - Maestría en Computación 31
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
La distribución de una variable aleatoria normal con media 0 y varianza 1
se llama distribución normal estándar.

Departamento de Sistemas - Maestría en Computación 32
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
De esa manera se reduce el número requerido de tablas de áreas de curva normal a solo una,
la de la distribución normal estándar.
[VER TABLA (PDF)]
En esa tabla se indica el área bajo la curva normal estándar que corresponde a P(Z < z)
para valores de z que van de –3.49 a 3.49.
Para ilustrar el uso de esta tabla calculemos la probabilidad de que Z sea menor que 1.74.
Primero, localizamos un valor de z igual a 1.7 en la columna izquierda, después nos movemos a lo
largo del renglón hasta la columna bajo 0.04, donde leemos 0.9591. Por lo tanto, P(Z < 1.74) = 0.9591.
Para calcular un valor z que corresponda a una probabilidad dada se invierte el proceso.
Por ejemplo, el valor z que deja un área de 0.2148 bajo la curva a la izquierda de z es –0.79.
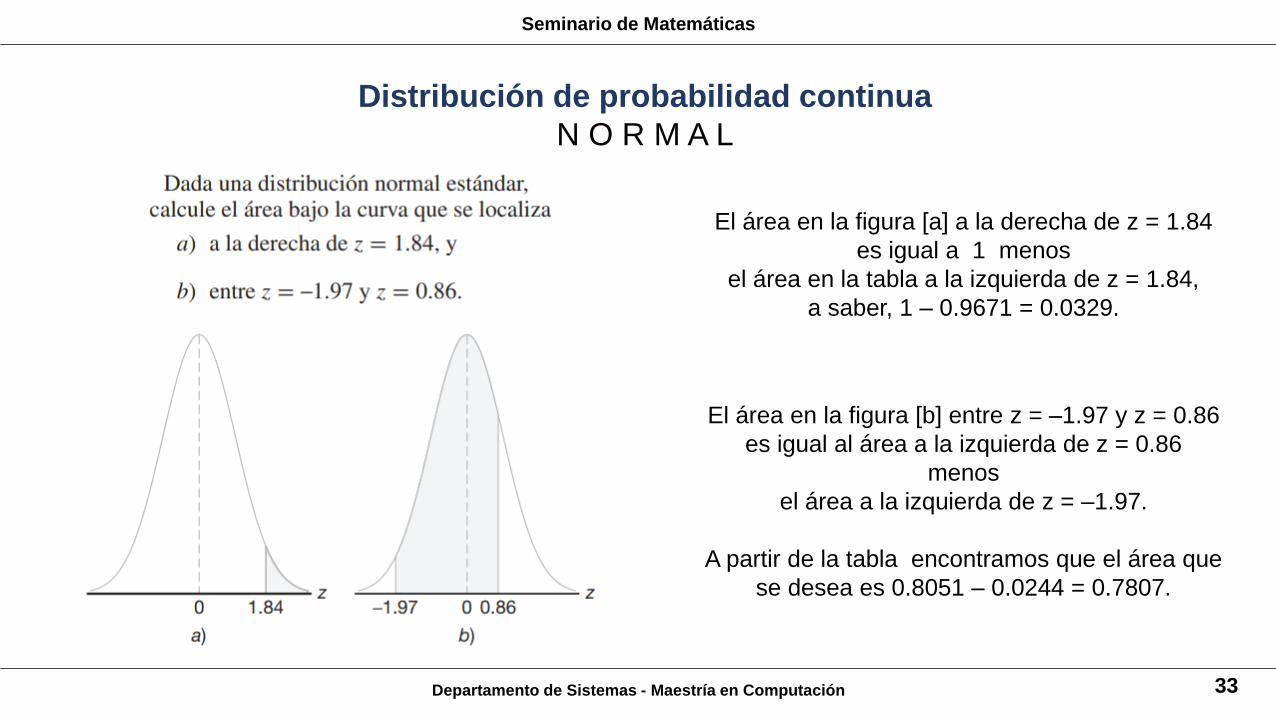
Departamento de Sistemas - Maestría en Computación 33
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
El área en la figura [a] a la derecha de z = 1.84
es igual a 1 menos
el área en la tabla a la izquierda de z = 1.84,
a saber, 1 – 0.9671 = 0.0329.
El área en la figura [b] entre z = –1.97 y z = 0.86
es igual al área a la izquierda de z = 0.86
menos
el área a la izquierda de z = –1.97.
A partir de la tabla encontramos que el área que
se desea es 0.8051 – 0.0244 = 0.7807.
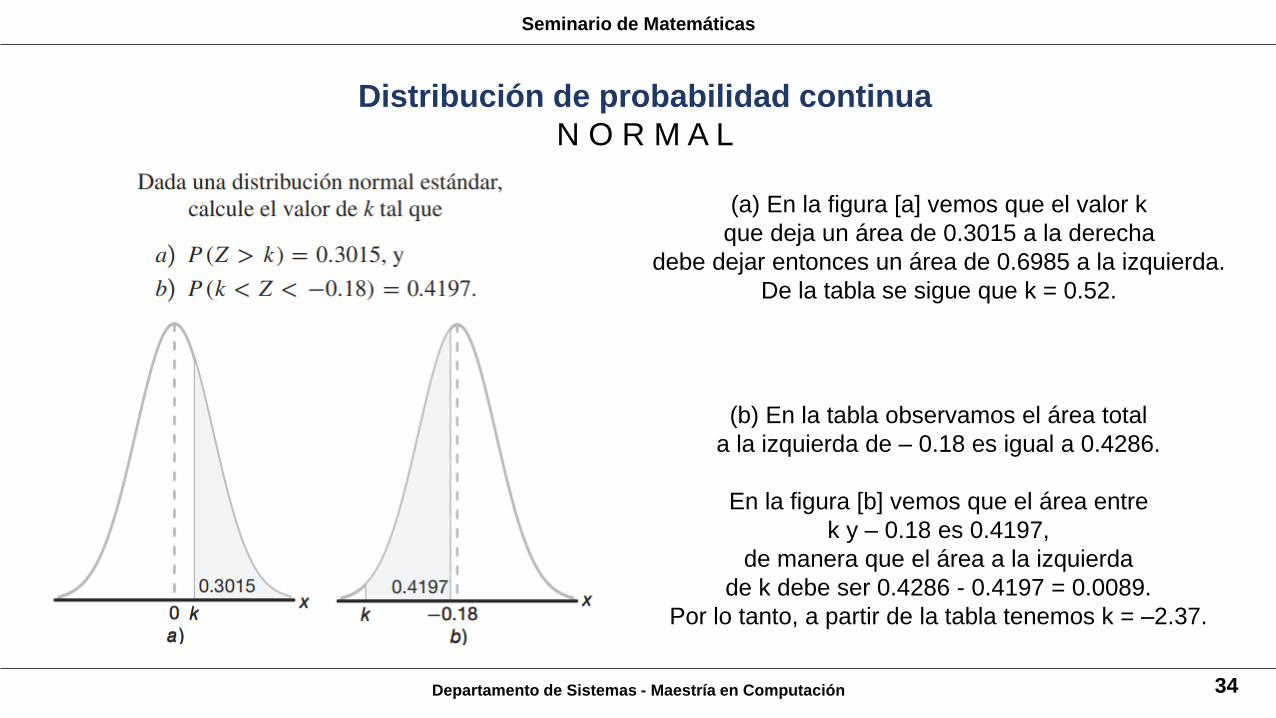
Departamento de Sistemas - Maestría en Computación 34
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
(a) En la figura [a] vemos que el valor k
que deja un área de 0.3015 a la derecha
debe dejar entonces un área de 0.6985 a la izquierda.
De la tabla se sigue que k = 0.52.
(b) En la tabla observamos el área total
a la izquierda de – 0.18 es igual a 0.4286.
En la figura [b] vemos que el área entre
k y – 0.18 es 0.4197,
de manera que el área a la izquierda
de k debe ser 0.4286 - 0.4197 = 0.0089.
Por lo tanto, a partir de la tabla tenemos k = –2.37.
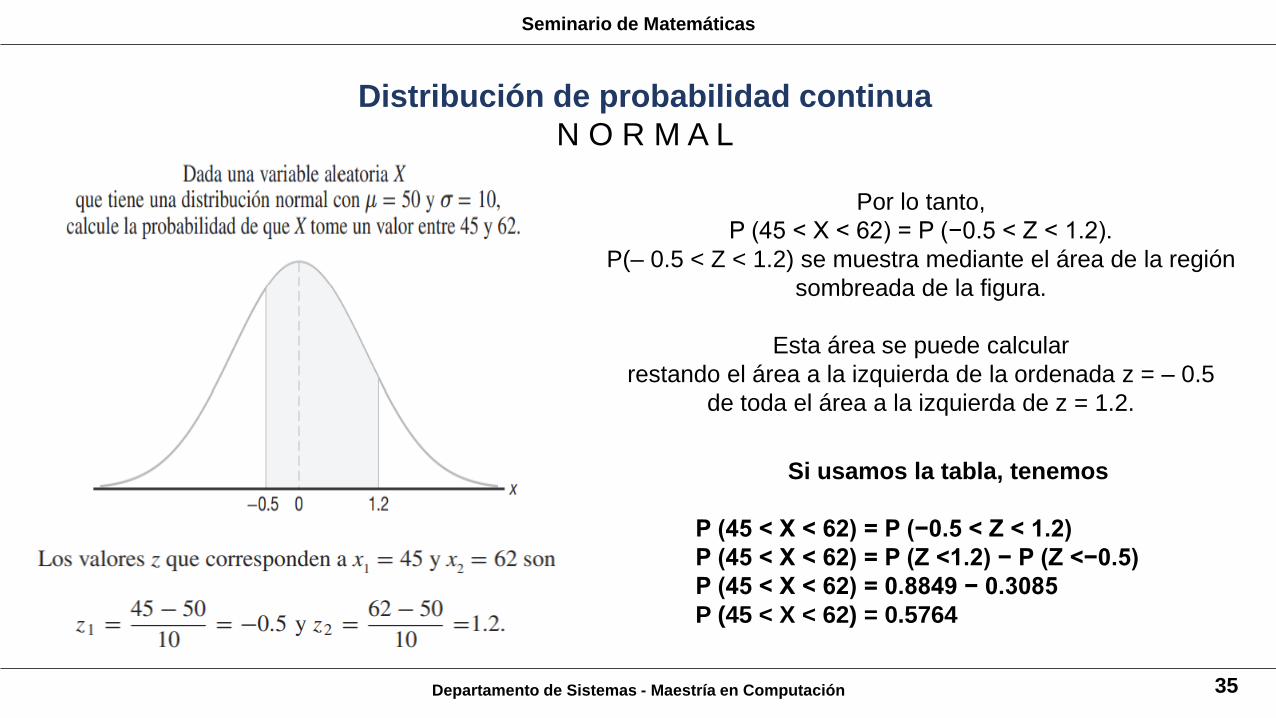
Departamento de Sistemas - Maestría en Computación 35
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
Por lo tanto,
P (45 < X < 62) = P (−0.5 < Z < 1.2).
P(– 0.5 < Z < 1.2) se muestra mediante el área de la región
sombreada de la figura.
Esta área se puede calcular
restando el área a la izquierda de la ordenada z = – 0.5
de toda el área a la izquierda de z = 1.2.
Si usamos la tabla, tenemos
P (45 < X < 62) = P (−0.5 < Z < 1.2)
P (45 < X < 62) = P (Z <1.2) − P (Z <−0.5)
P (45 < X < 62) = 0.8849 − 0.3085
P (45 < X < 62) = 0.5764
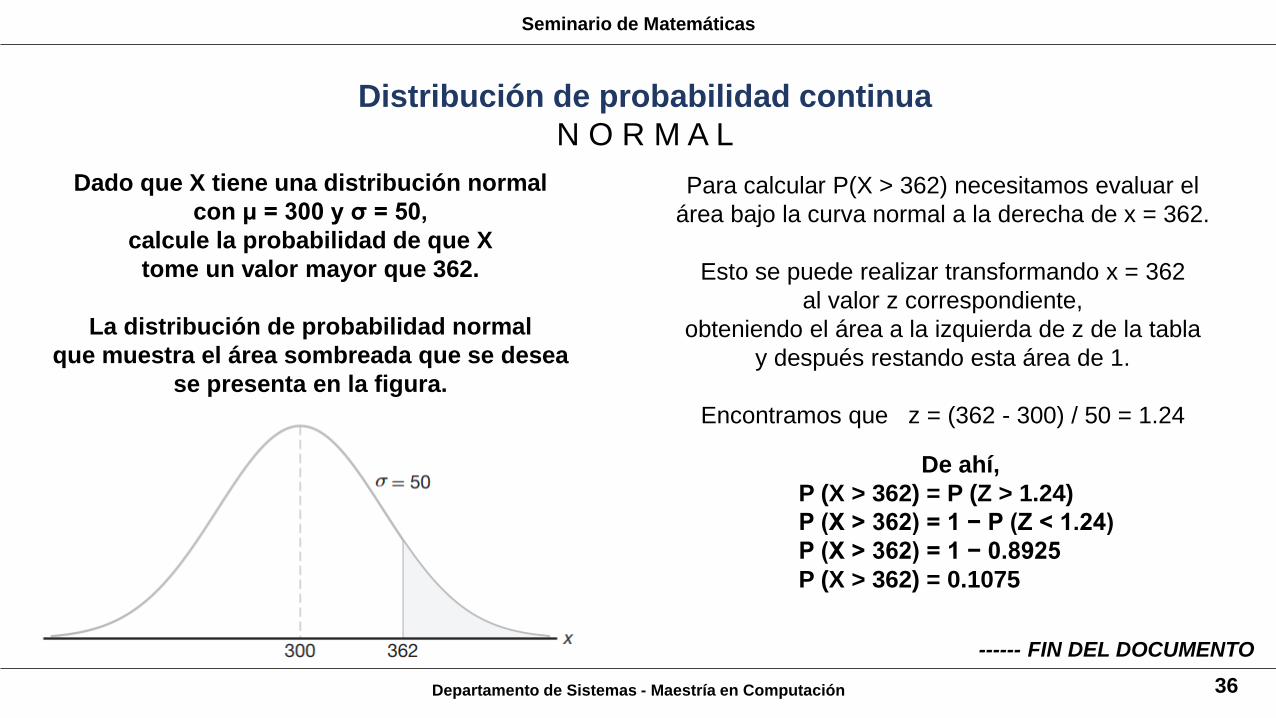
Departamento de Sistemas - Maestría en Computación 36
Seminario de Matemáticas
Distribución de probabilidad continua
N O R M A L
Dado que X tiene una distribución normal
con μ = 300 y σ = 50,
calcule la probabilidad de que X
tome un valor mayor que 362.
La distribución de probabilidad normal
que muestra el área sombreada que se desea
se presenta en la figura.
Para calcular P(X > 362) necesitamos evaluar el
área bajo la curva normal a la derecha de x = 362.
Esto se puede realizar transformando x = 362
al valor z correspondiente,
obteniendo el área a la izquierda de z de la tabla
y después restando esta área de 1.
Encontramos que z = (362 - 300) / 50 = 1.24
De ahí,
P (X > 362) = P (Z > 1.24)
P (X > 362) = 1 − P (Z < 1.24)
P (X > 362) = 1 − 0.8925
P (X > 362) = 0.1075
------ FIN DEL DOCUMENTO


















