







Idiomas
Páginas
Jurídico


Tecnologías Hadoop
Una introducción al ecosistema Hadoop
Quien soy
Angel Llosa Guillen
Architecture Manager in Capgemini
https://es.linkedin.com/in/anllogui
https://twitter.com/anllogui

Esta charla
● Introducción al ecosistema Hadoop
● Visión de conjunto de las principales tecnologías
● Orientada a desarrolladores y analistas de datos

➢ Qué es BigData
➢ Ecosistema Hadoop
➢ Distribuciones Hadoop
➢ Arquitecturas de referencia
➢ Recomendaciones y consideraciones
Agenda
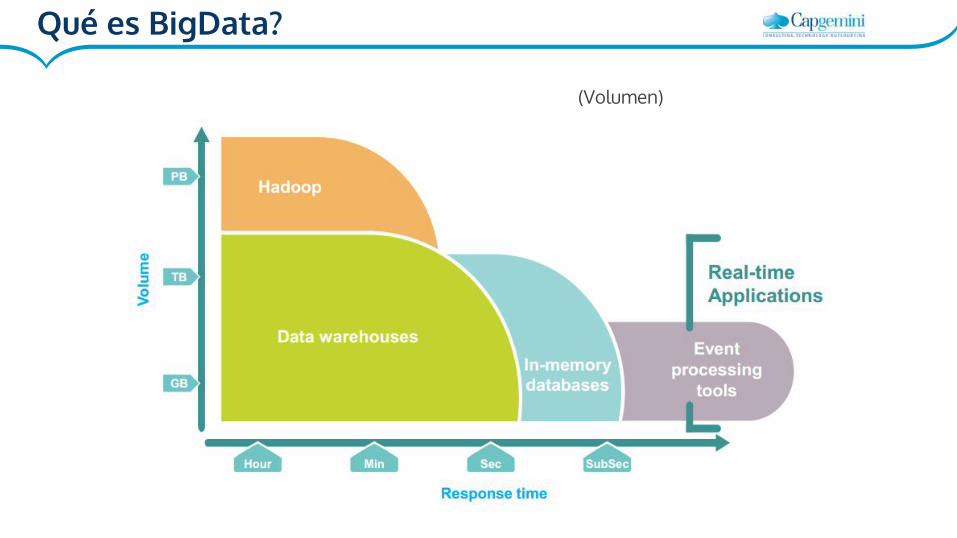
Qué es BigData?
(Volumen)

DW vs BigData
● Fuentes datos actuales (estructuradas)
● Las capacidades analíticas te las dan los orígenes de datos
● La velocidad y el volumen tienen costes altos
• Nuevas fuentes datos (estructuradas
y no)
• Nuevas capacidades analíticas
• Nuevas opciones de disponer de
velocidad y volumen a costes
reducidos
• Fuentes datos actuales (estructuradas)
• Las capacidades analíticas te las dan
los orígenes de datos
• La velocidad y el volumen tienen
costes altos
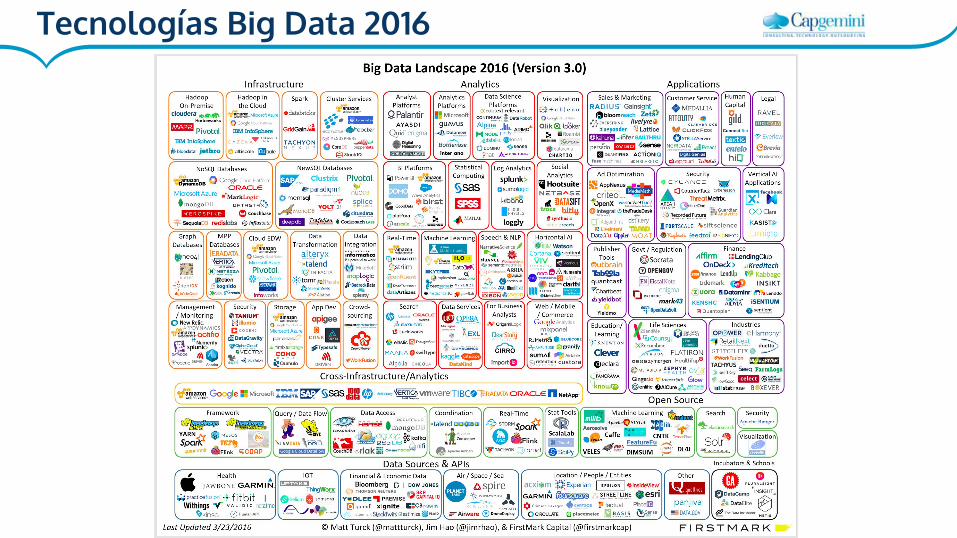
Tecnologías Big Data 2016

➢ Qué es BigData
➢ Ecosistema Hadoop
➢ Distribuciones Hadoop
➢ Arquitecturas de referencia
➢ Recomendaciones y consideraciones
Índice
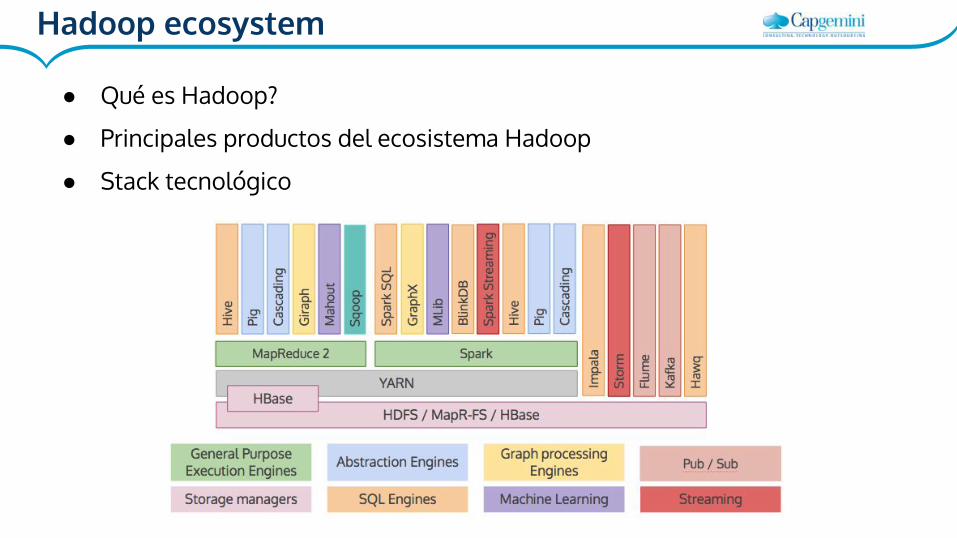
Hadoop ecosystem
● Qué es Hadoop?
● Principales productos del ecosistema Hadoop
● Stack tecnológico

Qué es Hadoop?
● Hadoop es un framework que permite el proceso distribuido de grandes volúmenes
de datos entre clusters de computación.
● Está diseñado para escalar desde un solo servidor a miles de máquinas, cada una
ofreciendo capacidad de cálculo y de almacenamiento.
● Tolerante a fallos
● Incluye:
○ Hadoop Commons
○ Hadoop Distributed File System (HDFS)
○ Hadoop YARN (yet another resource negotiator)
○ Hadoop MapReduce
● Yahoo: 4500 nodos (2*4cpu boxes w 4*1TB disk & 16GB RAM)
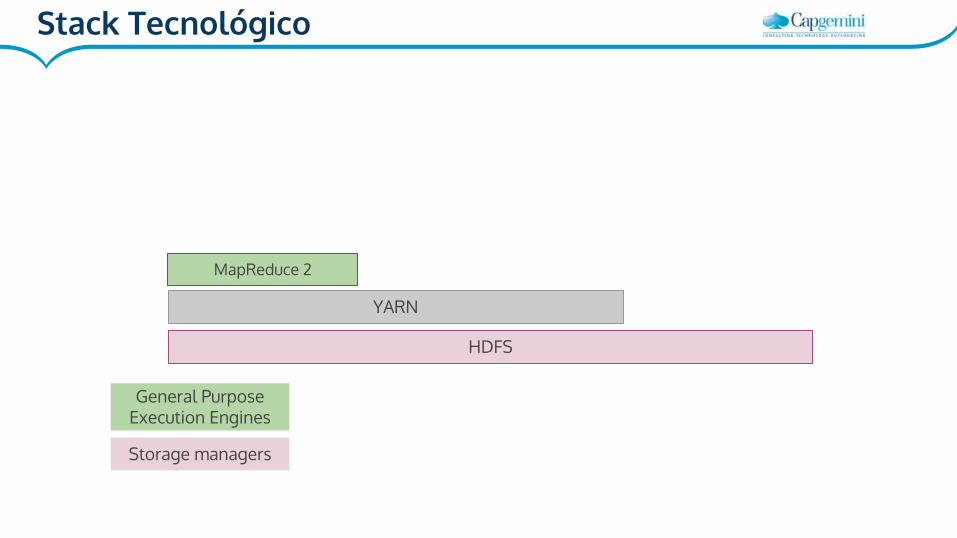
HDFS
MapReduce 2
Storage managers
General Purpose Execution Engines
YARN
Stack Tecnológico

HDFS
● Almacenamiento de datos distribuido, tolerante a fallos.
● Analogía con un sistema de ficheros, no una BD.
● HDFS ha demostrado que es escalable hasta 200 PB de almacenamiento
en un cluster de 4500 nodos
hdfs dfs -ls /user/hadoop/file1
hdfs dfs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
hdfs dfs -rm hdfs://nn.example.com/file /user/hadoop/emptydir

YARN / Mapreduce
● Procesamiento de bajo nivel.
● Distribuido, tolerante a fallos y orientado a batch
● MapReduce:
○ Fwk con servicios para distribuir trabajos y recolectar resultados, ordenar,
filtrar, etc.
● YARN:
○ Gestiona el acceso a los recursos de la aplicación (memoria, CPU)
○ Monitoriza los nodos.
○ Planifica los trabajos.
○ Soporta distintos tipos de aplicación (no solo MR).
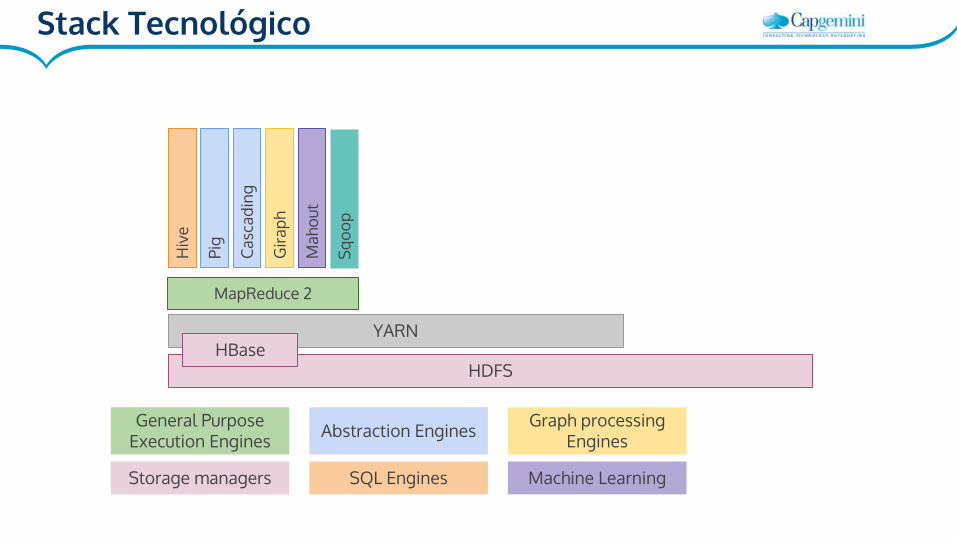
HDFS
MapReduce 2
Storage managers
General Purpose Execution Engines
Hiv
e
Pig
Casc
adin
g
Gira
ph
Mah
out
SQL Engines
Abstraction Engines Graph processing Engines
Machine Learning
YARNHBase
Stack Tecnológico
Sqoo
p

HBase
● Base de datos distribuida, columnar y no relacional, basada en Bigtable de
● Almacenamiento distribuido en un cluster de máquinas
● Modelo de datos sin esquemas predefinidos (“NoSQL”)
● Particiones de datos autogestionadas.

HBase
● Qué no es:
○ No es una BBDD SQL
○ No es relacional
○ No soporta Joins
○ Sin un motor de consultas sofisticado
○ No es transaccional por defecto
○ No es un sustituto a una RDBMS
● Entonces, para qué sirve? e.g.: para almacenar y procesar logs

HBase

Hive
● SQL-Like → HiveSQL
● Reduce el tiempo de desarrollo.
● Se ejecuta sobre Mapreduce, Spark o Tez.
● Orientado a batch. En progreso modo interactivo → Stinger Initiative
SELECT customers.cust_id, SUM(cost) AS total
FROM customers
JOIN orders
ON customers.cust_id = orders.cust_id
GROUP BY customers.cust_id
ORDER BY total DESC;

PIG
● Lenguaje de alto nivel para procesado de datos
● Procedural data flow:
○ Joining and transforming data.
● Se pueden utilizar funciones programadas en Java dentro de PIG
people = LOAD ‘/user/training/customers’ AS (cust_id, name);
orders = LOAD ‘/user/training/orders’ AS (ord_id, cust_id, cost);
groups = GROUP orders BY cust_id;
totals = FOREACH groups GENERATE group, SUM(orders.cost) AS t;
result = JOIN totals BY group, people BY cust_id;
DUMP result;

Sqoop
● Herramienta para realizar transferencias de datos masivas entre RDBMs y
Hadoop (HDFS, HIVE, HBase).
● Bases de datos soportadas:
○ MySQL
○ PostgreSQL
○ Oracle
○ HSQLDB
● Paralelizado (MR), incremental, etc.

Sqoop
[[email protected] ~] sqoop import-all-tables \
-- num-mappers 1 \
--connect jdbc:mysql://quickstart.cloudera:3306/retail_db \
--username=retail_dba \
--password=cloudera \
--compression-codec=snappy \
--as-avrodatafile \
--warehouse-dir=/user/hive/warehouse/userXX
[[email protected] ~] sqoop import \ --query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \

Otros
● Cascading: ETL basado en Java/Scala
● Giraph: Proceso de grafos
● Mahout: Librerías para machine learning
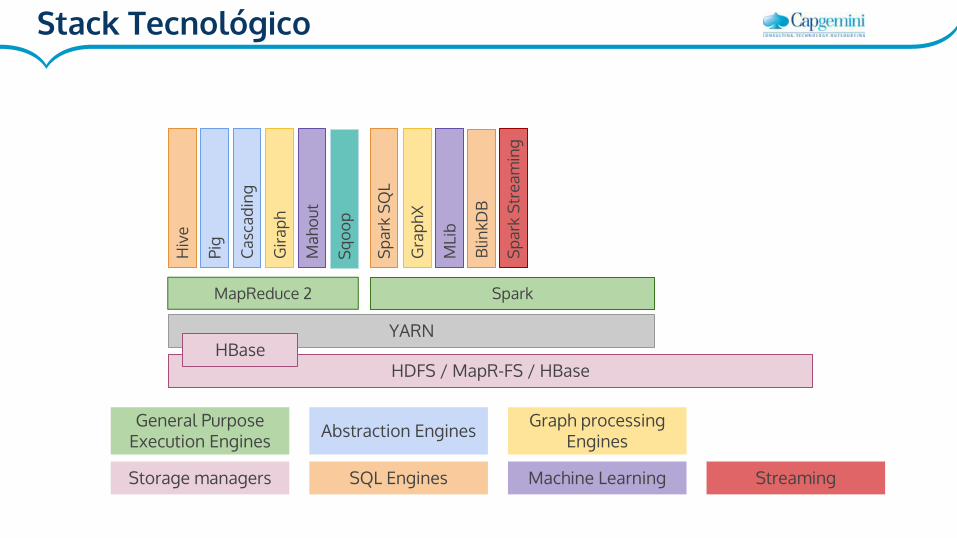
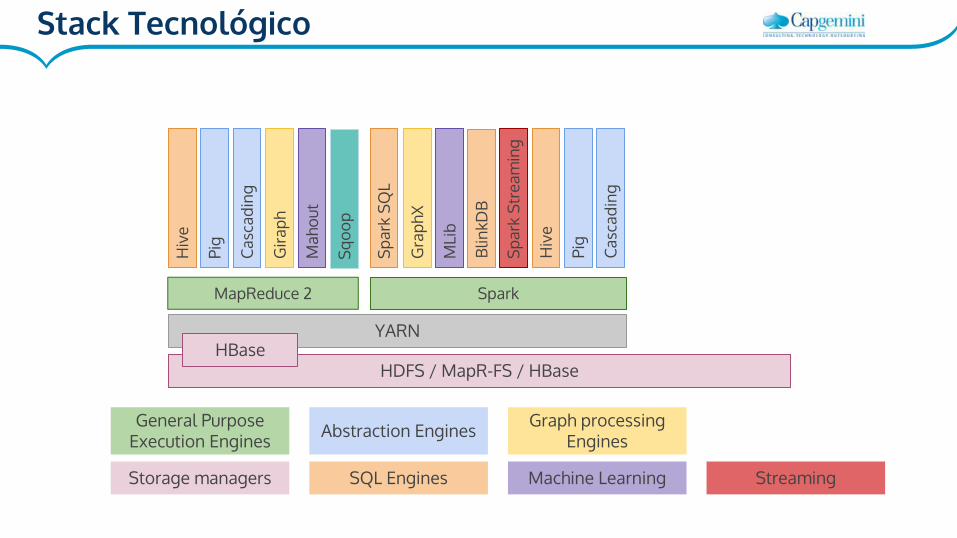
HDFS / MapR-FS / HBase
MapReduce 2 Spark
Storage managers
General Purpose Execution Engines
Hiv
e
Pig
Casc
adin
g
Gira
ph
Mah
out
SQL Engines
Abstraction Engines Graph processing Engines
Machine Learning
Gra
phX
MLi
b
Spar
k SQ
L
Spar
k St
ream
ing
Streaming
YARN
Stack Tecnológico
HBaseSq
oop
Blin
kDB

SparkDiferencias con Mapreduce:
● Es más rápido: Optimizado para trabajar en memoria
● Menos costoso mover datos durante el procesado
● Una API más potente que MR → Más fácil para desarrollar
● APIs en Scala, Python y Java.
Spark se puede ejecutar en modo standalone o sobre clusters:
● Amazon EC2
● Standalone Deploy Mode
● Apache Mesos
● Hadoop YARN
→ Escalable desde la fase de desarrollo
Spark
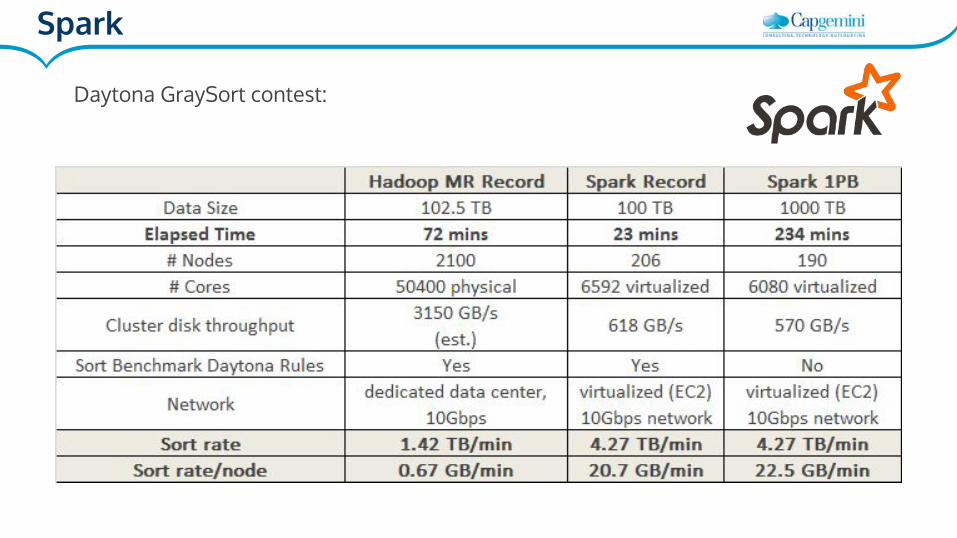
Daytona GraySort contest:

Spark SQL
● Integrado con Spark: Se pueden lanzar consultas desde código.
● Acceso a distintas fuentes de datos: JSON, tablas Hive
● Compatibilidad con Hive: HiveQL, datos y user defined functions.
● Trabaja con dataframes

Spark Streaming
● Fácil de usar, tolerante a fallos, integrado con Spark...
● Se puede usar con Mlib.
● Microbatches (input & output)
HDFS / MapR-FS / HBase
MapReduce 2 Spark
Storage managers
General Purpose Execution Engines
Hiv
e
Pig
Casc
adin
g
Gira
ph
Mah
out
SQL Engines
Abstraction Engines Graph processing Engines
Machine Learning
Gra
phX
MLi
b
Spar
k SQ
L
Spar
k St
ream
ing
Streaming
YARN
Stack Tecnológico
HBaseSq
oop
Hiv
e
Pig
Casc
adin
g
Blin
kDB
HDFS / MapR-FS / HBase
MapReduce 2 Spark
Storage managers
General Purpose Execution Engines
Hiv
e
Pig
Casc
adin
g
Gira
ph
Mah
out
SQL Engines
Abstraction Engines Graph processing Engines
Machine Learning
Gra
phX
MLi
b
Spar
k SQ
L
Spar
k St
ream
ing
Streaming
YARN
Stack Tecnológico
HBaseSq
oop
Hiv
e
Pig
Casc
adin
g
Blin
kDB
Haw
q
Stor
m
Flum
e
Kafk
a
Impa
la
Pub / Sub

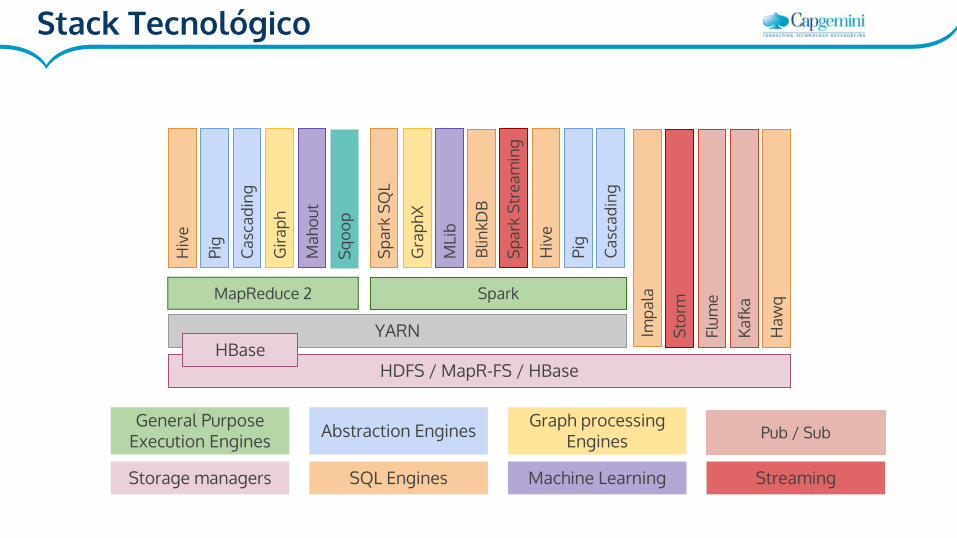
Impala
● Creado por Cloudera
● Open Source - Apache (incubating)
● Orientado a consultas interactivas:
○ Consultas ad-hoc
○ Para herramientas BI (Pentaho, Microstrategy)
● 10 más rápido que Hive o Pig (sobre MR)
● Motor de ejecución propio (no MapReduce)

Hawq
● Creado por Pivotal
● 100% ANSI SQL compatible
● Benchmark (hecho por Pivotal): ○ mejores resultados que Impala
○ 21x más rápido que Stinger (Hive).
○ Diseñado para gestionar PB

Kafka
● Sistema de mensajería de publicación-suscripción
● Rápido, escalable, durable y tolerante a fallos
● Posible sustituto a JMS y AMQP por su rendimiento, fiabilidad y
replicación
● Casos de uso:
○ Stream Processing
○ Seguimiento de actividad web
○ Recolección de métricas y monitorización
○ Recopilación de logs
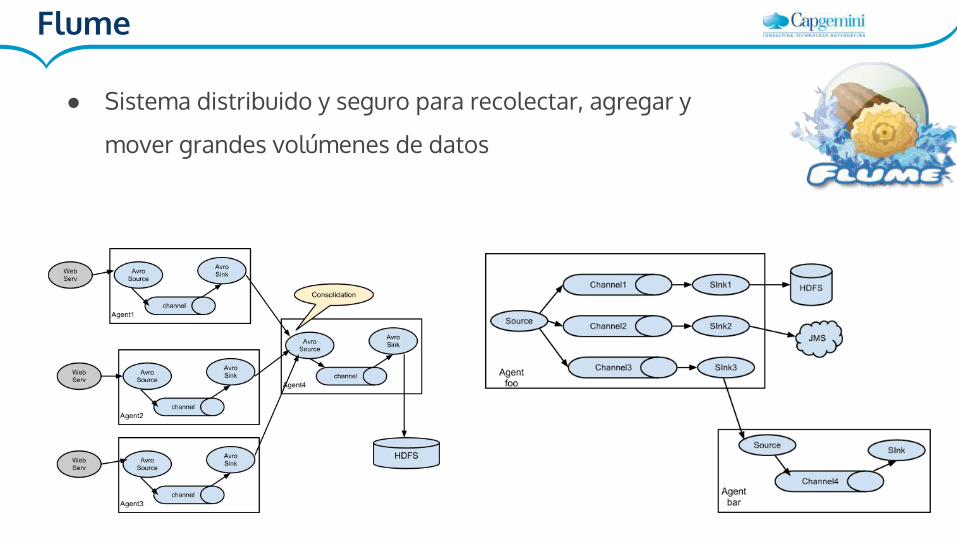
Flume
● Sistema distribuido y seguro para recolectar, agregar y
mover grandes volúmenes de datos

Flume
Sources:
● Avro Source● Thrift Source● JMS Source● Converter● Spooling Directory Source● BlobDeserializer● NetCat Source● Sequence Generator● Syslog Sources● HTTP Source● ...
Channels:
● Memory Channel● JDBC Channel● File Channel● Kafka Channel● Spillable Memory
Channel● Pseudo Transaction
Channel● Custom Channel
Sinks:
● HDFS Sink● Logger Sink● Avro Sink● Thrift Sink● IRC Sink● File Roll Sink● Null Sink● HBaseSink● MorphlineSolr Sink● ElasticSearch Sink● ...

Flume vs. Kafka
● Kafka es multipropósito, con algunas fuentes y sumideros.
● Flume fué creado para recopilación de logs y escritura en HDFS, aún así,
soporta más fuentes y sumideros por defecto que Kafka.
● Los dos son zero data loss, pero Kafka es high-available
● Kafka y Flume pueden ser utilizados juntos: Por ejemplo, para hacer
streaming a HDFS es recomendable utilizar Kafka como fuente y Flume
como sumidero.

Storm
● Open Source y adquirido por Twitter
● Capacidades:
○ Rápido - un millón de mensajes procesados por segundo por nodo
○ Escalable – Procesamiento en paralelo en distintos nodos
○ Tolerante a fallos
○ Seguro – Cada mensaje se procesa sólo una vez.

HDFS / MapR-FS / HBase
MapReduce 2 Spark
Storage managers
General Purpose Execution Engines
Hiv
e
Pig
Casc
adin
g
Gira
ph
Mah
out
SQL Engines
Abstraction Engines Graph processing Engines
Machine Learning
Gra
phX
MLi
b
Spar
k SQ
L
Spar
k St
ream
ing
Streaming
YARN
Stack Tecnológico
HBaseSq
oop
Hiv
e
Pig
Casc
adin
g
Blin
kDB
Haw
q
Stor
m
Flum
e
Kafk
a
Impa
la

➢ Qué es BigData
➢ Ecosistema Hadoop
➢ Distribuciones Hadoop
➢ Arquitecturas de referencia
➢ Recomendaciones y consideraciones
Índice

Distribuciones Hadoop
● Distribución: empaquetado de tecnologías del ecosistema Hadoop con
una capa de gestión añadida y soporte empresarial.
● Las tres principales:
○ Cloudera
○ Hortonworks
○ MapR

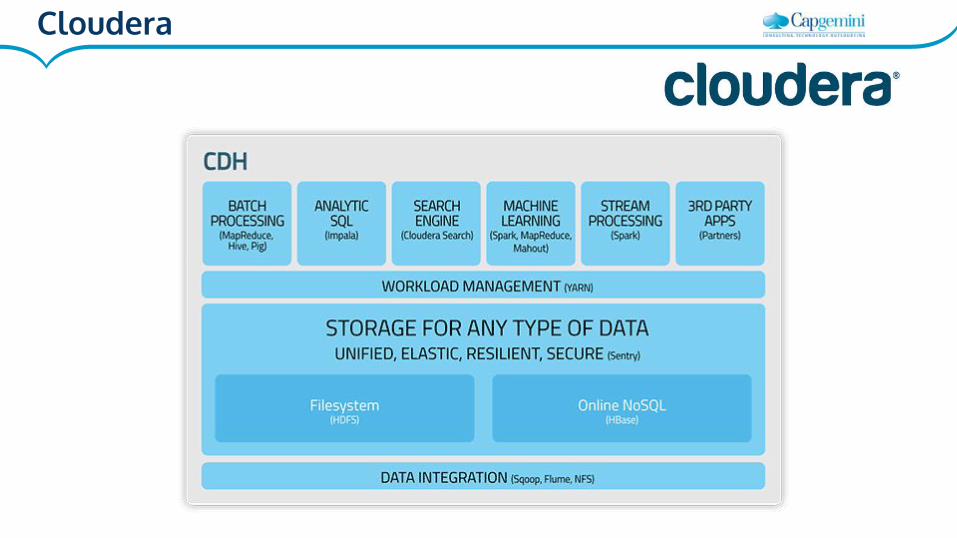
Cloudera
● Distribuye Cloudera Enterprise
● Contribuyente principal del proyecto Impala.
● Incluye, entre otros, los siguientes servicios:
○ Seguridad
○ Gobierno de dato
○ Gobierno operacional
● Cloudera Manager y Cloudera Navigator no son OS.
Cloudera

HortonWorks
● Distribuye la Hortonworks Data Platform (HDP)
● Contribuyente principal del proyecto Hive.
● HDP incluye los siguientes servicios:
○ Seguridad
○ Gobierno de dato
○ Gobierno operacional
● Propulsor de la "Stinger Initiative”:
○ Mejorar Hive para tratar consultas interactivas (no batch)
○ Consultas a escala de petabyte
● Todo Opensource

HortonWorks

MapR
● Mapr-FS en vez de HDFS:
○ Mejor rendimiento, confiabilidad, eficiencia, mantenibilidad y
facilidad de uso.
○ Se puede montar vía NFS.
○ Posix-compliant
○ Soporta Impala

MapR
● Mapr-DB en vez de HBase:
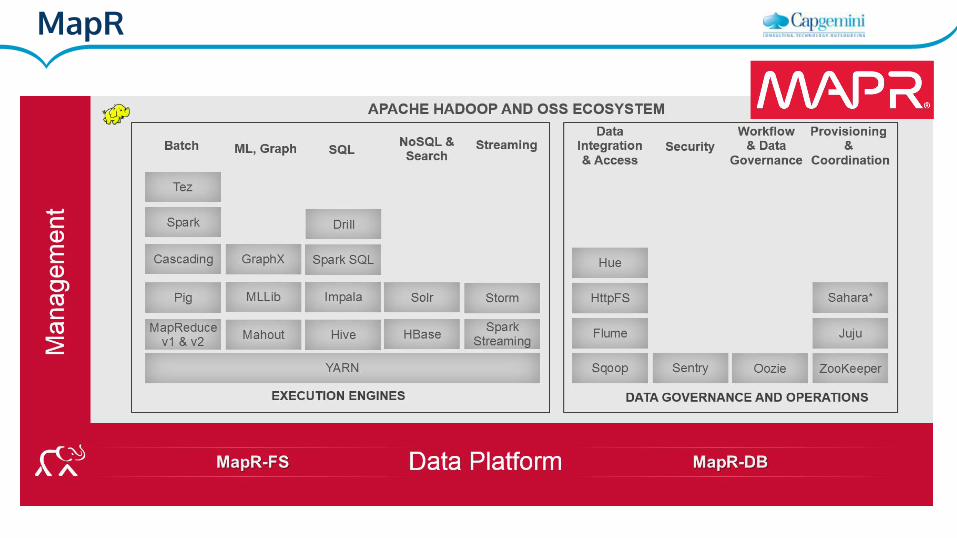
MapR
Bonus track: Stratio

➢ Qué es BigData
➢ Ecosistema Hadoop
➢ Distribuciones Hadoop
➢ Arquitecturas de referencia
➢ Recomendaciones y consideraciones
Índice

Conceptual Architecture

Data Lake
Un data lake es un repositorio donde se almacenan TODOS los datos de la
compañía, estructurados y sin estructurar, sin ningún tipo de
preprocesamiento (raw data) y sin ningún tipo de esquema, para ser
analizados posteriormente.
Los datos son vertidos en él y recuperados cuando es necesario. Solo en
ese instante se les da un orden y una estructura que permita su posterior
análisis.
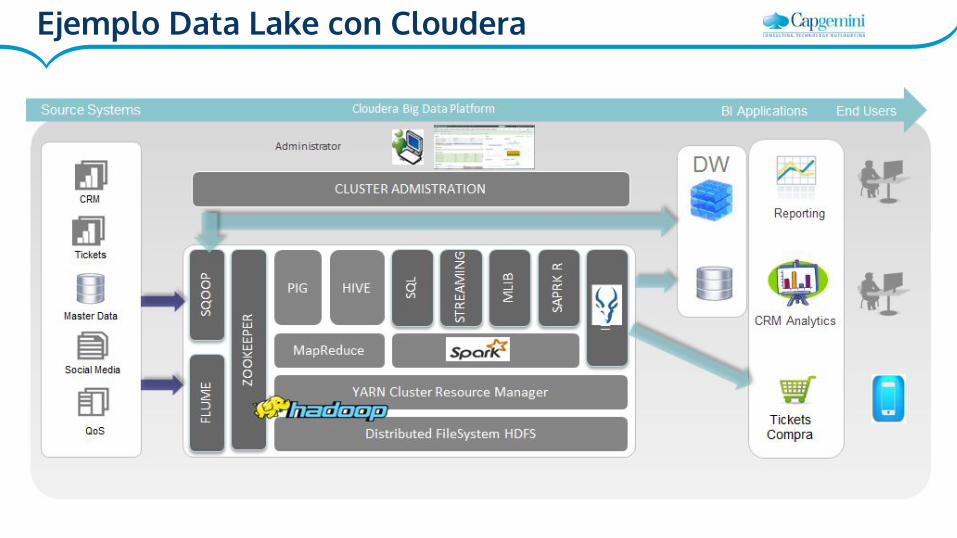
Ejemplo Data Lake con Cloudera

Arquitectura Lambda
Equilibrar la latencia, rendimiento y tolerancia a fallos mediante el uso de
procesamiento por lotes para proporcionar puntos de vista pre-computados
completos y exactos, mientras que al mismo tiempo utilizando el procesamiento de
flujo en tiempo real para proporcionar vistas dinámicas.

➢ Qué es BigData
➢ Ecosistema Hadoop
➢ Distribuciones Hadoop
➢ Arquitecturas de referencia
➢ Recomendaciones y consideraciones
Índice

Recomendaciones
Para los proyectos de Big Data, no hay que "obsesionarse" con la tecnología.
La arquitectura técnica, Hadoop sí o no, la distribución a elegir, etc… son
decisiones estratégicas basadas en qué queremos hacer y por tanto, cómo
vamos a usar la tecnología para conseguir esos fines. Y no al revés.
Las tecnologías Big Data son un facilitador
permiten hacer a un coste razonable lo que antes era sencillamente
imposible o estaba solo al alcance de unos pocos.

Pequeña guía
● Si se tienen consultas ad-hoc, las consultas y necesidades analíticas se conocen de
antemano y los datos son de menos de 600TB, la recomendación sería un Data
warehouse.
● Si el volumen de datos a gestionar es mayor de 600TB, la recomendación sería ir
hacia un modelo basado en Hadoop pero teniendo en cuenta la complejidad de las
consultas requeridas.
● Si los volúmenes de datos son pequeños, no se requiere analítica, pero se requiere
alta velocidad la recomendación podría ser NoSQL

Consideraciones
● Tecnología emergente. En continua evolución (cada menos de 6 meses
cambia)
● El % de implantación en el mercado Español es muy escaso por lo que no
hay experiencias y referencias maduras (Telcos en su mayoría)
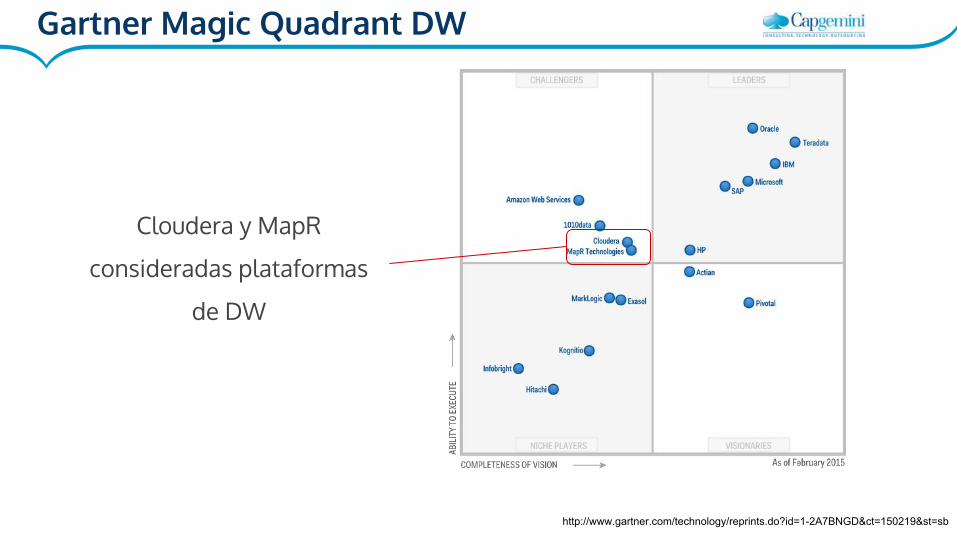
Gartner Magic Quadrant DW
Cloudera y MapR
consideradas plataformas
de DW
http://www.gartner.com/technology/reprints.do?id=1-2A7BNGD&ct=150219&st=sb
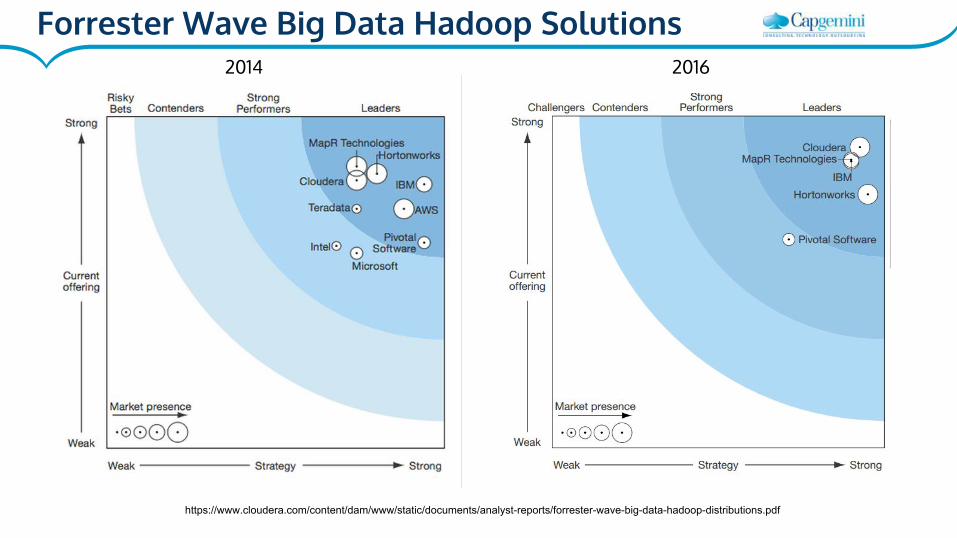
Forrester Wave Big Data Hadoop Solutions2014 2016
https://www.cloudera.com/content/dam/www/static/documents/analyst-reports/forrester-wave-big-data-hadoop-distributions.pdf

Q & A

Sesión Práctica
CCP: Data Scientist Challenge One Solution Kit:
http://certification.cloudera.com/prep/dsc1sk/intro.html

www.capgemini.com