
Motivación - Universidad Nacional de Córdoba · Motivación "We should forget about small...
44
Performance Performance Carlos Bederián, Carlos Bederián, [email protected] [email protected] Nicolás Wolovick, Nicolás Wolovick, [email protected] [email protected] 1 / 43 1 / 43
Transcript of Motivación - Universidad Nacional de Córdoba · Motivación "We should forget about small...
PerformancePerformanceCarlosBederián,CarlosBederián,[email protected]@unc.edu.ar
NicolásWolovick,NicolásWolovick,[email protected]@famaf.unc.edu.ar
1/431/43

Motivación"Weshouldforgetaboutsmalle�ciencies,sayabout97%ofthetime:
prematureoptimizationistherootofallevil"
-DonaldKnuth
1/43

Primero,antesquenada...Hastadóndellegamihardware?Cómoveosiesmalomicódigo?
2/43

CPU:PerformancepicoEjercicioteórico:GFLOPSquelepuedoexprimiralprocesadorsisealineantodoslosastros
1.Identi�carlasunidadesdevectoreseneldiagramadelaarquitecturaysuancho2.VersisoportanFMA,queduplicalacantidaddeoperacionesporciclo(caso
contrario:1porunidad)3.Buscarlafrecuenciamáximadelasunidadesdevectoresenelmodomásancho4.Multiplicartodo:
= Cores ∗ Unidade ∗ ∗ Frecuencia ∗ FMAGFLOPS64 s64
Ancho
64
= Cores ∗ Unidade ∗ ∗ Frecuencia ∗ FMAGFLOPS32 s32
Ancho
32
3/43
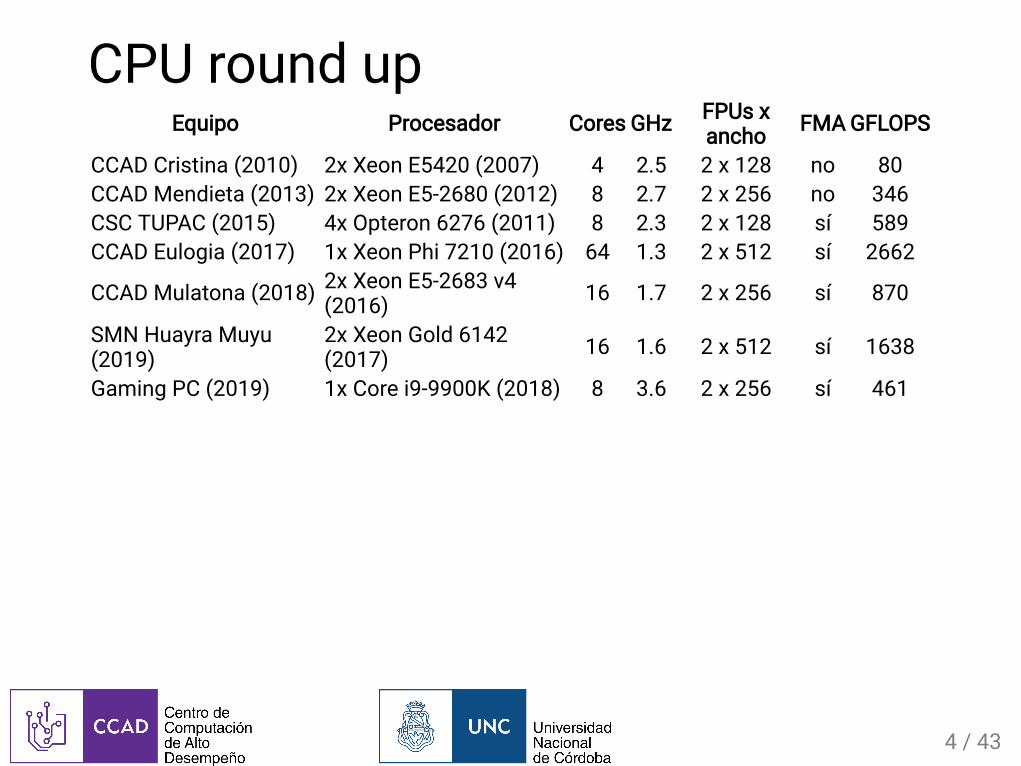
CPUroundupEquipo Procesador Cores GHz FPUsx
ancho FMAGFLOPS
CCADCristina(2010) 2xXeonE5420(2007) 4 2.5 2x128 no 80CCADMendieta(2013) 2xXeonE5-2680(2012) 8 2.7 2x256 no 346CSCTUPAC(2015) 4xOpteron6276(2011) 8 2.3 2x128 sí 589CCADEulogia(2017) 1xXeonPhi7210(2016) 64 1.3 2x512 sí 2662
CCADMulatona(2018) 2xXeonE5-2683v4(2016) 16 1.7 2x256 sí 870
SMNHuayraMuyu(2019)
2xXeonGold6142(2017) 16 1.6 2x512 sí 1638
GamingPC(2019) 1xCorei9-9900K(2018) 8 3.6 2x256 sí 461
4/43

Unsegundo...Equipo Procesador Cores GHz FPUsx
ancho FMAGFLOPS
CCADMulatona(2018) 2xXeonE5-2683v4(2016) 16 1.7 2x256 sí 870
SMNHuayraMuyu(2019)
2xXeonGold6142(2017) 16 1.6 2x512 sí 1638
5/43
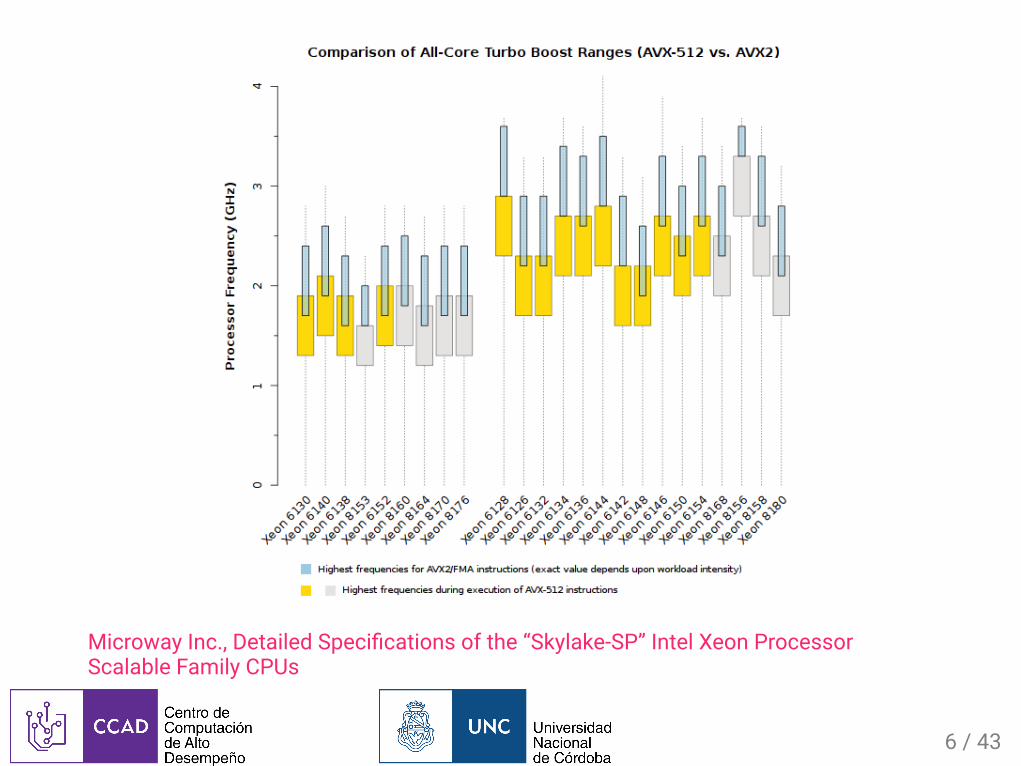
MicrowayInc.,DetailedSpeci�cationsofthe“Skylake-SP”IntelXeonProcessorScalableFamilyCPUs
6/43

Throttling
Sinceasigni�cantportionofthepowerconsumptionunderheavyloadisduetoleakagecurrent(whichincreasesveryrapidlywithtemperature),amoreaggressivecoolingsolutionthatkeepsthedietemperaturelowershouldalsohelptheprocessorattainhigherTurbofrequenciesbeforehittingthepowerlimit.
-JohnMcCalpina.k.a.Dr.Bandwidth
7/43

Memoria:PerformancepicoEjercicioteórico:GBpsquelepuedoexprimiralamemoriasisealineantodoslosastros
1.Identi�carlavelocidad(engigatransferencias/s)delamemoriaCadatransferenciaesde64bits
2.VerlacantidaddecanalesdememoriaquesoportacadaprocesadorRevisarqueesténefectivamentepoblados!sudodmidecode-tmemory
3.Verlacantidaddeprocesadoresinstalados4.Multiplicar
GBps = Procesadores ∗ Canales ∗ Velocidad ∗ 8
8/43

CPU:PerformanceprácticaElbenchmarkmásutilizadoenHPCesLINPACK
PrecisióndobleResuelveunsistemadensodeecuacioneslinealesFactorizaciónLUconpivotingparcialeintercambiode�las(dgesvdeLAPACK)
operacionesconNarbitrario
Highly-ParallelLINPACK
VersióndistribuidadeLINPACKusandoMPILlamaaBLASparaoperacionesmatriciales
�� = �
+ 22
3� 3 � 2
9/43

Top500Listadelas500supercomputadorasmáspotentesordenadasporperformanceobtenidaenHPL.
Datosdesde1993(!!!)Informacióndetalladadelacon�guracióndecadaclusterDosedicionesanuales:
Junio(ISC)Noviembre(SC)
Nuevosbenchmarkssimilares:Green500,HPCG,Graph500,IO500
10/43
11/43

Goodhart'sLawWhenameasurebecomesatarget,itceasestobeagoodmeasure.
Double-precisionFPUsinHigh-PerformanceComputing:anEmbarrassmentofRiches?
LamitaddelpoderdecómputodeunXeonPhi72x0sedesperdicia,inclusoenHPLUnaunidaddeprecisióndobleocupa~3xmástransistoresqueelequivalenteenprecisiónsimple
12/43

STREAMBenchmarkdeanchodebandadememoriaescritoporJohnMcCalpin
Para conarreglosdeNelementosquesonmuchomásgrandesquelacache
Copy:C[i]=A[i];Scale:B[i]=scalar*C[i];Add:C[i]=A[i]+B[i];Triad:A[i]=B[i]+scalar*C[i];
� ∈ [1..�]
13/43
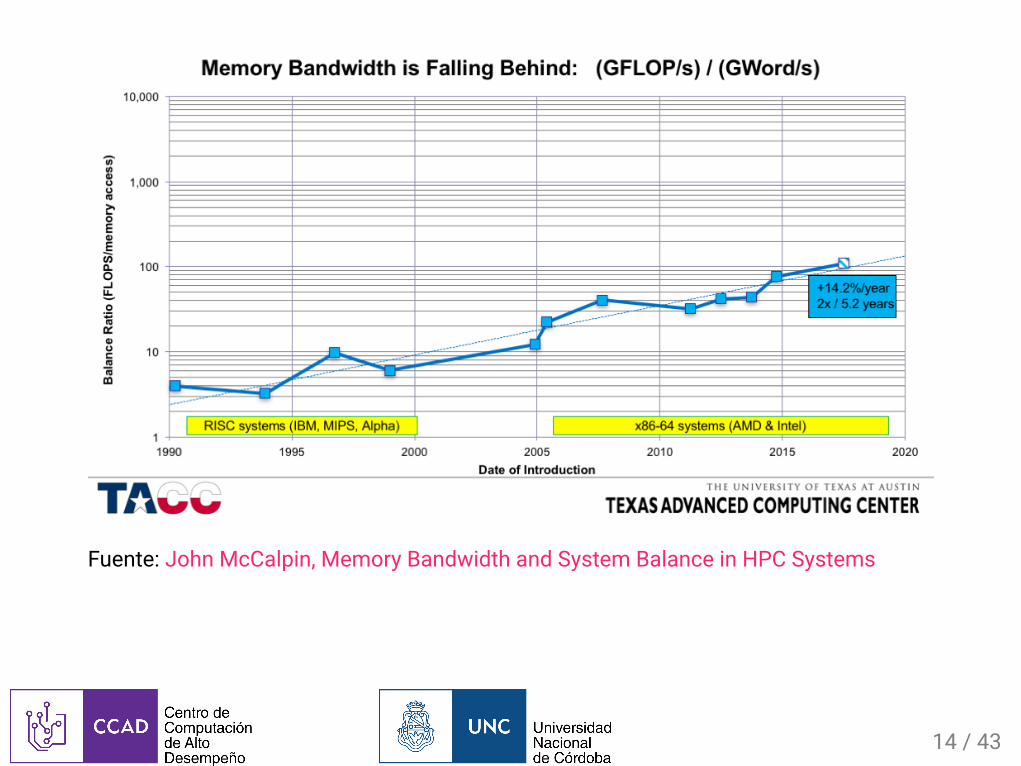
Fuente:JohnMcCalpin,MemoryBandwidthandSystemBalanceinHPCSystems
14/43

IntensidadaritméticaParaoperarsobredatosesnecesariotransportardatosdesdememoriaalprocesador,yviceversa.
Paraunproblemadado,laintensidadaritméticaeselratioentrelacantidaddeoperacionesylosbytestransferidospararealizarlas.
Intensidadbaja:Sumadedosmatricesenprecisiónsimple, operaciones
1op,12bytes(2lecturas,1escritura)porelemento=0.083ops/byte
Intensidadalta:Multiplicacióndedosmatrices enprecisiónsimple(optimista), operaciones
ops, bytestransferidos ops/byte
Paraproblemasdeintensidadaritméticabaja,ellímitenoeselpoderdecómputosinolacapacidaddetransferirdatos.
�(�)
���
�( )�3
− �� 3 4 ∗ 3� 2≈
�
12
15/43

Roo�inePerformanceModelModelodellímiteefectivodeunnododecómputo.
1.Medimoselpoderdecómputomáximo(Rmax,enGFLOPS)conHPLTechoparaproblemasdealtaintensidadaritmética
2.Medimoselanchodebandadememoria(MemBW,enGBps)conSTREAMTechoparaproblemasdebajaintensidadaritmética
3. :Intensidadaritméticamínimaparautilizartodoelpoderdecómputodelprocesador
4.Gra�carGFLOPSmáximorespectoalaintensidadaritmética
����
�����
16/43
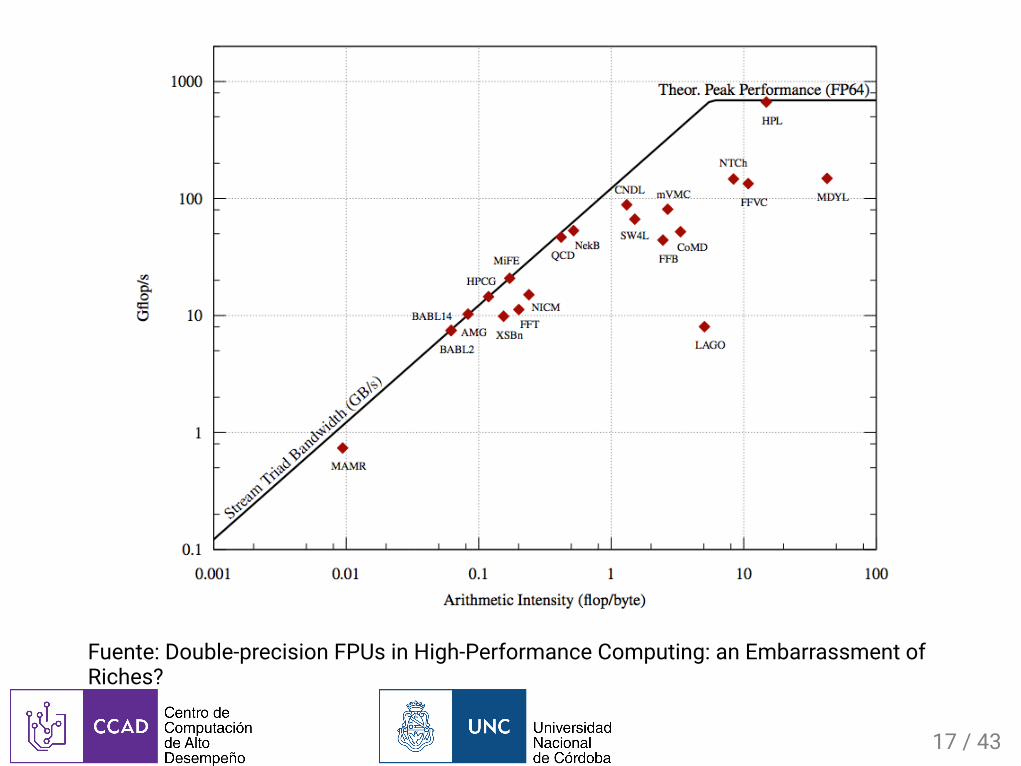
Fuente:Double-precisionFPUsinHigh-PerformanceComputing:anEmbarrassmentofRiches?
17/43

¿Cómoprocedo?Obtenerelgrá�co
Sinrenegar:usarIntelAdvisorSinollegamosaltecho,subir
Exprimirmáselprocesador(vectorización,paralelización)Nota:EltechoparaproblemasquenopuedenusarFusedMultiply-Add(FMA)eslamitad
Sieltechonoslimita,irhacialaderechaAumentarlalocalidaddelcódigoparaoperarmásencache
18/43

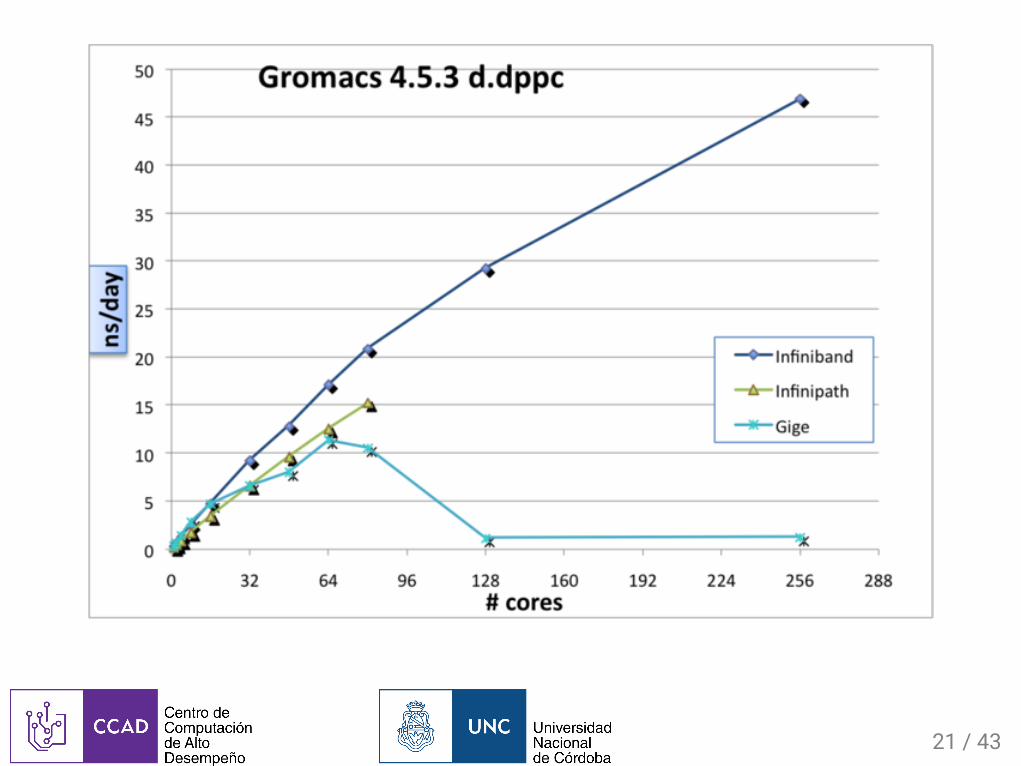
Escalabilidad:SpeedupSpeedupsede�necomoelratiodemejorasobreunaimplementacióndereferencia:
Donde y sontiemposdeejecución.
Seusaparacompararunaimplementaciónnuevaconunadereferencia,generalmenteunaparalelacontralasecuencialoriginal:
� =�����
����
����� ����
� =�1
��
19/43

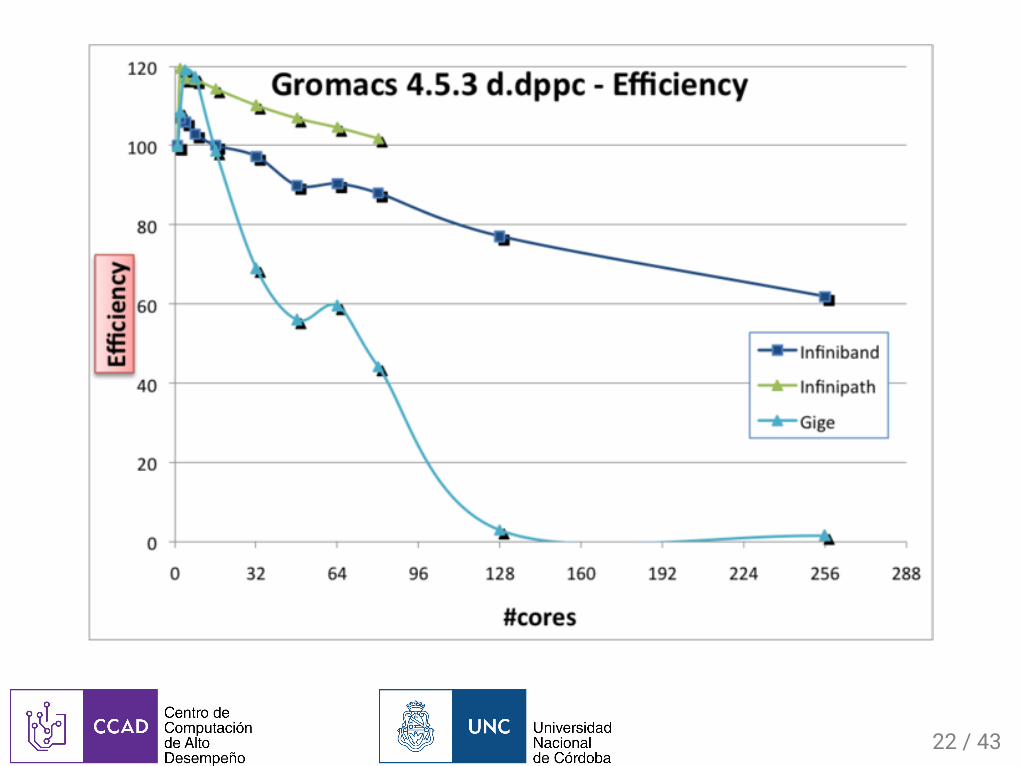
Escalabilidad:E�cienciaE�cienciamuestracuántoperdimosdeloteóricamenteposiblealapráctica:
Enelcasodeparalelización:
Eff =�efectivo
�teorico
Eff =�
�
20/43
21/43
22/43

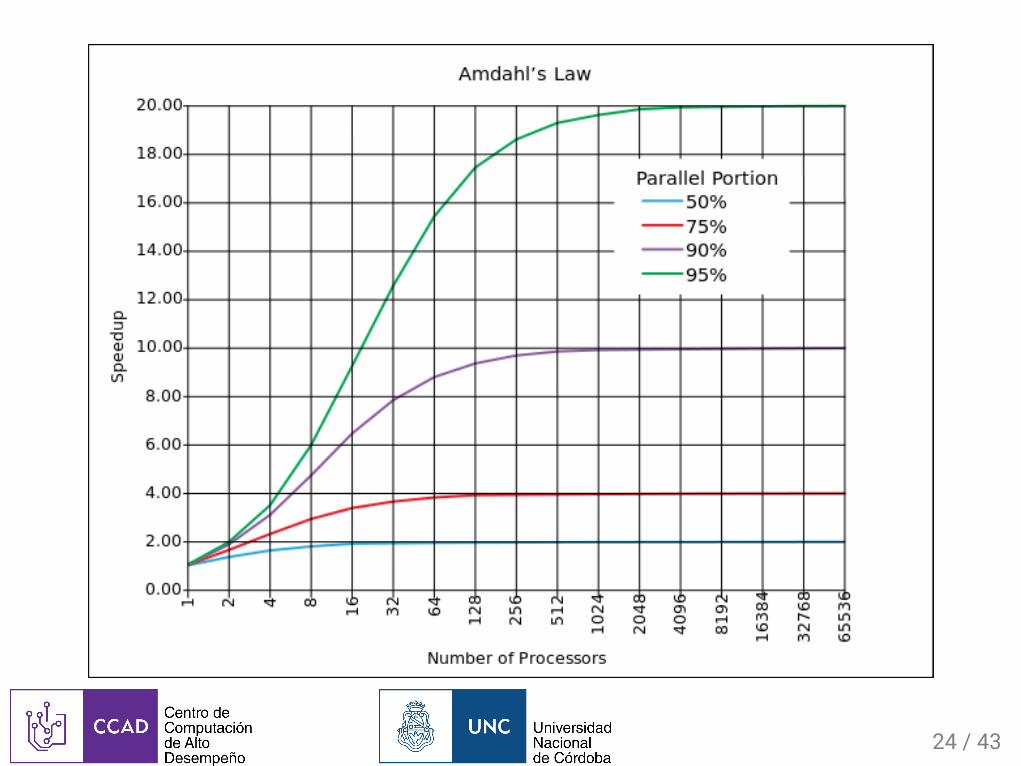
LeydeAmdahl…theeffortexpendedonachievinghighparallelprocessingratesiswastedunlessitisaccompaniedbyachievementsinsequentialprocessingratesofverynearlythesamemagnitude.
—GeneAmdahl
Elspeedupmáximoobtenibleagregandoprocesadoresestáacotadoporlaporciónsecuencialdelcódigo.
= (� + ) =�� �1
�
���
1
� +�
�
23/43
24/43

LeydeGustafsonObservación:Generalmentelapartesecuencialesindependientedeltamañodelproblema.
…speedupshouldbemeasuredbyscalingtheproblemtothenumberofprocessors,notby�xingtheproblemsize.
—JohnGustafson
Workaround:Sinoescala,agrandarelproblema.
= � − �(� − 1)��
25/43

ScalingStrongscaling:Escalabilidaddeunproblemadetamaño�jorespectoalacantidaddeprocesadores.
Weakscaling:Escalabilidaddeunproblemadetamaño�joporprocesadorrespectoalacantidaddeprocesadores.
26/43

Pro�lingengeneralTécnicasparaobtenerinformaciónsobrelaejecucióndeunprograma
GeneralmentemétricasconelobjetivodeoptimizarcuellosdebotellaDostiposgeneralessegúncómoobtienenlosdatos
Losqueinstrumentanelcódigoparahacerlasmedicionesnecesarias(e.g.gcc-pg,luegogprofogcov)Losqueobservanelcódigoenejecuciónsinrequerirmodi�caciones(e.g.perf,VTune...)
27/43

SamplingUnprocesadortieneunconjuntodecontadorescon�gurablesparallevarrastrodeunavariedaddeeventos
cpuidloslista
numberoffixedcounters=0x3(3)numberofcountersperlogicalprocessor=0x8(8)
Secon�gurauncontadorquealhacerover�owgeneraunainterrupciónyencadainterrupciónelkernelanotadóndeocurrióelevento
Puedenserciclos(tiempo)oeventosdelprocesadorDefault1kHz,máximokernel.perf_event_max_sample_rate(100kHz)
Limitaciones:
TeoremademuestreoAmuyaltafrecuencianoquedatiempoparatrabajoútil
28/43

CountingSecon�guranlosmismoscontadoresqueparasampling,peroenlugardepararcadatantosereportanlascantidadesal�nal
Pros:
Nosepierdendatos...hastaquepedimosmásmetricasqueloscontadoresdisponibles
Cons:
Difícildeacertarlealaetapaquequeremosenprogramascomplejos
29/43

TracingAveceslamuestranoalcanza,necesitamoscontextoparaverdedóndevenimos.
Soluciones:
CapturarmásinformaciónaltomarlamuestraGuardartodalainformaciónsiempre
Cosasinteresantesquetrazar:
CallstackLastBranchRecord(aceleradoenhardware)
Limitaciones:
TamañoOverhead
30/43

Sanitycheck:htopAntesdehacernada,veamosquetodoestéenorden.
htopesuntopalternativo,featuressimilares
UtilizacióndesglosadadecadacoreUtilizacióndememoriaListadeprocesosenejecución
Cosaspararevisar:
UnprocesoohiloporcoreohilodelprocesadorNosepeleaportiempodeprocesadorconotrosprogramas.
31/43

perfHerramientadepro�lingasociadaalasystemcallperf_event_opendelkerneldeLinux
NorequiereinstrumentaciónBajooverheadHacesampling,counting,tracing
Permiteobservar:
Laejecuciónenteradeunprograma(cuandosepasaelcomando)UnprocesoenejecuciónpasandoelPIDTodoloqueocurreentodoelsistema(-a)
32/43

Primerasmediciones:perfstatCountingpro�ler.Muestraunresumendemétricasdeejecucióndetodounprograma.
MétricaspordefectoTiempoenespaciodeusuarioyenkernel(comotimecomando)UtilizacióndeCPUsCiclos,instrucciones,IPCBranches,prediccionesdebrancheserradas(-ddd)Loadsdedistintosnivelesdecacheysusmisses
Sepuedecon�guraramanocualquierconjuntodeeventos(-e)ymétricasbasadaseneventos(-M)obtenidosconperflistTop-downpro�lingcon--topdown
33/43

perflistListaloseventosymétricasqueconoceperf
HaymuchosmásyconmuchomásdetalledeloquegeneralmentenecesitamosYaúnasínosontodos
HerramientaconlistaextendidaparaprocesadoresIntel:ocperf"Metricgroups"(al�nal)proveealgunasmétricasútilesyaprocesadas
34/43
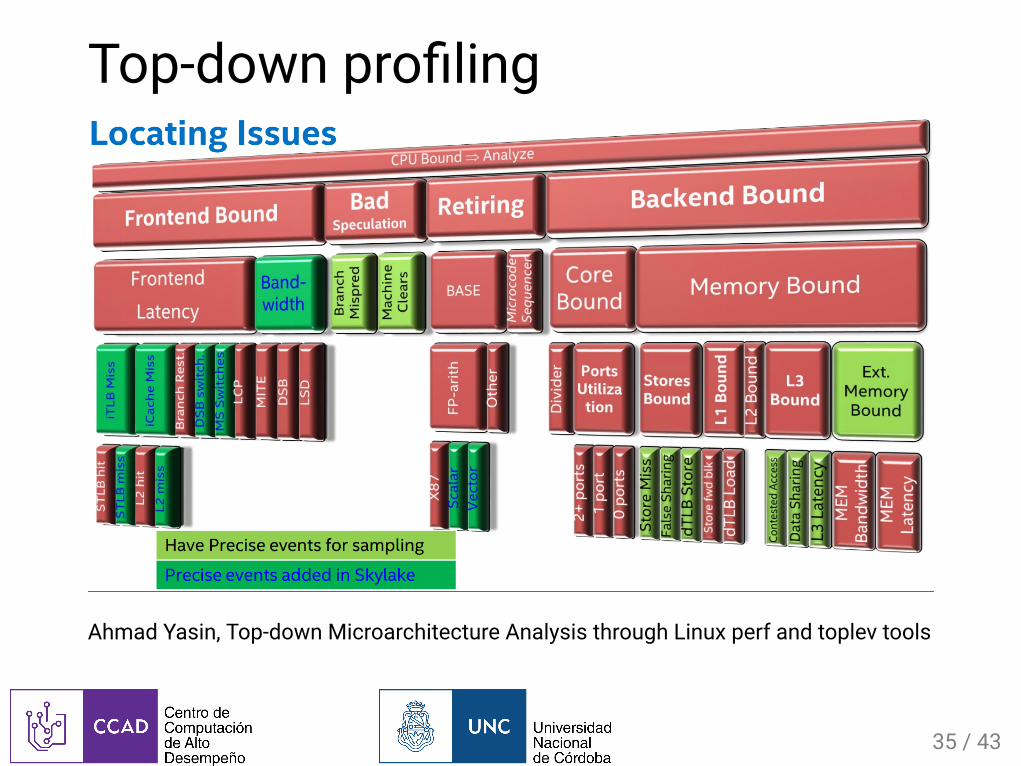
Top-downpro�ling
AhmadYasin,Top-downMicroarchitectureAnalysisthroughLinuxperfandtoplevtools
35/43

Explorando:perftopSamplingdetiempotodoelsistemaconinformaciónentiemporeal
InterfazdetextoReportedeutilizacióndeCPUporfunciónOpciónparahacerzoomenunafunciónyverutilizaciónporinstrucción
Sihayinformacióndedebugging,semuestraelcódigofuenteasociadoacadainstruccióntambién
Incluyeutilizacióndelkernel,quepuedeayudarparaproblemasmáscomplicadosconsystemcalls
36/43

Apartado:SymboltableElsamplingdeperfcreaunhistogramadeocurrenciasdeeventosporinstrucción.Parasacaralgoútildeestainformación,necesitamostenerunmapeoentreelbinarioenejecuciónyelcódigofuente.(latabladesímbolos)
Vieneconlainformacióndedebugging(compilarcon-g)
Atenerencuenta:
Algunoseventosdemoranalgunasinstruccionesennoti�carseyselecuentanalainstrucciónequivocadaLasoptimizacionesmásagresivasvistasayer(inlining,LTO,transformacionesdeloops)destruyenlarelación1:1entrebinarioycódigo
A�ojarleunpocoalasoptimizaciones(-O2)paraubicarse
37/43

Dumpdemétricas:perfrecordSamplingpro�ler.Secon�guranlasmétricasaobservaryseiniciaelpro�ling.perfvuelcalosdatosaperf.dataparaposterioranálisis.
Análisiso�ine:perfreportInterfazsimilaraperftop,procesaymuestraloguardadoenperf.data.
38/43

perfc2cSamplingpro�lerdepropósitoespecí�co.Sólocuentalíneasdecachequehansidoencontradasmodi�cadasenunlugarremoto(HITM)
Paradetectarcontenciónsobrelíneasdecache,enparticularfalsesharing(problemacomúnporelqueOpenMPnoparalelizaaunqueparezcatrivial)
39/43

IntelAdvisorPro�lerparaasistirconvectorizaciónyparalelizacióndecódigo.
Featuresinteresantes:
Roo�ineanalysisporfunciónAnálisismuyespecí�coparagenerarsugerenciasdeoptimizaciones
Parautilizar:
1.source(...)/intel/advisor/advixe-vars.sh2.Correrelpro�ler
advixe-guiparalainterfazgrá�caadvixe-clparaelprogramadelíneadecomandos(paraponerenjobs)
40/43

IntelVTuneAmpli�erPro�lerdepropósitogeneralconinterfazgrá�caamigable
Hotspots:Samplingpro�lersimilaraperfrecord+perfreportMicroarchitectureexploration:top-downmetricsporfunción
Parautilizar:
1.source(...)/intel/vtune_amplifier/amplxe-vars.sh2.Correrelpro�ler
amplxe-guiparalainterfazgrá�caamplxe-clparaelprogramadelíneadecomandos(paraponerenjobs)
41/43

Pro�lingenPython:cPro�le
Pro�lerdefuncionespython-mcProfilescript.py
line_pro�ler
Decorarfuncionesamedircon@profileCorrerelscriptconkernprof
42/43

¿Yahora?Paralelizar!
UsuariosFortran/C/C++:AprenderOpenMPmodernoompparallel,task,simd...
UsuariosCUDA,C/C++también:AprenderSYCLTodes:AprenderMPI
43/43


















