
Econometria Luis
47
4.1 INTRODUCCION AL PRONOSTICO Y SU APLICACIÓN EN LA PROYECCION DE MODELOS DE INNOVACION TECNOLOGICA DIAGNOSTICO ESTADISTICO. 1. Pronósticos a corto plazo: En las empresas modernas, este tipo de pronóstico se efectúa cada mes o menos, y su tiempo de planeación tiene vigencia de un año. Se utiliza para programas de abastecimiento, producción, asignación de mano de obra a las plantillas de trabajadores, y planificación de los departamentos de fabricación. 2. Pronósticos a mediano plazo: Abarca un lapso de seis meses a tres años. Este se utiliza para estimar planes de ventas, producción, flujos de efectivo y elaboración de presupuestos. 3. Pronósticos a largo plazo: Este tipo de pronóstico se utiliza en la planificación de nuevas inversiones, lanzamiento de nuevos productos y tendencias tecnológicas de materiales, procesos y productos, así como en la preparación de proyectos. Los pronósticos pueden ser utilizados para conocer el comportamiento futuros en muchas fenómenos, tales como: 1. Mercadotecnia: Tamaño del mercado. Participación en el mercado. Tendencia de precios. Desarrollo de nuevos productos. 2. Producción: Costo de materia prima. Costo de mano de obra. Disponibilidad de materia prima. Disponibilidad de mano de obra Requerimientos de mantenimiento. Capacidad disponible de la planta para la producción. 3. Finanzas: Tasas de interés. Cuentas de pagos lentos. 4. Recursos Humanos Número de trabajadores. Rotación de personal. Tendencias de ausentismo. Tendencia de llegadas tarde.
-
Upload
itzel-hallie -
Category
Documents
-
view
260 -
download
0
Transcript of Econometria Luis

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 1/47
4.1 INTRODUCCION AL PRONOSTICO Y SU APLICACIÓN EN LA PROYECCIONDE MODELOS DE INNOVACION TECNOLOGICA DIAGNOSTICO ESTADISTICO.
1. Pronósticos a corto plazo:
En las empresas modernas, este tipo de pronóstico se efectúa cada mes o menos, ysu tiempo de planeación tiene vigencia de un año. Se utiliza para programas de
abastecimiento, producción, asignación de mano de obra a las plantillas de
trabajadores, y planificación de los departamentos de fabricación.
2. Pronósticos a mediano plazo:
Abarca un lapso de seis meses a tres años. Este se utiliza para estimar planes de
ventas, producción, flujos de efectivo y elaboración de presupuestos.
3. Pronósticos a largo plazo:
Este tipo de pronóstico se utiliza en la planificación de nuevas inversiones,
lanzamiento de nuevos productos y tendencias tecnológicas de materiales, procesos y
productos, así como en la preparación de proyectos.
Los pronósticos pueden ser utilizados para conocer el comportamiento futurosen muchas fenómenos, tales como:
1. Mercadotecnia:
Tamaño del mercado. Participación en el mercado. Tendencia de precios. Desarrollo de nuevos productos.
2. Producción:
Costo de materia prima. Costo de mano de obra. Disponibilidad de materia prima. Disponibilidad de mano de obra Requerimientos de mantenimiento. Capacidad disponible de la planta para la producción.
3. Finanzas:
Tasas de interés. Cuentas de pagos lentos.
4. Recursos Humanos
Número de trabajadores. Rotación de personal. Tendencias de ausentismo.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 2/47
5. Planeación Estratégica.
Factores económicos. Cambios de precios. Costos. Crecimiento de líneas de productos.
Los pronósticos se utilizan para apoyar a la toma de decisiones por parte de las
Gerencias de Mercadeo, Ventas y Producción.
4.2 DELIMITACION CONOCIMIENTO Y DISEÑO DE SABANAS DE DATOS DE LOSDATOS
4.2.1 INSPECCION DE DATOS
¿Para qué se construye una Tabla de Datos?
Para que en la etapa de análisis de la información podamos evaluar:
la semejanza entre los individuos a través de los atributos seleccionados.
la asociación entre las características observadas sobre el conjunto deindividuos.
¿Cómo obtener los datos?
Existen tres métodos básicos con los cuales el investigador puede obtener los datosdeseados:
1) uso de fuentes de datos ya publicados,2) diseño de un experimento o diseño experimental, cuyos conceptos
fundamentales se estudiaran en otros capítulos.3) elaboración de una encuesta, que es el de mayor aplicación en una
investigación estadística.
Características de los datos:
Las características de los datos se estudian a través de sus medidas de posición ydispersión. La medida de posición es la característica más importante que describe oresume un grupo de datos. Todo grupo de datos tiene asociado un valor típicodescriptivo denominado promedio o media aritmética. La media aritmética es elpromedio que surge de sumar todos los valores de la muestra y dividirlos por el total deobservaciones.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 3/47
4.2.2 APLICACIÓN DE SUAVISAMIENTO COMO MEJORA DE RESULTADOS.
Este método contiene un mecanismo de autocorrección que ajusta los pronósticosen dirección opuesta a los errores pasados.
Es un caso particular de promedios móviles ponderados de los valores actuales yanteriores en el cual las ponderaciones disminuyen exponencialmente. Se empleatanto para suavizar como para realizar pronósticos. Se emplea la siguiente fórmula:
Cuando exista menos dispersión en los datos reales respecto a los datospronosticados entonces será más confiable el método empleado. Para saber cuanpreciso es el método empleado en la realización del pronóstico se utiliza la siguientefórmula del cuadrado medio del error (CME) como indicador de precisión del
pronóstico:
Siendo n el número de errores
Ejemplo ilustrativo: Con los siguientes datos acerca de la ventas en miles de dólaresde la Empresa D & M durante los últimos 12 meses:
1) Suavizar los datos empleando el método de suavización exponencial con a =0,5. Pronosticar las ventas para el mes de septiembre. Calcular el cuadradomedio del error. Elaborar un gráfico en el que consten las ventas y lospronósticos.
2) Suavizar los datos empleando el método de los promedios móviles de orden 3.Pronosticar las ventas para mes de septiembre. Calcular el cuadrado medio delerror. Elaborar un gráfico en el que consten las ventas y los promedios móviles.
3) ¿Qué método es el más preciso?
Meses Sep. Oct. Nov. Dic. Ene. Feb. Mar. Abr. May. Jun. Jul. Ago.
Ventas 6 7 6 12 7 10 6 4 9 7 8 6
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 4/47
Solución:
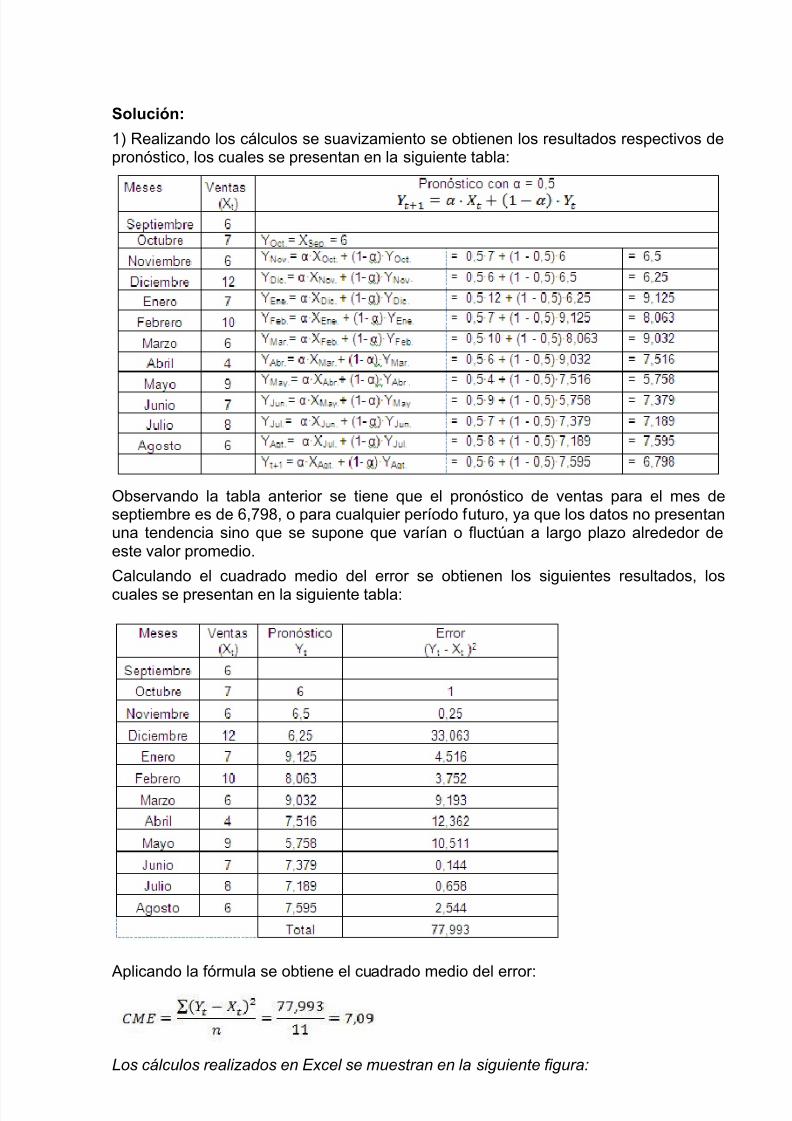
1) Realizando los cálculos se suavizamiento se obtienen los resultados respectivos depronóstico, los cuales se presentan en la siguiente tabla:
Observando la tabla anterior se tiene que el pronóstico de ventas para el mes deseptiembre es de 6,798, o para cualquier período futuro, ya que los datos no presentanuna tendencia sino que se supone que varían o fluctúan a largo plazo alrededor deeste valor promedio.
Calculando el cuadrado medio del error se obtienen los siguientes resultados, los
cuales se presentan en la siguiente tabla:
Aplicando la fórmula se obtiene el cuadrado medio del error:
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 5/47
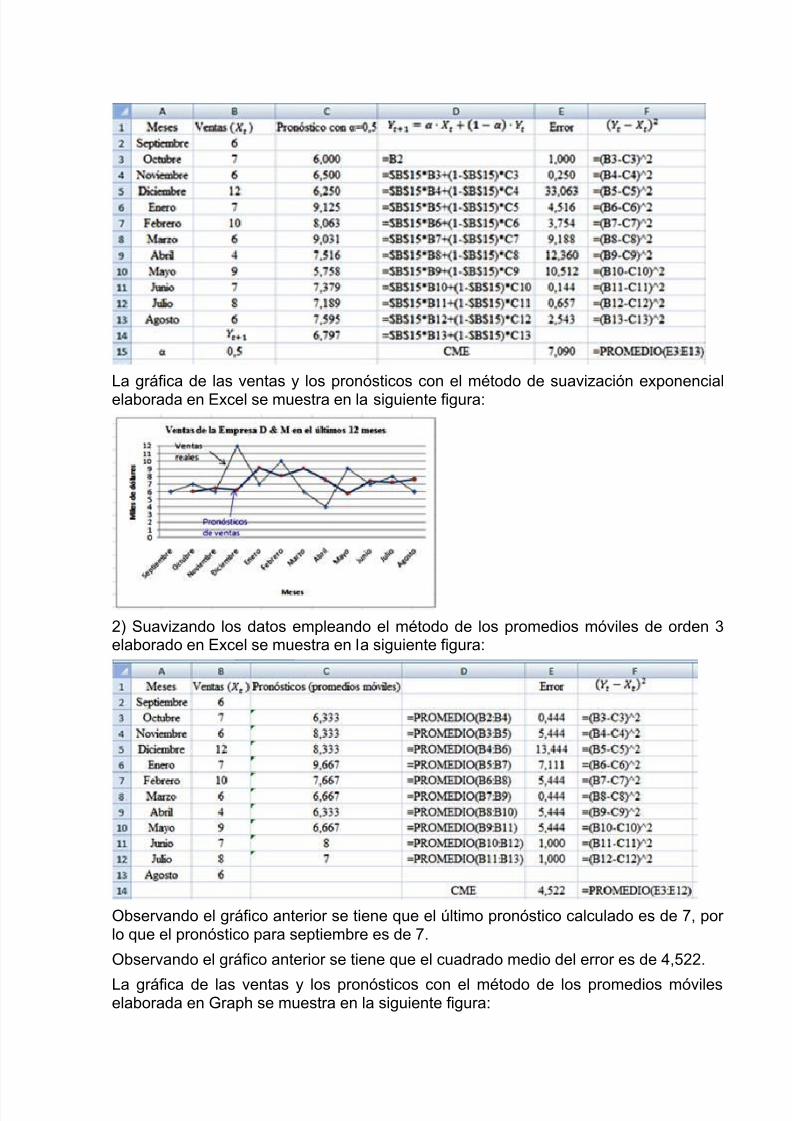
La gráfica de las ventas y los pronósticos con el método de suavización exponencialelaborada en Excel se muestra en la siguiente figura:
2) Suavizando los datos empleando el método de los promedios móviles de orden 3elaborado en Excel se muestra en la siguiente figura:
Observando el gráfico anterior se tiene que el último pronóstico calculado es de 7, porlo que el pronóstico para septiembre es de 7.
Observando el gráfico anterior se tiene que el cuadrado medio del error es de 4,522.
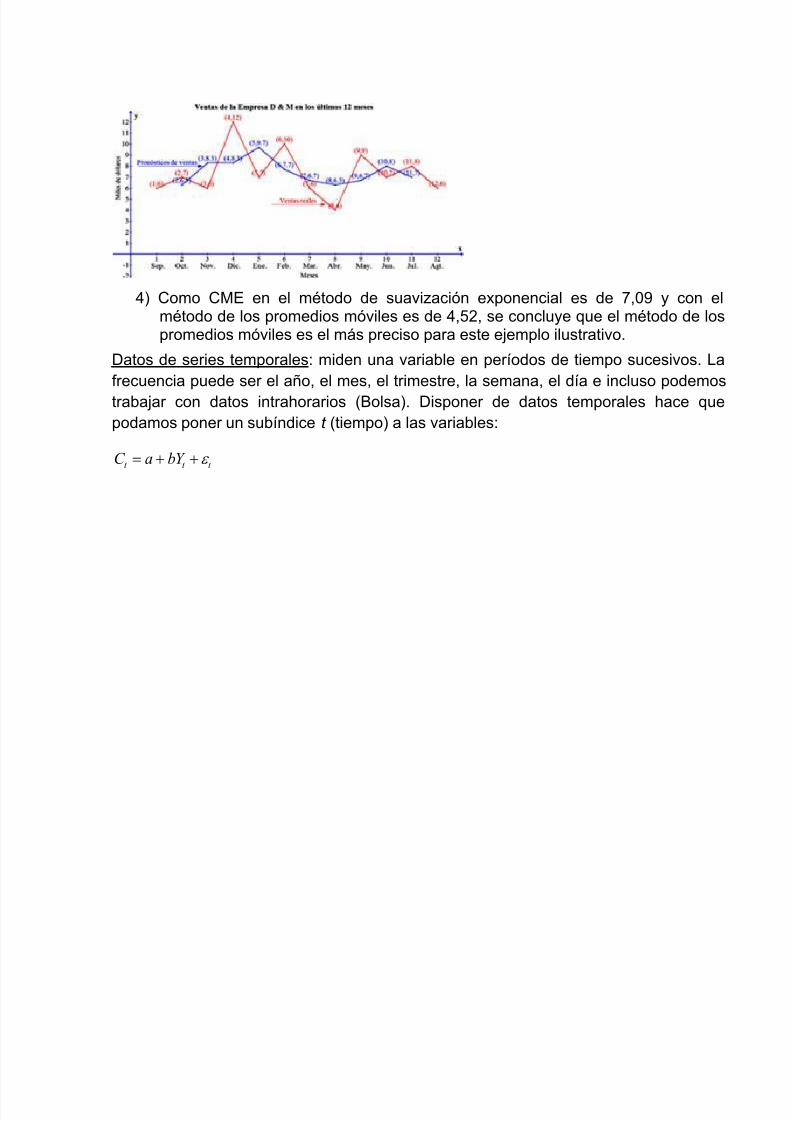
La gráfica de las ventas y los pronósticos con el método de los promedios móvileselaborada en Graph se muestra en la siguiente figura:
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 6/47
4) Como CME en el método de suavización exponencial es de 7,09 y con el
método de los promedios móviles es de 4,52, se concluye que el método de lospromedios móviles es el más preciso para este ejemplo ilustrativo.
Datos de series temporales: miden una variable en períodos de tiempo sucesivos. Lafrecuencia puede ser el año, el mes, el trimestre, la semana, el día e incluso podemostrabajar con datos intrahorarios (Bolsa). Disponer de datos temporales hace quepodamos poner un subíndice t (tiempo) a las variables:
t t t C a bY

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 7/47
4.3 EL USO DE TRANSFORMACIONES
4.3.1 LAS TRANSFORMACIONES LINEALES Y SU APLICACIÓN PRONOSTICA.
Se denomina transformación lineal a toda función cuyo dominio e imagen sean
espacios vectoriales y se cumplan las condiciones necesarias.Las transformaciones lineales ocurren con mucha frecuencia en el álgebra lineal y enotras ramas de las matemáticas, tienen una gran variedad de aplicacionesimportantes. Las transformaciones lineales tienen gran aplicación en la física, laingeniería y en diversas ramas de la matemática.
Estudiaremos las propiedades de las transformaciones lineales, sus diferentes tipos,así como la imagen, el núcleo, y como se desarrolla en las ecuaciones lineales.
Una función T: V
se dice una transformación lineal si, para todo a, b Î V,k Î K (K es el cuerpo de escalares) se tiene:
T (a + b) = T (a) + T (b)
T (k a) = k T (a)
a + b) = T (a) + T (b), llamada propiedad delinealidad.Si T: V W es una transformación lineal, el espacio V se llama dominio de T y el
espacio W se llama condominio de T.
Ejemplo
T: R2 R3 / x Î R2 : T ((x1, x2)) = (x1 + x2, x1 - x2, x2)
Se deben verificar las dos condiciones de la definición:
a) ¿ x, y Î R2 : T (x + y) = T (x) + T (y) ?
x = (x1, x2)y = (y1, y2)x + y = (x1 + y1, x2 + y2)
T (x + y) = T (x1 + y1, x2 + y2) = (x1 + y1 + x2 + y2, x1 + y1 - x2 - y2, x2 + y2) == (x1 + x2, x1 - x2, x2) + (y1 + y2, y1 - y2, y2) = T (x) + T (y)
b) ¿ x Î R2, k Î R : T (k x) = k T (x) ?
T (k x) = T (k (x1, x2)) = T (k x1, k x2) = (k x1 + k x2, k x1 - k x2, k x2) == k (x1 + x2, x1 - x2, x2) == k T (x)

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 8/47
−
4.3.2 LAS TRANSFORMACIONES NO LINEALES Y SU APLICACIÓNPRONOSTICA.
Se realizan las transformaciones no lineales para hacer la distribución más simétrica
para hacer lineal la relación entre variablesEscalera de potencias:
Si se desea estudiar el crecimiento del consumo de gasolina en diferentes ciudadesentonces el estudio consiste en estudiar las diferencias de consumo entre dosinstantes de tiempo crecimiento Ct − Ct−1, pero en general resulta más conveniente
considerar las diferencias relativas: (Ct − Ct−1)/Ct−1 o bien (Ct − Ct−1)/Ct.
Una medida más adecuada consiste en tomar logaritmos
ln C ln C = ln Ct t−1
Así, si se expresa la variable en logaritmos, su crecimiento en dicha escala es unabuena medida del relativo.
Por otro lado, dado que Ct ≥ Ct−1, entonces
Ct − Ct−1
Ct ≤
Ct
ln ≤
Ct − Ct−1
C
+---------------------------------------------+
| Potencia Transformación Re-expresión |
|---------------------------------------------|
| 3 Cubo x 3 || |
| 2 Cuadrado x 2 |
| |
| 1 NINGUNA x |
| |
| 1/2 Raíz cuadrada raíz x |
| |
| 0 Log log10 x |
| |
| -1/2 raíz del recíproco -1/(raíz x) || |
| -1 Recíproco -1 / x |
+---------------------------------------------+

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 9/47
4.3.3 SELECCIÓN DE UNA TRANSFORMACION
Los problemas son endémicos a casi todos los problemas econométricosaplicados, que hacen que la técnica de Heckman original, y las mejorasposteriores de sí mismo y de los demás, sean indispensables en econometría
aplicada.
Ejemplo
En la primera etapa, el investigador formula un modelo, basado en la teoríaeconómica, para la probabilidad de tener trabajo. La especificación canónica deesta relación es un regresión pro bit de la forma:
Donde D indica el empleo (D = 1 si el encuestado se emplea y D = 0 en caso
contrario), Z es un vector de variables explicativas, es un vector de parámetrosdesconocidos, y Φ es la función de distribución acumulativa de la norma
distribución normal. La estimación del modelo produce resultados que se puedenutilizar para predecir la probabilidad de empleo para cada individuo.
En la segunda etapa, el investigador corrige para la auto-selección mediante laincorporación de una transformación de estas probabilidades individualespredichas como una variable explicativa adicional. Se puede especificar laecuación de salarios del siguiente modo:
Donde denota una oferta salarial subyacente, que no se observa si el aludidono trabaja. La esperanza condicional de los salarios dada que la persona trabajaes entonces:
Bajo el supuesto de que los términos de error son normales en forma conjunta ,tenemos

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 10/47
4.4 APLICACIÓN DE CRITERIOS PARA ELEGIR UNA TECNICA DEPRONOSTICO QUE SE ADECUE A LA PROYECCION DE NEGOCIOS DEINNOVACION TECNOLOGICA.
4.5 MODELAJE DE PRONOSTICOS PARA LOS MODELOS DE INNOVACIONTECNOLOGICA
4.5.1 APLICACIÓN DE PRONOSTICOS CUANDO SE EJECUTAN TIEMPOS DESERIES NO ESTACIONALES
El pronóstico de las series de tiempo significa que extendemos los valoreshistóricos al futuro, donde aún no hay mediciones disponibles. El pronóstico serealiza generalmente para optimizar áreas como los niveles de inventario, lacapacidad de producción o los niveles de personal.
Existen dos variables estructurales principales que definen un pronóstico de seriede tiempo:
El período, que representa el nivel de agregación. Los períodos más comunes sonmeses, semanas y días en la cadena de suministro (para la optimización delinventario). Los centros de atención telefónica utilizan períodos de cuartos de hora(para la optimización del personal).
El horizonte, que representa la cantidad de períodos por adelantado que debenser pronosticados. En la cadena de suministro, el horizonte es generalmente igualo mayor que el tiempo de entrega.
PRONOSTICO EMPIRICO
Método usado con frecuencia con la practica el cual el pronóstico de la demandapara el siguiente periodo es igual a la demanda observada en el periodo actual(Ddt)
ESTIMACION DE PROMEDIO:
Promedio móvil simple: usados para estimar el promedio de una serie de tiempode demanda para suprimir los defectos de fluctuaciones solo requiere calcular lademanda promedio para los n periodos.
Promedio móvil ponderado:

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 11/47
Cada una de las demanda históricas intervienen en el promedio pueden tener supropia ponderación. La suma de las ponderaciones es igual 1.0 por ejemplo, es unmodelo con promedio móvil ponderado de tres periodos al periodo mas reciente sele asigna una ponderación de 0.50, al segundo mas reciente se le asingna unaponderación de 0.30, al tercero mas reciente es de 0.20 el promedio se obtiene
multiplicando la ponderación de cada promedio por el valor correspondiente adicho periodo y sumando finalmente los productos.
Ft+1 = 0.50Dt + 0.30Dt-1+0.20Dt-1
Suaviza miento exponencial: es un método de promedio móvil ponderado permitecalcular el promedio de una serie de tiempo. Asignando a las demandas recientesmayor ponderación que las demandas anteriores y se usa por la reducida cantidadde datos que se requiere.
4.5.2 APLICACIÓN DE PRONOSTICOS CUANDO SE EJECUTAN TIEMPOS DESERIES ESTACIONALES
La variación estacional, que tiene como característica de variación regular dentrode un año y que a su vez se repite cada año, casos típicos son la producción dealgunas frutas y/o comestibles o ventas asociadas a productos como ropa detemporada.
Una práctica frecuente en la modelización econométrica consiste en la utilización
del logaritmo en lugar del valor directo de la variable observada estatransformación resulta habitual ya que permite la resolución de algunos de losproblemas simples de heteroscedasticidad este tipo de transformación tiene laimportante propiedad de mantener la evolución temporal de la variable originalreduciendo proporcionalmente la variación relativa entre los distintos valores de laserie
Además permite la linealizacion de modelos originalmenteespecificados entérminos no lineales
Q= (T)(Kα)(Lβ)
Donde K, L representan las dotaciones (capital y trabajo)
Q es el nivel de producción
T es una medida de la eficiencia técnica

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 12/47
4.6 APLICACIÓN DE HERRAMIENTAS DE EVALUACION DE LOSPRONOSTICOS
Un pronóstico es una herramienta que proporciona un estimado cuantitativo -o unconjunto de estimados- acerca de la probabilidad de eventos futuros que se
elaboran en base en la información de interés en su dimensión pasada y actual(Pindyck y Rubinfeld, 2001); dicha información se encuentra expresada en laforma de un modelo y existen múltiples formas de estos expresadas a través detécnicas de pronósticos 2 . No obstante, sea cual sea el modelo elegido para laelaboración del pronóstico se debe seguir un proceso lógico para llevarlo a cabo;tal proceso consta de los siguientes pasos (Hanke y Wichern, 2006):
Formular el problema. Recolectar los datos. Manipular y limpiar los datos. Construir y evaluar el modelo3 . Aplicar el modelo. Evaluar el pronóstico.
4.7 ANALISIS DE SERIES DE TIEMPO.
Una serie de tiempo es un conjunto de datos numéricos que se obtienen enperíodos regulares a través del tiempo. Estos datos pueden ser muy variados,generalmente son usados para evaluar el comportamiento de las ventas de una
empresa, o para evaluar el comportamiento de los índices de precio de un país ode un tipo de producto pero en general pueden aplicarse a cualquier negocio y /oárea.
Este comportamiento puede tener características de tipo estacional, o cíclico osiguen alguna tendencia ya sea a la baja, de subida o sin variación.Una serie de tiempo o serie temporal es una colección de observaciones tomadasa lo largo del tiempo cuyo objetivo principal es describir, explicar, predecir ycontrolar algún proceso. Las observaciones están ordenadas respecto al tiempo ysucesivas observaciones son generalmente dependientes. De hecho esta
dependencia entre las observaciones jugará un papel importante en el análisis dela serie. Las series pueden ser utilizadas en diversos campos como por ejemplo:economía precios de venta en días sucesivos. exportaciones totales en sucesivosaños.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 13/47
Beneficios de una empresa en sucesivos años
física (meteorología, geofísica, etc...) lluvias en sucesivos días. temperatura en sucesivas horas. presión atmosférica en diversos días. Demografía población de un país medida anualmente.
Procesos de control el problema consiste en detectar cambios en la ejecución deun proceso de manufactura. Para ello se considera una variable que nos muestrala calidad del proceso. Esta medida se representa frente al tiempo y cuando sealeja de un determinado valor límite, entonces hemos de efectuar las correccionesoportunas sobre el proceso.
Procesos binarios: son unas series temporales especiales, en las que lasobservaciones, sólo toman dos valores (que usualmente se representan por 0 y 1),suelen darse en teoría de la comunicación. Por ejemplo la posición de un enchufe,bien apagado o encendido puede ser representado como 0 y 1, respectivamente.
Dependiendo del campo en el cual se utilizará esta metodología, las series sepueden clasificar en:
Serie continua.
Una serie de tiempo es continua cuando las observaciones son tomadascontinuamente en el tiempo, aun cuando la variable medida sólo tomeun número de valores finitos.
Serie discreta
Una serie temporal es discreta cuando las observaciones son tomadas en tiemposespecíficos, normalmente igualmente espaciados. Se supondrán los datos en
intervalos regulares de tiempo (horas, días, meses, años,..).

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 14/47
El término discreto es usado aun cuando la variable medida sea continua. Lasseries discretas pueden surgir de varias maneras:
Muestral dada una serie de tipo continua:
Es posible construir una serie de tipo discreta, tomando los valores en intervalosde tiempo de igual longitud. Un ejemplo de serie temporal de tipo continua esla temperatura en un lugar dado, considerando la temperatura diaria a las tres dela tarde, obtenemos una serie temporal discreta muestral.
Agregada o acumulada este tipo de series ocurre cuando una variable no tienevalor en un instante (sólo tiene sentido en algunos instantes de tiempo) pero sepueden acumular los valores en intervalos de tiempo igualmente espaciados.Ejemplos: las lluvias torrenciales, los accidentes de tráfico mensualmente,el número de pasajeros mensuales en las líneas aéreas españolas. De hecho losaccidentes de tráfico mensuales son una agregación de sucesos discretos.Los valores tomados no se observan en cada instante sino que se vanacumulando en intervalos de tiempo.
Inherentes o discretas las que realmente los datos se obtienen en momentosdiscretos. Por ejemplo el salario mensual. Teniendo en cuenta el número devariables que observamos en cada tiempo se pueden diferenciar:
Series temporales univariantes: cuando interviene una sola variable.
Series temporales multivariantes: cuando intervienen varias variables.
El primer paso a llevar a cabo en cualquier análisis de una serie de tiempo esrealizar la representación gráfica de la serie. En el eje horizontal se representa laescala del tiempo, y en el eje vertical, los valores asignados a los tiempos. Eshabitual observar que los datos aparentemente fluctúan a lo largo del tiempo entorno a algún patrón.
Desde un punto de vista formal, este hecho responde al concepto de procesoestocástico, concepto matemático que hay subyacente en una serie temporal.
La representación gráfica de una serie de tiempo es la representación de unatrayectoria del proceso estocástico subyacente. En dicha representación, podemosobservar las principales fuentes de variación.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 15/47
Enfoques en análisis de series de tiempo existen básicamente tresenfoques para analizar series de tiempo los cuales son:
Enfoque Clásico. Enfoque Box-Jenkins.
Enfoque ingenieril o Analisis Espectral.
4.8 ELEMENTOS DE ECUACIONES EN DIFERENCIA
Una ecuación en diferencias de orden k es una igualdad de la forma.
Donde la incógnita de la ecuación es la sucesión xn.
• Resolver la ecuación es hallar la forma explícita de todas las sucesiones quesatisfacen
Esa igualdad. Esto se llama solución general de la ecuación. Una soluciónconcreta de la
Ecuación se llama solución particular y generalmente se obtiene imponiendocondiciones
Iniciales en la solución general.
• Una ecuación en diferencias de orden k se dice lineal si y solo si es de la forma:
donde a0, a1, ..., ak−1 y b son funciones de n y a0(n) 6= 0 para algún n ∈ N.
Si b(n) = 0 para todo n ∈ N, la ecuación se llama homogénea.
Si las funciones ahí son constantes, la ecuación se llama de coeficientes
constantes.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 16/47
4.8.1 NOTAICION Y CONCEPTOS ELEMENTALES. Un computador es una maquina que puede llevar a cabo largas, complejas yrepetitivas secuencias de operaciones a velocidad muy alta. Estas operacionesson aplicadas a información o datos suministrados por el usuario para producirotra información o resultados que requiera el usuario. Los componentes
esenciales de un computador son un procesador, una memoria, y algún dispositivode entrada y salida.
El procesador es el que realiza la secuencia de operaciones especificadas por elprograma.
La memoria es usada para almacenar la información a la cual son aplicadas lasoperaciones del procesador.
La memoria es de dos clases, la memoria principal y la memoria secundaria. Lamemoria principal guarda tanto las instrucciones como los datos sobre los queopera el procesador. Los dispositivos de almacenamiento secundario son cintas
magnéticas, discos o tambores que tienen las siguientes características. Sucapacidad de almacenamiento es más grande que la memoria principal y lainformación puede ser guardada permanentemente en ellos.
Los dispositivos de entrada y salida son usados para transmitir información delmundo exterior a la memoria principal del computador (entrada) y la memoriaprincipal del mundo exterior (salida)
El uso de un computador para una labor particular implica tres pasos esenciales
a) especificar la labor que el computador realizara en términos de los datos deentrada que serán suministrados y los datos de salida.
b) crear un algoritmo o secuencia de datos por los cuales el computador puedaproducir la salida requerida a partir de la entrada.
c) expresa este algoritmo como un programa de computador en un lenguaje deprogramación tal como PASCAL.
La estructura de un algoritmo puede estructurar en un diagrama estructurado enforma de bloques donde se encuentran las diferentes tareas que deben serrealizadas y su relación entre ellas. Los diagramas de flujo han sido la herramientade programación por excelencia.
Un diagrama de flujo utiliza símbolos estándar y en el que cada paso del algoritmose visualiza dentro del símbolo adecuado y el orden en que estos pasos seejecutan se indica conectándolos con flechas llamadas líneas de flujo, porqueindican el flujo lógico del algoritmo.
Los programas deben ser escritos en un lenguaje que pueda entender lacomputadora, escribir los algoritmos en una imitación de código de lascomputadoras: pseudocódigo, este surgió para superar las principales desventajas

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 17/47
de el diagrama de flujo, es mas fácil de utilizar ya que maneja expresiones básicasde la lengua nativa del programador.
Así por ejemplo los símbolos matemáticos para expresar en pseudocódigos lasoperaciones matemáticas son:
+ Suma
- Resta
* Multiplicación
/ División
Como ejemplo de palabras reservadas de distintos lenguajes de alti nivelexpresadas en pseudocódigos podríamos tener las siguientes:
Inicio begin
Fin end/stop
Leer read/imput
Escribir write/print
Si if
Repetir repeat
Entero integer
Carácter char La ventaja de utilizar un lenguaje de programación de lato nivel, tal como PASCALes que un programa puede ser usado en cualquier computador para cual hayasido provisto el compilador del lenguaje. La provisión de un compilador para unlenguaje dado y un computador dado se llama una implementación del lenguaje.
Codificar es escribir en lenguaje de programación de alto nivel la representacióndel algoritmo, para realizar la conversión de algoritmo en programa se debesustituir las palabras reservadas en castellano por sus homónimos en ingles.
Una ves que el algoritmo se ha convertido en programa fuente mediante el
proceso de codificación, es preciso traducir a código o lenguaje maquina, únicoque la computadora es capas de entender y ejecutar. El encargado de realizaresta función es un programa traductor (compilador). Si tras la compilación sepresentan errores de compilación es preciso modificar la codificación del programade forma que esta se adapte alas reglas de sintaxis del lenguaje elegido con el finde corregir los errores.
Una ves obtenido el programa ejecutable se pone en funcionamiento con soloteclear su nombre suponiendo que no existen errores durante la ejecución se

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 18/47
obtendrá la salida de los resultados del programa. Las instrucciones u órdenespara compilar un programa pueden variar según el tipo de compilador.
Los objetivos de la programación son los siguientes:
Exactitud, un factor clave en el logro de exactitud es la simplicidad. La innecesaria
complejidad no cumple propósito alguno en la programación de computadores.
Claridad, el diseño y la limpieza del programa es indispensable para elprogramador y para otros que puedan leer y alterar el programa posteriormente.
Eficiencia, el tiempo tomado por el computador para llevar acabo la secuencia deoperaciones y la cantidad de memoria que el computador usa para esta tarea.
Un programa de computador primero es contruido como una secuencia desimbolos o caracteres que forman el texto del programa.
Ejemplo (programa simple escrito en lenguaje de programación (PASCAL)
program adicion (imput, output);
var primero, segundo, suma: integer;
begin
read (primero, segundo)
suma : =primero+segundo;
write (suma)
end.
Todo lenguaje de programación tiene todo un conjunto estrictamente definido dereglas asociadas con el que describe como puede ser construido en el lenguaje unprograma valido estas reglas son necesarias para que el programador pueda estarseguro de la corrección y el efecto del programa que describe y para que esteprograma pueda ser entendido tanto para el sistema como para quien lo lea.
Las reglas del lenguaje están constituidas de dos partes conocidas como lasintaxis y la semántica del lenguaje. Las reglas de sintaxis definen como laspalabras (o vocabulario) del lenguaje pueden ser puestas juntas para formarfrases. Las reglas de semántica atribuyen sentido y significado a estas
confinaciones de palabras. Estas reglas de semántica son usualmenteestablecidas con menos formalidad que las reglas de sintaxis las cuales para ellenguaje PASCAL están descritas mediante un formalismo conocido como FBNE(Forma Backus-Naur) la forma de un programa PASCAL esta definida por lasiguiente regla:
programa = encabezamiento bloque “.”

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 19/47
Esta regla es leída como “un programa esta definido como un encabezamientoseguido por un bloque seguido por un punto “.”
En el programa ejemplo dado antes la primera línea de símbolos es elencabezamiento. Los símbolos siguientes desde var hasta end forman un bloque.En una regla FBNE la aparición de un símbolo de lenguaje dentro de comillas “.”
Denota el símbolo mismo. Cada regla es terminada con un punto.
El vocabulario de lenguaje de programación PASCAL consiste de letras, dígitos ysímbolos especiales. Las frases del lenguaje son entonces construidas a partir deeste vocabulario de acuerdo con la sintaxis de PASCAL. Conforme a la definiciónestándar de PASCAL una letra puede ser cualquiera de las 26 del alfabetoromano, en forma mayúscula o minúscula, esto es, existen 52 letras en lacategoría sintáctica letra.
Letra = A, B, C, D, E, F, G, H, I, J, K, L, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, a, b,c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z.
Un digito en PASCAL es cualquiera de los diez dígitos arábigos, es decir:
Digito = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
El número de símbolos especiales requeridos por PASCAL para puntuación yotros propósitos es bastante alto. Muchos de estos símbolos especiales estánrepresentados como palabras más bien que como caracteres especiales.
Símbolo especial = +, -, *, /, =, <>, <, >, <=, >=, (, ), {, }, :=, ., , :, ;, div,nil, in, or, and, not, if, then, else, case, of, repeat, until, while, do, for, to, begin,end, with, goto, const, var, type,record, set, file, function, procedure, level, packed,program.
Los números en pascal pueden estar representados en una de las dos formas:números enteros o reales.
Un numero entero puede ser positivo, negativo o cero. El numero es escrito comouna secuencia de dígitos de cualquier longitud la cual puede o n estar precedidapor un signo (+ o -)
Ejemplo de enteros validos:
6, o, -6, +7000000
Enteros no validos:
6,437,876 un entero no puede contener no-dígitos
-6.0 un entero no puede contener un punto decimal
El número máximo de dígitos que pueden ser usados en un entero depende deltamaño de la localización de memoria en el computador que almacenara el entero.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 20/47
La representación de números reales en un computador es solamente unaaproximación mientras que los enteros son representados exactamente.
PASCAL requiere que las varias cantidades usadas en un programa, como laspiezas del texto del programa, le sean dados nombres por los cuales puedan seridentificados. Estos nombres son conocidos como identificadores, y son creadospor el programa. Un identificador consiste en una letra seguida por cualquiernúmero de letras y dígitos, es decir.
Identificador = letra {letra/digito}
Un identificador puede ser de cualquier longitud, PASCAL impone una restriccióna la longitud de cada línea de texto del programa. En implementaciones queprovean tanto mayúsculas como minúsculas, pueden ser usadas letras decualquiera de las dos formas en los identificadores pero el estándar PASCALexige que el significado de un programa no sea alterado por el cambio de forma dealguna letra, en tal caso los siguientes identificadores son considerados como
idénticos: algunnombre ALGUNNOMBRE Algun Nombre
Ejemplo de identificadores validos:
I
Ufo
PC49
unnombremylargo
Los siguientes son identificadores no permitidos:
1 abc un identificador debe comenzar con una letra
MA-ÑANA un identificador no debe contener un guiño
$100 un identificador debe comenzar con una letra
Algunos de los símbolos especiales de PASCAL son palabras reservadas que nopueden ser usadas para otros propósitos como array y begin no pueden serusadas como identificadores.
Ciertos identificadores, conocidos como identificadores estándar son predeclarados en toda implementación de PASCAL estándar, estos describencantidades estándar y facilidades proporcionadas por el lenguaje, tales comofunciones trigonométricas y aritméticas.
Lista completa de identificadores estándar:

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 21/47
abs, arctan, boolean, char, chr, cos, dispose, eof, eoln, exp, false, get, input,integer, in, maxint, new, odd, ord, output, pack, page, pred, put, read, readln, real,reset, rewrite, round, sin, sqr, sqrt, succ, text, true, trunc, unpack, write, writeln.
Una secuencia de caracteres ecerrada por apostrofes forma lo que es conocidacomo una cadena. Es usada dentro de un programa para denotar la secuencia decaracteres mismos. Si la cadena de caracteres incluye un apostrofe, entoncesdeberá ser escrito dos veces por consiguiente la definición sintáctica de unacadena es
Cadena = „ carácter -cadena {carácter-cadena} „
Carácter-cadena = cualquier-carácter-exepto-comillas(“…”)
Un programa PASCAL se expresa como una secuencia de identificadores,números, cadenas y símbolos especiales. En PASCAL estándar toda secuenciade caracteres encerrada por los símbolos { } forman lo que es conocido como uncomentario. Los comentarios pueden aparecer donde quiera que un blanco o unfin de línea pueda aparecer, pero no tiene absolutamente ningún significado encuanto a la ejecución del programa. Sirve solamente como un recurso con el cualun programador puede hacer el sentido d un programa mas claro mediante lainclusión de observaciones explicativas en lenguaje natural.
Ejemplo: {este es un comentario escrito en lenguaje natural}
En el siguiente ejemplo se muestra la estructura básica de un programa enPASCAL, el propósito es leer dos números enteros e imprimir su suma. La primeralínea es el encabezamiento, el cual da al programa en nombre de adición e indicaque serán ejecutadas tanto la entrada como la salida, la segunda línea es la parte
de declaraciones, que denomina los tres ítems de datos usados en el programa yestablece que serán números enteros.
program adicion (imput, output);
var primero, segundo, suma: integer;
begin
read (primero,segundo);
suma: =primero+segundo;
write (suma)
end.
La cabecera de un programa en PASCAL consta de tres partes claramentedefinidas: cabecera del programa, sección de declaraciones y cuerpo delprograma.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 22/47
La cabecera del programa consta de tres partes; la palabra reservada program, elnombre del programa (un identificador) y un punto y coma (;).
Los lenguajes de programación de alto nivel como PASCAL permite alprogramador ignorar la representación de maquina existente y expresar lanaturaleza de los datos en términos de tipos de datos. Un tipo de datos define unconjunto de valores todos los tipos de datos están estructurados de tipos noestructurados. En PASCAL un tipo no estructurado es definido por el programadoro en caso contrario es uno de los cuatro tipos predefinidos estándarproporcionados, los tipos integer, real, char, boolean.
El tipo integer representa el conjunto de números enteros y todo valor de este tipoes por tanto un número entero. PASCAL define un número de operadoresaritméticos que toman operandos enteros y retornan resultados enteros estos son.
Símbolo Operación resultado
+(adición) 7+3 10
-(sustracción) 7-3 4
*(multiplicación) 7*3 21
div(división con truncamiento) 7 div 3 2
mod(modulo) 7 mod 3 1
El tipo real son el conjunto de números reales PASCAL suministra un numero deoperadores matemáticos que toman operadores reales y producen resultadosreales, estos son
Símbolo operación resultado
+(Adición) 2.1+1.4 3.5
-(sustracción) 2.1-1.4 0.7
*(Multiplicación) 2.1*1.4 2.94
/(División) 2.1/1.4 1.5
En PASCAL el tipo char esta definido como e conjunto de caracteres disponible enel sistema computador que ejecuta el programa. Un valor particular de tipo char es
denotado por encerramiento del carácter en comillas sencillas (apostrofes) porejemplo.
„a‟ „4‟ „?‟ „ „ „+‟
Un valor boolean es uno de los valores de verdad lógicos representaos por losidentificadores PASCAL estándar true (verdadero) false (falso). PASCAL

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 23/47
proporciona operadores estándar que toman valores booleanos como operandos yproducen un resultado booleano. Estos operadores incluyen
and y lógica
or o inclusiva lógica
not negación lógica
Los valores booleanos pueden también ser producidos por aplicación deoperadores relacionales a operandos de otros tipos. PASCAL suministra los seisoperadores relacionales de las matemáticas, que son:
= igual a
<> No igual a
< menor o igual a
<= menor que o igual a
> Mayor que
>= mayor que igual a
Los ítems de datos que un programa manipula pueden ser divididos en dos clases,aquellos cuyos valores permanecen fijos durante la ejecución de un programa, yaquellos cuyos valores son cambiados por la ejecución. Los primerosmencionados son conocidos como constantes. Los segundos son conocidos comovariables. Los ítems introducidos en un programa pascal dependen de su clase.
123 denota un valor particular de tipo integer
12.72 denota un valor particular de tipo real
„A‟ denota un valor particular de tipo char
True denota un valor particular de tipo boolean
Corazón denota un valor particular de tipo enumerado
La sección de declaraciones de un programa esta compuesta por:
1. Declaración de unidades UEES
2. Declaración de etiquetas LAVEL 3. Declaración de constante CONST 4. Definición de tipos TYPE
5. Declaración de variables VAR 6. Declaración de procedimientos y funciones PROCEDIRE, FUNKTION

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 24/47
En PASCAL las constantes pueden ser de cualquier tipo, incluso constantesestructuradas, como arrays y registros las constantes se declaran después de lapalabra const y su forma es
Const
Nomconstante = valor;
… ;
La declaración de una constante comienza ocn un identificador o nombre deconstante seguido por el signo (=) y el valor correspondiente y terminado en uncarácter punto y coma (;)
Ejemplo
Const
Pueblo = „castillo chido‟; Peso = 75.5;
PASCAL tiene varias constantes con nombre.
MAXINT contiene el valor entero 32767
MAXLONGINT contiene el valor entero 2.147.483.647
PI contiene el valor de Pi = 3.1415926536
TRUE, FALSE típico lógico (boolean)
La declaración de etiquetas comienza con la palabra determinada label, seguidade todas la etiquetas del programa, separadas por comas. Una etiqueta serepresenta mediante un identificador o mediante un número entero comprendidoentre 0 y 9999. Las etiquetas se utilizan para la transferencia incondicional de flujode programa (sentencia GOTO)
Label
Cerrar, 1, 275;
La declaración de tipos sirve para definir los distintos tipos de datos la declaración
se inicia con la palabra reservada type seguida por las declaraciones de losdistintos tipos que el usuario quiere definir., a su vez una declaración de tipoconsta del identificador de tipo y la definición del mismo separadas por un signo =.El formato general de la sección tipe es:
Type
Identificador1 = tipodato1;

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 25/47
Identificador2 = tipodato2;
…
La declaración de variables va precedida por la palabra reservada var y seguidapor la declaración de las variables, la declaración de variables utiliza el carácter
(:) para separar el nombre de la variable de su tipo, el formato general de lasección var es:
Var
Nomvariable1 : tipo 1;
Nomvariable2 : tipo 2;
… : …
O bien el caso de diferentes variables del mismo tipo:
Var
Nomvariable1,
Nomvariable2,
Nomvariable3 : tipo 3;
Los procedimientos y funciones son de PASCAL son pequeños programas ogrupos de sentencias que realizan tareas especificas o bien que se ejecutan a lolargo del programa varias veces. La estructura de un procedimiento o función essimilar a la del programa con la diferencia de que los procedimientos y funciones
comienzan su declaración en su cabecera con las palabras reservadasPROCEDURE o FUNCTION en lugar de program y que en ves de terminar con unpunto finaliza con un punto y coma.
Tras la sección de declaraciones comienza el programa principal que se encuentraacotado por las palabras reservadas BEGIN y END. Todas las sentencias queperteneces al programa principal deben terminar con un punto y coma (;) lasreglas relativas a los puntos y coma separadores de sentencia son:
- Cada sentencia debe terminar con un punto y coma
- Se puede omitir el punto y coma final si va seguido de las palabras reservadas
end y until - Se debe omitir el punto y coma si le sigue la palabra reservada else
- 8salvo si se trata de una estructura selectiva case…of)
Ejemplo.
Program saludo;
Var

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 26/47
Tu nombre: string {40}
Begin
Write (‟dime tu nombre: „); (*sentencia de salida*)
Readln (tu nombre); (*entrada de datos*) Writeln („hola‟, tu nombre)
End.
Todo elemento del programa que quiera ser referenciado o usado en un momentodeterminado del programa debe haber sido previamente definido (declarado).
La parte de declaraciones de PASCAL son los tipos de datos, constantes yvariables. La manipulación que el programa ejecuta sobre sus ítems de datos esdefinida por su parte de sentencias. La parte de sentencias de fine las acciones a
ser llevadas a cabo como una secuencia de sentencias donde cada sentenciaespecifica una acción correspondiente. PASCAL es un lenguaje de programaciónsecuencial ya que estas sentencias son ejecutadas una después de otra y nuncasimultáneamente. La estructura de parte de sentencia es
4.8.2 USO DE OPERADORES CON RETRASO
4.9 MODELOS PARA SERIES UNIVARIADAS
4.9.1 IDENTIFICACION DE MODELOS ARIMA.
4.9.2 ESTIMACIÓN DE MODELOS ARIMA
4.9.3 VERIFICACION DE LOS MODELOS
4.10 PRUEBA DE RAICES UNITARIAS
Al desarrollar modelos de series de tiempo se necesita saber si se puede suponerque el proceso estocástico que los generó es invariable en el tiempo.
A este tipo de procesos se les denomina procesos estocásticos estacionarios. Si elproceso no es estacionario, será muy difícil representar a la serie de tiempodurante intervalos de tiempo pasados y futuros con un modelo algebraico simple.
Si el proceso es estacionario, entonces es modelable mediante una ecuación decoeficientes fijos estimables con datos pasados. En la práctica es complicadoencontrar series de tiempo surgidas de procesos estacionarios; sin embargo, haytécnicas que se encargan de convertir dichos procesos en estacionarios.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 27/47
Los procesos estacionarios tienen características deseables. Por ejemplo, unaserie y1, y 2, ...,yT puede considerarse como generada por un conjunto devariables aleatorias distribuidas en forma conjunta.
En otras palabras, y1,y 2,...,yT representa un resultado particular de la distribución
de probabilidad conjunta p (y1 , y 2 ,..., yT); esto es lo que se denomina“realización”.
De igual manera, una observación futura yT +1 puede ser considerada comogenerada por una función de distribución de probabilidad condicional p(yT+1 |y1,y2,...,yT), es decir, una distribución de probabilidad para yT +1 dadas lasobservaciones pasadas.
Entonces, de manera formal, un proceso estacionario se define como aquel cuyadistribución conjunta y distribución condicional es invariable respecto aldesplazamiento en el tiempo. Por lo que si la serie y t es estacionaria, se tiene que
p(yt,...., yt+k) = p(y t+m , ... y t+k +m) y p(y t) = p(yt+m ) ∀ t , k , m
Con base en este resultado se obtienen las características de una serieestacionaria:
1 Si la serie es estacionaria, la media de la serie definida como μy = E(yt), tambiéndebe ser constante a lo largo del tiempo, por lo que E(yt) = E(yt + m) ∀ t , m.
2 La varianza de la serie, definida como σ2y = E[(yt − μy)2], también debe serconstante, de tal manera que E[(yt − μy)2] = E[(yt + m − μy)2].
3 Para cualquier rezago k, la covarianza de la serie γk = Cov(yt,yt + k) = E[(yt−μy)(yt+k −μy)] debe ser estacionar ia, de modo que Cov(yt, yt+k ) = Cov(yt+m , yt+k +m).
Por tanto, si un proceso estocástico es estacionario, la distribución de probabilidadp(yt) es la misma para todo tiempo t y su forma o al menos algunas de suspropiedades pueden inferirse a través de un histograma de las observaciones y1,y2,...,yT. Si una serie no cumple con las tres características anteriores, se dice quees no estacionaria.
Sin embargo, en el trabajo de Granger y Newbold (1974) se ha demostrado que lamayoría de las series económicas no son estacionarias en niveles, es decir, queson integradas de algún orden mayor que 0. Esto acarrea algunos problemasgraves en la práctica, sobre todo porque se viola un supuesto básico del modeloclásico de regresión: la estacionariedad de las variables.
Este problema se remonta a los resultados que obtuvo Yule (1926). Llegó a laconclusión de que es relativamente sencillo encontrar correlaciones

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 28/47
estadísticamente significativas entre variables que no son estacionarias. De estamanera se demostró, por ejemplo, que la inflación anual de Gran Bretaña esexplicada por los casos de disentería que ocurrieron en Escocia el año anterior(Henry, 1980).
El problema fue abordado de manera profunda por Granger y Newbold (1974).Determinaron llamar a las regresiones econométricas que involucran variables noestacionarias “regresiones espurias”, debido a que se puede demostrar casicualquier relación estadísticamente significativa con variables I(d), donde d > 0.Según Granger y Newbold (1974), las regresiones espurias se caracterizan por:
Una elevada bondad de ajuste (R2).
Un valor del estadístico Durbin Watson, DW, excesivamente bajo, muy inferior alvalor 2 que corresponde a la ausencia de autocorrelación e inferior al límite inferiordel test DW.
Las principales consecuencias de la presencia de autocorrelación de los erroresen una regresión son:
Los coeficientes estimados por la regresión son sesgados e ineficientes.
Las proyecciones basadas en las ecuaciones son suboptimales.
La significancia de las pruebas sobre los coeficientes no es válida.
Para analizar si las regresiones son espurias o no, se analizaron en primera
instancia las raíces unitarias. El número de raíces unitarias equivale al número deveces que se tiene que diferenciar una serie para hacerla estacionaria. Así, sedice que una serie I(1) tiene una raíz unitaria y que una serie I(d) tiene d raícesunitarias.
Existen diferentes pruebas para analizar la presencia de raíces unitarias (o elorden de integración de las series); entre las más usuales están: Dickey-Fuller(DF), Dickey-Fuller Aumentada (ADF), Phillips-Perron (PP), Kwiatkoski, Phillips,Schmidt y Shin (KPSS), entre otras. A continuación se presentarán los resultadosobtenidos con la prueba de Dickey-Fuller Aumentada (ADF). Se dejarán las demáspruebas de lado, ya que muestran resultados equivalentes y, por tanto, no aportaninformación adicional. El cuadro 18 muestra que las series analizadas son deorden I(d) > 0, por lo que tienen por lo menos una raíz unitaria. Se tomaron lasseries en niveles y con tendencia e intercepto.
La hipótesis nula (Ho) propone que la serie tiene una raíz unitaria. La prueba dehipótesis se hace con el valor de la t estadística. Si ésta resulta positiva o está pordebajo del valor crítico, se acepta Ho.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 29/47
Este resultado se confirma un poco más intuitivamente cuando se observa que laprobabilidad de la prueba es mayor al 95% de confianza, lo cual se advierte en elvalor de probabilidad, que debe ser mayor a 0.05.
En tal caso se sabe de la existencia de al menos una raíz unitaria. En todos los
casos se demuestra la existencia de al menos una raíz unitaria.Por tal razón, es necesario saber si la serie es I(1) o I(2), lo que resulta al realizarlas pruebas especificando las variables en primeras diferencias.
La obtención de una probabilidad mayor a 0.05 sería prueba de que la serie tienedos raíces unitarias y que sería necesario sacar otra diferencia para tenerlaestacionaria.
De esta forma se analizaron las mismas series en primeras diferencias. En elcuadro 19 se observa que las series tienen una raíz unitaria, por lo que de aquí en
adelante se usarán las series en primeras diferencias para tener seriesestacionarias y evitar tener una regresión espuria. Al usar primeras diferencias yasólo se usó con intercepto y se obtuvieron resultados favorables entre 6 a 10rezagos. Con 11 rezagos Argentina y Chile mostrarían dos raíces unitarias. Sinembargo, la mayoría de los estudios no sobrepasan los seis rezagos.
Este resultado es congruente con los resultados de los trabajos de Peiró (1996) yOrtiz (2007a). No obstante, aunque pueda haber una raíz unitaria esto no evita laposibilidad de que exista una relación de largo plazo entre las series originales quese analizarán a continuación mediante la prueba de cointegración.
Lo anterior es relevante principalmente porque al obtener primeras diferencias sepierde información que puede ser valiosa para el análisis (Maddala, 2001).
Después de analizar las series bursátiles se estudiaron los PIB mensuales.
Al igual que con las series bursátiles se calculan las series originales en nivelescon tendencia e intercepto (véase cuadro 20). Se observa que todas las seriestienen por lo menos una raíz unitaria.
En el cuadro 21 se muestra la existencia de una sola raíz unitaria –al 5% – en lasseries en primeras diferencias.
De esta manera, es necesario analizar las dos series en primeras diferencias – excepto que las series cointegren para evitar cualquier regresión espuria (Loría,2007).

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 30/47
4.11 MODELOS PARA SERIES ESTACIONALES
4.11.1 ANALISIS DE SERIES ESTACIONALES
4.11.2 COSTRUCCION DE MODELOS4.12 PRONOSTICO PARA SERIES DE TIEMPO
4.12.1 CASO ESTACIONARIO
4.12.2 CASO NO ESTACIONARIO
4.13.4 APLICACIONES
El análisis practico de la estacionariedad de las series temporales
Queda clara que la aproximación a los procesos estocásticos con modelos AR o MA está restringida, en términos generales, a aquellos procesos estocásticosque cumplan, al menos de forma débil, la condición de estacionariedad1. Así puesdebemos analizar la estacionariedad de las series temporales analizadas antes deproceder a la identificación de la estructura del proceso estocástico AR ó MA.
¿Cómo verificamos si la serie a analizar es estacionaria en media?
La no estacionariedad en media recibe vulgarmente el nombre de “tendencia”
aunque, técnicamente, debería utilizarse el término “tendencia determinista”
diferenciándose de lo que más adelante denominaremos “tendencia aleatoria”.
Identificar “tendencias deterministas” en las series suele ser habitualmente muysencillo: normalmente es suficiente observar el gráfico de la serie para diagnosticarsi su valor medio se mantiene constante o, por el contrario, crece o decrece con eltiempo.
Debe recordarse, no obstante, que cuando observamos la estacionariedaden media, nos interesa la estabilidad de la serie en el medio plazo,independientemente de las variaciones de corto plazo alrededor de esa tendencia.
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 31/47
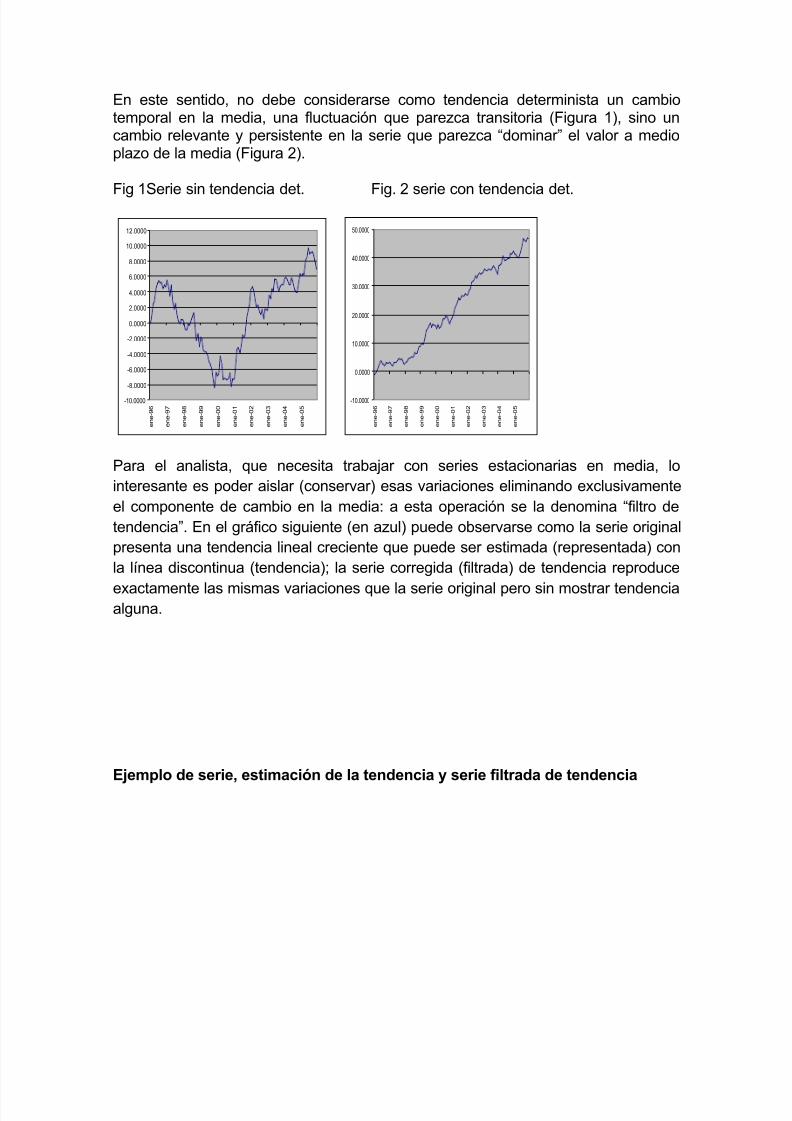
En este sentido, no debe considerarse como tendencia determinista un cambiotemporal en la media, una fluctuación que parezca transitoria (Figura 1), sino uncambio relevante y persistente en la serie que parezca “dominar” el valor a medioplazo de la media (Figura 2).
Fig 1Serie sin tendencia det. Fig. 2 serie con tendencia det.
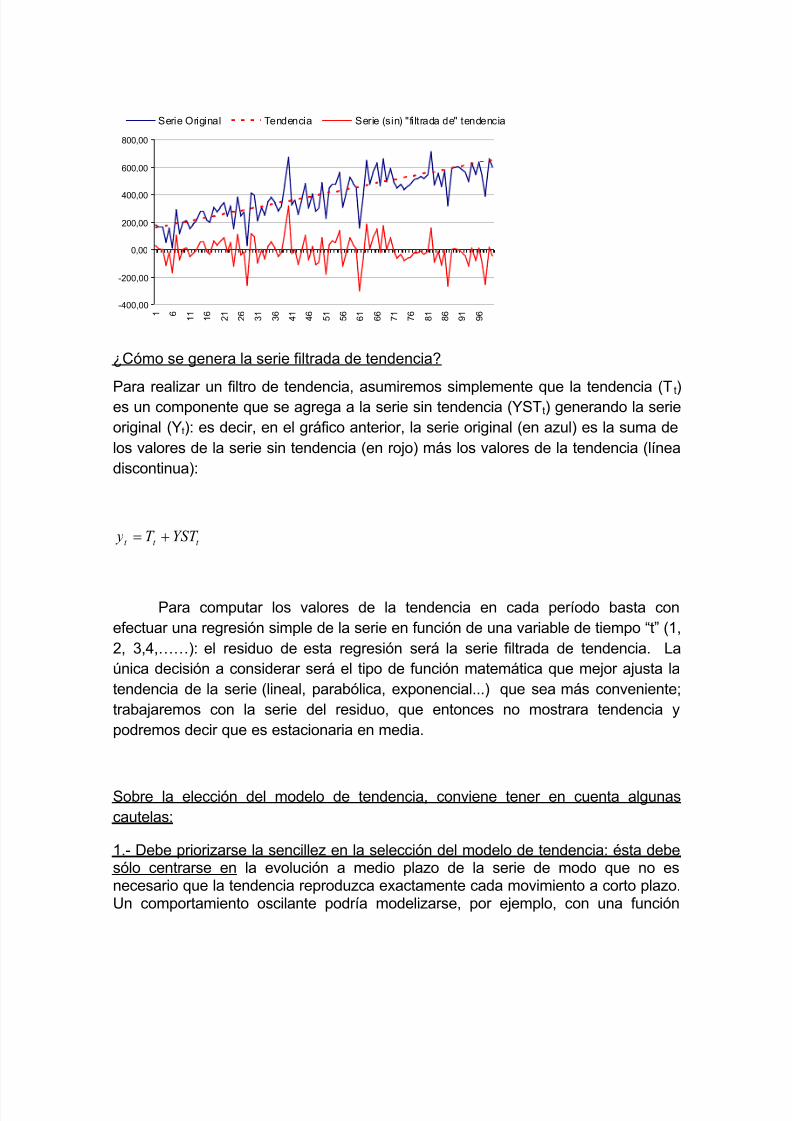
Para el analista, que necesita trabajar con series estacionarias en media, lointeresante es poder aislar (conservar) esas variaciones eliminando exclusivamenteel componente de cambio en la media: a esta operación se la denomina “filtro de
tendencia”. En el gráfico siguiente (en azul) puede observarse como la serie originalpresenta una tendencia lineal creciente que puede ser estimada (representada) conla línea discontinua (tendencia); la serie corregida (filtrada) de tendencia reproduce
exactamente las mismas variaciones que la serie original pero sin mostrar tendenciaalguna.
Ejemplo de serie, estimación de la tendencia y serie filtrada de tendencia
-10.0000
-8.0000
-6.0000
-4.0000
-2.0000
0.0000
2.0000
4.0000
6.0000
8.0000
10.0000
12.0000
e n e - 9 6
e n e - 9 7
e n e - 9 8
e n e - 9 9
e n e - 0 0
e n e - 0 1
e n e - 0 2
e n e - 0 3
e n e - 0 4
e n e - 0 5
-10.0000
0.0000
10.0000
20.0000
30.0000
40.0000
50.0000
e n e - 9 6
e n e - 9 7
e n e - 9 8
e n e - 9 9
e n e - 0 0
e n e - 0 1
e n e - 0 2
e n e - 0 3
e n e - 0 4
e n e - 0 5
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 32/47
¿Cómo se genera la serie filtrada de tendencia?
Para realizar un filtro de tendencia, asumiremos simplemente que la tendencia (T t)es un componente que se agrega a la serie sin tendencia (YSTt) generando la serieoriginal (Yt): es decir, en el gráfico anterior, la serie original (en azul) es la suma delos valores de la serie sin tendencia (en rojo) más los valores de la tendencia (líneadiscontinua):
t t t YST T y
Para computar los valores de la tendencia en cada período basta conefectuar una regresión simple de la serie en función de una variable de tiempo “t” (1,
2, 3,4,……): el residuo de esta regresión será la serie filtrada de tendencia. La
única decisión a considerar será el tipo de función matemática que mejor ajusta latendencia de la serie (lineal, parabólica, exponencial...) que sea más conveniente;trabajaremos con la serie del residuo, que entonces no mostrara tendencia ypodremos decir que es estacionaria en media.
Sobre la elección del modelo de tendencia, conviene tener en cuenta algunascautelas:
1.- Debe priorizarse la sencillez en la selección del modelo de tendencia: ésta debesólo centrarse en la evolución a medio plazo de la serie de modo que no esnecesario que la tendencia reproduzca exactamente cada movimiento a corto plazo.Un comportamiento oscilante podría modelizarse, por ejemplo, con una función
-400,00
-200,00
0,00
200,00
400,00
600,00
800,00
1 6 1 1
1 6
2 1
2 6
3 1
3 6
4 1
4 6
5 1
5 6
6 1
6 6
7 1
7 6
8 1
8 6
9 1
9 6
Serie Original Tendencia Serie (sin) "filtrada de" tendencia
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 33/47
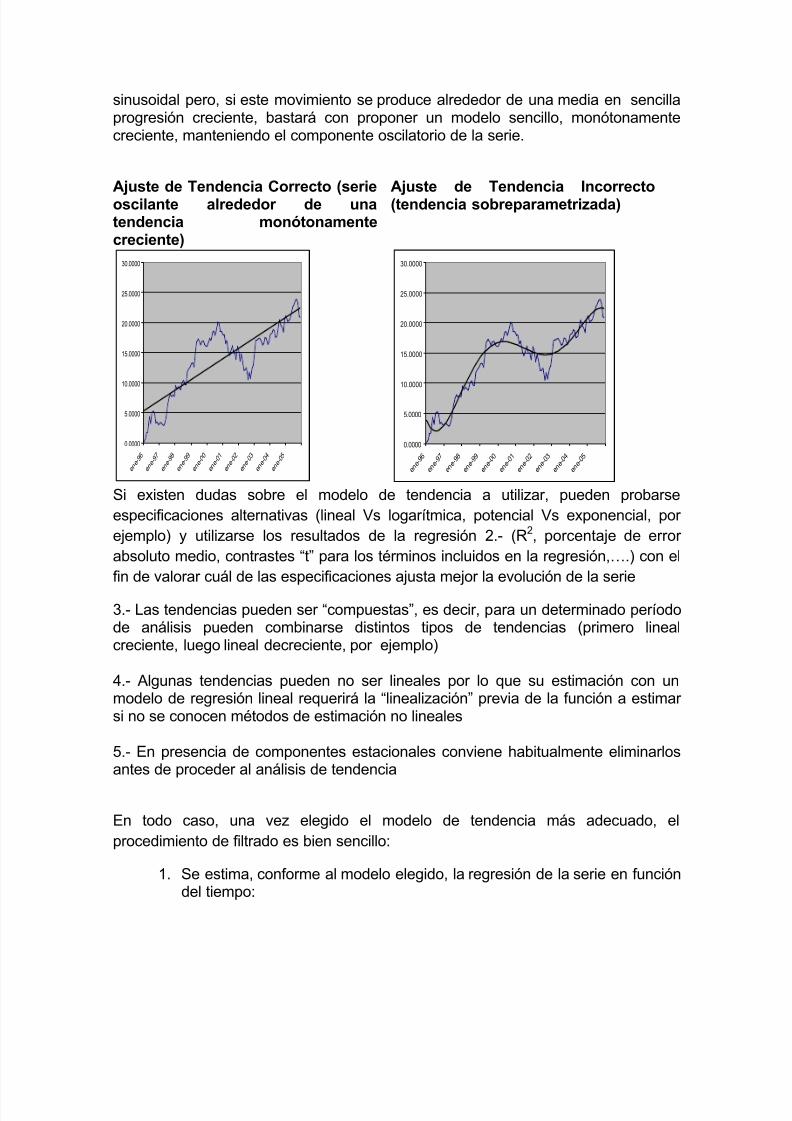
sinusoidal pero, si este movimiento se produce alrededor de una media en sencillaprogresión creciente, bastará con proponer un modelo sencillo, monótonamentecreciente, manteniendo el componente oscilatorio de la serie.
Ajuste de Tendencia Correcto (serieoscilante alrededor de unatendencia monótonamentecreciente)
Ajuste de Tendencia Incorrecto(tendencia sobreparametrizada)
Si existen dudas sobre el modelo de tendencia a utilizar, pueden probarseespecificaciones alternativas (lineal Vs logarítmica, potencial Vs exponencial, porejemplo) y utilizarse los resultados de la regresión 2.- (R2, porcentaje de errorabsoluto medio, contrastes “t” para los términos incluidos en la regresión,….) con el
fin de valorar cuál de las especificaciones ajusta mejor la evolución de la serie
3.- Las tendencias pueden ser “compuestas”, es decir, para un determinado períodode análisis pueden combinarse distintos tipos de tendencias (primero linealcreciente, luego lineal decreciente, por ejemplo)
4.- Algunas tendencias pueden no ser lineales por lo que su estimación con unmodelo de regresión lineal requerirá la “linealización” previa de la función a estimarsi no se conocen métodos de estimación no lineales
5.- En presencia de componentes estacionales conviene habitualmente eliminarlosantes de proceder al análisis de tendencia
En todo caso, una vez elegido el modelo de tendencia más adecuado, elprocedimiento de filtrado es bien sencillo:
1. Se estima, conforme al modelo elegido, la regresión de la serie en funcióndel tiempo:
0.0000
5.0000
10.0000
15.0000
20.0000
25.0000
30.0000
e n e - 9 6
e n e - 9 7
e n e - 9 8
e n e - 9 9
e n e - 0 0
e n e - 0 1
e n e - 0 2
e n e - 0 3
e n e - 0 4
e n e - 0 5
0.0000
5.0000
10.0000
15.0000
20.0000
25.0000
30.0000
e n e - 9 6
e n e - 9 7
e n e - 9 8
e n e - 9 9
e n e - 0 0
e n e - 0 1
e n e - 0 2
e n e - 0 3
e n e - 0 4
e n e - 0 5

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 34/47
En el ejemplo gráfico de la página 2 de este documento, el ajuste lineal por MCOimplica estimar:
t t t U bT a y
resultando de la estimación los siguientes parámetros:
t t T y 5150ˆ
1. La tendencia se corresponde con la serie estimada ( t y ) en tanto que la
serie filtrada es simplemente el residuo de esta regresión, es decir, laserie original ( t y ) menos la estimación de la tendencia ( t y ):
t t t t t T y y yeYST 5150ˆ
II.3.- ESTACIONARIEDAD DE LAS SERIES II: Estacionariedad en VARIANZA
Definición de la no estacionariedad en varianza. Porqué las seriesdeben corregirse de una varianza no estacionaria: el concepto detendencias estocásticas
La principal característica que define al componente tendencial es la depresentar efectos permanentes sobre una serie temporal yt.
En el apartado previo vimos series con un componente tendencial claro,
perfectamente, matemáticamente determinado, conocido, series quedenominamos con tendencia “determinista”.
Si observamos algunas series “con tendencia”, por ejemplo en economía,
podríamos caer en la tentación de calificarlas entre aquellas con tendenciasdeterministas como las anteriores; sin embargo, desde la teoría económica seríamuy difícil justificar una tendencia determinista: aún existiendo componentes

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 35/47
tendenciales importantes desde el punto de vista teórico, seguramente estosno serían de naturaleza determinista, perfectamente conocidos.
Es muy posible, por ejemplo, que la productividad tienda a crecer de forma“natural” en la medida en que, con el paso del tiempo, se va produciendo la mejora
tecnológica de los procesos productivos. También es “natural” que el valor añadidonominal en servicios tienda a crecer incluso de forma ligeramente exponencial,reemplazando la renta del sector primario, a medida que una economía vaalcanzando ciertos niveles de desarrollo.
Sin embargo, ambos procesos teóricos no se producirán, con total seguridad, deuna manera invariable, constante, predecible, determinista, con el paso del tiempo.
Frente a la tendencia determinista surge por tanto la necesidad de definir uncomponente tendencial, con efectos permanentes en la evolución de la serieanalizada, pero de naturaleza estocástica.
El caso más simple de modelo con tendencia estocástica viene determinado por loque se conoce como un paseo aleatorio simple:
t t t t y y t1 y
Con t ruido blanco. La solución a la anterior ecuación2
t
i
it y y1
0
Expresión que permite comprobar que aunque el paseo aleatorio simple es unproceso estacionario en media por definición:
00
1
0 y y E y E y E
t
i
it

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 36/47
Presenta una varianza no constante, que se amplía con el paso del tiempotendiendo a infinito a medida que “t” también lo hace.
222
2
2
13121
2
2
2
1
2
1
2
1
00
2
..............
t E E
E y y E y E y E yV
t
t
i
i
t
i
it t t
Lo más interesante del paseo aleatorio, si se observa la ecuación de su soluciónrecursiva, es que se observa claramente como cada uno de los shocks t pasados
que la serie recibió (0, 1, ... t-1, t) tiene sobre el valor actual y futuro de la serieun efecto permanente, que no se diluye, y, por tanto, tendencial, pero al tiempo, denaturaleza aleatoria.
El paseo aleatorio con deriva incorpora una constante a0 a la expresión delpaseo simple:
t t t t a ya y 0t10 y
La expresión “deriva” se aplica con mucho criterio ya que el proceso así definido
experimentará una variación constante definida por el término a0 dado que lasolución genérica a la anterior ecuación responde a la expresión:
Después de t períodos, el valor de yt se ve influido por todos los shocks pasados y
presentes a través del término de tendencia estocástica
t
i
t
1
y , al mismo tiempo,
de forma invariable, también permanente, pero además perfectamente conocida,por el término determinista a0 t .
A diferencia del proceso aleatorio simple, la deriva incluida en este otro modelosupone que el proceso no sólo no será estacionario en varianza sino tampoco enmedia.
t
i
it t a y y1
00

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 37/47
t a yt a y E t a y E y E t
i
it 0000
1
00
222
2
2
13121
2
2
2
1
2
1
2
0
1
000
2
.............
t E E
E t a yt a y E y E y E yV
t
t
i
i
t
i
it t t
Como ya se vio en el tema relativo a la autocorrelación, la utilización de series noestacionarias incrementa el riesgo de regresiones espurias.
Este fenómeno puede entenderse directamente, sin conocimientos adicionales, sinos referimos a series con tendencia determinista; tras la explicación previa,puede entenderse también porqué el problema persiste cuando utilizamos seriescon tendencia aleatoria, independientemente de si presentan tendenciadeterminista (cambio en la media) o no.
¿Cómo se comprueba si una serie es estacionaria en varianza? Ordende integración
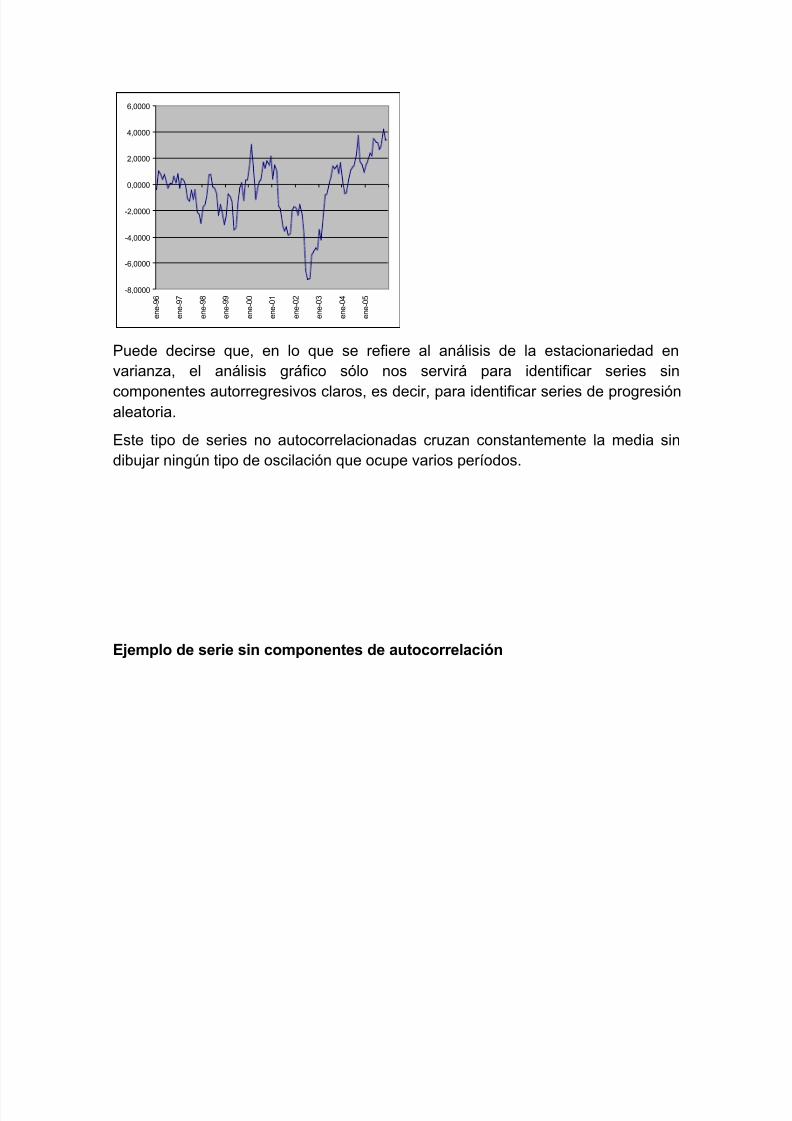
El análisis gráfico no es un instrumento válido para la detección de tendenciasestocásticas.
Este tipo de series no estacionarias en varianza, que pueden considerarse portanto series “con tendencia”, no tienen necesariamente una representación gráfica
con cambios evidentes en la media, ya que hablamos de no estacionariedad en
varianza, no en media:Ejemplo de representación de un paseo aleatorio sin deriva
(serie con tendencia aleatoria)
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 38/47
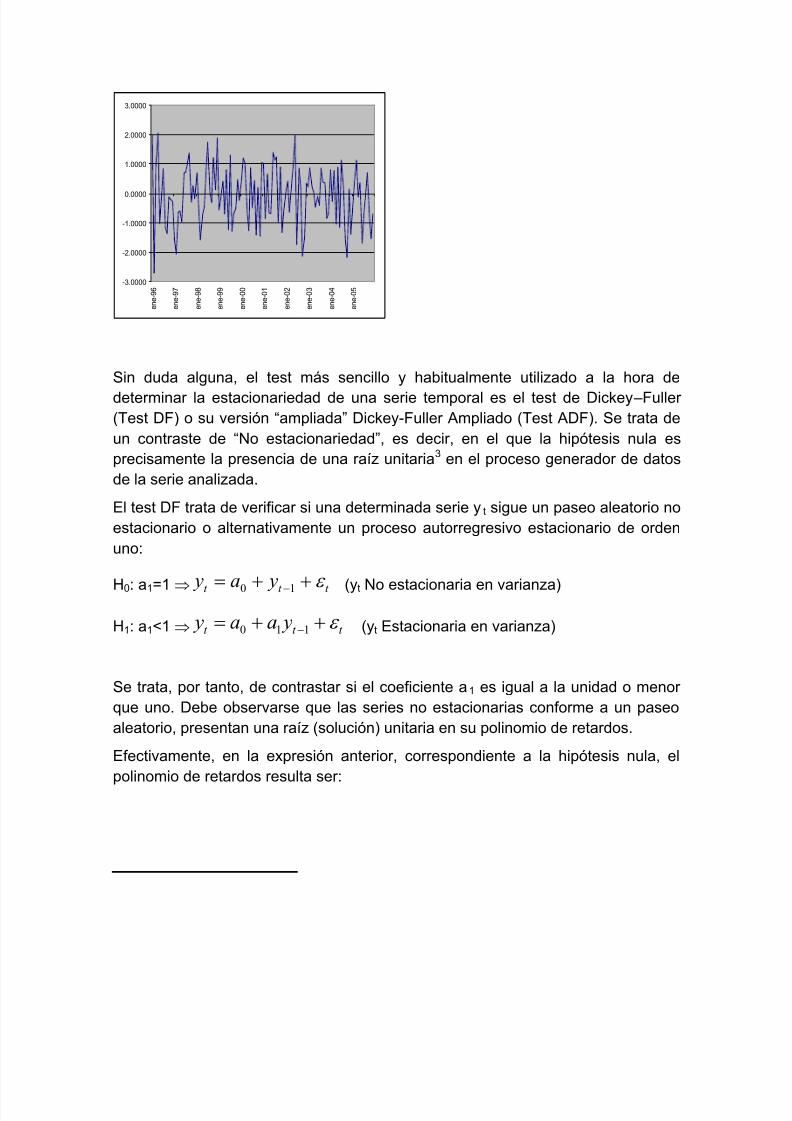
Puede decirse que, en lo que se refiere al análisis de la estacionariedad envarianza, el análisis gráfico sólo nos servirá para identificar series sin
componentes autorregresivos claros, es decir, para identificar series de progresiónaleatoria.
Este tipo de series no autocorrelacionadas cruzan constantemente la media sindibujar ningún tipo de oscilación que ocupe varios períodos.
Ejemplo de serie sin componentes de autocorrelación
-8,0000
-6,0000
-4,0000
-2,0000
0,0000
2,0000
4,0000
6,0000
e n e
- 9 6
e n e
- 9 7
e n e
- 9 8
e n e
- 9 9
e n e
- 0 0
e n e
- 0 1
e n e
- 0 2
e n e
- 0 3
e n e
- 0 4
e n e
- 0 5
7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 39/47
Sin duda alguna, el test más sencillo y habitualmente utilizado a la hora de
determinar la estacionariedad de una serie temporal es el test de Dickey –Fuller(Test DF) o su versión “ampliada” Dickey-Fuller Ampliado (Test ADF). Se trata deun contraste de “No estacionariedad”, es decir, en el que la hipótesis nula esprecisamente la presencia de una raíz unitaria3 en el proceso generador de datosde la serie analizada.
El test DF trata de verificar si una determinada serie y t sigue un paseo aleatorio noestacionario o alternativamente un proceso autorregresivo estacionario de ordenuno:
H0: a1=1 10 t t t ya y
(yt No estacionaria en varianza)
H1: a1<1 110 t t t yaa y (yt Estacionaria en varianza)
Se trata, por tanto, de contrastar si el coeficiente a1 es igual a la unidad o menorque uno. Debe observarse que las series no estacionarias conforme a un paseoaleatorio, presentan una raíz (solución) unitaria en su polinomio de retardos.
Efectivamente, en la expresión anterior, correspondiente a la hipótesis nula, elpolinomio de retardos resulta ser:
-3.0000
-2.0000
-1.0000
0.0000
1.0000
2.0000
3.0000
e n e -
9 6
e n e -
9 7
e n e -
9 8
e n e -
9 9
e n e -
0 0
e n e -
0 1
e n e -
0 2
e n e -
0 3
e n e -
0 4
e n e -
0 5

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 40/47
L L
L y y y y y t t t t t t t t
1
1 11
Cuya única raíz es, precisamente la unidad:
1010 L L L
Esta es la razón por la que habitualmente decimos que las series no estacionariasen varianza son series “con raíces unitarias”.
Debe advertirse que, en el caso de procesos autorregresivos de mayor orden, lasseries pueden presentar más de una raíz unitaria, lo que se corresponde con la
idea de que sus polinomios de retados (de orden superior a 1) tengan más de unaúnica raíz igual a la unidad. Por ejemplo, en el caso de un AR(2), el polinomio deretardos es:
2
21
2
2122112211
1
1
L L L
L L y y y y y y y t t t t t t t t t t
De modo que recordando la expresión genérica de las soluciones de un polinomiode grado 2 tenemos un polinomio de retardos:
2
211 L L L
Cuyas raíces son:
2
2
2
111
2
2
2
1112
4y
2
4
r r
De donde puede deducirse que si los valores de 1 y 2 suman la unidad, ambasraíces del polinomio de retardos serían iguales a la unidad:

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 41/47
10)1(
0)1(40444444
242412
4
1212
12221
2
2221
2
1
2
22
2
1
2
122
2
1122
2
1
2
2
2
11
1
r
Para contrastar la nulidad del coeficiente a1 en el test ADF se realiza primero unasencilla transformación del modelo autorregresivo tratando de transformar lahipótesis nula a1=1 en una hipótesis clásica “t” de nulidad del coeficiente.
Así, del modelo: 10 t t t ya y
Pasamos al transformado:
t t
t t
t t t t t
ya
yaa
y yaa y y
10t
110t
11101
y
)1(y
Donde, por tanto, la hipótesis nula inicial H0:a1=1 se transforma ahora en H0: =0
frente a H1: <0.
Decir que es nulo es lo mismo que decir que a1=1, o sea, que existe una raízunitaria, decir que es menor que cero equivale a decir que a 1 es menor que la
unidad (proceso autorregresivo estacionario)4
.
Una vez estimado el modelo previo, podríamos suponer que el p-value
correspondiente al contraste “t” de Student sobre el parámetro serviría paraaceptar o rechazar la hipótesis de nulidad; sin embargo, Dickey y Fullerdemostraron que no podemos utilizar el contraste “t” habitual sobre la ratiodel parámetro MCO entre su desviación estándar.
La estimación de a1 en t t t ya y 11 será siempre consistente pero, sin embargo,
su distribución variará según los valores que tome la estimación. Utilizando laspalabras de Novales (1993), la distribución de probabilidad asintótica delestimador de MCO del modelo AR(1) presenta una “discontinuidad” cuando a 1=1y, como sustituto, deberán utilizarse las distribuciones derivadas de formaempírica mediante un procedimiento de Montecarlo realizado por Dickey (1976).

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 42/47
Más recientemente, MacKinnon (1991) realizó un número mayor de simulacionesque las tabuladas por Dickey y Fuller.
Además, MacKinnon estimó la superficie de respuesta usando los resultados de la
simulación, lo que permite calcular los valores críticos del test DF para cualquiertamaño muestral y cualquier número de variables en el lado derecho de laecuación.
En todo caso, el procedimiento de contraste sigue siendo aparentemente sencillo:
1.- Se estima el modelo t t ya 10ty
2.- Se calcula la ratio habitual
ˆ
ˆ
DT
3.- Se compara el valor calculado con las distribuciones de DF o MacKinnonpara un determinado nivel de confianza.
4.- Si la ratio calculada supera el valor crítico de tablas, se rechaza la
hipótesis de nulidad de , es decir, se rechaza la hipótesis de presencia deraíces unitarias (hipótesis de no estacionariedad)
Sin embargo, este procedimiento estándar presenta en este caso algunaspeculiaridades. Quizá la más importante es que los valores críticos de lastablas DF o MacKinnon dependen de la presencia en el modelo de términosdeterministas (término constante o tendencia determinista). De ese modo,
antes de proceder a contrastar el valor de “” debe optarse por una de las
tres especificaciones siguientes (a).- Con tendencia y término
independiente. t t yt aa 110ty
(b).- Con término independiente. t t ya 10ty
(c).- Sin términos deterministas. t t
y 1t
y
Dolado et al. (1990) y Perron (1990) propusieron, entre otros autores, seguirun proceso en etapas a fin de garantizar el éxito en la elección del modelo dereferencia en el mayor número de ocasiones:

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 43/47
- En primer lugar se estimaría el modelo menos restringido (con términoconstante y tendencia determinista).
- Dado que el principal error de esta táctica inicial consistiría en la escasapotencia del contraste para el rechazo de la hipótesis nula por inclusión
de variables irrelevantes, si los valores críticos indican rechazo(ausencia de raíz unitaria), terminaríamos el procedimiento.
- En el caso de no rechazarse la hipótesis nula de presencia de una raízunitaria, es decir, en el caso en que admitamos la presencia de una raízunitaria (H0: =0) pasaríamos ahora a examinar la significatividad delparámetro tendencial determinista a1. Dado que, en este punto,estaríamos bajo la hipótesis ya admitida de que =0, utilizaríamos elvalor de referencia de las tablas DF para el término tendencial(denominado generalmente )
5 e incluso, para mayor seguridad,
también el contraste conjunto denominado 3 (a1==0).
- Si el término tendencial resulta significativo (a10) contrastaremos denuevo la presencia de una raíz unitaria (H0: =0) pero utilizandoentonces las tablas de una normal estandarizada. Sea cual sea elresultado del test con las nuevas tablas finalizaríamos aquí el contrasteadmitiendo o rechazando la presencia de una raíz unitaria.
- Si el término tendencial es no significativo, deberá replantearse elmodelo inicialmente estimado pasándose a examinar otro con término
constante pero sin esta tendencia determinista. Con este modelo sevuelve a analizar la presencia de una raíz unitaria (=0).
En el caso en que, nuevamente, se sostenga la presencia de una raíz unitaria, secontrastará entonces la adecuación del término independiente a0 bien con elcontraste , bien con el contraste conjunto denominado 1 (a0==0) 6. Si eltérmino independiente resulta significativo usamos de nuevo las tablas de unanormal para contrastar la presencia de la raíz unitaria, concluyendo de nuevo aquíel contraste.
- Sólo si entonces la constante a0 es no significativa se utiliza el modelo mássimple como modelo de referencia contrastándose, de nuevo, la presencia deraíz unitaria. En este caso, no tiene cabida el uso de la distribución normalestandarizada.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 44/47
En el caso de encontrar una raíz unitaria en la serie analizada, cabe preguntarsequé transformación requiere la serie para convertirse en una serieestacionaria en varianza.
Observando el caso de un paseo aleatorio simple utilizado en la hipótesis nula,
parece sencillo intuir que, si la serie original presenta una raíz unitaria, la serie enprimeras diferencias será una transformada estacionaria en varianza:
010 t t t t t a y ya y
Las series que requieren una transformación en diferencias (integración)para convertirse en series estacionarias en varianza se denominan seriesIntegradas de Orden 1, y se representan como I(1).
Si de una serie se dice que es I(0) es evidente que no son necesarias diferencias
para lograr la estacionariedad, es decir, que la serie original ya es estacionaria envarianza.

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 45/47
¿Puede una serie ser I(2) ó I(3)?. Es decir, ¿puede una serie tener más de unaraíz unitaria?.
Efectivamente, ya vimos anteriormente que en procesos autorregresivos de ordensuperior a uno cabe la posibilidad de que exista más de una raíz unitaria.
Así pues, una vez detectada la primera raíz de una serie, debe repetirse de nuevoel test DF sobre la serie diferenciada una vez, con el fin de localizar una segundaraíz.
En el caso de que el test DF detectase esa segunda raíz, la serie sería entoncesI(2), es decir, necesitaría ser diferenciada 2 veces para convertirse en estacionariaen varianza:
)0()1()2(
)0()1(
2
I y y I y I y
I y I y
t t t t
t t
Efectivamente, cuando una serie que sigue un proceso AR(2), por ejemplo:
2211 t t t t y y y
Presenta dos raíces unitarias, su polinomio de retardos puede descomponersefactorialmente en:
L L L L L L 111 2
21
De modo que la serie original Yt:
2211 t t t t y y y
Puede representarse como una serie estacionaria mediante la expresión:
t t a LY 0
o lo que es igual,

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 46/47
t t t yt t a ya L L ya L y 0
2
00 11
La presencia de más de una raíz unitaria en una serie exige que el procesogenerador de datos sea de orden superior a uno dado que de otra forma elpolinomio de retardos sólo puede tener una única raíz; sin embargo, el test DFsólo contempla la posibilidad de una modelo AR(1) frente aun paseo aleatorio (deorden 1).
Para dar cabida a modelos de orden superior (tanto en la hipótesis nula como enla alternativa), se propone una versión extendida del test DF que se conoce comotest ADF.
Para ilustrar el modelo de contraste del test ADF, supongamos un modelo AR(2)como base del proceso autorregresivo del que se desea analizar laestacionariedad:
2211 t t t t ya ya y
En este caso, vimos anteriormente como la presencia de raíces unitarias secorrespondía con la situación en la que:
112
aa
De modo que lo que debemos ahora contrastar con el test DF no es ya el valor deuno de los dos coeficientes sino el de la suma de ambos.
Es decir, en este caso, las hipótesis nula y alternativa se definen del siguientemodo:
H0: a1+ a2=1 22110 t t t t ya yaa y (yt No Estacionaria en varianza)
H0: a1+ a2<1 22110 t t t t ya yaa y (yt Estacionaria en varianza)

7/22/2019 Econometria Luis
http://slidepdf.com/reader/full/econometria-luis 47/47
Una vez más, para adaptar el test a una hipótesis clásica de nulidad de uncoeficiente, se propone la expresión:
p
i
t it it t y ya y2
110
Donde nuevamente, la hipótesis nula a contrastar es H0: =0 frente a H1: <0 dado
que no resulta complejo demostrar que el coeficiente es:
p
i
ia1
1
siendo:
p
j ji
a1
Así pues, como puede observarse, la presencia de más de una raíz unitaria enuna serie exigirá añadir a la regresión del test simple DF términos retardados de la
endógena 1 it y lo que, por otro lado, servirá para corregir la regresión decontraste de posibles problemas de autocorrelación.
http://martinmedina-pascal.blogspot.mx/p/notacion-y-conceptos-fundamentales.html


















